ADAPTIVE NEURO-FUZZY INFERENCE SYSTEM (ANFIS)
SKRIPSI
Oleh:
Arsyil Hendra Saputra NIM : J2E008009
JURUSAN STATISTIKA
FAKULTAS SAINS DAN MATEMATIKA
UNIVERSITAS DIPONEGORO
SEMARANG
2012
ADAPTIVE NEURO-FUZZY INFERENCE SYSTEM (ANFIS)
Oleh:
Arsyil Hendra Saputra NIM : J2E008009
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Sains pada Jurusan Statistika
JURUSAN STATISTIKA
FAKULTAS SAINS DAN MATEMATIKA
UNIVERSITAS DIPONEGORO
SEMARANG
2012
iv
Puji syukur penulis panjatkan ke hadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya, sehingga Tugas Akhir ini terselesaikan.
Tugas akhir yang berjudul “Analisis Data Runtun Waktu dengan Metode
Adaptive Neuro Fuzzy Inference System (ANFIS)“ ini disusun sebagai salah satu
syarat untuk memperoleh gelar Sarjana Strata Satu (S1) pada Jurusan Statistika Fakultas Sains dan Matematika Universitas Diponegoro.
Banyak pihak yang telah membantu dalam penyelesaian Tugas Akhir ini. Oleh karena itu, rasa hormat dan terimakasih penulis sampaikan kepada :
1. Dra. Dwi Ispriyanti, M.Si selaku Ketua Program Studi Statistika FSM Universitas Diponegoro Semarang.
2. Drs. Tarno, M.Si selaku Dosen Pembimbing I dan Budi Warsito, S.Si, M.Si selaku Dosen Pembimbing II yang telah meluangkan waktu memberikan masukan, bimbingan dan pengarahan kepada penulis.
3. Kementerian Badan Usaha Milik Negara (BUMN) selaku instansi yang telah memberikan beasiswa kepada penulis melalui “Program BUMN Peduli Beasiswa”.
3. Bapak/Ibu Dosen dan teman-teman mahasiswa Statistika Undip yang telah memberikan motivasi dan dukungan kepada penulis.
Semoga Tugas Akhir ini bisa membawa manfaat bagi penulis sendiri khususnya dan bagi para pembaca pada umumnya.
Semarang, 27 Juli 2012 Penulis
v
Salah satu metode analisis data runtun waktu yang populer adalah ARIMA. Metode ARIMA mensyaratkan beberapa asumsi antara lain residual model white noise, berdistribusi normal dan varian konstan. Model ARIMA cenderung lebih baik untuk data runtun waktu yang linier. Sedangkan untuk data runtun waktu nonlinier telah banyak dikaji dengan metode nonlinier, salah satunya adalah Adaptive Neuro Fuzzy Inference System atau ANFIS. Metode ANFIS adalah metode yang mengkombinasikan teknik Neural Network dan Fuzzy Logic. Dalam Tugas Akhir ini dibahas secara khusus mengenai metode ANFIS untuk analisis data runtun waktu yang mempunyai karakteristik antara lain stasioner, stasioner dengan outlier, nonstasioner dan nonstasioner dengan outlier, dan digunakan data harga minyak kelapa sawit Indonesia sebagai studi kasus. Hasil ANFIS yang diperoleh kemudian dibandingkan dengan hasil metode ARIMA berdasarkan nilai RMSE. Berdasarkan analisis dan pembahasan diperoleh bahwa hasil metode ANFIS lebih baik daripada metode ARIMA.
vi
One popular method of time series analysis is ARIMA. The ARIMA method requires some assumptions; residual of model must be white noise, normal distribution and constant variance. The ARIMA model tends to be better for time series data which is linear. Whereas for the nonlinear time series data have been widely studied by nonlinear methods, one of that is Adaptive Neuro
Fuzzy Inference System or ANFIS. The ANFIS method is a method that combines
techniques Neural Network and Fuzzy Logic. In this thesis discussed the ANFIS method specifically for the analysis of time series data that have characteristics such as stationary, stationary with outlier, non stationary and non stationary with outlier, and the data of Indonesian palm oil prices is used as a case study. The ANFIS results which were obtained are compared with the results of ARIMA method by the value of RMSE. Based on the analysis and discussion, it is obtained that the results of ANFIS method are better than the results of ARIMA method.
vii
HALAMAN JUDUL ………..… i
HALAMAN PENGESAHAN I ……….……… ii
HALAMAN PENGESAHAN II ……….……… iii
KATA PENGANTAR ……… iv
ABSTRAK ………. v
ABSTRACT ……… vi
DAFTAR ISI ……….. vii
DAFTAR TABEL ………..…….……… x
DAFTAR GAMBAR ……….. xiv
DAFTAR LAMPIRAN ……….. xvi
BAB I PENDAHULUAN ………... 1
1.1 Latar Belakang ………. 1
1.2 Tujuan ……….. 4
BAB II TINJAUAN PUSTAKA ……….………... 5
2.1 Pengertian Analisis Data Runtun Waktu .………... 5
2.2 Model ARIMA …...………. 6
2.3 Istilah-Istilah dalam Analisis Runtun Waktu ………... 7
2.3.1 Stasioner ……… 7
2.3.2 Differencing ……….. 8
2.3.3 Autocorrelation Function (ACF) ……….. 8
2.3.4 Partial Autocorrelation Function (PACF) ………... 9
2.4.Tahapan Pemodelan ARIMA ……….. 10
2.4.1 Identifikasi ……… 11
viii
2.4.4.1 Uji Ljung-Box ……… 12
2.4.4.2 Uji Normalitas ... 13
2.4.4.3 Uji Linieritas ……….. 13
2.5 Jaringan Syaraf Tiruan (Neural Network) ……… 14
2.6 Logika Fuzzy (Fuzzy logic) ……….……… 16
2.6.1 Teori Himpunan Fuzzy ………. 16
2.6.2 Fungsi Keanggotaan Fuzzy ………... 17
2.6.3 Fuzzy C-Means (FCM) ………. 19
2.6.4 Sistem Inferensi Fuzzy ……….. 21
2.6.5 FIS Model Sugeno (TSK) ………. 22
2.7 ANFIS: Adaptive Neuro Fuzzy Inference System ………... 23
2.7.1 Gambaran Umum ANFIS ………. 23
2.7.2 Arsitektur ANFIS ………. 24
2.7.3 Jaringan ANFIS ……… 25
2.7.4 Algoritma Pembelajaran Hybrid ………... 28
2.7.5 LSE Rekursif ……… 29
2.7.6 Model Propagasi Eror ……… 30
2.7.7 Root Mean Square Eror (RMSE) …………..……… 35
BAB III METODOLOGI ………... 36
4.1 Sumber Data ……… 36
4.1.1 Data Simulasi ……… 36
4.1.2 Data Studi Kasus ……….. 36
4.2 Metode Analisis ARIMA ……… 37
4.3 Metode Analisis ANFIS ……….. 38
BAB IV ANALISIS DAN PEMBAHASAN ………. 41
4.1 Analisis Data Runtun Waktu dengan ARIMA ……… 41
4.1.1 Analisis ARIMA pada Data Stasioner ………. 41 4.1.2 Analisis ARIMA pada Data Stasioner dengan Outlier …. 48
ix
4.2 Analisis Data Runtun Waktu dengan ANFIS ……….. 71 4.2.1 Analisis ANFIS pada Data Stasioner ……… 71 4.2.2 Analisis ANFIS pada Data Stasioner dengan Outlier …… 72 4.2.3 Analisis ANFIS pada Data Nonstasioner ……….. 75 4.2.4 Analisis ANFIS pada Data Nonstasioner dengan Outlier .. 77 4.3 Perbandingan Hasil ANFIS Terhadap Hasil ARIMA ………. 79 4.3.1 Analisis pada Data Stasioner ……… 79 4.3.2 Analisis pada Data Stasioner dengan Outlier …………... 80 4.3.3 Analisis pada Data Nonstasioner ……….. 81 4.3.4 Analisis pada Data Nonstasioner dengan Outlier ………. 82 4.4 Penerapan ANFIS pada Data Harga Minyak Kelapa Sawit
Indonesia ………... 84 4.4.1 Analisis ARIMA pada Data Harga Minyak Kelapa Sawit
Indonesia ………. 84 4.4.2 Analisis ANFIS pada Data Harga Minyak Kelapa Sawit
Indonesia ………. 91 4.4.3 Perbandingan Hasil ANFIS terhadap Hasil ARIMA …… 95
BAB V KESIMPULAN ………. 97 DAFTAR PUSTAKA ……… 98 LAMPIRAN ………... 101
x
Tabel 1. Pola ACF dan PACF dari proses yang stasioner ……… 11
Tabel 2. Prosedur pembelajaran Hybrid metode ANFIS……….……….. 29
Tabel 3. Statistik uji ADF pada data stasioner……….………. 42
Tabel 4. Estimasi model ARIMA pada data stasioner ……….…………. 43
Tabel 5. Uji Ljung-Box model ARIMA pada data stasioner ………….……... 45
Tabel 6. Uji ARCH-LM model ARIMA pada data stasioner ……….….. 46
Tabel 7. Uji Ramsey RESET model ARIMA pada data stasioner……… 47
Tabel 8. Nilai eror model ARIMA pada data stasioner……….……… 48
Tabel 9. Statistik uji ADF pada data stasioner dengan outlier ………. 49
Tabel 10. Estimasi model ARIMA pada data stasioner dengan outlier…….…. 50
Tabel 11. Uji Ljung-Box model ARIMA pada data stasioner dengan outlier… 52 Tabel 12. Uji ARCH-LM model ARIMA pada data stasioner dengan outlier ... 53
Tabel 13. Uji Ramsey RESET model ARIMA pada data stasioner dengan outlier……….. 54
Tabel 14. Nilai eror model ARIMA pada data stasioner dengan outlier …..….. 55
Tabel 15. Statistik uji ADF pada data nontasioner……….. 56
Tabel 16. Statistik uji ADF pada data nontasioner differencing satu ……... 57
Tabel 17. Estimasi model ARIMA pada data nonstasioner………. 58
Tabel 18. Uji Ljung-Box model ARIMA pada data nonstasioner………... 60
Tabel 19. Uji ARCH-LM model ARIMA pada data nonstasioner……….. 61
Tabel 20. Uji Ramsey RESET model ARIMA pada data nonstasioner……….. 62
xi
differencing satu ……….………… 65
Tabel 24. Estimasi model ARIMA pada data nonstasioner dengan outlier….... 66 Tabel 25. Uji Ljung-Box pada data nonstasioner dengan outlier……… 68 Tabel 26. Uji ARCH-LM model ARIMA pada data nonstasioner dengan
outlier……….. 69
Tabel 27. Uji Ramsey RESET model ARIMA pada data nonstasioner dengan
outlier ………..………..………. 70
Tabel 28. Nilai eror model ARIMA pada data nonstasioner dengan outlier ….. 71 Tabel 29. Pelatihan ANFIS pada data stasioner berdasarkan jumlah klaster ... 71 Tabel 30. Pelatihan ANFIS pada data stasioner berdasarkan fungsi
keanggotaan ……… 72 Tabel 31. Pelatihan ANFIS pada data stasioner dengan outlier berdasarkan
jumlah klaster ………..….……….. 73 Tabel 32. Pelatihan ANFIS pada data stasioner dengan outlier berdasarkan
fungsi keanggotaan ………. 74 Tabel 33. Pelatihan ANFIS pada data nonstasioner berdasarkan jumlah
klaster ………. 76 Tabel 34. Pelatihan ANFIS pada data nontasioner berdasarkan fungsi
keanggotaan ………..…..…… 76 Tabel 35. Pelatihan ANFIS pada data nonstasioner dengan outlier
xii
Tabel 37. (a) Ringkasan analisis ARIMA pada data stasioner ..………. 80 Tabel 37. (b) Ringkasan analisis ANFIS pada data stasioner…………...……... 80 Tabel 38. (a) Ringkasan analisis ARIMA pada data stasioner dengan outlier ... 81 Tabel 38. (b) Ringkasan analisis ANFIS pada data stasioner dengan outlier .... 81 Tabel 39. (a) Ringkasan analisis ARIMA pada data nonstasioner……...……... 82 Tabel 39. (b) Ringkasan analisis ANFIS pada data nonstasioner……… 82 Tabel 40. (a) Ringkasan analisis ARIMA pada data nonstasioner dengan
outlier ……….………..…….. 83
Tabel 40. (b) Ringkasan analisis ANFIS pada data nontasioner dengan outlier. 83 Tabel 41. Statistik uji ADF pada data harga minyak kelapa sawit Indonesia .... 85 Tabel 42. Model ARIMA yang diduga pada data harga minyak kelapa sawit
Indonesia ……….…..……. 86 Tabel 43. Estimasi model ARIMA pada data harga minyak kelapa sawit
Indonesia ………. 87 Tabel 44. Nilai eror dari model ARIMA pada data harga minyak kelapa sawit
Indonesia ……….………... 88 Tabel 45. Uji Ljung-Box model ARIMA pada data harga minyak kelapa
sawit Indonesia ………...……… 88 Tabel 46. Uji ARCH-LM model ARIMA pada data harga minyak kelapa
sawit Indonesia ……….…….……… 90 Tabel 47. Uji Ramsey RESET model ARIMA pada data harga minyak kelapa
xiii
Tabel 49. Input-input ANFIS yang dicobakan pada data harga minyak kelapa sawit Indonesia……… 92 Tabel 50. Pelatihan ANFIS pada data harga minyak kelapa sawit Indonesia
berdasarkan input dan jumlah klaster …………..………..……. 93 Tabel 51. Pelatihan ANFIS pada data harga minyak kelapa sawit Indonesia
berdasarkan fungsi keanggotaan ………..……….………. 94 Tabel 52. (a) Ringkasan analisis ARIMA pada data harga minyak kelapa
sawit Indonesia……… 95 Tabel 52. (b) Ringkasan analisis ANFIS pada data harga minyak kelapa sawit
xiv
Gambar 1. Bagan tahap-tahap analisis runtun waktu ARIMA ……....……..… 10
Gambar 2. Struktur jaringan syaraf tiruan dengan input Z1,t , Z2,t , …, Zm,t dan bobot koneksinya w1, w2, …, wn …...…………..……….………… 15
Gambar 3. Kurva fungsi keanggotaan Triangular…………..……… 17
Gambar 4. Kurva fungsi keanggotaan Trapezoidal………. 18
Gambar 5. Kurva fungsi keanggotaan Gaussian………..……….. 18
Gambar 6. Kurva fungsi keanggotaan Generalized Bell………. 19
Gambar 7. Diagram blok sistem inferensi fuzzy……….. 21
Gambar 8. ANFIS dengan model Sugeno………... 25
Gambar 9. Arsitektur jaringan ANFIS……… 25
Gambar 10.Contoh model ANFIS untuk 2 input dengan 9 aturan ………….... 28
Gambar 11.Flow chart ANFIS ……….………. 40
Gambar 12.Grafik runtun waktu data stasioner ……….……… 41
Gambar 13.(a) Plot ACF dari data stasioner ……….………. 42
Gambar 13.(b) Plot PACF dari data stasioner ……… 43
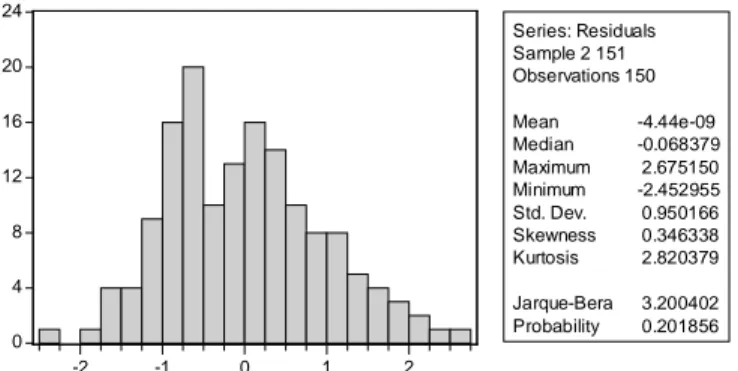
Gambar 14.Uji normalitas model ARIMA pada data stasioner …….………… 46
Gambar 15.Grafik runtun waktu data stasioner dengan outlier ………….…… 48
Gambar 16.(a) Plot ACF dari data stasioner dengan outlier ……….…………. 49
Gambar 16.(b) Plot PACF dari data stasioner dengan outlier ……… 50
Gambar 17.Uji normalitas model ARIMA pada data stasioner dengan outlier . 53 Gambar 18.Grafik runtun waktu data nonstasioner ………..….. 55
xv
Gambar 21.Uji normalitas model ARIMA pada data nonstasioner ………...…. 61 Gambar 22.Grafik runtun waktu data nonstasioner dengan outlier ……… 63 Gambar 23.Grafik runtun waktu data nonstasioner dengan outlier differencing
satu……… 64 Gambar 24.(a) Plot ACF dari data nontasioner dengan outlier differencing satu 65 Gambar 24.(b) Plot PACF dari data nontasioner dengan outlier differencing
Satu……… 66 Gambar 25.Uji normalitas model ARIMA pada data nonstasioner dengan
outlier ……….……….. 69
Gambar 26.Grafik runtun waktu data harga minyak kelapa sawit Indonesia …. 84 Gambar 27.Grafik runtun waktu data harga minyak kelapa sawit Indonesia
differencing satu ………..……… 85
Gambar 28.(a) Plot ACF dari data harga minyak kelapa sawit Indonesia …….. 86 Gambar 28.(b) Plot PACF dari data harga minyak kelapa sawit Indonesia .…. 86 Gambar 29.Uji normalitas model ARIMA pada data harga minyak kelapa
sawit Indonesia ……….………... 89 Gambar 30.Perbandingan target dan output ANFIS pada data harga minyak
kelapa sawit Indonesia……….. 94 Gambar 31.Hasil eror ANFIS pada data harga minyak kelapa sawit Indonesia.. 95
xvi
Lampiran 1. Data stasioner dibangkitkan dengan R……… 101 Lampiran 2. Data nonstasioner dibangkitkan dengan R ………. 103 Lampiran 3. Data harga minyak kelapa sawit Indonesia ……… 105 Lampiran 4. Training dan Checking ANFIS menggunakan Matlab ………….. 111 Lampiran 5. Pelatihan ANFIS pada data nonstasioner berdasarkan jumlah
klaster……….. 113 Lampiran 6. Pelatihan ANFIS pada data nonstasioner dengan outlier
berdasarkan jumlah klaster………..114 Lampiran 7. Estimasi model ARIMA pada data harga minyak kelapa sawit
Indonesia………. 115 Lampiran 8. Hasil pelatihan ANFIS pada data harga minyak kelapa sawit
Indonesia terhadap berbagai input……….. 120 Lampiran 9. Perintah pada Software………... 122
1
PENDAHULUAN
1.1 Latar Belakang
Analisis data runtun waktu (time series) merupakan salah satu bahasan penting dalam ilmu statistika. Dengan menganalisis bentuk pola deret data, dapat dilakukan peramalan untuk satu atau beberapa periode ke depan. Model runtun waktu konvensional yang umum digunakan untuk peramalan data runtun waktu seperti ARIMA (Box dan Jenkins, 1976), ARCH (Engle, 1982) dan GARCH (Bollerslev, 1986). Namun, seiring waktu ternyata teknik ini memiliki keterbatasan kemampuan dalam pemodelan data runtun waktu, terutama pada data runtun waktu nonlinier (Wei, 2011).
Salah satu metode yang digunakan dalam peramalan data runtun waktu nonlinier adalah Neural Network (McCulloch & Pitts, 1943) dan Fuzzy Logic (Zadeh, 1965). Kemampuan pembelajaran pada neural network memungkinkan lebih efektif menyelesaikan masalah nonlinier bahkan sistem yang kacau sekalipun dan pada fuzzy logic dapat mengubah masalah kompleks menjadi masalah sederhana menggunakan perkiraan penalaran. Kedua metode tersebut mengestimasi fungsi tanpa menggunakan model matematis melainkan dilakukan melalui proses pembelajaran data. Metode neural network melakukan komputasi dengan mensimulasikan struktur dan fungsi seperti jaringan syaraf dalam otak. Pada struktur jaringan neural network keseluruhan tingkah laku masukan-keluaran ditentukan oleh sekumpulan parameter-parameter yang dimodifikasi. Sedangkan pada fuzzy logic, dilakukan dengan cara melukiskan suatu sistem dengan
pengetahuan linguistik yang mudah dimengerti. Sistem fuzzy memiliki keunggulan dalam memodelkan aspek kualitatif dari pengetahuan manusia dan proses pengambilan keputusan.
Walaupun teknik neural network dan fuzzy logic dapat memecahkan masalah kompleks, akan tetapi tetap pula memiliki keterbatasan (Khan, 1998). Pada sistem yang semakin kompleks, fuzzy logic biasanya sulit dan membutuhkan waktu lama untuk menentukan aturan dan fungsi keanggotaan yang tepat. Pada
neural network, tahapan proses sangat panjang dan rumit sehingga tidak efektif
pada jaringan yang cukup besar. Fuzzy logic tidak memiliki kemampuan untuk belajar dan beradaptasi. Sebaliknya neural network memiliki kemampuan untuk belajar dan beradaptasi namun tidak memiliki kemampuan penalaran seperti yang dimiliki pada fuzzy logic. Oleh karena itu dikembangkan metode yang mengkombinasikan kedua teknik itu yaitu biasa disebut sistem hybrid, salah satunya adalah Adaptive Neuro Fuzzy Inference System atau ANFIS (Jang, 1993).
ANFIS merupakan metode yang menggunakan jaringan syaraf tiruan (neural network) untuk mengimplementasikan sistem inferensi fuzzy (fuzzy
inference system). Dengan kata lain ANFIS adalah penggabungan mekanisme
sistem inferensi fuzzy yang digambarkan dalam arsitektur jaringan syaraf tiruan. Pada pemodelan statistika, ANFIS diterapkan pada masalah klasifikasi, clustering, regresi, dan peramalan pada data runtun waktu.
ANFIS telah banyak diterapkan pada masalah peramalan data runtun waktu. Atsalakis, dkk (2007) menggunakan ANFIS untuk prediksi peluang tren pada nilai tukar mata uang (kurs) diperoleh bahwa metode ini handal untuk memprediksi naik turunnya fluktuasi nilai tukar. Wei (2011) menerapkan ANFIS
untuk peramalan saham TAIEX. Mordjaoi dan Boudjema (2011) melakukan peramalan dan pemodelan permintaan listrik dengan ANFIS. Aldrian dan Djamil (2008) mengaplikasikan ANFIS untuk prediksi curah hujan. Penelitian-penelitian yang dilakukan menunjukkan bahwa pendekatan metode ANFIS cukup handal dan akurat dalam peramalan data runtun waktu.
Data runtun waktu nonstasioner banyak sekali dijumpai dalam kehidupan sehari-hari. Metode konvensional seperti ARIMA seringkali tidak efektif untuk peramalan data runtun waktu nonstasioner, menghasilkan eror yang besar atau varian tidak konstan. Analisis ARIMA merupakan metode linier yang membutuhkan beberapa asumsi harus terpenuhi. Oleh karena itu diperlukan metode nonlinier yang mampu menyelesaikan masalah nonlinier. ANFIS menjadi salah satu pilihan yang efektif untuk peramalan data runtun waktu nonlinier.
Dalam penulisan Tugas Akhir ini akan dilakukan analisis data runtun waktu menggunakan metode Autoregressive Integrated Moving Average (ARIMA) dan Adaptive Neuro-Fuzzy Inference System (ANFIS) pada empat karakteristik data yaitu stasioner, stasioner dengan outlier, nonstasioner, dan nonstasioner dengan outlier. Studi kasus yang dilakukan adalah penerapan metode ANFIS pada data harga minyak kelapa sawit Indonesia. Hasil analisis metode ANFIS yang dihasilkan dibandingkan dengan hasil metode ARIMA berdasarkan nilai RMSE.
Analisis ANFIS dalam Tugas Akhir ini menggunakan model Sugeno orde satu. Proses pengklasteran dilakukan dengan menggunakan metode Fuzzy
C-Means (FCM). Algoritma pembelajaran yang digunakan adalah metode optimasi Hybrid. Perangkat lunak yang digunakan adalah R, Eviews, Minitab, dan Matlab.
1.2 Tujuan
Tujuan yang hendak dicapai dari Tugas Akhir ini adalah:
1. Mengimplementasikan metode ANFIS untuk analisis data runtun waktu stasioner, stasioner dengan outlier, nonstasioner dan nonstasioner dengan
outlier kemudian dibandingkan dengan hasil analisis menggunakan
metode ARIMA.
2. Mengimplementasikan metode ANFIS pada data runtun waktu harga minyak kelapa sawit indonesia.
5
TINJAUAN PUSTAKA
2.1 Analisis Runtun Waktu dan Peramalan
Data runtun waktu (time series) adalah jenis data yang dikumpulkan menurut urutan waktu dalam suatu rentang waktu tertentu. Jika waktu dipandang bersifat diskrit (waktu dapat dimodelkan bersifat kontinu), frekuensi pengumpulan selalu sama. Dalam kasus diskrit, frekuensi dapat berupa detik, menit, jam, hari, minggu, bulan atau tahun.
Analisis runtun waktu merupakan salah satu prosedur statistika yang diterapkan untuk meramalkan struktur probabilitas keadaan yang akan datang dalam rangka pengambilan keputusan. Dasar pemikiran runtun waktu adalah pengamatan sekarang (Zt) dipengaruhi oleh satu atau beberapa pengamatan
sebelumnya (Zt-k). Dengan kata lain, model runtun waktu dibuat karena secara
statistik ada korelasi antar deret pengamatan. Tujuan analisis runtun waktu antara lain memahami dan menjelaskan mekanisme tertentu, meramalkan suatu nilai di masa depan, dan mengoptimalkan sistem kendali (Makridakis, dkk, 1999).
Peramalan adalah kegiatan mengestimasi apa yang akan terjadi pada masa yang akan datang dengan waktu yang relatif lama. Sedangkan ramalan adalah situasi atau kondisi yang akan diperkirakan akan terjadi pada masa yang akan datang. Untuk memprediksikan hal tersebut diperlukan data yang akurat di masa lalu, untuk dapat melihat situasi di masa yang akan datang.
2.2 Model ARIMA
Model Autoregressive Integrated Moving Average (ARIMA) merupakan salah satu model yang populer dalam peramalan data runtun waktu. Proses ARIMA (p,d,q) merupakan model runtun waktu ARMA(p,q) yang memperoleh
differencing sebanyak d. Proses ARMA (p,q) adalah suatu model campuran antara autoregressive orde p dan moving average orde q.
Autoregressive (AR) merupakan suatu observasi pada waktu t dinyatakan sebagai fungsi linier terhadap p waktu sebelumnya ditambah dengan sebuah
residual acak at yang white noise yaitu independen dan berdistribusi normal
dengan rata-rata 0 dan varian konstan σa2, ditulis at ~ N(0, σa2). Bentuk umum
model autoregressive orde p atau lebih ringkas ditulis model AR(p) dapat dirumuskan sebagai berikut:
t p t p t t t Z Z Z a Z 1 12 2... Jika B adalah operator backshif yang dirumuskan sebagai:
BZt = Zt-1
maka model AR(p) dapat ditulis sebagai berikut:
B Zt at dengan
p
pB B B B 1 1 2 2...Moving average (MA) digunakan untuk menjelaskan suatu fenomena
bahwa suatu observasi pada waktu t dinyatakan sebagai kombinasi linier dari sejumlah eror acak at. Bentuk umum model moving average orde q atau lebih
q t q t t t t a a a Z 1... atau t t B a Z ( ) dengan, (B)(11B...qBq)
Bentuk umum dari model ARIMA adalah:
t t d a B Z B B)(1 ) ( ) ( dengan ) ... 1 ( ) ( 1 p pB B B merupakan operator AR ) ... 1 ( ) (B 1B qBq merupakan operator MA (Soejoeti, 1987) 2.3 Istilah-Istilah dalam Analisis Runtun Waktu
2.3.1 Stasioner
Suatu deret pengamatan dikatakan stasioner apabila proses tidak berubah seiring dengan adanya perubahan deret waktu. Jika suatu deret waktu Zt stasioner
maka nilai tengah (mean), varian dan kovarian deret tersebut tidak dipengaruhi oleh berubahnya waktu pengamatan, sehingga proses berada dalam keseimbangan statistik (Soejoeti, 1987).
Uji stasioner dengan Augmented Dickey Fuller (ADF) merupakan pengujian stasioner dengan menentukan apakah data runtun waktu mengandung akar unit (unit root). Untuk memperoleh gambaran mengenai uji akar-akar unit, berikut ini ditaksir model runtun waktu dengan proses AR(1) :
t 1 t
t Z a
Z
Hipotesis
H0 : = 1 (Data tidak stasioner).
H1 : < 1 (Data stasioner).
Statistik uji:
= − 1
( ) Kriteria Penolakan
H0 ditolak jika > pada taraf signifikansi α.
(Wei, 2006) 2.3.2 Differencing
Data runtun waktu yang tidak stasioner dapat distasionerkan dengan melakukan differencing derajat d. Untuk mendapatkan kestasioneran dapat dibuat deret baru yang terdiri dari differencing antara periode yang berurutan:
∇ = −
deret baru ∇ akan mempunyai n-1 buah nilai. Apabila differencing pertama tidak menunjukkan stasioner tercapai maka dapat dilakukan differencing kedua:
∇ = ∇ − ∇ = − 2 +
∇ dinyatakan sebagai deret differencing orde kedua. Deret ini akan mempunyai
n-2 buah nilai.
(Soejoeti,1987) 2.3.3 Autocorrelation Function (ACF)
Suatu proses (Zt) yang stasioner terdapat nilai rata-rata E(Zt)
, varian
2 2 t t E Z ZVar dan kovarian Cov(Zt,Ztk). Kovarian antara Ztdan
k t
), )( ( ) , (
k Cov Zt Ztk E Zt Ztk dan autokorelasi antara Ztdan Ztk adalah :
0 ) ( ) ( ) , ( k k t t k t t k Z Var Z Var Z Z Cov dengan 0 ) ( ) (Zt Var Ztk
Var . Fungsi
k dinamakan autokovarian dan
kdinamakan fungsi autokorelasi (ACF).
(Wei, 2006) 2.3.4 Partial Autocorrelation Function (PACF)
Fungsi Autokorelasi Parsial (PACF) dapat dinyatakan sebagai:
) ,..., , ( 1 1 t t k t t k kk Corr Z Z Z Z
atau dapat dihitung menggunakan persamaan berikut :
1 11
1 1 1 1 1 2 1 1 22 1 1 1 1 1 1 2 1 1 2 1 3 1 2 2 1 1 1 33 . . .1 2 2 1 1 1 3 2 1 2 3 1 1 2 2 1 1 1 3 2 1 2 3 1 1 1 1 1 1 k k k k k k kk k k k k k k k (Wei, 2006) 2.4 Tahapan Pemodelan ARIMA
Prosedur Box‐Jenkins adalah suatu prosedur standar yang banyak digunakan dalam pembentukan model ARIMA. Prosedur ini terdiri dari empat tahapan yang iteratif dalam pembentukan model ARIMA pada suatu data runtun waktu, yaitu tahap identifikasi, estimasi, diagnosis, dan peramalan (Suhartono, 2008).
Gambar 1. Bagan tahap-tahap analisis runtun waktu ARIMA
(Suhartono, 2008) 1. Tahap IDENTIFIKASI
(Identifikasi model dugaan sementara)
2. Tahap ESTIMASI (Estimasikan parameter model)
3. Tahap DIAGNOSIS (Verifikasi apakah model sesuai?)
4. Tahap PERAMALAN (Gunakan model untuk peramalan)
Ya Tidak
2.4.1 Identifikasi
Penentuan orde p dan q dari model ARIMA pada suatu data runtun waktu dilakukan dengan mengidentifikasi plot Autocorrelation Function (ACF) dan
Partial Autocorrelation Function (PACF) dari data yang sudah stasioner. Berikut
ini adalah petunjuk umum untuk penentuan orde p dan q pada suatu data runtun waktu yang sudah stasioner.
Tabel 1. Pola ACF dan PACF dari proses yang stasioner
Proses ACF PACF
AR(p) Turun cepat secara
eksponensial / sinusoidal Terputus setelah lag p MA(q) Terputus setelah lag q Turun cepat secara
eksponensial / sinusoidal ARMA(p,q) Turun cepat secara
eksponensial / sinusoidal
Turun cepat secara eksponensial / sinusoidal AR(p) atau
MA(q) Terputus setelah lag q Terputus setelah lag p
White noise
(Acak)
Tidak ada yang signifikan (tidak ada yang keluar batas)
Tidak ada yang signifikan (tidak ada yang keluar batas)
(Suhartono, 2008) 2.4.2 Estimasi
Setelah diperoleh model yang diperkirakan cocok, langkah selanjutnya adalah mengestimasi parameter model dan pengujian signifikansi parameter. Hipotesis :
H0 : parameter = 0 (parameter tidak signifikan terhadap model)
H1 : parameter ≠ 0 (parameter signifikan terhadap model)
Taraf signifikansi : α Statistik uji :
= ( )
Kriteria uji :
Tolak H0 jika > ⁄ ; atau p-value <
Dengan n = jumlah pengamatan
(Agung, 2009)
2.4.3 Diagnosis
Diagnosis dimaksudkan untuk memeriksa apakah model estimasi sudah cocok dengan data yang dipunyai. Jika ditemui penyimpangan yang cukup serius, harus dirumuskan kembali model baru, selanjutnya diestimasi dan verifikasi lagi model baru tersebut.
Pada tahap ini dilakukan pembandingan dengan model lain yaitu dengan menambah dan mengurangi parameter model yang telah diidentifikasi. Dalam verifikasi ini berlaku prinsip parsimonious (melibatkan parameter sedikit mungkin) dan MSE terkecil, sehingga dari langkah verifikasi ini diambil model yang paling cocok dan melibatkan parameter sedikit mungkin.
2.4.4 Pengujian Asumsi 2.4.4.1 Uji Ljung-Box
Uji Ljung-Box digunakan untuk menguji independensi residual antar lag pada model ARIMA (p,d,q).
Hipotesis :
H0: k = 0 (tidak ada korelasi residual antar lag).
H1: paling sedikit ada satu k0 dengan k = 1,2,3,...l (ada korelasi residual antar lag).
Statistik uji : ) ˆ ( ) 2 ( 1 2
m k k k n T T LB Kriteria uji : H0 ditolak jika LB > ( ,) 2 l
atau p-value < dengan T = ukuran sampel dan l = panjang lag
(Agung, 2009) 2.4.4.2 Uji Normalitas
Uji normalitas yang digunakan adalah uji Jarque-Bera, sebagai berikut : Hipotesis :
H0 : residual berdistribusi normal
H1 : residual tidak berdistribusi normal
Taraf signifikansi : α Statistik uji : = 6 + ( − 3) 4
dengan T = ukuran sampel, S = nilai skewness, dan K = nilai kurtosis. Kriteria uji :
H0 ditolak jika p-value < α
(Agung, 2009) 2.4.4.3 Uji Linieritas
Uji linieritas yang digunakan adalah dengan uji RESET (Regression Error
Specification Test) versi Ramsey. Uji Ramsey RESET merupakan uji yang
Least Squares. Uji ini dilakukan dengan memberi pangkat k ke nilai dugaan
variabel dependen ( ) kemudian ditambahkan ke model sebagai variabel independen (Agung, 2009). Hipotesis : H0 : Model linier H1 : Model nonlinier Taraf signifikansi : α Statistik uji : RESET =
vv n k
k v v e e / ˆ ' ˆ 1 / ˆ ' ˆ ˆ ' ˆdengan eˆ adalah nilai residual prediksi dari model linear (awal), ˆ adalah
residual dari model alternatif (baru) dan n adalah ukuran sampel.
Kriteria uji :
H0 ditolak jika p-value < α
(Warsito dan Ispriyanti, 2004) 2.5 Jaringan Syaraf Tiruan (Neural Network)
Jaringan syaraf tiruan (JST) atau yang biasa disebut Artificial Neural
Network (ANN) atau Neural Network (NN) saja, merupakan sistem pemroses
informasi yang memiliki karakteristik mirip dengan jaringan syaraf pada makhluk hidup. Neural network berupa suatu model sederhana dari suatu syaraf nyata dalam otak manusia seperti suatu unit threshold yang biner.
Neural network merupakan sebuah mesin pembelajaran yang dibangun
dari sejumlah elemen pemrosesan sederhana yang disebut neuron atau node. Setiap neuron dihubungkan dengan neuron yang lain dengan hubungan komunikasi langsung melalui pola hubungan yang disebut arsitektur jaringan.
Bobot-bobot pada koneksi mewakili besarnya informasi yang digunakan jaringan. Metode yang digunakan untuk menentukan bobot koneksi tersebut dinamakan dengan algoritma pembelajaran. Setiap neuron mempunyai tingkat aktivasi yang merupakan fungsi dari input yang masuk padanya. Aktivasi yang dikirim suatu neuron ke neuron lain berupa sinyal dan hanya dapat mengirim sekali dalam satu waktu, meskipun sinyal tersebut disebarkan pada beberapa neuron yang lain.
Misalkan input Z1,t, Z2,t, …, Zm,t yang bersesuaian dengan sinyal dan
masuk ke dalam saluran penghubung. Setiap sinyal yang masuk dikalikan dengan bobot koneksinya yaitu w1, w2, …, wm sebelum masuk ke blok penjumlahan yang
berlabel ∑. Kemudian blok penjumlahan akan menjumlahkan semua input terbobot dan menghasilkan sebuah nilai yaitu Zt_in.
Zt_in = ∑ , .wi = Zt,1.w1 + Zt,1.w2 + … + Zm,1.wm
Aktivasi Zt ditentukan oleh fungsi input jaringannya, Zt=f(Zt_in) dengan f
merupakan fungsi aktivasi yang digunakan.
Gambar 2. Struktur jaringan syaraf tiruan dengan input Z1,t, Z2,t, …, Zm,t dan bobot
koneksinya w1, w2, …, wm Zt wm w2 w1 Z1,t Z2,t Zm,t #
∑
Secara garis besar neural network mempunyai dua tahap pemrosesan informasi, yaitu tahap pelatihan dan tahap pengujian.
1. Tahap Pelatihan
Tahap pelatihan dimulai dengan memasukkan pola-pola pelatihan (data latih) ke dalam jaringan. Dengan menggunakan pola-pola ini jaringan akan mengubah-ubah bobot yang menjadi penghubung antar node. Pada setiap iterasi (epoch) dilakukan evaluasi terhadap output jaringan. Tahap ini berlangsung pada beberapa iterasi dan berhenti setelah jaringan menemukan bobot yang sesuai dan nilai eror yang diinginkan telah tercapai atau jumlah iterasi telah mencapai nilai yang ditetapkan. Selanjutnya bobot ini menjadi dasar pengetahuan pada tahap pengujian. 2. Tahap Pengujian
Pada tahap ini dilakukan pengujian terhadap suatu pola masukan yang belum pernah dilatihkan sebelumnya (data uji) menggunakan bobot-bobot yang telah dihasilkan pada tahap pelatihan. Diharapkan bobot-bobot hasil pelatihan yang sudah menghasilkan eror minimal juga akan memberikan eror yang kecil pada tahap pengujian.
(Warsito, 2009) 2.6 Logika Fuzzy (Fuzzy Logic)
2.6.1 Teori Himpunan Fuzzy
Berbeda dengan teori himpunan klasik yang menyatakan suatu objek adalah anggota (ditandai dengan angka 1) atau bukan anggota (ditandai dengan angka 0) dari suatu himpunan dengan batas keanggotaan yang jelas/tegas (crips), teori himpunan fuzzy memungkinkan derajat keanggotaan suatu objek dalam
himpunan untuk menyatakan peralihan keanggotaan secara bertahap dalam rentang antara 0 sampai 1 atau ditulis [0,1].
Definisi himpunan fuzzy (fuzzy set) adalah sekumpulan obyek x dengan masing-masing obyek memiliki nilai keanggotaan (membership function) “μ” atau disebut juga dengan nilai kebenaran. Jika Zi,t adalah sekumpulan obyek, Zi,t={Z1,t , Z2,t , … , Zm,t) dan anggotanya dinyatakan dengan Z maka himpunan fuzzy dari A
di dalam Z adalah himpunan dengan sepasang anggota atau dapat dinyatakan dengan:
= ( , ( ))| ∈ ,
Dengan F adalah notasi himpunan fuzzy, ( ) adalah derajat keanggotaan dari Z (nilai antara 0 sampai 1).
(Kusumadewi, 2006) 2.6.2 Fungsi Keanggotaan Fuzzy
Fungsi keanggotaan (membership function) adalah suatu fungsi yang menunjukkan pemetaan titik-titik input data ke dalam nilai keanggotaannya. Ada beberapa fungsi yang dapat digunakan melalui pendekatan fungsi untuk mendapatkan nilai keanggotaan, seperti Triangular, Trapezoidal, Gaussian, dan
Generalized Bell.
1. Fungsi Keanggotaan Triangular
Fungsi keanggotaan triangular terbentuk oleh tiga parameter: a,b,dan c, sebagai berikut: ( ) = ⎩ ⎪ ⎨ ⎪ ⎧( − )0 ( − ) ( − ) ( − ) ≤ ≥ ≤ ≤ ≤ ≤
2. Fungsi Keanggotaan Trapezoidal
Gambar 4. Kurva fungsi keanggotaan Trapezoidal
Fungsi keanggotaan trapezoidal terbentuk oleh empat parameter: a, b, c, dan d, sebagai berikut:
( ) = ⎩ ⎪ ⎨ ⎪ ⎧( − )0 ( − ) 1 ( − ) ( − ) ≤ ≥ ≤ ≤ ≤ ≤ ≤ ≤
3. Fungsi Keanggotaan Gaussian
Fungsi keanggotaan gaussian terbentuk oleh dua parameter: σ dan c, sebagai berikut:
( ) = 4. Fungsi Keanggotaan Generalized Bell
Gambar 6. Kurva fungsi keanggotaan Generalized Bell
Fungsi keanggotaan generalized bell terbentuk oleh tiga parameter: a,
b,dan c, sebagai berikut:
( ) = 1
1 + −
(Matlab, 1999) 2.6.3 Fuzzy C-Means (FCM)
Fuzzy C-Means (FCM) adalah suatu teknik pengklasteran data yang mana
keberadaan tiap data dalam suatu cluster ditentukan oleh nilai keanggotaan. Konsep FCM pertama kali adalah menentukan pusat cluster yang akan menandai lokasi rata-rata untuk tiap cluster. Pada kondisi awal pusat cluster ini masih belum akurat. Tiap-tiap data memiliki derajat keanggotaan untuk tiap cluster. Dengan cara memperbaiki pusat cluster dan nilai keanggotaan tiap-tiap data secara berulang maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi yang tepat.
Algoritma Fuzzy C-Means diberikan sebagai berikut: 1. Tentukan:
a. Matriks Z berukuran n x m, dengan n = jumlah data yang akan diklaster dan m = jumlah variabel (kriteria),
b. Jumlah cluster yang dibentuk = C (≥2), c. Pangkat (pembobot) = w (>1),
d. Maksimum iterasi,
e. Kriteria penghentian = ξ (nilai positif yang sangat kecil) f. Iterasi awal, t=1 dan ∆=1,
2. Bentuk matriks partisi awal U0 sebagai berikut:
= ⎣ ⎢ ⎢ ⎢ ⎡ ( , ) ( , ) … ( , ) ( , ) ( , ) ⋯ ( , ) ⋮ ( , ) ⋮ ( , ) ⋮ ⋯ ( , )⎦⎥ ⎥ ⎥ ⎤
(matriks partisi awal biasanya dipilih secara acak) 3. Hitung pusat cluster V untuk setiap cluster:
=∑ ( ) .
∑ ( )
4. Perbaiki derajat keanggotaan setiap data pada setiap cluster (perbaiki matriks partisi) sebagai berikut:
=
/( )
dengan
= ( , − ) = ( − )
5. Tentukan kriteria berhenti yaitu perubahan matriks partisi pada iterasi sekarang dengan iterasi sebelumnya sebagai berikut:
∆= ‖ − ‖
Apabila ∆ ≤ ξ maka iterasi dihentikan, namun apabila ∆ > ξ maka naikkan iterasi (t=t+1) dan kembalikan ke langkah 3.
(Kusumadewi, 2006) 2.6.4 Sistem Inferensi Fuzzy
Sistem Inferensi Fuzzy (Fuzzy Inference System atau FIS) merupakan suatu kerangka komputasi yang didasarkan pada teori himpunan fuzzy, aturan fuzzy berbentuk if-then, dan penalaran fuzzy. Sistem inferensi fuzzy menerima input
crisp. Input ini kemudian dikirim ke basis pengetahuan yang berisi n aturan fuzzy
dalam bentuk if-then. Fire strength (bobot) akan dicari pada setiap aturan. Apabila jumlah aturan lebih dari satu, maka akan dilakukan agregasi dari semua aturan. Selanjutnya, pada hasil agregasi akan dilakukan defuzzy untuk mendapatkan nilai
crisp sebagai keluaran sistem.
Gambar 7. Diagram blok sistem inferensi fuzzy
(Kusumadewi, 2006) aturan-n crisp fuzzy fuzzy fuzzy crisp Input If-then If-then Agregasi Defuzzy Agregasi aturan-1
Sistem inferensi fuzzy terdiri dari 5 (lima) bagian :
1. Basis aturan (rule base), terdiri dari sejumlah aturan fuzzy if-then,
2. Basis data (database) yang mendefinisikan fungsi keanggotaan dari himpunan fuzzy yang digunakan dalam aturan fuzzy, biasanya basis aturan dan basis data digabung dan disebut basis pengetahuan (knowledge base), 3. Satuan pengambilan keputusan (decision-making unit) yang membentuk
operasi inferensi pada aturan (rule),
4. Antarmuka fuzzifikasi (fuzzification interface) yang mengubah input ke dalam derajat yang sesuai dengan nilai linguistik (linguistik value),
5. Antarmuka defuzzifikasi (defuzzification interface) yang mengubah hasil
fuzzy inferensi ke bentuk output yang kompak.
(Jang, 1993) 2.6.5 FIS Model Sugeno (TSK)
Sistem inferensi fuzzy menggunakan metode Sugeno memiliki karakteristik yaitu konsekuen tidak merupakan himpunan fuzzy, namun merupakan suatu persamaan linier dengan variabel-variabel sesuai dengan variabel inputnya. Metode ini diperkenalkan oleh Takagi Sugeno Kang (TSK) pada 1985. Aturan fuzzy metode Sugeno adalah sebagai berikut:
If Z1,t is A1 and Z2,t is A2 then f=h(Z1,t , Z2,t)
Ada dua model untuk sistem inferensi fuzzy dengan menggunakan metode Sugeno, yaitu model Sugeno orde 0 dan model Sugeno orde 1, sebagai berikut:
1. Model Fuzzy Sugeno Orde 0
Secara umum bentuk model fuzzy Sugeno orde 0 adalah:
dengan Am adalah himpunan fuzzy ke-m sebagai anteseden, ° adalah
operator fuzzy (seperti AND atau OR), dan k adalah suatu konstanta (tegas) sebagai konsekuen.
2. Model fuzzy Segeno Orde 1
Secara umum bentuk fuzzy sugeno orde 1 adalah:
If (Z1,t is A1) ° (Z2,t is A2) °… ° (Zm,t is Am) then f=p1 Z1,t + … +pm Zm,t + q
dengan Am adalah himpunan fuzzy ke-m sebagai anteseden, ° adalah
operator fuzzy (seperti AND atau OR), pm adalah suatu konstanta (tegas)
ke-m dan q juga merupakan konstanta dalam konsekuen.
(Kusumadewi, 2006) 2.7 ANFIS: Adaptive Neuro Fuzzy Infererence System
2.7.1 Gambaran Umum ANFIS
Model Fuzzy dapat digunakan sebagai pengganti dari banyak lapisan. Dalam hal ini sistem dapat dibagi menjadi dua grup, yaitu satu grup berupa jaringan syaraf dengan bobot-bobot fuzzy dan fungsi aktivasi fuzzy, dan grup kedua berupa jaringan syaraf dengan input yang di-fuzzy-kan pada lapisan pertama atau kedua, namun bobot-bobot pada jaringan syaraf tersebut tidak di-fuzzy-kan. Menurut Osowski (2004) dalam Kusumadewi (2009), Neuro Fuzzy termasuk kelompok kedua .
ANFIS (Adaptive Neuro Fuzzy Inference System atau Adaptive
Network-based Fuzzy Inference System) adalah arsitektur yang secara fungsional sama
dengan fuzzy rule base model Sugeno. Arsitektur ANFIS juga sama dengan jaringan syaraf dengan fungsi radial dengan sedikit batasan tertentu. Bisa dikatakan bahwa ANFIS adalah suatu metode yang mana dalam melakukan
penyetelan aturan digunakan algoritma pembelajaran terhadap sekumpulan data. Pada ANFIS juga memungkinkan aturan-aturan untuk beradaptasi.
Agar jaringan dengan fungsi basis radial ekuivalen dengan fuzzy berbasis aturan model Sugeno orde 1 ini, diperlukan batasan:
a. Keduanya harus memiliki metode agregasi yang sama (rata-rata terbobot atau penjumlahan terbobot) untuk menurunkan semua outputnya.
b. Jumlah fungsi aktivasi harus sama dengan jumlah aturan fuzzy (if-then). c. Jika ada beberapa input pada basis aturannya, maka tiap fungsi aktivasi
harus sama dengan fungsi keanggotaan tiap-tiap inputnya.
d. Fungsi aktivasi dan aturan-aturan fuzzy harus memiliki fungsi yang sama untuk neuron-neuron dan aturan-aturan yang ada di sisi outputnya.
(Kusumadewi, 2006) 2.7.2 Arsitektur ANFIS
Misalkan input terdiri atas Z1,t dan Z2,t dan sebuah output Zt dengan aturan
model Sugeno orde 1. Orde satu dipilih dengan pertimbangan kesederhanaan dan kemudahan perhitungan. Model Sugeno orde satu dengan dua aturan fuzzy if-then adalah sebagai berikut:
Aturan 1 : If Z1,t is A1 and Z2,t is B1 then f1 = p1. Z1,t + q1. Z2,t + r1
Premis Konsekuen
Aturan 2 : If Z1,t is A2 and Z2,t is B2 then f2 = p2. Z1,t + q2. Z2,t + r2
dengan Ai dan Bi adalah nilai-nilai keanggotaan merupakan label linguistik
(seperti “kecil” atau “besar”), pi, qi, dan ri adalah parameter konsekuen.
Gambar 8. ANFIS dengan model Sugeno
Gambar 9. Arsitektur jaringan ANFIS
(Jang, Sun, dan Mizutani, 1997)
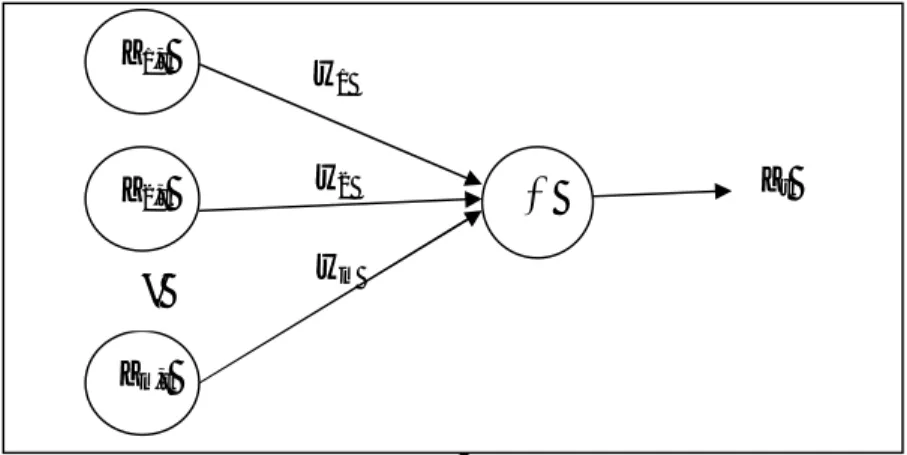
f = = + A1 A2 B1 B2 w1 w2 f1 = p1 Z1,t + q1 Z2,t + r1 f2 = p2 Z1,t + q2 Z2,t + r2 Parameter premis Parameter konsekuen 2f2 1f1 2 2 w2 w1 Zt Z1,t Z2,t ∑ A1 A2 B1 B2 N N Π Π Lapisan 1 2 3 4 5 Z1,t Z2,t Z1,t Z2,t
2.7.3 Jaringan ANFIS
Jaringan ANFIS terdiri dari lapisan-lapisan sebagai berikut (Jang, Sun, dan Mizutani, 1997):
Lapisan 1:
Lapisan ini merupakan lapisan fuzzifikasi. Pada lapisan ini tiap neuron adaptif terhadap parameter suatu aktivasi. Output dari tiap neuron berupa derajat keanggotaan yang diberikan oleh fungsi keanggotaan input. Misalkan fungsi keanggotaan Generalized Bell diberikan sebagai:
( ) =
+ −
Dengan Z adalah input, dalam hal ini Z ={Z1,t, Z2,t} dan {a, b, dan c} adalah
parameter-parameter, biasanya b=1. Jika nilai parameter-parameter ini berubah, maka bentuk kurva yang terjadi akan ikut berubah. Parameter-parameter ini biasanya disebut dengan nama parameter premis.
Lapisan 2:
Lapisan ini berupa neuron tetap (diberi simbol П) merupakan hasil kali dari semua masukan, sebagai berikut:
= .
Biasanya digunakan operator AND. Hasil perhitungan ini disebut firing strength dari sebuah aturan. Tiap neuron merepresentasikan aturan ke-i.
Lapisan 3:
Tiap neuron pada lapisan ini berupa neuron tetap (diberi simbol N) merupakan hasil perhitungan rasio dari firing strength ke-i (wi) terhadap jumlah
dari keseluruhan firing strength pada lapisan kedua, sebagai berikut: =
+ , = , . Hasil perhitungan ini disebut normalized firing strength.
Lapisan 4:
Lapisan ini berupa neuron yang merupakan neuron adaptif terhadap suatu output, sebagai berikut:
= , + , +
dengan adalah normalized firing strength pada lapisan ketiga dan pi, qi, dan ri
adalah parameter-parameter pada neuron tersebut. Parameter-parameter ini biasa disebut parameter konsekuen.
Lapisan 5:
Lapisan ini berupa neuron tunggal (diberi simbol ∑) merupakan hasil penjumlahan seluruh output dari lapisan keempat, sebagai berikut:
=∑ ∑
Gambar 10. Contoh model ANFIS untuk 2 input dengan 9 aturan
(Jang, Sun, dan Mizutani, 1997) 2.7.4 Algoritma Pembelajaran Hybrid
Pada saat parameter premis ditemukan keluaran keseluruhan akan merupakan kombinasi linier dari konsekuen parameter, yaitu:
=
+ + +
= ( , + , + ) + ( , + , + )
= ( , ) + ( , ) + ( ) + ( , ) + ( , ) + ( )
adalah linier terhadap parameter p1, q1, r1, p2, q2, dan r2.
Algoritma hibrida akan mengatur parameter-parameter konsekuen pi, qi,
dan ri secara maju (forward) dan akan mengatur parameter-parameter premis a, b,
dan c secara mundur (backward). Pada langkah maju, input jaringan akan merambat maju sampai pada lapisan keempat. Parameter-parameter konsekuen akan diidentifikasi dengan menggunakan least-square. Sedangkan pada langkah
Zt Z1,t
mundur, eror sinyal akan merambat mundur dan parameter-parameter premis akan diperbaiki dengan menggunakan metode gradient descent.
Tabel 2. Prosedur pembelajaran Hybrid metode ANFIS
Arah Maju Arah Mundur
Parameter Premis Tetap Gradient descent
Parameter Konsekuen Least-squares estimator Tetap
Sinyal Keluaran neuron Sinyal eror
(Jang, Sun, dan Mizutani, 1997) 2.7.5 LSE Rekursif
Apabila dimiliki m elemen pada vektor Zt (Zt berukuran m x 1) dan n
parameter ( berukuran n x 1), dengan baris ke-i pada matriks [A⋮ Zt]
dinotasikan sebagai [aiT⋮ Zt], Least-squares estimator ditulis sebagai berikut: ATA =AT Zt
Jika ATA adalah nonsingular dan bersifat unik maka dapat diberikan: = (ATA)-1AT Zt
atau dengan membuang ^ dan diasumsikan jumlah baris dari pasangan A dan Zt
adalah k maka diperoleh:
= (ATA)-1AT Zt
Pada LSE rekursif ditambahkan suatu pasangan data [aiT⋮ Zt], sehingga
terdapat sebanyak m+1 pasangan data. Kemudian LSE dihitung dengan bantuan . Karena jumlah parameter ada sebanyak n maka dengan metode inversi, sebagai berikut:
Selanjutnya iterasi dimulai dari data ke-(n+1), dengan P0 dan dihitung dengan
persamaan Pn dan , nilai Pk+1 dan dapat dihitung sebagai berikut:
= −( )
1 +
= + ( ( )− )
(Kusumadewi, 2006) 2.7.6 Model Propagasi Eror
Model propagasi eror digunakan untuk melakukan perbaikan terhadap parameter premis (a dan c). Konsep yang digunakan adalah gradient descent. Apabila dimiliki jaringan adaptif seperti Gambar 9, dan menyatakan eror pada neuron ke-j pada lapisan ke-i maka perhitungan eror pada tiap neuron pada tiap lapisan dirumuskan sebagai berikut:
a. Eror pada Lapisan 5
Pada lapisan 5 terdapat satu buah neuron. Propagasi eror yang menuju lapisan ini dirumuskan sebagai berikut:
= = −2( − )
dengan adalah output target, f adalah output jaringan, dan adalah jumlah kuadrat eror (SSE) pada lapisan kelima = ∑( − ) .
b. Eror pada Lapisan 4
Pada lapisan 4 terdapat sebanyak dua buah neuron. Propagasi eror yang menuju lapisan ini dapat dirumuskan sebagai berikut:
dengan adalah eror pada neuron ke-j (j=1,2), adalah output neuron lapisan 4 ke-j. Karena f=∑ = + , maka:
=
( )= 1 ; = ( )= 1 sehingga
= = (1) =
= = (1) =
c. Eror pada Lapisan 3
Pada lapisan 3 terdapat sebanyak dua buah neuron. Propagasi eror yang menuju lapisan ini dapat dirumuskan sebagai berikut:
=
dengan adalah eror pada neuron ke-j (j=1,2), adalah output neuron lapisan 3 ke-j. Karena = dan = maka:
= ( ) ( ) = ; = ( ) ( ) = sehingga = = = =
d. Eror pada Lapisan 2
Pada lapisan 2 terdapat sebanyak dua buah neuron. Propagasi eror yang menuju lapisan ini dapat dirumuskan sebagai berikut:
= +
= +
dengan adalah output neuron ke-1 dan adalah output neuron ke-2 pada lapisan 2. Karena = dan = maka:
= ( + ) = ( + ) = ( + ) = − ( + ) = ( + ) = ( + ) = ( + ) = − ( + ) sehingga = ( + ) + −( + ) =( + ) ( − ) = ( + ) + −( + ) =( + ) ( − )
e. Eror pada Lapisan 1
Pada lapisan 1 terdapat sebanyak empat buah neuron. Propagasi eror yang menuju lapisan ini dapat dirumuskan sebagai berikut:
= ; = ; = ; =
Karena = = ( ). ( ), = = ( ). ( ), = A1,
= ( ). ( ) ( ) = . ( ) = ( ). ( ) ( ) = . ( ) = ( ). ( ) ( ) = . ( ) = ( ). ( ) ( ) = . ( )
Eror tersebut digunakan untuk mencari informasi eror terhadap parameter a (a11 dan a12 untuk A1 dan A2, b11 dan b12 untuk B1 dan B2) dan c (c11 dan c12 untuk A1 dan A2, c11 dan c12 untuk B1 dan B2) sebagai berikut:
= + ; = +
= + ; = +
Karena fungsi keanggotaan yang digunakan adalah generalized bell :
( ) = 1 1 + − maka 1 1 + − = 2( − ) 1 + − dan
1 1 + − = 2( − ) 1 + − serta = 0 ; = 0 ; = 0 ; = 0 sehingga = ⎝ ⎜ ⎛ 2( − ) 1 + − ⎠ ⎟ ⎞ = ⎝ ⎜ ⎛ 2( − ) 1 + − ⎠ ⎟ ⎞ = ⎝ ⎜ ⎛ 2( − ) 1 + − ⎠ ⎟ ⎞ = ⎝ ⎜ ⎛ 2( − ) 1 + − ⎠ ⎟ ⎞ dan = ⎝ ⎜ ⎛ 2( − ) 1 + − ⎠ ⎟ ⎞
= ⎝ ⎜ ⎛ 2( − ) 1 + − ⎠ ⎟ ⎞ = ⎝ ⎜ ⎛ 2( − ) 1 + − ⎠ ⎟ ⎞ = ⎝ ⎜ ⎛ 2( − ) 1 + − ⎠ ⎟ ⎞
Kemudian ditentukan perubahan nilai parameter aij dan cij (∆aij dan ∆cij), i,j=1,2, dihitung sebagai berikut:
∆a11 = Z ; ∆a12 = Z ; ∆a21 = Z ; ∆a22 = Z
∆c11 = Z ; ∆c12 = Z ; ∆c21 = Z ; ∆c22 = Z
dengan adalah laju pembelajaran yang terletak pada interval [0,1]. Sehingga nilai aij dan cij yang baru adalah:
aij = aij (lama) + ∆aij dan cij = cij (lama) + ∆cij
(Kusumadewi, 2006) 2.7.7 Root Mean Square Eror (RMSE)
Hasil pelatihan dari metode ANFIS dapat diperiksa dengan ukuran root
mean square eror (RMSE) sebagai berikut:
= ∑ −
dengan n adalah banyak data, adalah data hasil prediksi, dan adalah data runtun waktu asli (data aktual).
36
METODOLOGI
4.1 Sumber Data
Data yang digunakan dalam penelitian ini adalah data simulasi dan data studi kasus. Data dibagi menjadi dua yaitu data in-sample dan out-sample. Data
in-sample digunakan untuk pemodelan sedangkan data out-sample digunakan
untuk menghitung nilai eror yang dihasilkan dari nilai ramalan model. Sehingga diperoleh RMSE model (in-sample) dan RMSE data peramalan (out-sample).
4.1.1 Data Simulasi
Data simulasi berasal dari komputer yang dibangkitkan menggunakan program R sejumlah 200 buah. Sebanyak empat karakteristik data yang dibangkitkan yaitu stasioner, stasioner dengan outlier, nonstasioner, dan nonstasioner dengan outlier. Data sebanyak 200 buah dibagi menjadi dua bagian yaitu data in-sample dan data out-sample. Data in-sample sebanyak 151 buah dan data out-sample sebanyak 49 buah.
4.1.2 Data Studi Kasus
Data studi kasus adalah berupa data harga minyak kelapa sawit Indonesia. Data berjumlah 1000 data, merupakan data harian dari tanggal 18 Juli 2005 sampai 31 Agustus 2009. Data sebanyak 1000 buah dibagi menjadi dua bagian yaitu data in-sample dan data out-sample. Data in-sample sebanyak 609 buah dan data out-sample sebanyak 391 buah.
4.2 Metode Analisis ARIMA
Analisis data dengan ARIMA dilakukan dengan beberapa tahap yaitu: 1. Tahap Identifikasi
Pada tahap ini dilakukan pengujian stasioner denan visual dan formal menggunakan uji Augmented Dickey Fuller (ADF). Jika tidak stasioner maka data dilakukan proses differencing. Setelah data hasil differencing telah stasioner selanjutnya adalah menganalisis plot ACF dan PACF. Dengan melihat plot ACF dan PACF ditentukan model yang diduga. 2. Tahap Estimasi
Pada tahap ini dilakukan estimasi parameter berdasarkan model yang telah diduga pada tahap sebelumnya. Kemudian parameter tersebut dilakukan pengujian apakah signifikan atau tidak. Model yang digunakan adalah model yang semua parameternya signifikan. Nilai RMSE dihitung dari nilai SSE, yaitu RMSE = /
3. Tahap Diagnosis
Pada tahap ini model ARIMA yang telah diperoleh dilakukan pengujian asumsi-asumsi:
a. Uji Ljung-Box, terpenuhi jika tidak ada korelasi residual antar lag, b. Uji Normalitas, terpenuhi jika residual berdistribusi normal, c. Uji ARCH-LM, tepenuhi jika tidak ada efek ARCH,
d. Uji Ramsey RESET, terpenuhi jika model linier. 4. Tahap Peramalan
Pada tahap ini dihitung nilai RMSE berdasarkan data out-sample terhadap data hasil peramalan dari model yang telah dibentuk.
4.3 Metode Analisis ANFIS
ANFIS merupakan penggabungan mekanisme sistem inferensi fuzzy yang digambarkan dalam arsitektur jaringan saraf (neural network). Sistem inferensi
fuzzy yang digunakan adalah sistem inferensi fuzzy model Tagaki-Sugeno Kang
(TSK) orde satu karena pertimbangan kesederhanaan dan kemudahan komputasi. Dalam proses pembelajaran, ANFIS menggunakan neural network, sedangkan penyelesaian menggunakan logika fuzzy. Parameter ANFIS dapat dipisahkan menjadi dua, yaitu parameter premis dan konsekuen yang dapat diadaptasikan dengan pelatihan hybrid.
Langkah-langkah yang dilakukan dalam mengimplementasikan ANFIS adalah sebagai berikut:
1. Memasukkan Data
Pada tahap ini ditentukan jumlah input dari struktur jaringan ANFIS. Input yang digunakan ditentukan berdasarkan hasil analisis ARIMA. Model ARIMA yang terbentuk menjadi dasar apa saja inputnya (seperti Zt-1, Zt-2,
dan lainnya). Sedangkan output yang digunakan adalah Zt. Kemudian data
dibagi menjadi dua, yaitu data pelatihan (training data) dan data pengecekan (checking data).
2. Membangun Sistem Inferensi Fuzzy (Fuzzy Inference System)
Pada tahap ini ditentukan model yang digunakan adalah Sugeno orde satu. Kemudian ditentukan jumlah klaster dan jenis fungsi keanggotaan yang digunakan yaitu trimf (Triangular), trapmf (Trapezoidal), gbellmf
Combination), pimf (Phi), dsigmf (Difference Sigmoidal), atau psigmf (Product Sigmoidal).
3. Menentukan Parameter Pelatihan
Pada tahap ini ditentukan metode optimasi yang digunakan adalah hybrid dan besar toleransi eror adalah sebesar 0. Kemudian ditentukan jumlah iterasi (epoch) maksimum yang diinginkan.
4. Proses Pelatihan
ANFIS dalam kerjanya mempergunakan algoritma belajar hybrid terdiri atas dua bagian yaitu arah maju (forward pass) dan arah mundur (backward pass), menggabungkan metode Least-squares estimator dan
Gradient Descent. Dalam struktur ANFIS metode Least-squares estimator
dilakukan di lapisan 4 dan Gradient Descent dilakukan di lapisan 1. Baik tidaknya kinerja dari pelatihan ANFIS dapat diperiksa berdasarkan nilai RMSE.
5. Analisis Hasil
Pada tahap ini dapat dilakukan evaluasi dari hasil pelatihan, apa pelatihan terbaik ANFIS berdasarkan jumlah input, jumlah klaster, dan fungsi keanggotaan, yaitu yang menghasilkan nilai RMSE terkecil.
Tidak
Ya Mulai
Masukkan data
training dan checking
Membangkitkan
fuzzy inference system
Membentuk struktur jaringan ANFIS dengan model Sugeno
Menentukan jenis fungsi keanggotaan dan jumlah klaster
Menentukan metode optimasi, toleransi eror, dan maksimum epoch/iterasi
Menjalankan pelatihan ANFIS
Dihasilkan eror kecil?
Membandingkan data dengan hasil prediksi
Peroleh model terbaik ANFIS
Selesai
41
ANALISIS DAN PEMBAHASAN
4.1 Analisis Data Runtun Waktu dengan ARIMA 4.1.1 Analisis ARIMA pada Data Stasioner
Data yang digunakan adalah data random ARIMA (1,0,0) dengan =0.5 sebanyak 200 buah dibangkitkan dengan program R (lampiran 1), grafik runtun waktu data tersebut sebagai berikut:
Gambar 12. Grafik runtun waktu data stasioner 1. Tahap Identifikasi
Uji stasioner secara visual dengan melihat grafik runtun waktu data tersebut dapat diduga data adalah stasioner karena runtun data berada di sekitar nilai tengah. Sedangkan uji secara formal dilakukan dengan uji Augmented
Dickey-Fuller (ADF) sebagai berikut:
Hipotesis
H0 : Data tidak stasioner
H1 : Data stasioner Time d a ta 1 0 50 100 150 200 -3 -2 -1 0 1 2
Taraf signifikansi α = 5% = 0.05 Statistik uji
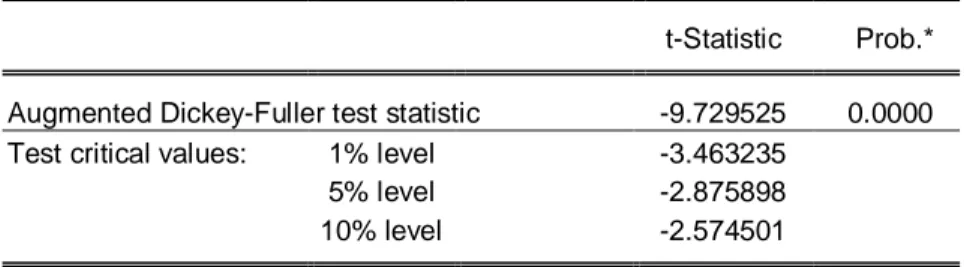
Dari output program Eviews diperoleh:
Tabel 3. Statistik uji ADF pada data stasioner
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -8.424989 0.0000
Test critical values: 1% level -3.463235
5% level -2.875898
10% level -2.574501
Kriteria uji : H0 ditolak jika | t-hitung | > t-tabel atau Prob < 0.05
Keputusan : Karena Prob = 0.0000 < 0.05 maka H0 ditolak
Kesimpulan: Data stasioner
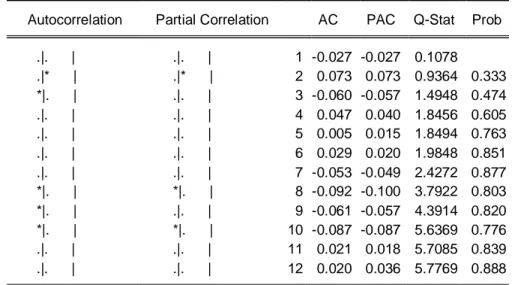
Karena data telah stasioner maka tidak perlu dilakukan differencing. Selanjutnya adalah pendugaan orde AR dan MA untuk pemodelan ARIMA dengan melihat plot ACF dan PACF, sebagai berikut:
Gambar 13. (a) Plot ACF dari data stasioner
0 5 10 15 20 -0 .2 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 Lag A C F Series data1newin
Gambar 13. (b) Plot PACF dari data stasioner
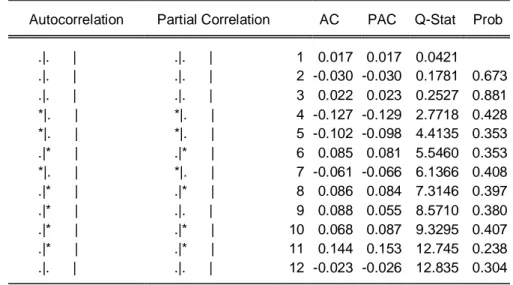
Koefisien parameter positif pada plot ACF adalah dies down (turun cepat secara eksponensial) dengan nilai ACF yang selalu positif. Sedangkan PACF menunjukkan pola yang terputus setelah lag 1. Dari gambar 13, dapat disimpulkan bahwa plot ACF dan PACF menunjukkan model AR(1).
2. Tahap Estimasi
Estimasi parameter model ARIMA (1,0,0) pada data tersebut digunakan program Eviews sebagai berikut:
Tabel 4. Estimasi model ARIMA pada data stasioner
Variable Coefficient Std. Eror t-Statistic Prob.
C -0.104233 0.156448 -0.666251 0.5063
AR(1) 0.497589 0.072070 6.904273 0.0000
R-squared 0.243621 Mean dependent var -0.112719
Adjusted R-squared 0.238510 S.D. dependent var 1.103032
S.E. of regression 0.962543 Akaike info criterion 2.774768
Sum squared resid 137.1204 Schwarz criterion 2.814909
Log likelihood -206.1076 F-statistic 47.66898
Durbin-Watson stat 2.043301 Prob(F-statistic) 0.000000
Model : = + 5 10 15 20 -0 .1 0 .0 0 .1 0 .2 0 .3 0 .4 0 .5 Lag P a rt ia l A C F Series data1newin