SKRIP SI
HARDIANI PUTRI SIREG AR 131402067
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOG I INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2019
PEMERIKSAAN STRUKTUR KALIMAT BAHASA INDONESIA DENGAN MENGUNAKAN PART-OF-SPEECH
TAGGING DAN LALR PARSER
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
HARDIANI PUTRI SIREGAR 131402067
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2019
ii
PERNYATAAN
PEMERIKSAAN STRUKTUR KALIMAT BAHASA INDONESIA DENGAN MENGGUNAKAN PART-OF-SPEECH
TAGGING DAN LALR PARSER
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing- masing telah disebutkan sumbernya.
Medan, 26 Juli 2019
HARDIANI PUTRI SIREGAR 131402067
Puji dan syukur penulis ucapkan kehadirat Allah SWT, karena rahmat dan izin-Nya penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, pada Program Studi S1 Teknologi Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
Demi terwujudnya penyelesaian dan penyusunan skripsi ini, penulis mengucapkan terimakasih kepada semua pihak yang telah tulus dan ikhlas dalam memberikan bantuan untuk memperoleh bahan-bahan yang diperlukan dalam penulisan skripsi ini.
Pada kesempatan ini penulis akan mengucapkan terimakasih yang sebesar- besarnya kepada :
1. Bapak Prof. Dr. Runtung Sitepu, SH., M.Hum selaku Rektor Universitas Sumatera Utara.
2. Bapak Prof. Dr. Drs. Opim Salim Sitompul, M.Sc selaku Dekan Fasilkom- TI Universitas Sumatera Utara.
3. Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc selaku Ketua Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
4. Bapak Dani Gunawan, ST., MT selaku Dosen Pembimbing I yang telah memberikan bimbingan dan saran kepada penulis.
5. Bapak Prof. Dr. Drs. Opim Salim Sitompul, M.Sc selaku Dosen Pembimbing II yang telah memberikan bimbingan dan saran kepada penulis.
6. Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc selaku Dosen Pembanding I yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
7. Ibu Ade Sarah Huzaifah, S.Kom., M.Kom selaku Dosen Pembanding II yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
8. Penulis juga mengucapkan terimakasih yang sebesar-besarnya kepada kedua orangtua penulis yaitu Ayahanda Drs. Harun Siregar dan Ibunda Asmiati Daulay atas segala kasih sayang, doa, nasehat, dan dukungan yang tiada henti kepada penulis. Tidak pernah memberi keluhan tentang penulis, orangtua yang tidak
iv
ayahanda dan ibunda karena kalianlah alasan utama penulis menyelesaikan skripsi ini. Tanpa kalian penulis tidak akan bisa menjadi seperti sekarang ini.
9. Terimakasih kepada abang penulis Ahmad Zulkifli, S.Pd, Langgean Rapim Daulay, Arpan Koto, Sagu Tanjung, Riswan effendi, S.Pd, serta kakak penulis Lenni Hamidah Siregar, S.Pd, Sukriah Lubis, S.Pd, Rik a Mulyanti, A.Md. Keb, Nuraisyah, S.Pd, Halimahtussa’diah, A.Md.Keb yang selalu memberikan doa, nasehat dan dukungan kepada penulis.
10. Seluruh keluarga, keponakan, dan sepupu penulis yang tak bisa penulis ucapkan satu persatu yang telah memberikan semangat dan motivasi kepada penulis 11. Para Barbie yaitu Putri Perdana Sari S.Kom, Tuti Simanjuntak S.Kom, Lisa
Noprianti Siregar S.Kom, Alvi Purnama Angkasih S.Kom, Anggi Fitriani Lumbanbatu S.Kom, dan Astria Martina Silaban S.Kom, para wanita tangguh yang telah menemani penulis melewati masa- masa terindah tugas besar selama perkuliahan dan selalu berbagi canda dan tawa disetiap kesempatan.
12. Sahabat penulis Lily Aulya, S.Kom, Wina Fajar Rahayu, A.Md, dan Yulia Handayani, S.Kg, Elfa Lestari, SKM yang selalu memberi sema ngat dan doa kepada penulis.
13. Emi Ariska, S.Kom, Nandar Cholid Siregar, S.Kom, Ahmadi Irmansyah Lubis, S.Kom, Nabil Munawar, S.Kom, Ony Naraulita, S,Kom yang telah menemani penulis selama perkuliahan.
14. Teman-teman seperjuangan yang selalu memberikan dukungan dan motivasi dari TI USU angkatan 2013
15. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu persatu yang telah membantu penyelesaians kripsi ini.
Semoga Allah SWT melimpahkan berkah kepada semua pihak yang telah memberikan bantuan, perhatian, serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, Juli 2019
Penulis
Penyajian bahasa dalam bentuk tulisan, dapat menyimpan pengetahuan dari generasi ke generasi. Setiap penulisan karya tulis seperti buku, hendaknya ditulis dengan tata bahasa yang benar sesuai kaidah-kaidah Bahasa Indonesia, karena akan berpengaruh pada kesempurnaan proses penyampaian ide atau pesan. Penelitian ini dilakukan untuk membantu memeriksa struktur kalimat Bahasa Indonesia, dengan tujuan untuk membantu memeriksa struktur kalimat Bahasa Indonesia menggunakan Part-Of- Speech Tagging dan Look-Ahead Left-to-Right Parser. POS Tagging merupakan suatu teknik yang digunakan untuk mengidentifikasi kelas kata yang ada dalam suatu kalimat, seperti kata benda, kata kerja, kata sifat, dan lain–lain. LALR Parser merupakan salah satu cara yang digunakan dalam pemeriksaan struktur kalimat. Dari 150 kalimat yang diuji pada sistem, 130 kalimat menunjukkan struktur kalimat ya ng benar. Sedangkan 20 kalimat menunjukkan struktur kalimat yang salah. Kegagalan deteksi disebabkan oleh beberapa faktor seperti struktur kalimat tidak sesuai dengan kaidah bahasa Indonesia dan kata yang terdapat pada kalimat tidak tersedia pada korpus.
Kata Kunci : Struktur Kalimat, Part-Of-Speech Tagging, LALR Parser
vi
EXAMINATION OF INDONESIAN SENTENCE STRUCTURE USING PART-OF-SPEECH TAGGING AND LALR PARSER
ABSTRACT
The presentation of language in written form can save knowledge from generation to generation. Every writing of a paper such as a book, should be written in a correct grammar according to the rules of Indonesian Language, because it will affect the perfection of the process of delivering ideas or messages. This research was conducted to help examine the Indonesian sentence structure, with the aim of helping to examine the sentence structure of the Indonesian language using the Part-Of- Speech Tagging and Look-Ahead Left-to-Right Parser. POS Tagging is a technique used to identify the class of words that are in a sentence, such as nouns, verbs, adjectives, and others. LALR Parser is one of the methods used in examining sentence structure. Of the 150 sentences tested on the system, 130 sentences show the correct sentence structure. Whereas 20 sentences show the wrong sentence structure.
Detection failure is caused by several factors such as sentence structure not in accordance with the rules of Indonesian language and the words contained in the sentence are not available on the corpus.
Keyword : Sentence Structure, Part-Of-Speech Tagging, LALR Parser.
Halaman
PERSETUJUAN i
PERNYATAAN ii
UCAPAN TERIMAKASIH iii
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR TABEL ix
DAFTAR GAMBAR x
BAB 1 PENDAHULUAN
1.1. Latar Belakang 1
1.2. Rumusan Masalah 4
1.3. Batasan Masalah 4
1.4. Tujuan Penelitian 4
1.5. Manfaat Penelitian 4
1.6. Metode Penelitian 5
1.7. Sistematika Penulisan 6
BAB 2 LANDASAN TEORI
2.1. Struktur Kalimat Bahasa Indonesia 8
2.2. Tokenizing 9
2.3. POS Tagging 10
2.4. LALR Parser 11
2.5. Penelitian Terdahulu 12
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
3.1. Data yang digunakan 16
viii
3.3. Perancangan Sistem 17
3.3.1. Arsitektur Umum 17
3.3.2. Diagram Aktifitas 27
3.3.3. Flowchart 29
3.3.4. Peranangan Antarmuka Sistem 31
BAB 4 IMPLEMENTASI DAN PENGUJIAN
4.1. Implementasi Sistem 33
4.1.1. Speifikasi perangkat keras 33
4.1.2. Spesifikasi perangkat lunak 33
4.1.3. Implementasi Tampilan Antarmuka sistem 34
4.1.4. Prosedur Operasional 35
4.2. Pengujian Sistem 38
BAB 5 KESIMPULAN DAN SARAN
5.1. Kesimpulan 46
5.2. Saran 46
DAFTAR PUSTAKA 47
LAMPIRAN 50
DAFTAR TABEL
Halaman
Tabel 2.1. Pola Kalimat Dasar 8
Tabel 2.2. Label Kata Bahasa Indonesia 9
Tabel 2.3. Penelitian Terdahulu 12
Tabel 3.1. Label Kata untuk Subjek 18
Tabel 3.2. Label Kata untuk Predikat 19
Tabel 3.3. Label Kata untuk Objek 19
Tabel 3.4. Label Kata untuk Pelengkap 20
Tabel 3.5. Label Kata untuk Keterangan 21
Tabel 4.1. Rancangan Struktur Kalimat Pengujian Pertama 36
Tabel 4.2. Hasil POS Tagging dan SPOK 37
Tabel 4.3. Aturan Produksi 40
Tabel 4.4. Action Table dan Goto Table 40
Tabel 4.5. Hasil Pengujian Sistem 42
x
DAFTAR GAMBAR
Halaman
Gambar 3.1. Arsitektur Umum 17
Gambar 3.2. LALR Parser 22
Gambar 3.3. Diagram Aktifitas 25
Gambar 3.4. Flowchart Sistem Pemeriksaan Struktur Kalimat 27
Gambar 3.5. Rancangan Tampilan Halaman Utama 28
Gambar 3.6. Rancangan Tampilan Menu Program 28
Gambar 4.1. Halaman Utama 31
Gambar 4.2. Menu Program 31
Gambar 4.3. Button Logo Usu 32
Gambar 4.4. Input Kalimat 33
Gambar 4.5. Pilih Button Open 33
Gambar 4.6. Pilih Button Proses 34
Gambar 4.7. Tampilan Hasil POS Tagging 34
Gambar 4.8. Tampilan Hasil SPOK 35
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Bahasa merupakan salah satu aspek penting dalam kehidupan manusia karena Bahasa adalah alat untuk berkomunikasi dengan manusia lain. Menurut Felicia (2001), berdasarkan sarananya ragam bahasa dibagi menjadi ragam lisan dan tulisan. Ragam lisan dapat disampaikan dengan berbicara langsung tentang apa yang akan disampaikan. Sedangkan ragam tulisan disampaikan secara tertulis dimana kata-kata dalam kalimat harus tersusun dengan baik atau sesuai dengan struktur kalimat sehingga makna kalimat dapat dipahami dengan baik. Pemahaman tentang makna kalimat akan lebih mudah dengan peran semantik dalam unsur pembentukan kalimat yang jelas.
Sistem kalimat Bahasa Indonesia tersusun menurut struktur kalimatnya, tidak tersusun secara acak atau sembarangan. Setiap penulisan karya ilmiah, skripsi, surat kabar, kalimat paragraf, bahkan kalimat tunggal hendaknya ditulis dengan kalimat efektif. Harus memperhatikan struktur kalimat dan maknanya karena berpengaruh dalam proses penyampaian dan penerima pesan. Bidang teknologi Natural Language Processing (NLP) atau yang biasa disebut dengan pemrosesan bahasa alami dapat digunakan untuk mempermudah pemeriksaan struktur kalimat yang benar (Arif, 2018).
Pemrosesan bahasa alami merupakan suatu topik yang banyak diperbincangkan oleh para ahli komputer. Sebagian besar dari para ahli ini memiliki pertanyaan yang hampir sama, yaitu seberapa jauh teknologi komputer yang ada yang mampu menerjemahkan atau menginterpretasikan bahasa manusia atau bahasa alami ini ke dalam bahasa komputer (Sager, 1981).
2
Penelitian sebelumnya melakukan penelitian tentang penguraian kalimat dengan pendekatan linguistic string analysis menggunakan aturan sintaks Backus Naur Form (BNF). Dari 65 kalimat yang diproses, 56 kalimat berhasil diuraikan. Namun pada penelitian tersebut masih membutuhkan tambahan aturan kalimat atau tata bahasa untuk menangani masalah tata bahasa yang semakin luas (Iqbal, et al. 2007).
Penelitian pemrosesan teks pada bahasa Indonesia telah dilakukan yaitu sistem yang menghasilkan simulasi dari pengurai bahasa Indonesia yang mengadaptasi proses yang digunakan pada algoritma Collins yang biasa digunakan untuk pemrosesan bahasa alami pada bahsa Inggris. Pada penelitian tersebut hanya menggunakan sampel kalimat berjumlah 30, 28 kalimat berhasil untuk diuraikan.
Namun akan memerlukan pengembangan pada sistem untuk menguraikan kalimat dengan jumlah yang besar (Sibarani, et al. 2013).
Berdasarkan penelitian pemrosesan teks diatas, proses penguraian (parsing) kalimat adalah kunci utamanya. Untuk memproses suatu bahasa alami, proses penguraian kalimat adalah masalah fundamental antara mesin dan manusia (Hasan, et.al. 2011). Sehingga pada penelitian ini penulis memperhatikan proses penguraian kalimat untuk mempermudah pemeriksaan struktur kalimatnya.
Proses penguraian kalimat dalam bahasa alami hampir sama dengan proses penguraian tata bahasa pemrograman dalam dunia komputer. Perbedaan yang mendasar pada keduanya adalah tata bahasa dalam dunia komputer merupakan tata bahasa yang bebas konteks (context free grammar), sedangkan tata bahasa pada manusia adalah tata bahasa yang peka terhadap konteks (context sensitive).
Pemrosesan bahasa alami merupakan suatu hal yang sangat kompleks. Sangat sulit untuk merancang dan membangun suatu aplikasi komputer yang dapat menganalisa dan memahami bahasa yang biasa dipakai oleh manusia dalam kehidupan sehari- hari. Pemrosesan bahasa alami memerlukan pengetahuan tentang kamus kata dan aturan tata bahasa (Rao, et.al. 2010). Kamus kata diperlukan untuk memeriksa apakah kata-kata yang dimasukkan merupakan kata-kata yang benar. Aturan tata bahasa diperlukan untuk memeriksa apakah kalimat yang dimasukkan sesuai dengan
kaidah tata bahasa dari bahasa yang digunakan. Beberapa pemrosesan bahasa memerlukan proses awal (preprocessing), diantaranya adalah perlu adanya proses pemberian jenis kata pada setiap kata masukan yaitu Part-Of-Speech Tagging. Part- Of-Speech Tagging perlu dilakukan untuk membuat sebuah file korpus masukan untuk pengurai, dan setiap kata pada file tersebut telah diberi tag (Sukamto, 2009)
Penelitian sebelumnya melakukan penelitian tentang mengekstraksi konteks link dari halaman web menggunakan metode Tag Tree dan LALR Parser (Gupta, 2013).
Hasil ekstraksi sangat berguna untuk mengindeks dokumen. Penelitian berikutnya yaitu perancangan penganalisis struktur kalimat Bahasa Indonesia dengan menggunakan algoritma Constraint-Based Formalism. Pada penelitian tersebut dilakukan penguraian dengan aturan-aturan sintaks yang di defenisikan (Sulastra, 2014). Penelitian lainnya yaitu analisis perbandingan algoritma LCP (Left-Corner- Parsing) dan algoritma CYK (Cocke-Younger-Kasami) untuk memeriksa pola kalimat baku Bahasa Indonesia (Susanti, 2016). Hasil Pengujian pemeriksaan pola kalimat baku didapatkan tingkat akurasi dari algoritma CYK sebesar 65% dengan laju error 0.35 dan algoritma LCP sebesar 60% dengan laju error 0.40. Namun tingkat akurasi yang di dapat belum cukup besar karena ka mus POS Tag yang digunakan masih terdapat kekurangan yaitu masih banyak kata yang tidak dapat dikenali.
Dalam skripsi ini, algoritma yang digunakan penulis untuk pemeriksaan struktur kalimat adalah LALR Parser. LALR Parser memiliki tingkat keberhasilan yang lebih tinggi dari algoritma lainnya, yaitu sebesar 70%. Namun pada penelitian tersebut belum memanfaatkan Part-Of-Speech Tagging dalam menentukan jenis kata. Dengan menambahkan Part-Of-Speech Tagging dipemrosesan awal, maka akan lebih memudahkan sistem dalam mengidentifikasi jenis kata pada kalimat masukan yang akan diproses dan diharapkan agar keberhasilan sistem dalam menguraikan kalimat bahasa Indonesia semakin baik.
Berdasarkan latar belakang diatas dan beberapa penelitian terdahulu sebagai pendukung, penulis mengajukan tugas akhir dengan judul “PEMERIKSAAN STRUKTUR KALIMAT BAHASA INDONESIA DENGAN MENGGUNAKAN
4
1.2. Rumusan Masalah
Dalam aturan tata bahasa Indonesia, sebuah kalimat yang efektif harus memiliki struktur kalimat yang benar agar mudah dimengerti oleh pembacanya. Pemeriksaan terhadap sebuah kalimat efektif sebenarnya dapat dilakukan oleh seorang ahli bahasa (Indonesia). Akan tetapi, pemeriksaan yang dilakukan akan memakan banyak waktu dan memerlukan pakar yang benar-benar menguasai struktur kalimat yang benar.
Pemeriksaan ini dapat dilakukan dengan lebih efektif bilamana dapat dilakukan secara otomatis oleh sebuah sistem komputer. Oleh karena itu diperlukan sebuah sistem untuk pemeriksaan struktur kalimat agar suatu kalimat tersebut memiliki struktur kalimat yang benar atau tidak.
1.3. Batasan Masalah
Untuk mencegah meluasnya pembahasan dan agar lebih terarah maka dibuat batasan masalah yang meliputi :
1. Struktur kalimat yang digunakan pada penelitian ini adalah str uktur kalimat yang sesuai dengan tata bahasa Indonesia berdasarkan ejaan yang disempurnakan.
2. Tidak memeriksa jenis kalimat berupa idiom dan peribahasa.
3. Kalimat yang digunakan berupa kalimat tunggal. Tidak memeriksa kalimat majemuk setara ataupun kalimat majemuk bertingkat.
4. Tidak memeriksa makna kalimat.
1.4. Tujuan Penelitian
Adapun Tujuan dari penelitian ini adalah untuk memeriksa kalimat Bahasa Indonesia berdasarkan struktur kalimat tunggal yang sesuai dengan tata bahasa indonesia menggunakan POS Tagging dan LALR Parser.
1.5. Manfaat Penelitian
Adapun manfaat yang diperoleh dari penelitian ini adalah:
1. Mempermudah dalam memeriksa struktur kalimat Bahasa Indonesia dengan sistem komputer.
2. Mengetahui kemampuan POS Tagging dan LALR Parser dalam pemeriksaan struktur kalimat Bahasa Indonesia.
1.6. Metodologi Penelitian
Dalam penelitian ini penulis melakukan beberapa tahap untuk menyelesaikan permasalah. Tahap-tahap yang dilakukan dalam penelitian ini adalah
1) Studi Literatur
Studi literatur dilakukan untuk mencari, mengumpulkan dan memplajari informasi dari buku, paper, jurnal, skripsi, internet, dan berbagai referensi lainnya yang berhubungan dengan penelitian struktur kalimat Bahasa Indonesia, algoritma LALR Parser, dan POS Tagging.
2) Analisis Permasalahan
Tahap ini dilakukan untuk menganalisis permasalahan yang diperoleh dari berbagai sumber yang terkait dengan penelitian untuk memperoleh cara atau metode yang sesuai dengan permasalahan dalam penelitian.
3) Perancangan Sistem
Pada tahap ini dilakukan perancangan sistem seperti perancangan arsitektur, pengumpulan data, perancangan algoritma dan perancangan antarmuka yang akan di implementasikan kedalam sistem.
4) Implementasi
Pada tahap ini dilakukan proses implementasi dari analisis dan perancangan yang telah dilakukan kedalam bentuk kode program.
5) Pengujian
6
Pada tahap ini dilakukan proes pengujian dan percobaan terhadap sistem sesuai dengan spesifikasi yang telah dilakukan sebelumnya serta memastikan program pada sistem dapat berjalan sesuai dengan yang diharapkan.
6) Dokumentasi dan Penyusunan Laporan
Pada tahap ini dilakukan dokumentasi dan penyusunan laporan hasil analisis dan implementasi POS Tagging dan LALR Parser untuk memeriksa struktur kalimat Bahasa Indonesia.
1.7. Sistematika Penulisan
Penulisan skripsi ini menggunakan sistematika penulisan yang membagi pembahasan skripsi dalam lima bagian utama, yang terdiri atas:
Bab 1: Pendahuluan
Pada bab ini berisi tentang latar belakang, rumusan masalah, batasan masalah, tujuan peenelitian, manfaat penelitian, dan metodologi penulisan skripsi.
Bab 2: Landasan Teori
Pada bab ini berisi tentang pembahasan teori-teori yang berhubungan dengan pembuatan skripsi untuk memahami permasalahan yang akan dibahas pada penelitian ini. Bab ini menjelaskan tentang struktur kalimat Bahasa Indonesia, semantik kalimat Bahasa Indonesia, POS Tagging, algoritma LALR Parser, dan data-data pendukung lainnya.
Bab 3: Analisis dan Perancangan Sistem
Pada bab ini berisi analisis terhadap permasalahan penelitian dan penjelasan tentang rancangan struktur dan antarmuka dari sistem yang akan dibuat.
Bab 4: Implementasi dan Pengujian Sistem
Pada bab ini berisi tentang implementasi dari analisis dan perancangan yang telah disusun pada bab 3. Selain itu, dilakukan juga pengujian terhadap sistem untuk mengetahui apakah hasil yang diperoleh sesuai dengan yang diharapkan.
Bab 5: Kesimpulan dan Saran
Pada bab ini berisi tentang kesimpulan dari keseluruhan pembahasan yang dilakukan pada bab-bab sebelumnya dan memuat saran-saran yang diajukan untuk pengembangan penelitian selanjutnya.
BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori-teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan POS Tagging dan LALR Parser untuk pemeriksaan struktur kalimat Bahasa Indonesia.
2.1 Struktur Kalimat Bahasa Indonesia
Dalam Bahasa Indonesia dikenal satuan bahasa seperti kata, frase, kalimat, dan lain- lain. Kalimat dalam bahasa Indonesia memiliki struktur berbeda-beda sesuai dengan jenis kalimatnya. Kalimat merupakan kumpulan kata dalam wujud lisan atau tulisan yang digunakan untuk mengungkapkan pikiran atau pendapat kepada orang lain.
Kalimat dasar adalah kalimat yang terdiri dari atas satu klausa, unsur-unsurnya lengkap, susunan unsur-unsurnya menurut urutan yang paling umum, dan tidak mengandung pertanyaan atau pengingkaran (Alwi, et al. 1998). Suatu kalimat bisa terdiri dari beberapa unsur seperti sub yek (S), predikat (P), objek (O), dan keterangan (K). Keberadaan unsur- unsur ini dalam sebuah kalimat inilah yang menyebabkan perbedaan struktur tiap kalimat. Untuk dapat disebut sebagai kalimat sempurna, dalam sebuah kalimat minimal harus memiliki unsur subyek dan predikat.
Pada struktur kalimat dasar, di antara kalimat dan kata, biasanya ada satuan- antara yang berupa kelompok kata. Kelompok kata yang menjadi salah satu unsur pembentuk kalimat ini dikenal dengan sebutan frase. Kalimat dasar disini identik dengan kalimat tunggal deklaratif afirmatif yang urutan unsur- unsurnya paling lazim.
Kalimat dasar dapat dibedakan kedalam enam tipe yang dapat dlihat pada tabel 2.1.
Tabel 2.1. Pola Kalimat Dasar
Tipe
Subjek (S)
Predikat (P)
Objek (O)
Pelengkap (Pel)
Keterangan (Ket) 1. S-P Saya Menari
2. S-P-O Eri Membeli Pensil
3. S-P-Pel Ali Berlari cepat
4. S-P-Ket Ibu Belanja Di Pasar
5. S-P-O-Pel Mereka Membeli Mobil yang bagus
6. S-P-O-Ket Kakak Memasak Nasi Di dapur
Kalimat tunggal merupakan kalimat sederhana yang biasanya tersusun atas unsur subyek dan predikat atau hanya berupa klausa saja. Hal itu berarti bahwa konstituen untuk tiap unsur kalimat, seperti subjek dan predikat, hanyala h satu atau merupakan satu kesatuan. Dalam kalimat tunggal tentu saja terdapat semua unsur wajib yang diperlukan. Disamping itu, boleh atau tidak ada unsur seperti keterangan tempat, waktu, dan alat (Alwi, et al. 1998).
2.2. Tokenizing
Proses tokenizing merupakan proses pemotongan string masukan berdasarkan tiap kata yang menyusunnya. Pada prinsipnya proses ini merupakan tahap pemotongan atau pemenggalan kata dalam suatu kalimat, paragraph, atau dokumen menjadi potongan–potongan kata yang berdiri sendiri. Contoh proses tokenizing adalah sebagai berikut.
Kalimat masukan :
Mereka makan bakso pedas di warung dekat sekolah.
10
Hasil dari proses tokenizing :
“Mereka”, “makan”, “bakso”, “pedas”, “di”, “warung”, “dekat”, “sekolah”.
2.3. POS Tagging
POS Tagging merupakan suatu teknik yang digunakan untuk mengidentifikasi label kata yang ada dalam suatu kalimat, seperti kata benda, kata kerja, kata sifat, dan lain- lain. POS Tagging adalah suatu proses memberikan label kata secara otomatis pada suatu kata dalam kalimat (Jurafsk y dan Martin, 2000). Secara umum label kata dapat dibedakan menjadi Kata Benda (Noun), Kata Kerja (Verb), Kata Sifat (Adjective), Kata Keterangan (Adverb), Kata Penghubung (Conjunction Word), Kata Ganti Orang (Personal Pronoun), Kata Bilangan (Numeral), dan lainnya termasuk di dalamnya tanda baca. Hal ini juga berlaku untuk label kata dalam bahasa Indonesia. Pada bahasa Indonesia ada beberapa label kata yang dapat digunakan seperti pada Tabel 2.2.
Tabel 2.2. Label Kata (Wicaksono & Purwarianti, 2010)
NO Label POS Nama POS Contoh
1 OP Open Parenthesis ({[
2 CP Close Parenthesis )}]
3 GM Slash /
4 ; Semicolon ;
5 : Colon :
6 “ Quotation “ ‟
7 . Sentence Ter minator . ! ?
8 , Comma ,
9 - Dash -
10 ... Ellipsis ...
11 JJ Adjective Bagus, Baik, Pintar
12 RB Adverb Nanti, Sementara
13 NN Common Noun Buku, Komputer
14 NNP Proper Noun Indonesia, Medan
15 NNG Genitive Noun Mobilnya
16 VBI Intransitive Verb Pergi, Belajar
17 VBT Transitive Verb Meminum, Membuka
18 IN Preposition Di, Ke, Dari
19 MD Modal Bisa, Akan
20 CC Coor-Conjunction Dan, Atau, Tetapi
21 SC Subor-Conjuction Jika, Ketika
22 DT Determiner Para, Ini, Itu
23 UH Interjection Wah, Aduh, Oi
24 CDO Ordinal Numerals Pertama, Kedua
25 CDC Collective Numerals Bertiga, Berdua
26 CDP Primary Numerals Satu, Dua
27 CDI Irregular Numerals Beberapa
28 PRP Personal Pronouns Saya, Kamu, Engkau
29 WP WH-Pronouns Apa, Siapa
30 PRN Number Pronouns Kedua-duanya
31 PRL Locative Pronouns Sini, Situ, Sana
32 NEG Negation Bukan, Tidak
33 SYM Symbols @#$%^&
34 RP Particles Pun, Kah
2.4. LALR Parser
LR Parser adalah parser yang membaca input dari kiri ke kanan. Berdasarkan bagaimana tabel parsing dihasilkan, parser ini mempunyai beberapa variant yaitu Simple LR Parser (SLR), Lookahead LR Parser (LALR), dan Cannonical LR Parser (Bermudez, 1988).
LALR Parser dapat menangani lebih banyak grammar dibanding dengan SLR Parser. LALR Parser menggunakan lookahead yang lebih spesifik karena LALR dapat menerima banyak konteks parsing. LALR akan melihat dulu konteks yang ada di depannya, sebelum menentukan konstituennya. Pada arsitektur LALR Parser
12
table. Aksi–aksi yang terdapat pada action table terdiri dari shift, reduce, dan accept (Bermudez, 1988).
1. Shift n yaitu mengambil kategori yang sedang dibaca, kemudian letakkan ke dalam stack, dan ubah state menjadi n.
2. Reduce yaitu mengambil tumpukan dari stack dan satukan dengan menggunaka n aturan ke n, kemudian letakkan kembali hasilnya ke stack, ubah state sesua i dengan goto table.
3. Accept yaitu masukan diterima dan proses parsing berhasil
2.5. Penelitian Terdahulu
Penelitian pemrosesan teks pada bahasa Indonesia telah dilakukan dengan mengadaptasi algoritma Collins yang biasa digunakan untuk pemrosesan bahasa alami pada bahsa Inggris. Pada penelitian tersebut ada beberapa tahap yaitu pemrosesan awal untuk menggenarasi korpus, analisis leksikal untuk konversi korpus menjadi token, dan analisis sintaks untuk membangun pohon pengurai yang memprediksi kemungkinan terbangunnya pohon kalimat. Pada pengujiannya 28 dari 30 kalimat berhasil diuraikan ( (Sibarani, et al. 2013).
LALR Parser sudah pernah dilakukan terlebih dahulu dimana metode ini digunakan untuk mengekstraksi konteks dari sebuah link pada halaman web. Hasil ekstraksi tersebut sangat berguna untuk mengindeks dokumen. LALR Parser digunakan karena kemampuannya lebih unggul dibanding varian LR yang lain yaitu SLR dan LR (Gupta, 2013).
Penelitian untuk struktur kalimat Bahasa Indonesia yaitu sistem menga nalisis struktur kalimat Bahasa Indonesia dengan menggunakan metode Constraint-Based Formalism. Pada penelitian tersebut dilakukan penguraian kalimat dengan aturan- aturan sintaks yang didefenisikan. Persentase kalimat terurai terhadap yang tidak terurai adalah 94,7% dari 360 kalimat (Sulastra, 2014).
Penelitian selanjutnya yaitu analisis perbandingan algoritma LCP (Left-Corner- Parsing) dan algoritma CYK (Cocke-Younger-Kasami) untu memeriksa pola kalimat baku Bahasa Indonesia. Algoritma Left Corner Parsing menggunakan top-down parsing dan bottom-up parsing yaitu merupakan strategi yang menggunakan data secara bottom-up parsing dan prediksi dari top-down parsing. Algoritma Cocke Younger Kasami merupakan algoritma parsing dan kanggotaan untuk tata bahasa bebas konteks. Algoritma CYK harus berada dalam bentuk CNF (Chomsky Normal Form). Hasil pengujian pola kalimat didapatkan tingkat akurasi dari algoritma CYK sebesar 65% dengan laju error 0.35 dan algoritma LCP sebesar 60% dengan laju error 0.40. Namun tingkat akurasi yang diperoleh belum cukup besar karena POS Tag yang digunakan masih terdapat kekurangan (Susanti, 2016)
Penelitian lainnya yaitu penerapan algoritma LALR Parser dan Context-Free Grammar untuk struktur kalimat Bahasa Indonesia. Dapat melakukan parsing dengan baik dan efektif dengan tingkat akurasi 70% (Pratama, et.al. 2017).
Penelitian berikutnya yaitu Sistem pemeriksaan struktur kalimat pada teks Bahasa Indonesia dengan menggunakan Part-Of-Speech Tagging dan Constraint- Based Formalism dengan hasil penguraian kalimat yaitu 93.3% (Arif, 2018).
Penelitian terdahulu yang telah dipaparkan akan diuraikan secara singkat pada tabel 2.3.
Tabel 2.3. Penelitian Te rdahulu
No Peneliti Judul Keterangan
1 Sibarani, et.al.
(2013)
A Study of Parsing Process on Natural Language Processing in Bahasa Indonesia
Algoritma Collins yang diadaptasi dari bahasa Inggris mampu
menguraikan 28 dari 30 kalimat tunggal.
2 Gupta (2013) Extraction of Link Context using Tag
Mengekstraksi konteks link dari halaman web. Hasil
14
Tree and LALR Parsing
ekstraksi sangat berguna untuk meengindeks dokumen.
3 Sulastra (2014) Perancangan
Penganalisis Struktur Kalimat Bahasa Indonesia Dengan Menggunakan Constraint-Based Formalism
Memeriksa struktur kalimat Bahasa Indonesia tanpa melakukan analisa
semantik. Hasil penguraian kalimat 94,7% dari 360 kalimat
4 Susanti (2016) Analisis Perbandingan Algoritma LCP (Left- Corner-Parsing) dan Algoritma CYK (Cocke-Younger- Kasami) Untuk Memeriksa Pola Kalimat Baku Bahasa Indonesia
Hasil pengujian pola kalimat di dapatkan tingkat akurasi dari algoritma CYK sebesar 65% dengan laju error 0.35 dan algoritma LCP sebesar 60% dengan laju error 0.40. Namun tingkat akurasi yang di dapat belum cukup besar karena kamus POS Tag yang digunakan masih terdapat kekurangan yaitu banyak kata yang tidak dapat dikenali.
5 Pratama, et.al.
(2017)
Penerapan Algoritma LALR Parser dan Context-Free Grammar Untuk Struktur Kalimat
Dapat melakukan parsing pada kalimat Bahasa Indonesia dengan baik dan efektif dengan tingkat akurasi 70%
Bahasa Indonesia 6 Arif (2018) Sistem Pemeriksaan
Struktur Kalimat Pada Teks Bahasa Indonesia dengan Menggunakan Part-Of-Speech Tagging dan Constraint-Based Formalism
Memeriksa struktur kalimat Bahasa Indonesia dengan aturan bebas konteks.
Artinya, setiap kalimat diuaikan tanpa melakukan analisa semantik atau analisa arti dari kalimat.
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini akan dibahas mengenai implementasi tentang POS Tagging dan LALR Parser untuk menemukan solusi dalam menentukan struktur kalimat Bahasa Indonesia dan tahap – tahap yang dilakukan dalam perancangan sistem yang akan dibangun.
3.1 Data yang Digunakan
Data pelatihan berupa korpus. Korpus pada penelitian ini merupakan file dengan format corpus (*.crp) yang berisikan kata-kata dalam susunan kalimat dan sudah diberikan pelabelan kelas katanya. Korpus yang digunakan dalam penelitian ini adalah korpus yang sudah pernah digunakan pada penelitian sebelumnya, yaitu korpus penelitian Wicaksono dan Purwarianti (2010). Data penguji yang d igunakan pada penelitian ini yaitu kalimat tunggal.
3.2 Analisis Sistem
Sistem yang dibangun pada penelitian ini adalah sistem untuk pemeriksaan struktur kalimat Bahasa Indonesia. Sistem dapat memeriksa struktur kalimat Bahasa Indonesia sesuai aturan tata Bahasa Indonesia, yaitu terdiri dari subjek, predikat, objek, dan keterangan atau yang biasa disebut dengan SPOK. Metode yang digunakan untuk melakukan pemeriksaan struktur kalimat Bahasa Indonesia ini adalah POS Tagging dan LALR Parser yang merupakan bagian dari LR Parser yang membaca input dari kiri ke kanan.
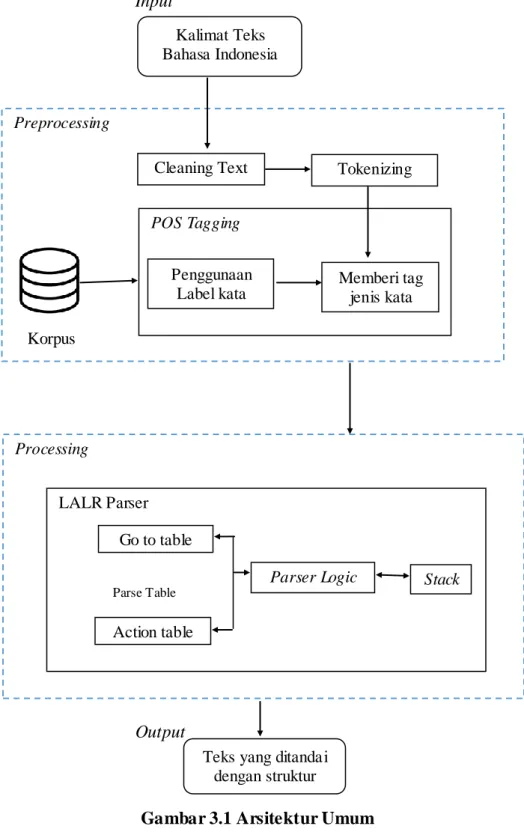
3.3. Perancangan Sistem 3.3.1 Arsitektur Umum
Sistem pemeriksaan struktur kalimat Bahasa Indonesia merupakan sistem yang memeriksa struktur kalimat yang digunakan berdasarkan aturan tata Bahasa Indonesia yaitu subjek, predikat, objek, dan keterangan. Pada penelitian untuk pemeriksaan struktur kalimat Bahasa Indonesia ini dilakukan 3 tahap yaitu preprocessing, processing, dan postprocessing. Pada tahapan preprocessing akan dilakukan proses cleaning text untuk pembersihan kalimat dari tanda baca seperti tanda titik(.), dan tanda Tanya(?). Setelah itu, dilakukan juga proses tokenizing untuk pemotongan atau pemenggalan kalimat menjadi kata per kata berdasarkan tiap kata penyusunnya.
Proses ini dilakukan untuk mempermudah dalam pelabelan kata atau proses POS Tagging. Kemudian tahap selanjutnya adalah processing untuk menentukan struktur kalimat Bahasa Indonesia yang digunakan. Penerapan LALR Parser yang akan menentukan struktur kalimat yang terdiri dari subjek, predikat, objek, dan keterangan.
Pada tahap postprocessing akan dihasilkan kalimat yang sudah tersusun berdasarkan struktur kalimat Bahasa Indonesia sesuai dengan aturan tata bahasa.
Adapun arsitektur umum yang menggambarkan tahapan - tahapan dalam pembangunan sistem ini dapat dilihat pada gambar 3.1. Tahapan keseluruhan proses pemeriksaan struktur kalimat akan dijelaskan sebagai berikut :
1) Input
Tahapan pertama dimulai dari input kalimat oleh user. Kalimat yang digunakan pada sistem ini berupa kalimat Bahasa Indonesia. Kalimat yang digunakan berupa kalimat tunggal, dapat juga beberapa kalimat tunggal tetapi dipisah dengan titik. Kalimat yang dimasukkan tidak akan diurai apabila terjadi kesalahan penulisan.
Proses input pada sistem ini yaitu mengetikkan satu kalimat tunggal ke dalam area teks input kalimat. Selain itu, user juga dapat mengetikkan beberapa kalimat tunggal dengan titik sebagai pemisah antar kalimatnya. Dan user juga dapat dilakukan dengan memasukkan dokumen yang berisi kalimat tunggal.
18
2) Praprocessing a. Cleaning Text
Setelah proses input dilakukan, maka sistem akan melakukan cleaning text. Tulisan dalam sebuah kalimat atau dokumen terkadang memiliki banyak tanda baca. Terdapat beberapa macam tanda baca, yaitu tanda titik (.) dan tanda tanya (?). Tanda baca ini tidak berpengaruh dalam pemeriksaan struktur kalimat sehingga diperlukan cleaning text untuk pembersihan kalimat dari tanda baca.
b. Tokenizing
Setelah proses cleaning text, dilakukan proses tokenizing. Proses tokenizing ini akan melakukan pemenggalan kalimat yang di inputkan, baik berupa sepenggal kalimat ataupun berupa dokumen, berdasarkan tiap kata yang menyusunnya. Proses ini dilakukan untuk mempermudah dalam memberi jenis kata untuk setiap katanya.
Contoh kalimat “Adik bermain bola di lapangan” di tokenizing menjadi [adik]
[bermain] [bola] [di] [lapangan].
c. Part-Of-Speech (POS) Tagging
Setelah dilakukan proses tokenizing, maka selanjutnya dilakukan proses POS Tangging untuk mendapatkan label pada setiap kata dari kalimat yang dimasukkan.
POS Tangging, yang juga disebut sebagai pelabelan kelas kata, merupakan suatu proses yang memberikan label pada suatu kalimat. Ada beberapa jenis label kata seperti kata kerja (Verb), kata benda (Noun), kata sifat (Adjective), kata keterangan (Adverb), kata depan (Preposition) dan lain sebagainya. Tahapan POS Tagging ini akan digunakan modul POS Tagging Bahasa Indonesia yang dikembangkan oleh Wicaksono dan Purwarianti (2010).
Contoh hasil POS Tagging:
Bibi/NNP sudah/MD datang/VBI dari/IN Jambi/NN kemarin/RB
Input
Output
Gambar 3.1 Arsitektur Umum Processing
LALR Parser
Parse Table
Kalimat Teks Bahasa Indonesia
Preprocessing
Korpus
Cleaning Text Tokenizing
POS Tagging
Penggunaan Label kata
Memberi tag jenis kata
Parser Logic Stack Go to table
Action table
Teks yang ditandai dengan struktur
20
3) Processing
Pada tahapan ini terlebih dahulu menentukan jenis kata apa saja untuk subjek, predikat, objek, pelengkap, dan keterangan (Arif, 2018). Kemudian ditentukan pola kalimat.
a. Subjek
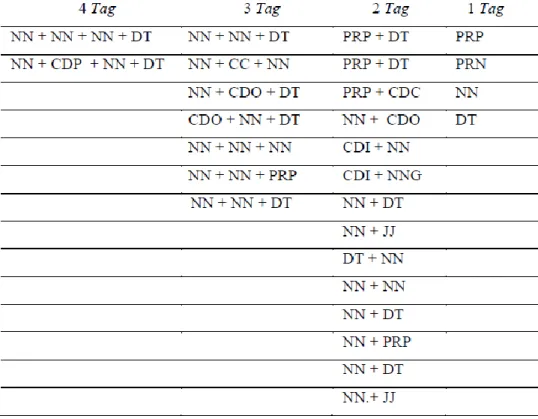
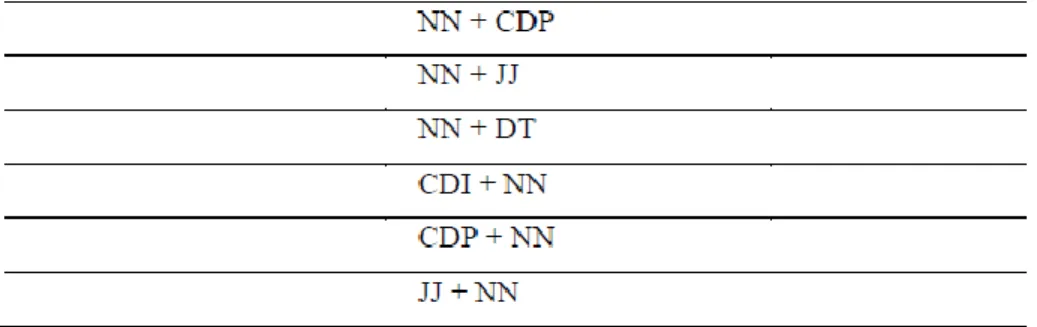
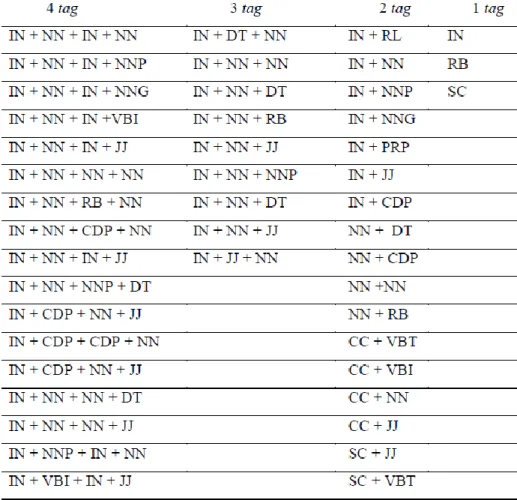
Untuk subjek dibatasi dengan 4 tag kemudian 3 tag, 2 tag, dan 1 tag. Adapun aturan yang telah dibuat terdapat pada tabel 3.1.
Tabel 3.1. Label Kata untu Subjek
Pemberian label kata pada subjek penulis membatasinya maksimum 4 ta g walaupun ada subjek yang lebih dari 4 tag/kata. Untuk 4 tag contohnya adalah “Ayah mertua Budi itu membelikan mobil untuk anaknya” sesuai dengan tag NN + NN +NN + DT. Subjek dengan 3 tag contohnya adalah “Pak dokter itu menolong pasien” sesuai dengan tag NN + NN + DT. Subjek dengan 2 tag contohnya adalah “Ibu Putri pergi ke pasar” sesuai dengan tag NN + NN. Subjek untu 1 tag contohnya adalah “Lisa menari” sesuai dengan tag NN.
b. Predikat
Untuk predikat dibatasi dengan maksimum 3 tag, kemudian 2 tag, dan 1 tag. Adapun aturan yang dibuat terdapat pada tabel 3.2.
Tabel 3.2. Label Kata untuk Predikat
Predikat dengan 3 tag contohnya adalah “Andi tidak akan menerima kenyataa n ini” sesuai dengan tag NEG + MD + VBT. Predikat dengan 2 tag contohnya adalah
“Dodi telah menyelesaikan tugas sekolah” sesuai dengan tag MD + VBT. Dan predikat dengan 1 tag contohnya adalah “ Pak camat mengumumkan masyarakat tentang peraturan baru” sesuai dengan tag VBT.
c. Objek
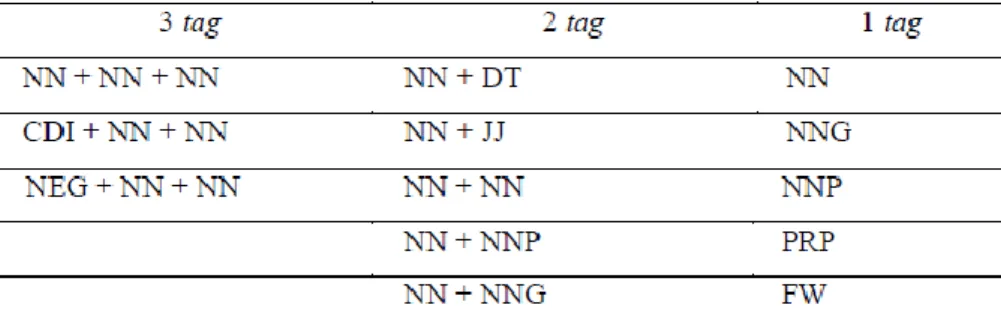
Untuk objek dibatasi dengan maksimum 3 tag, kemudian 2 tag, dan 1 tag. Adapun aturan yang dibuat terdapat pada tabel 3.3.
Tabel 3.3. Label Kata untuk Objek
22
Objek dengan 3 tag contohnya adalah “pak guru memberi semua murid laki-laki untuk memakai topi” sesuai dengan tag CDI + NN + NN. Objek dengan 2 tag contohnya adalah “Saya membawa buku bahasa ke sekolah” sesuai dengan tag NN + NN. Dan objek dengan 1 tag contohnya adalah “Deny meminjam buku dari perpustakaan” sesuai dengan tag NN.
d. Pelengkap
Untuk pelengkap dibatasi dengan maksimum 3 tag, kemudian 2 tag, dan 1 tag.
Adapun aturan yang dibuat terdapat pada tabel 3.4.
Tabel 3.4. Label Kata Untuk Pelengkap
Pelengkap dengan 3 tag contohnya adalah “Ani mengambil kursi yang tidak besar di kelas” sesuai dengan tag SC + NEG + JJ. Pelengkap dengan 2 tag contohnya adalah “Andi menyukai pelajaran yang sulit sejak kecil” sesuai dengan tag SC + JJ.
Dan pelengkap dengan 1 tag contohnya adalah “Melati adalah siswi pertama di sekolah ini” sesuai dengan tag CDO.
e. Keterangan
Untuk keterangan dibatasi dengan maksimum 4 tag, kemudian 3 tag, 2 tag, dan 1 tag.
Adapun aturan yang dibuat terdapat pada tabel 3.5.
Tabel 3.5. Label Kata untuk Keterangan
Keterangan dengan 4 tag contohnya adalah “Joni membeli kursi di rumah prabot itu” sesuai dengan tag IN + NN + NN + DT. Keterangan dengan 3 tag contohnya
24
adalah “Fotografer itu mengambil foto di gedung tua” sesuai dengan tag IN + NN + JJ. Keterangan dengan 2 tag contohnya adalah “Gubernur merayakan lebaran di desa”.
Tahap selanjutnya adalah proses LALR Parser. Dalam LALR Parseer terdapat parser logic. Hasil dari pelabelan kata yang diperoleh dari proses POS Tagging akan dikirim ke parser logic. Parser logic merupakan inti dari parser dimana proses stack dan parse table ada di dalamnya. Stack merupakan proses menyimpan kata yang akan di periksa dan sesudah di periksa. Selanjutnya memeriksa parse table yang terdiri dari action table dan goto table. Kata-kata yang sudah diberi label katanya akan diperiksa oleh action table terlebih dahulu. Action table akan memeriksa jenis kata apa yang digunakan oleh kata tersebut. Setelah diketahui jenis katanya, maka action table akan memberi aksi terhadap kata tersebut baik berupa shift atau reduce. Kemudian go to table yang akan menentukan reduce kata tersebut sebagai subjek, predikat, objek, dan keterangan. Kemudian diakhir akan diperoleh accept sebagai hasil dari pemeriksaan struktur kalimat yang sesuai dengan aturan sintaksis kalimat. Aksi-aksi yang terdapat pada action table terdiri dari shift, reduce, dan accept. LALR Parser saat melakukan pemeriksaan struktur kalimat dapat dilihat pada gambar 3.2.
Input
Stac k
output
Tabel
Gambar 3.2 LALR Parser
Berdasarkan gambar 3.2, penulis memberikan contoh proses LALR Parser dalam suatu kalimat. Misalkan diberi input “saya pergi.”. Kalimat ini dikenal sebagai a1, a2,…an. Sedangkan lambang $ merupakan batas dari akhir kalimat. Kalimat yang
a1 a2 .. an $
Sm
xm
sm-1 xm-1
Parser logic
action goto
telah di input akan masuk kedalam stack dalam bentuk kata per kata. Di dalam stack setiap kata dikenal sebagai Sm, Xm. Kata yang dikenal sebagai Sm dan Xm ini akan diperiksa ke action table dan goto table. Action table akan memberikan aksi berupa shift dan reduce kepada setiap kata. Kemudian goto table akan menentukan reduce kata tersebut sebagai subjek, predikat, objek, dan keterangan. Hasil dari action table dan goto table ini akan dikirim kembali ke parser logic yaitu kedalam stack yang dikenal sebagai Sm-1, Xm-1. Setelah itu akan diperoleh hasil atau output. Cara kerja LALR Parser dapat juga dilihat dari pseudocode (Jaber,1983) berikut.
BEGIN
READ input string;
consult table;
WHILE action != accept DO BEGIN
IF action = shift THEN call SHIFT
ELSE
call REDUCE;
consult table;
END;
Print an accepting message;
END;
procedure SHIFT;
BEGIN
stackptr = stackptr + 1;
stack[stackptr] = current symbol;
stackptr = stackptr + 1;
stack[stackptr] = new state;
END;
procedure REDUCE;
26
IF A != B THEN
stackptr = stackptr – 2*len of + 1 ELSE
stackptr = stackptr + 1;
stack[stackptr] = a;
stackptr = stackptr + 1;
stack[stackptr] = new state;
END;
Secara umum struktur kalimat Bahasa Indonesia terdiri dari subjek (S), predikat (P), objek (O), dan keterangan (K). Tetapi ada juga struktur kalimat yang menggunakan pelengkap (PEL). Dalam skripsi ini adapun aturan sintaksis kalimat yang digunakan berdasarkan aturan kalimat tunggal oleh Alwi, et.al. (1998) adalah sebagai berikut :
1. Kalimat berpredikat verba transitif dengan subkategori “ekatransitif”
KALIMAT = S + P + O + (K)
2. Kalimat berpredikat verba transitif dengan subkategori “dwitransitif”
KALIMAT = S + P + (O) + PEL + (K)
3. Kalimat berpredikat verba transitif dengan subkategori “semitransitif”
KALIMAT = S + P + (O) + (K)
4. Kalimat berpredikat verba intransitif dengan subkategori “berpelengkap”
KALIMAT = S + P + PEL + (K)
5. Kalimat berpredikat verba intransitif dengan subkategori “tberpelengkap”
KALIMAT = S + P + (K)
6. Kalimat berpredikat verba intransitif dengan subkategori “pasif”
KALIMAT = S + P + (PEL) + (K) 7. Kalimat berpredikat numeralia
KALIMAT = S + P + (K) 8. Kalimat berpredikat nomina
KALIMAT = S + P + O + (K)
9. Kalimat berpredikat adjektiva dengan subkategori “warna”
KALIMAT = S + P + (K)
10. Kalimat berpredikat adjektiva dengan subkategori “bandingan”
KALIMAT = S + P + PEL + (K)
11. Kalimat berpredikat adjektiva dengan subkategori “biasa”
KALIMAT = S + P + (PEL) + (K)
4) Post-processing
Pada tahap ini akan menampilkan hasil dari proses pemeriksaan struktur kalimat.
Hasil yang ditampilkan adalah hasil dari POS Tagging dan SPOK.
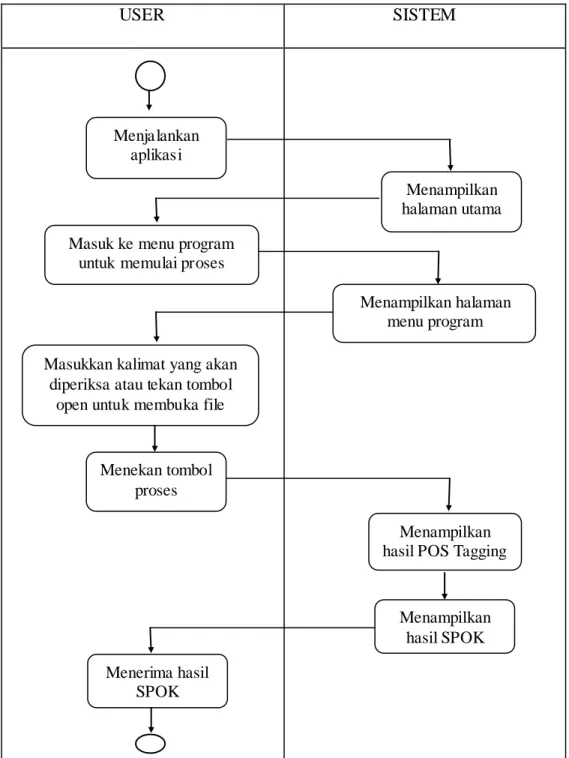
3.3.2 Diagram Aktifitas
Diagram aktifitas merupakan diagram yang menampilkan alur kerja atau kegiatan dari pengguna terhadap sebuah sistem atau menu yang ada pada perangkat lunak dan gambaran aktifitas-aktifitas ataupun proses yang terjad i pada sistem secara prosedural. Diagram aktifitas proses pemeriksaan struktur kalimat Bahasa Indonesia dapat dilihat pada gambar 3.3.
28
USER SISTEM
Gambar 3.3. Diagram Aktifitas Pemeriksaan Struktur Kalimat
Diagram aktifitas ini terdiri dari user dan sistem. Alur kerja pada sistem ini dimulai dari user. Saat user menjalankan sistem, maka user akan dibawa pada halaman utama. Setelah itu user bisa masuk ke menu program untuk melakukan proses pemeriksaan struktur kalimat. Pada tampilan menu program, user dapat
Menjalankan aplikasi
Masukkan kalimat yang akan diperiksa atau tekan tombol
open untuk membuka file
Menampilkan halaman menu program
Menerima hasil SPOK
Menampilkan halaman utama Masuk ke menu program
untuk memulai proses
Menekan tombol proses
Menampilkan hasil POS Tagging
Menampilkan hasil SPOK
memasukkan kalimat yang akan diperiksa struktur kalimatnya pada kolom input di sistem. User juga dapat memasukkan input kalimat berupa file atau dokumen yang berisi kalimat tungal untuk diperiksa struktur kalimatnya dengan menekan tombol open. Kemudian user dapat menekan tombol proses untuk melakukan pemeriksaan, setelah itu sistem akan menampilkan hasil penguraian dan pemeriksaan struktur kalimat Bahasa Indonesia.
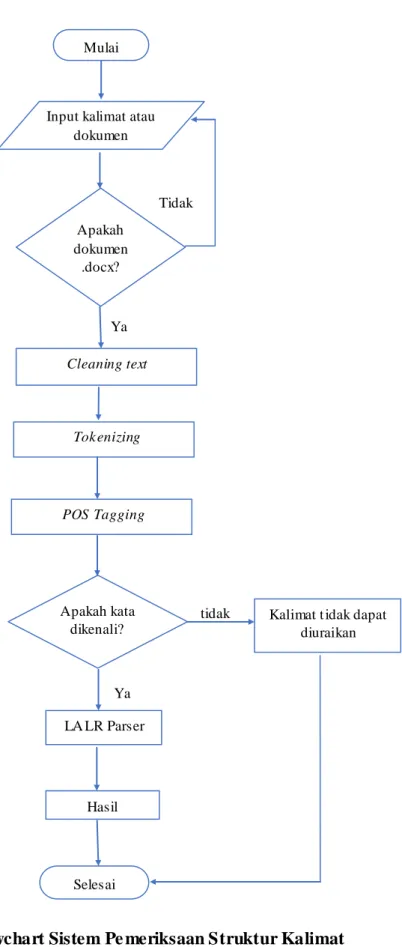
3.3.3 Flowchart Peme riksaan Struktur Kalimat
Tahap flowchart dimulai dari input kalimat atau dokumen. Setelah kalimat atau dokumen di input, sistem akan memeriksa ekstensi dokumen. Jika berekstensi .docx maka akan dilanjutkan ke proses cleaning text. Dalam sistem ini, dokumen berekstensi .docx dapat dibaca dengan menggunakan library poi-3.17-beta1.jar, poi-ooxml-3.17- beta1.jar, poi-ooxml-schemas-3.17.jar. Jika tidak, sistem akan meminta kembali dokumen yang berekstensi .docx. Tetapi jika user menginput kalimat secara langsung, sistem tetap akan melanjutkan proses cleaning text. Cleaning text merupakan proses pembersihan tanda baca pada kalimat. Setelah proses cleaning text, sistem melanjutkan proses tokenizing. Tokenizing adalah proses pemotongan kalimat berdasarkan kata yang menyusunnya. Lalu dilanjutkan ke proses POS Tagging. POS Tagging merupakan proses pelabelan kata pada suatu kalimat. Kemudian dilanjutkan ke proses pengenalan kata. Jika kata dikenali atau terdapat dalam korpus maka sistem akan melanjutkan ke proses LALR Parser. Jika tidak, kalimat tidak dapat diuraikan.
Setelah sistem melewati proses LALR Parser maka akan didapatkan hasil berupa struktur kalimat. Rancangan flowchart sistem pemeriksaan struktur kalimat ini dapat dilihat pada Gambar 3.4.
30
Tidak
Ya
tidak
Ya
Gambar 3.4 Flowchart Sistem Pe meriksaan Struktur Kalimat
Mulai
Input kalimat atau dokumen
Apakah dokumen
.docx?
Cleaning text
Tok enizing
POS Tagging
Apakah kata dikenali?
LA LR Parser
Hasil
Selesai
Kalimat t idak dapat diuraikan
3.3.4 Perancangan Antarmuka Sistem 1. Rancangan Tampilan Halaman Utama
Gambar 3.5 Rancangan Tampilan Halaman Utama Keterangan :
1: Logo aplikasi
2: Button untuk proses selanjutnya yang berupa logo USU 2. Rancangan Tampilan Menu Program
32
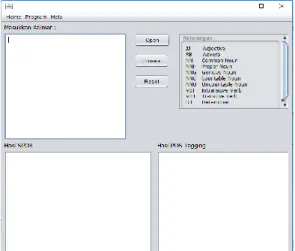
Keterangan :
1: Text Area untuk memasukkan kalimat atau menampilakan isi dokumen yang akan di proses
2: Button Open untuk membuka dokumen yang akan di proses
3: Button Proses untuk melakukan proses pemeriksaan struktur kalimat 4: Button Reset untuk meghapus data yang sudah ada
5: Text Area untuk menampilan hasil SPOK 6: Text Area untuk menampilkan hasil Penguraian 7: Text Area untuk keterangan
Pada bab ini akan dijelaskan tentang proses pengimplementasian POS Tagging dan LALR Parser pada sistem, sesuai perancangan sistem yang dilakukan pada bab 3 serta melakukan pengujian sistem yang telah dibangun.
4.1. Implementasi Sistem
4.1.1 Spesifikasi Perangkat Keras yang Digunakan
Spesifikasi perangkat keras yang digunakan untuk membangun sistem ini adalah sebagai berikut :
1. Processor Intel® Celeron® CPU B820 @ 1.70GHz (2 CPUs), ~1.7GHz 2. Kapasitas hardisk 500 GB
3. Memori RAM laptop 4,00 GB
4.1.2 Spesifikasi Perangkat Lunak yang Digunakan
Spesifikasi perangkat lunak yang digunakan untuk membangun sistem ini adalah sebagai berikut
1. Sistem operasi yang digunakan adalah Microsoft Windows 10 Pro 2. NetBeans IDE 8.0 JDK 1.8
3. Java: 1.8.0_5
4. Library yang digunakan yaitu poi-3.17-beta1.jar, poi-ooxml-3.17-beta1.jar, poiooxml-schemas-3.17-beta1.jar, Stanford-postagger.jar, dan xmlbeans- 2.6.0.jar untuk bahasa pemograman Java.
34
4.1.3 Implementasi Tampilan Antarmuka Sistem a. Tampilan Halaman Utama
Tampilan halaman utama ini merupakan tampilan awal dari sistem. Tampilan halaman Utama dapat dilihat pada gambar 4.1.
Gambar 4.1 Tampilan Halaman Utama
Gambar 4.1. Halaman Utama b. Tampilan Halaman Menu Program
Tampilan halaman ini merupakan tampilan untuk memproses pemeriksaa n struktur kalimat. Tampilan halaman menu program ini dapat dilihat pada gambar 4.2.
Gambar 4.2. Menu Program
4.1.4 Prosedur Operasional
Pada sistem pemriksaan struktur kalimat Bahasa Indonesia ini, tampilan yang pertama kali muncul adalah tampilan utama seperti yang ditunjukkan pada Gambar 4.1. Pada tampilan utama ini terdapat nama sistem, data pembuat, dan logo USU yang berupa button untuk lanjut ke menu program. Menu program ini yang akan menampilkan halaman untuk proses pemeriksaan struktur kalimat.
Prosedur operasional yang dilakukan user adalah sebagai berikut.
a. Pada tampilan awal, terdapat logo usu yang berupa button untuk proses selanjutnya. User dapat mengklik logo usu tersebut untuk menuju menu program seperti yang ditunjukkan pada gambar 4.3.
Gambar 4.3 Button Logo USU
36
b. Masukkan kalimat pada text area atau klik button open dokumen seperti yang ditunjukkan pada gambar 4.4
Gambar 4.4 Input Kalimat
c. Untuk klik button open, pilih dokumen yang akan diperiksa struktur kalimatnya seperti yang ditunjukkan pada gambar 4.5
Gambar 4.5 Pilih Button Open
d. Setelah kalimat dimasukkan, klik button proses untuk melakukan proses pemeriksaan struktur kalimat seperti pada gambar 4.6
Gambar 4.6 Pilih Button Proses
e. Setelah proses selasai, maka sistem akan menampilkan hasil pemeriksaan struktur dan penguraian kalimat. Hasil POS Tagging terdapat pada gambar 4.7.
38
f. Hasil SPOK terdapat pada gambar 4.8.
Gambar 4.8 Hasil SPOK
4.2. Pengujian Sistem
Ketika sistem sudah selesai dibangun maka akan dilakukan pengujian sistem.
Pengujian sistem ini bertujuan untuk mengetahui apakah sistem berfungsi dengan baik.
4.2.1. Pengujian Tahap Pertama
Pengujian tahap pertama dilakukan dengan mengambil data sampel dari buku Alwi, et.al. (1998). Tujuan uji coba tahap pertama ini adalah untuk memeriksa kebenaran aturan-aturan sintaks struktur kalimat yang telah di definisikan pada penelitian ini.
Oleh karena itu, masukan yang digunakan sebagai sampel pada pengujian ta hap pertama ini adalah kalimat-kalimat yang strukturnya sudah di definisikan dalam aturan–aturan sintaks pada penelitian ini.
Ada 11 rancangan struktur kalimat yang digunakan. Pada pengujian pertama dilakukan pengujian untuk mencocokkan kalimat masukan de ngan rancangan struktur kalimat tersebut. Rancangan struktur kalimat dan kalimat masukan untuk pengujian pertama dapat kita lihat pada tabel 4.1.
Tabel 4.1. Rancangan Struktur Kalimat Pengujian Pertama
No Rancangan Struktur Kalimat Bahasa
Indonesia Kalimat
1.
Kalimat berpredikat verba transitif dengan subkategori “ekatransitif”
KALIMAT = S + P + O + (K)
Saya harus membeli hadiah untuk Lisa.
2.
Kalimat berpredikat verba transitif dengan subkategori “dwitransitif”
KALIMAT = S + P + (O) + PEL + (K)
Wawan mencarikan pekerjaan yang bagus untuk adik.
3.
Kalimat berpredikat verba transitif dengan subkategori “semitransitif”
KALIMAT = S + P + (O) + (K)
Aku berlari kencang.
4.
Kalimat berpredikat verba intransitif dengan subkategori “berpelengkap”
KALIMAT = S + P + PEL + (K)
Ibu sudah terbiasa berjalan cepat ke kantor.
5.
Kalimat berpredikat verba intransitif dengan subkategori “tberpelengkap”
KALIMAT = S + P + (K)
Luna ingin tidur.
6
Kalimat berpredikat verba intransitif dengan subkategori “pasif” KALIMAT
= S + P + (PEL) + (K)
Mobil itu sudah dibawa ke Jakarta.
7. Kalimat berpredikat numeralia KALIMAT = S + P + (K)
Tabungannya hanya sedikit.
8. Kalimat berpredikat nomina KALIMAT = S + P + O + (K)
Paman adalah seorang koki di Surabaya.
9.
Kalimat berpredikat adjektiva dengan subkategori “warna” KALIMAT = S + P + (K)
Buku itu hitam.
40
10.
Kalimat berpredikat adjektiva dengan subkategori “bandingan” KALIMAT = S + P + PEL + (K)
Saya lebih putih dari kamu.
11.
Kalimat berpredikat adjektiva dengan subkategori “biasa” KALIMAT = S + P + (PEL) + (K)
Gadis itu cantik.
Kalimat masukan telah di input ke dalam sistem dan mengeluarkan hasil yang sesuai dengan struktur kalimat yang dibuat. Hasil dari POS Tagging dan SPOK dapat dilihat pada tabel 4.2
Tabel 4.2 Hasil POS Tagging dan SPOK Kalimat
Masukan
Hasil Pos Tagging Hasil SPOK Bedasarkan Buku
Hasil SPOK
Saya harus membeli hadiah untuk Siti.
[Saya/prp, harus/md, membeli/vbt, hadiah/nn, untuk/in, Siti/nnp]
S:Saya
P:harus membeli O:hadiah
K:untuk Siti
S:Saya
P:harus membeli O:hadiah
K:untuk Siti Wawan
mencarikan pekerjaan yang bagus untuk adik.
[Wawan/nnp, mencarikan/vbt, pekerjaan/nn, yang/sc, bagus/jj, untuk/in, adik/nnp]
S:Wawan P:mencarikan O:pekerjaan PEL:yang bagus K:untuk adik
S:Wawan P:mencarikan O:pekerjaan PEL:yang bagus K:untuk adik Aku berlari
kencang. [Aku/nnp, berlari/vbi, kencang/jj]
S:Aku P:berlari PEL:kencang
S:Aku P:berlari PEL:kencang Ibu sudah terbiasa
berjalan cepat ke kantor.
[Ibu/nnp, sudah/md, terbiasa/vbi,
berjalan/vbi, cepat/jj, ke//in, kantor//nn]
S:Ibu
P:sudah terbiasa berjalan
PEL:cepat
S:Ibu
P:sudah terbiasa berjalan
PEL:cepat
K:ke kantor K:ke kantor Luna ingin
tidur.
[Luna/nn, ingin/vbt, tidur/vbi]
S:Luna P:ingin tidur
S:Luna P:ingin tidur Mobil itu sudah
dibawa ke Bandung.
[Mobil/nn, itu/dt, sudah/md, dibawa/vbt, ke/in, Bandung/nnp]
S:Mobil itu P:sudah dibawa K:ke Bandung
S:Mobil itu P:sudah dibawa K:ke Bandung Tabungannya
hanya sedikit.
[Tabungannya/nnp, hanya/rb, sedikit/jj]
S:Tabungannya P:hanya sedikit
S:Tabungannya P:hanya sedikit Paman adalah
seorang koki di Surabaya.
[Paman/nnp, adalah/vbt, seorang/nn, koki/nn, di/in, Surabaya/nnp]
S:Paman P:adalah O:seorang koki K:di Surabaya
S:Paman P:adalah O:seorang koki K:di Surabaya Buku itu hitam. [Buku/nn, itu/dt,
hitam/jj]
S:Buku itu P:hitam
S:Buku itu P:hitam Saya lebih putih
dari kamu.
[Saya/prp, lebih/rb, putih/jj, dari/in, kamu/prp]
S:Saya P:lebih putih K:dari kamu
S:Saya P:lebih putih K:dari kamu Gadis itu cantik. [Gadis/nn, itu/dt,
cantik/jj]
S:Gadis itu P:cantik
S:Gadis itu P:cantik
Pada kalimat masukan nomor 1 sistem mengeluarkan hasil POS Tagging yaitu kata Saya dengan label PRP (Personal Promouns), kata harus dengan label MD (Modal), kata membeli dengan label VBT (Transitive Verb), kata hadiah dengan label NN (Common Noun), kata untuk dengan label IN (Preposition), kata Siti dengan label NN (Common Noun). Keterangan mengenai label secara lengkap dapat dilihat pada bab 2 tabel 2.1.
Selanjutnya proses pemeriksaan struktur kalimat menggunakan algortima LALR Parser menghasilkan Saya sebagai S (subjek), harus membeli sebagai P (predikat), hadiah sebagai O (objek) dan untuk Siti sebagai K (keterangan). Proses diatas
42
diterapkan pada kalimat masukan nomor 2 dan seterusnya. Proses pengujian secara detail dijelaskan pada pengujian tahap kedua.
4.2.2 Pengujian Tahap Kedua
Pengujian tahap kedua ini menggunakan kalimat-kalimat masukan yang berasal dari media cetak Kompas edisi Januari 2018. Hasil dari pengujian dapat kita lihat pada proses pengujian sistem berikut.
1) Proses input data
Masukkan Kalimat:
Saya ingin makan pizza.
2) Proses Cleaning Text yang bertujuan untuk menghapus tanda baca seperti titik (.) yang ditemukan pada data. Hasil Cleaning Text dapat dilihat dibawah sebagai berikut.
Hasil Cleaning Text:
Saya ingin makan pizza
3) Proses Tokenizing dilakukan untuk memisahkan kata per kata yang akan berguna saat proses Part-Of-Speech Tagging selanjutnya. Hasil Tokenizing :
saya Ingin makan pizza
4) Selanjutnya masuk ke proses Part-Of-Speech Tagging. Proses ini membutuhkan data korpus sebagai data yang akan ditraining. Korpus pada sistem ini menggunakan korpus dari penelitian Wicaksono dan Purwarianti. Hasil dari proses Part-Of-Speech Tagging dari data masukan diatas dapat dilihat dibawah sebagai berikut.
Hasil Part-Of-Speech Tagging:
[Saya/prp, ingin/vbt, makan/vbt, pizza/nn]
5) Setelah melakukan proses Part-Of-Speech Tagging selanjutnya masuk ke pemeriksaan struktur kalimat dengan menggunakan algoritma LALR Parser. Untuk itu diperlukan action table, goto table, dan aturan produksi. Action table merupakan aksi yang akan diberikan terhadap kata yang akan diperiksa sedangkan goto table merupakan proses yang akan menentukan pola setiap kata. Berikut merupakan tabel aturan produksi yang dapat dilihat pada tabel 4.3.
Tabel 4.3 Aturan Produksi
K -> SPOK S P O Pel K
R1 R2 R3 R4 R5
Tabel aturan produksi merupakan aturan yang digunakan dalam proses pemeriksaan struktur kalimat Bahasa Indonesia. Bilamana subjek (S) merupakan R1 (Reduce 1), predikat (P) merupakan R2 (Reduce 2), objek (O) merupakan R3 (Reduce 3), Pelengkap (Pel) merupakan R4 (Reduce 4), dan keterangan (K) merupakan R5 (Reduce 5). Untuk proses action table dan goto table dapat dilihat pada tabel 4.4.
Tabel 4.4. Action Table dan Goto Table
state
Action table Goto table
Prp Vbt Vbt Nn $ R1
(S)
R2 (P)
R3 (O)
R4 (Pel)
R5 (K)
0 S2 1
1 S10 3 4 5 7
2 R1
3 S10 S8
4 Accept