METODE CLUSTER SELF-ORGANIZING MAP
UNTUK TEMU KEMBALI CITRA
Chita Ralina Rahardjo, Yeni Herdiyeni, Firman Ardiansyah
Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor, Kampus Dramaga Wing 20 Level V, Bogor, Jawa Barat, Indonesia
Email: [email protected]
Abstract
The advent of multimedia computing has led to increased demands for digital images. Large number of people has not been satisfied with the result of image that has been retrieved. Image clustering is one of the crucial process in content-based image retrieval (CBIR). This research implement Self-Organizing Map (SOM) for clustering , not only by color-based image retrieval but also combine it with shape-color-based image retrieval. As a comparison, this research compare method without clustering with method that using SOM as a clustering method. Recall and precision is used to evaluate the retrieval performaces. According to this research, cluster method SOM for color-based image retrieval has average precision 88.98 %, while method without cluster has 75%. The better result is accomplished by combining the color-based with shape-based image retrieval. By using the combination, average precision for cluster method SOM has increased to 89.25 %.
Keywords : content-based image retrieval, expectation-maximization, fuzzy color histogram, hough transform, self organizing map.
1 PENDAHULUAN
Perkembangan dunia multimedia telah mengarah pada tingginya permintaan terhadap citra digital. Hal ini terbukti dengan semakin banyaknya orang yang menggunakan fasilitas internet untuk melakukan pencarian terhadap basis data citra. Namun, sering kali hasil pencarian citra digital tidak sesuai dengan keinginan pengguna. Hal tersebut dikarenakan pencarian dilakukan hanya berdasarkan teks bukan berdasarkan kandungan citra.
Pencarian yang dilakukan berdasarkan kandungan citra dapat disebut juga dengan Content Based Image
Retrieval (CBIR). Penggunaan kandungan citra (warna,
bentuk dan tekstur) dalam CBIR digunakan sebagai kondisi temu kembali citra dimana kandungan citra tersebut akan membentuk vektor ciri. Penggunaan vektor ciri warna telah dilakukan dalam penelitian Balqis (2006) dan vektor ciri bentuk dalam Wahyuningtyas (2006). Dalam penelitian tersebut, temu kembali citra dilakukan tanpa melalui proses pembentukan cluster. Hasil temu kembali citra yang dilakukan tanpa proses pembentukan
cluster masih belum efektif dikarenakan untuk tiap citra
kueri, proses pengukuran kemiripan akan dilakukan terhadap seluruh citra dalam basis data citra.
Untuk meningkatkan hasil temu kembali citra digunakanlah metode Self-Organizing Map (SOM), karena pada metode ini dilakukan proses pembentukan
cluster data citra. Dengan adanya proses tersebut,
pengukuran kemiripan untuk tiap citra kueri dilakukan
hanya terhadap cluster citra yang telah terbentuk. SOM merupakan metode yang diajukan Kohonen (1982), dan metode ini juga digunakan oleh Kaneko et al (1999) untuk pembentukan cluster data citra dengan menggunakan ciri warna dan tekstur. Berdasarkan hasil penelitian tersebut, metode SOM terbukti mampu meningkatkan hasil temu kembali citra. Oleh karena itu, pada paper ini digunakan metode Self-Organizing Map (SOM) untuk sistem temu kembali citra menggunakan ciri warna dan bentuk.
2 SELF-ORGANIZING MAP
2.1 Segmentasi dengan Expectation-
Maximization
Tahap pertama dalam penelitian ini adalah melakukan proses segmentasi terhadap seluruh citra dalam basis data. Setiap citra akan disegmentasi untuk mengelompokkan warna yang dikandung oleh setiap piksel dari citra ke beberapa segmen yang telah ditentukan jumlahnya. Segmen ini merupakan representasi dari warna-warna dominan citra. Tujuan dari proses ini adalah untuk mendapatkan kelompok-kelompok warna dominan dan mengurangi jumlah warna citra asli. Setiap piksel dari citra dibangkitkan dari parameter yang terdiri dari mean,
covariance dan mixing weight yang terkumpul dalam
suatu vektor parameter Θ=(п1,...,п2,θ1,...,θ2).
Masing-masing segmen diasumsikan memiliki distribusi normal Gaussian.
Algoritma EM mempunyai dua tahapan utama yaitu tahapan dugaan (E-step) dan maksimisasi (M-step). Pada tahapan dugaan (E-step), data X diasumsikan merupakan data yang tidak lengkap dengan missing value berupa label yang menyatakan keanggotaan tiap piksel dari X ke dalam salah satu G segmen. Pada tahapan ini, peluang tiap piksel berasal dari tiap segmen dihitung dan selanjutnya membentuk matriks Z yang akan melengkapi data X sehingga data yang lengkap dapat dinyatakan sebagai Y=(X,Z). Label tiap piksel didapatkan dari segmen yang mempunyai peluang tertinggi dalam Z. Pada tahapan M-Step, parameter untuk iterasi berikutnya ditentukan sesuai dugaan variabel dari Z.
Nilai parameter yang baru dari M-step ini akan digunakan kembali untuk E-step iterasi berikutnya. Proses E-step dan M-step akan terus berulang sampai didapatkan log likelihood yang kecil sehingga hasil perhitungan sudah tidak terlalu banyak mengalami perubahan. Ketika log likelihood hanya sedikit berubah, maka hasil dianggap konvergen dan hasil akhir merupakan hasil segmentasi dengan label untuk tiap-tiap piksel ke dalam segmen dapat ditentukan dari matriks Z.
2.2 Ekstraksi Warna Menggunakan Fuzzy
Color histogram (FCH)
Pertama, kita melakukan kuantisasi awal dengan memetakan seluruh warna piksel dari citra hasil segmentasi ke n bin histogram. Proses tersebut diawali dengan melakukan penghitungsn histogram warna. Penghitungan histogram warna dilanjutkan dengan penghitungan FCM yang akan menghasilkan jumlah bin sebagai ciri warna seluruh citra dalam basis data. Berdasarkan eksperimen menggunakan FCM, diperoleh jumlah bin optimal yaitu 25 bin seperti yang terlihat pada Tabel 1.
Tabel 1 Warna kuantisasi 25 bin histogram
Warna R G B 67 96 106 86 111 120 110 128 156 238 160 43 179 125 129 142 61 71 125 126 127 227 186 121 236 221 43 193 199 216 225 182 180 222 140 56 56 56 58 153 139 134 171 111 116 241 245 248 84 62 48 105 105 106 139 104 109 243 235 214 231 148 80 100 75 65 208 96 33 234 179 8 4 63 227
Nilai bin tersebut akan digunakan untuk penghitungan FCH dengan pengambilan derajat keanggotaan FCM. Perhitungan derajat keanggotaan (membership degrees) FCH dilakukan dengan Fungsi Cauchy.
α σ μ ) / ) ,' ( ( 1 1 ) ( ' c c d c c = + (1) dengan
d(c’,c) = jarak Euclidean antara warna c dengan c’, c’ = warna pada bin FCH,
c = semesta warna (universe color), α = digunakan untuk menentukan bentuk atau kehalusan dari fungsi,
σ = untuk menentukan lebar dari fungsi keanggotaan.
Berdasarkan percobaan, diperoleh parameter
α
=
2
dan15
=
σ
. Setelah itu, dilakukan penghitungan FCH menggunakan:∑
∈ = μ μ c c c h c c h2( ') '( )* ( ) (2) dengan 2h = fuzzy color histogram, h© = convensional color histogram,
) (
' c
c
μ = nilai keanggotaan dari warna c ke warna c’.
Pada penghitungan tersebut akan menghasilkan hasil kali dari matriks derajat keanggotaan dengan histogram awal.
2.3 Segmentasi Bentuk dengan Canny Edge
Detection
Canny edge detector merupakan salah satu metode pendeteksi tepi yang dikembangkan secara optimal. Algoritma Canny diawali dengan penghlusan citra untuk menghilangkan gangguan (noise). Kemudian mencari nilai gradient pada citra untuk menandai wilayah yang memiliki turunan spasial yang cukup besar
sekaligus menghilangkan piksel-piksel yang nilainya tidak pada maksimum (nonmaximum supression).
Algoritma Canny lalu menggunakan nilai threshold untuk memproses piksel-piksel lainnya yang tidak dihilangkan. Apabila piksel-piksel tersebut memiliki nilai
magnitude di bawah nilai threshold, maka piksel tersebut
dijadikan titik tepi bernilai satu. Berdasarkan proses tersebut, maka hasil akhir dari algoritma canny ini adalah citra biner.
2.4 Ektraksi Bentuk Menggunakan Hough
Transform
Konsep dasar dari Hough transformadalah bahwa terdapat garis dan kurva potensial yang tak terhitung jumlahnya di dalam gambar yang melalui titik mana saja pada berbagai ukuran dan orientasi.
Metode Hough transform dengan pendekatan elips menggunakan parameter (xi, yi, rx, ry, Ө), dengan (xi ,yi)
adalah titik pusat dari elips, rx dan ry sebagai sumbu
mayor dan minor elips, dan Ө adalah orientasi dari sumbu mayor elips (Gambar 1).
Gambar 1 Elips yang berpusat pada (x0 ,y0) dengan
sumbu mayor rx dan sumbu minor ry.
Digunakannya pendekatan Hough Transform elips, untuk menyelesaikan parameter-parameter yang dibutuhkan dalam mencari keberdaan elips dengan menggunakan persamaan (Nixon & Aguado 2002):
xo =x - rx cos Ө
y0=yo – ry sin Ө (3) Hough transform elips menggunakan titik-titik tepi
hasil pendeteksi tepi Canny untuk mendefinisikan elips pada setiap kemungkinan nilai mayor dan minor. Setiap piksel yang ditandai oleh pendeteksi tepi atau yang bernilai 1,diperiksa untuk mencari semua kemungkinan garis, kurva ataupun representsi bentuk lainnya yang melalui piksel tersebut. Nilai-nilai tersebut menandakan frekuensi banyaknya representasi bentuk yang melalui titik tersebut dan nilai-nilai tertinggi yang menandakan bahawa kemungkinan besar bentuk-bentuk yang
(membentuk voting) melalui titik-titik tersebut memang berada dalam citra.
Titik-titik yang memiliki nilai voting tertinggi disebut sebagai peak atau local maxima. Kemudian peak yang ditemukan diperiksa kembali apakah kurva yang berasal dari titik tersebut benar mendekati data sebenarnya dalam citra. Peak yang nantinya menjadi fitur ciri dari citra adalah peak yang setelah diperiksa kembali merupakan titik asal dari kurva yang paling banyak mendekati data pada citra sebenarnya. Berdasarkan eksperimen, threshold paling optilmal diperoleh pada threshold 10.
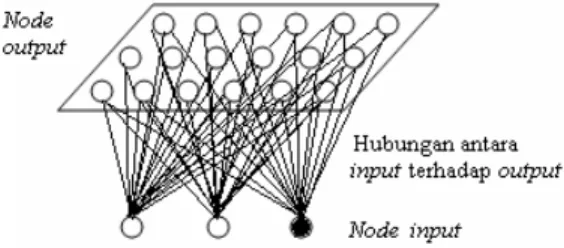
2.3 SELF-ORGANIZING MAP
Self-organizing map (SOM) diperkenalkan pertama
kali oleh Teuvo kohonen pada tahun 1982. Jaringan Kohonen tersebut memberikan sebuah tipe dari SOM di mana SOM merupakan algoritma unsupervised neural
network yang melibatkan interaksi antara activity dan connectivity. Ilustrasi dari Kohonen dapat dilihat pada
Gambar 2.
Gambar 2 Ilustrasi model Kohonen.
Algoritma Self-Organizing Map (SOM)
Misalkan m adalah dimensi dari vektor input x = [x1,x2,...xm]T. Vektor bobot untuk node output j memiliki
dimensi yang sama dengan vektor input, sehingga untuk neuron j, bobot vektor akan menjadi: wj = [wj1, wj2,
…,wjm]T.
Berikut ini adalah algoritma SOM: Untuk setiap vektor input x,
• Kompetisi. Dengan menggunakan fungsi jarak, hitung nilai D(wj,xn) untuk setiap node output j. Cari node pemenang J (Best matching Unit (BMU)), yaitu
node output yang memiliki kemiripan tertinggi
dengan vektor input, dengan nilai yang meminimumkan D(wj,xn).
• Kooperasi. Identifikasi seluruh node output j dalam lingkungan node pemenang J dengan menggunakan ukuran node tetangga (neighborhood function) hji.
Untuk setiap node tersebut , lakukan: • Adaptasi, perbaharui nilai bobot vektor:
• Perbaharui learning rate
( )
η dan ukuran node tetangga hji.• Hentikan perlakuan ketika kriteria pemberhentian telah dicapai.
Keterangan :
• Inisialisasi nilai bobot awal biasanya menggunakan nilai tengah (middle point) atau menggunakan nilai acak.
• Fungsi jarak menggunakan jarak euclid (Euclidean
Distance)
• D(wj,xn)= ∑i
(
wij−xni)
2 (7)• Ukuran node tetangga (hij) digunakan untuk
mengetahui derajat keanggotaan (degree of
membership) dari node i dalam lingkungan yang
berpusat pada node j. Ukuran node tetangga ini diperoleh dengan menggunakan fungsi Gaussian
(8) dengan dij merupakan jarak antara node i dan j dan
parameter sebagai ‘lebar efektif’ dari lingkungan. • Kriteria pemberhentian bisa berupa pembatasan
jumlah iterasi, atau ketika
( )
η =0 (Willson 2006).2.3.1 Menentukan Citra Latih dan Citra Uji
K-fold cross validation merupakan salah satu metode
estimasi error. Cross Validation akan melakukan proses pengulangan sebanyak k-kali untuk himpunan contoh secara acak yang akan dibagi menjadi k-subset yang saling bebas, dimana pada tiap tahap pengulangan akan diambil satu subset untuk data testing dan sisanya untuk
data training (Fu 1994). Data yang digunakan diambil
dari basis data sebanyak 300 citra untuk berbagai macam objek. Format citra adalah JPEG. Sesuai dengan metode 5-fold cross validation, maka dalam penelitian ini, digunakan lima buah subset dengan tiap subset memiliki jumlah yang sama dan nilai yang berbeda.
2.3.2 Pelatihan (training) menggunakan
SOM
Ukuran map SOM yang digunakan pada penelitian ini adalah 2*5 dan iterasi sebanyak 50 kali. Pada SOM, terdapat beberapa parameter yang dapat mempengaruhi hasil cluster, diantaranya learning rate
( )
η sebagai parameter kontrol pelatihan dan ukuran node tetangga (hij). Penggunaan kombinasi parameter yang tepat, dapatmemberikan hasil cluster yang lebih efektif. Oleh karena itu, dilakukanlah proses pelatihan terhadap kedua parameter tersebut. Pada penelitian ini parameter
learning rate
( )
η yang digunakan adalah 0.01, 0.02, 0.03,0.04, 0.05, 0.06, 0.07, 0.08, 0.09 dan 0.1. Sedangkan
untuk parameter ukuran node tetangga (hij) adalah 1, 2, 3,
dan 4. Tiap-tiap kombinasi dari kedua parameter tersebut akan digunakan dalam algoritma SOM.
Hasil dari tahap pelatihan ini adalah vektor bobot akhir yang akan digunakan sebagai model clustering untuk mengelompokkan citra-citra dalam basis data.
2.3.3 Pengujian (testing) menggunakan SOM
Tahapan pengujian dilakukan dengan melakukan pengukuran kedekatan antara vektor input terhadap vektor bobot akhir yang diperoleh pada tahap pelatihan. Hasil dari pengukuran kedekatan tersebut adalah
clustering vektor input kedalam sepuluh cluster citra,
yaitu (1) MotorBikes, (2) CarSide, (3) Sunflower, (4)
Airplane, (5) Ketch, (6) Face,(7) Bunga Daffodil Orange,
(8) Hawksbill, (9) Barrel dan (10) Buddha. Tahapan dilanjutkan dengan mengukur kualitas SOM menggunakan mapping precision, topology preservation dan persentase error. Model clustering yang digunakan adalah model clustering yang menghasilkan error minimal.
2.3.2.1 Mapping Precision
Quantization Error menjelaskan hubungan antara tipe
data suatu cluster dengan BMU. Pengukuran quantization
error merupakan jarak rataan untuk setiap vektor x
terhadap BMU. Jarak rataan dari vektor input x terhadap bobot vektor w terdekat,
Eq = 1/N ∑ || x-wj ||
(9)N
dengan cluster terbaik akan dicapai bila Eq bernilai minimal (Yoo 2004).
2.3.2.2 Topology Preservation
Pengukuran topology preservation menjelaskan reaksi penyesuaian SOM terhadap data input. Berbeda dengan pengukuran mapping precision, topology
preservation mempertimbangkan struktur dari peta.
Kalkulasi tersebut dilakukan dengan menggunakan
Topograhic Error (Eq):
N
Eq = 1/N ∑ u (x
i)
(10)i=1
dengan u(xk) =1 jika BMU pertama dan kedua tidak
terletak bersebelahan, selainnya u(xk) = 0 (Vorovokos L
2.3.2.3 Persentase Error
Persentase error merupakan salah satu metode pengukuran kualitas SOM. Perhitungan persentase error hanya didasarkan pada perhitungan data citra yang salah dalam tiap cluster (Yoo 2004).
2.4 Hasil Temu Kembali
Dari hasil model clustering akhir, diambil citra di dalam basis data yang memiliki cluster yang sama dengan citra kueri dan citra dari kelas lain yang memiliki kedekatan tertinggi. Pengukuran tingkat kemiripan citra kueri terhadap citra dari kelas lain menggunakan perhitungan jarak euclid. Jarak euclid antara bobot akhir w dan vektor input x dirumuskan dengan formula:
(
)
∑ − = i ij ni n j x w x w D( , ) 2 (11)2.5 Evaluasi Hasil Temu Kembali
Tahapan evaluasi dilakukan dengan melakukan penilaian terhadap tingkat keberhasilan dalam proses temu kembali terhadap sejumlah koleksi pengujian dengan menghitung nilai recall dan precision. Recall adalah perbandingan antara materi relevan yang ditemukembalikan terhadap seluruh materi relevan yang terdapat dalam basis data. Sedangkan precision adalah perbandingan antara materi relevan yang ditemukembalikan terhadap seluruh materi yang ditemukembalikan (Grossman 2002) .
3 HASIL
3.1 Temu kembali Citra Berdasarkan Ciri
Warna
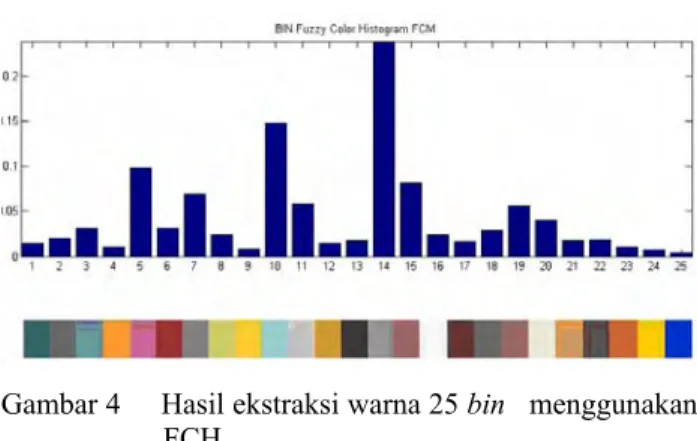
Hasil segmentasi dengan algoritma EM dapat dilihat pada Gambar 3, dan hasil ekstraksi ciri warna dengan FCH dari Gambar 3 dapat dilihat pada Gambar 4.
Gambar 3 Contoh citra kueri dan citra hasil segmentasi EM.
Gambar 4 Hasil ekstraksi warna 25 bin menggunakan FCH.
Perhitungan kombinasi parameter dilakukan berdasarkan
mapping precision, topology preservation dan persentase error. Tabel 2, 3 dan 4 menunjukkan error yang
dihasilkan untuk tiap kombinasi parameter η dan hij.
Tabel 2 Perhitungan quantization error berdasarkan ciri warna
( )
η 1 2 3 4 0.01 0.161 0.165 0.168 0.179 0.02 0.153 0.15 0.184 0.15 0.03 0.149 0.146 0.154 0.157 0.04 0.159 0.146 0.148 0.155 0.05 0.146 0.289 0.147 0.158 0.06 0.164 0.151 0.148 0.154 0.07 0.149 0.161 0.146 0.145 0.08 0.163 0.145 0.157 0.171 0.09 0.136 0.161 0.152 0.164 0.1 0.153 0.146 0.159 0.148 Tabel 3 Perhitungan topology preservation berdasarkanciri warna
( )
η 1 2 3 4 0.01 0.267 0.123 0.119 0.156 0.02 0.122 0.103 0.137 0.127 0.03 0.13 0.089 0.104 0.112 0.04 0.152 0.108 0.1 0.091 0.05 0.133 0.116 0.119 0.097 0.06 0.102 0.118 0.101 0.123 0.07 0.151 0.120 0.125 0.99 0.08 0.111 0.108 0.123 0.069 0.09 0.109 0.134 0.108 0.139 0.1 0.106 0.126 0.087 0.095Ukuran Node Tetangga (hij)