i
SISTEM TEMU BALIK INFORMASI DOKUMEN MAKALAH ILMIAH
BERBAHASA INDONESIA MENGGUNAKAN STRUKTUR DATA
INVERTED INDEX BERBASIS HASH TABLE DAN LINKED LIST
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Reza Mohammad Darojad NIM:085314024
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
INFORMATION RETRIEVAL SISTEM OF INDONESIAN SCIENTIFIC
PAPER USING INVERTED INDEX DATA STRUCTURE BASED ON
HASH TABLE AND LINKED LIST
THESIS
Presented as Partial Fullfilment of the Requirements To Obtain the Computer Bachelor Degree
In Informatics Engineering
By:
Reza Mohammad Darojad NIM:085314024
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iii
HALAMAN PERSTETUJUAN
SKRIPSI
SISTEM TEMU BALIK INFORMASI DOKUMEN MAKALAH ILMIAH
BERBAHASA INDONESIA MENGGUNAKAN STRUKTUR DATA
INVERTED INDEX BERBASIS HASH TABLE DAN LINKED LIST
Oleh:
Reza Mohammad Darojad NIM:085314024
Telah disetujui oleh:
Dosen Pembimbing
iv
HALAMAN PERSTETUJUAN
SKRIPSI
SISTEM TEMU BALIK INFORMASI DOKUMEN MAKALAH ILMIAH BERBAHASA INDONESIA MENGGUNAKAN STRUKTUR DATA INVERTED INDEX BERBASIS HASH TABLE DAN LINKED LIST
Dipersiapkan dan ditulis oleh
Reza Mohammad Darojad NIM:085314024
Telah dipertahankan di depan Panitia Penguji
Pada tanggal 15 Februari 2013
dan dinyatakan memenuhi syarat
Susunan Panitia Penguji
Nama Lengkap Tanda Tangan
Ketua Sri Hartati Wijono, S. Si., M. Kom. ...
Sekretaris Puspaningtyas Sanjoyo Adi, S.T., M.T. ...
Asnggota JB. Budi Darmawan, S.T., M. Sc. ...
Yogyakarta , .... Februari 2013
Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan,
v
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan seungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya orang lain kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, Februari 2013 Penulis,
vi
ABSTRAKSI
Makalah ilmiah adalah karya ilmiah akademik yang dipublikasikan. Makalah
ilmiah berbahasa Indonesia lebih ditujukan untuk ruang lingkup pembaca
nasional.
Seiring bertambahnya jumlah makalah ilmiah yang beredar para akademisi
memerlukan informasi mengenai makalah-makalah yang akan mereka baca atau
referensikan. Informasi tersebut dapat diperoleh menggunakan sistem
temu-kembali informasi (Information retrieval) agar pengguna mendapatkan keputusan sumber informasi yang tepat sesuai kebutuhan pengguna.
Sistem Pemerolehan informasi yang dibangun berfokus pada model TF-IDF
dengan algoritma stemming Nazief & Adriani karena dokumen makalah yang
akan di cari adalah makalah ilmiah berbahasa Indonesia dan algoritma tersebut
vii
ABSTRACT
Scientific papers are academic papers that published. Indonesian-language
scientific papers aimed more at the national scope of the reader.
With the growing number of outstanding scientific papers, academics need
information about the papers they would read or refer. Such information can be
obtained using Information Retrieval Systems so that users get the right decision
sources of information according to user needs.
Information Retrieval System is built focusing on the model TF-IDF with
Nazief & Adriani stemming algorithms for paper documents that will be looking
for is a scientific paper in Indonesian language and the algorithm is the optimal
viii
HALAMAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata
Dharma:
Nama : Reza Mohammad Darojad
NIM : 085413024
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
SISTEM TEMU BALIK INFORMASI DOKUMEN MAKALAH ILMIAH
BERBAHASA INDONESIA MENGGUNAKAN STRUKTUR DATA
INVERTED INDEX BERBASIS HASH TABLE DAN LINKED LIST
Berserta perangkat yang diperlukan bila ada. Dengan demikian saya memberikan
kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan,
mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan
data, mendistribusikan secara terbatas, dan mempublikasikannya di internet atau
media laiin untuk kepentingan akademis tanpa perlu meminta ijin dari saya
maupun memberi royalti kepada saya selama tetap mencantumkan nama saya
sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta
Pada tanggal:
Yang menyatakan
ix
KATA PENGANTAR
Puji syukur kepada Yesus Kristus yang telah memberikan karunia, rahmat, dan kesempatan, sehingga penulis dapat menyelesaikan skripsi ini. Penyusunan skripsi ini tidak lepas dari semua pihak yang turut memberikan dukungan, doa, semangat, dan bantuan yang sangat bermanfaat bagi penulis. Pada kesempatan ini penulis mengucapkan terima kasih sebesar besarnya kepada :
1. Bapak JB. Budi Darmawan, S.T., M.Sc. selaku dosen pembimbing
senantiasa memberikan masukkan dan bantuan dalam membimbing penulis untuk menyelesaikan skripsi ini.
2. Segenap dosen Universitas Sanata Dharma yang telah membantu memberikan bekal pengetahuan kepada penulis.
3. Ibu Sulistyaningtyas dan Kakak Tyas yang selalu memberi dukungan. 4. Seluruh sahabat dan rekan-rekan TI yang tidak dapat penulis sebutkan atas
kesediaanya dalam memberikan masukkan, menemani dan memberi dukungan kepada penulis.
Penulis menyadari bahwa masih banyak kekurangan yang terdapat pada skripsi ini. Saran dan kritik penulis harapkan untuk kebaikan bersama. Semoga bermanfaat.
Yogyakarta, Februari 2013 Penulis,
x
Daftar Isi
HALAMAN JUDUL... i
HALAMAN PERSETUJUAN SKRIPSI ... iii
PERNYATAAN KEASLIAN KARYA ... v
ABSTRAKSI ... vi
ABSTRACT ... vii
HALAMAN PERSETUJUAN PUBLIKASI KARYA ILMIAH ... viii
KATA PENGANTAR... ix
1.5. Metodologi Penelitian ... 4
1.6. Sistematika Penulisan ... 5
Bab II Landasan Teori ... 7
2.1 Information Retrieval ... 7
2.2 Proses Indexing ... 9
2.3 Pembobotan Kata ... 14
2.4 Hash Table ... 17
2.5 LinkedList ... 17
2.6 Precision dan Recall ... 17
BAB III ANALISA DAN PERANCANGAN SISTEM ... 18
3.1 Analisa Sistem ... 18
3.2 Perancangan Sistem ... 33
BAB IV IMPLEMENTASI SISTEM ... 48
4.1. Spesifikasi Perangkat Lunak dan Perangkat Keras ... 48
4.3. Implementasi Inverted Index ... 59
4.4. Implementasi Antarmuka ... 65
xi
4.6. Implementasi Model ... 72
BAB V ANALISA HASIL ... 73
BAB VI KESIMPULAN DAN SARAN ... 87
6.1 Kesimpulan ... 87
Daftar Pustaka ... 89
1
Bab I
Pendahuluan
1.1. Latar belakang
Jumlah dokumen makalah ilmiah digital di Indonesia terus bertambah
sehingga masyarakat terutama akademisi memerlukan suatu sistem yang dapat
mengakses dan menyediakan berbagai informasi sesuai kebutuhannya. Informasi
tersebut dapat diperoleh menggunakan sistem temu-kembali informasi
(Information retrieval) agar pengguna mendapatkan sumber informasi yang tepat sesuai kebutuhan pengguna dari sekumpulan dokumen yang besar (Manning,
2009).
TF-IDF adalah salah satu metode dari Information Retrieval untuk memberikan bobot hubungan suatu kata (term) terhadap dokumen. Metode TF-IDF yang digunakan menggunakan teknik pembobotan Savoy karena pada teknik
pembobotan ini, bobot istilah telah dinormalisasi. Teknik ini memperhitungkan
jumlah dokumen yang mengandung istilah yang bersangkutan dan jumlah
keseluruhan dokumen. Sehingga jika sebuah istilah mempunyai frekuensi
kemunculan yang sama pada dua dokumen belum tentu mempunyai bobot yang
sama. Teknik ini sudah diterapkan pada dokumen berbahasa Indonesia dan cukup
baik dalam memberikan bobot dokumen terurut(Baeza, 1999).
Data yang berisi daftar term dan hubungannya dengan dokumen disimpan
dalam sebuah Inverted Index. Inverted index terdiri dari dua bagian utama,
2
pengurutan data tidak diutamakan. Posting List memerlukan struktur data penyimpanan yang terurut dan dinamis, Ordered Linked List diimplementasikan untuk Posting List karena ukuran Linked List yang dapat melebar menyesuaikan data yang ditambahkan. Ordered Linked List berdasarkan pada Linked List dengan penambahan pengurutan data (Robert, 2003).
Pencarian dokumen makalah ilmiah yang sudah ada sebagian besar
menghasilkan informasi berdasarkan abstrak, judul,pengarang, penerbit, dan
subjek makalah. bukan seluruh isi makalah. Peneliti mengembangkan Sistem
Pemerolehan Informasi untuk dokumen makalah berbahasa Indonesia
menggunakan seluruh isi teks dokumen.
1.2. Rumusan Masalah
Dari latar belakang di atas dapat dirumuskan beberapa masalah yang akan
dikaji, yaitu:
1. Sejauh mana performa struktur data Hash dan LinkedList terhadap
pencarian dokumen?
2. Bagaimana sistem temu balik informasi ini dapat menghasilkan dokumen
yang relevan yang teranking berdasarkan query masukan oleh pengguna?
3. Seberapa relevankah dokumen hasil dari metode pembobotan TD-IDF
3
1.3. Tujuan
Penelitian ini bertujuan untuk mengimplementasikan sistem pemerolehan
informasi untuk pencarian makalah ilmiah berbahasa Indonesia menggunakan
seluruh isi teks makalah ilmiah dan mengetahui unjuk kerja sistem yang
menggunakan Inverted Index klasik dengan struktur data Hash Table dan Ordered LinkedList dengan operasi boolean dasar
1.4. Batasan Masalah
1. Sistem ini berfokus pada dokumen berbahasa Indonesia yang mengandung
format Portable Document Format(PDF).
2. Dokumen hasil Query yang akan dipilih user telah tersedia dalam indeks sistem dan merupakan bagian dari koleksi pengujian sebanyak 281
dokumen berbahasa Indonesia.
3. Koleksi pengujian diambil dari kolesi dokumen makalah ilmiah berbahasa
Indonesia.
4
1.5. Metodologi Penelitian
Dalam penelitian ini dilakukan tahap-tahap penelitian sebagai berikut:
1. Studi Pustaka
Studi pustaka penerapan inverted index klasik menggunakan pembobotan
TF-IDF dengan operasi AND. 2. Pengumpulan Data
Pengumpulan dokumen-dokumen makalah ilmiah yang berbahasa
Indonesia sebagai corpus sebanyak 281 dokumen. 3. Implementasi
Implementasi penerapan TF-IDF dan struktur data classical yaitu Inverted Index yang berbasis pada Hash dan Ordered LinkedList untuk mendukung
inverted index dengan menggunakan rumus pembobotan Savoy. 4. Pengujian
Pengujian relevansi pencarian menggunakan recall precision dan
Pengamatan unjuk kerja waktu query dengan operasi AND dengan dua belas kelompok kata yang mengandung frekuensi dokumen tertentu.
Kelompok kata tersebut adalah kelompok kata yang memiliki dfk 1 sampai
2, dfk mendekati 140, dan dfk kurang lebih 280, 1 kata kunci pencarian
5
1.6. Sistematika Penulisan
Sistematika penulisan dan penyusunan tugas akhir ini dibagi
menjadi 6 (enam) bab, yaitu :
BAB I PENDAHULUAN
Bab ini berisi penjelasan tentang latar belakang, rumusan masalah,
batasan masalah, tujuan penelitian, manfaat penelitian, metodologi
penelitian, dan sistematika dari penulisan tugas akhir.
BAB II LANDASAN TEORI
Bab ini berisi penjelasan tentang teori-teori yang berkaitan dengan
penulisan tugas akhir.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi penjelasan mengenai identifikasi masalah yang ada, kerja
dari sistem yang ada, dan analisis sistem yang meliputi analisis masalah
dalam sistem lama dan analisis kebutuhan sistem baru. Terdapat pula
perancangan sistem meliputi perancangan proses, perancangan
basisdata, dan perancangan antarmuka untuk para pengguna sistem.
BAB IV IMPLEMENTASI SISTEM
Bab ini berisi implementasi dari sistem yang sudah dirancang
BAB V ANALISA HASIL
6
BAB VI KESIMPULAN DAN SARAN
Bab ini berisi tentang kesimpulan dan saran dari analisis dan
7
Bab II Landasan
Teori
2.1Information Retrieval
Sistem temu kembali informasi (information retrieval system) merupakan sistem untuk menemukan kembali (retrieve) informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara
otomatis. Penekanannya ada pada penemukembalian informasi yang sifatnya
tidak terstruktur. Salah satu contoh dari sistem temu kembali informasi adalah
search-engine atau mesin pencarian (Mandala,2004).
Tujuan yang harus dipenuhi dari Sistem temu kembali informasi adalah
bagaimana mendapatkan dokumen relevan dan tidak mendapatkan dokumen
yang tidak relevan. Tujuan lainnya adalah bagaimana menyusun dokumen
yang telah didapatkan tersebut ditampilkan terurut dari dokumen yang
memiliki tingkat relevansi lebih tingi ke tingkat relevansi rendah. Penyusunan
dokumen terurut tersebut disebut sebagai perangkingan dokumen.
Dokumen diwakili melalui set index term.Index term menyediakan
logical view dari dokumen Jika kolesi dokumen cukup besar komputer akan melakukan pengurangan jumlah set term melalui penghapusan
8
index term. Gambar 2.1 menunjukkan logical view yang digunakan sistem pemerolehan informasi(Baeza, 1999).
Gambar 2.1 Logikal view dari sebuah dokumen: dari full text menjadi sebuah
set indeks term(Baeza, 1999).
Sistem pemerolehan informasi memiliki beberapa tahap.Pertama
melakukan indentifikasi terhadap dokumen-dokumen yang akan digunakan,
operasi yang akan dilakukan terhadap teks, dan model teks. Text operations
mentransformasikan dokumen asal menjadi logicalview. Setelah logicalview
9
Gambar 2.2 Proses dari pemerolehan informasi(Baeza, 1999).
2.2Proses Indexing
Indeks kata dibuat dalam bentuk inverted index. Inverted index terdiri dari dua bagian utama, dictionary dan posting list. Dictionary menyimpan daftar kata, sedangkan posting list menyimpan identitas dokumen yang
mengandung kata yang bersangkutan. Setiap kata terhubung dengan satu
rangkaian posting list menggunakan penunjuk.(Manning,2009).
10
Parsing
Proses ini mengambil query dari kata-kata kunci pengguna dengan cara memotong string input berdasarkan tiap kata yang menyusunnya
Elemen teks (string input) dipisahkan dengan teknik parsing
menggunakan pemisahan string dilakukan berdasarkan operator
pemisah untuk kemudian di eksekusi terhadap index.(Manning,2009).
Stopword Removing
Proses ini menghilangkan stopword pada string input yang menyusun dokumen dan query. Dalam proses ini digunakan sebuah daftar kata buang (stoplist) yaitu daftar kata-kata yang tidak digunakan (dibuang) karena tidak signifikan dalam membedakan
dokumen atau query. Stoplist ini umumnya berupa kata tugas, kata hubung, kata bantu, yang mempunyai fungsi dalam kalimat penyusun
dokumen tetapi tidak memiliki arti..
Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem IR
yang mentransformasi kata-kata yang terdapat dalam suatu dokumen
ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Sebagai contoh, kata bersama, kebersamaan, menyamai, akan
11
berbahasa Indonesia berbeda dengan stemming pada teks berbahasa
Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya
proses menghilangkan sufiks. Sedangkan pada teks berbahasa
Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan.
Algoritma yang dibuat oleh Bobby Nazief dan Mirna Adriani ini
memiliki tahap-tahap sebagai berikut:
1. Cari kata yang akan distem dalam kamus. Jika ditemukan
maka diasumsikan bahwa kata tesebut adalah root word. Maka algoritma berhenti.
2. Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “
-nya”) dibuang. Jika berupa particles (“-lah”, “-kah”, “-tah”
atau “-pun”) maka langkah ini diulangi lagi untuk
menghapus Possesive Pronouns (“-ku”, “-mu”, atau “
-nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika
tidak maka ke langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari
kata tersebut adalah “-k”, maka “-k” juga ikut
dihapus. Jika kata tersebut ditemukan dalam
kamus maka algoritma berhenti. Jika tidak
12
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”)
dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke
langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang
tidak diijinkan. Jika ditemukan maka algoritma
berhenti, jika tidak pergi ke langkah 4b.
b. For i = 1 to 3, tentukan tipe awalan kemudian
hapus awalan. Jika root word belum juga
ditemukan lakukan langkah 5, jika sudah maka
algoritma berhenti. Catatan: jika awalan kedua
sama dengan awalan pertama algoritma berhenti.
5. Melakukan Recoding.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil
maka kata awal diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe
awalannya secara berturut-turut adalah “di-”, “ke-”, atau “se
13
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka
dibutuhkan sebuah proses tambahan untuk menentukan tipe
awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”,
“be-”, “me-”, atau “pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe
awalan adalah bukan “none” maka awalan dapat dilihat pada
Tabel 2. Hapus awalan jika ditemukan.
Untuk mengatasi keterbatasan pada algoritma di atas, maka
ditambahkan aturan-aturan dibawah ini(Agusta,2009):
14
Jika kedua kata yang dihubungkan oleh kata penghubung
adalah kata yang sama maka root word adalah bentuk
tunggalnya, contoh: “buku-buku” root word-nya adalah
“buku”.
Kata lain, misalnya “bolak-balik”, “berbalas-balasan, dan
”seolah-olah”. Untuk mendapatkan root word-nya,kedua kata
diartikan secara terpisah. Jika keduanya memiliki root word
yang sama maka diubah menjadi bentuk tunggal, contoh: kata
“berbalas-balasan”, “berbalas” dan “balasan” memiliki root
word yang sama yaitu “balas”, maka root word “berbalas
-balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”,
“bolak” dan “balik” memiliki root word yang berbeda, maka
root word-nya adalah “bolak-balik”
2. Tambahan bentuk awalan dan akhiran serta aturannya.
Untuk tipe awalan “mem-“, kata yang diawali dengan awalan
“memp-” memiliki tipe awalan “mem-”.
Tipe awalan “meng-“, kata yang diawali dengan awalan
“mengk-” memiliki tipe awalan “meng-”.
2.3Pembobotan Kata
2.3.1 Term Frequency
15
Nilai jumlah kemunculan suatu kata (term frequency) diperhitungkan dalam pemberian bobot terhadap suatu kata. Semakin besar jumlah kemunculan suatu
term (tf tinggi) dalam dokumen, semakin besar pula bobotnya dalam dokumen atau akan memberikan nilai kesesuian yang semakin besar.
Frekuensi kata dinotasikan sebagai , ′ dengan menotasikan kata and
′ sebagai urutan dokumen. Untuk sebuah dokumen d, jumlah bobot dapat
diketahui dari bobot tf diatas.(Manning,2009).
2.3.2 Inverse Document Frecuency
Inverse Document Frequency (idf) factor, yaitu pengurangan dominansi
term yang sering muncul di berbagai dokumen. Hal ini diperlukan karena term
yang banyak muncul di berbagai dokumen, dapat dianggap sebagai term umum (common term) sehingga tidak penting nilainya. Sebaliknya faktor kejarangmunculan kata (term scarcity) dalam koleksi dokumen harus diperhatikan dalam pemberian bobot. Kata yang muncul pada sedikit dokumen harus
dipandang sebagai kata yang lebih penting (uncommon tems) daripada kata yang muncul pada banyak dokumen. Pembobotan akan memperhitungkan faktor
kebalikan frekuensi dokumen yang mengandung suatu kata (inverse document frequency).(Manning,2009).
16
Pembobotan TF-IDF mengkombinasikan frekuensi kata dan inverse document frequency . Pembobotan TF-IDF didapat dengan menggunakan rumus berikut (savoy) (Hasibuan, 2001)
Wik = ntfik * nidfk,
tfikmerupakan frekuensi dari istilah k dalam dokumen i.
n adalah jumlah dokumen dalam kumpulan dokumen.
dfk adalah jumlah dokumen yang mengandung istilah k.
Maxj tfij adalah frekuensi istilah terbesar pada satu dokumen.
Wd= bobot sebuah dokumen
Dengan kata lain, tf-idft,d berlaku untuk termt bobotdi dokumen d yang 1. Tertinggi jika t sering muncul dengan jumlah dokumen yang kecil. 2. Lebih rendah jika term muncul beberapa kali di dalam dokumen,
atau muncul di banyak dokumen.
17
2.4Hash Table
Hash Table adalah struktur data yang menawarkan pemasukan dan pencarian
data dengan sangat cepat. Ide dari Hash Table adalah memperbolehkan banyak dari kemungkinan key berbeda yang mungkin di petakan ke lokasi yang sama di
dalam array dibawah fungsi tindakan pengindeksan. Hash Table beroperasi relatif
cepat O(logN) kali. Untuk pembuatan daftar kamus kata, hash table adalah pilihan
yang baik.(Robert,2003).
2.5 LinkedList
LinkedList adalah struktur data yang berbentuk node yang node lainnya
menunjuk menggunakan pointer. Ukuran LinkedList menjadi dinamis karena
ukurannya bertambah mengikuti jumlah node yang dimasukkan kedalam rantai
node.(Kruse,1994).
2.6Precision dan Recall
Dalam Information Retrieval, sebuah metode perlu diukur keefektifannya. Dalam hal ini menggunakan pengukuran precision dan recall. Pengukuran
precison dan recall dinyatakan dalam rumus berikut.
=#( � �� � )
#( �� � )
� = #( � �� � )
18
BAB III
ANALISA DAN PERANCANGAN SISTEM
3.1 Analisa Sistem
3.1.1 Gambaran Sistem
Sistem Pemerolehan Informasi Makalah Ilmiah dikembangkan untuk
membantu pengguna mencari makalah ilmiah yang sesuai dan relevan dengan
kata kunci yang dimasukkan oleh pengguna.
Arsitektur sistem pemerolehan informasi ditunjukkan pada gambar 3.1.
Dokumen koleksi berupa file makalah ilmiah berbahasa Indonesia dengan
ekstensi .pdf. Sistem melakukan text operation pada dokumen tersebut, berupa pembuangan kata buang dan stemming menggunakan algoritma Nazief & Adriani untuk teks berbahasa Indonesia, lalu melakukan proses indexing kata dan dokumen pada RDBMS. Sistem mengambil index dari RDBMS ke random access
19
Gambar 3.1. Rancangan Sistem Pemerolehan Informasi.
Inverted Index yang dibuat menggabungkan antara Hash Table sebagai
dictionary dan Ordered Linked List sebagai posting list seperti pada gambar 3.2.
Beberapa variabel untuk rumus perhitungan pembobotan Savoy di simpan pada term, posting, dan dokumen. Term menyimpan dfk dan nidfk. Posting menyimpan ntifk tfik dan w. Dokumen menyimpan maxtf.
Ordered Linked List berdasarkan pada Linked List, namun akan dilakukan
20
Gambar 3.2 Representasi Inverted Index
3.1.2 Analisis Kebutuhan Pengguna
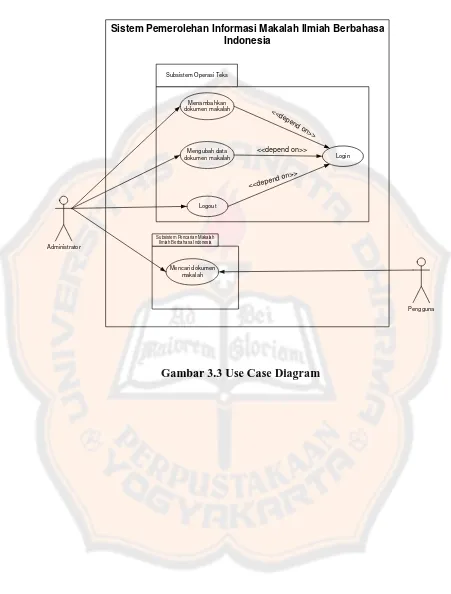
3.1.2.1 Use Case Model
HashTable Ordered Linked List
Term Jurnal Jurnal Jurnal
21
Sistem Pemerolehan Informasi Makalah yang akan dikembangkan diakses 2 aktor
yaitu administrator dan pengguna. Tabel berikut menjelaskan deskripsi untuk
setiap aktor:
Tabel 3.1. Tabel Use Case Model
Aktor Keterangan
Administrator 1. Dapat melakukan login sebagai administrator
2. Menangani pengelolaan data makalah
3. Dapat melakukan pencarian
4. Dapat melihat isi makalah
Pengguna 1. Dapat melakukan pencarian (searching) data makalah sesuai kata kunci yang dimasukan
2. Dapat melihat isi dari makalah
22 Subsistem Pencarian Makalah
Ilmiah Berbahasa Indonesia Subsistem Operasi Teks
Menambahkan dokumen makalah
Mengubah data
dokumen makalah Login
Mencari dokumen makalah
Logout
Administrator
Pengguna
<< dep
end on >>
<<depend on>>
<<depend on>>
Sistem Pemerolehan Informasi Makalah Ilmiah Berbahasa Indonesia
23
3.1.2.3 Skenario Use Case
a. Login
Deskripsi Use case ini menggambarkan proses login
bagiAdministrator
Pra-kondisi Administrator mempunyai username dan password
Pemicu Administrator ingin melakukan penambahan atau
perubahan data makalah
Langkah umum Langkah 1:
User/administrator/staff
Langkah 4: Sistem masuk
24
Administrator
Langkah
alternatif
Alternatif-Langkah 4: Jika data ( username dan password)
yang
dimasukkan tidak sesuai maka sistem akan
mengembalikan ke halaman awal login.
Kesimpulan Use case ini berhenti apabila administrator
telah berhasil masuk ke dalam halaman Administrator
Pasca kondisi Administrator berhasil masuk ke halaman utama
Administrator.
Administrator tidak jadi melakukan login.
25
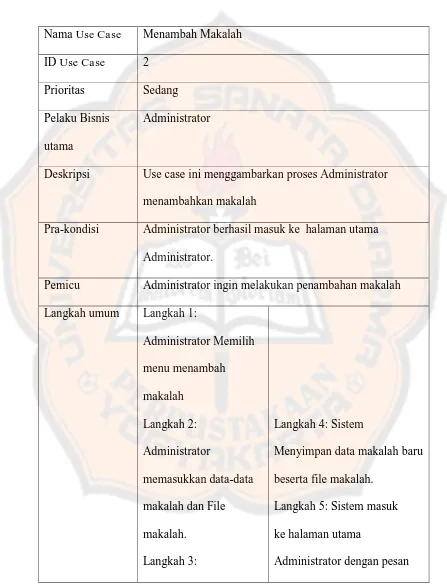
b. Menambah Makalah
Tabel 3.3 Menambah Makalah
Nama Use Case Menambah Makalah
ID Use Case 2
Prioritas Sedang
Pelaku Bisnis
utama
Administrator
Deskripsi Use case ini menggambarkan proses Administrator
menambahkan makalah
Pra-kondisi Administrator berhasil masuk ke halaman utama
Administrator.
Pemicu Administrator ingin melakukan penambahan makalah
Langkah umum Langkah 1:
Administrator Memilih
Menyimpan data makalah baru
beserta file makalah.
Langkah 5: Sistem masuk
ke halaman utama
26
Administrator menekan
tombol simpan
berhasil menyimpan
Langkah
alternatif
Alternatif-Langkah 4: Jika data yang
dimasukkan tidak lengkap maka sistem akan
meminta Administrator untuk melengkapi data yang
diperlukan.
Kesimpulan Use case ini berhenti apabila Sistem
telah berhasil Menyimpan data makalah baru.
Pasca kondisi Data makalah bertambah
c. Merubah Makalah
Tabel 3.4. Narasi Use Case Menambah Data Makalah
Nama Use Case Mengubah Data Makalah
ID Use Case 3
Prioritas High
27
Deskripsi Use case ini menggambarkan proses mengubah data makalah
Pra-kondisi Administrator berada di halaman hasil pencarian
Pemicu Use case ini digunakan oleh administrator untuk mengubah data makalah
Langkah utama Aksi aktor Respon sistem
Langkah 1 :
Administrator menge-klik link mengubah data makalah
Langkah 3 :
Administrator memasukkan
data baru makalah dan
menekan tombol ubah
Langkah 2 :
Sistem akan
menampilkan halaman
mengubah data
makalah
Langkah 4 :
Sistem akan
mengganti data lama
dengan data baru yang
28
Langkah alternatif Alternatif langkah 3 : Administrator batal mengganti
data makalah dan kembali ke halaman administrator
Kesimpulan Use case ini berhenti jika administrator telah berhasil mengubah data makalah
Pasca kondisi Data di database telah berubah
d. Mencari Makalah
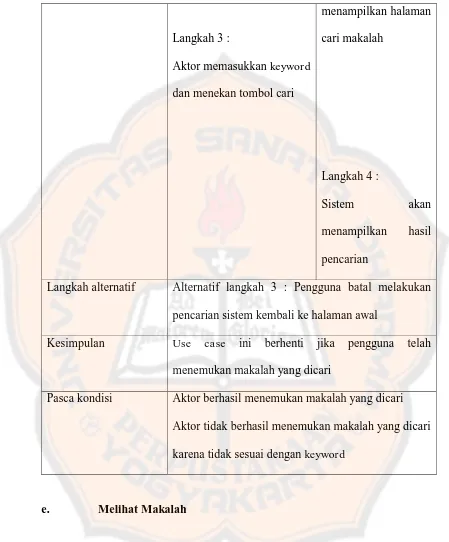
Tabel 3.5 Narasi Use Case Mencari Makalah
Nama Use Case Cari Makalah
ID Use Case 6
Prioritas High
Pelaku bisnis utama Administrator dan Pengguna
Deskripsi Use case ini menggambarkan proses pencarian makalah
Pra-kondisi Aktor berada di halaman utama
Pemicu Use case ini digunakan untuk mencari makalah
Langkah utama Aksi aktor Respon sistem
Langkah 1 :
Aktor memilih menu cari
makalah
Langkah 2 :
29
Langkah 3 :
Aktor memasukkan keyword
dan menekan tombol cari
menampilkan halaman
cari makalah
Langkah 4 :
Sistem akan
menampilkan hasil
pencarian
Langkah alternatif Alternatif langkah 3 : Pengguna batal melakukan
pencarian sistem kembali ke halaman awal
Kesimpulan Use case ini berhenti jika pengguna telah menemukan makalah yang dicari
Pasca kondisi Aktor berhasil menemukan makalah yang dicari
Aktor tidak berhasil menemukan makalah yang dicari
karena tidak sesuai dengan keyword
e. Melihat Makalah
Tabel 3.6. Narasi Use Case Melihat Makalah
Nama Use Case Lihat Makalah
30
Prioritas High
Pelaku bisnis utama Administrator dan Pengguna
Deskripsi Use case ini menggambarkan proses melihat data makalah
Pra-kondisi Aktor berada di halaman pencarian
Pemicu Use case ini digunakan oleh aktor untuk melihat data makalah
Langkah utama Aksi aktor Respon sistem
Langkah 1 :
Aktor menge-klik link lihat makalah
Langkah 2 :
Sistem akan
menampilkan data
makalah
Langkah alternatif -
Kesimpulan Use case ini berhenti jika aktor telah berhasil melihat data makalah
Pasca kondisi Aktor berhasil melihat data makalah
Aktor tidak berhasil melihat data makalah karena
31
f. Logout
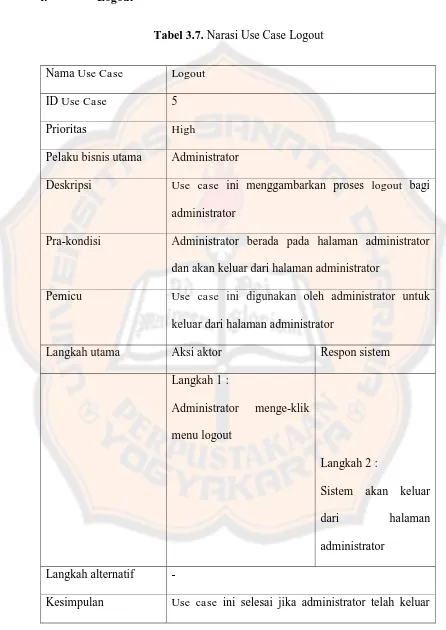
Tabel 3.7. Narasi Use Case Logout
Nama Use Case Logout
ID Use Case 5
Prioritas High
Pelaku bisnis utama Administrator
Deskripsi Use case ini menggambarkan proses logout bagi administrator
Pra-kondisi Administrator berada pada halaman administrator
dan akan keluar dari halaman administrator
Pemicu Use case ini digunakan oleh administrator untuk keluar dari halaman administrator
Langkah utama Aksi aktor Respon sistem
Langkah 1 :
Administrator menge-klik
menu logout
Langkah 2 :
Sistem akan keluar
dari halaman
administrator
Langkah alternatif -
32
dari halaman administrator
33
3.2 Perancangan Sistem
3.2.1 Desain Logikal
3.2.1.1 Diagram Akifitas
3.2.1.3.1. Administrator Login
34
3.2.1.3.2. Menambah Makalah
Berikut adalah diagram dari aktifitas menambah makalah.
3.2.1.3.3. Merubah Data Makalah
35
3.2.1.3.4. Mencari Makalah
Berikut adalah diagram dari aktifitas mencari makalah .
3.2.1.3.5. Melihat Makalah
36
3.2.1.2 Model Kelas Analisis
Berikut ini adalah rancangan diagram model kelas analisis.
Login.jsp
beanLogin
Administrator Administrator
InvertedIndex
Jurnal
Word Posting
StopList benCariJurnal
beanKelolajurnal Pengguna
Adminhome.jsp
Halamancari.jsp
Tambahjurnal.jsp
Ubahhapusjurnal.jsp
37
3.2.1.3Diagram Sequence
3.2.1.3.1. Mencari Jurnal
Berikut adalah rancangan diagram sequence pencarian jurnal.
3.2.1.4 Diagram Kelas Analisis
3.2.1.3.1. Case Login
Berikut ini adalah rancangan diagram kelas pada case login
login.jsp
+validasiLoginAdministrator(in username : string, in password : string) : void +logoutAdministrator() : string
38
3.2.1.3.2. Case Ubah Data
Berikut ini adalah rancangan diagram kelas pada case ubah data
+setUserName(in : string) : void +getUserName() : string +setPassword(in : string) : void +getPassword() : string
+getAdmistrator(in username) : Administrator -username : string
-password : string
Administrator
39
3.2.1.3.3. Case Pencarian Informasi Makalah
Berikut ini adalah rancangan diagram kelas pada case pencarian
+setUserName(in : string) : void +getUserName() : string +setPassword(in : string) : void +getPassword() : string
+getAdmistrator(in username) : Administrator -username : string
-password : string
Administrator
+Cari()
beanCariJurnal
-wordlist : HashMap
InvertedIndex
1
1 *
1
halamanhasilcari.jsp halamancari.jsp
40
3.2.1.3.4. Diagram Kelas Pemodelan Struktur Data Inverted Index
Berikut ini adalah rancangan diagram kelas untuk memodelkan Struktur Data
41
3.2.1.5 Perancangan Database
3.2.1.3.1. Conceptual Design
Berikut ini adalah desain database secara konseptual.
42
3.2.2 Desain Fisikal
3.2.2.1Desain Antarmuka
3.2.1.1.1. Halaman Beranda dan Pencarian
Pada halaman pencarian jurnal terdapat kolom isian untuk mengisikan kata
kunci pencarian. Pencarian dapat dimulai dengan menekan tombol keyboard Enter
atau menekan tombol cari pada tampilan Gambar 3.4.
Gambar 3.4. Halaman Beranda
Copyright © 2012 | Login
Header Title
43
3.2.1.1.2. Halaman Hasil Pencarian
Pada halaman hasil pencarian, Gambar 3.5 ditampilkan tambahan
informasi waktu pencarian dan daftar dokumen yang sudah diurutkan sesuai
relevansinya terhadap kata kunci pencarian. Pengguna dapat melihat isi setiap
dokumen dari hasil pencarian dengan membuka link judul dokumen yang dipilih.
44
3.2.1.1.3. Halaman Login Administrator
Halaman Login Administrator Gambar 3.6 menampilkan dua kolom isian
yang diisi dengan nama pengguna dan kata sandi. Untuk melanjutkan masuk,
pengguna dapat menekan tombol keyboard Enter atau menekan tombol masuk pada tampilan.
Header
Title
Home
Kelola Jurnal Logout
Nama Pengguna
Kata Sandi
Masuk
Halaman Login Administrator
Copyright © 2012
45
3.2.1.1.4. Halaman Beranda Administrator
Halaman beranda administrator Gambar 3.7 terdapat menu “Kelola
Makalah” dengan submenu “Tambah Makalah” untuk menuju halaman tambah
makalah dan submenu “Edit Makalah” untuk menuju halaman edit makalah.
Pengguna dapat menekan tombol beranda untuk kembali ke halaman utama
administrator. Tombol “Logout” berfungsi untuk keluar dari halaman utama
administrator.
Gambar 3.7. Halaman Beranda Administrator
Selamat datang di halaman Administrator
Copyright © 2012
Header Title
Beranda Kelola Makalah
46
3.2.1.1.5. Halaman Menambah Makalah
Pada halaman tambah makalah Gambar 3.8 administrator dapat
menambahkan dokumen makalah baru dengan memasukkan data judul, penulis,
tahun pada kolom yang disediakan. Pada kolom file, administrator dapat memilih
file makalah yang berformat pdf yang akan diupload. Setelah semua data lengkap
administrator dapat menekan tombol simpan.
Gambar 3.8. Halaman Menambah Makalah
Judul Penulis File
Copyright © 2012
Header Title
Beranda Kelola Makalah
Logout
pilih
47
3.2.1.1.6. Halaman Kelola Makalah
Halaman kelola jurnal ditunjukkan pada Gambar 3.9 administrator dapat
melakukan pengubahan data makalah yang meliputi judul makalah, nama penulis,
dan tahun dengan menekan icon edit pada baris yang sesuai dengan dokumen yang akan dirubah datanya. Sebuah form akan muncul saat icon edit dipilih. Administrator dapat memasukkan data-data baru pada setiap kolom dan menekan
tombol simpan jika akan menyimpan perubahan tersebut.
Header Title
Home Kelola Jurnal Logout
N o Judul Penulis Tahun N ama File
x
x x
Judul Penulis Tahun File
Simpan
Cari
Menghapus dan Mengubah Data Jurnal
Copyright © 2012
48
BAB IV
IMPLEMENTASI SISTEM
4.1. Spesifikasi Perangkat Lunak dan Perangkat Keras
4.1.1. Spesifikasi Perangkat Lunak
Sistem menggunakan spesifikasi beberapa perangkat lunak pendukung untuk
implementasi sistem pemrosesan teks dan sistem pencarian makalah ilmiah
berbahasa Indonesia sebagai berikut :
1. Sistem operasi: Oracle Linux Server Release 5.8
2. Oracle 11g,
3. Oracle SQL Developer 3.0.04,
4. Java JDK 1.6.0 dan OODBC
5. Netbeans 6.9.1
6. Browser : Mozilla Firefox
4.1.2. Spesifikasi Perangkat Keras
Spesifikasi perangkat keras yang digunakan untuk implementasi sistem
pemrosesan teks dan sistem pencarian makalah ilmiah berbahasa Indonesia adalah
sebagai berikut :
4.1.Prosesor: Intel XEON E5620 (4 Core, 2, 40 GHz)
4.2.Memori RAM: 8 GB RDIMM
4.3.Hardisk: RAID 5 Logical 2TB
49
4.2. Implementasi Basis Data
Pada sistem ini diimplementasikan database teks untuk menyimpan hasil seluruh proses preprocessing dokumen jurnal yang berbasis RDBMS. Database
sistem ini dibuat menggunakan Oracle 11g. Aplikasi pendukung untuk melakukan pengolahan query adalah SQL Developer.
Langkah – langkah dalam pembuatan database adalah seperti berikut :
1. Membuat database baru dengan login sebagai SYSTEM menggunakan SQL Developer.
2. Membuat tabel-tabel dalam database yang telah dibuat dengan menuliskan perintah create tabel diikuti nama tabel dan kolom-kolom dalam tabel. Di dalam
database terdapat 8 tabel.
50
Gambar 4.1. Database berbasis RDBMS pada sistem pemrosesan teks
Berikut proses pembuatan tabel untuk database text RDBMS : 1. Tabel Status
Tabel 4.1. Tabel Status
Nama Field Tipe Data Ukuran Keterangan
id_status NUMBER - Primary key untuk
tabel status
description VARCHAR2 20 Deskripsi status
Berikut query untuk membuat tabel status :
2. Tabel Documents
Tabel 4.2. Tabel Documents
Nama Field Tipe Data Ukuran Keterangan
id_document NUMBER - Primary key untuk
tabel documents
title VARCHAR2 256 Judul dari dokumen
path VARCHAR2 256 Nama file dari
CREATE TABLE STATUS (
ID_STATUS NUMBER NOT NULL , DESCRIPTION VARCHAR2 (20) )
;
ALTER TABLE STATUS
51
dokumen
max_term NUMBER - Frekuensi terbesar
dari sebuah dokumen
authors VARCHAR2 100 Penulis dari dokumen
year NUMBER - Tahun dari dokumen
id_status_ready NUMBER - Status untuk dokumen
id_status2 NUMBER - Status untuk untuk
sistem pencarian
id_status3 NUMBER - Status untuk untuk
sistem pencarian
Berikut perintah untuk membuat tabel documents :
CREATE TABLE DOCUMENTS (
ALTER TABLE DOCUMENTS
ADD CONSTRAINT documents_PK PRIMARY KEY ( ID_DOCUMENT ) ;
ALTER TABLE DOCUMENTS
ADD CONSTRAINT DOCUMENTS_STATUS1_FK FOREIGN KEY (
ID_STATUS_READY )
52
(
ID_STATUS )
;
ALTER TABLE DOCUMENTS
ADD CONSTRAINT DOCUMENTS_STATUS2_FK FOREIGN KEY (
ALTER TABLE DOCUMENTS
ADD CONSTRAINT DOCUMENTS_STATUS_FK FOREIGN KEY (
Tabel 4.3. Tabel Posting
Nama Field Tipe Data Ukuran Keterangan
id_document NUMBER - Foreign key dari tabel documents
id_term NUMBER - Foreign key dari tabel terms frequency NUMBER - Frekuensi kata pada dokumen
ntfik NUMBER - Hasil perhitungan
frequency/frequency terbesar pada sebuah dokumen
53
rumus perhitungannya
ndfik*ntfik
Berikut perintah untuk membuat tabel posting :
CREATE TABLE POSTING (
ALTER TABLE POSTING
ADD CONSTRAINT POSTING_DOCUMENTS_FK FOREIGN KEY
ALTER TABLE POSTING
54
4. Tabel Terms
Tabel 4.4. Tabel Terms
Nama Field Tipe Data Ukuran Keterangan
id_term NUMBER - Primary key untuk tabel
terms
terms VARCHAR2 50 Kata sebelum proses
stemming
stemmed_word VARCHAR2 50 Kata setelah proses
stemming
is_root_word CHAR 1 Keterangan apakah terms
ada di kamus
Berikut perintah untuk membuat tabel terms :
CREATE TABLE TERMS (
TERMS VARCHAR2 (50) ,
STEMMED_WORDS VARCHAR2 (50) , IS_ROOT_WORD CHAR (1)
) ;
ALTER TABLE TERMS
55
5. Tabel Posting_Stopword
Tabel 4.5. Tabel Posting_stopword
Nama Field Tipe Data Ukuran Keterangan
id_document NUMBER - Foreign key dari tabel
documents
id_stopword NUMBER - Foreign key dari tabel
stopwords
frequency NUMBER - Frekuensi stopword pada
dokumen
Berikut perintah untuk membuat tabel posting_stopword :
CREATE TABLE POSTING_STOPWORD (
FREQUENCY NUMBER,
ID_STOPWORD NUMBER NOT NULL , ID_DOCUMENT NUMBER NOT NULL )
;
ALTER TABLE POSTING_STOPWORD
56
6. Tabel Stopwords
Tabel 4.6. Tabel Stopwords
Nama Field Tipe Data Ukuran Keterangan
id_stopword NUMBER - Primary key untuk tabel stopwords
stopword VARCHAR2 20 Daftar kata buang
Berikut perintah untuk tabel stopwords :
FOREIGN KEY
ALTER TABLE POSTING_STOPWORD
ADD CONSTRAINT POSTING_STOPWORD_STOPWORDS_FK FOREIGN KEY (
CREATE TABLE STOPWORDS (
ID_STOPWORD NUMBER NOT NULL , STOPWORD VARCHAR2 (20) }
;
CREATE INDEX STOPWORDS__IDX ON STOPWORDS (
ID_STOPWORD ASC , STOPWORD ASC )
;
ALTER TABLE STOPWORDS
57
7. Tabel Dictionary
Tabel 4.7. Tabel Dictionary
Nama Field Tipe Data Ukuran Keterangan
id_dictionary NUMBER - Primary key untuk tabel dictionary
root_word VARCHAR2 20 Daftar kata dasar Bahasa
Indonesia
Berikut perintah untuk membuat tabel dictionary :
8. Tabel Administrator
Tabel 4.8. Tabel Administrator
CREATE TABLE DICTIONARY (
ID_DICTIONARY NUMBER NOT NULL , ROOT_WORD VARCHAR2 (20)
) ;
CREATE UNIQUE INDEX DICTIONARY__IDX ON DICTIONARY (
ID_DICTIONARY ASC , ROOT_WORD ASC
) ;
ALTER TABLE DICTIONARY
58
Nama Field Tipe Data Ukuran Keterangan
id_administrator NUMBER - Primary key untuk tabel administrator
username VARCHAR2 10 Username
pasword VARCHAR2 20 Password
Berikut perintah yang digunakan untuk membuat tabel administrator :
9. Tabel Sourceterm
Tabel 4.9. Tabel Sourceterm
Nama Field Tipe Data Ukuran Keterangan
id_sourceterm NUMBER - Primary key
CREATE TABLE ADMINISTRATOR (
ALTER TABLE ADMINISTRATOR
59
is_root_word CHAR 1 Keterangan
apakah terms
ada di kamus
Berikut perintah yang digunakan untuk membuat tabel administrator :
4.3. Implementasi Inverted Index
Dari pemodelan Inverted Index di dalam bab sebelumnya, di dalam struktur
Inverted Index pada bagian Ordered Linked List dilakukan sorting pada saat akan menambahkan data sehingga posting dimasukkan secara terurut berdasarkan id document. Setiap data posting baru yang akan ditambahkan dilakukan sequensial search dari indek posisi 0 dengan cara melakukan casting LinkedList ke
ListIterator dan menemukan posisi indek yang tepat berdasarkan nomor id dokumen data posting baru dibandingkan dengan id dokumen yang sudah ada di
dalam List. Proses sorting pada saat penambahan posting di implementasikan dalam listing code 1 pada method addWord di dalam kelas InvertedIndex.
Listing Code 1. Method addWord
CREATE TABLE SOURCETERM (
ALTER TABLE SOURCETERM
60
Term freqtambah = getWordlist().get(term); //ambil Posting Listnya
ListIterator<Posting> iteratorPosting = freqtambah.getPostlist().listIterator(); //selama iterator posting punnya data berikutnya
while (iteratorPosting.hasNext()) {
//jika jurnal_id Jurnal Posting sama dengan jurnal_id dari parameter
Untuk melakukan search sistem akan menyaring dan memproses kata
kunci masukan dari pengguna kemudian mengakses hashtable Term dengan kata kunci masukan dari pengguna sebagai key. Sistem akan memperoleh sebuah objek
Term untuk setiap kata kunci dan melakukan interseksi dengan method AND pada
Listing Code 2 antar posting list pada setiap Term dengan mencari id dokumen
yang sama. Interseksi akan menghasilkan sebuah posting list baru dengan bobot posting yang sudah diakumulasi untuk setiap posting yang memiliki id dokumen
sama pada saat Interseksi. Jumlah term yang memiliki posting list yang harus di interseksikan adalah sama dengan jumlah kata kunci yang dapat ditemukan oleh
61
bobot terbersar hingga bobot terkecil. Listing code untuk pencarian dapat dilihat pada lampiran bagian b.
Dalam proses interseksi antara dua term sistem mengambil posting
masing-masing term dan melakukan casting ke type objek ListIterator agar dapat dilakukan traversal pada posting. Posting yang memiliki dokumen paling sedikit akan diprioritaskan sebelum posting yang lain. Untuk dapat melakukan traversal
di masing-masing posting maka dibuat variabel objek bertipe Posting penunjuk bantu1 dan bantu2. Penunjuk bantu1 dan bantu2 mulai dari indek pertama dan
mulai membandingkan id dokumen masing-masing. Jika ditemukan dokumen
yang sama maka akan diambil posting keduanya dan mengakumulasikan bobot
kedua posting kemudian bantu1 bergeser ke posisi index berikutnya. Jika pada
posisi bantu2 yang sedang ditunjuk tidak ditemukan dokumen yang sama, bantu2
akan bergeser ke posisi indek berikutnya hingga ditemukan atau sampai tidak ada
lagi indek berikutnya. Hasil posting interseksi dikembalikan dengan bobot
terakumulasi.
Listing Code 2. Method AND
/*---method untuk operasi AND---*/
public Term AND(Term term1, Term term2) {
ListIterator<Posting> t1;
ListIterator<Posting> t2;
/*jika term1 mempunyai dokumen lebih sedikit dengan term2*/
if (term1.getPostlist().size() < term2.getPostlist().size()) {
t1 = term1.getPostlist().listIterator();
t2 = term2.getPostlist().listIterator();
62
System.out.print(term1.getPostlist().get(i).getJurnal().getJurnal_id() + " , " + term1.getPostlist().get(i).getTfik() + "| ");
}
System.out.println("");
/*menampilkan kata2*/
System.out.print(term2.getTerm() + " | " + term2.getDfk() + " | ");
for (int i = 0; i < term2.getPostlist().size(); i++) {
System.out.print(term2.getPostlist().get(i).getJurnal().getJurnal_id() + " , " + term2.getPostlist().get(i).getTfik() + "| ");
}
System.out.println("");
/*AND operator*/
Posting bantu1 = t1.next(); /*membuat bantu1 untuk kata t1.next*/
/*membuat penunjuk yang digunakan untuk membandingkan dokumen*/
65
hasil.setDfk(hasil.getDfk() + bantu1.getWord().getDfk());
bantu1.setW(bantu1.getW()+bantu2.getW());
} /*jk tdk tmbh bantu2*/ else {
hasil.getPostlist().add(bantu2);
hasil.setDfk(hasil.getDfk() + bantu2.getWord().getDfk());
bantu2.setW(bantu2.getW()+bantu1.getW());
}
}
}
}
}
}
return hasil;
}
4.4. Implementasi Antarmuka
4.5.3. Halaman Pencarian
Pada halaman pencarian jurnal terdapat kolom isian untuk mengisikan kata
kunci pencarian. Pencarian dapat dimulai dengan menekan tombol keyboard Enter
66
Gambar 4.3 Halaman Utama Pencarian Jurnal
4.5.4. Halaman Hasil Pencarian
Pada halaman hasil pencarian, Gambar 4.4 ditampilkan tambahan
informasi waktu pencarian dan daftar dokumen yang sudah diurutkan sesuai
relevansinya terhadap kata kunci pencarian. Pengguna dapat melihat isi setiap
dokumen dari hasil pencarian dengan membuka link judul dokumen yang dipilih.
Gambar 4.4 Halaman Hasil Pencarian
4.5.5. Halaman Login Administrator
Halaman Login Administrator Gambar 4.5 menampilkan dua kolom isian
67
pengguna dapat menekan tombol keyboard Enter atau menekan tombol masuk pada tampilan.
Gambar 4.5 Halaman Login Administrator
4.5.6. Halaman Utama Administrator
Halaman utama administrator Gambar 4.6 terdapat menu “Kelola
Makalah” dengan submenu “Tambah Makalah” untuk menuju halaman tambah
makalah dan submenu “Edit Makalah” untuk menuju halaman edit makalah.
Pengguna dapat menekan tombol beranda untuk kembali ke halaman utama
administrator. Tombol “Logout” berfungsi untuk keluar dari halaman utama
68
Gambar 4.6 Halaman Utama Administrator
4.5.7. Halaman Tambah Makalah
Pada halaman tambah makalah Gambar 4.7 administrator dapat
menambahkan dokumen makalah baru dengan memasukkan data judul, penulis,
tahun pada kolom yang disediakan. Pada kolom file, administrator dapat memilih
file makalah yang berformat pdf yang akan diupload. Setelah semua data lengkap
69
Gambar 4.7 Halaman Tambah Makalah
4.5.8. Halaman Kelola Jurnal
Halaman kelola jurnal ditunjukkan pada Gambar 4.8 administrator dapat
melakukan pengubahan data makalah yang meliputi judul makalah, nama penulis,
dan tahun dengan menekan icon edit pada baris yang sesuai dengan dokumen yang akan dirubah datanya. Sebuah form seperti pada Gambar 4.9 akan muncul
70
Gambar 4.8 Halaman Edit Makalah
Gambar 4.9 Form Edit Data Makalah
4.5. Implementasi Control
4.4.1. Subsistem Server Pemrosesan Dokumen
71
beanEditJurnal beanEditJurnal.java
beanLogin beanLogin.java
beanTambahJurnal beanTambahJurnal.java
DocProcessing DocProcessing.java
DbConnection DbConnection.java
DocProcess DocProcess.java
JobScheduler JobScheduler.java
Tokenizer Tokenizer.java
4.4.2. Subsistem Pencarian
Tabel 4.11. Implementasi Control Subsistem Pencarian
Tokenizer Tokenizer.java
beanBuildIndex beanBuildIndex.java
beancarijurnal beancarijurnal.java
Beankelolajurnal beankelolajurnal.java
beanlogin beanlogin.java
beanTambahJurnal beanTambahJurnal.java
DatabaseConnector DatabaseConnector.java
InformationRetrieval InformationRetrieval.java
JobScheduler JobScheduler.java
72
4.6. Implementasi Model
4.5.1. Subsistem Server Pemrosesan Dokumen
Tabel 4.10. Implementasi Model Subsistem Pemrosesan Dokumen
Administrator Administrator.java
Documents.java Documents.java
Posting.java Posting.java
Stemming.java Stemming.java
Terms.java Terms.java
4.5.2. Subsistem Pencarian
DaftarJurnal DaftarJurnal.java
DocFilter DocFilter.java
InvertedIndex InvertedIndex.java
Jurnal Jurnal.java
JurnalScore JurnalScore.java
Posting Posting.java
StopList StopList.java
73
BAB V
ANALISA HASIL
5.1. Pengujian Relevance Feedback
Dari 281 dokumen yang di diproses dalam indexing dengan menggunakan jumlah kamus kata dasar 3278 dan 395 kata buang kata menghasilkan 25737 term
yang digunakan dalam pengujian.
Pengujian menggunakan media kuesioner yang dibagikan kepada 4 orang
mahasiswa Sanata Dharma Yogyakarta. kuesioner dibagi menjadi 2 tahap, yaitu
form kuesioner precision dan form kuesioner recall. Pada tahap pertama
responden diminta untuk melakukan pencarian, mencatat seluruh dokumen hasil
pencarian, dan menandai dokumen yang relevan. Pada tahap kedua responden
diminta untuk melihat seluruh koleksi daftar dokumen dan menandai dokumen
yang relevan terhadap kata kunci yang digunakan dalam pencarian sebelumnya.
1. Kata kunci “penambangan data”
Sistem menghasilkan 2 dokumen dari kata kunci “penambangan data”. Dari 2
dokumen hasil pencarian, responden menemukan 1 dokumen yang relevan. Pada
tahap kedua responden menemukan 8 dokumen yang relevan dari 281 dokumen
koleksi. Perhitungan recall diperoleh. Hasil perhitungan Recall dan precision
dapat dilihat padat tabel 5.1.
Berikut dokumen hasil pencarian.
1. ANALISIS ASOSIASI HASIL EVALUASI PEMBELAJARAN
MEMPERGUNAKAN ALGORITMA APRIORI
2. ARSITEKTUR DATA SPASIAL UNTUK INFORMASI TEMATIS
74
Tabel 5.1 Recal Precision query “penambangan data”
ID Relevan Recall Precision
257 R 0,125 1
115 0,125 0,5
Tabel 5.2 Interpolasi Recall Precision query “penambangan data”
Recall Precision 0% 100% 10% 100%
20% 0%
30% 0%
40% 0%
50% 0%
60% 0%
70% 0%
80% 0%
90% 0%
100% 0%
Dari tabel 5.2 dan Gambar 5.1 dapat dilihat diperoleh precision 100% dari
nilai recall 0-10% dan menurun hingga 0% pada nilai recall 20-100%.. Hal ini
dikarenakan dokumen relevan yang ditemukan responden yaitu 8 dokumen lebih
banyak daripada dokumen relevan yang ditemukan menurut sistem yaitu 1,
dimana beberapa dari dokumen tersebut mengandung kata “data mining” yang
75
Gambar 5.1 Grafik Recall precision query “penambangan data”
Istilah “penambangan data” memiliki sinonim dalam bahasa inggris sehingga
dilakukan pengujian dengan kata kunci “data mining” untuk memberi
perbandingan.
Dokumen hasil pencarian dengan kata kunci “data mining”.
1. PERANCANGAN APLIKASI DATA MINING STUDI KASUS: ANALISIS
KEPUASAN PELANGGAN PT. XYZ
2. PENGGUNAAN ANALISA ASOSIASI (ASSOCIATION ANALYSIS)
DALAM PEMILIHAN LOKASI WISATA BERDASARKAN
KARAKTERISTIK SOSIO-DEMOGRAFIS WISATAWAN
3. KLASIFIKASI EVENT PADA PROCESS LOGS MENGGUNAKAN
MODEL REGRESI LOGISTIK
4. PENERAPAN DATA MINING MENGGUNAKAN ALGORITMA
ASSOCIATION RULES UNTUK MEMPREDIKSI PILIHAN PROGRAM
STUDI DI SEKOLAH TINGGI XYZ
76
5. Market Basket Analysis Berbasis Classifier Characterictic untuk
MENENTUKAN PERSENTASE MODEL DESKRIPSI MEDIA
RELATIONS PERGURUAN TINGGI
6. ANALISIS ASOSIASI HASIL EVALUASI PEMBELAJARAN
MEMPERGUNAKAN ALGORITMA APRIORI
7. ANALISIS KEMUNGKINAN PENGUNDURAN DIRI CALON
MAHASISWA DI STMIK STIKOM BALI DENGAN ALGORITMA
BAYESIAN CLASSIFICATION
8. PENGOLAHAN DATA WAREHOUSE AKADEMIK SEBAGAI
PENUNJANG KEPUTUSAN DI PERGURUAN TINGGI
9. PERANCANGAN e-HEALTH MANAGEMENT SYSTEM
10.CUSTOMER RELATIONSHIP MANAGEMENT (CRM) UNTUK USAHA
KECIL DAN MENENGAH
11.PEMANFAATAN BUSINESS INTELLIGENCE DALAM PERENCANAAN
PEMBANGUNAN NASIONAL: STUDI KASUS BADAN PERENCANAAN
PEMBANGUNAN NASIONAL
12.PEMANFAATAN KNOWLEDGE MANAGEMENT SYSTEM BERBASIS
OPENSOURCES UNTUK INSTANSI PEMERINTAH STUDI KASUS:
DIREKTORAT E-GOVERNMENT KEMENTERIAN KOMUNIKASI DAN
INFORMATIKA
13.DASHBOARDING INFORMATION SYSTEMS FOR THE EDUCATION
77
14.EFISIENSI MATRIKS: PERBEDAAN SISTEM TUNGGAL DAN
CLUSTER DENGAN ALGORITMA MAPREDUCE
15.MODEL KNOWLEDGE MANAGEMENT PADA PERUSAHAAN
DISTRIBUTOR FARMASI DAN CONSUMER PRODUCT
16.SISTEM ANALISIS OPINI MICROBLOGGINGBERBAHASA INDONESIA
17.FAKTOR KONTEKSTUAL DALAM PEMANFAATAN WEB SEBAGAI
MEDIA KOMUNIKASI CSR OLEH PERUSAHAAN
18.ALGORITMA UNTUK EKSTRAKSI TABEL HTML DI WEB
19.PERBANDINGAN ALGORITMA BINERISASI PADA CITRA TULANG
ABNORMAL TELAPAK TANGAN MANUSIA
20.PENJADWALAN PERKULIAHAN DENGAN METODE COMPACT
GENETIC ALGORITHM (STUDI KASUS UNIVERSITAS WIDYATAMA)
21.PENERAPAN CRM DENGAN SISTEM INFORMASI BERBASIS WEB
UNTUK KEPUASAN PELANGGAN
22.MUSIC THERAPY ISSUES ON MUSIC INFORMATION RETRIEVAL
Sistem menghasilkan 22 dokumen dari kata kunci “data mining”. Dari 22
dokumen hasil pencarian, responden menemukan 8 dokumen yang relevan. Pada
tahap kedua responden menemukan 8 dokumen yang relevan dari 281 dokumen
koleksi. Perhitungan recall diperoleh. Hasil perhitungan Recall dan precision
dapat dilihat padat tabel 5.4. dan tabel 5.5.
Tabel 5.4 Recal Precision query “data mining”
No Urut Relevan Recall Precision
78
Tabel 5.5 Interpolasi Recall Precision query “data mining”
79
dengan grafik pada gambar 5.1 query “data mining” menghasilkan precision
yang lebih baik karena dokumen yang mengandung kata “data mining” lebih
banyak jumlahnya daripada dokumen yang mengandung kata “penambangan
data” .
Gambar 5.2 Grafik Recall precision query “data mining”
2. Kata kunci “pemerolehan informasi”
Sistem menghasilkan 1 dokumen dari kata kunci “pemerolehan informasi”.
Dari 1 dokumen hasil pencarian, responden menemukan 1 dokumen yang relevan.
Pada tahap kedua responden menemukan 5 dokumen yang relevan dari 281
dokumen koleksi. Perhitungan recall diperoleh. Hasil perhitungan Recall dan
precision dapat dilihat padat tabel 5.3.
0% 20% 40% 60% 80% 100% 120%
Interpolasi
80
Tabel 5.3 Recal Precision query “pemerolehan informasi”
Hasil Relevan Recall Precision
257 R 0,2 1
Tabel 5.4 Interpolasi Recall Precision query “pemerolehan informasi”
Recall Precision
Gambar 5.2 Recall precision query “pemerolehan informasi”
81
dikarenakan dokumen relevan yang ditemukan responden yaitu 5 dokumen lebih
banyak daripada dokumen relevan yang ditemukan menurut sistem yaitu 1 dimana
4 dokumen yang mengandung istilah “information retrieval” dan 1 dokumen yang
mengandung istilah “pemerolehan informasi” dan menurut responden relevan.
Kata kunci “apriori”
Sistem menghasilkan 2 dokumen dari kata kunci “apriori”. Dari 2 dokumen
hasil pencarian, responden menemukan 2 dokumen yang relevan. Pada tahap
kedua responden menemukan 2 dokumen yang relevan dari 281 dokumen koleksi.
Perhitungan recall diperoleh. Hasil perhitungan Recall dan precision dapat dilihat
padat tabel 5.5.
Tabel 5.5 Recal Precision query “apriori”
Hasil Relevan Recall Precision
257 R 0,5 1
278 R 1 1
Tabel 5.6 Interpolasi Recal Precision query “apriori”
82 100% 100%
Gambar 5.3 Recall precision query “apriori”
Dari tabel 5.6 dan Gambar 5.3 dapat dilihat diperoleh precision 100% dari nilai recall 0-100%. Untuk kata kunci tersebut sistem menghasilkan dokumen relevan yang sama dengan menurut responden.
3. Kata kunci “pemanfaatan data warehouse”
Sistem menghasilkan 1 dokumen dari kata kunci “pemanfaatan data
warehouse”. Dari 1 dokumen hasil pencarian, responden menemukan 1 dokumen
yang relevan. Pada tahap kedua responden menemukan 3 dokumen yang relevan
dari 281 dokumen koleksi. Perhitungan recall diperoleh. Hasil perhitungan Recall
dan precision dapat dilihat padat tabel 5.7.
Tabel 5.7 Recall precision query “pemanfaatan data warehouse”
0% 20% 40% 60% 80% 100% 120%
Interpolasi
83
Hasil Relevan Recall Precision
234 R 0,333333 1
Tabel 5.8 Interpolasi recall precision query “pemanfaatan data warehouse”
Recall Precision
Gambar 5.4 Recall precision query “pemanfaatan data warehouse”
Dari tabel 5.8 dan Gambar 5.2 dapat diperoleh precision 100% dari nilai
recall 0-40% dan menurun hingga 0% pada nilai recall 40-100%. Hal ini dikarenakan dokumen relevan yang ditemukan responden yaitu 4 dokumen lebih
84
banyak daripada dokumen relevan yang ditemukan menurut sistem yaitu 1 karena
responden juga menemukan dokumen-dokumen yang mengandung kata “gudang
data” dan menurut responden relevan.
Dari pencarian tersebut ditemukan juga 2 kata kunci yaitu data warehouse
yang sebenarnya di dalam dokumen terletak pada daftar pustaka dimana sistem
melakukan index pada seluruh isi dokumen. Hal tersebut ditemukan pada
dokumen dengan judul “IMPLEMENTASI TABEL AGREGAT UNTUK
MENINGKATKAN UNJUK KERJA MODEL BASISDATA MULTIDIMENSI
(STUDI KASUS PERUSAHAAN PERSEWAAN BAN "XYZ") “.
5.2. Pengujian Performa Inverted Index
Percobaan menggunakan operasi AND dengan melakukan interseksi antar
postinglist yang diperoleh saat pencarian ke dalam InvertedIndex.
Pada tabel 1 menunjukkan pada kelompok dfk 1-2 untuk untuk kelompok 1
hingga 4 kata kunci berada pada 0,001 detik, hal ini karena sistem masih belum
bisa mencatat waktu kurang dari 0,001 detik, kemungkinan waktu tersebut
kurang dari 0,001 detik. Pada kelompok dfk ±140, waktu akses diperoleh 0,0017
detik untuk 1 kata kunci hingga 0,0041 detik untuk 4 kata kunci. Pada grafik
gambar 8 terlihat peningkatan waktu akses tersebut linear. Pada kelompok dfk 281 terjadi peningkatan waktu akses dari 0,0033 detik untuk 1 kata kunci hingga
0,0491 detik untuk 4 kata kunci. Peningkatan waktu akses dari 1 kata kunci ke 2