ANALISIS BIG DATA
(Teori & Aplikasi)
“Big Data vs Big Information vs Big Knowledge”
Oleh:
lanjut secara mendetail sebagai solusi dalam penyelesaian untuk kasus apapun dengan konsep Sistem Cerdas melalui pemanfaatan teknologi Big Data mulai dari tingkat dasar sebagai cara yang paling mudah untuk awalan dalam pemahaman, sampai pada implementasi algoritma tanpa Library apapun, misal tidak menggunakan MLlib dari Spark sama sekali atau lainnya, serta melatih dalam memodifikasi algoritma maupun penggabungan dua tools atau lebih untuk membangun ekosistem Big Data yang powerfull. Materi yang tersedia selain memudahkan bagi para pembaca, juga untuk mendukung ma-teri perkuliahan yang dapat membantu pengayaan mahasiswa yang fokus pada pengembangan Artificial Intelligence (AI) untuk Big Data, yang meliputi banyak Machine Learning yang digunakan.Imam Cholissodin
Dosen Pengampu MK Analisis Big Data FILKOM UB
Kata Pengantar
Alhamdulillahhi robbil alamin, puji syukur kehadirat Allah SWT atas segala rahmat dan karunia-Nya dengan terselesaikannya penu-lisan buku ini dengan judul “Analisis Big Data”. Buku ini merupakan
uraian untuk memudahkan pemahaman konsep, tingkat dasar sampai lanjut dalam sistem cerdas dan penerapannya melalui pemanfaatan teknologi Big Data, dengan mengedepankan keterampilan dalam pembuatan dan hasil implementasi dengan berbagai kombinasi algoritma berbasis sistem cerdas maupun dengan perpaduan berbagai macam tools untuk membangun ekosistem analisis Big Data yang
powerfull. Konsep sederhana Analisis Big Data mencakup Volume, Ve-locity, dan Variety (3V), dan pengembangannya ada yang menyebut (7V) termasuk Volume, Velocity, Variety, Variability, Veracity, Value dan Visualization, atau 10V bahkan lebih dari itu, tetapi sebaiknya tidak membatasi pemahaman Big Data ini hanya dengan sedikit banyaknya istilah dari huruf V yang digunakan . Kemudian dengan adanya ekosistem tersebut, jika dibutuhkan analisis sederhana maupun yang lebih kompleks, maka harapannya tidak akan ada kendala dari besarnya data yang diolah. Adanya kemajuan teknologi dalam hal penyimpanan, pengolahan, dan analisis Big Data meliputi (a) penurunan secara cepat terhadap biaya penyimpanan data dalam be-berapa tahun terakhir; (b) fleksibilitas dan efektivitas biaya pada pusat data dan komputasi awan untuk perhitungan dengan konsep elastisitas dan penyimpanannya; serta (c) pengembangan kerangka kerja baru seperti Hadoop ecosystem (salah satu peluang bisnis yang besar untuk developer untuk saat ini dan ke depannya dalam rangka membangun ekosistem analisis Big Data yang sangat powerfull sekelas Cloudera, Hortonworks, etc), yang memungkinkan pengguna untuk mengambil manfaat dari sistem komputasi terdistribusi, misal untuk menyimpan sejumlah data yang besar melalui pemrosesan parallel, dukungan da-tabase NoSQL, dan komputasi berbasis streaming. Sehingga kema-juan teknologi ini telah menciptakan beberapa perbedaan yang sangat signifikan, misal dalam hal kecepatan maupun ketepatan dari hasil yang didapatkan antara analisis tradisional dengan tools yang bukan dengan konsep Big Data versus analisis modern untuk saat ini dan masa depan dengan membangun ekosistem Big Data yang sangat
powerfull.
1. Para penulis artikel Analisis Big Data di forum, web, blog dan buku yang menjadi referensi buku ini untuk memberikan masukan yang sangat berharga sekali untuk perbaikan dan penyelesaian buku ini. 2. Mbak Efi Riyandani, yang telah banyak membantu penulisan buku,
dan mahasiswa-mahasiswa terbaik saya semester Ganjil 2016/2017, yaitu: Maryamah, Moh. Fadel Asikin, Daisy Kurniawaty, Selly Kurnia Sari, Nanda Agung Putra, Ardisa Tamara Putri, Dhimas Anjar Prabowo, Listiya Surtiningsih, Raissa Arniantya, Brillian Aristyo Rahadian, Diva Kurnianingtyas, Dyan Putri Mahardika, Tusty Nadia Maghfira.
3. Mahasiswa-mahasiswa terbaik saya semester Ganjil 2017/2018, yaitu: Yessica Inggir F., Kholifaul K., Ni Made Gita D. P., Ema Agasta, Retiana Fadma P. Sinaga, Fachrul Rozy Saputra Rangkuti, Yunita Dwi Alfiyanti, Dyah Ayu Wahyuning Dewi, Annisaa Amalia Safitri, Sarah Aditya Darmawan, Danastri Ramya Mehaninda, Eka Novita Shandra, Fakharuddin Farid Irfani, Rio Cahyo Anggono, Robih Dini, Yulia Kurniawati, Novirra Dwi Asri, Muhammad Vidi My-charoka, Vania Nuraini Latifah, Olivia Bonita, Eka Miyahil Uyun, Cusen Mosabeth, Evilia Nur Harsanti, Ivarianti Sihaloho.
Semoga kontribusi kalian menjadi ilmu yang barokah dan ber-manfaat. Aamiin. :). Tidak ada gading yang tak retak. Maka penulis memohon kritik dan saran untuk perbaikan dan penyempurnaan buku ini. In Syaa Allah pada edisi berikutnya, kami akan memberikan manualisasi Map Reduce, Spark, etc. dari setiap algoritma pada setiap contoh kasusnya. Selamat membaca buku ini dan semoga bermanfaat.
Malang, 19 Juli 2016-24 Mei 2018
Daftar Isi
Judul ... i
Kata Pengantar ... ii
Daftar Isi ... iv
Daftar Tabel ... viii
Daftar Gambar ... ix
Daftar Source Code ... xxvi
BAB 1 Konsep Big Data ... 1
1.1 Pengantar ... 1
1.2 Gambaran Umum Big Data ... 3
1.3 Karakteristik Big Data (3V) ... 5
1.4 Ekosistem Big Data Analytics ... 7
1.5 Ekosistem Tool Big Data Analytics ... 9
1.6 Tugas Kelompok ... 13
BAB 2 Analitik Big Data & Lifecycle ... 14
2.1 Pengantar ... 14
2.2 Teknologi Advaced (Tools) Big Data ... 14
2.3 Arsitektur Big Data ... 16
2.4 Key Roles Kunci Sukses Proyek Analitik ... 20
2.5 Lifecycle Analitik Data ... 22
2.6 Tugas Kelompok ... 24
BAB 3 Teknologi dan Tools Big Data (Bagian 1) ... 26
3.1 Konsep Pengolahan Big Data ... 26
3.2 Introduction to Hadoop ... 27
3.2.1 Hadoop Distributed File System (HDFS) ... 28
3.2.2 MapReduce (MR) ... 30
3.3 Konfigurasi Hadoop Single Node Cluster di Linux ... 34
3.3.1 Studi Kasus & Solusi Hadoop ... 35
3.3.2 Konfigurasi dengan Eclipse IDE ... 53
3.3.4 Konfigurasi dengan Spark ... 93
3.3.5 Konfigurasi dengan Mahout ... 132
3.4 Konfigurasi Hadoop Single Node Cluster di Windows . 140 3.4.1 Konfigurasi dengan Syncfusion ... 154
3.4.2 Konfigurasi dengan Eclipse IDE ... 161
3.4.3 Konfigurasi dengan Spark ... 170
3.5 Tugas Kelompok ... 173
BAB 4 Teknologi dan Tools Big Data (Bagian 2) ... 175
4.1 Konsep Single (Standalone) Vs Multi-Node Cluster .... 175
4.2 Hadoop Multi Node Cluster (Pseudo-Distributed) ... 176
4.3 Hadoop Multi Node Cluster (Full Distributed) ... 204
4.4 Studi Kasus (Sederhana) ... 217
4.5 Studi Kasus (Run Kode Program)... 225
4.5.1 Klasifikasi: NB dengan Terminal ... 225
4.5.2 Klasifikasi: NB dengan Eclipse ... 230
4.5.3 Clustering: K-Means ... 237
4.6 Tugas Kelompok ... 242
BAB 5 Analitik Data Tingkat Lanjut (Clustering) ... 244
5.1 Konsep Clustering ... 244
5.2 K-Means vs Kernel K-means ... 245
5.3 Studi Kasus ... 188
5.4 Tugas Kelompok ... 195
BAB 6 Analitik Data Tingkat Lanjut (Regresi) ... 197
6.1 Konsep Regresi ... 197
6.2 Analisis Teknikal dan Fundamental ... 198
6.3 Regresi Linear & Regresi Logistic ... 199
6.4 Extreme Learning Machine (ELM) ... 200
6.5 Tugas Kelompok ... 207
BAB 7 Analitik Data Tingkat Lanjut (Klasifikasi) ... 208
7.1 Konsep Klasifikasi ... 208
7.3 Algoritma Klasifikasi ... 210
7.3.1 ELM Untuk Regresi Vs Untuk Klasifikasi ... 210
7.3.2 Support Vector Machine (SVM) Linear dan Non-Linear 211 7.4 Tugas Kelompok ... 221
BAB 8 Teknologi dan Tools Big Data (Bagian 3) ... 223
8.1 Editor + GUI untuk Spark Java/ Spark Scala/ PySpark223 8.1.1 Install Sublime Text ... 224
8.1.2 Eclipse + Spark Standalone (Java EE) ... 224
8.1.3 Eclipse + Spark + Scala IDE + Maven ... 225
8.1.4 Eclipse + Spark + Scala IDE + SBT ... 243
8.1.5 Eclipse + PySpark + PyDev ... 254
8.1.6 PySpark + Pycharm ... 318
8.1.7 IntelliJ IDEA + SBT ... 340
8.1.8 Konfigurasi & Solusi Error/Bug ... 361
8.2 Konfigurasi Tambahan ... 364
8.2.1 Create VM dari file *.vdi dan UUID Baru ... 364
8.2.2 Share Folder Pada Linux Pada VirtualBox ... 367
8.3 Konfigurasi Hadoop + MongoDB ... 373
8.3.1 WordCount ... 386
8.3.2 Movie Ratings ... 399
8.4 Tugas Kelompok ... 412
BAB 9 Project Pilihan Analisis Big Data ... 413
9.1 Seleksi Asisten Praktikum ... 413
9.1.1 Dasar Teori ... 414
9.1.2 Impelementasi ... 417
9.2 Klasifikasi Kendaraan Bermotor ... 423
9.2.1 Dasar Teori ... 424
9.2.2 Implementasi ... 427
9.3 Clustering Judul Majalah ... 432
9.3.1 Dasar Teori ... 434
9.4 Collaborative Filtering ... 440
9.4.1 Dasar Teori ... 440
9.4.2 Implementasi ... 443
9.5 Klasifikasi Data Kualitatif (C4.5) ... 446
9.5.1 Dasar Teori ... 447
9.5.2 Implementasi ... 452
9.6 Clustering Tingkat Pengetahuan ... 456
9.6.1 Dasar Teori ... 457
9.6.2 Implementasi ... 460
9.7 Klasifikasi Kanker Payudara (SVM) ... 462
9.7.1 Dasar Teori ... 464
9.7.2 Implementasi ... 467
Daftar Pustaka ... 470
Daftar Tabel
Tabel 5.1 Contoh Data 2 Dimensi ... 188
Tabel 5.2
x
i ... 190Tabel 5.3
(
x
i)
... 190Tabel 5.4 Fungsi Pemetaan Cluster 1 ... 190
Tabel 5.5 Fungsi Pemetaan Cluster 2 ... 191
Tabel 5.6 Nilai Kernel data i terhadap semua data cluster 1 iterasi 1 ... 192
Tabel 5.7 Nilai Kernel Antar Data Pada Cluster j untuk iterasi 1... 193
Tabel 5.8 Jarak dan alokasi data untuk centroid terdekat iterasi 1 .. 194
Tabel 6.1 Dataset ... 199
Tabel 6.2 Data Training ... 202
Tabel 7.1 Data Training dan Data Testing ... 214
Tabel 7.2 𝛼
Tabel 7.8 Hasil Perhitungan xtest 1 ... 218
Tabel 7.9 Contoh 3 SVM Biner dengan Metode One-Against-All .... 218
Tabel 7.10 Metode One-Against-One dengan 4 Kelas ... 219
Tabel 7.11 Metode BDTSVM dengan 7 Kelas ... 220
Tabel 8.1 Perbedaan SQL dengan MongoDB... 376
Daftar Gambar
Gambar 1.1 Perkembangan data ... 1
Gambar 1.2 Data Science vs Business Intelligence ... 2
Gambar 1.3 Gambaran Umum Big Data ... 3
Gambar 1.4 Big Data dengan 6V+ 1V(Visualization)=7V ... 4
Gambar 1.5 Big Data dengan 10V ... 4
Gambar 1.6 Tradisional vs Big Data ... 5
Gambar 1.7 Bentuk Infrastruktur Data Center ... 6
Gambar 1.8 Google Cloud Platform ... 6
Gambar 1.9 Analyze small subsets of data ... 6
Gambar 1.10 Analyze all data ... 6
Gambar 1.11 Batch dan stream processing ... 37
Gambar 1.12 Traditional Approach ... 6
Gambar 1.13 Big Data Approach ... 6
Gambar 1.14 Variety Data ... 6
Gambar 1.15 Rangkuman 3V dan Veracity ... 6
Gambar 1.16 Gambaran Ekosistem Big Data ... 7
Gambar 1.17 Perkembangan Analytics ... 7
Gambar 1.18 Contoh Ekosistem Hadoop ke-1... 10
Gambar 1.19 Contoh Ekosistem Hadoop ke-2... 11
Gambar 1.20 Cloudera vs Hortonworks vs MapR ... 13
Gambar 2.1 Daftar Perusahaan ... 14
Gambar 2.2 Faktor yang mendorong (driving) adopsi Big Data ... 15
Gambar 2.3 Arsitektur Big Data ... 17
Gambar 2.4 Data Integration Using Apache NiFi dan Apache Kafka 19 Gambar 2.5 Integrating Apache Spark dan NiFi for Data Lakes ... 19
Gambar 2.6 Key Roles Kunci Sukses Proyek Analitik ... 20
Gambar 2.7 Gambaran Umum dari Lifecycle Analitik Data ... 22
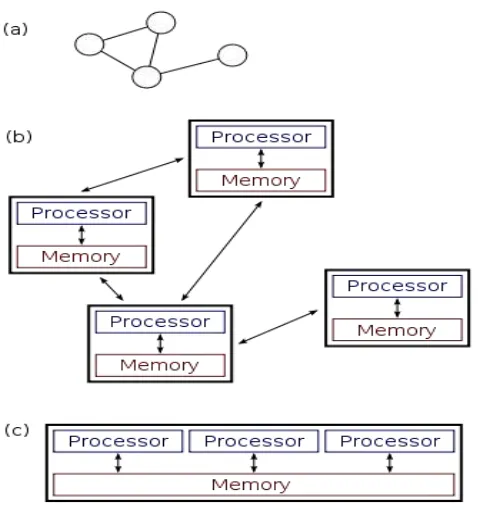
Gambar 3.1 Distributed System (a) dan Paralel System (b) ... 26
Gambar 3.3 Arsitektur HDFS... 30
Gambar 3.4 Hadoop 2.x Core Components ... 30
Gambar 3.5 High Level Arsitektur Hadoop dan The Job Tracker ... 31
Gambar 3.6 The Job Tracker ... 32
Gambar 3.7 Diagram Cara Kerja Map Reduce ... 33
Gambar 3.8 Ilustrasi MR vs YARN ... 33
Gambar 3.9 Persiapan Pada Virtual Box ... 34
Gambar 3.10 Studi Kasus Wordcount ... 35
Gambar 3.11 Hasil: hduser@Master:/usr/local/hadoop$ jar cf wc.jar WordCount*.class ... 41
Gambar 3.12 Hasil: hduser@Master:/usr/local/hadoop$ jar cf wc.jar WordCount*.class ... 41
Gambar 3.13 Hasil: hduser@Master:/usr/local/hadoop$ jar cf wc.jar WordCount*.class ... 42
Gambar 3.14 Hasil Menjalankan JAR untuk wordcount (file a.txt saja): .. 46
Gambar 3.15 Hasil menjalankan JAR untuk wordcount (file b.txt saja): .... 49
Gambar 3.16 Menjalankan JAR untuk wordcount untuk semua file dalam satu folder (file a.txt dan b.txts) ... 50
Gambar 3.17 Menjalankan JAR untuk wordcount untuk semua file dalam satu folder (file a.txt dan b.txts) Cont. ... 51
Gambar 3.18 Cara menghapus folder HDFS ... 51
Gambar 3.19 Cara menghapus folder HDFS Cont ... 52
Gambar 3.20 Link download Eclipse ... 53
Gambar 3.21 Extract Here - Eclipse ... 53
Gambar 3.22 Copy file, dan cek dengan “ls” ... 54
Gambar 3.23 Install eclipse ... 54
Gambar 3.24 Pilih Eclipse IDE for Java EE Developers ... 54
Gambar 3.25 Klik Install, tunggu beberapa waktu ... 55
Gambar 3.26 Klik Launch ... 55
Gambar 3.27 Klik “Launch”, tunggu beberapa saat ... 56
Gambar 3.28 Klik “restore” ... 56
Gambar 3.29 Masuk ke folder instalasi hadoop ... 57
Gambar 3.31 Klik Finish ... 58
Gambar 3.32 Klik Open Pers.. ... 59
Gambar 3.33 Project “HadoopIDE” ... 59
Gambar 3.34 Klik kanan “src”, tambahkan new “Package” ... 59
Gambar 3.35 Berikan name “org.hadoop.trainings”, klik “Finish” ... 60
Gambar 3.36 Klik kanan pada “org.hadoop.trainings”, klik new “Class” ... 60
Gambar 3.37 Berikan nama “WordCount”, klik “Finish” ... 60
Gambar 3.38 klik “Configure Build Path..” ... 61
Gambar 3.39 klik “Configure Build Path..” ... 61
Gambar 3.40 Masuk ke folder instalasi hadoop ... 62
Gambar 3.41 Add *.jar hadoop part 1 ... 62
Gambar 3.42 Add *.jar hadoop part 2 ... 63
Gambar 3.43 Add *.jar hadoop part 3 ... 63
Gambar 3.44 Add *.jar hadoop part 4 ... 64
Gambar 3.45 Add *.jar hadoop part 5 ... 64
Gambar 3.46 Add *.jar hadoop part 6 ... 65
Gambar 3.47 Add *.jar hadoop part 7 ... 65
Gambar 3.48 Add *.jar hadoop part 8 ... 66
Gambar 3.49 Add *.jar hadoop part 9 ... 66
Gambar 3.50 Daftar “Referenced Libraries” Hadoop ... 67
Gambar 3.51 Download code WordCount dari “https://goo.gl/wPa2ef” ... 67
Gambar 3.52 Sebelum dan setelah dicopykan ... 68
Gambar 3.53 About Hue ... 69
Gambar 3.54 Cara kerja Hue Server ... 69
Gambar 3.55 JVM Process Status Tool (jps) ... 70
Gambar 3.56 Cek Hadoop Version ... 70
Gambar 3.57 sudo apt-get install git ... 71
Gambar 3.58 Lakukan git clone ... 71
Gambar 3.59 Download Hue Selesai ... 72
Gambar 3.61 Install library development packages dan tools, selesai
... 73
Gambar 3.62 Masuk ke hduser ... 73
Gambar 3.63 Error ketika make apps Hue ke-1 ... 74
Gambar 3.64 Update beberapa komponen ... 74
Gambar 3.65 Error ketika make apps Hue ke-2 ... 75
Gambar 3.66 Install Hue, selesai. :D ... 76
Gambar 3.67 Jalankan Server Hue ... 76
Gambar 3.68 Starting pada http://127.0.0.1:8000 ... 77
Gambar 3.69 Set Username dan Password ... 77
Gambar 3.70 Tampilan Hue ke-1 ... 78
Gambar 3.71 Tampilan Hue ke-2 ... 78
Gambar 3.72 Load HDFS dari Hue ... 79
Gambar 3.73 Solusi ke-1 Error pada Hue ... 79
Gambar 3.74 Solusi ke-2 Error pada Hue ... 80
Gambar 3.75 Setting file “hdfs-site.xml” ... 81
Gambar 3.76 Setting file “core-site.xml” ... 82
Gambar 3.77 Edit file “hue.ini” Part 1 of 7 ... 83
Gambar 3.78 Edit file “hue.ini” Part 2 of 7 ... 84
Gambar 3.79 Edit file “hue.ini” Part 3 of 7 ... 85
Gambar 3.80 Edit file “hue.ini” Part 4 of 7 ... 86
Gambar 3.81 Edit file “hue.ini” Part 5 of 7 ... 86
Gambar 3.82 Edit file “hue.ini” Part 6 of 7 ... 87
Gambar 3.83 Edit file “hue.ini” Part 7 of 7 ... 87
Gambar 3.84 Jalankan lagi Hadoop ... 88
Gambar 3.85 Jalankan lagi Hue ... 89
Gambar 3.86 Buka Hue di Web Browser ... 89
Gambar 3.87 Buka Hue di Web Browser 1 ... 90
Gambar 3.88 Buka Hue di Web Browser 2 ... 91
Gambar 3.89 Buka Hue di Web Browser 3 ... 92
Gambar 3.90 Buka Hue di Web Browser 4 ... 92
Gambar 3.92 Spark dan Tool lainnya ... 93
Gambar 3.93 Spark dan Bahasa Pemrograman ... 94
Gambar 3.94 Cek versi Linux ... 94
Gambar 3.95 Cek Hadoop Version dan Run Hadoop ... 95
Gambar 3.96 Download Spark ... 95
Gambar 3.97 Hasil download Spark ... 95
Gambar 3.98 Cek Java Version ... 96
Gambar 3.99 Tekan enter, tunggu sampai selesai ... 96
Gambar 3.100 Tekan enter, tunggu sampai selesai ... 97
Gambar 3.101 Instalasi Spark selesai :D ... 97
Gambar 3.102 - Set PATH Spark ... 98
Gambar 3.103 Install java terbaru part 1 ... 98
Gambar 3.104 Install java terbaru part 2 ... 98
Gambar 3.105 Install java terbaru part 2 ... 99
Gambar 3.106 Install java terbaru part 4 ... 99
Gambar 3.107 Install java terbaru part 4 (lanj. 1) ... 99
Gambar 3.108 Install java terbaru part 4 (lanj. 2) ... 100
Gambar 3.109 Install java terbaru Selesai ... 100
Gambar 3.110 Cek java version sudah terupdate ... 101
Gambar 3.111 Update “sudo gedit ~/.bashrc” ... 101
Gambar 3.112 Restart Hadoop ... 102
Gambar 3.113 install python-pip ... 102
Gambar 3.114 Cek python –version ... 104
Gambar 3.115 Install Anaconda ... 104
Gambar 3.116 Tekan spasi, ketik yes, tekan enter ... 105
Gambar 3.117 set folder instalasinya ... 105
Gambar 3.118 Ketik yes (untuk set PATH di /home/hduser/.bashrc) ... 106
Gambar 3.119 Install Anaconda (Done) ... 106
Gambar 3.120 Set PATH Anaconda ... 107
Gambar 3.121 Cek python –version ... 108
Gambar 3.123 Spark di web ... 109
Gambar 3.124 Koding scala sederhana pada Spark ... 110
Gambar 3.125 Demo: WordCount (ScalaSpark) ke-1 ... 110
Gambar 3.126 Demo: WordCount (ScalaSpark) ke-2 ... 111
Gambar 3.127 Demo: WordCount (ScalaSpark) ke-3 ... 111
Gambar 3.128 Demo: WordCount (ScalaSpark) ke-4 ... 112
Gambar 3.129 Demo: WordCount (ScalaSpark) ke-5 ... 112
Gambar 3.130 Demo: WordCount (ScalaSpark) ke-6 ... 113
Gambar 3.131 Demo: WordCount (ScalaSpark) ke-7 ... 113
Gambar 3.132 cek JPS ... 113
Gambar 3.133 Hadoop sudah jalan ... 114
Gambar 3.134 Tampilan hadoop di Web ... 114
Gambar 3.135 Browse the file system ... 114
Gambar 3.136 Buat folder di hadoop melalui Terminal ... 115
Gambar 3.137 Cek isi dari “/user/hduser” ... 115
Gambar 3.138 CopyFromLocal file *.txt to hdfs ... 115
Gambar 3.139 Scala: load data input dari hdfs ... 116
Gambar 3.140 Lihat di web hasil output Spark ... 117
Gambar 3.141 Tampilan di web ... 117
Gambar 3.142 PySpark sudah aktif ... 118
Gambar 3.143 Python pada Spark ... 118
Gambar 3.144 PySpark counts.collect() ... 119
Gambar 3.145 Tampilan di web (Spark) ... 119
Gambar 3.146 koding python sederhana (map) ... 120
Gambar 3.147 koding python sederhana (filter) ... 121
Gambar 3.148 koding python sederhana (reduce) ... 121
Gambar 3.149 koding python sederhana (lambda) ... 122
Gambar 3.150 koding python sederhana (lambda): Latihan ... 123
Gambar 3.151 koding python sederhana (flatmap) ... 124
Gambar 3.152 run pyspark part 1 ... 125
Gambar 3.154 run pyspark part 3 ... 126
Gambar 3.155 run pyspark part 4 ... 127
Gambar 3.156 run pyspark part 5 ... 128
Gambar 3.157 run pyspark part 6 ... 128
Gambar 3.158 run pyspark part 7 ... 129
Gambar 3.159 run pyspark part 8 ... 129
Gambar 3.160 run pyspark part 9 ... 129
Gambar 3.161 Hasil k-means clustering ... 130
Gambar 3.162 Apache Mahout ... 132
Gambar 3.163 Recommender Engines ... 132
Gambar 3.164 User-User, Item-Item, atau diantara keduanya ... 133
Gambar 3.165 Tanimoto Coefficient ... 133
Gambar 3.166 Cosine Coefficient ... 133
Gambar 3.167 JVM Process Status Tool (jps) ... 134
Gambar 3.168 Cek Hadoop Version ... 134
Gambar 3.169 Buka web Apache Mahout ... 135
Gambar 3.170 Download Mahout ... 135
Gambar 3.171 Hasil Download Mahout ... 136
Gambar 3.172 Extract Mahout ... 136
Gambar 3.173 Buat folder “mahout” ... 137
Gambar 3.174 Instalasi Mahout Selesai :D ... 137
Gambar 3.175 Cek Owner dan Nama Group “/usr/local/mahout” .... 138
Gambar 3.176 ubah Owner dan Nama Group “/usr/local/mahout” .. 138
Gambar 3.177 Update “sudo gedit ~/.bashrc” ... 139
Gambar 3.178 Restart “~/.bashrc” lalu Restart Hadoop... 139
Gambar 3.179 Persiapan Install Hadoop di Windows ke-1 ... 140
Gambar 3.180 Ekstraks file “bin-master.zip” ... 143
Gambar 3.181 Masuk ke Control Panel ... 143
Gambar 3.182 Set JAVA_HOME ... 144
Gambar 3.183 Edit file “hadoop-env.cmd” ... 144
Gambar 3.185 Hasil edit file “hdfs-site.xml” ... 146
Gambar 3.186 Buat folder namenode dan datanode ... 146
Gambar 3.187 Hasil edit file “mapred-site.xml.template” ... 147
Gambar 3.188 Pilih Advanced system settings ... 149
Gambar 3.189 Ketik HADOOP_HOME ... 149
Gambar 3.190 Pada Variable “Path” klik Edit.. ... 150
Gambar 3.191 Tambahkan bin hadoop pada Path ... 150
Gambar 3.192 Cek hadoop version di CMD ... 151
Gambar 3.193 Hasil format namenode ... 151
Gambar 3.194 Hasil start-all.cmd ... 152
Gambar 3.195 Hasil localhost:50070 ke-1 ... 153
Gambar 3.196 Hasil Hasil localhost:50070 ke-2 ... 153
Gambar 3.197 Hasil “http://localhost:8088” ... 153
Gambar 3.198 Download syncfusion ... 154
Gambar 3.199 Hasil klik “Proceed to the …” ... 155
Gambar 3.200 Klik “Download link ..” ... 155
Gambar 3.201 Install “syncfusionbigdataplatform.exe” ... 155
Gambar 3.202 Hasil klik Install ... 156
Gambar 3.203 Hasil klik Finish ... 156
Gambar 3.204 Hasil klik Launch Studio ... 157
Gambar 3.205 Klik OK ... 157
Gambar 3.206 Syncfusion Big Data Agent dan Remote Agent ... 157
Gambar 3.207 Big Data Platform (1 of 4) ... 158
Gambar 3.208 Big Data Platform (2 of 4) ... 158
Gambar 3.209 Big Data Platform (3 of 4) ... 159
Gambar 3.210 Big Data Platform (4 of 4) ... 159
Gambar 3.211 Hasil Install “syncfusionbigdatacluster.exe” ... 160
Gambar 3.212 Download Eclipse ... 161
Gambar 3.213 Klik Install ... 161
Gambar 3.214 Tunggu beberapa Waktu ... 162
Gambar 3.216 Klik Launch ... 163
Gambar 3.217 Tunggu beberapa waktu ... 163
Gambar 3.218 Eclipse siap digunakan ... 164
Gambar 3.219 Hasil “bin\hdfs dfs -mkdir /user”... 164
Gambar 3.220 Hasil “bin\hdfs dfs -mkdir /user/hduser” ... 165
Gambar 3.221 Hasil di HDFS (browser) ... 167
Gambar 3.222 Setting koding NB Hadoop ... 167
Gambar 3.223 Hasil run koding NB Hadoop ... 168
Gambar 3.224 Set bin Spark ... 172
Gambar 4.1 Running Java Process ... 175
Gambar 4.2 Setting PCMaster + (PC Node1, Node2, Node3): ... 176
Gambar 4.3 nidos@master:~$ sudo gedit /etc/hostname ... 179
Gambar 4.4 nidos@master:~$ sudo gedit /etc/hosts ... 179
Gambar 4.5 Tampilan Menu ... 180
Gambar 4.6 Tampilan Menu Edit ... 180
Gambar 4.7 Tampilan Connection Information ... 181
Gambar 4.8 Tampilan Menu ... 181
Gambar 4.9 Tampilan Edit Pada Gateway dan DNS Server ... 181
Gambar 4.10 Hasil nidos@master:~$ sudo gedit /etc/hosts ... 182
Gambar 4.11 Tampilan Edit Method Menjadi Manual ... 182
Gambar 4.12 Hasil nidos@master:~$ sudo gedit /usr/local/hadoop/etc/hadoop/masters ... 183
Gambar 4.13 Hasil nidos@master:~$ sudo gedit /usr/local/hadoop/etc/hadoop/slaves ... 184
Gambar 4.14 Clone PC Master ... 186
Gambar 4.15 Setting PC Master ... 186
Gambar 4.16 Setting PC Node1, Node2 dan Node3:... 186
Gambar 4.17 Tampilan Lihat IP Master ... 187
Gambar 4.18 Setting IP PC Node 1 ... 187
Gambar 4.19 Setting IP PC Node 2 ... 187
Gambar 4.21 Tampilan nidos@node1:~$ sudo gedit
/usr/local/hadoop/etc/hadoop/masters ... 189
Gambar 4.22 Tampilan nidos@node1:~$ sudo gedit /usr/local/hadoop/etc/hadoop/slaves ... 190
Gambar 4.23 Tampilan Ubah Setting Network pada Virtual Box ... 196
Gambar 4.24 Tampilan pada Adapter 1 ... 196
Gambar 4.25 Tampilan Call SSH ... 197
Gambar 4.26 Tampilan Call SSH ... 198
Gambar 4.27 Format Namenode dari PC Master ... 199
Gambar 4.28 Tampilan star start-dfs.sh ... 200
Gambar 4.29 Tampilan Start-yarn.sh ... 200
Gambar 4.30 Tampilan http://localhost:50070 di Firefox ... 201
Gambar 4.31 Tampilan Datanode Information di Firefox ... 201
Gambar 4.32 Tampilan http://localhost:50090/status.html di Firefox .. 202
Gambar 4.33 Tampilan http://localhost:8088/cluster di Firefox ... 202
Gambar 4.34 Tampilan Nodes Of the Cluster pada Firefox ... 202
Gambar 4.35 Setting IP Windows ke-1 ... 204
Gambar 4.36 Setting IP PC Master ... 204
Gambar 4.37 Setting IP PC Slave ... 205
Gambar 4.38 Pilih NAT ... 205
Gambar 4.39 Pilih PCI (Master) ... 206
Gambar 4.40 Pilih PCI (Slave) ... 206
Gambar 4.41 Ketik sudo .. (Master) ... 207
Gambar 4.42 Ketik sudo .. (Slave) ... 207
Gambar 4.43 Ketik sudo ifdown eth1 ... 208
Gambar 4.44 Ketik sudo nano /etc/hostname ... 208
Gambar 4.45 Ketik sudo nano /etc/hosts ... 208
Gambar 4.46 Ketik sudo nano /etc/hostname ... 209
Gambar 4.47 Ketik sudo nano /etc/hosts ... 209
Gambar 4.48 Cek Koneksi ke PC Slave ... 209
Gambar 4.50 Ketik “sudo nano /usr/local/hadoop/etc/hadoop/masters”
... 210
Gambar 4.51 Ketik “sudo nano /usr/local/hadoop/etc/hadoop/slaves” 210 Gambar 4.52 Ketik sudo nano /usr/local/hadoop/etc/hadoop/hdfs-site.xml ... 210
Gambar 4.53 Ketik sudo nano /usr/local/hadoop/etc/hadoop/hdfs-site.xml ... 211
Gambar 4.54 Ketik sudo nano /usr/local/hadoop/etc/hadoop/core-site.xml ... 212
Gambar 4.55 Ketik sudo nano /usr/local/hadoop/etc/hadoop/mapred-site.xml ... 212
Gambar 4.56 Buat namenode ... 213
Gambar 4.57 Buat datanode ... 213
Gambar 4.58 Call SSH dari PC Master ... 214
Gambar 4.59 Call SSH dari PC Slave ... 214
Gambar 4.60 Ketik hdfs namenode -format ... 214
Gambar 4.61 Ketik start-all.sh ... 215
Gambar 4.62 JPS pada Master dan Slave ... 215
Gambar 4.63 Cek datanode ... 215
Gambar 4.64 Copy File ... 216
Gambar 4.65 bin hadoop ... 216
Gambar 4.66 bin hdfs ... 216
Gambar 4.67 Cek pada PC Slave ... 216
Gambar 4.68 Cek pada PC Master ... 217
Gambar 4.69 Tampilan Dokumen Uji ... 217
Gambar 4.70 Tampilan File wordcount.java ... 220
Gambar 4.71 Tampilan WordCount.Java dalam folder ... 221
Gambar 4.72 Hasil nidos@master:/usr/local/hadoop$ jar cf wc.jar WordCount*.class ... 221
Gambar 4.73 Tampilan nidos@master:/usr/local/hadoop$ bin/hdfs dfs -cat /user/nidos/wordcount/output/part* ... 222
Gambar 4.74 Browse Directory pada Forefox ... 223
Gambar 4.76 File Information Pada Firefox ... 224
Gambar 4.77 File *.java dari Algoritma Naive_Bayes_Classifier_MapReduce ... 225
Gambar 4.78 Folder /usr/local/hadoop ... 226
Gambar 4.79 File *.java ... 227
Gambar 4.80 File *.java pada Folder Hadoop ... 227
Gambar 4.81 File *.class pada Folder Hadoop ... 228
Gambar 4.82 Hasill 1 of 2 ... 229
Gambar 4.83 Hasil 2 of 2 ... 229
Gambar 4.84 NBbyArgument pada Eclipse ... 230
Gambar 4.85 Running “NBbyArgument” ke-1 ... 231
Gambar 4.86 Running “NBbyArgument” ke-2 ... 231
Gambar 4.87 Running “NBbyArgument” ke-3 ... 232
Gambar 4.88 Running “NBbyArgument” ke-4 ... 232
Gambar 4.89 Running “NBbyArgument” ke-5 ... 233
Gambar 4.90 Running “NBbyArgument” ke-6 ... 233
Gambar 4.91 Running “NBbyArgument” ke-7 ... 234
Gambar 4.92 Running “NBbyArgument” ke-8 ... 234
Gambar 4.93 Running “NBtanpaArgument” ke-1 ... 235
Gambar 4.94 Running “NBtanpaArgument” ke-2 ... 235
Gambar 4.95 Running “NBtanpaArgument” ke-3 ... 236
Gambar 4.96 Running “NBtanpaArgument” ke-4 ... 236
Gambar 4.97 File *.java dari Algoritma K-Means ... 237
Gambar 4.98 Folder Com ... 237
Gambar 4.99 File *.class ... 238
Gambar 4.100 File KMeans.jar ... 238
Gambar 4.101 Hasil 1 of 2... 239
Gambar 4.102 Folder mapreduce dan model ... 239
Gambar 4.103 Folder com dalam folder hadoop ... 240
Gambar 4.104 File *.class ... 240
Gambar 4.105 File KMeans.jar ... 241
Gambar 4.107 Hasil 2 of 2... 242
Gambar 5.1 Konsep HierarchicalClustering ... 244
Gambar 5.2 Konsep Non-Hierarchical Clustering ... 245
Gambar 5.3 K-Means ... 249
Gambar 5.4 Kernel K-Means ... 249
Gambar 5.5 Visualisasi Hasil Mapping Data Kernel K-means ... 188
Gambar 5.6 Visualisasi Data 2 Dimensi ... 189
Gambar 5.7 Visualisasi data hasil update anggota cluster iterasi 1 195 Gambar 6.1 Visualisasi Hasil Peramalan Iterasi SVR 100000 ... 197
Gambar 6.2 Regresi ... 199
Gambar 6.3 Arsitektur ELM ... 200
Gambar 6.4 Training Algoritma ELM ... 201
Gambar 6.5 Training ELM dengan Bias ... 201
Gambar 6.6 Arsitektur Artificial Neural Network Backpropagation... 202
Gambar 7.1 Gambaran Perbedaan Klasifikasi dan Regresi ... 208
Gambar 7.2 Contoh Regresi... 208
Gambar 7.3 Contoh Klasifikasi ... 209
Gambar 7.4 Linear Clasifier... 209
Gambar 7.5 Non-Linear Clasifier ... 209
Gambar 7.6 Ilustrasi SVM Linear ... 211
Gambar 7.7 SVM Non-Linear ... 212
Gambar 7.8 Gambaran SVM dengan Slack Variable ... 212
Gambar 7.9 Contoh Klasifikasi dengan Metode One-Against-All .... 218
Gambar 7.10 Klasifikasi One-Against-One untuk 4 Kelas ... 219
Gambar 7.11 Ilustrasi Klasifikasi dengan BDTSVM ... 220
Gambar 7.12 Ilustrasi Klasifikasi dengan metode DAGSVM ... 221
Gambar 8.1 Get Eclipse OXYGEN ... 223
Gambar 8.2 Bahasa Java/ Scala/ Python/ R ... 223
Gambar 8.5 Copy paste file *.vdi ... 364
Gambar 8.6 Buka cmd as administrator ... 364
Gambar 8.38 copy file jars (“mongo-hadoop-core-2.0.1.jar” dan “mongo-java-driver-3.4.0.jar”) ke dir. lib pada tiap di hadoop cluster ... 386 Gambar 8.39 Buat DB “testmr” ... 386 Gambar 8.40 Tampilan Add Collection ... 387 Gambar 8.41 Import file “*.json” as collection pada DB “testmr” ke collection “in” ... 387 Gambar 8.42 Text Input ... 388 Gambar 8.43 Import Document Untuk file “in.json” tidak standar Mongo ... 389
Gambar 8.44 Import Document Untuk file “in.json” tidak standar Mongo ... 389
Gambar 8.45 file in_standard.json standar Mongo ... 390 Gambar 8.46 in_standard.json standar Mongo (Klik Open) ... 390 Gambar 8.47 Import Document ... 391 Gambar 8.48 Hasil dari Klik Import ... 391 Gambar 8.49 file “WordCountMongo.java”: ... 394 Gambar 8.50 Hasil: nidos@master:/usr/local/hadoop$ bin/hdfs
com.sun.tools.javac.Main WordCountMongo.java ... 396
Gambar 8.51 Hasil: nidos@master:/usr/local/hadoop$ jar cf wcmongo.jar WordCountMongo*.class ... 396
Gambar 8.64 Compile Semua file *.java ke *.jar ... 407 Gambar 8.65 Hasil: nidos@master:/usr/local/hadoop$ jar cf ratemovie.jar comratingbymovies/nidos/*.class ... 408
Gambar 8.66 Hasil: nidos@master:/usr/local/hadoop$ jar cf ratemovie.jar comratingbymovies/nidos/*.class ... 408
Daftar Source Code
Source Code 3.1 Solusi Localhost:50070 tidak ada koneksi ... 37 Source Code 3.2 Membuat Directories di HDFS ... 37 Source Code 3.3 File *.java Part 1 ... 37 Source Code 3.4 File *.java Part 1 Cont ... 38 Source Code 3.5 File *.Java Part 2 ... 39 Source Code 3.6 File *.Java Cont ... 40 Source Code 3.7 Solusi Error: Could not find or load main class
com.sun.tools.javac.Main ... 40
Source Code 3.8 Solusi Error: Could not find or load main class fs: ... 42 Source Code 3.9 Solusi Error: Could not find or load main class fs: Cont 43 Source Code 3.10 Hasil: hduser@Master:/usr/local/hadoop$ bin/hdfs dfs -copyFromLocal /home/nidos/Desktop/data/a.txt
/user/hduser/wordcount/input ... 43 Source Code 3.11 Solusi jika sering muncul warning: WARN
Source Code 4.8 Setting PC Master (Node1, Node2, Node 3) ... 189 Source Code 4.9 Setting PC Master ... 190 Source Code 4.10 Setting PC Master ... 190 Source Code 4.11 Setting PC Master ... 191 Source Code 4.12 Call SSH ... 192 Source Code 4.13 Cek Status SSH Ok ... 192 Source Code 4.14 Cek Status SSH Error ... 192 Source Code 4.15 Re-install SSH dan Cek Status OK ... 193 Source Code 4.16 Call SSH untuk Node 2 ... 193 Source Code 4.17 Cek Status SSH Ok ... 194 Source Code 4.18 Cek Status SSH Error ... 194 Source Code 4.19 Re-Install SSH dan Cek Status ... 194 Source Code 4.20 Call SSH untuk Node 3 ... 194 Source Code 4.21 Call SSH untuk Node 3 Cont. ... 195 Source Code 4.22 Cek Status SSH Ok ... 195 Source Code 4.23 Cek Status SSH Error ... 195 Source Code 4.24 Re-Install SSH dan Cek Status ... 195 Source Code 4.25 Solusi untuk error “ssh: connect to host
BAB 1 Konsep Big Data
1.1 Pengantar
Banyak perdebatan yang signifikan tentang apa itu Big Data dan apa jenis keterampilan yang diperlukan untuk penggunaan terbaik dari Big Data tersebut. Banyak yang menulis tentang Big Data dan kebutuhan untuk analisis yang canggih dalam industri, akademisi, dan pemerintah, maupun lainnya. Ketersediaan sumber data baru dan munculnya peluang analitis yang lebih kompleks telah menciptakan kebutuhan untuk memikirkan kembali arsitektur data yang ada untuk memungkinkan analisis yang dapat dengan optimal memanfaatkan Big Data.
Bab ini menjelaskan beberapa konsep utama Big Data, mengapa analisis canggih diperlukan, perbedaan Data Science vs Business Intelligence (BI), dan apa peran baru yang diperlukan untuk ekosistem Big Data. Berikut berbagai perkembangan data dan munculnya sumber data yang besar dari tahun ke tahun yang ditunjukan oleh Gambar 1.1 berikut:
Gambar 1.1 Perkembangan data
Gambar 1.2 Data Science vs Business Intelligence
Sebuah penelitian eksplanatori (Explanatory Research) menurut Singarimbun dalam Singarimbun dan Effendi (Ed 1995) merupakan penelitian yang menjelaskan hubungan kausal (sebab akibat) antara variabel penelitian dengan pengujian hipotesa (menguji suatu teori atau hipotesis guna memperkuat atau bahkan menolak teori atau hipotesis hasil penelitian yang sudah ada sebelumnya). Di dalam penelitian eksplanatori, pendekatan yang dipakai dalam penelitian ini adalah metode survey, yaitu penelitian yang dilakukan untuk memperoleh fakta-fakta mengenai fenomena-fenomena yang ada di dalam obyek penelitian dan mencari keterangan secara aktual dan sistematis.
Pengertian riset eksploratori adalah riset yang ditujukan untuk mengeksplor atau untuk mengumpulkan pemahaman mendalam (penyelidikan) mengenai suatu masalah, bukan untuk menguji variabel karena variabel-tersebut biasanya belum diketahui dan baru akan diketahui melalui riset. Riset eksploratori bersifat fleksibel dan tidak terstruktur. Umumnya riset ini berbentuk riset kualitatif dengan metode pengumpulan data yang lazim digunakan yaitu wawancara dan diskusi kelompok.
1.2 Gambaran Umum Big Data
Dari sudut pandang ilmu pengetahuan, media penyimpanan pada hardware yang dapat digunakan adalah HDD, FDD, dan yang sejenisnya. Sedangkan media penyimpanan pada jaringan biologi, pada diri kita dikaruniai Otak oleh Sang Creator atau Sang Pencipta. Seberapa penting mengolah data-data yang kecil kemudian berkumpul menjadi data yang besar (Big Data) tersebut. Berikut gambaran umum Big Data yang ditunjukkan oleh Gambar 1.3.
Gambar 1.3 Gambaran Umum Big Data
Dari gambar 1.3 diatas dapat dilihat beberapa elemen penting dalam big data diantaranya:
- Data (Facts, a description of the World)
- Information (Captured Data and Knowledge): Merekam atau
mengambil Data dan Knowledge pada satu waktu tertentu (at a single point). Sedangkan Data dan Knowledge dapat terus berubah dan bertambah dari waktu ke waktu.
- Knowledge (Our personal map/model of the world): apa yang kita
ketahui (not the real world itself) Anda saat ini tidak dapat menyimpan pengetahuan dalam diri anda dalam apa pun selain otak, dan untuk membangun pengetahuan perlu informasi dan data.
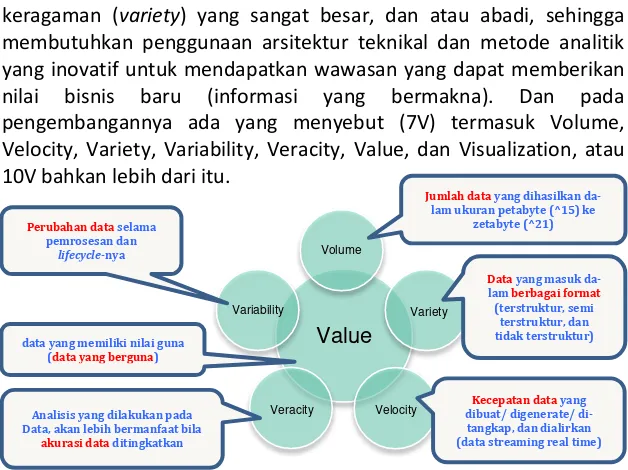
keragaman (variety) yang sangat besar, dan atau abadi, sehingga membutuhkan penggunaan arsitektur teknikal dan metode analitik yang inovatif untuk mendapatkan wawasan yang dapat memberikan nilai bisnis baru (informasi yang bermakna). Dan pada pengembangannya ada yang menyebut (7V) termasuk Volume, Velocity, Variety, Variability, Veracity, Value, dan Visualization, atau 10V bahkan lebih dari itu.
Gambar 1.4 Big Data dengan 6V+ 1V(Visualization)=7V
Big data merupakan istilah untuk sekumpulan data yang begitu besar atau kompleks dimana tidak bisa ditangani lagi dengan sistem teknologi komputer konvensional (Hurwitz, et al., 2013). Kapan suatu
data dapat dikatakan sebagai “Big Data”?
Gambar 1.5 Big Data dengan 10V datayang memiliki nilai guna
(data yang berguna)
Volume
Perubahan data selama pemrosesan dan
lifecycle-nya
Variability
Data yang masuk da-lam berbagai format
(terstruktur, semi terstruktur, dan tidak terstruktur)
Variety
Veracity
Analisis yang dilakukan pada Data, akan lebih bermanfaat bila
akurasi data ditingkatkan
Velocity dibuat/ digenerate/ di-Kecepatan data yang tangkap, dan dialirkan (data streaming real time)
Value
Jumlah data yang dihasilkan da-lam ukuran petabyte (^15) ke
zetabyte (^21)
Ukuran Data
Teka-teki terhadap teknik meaning
Big Data dan Tools yang digunakan Kecepatan Data
yang dihasilkan
Model Data, Semantik yang menggambarkan Struktur data
Kualitas data, Tata Kelola, Pengelolaan Data Master secara Massive
Data yang punya nilai guna
Perilaku Berkembang, Dinamis dari Sumber Data
Akurasi data Berbagai tipe data
1.3 Karakteristik Big Data (3V)
1. Volume
- Facebook menghasilkan 10TB data baru setiap hari, Twitter 7TB
- Sebuah Boeing 737 menghasilkan 240 terabyte data pen-erbangan selama penpen-erbangan dari satu wilayah bagian AS ke wilayah yang lain
- Microsoft kini memiliki satu juta server, kurang dari Google, tetapi lebih dari Amazon, kata Ballmer (2013).
Catatan: Kita dapat menggunakan semua data ini untuk memberitahu kita sesuatu, jika kita mengetahui pertanyaan yang tepat untuk bertanya.
Kata Big Data mengarah kepada managemen informasi skala besar (large-scale) dan teknologi analisis yang melebihi kapabilitas teknologi data secara tradisional. Terdapat perbedaan yang paling utama dalam tiga hal antara Tradisional dengan Big Data, yaitu amount of data (vol-ume), the rate of data generation and transmission (velocity), dan the types of structured and unstructured data (variety).
Gambar 1.7 Bentuk Infrastruktur
Data Center Gambar 1.8 Google Cloud Platform
Berikut gambaran traditioonal approach dan big data approach yang ditunjukkan oleh Gambar 1.6 dan 1.7.
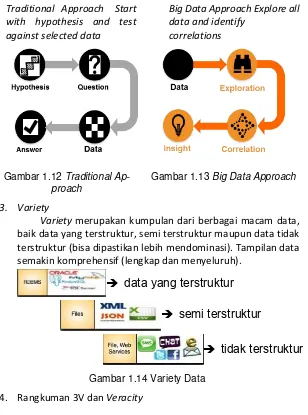
Traditional Approach
Gambar 1.9 Analyze small subsets of data
Big Data Approach
Gambar 1.10 Analyze all data
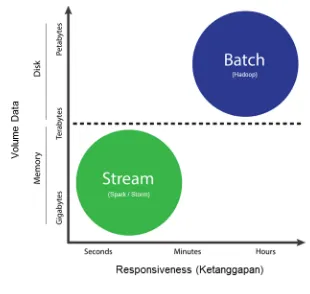
Gambar 1.11 Batch dan stream processing
2. Velocity
Traditional Approach Start with hypothesis and test against selected data
Gambar 1.12 Traditional Ap-proach
Big Data Approach Explore all data and identify
correlations
Gambar 1.13 Big Data Approach
3. Variety
Variety merupakan kumpulan dari berbagai macam data, baik data yang terstruktur, semi terstruktur maupun data tidak terstruktur (bisa dipastikan lebih mendominasi). Tampilan data semakin komprehensif (lengkap dan menyeluruh).
Gambar 1.14 Variety Data
4. Rangkuman 3V dan Veracity
Gambar 1.15 Rangkuman 3V dan Veracity
data yang terstruktur
semi terstruktur
Data streaming pada sepersekian detik
Kepastian kondisi data, apakah datanya
1.4 Ekosistem Big Data Analytics
Berikut gambaran dari Ekosistem Big Data yang ditunjukkan oleh Gambar 1.15:
Gambar 1.16 Gambaran Ekosistem Big Data
Keterangan:
1. Data Devices
2. Data Collectors
3. Data Aggregators: kompilasi informasi dari database dengan tujuan untuk mempersiapkan dataset gabungan untuk pengolahan data.
4. Data Users/ Buyers
Apa yang dimasud dengan Analytics? Sebuah titik awal untuk memahami Analytics adalah Cara untuk mengeksplorasi/ menyelidiki/ memahami secara mendalam suatu objek sampai ke akar-akarnya. Hasil analytics biasanya tidak menyebabkan banyak kebingungan, karena konteksnya biasanya membuat makna yang jelas. Perkembangan analytics dimulai dari DSS kemudian berkem-bang menjadi BI (BussinesIntelligence) baru kemudian menjadi ana-lytics yang ditunjukkan oleh Gambar 1.16 berikut:
Gambar 1.17 Perkembangan Analytics
Decision Support Systems
Business
Intelligence
Analytics
BI dapat dilihat sebagai istilah umum untuk semua aplikasi yang mendukung DSS, dan bagaimana hal itu ditafsirkan dalam industri dan semakin meluas sampai di kalangan akademisi. BI berevolusi dari DSS, dan orang dapat berargumentasi bahwa Analytics berevolusi dari BI (setidaknya dalam hal peristilahan). Dengan demikian, Analytics merupakan istilah umum untuk aplikasi analisis data.
Big Data Analytics merupakan Alat dan teknik analisis yang akan sangat membantu dalam memahami big data dengan syarat algoritma yang menjadi bagian dari alat-alat ini harus mampu bekerja dengan jumlah besar pada kondisi real-time dan pada data yang berbeda-beda.
Bidang Pekerjaan baru Big Data Analytics:
- Deep Analytical Talent / Data scientists (Memiliki bakat
analitik yang mendalam/ Ilmuwan Data): orang-orang dengan latar belakang yang kuat dalam algoritma-algoritma sistem cerdas, atau matematika terapan, atau ekonomi, atau ilmu pengetahuan lainnya melalui inferensi data dan ek-splorasi.
- Data Savvy Professionals (Para profesional Data Cerdas):
Mereka tahu bagaimana untuk berpikir tentang data, bagaimana mengajukan jenis pertanyaan (goal) yang tepat sesuai dengan kebutuhan lembaga/perusahaan/lainnya dan mampu memahami dan mengklarifikasi jawaban (hasil analisis) yang mereka terima.
- Technology and data enablers: Mampu memberikan
dukungan integrasi antara data dengan teknologi yang sesuai, dan yang paling berkembang saat ini.
Contoh perusahaan atau developer yang menggunakan analisis Big Data:
- Starbucks (Memperkenalkan Produk Coffee Baru). Pagi itu
dan menjelang akhir hari semua komentar negatif telah menghilang. Bagaimana jika menggunakan analisis tradisional?
Contoh tersebut menggambarkan penggunaan sumber data yang berbeda dari Big Data dan berbagai jenis analisis yang dapat dilakukan dengan respon sangat cepat oleh pihak Starbucks.
- Pemilihan Presiden atau walikota atau lainnya di suatu Negara atau kota melalui analisis tweet dengan Apache HDF/NiFi, Spark, Hive dan Zeppelin.
o Apache NiFi, get filtered tweets yang berhubungan dengan Pemilihan Presiden atau walikota, misal di Indonesia atau di kota tertentu.
o Apache Spark, getthe stream of tweets dari Apache NiFi.
o Spark streaming, untuk mentransformasi dan menyimpan data ke dalam suatu tabel pada Apache Hive.
o Apache Zeppelin notebook, untuk menampilkan data hasil secara real-time.
Hasil analytics:
o Frekuensi dari tweets sepanjang waktu per kandidat
o Persentase tweet negatif, positive dan neutral per kandi-dat
o Tren opini sepanjang waktu untuk tiap kandidat
1.5 Ekosistem Tool Big Data Analytics
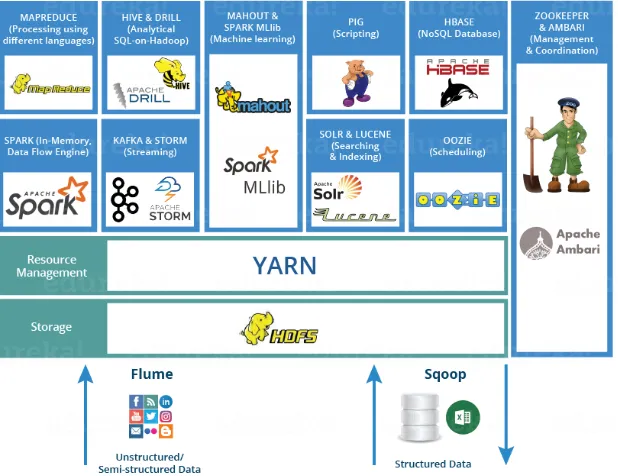
Gambar 1.18 Contoh Ekosistem Hadoop ke-1
Berdasarkan dari Ekosistem Big Data yang begitu kompleks pada bab sebelumnya, maka hal yang sangat penting dilakukan pertama kali sebagai kunci sukses untuk membangun Ekosistem Hadoop adalah mengidentifikasi kegunaan dan bagaimana interaksi antara, atau dari masing-masing Tool Big Data, serta apa saja yang nantinya akan digunakan dalam melakukan pembuatan implementasi pada lingkungan Hadoop. Gambar 1.17 memberikan contoh gambaran umum tentang interaksi aplikasi, tool dan interface yang ada di ekosistem Hadoop yang dibangun, misal berdasarkan kategori atau spesifikasi dari setiap produk-produk Apache berdasarkan fungsinya, mana yang spesifik digunakan untuk; (Storage, Processing, Querying, External Integration & Coordination), dan bagaimana kecocokan interaksi diantara mereka.
Gambar 1.19 Contoh Ekosistem Hadoop ke-2
Fokus dari adanya visualisasi ekosistem dari Tool Big Data adalah terkait suatu gambaran sistem yang mempelajari interaksi antara satu Tool Big Data satu dengan lainnya, maupun interakti suatu Tool Big Data yang ada dengan Lingkungannya (misal Data, Kondisi Kasusnya, dll), sedangkan fokus dari pembuatan arsitektur Tool Big Data (akan dibahas lebih detil pada bab selanjutnya) adalah lebih ke arah seni dan ilmu yang digunakan untuk merancang, mendesain dan membangun produk dari mengkombinasikan dari banyaknya pilihan Tool -Tool Big Data yang ada sesuai dengan seberapa komplek kasus yang ditangani untuk projek analitik dalam Scope Big Data, dan memungkinkan akan adanya modifikasi atau perbaikan kembali arsitektur yang ada sebelumnya dari waktu ke waktu, misal dalam beberapa bulan atau tahun produk arsitertur tersebut mungkin akan menjadi usang dan harus diganti dengan arsitektur yang lain yang lebih baik dan optimal.
kesehatan (Healthcare), dsb bisa menggunakan Hadoop Distribution (HD) dari hasil karya terbaik beberapa perusahaan berikut,
1. Cloudera: didirikan orang-orang yang berkontribusi di project Hadoop di Apache, Memiliki pangsa pasar paling besar, membuat HD versi gratis dan juga versi enterprise yang tidak gratis, menambahkan software khusus milik mereka yang disebut Impala (Query Engine diatas HDFS, seperti Map Reduce yang bisa dijalankan dengan low-latency atau dengan waktu yang lebih pendek dibanding Map Reduce).
2. HortonWorks: didirikan orang-orang yang berkontribusi di project Hadoop juga, diadopsi di Microsoft Azure dan menjadi Microsoft HD Insight. Partnership ini yang membuat Hortonworks sampai saat ini satu-satunya Hadoop yang compatible dan mudah dijalankan di Microsoft Windows, HD versi enterprise dari Hortonworks adalah gratis. Hortonworks mendapatkan keuntungan dari support dan training.
3. MapR Technologies: seperti Hortonworks, memberikan gratis untuk versi enterprisenya dan mendapat keuntungan dari support dan training, digunakannya oleh dua perusahaan cloud computing yang besar Amazon dan Google, maka MapR banyak digunakan oleh pengguna cloud computing.
4. etc
kemudian disusul Tool yang lainnya , hal ini akan memudahkan anda belajar untuk menjadi sangat ahli dalam bidang Big Data dan Tool-nya, sehingga setelah mahir, anda akan merasa sangat mudah dalam membuat Hadoop Distribution secara mandiri.
Gambar 1.20 Cloudera vs Hortonworks vs MapR
1.6 Tugas Kelompok
1. Jelaskan Pengertian dan keberadaan (ada atau tidak adanya) dari Big Data, dari sudut pandang spesifikasi hardware:
a. Jika belum memenuhi kebutuhan Big Data tersebut. b. Jika sudah memenuhi kebutuhan Big Data tersebut. 2. Sebutkan permasalahan apa saja yang sering muncul pada Big
Data?
3. Jelaskan apa yang dimaksud dengan Volume, Velocity, Variety, dan Veracity dalam Big Data!
4. Jelaskan Perbedaan antara analisis dan analitik (analytics)! 5. Apa pendapat anda antara Big Data vs Big Information vs Big
Knowledge, manakah diantara ke-3 hal tersebut yang lebih utama?
BAB 2 Analitik Big Data
& Lifecycle
2.1 Pengantar
Fakta-fakta terkait dengan kondisi existing Perusahaan:
Gambar 2.1 Daftar Perusahaan
Informasi apa saja yang bisa digali dari Big Data pada perusahaan di atas? Dan strategi apa saja yang bisa dilakukan dari masing-masing perusahaan di atas terkait Analitik Data.
- Advance Technology (Tools) Big Data
- Key Roles Kunci Sukses Proyek Analitik
- Lifecycle Analitik Data
2.2 Teknologi Advaced (Tools) Big Data
Teknologi yang digunakan dalam pentyimpanan (storage), pemrosesan (processing), dan analisis dari Big Data meliputi:
a. Dengan cepat menurunnya biaya penyimpanan dan daya CPU dalam beberapa tahun terakhir.
b. Fleksibilitas dan efektivitas biaya pusat data (datacenters) dan komputasi awan (cloud computing) untuk perhitungan dan penyimpanan elastis;
Gambar 2.2 Faktor yang mendorong (driving) adopsi Big Data
Beberapa tools yang dapat membantu untuk membuat query yang kompleks dan menjalankan algoritma dari machine learning di atas hadoop, meliputi:
- Pig (sebuah platform dan scripting language untuk complex queries)
- Hive (suatu SQL-friendly query language)
- Mahout dan RHadoop (data mining dan machine learning algorithms untuk Hadoop)
- Selain hadoop, terdapat frameworks baru seperti Spark yang didesain untuk meningkatkan efisiensi dari data mining dan algoritma pada machine learning pada hadoop, sehingga dapat digunakan secara berulang-ulang untuk mengerjakan pengolahan/ analitik secara mendalam dari kumpulan data
Dan juga terdapat beberapa database yang didesain untuk efisiensi peyimpanan dan query Big Data, meliput:
- MongoDB
- Cassandra
- CouchDB
- Greenplum Database
- HBase, MongoDB, dan
Pengolahan secara stream (Stream processing) yang artinya adalah pemrosesan data yang memiliki arus atau aliran data/informasi secara terus-menerus yang hampir setiap waktu ada data baru yang masuk dan butuh untuk dilakukan pengolahan terus-menerus pula. Stream processing tidak memiliki teknologi tunggal yang dominan seperti Hadoop, namun merupakan area untuk menumbuhkan penelitian menjadi lebih luas serta mendalam dan pengembangan lebih lanjut (Cugola & Margara 2012). Salah satu model untuk Stream processing adalah Complex Event Processing (Luckham 2002), yang menganggap arus informasi sebagai notifikasi kreasi atau indikasi akan munculnya peristiwa tertentu (melalui pola/pattern yang diidentifikasi) yang perlu digabungkan untuk menghasilkan pengetahuan akan adanya indikasi kejadian sangat penting atau tingkat tinggi (high-level events). Implementasi teknologi stream antara lainnya meliputi:
- InfoSphere Streams
- Jubatus, dan
- Storm
2.3 Arsitektur Big Data
Cara Terbaik untuk mendapatkan solusi dari Permasalahan Big Data (Big Data Solution) adalah dengan "Membagi Masalahnya". Big Data Solution dapat dipahami dengan baik menggunakan Layered Architecture. Arsitektur Layered dibagi ke dalam Lapisan yang berbeda dimana setiap lapisan memiliki spesifikasi dalam melakukan fungsi tertentu. Arsitektur tersebut membantu dalam merancang Data Pipeline (jalur data) dengan berbagai mode, baik Batch Processing System atau Stream Processing System. Arsitektur ini terdiri dari 6 lapisan yang menjamin arus data yang optimal dan aman.
mentah, dan semua datanya disimpan, tidak hanya data yang digunakan saja, tapi juga data yang mungkin digunakan di masa depan. Di Data Lake semua data tersimpan dalam bentuk aslinya.
Lapisan Kolektor Data (Data Collector Layer) - Di Lapisan ini, lebih fokus pada penyaluran data dari lapisan penyerapan atau pengambilan data awal (ingestion) ke jalur data yang lainnya. Pada Lapisan ini, data akan dipisahkan sesuai dengan kelompoknya atau komponen-komponennya (Topik: kategori yang ditentukan pengguna yang pesannya dipublikasikan, Produser - Produsen yang memposting pesan dalam satu topik atau lebih, Konsumen - berlangganan topik dan memproses pesan yang diposkan, Brokers - Pialang yang tekun dalam mengelola dan replikasi data pesan) sehingga proses analitik bisa dimulai. Tool yang dapat digunakan, yaitu Apache Kafka.
Gambar 2.3 Arsitektur Big Data
diarahkan dan ini adalah titik awal di mana analitik telah dilakukan. Data pipeline merupakan komponen utama dari Integrasi Data. Data pipeline mengalirkan dan mengubah data real-time ke layanan yang memerlukannya, mengotomatiskan pergerakan dan transformasi data, mengolah data yang berjalan di dalam aplikasi Anda, dan mentransformasikan semua data yang masuk ke dalam format standar sehingga bisa digunakan untuk analisis dan visualisasi. Jadi, Data pipeline adalah rangkaian langkah yang ditempuh oleh data Anda. Output dari satu langkah dalam proses menjadi input berikutnya. Langkah-langkah dari Data pipeline dapat mencakup pembersihan, transformasi, penggabungan, pemodelan dan banyak lagi, dalam bentuk kombinasi apapun. Tool yang dapat digunakan, yaitu Apache Sqoop, Apache Storm, Apache Spark, Apache Flink.
Lapisan Penyimpanan Data (Data Storage Layer) - Media penyimpanan menjadi tantangan utama, saat ukuran data yang digunakan menjadi sangat besar. Lapisan ini berfokus pada "tempat menyimpan data yang begitu besar secara efisien". Tool yang dapat digunakan, yaitu Apache Hadoop (HDFS), Gluster file systems (GFS), Amazon S3.
Lapisan Query Data (Data Query Layer) - lapisan ini merupakan tempat berlangsungnya pemrosesan secara analitik yang sedang dalam keadaaan aktif. Di sini, fokus utamanya adalah mengumpulkan data value sehingga dapat dibuat lebih bermanfaat dan mudah digunakan untuk lapisan berikutnya. Tool yang dapat digunakan, yaitu Apache Hive, Apache (Spark SQL), Amazon Redshift, Presto.
menemukan dan memfilter informasi saat Anda melihat data perusahaan atau berselancar di Internet dan tidak tahu di mana informasi yang tepat, “React.js” sebagai sistem recommender untuk memprediksi tentang kriteria pengguna, yaitu menentukan model penggunanya seperti apa.
Gambar 2.4 Data Integration Using Apache NiFi dan Apache Kafka
Gambar 2.5 Integrating Apache Spark dan NiFi for Data Lakes
dengan memasukkan data dalam satu kumpulan data besar di Hadoop.
2.4 Key Roles Kunci Sukses Proyek
Analitik
Gambar 2.6 Key Roles Kunci Sukses Proyek Analitik
Terdapat beberapa komponen Key roles: 1. Bussines User
Business User: Seseorang yang memahami wilayah domain
(kondisi existing) dan dapat mengambil manfaat besar dari hasil proyek analitik, dengan cara konsultasi dan menyarankan tim proyek pada scope proyek, hasil, dan operasional output (terkait dengan cara mengukur suatu variabel). Biasanya yang memenuhi peran ini adalah analis bisnis, manajer lini, atau ahli dalam hal pokok yang mendalam.
2. Project Sponsor
Project Sponsor: Bertanggung jawab terkait asal proyek.
Memberi dorongan, persyaratan proyek dan mendefinisikan masalah core bisnis. Umumnya menyediakan dana dan konsep pengukur tingkat nilai output akhir dari tim kerja. Menetapkan prioritas proyek dan menjelaskan output yang diinginkan.
3. Project Manager
Project Manager: Memastikan bahwa pencapaian utama
projek dan tujuan terpenuhi tepat waktu dan sesuai dengan kualitas yang diharapkan.
Business Intelligence Analyst: Menyediakan keahlian dalam domain bisnis berdasarkan pemahaman yang mendalam mengenai data, indikator kinerja utama (KPI), metrik kunci, dan intelijen bisnis dari perspektif pelaporan. Analis Business Intelligence umumnya membuat dashboard (panel kontrol) dan laporan dan memiliki pengetahuan tentang sumber data dan mekanismenya.
5. Database Administrator (DBA)
Database Administrator (DBA): Set up dan mengkonfigurasi database untuk mendukung kebutuhan analitik. Tanggung jawab ini mungkin termasuk menyediakan akses ke database keys atau tabel dan memastikan tingkat keamanan yang sesuai berada di tempat yang berkaitan dengan penyimpanan data.
6. Data Engineer
Data Engineer: Memilki keterampilan teknis yang mendalam
untuk membantu penyetelan query SQL untuk pengelolaan data dan ekstraksi data, dan mendukung untuk konsumsi data ke dalam sandbox analitik. Data Engineer melakukan ekstraksi data aktual dan melakukan manipulasi data yang cukup besar untuk memfasilitasi kebutuhan proyek analitik. Insinyur data (Data Engineer) bekerja sama dengan ilmuwan data (Data Scientist) untuk membantu membentuk data yang sesuai dengan cara yang tepat untuk analisis 7. Data Scientist
2.5 Lifecycle Analitik Data
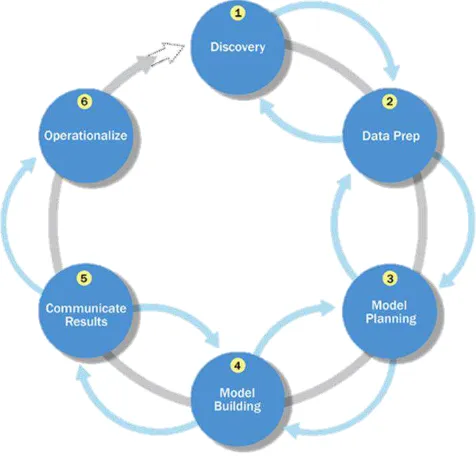
Gambar 2.7 Gambaran Umum dari Lifecycle Analitik Data
Dari gambaran umum lifecycle analitik yang ditunjukkan pada Gambar 2.3 dapat dilihat terdapat beberapa fase diantaranya se-bagai berikut:
1. Fase 1 Discovery
Pada tahap ini, tim lmuwan data (Data Scientist) harus belajar, mencari dan menyelidiki fakta-fakta, masalah (identifikasi problem base), mengembangkan konteks dan pemahaman, dan belajar tentang sumber data yang dibutuhkan dan yang telah tersedia untuk kesuksesan proyek analitik. Selain itu, tim merumuskan hipotesis awal yang nantinya dapat diuji dengan data.
Kegiatan penting dalam fase ini meliputi membingkai masalah bisnis sebagai tantangan analitik yang dapat dibahas dalam fase berikutnya dan merumuskan hipotesis awal (IHs) untuk menguji dan mulai mempelajari data.
2. Fase 2 Data Preparation
Tahap ini membutuhkan adanya sandbox analitik, di mana tim dapat bekerja dengan data dan melakukan analitik selama proyek tersebut. tim perlu melaksanakan proses ekstrak, load dan transformasi (ELT) atau ekstrak, transform dan load (ETL) untuk menyiapkan data ke sandbox.
ETLT adalah proses integrasi data untuk mentransfer data mentah dari server sumber ke sebuah gudang data pada server target dan kemudian menyiapkan informasi untuk keperluan hasil akhir.
Data Sandbox, dalam konteks Big Data, adalah platform terukur dan berkembang yang digunakan untuk mengeksplorasi informasi besar suatu perusahaan. Hal ini memungkinkan perusahaan untuk mewujudkan nilai investasi yang sebenarnya dalam Big Data.
Sebuah sandbox data, utamanya dieksplorasi oleh tim Data Scientist yang menggunakan platform sandbox stand-alone, misal untuk analitik data marts, logical partitions pada suatu media penyimpanan di perusahaan. platform Data sandbox menyediakan komputasi yang diperlukan bagi para ilmuwan Data (Data Scientist) untuk mengatasi beban kerja analitik yang biasanya kompleks. 3. Fase 3 Model Planning
Dalam tahap ini tim menentukan metode, teknik, dan alur kerja. Mereka berniat untuk mengikuti tahap pembentukan model berikutnya. Tim mengeksplorasi data untuk belajar tentang hubungan antara variabel dan kemudian memilih variabel kunci dan model yang paling cocok untuk digunakan.
4. Fase 4 Model Building
Selain itu, dalam fase ini tim membangun dan mengeksekusi model yang didasarkan pada kerja yang dilakukan di dalam fase Model Planning.
Tim juga mempertimbangkan apakah ini alat yang ada akan cukup untuk menjalankan model, atau jika itu akan membutuhkan lingkungan yang lebih robust untuk mengeksekusi model dan alur kerja (misalnya, hardware yang cepat, teknik dekomposisi data dan pemrosesan paralel, jika dapat diterapkan).
5. Fase 5 CommunicateResult
tim bekerja sama dengan pemangku kepentingan (stakeholders) utama, menentukan apakah hasil proyek tersebut sukses atau mengalami kegagalan berdasarkan kriteria yang dikembangkan di Fase 1.
Tim harus mengidentifikasi temuan kunci, mengukur nilai bisnis, dan mengembangkan narasi untuk meringkas dan menyampaikan temuan kepada para pemangku kepentingan.
6. Fase Operationalize
tim memberikan laporan akhir, pengarahan, kode, dan dokumen teknis. Selain itu, tim dapat menjalankan pilot project untuk menerapkan model dalam lingkungan produksi.
Pilot Project adalah sebuah studi percontohan, proyek percontohan atau studi pendahuluan skala kecil yang dilakukan untuk mengevaluasi kelayakan, waktu, biaya, efek samping, dan efek ukuran dalam upaya untuk memprediksi ukuran sampel yang tepat dan memperbaiki design penelitian sebelum kepada proyek penelitian skala penuh.
2.6 Tugas Kelompok
1. Jelaskan apa yang dimaksud dengan Data Sandbox pada konteks Big Data!
3. Jelaskan perbedaan antara Data Science dengan Data Engineer!
4. Dari beberapa macam “Key Roles Kunci Sukses Proyek
Anali-tik”, manakah 2 pekerjaan paling banyak dibutuhkan pada saat
ini, terutama diperusahaan besar?
5. Dari “Gambaran Umum dari Lifecycle Analitik Data”, Buatlah studi kasus dengan mengambil salah satu perusahaan besar yang ada di Indonesia atau perusahaan Asing di dunia untuk melakukan fase ke-1, yaitu Discovery. Berikan penjelasan detail terkait hasil penyelidikan anda dari:
a. Fakta-fakta (Analisis kondisi existing yang ada disana) b. Permasalahan yang ditemukan (identifikasi problem
base), yang membutuhkan teknik optimasi, pemodelan, prediksi (1. output berupa value, 2. supervised, atau 3. unsupervised), dan peramalan. c. Dari hasil penjabaran permasalahan pada point (b),
BAB 3 Teknologi dan Tools
Big Data (Bagian 1)
3.1 Konsep Pengolahan Big Data
Bayangkan ada sekumpulan data yang sangat besar (Big Data), bagaimana kita dapat melakukan Parallel atau Distributed Processing.
FileSistemTerdistribusi (DistributedFileSystem, atau disingkat dengan DFS) adalah file sistem yang mendukung sharing files dan resources dalam bentuk penyimpanan persistent (tetap) untuk tujuan tertentu di sebuah network.
3.2 Introduction to Hadoop
Hadoop: Suatu software framework (kerangka kerja perangkat
lunak) open source berbasis Java di bawah lisensi Apache untuk aplikasi komputasi data besar secara intensif.
Gambar 3.2 Ilustrasi Hadoop HDFS
HadoopFile System dikembangkan menggunakan desain sistem file yang terdistribusi. Tidak seperti sistem terdistribusi, HDFS sangat faulttolerant dan dirancang menggunakan hardwarelow-cost. Atau dalam arti lain, Hadoop adalah Software platform (platform perangkat lunak) sebagai analytic engine yang memungkinkan seseorang dengan mudah untuk melakukan pembuatan penulisan perintah (write) dan menjalankan (run) aplikasi yang memproses data dalam jumlah besar, dan di dalamnya terdiri dari:
- HDFS –Hadoop Distributed File System
- MapReduce –offline computing engine
Dalam komputasi, platform menggambarkan semacam (hardware architecture) arsitektur perangkat keras atau (software framework) kerangka kerja perangkat lunak (termasuk kerangka kerja aplikasi), yang memungkinkan perangkat lunak dapat berjalan. Ciri khas dari platform meliputi arsitekturnya komputer, sistem operasi, bahasa pemrograman dan runtimelibraries atau GUI yang terkait.
Apa yang ada pada Hadoop dari sudut pandang:
- Framework: HDFS Explorer, .. ?
3.2.1 Hadoop Distributed File System (HDFS)
Hadoop terdiri dari HDFS (Hadoop Distributed file System) dan Map Reduce. HDFS sebagai direktori di komputer dimana data hadoop disimpan. Untuk pertama kalinya, direktori ini akan di
“for-mat” agar dapat bekerja sesuai spesifikasi dari Hadoop. HDFS sebagai file system, tidak sejajar dengan jenis file system dari OS seperti NTFS, FAT32. HDFS ini menumpang diatas filesystem milik OS baik Linux, Mac atau Windows.
Data di Hadoop disimpan dalam cluster.
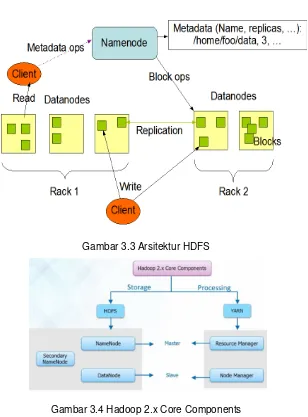
Cluster biasanya terdiri dari banyak node atau komputer/server. Setiap node di dalam cluster ini harus terinstall Hadoop untuk bisa jalan.
Hadoopversi 1.x ada beberapa jenis node di dalam cluster:
- Name Node: Ini adalah node utama yang mengatur penempatan data di cluster, menerima job dan program untuk melakukan pengolahan dan analisis data misal melalui Map Reduce. Name Node menyimpan metadata tempat data di cluster dan juga replikasi data tersebut.
- Data Node: Ini adalah node tempat data ditempatkan. Satu block di HDFS/data node adalah 64 MB. Jadi sebaiknya data yang disimpan di HDFS ukurannya minimal 64 MB untuk memaksimalkan kapasitas penyimpanan di HDFS.
- Secondary Name Node: Bertugas untuk menyimpan informasi penyimpanan data dan pengolahan data yang ada di name node. Fungsinya jika name node mati dan diganti dengan name node baru maka name node baru bisa langsung bekerja dengan mengambil data dari secondary name node.
Kelemahan HDFS di hadoop versi 1.x adalah jika name node mati. Maka seluruh cluster tidak bisa digunakan sampai name node baru dipasang di cluster.
Hadoop versi 2.x ada beberapa jenis node di dalam cluster:
- Lebih dari satu name nodes. Hal ini berfungsi sebagai implementasi dari High Availability. Hanya ada satu name node yang berjalan di cluster (aktif) sedangkan yang lain dalam kondisi pasif. Jika name node yang aktif mati/rusak, maka name node yang pasif langsung menjadi aktif dan mengambil alih tugas sebagai name node.
- Secondary name node, checkpoint node dan backup node tidak lagi diperlukan. Meskipun ketiga jenis node tersebut menjadi optional, tetapi kebanyakan tidak lagi ada di cluster yang memakai hadoop versi 2.x. Hal ini karena selain fungsi yang redundan, juga lebih baik mengalokasikan node untuk membuat tambahan name node sehingga tingkat High Availability lebih tinggi.
- Data node tidak ada perubahan yang signifikan di versi hadoop 2.x dari versi sebelumnya.
Gambar 3.3 Arsitektur HDFS
Gambar 3.4 Hadoop 2.x Core Components
3.2.2 MapReduce (MR)
Paradigma (pandangan mendasar) terkait MR:
- Model pemrograman yang dikembangkan Google, Sortir /