BAB 2
LANDASAN TEORI
2.1Clustering
Pada dasarnya clustering terhadap data adalah suatu proses untuk mengelompokkan
sekumpulan data tanpa suatu atribut kelas yang telah didefinisikan sebelumnya,
berdasarkan pada prinsip konseptual clustering yaitu memaksimalkan dan juga
meminimalkan kemiripan intra kelas. Misalnya, sekumpulan obyek-obyek komoditi
pertama-tama dapat di clustering menjadi sebuah himpunan kelas-kelas dan lalu
menjadi sebuah himpunan aturan-aturan yang dapat diturunkan berdasarkan suatu
klasifikasi tertentu.
Proses untuk mengelompokkan secara fisik atau abstrak obyek-obyek ke
dalam bentuk kelas-kelas atau obyek-obyek yang serupa, disebut dengan clustering
atau unsupervised classification. Melakukan analisa dengan clustering, akan sangat
membantu untuk membentuk partisi-partisi yang berguna terhadap sejumlah besar
himpunan obyek dengan didasarkan pada prinsip "divide and conquer" yang
mendekomposisikan suatu sistem skala besar, menjadi komponen-komponen yang
lebih kecil, untuk menyederhanakan proses desain dan implementasi. Perbedaan
utama antara Clustering Analysis dan klasifikasi adalah bahwa Clustering Analysis
digunakan untuk memprediksi kelas dalam format bilangan real dan pada format
katagorikal atau Boolean.
2.2Data Clustering
Data Clustering merupakan salah satu metode data miningyang bersifat tanpa arahan
(unsupervised). Ada dua jenis data clustering yang sering dipergunakan dalam proses
pengelompokan data yaitu hierarchical dataclustering dan non-hierarchical
dataclustering. K-Means merupakan salah satu metode data clustering non hirarki
yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih
data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster
yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke
dalam kelompok yang lain.
Adapun tujuan dari data clustering ini adalah untuk meminimalisasikan
objective function yang diset dalam proses clustering, yang pada umumnya berusaha
meminimalisasikan variasi di dalam suatu cluster dan memaksimalisasikan variasi
antar cluster. Data clustering menggunakan metode K-Means ini secara umum
dilakukan dengan algoritma dasar sebagai berikut:
1. Tentukan jumlah cluster
2. Alokasikan data ke dalam cluster secara random
3. Hitung centroid (rata-rata) dari data yang ada di masing-masing cluster
4. Alokasikan masing-masing data ke centroid (rata-rata) terdekat
5. Kembali ke Step 3, apabila masih ada data yang berpindah cluster atau apabila
perubahan nilai centroid, ada yang di atas nilai threshold yang ditentukan atau apabila
perubahan nilai pada objective function yang digunakan di atas nilai threshold yang
ditentukan.
2.2.1 Perkembangan Penerapan K-Means
Beberapa alternatif penerapan K-Means dengan beberapa pengembangan teori-teori
penghitungan terkait telah diusulkan. Hal ini termasuk pemilihan:
1. Distance space untuk menghitung jarak di antara suatu data dan centroid.
2. Metode pengalokasian data kembali ke dalam setiap cluster.
2.2.1.1Distance Space Untuk Menghitung Jarak Antara Data dan Centroid
Beberapa distance space telah diimplementasikan dalam menghitung jarak (distance)
antara data dan centroid termasuk di antaranya L1 (Manhattan/City Block) distance
space, L2 (Euclidean) distance space, dan Lp (Minkowski) distance space.
Jarak antara dua titik x1 dan x2 pada Manhattan/City Block distance space dihitung
dengan menggunakan rumus sebagai berikut:
……… (1)
dimana:
p : Dimensi data
| . | : Nilai absolut
Sedangkan untuk L2 (Euclidean) distance space, jarak antara dua titik dihitung
menggunakan rumus sebagai berikut:
--- (2)
dimana:
p : Dimensi data
Lp (Minkowski) distance space yang merupakan generalisasi dari beberapa distance
space yang ada seperti L1 (Manhattan/City Block) dan L2 (Euclidean), juga telah
diimplementasikan. Tetapi secara umum distance space yang sering digunakan adalah
Manhattan dan Euclidean. Euclidean sering digunakan karena penghitungan jarak
dalam distance space ini merupakan jarak terpendek yang bisa didapatkan antara dua
titik yang diperhitungkan, sedangkan Manhattan sering digunakan karena
kemampuannya dalam mendeteksi keadaan khusus seperti keberadaaan outliers
2.2.1.2Metode Pengalokasian Ulang Data ke Dalam Masing-Masing Cluster
Secara mendasar, ada dua cara pengalokasian data kembali ke dalam masing-masing
cluster pada saat proses iterasi clustering. Kedua cara tersebut adalah pengalokasian
dengan cara tegas (hard), dimana data item secara tegas dinyatakan sebagai anggota
cluster yang satu dan tidak menjadi anggota cluster lainnya, dan dengan cara fuzzy,
dimana masing-masing data item diberikan nilai kemungkinan untuk bisa bergabung
ke setiap cluster yang ada. Kedua cara pengalokasian tersebut diakomodasikan pada
dua metode Hard K-Means dan Fuzzy K-Means. Perbedaan di antara kedua metode ini
terletak pada asumsi yang dipakai sebagai dasar pengalokasian. Hard K-Means adalah
pengalokasian kembali data ke dalam masing-masing cluster dalam metode Hard
K-Means didasarkan pada perbandingan jarak antara data dengan centroid setiap cluster
yang ada. Data dialokasikan ulang secara tegas ke cluster yang mempunyai centroid
terdekat dengan data tersebut. Pengalokasian ini dapat dirumuskan sebagai berikut:
𝑎𝑖𝑘 =�
Metode Fuzzy K-Means atau lebih sering disebut sebagai Fuzzy C-Means,
mengalokasikan kembali data ke dalam masing-masing cluster dengan memanfaatkan
teori Fuzzy. Teori ini mengeneralisasikan metode pengalokasian yang bersifat tegas
(hard) seperti yang digunakan pada metode Hard K-Means. Dalam metode Fuzzy
K-Means dipergunakan variabel membership function, ik u , yang merujuk pada seberapa
besar kemungkinan suatu data bisa menjadi anggota ke dalam suatu cluster. Pada
Fuzzy K-Means yang diusulkan oleh Bezdek, diperkenalkan juga suatu variabel m
yang merupakan weighting exponent dari membership function. Variabel ini dapat
mengubah besaran pengaruh dari membership function, ik u , dalam proses clustering
menggunakan metode Fuzzy K-Means. m mempunyai wilayah nilai m>1. Sampai
sekarang ini tidak ada ketentuan yang jelas berapa besar nilai m yang optimal dalam
melakukan proses optimasi suatu permasalahan clustering. Nilai m yang umumnya
Membership function untuk suatu data ke suatu cluster tertentu dihitung menggunakan
rumus sebagai berikut:
……… (4)
dimana:
uik: Membership function data ke-k ke cluster ke-i
vi: Nilai centroid cluster ke-i
m : Weighting Exponent
Membership function, ik u , mempunyai wilayah nilai 0≤ ik u ≤1. Data item yang
mempunyai tingkat kemungkinan yang lebih tinggi ke suatu kelompok akan
mempunyai nilai membership function ke kelompok tersebut yang mendekati angka 1
dan ke kelompok yang lain mendekati angka 0.
2.2.1.3Objective Function Yang Digunakan
Objective function yang digunakan khususnya untuk Hard K-Means dan Fuzzy
K-Means ditentukan berdasarkan pada pendekatan yang digunakan dalam poin 2.1. dan
poin 2.2. Untuk metode Hard K-Means, objective function yang digunakan adalah
sebagai berikut:
……….. (5)
dimana:
N : Jumlah data
c : Jumlah cluster
u
ik: Keanggotaan data ke-k ke cluster ke-ivi: Nilai centroid cluster ke-i
a mempunyai nilai 0 atau 1. Apabila suatu data merupakan anggota suatu kelompok
maka nilai ik a =1 dan sebaliknya. Untuk metode Fuzzy K-Means, objective function
……… (6)
dimana:
N : Jumlah data
c
: Jumlah clusterm : Weighting exponent
u
ik: Membership function data ke-k ke cluster ke-iv
i: Nilai centroid cluster ke-iDi sini
u
ikbisa mengambil nilai mulai dari 0 sampai 1.2.3Beberapa Permasalahan yang Terkait Dengan K-Means
Beberapa permasalahan yang sering muncul pada saat menggunakan metode K-Means
untuk melakukan pengelompokan data adalah:
1. Ditemukannya beberapa model clustering yang berbeda
2. Pemilihan jumlah cluster yang paling tepat
3. Kegagalan untuk converge
4. Pendeteksian outliers
5. Bentuk masing-masing cluster
6. Masalah overlapping
Keenam permasalahan ini adalah beberapa hal yang perlu diperhatikan pada saat
menggunakan K-Means dalam mengelompokkan data. Permasalahan 1 umumnya
disebabkan oleh perbedaan proses inisialisasi anggota masing-masing cluster. Proses
initialisasi yang sering digunakan adalah proses inisialisasi secara random. Dalam
suatu studi perbandingan, proses inisialisasi secara random mempunyai
kecenderungan untuk memberikan hasil yang lebih baik dan independent, walaupun
dari segi kecepatan untuk converge lebih lambat.
Permasalahan 2 merupakan masalah laten dalam metode K-Means. Beberapa
pendekatan telah digunakan dalam menentukan jumlah cluster yang paling tepat untuk
Statistics. Satu hal yang patut diperhatikan mengenai metode-metode ini adalah
pendekatan yang digunakan dalam mengembangkan metode-metode tersebut tidak
sama dengan pendekatan yang digunakan oleh K-Means dalam mempartisi data item
ke masing-masing cluster. Permasalahan kegagalan untuk converge, secara teori
memungkinkan untuk terjadi dalam kedua metode K-Means. Kemungkinan ini akan
semakin besar terjadi untuk metode Hard K-Means, karena setiap data di dalam
dataset dialokasikan secara tegas (hard) untuk menjadi bagian dari suatu cluster
tertentu. Perpindahan suatu data ke suatu cluster tertentu dapat mengubah
karakteristik model clustering yang dapat menyebabkan data yang telah dipindahkan
tersebut lebih sesuai untuk berada di cluster semula sebelum data tersebut
dipindahkan dan demikian juga dengan keadaan sebaliknya. Kejadian seperti ini tentu
akan mengakibatkan pemodelan tidak akan berhenti dan kegagalan untuk converge
akan terjadi. Untuk Fuzzy K-Means walaupun ada, kemungkinan permasalahan ini
untuk terjadi sangatlah kecil, karena setiap data diperlengkapi dengan membership
function (Fuzzy K-Means) untuk menjadi anggota cluster yang ditemukan.
Permasalahan 4 merupakan permasalahan umum yang terjadi hampir di setiap
metode yang melakukan pemodelan terhadap data. Khusus untuk metode K-Means hal
ini memang menjadi permasalahan yang cukup menentukan. Beberapa hal yang perlu
diperhatikan dalam melakukan pendeteksian outliers dalam proses pengelompokan
data termasuk bagaimana menentukan apakah suatu data item merupakan outliers dari
suatu cluster tertentu dan apakah data dalam jumlah kecil yang membentuk suatu
cluster tersendiri dapat dianggap sebagai outliers. Proses ini memerlukan suatu
pendekatan khusus yang berbeda dengan proses pendeteksian outliers di dalam suatu
Permasalahan kelima adalah menyangkut bentuk cluster yang ditemukan.
Tidak seperti metode data clustering lainnya termasuk Mixture Modelling, K-Means
umumnya tidak mengindahkan bentuk dari masing-masing cluster yang mendasari
model yang terbentuk, walaupun secara alamiah masing-masing cluster umumnya
berbentuk bundar. Untuk dataset yang diperkirakan mempunyai bentuk yang tidak
biasa, beberapa pendekatan perlu untuk diterapkan.
Masalah overlapping sebagai permasalahan terakhir sering sekali diabaikan karena
umumnya masalah ini sulit terdeteksi. Hal ini terjadi untuk metode Hard K-Means dan
Fuzzy K-Means, karena secara teori metode ini tidak diperlengkapi feature untuk
mendeteksi apakah di dalam suatu cluster ada cluster lain yang kemungkinan
tersembunyi.
K-Means merupakan metode data clustering yang digolongkan sebagai metode
pengklasifikasian yang bersifat unsupervised (tanpa arahan). Pengkategorian
metode-metode pengklasifikasian data antara supervised dan unsupervised classification
didasarkan pada adanya dataset yang data itemnya sudah sejak awal mempunyai label
kelas dan dataset yang data itemnya tidak mempunyai label kelas. Untuk data yang
sudah mempunyai label kelas, metode pengklasifikasian yang digunakan merupakan
metode supervised classification dan untuk data yang belum mempunyai label kelas,
metode pengklasifikasian yang digunakan adalah metode unsupervised classification.
Selain masalah optimasi pengelompokan data ke masing-masing cluster, data
clustering juga diasosiasikan dengan permasalahan penentuan jumlah cluster yang
paling tepat untuk data yang dianalisa. Untuk kedua jenis K-Means, baik Hard
K-Means dan Fuzzy K-Means, yang telah dijelaskan di atas, penentuan jumlah cluster
untuk dataset yang dianalisa umumnya dilakukan secara supervised atau ditentukan
dari awal oleh pengguna, walaupun dalam penerapannya ada beberapa metode yang
sering dipasangkan dengan metode K-Means. Karena secara teori metode penentuan
jumlah cluster ini tidak sama dengan metode pengelompokan yang dilakukan oleh
Melihat keadaan dimana pengguna umumnya sering menentukan jumlah
cluster sendiri secara terpisah, baik itu dengan menggunakan metode tertentu atau
berdasarkan pengalaman, di sini kedua metode K-Means ini dapat disebut sebagai
metode semi-supervised classification, karena metode ini mengalokasikan data item
ke masing-masing cluster secara unsupervised dan menentukan jumlah cluster yang
paling sesuai dengan data yang dianalisa secara supervised.
2.4K-Means untuk Data yang Mempunyai Bentuk Khusus
Beberapa dataset yang mempunyai bentuk tertentu memerlukan suatu metode
pemecahan khusus yang disesuaikan dengan keadaan data tersebut. Gambar 2.2.
mengilustrasikan suatu dataset yang mempunyai bentuk khusus yang kalau dimodel
dengan metode K-Means, baik Hard K-Means dan Fuzzy K-Means akan memberikan
hasil yang tidak mewakili keadaan dataset tersebut. Untuk keperluan seperti itu,
beberapa peneliti telah mengusulkan pengembangan metode K-Means yang secara
khusus memanfaatkan kernel trik, dimana data space untuk data awal di-mapping ke
feature space yang berdimensi tinggi. Beberapa hal yang perlu diperhatikan dalam
pengembangan metode K-Means dengan kernel trik ini adalah bahwa data pada
feature space tidak lagi dapat didefinisikan secara eksplisit, sehingga penghitungan
Beberapa trik penghitungan telah diusulkan dalam menurunkan nilai kedua
variabel yang diperlukan tersebut. Dengan penerapan trik perhitungan terhadap kedua
variabel tersebut, objective function yang digunakan dalam menilai apakah suatu
proses pengelompokan sudah converge atau tidak juga akan berubah.
Sumber: Agusta, 2006
Gambar 2.1 Salah Satu Dataset yang Mempunyai Bentuk Khusus
2.5Berat Badan Ideal
Berat badan ideal sangat berpengaruh terhadap kondisi kesehatan tubuh manusia.
Seseorang yang memiliki berat badan ideal, akan lebih kecil kemungkinannya untuk
terserang penyakit dibandingkan dengan orang yang memiliki berat badan yang tidak
ideal (Hartono, 2006).
Ada beberapa faktor yang mempengaruhi ideal atau tidaknya berat tubuh
seseorang. Adapun faktor-faktor tersebut adalah:
1. Keseimbangan Asupan Nutrisi
Manusia membutuhkan nutrisi yang seimbang untuk menjaga kondisi tubuhnya
agar tetap fit. Asupan nutrisi ini diperoleh dari makanan dengan kadar yang
Kekurangan nutrisi akan menyebabkan kinerja organ-organ tubuh menurun yang
mengakibatkan tubuh seseorang rentan terhadap serangan penyakit, karena
tubuhnya tidak mampu memproteksi diri dari serangan yang terjadi. Sebaliknya,
nutrisi yang berlebihan dalam tubuh menyebabkan berat tubuh naik secara drastis.
Hal ini diakibatkan oleh nutrisi yang masuk lebih besar daripada nutrisi yang
dibutuhkan, sehingga tubuh tidak dapat menyerap seluruh nutrisi tersebut yang
mana sisanya akan menjadi timbunan lemak dalam tubuh.
2. Aktivitas Gerakan Tubuh
Tubuh manusia terdiri dari jutaan sel yang selalu aktif setiap hari menyokong
sistem organ tubuh manusia. Agar sel ini selalu dalam kondisi yang baik,
sel-sel ini harus sering diaktifkan dengan cara menggerakkan tubuh secara aktif.
Salah satu aktivitas yang cocok untuk mengaktifkan gerakan tubuh adalah dengan
melakukan olah raga, karena dengan melakukan olah raga, selain mengaktifkan
sel-sel di dalam tubuh, timbunan lemak juga akan berkurang, karena dibakar
sebagai bahan bakar dari aktivitas olah raga yang dilakukan.
3. Gaya Hidup dan Pola Makan
Gaya hidup yang kita terapkan sehari-hari sangat berpengaruh terhadap ideal atau
tidaknya berat badan kita. Merokok, minum minuman keras akan membawa efek
samping yang serius bagi sel-sel tubuh ynag selanjutnya akan mengakibatkan berat
LLB TB UK= 2.5.1 Ukuran Kerangka
Untuk menentukan ukuran kerangka tubuh, dilakukan pengukuran lingkar
pergelangan tangan dengan pita meteran serta nilai tinggi badannya. Untuk
menghitung nilai ukuran kerangka manusia, dapat dilihat dari ukuran lingkar lengan
bawahnya sebagaimana terlihat pada Gambar 2.3. Untuk menghitung nilai ukuran
kerangka manusia, dapat dilihat dari ukuran lingkar lengan bawahnya.(Hartono,
2006).
Gambar 2.2 Lingkar Lengan Bawah
Rumus untuk menghitung ukuran kerangka manusia seperti ditunjukkan pada
persamaan berikut :
………. (7)
Dimana :
UK = Ukuran Kerangka
TB = Nilai Tinggi Badan
LLB = Ukuran Lingkar Lengan Bawah
Setelah ukuran kerangka diperoleh, untuk menentukan apakah ukuran
kerangka manusia tersebut termasuk kategori kecil sedang atau besar ditentukan
dengan melihat jenis kelamin dan nilai ukuran kerangkanya berdasarkan aturan yang
ditunjukkan pada Tabel 2.1.
2 TB
BB BMI=
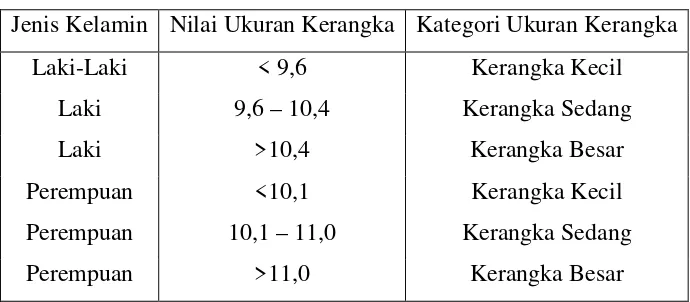
Tabel 2.1 Aturan Kategori Ukuran Kerangka
Jenis Kelamin Nilai Ukuran Kerangka Kategori Ukuran Kerangka
Laki-Laki < 9,6 Kerangka Kecil
Laki 9,6 – 10,4 Kerangka Sedang
Laki >10,4 Kerangka Besar
Perempuan <10,1 Kerangka Kecil
Perempuan 10,1 – 11,0 Kerangka Sedang
Perempuan >11,0 Kerangka Besar
Sumber: Terapi Gizi & Diet Rumah Sakit, Hartono, 2006.
2.5.2 BMI (Body Mass Index)
BMI (Body Mass Index) merupakan suatu pengukuran yang membandingkan berat
badan dengan tinggi badan. BMI merupakan teknik untuk menghitung index berat
badan, sehingga dapat diketahui kategori tubuh kita apakah tergolong kurus, normal
atau gemuk. BMI dapat digunakan untuk mengontrol berat badan sehingga dapat
mencapai berat badan normal yang sesuai dengan tinggi badan (Judic, 2009).
Dalam menghitung BMI diperlukan dua parameter, yaitu berat badan (kg) dan
tinggi badan (cm). BMI dapat dihitung dengan menggunakan persamaan berikut :
……… (8)
Dimana :
BMI = Nilai body mass index
BB = Berat badan dalam kilogram
TB = Tinggi Badan dalam centimeter.
Untuk mengukur apakah berat badan seseorang ideal atau tidak, dapat
dilakukan dengan melihat nilai BMI (Body Mass Index) tubuhnya dan
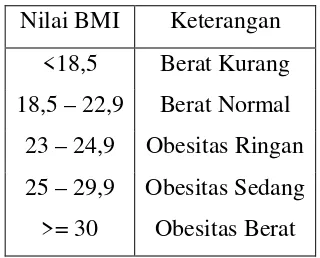
Tabel 2.2 Aturan Perhitungan Berat Badan Ideal
Nilai BMI Keterangan
<18,5 Berat Kurang
18,5 – 22,9 Berat Normal
23 – 24,9 Obesitas Ringan
25 – 29,9 Obesitas Sedang
>= 30 Obesitas Berat
Sumber: Terapi Gizi & Diet Rumah Sakit, Hartono, 2006.
Batas ambang BMI ditentukan dengan merujuk ketentuan FAO/WHO, yang
membedakan batas ambang untuk laki-laki dan perempuan. Disebutkan bahwa batas
ambang normal untuk laki-laki adalah 20,1 – 25,0 dan perempuan adalah 18,7 – 23,8.
Untuk kepentingan monitoring dan tingkat defesiensi kalori ataupun tingkat
kegemukan, lebih lanjut FAO/WHO menyarankan menggunakan satu batas ambang
antara laki-laki dan perempuan. Ketentuan yang digunakan adalah menggunakan
ambang batas laki-laki untuk kategori kurus tingkat berat danmenggunakan ambang
batas pada perempuan untuk kategori gemuk tingkat berat. Untuk kepentingan
Indonesia, batas ambang dimodifikasi lagi berdasarkan pengalaman klinis dan hasil
penelitian dibeberapa negara berkembang.
2.5.3 BMR (Basal Metabolic Rate)
BMR (Basal Metabolic Rate) adalah kebutuhan kalori minimum yang
diperlukan untuk mempertahankan hidupsi individu dalam keadaan istirahat. Hal ini
dapat dilihat sebagai jumlah energi (diukur dalam kalori) dikeluarkan oleh tubuh
dalam keadaan statis tanpa aktifitas.
BMR bertanggung jawab atas pembakaran hingga 70% dari total yang kalori
yang dikeluarkan, namun angka ini bervariasi berdasarkan faktor-faktor berikut ini :
• Genetika
Beberapa orang dilahirkan dengan metabolime yang berbeda-beda.
Pria yang notabennya memiliki massa otot yang lebih besar dan presentase
lemak tubuh yang rendah berarti mereka memiliki BMR yang lebih rendah
dibanding wanita.
• Usia
Semakin bertambah usia seseorang maka semakin rendah nilai BMR yang
mereka butuhkan. Turun setelah berusia diatas 20 tahun. Turun sekitar 2%
selama kurun waktu 10 tahun.
• BMI
BMI seseorang juga menjadi faktor besar dari kebutuhan BMR seseorang.
Semakin gemuk seseorang, maka tinggi pula BMR orang tersebut.
• Aktifitas & Olahraga
Aktifitas atau latihan fisik seseorang tidak hanya mempengaruhi berat badan
dan pembakaran kalori saja, tapi juga berpengaruh kepada nilai BMR seorang
pasien.
Rumus BMR sendiri menggunakan variabel usia, tinggi badan, berat badan
dan jenis kelamin. Rumus ini lebih akurat daripada menghitung kebutuhan kalori
berdasarkan berat badan saja.
BMR pasien dapat dihitung melalui rumus berikut ini, dan dibedakan
berdasarkan jenis kelamin:
BMR (wanita) = 655 + (9,6 x BB) + (1,8 x TB - (4,7 x U)
BMR (pria) = 66 + (13,7 x BB) + (5 x TB - (6,8 x U)…………..(9)
Dimana :
BB = Berat badan dalam kilogram
TB = Tinggi Badan dalam centimeter
Setelah kita mendapatkan hasil BMR pasien, kita harus menghitung kebutuhan kalori
harian dengan menggunakan Persamaan Harris Benedict, sebagai berikut :
Kelompok 1 : Tidak berolah raga
Kebutuhan Kalori Harian = BMR x 1.2
Kelompok 2 : Berolah raga ringan (1-3 kali seminggu)
Kebutuhan Kalori Harian = BMR x 1.375
Kelompok 3 : Berolah raga sedang (3-5 kali seminggu)
Kebutuhan Kalori Harian = BMR x 1.55
Kelompok 4 : Berolah raga berat (6-7 kali seminggu)
Kebutuhan Kalori Harian = BMR x 1.725
Kelompok 5 : Berolah raga berat dan sangat aktif
Kebutuhan Kalori Harian = BMR x 1.9………(10)
2.5.4 Manfaat Mengetahui BMI& BMR
Dengan mengetahui nilai BMI seseorang maka dapat diketahui apakah termasuk
kategori kurang berat badan, normal atau kelebihan berat atau obesitas (kegemukan).
Resiko penyakit yang berhubungan dengan derajat kegemukan seperti penyakit
jantung, kencing manis bahkan stroke dapat dilihat dari nilai BMI yang dihasilkan.
Nilai BMI dipengaruhi oleh usia namun sama pada kedua jenis kelamin. Nilai BMI
dapat tidak sesuai pada derajat kegemukan dari populasi yang berbeda, dalam
hubungannya dengan perbedaan proporsi tubuh. Sebagai contoh, ada orang Amerika
dan orang Asia yang memiliki nilai BMI yang sama. Namun dilihat dari kenyataan,
orang Asia tersebut memiliki proporsi massa lemak yang lebih banyak dari pada
massa otot dibandingkan dengan orang Amerika.
Berdasarkan penelitian di bidang kesehatan, dengan mengetahui dan
mengontrol nilai BMI, seseorang dapat mengurangi resiko penyakit 35 – 55 %
dibandingkan orang yang tidak mengetahui berapa nilai BMI untuk standar ideal
tubuhnya. Jadi dengan mengetahui cara menghitung BMI, seseorang dapat mengontrol
diet makanannya sehari-hari berdasarkan kandungan gizi yang dibutuhkan tubuh
Sedangkan dengan mengetahui nilai BMR seseorang yang artinya kita dapat
mengetahui jumlah kalori yang dibutuhkan untuk menjaga berat badan ideal. Kita
dapat dengan mudah menghitung jumlah kalori yang kita butuhkan untuk menurunkan
dan menaikkan berat badan sesuai dengan kondisi ideal yang kita inginkan.
2.6Penelitian Terkait
Penelitian oleh Tedy Rismawan dan Sri Kusumadewi yang berjudul Aplikasi K-Means
untuk Pengelompokkan Mahasiswa Berdasarkan Nilai Body Mass Index (BMI) dan
Ukuran Kerangka dilakukan proses pengelompokkan 20 data sampel menjadi 3
kelompok berdasarkan nilai BMI dan ukuran kerangka. Ketiga kelompok tersebut
adalah BMI normal dan kerangka besar, BMI obesitas sedang dan kerangka sedang,
BMI obesitas berat dan kerangka kecil. Pengelompokkan tersebut berdasarkan status
gizi dan ukuran kerangka dengan memasukkan parameter kondisi fisik dari orang
tersebut. Algoritma k-means dimulai dengan menetapkan nilai-nilai pusat dari cluster
atau biasa disebut dengan centroid atau meanssecara acak. Selanjutnya dihitung jarak
setiap data yang ada terhadap masing-masing centroid menggunakan rumus Euclidian
hingga ditemukan jarak yang paling dekat dari setiap data dengan centroid. Setelah
itu, setiap data diklasifikasikan berdasarkan kedekatannya dengan centroid. Proses
perhitungan jarak setiap data terhadap masing-masing centroid dilakukan terus hingga
nilai centroid tidak mengalami perubahan (Rismawan, 2008).
Penelitian lainnya oleh Dadan Saepulloh yang berjudul Analisis Data Mining
K-Means Cluster Analysis untuk Data Berjenis Biner dilakukan proses
pengelompokkan rumah tangga sasaran (RTS) bantuan langsung tunai (BLT).
Penelitian ini menggabungkan algoritma K-Means Clusteringdenganmetode
perhitungan tingkat similaritas seperti Jaccard similarity, Anderberg similarity,
Czekanowsky similarity, dan Kulczynski similarity. Algoritma K-Means Cluster
Analysis mempergunakan metode perhitungan jarak untuk mengukur tingkat
kedekatan antara data dengan titik tengah dengan Euclidean distance. Untuk data yang
berjenis biner, metode perhitungan jarak ini menjadi tidak tepat diterapkan secara
langsung sehingga perlu dilakukan perubahan yaitu dengan cara mempergunakan