BAB 2 KAJIAN PUS TAKA 2.1. Data Mining
Dalam membuat sebuah keputusan bisnis, dibutuhkan sejumlah pengetahuan mengenai kondisi pasar sehingga keputusan bisnis tersebut dapat menghasilkan perkembangan yang bermanfaat dan menguntungkan bagi perusahaan. Pengetahuan ini dapat diperoleh dengan cara melakukan analisis terhadap data-data yang telah ada.
Pada awalnya, data mining hadir dengan dilatarbelakangi dengan masalah pembengkakan data yang dialami oleh organisasi. Dengan adanya data yang terus menerus bertambah setiap harinya, lama kelamaan data tersebut akan menjadi bertumpuk dan tidak menghasilkan sesuatu yang berguna. Oleh karena itu muncullah sebuah pemikiran untuk “menambang” emas (informasi) dengan memanfaatkan data dalam jumlah banyak tersebut.
Berdasarkan pendapat Han dan Kamber (2006, p5) data mining dapat didefinisikan sebagai proses mengekstrak atau menambang pengetahuan yang dibutuhkan dari sejumlah besar data. Pada prosesnya data mining akan mengekstrak informasi yang berharga dengan cara menganalisis adanya pola-pola ataupun hubungan keterkaitan tertentu dari data-data yang berukuran besar.
Data mining sering kali disamakan dengan Knowledge Discovery Data (KDD), akan tetapi sebenarnya data mining merupakan salah satu langkah yang penting dalam penemuan pengetahuan itu sendiri. Proses penemuan pengetahuan meliputi tujuh langkah (Han dan Kember, 2006, p7), sebagai berikut:
2. Data integration (menggabungkan data dari berbagai sumber data). 3. Data selection (memilih data yang relevan dengan analisis).
4. Data transformation (transformasi atau konsolidasi data ke dalam bentuk yang tepat untuk mining).
5. Data mining (mengekstrak pola data dengan mengaplikasikan metode intelijen). 6. Pattern evaluation (mengidentifikasi pola menarik dan merepresentasikan basis
pengetahuan).
7. Knowledge presentation (penggunaan teknik representasi visual untuk menyajikan pengetahuan yang telah diperoleh kepada user).
Langkah 1 hingga 4 merupakan bentuk dari data preprocessing. Data preprocessing ini dibutuhkan dikarenakan data yang ada pada umumnya sering kali tidak konsisten, memiliki noise, atau terdapat bagian dari data yang hilang. M elalui data preprocessing, data yang ada kemudian dapat dipergunakan untuk menghasilkan pengetahuan yang akurat melalui tahap data mining.
Pada dasarnya data mining digunakan untuk menyelesaikan tugas yang berkaitan dengan masalah prediktif dan deskriptif. Pada tugas prediktif, sejumlah variabel akan digunakan untuk memprediksikan nilai yang belum diketahui dari variabel lainnya, sedangkan untuk tugas deskriptif, akan dilakukan penginterpretasian pola untuk mendeskripsikan data tersebut.
Dari kedua jenis tugas di atas, Berry dan Linnof (2004, p8-p12) kemudian membagi menjadi beberapa jenis tugas-tugas yang lebih detail, di antaranya adalah klasifikasi, estimasi, prediksi, affinity grouping, clutering, dan description and profilling. Berikut ini merupakan penjelasan dari masing-masing tugas tersebut:
1. Klasifikasi
Klasifikasi merupakan proses menemukan sebuah model atau fungsi yang mendeskripsikan dan membedakan data ke dalam kelas-kelas atau konsep-konsep. Klasifikasi melibatkan proses pemeriksaan karakteristik dari objek dan memasukkan objek ke dalam salah satu kelas yang sudah didefinisikan sebelumnya. Sebagai contoh, sebuah bank ingin menganalisis data pengaju dana pinjaman apakah peminjam dana tersebut masuk ke dalam kategori beresiko dalam artian dana yang dipinjamkan akan sulit dikembalikan atau dalam kategori aman, mengkategorikan apakah sebuah sel tumor termasuk dalam kategori ganas atau jinak, dan lain-lain.
2. Estimasi
Estimasi digunakan untuk memprediksikan hasil keluaran berupa sebuah nilai kontinu. Estimasi juga sering digunakan untuk melakukan tugas klasifikasi. Contoh penggunaan data mining untuk tugas estimasi adalah memperkirakan minimum, maksimum, dan rata-rata temperatur harian (Kotsiantis, 2007).
3. Prediksi
Prediksi memiliki kemiripan dengan klasifikasi, akan tetapi data
diklasifikasikan berdasarkan perilaku atau nilai yang diperkirakan pada masa yang akan datang. Contoh dari tugas prediksi misalnya untuk memprediksikan adanya pengurangan jumlah pelanggan dalam waktu dekat.
4. Affinity grouping
Affinity group digunakan untuk menentukan hal-hal yang terjadi bersamaan. Affinity group disebut juga dengan dependency modeling. Affinity
data. Sebagai contoh sebuah retail ingin merencanakan pengaturan tampilan katalog, maka produk-produk yang sering dibeli pada waktu yang bersamaan akan ditampilkan bersama-sama. Affinity group juga dapat digunakan untuk mengidentifikasi kesempatan cross-selling.
5. Pengelompokan (Clustering)
Clustering merupakan proses untuk melakukan segmentasi atas sebuah populasi yang heterogen menjadi sub kelompok atau cluster yang homogen. Berbeda dengan klasifikasi dan prediksi, clustering membagi objek data tanpa mengetahui jumlah label kelas.
Cluster dapat digunakan untuk menghasilkan label-label. Objek-objek dikelompokkan berdasarkan prinsip maksimalisasi kemiripan dalam satu kelas dan minimalisasi kemiripan antar kelas. Kelak sebuah cluster akan memiliki tingkat kemiripan yang tinggi dan berbeda jauh dari objek pada cluster lainnya.
Contoh penggunaan dari tugas clustering antara lain untuk
mengelompokkan protein dengan fungsi yang sama atau pengelompokkan stok saham yang memiliki fluktuasi sama.
6. Description and Profilling
Tujuan dari penggunaan data mining untuk menyelesaikan tugas
deskripsi adalah untuk mendeksripsikan apa yang terjadi pada sebuah database yang dimiliki. Dengan demikian diharapkan pemahaman mengenai pelanggan, produk atau jasa, penjualan, dapat ditingkatkan.
2.2. Peramalan (Forecasting)
Terdapat beberapa faktor yang memegang peranan penting dalam kesuksesan suatu perusahaan atau organisasi seperti waktu, sumber daya, dan biaya. Namun demikian, untuk dapat menentukan seberapa banyak waktu, sumber daya, ataupun biaya yang dibutuhkan merupakan hal yang sulit dilakukan karena situasi pasar yang senantiasa berubah-ubah menimbulkan ketidakpastian.
Tujuan diadakannya peramalan atau forecasting adalah untuk meminimalisasi resiko serta faktor ketidakpastian tersebut. Dengan adanya hasil peramalan, diharapkan tindakan atau keputusan dari suatu perusahaan dapat memberi dampak lebih baik pada jangka yang akan datang.
Oleh karena itu, peramalan dapat dikatakan sebagai bagian awal dari suatu proses pengambilan suatu keputusan. Namun, sebelum melakukan peramalan harus diketahui terlebih dahulu apa sebenarnya persoalan dasar dalam pengambilan keputusan itu.
Peramalan atau forecasting sendiri dapat didefinisikan sebagai suatu proses memperkirakan apa yang akan terjadi di masa yang akan datang, dengan melihat pola–pola yang terbentuk dari fakta–fakta yang sudah ada sebelumnya.
2.2.1. Sifat Peramalan
Dalam melakukan peramalan, terdapat beberapa sifat peramalan yang harus dipertimbangkan, yaitu:
a) Peramalan pasti mengandung unsur kesalahan, artinya peramalan hanya dapat mengurangi unsur ketidakpastian yang akan terjadi, namun tidak untuk menghilangkan unsur ketidakpastian tersebut.
b) Peramalan seharusnya memberikan informasi mengenai seberapa besar ukuran kesalahan dari model peramalan yang telah dibentuk, sehingga pengguna dapat mengetahui kurang lebih jumlah akurasi peramalan tersebut untuk kemudian pengguna dapat menentukan tindakan selanjutnya berdasarkan pada hasil peramalan.
c) Peramalan jangka pendek memiliki akurasi yang lebih baik daripada peramalan jangka panjang. Hal ini disebabkan karena pada peramalan jangka pendek, faktor yang mempengaruhi relatif masih konstan sedangkan pada semakin panjang periode peramalan, maka semakin besar kemungkinan terjadinya perubahan faktor-faktor yang mempengaruhi peramalan.
2.2.2. Metode Peramalan
Berdasarkan rentang waktu pada peramalan, peramalan dapat diklasifikasikan menjadi tiga kategori:
1. Peramalan jangka pendek
Peramalan jangka pendek mencakup jangka waktu 3 hingga 6 bulan. Peramalan dengan jangka pendek umumnya memiliki ketepatan yang lebih tepat, dikarenakan faktor-faktor yang mempengaruhi hasil peramalan cenderung berubah setiap harinya. Contoh penggunaan peramalan jangka pendek adalah untuk perencanaan produksi, distribusi dan penjadwalan kerja.
Peramalan jangka menengah mencakup jangka waktu lebih dari 6 bulan hingga 2 tahun. Contoh penggunaan peramalan jangka menengah adalah untuk penyewaan lokasi dan peralatan, perencanaan anggaran kas, dan perencanaan anggaran produksi.
3. Peramalan jangka panjang.
Peramalan jangka panjang mencakup jangka waktu lebih dari 2 tahun. Contoh penggunaan peramalan jangka panjang adalah untuk penelitian dan pengembangan untuk akuisisi dan merger dan perencanaan pembuatan produk baru.
Tabel 2.1 Rentang Waktu dalam Peramalan Rentang Waktu Tipe Keputusan Contoh Jangka Pendek ( 3 – 6 bulan) Operasional Perencanaan Produksi, Distribusi Jangka M enengah ( 2 tahun) Taktis
Penyewaan Lokasi dan Peralatan
Jangka Panjang (Lebih dari 2 tahun)
Strategis
Penelitian dan
Pengembangan untuk akuisisi dan merger Atau pembuatan produk baru
Sedangkan berdasarkan cara peramalan dilakukan, terdapat dua klasifikasi dari metode peramalan yang ada, antara lain:
M etode ini digunakan tanpa adanya model matematik karena data yang ada dinilai kurang representatif untuk dapat digunakan meramalkan masa yang akan datang. Peramalan kualitatif didasarkan pada penilaian dan pertimbangan pendapat dari para ahli pada bidangnya.
Kelebihan dari penggunaan peramalan dengan metode ini adalah cepat diperoleh serta biaya yang dikeluarkan relatif lebih murah karena tidak perlu menggunakan data. Akan tetapi, kekurangan metode ini adalah dinilai kurang ilmiah dan bersifat subjektif dalam artian hasil dari peramalan sangat bergantung kepada orang yang menyusunnya. Salah satu metode peramalan kualitatif yang cukup sering digunakan adalah metode Delphi.
Pada metode Delphi, sekelompok pakar akan mengisi kuisioner, moderator kemudian membuat simpulan dari hasil pengisian tersebut dan menformulasikan menjadi sebuah kuisioner baru yang kemudian akan diisi kembali oleh kelompok tersebut. Hal tersebut akan diulangi seterusnya dalam beberapa tahap yang berulang.
2. M etode kuantitatif
Peramalan kuantitatif dapat didefinisikan sebagai suatu metode peramalan yang didasarkan atas data kuantitatif pada masa lalu. Peramalan kuantitatif hanya dapat digunakan apabila terdapat informasi mengenai data masa lalu, informasi tersebut juga harus dapat diwujudkan dalam bentuk angka serta dapat diasumsikan bahwa pola masa lalu akan berlanjut ke masa yang akan datang.
Berdasarkan pola pendekatan digunakan untuk memprediksikan hasil peramalan metode kuantitatif dapat diklasifikasikan menjadi dua jenis, yaitu:
1) Deret Waktu (Time Series)
Data time series dapat didefinisikan sebagai data yang sudah
dikumpulkan ataupun diobservasi berdasarkan urutan waktu, yang bertujuan untuk menemukan bentuk pola variasi umum dari data di masa lampau, sehingga dapat digunakan untuk melakukan peramalan terhadap sifat–sifat data di masa yang datang.
Peramalan dengan metode time series mendasarkan pada pola hubungan variabel yang ingin dicari dengan variabel waktu yang dapat mempengaruhi variabel lainnya. Dalam metode time series diperlukan mencari alur pola yang bisa didapat dari melihat pergerakan data dari waktu ke waktu, sehingga pola tersebut dapat digunakan untuk masa yang akan datang.
Terdapat empat komponen utama yang mempengaruhi analisis dengan menggunakan metode ini, antara lain:
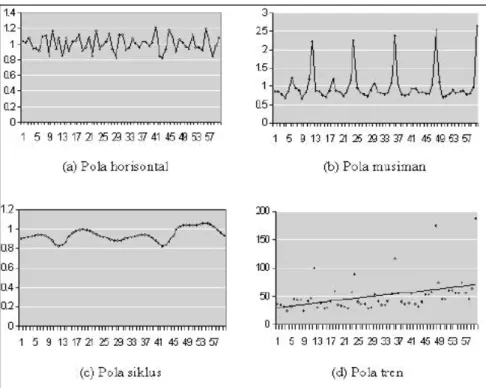
a) Pola Horizontal atau Stationer
Data deret waktu pada pola ini bersifat stationer atau dapat dikatakan memiliki nilai kenaikan dan penurunan yang berkisar pada nilai rata-rata. Hal ini disebabkan pola permintaan yang mempengaruhi data relatif stabil.
Sesuai dengan musim, pola ini menggambarkan data yang berulang setiap periode waktu tertentu, umumnya secara tahunan. Pola ini terjadi bila nilai data yang digunakan dipengaruhi oleh musim, sebagai contoh permintaan bahan baku jagung untuk makanan ternak ayam pada pabrik pakan ternak. Harga jagung akan menjadi turun ketika masa panen, hal ini disebabkan jumlah jagung yang tersedia besar. Selama musim panen harga jagung akan menjadi turun karena jumlah jagung yang dibutuhkan tersedia dalam jumlah yang besar.
c) Pola Siklus (Cycle)
Pola dalam data memiliki fluktuasi bergelombang di sekitar garis trend. Naik turunnya fluktuasi jarang berulang pada jarak waktu yang tetap. Besarnya fluktuasi juga senantiasa berubah-ubah. Oleh karena ketidakstabilan pola, sulit untuk membuat model dari pola siklus ini.
d) Pola Trend
Pergerakan data pada pola trend cenderung sedikit demi sedikit meningkat atau menurun sepanjang suatu periode waktu jangka panjang. Perubahan pendapatan, populasi, penyebaran umur, atau pandangan budaya dapat mempengaruhi pergerakan trend.
Gambar 2.1 Empat Komponen Utama Model Time Series Adapun, metode peramalan yang termasuk model time series antara lain:
a) M etode Smoothing
M etode smoothing digunakan untuk mengurangi ketidakteraturan musiman dari data masa lalu dengan cara membuat keseimbangan rata-rata dari data masa lampau. M etode ini memiliki ketepatan cukup baik untuk peramalan jangka pendek, sedangkan kurang akurat untuk jangka panjang.
Pada metode ini, terdapat beberapa cara untuk menentukan peramalan pada periode ke depan. Cara yang cukup mudah dan sering dipergunakan antara lain metode rata-rata bergerak (moving average) dan metode exponential smoothing.
Moving average banyak digunakan untuk menentukan trend dari suatu deret waktu. Dengan menggunakan metode moving average ini, deret berkala dari data asli diubah menjadi deret rata-rata bergerak yang lebih mulus. M etode ini dapat diterapkan pada data yang memiliki perubahan yang tidak terlalu cepat serta tidak memiliki karakteristik data musiman. M etode moving average ini dilakukan dengan mengelompokkan data periode waktu kemudian melakukan perhitungan berdasarkan rata-rata data masa lalu yang telah terkumpul yang dinilai dapat mewakili sifat data yang akan dihitung.
Perbedaan metode moving average dengan metode exponential smoothing terletak pada pemberian nilai bobot pada data observasi. Pada metode moving average, semua data observasi pembentuk nilai rata-rata memiliki bobot yang sama, sedangkan pada metode exponential smoothing data observasi terbaru dianggap seharusnya memiliki bobot yang lebih besar dibandingkan dengan data observasi di masa lalu.
b) M etode Proyeksi Kecenderungan dengan Regresi
M etode kecenderungan dengan regresi merupakan dasar garis kecenderungan untuk suatu persamaan, sehingga dengan dasar persamaan tersebut dapat diproyeksikan hal-hal yang akan diteliti pada masa yang akan datang. Untuk peramalan jangka pendek dan jangka panjang, ketepatan peramalan dengan metode ini sangat baik. Data yang dibutuhkan untuk metode ini adalah tahunan,
minimal lima tahun. Namun, semakin banyak data yang dimiliki semakin baik hasil yang diperoleh.
Persamaan regresi merupakan persamaan matematik yang menunjukkan hubungan antara dua variabel sehingga salah satu variabel dapat diramalkan dari variabel lainnya. Variabel yang ingin diramalkan disebut dengan variabel terikat (dependent variable), sedangkan variabel yang ingin digunakan untuk melakukan peramalan disebut sebagai variabel bebas (independent variable).
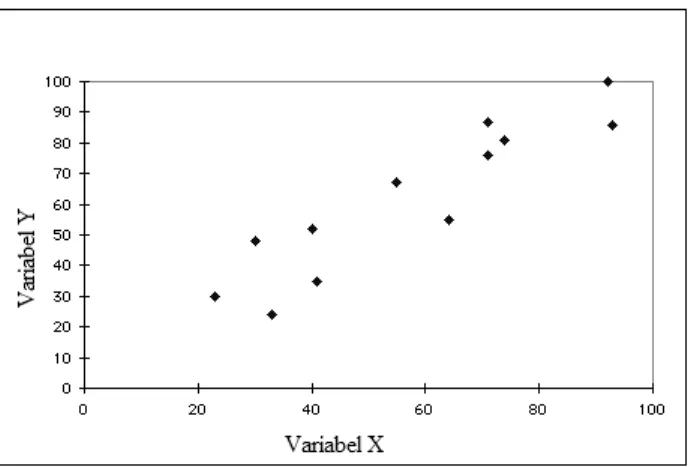
Persamaan regresi ini kemudian digambarkan dengan menggunakan diagram pencar (scatter diagram) yaitu diagram yang menggambarkan nilai-nilai observasi dari kedua variabel tersebut. Umumnya variabel bebas digambarkan pada sumbu X sedangkan variabel terikat digambarkan pada sumbu Y.
Gambar 2.2 Contoh Scatter Diagram
Hubungan linier antara kedua variabel tersebut dapat dituliskan sebagai Y = a + bX, dimana a dan b adalah parameter
yang menggambarkan konstanta dan kemiringan dari garis regresi.
∑
+
∑ =
Y
na
b
X
dan∑
XY =a∑
X+b∑
X
2Dengan mempergunakan kedua persamaan di atas nilai a dan b dapat diperoleh, ∑ − ∑ − = 2 2 nX X Y X n XY b dan
a
=
Y
−
b
X
Dari nilai a dan b baru yang dihasilkan, sebuah persamaan akan diperoleh dan kemudian dapat digunakan untuk melakukan prediksi terhadap nilai Y yang baru.
2) Analisa Kausal atau Asosiatif
Analisa kausal dapat didefinisikan sebagai suatu peramalan yang menggunakan pendekatan sebab-akibat, dan bertujuan untuk meramalkan keadaan di masa yang akan datang dengan menemukan dan mengukur beberapa variabel bebas yang penting beserta pengaruhnya terhadap variabel terikat yang akan diramalkan.
Contoh metode peramalan yang menggunakan analisa kausal ini adalah ekonometrik dan penggunaan koefisien korelasi.
a) Ekonometrik
Ekonometrik merupakan kombinasi dari teori ekonomi, analisa statistik serta model matematis yang dipergunakan untuk menjelaskan hubungan-hubungan ekonomi. M odel ini kemudian dimanfaatkan untuk memperoleh ramalan untuk variabel utama
seperti pengeluaran untuk konsumsi, inflasi, tingkat harga, permintaan barang, dan variabel ekonomi lainnya.
M odel ekonometrik menggunakan variabel masukkan (input) ke dalam sistem. Variabel yang ditentukan dari luar model meliputi variabel-variabel kebijakan (policy variable) dan peristiwa-peristiwa yang tidak dapat diatasi, variabel-variabel tersebut dikenal sebagai “exogenous variable”. Selain itu, model-model ekonometri juga berisi variabel yang ditentukan dari dalam sistem yang dikenal dengan “endogenous variables”.
Dalam mengformulasikan peramalan dengan metode ini, terdapat empat tahapan, yaitu:
a. M embangun suatu model teori b. M engumpulkan data
c. M emilih bentuk persamaan fungsi yang diestimasi d. M engestimasi dan menginterpretasi hasil
b) Koefisien Korelasi
Umumnya penggunaan koefisien korelasi ini digabungkan dengan metode regresi seperti yang telah dijelaskan sebelumnya. Koefisien korelasi digunakan untuk menentukan hubungan antara dua variabel tersebut. Ketika nilai dari sebuah variabel berhubungan dengan nilai lainnya, variabel-variabel tersebut dikatakan berkorelasi.
r ∑ Y Y ∑ Y Y
n ∑ XY ∑ X ∑ Y
n ∑ X ∑ X n ∑ Y ∑ Y
Apabila nilai dari r = 0, maka dapat dikatakan dari kedua variabel tidak terdapat pengaruh secara signifikan, sebaliknya jika nilai koefisien bukan 0, maka dapat dinyatakan kedua variabel tersebut memiliki pengaruh. Semakin besar nilai variabel koefisien korelasi, maka dapat dikatakan keterkaitan antara variabel satu dengan yang lainnya semakin besar (mendekati angka 1).
2.2.3. Ukuran Ketepatan Peramalan
Sesuai dengan sifat peramalan yang telah disebutkan sebelumnya, peramalan pasti memiliki unsur kesalahan, sehingga yang penting diperhatikan adalah usaha untuk memperkecil kemungkinan kesalahannya tersebut, serta baik tidaknya suatu ramalan tergantung pada faktor data dan metode yang digunakan.
Dalam melakukan peramalan, suatu hasil dapat dikatakan baik jika ketepatan meramalnya bernilai yang tinggi. Sebuah model peramalan dengan kesalahan yang kecil tentunya lebih dapat digunakan untuk melakukan prediksi atau peramalan untuk masa yang akan datang. Besar kesalahan yang dibuat oleh model peramalan dapat dihitung dengan beberapa ukuran kesalahan peramalan:
MAPE merupakan ukuran akurasi yang memberikan petunjuk seberapa besar kesalahan peramalan dibandingkan dengan nilai sebenarnya. MAPE lebih banyak digunakan untuk mengukur akurasi pada nilai time series, khususnya untuk mengukur trend. Akurasi dari MAPE umumnya diekspresikan dalam bentuk persentase. Semakin kecil nilai persentase yang dihasilkan pada perhitungan M APE, maka semakin baik akurasi dari peramalan. Berikut ini merupakan rumus perhitungan MAPE:
1
100
dimana merupakan nilai aktual dan merupakan nilai hasil
peramalan.
M eskipun penggunaan M APE sebagai ukuran akurasi dapat
dinilai sederhana dan mudah digunakan, M APE memiliki kelemahan tersendiri yaitu apabila terdapat nilai 0 pada nilai aktual, maka akan terdapat sebuah pembagian dengan angka 0. Tentu saja hal ini dapat memicu terjadinya error.
b. Mean Absolute Deviation (MAD)
MAD mengukur akurasi peramalan dengan merata-ratakan nilai
absolut kesalahan peramalan. Kesalahan diukur dalam unit ukuran yang sama saperti data aslinya. Berikut ini merupakan rumus perhitungan MAD:
dimana y merupakan nilai aktual dan y merupakan nilai hasil peramalan.
c. Mean Squared Error (M SE)
M SE merupakan salah satu cara untuk mengukur perbedaan atau perbandingan nilai antara nilai aktual dengan nilai hasil prediksi. Perbandingan nilai M SE yang terjadi selama tahap pencocokan peramalan mungkin memberikan sedikit indikasi ketepatan model dalam peramalan. Jika terdapat nilai pengamatan dan ramalan untuk n periode waktu, maka akan terdapat n buah galat, oleh karena itu perhitungan tingkat kesalahan dapat dirumuskan sebagai berikut:
1
dimana merupakan nilai aktual dan merupakan nilai hasil
peramalan.
2.3. Machine Learning
Di dalam perkembangan teknologi sekarang ini, dapat terlihat adanya peralihan yang terjadi di berbagai bidang kehidupan, seperti perindustrian dan perkantoran. Banyak pekerjaan–pekerjaan yang semulanya dilakukan oleh manusia, sekarang tergantikan oleh mesin. Otomatisasi membuat perkerjaan menjadi praktis dan cepat untuk dilakukan sehingga produktivitas pun meningkat. Hal ini bermula dari pembelajaran yang dilakukan melalui machine learning.
Parrella (2007, p6) menyatakan bahwa machine learning menurut adalah ilmu yang mempelajari tentang tingkah laku, pola pikir dan teknik pembelajaran manusia (human learning) ke sebuah mesin.
M enurut Santosa (2007, p10) machine learning adalah suatu area dalam artificial intelligence atau kecerdasan buatan yang berhubungan dengan pengembangan teknik–teknik yang bisa diprogramkan dan belajar dari data masa lalu.
Sehingga dapat diartikan machine learning adalah ilmu yang mempelajari bagaimana proses pembelajaran manusia dapat diterapkan pada sebuah mesin dengan mengolah data–data masa lalu untuk menyelesaikan suatu masalah. Machine learning dikembangkan untuk menyelesaikan berbagai permasalahan programming yang tidak dapat terselesaikan dengan teknik yang umum. Beberapa contoh permasalahan yang dapat diselesaikan:
• Pengenalan karakter, manusia dapat dengan mudah membedakan huruf abjad atau kata untuk membuat sebuah kata-kata dan memberinya arti. Sedangkan komputer melihat karakter sebagai sebuah rangkaian perintah 0 dan 1, tanpa adanya pemahaman mengenai arti kata (semantic). Machine learning memungkinkan untuk mengenali sebuah karakter, memberikan arti kata dan membedakan satu sama lain dengan melakukan tahap pelatihan terlebih dahulu. • Prediksi untuk penjualan, dengan melihat pola penjualan yang telah dilakukan
sebelumnya dapat terlihat barang apa yang perlu diproduksi lebih dan yang tidak. Hal ini dapat dimudahkan dengan menerapkan machine learning di mana
pola–pola tersebut akan dipelajari yang kemudian diolah menjadi formulasi yang menghasilkan sebuah prediksi yang baik.
Secara garis besar, machine learning dibagi menjadi 2 bagian yaitu supervised learning dan unsupervised learning.
2.3.1. Unsupervised Learning
Unsupervised learning merupakan teknik dari machine learning yang diterapkan tanpa adanya latihan (training) dan tanpa ada label dari data. Unsupervised learning menghilangkan guru dan menuntut pembentukan dan pengevaluasian konsep sendiri. Apabila terdapat sekelompok pengamatan atau data tanpa label, maka pada unsupervised learning, data akan dikelompokkan ke dalam beberapa kelas yang dikehendaki.
Pola input akan diberikan pada sistem, kemudian sistem akan diperintahkan untuk mencari keteraturan pola. Sebagai contoh, misalkan sekelompok pelanggan ingin dibagi berdasarkan dengan status ekonomi.
M aka dengan teknik unsupervised, pelanggan sebagai objek dapat dikelompokkan berdasarkan tingkat kepemilikan properti tertentu atau dapat juga berdasarkan penghasilan per tahunnya. Pengelompokkan ini dilakukan dengan mengasumsikan bahwa, dalam satu kelompok anggota-anggotanya harus memiliki kesamaan yang tinggi dibandingkan dengan kelompok lain.
Beberapa teknik popular yang termasuk memiliki metode pembelajaran unsupervised learning adalah teknik Clustering dan Self Organizing Map.
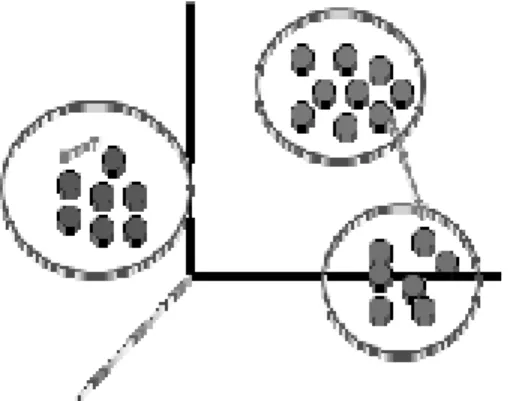
Teknik clustering memiliki tujuan utama untuk mengelompokkan sejumlah data/objek ke dalam cluster atau grup sehingga setiap cluster akan berisikan data yang semirip mungkin. Ini berarti data dalam cluster yang sama (intracluster) diharapkan memiliki jarak seminimal mungkin dan dalam cluster yang berbeda (intercluster) akan memiliki jarak semaksimal mungkin.
Teknik clustering ini termasuk ke dalam unsupervised learning dikarenakan pelatihan dari metode ini tidak membutuhkan label atau pun keluaran dari setiap data yang diinvestigasi.
Gambar 2.3 Jarak Intracluster Minimal dan Jarak Intercluster Maksimal
Terdapat dua pendekatan dalam clustering yaitu:
1. Pendekatan partiosioning. Pada pendekatan partisioning, awalnya ditetapkan pengelompokan dari x1, x2, … xn ke dalam
sejumlah cluster. Selanjutnya dilakukan realokasi objek berdasarkan kriteria tertentu hingga pengelompokan optimum
2. Pendekatan hirarki, akan membuat n cluster dimana setiap cluster hanya beranggotakan sebuah objek pada awalnya. Selanjutnya pada setiap tahap prosedur, sebuah cluster akan digabungkan dengan sebuah cluster lain.
Berikut merupakan beberapa algoritma clustering yang umum digunakan:
a. Hierarchical Clustering
Tugas hierarchical clustering adalah mengatur sekumpulan objek menjadi sebuah hirarki hingga terbentuk kelompok yang memiliki kesamaan. Berikut merupakan langkah-langkah yang untuk melakakukan hierarchical clustering:
1. Kelompokkan setiap objek dalam sebuah cluster.
2. Temukan pasangan yang paling mirip untuk dimasukkan ke dalam cluster yang sama dengan melihat data dalam matriks kemiripan.
3. Kedua objek kemudian digabungkan dalam satu cluster.
4. Ulangi dari langkah kedua dan ketiga hingga tersisa sebuah cluster.
Untuk mengukur kemiripan dari objek-objek ini dapat dengan menggunakan cosinus, kovarian, dan korelasi (Santosa, 2006, p35). Sedangkan untuk ukuran ketidakmiripan digunakan perhitungan untuk jarak seperti Euclidean sebagai berikut:
,
b. K-means
Pada K-means, objek data dikelompokkan ke dalam k cluster. Jumlah cluster harus ditentukan terlebih dahulu, oleh karena itu umumnya pengguna telah memiliki informasi awal mengenai objek dan jumlah cluster yang paling tepat. Selanjutnya dengan menggunakan perhitungan jarak, maka pengelompokkan objek-objek tersebut dapat dibentuk.
Langkah-langkah yang untuk melakakukan clustering dengan menggunakan algoritma K-means adalah:
1. M enentukan jumlah cluster k.
2. M enentukan pusat dari cluster. Penentuan pusat dari cluster dapat dilakukan dengan berbagai cara, namun yang paling sering digunakan adalah dengan random.
3. Setiap objek yang dekat satu sama lain akan dikelompokkan. Kedekatan ditentukan dengan menghitung jarak tiap data dengan pusat cluster.
4. Tentukan kembali pusat cluster melalui perhitungan rata-rata dari semua objek dibagi dengan objek dalam cluster. Selain dari rata-rata, perhitungan pusat cluster juga dapat menggunakan median.
5. Tugaskan setiap objek dengan menggunakan pusat cluster, hingga pusat cluster tidak berubah lagi.
c. Fuzzy K-means
Fuzzy k-means merupakan pengembangan dari teknik K-means. Perbedaan dari clustering fuzzy K-means dengan k-means adalah pada K-means objek hanya dapat menjadi anggota dari satu cluster, sedangkan pada fuzzy K-means, sesuai dengan namanya, setiap objek dapat saja menjadi anggota beberapa cluster.
Langkah-langkah yang untuk melakakukan clustering dengan menggunakan algoritma Fuzzy K-means adalah:
1. Tentukan k jumlah pusat cluster.
2. Tempatkan setiap data ke cluster terdekat.
3. Hitung pusat cluster lalu pindahkan pusat cluster ke hasil yang baru tersebut. Pada Fuzzy K-means pusat cluster dihitung dengan mencari rata-rata dari semua titik dalam suatu cluster dengan diberi bobot berupa tingkat keanggotaan (degree of belonging) dalam cluster tersebut.
4. Tempatkan kembali setiap data ke cluster terdekat. Evaluasi data mana yang berubah cluster.
5. Hitung kembali pusat cluster, dan ulangi langkah ketiga dan seterusnya.
Dengan tingkat keanggotaan, dapat dilihat data mana yang sebenarnya berada dalam daerah abu-abu. Dengan nilai tingkat keanggotaan harus diambil keputusan ke cluster mana suatu data
akan dimasukkan, Hasil dari Fuzzy K-means ini sangat bergantung pada penentuan nilai awal dari pusat cluster.
2.3.1.2. Self Organizing Map (SOM)
Self-organizing map (SOM ) merupakan sebuah tipe dari artificial neural network yang menggunakan metode training data unsupervised learning untuk memproduksi representasi diskrit dari sampel data training, yang disebut dengan peta (map).
Self-organizing map terdiri dari komponen-komponen yang disebut dengan node atau neuron. Setiap node berasosiasi dengan sebuah weight vector yaitu sebuah vector yang memiliki bobot. Neuron-neuronnya biasanya dibuat beberapa dimensi, tapi yang sering di pakai adalah 1 dimensi atau 2 dimensi.
Proses dari self-organizing map mirip dengan artificial neural network yaitu mengubah bobot pada neuron. Setalah memasukkan input dan melakukan proses pembelajaran (learning), neuron-neuron dengan bobot yang mirip akan berkumpul membentuk cluster. Langkah algoritma dari self-organizing map antara lain: 1. Tentukan bobot awal dari vektor secara random.
2. Set jumlah tetangga yang memberi pengaruh dan kadar pembelajaran.
3. Hitung jarak antara input pada setiap node, dapat dengan menggunakan rumus jarak Eucledian.
5. Ubah nilai bobot pada node dengan jarak terkecil tersebut serta node tetangga yang berada pada radius jumlah tetangga yang memberikan pengaruh.
6. Ulangi langkah 3 sampai 5 untuk setiap nilai x.
7. Kurangi nilai kadar pembelajaran serta jumlah tetangga yang memberi pengaruh.
8. Selama syarat menghentikan proses belajar belum terpenuhi ulang langkah 3 hingga 7.
2.3.2. Supervised Learning
Supervised learning merupakan teknik pembelajaran untuk membuat suatu pembagian atau klasifikasi dari suatu data yang ada. M isalkan dari suatu program diharapkan dapat membedakan apakah itu bus atau mobil ketika diberi suatu gambar. Output yang diinginkan adalah program tersebut dapat memilah–milah objek tersebut ke dalam klasifikasi yang cocok.
Pembelajaran ini memerlukan beberapa langkah yang perlu dilakukan yaitu menentukan set training dan set testing. Set training merupakan kumpulan contoh data yang digunakan untuk keperluan analisa. Dari set training ini diolah untuk mendapatkan pembagian yang tepat. Classifier ini perlu diuji ketepatannya dengan menggunakan set testing sehingga akan tampak presentase keberhasilannya. Semakin tinggi persentasenya maka program tersebut semakin baik dan layak untuk digunakan untuk prediksi.
Beberapa algoritma yang menerapkan supervised learning ini yaitu Decision Tree, Artificial Neural Networks, Support Vector Machine dan Support Vector Regression.
2.3.2.1. Decision Tree
Sering kali dalam kehidupan sehari–hari ditemukan berbagai masalah yang tak terduga terjadi. Ketika suatu masalah telah terselesaikan, muncul masalah yang lain lagi dan ini berlangsung secara terus–menerus. Banyak hal yang berkaitan sehingga masalah tersebut muncul. M isalkan seorang siswa mendapatkan nilai buruk, setelah ditinjau lagi, nilai buruk tersebut didapat karena anak itu malas belajar, penyebab dari malas berlajar itu pun dapat dijabarkan lagi karena terlalu banyak bermain game, pergi dengan teman dan setelah kelelahan langsung tidur dan tidak belajar. Untuk menangani hal itu, diciptakan solusi tentang suatu pemikiran yang dapat membantu manusia untuk mengambil sebuah keputusan.
Dengan menggambarkan dan menguraikan permasalahan yang ada dengan faktor–faktor yang mendukungnya maka akan didapatkan suatu solusi untuk memecahkan masalah tersebut. Pohon keputusan atau decision tree ini akan membantu untuk menjabarkan setiap permasalahan yang ada sehingga keputusan pun akan dengan mudah dipilih.
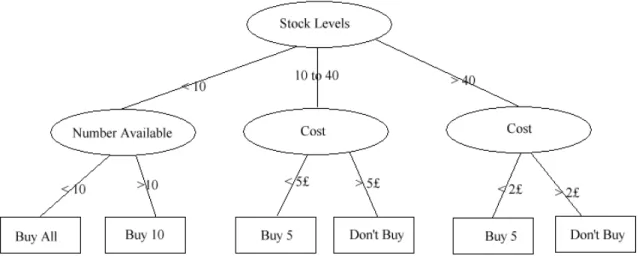
mana masing–masing cabangnya mengklasifikasikan pertanyaan dan daun–daunnya merupakan bagian dari set data dengan klasifikasinya. Konsep dasar dari decision tree adalah mengubah data menjadi sebuah pohon keputusan dan aturan-aturan.
Gambar 2.4 Konsep Dasar Decision Tree
Pada decision tree pertanyaan pertama menjadi simpul akar yang jawabannya akan menjadi cabang–cabang, yang kemudian cabang tersebut akan menjadi simpul bagi cabang–cabang di bawahnya lagi. Setiap cabang merepresentasikan kumpulan dari alternatif keputusan, pada setiap langkah, hanya satu keputusan yang dapat diambil. Langkah ini berakhir ketika suatu simpul merupakan objek yang dicari.
Gambar 2.5 Contoh Model Decision Tree
Hal yang menarik pada decision tree:
a) Decision tree membagi data pada setiap leaf tanpa kehilangan data satupun (total record pada parent sama dengan jumlah total record yang dimiliki anak - anaknya).
b) Label atau output data biasanya bernilai diskrit.
c) Data mempunyai missing value. Terkadang nilai dari suatu atribut tidak diketahui, dalam keadaan seperti ini decision tree masih dapat memberikan solusi yang baik.
d) Decision tree memiliki konsep yang mudah untuk dimengerti. Tujuan utama dari decision tree sebenarnya adalah untuk mengeksplorasi, kemudian dikembangkan untuk keperluan prediksi. Dengan membangun sebuah predictive model, diharapkan decision tree dapat memiliki data standar untuk forecasting. Hal ini dapat bermanfaat untuk menentukan peluang yang ada dengan melihat
kondisi–kondisi yang terjadi sehingga mendukung keputusan yang perlu diambil.
Beberapa contoh penggunaan decision tree antara lain untuk mendiagnosa penyakit tertentu, seperti kanker, stroke, dan lain-lain, deteksi gangguan pada komputer atau jaringan komputer seperti deteksi virus, pemilihan pegawai teladan.
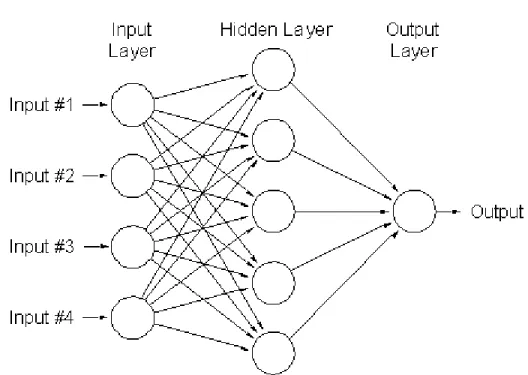
2.3.2.2. Artificial Neural Network (ANN)
M engetahui cara kerja otak merupakan tantangan bagi para ilmuwan untuk dapat mengetahuinya. Hal ini berkembang dengan dibuatnya kecerdasan buatan yang kemudian diterapkan dengan menanamkan kecerdasan ke dalam suatu sistem. Analoginya seperti mengajarkan seorang anak untuk belajar berjalan, dimulai dari belajar merangkak. Setelah beberapa waktu berlalu anak tersebut akan dapat berjalan sendiri ke arah yang diinginkan. Pembelajaran yang dilakukan ini disebut Artificial Neural Network.
Neural Network menurut Berson and Smith (2000, p167) merupakan biological system yang dapat mendeteksi pola, membuat prediksi dan belajar.
Contoh penerapan ANN ini dilakukan untuk sistem sekuriti seperti Intrusion Detection System (IDS). Aplikasi ini dapat mendeteksi hal-hal yang mencurigakan pada sebuah sistem atau jaringan. Pendeteksian tersebut berguna untuk mencegah penyusupan dan serangan. Pembelajaran tersebut dilakukan dengan
mengimplementasikan pendeteksian pola dan algoritma machine learning ke dalam mesin untuk membuat sebuah predictive model dari data–data yang ada.
Untuk proses prediksi neural network memerlukan sebuah nilai yang disebut input node. Secara sederhana proses kerjanya sebagai berikut, nilai ini dikalikan dengan nilai yang disimpan dalam link yang menghubungkan dengan satu node dengan node lain yang kemudian dihitung sehingga menghasilkan sebuah nilai prediksi. Di mana nilai 0 merupakan nilai yang baik (non default) dan nilai 1 merupakan nilai yang buruk (default).
Kelebihan dari artificial neural network adalah kemampuannya dalam memprediksi di mana ANN mempunyai toleransi yang tinggi terhadap data yang mengandung noise dan mampu menangkap hubungan yang sangat kompleks antara variabel–variabel prediktor dan outputnya. Sedangkan kekurangannya pada hasil prediksinya, ANN harus membutuhkan data training yang cukup.
2.3.2.3. Support Vector Machine (S VM)
Konsep dasar dari support vector machine sebenarnya merupakan penggabungan dari teori–teori komputasi yang telah ada seperti hyperplane, kernel, dan konsep–konsep pendukung lain. Konsep ini diperkenalkan oleh Vapnik, Boser dan Guyon pada tahun 1992.
Penerapan dari metode ini telah dilakukan untuk pengolahan citra dan pengenalan wajah. Sistem classifier diciptakan untuk dapat mendeteksi citra yang merupakan wajah. Sehingga hasilnya akan dapat membedakan antara wajah dan bukan wajah.
Tujuan utama dari proses training dengan tujuan klasifikasi data adalah memakai set training untuk menemukan garis pemisah dua buah class, yang memiliki generalisasi baik. Generalisasi baik maksudnya mampu memberikan keputusan yang benar terhadap data baru yang tidak dilibatkan dalam proses training, dengan kata lain meminimalisasi tingkat error model yang dihasilkan terhadap test-sample.
Support vector machine menerapkan structural risk minimization untuk meminimalisasi kesalahan yang ada tersebut. Teori SVM bertujuan untuk mencari hyperplane atau garis pemisah terbaik dengan memaksimalkan margin. Margin sendiri dapat didefinisikan sebagai jarak terdekat dari hyperplane ke data sebuah class.
Terdapat dua jenis data yang dapat diklasifikasikan dengan menggunakan SVM , yang pertama adalah linearly separable data yaitu data yang dapat dipisahkan secara linier dan nonlinearly separable data yaitu data yang tidak dapat dipisahkan secara linier.
Pada umumnya data-data pada dunia real jarang yang berbentuk linearly separable. Oleh karena itu, dengan adanya metode kernel, perhitungan fungsi pemisah (classifier) digunakan untuk mengklasifikasikan non linear pun dapat dilakukan. Untuk mendapatkan hasil yang lebih sempurna maka perlu dilakukan optimasi dengan quadratic programming sehingga pola yang ada akan semakin mudah untuk dikenali.
Seperti yang dapat dilihat pada gambar di atas, terdapat 2 buah kelas yang dipisahkan oleh sebuah hyperplane yaitu: class +1 dan class -1. M asalah klasifikasi digambarkan pada hyperplane yang memisahkan 2 kelompok tersebut. Semakin jelas pembagian kelasnya maka tujuan dari support vector machine ini tercapai.
SVM sendiri sebenarnya pertama kali diperkenalkan oleh Vapnik, hanya dapat mengklasifikasikan data ke dalam dua kelas. Akan tetapi dengan diadakannya pengembangan lebih lanjut, maka saat ini SVM telah memiliki kemampuan untuk mengklasifikasikan data lebih dari dua kelas. Terdapat dua cara untuk mengimplementasikan multi class SVM ini yaitu dengan metode “one-against-all” dan “one-against-one”.
2.3.2.4. Support Vector Regression (S VR)
Support vector regression (SVR) merupakan pengembangan dari support vector machine (SVM ) yang bisa menghasilkan performansi yang lebih baik dan mengatasi masalah overfitting. Seperti yang diketahui SVM diterapkan untuk kasus klasifikasi dan output datanya berupa bilangan bulat atau diskrit, sedangkan SVR sendiri penerapannya pada kasus regresi yang mana output datanya berupa bilangan riil atau kontinu.
Contoh penerapan SVR yaitu untuk memprediksi besar bonus untuk karyawan pada perusahaan. Dengan menerapkan fungsi dan penetapan nilai variabel yang tepat, perhitungan persentase bonus
untuk karyawan menunjukan error yang kecil, fungsi yang tipis dan banyak support vector (Puspita Sari, 2009, p1).
2.4. Support Vector Regression (S VR)
Tujuan dari support vector regression adalah untuk mendapatkan suatu fungsi dengan tingkat kesalahan paling kecil sehingga menghasilkan suatu prediksi yang bagus.
Ide dasar dari support vector regression dengan menentukan set data yang dibagi menjadi set training dan set validasi. Kemudian dari set training tersebut ditentukan suatu fungsi regresi dengan batasan deviasi tertentu sehingga dapat menghasilkan prediksi yang mendekati dari target aktual.
(a) (b)
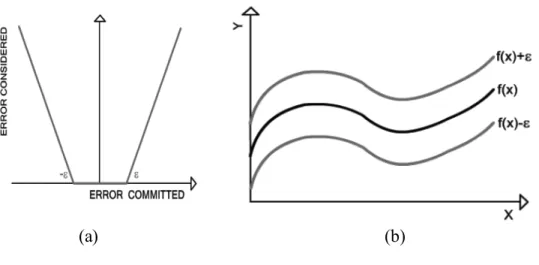
Gambar 2.8 Batas Error dalam Support Vector Regression
Gambar 2.8 (a) menunjukkan bagaimana error pada SVR dihitung. Sampai dengan garis batas error , nilai error dianggap sama dengan 0, sedangkan di luar batas tersebut, nilai error akan dihitung sebagai “error-epsilon”. Solusi pada
masalah ini adalah dari sebuah garis, akan dibentuk sebuah tabung yang memiliki toleransi terhadap error seperti yang ditunjukkan pada Gambar 2.8 (b).
Fungsi regresi tersebut akan sempurna apabila batas deviasinya sama dengan 0 sehingga dapat dituliskan sebagai berikut:
f(x) = wT φ(x) + b
di mana φ(x) menunjukan suatu titik di dalam feature space F yang merupakan hasil pemetaan x di dalam input space. Koefisien w dan b di sini berfungsi untuk meminimalkan fungsi resiko (risk function).
Dengan meminimalkan fungsi resiko tersebut akan membuat suatu fungsi menjadi setipis mungkin, sehingga kapasitas fungsi (function capacity) dapat terkontrol, hal ini dinamakan regularisasi. Faktor lain yang dapat mendukung ketelitian fungsi ini adalah dengan meperhitungkan kesalahan empirik (empirical error) yang diukur dengan besarnya ε-insensitive loss function. Menurut Weber dan Guajardo (2008, p58), nilai e mendefinisikan derajat toleransi terhadap error.
Suatu fungsi dianggap layak dan baik apabila semua titik ada dalam rentang yang seharusnya, sebaliknya bila ada beberapa titik keluar dari rentang yang seharusnya maka fungsi tersebut tidak layak digunakan untuk sebuah prediksi. Untuk mengatasi masalah pembatas yang tidak layak tersebut diperlukan suatu variabel tambahan yang disebut variabel slack. Sehingga fungsi di atas perlu dioptimisasi lagi menjadi:
min ||w||2 + C ∑ t t
Konstanta C > 0 menentukan tawar menawar (trade off) antara batas deviasi yang masih bisa ditoleransi.
Dalam permasalahan dual, optimisasi perlu dilakukan dengan Lagrange multiplier sehingga didapat rumus sebagai berikut:
f(x) = ∑ α α K x , x b
Dimana K x , x merupakan fungsi kernel. Fungsi kernel ini akan
membantu menghasilkan suatu fungsi dengan hasil yang berbeda–beda dengan berbagai jenis yang ada pada kasus non-linear. Nilai dari kernel ini sama dengan inner product dari dua buah vector xi dan pada feature space φ(xi) dan φ(xj).
Keunggulan dari penggunaan fungsi kernel ini adalah kemampuannya untuk berhubungan dengan feature space tanpa perlu menghitung mapping dari φ(x) secara eksplisit.
Secara garis besar, terdapat beberapa jenis kernel yaitu linear, polynomial, radial basis function (RBF), dan exponential RBF.
• Kernel Linear i i x x x x K( , )= , • Kernel Polynomial d i i x x x x K( , )= ,
Di mana d adalah derajat kernel polynomial. • Kernel radial basis function
⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − − = 2 2 2 exp ) , ( σ i i x x x x K
Di mana
σ
2 merupakan bandwith dari Kernel radial basis function. • Kernel exponential RBF⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ − − = 2 2 exp ) , ( σ i i x x x x K
Kernel merupakan suatu fungsi untuk memetakan data ke dalam ruang vektor yang berdimensi lebih tinggi. Kernel trick ini sangat membantu untuk perhitungan prediksi, dengan hanya menganalisa permasalahan yang ada. Hal yang perlu dilakukan hanyalah menyesuaikan dengan tipe kernel yang sudah ada tanpa melakukan perhitungan untuk melakukan pemetaan. Terdapat beberapa tipe kernel yang sering dijumpai dan setiap tipe kernel tersebut akan menghasilkan nilai output yang berbeda.
Untuk menangani masalah regresi support vector regression juga menerapkan loss function, dengan memberikan pinalti pada kesalahan–kesalahan atau error yang akan terjadi maka kesalahan perhitungan akan semakin kecil.
Loss–function merupakan fungsi untuk menggambarkan bentuk hyperplane yang akan dihasilkan pada predective model, pada umumnya loss-function yang banyak digunakan adalah tipe quadratical dan e-insensitive. Loss–function akan menentukan bentuk garis batas error yang besarnya sesuai dengan nilai e yang telah di input. Menurut Gunn (p29, 1998), terdapat beberapa macam loss function yaitu quadratic, Laplace, Huber dan e-insensitive.
Quadratic Laplace
Huber -insensitive Gambar 2.9 Contoh Loss Function
Dalam support vector regression, data terbagi menjadi 3 kondisi yaitu support set, error set dan remaining set. Seperti yang diketahui support vector regression mempunyai batasan error, kondisi di mana data berada di dalam garis batas disebut remaining set, support set merupakan kondisi di mana data berada pada garis batas dan apabila data tersebut di luar garis batas dinamakan error set.