BAB II
STUDI PUSTAKA
2.1 Search Engine
2.1.1 Latar belakang Search Engine
Perkembangan search engine berawal dari Montreal ketika Alan Emtage, seorang mahasiswa Universitas McGill, Montreal, pada tahun 1990 membuat Archie, ‘kakek’ dari semua search engine. Kemudian the University of Nevada System Computing Service Group membangun sebuah tipe search engine yang diberi nama Veronica, 1993. Search service ini merupakan ‘nenek’ dari search engine. Kemudian Matthew Gray’s WWW Wanderer adalah ibu dari semua search engine. The Wanderer adalah robot pertama di web. Kemudian Martijn Koster menciptakan Aliweb pada Oktober 1993. Aliweb adalah search engine yang sama dengan Archie. Search service ini masih menggunakan daftar list dari masing-masing informasi yang dibuat.
Pada Desember 1993 telah dihasilkan tiga search engine yang menggunakan program robot yaitu Jumpstation, WWW Worm dan The Repository-based Software Engineering (RBSE) Spider. Pada saat sebelumnya enam orang undergraduate dari Universitas Stanford memulai proyek pembangunan sebuah search engine yang diberi nama Excite pada bulan Februari 1993. Pada awalnya Excite bernama Architext dan hanya berupa sebuah software bagi webmaster untuk digunakan pada website di lingkungan internal. Kemudian muncul Yahoo!, sebuah search engine yang dibangun oleh dua orang kandidat doktoral dari Universitas Stanford, David Filo and Jerry Yang. Lalu menyusul Lycos yang merupakan sebuah proyek dari sebuah lab di Universitas Carnigie Mellon, Juli 1994, oleh Michael Maudlin. Altavista di keluarkan bulan Desember 1995 oleh Digital Equipment Corporation’s (DEC). Hotbot dibangun pada tanggal 20 Mei 1996 dan merupakan produk keluaran Inkomotomi Corporation yang didirikan oleh Eric Brewer dan Paul Gauthier dari Universitas California Berkeley.
Perkembangan selanjutnya adalah meta-search engine. Meta-search engine pertama adalah Metacrawler yang menggabungkan dan mengambil
sumber dari Lycos, Altavista, Yahoo!, Excite, Webcrawler dan Infoseek. Dibangun pada tahun 1995 oleh Eric Selburg, seorang mahasiswa master dari Universitas Washington (Lubis 2003).
2.1.2 Definisi Search Engine
The American Heritage Dictionary (2006) mendefinisikan search engine sebagai sebuah program perangkat lunak (software) yang menelusur, menjaring, dan menampilkan informasi dari pangkalan data. Informasi yang ditampilkan mengandung atau berhubungan dengan suatu istilah spesifik. Sedangkan menurut Wikipedia, search engine adalah program komputer yang dirancang untuk membantu seseorang menemukan file-file yang disimpan dalam komputer, misalnya dalam sebuah server umum di web (WWW) atau dalam komputer sendiri. Search engine merupakan salah satu fasilitas vital dari Internet untuk menjelajahi lautan informasi yang begitu luas. Hanya dalam waktu beberapa detik search engine dapat menyuguhkan ribuan bahkan jutaan alamat web (URL) yang memuat informasi berkaitan dengan kata kunci (keyword) yang diketikkan sebagai query.
2.1.3 Prinsip Umum Dari Search Engine
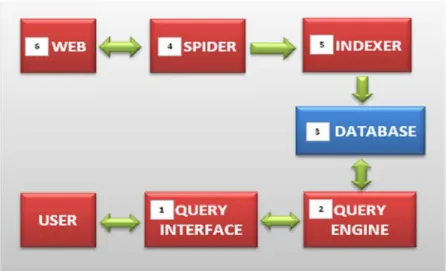
Secara prinsip, tujuan dari sebuah program search engine adalah menemukan dokumen atau arsip elektronis di Internet yang sesuai dengan kebutuhan atau permintaan pengguna dalam waktu yang sesingkat-singkatnya. Kedua hal ini, yaitu kualitas hasil temuan dan waktu pencarian, kemudian menjadi ukuran kinerja sebuah search engine. Pada Gambar 2.1 terlihat enam komponen utama dari arsitektur sebuah program search engine.
Gambar 2.1 Komponen Arsitektur Dari Search Engine (Febrian, 2007)
Ke enam komponen utama tersebut adalah sebagai berikut :
1. Komponen pertama adalah query interface, yang merupakan bentuk tampilan atau format situs yang menyediakan fasilitas searching engine. Bentuk yang paling sederhana adalah tersedianya sebuah kotak kosong di situs dimana pengguna Internet dapat menuliskan data atau informasi yang akan dicari.
2. Komponen kedua adalah query engine, merupakan program yang bertugas untuk menterjemahkan keinginan user ke dalam bahasa yang dimengerti oleh mesin komputer. Query Engine ini pulalah yang segera melakukan pencarian arsip dan dokumen yang tepat di dalam sistem basis data (database) yang bersangkutan.
3. Komponen selanjutnya adalah database, yang pada dasarnya merupakan kumpulan atau daftar dari dokumen maupun arsip dari seluruh situs yang ada di Internet. Semakin besar skala Internet, akan semakin besar pula kapasitas penyimpan yang dibutuhkan.
4. Komponen keempat yang merupakan komponen terpenting dalam sebuah searching engine adalah spider. Secara berkala dan kontinyu, spider akan mendata setiap situs yang ada di Internet, baik yang baru maupun yang lama. Terhadap masing-masing situs, selain alamatnya, akan diambil kata-kata kunci dari arsip maupun dokumen yang ditemukan. Misalnya dari
situs Kompas.com akan diambil setiap kata pada kalimat judul berita, atau pada Amazon.com akan diambil setiap kata pada judul buku. Di sinilah persaingan antar situs terjadi, yaitu strategi dan teknik yang digunakan dalam melakukan sampling terhadap kata-kata yang menjadi kunci dalam pencarian arsip dan dokumen.
5. Komponen kelima disebut sebagai Indexer, yang merupakan sebuah program untuk mempercepat proses pencarian. Filosofi yang digunakan mirip dengan prinsip penggunaan indeks pada kamus atau buku-buku. Persaingan antar situs terjadi, karena teknik melakukan indeks akan sangat berpengaruh terhadap kecepatan pencarian data atau informasi.
6. Dalam hal ini web yang dimaksud adalah web server yaitu merupakan komputer yang melayani permintaan dan memberikan respon balik dari permintaan tersebut. Web server ini biasanya menghasilkan informasi atau dokumen dalam format HTML (Hyper Text Markup Language).
2.1.4 Cara Kerja Search Engine
Search engine, tidaklah benar-benar melakukan pencarian ke seluruh World Wide Web secara langsung. Pencarian dilakukan dalam database yang menyimpan teks dari dokumen yang tersedia di Internet. Teks dari halaman demi halaman disimpan di dalam server database.
Ketika pengguna Internet melakukan pencarian web dengan menggunakan search engine, yang dilakukan adalah pencarian salinan halaman yang disimpan pada database search engine yang berisi salinan halaman tersebut pada saat terakhir diakses.
Ketika pengguna Internet meng-click link yang disediakan oleh halaman hasil pencarian yang dilakukan oleh search engine, sebenarnya alamat tersebut diberikan dari server search engine melalui versi saat ini yang ada di dalam database search engine.
Database dokumen yang ada pada search engine dipilih dan dijaring oleh program robot yang disebut dengan spider. Untuk menemukan halaman potensial lainnya, spider mengacu pada link-link yang terdapat pada halaman-halaman yang telah disimpan di dalam database. Mesin ini tidak dapat menuliskan suatu URL
dan berfikir halaman-halaman yang mana yang akan ”dicoba” untuk dikunjungi. Jika suatu halaman web tidak pernah di-link-kan, maka spider dari search engine tidak dapat menemukan halaman tersebut. Spider hanya memantau dari database yang dimiliki.
Untuk situs yang benar-benar baru, dan belum ada satupun situs lain yang membuat link ke situs tersebut, maka spider tidak akan mengenalinya. Agar situs baru tersebut bisa dikenal dan terdaftar pada search engine, khususnya untuk situs yang belum dapat link dari situs lain, adalah dengan cara memberitahu langsung search engine tersebut bahwa ada situs baru. Caranya adalah dengan membuka search engine dan mengetikan alamat situs sebagai keyword-nya atau mengetikkan salah satu kata kunci yang terdapat di dalam situs tersebut lalu klik pada menu search. Hampir semua search engine memberikan fasilitas atau penawaran untuk ini.
Setelah spider menemukan suatu halaman, maka hasil penemuan tersebut dikirimkan ke komputer lain untuk diberi indeks. Program ini mengidentifikasi teks, link serta isi lain pada halaman tersebut, lalu menyimpannya ke dalam file database, sehingga melalui database tersebutlah bisa dilakukan pencarian kata kunci atau apapun dalam bentuk tingkat lanjut lainnya yang ditawarkan, sampai akhirnya situs ini dapat ditemukan pada hasil pencarian.
Beberapa tipe dari halaman dan link tidak dimasukkan ke dalam kebanyakan search engine karena aturan-aturan tertentu. Beberapa yang lainnya tidak dimasukkan juga karena spider tidak dapat mengakses halaman tersebut. Halaman yang tidak dimasukkan ke dalam indeks disebut dengan ”invisible web”, dimana kita tidak dapat melihat halaman dari hasil pencarian. Jumlah halaman ini bisa mencapai dua hingga tiga kali lebih besar dari halaman yang boleh ditampilkan (Febrian 2007).
2.1.5 Ranking
Dalam mesin pencari Internet, pengambilan data merupakan hasil kerja sama dari tiga komponen, crawler (spider/robot), database, dan algoritma pencarian. Ketiga komponen bekerjasama untuk memberi “jawaban” dari “pertanyaan” pengguna Internet yang dimasukkan melalui antar-muka pencarian.
Mekanisme kerja ketiganya merupakan “rahasia dapur” masing-masing mesin pencari.
Bagian yang sangat krusial adalah menentukan peringkat hasil pencarian yang telah diambil dari database. Peringkat hasil pencarian menentukan berapa kuantitas pengguna melihat dan mengunjungi suatu website. Permasalahannya adalah algoritma perangkingan suatu mesin pencari sangat dirahasiakan. Apa yang dapat dilakukan untuk “mempengaruhi” ranking di mesin pencari, atau lebih dikenal sebagai SEO (Search Engine Optimization), tidak lebih dari “perkiraan terstruktur” dari pengalaman menganalisis hasil mesin pencari, kemudian menyesuaikan website dengan pola yang merupakan sinergi kompleks dari berbagai elemen website yang memiliki ranking yang baik. Dengan tetap mengingat bahwa masing-masing perangkat lunak memberikan bobot yang berbeda-beda. Terdapat 2 faktor utama yang secara umum paling berpengaruh pada ranking sebuah halaman web, yaitu faktor internal dan faktor eksternal.
1. Faktor Internal (berhubungan dengan penulisan isi website dan HTML)
Dalam menentukan rangking, search engine sangat memperhatikan konten website sebagai salah satu acuan untuk menentukan tingkat relevansi. Halaman web yang menampilkan citra yang hanya terdiri atas gambar dan flash serta tidak menyertakan teks biasa, sangat sulit dibaca oleh search engine. Walaupun Google saat ini sudah mulai menerapkan teknik kecerdasan buatan (Artificial Intelegence), tetap saja belum dapat membaca makna dari sebuah gambar. Oleh karena itu konten berupa teks murni harus dipakai agar suatu website mudah dikenal. Dalam menyusun konten teks, suatu kata kunci atau keyword yang dibuat, diusahakan dapat terpakai pada kalimat-kalimat dalam teks tersebut. Penggunaan keyword yang dimaksud adalah penggunaan dalam batas yang wajar dengan catatan kalimat masih enak untuk dibaca. Menentukan keyword yang tepat untuk website tidaklah mudah. Jika website dioptimalkan dengan keyword yang salah bisa berakibat fatal. Meskipun websitenya sudah berada di posisi paling atas pada halaman pertama, tetap saja tidak berguna sebab keyword yang dioptimalkan tidak pernah dicari orang. Salah satu cara untuk mengatasi masalah ini dengan
menggunakan alat bantu seperti yang disediakan WordTracker.com. WordTracker.com memiliki database keyword-keyword populer berdasarkan data dari beberapa search engine utama, dengan mengetikkan topik dari konten website, dalam beberapa saat WordTracker bisa memberikan keyword-keyword yang berhubungan dengan topik tersebut. Faktor lain yang perlu diperhatikan adalah adanya broken link atau javascript error pada website.
2. Faktor Eksternal (berhubungan dengan link popularity)
Seperti yang telah dijelaskan sebelumnya, faktor internal lebih berkaitan dengan aspek yang ada dalam sebuah website. Faktor internal sangat mudah dimanipulasi, sehingga search engine tidak mungkin menggunakannya 100% sebagai acuan untuk menghasilkan hasil pencarian yang berkualitas. Manipulasi yang dimaksud adalah spamming, seperti penulisan konten menggunakan keyword yang diulang-ulang secara berlebihan, penulisan teks yang warnanya sama dengan warna pada latar belakangnya (background) sehingga pengunjung tidak dapat membacanya. Hal-hal semacam ini tujuannya tidak lain untuk mengecoh crawler. Search engine biasanya menggunakan faktor eksternal sebagai acuan relevansi antara konten website dan keyword. Faktor yang dimaksud adalah link popularity, yaitu banyaknya link dari website lain yang mengarah ke website. Semakin banyak link dari luar, berarti nilai link popularity-nya semakin besar. Hal ini menyebabkan semakin baik pula konten yang dimiliki. Link popularity sudah umum dipakai acuan oleh search engine (Teknik SEO Indonesia, 2008).
2.2 Search Engine Google
Google Inc. merupakan sebuah perusahaan publik Amerika Serikat, berperan dalam pencarian Internet dan iklan online. Perusahaan ini berbasis di Mountain View, California, dan memiliki karyawan berjumlah 19.604 orang (30 Juni 2008). Filosofi Google meliputi slogan seperti "Don't be evil", dan "Kerja harusnya menantang dan tantangan itu harusnya menyenangkan", menggambarkan budaya perusahaan yang santai.
Google didirikan oleh Larry Page dan Sergey Brin ketika masih mahasiswa di Universitas Stanford dan perusahaan ini merupakan perusahaan
saham pribadi pada 7 September 1998. Penawaran umum perdananya dimulai pada tanggal 19 Agustus 2004, mengumpulkan dana $1,67 milyar, menjadikannya bernilai $23 milyar. Melalui berbagai jenis pengembangan produk baru, pengambilalihan dan mitra, perusahaan ini telah memperluas bisnis pencarian dan iklan awalnya hingga ke area lainnya, termasuk email berbasis web, pemetaan online, produktivitas perusahaan, dan bertukar video.
2.3 Search Engine Yahoo
Yahoo! adalah sebuah portal web populer yang dioperasikan oleh perusahaan yang bernama Yahoo! Inc., yang dirintis oleh oleh David Filo dan Jerry Yang. Yahoo! pada awalnya hanyalah semacam bookmark (petunjuk halaman buku), ide itu berawal pada bulan April 1994, saat itu dua orang alumni Universitas Stanford mendapat liburan ketika profesor mereka pergi ke luar kota karena cuti besar. Dua mahasiswa teknik tersebut mempunyai sedikit pekerjaan yang harus dilakukan selain menjelajah internet, sehingga tidak membutuhkan waktu lama untuk mengkompilasi sebuah daftar bookmark yang besar, yang dikelompokkan berdasarkan subyek. Kemudian mereka berpikir, mengapa tidak memasukannya di web. Mereka kemudian bekerja membuat sebuah program database untuk menanganinya, yang dapat memberikan hasil secara online. Koleksi bookmark tersebut, sekarang dikenal sebagai Yahoo!, menerima sejumlah 80 juta pengunjung setiap bulan (sensus tahun 2000).
2.4 Search engine Ask Jeeves (Ask.com)
Ask.com (atau Ask Jeeves di Inggris Raya) adalah sebuah mesin pencari yang dimulai pada tahun 1996 oleh Garrett Gruener dan David Warthen di Berkeley, California. Original perangkat lunak mesin pencari ini dilaksanakan oleh Gary Chevsky dari desain sendiri. Chevsky, Justin Grant, dan lain-lain membangun situs Ask Jeeves. Tiga perusahaan modal ventura, Highland Capital Partners, Institutional Venture Partner, dan The RODA Group adalah investor awal. Ask.com saat ini dimiliki oleh IAC/Inter ActiveCorp di bawah symbol NASDAQ IACI. Ask.Com Ini awalnya dikenal sebagai Ask Jeeves. "Jeeves" adalah nama "Pribadi Pria Gentleman", atau pelayan (Diilustrasikan Oleh Marcos Sorensen), mengambil jawaban untuk setiap pertanyaan yang diajukan. Karakter didasarkan pada Jeeves, Bertie Wooster fiksi pelayan dari karya-karya PGWodehouse.
2.5 Search engine Altavista
AltaVista diciptakan oleh para peneliti dari Digital Equipment Corporation's Western Research Laboratory yang mencoba memberikan layanan untuk di jaringan publik agar lebih mudah mendapatkan file. Ide awal ditemukan oleh dua orang yaitu Louis Monier yang menulis crawler dan Michael Burrows yang menulis indexer. Nama AltaVista merupakan nama yang dipilih oleh perusahaan di Palo Alto. AltaVista diluncurkan ke publik umum sebagai search engine Internet pada tanggal 15 Desember 1995 dengan alamat http://altavista.digital.com/.
Saat peluncuran, layanan search engine ini mempunyai dua inovasi yang mana men-setnya di depan search engine lainnya. Penggunaannya cepat, multi-threaded crawler (Scooter) yang meliputi lebih banyak halaman web dan suatu pencarian back-end efisien running pada advanced hardware. Terhitung sejak tahun 1998, search engine ini menggunakan 20 mesin multi-processor DEC’s 64-bit Alpha processor. Setiap mesin mempunyai 130 GB RAM, 500 GB space harddisk dan menerima 13 juta queries perhari. Hal ini membuat AltaVista pencari pertama, full-text database dari bagian besar World Wide Web. Fitur pembeda AltaVista dengan Search engine lainnya saat ini adalah minimalistic
inteface yang dimilikinya; fitur akan hilang ketika ia menjadi suatu portal, tetapi ada kembali saat ia mengulang kembali usahanya pada fungsi pencariannya
Site AltaVista tergolong sukses, terlihat dari Traffic-nya yang meningkat tajam dari 300.000 pengunjung pada hari pertama menjadi 80 juta pengunjung setiap hari. Kemampuan pencarian web, dan layanan AltaVista khususnya, menjadi pokok materi pada banyak artikel dan bahkan beberapa buku. AltaVista sendiri menjadi salah satu tujuan teratas pada web, dan tahun 1997 akan layak mendapatkan US$50 juta dalam sponsorship revenue.
2.6 Search engine Scirus
Scirus adalah search engine yang khusus secara komprehensif digunakan untuk pencarian ilmiah. Seperti halnya dengan CiteSeer dan Google Scholar yang di fokuskan pada informasi ilmiah. Tidak seperti CiteSeer, Scirus tidak hanya untuk informasi teknologi dan ilmu komputer serta tidak hanya hasil tetapi seluruh teks dapat ditampilkan. Scirus juga berguna untuk hasil pencarian ilmiah pada scopus, abstrak dan rujukan database meliputi keluaran pencarian ilmiah secara global. Scirus dimiliki dan dioperasikan oleh Elsevier.
Scirus adalah sebuah mesin pencari web gratis yang dikembangkan terutama bagi para ilmuwan, peneliti dan mahasiswa. Ini memungkinkan seseorang mencari informasi ilmiah untuk menentukan informasi yang mereka perlukan - termasuk peer-review artikel, informasi paten, penulis halaman rumah dan situs web universitas - dengan cepat dan mudah. Scirus menawarkan pilihan pencarian Dasar dan Advanced. Dengan fasilitas pencarian Advanced, pengguna dapat lebih spesifik memilih informasi apa yang dicari (memilih area subyek atau sumber konten misalnya) sebelum melakukan pencarian.
2.7 Precision and Recall
Cara yang paling efektif untuk menguji kehandalan sebuah search engine adalah dengan meneliti tingkat precision and recall nya . Precision adalah jumlah kelompok dokumen relevan dari total jumlah dokumen ditemukan oleh sistem. Sedangkan, recall diartikan sebagai jumlah dokumen relevan yang ditemukan oleh sistem (Hardi 2006).
Precision dan Recall adalah dua alat pengukur yang efektif untuk mengevaluasi kualitas hasil di dalam domain seperti sistem temu kembali informasi dan pengklasifikasian secara statistik.
Pengujian Precision and Recall pada search engine Google, Yahoo, Ask Jeeves, Altavista dan Scirus
Proses pengujian terdiri dari 3 tahap:
1. Mengumpulkan literatur baik dalam bentuk cetak maupun elektronik. 2. Menyeleksi search engine dan menentukan query yang akan
digunakan untuk penelusuran. 3. Penelusuran dengan search engine Pemilihan search engine mengacu pada:
1. Banyaknya hasil pembahasan mengenai search engine oleh para pakar/penulis di Internet
2. Banyaknya publik/orang yang menggunakannya (search engine) 3. Popularitas search engine
Search engine yang dipilih yaitu : 1. Google
2. Yahoo 3. Ask Jeeves 4. AltaVista 5. Scirus
Penelitian ini menggunakan 15 istilah kata bidang ilmu komputer. Bahan diambil dari Prosiding “2003 Congress on Evolutionary Computation CEC 2003”. Istilah kata pencarian yang diperoleh diklasifikasikan ke dalam 3 kelompok yaitu Kata Tunggal, Gabungan dan Kompleks.
1. Kata Tunggal antara lain : a. “Hybrid”
b. “Optimization” c. “Evolutionary” d. “Mining” e. “Genetic”
2. Kata Gabungan antara lain : a. “genetic algorithm”
b. “singular value decomposition” c. “dynamic environment”
d. “explicit learning” e. “foot patterns”
3. Kata Kompleks antara lain :
a. “genetic programming” OR “distribution programming” AND problem
b. “multi-criteria evaluation” AND “ “data mining” c. “genetic mining” AND genes
d. “singular value decomposition” AND genetic algorithm” AND performance
e. Clustering OR “memetic algorithms”
Di dalam search engine terdapat dua metode pencarian yaitu simple dan advance mode. Di dalam penelitian ini, pencarian dokumen yang dilakukan pada lima search engine menggunakan advanced mode. Metode ini dipilih agar penjaringan informasi memiliki tingkat precision yang lebih tinggi. Untuk kata tunggal dan kompleks digunakan “match all of the words” dan “exact phrase”, sedangkan untuk gabungan digunakan “exact phrase”. Hasil temuan dikontrol dengan hanya menggunakan bahasa Inggris.
Dari masing-masing search engine diperoleh hasil pencarian dalam jumlah yang sangat besar, akan tetapi dalam penelitian ini dibatasi hanya pada 10 hasil temuan yang muncul pada halaman pertama saja. Pengujian dilakukan pada hari yang sama untuk kelima search engine tersebut, guna menghindari terjadinya variasi hasil pencarian yang disebabkan oleh updating algoritma pengindeksan dari masing-masing search engine (Clarke & Willet, 1997). Pengujian precision and recall terhadap lima search engine ini dilakukan di bulan Mei, Juni dan Juli tahun 2009.
Pengujian yang dilakukan dalam penelitian ini yaitu dengan menilai precision dan recall dari search engine Google, Yahoo, Ask Jeeves, Altavista dan Scirus. Precision adalah jumlah kelompok dokumen relevan dari total dokumen
ditemukan oleh sistem (Clarke & Willet, 1997). Rumus penilaian precision menurut Shafi dan Rather (2005) dalam artikel ilmiah yang berjudul “Precision and Recall of Five Search Engines for Retrieval of Scholarly Information in The Field of Biotechnology” serta Hardi (2006) dalam artikel berjudul “Sebuah Eksperimentasi Penilaian Precision and Recall Untuk Informasi Ilmiah Bidang Ilmu Perpustakaan Dan Informasi“ , sebagai berikut :
Jumlah skor dokumen ilmiah ditemukan oleh search engine Precision = ---
Total number dari hasil temuan yang di evaluasi
Dalam mendefinisikan relevansi tiap halaman, digunakan poin skala empat untuk menghitung precision, kriterianya adalah sebagai berikut :
• Halaman yang menampilkan dokumen-dokumen ilmiah, skor 3, • Halaman yang menampilkan abstrak, skor 2,
• Halaman yang menampilkan buku atau pangkalan data, skor 1, • Halaman yang menampilkan selain poin-poin diatas, skor 0,
• Halaman yang tidak bisa ditampilkan karena server yang tidak merespon setelah tiga kali penelusuran, skor 0.
Relative Recall adalah jumlah dokumen relevan yang ditemukan oleh sistem (Clarke & Willet, 1997). Nilai Relative Recall menurut Shafi dan Rather (2005) serta Hardi (2006) dapat dihitung dengan rumus :
Total dokumen ilmiah yang ditemukan Search Engine Relative Recall = --- Jumlah dokumen ilmiah yang ditemukan oleh ke 5 Search Engine
Jika terjadi overlap pada hasil temuan search engine, maka hanya temuan yang mengalami overlap yang dimasukkan ke dalam kalkulasi dari 5 buah Search Engine tersebut.
Sebagai contoh, jika ada 5 buah Search Engine yaitu a, b, c, d dan e, yang akan mendapatkan dokumen a1, b1, c1, d1 dan e1, apabila Tidak Ada Overlap diantara Search Engine- Search Engine (a ∩ b, a ∩ c, a ∩ d dan a ∩ e adalah nol)
Jika terdapat Overlap antar Search Engine yaitu a ∩ b = b2, a ∩ c = c2, a ∩ d = d2 dan a ∩ e = e2 maka Relative Recall dari Search Engine a adalah = a1/(a1 + b2 + c2 + d2 + e2). Huruf b2 atau c2 atau d2 atau e2 adalah hasil temuan yang Overlap.
Nilai tengah Precision dan Relative recall diperoleh dari perhitungan rata-rata mikro (Clarke & Willet, 1997; Tague, 1992). Rata-rata-rata skor untuk tiap search engine suatu query adalah hasil penjumlahan keseluruhan lima belas query, dan nilai tengah diperoleh dari jumlah masing-masing kata tunggal, gabungan, dan kompleks.
2.8 Penelitian Sebelumnya Yang Relevan
Shafi dan Rather (2005) dari Departement of Library and Information Science, University of Kashmir, Srinagar-India, melakukan uji precision and recall yang dikhususkan untuk bidang Biotechnology. Penelitian yang berjudul “Precision and Recall of Five Search Engines for Retrieval of Scholarly Information in The Field of Biotechnology” bertujuan untuk mengidentifikasi kelima search engine yaitu Altavista, Google, Hotbot, Scirus dan Bioweb dan melakukan penilaian precision and recall dari kelima search engine tersebut. Kesimpulannya adalah search engine Scirus memiliki performance yang baik sekali dalam pencarian dokumen ilmiah, Google merupakan alternatif pilihan yang terbaik dalam mendapatkan dokumen ilmiah berbasis web, Hotbot unggul dalam kombinasi precision and recall tetapi mempunyai overlap yang besar terhadap search engine Google, kecepatan pencarian informasi pada Altavista rendah, dan Bioweb paling lemah dalam hasil pencariannya.
Hardi (2006), peneliti pada Veritas Dokumen Management, Jakarta, melakukan pengukuran kinerja search engine. Penelitiannya yang berjudul “Sebuah Eksperimentasi Penilaian Precision and Recall Untuk Informasi Ilmiah Bidang Ilmu Perpustakaan Dan Informasi”, bertujuan untuk mengevaluasi kinerja enam search engine yaitu Google, Yahoo, Scirus, Sciseek, Ask Jeeves dan American Online (AOL). Dari hasil pengujian terhadap enam search engine diperoleh nilai tengah untuk precision dan relative recall. Peringkat pertama untuk penilaian precision diperoleh oleh Scirus (0.37), Google dan Yahoo
mendapat nilai yang sama (0.22), AOL (0.20), Sciseek (0.18) dan terakhir Ask Jeeves (0.15). Sedangkan untuk nilai tengah Relative Recall peringkat pertama diperoleh oleh Scirus (0.24), Google (0.19), Yahoo (0.18), AOL (0.17), Ask Jeeves (0.14) dan terakhir Sciseek (0.09). Artinya bahwa Scirus merupakan search engine yang mampu dan handal untuk konsep tunggal, gabungan dan kompleks dibandingkan dengan lima search engine lainnya.
Pada penelitian ini pengujian precision and recall dilakukan adalah sebagai salah satu kegiatan metode uji dari pengujian-pengujian fasilitas dan metode pencarian dokumen ilmiah yang penulis lakukan.