BAB 6 ANALISIS CLUSTER Pendahuluan
Analisis cluster membagi data ke dalam grup (cluster) yang bermakna, berguna, atau keduanya.Jika tujuannya mencari grup yang memiliki makna, maka cluster seharusnya menangkap struktur alami dari data, disebut juga clustering for understanding. Dalam beberapa kasus, analisis cluster hanya berguna sebagai titik awal bagi penggunaan yang lain - seperti peringkasan data (data summarization), disebut juga clustering for utility. Apakah untuk mencari grup yang bermakna atau sebagai perangkat awal bagi penggunaan yang lain, analisis cluster telah lama memainkan peran penting dalam berbagai bidang seperti: psikologi dan ilmu sosial lainnya, biologi, statistika, pengenalan pola, temu kembali informasi, machine learning, dan data mining.
Analisis cluster telah diterapkan dalam banyak masalah praktis, seperti
Clustering for Understanding. Kelas, atau kelompok obyek yang memiliki makna secara konsep dengan karakteristik umum yang sama, memainkan peran penting dalam bagaimana orang menganalisis dan menjelaskan fenomena di alam. Sebenarnya, manusia memiliki keterampilan untuk membagi obyek-obyek ke dalam grup (clustering) dan memberikan obyek tertentu dalam grup-grup tersebut (classification). Sebagai contoh, bahkan anak kecil dapat dengan cepat memberikan label obyek-obyek dalam foto sebagai bangunan, kendaraan, manusia, binatang, tumbuhan, dan sebagainya. Dalam konteks pemahaman data, cluster merupakan kelas-kelas yang potensial dan analisis cluster merupakan kajian tentang teknik menemukan kelas-kelas tersebut secara otomatis. Berikut adalah contoh clustering for understanding di berbagai bidang :
• Biologi. Ahli biologi telah lama menciptakan taksonomi (klasifikasi secara hirarki) bagi seluruh makhluk hidup : kingdom, phylum, kelas, ordo, famili, genus dan spesies. Sehingga tidak mengherankan jika pada awalnnya banyak pekerjaan analisis cluster yang bertujuan menciptakan taksonomi matematis yang dapat menemukan struktur klasifikasi secara otomatis. Saat ini, ahli biologi menerapkan clustering dalam analisis informasi genetik yang sangat besar. Sebagai contoh, clustering digunakan untuk mencari kelompok-kelompok gen yang memiliki fungsi sama.
• Temu-Kembali Informasi. World Wide Web mengandung jutaan halaman web, dan hasil query kepada mesin pencari dapat menghasilkan ribuan halaman. Clustering dapat digunakan untuk mengelompokkan hasil pencarian ini ke dalam sejumlah kecil cluster, masing-masing cluster menangkap aspek tertentu dari query. Sebagai contoh, query “movie” mungkin akan menghasilkan halaman web yang dikelompokkan dalam beberapa kategori, seperti review, trailer, bintang dan teater. Setiap kategori (cluster) dapat dipecah ke dalam sub-kategoru (sub-claster), menghasilkan struktur hirarki yang membantu pengguna untuk melakukan eksplorasi hasil query.
• Iklim. Agar dapat memahami iklim bumi, perlu mencari pola atmosfer dan lautan. Untuk itu, analsis cluster telah digunakan untuk mencari pola tekanan atmosfer di daerah kutub dan wilayah lautan yang memiliki dampak berarti bagi iklim di daratan.
• Psikologi dan Pengobatan. Kondisi kesehatan seseorang seringkali bervariasi, dan analisis cluster dapat digunakan untuk melakukan identifikasi sub-kategori kondisi kesehatan. Sebagai contoh, clustering telah digunakan untk melakukan identifikasi berbagai jenis depresi. Analisis cluster juga dapat digunakan untuk mendeteksi pola penyebaran penyakit secara spasial maupun temporal.
• Bisnis. Bisnis mengumpulkan sejumlah besar informasi tentang pelanggan saat ini serta orang yang potensial menjadi pelanggan. Clustering dapat digunakan untuk membagi pelanggan ke dalam sejumlah kecil kelompok untuk analisis dan kegiatan pemasaran.
Clustering for Utility. Analisis cluster menyediakan abstraksi dari obyek data individu kepada cluster dimana obyek tersebut berada. Sebagai tambahan, beberapa teknik clustering dapat menentukan karakteristik cluster dalam bentuk cluster prototype, yaitu obyek data yang mewakili obyek-obyek lainnya di dalam cluster. Cluster prototype ini dapat digunakan sebagai dasar bagi sejumlah teknik analisis data dan pengolahan data. Dengan demikian, dalam konteks penggunaan (utility), analisis cluster adalah kajian tentang teknik untuk mencari cluster prototype yang paling mewakili.
• Summarization. Banyak teknik analisis data, seperti regresi atau PCA, memiliki kompleksitas O(m2) atau lebih tinggi (dimana m adalah jumlah obyek), sehingga tidak praktis untuk dataset yang besar. Namun, daripada menerapkan algoritma ke seluruh dataset, algoritma tersebut dapat diterapkan ke dataset yang telah dikurangi, mengandung hanya cluster prototype. Tergantung dari tipe analisis, jumlah prototipe, dan tingkat akurasi prorotipe dalam mewakili data, hasil algoritma dapat dibandingkan dengan jika menggunakan seluruh data.
• Compression. Cluster prototype dapat juga digunakan untuk kompresi data. Secara umum, dibuat sebuah tabel yang berisi prototipe dari setiap cluster, misal masing-masing prototipe diberikan nilai integer berupa indeks dari prototipe yang terasosiasi dengan cluster-nya. Tipe kompresi ini dikenal sebagai vector quantization dan sering diterapkan pada data citra, suara dan video, dimana (1) banyak obyek data yang sangat mirip satu dengan lainnya, (2) kehilangan informasi sampai tingkat tertentu masih dapat ditolerir, dan (3) diinginkan tingkat pengurangan ukuran data yang nyata.
• Efficiently Finding Nearest Neighbors. Mencari nearest neighbors memerlukan perhitungan jarak antar pasangan obyek, untuk semua titik. Seringkali cluster dan cluster prototype dapat ditemukan dengan jauh lebih efisien.
6.1. Gambaran Umum
6.1.1. Apakah Analisis Cluster ?
Analisis cluster akan mengelompokkan obyek-obyek data hanya berdasarkan pada informasi yang terdapat pada data, yang menjelaskan obyek dan relasinya. Tujuan analisis cluster adalah agar obyek-obyek di dalam grup adalah mirip (atau berhubungan) satu dengan lainnya, dan berbeda (atau tidak berhubungan) dengan obyek dalam grup lainnya. Semakin besar tingkat kemiripan/similarity (atau homogenitas) di dalam satu grup dan semakin besar tingkat perbedaan diantara grup, maka semakin baik (atau lebih berbeda) clustering tersebut. Gambar 6.1 merupakan ilustrasi prinsip clustering.
Gambar 6.1. Prinsip Clustering
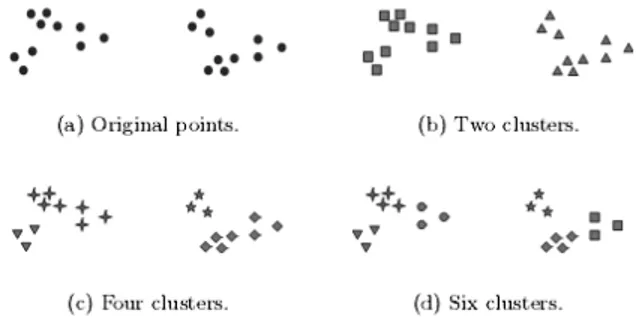
Gambar 6.2 memperlihatkan dua puluh titik dan tiga cari membagi titik-titik tersebut dalam cluster. Gambar 6.2 merupakan ilustrasi bagaimana definisi cluster tidak presisi dan definisi terbaik tergantung dari kondisi data serta hasil yang diinginkan.
Gambar 6.2. Beberapa cara menentukan cluster bagi dataset yang sama 6.1.2. Tipe Clustering.
Ada beberapa tipe clustering jika dilihat dari beberapa sudut pandang, yaitu: • Hierarchical versus Partitional.
Partitional Clustering adalah membagi himpunan obyek data ke dalam sub-himpunan (cluster) yang tidak overlap, sehingga setiap obyek data berada dalam tepat satu cluster. Dilihat secara individual, setiap koleksi cluster dalam Gambar 1(b-d) adalah partitional clustering.
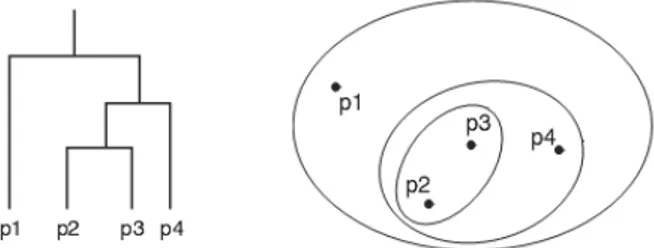
Jika kita mengizinkan cluster untuk memiliki subcluster, maka akan terbentuk Hierarchical Clustering, yang merupakan himpunan nested cluster yang diatur dalam bentuk tree. Gambar 6.3 memperlihatkan empat obyek data sebagai dendogram dan nested cluster.
Gambar 6.3. Dendogram dan Nested Cluster. • Exclusive versus Overlapping versus Fuzzy
Clustering pada Gambar 6.2 semuanya bersifat exclusive, karena masing-masing obyek ditempatkan dalam satu cluster. Dalam banyak situasi dimana satu titik masuk akal ditempatkan dalam lebih satu cluster maka situasi ini menimbulkan overlapping clustering atau non-exclusive clusering. Misalnya, seseorang dalam universitas bisa menjadi mahasiswa sekaligus karyawan universitas tersebut. Dalam fuzzy clustering, setiap obyek menjadi milik setiap cluster dengan nilai keanggotaan diantara 0 (multak bukan anggota cluster) dan 1 (mutlak anggota cluster). Dengan kata lain, cluster diperlakukan sebagai himpunan fuzzy.
• Complete versus Partial
Complete clustering akan menetapak setiap obyek ke dalam cluster, sedangkan partial clustering tidak. Alasan partial clustering adalah karena beberapa obyek dalam dataset mungkin bukan anggota kelompok yang telah didefinisikan dengan baik. Banyak obyek dalam dataset mungkin mewakili noise, outlier atau “uninteresting background”. Sebagai contoh, beberapa artikel surat kabar mungkin berbagai tema yang sama, seperti pemanasan global, sedangkan artikel lainnya lebih umum atau one-of-a-kind. Sehingga, untuk mencari topik yang penting dalam artikel bulan lalu, kita hanya ingin mencari cluster dokumen yang terkait erat dengan tema umum. Dalam kasus lain, mungkin yang diperlukan adalah complete clustering. Misal, aplikasi yang menggunakan clustering untuk mengatur dokumen untuk browsing yang perlu menjamin semua dokumen dapat di-browse.
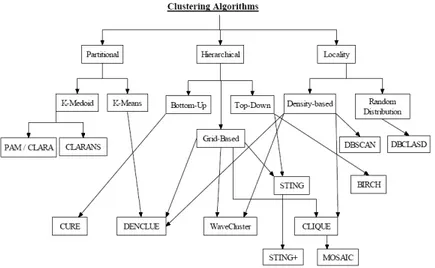
Telah banyak algoritma clustering yang dikembangkan, Gambar 6.4 menyajikan beberapa algoritma clustering dan hubungan diantara algoritma-algoritma tersebut. Sedangkan yang akan dibahas pada modul ini hanya algoritma K-mean, Agglomerative Hierarchical dan DBSCAN.
Gambar 6.4. Algoritma Clustering. 6.1.3. Tipe Cluster
Clustering bertujuan mencari kelompok obyek (cluster) yang bermanfaat, sedangkan tingkat manfaat ditentukan oleh tujuan analisis data yang ditetapkan. Oleh karena itu, terdapat beberapa jenis cluster, yaitu:
• Well-Separated. Cluster merupakan himpunan titik sehingga sembarang titik dalam cluster lebih dekat (atau lebih mirip) dengan setiap titik dalam cluster dibandingkan dengan sembarang titik yang tidak di dalam cluster. Gambar 6.5 merupakan ilustrasi Well-Separated Cluster.
Gambar 6.5 Tiga Well-Separated Cluster
• Prototype-Based/Center-Based. Cluster merupakan himpunan obyek, sehingga sebuah obyek dalam cluster lebih dekat (lebih mirip) dengan “pusat” cluster, daripada dengan pusat cluster lainnya. Yang sering dijadikan pusat cluster adalah centroid dan medoid. Centroid adalah rataan semua titik dalam cluster, sedangkan medoid adalah titik yang paling mewakili cluster. Center-based cluster di-ilustrasikan pada Gambar 6.
Gambar 6.6. Empat Center-Based Cluster
• Graph-Based. Jika data direpresentasikan sebagai graph, dimana obyek menjadi node dan link menyatakan koneksi diantara obyek, maka cluster dapat didefinisikan sebagai connected component; yaitu grup obyek yang terkoneksi satu sama lain, tetapi tidak memiliki koneksi dengan obyek di luar grup. Contoh penting dari graph-based cluster adalah contiguity-based cluster, dimana dua obyek terkoneksi hanya jika keduanya berada
dalam jarak tertentu satu sama lain. Contoh contiguity-based cluster dapat dilihat pada Gambar 6.7
Gambar 6.7 Contiguity-based cluster
• Density-Based. Sebuah cluster adalah wilayah yang padat obyek dikelilingi oleh wilayah dengan kepadatan rendah. Cluster tipe ini berguna untuk membentuk cluster dengan bentuk tak-teratur (irregular) atau terpilin (intertwined), dan juga jika terdapat noise dan outlier. Gambar 6.8 merupakan contoh Density-Based Clustering
Gambar 6.8 Density-Based Clustering.
• Shared-Property (Conceptual Cluster). Mencari cluster dengan beberapa sifat yang sama, atau menyatakan konsep tertentu. Gambar 6.9 merupakan cluster yang mempunyai sifat “lingkaran”
Gambar 6.9 Dua Overlapping Circles 6.2. K-mean
Algoritma k-means mengambil parameter input k,dan membagi sebuah himpunan dari objek kedalam k cluster,sehingga menghasilkan similaritas intracluster adalah tinggi tetapi similaritas intercluster adalah rendah . similaritas cluster diukur dari banyaknya nilai m obyek yang ada pada sebuah cluster,sehingga dapat dilihat sebagai cluster’s centre gravity.
“Bagaimana algoritma k-means bekerja ? ” proses algoritma k-means sebagai berikut. Pertama menentukan secara random k obyek, masing masing obyek tersebut pada awalnya menggambarkan sebuah cluster mean atau cluster center. Untuk tiap-tiap obyek yang tersisa dimasukkan ke dalam cluster yang mempunyai kesamaan yang lebih, didasarkan pada jarak antara obyek dengan sebuah cluster mean. Kemudian hitung nilai mean yang baru untuk masing – masing cluster.proses ini berulang sampai fungsi kriteria di temukan.
Algoritma ini mencoba untuk menentukan k partisi yang memiliki fungsi squared error minimal. Metode ini relatif lebih scalable dan effisien untuk pemrosesan data dengan jumlah yang besar karena perhitungan kompleksitas dari algoritma
tersebut adalah O(nkt) dimana n adalah jumlah total obyek sedangkan k adalah jumlah cluster dan t adalah banyaknya iterasi. Pada umumnya, k<<n dan t<<n. metoda ini sering menghasilkan optimal lokal.
Metode k-mean, bagaimanapun juga dapat diaplikasikan hanya jika mean dari sebuah cluster didefinisikan. Ini mungkin tidak bisa sebagai pilihan di beberapa aplikasi, seperti halnya untuk data dengan atribut kategorik. Perlunya seorang user menentukan nilai k sebagai jumlah final cluster dilihat dari segi kecepatan mungkin merupakan suatu kerugian. Metode k-mean tidak cocok digunakan untuk menemukan cluster dengan bentuk nonconvex atau cluster dengan ukuran yang sangat berbeda selain itu metode ini sangat sensitif terhadap noise dan outlier.
Algoritma : k-means, algoritma untuk partitioning yang di dasarkan pada nilai mean dari obyek-obyek di dalam sebuah cluster.
Input : sejumlah cluster k,dan sebuah database dengan n obyek.
Output : sebuah himpunan k cluster dengan squared error criterion minimum. Metode :
1. tentukan k object sebagai cluster center awal; 2. ulangi
3. tandai masing masing obyek untuk sebuah cluster, dimana obyek tersebut lebih “similar,” didasarkan pada nilai mean obyek tersebut dalam sebuah cluster; 4. hitung nilai cluster mean untuk masing masing cluster;
5. sampai tidak ada perubahan.
Ada beberapa varian dari metode k-means, ini dapat berbeda pada pemilihan dari nilai awal k-means, perhitungan dissimilarity, dan strategi untuk menghitung nilai cluster means. Sebuah strategi yang menarik dan sering menghasilkan hasil yang bagus untuk awalnya lakukan sebuah algoritma hirarchical agglomeration yang digunakan untuk menentukan jumlah cluster dan untuk menemukan sebuah initial clustering, dan kemudian menggunakan proses iterasi relokasi untuk meningkatkan clustering tersebut.
Varian yang lain untuk k-means adalah metode k-modes, dengan memperluas paradigma k-means untuk mengelompokkan data kategorik dengan menggantikan mean cluster dengan modes (modus), menggunakan ukuran dissimiliritas baru untuk hubungan dengan obyek kategorik, dan dengan menggunakan sebuah metode yang didasarkan pada frequency atau keseringan untuk mengupdate modes dari cluster. Metode K-mean dan K-modes dapat digabungkan untuk mengelompokkan data dengan mixed numeric dan nilai kategori yang di hasilkan dengan metode k-prototype.
Algoritma EM (Expact on Maximization) adalah algoritma dengan mengembangkan paradigma algoritma k-mean dengan sebuah cara yang lain. Untuk menandakan tiap tiap obyek ke dalam sebuah calon atau dedicated cluster, untuk menandakan masing masing obyek ke dalam sebuah cluster diperhitungkan menurut lebar yang mewakili kemungkinan keanggotaan. Dengan kata lain,tidak ada batasan yang tegas antar cluster. Oleh karena itu nilai mean yang baru dihitung berdasarkan ukuran lebar yang ditentukan.
Properties algoritma k-means : • Selalu ada K cluster.
• Minimal ada satu item data pada masing masing cluster.
• Cluster adalah metode non-hierarchical dan cluster tersebut tidak overlap. • Setiap anggota sebuah cluster merupakan “closest” untuk cluster tersebut
dari cluster lain karena kedekatan tidak selalu melibatkan ‘center’ dari cluster
Contoh Kasus :
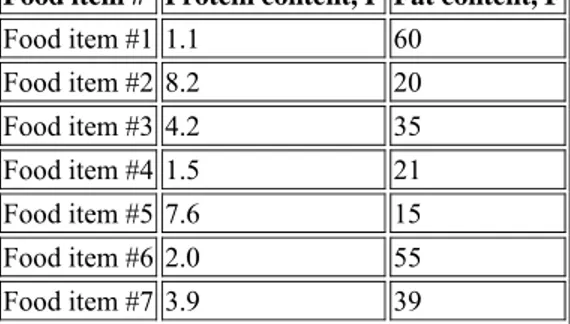
Kita mencoba menerapkan algoritma clustering k-Means dengan final cluster sejumlah empat cluster dari data yang terdapat pada Tabel 6.1
Tabel 6.1 Dataset Food
Food item # Protein content, P Fat content, F Food item #1 1.1 60 Food item #2 8.2 20 Food item #3 4.2 35 Food item #4 1.5 21 Food item #5 7.6 15 Food item #6 2.0 55 Food item #7 3.9 39
Untuk lebih memahami permasalahan ini kita gambar data tersebut ke dalam diagram, dari gambar tersebut kita dapat menentukan empat point dengan jarak terjauh (Gambar 6.10):
Gambar 6.10. Plot data Fat Content vs Protein Content
Dari Gambar 8 di atas dapat kita ketahui bahwa jarak antara point 1 dan point 2, 1 dan 3, 1 dan 4, 1 dan 5, 2 dan 3, 2 dan 4, 3 dan 4 adalah maksimum.
Sehingga, ke-empat cluster tersebut yang terpilih adalah :
Cluster number Protein content, P Fat content, F C1 1.1 60 C2 8.2 20 C3 4.2 35 C4 1.5 21
Dan juga kita dapat mengamati bahwa point 1 merupakan close untuk point 6 sehingga kita dapat mengelompokkan kedua point tersebut ke dalam satu cluster, misalnya kita sebut kluster ini kita sebut dengan nama cluster C16. Kemudian kita hitung nilai centroidnya, nilai P untuk centroid C16 adalah (1.1+2.0)/2=1.55 dan nilai F untuk centroid C16 adalah (60+55)/2=57.50.
Kemudian kita hitung titik-titik yang lain, point 2 dapat kita gabungkan dengan point 5 menjadi satu closer,kita namakan cluster ini kita sebut dengan nama cluster C25,nilai P untuk centroidnya C25 adalah (8.2+7.6)/2=7.9 dan nilai F untuk centroidnya C25 adalah (20+15)/2=17.50.
Point 4 tidak termasuk close pada cluster manapun,sehingga kita dapat masukkan point ini kedalam cluster yang ke empat, kita namakan cluster ini dengan nama cluster C4 dengan nilai P untuk centroidnya C4 adalah 1.5 dan nilai F untuk centroidnya C4 adalah 21.
Akhirnya,kita dapatkan nilai akhir untuk masing masing centroid : Cluster number Protein content, P Fat content, F C16 1.55 57.50
C25 7.9 17.5
C37 4.05 37
C4 1.5 21
Pada contoh diatas merupakan langkah yang mudah untuk menentukan jarak antar point.pada kasus yang lain tidak jarang dijumpai bahwa sulit untuk menentukan jarak, salah satu cara yang bisa digunakan adalah dengan menggunakan euclidean metric untuk mengukur jarak antara dua point dan memasukkan point tersebut ke dalam sebuah cluster.
6.3. Agglomerative dan Divisive Hierarchical Clustering
Agglomeretive Hierarchical Clustering : Strategi bottom-up ini dimulai dengan menempatkan setiap obyek pada clusternya masing-masing dan menggabungkan cluster-cluster atomik ini menjadi cluster-cluster yang lebih besar, terus sampai semua obyek berada pada 1 cluster atau sampai kondisi berhenti tercapai. Kebanyakan metode clustering hirarkis menggunakan metode
yang masuk ke kategori ini. Perbedaannya hanya pada definisi similarity intercluster.
Divise Hierarchical Clustering : Strategi top-down ini merupakan kebalikan dari Agglomeretive Hierarchical Clustering. Dimulai dengan menempatkan seluruh obyek pada satu cluster. Kemudian dibagi-bagi terus sampai menjadi bagian yang lebih kecil sampai tiap obyek memiliki cluster sendiri atau kriteria berhenti tercapai.
Pendekatan agglomerative dan divise di-ilustrasikan pada Gambar 6.11
Gambar 6.11 . Agglomerative dan Divisive Hierarchical Clustering
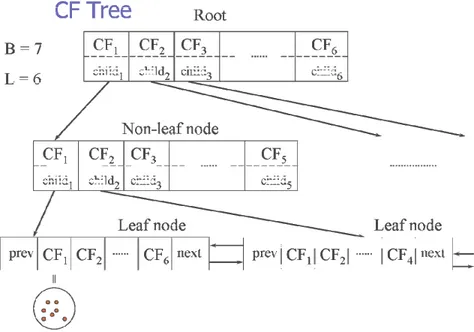
Untuk meningkatkan kualitas clustering salah satu cara yang dapat dilakukan adalah dengan mengintegrasikan hierachical clustering dengan teknik clustering lainnya membentuk multiple phase clustering. Beberapa metode telah ditemukan antara lain BIRCH. BIRCH dimulai dengan mempartisi obyek secara hirarkis dengan struktur tree, dan kemudian mengaplikasikan algoritma clustering lainnya untuk menemukan cluster.
BIRCH: Balanced Iterative Reducing and Clustering Using Hierarchies BIRCH memperkenalkan dua konsep yaitu clustering feature dan clustering feature tree (CF-tree). CF adalah informasi tentang sub-cluster dari obyek
Step 0
Step 1
Step 2 Step 3 Step 4
b
d
c
e
a
a b
d e
c d e
a b c d e
Step 4
Step 3
Step 2 Step 1 Step 0
agglomerative
(AGNES)
divisive
(DIANA)
CF tree adalah height-balanced tree yang menyimpan CF untuk hierarchical clustering
BIRCH bekerja dalam dua fase :
1. Scan database untuk inisialisasi in-memori CF tree (kompresi multi level data yang mencoba menyimpan struktur clustering yang melekat pada data). Fase scan disajikan dalam Gambar 6.12.
Gambar 6.12. Fase Scan Database
2. Gunakan algoritma clustering yang diinginkan untuk mencari cluster pada leaf node pada CF tree. Fase ini digambarkan pada Gambar 6.13
6.4. DBSCAN
DBSCAN adalah salah satu algoritma clustering density-based. Algoritma memperluas wilayah dengan kepadatan yang tinggi ke dalam cluster dan menempatkan cluster irregular pada database spasial dengan noise. Metode ini mendefiniskan cluster sebagai maximal set dari titik-titik yang density-connected.
DBSCAN memiliki 2 parameter yaitu Eps (radius maksimum dari
neighborhood) dan MinPts (jumlah minimum titik dalam Eps-neighborhood dari suatu titik).
Ide dasar dari density-based clustering berkaitan dengan beberapa definisi baru 1. Neighborhood dengan radius Eps dari suatu obyek disebut
Eps-neighborhood dari suatu obyek tersebut
2. Jika Eps-neighborhood dari suatu obyek mengandung titik sekurang-kurangnya jumlah minimum, MinPts, maka suatu obyek tersebut dinamakan core object
3. Diberikan set obyek D, obyek p dikatakan directly density-reachable dari obyek q jika p termasuk dalam Eps-neighborhood dari q dan q adalah core objek.
Gambar 6.14 memberikan ilustrasi Eps-neighborhood
Gambar 6.14 Eps-neighborhood
4. Sebuah obyek p adalah density-reachable dari obyek q dengan memperhatikan Eps dan MinPts dalam suatu set objek ,D, jika terdapat serangkaian obyek p1,…,pn, p1=q dan pn=p dimana pi+1 adalah directly density-reachable dari pi dengan memperhatikan Eps dan MinPts, untuk 1 <= i <= n, pi elemen D. Konsep density-reachable di-ilustrasikan pada Gambar 6.15.
Gambar 6.15. Density-reachable
5. Sebuah obyek p adalah density-connected terhadap obyek q dengan memperhatikan Eps dan MinPts dalam set obyek D, jika ada sebuah obyek o elemen D sehingga p dan q keduanya density-reachable dari o dengan
memperhatikan Eps dan MinPts. Gambar 6.16 merupakan ilustrasi dari konsep density-connected.
Gambar 6.16 Density-connected
Sifat density-reachability adalah transitive closure dari direct density reachable dan relasi ini simetris. Sedangkan density connectivity adalah relasi simetris.
Algoritma DBSCAN
Arbitrary select a point p
Retrieve all points density-reachable from p wrt Eps and MinPts.
If p is a core point, a cluster is formed.
If p is a border point, no points are density-reachable from p and DBSCAN visits the next point of the database.
Continue the process until all of the points have been processed
Contoh :
Contoh Studi kasus dengan data base yang diujikan :
Pemakaian DBSCAN:
Diketahui MinPts= 3 dan ε = 1 cm a.
Misalkan dalam iterasi terpilih node C1. Maka dicari node-node ε -neighborhood dari C1. Sesuai dengan ketentuan bahwa ε yaitu 1 cm maka diperoleh ε-neighborhood dari C1 yaitu 1,2,3,4, dan 5. Karena ketentuan bahwa MinPts yang ada adalah 3 node, maka node C1 dengan ε -neighborhood sebanyak 5 node (lebih banyak dari pada MinPts) menjadi Core Object.
b.
Iterasi dilanjutkan dengan node lain dalam database. Diperoleh titik C2. Didapat ε-neighborhood dari C2 yaitu 1,2,4,6 dan 7. Karena ε-neighborhood berjumlah 5 dan itu lebih besar dari MinPts-nya maka C2 merupakan Object core.
c.
Dipilih titik C3 didapat ε-neighborhood nya yaitu node 4,5, dan 6. Sesuai dengan ketentuan bahwa ε-neighborhood dari suatu titik jika dia lebih banyak atau sama dengan MinPts maka node tersebut merupakan core object.
C1, C2 dan C3 adalah density-reachable. Hal ini terjadi karena C1 direct-density-reachable dari C2 maupun C3 dan node 4 sendiri merupakan core object maka semua merupakan Core object maka mereka saling density-connected.
Iterasi terus dilakukan terhadap node yang belum pernah menjadi core-object masuk
Dari iterasi tersebut didapat 4, 7, C1, C2, C3, C4, C5, dan C6 sebagai core, mereka density-reachable dan saling density-connected.
Iterasi dilanjutkan untuk semua node/ object pada database.
Ci dan Cn direct density reachable dan sudah tentu mereka density-connected.
Iterasi yang terus dilakukan saat berada di node n. Maka akan dicari
ε-neighborhood dari n didapat node h dan i, karena jumlah ε-neighborhood tidak mencapai MinPts maka n bukan merupakan core object dan karena n,h,i tidak termasuk ε-neighborhood dari core object yang ada maka mereka dianggap sebagai noise.