Analisa Klasifikasi Genre Film pada Linked Open Data menggunakan Ekstraksi Fitur Principal Component Analysis (PCA) dan
Algoritma Naïve Bayes
Analysis of Movie Genre Classification on Linked Open Data using feature extraction Principal Component Analyis (PCA) and Naïve Bayes
Algorithm
A Khaerul Anwar1, Guruh Fajar Shidik2,
1,2Universitas Dian Nuswantoro, Semarang, Indonesia
e-mail: 1[email protected]., 2[email protected] Abstrak
Perkembangan industri perfilman berdampak pada munculnya film dengan berbagai genre.
Genre film merupakan salah satu aspek penting dalam sistem rekomendasi. Genre film dapat membantu proses penyaringan konten film secara otomatis. Saat ini, banyak situs film yang memberikan informasi secara online dan bersifat real-time dengan memanfaatkan teknologi web of data. Web of data tidak hanya menyediakan data dalam jumlah besar yang tersedia dalam format standar untuk diolah, namun juga menyediakan hubungan antar data yang tersedia dan terbuka yang disebut dengan linked open data. Dengan memanfaatkan linked open data, data yang saling terhubung dalam internet dapat diambil kemudian diolah untuk mendapatkan informasi tertentu. Teknologi tersebut sudah banyak dimanfaatkan termasuk di dunia hiburan, salah satu contohnya untuk memprediksi performa film box office. Dalam penelitian ini, peneliti melakukan klasifikasi genre film menggunakan linked open data sebagai basis pengetahuannya. Klasifikasi dilakukan berdasarkan abstrak film menggunakan algoritma Naïve Bayes dan ekstraksi fitur Principal Component Analysis (PCA). Akurasi hasil klasifikasi genre film menggunakan algoritma naïve bayes dibandingkan dengan akurasi hasil klasifikasi genre film menggunakan algoritma naïve bayes dan ekstraksi fitur PCA. Hasil akurasi menunjukan bahwa proses klasifikasi yang paling optimal adalah dengan menggunakan algoritma naïve bayes tanpa ekstraksi fitur PCA.
Kata kunci—Linked Open Data, Klasifikasi, Genre Film, Naive Bayes, Principal Component Analysis
Abstract
The development of the film industry have an impact on the appearance of the film with various genres. Genre films is one of the important aspects of the recommendation system. Genre of the film, can help in the process of screening movie content automatically. Nowadays, many movie sites providing information online and in real-time by utilizing the web of data. Web of data is not only providing large amounts of data available in a standard format to be processed, but also provides the relationships among the data available and open called the linked open data.
By utilizing the linked open data, which are linked in the internet can be taken and processed to
obtain certain information. The technology is already widely used, including in the world of entertainment, one example to predict the box office performance of the film. In this study, researchers conducted a movie genre classification using linked open data as a knowledge base.
Classification is based on an abstract film using Naïve Bayes algorithm and feature extraction Principal Component Analysis (PCA). The accuracy of the classification of film genres use naïve Bayes algorithm compared with the accuracy of the classification of film genres use naïve Bayes algorithm and feature extraction PCA. The results showed that The most PCA.
Keywords— Linked Open Data, Classify, Movie Genre, Naive Bayes, Principal Component Analysis
1. PENDAHULUAN
Film merupakan salah satu bagian besar dari industri hiburan. Semakin berkembangnya industri perfilman baik dari dalam maupun luar negeri mengakibatkan munculnya film dengan berbagai genre, ide cerita hingga teknologi yang digunakan. Keberagaman tersebut, membuat para penikmat film membutuhkan informasi yang lengkap tentang sebuah film. Sehingga mereka dapat menemukan film yang tepat untuk ditonton. Saat ini, beberapa situs film memberikan fasilitas kepada pengguna untuk mendapatkan informasi tentang film dan menonton film secara online. Salah satu contoh yaitu situs Internet Movie Database atau imdb.com.
Pemanfaatan informasi dari situs imdb.com saat ini cukup mudah. Dengan menggunakan teknologi web of data, informasi dari situs imdb.com dapat diolah menjadi sebuah data online dan bersifat real-time [1]. Situs dbpedia.org dan linkedmdb.org merupakan situs yang memanfaatkan teknologi web of data untuk mengolah data film yang diambil dari situs imdb.com. Web of data memungkinkan pengguna internet dapat membuat dan menyimpan data di web, membangun kosakata, menulis aturan untuk mengolah data dan menarik kesimpulan. Semantic web diberdayakan oleh teknologi seperti RDF, SPARQL, OWL, dan SKOS agar pengguna internet dapat menggunakan data yang terdapat di dalam web.
Web of data tidak hanya menyediakan data dalam jumlah besar yang tersedia dalam format standar untuk diolah, namun juga menyediakan hubungan antar data yang tersedia.
Koleksi dataset yang saling terkait tersebut disebut dengan linked data. Dengan linked data, pengguna internet dapat menemukan data dari satu sumber kemudian diarahkan menuju sumber terkait lainnya. Sehingga pengguna dapat menemukan data yang lebih lengkap [2].
Namun tidak semua data di dalam web of data bersifat terbuka (open data) dan dapat diolah secara langsung. JISC Linked Data Horizon Scan[3] menyatakan bahwa linked data dapat bersifat terbuka dan open data dapat saling terhubung (linked). Sehingga tidak semua linked data bersifat terbuka dan tidak semua open data saling terhubung. Linked data akan bersifat terbuka apabila terdapat perjanjian lisensi tentang data yang bersangkutan.
Dari tahun ke tahun, perkembangan linked open data sangatlah pesat. Pada tahun 2007 dataset yang terbuka dan terhubung berjumlah 12 dataset, dan meningkat pada tahun 2010 menjadi 203 dataset [4]. Pada tahun 2014, menurut situs lod-cloud.net, jumlah dataset meningkat menjadi 570 dataset. Perkembangan tersebut menunjukkan bahwa linked open data berperan penting pada ketersediaan data di dunia. Data akan tersedia secara lebih luas dan setiap orang dapat memperolehnya dengan mudah dan bebas. Mark van Rijmenam, yang merupakan founder Datafloq mengatakan bahwa big data akan merevolusi kehidupan manusia di dunia pada tahun 2020. Big data akan membawa skalabilitas dan performa yang lebih baik pada keamanan informasi disertai kemampuan analisa tipe data baru dengan kecepatan yang meningkat.
Salah satu contoh linked open data adalah data-gov Wiki yang dibangun oleh Ding et al [5]. Mereka mencoba mengintegrasikan dataset yang diterbitkan di Data.gov ke dalam linked
open data. Data.gov merupakan sebuah website yang menyediakan data Pemerintah Amerika Serikat untuk masyarakat umum yang menjamin akuntabilitas dan transparansi yang lebih baik.
Mereka juga membangun TWC Linked Open Government Data (LOGD)[6] sebagai portal untuk mengakses Linked Open Government Data dari Data.gov. Menurut [7], linked open data dapat digunakan sebagai latar belakang pengetahuan dalam data mining. Di mana jumlah fitur yang berhubungan dengan tujuan data mining dapat diambil terutama dalam memprediksi permasalahan-permasalahan di dunia nyata. Linked open data menjadi semakin penting di bidang informasi dan manajemen data. Hal ini sudah digunakan oleh banyak organisasi terkenal, produk dan jasa untuk membuat portal, platform, layanan berbasis internet dan aplikasi [8].
Salah satu penelitian yang memanfaatkan teknologi linked open data sebagai basis pengetahuannya yaitu Linked Open Government Data as Background Knowledge in Predicting Forest Fire [1]. Penelitian ini menganalisa prediksi kebakaran hutan dengan menggunakan Linked Open Government Data sebagai basis pengetahuannya. Teknologi linked open data juga digunakan di dunia hiburan, salah satu contohnya untuk prediksi performa film box office.
Krushikanth R.Apala [9] menggunakan data dari social media dan web source diantaranya twitter, youtube dan imdb movie database untuk memprediksi performa film box office.
Berdasarkan uraian diatas, maka peneliti bermaksud untuk melakukan analisa klasifikasi genre film menggunakan linked open data sebagai basis pengetahuannya. Linked open data yang digunakan bersumber dari web of data dbpedia.org dan linkedmdb.org. Linkedmdb.org merupakan linked open data yang menyediakan dataset film dari beberapa situs film populer [10]. Genre film merupakan salah satu aspek utama dalam sistem rekomendasi. Klasifikasi genre film memiliki beberapa manfaat yaitu (1) melakukan pengindeksan database multimedia untuk membantu mencari jenis film tertentu, (2) mengidentifikasi film secara otomatis untuk konsumen melalui pemodelan preferensi pengguna, (3) memfasilitasi penyaringan konten film secara otomatis [11].
Klasifikasi dilakukan berdasarkan abstrak film menggunakan algoritma Naïve Bayes.Algoritma Naïve Bayes merupakan salah satu algoritma klasifikasi tertua, yang sederhana dan sangat efektif. Algoritma ini banyak digunakan untuk klasifikasi teks, seperti filtering spam, dan klasifikasi artikel berita[12][13]. Dalam penelitian ini, peneliti juga menggunakan Principal Component Analysis (PCA) untuk ekstraksi fitur dalam proses klasifikasi. Klasifikasi genre film telah banyak dilakukan dengan berbagai metode[11][14]. Namun, yang membedakan penelitian ini adalah pada penggunaan linked open data sebagai basis pengetahuannya. Diharapkan penelitian ini dapat membuktikan bahwa linked open data dapat digunakan sebagai basis pengetahuan dalam klasifikasi genre film.
2. METODE PENELITIAN
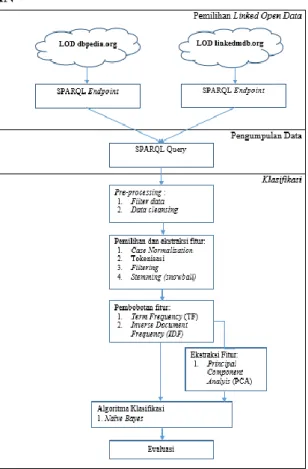
Gambar 1. Usulan metode
Gambar diatas merupakan diagram alir dari metode yang diusulkan. Dalam penelitian ini, pengumpulan data dilakukan dengan melakukan query pada SPARQL endpoint situs dbpedia.org dan linkedmdb.org. Kemudian kumpulan data tersebut digabungkan dengan melakukan join terhadap kedua kumpulan data tersebut. Setelah data terkumpul, langkah selanjutnya yaitu pre-processing data dimana pada langkah tersebut berisi dua tahap yaitu filter data dan data cleansing. Filter data berfungsi untuk memilih data film dengan genre yang sudah ditentukan, yaitu action, adventure, comedy, drama, horror dan musical. Selain itu, film dengan genre yang sejenis dengan genre utama akan digabung dengan genre tersebut. Sedangkan pada tahap data cleansing dilakukan proses penghapusan data genre film yang memiliki jumlah data sedikit dan diluar genre yang sudah ditentukan.
Langkah selanjutnya adalah pemilihan dan ekstraksi fitur, dimana pada langkah tersebut terdiri dari empat tahapan, yaitu case normalization, tokenisasi, filtering, dan stemming. Tahap case normalization digunakan untuk mengubah seluruh karakter menjadi huruf kecil.
Dilanjutkan dengan tahap tokenisasi yaitu proses pemisahan kata atau term pada abstrak film, sehingga didapatkan term tiap dokumen film. Tahap selanjutnya yaitu filtering, yang digunakan untuk menghapus term yang termasuk kedalam stopword-list. Tahap terakhir pada langkah ini yaitu stemming dimana pada tahap tersebut digunakan untuk mencari kata dasar dari tiap term atau kata.
Setelah pemilihan fitur, langkah selanjutnya yaitu pembobotan fitur menggunakan Term Frequency Inverse Document Frequency (TF-IDF). Fitur pada penelitian ini berjumlah sangat banyak, sehingga dibutuhkan adanya penggalian informasi penting dari semua fitur. Proses tersebut dilakukan menggunakan ekstraksi fitur Principal Component Analysis (PCA). Dalam penelitian ini, peneliti mereduksi dimensi dengan variance threshold sebesar 0.9, 0.8, dan 0.7.
Setelah fitur baru terbentuk, langkah selanjutnya yaitu proses klasifikasi menggunakan algoritma Naïve Bayes.
Langkah terakhir pada metode ini yaitu evaluasi. Proses evaluasi dalam penelitian ini menggunakan metode confusion matrix. Metode ini menunjukan berbagai prediksi yang benar maupun salah berdasarkan desain klasifikasi yang telah dibuat. Matriks berbentuk NxN dimana N merupakan jumlah class
3. HASIL DAN PEMBAHASAN
Klasifikasi genre film pada penelitian ini memanfaatkan Linked Open Data (LOD) sebagai basis pengetahuan. Linked Open Data (LOD) merupakan semantic web yang digunakan untuk mempublikasikan data. Semantik web merupakan perkembangan dari World Wide Web (WWW) yang tidak hanya digunakan untuk menempatkan suatu data, tapi dapat membuat hubungan antar data satu dengan yang lainnya sehingga manusia dan mesin dapat menjelajahinya. Semantik web memberikan cara yang lebih mudah dan efisien untuk berbagi, mencari, dan mengkombinasikan data dan informasi dari sumber yang berbeda sehingga nantinya dapat digunakan kembali. Sehingga, dengan Linked Open Data pengguna dapat menarik data dari berbagai sumber yang berbeda ke dalam ruang informasi global yang tunggal.
Berbeda apabila diakses melalui Web API karena untuk mengambil data dari sumber berbeda diperlukan akses ke setiap API satu per satu sedangkan pada Linked Open Data sumber-sumber data berbeda dapat diakses melalui suatu link RDF.
RDF (Reseource Description Framework) merupakan standar dalam semantik web yang mampu merepresentasikan data di web sehingga data dapat diproses oleh mesin. RDF merupakan bahasa yang digunakan untuk merepresentasikan metadata dan dapat diakses dengan SPARQL. SPARQL (SPARQL Protocol and RDF Query Language) merupakan Bahasa query untuk RDF yang dapat dijalankan melalui SPARQL endpoint. SPARQL endpoint akan mengubah dataset menjadi baris dan kolom sehingga nantinya data dapat diolah dengan metode data mining.
Pada penelitian ini, terdapat dua query atau perintah yang digunakan yaitu query untuk mengakses film dari SPARQL endpoint dbpedia.org dan query untuk mengakses data genre film dari SPARQL endpoint. Hasil data dari kedua query tersebut dihubungkan berdasarkan kesamaan url data dan menghasilkan data sebanyak 559 film dari 6 genre film utama dengan rincian sebagai berikut ini :
Tabel 1.Rincian jumlah film tiap genre Genre Jumlah Film
Action 79 film Adventure 44 film Comedy 15 film
Drama 345 film Horror 37 film Musical 39 film
Hasil penelitian menunjukan bahwa algoritma Naïve Bayes dapat digunakan untuk klasifikasi genre film dan Linked Open Data dapat digunakan sebagai basis data dalam klasifikasi genre film. Karena Linked Open Data memberikan kemudahan dalam mengakses
data dari seluruh dunia dengan mudah melalui SPARQL endpoint. Selain itu, ekstraksi fitur Principal Component Analysis (PCA) juga dapat digunakan untuk menggali informasi penting dan menentukan fitur-fitur utama.
Hasil akurasi dari klasifikasi genre film pada Linked Open Data antara klasifikasi genre film menggunakan algoritma Naïve Bayes dengan ekstraksi fitur Principal Component Analysis dan klasifikasi genre film menggunakan algoritma naïve bayes tanpa ekstraksi fitur Principal Component Analysis ditunjukan pada tabel 19.
Tabel 2. Hasil akurasi klasifikasi genre film Naïve Bayes
tanpa PCA
Naïve Bayes dengan PCA (0.9)
Naïve Bayes dengan PCA (0.8)
Naïve Bayes dengan PCA (0.7)
60.47 % 50.46% 50.10% 50.46%
Berdasarkan tabel diatas, hasil akurasi klasifikasi genre film menggunakan algoritma naïve bayes tanpa ekstraksi fitur Principal Component Analysis (PCA) merupakan hasil akurasi paling besar, yaitu 60.47%. Selain itu, pada saat pembelajaran (learning), proses klasifikasi menggunakan algortima naïve bayes tanpa ekstraksi fitur Principal Component Analysis sangat cepat, karena tidak adanya proses ekstraksi fitur.
Gambar 2: Hasil akurasi klasifikasi menggunakan algoritma naïve bayes tanpa PCA Gambar 2, menunjukan hasil akurasi klasifikasi genre film menggunakan algoritma naïve bayes tanpa ekstraksi fitur Principal Component Analysis (PCA) menggunakan metode confusion matrix. Dengan akurasi sebesar 60.47% dan standar deviasi sebesar 4.80% .
Sedangkan hasil akurasi klasifikasi genre film menggunakan algoritma naïve bayes dan ekstraksi fitur Principal Component Analysis (PCA) menghasilkan akurasi kurang baik.
Berdasarkan 3 kali pengujian dengan variance threshold yang berbeda-beda yaitu 0.7, 0.8, dan 0.9, menghasilkan akurasi sebesar 50.46%, 55.10%, dan 50.46%.
Gambar 3: Hasil akurasi klasifikasi menggunakan algoritma naïve bayes dan PCA dengan variance threshold 0.7
Gambar 10, menunjukan hasil akurasi klasifikasi genre film menggunakan algoritma naïve bayes tanpa ekstraksi fitur Principal Component Analysis (PCA) menggunakan metode confusion matrix. Dengan hasil akurasi sebesar 50.46% dan standar deviasi sebesar 5.08%.
Gambar 4: Hasil akurasi klasifikasi menggunakan algoritma naïve bayes dan PCA dengan variance threshold 0.8
Gambar 11, menunjukan hasil akurasi klasifikasi genre film menggunakan algoritma naïve bayes tanpa ekstraksi fitur Principal Component Analysis (PCA) menggunakan metode confusion matrix. Dengan hasil akurasi sebesar 50.10% dan standar deviasi sebesar 4.51%.
Gambar 5: Hasil akurasi klasifikasi menggunakan algoritma naïve bayes dan PCA dengan variance threshold 0.9
Gambar 12, menunjukan hasil akurasi klasifikasi genre film menggunakan algoritma naïve bayes tanpa ekstraksi fitur Principal Component Analysis (PCA) menggunakan metode confusion matrix. Dengan hasil akurasi sebesar 50.46% dan standar deviasi sebesar 4.55%.
Hal ini disebabkan oleh hilangnya informasi pada saat ekstraksi fitur menggunakan Principal Component Analysis. Selain itu, proses pembelajaran (learning) pun memakan waktu yang cukup lama. Hal tersebut disebabkan oleh lamanya proses ekstraksi fitur menggunakan Principal Component Analysis (PCA) dimana harus menggali informasi penting dan menentukan fitur utama dari 6.653 fitur yang ada. Namun, dengan adanya ekstraksi fitur Principal Component Analysis (PCA), pada saat proses klasifikasi lebih cepat karena fitur yang digunakan lebih sedikit.
4. KESIMPULAN
Dalam penelitian ini, dapat disimpulkan bahwa Linked Open Data (LOD) dapat digunakan sebagai basis pengetahuan dalam melakukan klasifikasi genre film. Peneliti menggunakan salah satu algoritma klasifikasi yaitu naïve bayes untuk melakukan klasifikasi genre film. Untuk membandingkan hasil akurasi klasifikasi genre film menggunakan algoritma naïve bayes, pengujian juga dilakukan dengan menambahkan ekstraksi fitur Principal Component Analysis (PCA).
Berdasarkan hasil analisa penelitian, didapatkan akurasi klasifikasi paling baik adalah menggunakan algoritma Naïve Bayes tanpa ekstraksi fitur Principal Component Analysis (PCA) dengan hasil akurasi sebesar 60.47%. Sedangkan akurasi paling buruk yaitu menggunakan algoritma Naïve Bayes dengan ekstraksi fitur Principal Component Analysis (PCA) dan variance threshold sebesar 0.8 dimana menghasilkan akurasi sebesar 50.10%. Hal ini disebabkan oleh hilangnya informasi pada saat ekstraksi fitur menggunakan Principal Component Analysis.
5. SARAN
Dalam penelitian selanjutnya diharapkan muncul penelitian di bidang lain dengan memanfaatkan Linked Open Data (LOD) sebagai basis pengetahuannya. Selain itu pada penelitian selanjutnya dapat menggunakan metode-metode data mining lain untuk meningkatkan hasil akurasi proses klasifikasi. Sebagai contoh, menggabungkan atau membandingkan beberapa metode data mining tradsional atau dapat juga memanipulasi proses pembobotan fitur sehingga informasi penting dari semua fitur dapat diambil secara optimal.
DAFTAR PUSTAKA
[1] G. F. Shidik and A. Ashari, “Linked Open Government Data As Background Knowledge in Predicting Forest Fire,” J. Theor. Appl. Inf. Technol., vol. 62, no. 3, pp. 570–581, 2014.
[2] C. Bizer, T. Heath, and T. Berners-Lee, “Linked data-the story so far,” Int. J. Semant.
Web Inf. Syst., vol. 5, no. 3, pp. 1–22, 2009.
[3] L. M. Campell and S. MacNeill, “The Semantic Web , Linked and Open Data,” World Wide Web Internet Web Inf. Syst., 2010.
[4] T. Heath, C. Bizer, and F. U. Berlin, Linked Data : Evolving the Web into a Global Data Space. 2011.
[5] L. Ding, D. Difranzo, A. Graves, J. R. Michaelis, X. Li, D. L. Mcguinness, and J.
Hendler, “Data-Gov Wiki : Towards Linking Government Data The Data-Gov Wiki,”
IEEE Internet Comput., pp. 38–43, 2010.
[6] D. Li, L. Timothy, E. John S, D. Dominic, W. Gregory, L. Xian, M. James, G. Alvaro, J.
G. Zheng, Z. Shangguan, J. Flores, and H. Deborah L, McGuinness James A, “Twc logd:
A portal for linking open government data,” Web Semant. Sci. Serv. Agents World Wide Web, vol. 9, pp. 325–333, 2011.
[7] H. Paulheim, “Exploiting Linked Open Data as Background Knowledge in Data Mining,” CEUR Work. Proc. DMoLD 2013 Proc. Int. Work. Data Min. Linked Data, with Linked Data Min. Chall. collocated with ECMLPKDD 2013, pp. 1–10, 2013.
[8] F. Bauer and M. Kaltenbock, Linked Open Data : The Essentials. 2012.
[9] K. R. Apala, M. Jose, S. Motnam, C. Chan, K. J. Liszka, and F. De Gregorio, “Prediction of Movies Box Office Performance Using Social Media,” IEEE/ACM Int. Conf. Adv.
Soc. Networks Anal. Min., no. July, pp. 1209–1214, 2013.
[10] O. Hassanzadeh, “Linked Movie Data Base,” 2002.
[11] H. Zhou, T. Hermans, A. V Karandikar, and J. M. Rehg, “Movie Genre Classification via Scene Categorization,” Transform, pp. 6–9, 2010.
[12] X. Wu, V. Kumar, J. R. Quinlan, J. Ghosh, Q. Yang, H. Motoda, G. J. Mclachlan, A. Ng, B. Liu, P. S. Yu, Z. Z. Michael, S. David, and J. H. Dan, Top 10 algorithms in data mining. 2008.
[13] S. Kim, K. Han, H. Rim, and S. H. Myaeng, “Some Effective Techniques for Naive Bayes Text Classification,” vol. 18, no. 11, pp. 1457–1466, 2006.
[14] Z. Rasheed and M. Shah, “Movie genre classification by exploiting audio-visual features of previews,” Object Recognit. Support. by user Interact. Serv. Robot., vol. 2, no. i, pp.
1086–1089, 2002.