1
Program Studi Teknik Informatika – S1, Fakultas Ilmu Komputer, Universitas Dian Nuswantoro
Jl. Nakula 1 No. 5-11 Semarang 50131 email : [email protected]
Abstract - The resignation of prospective students are already common in universities. In Universitsas Dian Nuswantoro for example, in 2010 only 1147 students who registered for the Faculty of Computer Science .Where the university knew of students who will resign, then the students who managed to get into university is definitely more. One way to predict the resignation of prospective students are using data mining methods. The purpose of this research is to develop an application to determine which students will resign. This application can estimate the prospective students who will resign at the faculty of computer science at the University of Dian Nuswantoro. References used in this application using a data PMB 2013 with variables that will be used is the id list, name, registration, city, course of study, the status of registration, and waves. The algorithm will be used using the naïve Bayes calculations using probabilities, and to measure the performance and accuracy of applications using Confussion Matrix. Based on the research conducted, it was found that several factors influence the final outcome of the application is the city, the course, the status of registration, and waves. Measuring accuracy of the applications created using the confusion matrix, and the result is equal to78%.
Keywords— Data Mining, Naïve Bayes, The Withdrawal of Students
I. PENDAHULUAN1
Dalam beberapa tahun terakhir, penggunaan data mining di dunia pendidikan yang dikenal sebagai educational data mining (EDM) semakin berkembang (Rahmayuni, 2014).
Menurut Williams (2011), data mining merupakan bagian dari seni dan ilmu tentang intelligent data analysis yang bertujuan untuk mendapatkan informasi dari suatu data.
Oleh karena itu Data mining sering dijadikan metode yang dipakai dalam menyelesaikan sebuah masalah. Banyak teknik dari data mining yang dapat digunakan.
Dalam penelitian ini data mining digunakan untuk memperkirakan pengunduran diri calon mahasiswa di Universitas Dian Nuswantoro. Pengunduran diri calon mahasiswa merupakan hal yang biasa terjadi pada setiap universitas, yang mengakibatkan universitas tidak mendapat jumlah mahasiswa yang maksimal. Kebanyakan calon mahasiswa mengundurkan diri karena tidak melakukan tahap registrasi (Kusrini, 2009), seperti data dari BIKU di Universitas Dian Nuswantoro pada tahun 2010 misalnya, yang berhasil masuk menjadi mahasiswa pada FIK 1147 dari total pendaftar sebanyak 2555. Pihak universitas pasti menginginkan agar dapat mengetahui calon mahasiswa
mana saja yang diperkirakan akan mengundurkan diri, karena ketika dapat diketahui calon mahasiswa yang akan mengundurkan diri sejak dini, pihak kampus dapat mencari solusi untuk memperkecil jumlah calon mahasiswa yang mengundurkan diri. Penelitian yang dilakukan (Kusrini, 2009) untuk menentukan pengunduran diri calon mahasiswa menggunakan penalaran berbasis kasus (case based reasoning), dengan membandingkan data kasus yang baru dengan data kasus yang lama untuk mencari solusi yang akan digunakan. Sedangkan algoritma yang dipakai menggunakan C4.5 dan Nearest Neighbor. Hasil dari perbandingan algoritma C4.5 dan Nearest Neighbor menunjukan bahwa Nearest Neighbor tidak lebih akurat dibanding algortima C4.5, dan tahap proses klasifikasi yang dilakukan lebih panjang dan memakan waktu yang cukup lama. Sedangkan penulis ingin mencoba menggunakan algoritma Naïve Bayes dalam menentukan pengunduran diri calon mahasiswa, karena dari studi pustaka yang dilakukan, Naïve Bayes juga akurat dari beberapa algoritma klasifikasi yang sering digunakan.
IMPLEMENTASI DATA MINING MENGGUNAKAN ALGORITMA NAÏVE BAYES DALAM MENENTUKAN PENGUNDURAN DIRI CALON
MAHASISWA PADA UNIVERSITAS DIAN NUSWANTORO SEMARANG
Muhammad Efendi
A. Data Mining
Data mining merupakan suatu metode menemukan suatu pengetahuan dalam suatu database yang cukup besar.
Data mining sendiri adalah proses menggali dan menganalisa sejumlah data yang sangat besar untuk memperoleh sesuatu yang benar, baru, sangat bermanfaat dan akhirnya dapat dimengerti suatu corak atau pola dalam data tersebut. Menurut (Jananto, 2010) alasan utama mengapa data mining diperlukan adalah karena adanya sejumlah besar data yang dapat digunakan untuk menghasilkan informasi dan knowledge yang berguna.
Informasi yang didapat tersebut dapat digunakan pada banyak bidang, mulai dari bisnis, kontrol produksi, kesehatan, dan lain-lain.
Secara sederhana, data mining dapat diartikan sebagai proses mengekstrak atau “menggali” knowledge yang ada pada sekumpulan data. Banyak orang setuju bahwa data mining adalah sinonim dari Knowledge Discovery in Database, atau sering disebut dengan KDD.
Dari sudut pandang yang lain, data mining dianggap sebagai suatu langkah yang penting dalam KDD (Jananto, 2010).
Proses KDD ini terdiri dari serangkaian langkah-langkah transformasi, dari proses data preprocessing dan proses data postprocessing dari data yang merupakan hasil penggalian.
Tujuan dari proses data preprocessing adalah untuk mengubah data input mentah menjadi format yang sesuai untuk analisis selanjutnya
B. Naïve Bayes
Simple Naive Bayesian Classifier merupakan salah satu metode pengklasifikasi berpeluang sederhana yang berdasarkan pada penerapan Teorema Bayes dengan asumsi antar variabel penjelas saling bebas (independen).
Algoritma ini memanfaatkan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman di masa sebelumnya.
Dua kelompok peneliti, satu oleh Pantel dan Lin, dan yang lain oleh Microsoft Research memperkenalkan metode statistik Bayesian ini pada teknologi anti spam filter. Tetapi yang membuat algoritma Bayesian filtering ini popular adalah pendekatan yang dilakukan oleh Paul Graham.
Menurut (Jananto, 2013) algortima Naïve Bayes atau Bayesian Classification adalah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Bayesin classification didasarkan pada teorema bayes yang memiliki kemampuan klasifikasi serupa dengan decision tree dan neural network. Bayesin classification terbukti memiliki kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar.
Teorema Bayes memiliki bentuk umum sebagai berikut :
X = Data dengan class yang belum diketahui
spesifik
P(H|X) = Probabilitas hipotesis H berdasarkan kondisi x (posteriori prob.)
P(H) = Probabilitas hipotesis H(prior prob.) P(X|H) = Probabilitas X berdasarkan kondisi tersebut
P(X) = Probabilitas dari X
III. IMPLEMENTASI
A. Frekuensi Kemunculan
Contoh hasil perhitungan frekuensi kemunculan : Contoh kasus baru yang akan diinputkan :
1. Nama : Muhammad Efendi 2. Gelombang : IIA
3. Kota : Pemalang
4. Pilihan : Teknik Informatika 5. Jalur : Bebas Tes
Untuk menentukan hasil registrasi atau tidaknya dari data tersebut maka perlu dilakukan perhitungan probabilitas dengan acuan data frekuensi kemunculan pada table sebelumnya.
Untuk penyelesaian, yang pertama dilakukan yaitu hitung nilai probabilitas tiap-tiap atribut, perhitungannya sebagai berikut :
P( Tidak Registrasi) = = 0,45 P( Registrasi) = = 0,55
P( IIA | Tidak Registrasi) = = 0,0711 P( IIA | Registrasi) = = 0,2109
P(Pemalang | Tidak Registrasi) = = 0,0356 P(Pemalang | Registrasi) = = 0,0127
P(Teknik Informatika | Tidak Registrasi) = = 0,6044 P(Teknik Informatika | Registrasi) = = 0,5273 P(Bebas Tes | Tidak Registrasi) = = 0,4267 P(Bebas Tes | Registrasi) = = 0,7055
Bandingkan hasil akhir probabilitas dari class Registrasi dan class Tidak Registrasi
- Class Tidak Registrasi
P( Tidak Registrasi) * P( IIA | Tidak Registrasi) * P(Pemalang | Tidak Registrasi) * P(Teknik Informatika | Tidak Registrasi) * P(Bebas Tes | Tidak Registrasi)
= 0,45 * 0,0711 * 0,0356 * 0, 6044 * 0, 4267
= 0,00029375 - Class Registrasi
3 P(Registrasi) * P( IIA | Registrasi) * P(Pemalang | Registrasi) *
P(Teknik Informatika | Registrasi) * P(Bebas Tes | Registrasi)
= 0,55 * 0, 2109 * 0,0127 * 0,5273 * 0, 7055
= 0,00054802
Dari hasil diatas nilai class Registrasi lebih besar probabilitasnya dibandingkan dengan nilai class Tidak Registrasi, jadi calon mahasiswa diprediksikan melakukan Registrasi dengan class akhir YA
B. Akurasi
Dalam mengukur pada akurasi pada aplikasi ini menggunakan confusion matrix. Confusion matrix diterapkan pada 300 data testing yang sudah disiapkan, data testing tersebut dihitung dengan menggunakan algoritma naïve bayes, kemudian hasil dari semua data testing dipakai dalam menentukan akurasi dengan menggunakan confusion matrix.
Keputusan Asli
Identifikasi Tidak Oleh Naïve Bayes
Identifikasi Ya Oleh Naïve Bayes
Tidak = TN FN
Ya = FP TP
Tabel Tabel Confussion Matrix Keterangan :
TN = Hasil yang diidentifikasi oleh Naïve Bayes TIDAK dengan class asli TIDAK
FN = Hasil yang diidentifikasi oleh Naïve Bayes YA dengan class asli TIDAK
FP = Hasil yang diidentifikasi oleh Naïve Bayes TIDAK dengan class asli YA
TP = Hasil yang diidentifikasi oleh Naïve Bayes YA dengan class asli YA
Keputusan Asli
Identifikasi Tidak Oleh Naïve Bayes
Identifikasi
Ya Oleh
Naïve Bayes Tidak =
100
61 39
Ya = 200 26 174
Tabel Tabel Kinerja
Tabel diatas merupakan hasil perhitungan dari data testing setelah dihitung dengan algoritma naïve bayes.
Untuk melakukan proses kinerja pada data mining maka dilakukan perhitungan presision, recal, dan akurasi.
1. Recal
Recal adalah proporsi kasus posotif yang diidentifikasi dengan benar, rumus dari recal sebagai berikut :
TP / ( FN + TP ) * 100%
Dengan data pada table kinerja maka : 174 / ( 39 + 174 ) * 100% = 87%
Recal yang dihasilkan aplikasi sebesar 87%.
2. Presision
Presision merupakan proporsi kasus dengan hasil positif yang benar, rumusnya sebagai berikut :
TP / ( FP + TP ) * 100%
Dengan data pada table kinerja maka : 174 / ( 26 + 174 ) * 100% = 81,69%
Presision yang dihasilkan sebesar 81,69%.
3. Akurasi
Akurasi merupakan perbandingan kasus yang diidentifikasi benar dengan jumlah semua kasus, rumusnya sebagai berikut :
( TN + TP ) / ( TP + TN + FP + FN ) *100%
Dengan memakai data pada tabel kinerja maka :
( 61 + 174 ) / ( 174 + 61 + 26 + 39 ) *100% = 78,33%
Akurasi yang dihasilkan sebesar 78,33%.
IV. HASIL&PEMBAHASAN
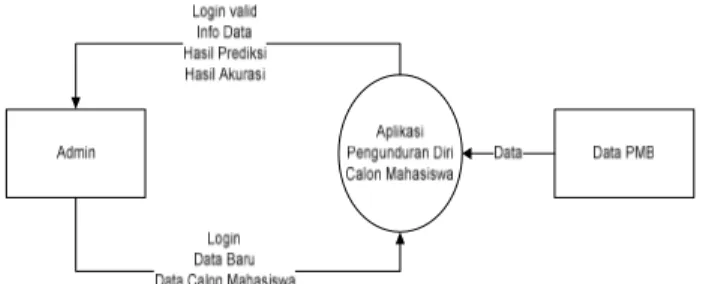
A. Context Diagram
Context Diagram merupan diagram yang terdiri dari proses yang menggambarkan suatu sistem. Contex Diagram merupakan level tertinggi dari Data Flow Diagram yang menggambarkan seluruh input ke sistem atau output dari sistem.
DFD lvl 1 merupakan pemecahan dari context diagram, yang ditujukan unutk menggambarkan keseluruhan proses kerja sistem.
C. Halaman homepage
Pada halaman menu merupakan halaman sambutan bagi user, pilih menu menu yang ada untuk menggunakan aplikasi, Menu yang tersedia diantaranya :Data Mahasiswa, Naïve Bayes, Kinerja, Penentu Keputusan, dan About.
D. Halaman Naïve Bayes
Pada halaman naïve bayes di tunjukan frekuensi dari jumlah data yang akan digunakan, frekuensi kemunculan ini nantinya akan digunakan dalam menentukan pengunduran diri calon mahasiswa.
Keterangan :
frekuensi kemunculan apabila di inputkan data baru pada databse.
- Menu Frekuensi Kemunculan digunakan untuk menampilkan frekuensi kemunculan dari database.
E. Halaman Kinerja
Use Pada halaman ini user dapat melihat akurasi dari aplikasi data mining.
Keterangan :
- Menu Kinerja untuk menunjukan semua data testing yang akan dipakai dalam menghitung akurasi.
- Menu Lakukan Proses Kinerja digunakan untuk menghitung ulang data yang ada, apabila ada data testing baru yang dimasukan kedalam database.
- Menu Tabel Penilaian digunakan untuk melihat hasil akurasi pada aplikasi.
F. Halaman Penentu Keputusan
Pada halaman ini dimana user menginput data baru yang akan diprediksi dan hasilnya akan langsung ditunjukan dibawah form input.
Keterangan :
- Button Input digunakan untuk perintah input pada data mahasiswa baru.
- Menu Edit digunakan untuk mengedit informasi pada data mahasiswa baru.
- Menu Perhitungan digunakan untuk menunjukan perhitungan pada kasus yang baru di inputkan.
5
V. PENUTUP A. Kesimpulan
Hasil yang dapat diambil dari penelitian ini adalah algoritma Naïve Bayes dapat digunakan dalam prediksi registrasi calon mahasiswa baru pada Universitas Dian Nuswantoro dengan keakuratan sebesar 78%. Aplikasi ini dapat memudahkan pihak universitas dalam melakukan pencegahan calon mahasiswa yang akan mengundurkan diri agar dapat memperoleh jumlah calon mahasiswa yang maksimal. Penulis berharap aplikasi ini dapat membantu pihak universitas karena pengguna aplikasi ini cukup mengisi form yang berisi data calon mahasiswa.
Selanjutnya aplikasi akan memberikan hasil dimana calon mahasiswa tersebut akan registrasi atau tidak.
B. Saran
Saran yang penulis berikan untuk penelitian selanjutnya adalah sebagai berikut :
1. Perbaiki desain aplikasi, karena untuk aplikasi sekarang masih menggunakan desain yang sangat sederhana.
2. Keterbatasan aplikasi ini yaitu hanya dapat digunakan pada fakultas ilmu computer saja. Jadi penulis menyarankan untuk menggunakan semua data fakultas yang ada di UDINUS, karena data sangat berpengaruh pada penggunaan algoritma naïve bayes. Apabila menggunakan data semua fakultas, maka aplikasi ini dapat memprediksi calon mahasiswa dari semua jurusan.
3. Menggunakan perhitungan probabilitas dalam menentukan prediksi, penelitian selanjutnya diharapkan dapat menggukanan algortima data mining yang lain untuk dibandingkan hasilnya dengan penelitian saat ini.
REFERENCES
1.
Rahmayuni, "Perbandingan Performasi Algoritma C4.5 dan Cart Dalam Klasifikasi Data nilai Mahasiswa Prodi Teknik Komputer Politeknik Negeri Padang," 2014.2.
S. H. R. W. A. H. Kusrini, "Perbandingan Metode Nearest Neighbor dan Algoritma C4.5 Untuk Menganalis Kemungkinan Pengunduran Diri CalonMahasiswa di STIMIK AMIKOM
YOGYAKARTA," 2009