i
VOCABULARY PROFILE OF ACADEMIC LISTENING MATERIALS USED IN THE ENGLISH LANGUAGE EDUCATION PROGRAM
THESIS
Submitted in Partial Fulfilment of the Requirements for the Degree of
Sarjana Pendidikan
Joannita Ratih Wiharmastu 112012018
ENGLISH LANGUAGE EDUCATION PROGRAM FACULTY OF LANGUAGE AND LITERATURE
ii
vi TABLE OF CONTENT
COVER ...
INSIDE COVER PAGE ... i
APPROVAL PAGE ... ii
COPYRIGHT STATEMENT ... iii
PUBLICATION AGREEMENT DECLARATION ... iv
TABLE OF CONTENT ... v
VOCABULARY PROFILE OF ACADEMIC LISTENING MATERIALS USED IN THE ENGLISH LANGUAGE EDUCATION PROGRAM ... 1
ABSTRACT ... 1
A. INTRODUCTION ... 1
B. LITERATURE REVIEW ... 3
1. Definition of Vocabulary ... 3
2. Importance of Learning Vocabulary ... 4
3. Lexical Coverage for Comprehension ... 4
4. Definition of Vocabulary Profile and Vocabulary Profiler ... 5
5. Categories Based on The Word Frequency ... 5
6. Benefits of Knowing Low and High Frequency Words ... 7
7. Relevant Previous Studies ... 8
C. THE STUDY ... 9
1. Context of The Study ... 9
2. Material ... 10
3. Data Collection Instrument ... 10
4. Data Collection Procedure ... 10
5. Data Analysis ... 11
D. FINDING AND DISCUSSION ... 11
1. Overall Result ... 12
vii
a. Negative Vocabulary Profile of K1 ... 14
b. Negative Vocabulary Profile of K2 ... 14
c. Negative Vocabulary Profile of AWL ... 15
3. Block Frequency Output of Off-list Words ... 16
4. Comparison of Vocabulary Frequency across Materials Used in Each Meeting ... 17
5. Text Comparison of Materials ... 20
a. Comparison of Materials for Meeting 2 vs. Meeting 11... 20
b. Comparison of Materials for Meeting 8 vs. Meeting 16 ... 22
c. Comparison of Materials for Meeting 10 vs. Meeting 17... 23
E. CONCLUSION ... 24
ACKNOWLEDGEMENT ... 26
REFERENCES ... 27
1
VOCABULARY PROFILE OF ACADEMIC LISTENING MATERIALS
USED IN THE ENGLISH LANGUAGE EDUCATION PROGRAM
Joannita Ratih Wiharmastu 112012018
A. INTRODUCTION
Knowing the content of the materials which are used in a language class is very crucial because the students can expect what they are going to learn. The most visible content that can be analysed in a language lesson material is the grammar and vocabulary. Discoursing vocabulary learning, getting exposed to as many vocabulary items as possible in the target language would be beneficial because it is the “basic building block of language” (Read, 2000, p.1). As the result, it becomes the call for material developers to create course books that would be able to maximize the input and carefully choose what vocabulary the learners need to know (Kafipour & Naveh, 2011; Lessard-Clouston, 2013, as cited in Farjami, 2014).
Because of the importance of vocabulary learning, the teachers need to know the vocabulary levels that are appropriate for the students. As what Krashen (1982) presents about the input hypothesis, the second language acquisition can only take place if the
language used is above the students’ level, but not too advanced. Therefore, the educators
should adjust the difficulty of the vocabulary items based on their students’ level. To see the most used and uncommon words in a book, vocabulary profiler can be utilized.
2
2014 was converted from three to four credit hours. This led to changing the content of the materials. The Academic Listening course in English Language Education program used a material that was compiled from TOEFL, IELTS, and book chapters. Since these materials have just been used in 2014, there is no research investigating the vocabulary items of it. These newly generated materials need to be investigated in its early practice and hence, immediate action could be carried out if needed.
In response to the change of the material, this study attempted to provide the vocabulary profile of the newest Academic Listening course materials. Vocabulary profile is a description of breakdowns that includes the ratio of how many times a word occurs in a text (Morris & Cobb, 2004). Farjami (2014) mentioned that studies on vocabulary profile were able to give information about the frequency of function and content words. The information about the vocabulary profile will be broken down into four parts which are the first thousand most common words (K1), the second thousand most common words (K2), Academic Word List (AWL), and Off-list words (Cobb, n.d.).
In this study, an investigation was completed to profile the vocabulary in the Academic Listening class materials. This study was aimed to answer three research questions that were:
1. What is the vocabulary profile used in the Academic Listening course material? 2. What is the number of vocabulary items that was not covered in the Academic
Listening course material?
3. What is the token recycling index of the Academic Listening course material? The objectives of this study were:
1. To investigate the vocabulary profile of the Academic Listening course materials used in English Education Program in Satya Wacana Christian University.
3
3. To generate the token recycling index of the material.
From the result of this vocabulary profile study, the material developers can have the insight whether the vocabulary coverage can be taught and understandable for a particular
students’ level (Laufer, 2010). The researcher hopes that this study could give beneficial inputs for the language teaching practitioners in this university. After knowing the degree of vocabulary occurrence in the new class, the material developers may be able to design their teaching by deciding which vocabulary is worth highlighting and being remedied. In addition, they could also see whether the vocabulary items were appropriate for the students or not.
B. LITERATURE REVIEW
1. Definition of Vocabulary
The scientific study of language can cover some areas namely syntax, morphology, phonology, and lexicon. The last mentioned area, commonly known as vocabulary, is defined
by Richards and Schmidt as “a set of lexemes (the smallest unit in the meaning system of a
language that can be distinguished from other similar units), including single words,
compound words and idioms” (2002, as cited in Hassani, Zarei, & Sadeghpour, 2013).
2. Importance of Learning Vocabulary
4
Schmitt, & Calpham, 2001; Read, 2000; Mayer & Alexander, 2010). In addition, it is suggested that various types of vocabulary tests could be used to predict one’s language proficiency in a second or foreign language (Stæhr, 2008; Zavera in Golkar & Yamini, 2007).
3. Lexical Coverage for Comprehension
In order to gain comprehension, only one word in every 20 words within the overall text is allowed to be left unknown by the reader. In other words, the vocabulary coverage should reach 95% to achieve understanding. However, most learners will make an adequate comprehension when only one word in every 50 words is unknown or 98% coverage (Nation, 2006). Another theory proposed by Betts (as cited in Mikulecky, 2007) was written as follows:
Independent: 99% of words already known for fluent, enjoyable reading.
Instructional: 98%-95% of words known and some instructional support such as teacher suggestions, vocabulary explanations, illustrations etc. needed for the benefit.
Frustrational: Below 95% of words known can damage fluency and lead to disruptions in comprehension strategies. (p.1)
5
4. Definition of Vocabulary Profile and Vocabulary Profiler
Vocabulary profile, according to Graves (2005), is a collection of words classified by their tokens, families, and frequencies. Browne and Culligan (2008) assert that the integration between a work under CALL (Computer Assisted Language Learning) and vocabulary teaching leads to the emerging of a vocabulary profiler program. Therefore, a vocabulary
profiler is an online “public domain computer program” (Laufer, 1994) developed by Tom
Cobb which can group the vocabulary in a text into frequency levels (Paul, 2005; Nemati, 2009).
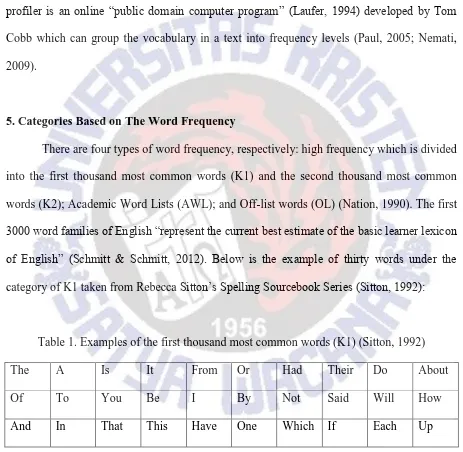
5. Categories Based on The Word Frequency
There are four types of word frequency, respectively: high frequency which is divided into the first thousand most common words (K1) and the second thousand most common words (K2); Academic Word Lists (AWL); and Off-list words (OL) (Nation, 1990). The first
3000 word families of English “represent the current best estimate of the basic learner lexicon
of English” (Schmitt & Schmitt, 2012). Below is the example of thirty words under the
category of K1 taken from Rebecca Sitton’s Spelling Sourcebook Series (Sitton, 1992):
Table 1. Examples of the first thousand most common words (K1) (Sitton, 1992)
The A Is It From Or Had Their Do About
Of To You Be I By Not Said Will How
And In That This Have One Which If Each Up
6
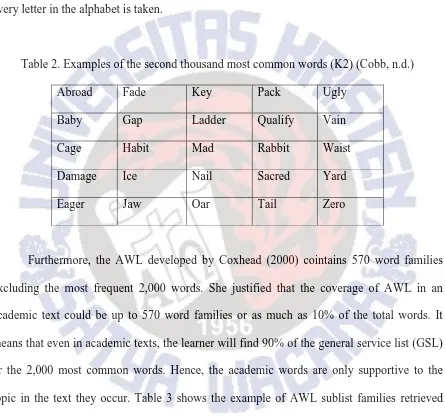
content words (nouns, verbs, adjectives, and adverbs) define the lexical density in a text (Vidiakovic & Barker, 2010). The AWL is split up into two parts which are university word lists and academic word lists. However, this study grouped all the academic words into AWL. On the web, the list is presented in an alphabetical order. Here is the example of the K2 word lists from the online Compleat Lexical Tutor. Only one word which is the first appearance for every letter in the alphabet is taken.
Table 2. Examples of the second thousand most common words (K2) (Cobb, n.d.)
Abroad Fade Key Pack Ugly
Baby Gap Ladder Qualify Vain
Cage Habit Mad Rabbit Waist
Damage Ice Nail Sacred Yard
Eager Jaw Oar Tail Zero
Furthermore, the AWL developed by Coxhead (2000) cointains 570 word families excluding the most frequent 2,000 words. She justified that the coverage of AWL in an academic text could be up to 570 word families or as much as 10% of the total words. It means that even in academic texts, the learner will find 90% of the general service list (GSL) or the 2,000 most common words. Hence, the academic words are only supportive to the topic in the text they occur. Table 3 shows the example of AWL sublist families retrieved
from Sublist Families of the Academic Word Lists (2015) cited in Cobb’s online vocabulary
profiler.
Table 3. Examples of the Academic Word Lists (Cobb, n.d.)
7
Approach Assume Benefit Constitue Create Derive Environment Area Authority Concept Context Data Distribute Establish
Off-list family words consist of proper nouns, unusual words, specialist vocabulary, acronyms, abbreviations, and misspelling (Cobb, n.d.). Table 4 provides the examples of some Off-list words appearing in various articles.
Table 4. Examples of the Off-list words (Menken, 2010; Walinski, Kredens, & Goźdź -Roszkowski, 2007; Laufer & Ravenhorst-Kalovski, 2010)
Appeal Biology Criticism
Moscow Opposition Rebar
Reference Richard Shish
6. Benefits of Knowing Low and High-Frequency Words
8
7. Relevant Previous Studies
The previous study by Farjami (2014) using the vocabulary profiler was aimed to provide a specific detail about the vocabulary coverage in seven English textbooks used in Iranian context. The researcher excluded the marginal information such as the table of content, page numbers, and the index at the end of the book but included the metatextual information such as instructions and summaries to be analyzed. The result was presented in the form of table showing the numbers of the frequency profile of vocabulary in those seven textbooks. From the analysis, the researcher could notice that the lexical input containing high frequency and academic vocabulary in the material should be developed.
Another study was conducted by Liontou (2015). VocabProfile 3.0 was used to examine the lexicogrammatical differences between intermediate and advanced reading comprehension tests in Greek. The program was utilized to analyze 135 texts and the result showed Fhigh differences between those two levels. The text in the intermediate level contained a higher proportion of unique words, whereas the advanced level is richer according to the lexical density.
The two previous studies mentioned above utilized vocabulary profiler generated by Cobb. They described the representativeness of exposure to English in the texts analyzed. In addition, Farjami also investigated the word recycling index.
C. THE STUDY
9
study because the result of the vocabulary profile reported will aspire to describe the word frequencies of the material.
1. Context of The Study
The context of this study was the English Language Education program of the Faculty of Language and Literature in Satya Wacana Christian University. The students in this study program have to take compulsory courses, and one of the required skill courses is Academic Listening. Academic Listening course was the last listening course in this study program, so the vocabulary was expected to contain adequate academic words appropriate for intermediate to advanced level students. Meanwhile, Satya Wacana Christian University in Salatiga has implemented a new curriculum named Indonesian National Qualification Framework. Due to the change of the curriculum, the material of this course has to undergo some modifications. The number of the academic credit for this course was increased from three to four. As a result, there must be addition in the lexical coverage of its material.
2. Material
10
3. Data Collection Instrument
This study used vocabulary profiler that can be accessed from http://www.lextutor.ca/ to get the data. This Lextutor program is an electronic tool for profiling vocabulary, created by Tom Cobb in 1999. The online program breaks down words in the text to four classifications which are K1 (1-1,000 most common words), K2 (1,001-2,000 most common words), Academic Word Lists, and Off-list words.
4. Data Collection Procedures
For the data collection, the main purpose is to provide the text in form of a word document to make them compatible with the vocabulary profiler. In order to do so, this study used Microsoft Word for the word-processing software. The transcripts of the audio-visual materials were transcribed first. However, during the transcribing process, there were some categories of words were omitted i.e. names (people’s names, brand, and places), foreign vocabulary items, and abbreviations. Therefore, only the meaningful words to English were involved in the data analysis.
5. Data Analysis
The first step to analyse the data is accessing the vocabulary profiler. Go to http://www.lextutor.ca/ and then click on Vocabprofile. Click VP-Classic to get the result
categorized into Laufer & Nation’s 4-way sorter. Go back to the word document, copy, and paste the text per chapter into the dialogue box provided. There is a limitation of the text i.e. 200,000 characters or 35,000 words. Finally, submit the word by clicking SUBMIT_Window and the program will start doing the analysis.
11
and the colour represent them respectively are blue, green, yellow, and red. This result will be discussed to answer the first research question. For the second research question, displaying the negative vocabulary profile was done by clicking VP negative under the family list of each category. For the third research question, go back to the home page, click Text Lex Compare.
D. FINDINGS AND DISCUSSIONS
This part would attempt to present the vocabulary profile of the Academic Listening course material used. The discussion is divided into three parts. The first one is the overall result to show the vocabulary profile of the Academic Listening course material. The second part shows the negative vocabulary and the list of vocabulary items that were not found in the course material. The third part is the comparison of vocabulary profile between two materials used in two meetings. This last part shows the repeated and unrepeated words in the material being compared. The result of the analysis is presented in forms of tables to show the percentage and number of words.
1. Overall Result
This section shows the finding of vocabulary profile of the Academic Listening material for the whole meeting. The data analysis using The Compleat Lexical Tutor v.4 yielded the result shown in Table 5. As can be seen in the table, the Academic Listening material comprised 59,377 words. It also shows the information of families and types found in the material. According to Bauer and Nation (1993), a word family is the bare stem form of a word and all its derived and inflected varieties. A word type is defined as “any word
12
Lamy, & Jones, 2002). For example, the words does, did, doing, and done may all be part of the same word family, but they are considered four different word types. The token is the total number of words found in the text. If for example, there are words could_[2], insects_[2], of_[5], and previously_[1] in a text, the number of tokens is 10. Table 5 shows that there were 1,8585 word families and 5,084 word types out of the total words.
Table 5 indicates that K1 got the highest proportion of the whole material used in the Academic Listening course. Of the vocabulary in all the material, 86.37% of the words were the K1. K2 calculated in the material was as much as 5.29%. The sum of K1 and K2 would be 91.66%. This percentage was below the suggested amount of known words for uninterrupted comprehension which should be at least 95%. Thus, according to Nation (2006), this material could probably be described as linguistically complex for advanced language users, such as students in university level (Schmitt & Schmitt, 2012). The lowest category is from the AWL. It only represented 3.96% from the material. It needs to investigate whether the 389 families of AWL in the Academic Listening material was adequate or not for university levels. The cumulative of K1, K2, and AWL would reach 95.62%. From this percentage, the students would be assumed to have an uninterrupted understanding if they knew all the words from K1 until AWL. The remaining 4.38% (2,600 tokens) of the vocabulary items were from the Off-list words. Despite the fact that the Off-list words are not in the frequency list, they could probably determine the main idea of discussions and be the keywords for the topic. Therefore, this list should not be neglected when teachers are making the selection for vocabulary list to teach.
Table 5. Overall vocabulary profile
Frequency Level
Families (%)
Types (%)
Tokens (%)
13
K1 Words 901
48.49%
2,058 40.48%
51,285
86.37% 86.37%
K2 Words 568
30.57%
961 18.90%
3,142
5.29% 91.66%
AWL [570 Fams.]
Tot. 2,570
389 20.94%
704 13.85%
2,350
3.96% 95.62%
Off-list ?? 1,361
26.77%
2,600
4.38% 100.00%
Total
(Unrounded) 1858+?
5,084 100%
59,377
100% ≈100.00%
2. Negative Vocabulary Profiles of the Academic Listening Course Material
This section shows the description of negative vocabulary profile of the Academic Listening course material. The analysis of negative vocabulary profile covered the data from K1, K2, and AWL. Negative vocabulary is vocabulary items which are members of New General Service List (Browne, Culligan, & Phillips, 2013) but not found in the text. Negative vocabulary profile lists would seem to be useful for the teacher to help students enrich their language productions.
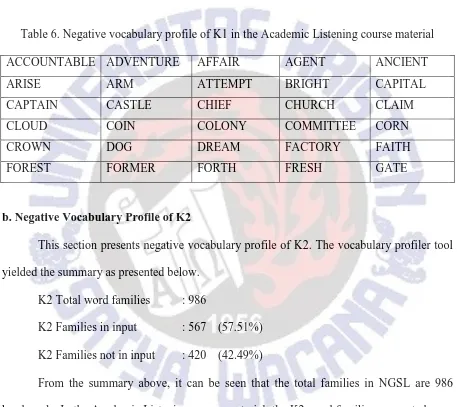
a. Negative Vocabulary Profile of K1
In this section, the negative vocabulary profile of K1 words is presented. The summary of data analysis of K1 words that were not found in the material is shown as follows:
K1 Total word families : 964
14
As can be seen in the summary, the material comprised 92.22% of word families from NGSL. Therefore, the remaining 7.88% of word families were missing from the material. The numbers indicate the material used in the course appeared to be quite rich in words families. Table 6 shows some word families that were not involved in the course material. The complete list has been put in Appendix A.
Table 6. Negative vocabulary profile of K1 in the Academic Listening course material
ACCOUNTABLE ADVENTURE AFFAIR AGENT ANCIENT
ARISE ARM ATTEMPT BRIGHT CAPITAL
CAPTAIN CASTLE CHIEF CHURCH CLAIM
CLOUD COIN COLONY COMMITTEE CORN
CROWN DOG DREAM FACTORY FAITH
FOREST FORMER FORTH FRESH GATE
b. Negative Vocabulary Profile of K2
This section presents negative vocabulary profile of K2. The vocabulary profiler tool yielded the summary as presented below.
K2 Total word families : 986
K2 Families in input : 567 (57.51%) K2 Families not in input : 420 (42.49%)
From the summary above, it can be seen that the total families in NGSL are 986 headwords. In the Academic Listening course material, the K2 word families accounted were as much as 57.51%, which means 42.49% were missing in the material. In Table 7, some examples from the list of K2 word families that were not found in the material is presented. The complete list has been put in Appendix B.
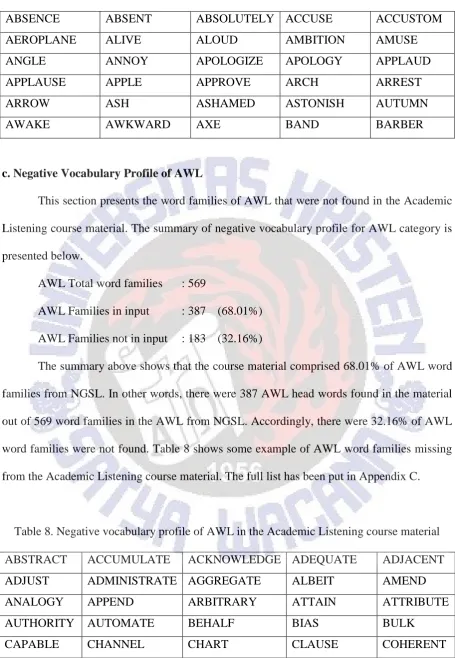
15
ABSENCE ABSENT ABSOLUTELY ACCUSE ACCUSTOM
AEROPLANE ALIVE ALOUD AMBITION AMUSE
ANGLE ANNOY APOLOGIZE APOLOGY APPLAUD
APPLAUSE APPLE APPROVE ARCH ARREST
ARROW ASH ASHAMED ASTONISH AUTUMN
AWAKE AWKWARD AXE BAND BARBER
c. Negative Vocabulary Profile of AWL
This section presents the word families of AWL that were not found in the Academic Listening course material. The summary of negative vocabulary profile for AWL category is presented below.
AWL Total word families : 569
AWL Families in input : 387 (68.01%) AWL Families not in input : 183 (32.16%)
The summary above shows that the course material comprised 68.01% of AWL word families from NGSL. In other words, there were 387 AWL head words found in the material out of 569 word families in the AWL from NGSL. Accordingly, there were 32.16% of AWL word families were not found. Table 8 shows some example of AWL word families missing from the Academic Listening course material. The full list has been put in Appendix C.
Table 8. Negative vocabulary profile of AWL in the Academic Listening course material
ABSTRACT ACCUMULATE ACKNOWLEDGE ADEQUATE ADJACENT
ADJUST ADMINISTRATE AGGREGATE ALBEIT AMEND
ANALOGY APPEND ARBITRARY ATTAIN ATTRIBUTE
AUTHORITY AUTOMATE BEHALF BIAS BULK
CAPABLE CHANNEL CHART CLAUSE COHERENT
16
3. Block Frequency Output of Off-list Words
For the reason that each of Off-list words could not be sorted into certain word families, the negative vocabulary of this category is not able to be analysed. Consequently, this study utilized the vocabulary profiler to count the frequency of Off-list words. This online tool sorted the data in a descending order (from high to low) and frequency-blocked them per ten words. The data analysed covered 1,361 types and 2,600 tokens of Off-list words. Table 9 shows the three highest block frequency of Off-list words. In the table, RANK is the ranking of words, FREQ is the number of word occurrence in the text, COVERAGE is the percentage of individual and cumulative word occurrences, and the last column contains the vocabulary items. The complete list of the block frequency has been put in Appendix D. The frequency list yielded by the tool in the vocabulary profiler could probably serve as clues to make a selection of useful and relevant words to teach.
Table 9. The three highest block-frequency output of Off-list words
RANK FREQ COVERAGE WORD
individ. cumulative
1. 1 0.07% 0.07% ABACK
2. 1 0.07% 0.14% ABBREVIATE
3. 1 0.07% 0.21% ABBREVIATED
4. 1 0.07% 0.28% ABBREVIATIONS
5. 1 0.07% 0.35% ABSORBED
6. 1 0.07% 0.42% ABSORBING
7. 1 0.07% 0.49% ABSORBS
8. 1 0.07% 0.56% ABUNDANCE
9. 1 0.07% 0.63% ACCLAIM
10. 1 0.07% 0.70% ACCOMPLISH
11. 1 0.07% 0.77% ACE
17
13. 1 0.07% 0.91% ADMISSIONS
14. 1 0.07% 0.98% ADO
15. 1 0.07% 1.05% ADOLESCENCE
16. 1 0.07% 1.12% ADVISOR
17. 1 0.07% 1.19% AERIAL
18. 1 0.07% 1.26% AERONAUTICS
19. 1 0.07% 1.33% AFFECTION
20. 1 0.07% 1.40% AGENDA
21. 1 0.07% 1.47% AGGIE
22. 1 0.07% 1.54% AGGRESSIVENESS
23. 1 0.07% 1.61% AIRPORT
24. 1 0.07% 1.68% AIRY
25. 1 0.07% 1.75% AJAR
26. 1 0.07% 1.82% ALERT
27. 1 0.07% 1.89% ALGEBRA
28. 1 0.07% 1.96% ALLERGEN
29. 1 0.07% 2.03% ALLERGIC
30. 1 0.07% 2.10% ALLERGIES
4. Comparison of Vocabulary Frequency across Materials Used in Each Meeting
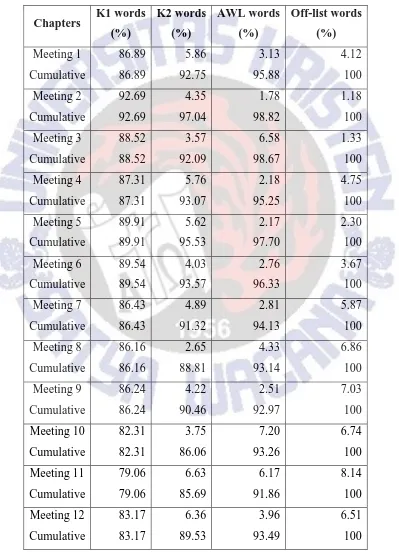
This section compares the finding of vocabulary profile of the Academic Listening material across meeting. Table 10 shows the comparison of K1, K2, AWL, and Off-list frequencies among materials used in each Academic Listening course meeting.
As can be seen in Table 10, for the K1 category, the highest coverage was found in the material for meeting 2 with 92.69% and the lowest was for meeting 11 which only comprised 79.06% of K1. The highest and lowest proportions of K2 were respectively found in the material for meeting 16 (7.24%) and 8 (2.65%). The AWL coverage ranged from 0.94% (meeting 17) to 7.20% (meeting 10). For the Off-list category, the highest coverage was found in meeting 17 with 7.24% and the lowest was in meeting 2 with only 1.18% of Off-list. The amount of word frequency level in each meeting may highly depend on the main topic of the discussion.
18
required percentage for a good understanding. Thus, according to Nation (2006), the material could generally be described as linguistically complex for advanced language users, such as students in university level (Schmitt & Schmitt, 2012).
Table 10. Comparison of word frequency levels
20
5. Text Comparison of Materials
This last section displays the comparison of text between materials for two meetings of the Academic Listening course. The data of comparison also presents the token recycling index of the materials being compared. Recycling index is the recycled words found in the second text (Cobb, 2007). In other words, recycling index is the ratio between words that are shared by two texts and the total number of words in the second text. It provides useful information about what words are shared in both texts and what words are new or unique in the second text. The higher the token recycling index, the higher the text comprehensibility would be. After knowing the shared and unique words in two texts, teachers could highlight important words that are not covered in the first text. The materials that were compared in this section are those having the highest and lowest percentage of word frequency levels.
a. Comparison of Materials for Meeting 2 vs. Meeting 11
21
Table 11. Shared and unique words in materials for meeting 2 and 11 TOKEN Recycling Index: (897 repeated tokens : 1704 tokens in new text) = 52.64% FAMILIES Recycling Index: (110 repeated families : 502 families in new text) = 21.91%
Unique to first 121 tokens 70 families 001. write 7 002. week 6 003. assign 5 004. book 5 005. find 5 006. last 5 007. go 4 008. really 4 009. bed 3 010. feel 3 011. tire 3 012. early 2 013. essay 2 014. haven’ 2 015. hullo 2 016. i’ll 2 017. library 2 018. lot 2 019. night 2 020. note 2
Shared 897 tokens 110 families 001. the 82 002. be 69 003. to 57 004. this 50 005. a 45 006. i 43 007. in 42 008. of 42 009. and 35 010. it 34 011. have 24 012. they 19 013. do 17 014. use 14 015. as 13 016. for 12 017. not 12 018. some 11 019. you 10 020. but 9
Unique to second 807 tokens
392 families Freq first (then alpha)
001. autoclave 22 002. heat 12 003. water 12 004. with 12 005. if 11 006. will 11 007. indicate 10 008. sterilise 10 009. he 9
010. instrument 9 011. medical 8 012. or 8 013. want 8 014. by 7 015. care 7 016. pressure 7 017. bacterium 6 018. boil 6
VP novel items
Same list Alpha first 001. aback 1 002. above 2 003. absorb 1 004. access 1 005. add 2
006. advertise 1 007. after 1 008. against 1 009. air 2 010. ajar 1 011. also 5 012. although 1 013. angry 1 014. anticipate 1 015. any 2
016. approximate 1 017. artificial 1
b. Comparison of Materials for Meeting 8 vs. Meeting 16
22
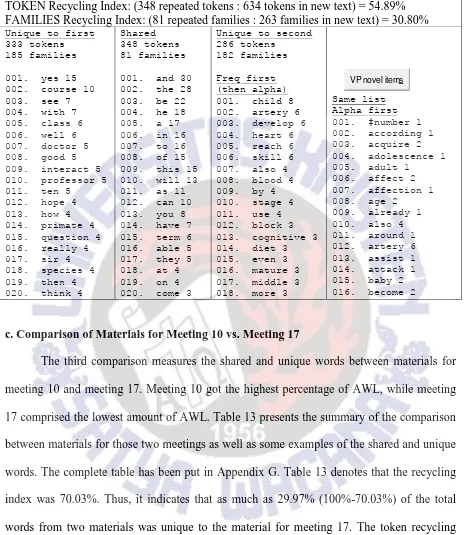
Table 12. Shared and unique words in materials for meeting 8 and 16 TOKEN Recycling Index: (348 repeated tokens : 634 tokens in new text) = 54.89% FAMILIES Recycling Index: (81 repeated families : 263 families in new text) = 30.80%
Unique to first 333 tokens 185 families 001. yes 15 002. course 10 003. see 7 004. with 7 005. class 6 006. well 6 007. doctor 5 008. good 5 009. interact 5 010. professor 5 011. ten 5
012. hope 4 013. how 4 014. primate 4 015. question 4 016. really 4 017. sir 4 018. species 4 019. then 4 020. think 4
Shared 348 tokens 81 families 001. and 30 002. the 28 003. be 22 004. he 18 005. a 17 006. in 16 007. to 16 008. of 15 009. this 15 010. will 13 011. as 11 012. can 10 013. you 8 014. have 7 015. term 6 016. able 5 017. they 5 018. at 4 019. on 4 020. come 3
Unique to second 286 tokens
182 families Freq first (then alpha) 001. child 8 002. artery 6 003. develop 6 004. heart 6 005. reach 6 006. skill 6 007. also 4 008. blood 4 009. by 4 010. stage 4 011. use 4 012. block 3 013. cognitive 3 014. diet 3 015. even 3 016. mature 3 017. middle 3 018. more 3
VP novel items
Same list Alpha first 001. #number 1 002. according 1 003. acquire 2 004. adolescence 1 005. adult 1
006. affect 2 007. affection 1 008. age 2
009. already 1 010. also 4 011. around 1 012. artery 6 013. assist 1 014. attack 1 015. baby 2 016. become 2
c. Comparison of Materials for Meeting 10 vs. Meeting 17
The third comparison measures the shared and unique words between materials for meeting 10 and meeting 17. Meeting 10 got the highest percentage of AWL, while meeting 17 comprised the lowest amount of AWL. Table 13 presents the summary of the comparison between materials for those two meetings as well as some examples of the shared and unique words. The complete table has been put in Appendix G. Table 13 denotes that the recycling index was 70.03%. Thus, it indicates that as much as 29.97% (100%-70.03%) of the total words from two materials was unique to the material for meeting 17. The token recycling index in this section is the highest compared to the other two results.
23
Unique to first 703 tokens 335 families 001. compute 28 002. rule 17 003. thou 16 004. ethics 13 005. language 12 006. write 12 007. internet 11 008. number 11 009. tale 9 010. command 8 011. ethical 8 012. example 8 013. it’ 8 014. wrong 8 015. else’ 7 016. read 7 017. ten 7 018. people 6 019. develop 5 020. file 5
Shared 1397 tokens 172 families 001. the 83 002. be 78 003. you 77 004. i 62 005. it 45 006. to 44 007. not 42 008. a 39 009. no 36 010. this 34 011. he 32 012. of 32 013. and 29 014. have 29 015. do 26 016. but 24 017. one 24 018. for 22 019. she 21 020. so 19
Unique to second 598 tokens
290 families Freq first (then alpha) 001. wait 15 002. aree 13 003. master 10 004. just 9 005. total 9 006. bad 8 007. cool 8 008. secret 8 009. awesome 7 010. dance 7 011. fang 7 012. fast 7 013. leave 7 014. let 7 015. monster 7 016. too 7 017. best 6 018. crocodile 5
VP novel items
Same list Alpha first 001. academy 2 002. actual 1 003. adopt 1 004. adult 1 005. afraid 4 006. after 1 007. again 4 008. ago 3 009. almost 1 010. amaze 3 011. aree 13 012. armour 2 013. around 1 014. art 2 015. attend 1 016. awe 2
E. CONCLUSION
24
the token recycling index of two materials. There were three pairs of material being compared in this study. The analysis demonstrates the recycling index for the material for meeting 2 and 11 was 52.64%. The material for meeting 8 and 16, the recycling index was 54.89%. The highest percentage of token recycling index was found in the material for meeting 10 and 17 which contained 70.03% shared vocabulary items. All the yielded result was hoped to be fruitful for the course developer in order to create the vocabulary learning strategies for the students.
The limitation of this study is the data taken to analyse neglected to differentiate the material sources. In the Academic Listening course material, the material was compiled from TOEFL, IELTS, textbooks, video podcasts, and a short movie. Yet, the sources were treated the same because this study focused more on the material used in each meeting.
For the further research, it is suggested to profile the material of the Academic Listening course based on its material source, whether it is from TOEFL, IELTS, textbooks, or other sources. This is based on the consideration that spoken texts from various resources would have different vocabulary profile characteristics.
25
ACKNOWLEDGEMENT
This undergraduate thesis could be completed with the kind support and help from many individuals. I would like to extend my sincere thanks to all of them.
Foremost, I want to offer this endeavour to God Almighty for the blessings He bestowed upon me, peace of my mind, and good health in order to finish this study.
I would like to express my gratitude towards my beloved father (Simon Slamet S.) and mother (Christina Yustina) for the abundant encouragement and motivation to pursue this undertaking.
I feel indebted to my supervisor, Anne Indrayanti Timotius, M.Ed., for imparting her knowledge and expertise in this study. I cannot also express my gratitude enough to Prof. Dr. Gusti Astika, M. A., for the tutorial and approval of my work.
26
REFERENCES
Bauer, L., & Nation P. (1993). Word families. International Journal of Lexicography, 6(4), 253-279.
Browne, C., & Culligan, D. B. (2008). Combining technology and IRT testing to build student knowledge of high frequency vocabulary. The JALT CALL Journal, 4(2), 3-16.
Browne, C., Culligan, B. & Phillips, J. (2013). The New General Service List. Retrieved from http://www.newgeneralservicelist.org.
Capel, A. (2012). Completing the English vocabulary profile: C1 and C2 vocabulary. English Profile Journal, 3(1), 1-14.
Cobb, T. (2007). Computing the vocabulary demands of L2 reading. Language Learning & Technology, 11(3), 38-64.
Cobb, T. (n.d.). English Classic. Retrieved October 17, 2015, from http://www.lextutor.ca/list_learn/eng/
Cobb, T. (n.d.). The compleat lexical tutor for data-driven learning on the web. Retrieved September 10, 2015, from http://lextutor.ca
Coxhead, A. (2000). A new academic word list. TESOL Quarterly, 34(2), 213-238.
Farjami, H. (2014). The vocabulary profile of Iranian English teaching school books. Iranian Journal of Applied Linguistics, 17(2), 1-26.
Golkar, M., & Yamini, M. (2007). Vocabulary, proficiency, and reading comprehension. The Reading Matrix, 7(3), 88-112.
Goodfellow, R., Lamy M.-N., & Jones G. (2002). Assessing learners’ writing using lexical frequency. ReCALL, 14(1), 133-145.
27
Hassani, M. T., Zarei, A., & Sadeghpour, M. (2013). Vocabulary teaching strategies: How do they affect L2 learners' lexical recall? Journal of Advances in English Language Teaching, 1(4), 96-102.
Kafipour, R., & Naveh, M. H. (2011). Vocabulary learning strategies and their contribution to reading comprehension of EFL undergraduate students in Kerman profince. European Journal of Social Sciences, 23(4), 626-647.
Koosha, M., & Akbari, G. R. (2010). An evaluation of the vocabulary used in Iranian EFL secondary and high school textbooks based on the BNC first three 1000 high frequency word lists. Knowledge & Research Educational Sciences, 26, 157-186. Krashen, S. (1982). Principles and practice in second language acquisition. Pregamon:
Oxford.
Laufer, B. (1994). The lexical profile of second language writing: Does it change over time? RELC Journal, 25(21), 21-33.
Laufer, B. (1999). A vocabulary-size test of controlled productive ability. Language Testing, 16(1), 33-51.
Laufer, B., & Ravenhorst-Kalovski, G. C. (2010). Lexical treshold revisited: Lexical text
coverage, learners’ vocabulary size and reading comprehension. Reading in a Foreign Language, 22(1), 15-30.
Liontou, D. T. (2015). Towards a text classification profile per level of English language competence: Intermediate vs. advanced reading comprehension texts. Internation Journal of Language and Linguistics, 2(1), 22-32.
Mayer, R. E., & Alexander, P. A. (2010). Handbook of research on learning and instruction. New York: Routledge.
Menken, K. (2010). NCLB and English language learners: Challenges and consequences. Theory Into Practice, 49, 121-128.
28
Morris, L., & Cobb, T. (2004). Vocabulary profiles as predictors of the academic performance of teaching English as a second language trainees. System, 32, 75-87. Nation, P. (2006). How large a vocabulary is needed for reading and listening? The Canadian
Modern Language Review, 63(2), 59-82.
Nation, P. (1990). Teaching and learning vocabulary. Boston: Heinle & Heinle Publisher. Nation, P. (2014). What do you need to know to learn a foreign language. New Zealand:
Victoria University of Wellington.
Nemati, A. (2009). Evaluation of an ESL English course book: A step towards systematic vocabulary evaluation. Journal of Social and Science, 20(9), 91-99.
Paul, M. (2005). Lexical frequency profiles: A Monte Carlo Analysis. Applied Linguistics, 26(1), 32-47.
Read, J. (2000). Assessing vocabulary. Cambridge: Cambridge university press.
Schmitt, N., & Schmitt, D. (2012). A reassessment of frequency and vocabulary size in L2 vocabulary teaching. Language Teaching, 47(4), 484 - 503.
Schmitt, N., Schmitt, D., & Calpham, C. (2001). Developing and exploring the behaviour of two new versions of the vocabulary level test. Language Testing, 18(1), 55-88.
Sitton, R. (1992). Rebecca Sitton's spelling sourcebook series. Scottdale: Egger Publishing, Inc.
Stæhr, L. S. (2008). Vocabulary size and the skills of listening, reading and writing. Language Learning Journal, 36(2), 139-152.
Sublist Families of the Academic Word List. (2015). Retrieved October 17, 2015, from http://www.victoria.ac.nz/lals/resources/academicwordlist/sublists.
29
Walinski, J., Kredens, K., & Goźdź-Roszkowski, S. (2007). Practical applications in language and computers 2005. In M. Paquot, Towards a productively-oriented academic word list (pp. 127-140). Frankfurt: Peter Lang.
30
APPENDICES
Appendix A
The complete list of K1 negative vocabulary profile
ACCOUNTABLE ADVENTURE AFFAIR AGENT ANCIENT
ARISE ARM ATTEMPT BRIGHT CAPITAL
CAPTAIN CASTLE CHIEF CHURCH CLAIM
CLOUD COIN COLONY COMMITTEE CORN
CROWN DOG DREAM FACTORY FAITH
FOREST FORMER FORTH FRESH GATE
GIFT HEAVY INCH IRON JUSTICE
LAUGHTER LAY LIP LORD MILK
MINISTER MOTOR MRS NECESSITY NEIGHBOUR NOBLE NUMERICAL ORDINARY OWE PROMISE
PROVISION QUARTER RACE RANK RELIGION
REPLY REPUBLIC SHADOW SHINE SILENCE
SKY SOUL SPITE SQUARE STONE
STREAM SWORD TEMPLE TRUST VICTORY
VIRTUE WAGE WAR WEALTH WINDOW
YIELD
Appendix B
The complete list of K2 negative vocabulary profile
ABSENCE ABSENT ABSOLUTELY ACCUSE ACCUSTOM AEROPLANE ALIVE ALOUD AMBITION AMUSE ANGLE ANNOY APOLOGIZE APOLOGY APPLAUD
APPLAUSE APPLE APPROVE ARCH ARREST
ARROW ASH ASHAMED ASTONISH AUTUMN
AWAKE AWKWARD AXE BAND BARBER
BARE BASIN BASKET BATH BATHE
BEAM BEG BELL BERRY BLADE
BLESS BOLD BOUND BOWL BRAVE
BREATH BRIBE BROWN BRUSH BUNDLE
BURIAL BURST BURY BUTTER BUTTON
CAGE CALCULATE CANAL CAPE CARRIAGE
CART CATTLE CAUTION CENTIMETRE CHARM
CHEAT CHEER CHEESE CHEQUE CHEST
CHIMNEY CHRISTMAS CIVILISE CLAY COARSE COLLAR COMB COMPANION CONFESS CONSCIOUS
COPPER CORK COTTAGE COW COWARD
CRASH CREAM CRIME CRIMINAL CRUEL
CUPBOARDS CURL CURSE CURVE CUSHION
DARE DEAF DEBT DECAY DECEIVE
DEED DEER DELICATE DESPAIR DECIL
DIAMOND DISGUST DISMISS DITCH DONKEY
DRAG DRAWER DULL DUST EARNEST
EASE ELASTIC ELDER ELEPHANT ENCLOSE
ESSENCE EXCESS FADE DAINT FANCY
31
FEVER FIERCE FLASH FLESH FORBID
FORGIVE FORK FRY FUNERAL GALLON
GAP GARAGE GAY GLORY GOAT
GRAIN GRAM GRAVE GREED GRIND
GUARD GUILTY HAMMER HANDKERCHIEF HASTE
HAY HEAL HEAP HINDER HOLE
HOLY HORIZON HOST HUMBLE HURRAH
HUT IDEAL IDLE IMMENSE INFORMALLY
INN INSULT JAW JEALOUS JEWEL
HUICE JUMP KILOGRAM KISS KNEEL
KNIFE KNOT LADDER LAMP LAZY
LEAF LEAN LIBERTY LIMB LIQUID
LITRE LOAF LODGING LOG LOOSE
LUMP LUNG MAD MEANTIME MEANWHILE
MEND MERCY MERRY MESSENGER MILD
MILL MILLIGRAM MILLILITRE MILLIMETRE MINERAL
MISERABLE MODEST MOTION MOUSE MUD
MURDER NEAT NECK NEPHEW NEST
NET NIECE NOSE NOUN NUISANCE
OAR OBEY OFFEND OMIT OPPOSE
ORANGE ORNAMENT OVERCOME PALE PAN
PARCEL PARDON PASSAGE PASTE PATH
PATRIOTIC PAUSE PAW PEARL PECULIAR
PENNY PET PIG PIGEON PIN
PINCH PINK PINT PIPE PLASTER
PLOUGH PLURAL POLITE POSTPONE POUR
POWDER PRAISE PRAY PREACH PREJUDICE
PRIEST PROCESSION PROFESSION PROGRAMME PRONOUNCE
PUMP PUNCTUAL PUNISH PUPIL PURE
PURPLE QUARREL QUART RABBIT RAIL
RAKE RAT RAW RAY RAZOR
REFRESH REJOICE REMEDY REQUEST RESCUE
RESIGN REVENGE RICE ROAR ROAST
ROB ROD ROPE ROT RUB
RUBBER RUBBISH RUIN RUSH RUST
SCARED SACRIFICE SADDLE SALARY SAND
SAUCE SAUCER SAWS SCENT SCISSORS
SCOLD SCORN SCRAPE SCREEN SEED
SEIZE SELDOM SEVERE SHAVE SLIDE
SOCK SOLEMN SORE SOUP SOUR
SOW SPADE SPARE SPIN SPIT
SPLENDID SPLIT SPOON STAIN STEEP
STEM STIR STOCKING STOVE STRAP
STRAW STRING STRIP STRIPE SUGAR
SUPPER SUSPECT SUSPICION SWALLOW SWEAR
SWING SYMPATHY TAILOR TAP TAXI
TELEGRAPH TENDER THICK THIEF THIN
THIRST THORN THREAD THROAT THUMB
TIDY TIN TOBACCO TOWEL TRANSLATE
TRAY TREASURE TRUNK TUBE TUNE
TWIST UGLY UMBRELLA UPPER UPRIGHT
VAIN VEIL VERB VERSE VOYAGE
WAIST WAX WEAPON WEAVE WEED
WET WHEAT WHIP WHISPER WICKED
32
WRAP WRECK WRIST YELLOW
Appendix C
The complete list of AWL negative vocabulary profile
ABSTRACT ACCUMULATE ACKNOWLEDGE ADEQUATE ADJACENT ADJUST ADMINISTRATE AGGREGATE ALBEIT AMEND
ANALOGY APPEND ARBITRARY ATTAIN ATTRIBUTE
AUTHORITY AUTOMATE BEHALF BIAS BULK
CAPABLE CHANNEL CHART CLAUSE COHERENT
COMMENCE COMMIT COMPATIBLE COMPENSATE COMPILE COMPLEMENT COMPONENT COMPRISE CONCEIVE CONCURRENT
CONFINE CONSENT CONTEXT CONTRACT CONTRARY
CONTROVERSY CONVENE CORPORATE CURRENCY DECLINE
DEDUCE DENOTE DEPRESS DERIVE DEVIATE
DIMINISH DISCRETE DISCRIMINATE DISPLAY DOMAIN DURATION ELEMENT ELIMINATE EMPIRICAL ENHANCE
ENTITY ERROR ESTATE EVALUATE EXCEED
EXPLOIT EXTERNAL EXTRACT FEDERAL FINITE
FLEXIBLE FLUCTUATE FORMULA FORTHCOMING FOUNDATION FRAMEWORK FURTHERMORE HENCE HIERARCHY HYPOTHESIS IDEOLOGY IGNORANT IMPLICIT IMPOSE INCLINE INCOME INEVITABLE INFRASTRUCTURE INHERENT INITIAL
INITIATE INJURE INPUT INSERT INTEGRITY
INTERVAL INTERVENE INTRINSIC INVOKE ISOLATE
JUSTIFY LABOUR LAYER LEGISLATE LEVY
LIKEWISE MANIPULATE MINIMISE MINISTYR MINOR
MODE MODIFY MUTUAL NEUTRAL NONETHELESS
NORM NOTWITHSTANDING OBTAIN OFFSET ONGOING OUTCOME OVERLAP PARAMETER PARTNER PERCEIVE PERSIST PORTION PRACTICIONER PREDOMINANT PRELIMINARY
PRINCIPAL PRIOR RATIONAL RECOVER REGIME
REINFORCE REJECT RELUCTANCE RESTORE RESTRAIN
RETAIN REVEAL REVENUE REVERSE REVOLUTION
RIGID SCENARIO SECTOR SECURE SEEK
SEX SIMULATE SO-CALLED SPECIFY SPHERE
SUBORDINATE SUBSIDY SUBTITUTE SUCCESSOR SUM
SUSPEND SUSTAIN TRIGGER ULTIMATE UNDERGO
33 Appendix D
Block Frequency output of off-list words
RANK FREQ.
COVERAGE
WORD individ. cumulative
1. 1 0.07% 0.07% ABACK
2. 1 0.07% 0.14% ABBREVIATE
3. 1 0.07% 0.21% ABBREVIATED
4. 1 0.07% 0.28% ABBREVIATIONS
5. 1 0.07% 0.35% ABSORBED
6. 1 0.07% 0.42% ABSORBING
7. 1 0.07% 0.49% ABSORBS
8. 1 0.07% 0.56% ABUNDANCE
9. 1 0.07% 0.63% ACCLAIM
10. 1 0.07% 0.70% ACCOMPLISH
11. 1 0.07% 0.77% ACE
12. 1 0.07% 0.84% AD
13. 1 0.07% 0.91% ADMISSIONS
14. 1 0.07% 0.98% ADO
15. 1 0.07% 1.05% ADOLESCENCE
16. 1 0.07% 1.12% ADVISOR
17. 1 0.07% 1.19% AERIAL
18. 1 0.07% 1.26% AERONAUTICS
19. 1 0.07% 1.33% AFFECTION
20. 1 0.07% 1.40% AGENDA
21. 1 0.07% 1.47% AGGIE
22. 1 0.07% 1.54% AGGRESSIVENESS
23. 1 0.07% 1.61% AIRPORT
24. 1 0.07% 1.68% AIRY
25. 1 0.07% 1.75% AJAR
26. 1 0.07% 1.82% ALERT
27. 1 0.07% 1.89% ALGEBRA
28. 1 0.07% 1.96% ALLERGEN
29. 1 0.07% 2.03% ALLERGIC
30. 1 0.07% 2.10% ALLERGIES
34
32. 1 0.07% 2.24% ALPHABET
33. 1 0.07% 2.31% ALRIGHT
34. 1 0.07% 2.38% ALTITUDE
35. 1 0.07% 2.45% ALTITUDES
36. 1 0.07% 2.52% AMAZING
37. 1 0.07% 2.59% ANNOTATED
38. 1 0.07% 2.66% ANNOUNCEMENT
39. 1 0.07% 2.73% ANNUALS
40. 1 0.07% 2.80% ANT
41. 1 0.07% 2.87% ANTHROPOLOGIST
42. 1 0.07% 2.94% ANYTIME
43. 1 0.07% 3.01% APARTMENT
44. 1 0.07% 3.08% APPALLING
45. 1 0.07% 3.15% APPETITE
46. 1 0.07% 3.22% ARCHAEOLOGICAL
47. 1 0.07% 3.29% ARCHAEOLOGY
48. 1 0.07% 3.36% ARCHITECTURE
49. 1 0.07% 3.43% ARENA
50. 1 0.07% 3.50% ARGUABLY
51. 1 0.07% 3.57% ARISTOCRAT
52. 1 0.07% 3.64% ARITHMETIC
53. 1 0.07% 3.71% ARMOR
54. 1 0.07% 3.78% ARROGANT
55. 1 0.07% 3.85% ARTERIES
56. 1 0.07% 3.92% ARTERY
57. 1 0.07% 3.99% ASSET
58. 1 0.07% 4.06% ASTEROIDS
59. 1 0.07% 4.13% ATHLETE
60. 1 0.07% 4.20% ATHLETES
61. 1 0.07% 4.27% ATHLETIC
62. 1 0.07% 4.34% ATLAS
63. 1 0.07% 4.41% ATMOSPHERE
64. 1 0.07% 4.48% ATMOSPHERIC
65. 1 0.07% 4.55% ATTENTIVE
66. 1 0.07% 4.62% ATTEST
35
68. 1 0.07% 4.76% AUDIO
69. 1 0.07% 4.83% AUDIT
70. 1 0.07% 4.90% AUDITING
71. 1 0.07% 4.97% AUDITORIUM
72. 1 0.07% 5.04% AUTOCLAVE
73. 1 0.07% 5.11% AUTOCLAVED
74. 1 0.07% 5.18% AUTOCLAVES
75. 1 0.07% 5.25% AUTOCLAVING
76. 1 0.07% 5.32% AWARD
77. 1 0.07% 5.39% AWE
78. 1 0.07% 5.46% AWESOME
79. 1 0.07% 5.53% AWESOMENESS
80. 1 0.07% 5.60% AWFUL
81. 1 0.07% 5.67% AWFULLY
82. 1 0.07% 5.74% BACHELOR
83. 1 0.07% 5.81% BACKPACKS
84. 1 0.07% 5.88% BACKSTAGE
85. 1 0.07% 5.95% BACTERIA
86. 1 0.07% 6.02% BACTERIAL
87. 1 0.07% 6.09% BACTERIUM
88. 1 0.07% 6.16% BADMINTON
89. 1 0.07% 6.23% BALD
90. 1 0.07% 6.30% BANANA
91. 1 0.07% 6.37% BANANAS
92. 1 0.07% 6.44% BANDIT
93. 1 0.07% 6.51% BANDITS
94. 1 0.07% 6.58% BARBECUE
95. 1 0.07% 6.65% BARRELLING
96. 1 0.07% 6.72% BARRIERS
97. 1 0.07% 6.79% BASEBALL
98. 1 0.07% 6.86% BASEMENT
99. 1 0.07% 6.93% BASICS
100. 1 0.07% 7.00% BASKETBALL
101. 1 0.07% 7.07% BASTIONS
102. 1 0.07% 7.14% BATCH
36
104. 1 0.07% 7.28% BEACH
105. 1 0.07% 7.35% BEAUTIES
106. 1 0.07% 7.42% BEDTIME
107. 1 0.07% 7.49% BEE
108. 1 0.07% 7.56% BEER
109. 1 0.07% 7.63% BEES
110. 1 0.07% 7.70% BEFOREHAND
111. 1 0.07% 7.77% BEHOLD
112. 1 0.07% 7.84% BENCHES
113. 1 0.07% 7.91% BET
114. 1 0.07% 7.98% BEVERAGES
115. 1 0.07% 8.05% BIBLE
116. 1 0.07% 8.12% BIBLICAL
117. 1 0.07% 8.19% BIBLIOGRAPHY
118. 1 0.07% 8.26% BIKING
119. 1 0.07% 8.33% BILINGUAL
120. 1 0.07% 8.40% BIMONTHLY
121. 1 0.07% 8.47% BIODEGRADES
122. 1 0.07% 8.54% BIOLOGICAL
123. 1 0.07% 8.61% BIOLOGIST
124. 1 0.07% 8.68% BIOLOGY
125. 1 0.07% 8.75% BIOMETRICS
126. 1 0.07% 8.82% BIOPHYSICAL
127. 1 0.07% 8.89% BISON
128. 1 0.07% 8.96% BIZARRE
129. 1 0.07% 9.03% BLANKET
130. 1 0.07% 9.10% BLEND
131. 1 0.07% 9.17% BLENDED
132. 1 0.07% 9.24% BLINK
133. 1 0.07% 9.31% BLOCKAGE
134. 1 0.07% 9.38% BLOG
135. 1 0.07% 9.45% BLOGGER
136. 1 0.07% 9.52% BLOGGING
137. 1 0.07% 9.59% BLONDE
138. 1 0.07% 9.66% BLOSSOM
37
140. 1 0.07% 9.80% BONUS
141. 1 0.07% 9.87% BOOKCASE
142. 1 0.07% 9.94% BOOKCASES
143. 1 0.07% 10.01% BOOKED
144. 1 0.07% 10.08% BOOKING
145. 1 0.07% 10.15% BOOKLISTS
146. 1 0.07% 10.22% BOOKSELLERS
147. 1 0.07% 10.29% BOOKSHELF
148. 1 0.07% 10.36% BOOKSHOP
149. 1 0.07% 10.43% BOOKSTORE
150. 1 0.07% 10.50% BOOM
151. 1 0.07% 10.57% BOOSTER
152. 1 0.07% 10.64% BOOTH
153. 1 0.07% 10.71% BOOTS
154. 1 0.07% 10.78% BORING
155. 1 0.07% 10.85% BORROWINGS
156. 1 0.07% 10.92% BOSS
157. 1 0.07% 10.99% BOTANISTS
158. 1 0.07% 11.06% BOXING
159. 1 0.07% 11.13% BOYFRIEND
160. 1 0.07% 11.20% BRAND
161. 1 0.07% 11.27% BREEDING
162. 1 0.07% 11.34% BREEZE
163. 1 0.07% 11.41% BRILLIANT
164. 1 0.07% 11.48% BROADCASTER
165. 1 0.07% 11.55% BROCHURE
166. 1 0.07% 11.62% BRONZE
167. 1 0.07% 11.69% BUDGET
168. 1 0.07% 11.76% BUFFALO
169. 1 0.07% 11.83% BUG
170. 1 0.07% 11.90% BULLET
171. 1 0.07% 11.97% BULLYING
172. 1 0.07% 12.04% BUMMER
173. 1 0.07% 12.11% BUNK
174. 1 0.07% 12.18% BUNNIES
38
176. 1 0.07% 12.32% BURDEN
177. 1 0.07% 12.39% BUSTER
178. 1 0.07% 12.46% BUTLER
179. 1 0.07% 12.53% BUTT
180. 1 0.07% 12.60% BUTTERFLIES
181. 1 0.07% 12.67% BYE
182. 1 0.07% 12.74% CAB
183. 1 0.07% 12.81% CAFE
184. 1 0.07% 12.88% CAFETERIA
185. 1 0.07% 12.95% CALCULUS
186. 1 0.07% 13.02% CALMER
187. 1 0.07% 13.09% CAMPAIGN
188. 1 0.07% 13.16% CAMPER
189. 1 0.07% 13.23% CAMPSITES
190. 1 0.07% 13.30% CAMPUS
191. 1 0.07% 13.37% CANCELLED
192. 1 0.07% 13.44% CAPITALISM
193. 1 0.07% 13.51% CARBON
194. 1 0.07% 13.58% CAREER
195. 1 0.07% 13.65% CAREERS
196. 1 0.07% 13.72% CARTOGRAPHY
197. 1 0.07% 13.79% CARTONS
198. 1 0.07% 13.86% CASH
199. 1 0.07% 13.93% CASHIER
200. 1 0.07% 14.00% CASSETTES
201. 1 0.07% 14.07% CASUALTIES
202. 1 0.07% 14.14% CATALOGUES
203. 1 0.07% 14.21% CATER
204. 1 0.07% 14.28% CATSUP
205. 1 0.07% 14.35% CELEBRATE
206. 1 0.07% 14.42% CELEBRATION
207. 1 0.07% 14.49% CELL
208. 1 0.07% 14.56% CELLS
209. 1 0.07% 14.63% CELLULAR
210. 1 0.07% 14.70% CENSUS
39
212. 1 0.07% 14.84% CHAMPIONS
213. 1 0.07% 14.91% CHAPEL
214. 1 0.07% 14.98% CHAT
215. 1 0.07% 15.05% CHEMIST
216. 1 0.07% 15.12% CHEMISTRY
217. 1 0.07% 15.19% CHERRIES
218. 1 0.07% 15.26% CHILLED
219. 1 0.07% 15.33% CHIMPANZEES
220. 1 0.07% 15.40% CHOLERA
221. 1 0.07% 15.47% CHRYSANTHEMUM
222. 1 0.07% 15.54% CHUCK
223. 1 0.07% 15.61% CHUNKS
224. 1 0.07% 15.68% CINEMA
225. 1 0.07% 15.75% CIRCULATED
226. 1 0.07% 15.82% CLAN
227. 1 0.07% 15.89% CLASSROOM
228. 1 0.07% 15.96% CLASSROOMS
229. 1 0.07% 16.03% CLEANSED
230. 1 0.07% 16.10% CLERGY
231. 1 0.07% 16.17% CLICKS
232. 1 0.07% 16.24% CLIMATE
233. 1 0.07% 16.31% CLIP
234. 1 0.07% 16.38% CLIPPED
235. 1 0.07% 16.45% CLIPPER
236. 1 0.07% 16.52% CLOAKROOM
237. 1 0.07% 16.59% CLOSET
238. 1 0.07% 16.66% CLUES
239. 1 0.07% 16.73% CLUMPS
240. 1 0.07% 16.80% CLUSTERED
241. 1 0.07% 16.87% CO
242. 1 0.07% 16.94% COACH
243. 1 0.07% 17.01% COASTAL
244. 1 0.07% 17.08% COASTLINES
245. 1 0.07% 17.15% COGENT
246. 1 0.07% 17.22% COGNITION
40
248. 1 0.07% 17.36% COINING
249. 1 0.07% 17.43% COLLATING
250. 1 0.07% 17.50% COLLIDE
251. 1 0.07% 17.57% COLLISIONS
252. 1 0.07% 17.64% COLUMN
253. 1 0.07% 17.71% COMBAT
254. 1 0.07% 17.78% COMBUSTIBILITY
255. 1 0.07% 17.85% COMEDY
256. 1 0.07% 17.92% COMETS
257. 1 0.07% 17.99% COMMANDMENT
258. 1 0.07% 18.06% COMMANDMENTS
259. 1 0.07% 18.13% COMMUNISM
260. 1 0.07% 18.20% COMPASS
261. 1 0.07% 18.27% COMPASSION
262. 1 0.07% 18.34% COMPETENCE
263. 1 0.07% 18.41% CONCERT
264. 1 0.07% 18.48% CONDITIONING
265. 1 0.07% 18.55% CONDUCTOR
266. 1 0.07% 18.62% CONFIDENTIAL
267. 1 0.07% 18.69% CONTAGIOUS
268. 1 0.07% 18.76% CONTAINMENT
269. 1 0.07% 18.83% CONTINENTAL
270. 1 0.07% 18.90% CONTINUALLY
271. 1 0.07% 18.97% CONTRACTIONS
272. 1 0.07% 19.04% CONVENORS
273. 1 0.07% 19.11% CONVEY
274. 1 0.07% 19.18% COPE
275. 1 0.07% 19.25% COPYRIGHT
276. 1 0.07% 19.32% COSMIC
277. 1 0.07% 19.39% COUCHANT
278. 1 0.07% 19.46% COUNTERACT
279. 1 0.07% 19.53% COUNTY
280. 1 0.07% 19.60% COURIER
281. 1 0.07% 19.67% COURTESIES
282. 1 0.07% 19.74% COVENTRY
41
284. 1 0.07% 19.88% COWER
285. 1 0.07% 19.95% CRAFTS
286. 1 0.07% 20.02% CRAZINESS
287. 1 0.07% 20.09% CREST
288. 1 0.07% 20.16% CRESTS
289. 1 0.07% 20.23% CRITICIZE
290. 1 0.07% 20.30% CROCODILE
291. 1 0.07% 20.37% CROCODILES
292. 1 0.07% 20.44% CROWED
293. 1 0.07% 20.51% CRUDE
294. 1 0.07% 20.58% CRUST
295. 1 0.07% 20.65% CUES
296. 1 0.07% 20.72% CUMBERSOME
297. 1 0.07% 20.79% CURRICULUM
298. 1 0.07% 20.86% CURVIER
299. 1 0.07% 20.93% CUTE
300. 1 0.07% 21.00% DADDY
301. 1 0.07% 21.07% DATABASE
302. 1 0.07% 21.14% DAUNTING
303. 1 0.07% 21.21% DEADLINE
304. 1 0.07% 21.28% DEADLINES
305. 1 0.07% 21.35% DEBILITATING
306. 1 0.07% 21.42% DEBRIS
307. 1 0.07% 21.49% DECEPTIVE
308. 1 0.07% 21.56% DECODE
309. 1 0.07% 21.63% DEDICATED
310. 1 0.07% 21.70% DEDICATION
311. 1 0.07% 21.77% DEFICIENCY
312. 1 0.07% 21.84% DEFICIENT
313. 1 0.07% 21.91% DEFIES
314. 1 0.07% 21.98% DEGRADATION
315. 1 0.07% 22.05% DELIBERATE
316. 1 0.07% 22.12% DELIBERATELY
317. 1 0.07% 22.19% DELICIOUS
318. 1 0.07% 22.26% DEMOCRACY
42
320. 1 0.07% 22.40% DENTIST
321. 1 0.07% 22.47% DEPARTURE
322. 1 0.07% 22.54% DEPICT
323. 1 0.07% 22.61% DEPICTED
324. 1 0.07% 22.68% DEPICTION
325. 1 0.07% 22.75% DEPOSIT
326. 1 0.07% 22.82% DEPOSITS
327. 1 0.07% 22.89% DESPERATE
328. 1 0.07% 22.96% DESSERT
329. 1 0.07% 23.03% DETERGENT
330. 1 0.07% 23.10% DETERGENTS
331. 1 0.07% 23.17% DEVASTATING
332. 1 0.07% 23.24% DEVISED
333. 1 0.07% 23.31% DEVISING
334. 1 0.07% 23.38% DIET
335. 1 0.07% 23.45% DIETS
336. 1 0.07% 23.52% DIGEST
337. 1 0.07% 23.59% DINOSAUR
338. 1 0.07% 23.66% DINOSAURS
339. 1 0.07% 23.73% DIPLOMAT
340. 1 0.07% 23.80% DISARRAY
341. 1 0.07% 23.87% DISASTER
342. 1 0.07% 23.94% DISASTERS
343. 1 0.07% 24.01% DISCARDED
344. 1 0.07% 24.08% DISCERNIBLE
345. 1 0.07% 24.15% DISCOMFORTS
346. 1 0.07% 24.22% DISCONSOLATE
347. 1 0.07% 24.29% DISCOUNT
348. 1 0.07% 24.36% DISCOUNTS
349. 1 0.07% 24.43% DISCOURSE
350. 1 0.07% 24.50% DISHWASHERS
351. 1 0.07% 24.57% DISPUTES
352. 1 0.07% 24.64% DISRUPTION
353. 1 0.07% 24.71% DISSERTATION
354. 1 0.07% 24.78% DISSIPATE
43
356. 1 0.07% 24.92% DIVINE
357. 1 0.07% 24.99% DIVORCE
358. 1 0.07% 25.06% DOCK
359. 1 0.07% 25.13% DOCUMENTARIES
360. 1 0.07% 25.20% DOLPHIN
361. 1 0.07% 25.27% DOLPHINS
362. 1 0.07% 25.34% DORMITORY
363. 1 0.07% 25.41% DOS
364. 1 0.07% 25.48% DOWNLOAD
365. 1 0.07% 25.55% DOWNLOADING
366. 1 0.07% 25.62% DOWNSIDE
367. 1 0.07% 25.69% DOWNWARD
368. 1 0.07% 25.76% DRAGON
369. 1 0.07% 25.83% DRAGONS
370. 1 0.07% 25.90% DRAINED
371. 1 0.07% 25.97% DRAWBACK
372. 1 0.07% 26.04% DRAWBACKS
373. 1 0.07% 26.11% DREADING
374. 1 0.07% 26.18% DRESSER
375. 1 0.07% 26.25% DROPLETS
376. 1 0.07% 26.32% DROUGHT
377. 1 0.07% 26.39% DRUGSTORE
378. 1 0.07% 26.46% DUCTS
379. 1 0.07% 26.53% DUDES
380. 1 0.07% 26.60% DYSLEXIA
381. 1 0.07% 26.67% DYSLEXIC
382. 1 0.07% 26.74% EARDRUMS
383. 1 0.07% 26.81% EATER
384. 1 0.07% 26.88% EATERS
385. 1 0.07% 26.95% EDIFICES
386. 1 0.07% 27.02% EFFICIENTLY
387. 1 0.07% 27.09% EGOMANIAC
388. 1 0.07% 27.16% ELECTIVE
389. 1 0.07% 27.23% ELECTIVES
390. 1 0.07% 27.30% ELECTRONIC
44
392. 1 0.07% 27.44% ELECTRONICS
393. 1 0.07% 27.51% ELEGANT
394. 1 0.07% 27.58% ELIGIBLE
395. 1 0.07% 27.65% EMAIL
396. 1 0.07% 27.72% EMBARRASS
397. 1 0.07% 27.79% EMBARRASSED
398. 1 0.07% 27.86% EMBOSSED
399. 1 0.07% 27.93% EMOTIONAL
400. 1 0.07% 28.00% EMOTIONS
401. 1 0.07% 28.07% EMPATHIZE
402. 1 0.07% 28.14% ENCYCLOPAEDIA
403. 1 0.07% 28.21% ENDINGS
404. 1 0.07% 28.28% ENDOSPORES
405. 1 0.07% 28.35% ENDURED
406. 1 0.07% 28.42% ENGAGEMENT
407. 1 0.07% 28.49% ENGAGING
408. 1 0.07% 28.56% ENGRAVED
409. 1 0.07% 28.63% ENGRAVING
410. 1 0.07% 28.70% ENGRAVINGS
411. 1 0.07% 28.77% ENGULFED
412. 1 0.07% 28.84% ENROL
413. 1 0.07% 28.91% ENROLMENT
414. 1 0.07% 28.98% ENTERPRISE
415. 1 0.07% 29.05% ENTERPRISING
416. 1 0.07% 29.12% ENTHUSIASTIC
417. 1 0.07% 29.19% EPHEMERA
418. 1 0.07% 29.26% EPICENTRE
419. 1 0.07% 29.33% EPICS
420. 1 0.07% 29.40% EPISODE
421. 1 0.07% 29.47% EQUILIBRIUM
422. 1 0.07% 29.54% ERA
423. 1 0.07% 29.61% ERADICATED
424. 1 0.07% 29.68% ERECTED
425. 1 0.07% 29.75% ERUPTION
426. 1 0.07% 29.82% ERUPTIONS
45
428. 1 0.07% 29.96% ESSAYS
429. 1 0.07% 30.03% ESTEEM
430. 1 0.07% 30.10% ETHOLOGY
431. 1 0.07% 30.17% EVAPORATE
432. 1 0.07% 30.24% EVAPORATING
433. 1 0.07% 30.31% EVAPORATION
434. 1 0.07% 30.38% EXAGGERATE
435. 1 0.07% 30.45% EXIT
436. 1 0.07% 30.52% EXTENUATING
437. 1 0.07% 30.59% EXTERIOR
438. 1 0.07% 30.66% FABLED
439. 1 0.07% 30.73% FACIAL
440. 1 0.07% 30.80% FACULTY
441. 1 0.07% 30.87% FAITHFULNESS
442. 1 0.07% 30.94% FAKE
443. 1 0.07% 31.01% FAMED
444. 1 0.07% 31.08% FAMILIARISING
445. 1 0.07% 31.15% FAMOUSLY
446. 1 0.07% 31.22% FANG
447. 1 0.07% 31.29% FANGED
448. 1 0.07% 31.36% FANGLED
449. 1 0.07% 31.43% FANGS
450. 1 0.07% 31.50% FANTASTIC
451. 1 0.07% 31.57% FANTASTICALLY
452. 1 0.07% 31.64% FARE
453. 1 0.07% 31.71% FASCINATED
454. 1 0.07% 31.78% FASCINATING
455. 1 0.07% 31.85% FASCINATION
456. 1 0.07% 31.92% FAX
457. 1 0.07% 31.99% FEAT
458. 1 0.07% 32.06% FEEDBACK
459. 1 0.07% 32.13% FEROCIOUS
460. 1 0.07% 32.20% FESTIVAL
461. 1 0.07% 32.27% FIELDWORK
462. 1 0.07% 32.34% FIRSTBORN
46
464. 1 0.07% 32.48% FISTS
465. 1 0.07% 32.55% FLAMMABLE
466. 1 0.07% 32.62% FLAP
467. 1 0.07% 32.69% FLEET
468. 1 0.07% 32.76% FLOCK
469. 1 0.07% 32.83% FLORA
470. 1 0.07% 32.90% FLOWCHART
471. 1 0.07% 32.97% FLU
472. 1 0.07% 33.04% FLUTES
473. 1 0.07% 33.11% FOCAL
474. 1 0.07% 33.18% FOOTERS
475. 1 0.07% 33.25% FOOTNOTES
476. 1 0.07% 33.32% FOOTPRINTS
477. 1 0.07% 33.39% FORCEPS
478. 1 0.07% 33.46% FOREARMED
479. 1 0.07% 33.53% FORECASTER
480. 1 0.07% 33.60% FORECASTS
481. 1 0.07% 33.67% FOREIGNNESS
482. 1 0.07% 33.74% FOREWARNED
483. 1 0.07% 33.81% FORMERS
484. 1 0.07% 33.88% FOSTERED
485. 1 0.07% 33.95% FOYER
486. 1 0.07% 34.02% FRACTION
487. 1 0.07% 34.09% FRAGILE
488. 1 0.07% 34.16% FRANTICALLY
489. 1 0.07% 34.23% FRAT
490. 1 0.07% 34.30% FRESHMAN
491. 1 0.07% 34.37% FRESHMEN
492. 1 0.07% 34.44% FRESHWATER
493. 1 0.07% 34.51% FRICTION
494. 1 0.07% 34.58% FRICTIONS
495. 1 0.07% 34.65% FRIDGE
496. 1 0.07% 34.72% FUELLED
497. 1 0.07% 34.79% FUELS
498. 1 0.07% 34.86% FUNGI
47
500. 1 0.07% 35.00% FURRY
501. 1 0.07% 35.07% GANG
502. 1 0.07% 35.14% GARBAGE
503. 1 0.07% 35.21% GASEOUS
504. 1 0.07% 35.28% GAUGES
505. 1 0.07% 35.35% GEARS
506. 1 0.07% 35.42% GENERALIZE
507. 1 0.07% 35.49% GENETICS
508. 1 0.07% 35.56% GENRE
509. 1 0.07% 35.63% GEOGRAPHER
510. 1 0.07% 35.70% GEOGRAPHERS
511. 1 0.07% 35.77% GEOGRAPHICAL
512. 1 0.07% 35.84% GEOGRAPHICALLY
513. 1 0.07% 35.91% GEOGRAPHY
514. 1 0.07% 35.98% GEOMETRY
515. 1 0.07% 36.05% GERMINATE
516. 1 0.07% 36.12% GERMS
517. 1 0.07% 36.19% GESTURE
518. 1 0.07% 36.26% GESTURES
519. 1 0.07% 36.33% GIANT
520. 1 0.07% 36.40% GIBBONS
521. 1 0.07% 36.47% GILDING
522. 1 0.07% 36.54% GIRAFFE
523. 1 0.07% 36.61% GLIMMER
524. 1 0.07% 36.68% GLOSSARY
525. 1 0.07% 36.75% GOLF
526. 1 0.07% 36.82% GOODS
527. 1 0.07% 36.89% GORILLA
528. 1 0.07% 36.96% GOTHIC
529. 1 0.07% 37.03% GRAB
530. 1 0.07% 37.10% GRADUATE
531. 1 0.07% 37.17% GRADUATED
532. 1 0.07% 37.24% GRADUATES
533. 1 0.07% 37.31% GRADUATING
534. 1 0.07% 37.38% GRADUATION
48
536. 1 0.07% 37.52% GRAPES
537. 1 0.07% 37.59% GRID
538. 1 0.07% 37.66% GRIPS
539. 1 0.07% 37.73% GROCERIES
540. 1 0.07% 37.80% GROSS
541. 1 0.07% 37.87% GROWERS
542. 1 0.07% 37.94% GUARDIAN
543. 1 0.07% 38.01% GUIDANCE
544. 1 0.07% 38.08% GUITAR
545. 1 0.07% 38.15% GUITARS
546. 1 0.07% 38.22% GUNG
547. 1 0.07% 38.29% GUY
548. 1 0.07% 38.36% GUYS
549. 1 0.07% 38.43% GYMNASIUM
550. 1 0.07% 38.50% GYMNASTICS
551. 1 0.07% 38.57% HABITAT
552. 1 0.07% 38.64% HABITUS
553. 1 0.07% 38.71% HACK
554. 1 0.07% 38.78% HACKED
555. 1 0.07% 38.85% HACKERS
556. 1 0.07% 38.92% HACKING
557. 1 0.07% 38.99% HAIRCUT
558. 1 0.07% 39.06% HANDBAG
559. 1 0.07% 39.13% HANDIER
560. 1 0.07% 39.20% HANDOUT
561. 1 0.07% 39.27% HANDOUTS
562. 1 0.07% 39.34% HANDSHAKE
563. 1 0.07% 39.41% HANDSHAKES
564. 1 0.07% 39.48% HANDSHAKING
565. 1 0.07% 39.55% HANKS
566. 1 0.07% 39.62% HARMONY
567. 1 0.07% 39.69% HASSLE
568. 1 0.07% 39.76% HAUL
569. 1 0.07% 39.83% HAVER
570. 1 0.07% 39.90% HAZARDOUS
49
572. 1 0.07% 40.04% HEADINGS
573. 1 0.07% 40.11% HEADLINES
574. 1 0.07% 40.18% HEALTHCARE
575. 1 0.07% 40.25% HECK
576. 1 0.07% 40.32% HECTARES
577. 1 0.07% 40.39% HEED
578. 1 0.07% 40.46% HEEL
579. 1 0.07% 40.53% HEIGHT
580. 1 0.07% 40.60% HENCEFORTH
581. 1 0.07% 40.67% HEPATITIS
582. 1 0.07% 40.74% HEREDITY
583. 1 0.07% 40.81% HERITAGE
584. 1 0.07% 40.88% HERO
585. 1 0.07% 40.95% HEROICS
586. 1 0.07% 41.02% HIKE
587. 1 0.07% 41.09% HIKING
588. 1 0.07% 41.16% HILLSIDES
589. 1 0.07% 41.23% HOAX
590. 1 0.07% 41.30% HOCKEY
591. 1 0.07% 41.37% HOMECOMING
592. 1 0.07% 41.44% HOMESICK
593. 1 0.07% 41.51% HOMETOWN
594. 1 0.07% 41.58% HOMEWORK
595. 1 0.07% 41.65% HONEY
596. 1 0.07% 41.72% HOPEFULLY
597. 1 0.07% 41.79% HORRIFIED
598. 1 0.07% 41.86% HORSING
599. 1 0.07% 41.93% HOSTEL
600. 1 0.07% 42.00% HOSTELS
601. 1 0.07% 42.07% HUFFING
602. 1 0.07% 42.14% HUGE
603. 1 0.07% 42.21% HUMIDITY
604. 1 0.07% 42.28% HUMOROUS
605. 1 0.07% 42.35% HUMOUR
606. 1