HASIL DAN PEMBAHASAN
Algoritma Cepat Penduga GS
Sebagaimana halnya dengan algoritma cepat penduga S, algoritma cepat penduga GS dikembangkan dengan mengkombinasikan algoritma resampling dan algoritma I-step. Dalam hal ini, algoritma resamping dan algoritma I-step yang digunakan dalam algoritma cepat penduga S dimodifikasi guna menyelaraskan formula yang diterapkan dengan rumusan yang dipakai dalam penghitungan penduga GS. Inti dari modifikasi ini terletak pada penggantian skala sisaan dengan skala selisih sisaan dalam semua penghitungan. Untuk algoritma resampling, hasil modifikasi dimaksud diintegrasikan dalam langkah penghitungan algoritmik yang dibahas pada paragraf di bawah ini. Sementara untuk algoritma I-step, formula iteratif yang telah dimodifikasi dapat dilihat pada Persamaan (8) dan Persamaan (9).
Algoritma resampling untuk algoritma cepat penduga GS diawali dengan pengambilan secara acak resampel berukuran dari data untuk mendapatkan dan ̂ ∆ yang merupakan nilai awal kandidat dugaan kekar parameter regresi dan kandidat dugaan kekar skala sisaan ̂ ∆ pada resampel ke- dengan 1, … , . Dalam hal ini, adalah dugaan kuadrat terkecil yang dihitung dengan data resampel dan ̂ ∆ ialah dugaan kekar skala selisih sisaan yang diperoleh dengan data asli dengan rumus
̂ ∆ ∆ ′
. , 1 ′ . Proses ini diilustrasikan dengan
diagram alir Gambar 6.
Sementara itu, untuk algoritma I-step, formula iteratif penghitungan dugaan kekar skala sisaan ke- 1 , ̂ ∆ yang dirumuskan sebagai:
̂ ∆ ̂ ∆ 1 ∆
Gambar 6 Diagram alir algoritma resampling untuk penduga GS dan dugaan kekar regresi dari penyelesaian persamaan:
, 0 9
dengan ,
∆ ′
̂ ∆ , 1 dimana untuk
fungsi pada Persamaan (3). Misalkan hasil yang diperoleh di sini dilambangkan dengan dan ̃ ∆ . Diagram alir algoritma I-step dalam konteks ini diilustrasikan pada Gambar 7 dan proses penghitungannya dijabarkan sebagai berikut:
Untuk 0,1, … hitung:
1 bobot , ′ ∆ ′
̂ ∆ , 1
′ ;
Start
Untuk 1 sampai dengan
Hitung dugaan kuadrat terkecil berdasarkan data resampel ke-
Dengan data asli, hitung sisaan Ambil subsampel berukuran
Hitung dugaan kekar skala ̂ ∆
End
2 dengan menyelesaikan persamaan ∑ ′ , ′ ′ ′
′ ′′ 0;
3 sisaan ′ , 1 ;
4 selisih sisaan ∆ ′ ′ , 1 ′ ;
5 skala selisih sisaan yang diperbaiki
̂ ∆ ̂ ∆ ∑ ∆ ′
̂ ∆
′ .
Gambar 7 Diagram alir algoritma I-step untuk penduga GS Start
Untuk 1 sampai dengan
Masukkan ̂ Untuk 0, 1, 2, … Hitung bobot , ′ ∆ ′ ̂ ∆ , 1 ′ , 0, 1, 2,… Hitung dari ∑ ′ , ′ ′ ′ ′ ′′ 0 Hitung sisaan ′ , 1 Hitung ̂ ∆ ̂ ∆ ∑ ∆ ′ ̂ ∆ ′ End
Hitung selisih sisaan
Seperti yang diterapkan pada penduga S, hasil yang diperoleh dengan algoritma resampling dan algoritma I-step, yang diterapkan sebanyak 3 ulangan, dalam membangun algoritma cepat penduga GS merupakan kandidat dugaan yang mesti diperbaiki dengan penghitungan lebih lanjut hingga hasil yang dapat bersifat konvergen. Dalam hal ini, penghitungan juga dilakukan hanya untuk 5 kandidat dugaan terbaik dan proses dilalui dijabarkan sebagai berikut:
1 Untuk 1 , hitung dan ̃ ∆ , 0,1,2, …,
hingga konvergen dengan algoritma I-step untuk nilai awal dan
̃ ∆ , bangun gugus pasangan dugaan
, ̃ ∆ , 1 dan misalkan
max ̃ ∆ ;
2 untuk , jika ∑ ∆ maka hitung
dan ̃ ∆ hingga konvergen dengan algoritma I-step,
perbaharui gugus pasangan , ̃ ∆ yang sudah ada
dengan mensubstitusi nilai dugaan dan ̃ ∆ yang baru diperoleh dan mengeluarkan pasangan yang hasilkan pada iterasi
sebelumnya, dan hitung kembali
max ̃ ∆ ;
3 ulangi langkah 2 hingga .
Misalkan dugaan regresi dan dugaan kekar skala sisaan yang dihasilkan pada tahap ini adalah dan ̃ , 1 . Diagram alir untuk pendekatan di atas diilustrasikan pada Gambar 8.
Gambar 8 Diagram alir penghitungan kandidat terbaik dalam algoritma
cepat penduga GS Start
Untuk 1sampai dengan
Hitung dengan I-step
dan ̃ ∆ , hingga konvergen Bangun gugus pasangan dugaan , ̃ ∆ Hitung sebagai max ̃ ∆ Ya ∆
Masukkan nilai dan
̃ ∆
Hitung dengan I-step hingga konvergen
dan ̃ ∆
Perbaharui gugus pasangan dugaan dengan substitusi nilai yang baru diperoleh
, ̃ ∆
Ya Tidak
Tidak
max ̃ ∆
Hitung kembali sebagai
Berdasarkan pembahasan di atas, algoritma cepat penduga GS untuk pendugaan parameter model regresi linear berganda dapat disarikan seperti berikut:
1 ambil resampel berukuran yang tidak kolinear dari data asli, hitung dugaan , 1, … , dengan metoda kuadrat terkecil dengan menggunakan data resampel, dan hitung ̂ ∆ dengan data asli;
2 terapkan kali I-step dengan nilai awal dan ̂ ∆ untuk memperoleh dugaan regresi dan dugaan kekar skala selisih sisaan yang diperbaiki yang dilambangkan dengan dan ̃ ∆ ;
3 hitung dugaan regresi dan dugaan kekar skala selisih sisaan menerapkan I-step untuk kandidat penduga yang memenuhi syarat hingga konvergen dengan nilai awal dan ̃ ∆ dan menghasilkan ′ dan ̃ ′ ∆ ′ ,
1 ′ ;
4 ambil dugaan ′ dengan dugaan kekar skala selisih sisaan ̃ ′ ∆ ′ yang minimal sebagai dugaan regresi .
Diagram alir untuk langkah di atas diilustrasikan dengan Gambar 9.
Dugaan parameter ′ yang dihasilkan pada langkah di atas kemudian digunakan dalam pendugaan intersep yang dipandang sebagai sisaan ′
′ ′. Dugaan intersep didapatkan dengan menggunakan pendugaan M lokasi dengan dugaan skala diketahui. Formula yang dipakai dalam penghitungan ini didasarkan pada pendekatan yang dikemukakan Maronna et al. (2006, 39). Berikut ini proses yang dimaksud.
1 Masukkan nilai ′.
2 Hitung sisaan ′ ′ ′, dugaan awal intersep med ′ , skala ̂ ′
. med ′ , dan bobot
awal , ′
Persamaan (3) namun tuning constant yang digunakan pada fungsi adalah 4.68. 3 Untuk 0, 1, 2, … a hitung ∑ ∑ , ′ , ; b hitung , ′ ̂ ′ ; c berhenti jika 10 ̂ ′ .
Diagram alir untuk langkah penghitungan ini diilustrasikan dengan Gambar 10 dan kode R untuk semua langkah di atas dilampirkan pada Lampiran 1.
Gambar 9 Diagram alir algoritma cepat penduga GS Start
Masukkan data
ambil resampel berukuran , hitung dugaan , 1, … , ̂ ∆
terapkan kali I-step untuk memperoleh dan
̃ ∆ dengan nilai awal dan ̂ ∆
hitung dugaan dan ̃ ∆ , 1
dengan I-step untuk kandidat penduga yang memenuhi syarat hingga konvergen dengan nilai awal dan ̃ ∆
ambil dugaan dengan dugaan kekar skala sisaan ̃ ∆ yang minimal sebagai dugaan regresi
Gambar 10 Diagram alir penghitungan intersep pada algoritma cepat penduga GS
Start
Masukkan ′
Hitung sisaan ′ ′ ′ Hitung dugaan awal intersep
med ′
Hitung skala ̂ ′
. med ′
Hitung bobot awal , ′
̂ ′
End
Misalkan eps = 1e-20, error = 1, dan 0 error > eps? Hitung ∑ ∑ , ′ , Hitung , ′ ̂ ′ Hitung ̂ ′ Hitung 1 Ya Tidak
Dengan merangkum ulasan tentang penduga S, algoritma cepat penduga S, penduga GS, dan algoritma cepat penduga GS yang telah dikemukakan sebelumnya, perbandingan proses penghitungan keempat pendekatan tersebut dapat ditunjukkan dengan Tabel 1.
Tabel 1 Perbandingan cara kerja penduga S, algoritma cepat penduga S, penduga GS, dan algoritma cepat penduga GS
Metoda Komputasi Keterangan
Penduga S
Metoda projection pursuit Dikemukakan oleh Rousseeuw dan Yohai (1984) Kombinasi algoritma resampling
dan langkah perbaikan lokal
Dikemukakan oleh Ruppert (1992 diacu dalam Salibian-Barrera dan Yohai 2006)
Algoritma cepat Penduga S
Kombinasi algoritma resampling dan algoritma I-step
Dikemukakan oleh Salibian-Barrera dan Yohai (2006) Penduga GS Kombinasi algoritma resampling
dan langkah perbaikan lokal
Dikemukakan oleh Croux et al. (1994) Algoritma cepat
Penduga GS
Kombinasi algoritma resampling dan algoritma I-step
Selanjutnya, perbedaan spesifik antara penduga S dan penduga GS dapat disarikan seperti Tabel 2.
Tabel 2 Perbedaan Penduga S dan Penduga GS
Kriteria Penduga S Penduga GS
Besaran skala yang digunakan
Skala sisaan Skala selisih sisaan Tuning constant dalam
fungsi biweight Tukey
1.547 0.9958
Aplikasi pada model dengan atau tanpa intersep
Bisa digunakan untuk pendugaan model dengan atau tanpa intersep
Hanya bisa digunakan untuk model dengan intersep
Dugaan intersep Diperoleh bersamaan dengan parameter yang lain
Tidak bisa dihitung secara langsung dalam pendugaan parameter melainkan diduga secara terpisah dengan dugaan kekar lokasi
Pembangkitan Data
Data dibangkitkan dengan menggunakan model regresi 1 untuk jumlah peubah penjelas 2 dan 1
untuk 5. Pada kedua kondisi, data yang dibangkitkan berukuran contoh 60 untuk kasus tanpa nilai pencilan dan dengan nilai pencilan, yakni dengan proporsi 0.05, dan 0.15. Pencilan yang dibangkitkan adalah pencilan sisaan dengan rataan 10 dan 100 dan ragam 1 dan 3.
Di samping itu, data juga dibangkitkan dengan mengunakan model 0.5 3 2 untuk jumlah peubah penjelas 2 dan 1 2 1.5 0.5 0.5 1.5 untuk 5. Data yang dibangkitkan yang berukuran contoh 60 untuk kasus tanpa nilai pencilan dan dengan nilai pencilan dengan proporsi 0.05, dan 0.15, namun data hanya memuat pencilan sisaan dengan rataan 10 dan ragam 1.
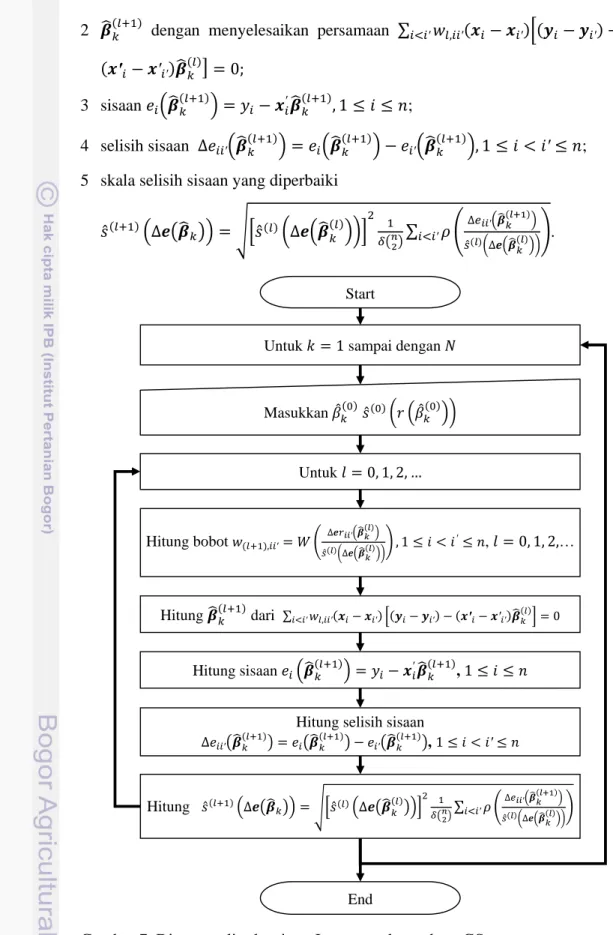
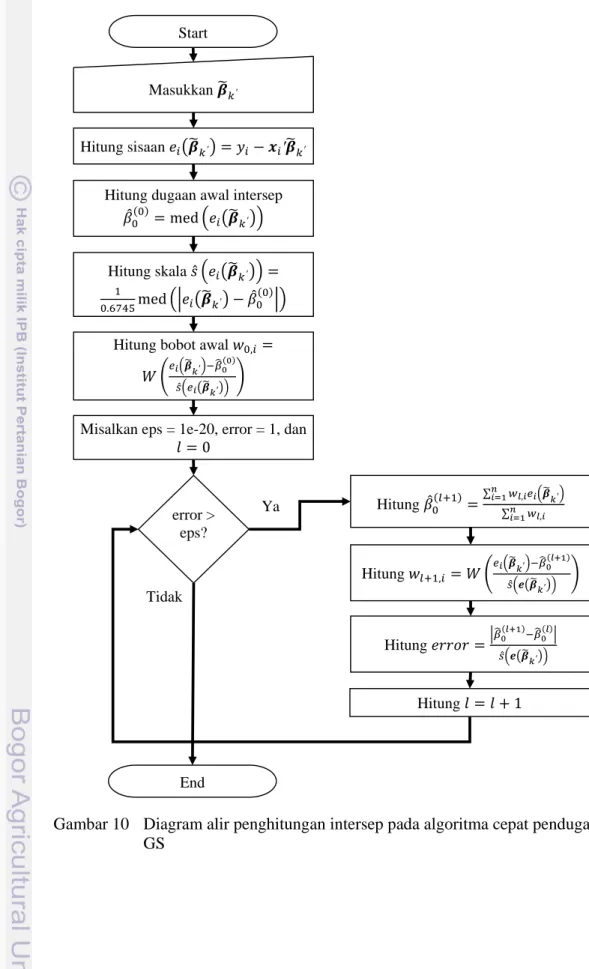
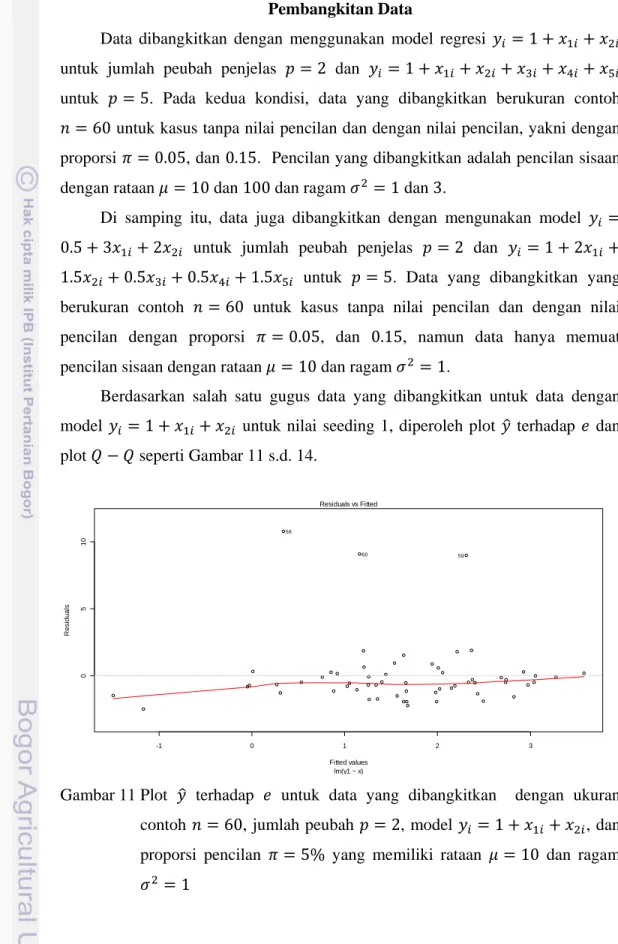
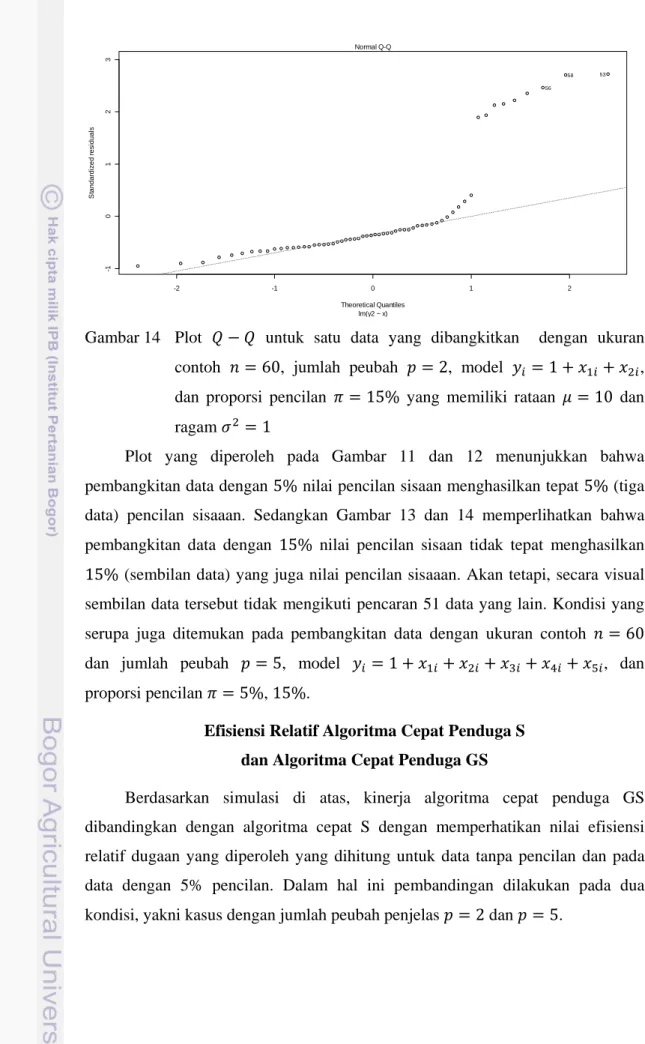
Berdasarkan salah satu gugus data yang dibangkitkan untuk data dengan model 1 untuk nilai seeding 1, diperoleh plot terhadap dan plot seperti Gambar 11 s.d. 14.
Gambar 11 Plot terhadap untuk data yang dibangkitkan dengan ukuran contoh 60, jumlah peubah 2, model 1 , dan proporsi pencilan 5% yang memiliki rataan 10 dan ragam
1 -1 0 1 2 3 05 1 0 Fitted values R es idual s lm(y1 ~ x) Residuals vs Fitted 58 60 59
Gambar 12 Plot untuk satu data yang dibangkitkan dengan ukuran contoh
60, jumlah peubah 2, model 1 , dan
proporsi pencilan 5% yang memiliki rataan 10 dan ragam 1
Gambar 13 Plot terhadap untuk satu data yang dibangkitkan dengan ukuran contoh 60, jumlah peubah 2, model 1 , dan proporsi pencilan 15% yang memiliki rataan 10 dan ragam 1 -2 -1 0 1 2 -1 0123 45 Theoretical Quantiles S tanda rd iz ed r es idua ls lm(y1 ~ x) Normal Q-Q 58 60 59 0 1 2 3 4 -5 0 5 1 0 Fitted values R es idual s lm(y2 ~ x) Residuals vs Fitted 53 58 56
Gambar 14 Plot untuk satu data yang dibangkitkan dengan ukuran contoh 60, jumlah peubah 2, model 1 , dan proporsi pencilan 15% yang memiliki rataan 10 dan ragam 1
Plot yang diperoleh pada Gambar 11 dan 12 menunjukkan bahwa pembangkitan data dengan 5% nilai pencilan sisaan menghasilkan tepat 5% (tiga data) pencilan sisaaan. Sedangkan Gambar 13 dan 14 memperlihatkan bahwa pembangkitan data dengan 15% nilai pencilan sisaan tidak tepat menghasilkan 15% (sembilan data) yang juga nilai pencilan sisaaan. Akan tetapi, secara visual sembilan data tersebut tidak mengikuti pencaran 51 data yang lain. Kondisi yang serupa juga ditemukan pada pembangkitan data dengan ukuran contoh 60
dan jumlah peubah 5, model 1 , dan
proporsi pencilan 5%, 15%.
Efisiensi Relatif Algoritma Cepat Penduga S dan Algoritma Cepat Penduga GS
Berdasarkan simulasi di atas, kinerja algoritma cepat penduga GS dibandingkan dengan algoritma cepat S dengan memperhatikan nilai efisiensi relatif dugaan yang diperoleh yang dihitung untuk data tanpa pencilan dan pada data dengan 5% pencilan. Dalam hal ini pembandingan dilakukan pada dua kondisi, yakni kasus dengan jumlah peubah penjelas 2 dan 5.
-2 -1 0 1 2 -1 01 23 Theoretical Quantiles S tanda rd iz ed r es idua ls lm(y2 ~ x) Normal Q-Q 53 58 56
Pembandingan pada kasus pertama dilakukan dengan menggunakan data yang dibangkitkan dengan model 1 untuk nilai pencilan dengan rataan 10 dan 100 dan ragam 1 dan 3. Hal yang sama juga dilakukan pada kasus dengan jumlah peubah penjelas 5 yang menggunakan model pembangkit
1 . Hasil penghitungan untuk 2
ditampilkan pada Tabel 3 dan untuk 5 pada Tabel 4.
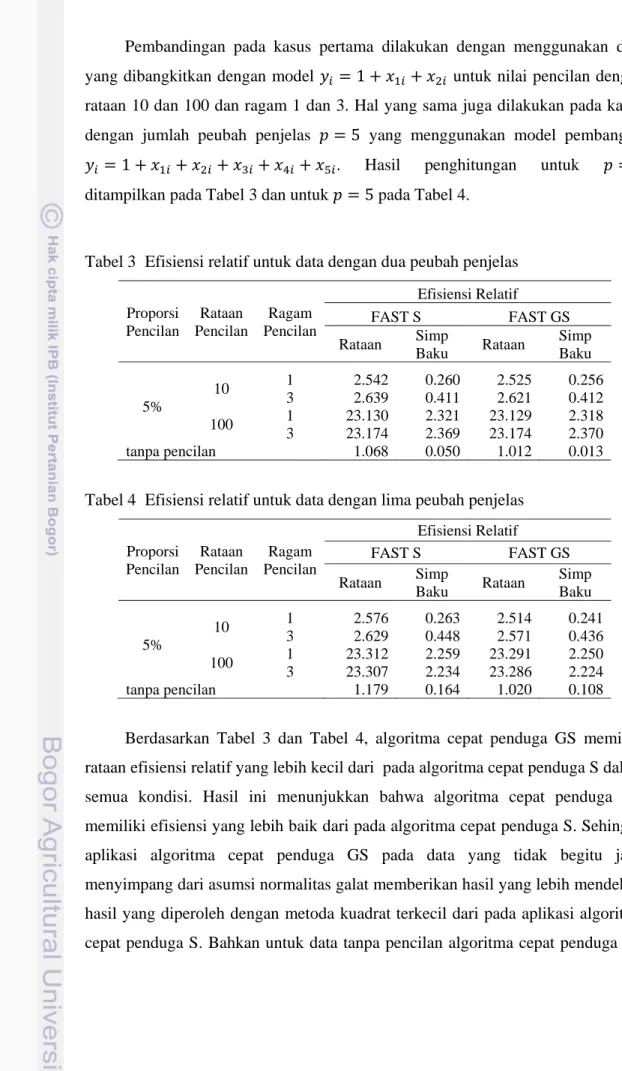
Tabel 3 Efisiensi relatif untuk data dengan dua peubah penjelas
Proporsi Pencilan Rataan Pencilan Ragam Pencilan Efisiensi Relatif FAST S FAST GS Rataan Simp Baku Rataan Simp Baku 5% 10 1 2.542 0.260 2.525 0.256 3 2.639 0.411 2.621 0.412 100 1 23.130 2.321 23.129 2.318 3 23.174 2.369 23.174 2.370 tanpa pencilan 1.068 0.050 1.012 0.013
Tabel 4 Efisiensi relatif untuk data dengan lima peubah penjelas
Proporsi Pencilan Rataan Pencilan Ragam Pencilan Efisiensi Relatif FAST S FAST GS Rataan Simp Baku Rataan Simp Baku 5% 10 1 2.576 0.263 2.514 0.241 3 2.629 0.448 2.571 0.436 100 1 23.312 2.259 23.291 2.250 3 23.307 2.234 23.286 2.224 tanpa pencilan 1.179 0.164 1.020 0.108
Berdasarkan Tabel 3 dan Tabel 4, algoritma cepat penduga GS memiliki rataan efisiensi relatif yang lebih kecil dari pada algoritma cepat penduga S dalam semua kondisi. Hasil ini menunjukkan bahwa algoritma cepat penduga GS memiliki efisiensi yang lebih baik dari pada algoritma cepat penduga S. Sehingga aplikasi algoritma cepat penduga GS pada data yang tidak begitu jauh menyimpang dari asumsi normalitas galat memberikan hasil yang lebih mendekati hasil yang diperoleh dengan metoda kuadrat terkecil dari pada aplikasi algoritma cepat penduga S. Bahkan untuk data tanpa pencilan algoritma cepat penduga GS
memiliki kinerja yang baik yang ditandai dengan efisiensi relatif yang mendekati 1.
Berbeda dengan hasil yang diperoleh untuk dugaan yang akan diulas pada bagian berikut, nilai efisiensi relatif dipengaruhi oleh nilai rataan dan ragam pencilan yang ditunjukkan oleh perbedaan rataan nilai efisiensi relatif yang signifikan antara data tanpa pencilan, data dengan pencilan yang mempunyai rataan 10, dan data dengan pencilan yang memiliki rataan 100 untuk kedua kasus pada Tabel 3 dan Tabel 4. Perbedaan ini terjadi karena kekekaran penduga S dan penduga GS hanya untuk dugaan bukan untuk nilai fitted.
Namun demikian, kondisi ini tidak menjadi masalah karena aspek yang diperhatikan pada tinjauan tentang efisiensi relatif hanya pada perilaku hasil penghitungan untuk data yang tidak begitu menyimpang dari asumsi normalitas atau bahkan dengan sempurna memenuhi asumsi normalitas. Proporsi, rataan, dan ragam pencilan bukanlah aspek yang dipertimbangkan dalam melihat efisiensi relatif.
Perbandingan Metoda Kuadrat Terkecil, Algoritma Cepat Penduga S, dan Algoritma Cepat Penduga GS
Data simulasi di atas, kinerja algoritma cepat penduga GS juga dapat dibandingkan dengan algoritma cepat S dan metoda kuadrat terkecil dengan memperhatikan nilai dugaan yang diperoleh dari ketiga pendekatan. Dalam hal ini pembandingan dilakukan pada dua kondisi, yakni kasus dengan model yang sama dan model yang berbeda.
Pembandingan pada kasus model yang sama dilakukan dengan menggunakan data yang dibangkitkan dengan model 1 untuk jumlah peubah penjelas 2 dan dengan model 1
untuk 5. Hasil dimaksud ditampilkan pada Tabel 5 dan Tabel 6. Sedangkan pembandingan pada kasus dua model yang berbeda dilaksanakan dengan menggunakan data yang dibangkitkan dengan model 1
dan 0.5 3 2 untuk jumlah peubah penjelas 2 dan dengan
model 1 dan 1 2 1.5
dengan nilai pencilan yang memiliki rataan 10 dan ragam 1. Hasil pembandingan yang kedua ini ditampilkan pada Tabel 7.
Tabel 5 Perbandingan dugaan untuk data dengan nilai pencilan Rataan
Pencilan
Ragam
Pencilan OLS Fast S Fast GS 2 peubah penjelas dengan 5% data pencilan
10 1 0.671 0.459 0.294
3 0.672 0.459 0.296
100 1 6.549 0.459 0.294
3 6.539 0.459 0.294
2 peubah penjelas dengan 15% data pencilan
10 1 1.664 0.441 0.353
3 1.675 0.446 0.356
100 1 16.651 0.441 0.354
3 16.649 0.441 0.355
5 peubah penjelas dengan 5% data pencilan
10 1 0.873 0.661 0.403
3 0.921 0.670 0.392
100 1 8.092 0.669 0.392
3 8.120 0.669 0.392
5 peubah penjelas dengan 15% data pencilan
10 1 1.883 0.646 0.446
3 1.951 0.642 0.449
100 1 18.826 0.640 0.437
3 18.839 0.640 0.444
Berdasarkan Tabel 5, dugaan yang diperoleh dengan algoritma cepat penduga GS lebih kecil dari pada yang didapatkan dengan metoda kuadrat terkecil dan algoritma cepat penduga S untuk jumlah peubah penjelas, proporsi, rataan, dan ragam pencilan yang sama. Hasil ini menunjukkan bahwa dugaan yang diperoleh dengan algoritma cepat penduga GS untuk data dengan pencilan mempunyai efisiensi yang lebih baik dari pada yang diperoleh dengan metoda metoda kuadrat terkecil dan algoritma cepat penduga S dalam semua kondisi. Hal ini sesuai dengan teori penduga GS mempunyai efisiensi yang lebih baik dari pada penduga S.
Tabel di atas juga memperlihatkan bahwa dugaaan yang diperoleh dengan algoritma cepat penduga GS maupun algoritma cepat penduga S pada suatu proporsi pencilan tertentu memiliki nilai yang sama meskipun data dibangkitkan dengan pencilan yang mempunyai rataan dan ragam yang berbeda. Hasil ini menunjukkan perilaku kekekaran penduga GS dan penduga S. Kedua penduga resisten terhadap pencilan.
Namun tidak demikian halnya dengan dugaan yang diperoleh dengan metoda kuadrat terkecil. Dugaan kuadrat terkecil sangat sensitif terhadap pencilan. Sehingga peningkatan rataan pencilan mengakibatkan peningkatan dugaan secara signifikan. Akan tetapi peningkatan ragam pencilan hanya mengakibatkan sedikit menurunkan nilai . Penurunan nilai ini disebabkan oleh fakta bahwa peningkatan ragam menyebabkan nilai pencilan yang dihasilkan lebih menyebar sehingga pencilan yang diperoleh akan mendekati data yang bukan pencilan.
Di sisi lain, Tabel 5 juga menunjukkan bahwa pertambahan jumlah peubah penjelas juga diikuti dengan peningkatan nilai dugaan yang diperoleh dari ketiga pendekatan. Peningkatan ini lebih dipengaruhi oleh bertambahnya suku positif pada penjumlahan yang digunakan dalam penghitungan karena
merupakan jumlah kuadrat. Sehingga penambahan jumlah peubah penjelas mengakibatkan peningkatan suku positif yang dijumlahkan.
Peningkatan nilai juga seiring dengan pertambahan proporsi pencilan untuk dugaan yang dihasilkan dengan algoritma cepat penduga GS dan metoda kuadrat terkecil. Sebaliknya, nilai dugaan yang didapatkan dengan algoritma cepat penduga S cenderung menurun, namun bila dibandingkan dengan
dugaan dari algoritma cepat GS maka nilai yang dihasilkan tetap lebih besar. Hal ini menunjukkan bahwa algoritma cepat penduga GS mempunyai efisiensi yang semakin baik bila digunakan pada data dengan proporsi pencilan yang semakin rendah. Kondisi yang lebih ekstrim dapat ditemukan pada data tanpa pencilan.
Pada data tanpa pencilan, dugaan yang diperoleh dengan algoritma cepat penduga GS mendekati nilai yang diperoleh dengan metoda kuadrat terkecil. Sementara itu, nilai yang diperoleh dengan algoritma cepat penduga S lebih besar
dari apa yang diperoleh dari kedua pendekatan tersebut. Fakta ini sesuai dengan perilaku penduga S yang merupakan penduga kekar yang memiliki nilai titik breakdown yang tinggi namun mempunyai efisiensi yang rendah. Penggunaan penduga S untuk pendugaan parameter model pada data yang tidak begitu jauh menyimpang dari asumsi normalitas menghasilkan nilai dugaan yang tidak baik. Perbandingan dugaan pada data tanpa pencilan dapat dilihat pada Tabel 6.
Tabel 6 Perbandingan dugaan untuk data tanpa nilai pencilan Jumlah Peubah
Penjelas OLS Fast S Fast GS
2 0.221 0.467 0.287
5 0.327 0.697 0.392
Seperti yang telah dikemukakan sebelumnya, pembangkitan data dalam penelitian ini juga dilakukan dengan menggunakan model yang berbeda. Tabel 7 menampilkan perbandingan dugaan yang diperoleh dari ketiga pendekatan.
Tabel 7 Perbandingan dugaan untuk dua model berbeda Model
OLS Fast S Fast GS 2 peubah penjelas dengan 5% data pencilan
1 0.671 0.459 0.294
2 0.671 0.459 0.294
2 peubah penjelas dengan 15% data pencilan
1 1.664 0.441 0.353
2 1.664 0.441 0.353
5 peubah penjelas dengan 5% data pencilan
3 0.873 0.661 0.403
4 0.873 0.661 0.403
5 peubah penjelas dengan 15% data pencilan
3 1.883 0.646 0.446 4 1.883 0.643 0.446 Keterangan : 1 : 1 2 : 0.5 3 2 3 : 1 4 : 1 2 1.5 0.5 0.5 1.5
Tabel 7 memperlihatkan bahwa jika data dibangkitkan secara simultan dengan rataan dan ragam pencilan yang bernilai sama, maka dugaan yang diperoleh untuk dua model yang berbeda akan bernilai sama pula. Hal ini disebabkan oleh fakta bahwa perbedaan model yang digunakan pada pembangkitan data hanya mengakibatkan penambahan atau pengurangan pada nilai dugaan. Sebagai contoh, misalkan data dibangkitkan dengan menggunakan model yang berkoefisien , … , dan menghasilkan dugaan
, … , , maka untuk , … , dengan diperoleh
, … , dengan dimana sebarang konstanta dan