IMPLEMENTASI K-MEANS CLUSTERING PADA LINGKUNGAN BIG DATA MENGGUNAKAN MODEL PEMROGRAMAN MAPREDUCE
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Oleh : Engelbertus Vione
125314112
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2016
K-MEANS CLUSTERING IMPLEMENTATION IN BIG DATA ENVIRONMENT WITH MAPREDUCE PROGRAMMING MODEL
A THESIS
Presented as Partial Fulfillment of Requirements to Obtain Sarjana Komputer Degree in Informatics Engineering Department
By :
Engelbertus Vione 125314112
INFORMATICS ENGINEERING STUDY PROGRAM INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA 2016
SKRIPSI
IMPLEMENTASI K-MEANS CLUSTERING PADA LINGKUNGAN BIG DATA MENGGUNAKAN MODEL PEMROGRAMAN MAPREDUCE
Oleh:
Engelbertus Vione
125314112
Telah disetujui oleh :
Pembimbing,
J.B. Budi Darmawan, S.T., M.Sc. Tanggal: ……….
HALAMAN PENGESAHAN
IMPLEMENTASI K-MEANS CLUSTERING PADA LINGKUNGAN BIG DATA MENGGUNAKAN MODEL PEMROGRAMAN MAPREDUCE
Dipersiapkan dan ditulis oleh : ENGELBERTUS VIONE
NIM : 125314112
Telah dipertahankan di depan panitia penguji pada tanggal 9 Januari 2017
dan dinyatakan memenuhi syarat
Susunan Panitia Penguji
Nama Lengkap Tanda Tangan
Ketua : Puspaningtyas Sanjoyo Adi, S.T., M.T. ...
Sekretaris : Drs. Haris Sriwindono, M.Kom ...
Anggota : J.B. Budi Darmawan, S.T., M.Sc. ...
Yogyakarta, ………. Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan,
Sudi Mungkasi, S.Si.,M.Math.Sc.,Ph.D.
MOTTO
I have no special talents. I am only passionately curious. – Albert Einstein
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa di dalam skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, ... Penulis
Engelbertus Vione
LEMBARAN PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma: Nama : Engelbertus Vione
NIM : 125314112
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah yang berjudul:
IMPLEMENTASI KMEANS CLUSTERING PADA LINGKUNGAN BIG DATA MENGGUNAKAN MODEL PEMROGRAMAN MAPREDUCE
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta
Pada tanggal...…
Yang Menyatakan
Engelbertus Vione
Perkembangan data yang sangat pesat membuat teknologi big data menjadi inovasi baru dalam menyimpan data. Apache Hadoop merupakan framework big data yang mampu menyimpan data tanpa memperhatikan jenis data. Apache
Hadoop menggunakan model pemrograman MapReduce dalam menganalisa data. Apache Mahout merupakan library analisa data yang mampu menjalankan komputasi berbasis pemrograman MapReduce. Apache Mahout telah menyediakan komputasi penambangan data yang dapat digunakan dalam menganalisa data. K-Means merupakan metode penambangan data yang dapat mengelompokkan data berdasarkan kemiripan sifat.
Penelitian ini menggunakan 4 komputer klaster yang berjalan pada jaringan lokal. Apache Hadoop yang berjalan pada sistem Linux dibagi menjadi 1 master slave dan 3 slave node. Master node mengatur komputasi MapReduce.
Slave node bertugas sebagai media penyimpan data. Hasil K-Means dengan
menggunakan library Mahout diuji dengan hasil dari metode manual. Hasil pengujian menunjukkan bahwa library Mahout mampu memberikan hasil analisa dengan benar. Sedangkan pengujian unjuk kerja dilakukan dengan menjalankan K-Means sebanyak 10 kali pada jumlah slave node yang berbeda. Kesimpulan unjuk kerja sistem Hadoop dilakukan dengan mencari nilai rata-rata dari percobaan-percobaan tersebut. Hasil unjuk kerja menunjukkan bahwa semakin banyak jumlah slave node maka semakin cepat proses komputasi.
Kata Kunci: Big Data, Hadoop, MapReduce, Mahout, Data Mining, K-Means
The growth of massive data makes big data technology as a new innovation in storing data. Apache Hadoop is a big data framework that able to stroing data without considering the variety of data. Apache Hadoop uses MapReduce programming model to analyze data. Apache Mahout is a data analyze library that able to analyze data in MapReduce programming model. Apache Mahout has provided data mining method as analyze data algorithm. K-Means is a data mining algorithm that can group item data into specific cluster based on similarity measure.
This research is developed in 4 computer cluster which is clustered in local network. Apache Hadoop that is adopted in Linux system is divided into 1 master node and 3 slave nodes. Master node handles MapReduce. Slave nodes roles as storage system. The output of K-Means Mahout library is evaluated with manual calculation. The evaluation result describe that Mahout library can analyze data well. The performance of Hadoop system is evaluated by running 10 times of K-Means with Mahout library in difference quantity of slave node. The conclusion is taken by calculate the mean value of each 10 trainings. The performance evaluation result explained that increasing the number of slave node can make time execution of computation to be faster.
Keyword : Big Data, Hadoop, MapReduce, Mahout, Data Mining, K-Means
KATA PENGANTAR
Puji dan syukur penulis penjatkan kepada Tuhan Yang Maha Esa, telah memberikan berkat dan karunia sehingga penulis mampu menyelesaikan tugas akhir ini dengan baik.
Penulis menyadari selama proses pengerjaan tugas akhir telah mendapatkan banyak bantuan dari berbagai pihak, baik berupa dukungan, kritik, saran, dan doa yang mampu menjadi semangat dan motivasi demi terselesainya tugas akhir ini. Sehingga, pada kesempatan ini penulis akan menyampaikan ucapan terima kasih kepada:
1. Tuhan Yang Maha Esa yang senantiasa memberikan limpahan berkat dan karunia-Nya, serta menyertai penulis dalam mengerjakan tugas akhir ini. 2. Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan
Teknologi Universitas Sanata Dharma Yogyakarta.
3. JB. Budi Darmawan S.T., M.Sc. selaku dosen pembimbing tugas akhir yang telah dengan sabar dan penuh perhatian membimbing penulis dalam menyusun tugas akhir.
4. Dr. Anastasia Rita Widiarti M.Kom selaku Ketua Program Studi Teknik Informatika yang selalu memberikan dukungan dan perhatian serta saran kepada mahasiswa tugas akhir dalam pengerjaan tugas akhir.
5. Kedua orang tua tercinta Bapak Siprianus Madu dan Ibu Ni Made Partini yang selalu mendoakan, memotivasi, menasihati, dan memberikan dukungan baik moral maupun materi kepada penulis.
6. Seluruh dosen program pendidikan Teknik Informatika atas ajaran dan didikan selama perkuliahan, serta pengalaman-pengalaman yang memotivasi bagi penulis.
7. Teman-teman program pendidikan Teknik Informatika angkatan 2012 Universitas Sanata Dharma, terima kasih kebersamaan atas dukungan yang kalian berikan.
pengalaman selama mengerjakan tugas akhir ini.
9. Terima kasih kepada semua pihak yang tidak dapat penulis sebutkan satu persatu yang mendukung dan memotivasi penulis baik secara langsung maupun secara tidak langsung.
Penulis menyadari bahwa masih adanya kekurangan dalam penulisan laporan tugas akhir ini. Kritk dan saran sangat penulis harapkan untuk menjadi motivasi dalam berkarya lagi. Akhir kata, penulis berharap laporan tugas akhir bisa berguna bagi perkembangan ilmu pengetahun dan wawasan pembaca.
Yogyakarta, ……… Penulis
Engelbertus Vione
DAFTAR ISI
LEMBARAN PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS...vii
ABSTRAK...viii
BAB 1 PENDAHULUAN...1
1.1 Latar Belakang...1
BAB 2 LANDASAN TEORI...6
2.1 Penambangan Data...6
2.1.1 Definisi Penambangan Data...6
2.1.2 Clustering...7
2.2 Big Data...10
2.3 Hadoop...11
2.3.1 Definisi Hadoop...11
2.3.2 Hadoop Distributed File System...12
2.3.3 Yarn...14
2.4 MapReduce...15
2.4.1 Definisi MapReduce...15
2.4.2 Proses MapReduce...17
2.5 Apache Mahout...19
2.5.1 Konsep MapReduce Pada Library Mahout Berdasarkan Algoritma K-Means...20
2.5.2 Metode Menjalankan Library Mahout...22
BAB 3 ANALISA PERANCANGAN...24
3.1 Gambaran Penelitian...24
3.1.1 Data...25
3.1.2 K-Means Mahout...26
3.2 Kebutuhan Sistem...27
3.3 Skema Sistem Big Data...30
3.3.1 Skema Single Node Cluster...30
3.3.2 Skema Multi Node Cluster...31
BAB 4 IMPLEMENTASI...33
4.1 Perancangan Sistem Big Data...33
4.1.1 Konfigurasi Single Node Cluster...33
4.1.2 Konfigurasi Multi Node Cluster...42
4.2 Implementasi Library Mahout Pada Sistem Hadoop...45
4.2.1 Install Maven...45
4.2.2 Install Eclipse...46
4.2.3 Install Mahout...46
4.3 Implementasi Metode K-Means Menggunakan Library Mahout...47
4.3.1 Preprocessing...47
4.3.2 Proses Menjalankan Komputasi K-Means...50
5.1 Analisa Implementasi K-Means Menggunakan Library Mahout Pada
Lingkungan Big Data...56
5.2 Analisa Unjuk Kerja Implementasi K-Means Menggunakan Library Mahout Pada Lingkungan Big Data...58
BAB 6 PENUTUP...60
6.1 Kesimpulan...60
6.2 Saran...60
DAFTAR PUSTAKA...61
LAMPIRAN-LAMPIRAN...64
DAFTAR TABEL
Tabel 2.1: Metode Menjalankan Library Mahout berdasarkan algoritma
K-Means menggunakan Command Line (Mahout, 2016)...23
Tabel 3.1: Informasi data liver disorder...26
Tabel 3.2: Spesifikasi Komputer Cluster...28
Tabel 5.1: Perbandingan hasil penghitungan manual dan library Mahout...58
Tabel 5.2: Unjuk kerja implementasi K-Means menggunakan library mahout pada lingkungan big data...59
DAFTAR GAMBAR
Gambar 2.1: Visualisasi K-Means (The Glowing Python, 2012)...9
Gambar 2.2: Distribusi chunk data (Yahoo!, 2014)...12
Gambar 2.3: Yarn berfungsi sebagai ResourceManager pada sistem Hadoop...15
Gambar 2.4: Proses Task Mapper dan Task Reducer (Yahoo!, 2014)...16
Gambar 2.5: Proses Mapping (Yahoo!, 2014)...18
Gambar 2.6: Proses Reducing (Yahoo!, 2014)...18
Gambar 2.7: Proses Shuffle(Yahoo!, 2014)...19
Gambar 2.8: Konsep MapReduce pada library Mahout berdasarkan algoritma K-Means (Vishnupriya N. et al., 2015)...22
Gambar 3.1: Flowchart pelitian...24
Gambar 3.2: Skema single node cluster...31
Gambar 3.3: Skema multi node cluster...32
Gambar 4.1: Menjalankan metode seqdumper pada command line...48
Gambar 4.2: Membuat direktori data dan direktori centroid pada hdfs...49
Gambar 4.3: Menyimpan sebuah file data trining dari sistem lokal ke dalam HDFS...49
Gambar 4.4: Menyimpan sebuah file centroid pada sistem lokal ke dalam HDFS...50
Gambar 4.5: Menjalankan K-Means menggunakan library Mahout...51
Gambar 4.6: Akhir dari iterasi K-Means...51
Gambar 4.7: Perintah $hdfs dfs -ls output...52
Gambar 4.8: Hasil proses K-Means pada direktori /user/hduser/output...52
Gambar 4.9: Summary berisi ringkasan informasi DataNode...53
Gambar 4.10: Informasi DataNode pada aplikasi NameNode Web Interface...54
Gambar 4.11: Informasi direktori /user/hduser pada HDFS...54
Gambar 4.12: Informasi direktori /user/hduser/data...55
Gambar 4.13: Informasi file sampleseqfile...55
Gambar 5.2: Beberapa hasil analisa cluster data dengan identitas VL-27...57 Gambar 5.3: Beberapa hasil analisa cluster data dengan identitas VL-49...57 Gambar 5.4: Diagram hasil unjuk keja sistem Hadoop...59
DAFTAR LAMPIRAN
Lampiran 1 : Install Java...64
Lampiran 2 : Konfigurasi Group Dan User Sistem Hadoop...66
Lampiran 3 : Melakukan Disable IPv6...68
Lampiran 4 : Install Hadoop...68
Lampiran 5 : Konfigurasi Environment Hadoop Single Node Cluster...70
Lampiran 6 : Konfigurasi Hostname, Hosts, & SSH...74
Lampiran 7 : Identifikasi Master Node & Slave Node...75
Lampiran 8 : Konfigurasi Environment Hadoop Multi Node Cluster...76
Lampiran 9 : Install maven...84
Lampiran 10 : Install Mahout...85
Lampiran 11 : Source code kelas KmeansDriver.java...86
Lampiran 12 : Source code kelas ClusterIterator.java...93
Lampiran 13 : Source code Kelas CIMapper.java...98
Lampiran 14 : Source code Kelas CIReducer.java...100
Lampiran 15 : Source code Kelas VectorDataCreator.java...102
Lampiran 16 : Source code Kelas VectorCentroidCreator.java...104
Lampiran 17 : Source code file core-site.xml...106
Lampiran 18 : Source code file mapred-site.xml...107
Lampiran 19 : Source code file hdfs-site.xml...108
Lampiran 20 : Source code file yarn-site.xml...109
Lampiran 21 : Hasil kalkulasi manual...110
Lampiran 22 : Hasil K-Means dengan menggunakan library Mahout...118
BAB 1 PENDAHULUAN
1.1 Latar Belakang
Perkembangan data yang sangat pesat membuat organisasi mencari metode untuk menyimpan dan mengolah data. Teknologi big data menjadi solusi untuk menyimpan data dan juga mampu mengolah data tersebut. Hadoop merupakan sebuah framework yang dapat menyimpan data dalam skala besar tanpa memperhatikan struktur dari data.
Koleksi data yang besar dapat diolah dan dianalisis untuk mendapatkan nilai atatu value pada data. Hasil analisa data tersebut berupa informasi yang dapat dijadikan pengambilan kebijakan pada organisasi. Hadoop menggunakan konsep pemrograman MapReduce untuk mengolah data menjadi informasi. MapReduce mampu melakukan komputasi secara paralel dan terdistribusi pada sistem Hadoop.
Mahout merupakan library yang menggunakan konsep pemrograman MapReduce dan dapat beradaptasi pada sistem Hadoop. Sehingga, Mahout dapat digunakan untuk menganalisa data dengan ukuran yang besar. Mahout menyediakan komputasi data mining atau penambangan data untuk menganalisa data. Means merupakan salah satu algoritma yang disediakan oleh Mahout. K-Means menganalisa data dengan mengelompokkan data berdasarkan kemiripan sifat.
1.2 Rumusan Masalah
Berikut beberapa rumusan masalah yang dapat dijadikan acuan dalam melakukan penelititan :
1) Bagaimana mengimplementasikan K-Means clustering pada lingkungan big data dengan menggunakan library Mahout berbasis model
pemrograman MapReduce?
2) Bagaimana unjuk kerja implementasi K-Means clustering pada lingkungan big data?
1.3 Tujuan
Berdasarkan rumusan-rumusan masalah, maka tujuan dari penelitian dapat dijabarkan sebagai berikut:
1) Mengimplementasikan K-Means clustering pada lingkungan big data dengan menggunakan library Mahout berbasis model pemrograman MapReduce.
2) Mengetahui unjuk kerja implementasi K-Means clustering pada lingkungan big data.
1.4 Manfaat
Manfaat yang dapat diperoleh dari penelitian ini ialah sebagai berikut: 1) Sebagai referensi oleh instansi dan organisasi tertentu yang hendak
menyimpan dan menganalisa koleksi data yang besar.
1.5 Batasan Masalah
Batasan masalah dalam penelitian ini ialah sebagai berikut:
1) Koleksi data diperoleh dari repositori UCI Machine Learning dengan alamat https://archive.ics.uci.edu/ml/data sets/liver+Disorders.
2) Format koleksi data ialah .CSV
3) Teknologi big data yang digunakan ialah Apache Hadoop versi 2.6.0. 4) Model pemrograman yang digunakan ialah MapReduce.
5) Library MapReduce yang digunakan ialah Apache Mahout yang berbasis bahasa pemrograman Java.
6) Proses coding menggunakan Eclipse IDE.
7) Proses compile library Mahout menggunakan Apache Maven.
8) Proses Monitoring Hadoop Distributed File System dilakukan pada browser Mozilla Firefox.
9) Sistem operasi yang digunakan ialah Ubuntu versi 14.04.
1.6 Metodologi Penelitian
Metodologi penelitian akan dijabarkan sebagai berikut: 1. Studi pustaka
Studi pustaka menjelaskan teori-teori yang digunakan dalam penelitian. Adapun teori-teori yang digunakan ialah data mining, K-Means clustering, big data, Hadoop, Hadoop Distributed File System (HDFS), Yarn,
MapReduce, dan Mahout. 2. Perancangan sistem
Perancangan sistem meliputi segala perangkat lunak dan perangkat keras yang dibutuhkan dalam mengembangkan sistem.
Luaran sistem ini ialah sebuah sistem big data dengan menggunakan menggunakan framework Hadoop. Sistem Hadoop ini berjalan pada jaringan lokal. Library Mahout yang berjalan pada sistem Hadoop digunakan untuk menganalisa koleksi data pada sistem Hadoop.
4. Evaluasi
Evaluasi sistem ini akan dibagi kedalam 2 bagian yakni:
a) Membandingkan hasil komputasi K-Means dengan menggunakan library Mahout dengan menggunakan penghitungan manual. Hasil
pengujian memperlihatkan kecocokan centroid dari hasil komputasi dengan menggunakan library Mahout berdasarkan hasil dari penghitungan manual.
b) Menguji unjuk kerja implementasi K-Means clustering pada lingkungan big data. Pengujian dilakukan dengan menjalankan komputasi K-Means menggunakan library Mahout sebanyak 10 kali pada jumlah slave node yang berbeda. Hasil pengujian memperlihatkan rata-rata waktu eksekusi komputasi K-Means pada jumlah slave node yang berbeda.
1.7 Sistematika Penulisan
Tugas akhir ini akan disusun ke dalam 6 bab dengan sistematika penulisan sebagai berikut:
Pendahuluan berisi tentang latar belakang, rumusan masalah, tujuan, manfaat, batasan masalah, metode penelitian dan sistematika penulisan.
BAB II : LANDASAN TEORI
Tinjauan pustaka dan dasar teori menjelaskan teori-teori yang digunakan dalam menyusun tugas akhir ini.
BAB III : ANALISA PERANCANGAN
Analisa perancangan menjelaskan skema perancangan implementasi K-Means pada lingkungan big data dengan menggunakan library Mahout berbasis konsep pemrograman MapReduce. Bagian ini menjelaskan pula media-media yang akan digunakan untuk mengembangkan sistem
BAB IV : IMPLEMENTASI
Implementasi menjelaskan tahap-tahap pengembangan sistem big data. Bagian ini menjelaskan pula mengenai implementasi library Mahout pada sistem Hadoop.
BAB V : ANALISA HASIL
Analisa hasil perancangan dan pengembangan sistem dibahas secara lengkap.
BAB VI : KESIMPULAN DAN SARAN
BAB 2 LANDASAN TEORI
Bab ini membahas teori-teori yang berkaitan dengan penulisan tugas akhir ini. Teori-teori tersebut yakni penambangan data, metode clustering, K-Means sebagai salah satu algoritma clustering, big data, Hadoop, Hadoop Distributed File System (HDFS), MapReduce, dan Apache Mahout.
2.1 Penambangan Data
2.1.1 Definisi Penambangan Data
Perkembangan data menjadi sebuah hal yang lumrah dewasa ini. Data pada komputer yang terhubung melalui jaringan internet mampu mencapai ukuran terabyte (TB) bahkan pentabyte (PB). Perkembangan data ini menghasilkan data mentah. Sehingga organisasi tertentu berusaha untuk mencari informasi tersembunyi pada data yang kemudian dapat digunakan untuk mengembangkan organisasi mereka.
Penambangan data atau data mining sering disebut Knowledge Discovery in Database (KDD) adalah kegiatan yang meliputi pengumpulan, pemakaian data
historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Hasil data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santosa, 2007).
2.1.2 Clustering
Clustering merupakan salah satu metode pada penambangan data. Tujuan
utama dari metode clustering ialah mengelompokkan sejumlah objek data ke dalam sebuah cluster atau grup. Sebuah objek pada sebuah cluster memiliki kemiripan yang sama dengan objek lain dan sebuah objek memiliki perbedaan dengan objek pada cluster lain. Clustering menggunakan teknik unsupervised learning yang digunakan untuk mengelompokkan data atau objek ke dalam
kelompok tertentu tanpa adanya label cluster sebelumnya. Teknik ini baik digunakan pada koleksi data yang tidak memiliki label sebelumnya. Sedangkan untuk data yang memiliki label, teknik ini dapat dijadikan sebagai pembanding antara hasil clustering dengan label sebenarnya. Sehingga diketahui tingkat akurasi pada metode clustering tersebut. Teknik yang membutuhkan data label disebut supervised learning. Metode yang digunakan dalam menentukan kemiripan antar objek ialah dengan menghitung jarak terpendek. Salah satu metode untuk menghitung jarak terpendek ialah Euclidean Distance.
Dalam matematika, Euclidean Distance adalah jarak antara dua titik yang dapat diukur menggunakan formula pythagoras. Euclidean Distance sering disebut sebagai dengan vector geometri yang memiliki panjang (magnitude) dan arah (direction). Sedangkan ruang vektor adalah sebuah struktur matematika yang dibentuk oleh sekumpulan vektor. Vektor-vektor tersebut dapat ditambahkan dikalikan dengan bilangan real dan lain-lain (Prasetya, 2013).
‖A‖=
√
X12+Y12 dan ‖B‖=√
X22+Y22Sedangkan untuk menghitung kedua jarak antara kedua vektor tersebut
ialah sebagai berikut: d( ¯A ,¯B)=
√
(X1−X2)2+(Y1−Y2)22.1.2.1 KMeans
K-Means merupakan salah satu algoritma penambangan data yang menerapkan metode clustering. Jika diberikan sekumpulan data X = {x1, x2, ..., xn} dimana xi = (xi1, xi2, ..., xin) adalah vector, maka algoritma K-Means akan mempartisi x dalam k buah cluster (Prasetya, 2013). Sehingga proses awal dalam menggunakan algoritma ini ialah dengan menentukan jumlah cluster atau K terlebih dahulu. Pengelompokkan objek berdasarkan ukuran jarak terpendek dengan pusat cluster atau centroid (Han J. et al., 2000).
Algoritma K-Means dapat diterangkan melalui pseudocode berikut (Santosa, 2007):
1) Langkah pertama ialah memilih jumlah cluster atau K.
2) Inisialisasi K pusat kelompok atau pemilihan nilai awal centroid dilakukan dengan cara random.
3) Penentuan kemiripan antar objek dilakukan dengan menghitung jarang terdekat antara objek. Demikian untuk penentuan suatu objek dengan centroid tertentu. Tahap ini menghitung jarak suatu objek dengan
centroid. Jika suatu objek memiliki jarak terpendek dengan centroid A
4) Penentuan centroid baru kembali dilakukan dengan cara menghitung nilai rata-rata dari semua objek pada kelompok tertentu.
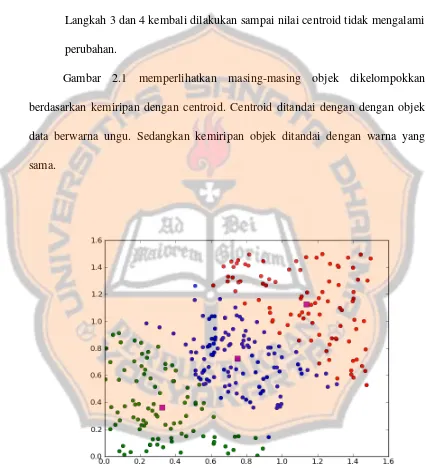
5) Objek pada setiap cluster dikelompokkan berdasarkan centroid baru. Langkah 3 dan 4 kembali dilakukan sampai nilai centroid tidak mengalami perubahan.
Gambar 2.1 memperlihatkan masing-masing objek dikelompokkan berdasarkan kemiripan dengan centroid. Centroid ditandai dengan dengan objek data berwarna ungu. Sedangkan kemiripan objek ditandai dengan warna yang sama.
2.2 Big Data
2.2.1 Definisi Big Data
Big data dapat diartikan sebagai sebuah koleksi atau kumpulan data yang
besar dan kompleks. Berdasarkan perkembangannya, big data memiliki 3 dasar definisi yakni volume, velocity, dan variety (Rathi R. et al., 2014).
1) Volume
Volume menjelaskan bahwa big data memiliki ukuran data yang besar.
Kumpulan data seperti data kesehatan merupakan jenis data yang sesuai dengan konsep big data karena data tersebut terus berkembang (Rathi R. et al., 2014). Teknologi big data hadir untuk menyimpan data-data yang belum diketahui nilai bisnisnya dan dalam volume besar, platform berbasis big data seperti Hadoop memberikan solusi (Data Science Indonesia,
2015). 2) Variety
berupa data teks lainnya, data gambar, data suara, dan data video (Ronk, J. 2014).
3) Velocity
Data velocity atau kecepatan data berbanding lurus dengan volume data.
Data tidak hanya datang dalam jumlah besar, tetapi juga dalam tempo yang lebih singkat dan bahkan ada yang real-time. Hal ini menjadi tantangan pada teknologi big data (Data Science Indonesia, 2015).
2.3 Hadoop
2.3.1 Definisi Hadoop
Apache Hadoop software library adalah sebuah framework yang sesuai
digunakan untuk proses terdistribusi dari kumpulan data yang besar pada komputer cluster dengan model-model pemrograman yang sederhana (Apache, 2015). Hadoop merupakan open source framework yang dikembangkan oleh Apache Software Foundation. Hadoop digunakan untuk memproses kumpulan data yang besar dalam sebuah server paralel komputer (Rathi R. et al., 2014). Hadoop dikembangkan untuk memproses skalabilitas data web atau web-scale data yang mampu mendistribusikan data dengan kapasitas ukuran yang besar.
2.3.2 Hadoop Distributed File System
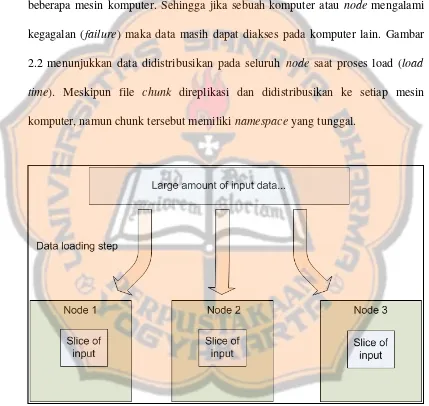
Pada cluster Hadoop, data didistribusikan ke seluruh node. Hadoop Distributed File System (HDFS) akan membagi data yang besar ke dalam chunk
yang dikelola oleh setiap node pada cluster. Setiap chunk akan direplikasi pada beberapa mesin komputer. Sehingga jika sebuah komputer atau node mengalami kegagalan (failure) maka data masih dapat diakses pada komputer lain. Gambar 2.2 menunjukkan data didistribusikan pada seluruh node saat proses load (load time). Meskipun file chunk direplikasi dan didistribusikan ke setiap mesin
komputer, namun chunk tersebut memiliki namespace yang tunggal.
Data pada Hadoop programming framework menggunakan konsep record-oriented. Setiap input file akan dipecah dalam baris atau format lain yang spesifik
kemudian akan memproses subset dari record tersebut. Hadoop kemudian menjadwalkan proses-proses tersebut di berdasarkan kedekatan lokasi data/ record menggunakan konsep kerja dari sistem file terdistribusi. Sejak file-file
tersebar pada sistem file terdistribusi sebagai chunk, setiap proses komputasi yang berjalan pada sebuah node beroperasi pada sebuah subset dari data. Data yang dioperasikan oleh sebuah node dipilih berdasarkan locality dari node: data paling banyak dibaca dari disk lokal langsung ke CPU, untuk mengurangi ketegangan bandwidth jaringan dan mencegah transfer jaringan yang tidak perlu. Locality data yang tinggi ini menjadi sebuah keunggulan pada Hadoop (Yahoo!, 2014).
HDFS memiliki 2 tipe operasi node yakni service NameNode pada master node dan service DataNode pada slave node. NameNode bertugas dalam
mengatur namespace sistem file. NameNode mengatur susunan sistem file dan metadata untuk semua file dan direktori pada susunan tersebut. Informasi tersebut disimpan pada local disk kedalam 2 bentuk file yakni namespase image dan edit log. NameNode juga mengetahui proses kerja dari DataNode, seperti letak lokasi
dari block data (chunk). Namun NameNode tidak bertugas dalam menyimpan data tersebut, DataNode berfungsi sebagai tempat kerja dari sistem file. DataNode bertugas menyimpan dan menerima block data ketika mendapatkan perintah dari pengguna atau NameNode. DataNode melaporkan kepada NameNode secara periodik tentang daftar block data yang disimpan.
membaca susunan block data pada DataNode. HDFS memiliki sebuah service Secondary NameNode. Tugas utama dari secondary NameNode ialah menggabungkan namespace image dengan edit log untuk mencegah edit log berukuran sangat besar. Secondary NameNode membutuhkan memory yang hampir sama besar dengan NameNode. Secondary NameNode membuat gabungan file tersebut agar dapat digunakan ketika NameNode mengalami kegagalan (White, 2015).
2.3.3 Yarn
Sedangkan NodeManager berjalan pada slave node. NodeManager betugas mencari sumber daya yang memungkinkan untuk memproses data pada slave node dan mengirimkan laporan aktivitas secara periodik kepada ResourceManager. Sumber data proses pada sistem Hadoop membutuhkan potongan bite-size yang disebut containers. Container adalah sebuah koleksi dari semua sumber daya yang diperlukan untuk menjalankan aplikasi seperti CPU cores, memory, network bandwidth, dan ruang pada disk. Container bersifat umum
atau generic sehingga dapat menjalankan berbagai jenis model komputasi, selama sumber daya yang diperlukan cukup untuk menjalankan model komputasi tersebut. Semua proses Container yang berjalan pada slave node dimonitor oleh service NodeManager pada slave node (deRoos, D. et al., 2014).
2.4 MapReduce
2.4.1 Definisi MapReduce
Hadoop mengurangin komunikasi yang dapat dikerjakan oleh sebuah proses. Setiap record diproses oleh sebuah task yang terisolasi dari task yang lain. Model pemrograman yang digunakan untuk manajemen data disebut MapReduce.
Pada MapReduce, record diproses dalam sebuah task yang disebut Mapping. output dari Mapping task akan dibawa dan diproses pada task kedua yang disebut
sebagai Reducing, dimana hasil dari Mapping yang berbeda akan digabung (Yahoo!, 2014).
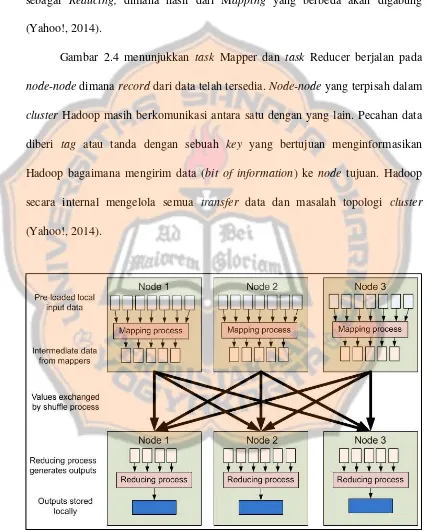
Gambar 2.4 menunjukkan task Mapper dan task Reducer berjalan pada node-node dimana record dari data telah tersedia. Node-node yang terpisah dalam
cluster Hadoop masih berkomunikasi antara satu dengan yang lain. Pecahan data
diberi tag atau tanda dengan sebuah key yang bertujuan menginformasikan Hadoop bagaimana mengirim data (bit of information) ke node tujuan. Hadoop secara internal mengelola semua transfer data dan masalah topologi cluster (Yahoo!, 2014).
2.4.2 Proses MapReduce
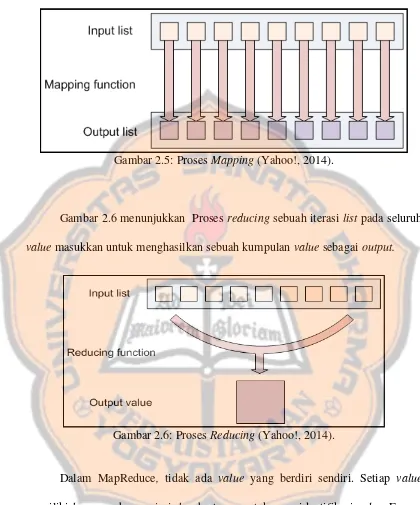
Fase pertama dari program MapReduce disebut mapping. Sebuah list elemen data melalui sebuah fungsi yang disebut Mapper yang akan mentransformasikan setiap elemen individual ke elemen data output. Fungsi Mapper tidak memodifikasi list input string tetapi menghasilkan sebuah string
baru yang menjadi bagian dari sebuah list output yang baru (Yahoo!, 2014). Setiap element data output akan dipecah ke dalam sebuah pasangan data key dan value (DeZyre, 2015). Key berfungsi sebagai identitas unik pada data, sedangkan
value merupakan nilai dari data itu sendiri.
Gambar 2.5 menunjukkan task Mapping membuat sebuah list output yang baru pada seluruh list data elemen input. Reducing memungkinkan pengumpulan value bersama. Fungsi Reducer menerima sebuah iterator dari value masukkan
(input value) dari sebuah list input. Kemudian Reducer task menggabungkan nilai-nilai ini bersama. Reducer task mengembalikan nilai output tunggal. Reducing sering digunakan untuk menghasilkan data summary atau mengubah
Gambar 2.6 menunjukkan Proses reducing sebuah iterasi list pada seluruh value masukkan untuk menghasilkan sebuah kumpulan value sebagai output.
Dalam MapReduce, tidak ada value yang berdiri sendiri. Setiap value memiliki key yang berasosiasi. key bertugas untuk mengidentifikasi value. Fungsi mapping dan reducing tidak hanya menerima value, tetapi pasangan key dan
value. Sebuah fungsi reducing berfungsi untuk mengubah sebuah list dari value
yang besar ke dalam sebuah (atau beberapa) value output. Semua output value tidak mengalami proses reduce bersamaan. Tetapi semua value yang memiliki key
Gambar 2.5: Proses Mapping (Yahoo!, 2014).
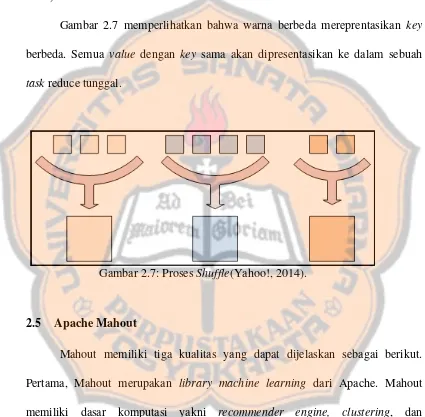
sama yang akan mendapatkan proses reduce bersama (Yahoo!, 2014). Proses ini biasa disebut shuffle task. Hal ini dikarenakan semua value yang memiliki key yang sama akan dikelompokkan sebelum melalui proses reduce (Voruganti, S., 2014).
Gambar 2.7 memperlihatkan bahwa warna berbeda mereprentasikan key berbeda. Semua value dengan key sama akan dipresentasikan ke dalam sebuah task reduce tunggal.
2.5 Apache Mahout
Mahout memiliki tiga kualitas yang dapat dijelaskan sebagai berikut. Pertama, Mahout merupakan library machine learning dari Apache. Mahout memiliki dasar komputasi yakni recommender engine, clustering, dan classification. Selain itu, Apache Mahout bersifat scalable. Apache Mahout dapat
digunakan sebagai pilihan alat machine learning ketika koleksi data yang akan diproses sangat besar yang ukurannya tidak dapat disimpan dalam sebuah komputer. Mahout ditulis dengan menggunakan bahasa Java dan beberapa dari
Mahout dikembangkan pada proyek komputasi Apache’s Hadoop Distributed. Oleh karena Mahout merupakan sebuah library Java. Sehingga library ini tidak menyediakan sebuah antarmuka pengguna atau user interface, prepackaged server, dan sebuah installer. Mahout merupakan sebuah framework yang cocok
digunakan dan diadaptasikan oleh pengembang.
Mahout menempatkan skalabilitas pada prioritas yang paling tinggi. Metode machine learning yang mutakhir diterapkan pada level skalabititas. Library Mahout yang bersifat open source atau sumber terbuka digunakan pada
lingkungan Hadoop, sehingga Mahout mampu menggunakan konsep komputasi MapReduce (Owen, S. et al., 2012).
2.5.1 Konsep MapReduce Pada Library Mahout Berdasarkan Algoritma K-Means
Berdasarkan penelitian Vishnupriya, N. dan Francis, S. (2015), proses algorima K-Means clustering pada library Mahout yang menggunakan konsep pemrograman MapReduce dapat dijabarkan ke dalam beberapa fase:
1) Initial
penelitian Vishnupriya, N. et al. (2015), inisial centroid dipilih secara random pada koleksi data.
2) Mapper
Pada fase Mapper, proses dilanjutkan dengan menghitung jarak antara setiap item data dengan K centroid. Penghitungan jarak terdekat dilakukan pada selutuh item data. Luaran dari penghitungan ialah item data dengan format <ai, zj>. ai merupakan pusat dari kelompok (cluster) data zj. 3) Reducer
Berdasarkan penelitian Vishnupriya, N. dan Francis, S. (2015), maka konsep K-Means pada library Mahout dengan menggunakan model pemrograman MapReduce dapat visualisasikan pada gambar 2.8.
2.5.2 Metode Menjalankan Library Mahout
Berdasarkan website resmi Mahout (2016), library Mahout dapat berjalan pada sistem lokal atau pun pada Hadoop Distributed File System (HDFS). Metode yang digunakan dalam menjalankan library Mahout ialah melalui command line. Metode yang digunakan untuk menjalankan perintah K-Means ialah dengan menjalankan perintah $mahout kmeans pada command line lalu diikuti dengan parameter pada yang tertera pada tabel 2.1.
Tabel 2.1: Metode Menjalankan Library Mahout berdasarkan algoritma K-Means menggunakan Command Line (Mahout, 2016)
Perintah Penjelasan
--input atau -i Merupakan alamat file input yang harus berupa Sequence File
--clusters atau -c Merupakan alamat input file centroid yang harus berupa sequence file
--output atau -o Merupakan alamat file output yang harus berupa Sequence File
--distanceMeasure atau -dm
Algoritma pengukuran jarak.
--convergenceDelta atau -cd
Nilai konvergen merupakan nilai untuk menetukan proses iterasi berhenti. Secara default, convergen delta bernilai 0.5
--maxIter (-x) maxIter Jumlah maksimal iterasi
--maxRed (-r) maxRed Jumlah Task Reducin. Secara default, bernilai 2 --k (-k) k Nilai jumlah kelompok data atau cluster
--overwrite (-ow) Jika direktori ada, maka perintah ini akan menghapus direktori tersebut, sebelum menjalankan perintah atau Job.
--help (-h) Menampilkan informasi help
BAB 3 ANALISA PERANCANGAN
Bab ini akan menjabarkan tentang mekanisme perancangan sistem yang dibagi dalam gambaran penetilian, kebutuhan sistem, dan skema sistem big data.
3.1 Gambaran Penelitian
Gambar 3.1: Flowchart pelitian
Gambar 3.1 menunjukkan gambaran proses pada penelitian yang divisualisasikan dalam diagram flowchart.
3.1.1 Data
Peneliti menggunakan sumber data atau dataset dari bank data UCI Machine Learning mengenai liver Disorders Data Set. Berikut beberapa informasi
mengenai data Liver Disorders: 1. Judul data ialah Liver Diorders 2. Beberapa informasi dataset yakni:
a. Data diciptakan oleh BUPA Medical Research Ltd.
b. Penyumbang data ialah Richard S. Forsyth, 8 Grosvenor Avenue, Mapperley Park, Nottingham NG3 5DX, 0602-621676.
c. Data dibuat pada tanggal 15 Mei 1990.
3. Lima variabel pertama ialah hasil tes darah yang dianggap sensitif untuk penyakit liver disorder atau kelainan hati yang kemudian konsumsi alkohol menjadi salah satu penyebab. Setiap baris pada file bupa.data merupakan hasil uji coba pada seseorang pria.
4. Baris data berjumlah 345 baris. 5. Atribut data berjumlah 7.
Tabel 3.1: Informasi data liver disorder
No Atribut Keterangan
1. mcv mean corpuscular volume yaitu rata-rata volume korpuskuler darah
2. alkphos alkaline phosphotase yaitu kadar alkali fosfat dalam darah
3. sgpt alamine aminotransferase yaitu kadar alamin aminotransferase dalam darah
4. sgot aspartate aminotransferase yaitu kadar aspartat aminotrasferase dalam darah
5. gammagt glutamyl transpeptidase yaitu kadar gamma-glutamil transpeptidase dalam darah
6. drink jumlah minum minuman beralkohol per hari dalam satuan half-pint (257 ml per satuan)
7. selector Attribut ini adalah atribut class yang nantinya menjadi sumber penghitungan akurasi. Bernilai 1 atau 2. Jika 1 maka instance tersebut menderita penyakit hati. Jika 2 maka instance tersebut normal.
7. Data liver disorder tidak memiliki missing value atau hilangnya sebuah item data.
3.1.2 K-Means Mahout
Metode K-Means clustering digunakan dalam menganalisis data liver disorder karena mampu untuk mengelompokkan data berdasarkan kemiripan sifat
Beberapa hal yang harus diperhatikan dalam K-Means Mahout yakni: 1) Data training yang akan menjadi input harus berformat sequence. File
Sequence merupakan format file yang dapat dibaca oleh library Apache
Mahout. File Sequence sendiri akan memiliki struktur format key dan
value.
2) Data centroid juga harus berformat sequence.
3) Hasil atau output dari proses K-Means akan berupa sebuah direktori yang berisi dari proses iterasi dari K-Means.
1) Pengukuran kesamaan sifat menggunakan rumus jarak terpendek atau similarity measure. Adapun dalam penelitian ini similarity measure yang
digunakan ialah Euclidean Distance,
2) Convergen threshold merupakan nilai yang telah ditetapkan untuk menentukan bahwa iterasi pada proses K-Means berhenti.
3) Jumlah iterasi yang maksimal yang dapat dikerjakan oleh sistem.
4) Jumlah kelompok atau nilai K dari sistem K-Means. Adapun dalam penelitian ini, jumlah K yang akan digunakan ialah 2.
3.2 Kebutuhan Sistem
Alat yang dibutuhkan untuk mengembangkan sistem ialah: 1. Perangkat keras
Tabel 3.2: Spesifikasi Komputer Cluster Jenis Node Processor Memory Hard Drive Network Master Node Intel®
b) Perangkat keras lainnya yakni 1) Kabel RJ45 berjumlah 4
2) Router D-Link DES-1024D berjumlah 1. 2. Perangkat Lunak
Perangkat lunak yang digunakan ialah sebagai berikut: a) Ubuntu 14.04
Ubuntu merupakan sistem operasi yang menggunakan Linux sebagai kernelnya.
Hadoop memerlukan Java agar dapat berjalan pada sistem Ubuntu. Sedangkan versi Java yang dibutuhkan Hadoop ialah diatas versi 5. Penelitian ini menggunakan Java versi 7.
c) SSH (Secure Shell)
Sistem big data ini menggunakan SSH akses untuk mengatur seluruh node. Cara mengaturnya ialah dengan melakukan remote sebuah slave
node pada sebuah master node.
d) Apache Hadoop 2.6.0
Versi Hadoop yang digunakan ialah 2.6.0. Versi ini sudah mendukung fitur Yarn. Yarn merupakan bagian penting dalam Hadoop selain daripada Hadoop Distributed File System (HDFS), dan MapReduce. Yarn berfungsi untuk mengatur penggunaan resource atau sumber daya dari komputer cluster.
e) Apache Mahout 0.10.1
Versi Mahout yang digunakan ialah 0.10.1. f) Apache Maven 3.3.9
Apache maven merupakan library yang digunakan untuk proses build dan compile library Mahout.
g) Eclipse Kepler
Eclipse merupakan IDE yang berfungsi untuk menulis dan mengelola sumber kode atau source code dari Apache Mahout.
LibreOffice Calc merupakan aplikasi perkantoran dari LibreOffice yang umum digunakan untuk mengolah data angka yang ditampilkan dalam bentuk spreadsheet.
i) Editor nano dan pluma
Editor nano dan pluma berfungsi untuk menampilkan data. Namun, editor nano hanya dapat berjalan pada terminal atau command line. j) MATE Terminal
Aplikasi MATE Terminal digunakan sebagai command line untuk menjalankan perintah-perintah sistem Linux dan mengeksekusi aplikasi atau paket program pada sistem Linux termasuk perintah dari Hadoop dan Mahout.
3.3 Skema Sistem Big Data
Berdasarkan proses implementasinya, sistem big data pada mulanya dikembangkan dalam masing-masing node. Implementasi sistem big data pada sebuah komputer disebut single node cluster. Setelah sistem big data diimplementasikan pada masing-masing node, maka langkah selanjutnya ialah menyatukan selutuh node menjadi satu. Proses ini disebut multi node cluster.
3.3.1 Skema Single Node Cluster
SecondaryNamenode, ResourceManager, dan NodeManager. Router digunakan untuk membuat koneksi jaringan lokal. Sehingga setiap komputer tunggal (single node) memiliki IP Address. Adapun setiap komputer memiliki IP Address yang
tergabung dalam satu jaringan. Sehingga ketika setiap komputer memiliki IP Address yang saling terhubung dalam jaringan komputer, maka setiap komputer dapat dikonfigurasi ke dalam multi node cluster.
3.3.2 Skema Multi Node Cluster
Skema multi node cluster yang memperlihatkan sistem Hadoop yang diimplementasikan pada multi komputer dapat dilihat pada gambar 3.3. Perancangan multi node cluster menggunakan 4 komputer yang terdiri dari 1
master node dan 3 slave node. Router digunakan untuk membuat koneksi jaringan
lokal. Router bertindak sabagai gateway pada sistem jaringan, yang berfungsi untuk menghubungkan sebuah node dengan node yang lain. IP Address digunakan untuk memberi alamat pada masing-masing node. Master node akan menjalankan service NameNode, SecondaryNamenode dan ResourceManager. Sedangkan
slave node akan menjalankan service DataNode dan NodeManager.
BAB 4 IMPLEMENTASI
Bab ini menjabarkan implementasi perancangan sistem big data yakni konfigurasi single node cluster dan multi node cluster, serta implementasi library Mahout pada sistem Hadoop yang terdiri dari proses install Maven, IDE Eclipse, dan Mahout.
4.1 Perancangan Sistem Big Data
Perancangan sistem Hadoop dimulai dengan melakukan konfigurasi pada masing-masing komputer, setelah itu proses dilanjutkan dengan menggabungkan semua node menjadi satu.
4.1.1 Konfigurasi Single Node Cluster
Konfigurasi single node cluster diterapkan pada seluruh komputer cluster. Oleh karena itu, konfigurasi ini akan diimplementasikan pada 4 komputer cluster yaitu 1 master node dan 3 slave node. Secara teknis, proses konfigurasi menerapkan metode yang sama. Adapun beberapa paket aplikasi yang diinstall berada pada direktori /home/mnode/big\ data\ applikasi.
4.1.1.1 Install Java
Paket Java dibutuhkan karena framework Hadoop dan library Mahout berjalan diatas lingkungan Java. Screenshot proses install Java dapat dilihat pada bagian Lampiran 1. Adapun berikut merupakan proses menginstall Java :
1. Melakukan proses extract file pada file arsip Java
Perintah yang digunakan untuk melakukan proses extract file Java ialah tar -xzf file-paket-Java.tar.gz. tar merupakan command atau perintah yang digunakan untuk melakukan extract file pada arsip file yang berekstensi .tar.gz. Parameter -x atau --exclude-from merupakan perintah mengecualikan susunan pola pada file. Parameter f atau –file menunjukkan ekstrak data dilakukan pada file arsip atau archive file. Sedangkan parameter -z atau --uncompress digunakan untuk perintah uncompress atau ekstrak file.
2. Membuat direktori java pada direktori /usr/local
Tujuan dari langkah ini ialah untuk membuat direktori khusus untuk menyimpan paket Java pada sistem Linux Ubuntu. Perintah yang digunakan ialah $sudo mkdir /usr/local/java. Mkdir merupakan perintah untuk membuat sebuah atau beberap direktori. Perintah sudo menunjukkan bahwa perintah harus dilakukan pada sisi administrator pada sistem Linux Ubuntu.
Proses ini harus dilakukan karena proses install java menggunakan source code java. Variabel JAVA_HOME merupakan variable yang
menunjukkan direktori tempat menyimpan source code java. Perintah export digunakan untuk mengenali Java pada sistem Ubuntu.
5. Uji coba environment Java
echo merupakan perintah yang digunakan untuk menampilkan sebuah data suatu variable. Sehingga echo dapat digunakan untuk menampilkan data variabel JAVA_HOME yang merupakan lokasi Java pada sistem Linux.
4.1.1.2 Konfigurasi Group Dan User Sistem Hadoop
User merupakan pengguna sistem Ubuntu yang telah terdaftar. Sedangkan
group merupakan sebuh wadah untuk mengelompokkan user atau pengguna pada
sistem Ubuntu. Implementasi ini menggunakan group dan user khusus untuk memudahkan dalam membangun sistem Hadoop. Screenshot langkah-langkah konfigurasi group dan user sistem Hadoop dapat dilihat pada Lampiran 2. Berikut penjelasan langkah-langkah konfigurasi group dan user atau pengguna dari sistem Hadoop:
1. Menambah group Hadoop
2. Menambah user hduser pada group hadoop
Adduser merupakan perintah untuk menambahkan pengguna pada sistem Ubuntu. Perintah --ingroup merupakan perintah untuk menambahkan pengguna secara langsung pada sebuah group. Sehingga perintah $sudo adduser –ingroup hadoop hduser merupakan perintah untuk menambahkan pengguna hduser pada group hadoop. Pengguna hduser sendiri akan secara khusus bertugas untuk menjalankan aktivitas pada sistem hadoop.
3. Menginstall openssh-server
Protokol SSH digunakan untuk melakukan manajemen komputer cluster. Dengan menggunakan protokol SSH, maka administrator dapat mudah dalam memanajemen komputer atau node lain dengan melakukan monitoring. Paket yang digunakan dalam mengintal SSH ialah open-ssh
server.
4. Login sebagai pengguna hduser
Langkah ini dimaksudkan bahwa proses konfigurasi selanjutnya dilakukan pada host hduser.
5. Membuat kunci RSA atau RSA Key untuk pengguna hduser
keseluruhan sistem Hadoop. Namun karena implementasi sistem dilakukan di jaringan local, maka menggunakan password kosong.
6. Membuat authorized_keys
authorized_keys dibutuhkan untuk mengijinkan akses SSH dari node ke
sistem lokal.
7. Mengetes SSH pada sistem lokal
Proses ini tidak hanya mengetes SSH pada sistem lokal. Namun, proses
dilakukan untuk menyimpan host key fingerprint pada sistem local yang
terletak pada file known_hosts yang terletak pada direktori /home/.ssh.
4.1.1.3 Melakukan Disable IPv6
Screenshot langkah ini dapat dilihat pada Lampiran 3. Berikut penjelasan
langkah-langkah dalam melakukan disable IPv6: 1. Konfigurasi pada file /etc/sysctl.conf
Konfigurasi disable IPv6 dilakuakn pada file /etc/sysctl.conf. Adapun Pengembangan sistem Hadoop tidak membutuhkan konfigurasi IPv6 2. Mengecek status disable IPv6
4.1.1.1 Install Hadoop
Screenshot langkah ini dapat diliaht pada Lampiran 4. Berikut penjelasan langkah-langkah proses install Hadoop:
1. Melakukan extract file pada file arsip Hadoop
Langkah ini sama seperti langkah dalam mengekstrak file Java, karena paket source code Hadoop dikemas dalam file tar.gz.
2. Menyalin source code Hadoop ke folder /usr/local 3. Mengubah privilege atau hak akses pada folder hadoop
Perintah chown digunakan untuk mengubah hak akses sebuah file atau folder berdasarkan pengguna dan group. Direktori hadoop secara khusus
diperuntukkan untuk pengguna hduser dan digunakan pada group Hadoop. 4. Melakukan konfigurasi variable Hadoop pada file .bashrc
Proses sama seperti langkah sebelumnya, yakni agar Hadoop mudah dikenali oleh sistem Linux.
5. Mengetes implementasi Hadoop
Mengetes Hadoop dilakukan pada sisi pengguna hduser dengan cara mengecek versi dari Hadoop. Hasil dari perintah $hadoop version ialah berupa versi Hadoop dan metadata Hadoop lainnya.
4.1.1.2 Konfigurasi Environment Hadoop Single Node Cluster
Konfigurasi ini dilakukan pada node klaster tunggal atau single node cluster. Konfigurasi dilakukan pada direktori sistem Hadoop yang terletak pada
dilihat pada bagian Lampiran 5. Berikut langkah-langkah konfigurasi lingkungan atau environment Hadoop Single Node Cluster:
1. Melakukan konfigurasi JAVA_HOME pada file hadoop-env.sh
Konfigurasi dlakuakn pada file hadoop-env.sh dengan mengubah alamat direktori atau path JAVA_HOME dengan lokasi tempat menginstall Java pada sistem Ubuntu. Java sangat dibutuhkan agar sistem Hadoop dapat berjalan. Hal ini dikarena framework Hadoop dikembangkan menggunakan Java dan hanya dapat berjalan diatas Java environment atau lingkungan Java.
2. Konfigurasi core-site.xml
Konfigurasi pada file core-site.xml merupakan konfigurasi lokasi temporary direktory dari Hadoop Distributed File System (HDFS).
Dengan kata lain langkah ini menjelaskan lokasi data Hadoop dan semua metadata Hadoop disimpan. Adapun dalam penelitian ini, lokasi HDFS ditempatkan pada direktori /app/hadoop/tmp. Konfigurasi ditempatkan pada tag <value></value>.
3. Membuat direktori /app/hadoop/tmp
Proses membuat direktori /app/hadoop/tmp dilakukan pada sisi pengguna mnode yang berperan sebagai administrator pada sistem Ubuntu. Hal ini dikarena direktori /app/hadoop/tmp ditempatan pada direktori root yang hanya dapat diakses oleh administrator.
Direktori /app/hadoop/tmp temporary directory digunakan untuk menempatkan HDFS pada local disk. Sehingga direktori ini secara khusus diperuntukkan untuk pengguna hduser.
5. Mengatur permission pada direktori /app/hadoop/tmp
Proses ini bertujuan untuk menjaga keamanan pada direktori /app/hadoop/tmp. Dengan kata lain, tidak semua jenis dapat dieksekusi pada direktori ini.
6. Konfigurasi mapred-site.xml
Secara default, file mapred-site.xml belum terdapat pada sistem direktori konfigurasi Hadoop. Sehingga langkah yang dilakukan ialah menyalin template mapred-site.xml ke dalam sebuah file mapred-site.xml.
Selanjutnya konfigurasi file mapred-site ialah mengisi parameter <value></value> dengan localhost. Langkah ini menunjukkan proses mapreduce hanya berjalan pada localhost atau sistem lokal.
7. Konfigurasi hdfs-site.xml
konfigurasi file hdfs-site.xml memperlihatkan jumlah replikasi pada sistem. Dengan kata lain, langkah ini menunjukkan berapa jumlah slave node yang akan digunakan. Konfigurasi ini menggunakan parameter 1
karena konfigurasi masih dilakukan pada single node. 8. Konfigurasi yarn-site.xml
9. Melakukan format HDFS
Langkah ini akan menghapus semua data pada HDFS. Namun langkah ini tidak direkomendasikan dilakukan pada saat yang bersamaan dengan manajemen data karena dapat mengakibatkan kerusakan atau kegagalan data.
10. Menjalankan perintah start-dfs.sh
Perintah start-dfs.sh yang digunakan untuk menjalankan service dari NameNode dan SecondaryNamenode pada master node dan DataNode pada slave node. Karena sistem ini bersifat single node cluster maka semua service berjalan pada localhost atau lokal sistem Ubuntu.
11. Menjalankan perintah start-yarn.sh
Perintah start-yarn.sh yang digunakan untuk menjalankan service ResourceManager dan NodeManager yang dimiliki oleh fitur Yarn. Adapun konfigurasi ini dilakukan pada single node cluster sehingga ResourceManager dan NodeManager berjalan pada localhost.
12. Menjalankan jps
4.1.2 Konfigurasi Multi Node Cluster
Langkah ini dilakukan ketika konfigurasi single node cluster sudah diterapkan pada seluruh komputer cluster. Proses multi node cluster merupakan proses penggabungan seluruh single node cluster menjadi satu kelompok dalam sistem Hadoop. Berikut langkah-langkah konfigurasi multi node cluster:
4.1.2.1 Konfigurasi Hostname, Hosts, & SSH
Screenshot dari langkah ini dapat dilihat pada bagian Lampiran 6. Berikut merupakan urutan langkah-langkah konfigurasi Hostname, Hosts, dan SSH:
1. Mengubah hostname
Proses mengubah hostname yang merupakan nama mesin komputer. Penelitian ini menggunakan hostname master untuk komputer master node, hostname slave1 untuk komputer slave node 1, hostname slave2
untuk komputer slave node 2, dan hostname slave3 untuk komputer slave node 3. Tujuan mengubah hostname ialah untuk memudahkan mengenali
masing-masing komputer cluster.
2. Konfigurasi IP Address pada seluruh komputer cluster
Penelitian ini seluruh IP Address pada komputer cluster diberi nama host yang berfungsi untuk memudahkan dalam mengingat alamat komputer cluster. Pemberian nama host dilakukan pada file /etc/hosts. Konfigurasi
tidak hanya dilakukan pada sisi master node saja, tetapi juga pada seluruh slave node. Adapaun host yang digunakan untuk master node ialah master.
3. Konfigurasi akses SSH
Konfigurasi SSH dilakukan dengan menyalin SSH public key dari master node ke semua slave node. Konfigurasi akses SSH dilakukan untuk memudahkan dalam memanajemen sistem Hadoop. Ketika melakukan monitoring menggunakan SSH, sistem tidak perlu untuk meminta password tetapi akan mengarahkan langsung ke dalam sistem yang aktif. Adapun pada konfigurasi single node, Public SSH key atau kunci publik SSH telah ditempatkan pada file authorized_keys. Dengan menggunakan perintah ssh-copy-id maka maka sebuah node dapat mengakses node lain dengan menggunakan SSH akses tanpa menggunakan password. Adapun perintah untuk mengakses node lain ialah $ssh master untuk mengakses node lokal master, $ssh slave1 untuk mengakses node slave1, $ssh slave2
untuk mengakses node slave2, dan $ssh slave3 untuk mengakses node slave3.
4.1.2.2 Identifikasi Master Node & Slave Node
4.1.2.3 Konfigurasi Environment Hadoop Multi Node Cluster
Konfigurasi environment Hadoop multi node cluster dilakukan pada 4 file konfigurasi yakni core-site.xml, mapred-site.xml, dan hdfs-site.xml. Adapaun screenshot langkah ini dapat dilihat pada Lampiran 8. Berikut penjelasan
langkah-langkah konfigurasi environment Hadoop multi node cluster: 1. Konfigurasi core-site.xml
Terdapat perubahan pada parameter fs.default.name, hal ini dikarenakan nilai dari parameter dikhsusukan buat host dan port dari master node. Sehingga perubahan dilakukan dengan mengubah localhost menjadi master. Adapun perubahan pada file core-site.xml ini dilakukan pada semua node.
2. Konfigurasi mapred-site.xml
Terdapat perubahan konfigurasi pada parameter mapred.job.trackern yakni mengubah localhost menjadi master. Hal ini dikarenakan karena komputasi MapReduce dijalankan pada master node. Adapun perubahan ini diterapkan pada seluruh node.
3. Konfigurasi hdfs-site.xml
Konfigurasi hdfs-site.xml ialah mengganti nilai block replication. Penelitian ini menggunakan 3 slave node. Sehingga parameter value memiliki nilai 3.
Proses ditujukan untuk memberikan inisialisasi HDFS atau temporary directory. Selama melakukan penelitian, proses format HDFS tidak
sepenuhnya dapat menghapus semua data pada HDFS. Oleh karena itu, cara yang digunakan ialah menghapus secara manual semua file.
5. Mengetes konfigurasi multi node cluster
Mengetes konfigurasi dilakukan dengan menjalankan dfs.sh dan start-yarn.sh di master node. Perintah ini bertujuan untuk menjalankan service HDFS yaitu NameNode, SecondaryNamenode, dan DataNode. Hasil dari perintah start-dfs.sh ialah service NameNode dan SecondaryNamenode berjalan pada master node. Luaran dari perintah start-dfs.sh pada slave node ialah service DataNode yang berjalan pada slave1 node, slave2 node,
dan slave3 node. Sedangkan luaran perintah start-yarn.sh yakni service ResourceManager yang berjalan pada master node dan service NodeManager yang berjalan pada slave node.
4.2 Implementasi Library Mahout Pada Sistem Hadoop Berikut implementasi library Mahout pada sistem Hadoop:
4.2.1 Install Maven
lingkungan pengguna hduser, sehingga maven diberikan hak akses khusus dengan menggunakan perintah $chown hduser:hadoop.
Konfigurasi variable Maven juga dilakukan karena maven diinstall menggunakan source code. Sama seperti konfigurasi pada Java dan Hadoop, langkah ini bertujuan agar Maven dapat dikenali oleh sistem Linux. Proses mengetes Maven ialah dengan menjalankan perintah mvn –version. Luaran dari perintah tersebut ialah versi Maven dan metadata lain. Adapun sreenshot langkah ini dapat dilihat pada bagian Lampiran 9.
4.2.2 Install Eclipse
IDE Eclipse dibutuhkan karena proses pengembangan dan pengujian sistem ini menggunakan source code tambahan. Eclipse juga memiliki plugin m2e yang dapat berintegrasi dengan Maven, sehingga selain melakukan compile dan build source code menggunakan perintah di terminal. Eclipse pun dapat
melakuakan compile dengan menggunakan perintah yang telah tersedia.
4.2.3 Install Mahout
Proses konfigurasi Mahout dilakukan pada master node. Konfigurasi dilakukan dengan menulis variabel Mahout pada sistem Linux. Oleh karena Mahout berjalan pada lingkungan Hadoop, maka konfigurasi juga dilakukan dengan mengintegrasikan Hadoop dan Mahout.
Source code Mahout dapat dibukan pada Eclipse dengan menggunakan
menginput atau melakukan import dan secara otomatis Eclipse akan melakukan compile source code Mahout.
4.3 Implementasi Metode K-Means Menggunakan Library Mahout 4.3.1 Preprocessing
Sebelum menjalankan komputasi K-Means, ada beberapa hal yang harus dilakukan yakni mengkonversi data dari format csv ke format sequence dan membuat direktori untuk menyimpan data trining dan data centroid pada HDFS.
Konversi data numerik pada file csv akan dilakukan dengan menggunakan
program tambahan berbasis bahasa pemrograman Java.
Data liver disorder memiliki susunan informasi yakni id, mvc, alkphos, sqpt, sgot, gammagt, drink, dan selector. Namun dalam melakukan konversi, susunan file tersebut diubah menjadi selector, id, mvc, alkphos, sqpt, sgot, gammagt, dan drink. Hasil atau output yang akan dicapai ialah file data liver disorder dan file centroid yang masing-masing berformat sequence. Adapun data
centroid dipilih secara manual. Hasil output tersebut akan diinputkan ke dalam Hadoop Distributed File System.
olah nama file. | less merupakan perintah dari bash linux yang digunakan untuk menerima output dari perintah sebelumnya, lalu kemudian menginputkan perintah tersebut ke dalam perintah less. Less merupakan perintah bash yang digunakan untuk membaca sebuah file atau output.
Langkah selanjutnya ialah dengan menjalankan perintah start-dfs.sh dan start-yarn.sh, Perintah start-dfs.sh berfungsi untuk menjalankan service NameNode dan SecondaryNamenode pada master node, dan DataNode pada slave node. Sedangkan perintah start-yarn.sh berfungsi untuk menjalankan service
ResourceManager pada master node dan service NodeManager pada slave node. Gambar 4.2 menunjukkan proses membuat direktori pada HDFS. Perintah yang digunakan ialah $hdfs dfs -mkdir diikuti nama direkori. Direktori yang
digunakan dalam penelitian ini ialah /user/hduser/data dan /user/hduser/centroid. Direktori /user/hduser/data digunakan untuk menyimpan data training. Sedangkan direktori /user/hduser/centroid digunakan untuk menyimpan data centroid. Parameter -p digunakan untuk mebuat direktori dalam direktori. Sehingga perintah yang digunakan ialah $hdfs dfs -mkdir -p diikuti nama direktori. Perintah $hdfs dfs -ls digunakan untuk melihat sebuah file atau direktori. Sehingga perintah dapat digunakan untuk mengecek keberhasilan dalam membuat direktori.
Gambar 4.3 menunjukkan proses menyimpan file data training pada HDFS.
Sedangkan gambar 4.4 menunjukkan proses menyimpan file data centroid pada HDFS. Perintah yang digunakan dalam menyimpan file ialah $hdfs dfs -copyFromLocal kemudian diikuti lokasi input data dan diakhir dengan lokasi output data. Lokasi input data berasal dari sistem lokal, sedangkan lokasi output
ditujukan pada direktori pada HDFS. Perintah $hdfs dfs -ls digunakan mengecek keberhasilan dalam menyimpan file pada HDFS.
Gambar 4.2: Membuat direktori data dan direktori centroid pada hdfs
4.3.2 Proses Menjalankan Komputasi K-Means
Perintah yang digunakan untuk menjalankan komputasi K-Means ialah $mahout kmeans diikuti lokasi file data, lokasi file centroid, lokasi file output, distance measure atau algoritma yang digunakan untuk menghitung jarang antara
item data dan pusat cluster atau centroid, iterasi maksimal, jumlah K atau cluster dari data, convergen delta atau nilai untuk menentukan proses iterasi berhenti, execution method atau metode yang digunakan untuk mengeksekusi data, dan
clustering menentukan agar proses clustering berjalan setelah proses iterasi telah
berlangsung.
Adapun semua lokasi data yang digunakan dalam perintah $mahout kmeans berada pada HDFS. Sehingga lokasi output data juga terdapat dalam HDFS. Gambar 4.5 menunjukkan bahwa Distance Measure (parameter -dm) yang digunakan dalam penelitian ini ialah Euclidean Distance Measure. Iterasi maksimal (parameter -x) yang digunakan berjumlah 100. Total K (parameter -k) yang digunakan berjumlah 2. Hal ini dikarenakan data dikelompokkan dalam 2 kategori yakni kelompok yang memiliki kelainan hati (liver disorder) dan kelompok yang tidak memiliki kelainan hati (non liver disorder). Convergen delta
(parameter -cd) yang digunakan bernilai 0.1. Execution method (parameter -xm) yang digunakan ialah mapreduce. Parameter -ow atau –overwrite berfungsi untuk memaksa sistem untuk menulis hasil output walaupun sistem sudah memiliki lokasi output tersebut sebelumnya.
Gambar 4.6 menunjukkan hasil akhir dari iterasi yan gditunjukkan dengan menampilkan beberapa metadata dari proses K-Means dan waktu komputasi dijalankan.
Gambar 4.7 menunjukkan perintah $hdfs dfs -ls dapat digunakan untuk melihat hasil dari proses K-Means. Sedangkan perintah $hdfs dfs -ls output atau
Gambar 4.5: Menjalankan K-Means menggunakan library Mahout
$hdfs dfs -ls /user/hduser/output digunakan untuk melihat isi dari direktori output. Hasil proses K-Means dapat dilihat dari aplikasi NameNode Web Interface yang beralamat di master:50070.
Gambar 4.8 menunjukkan hasil K-Means melalui aplikasi NameNode web interface.
Gambar 4.9 menunjukkan bahwa aplikasi ini dapat menunjukkan aktivitas dan semua informasi dari sistem Hadoop baik sebelum dan sesudah komputasi
Gambar 4.7: Perintah $hdfs dfs -ls output
MapReduce dijalankan. Beberapa informasi yang ditunjukkan pada sistem ini ialah DataNode information atau informasi DataNode (slave node). Informasi DataNode ini menunjukkan slave node yang aktif dan tidak aktif, kapasitas HDFS dari masing-masing DataNode, dan storage HDFS yang telah digunakan, Aplikasi ini juga dapat digunakan untuk mencari dan melihat data pada HDFS.
NameNode web interface juga dapat memperlihatkan informasi tentang DataNode. Gambar 4.10 menampilkan beberapa informasi DataNode pada sistem Hadoop. Beberapa informasi DataNode yang ditampilkan ialah alamat slave node. Status slave node digunakan yang diperlihatkan pada Admin State. Informasi ukuran HDFS juga diperlihatkan seperti total ukuran disk yang dapat digunakan untuk menyimpan data (capacity) dan total kapasitas disk yang telah digunakan (used).
Gambar 4.11 menjelaskan bahwa HDFS memiliki direktori data, centroid, dan output.
Gambar 4.12 menunjukkan informasi direktori /user/hduser/data pada HDFS yakni permission, owner, group, size, replication, block size, dan name. Permission merupakan hak akses atau priviledge yang diijinkan olah sistem
Hadoop. Owner merupakan pemilik atau pengguna sistem Hadoop. Group merupakan pengelompokkan data pada sistem Hadoop. Replication menjelaskan bahwa data mengalami proses replikasi di beberapa node. Block size merupakan ukuran blok data. Sedangkan name merupakan name file tersebut.
Gambar 4.10: Informasi DataNode pada aplikasi NameNode Web Interface
Aplikasi ini juga mampu menampilkan metadata dari file pada HDFS. Gambar 4.13 menampilkan metadata dan availability dari file sampleseqfile. Availability menunjukkan bahwa file sampleseqfile telah mengalami proses replikasi pada 3 DataNode.