PENERAPAN DATA MINING PADA PENERIMAAN MAHASISWA BARU DENGAN ALGORITMA K-MEANS CLUSTERING
Septian Isnanto1)*, Suryarini Widodo2)
1 Magister Manajemen Sistem Informasi, Universitas Gunadarma email: [email protected]
2 Magister Manajemen Sistem Informasi, Universitas Gunadarma email: [email protected]
Abstract
This paper aims to grouping data using Clustering method with k-means algorithm to find potential majors and type of schools that produce feature students who have a good GPA score in semester 1 and semester 2 at Politeknik STMI Jakarta. Dataset from academic data for 2017-2020 has been processed with Rapid Miner showing that in Automotive Business Administration study program there are 3 clusters of students where cluster 0 marked as best cluster is dominated by high school students majoring in Science and Social Sciences. Automotive Industry Information System study program produces 2 clusters of students where cluster 0 marked as best cluster is dominated by high school students majoring in science and vocational high school majoring in mechanical engineering. Automotive Industrial Engineering study program produces 2 clusters of students where cluster 1 marked as best cluster is dominated by high school students majoring in science. Polymer Chemical Engineering study program produces 6 student clusters where cluster 4 marked as best cluster which all come from high school students majoring in science.
Keywords: Clustering, K-Means, Admission, Student
1. PENDAHULUAN
Penerimaan mahasiswa baru (PMB) adalah program rutin yang dilakukan oleh setiap institusi pendidikan seperti perguruan tinggi untuk merekrut calon mahasiswa baru setiap tahun[1].
Politeknik STMI Jakarta adalah perguruan tinggi yang berada pada naungan Kementrian Perindustrian dimana setiap tahun jumlah mahasiswa yang mendaftar terus meningkat.
Banyaknya pendaftar pada penerimaan calon mahasiswa baru di STMI Jakarta berbanding lurus dengan banyaknya mahasiswa kurang kompeten yang tidak dapat menyelesaikan pendidikan tepat waktu atau mengundurkan diri sebelum menyelesaikan pendidikan. Maka dari itu, peningkatan pada penerimaan mahasiswa baru harus diimbangi dengan strategi seleksi penerimaan mahasiswa baru yang baik agar mendapat calon mahasiswa yang berkualitas [2]
dimana kualitas prestasi mahasiswa dalam bidang akademik salah satunya bisa diukur melalui Indeks Prestasi yang merupakan cerminan mutu dari
keberhasilan belajar mahasiswa di perguruan tinggi [3].
Beberapa penelitian membahas proses penerimaan mahasiswa baru menggunakan metode Analytical Hierarchy Process (AHP) [4], [5] dimana metode AHP sangat bergantung dari input berupa persepsi pakar [6], [7]. Sementara Penelitian [8], [9], [10], [11] menggunakan data mining sebagai alat bantu dalam mengelompokan (Clustering) sesuai atribut pada data penerimaan mahasiswa baru untuk mendapatkan informasi tertentu yang mana metode ini mampu menangani data numerik dan kategorikal juga dapat menangani dataset besar[12], [13].
Data Mining merupakan proses untuk mengidentifikasi pola dalam hubungan antar data, menentukan suatu aturan atau mengeksplorasi karakteristik data menggunakan algoritma tertentu [14]. Dalam penelitian ini digunakan Metode Clustering dengan menggunakan algoritma K- Means yang menggunakan jarak sebagai indeks evaluasi kemiripan, yaitu semakin dekat jarak
antara dua objek maka semakin besar kesamaannya [15].
Dengan bantuan data mining, data calon mahasiswa baru dan data mahasiswa yang tersimpan selama empat tahun belakangan dapat digunakan untuk mengelompokan jenis asal sekolah dan jurusan asal sekolah mahasiswa baru yang berkualitas sehingga penelitian ini bertujuan agar dapat menjadi informasi berguna bagi panitia penerimaan mahasiswa baru Politeknik STMI Jakarta untuk memprioritaskan jurusan dan jenis sekolah tertentu calon mahasiswa baru pada proses seleksi penerimaan mahasiswa baru di Politeknik STMI Jakarta.
2. METODE PENELITIAN
Tahapan-tahapan yang dilakukan pada penelitian kali ini mengikuti proses standar dari data mining yaitu Cross-Industry Standard for Data Mining (CRISP-DM) dimana ada enam fase yaitu:
1. Business Understanding 2. Data Understanding 3. Data Preparation 4. Modeling
5. Evaluation 6. Deployment[16]
2.1. Business Understanding
Pada penerimaan calon mahasiswa baru di Politeknik STMI Jakarta terdapat syarat-syarat yang menentukan diterima atau tidaknya calon mahasiswa yaitu kesesuaian jurusan sekolah dengan prodi yang dipilih, nilai rapor dan nilai ujian masuk berupa tes tulis ataupun wawancara.
2.2. Data Understanding
Data yang digunakan yakni data primer yang didapatkan dari data penerimaan mahasiswa baru tiap prodi tahun 2017 - 2020 sebanyak 4939 data yang terdiri dari Nama, Nama Sekolah, Jurusan dan Nilai Tes Masuk. Diambil pula data primer dari data mahasiswa setiap prodi di Politeknik STMI Jakarta tahun 2017 - 2020 sebanyak 1104 data yang terdiri dari Nama, Prodi, Tahun Angkatan, Indeks Prestasi Semester 1 dan 2. Data-data tersebut diintegrasikan yang
bertujuan untuk menggabungkan field-field dari database Penerimaan Calon Mahasiswa Baru dan Mahasiswa pada tahun 2017 sampai 2020 sehingga terbentuk dataset berisi atribut yang dapat diproses. Tabel 1. menunjukan sumber data table dari atribut-atribut target yang akan diclustering.
Tabel 1. Atribut Serta Sumber Tabel
Atribut Sumber Tabel
Jenis Sekolah Data Calon Mahasiswa Jurusan Sekolah Data Calon Mahasiswa Nilai Tes Masuk Data Calon Mahasiswa Indeks Prestasi Semester
1
Data Mahasiswa Indeks Prestasi Semester
2
Data Mahasiswa
2.3. Data Preparation
Dataset kemudian dipecah sesuai masing- masing prodi yaitu Sistem Informasi Industri Otomotif (SIIO), Administrasi Bisnis Otomotif (ABO), Teknik Kimia Polimer (TKP) dan Teknik Industri Otomotif (TIO) dengan variabel atribut yang sama di setiap data.
Preprocessing yang dilakukan adalah data cleaning yaitu mengidentifikasi dirty data berupa data tidak lengkap (null), data noise, outliner dan data yang tidak konsisten yang kemudian akan diperbaiki, dimodifikasi atau dihilangkan sehingga menghasilkan data yang clean untuk diproses.
Juga dilakukan transformasi data dengan cara menormalisasikan perbedaan rentang nilai pada setiap atribut yang dapat menyebabkan tidak berfungsinya atribut yang memiliki nilai jauh lebih kecil dibandingkan dengan atribut-atribut lainnya. Agar dapat menghasilkan data mining yang lebih baik, Transformasi data dengan normalisasi dapat dilakukan dengan beberapa cara salah satunya adalah Z-Score atau Z Transformation [17].
Tabel 2. Kolom Tabel Yang Akan Diproses Kolom Tabel Tipe Data Range Data/
Keterangan Jenis Sekolah polynomial SMK/ SMA/
MadrasahAliyah/
Lainnya
Jurusan Sekolah
polynomial Jurusan Sekolah Calon
Mahasiswa Baru Nilai Tes
Masuk
Integer 1-10 Indeks
Prestasi Semester 1
Real 0.00-4.00
Indeks Prestasi Semester 2
Real 0.00-4.00
Selain kolom tabel 2, kolom baru ditambahkan sebagai hasil kategorisasi Indeks Prestasi Semester 1 dan 2. Kategorisasi nilai Indeks Prestasi Semester dibagi 5 bobot yaitu, A, B, C, D dan E yang dilambangkan dengan angka bulat sebagaimana terlihat pada tabel 3 berikut:
Tabel 3. Kategorisasi IPS
No. IPS Predikat
1 < 1.00 E
2 2.00 – 1.00 D
3 2.00 - 3.00 C
4 3.50- 3.00 B
5 4.00 – 3.50 A
2.4 Modeling
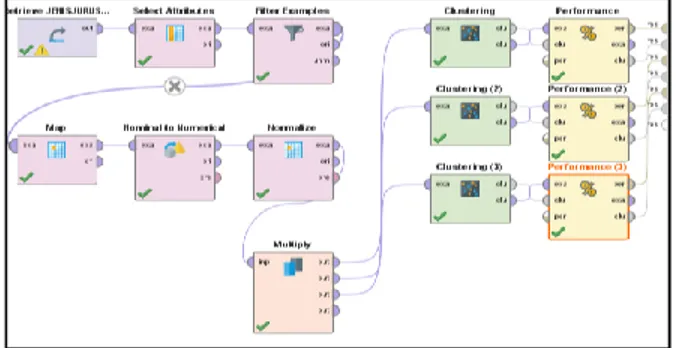
Dari proses modifikasi data tersebut, terbentuklah sebuah dataset yang akan di import ke dalam Tools RapidMiner menggunakan metode clustering dengan algoritma K-Means yang berfungsi mengidentifikasi sekelompok objek yang mempunyai kemiripan karakteristik tertentu yang dapat dipisahkan dengan kelompok obyek lainnya sehingga obyek yang berada dalam kelompok yang sama relatif lebih homogen dari pada obyek yang berada pada kelompok yang berbeda[18]. Operator yang digunakan pada RapidMiner dapat dilihat seperti pada Gambar 1.
Gambar 1. Operator RapidMiner
2.5. Evaluation
Untuk mengukur seberapa baik hasil clustering nilai Davies Bouldin Index digunakan untuk mengukur kedekatan antar data dalam cluster. Nilai k dengan hasil nilai Davies Bouldin Indeks yang paling minimum merupakan pembagian kluster paling optimal[19].
2.6. Deployment
Tools RapidMiner digunakan untuk deployment karena mampu menganalisa data yang berukuran sangat besar sampai ke level big data dengan tampilan yang baik[20]. Dari hasil analisa data menggunakan RapidMiner, didapatkan data output berupa pola cluster yang kemudian disimpulkan sehingga didapatkan pengetahuan yang bisa menjadi acuan untuk pengambilan keputusan.
3. HASIL DAN PEMBAHASAN
Data yang dihasilkan dari tahapan preprocessing adalah data dengan tipe data seluruh atribut berbentuk numerik sehingga peranan data mining Clustering dapat dilakukan menggunakan algoritma K-means. Nilai k yang dipilih menjadi pusat awal akan dihitung dengan menggunakan rumus Euclidean Distance yaitu mencari jarak terdekat antara titik centroid dengan data sehingga data yang memiliki jarak pendek akan membentuk sebuah cluster.
3.1. Prodi Administrasi Bisnis Otomotif (ABO) Pada dataset prodi Administrasi Bisnis Otomotif (ABO) yang diolah pada RapidMiner, k=3 mendapatkan nilai Davies Bouldin yang paling kecil yaitu sebesar 0.619 yang dapat dilihat paada tabel 4. Sehingga k= 3 diambil sebagai hasil clustering yang digunakan dalam penelitian.
Tabel 4. Perbandingan Jumlah Cluster (k) dan Nilai Davies Bouldin Data Prodi ABO Jumlah Cluster Nilai Davies Bouldin
2 0.623
3 0.619
4 1.024
Pada tabel 5 dari total 355 item yang terproses, Cluster model yang dihasilkan terdiri dari cluster 0 sebanyak 308 item (86.8%), cluster
1 sebanyak 24 item (6.7%) dan cluster 2 sebanyak 23 item (6.5%).
Tabel 5. Cluster Model untuk Prodi Administrasi Bisnis Otomotif (ABO)
Cluster Model
Cluster 0 308 items
Cluster 1 24 items
Cluster 2 23 items
Total Number of items 355
Berikut beberapa anggota cluster yang karakteristiknya dijelaskan pada tabel 6 dan tabel 7.
Tabel 6. Karakteristik Anggota Cluster Prodi Administrasi Bisnis Otomotif (ABO) Cluster 0 Cluster 0
Jenis Sekolah SMA SMK
Madrasah Aliyah Lainnya
Nilai Tes Masuk Rata - rata 59.7
Kategori Indeks Prestasi Semester 1
1 0
2 1
3 44
4 113
5 150
Kategori Indeks Prestasi Semester 2
1 4
2 9
3 61
4 136
5 98
Jurusan IPA 162
IPS 141
Kesehatan 1
Pemasaran 4
Tabel 7. Karakteristik Anggota Cluster Prodi Administrasi Bisnis Otomotif (ABO)
Cluster 1 Cluster 2
Jenis Sekola h
SMA 0 Jenis
Sekola h
SMA 0
SMK 23 SMK 23
Madrasa h Aliyah
1 Madrasa
h Aliyah 0
Lainnya 0 Lainnya 0
Nilai Tes Masuk
Rata - rata
53.
7
Nilai Tes Masuk
Rata - rata
53.
2 Kateg
ori Indeks
1 0 Kateg
ori Indeks
1 1
2 0 2 2
3 2 3 12
Presta si Semes ter 1
4 6 Presta
si Semes ter 1
4 8
5 16 5 0
Kateg ori Indeks Presta si Semes ter 2
1 1 Kateg
ori Indeks Presta si Semes ter 2
1 3
2 0 2 7
3 7 3 12
4 8 4 1
5 8 5 0
Jurusa n
Akutans i
19 Jurusa n
Multime dia
2 Bisnis
Manaje men
1 Nautika 1
Jasa Boga
1 Perhotel
an
1 Keagam
aan
1 Perkanto
ran
13 Perbank
an
2 Tata
Kecantik an
1
Teknik Fabrikas i Logam
1
Teknik Kendara an Ringan
1
Teknik Komput er Jaringan
2
Teknik Mesin
1 Statistik berupa rata-rata dan kenaikan atau penurunan indeks prestasi semester dapat dilihat pada tabel 8 sebagai berikut:
Tabel 8. Statistik Indeks Prestasi Semester 1 dan 2 Prodi Administrasi Bisnis Otomotif (ABO)
Cluster
0
Cluster 1
Cluster 2 Jumlah
Mahasiswa
282 24 23
Rata-rata IPS1 3,42 3,53 3,10 Rata-rata IPS2 3,19 3,12 2,70
Selisih 0,23 0,41 0,39
Persentase Penurunan
5,732899 10,125 9,869565
Dari data ke tiga tabel tersebut diperoleh informasi Mahasiswa yang masuk dalam anggota
cluster 0 didominasi mahasiswa dengan asal sekolah berjenis SMA jurusan IPA dan memiliki rata-rata nilai ujian masuk sebesar 59.7 yang lebih besar dari nilai ujian masuk seluruh cluster.
Sementara pada cluster 1 kebanyakan adalah mahasiswa dengan asal sekolah berjenis SMK jurusan Akutansi dan memiliki rata-rata nilai ujian masuk lebih rendah dari cluster 0 dan lebih tinggi dari cluster 2 yakni sebesar 53.7.
Terakhir pada cluster 2 kebanyakan adalah mahasiswa dengan asal sekolah berjenis SMK dengan berbagai jurusan dan memiliki rata-rata nilai ujian masuk paling rendah dari seluruh cluster yakni sebesar 53.2.
3.2. Prodi Sistem Informasi Industri Otomotif (SIIO)
Pada dataset prodi Sistem Informasi Industri Otomotif (SIIO) yang diolah pada RapidMiner, k=2 mendapatkan nilai Davies Bouldin yang paling kecil yaitu sebesar 0.727. Sehingga k= 2 diambil sebagai hasil clustering yang digunakan dalam penelitian.
Tabel 9. Perbandingan Jumlah Cluster (k) dan Nilai Davies Bouldin Data Prodi SIIO Jumlah Cluster Nilai Davies Bouldin
2 0.727
3 0.808
4 1.010
Pada tabel 10 dari total 349 item yang terproses, Cluster model yang dihasilkan terdiri dari cluster 0 sebanyak 225 item (65%) dan cluster 1 sebanyak 124 item (35%).
Tabel 10. Cluster Model untuk Prodi Sistem Informasi Industri Otomotif (SIIO)
Cluster Model
Cluster 0 225 items
Cluster 1 124 items
Total number of items 349
Berikut beberapa anggota cluster yang karakteristiknya dijelaskan pada tabel 11.
Tabel 11. Karakteristik Anggota Cluster Prodi Sistem Informasi Industri Otomotif (SIIO)
Cluster 0 Cluster 1
SMA 20
8
SMA 62
Jenis Sekola h
SMK 3 Jenis Sekola h
SMK 10
Madras ah Aliyah
14 Madrasa
h Aliyah 52
Lainny a
0 Lainnya 0
Nilai Tes Masuk
Rata- rata
58, 7
Nilai Tes Masuk
Rata-rata 54, 8 Katego
ri Indeks Prestas i Semest er 1
1 0 Katego
ri Indeks Prestas i Semest er 1
1 0
2 2 2 2
3 46 3 52
4 72 4 46
5 10
5
5 24
Katego ri Indeks Prestas i Semest er 2
1 0 Katego
ri Indeks Prestas i Semest er 2
1 2
2 5 2 11
3 33 3 34
4 89 4 38
5 98 5 39
Jurusa n
Agama (Soshu m)
1 Jurusa n
Fisika 1
IPA 22
1
Informati ka
4 Teknik
Mesin
3 IPS 70
Kelistrik
an Pesawat Udara
2
Multime
dia
10
Perhotela
n
1
Rekayas
a Perangka t Lunak
10
Teknik
Elektroni ka
3
Teknik
Kendara an Ringan
4
Teknik Kompute r Jaringan
19
Statistik berupa rata-rata dan kenaikan atau penurunan indeks prestasi semester dapat dilihat pada tabel 10 berikut:
Tabel 12. Statistik Indeks Prestasi Semester 1 dan 2 Prodi Sistem Informasi Industri Otomotif
(SIIO) per cluster
Cluster 0 Cluster 1
Jumlah Mahasiswa 225 124
Rata-rata IPS1 3,36 3,06
Rata-rata IPS2 3,37 3,00
Selisih 0,01 0,06
Persentase Penurunan 0,18 1,60
Dari data diatas diperoleh informasi Mahasiswa yang masuk dalam anggota cluster 0 didominasi mahasiswa dengan asal sekolah berjenis SMA jurusan IPA dan SMK Teknik Mesin yang memiliki rata-rata nilai ujian masuk sebesar 58.7.
Anggota cluster 1 kebanyakan adalah mahasiswa dengan asal sekolah berjenis SMA dan MA jurusan IPS juga memiliki rata-rata nilai ujian masuk lebih rendah dari cluster 0 yakni sebesar 54.8.
3.3. Prodi Teknik Industri Otomotif (TIO) Pada dataset prodi Teknik Industri Otomotif (TIO) yang diolah pada RapidMiner, k=2 mendapatkan nilai Davies Bouldin yang paling kecil yaitu sebesar 0.335. Sehingga k=2 diambil sebagai hasil clustering yang digunakan dalam penelitian.
Tabel 13. Perbandingan Jumlah Cluster (k) dan Nilai Davies Bouldin Data Prodi TIO Jumlah Cluster Nilai Davies Bouldin
2 0.335
3 0.967
4 0.949
Pada tabel 14 dari total 233 item yang terproses, Cluster model yang dihasilkan terdiri dari cluster 0 sebanyak 60 item (25.8%) dan cluster 1
sebanyak 173 item (74.2%).
Tabel 14. Cluster Model untuk Prodi Teknik Industri Otomotif (TIO)
Cluster Model
Cluster 0 60 items
Cluster 1 173 items
Total number of items 233
Berikut beberapa anggota cluster yang karakteristiknya dijelaskan pada tabel 15.
Tabel 15. Karakteristik Anggota Cluster Prodi Teknik Industri Otomotif (TIO)
Cluster 0 Cluster 1
Jenis Sekola h
SMA 0 Jenis
Sekola h
SMA 15
8
SMK 60 SMK 6
Madrasah Aliyah
0 Madras
ah Aliyah
8
Lainnya 0 Lainnya 1
Nilai Tes Masuk
Rata-rata 62, 6
Nilai Tes Masuk
Rata- rata
56, 2 Kateg
ori Indeks Presta si Semes ter 1
1 1 Kateg
ori Indeks Presta si Semes ter 1
1 2
2 14 2 10
3 21 3 48
4 13 4 46
5 11 5 67
Kateg ori Indeks Presta si Semes ter 2
1 2 Kateg
ori Indeks Presta si Semes ter 2
1 3
2 8 2 5
3 24 3 40
4 18 4 82
5 8 5 43
Jurusa n
Airframe dan Powerpla nt
1 Jurusa n
IPA 16
6
Audio Video
1 Kimia 2
Multimed ia
1 Pemasa
ran
1 Pemelihar
aan
1 Rekaya
sa Perangk
1
at Lunak Teknik
Otomasi Industri
1 Tav 1
Teknik Elektroni ka
4 Teknik
Komput er Jaringa n
2
Teknik Kendaraa n Ringan
40
Teknik Permesin an
11
Statistik berupa rata-rata dan kenaikan atau penurunan indeks prestasi semester dapat dilihat pada tabel 16 berikut :
Tabel 16. Statistik Indeks Prestasi Semester 1 dan 2 Prodi Teknik Industri Otomotif (TIO) per
cluster
Cluster 0 Cluster 1
Jumlah Mahasiswa 60 173
Rata-rata IPS1 2,64 3,12
Rata-rata IPS2 2,72 3,12
Selisih 0,08 0,00
Persentase 1,97 0,00
Dari data diatas diperoleh informasi Mahasiswa yang masuk dalam anggota cluster 0 seluruhnya adalah mahasiswa dengan asal sekolah berjenis SMK yang didominasi jurusan Teknik Kendaraan Ringan dan Teknik Permesinan dimana cluster ini memiliki rata-rata nilai ujian masuk lebih tinggi dari cluster 1 yakni sebesar 62.6.
Sementara Mahasiswa yang masuk dalam anggota cluster 1 didominasi mahasiswa dengan asal sekolah berjenis SMA dan MA dengan jurusan IPA yang memiliki rata-rata nilai ujian masuk sebesar 56.2.
3.4. Prodi Teknik Kimia Polimer (TKP)
Pada dataset prodi Teknik Kimia Polimer (TKP) yang diolah pada RapidMiner, k=6 mendapatkan nilai Davies Bouldin yang paling kecil yaitu sebesar 0.984. Sehingga k=6 diambil
sebagai hasil clustering yang digunakan dalam penelitian.
Tabel 17. Perbandingan Jumlah Cluster (k) dan Nilai Davies Bouldin Data Prodi SIIO Jumlah Cluster Nilai Davies Bouldin
2 1.142
3 1.134
4 1.909
5 1.036
6 0.984
7 1.068
Pada tabel 18 dari total 142 item yang terproses, Cluster model yang dihasilkan terdiri dari cluster 0 sebanyak 26 item (18.7%) , cluster 1 sebanyak 31 item (22.3%), cluster 2 sebanyak 22 item (15.8%), cluster 3 sebanyak 24 item (17.2%), cluster 4 sebanyak 24 item (17.2%) dan cluster 5 sebanyak 12 item (8.6%).
Tabel 18. Cluster Model untuk Prodi Teknik Kimia Polimer (TKP)
Cluster Model
Cluster 0 26 items
Cluster 1 31 items
Cluster 2 22 items
Cluster 3 24 items
Cluster 4 24 items
Cluster 5 12 items
Total number of items 139
Berikut beberapa anggota cluster yang karakteristiknya dijelaskan pada tabel 15, tabel 16 dan taabel 17.
Tabel 19. Karakteristik Anggota Cluster Prodi Teknik Kimia Polimer (TKP) cluster 0 dan cluster
1
Cluster 0 Cluster 1
Jenis Sekola h
SMA 0 Jenis
Sekola h
SMA 29
SMK 25 SMK 0
Madras ah Aliyah
6 Madras
ah Aliyah
2
Lainnya 1 Lainny
a
0 Nilai
Tes Masuk
Rata- rata
55, 9
Nilai Tes Masuk
Rata- rata
49, 9
1 0 1 0
Katego ri Indeks Prestas i Semest er 1
2 0 Katego
ri Indeks Prestas i Semest er 1
2 0
3 1 3 0
4 15 4 31
5 10 5 0
Katego ri Indeks Prestas i Semest er 2
1 0 Katego
ri Indeks Prestas i Semest er 2
1 0
2 0 2 0
3 1 3 0
4 19 4 23
5 6 5 6
Jurusa n
Analis Kesehat an
1 Jurusa n
IPA 31
Farmasi 3 Kimia Analis
18 Kimia Industri
4
Tabel 20. Karakteristik Anggota Cluster Prodi Teknik Kimia Polimer (TKP) cluster 2 dan cluster
3
Cluster 2 Cluster 3
Jenis Sekola h
SMA 19 Jenis Sekola h
SMA 1
8
SMK 1 SMK 1
Madras ah Aliyah
2 Madras
ah Aliyah
5
Lainnya 0 Lainnya 0
Nilai Tes Masuk
Rata- rata
84, 6
Nilai Tes Masuk
Rata- rata
4 0 Katego
ri Indeks Prestasi Semest er 1
1 0 Katego
ri Indeks Prestasi Semest er 1
1 0
2 0 2 0
3 0 3 0
4 1 4 0
5 21 5 2
4 Katego
ri Indeks Prestasi Semest er 2
1 0 Katego
ri Indeks Prestasi Semest er 2
1 0
2 0 2 0
3 0 3 1
4 9 4 2
3
5 13 5 0
Jurusan IPA 21 Jurusan IPA 2 3 Kimia
Industri
1 Kimia
Industri 1
Tabel 21. Karakteristik Anggota Cluster Prodi Teknik Kimia Polimer (TKP) cluster 4 dan cluster
5
Cluster 4 Cluster 5
Jenis Sekola h
SMA 22 Jenis Sekola h
SMA 9
SMK 0 SMK 0
Madras ah Aliyah
2 Madras
ah Aliyah
3
Lainnya 0 Lainnya 0
Nilai Tes Masuk
Rata- rata
51, 3
Nilai Tes Masuk
Rata- rata
5 5 Katego
ri Indeks Prestasi Semest er 1
1 0 Katego
ri Indeks Prestasi Semest er 1
1 0
2 0 2 0
3 0 3 4
4 0 4 7
5 24 5 1
Katego ri Indeks Prestasi Semest er 2
1 0 Katego
ri Indeks Prestasi Semest er 2
1 2
2 0 2 1
3 0 3 9
4 0 4 0
5 24 5 0
Jurusan IPA 24 Jurusan IPA 1 2 Statistik berupa rata-rata dan kenaikan atau penurunan indeks prestasi semester dapat dilihat pada tabel 18 dan tabel 19 berikut:
Tabel 22. Statistik Indeks Prestasi Semester 1 dan 2 Prodi Teknik Kimia Polimer (TKP) cluster 0,
cluster 1 dan cluster 2
Cluster
0
Cluster 1
Cluster 2 Jumlah
Mahasiswa
26 31 22
Rata-rata IPS1 3,43 3,35 3,69 Rata-rata IPS2 3,36 3,29 3,55
Selisih 0,07 0,06 0,15
Persentase 1,77 1,43 3,73
Tabel 23. Statistik Indeks Prestasi Semester 1 dan 2 Prodi Teknik Kimia Polimer (TKP) cluster 3,
cluster 4 dan cluster 5
Cluster 3
Cluster 4
Cluster 5 Jumlah
Mahasiswa
24 24 12
Rata-rata IPS1 3,67 3,77 3,13 Rata-rata IPS2 3,37 3,69 2,38
Selisih 0,30 0,08 0,75
Persentase 7,52 1,90 18,81
Dari data diatas diperoleh informasi Mahasiswa yang masuk dalam anggota cluster 0 kebanyakan adalah mahasiswa dengan asal sekolah berjenis SMK dimana cluster ini memiliki rata-rata nilai ujian masuk sebesar 55.9.
Berikutnya pada cluster 1 beranggotakan mahasiswa dengan asal sekolah berjenis SMA dan MA jurusan IPA dimana rata-rata nilai ujian masuk sebesar 49.9. Selanjutnya di cluster 2 didominasi mahasiswa dengan asal sekolah berjenis SMA jurusan IPA yang rata-rata nilai ujian masuk paling tinggi diantara cluster lainnya yaitu sebesar 84.6. Penurunan Indeks Prestasi Semester sebesar 3.73%. Dan memiliki rata-rata nilai Indeks Prestasi Semester 1 dan 2 masing- masing sebesar 3.69 dan 3.55.
Mahasiswa dalam anggota cluster 3 didominasi mahasiswa dengan asal sekolah berjenis SMA jurusan IPA yang rata-rata nilai ujian masuk paling kecil diantara cluster lainnya yaitu sebesar 40. Berikutnya di cluster 4 seluruhnya adalah mahasiswa dengan asal sekolah berjenis SMA jurusan IPA yang rata-rata nilai ujian masuk yaitu sebesar 51.3. Selanjutnya di cluster 5 seluruhnya adalah mahasiswa dengan asal sekolah berjenis SMA jurusan IPA yang rata- rata nilai ujian masuk yaitu sebesar 55.
4. KESIMPULAN
Didapatkan beberapa kesimpulan berdasarkan hasil analisis dan pembahasan yang telah peneliti lakukan. Berikut merupakan kesimpulannya.
1. Clustering yang dilakukan dengan menggunakan K-Means berdasarkan 5 atribut target yaitu Jenis Sekolah, Jurusan Sekolah, Nilai Tes Masuk, Indeks Prestasi Semester 1 dan 2 pada data di Politeknik STMI Jakarta
menghasilkan sebuah informasi gambaran karakteristik mahasiswa sesuai prodi.
2. Clustering yang dilakukan pada data prodi Administrasi Bisnis Otomotif (ABO) menghasilkan tiga cluster mahasiswa dari total 355 item.
3. Clustering yang dilakukan pada data prodi Sistem Informasi Industri Otomotif (SIIO) menghasilkan dua cluster mahasiswa dari total 349 item.
4. Clustering yang dilakukan pada data prodi Teknik Industri Otomotif (TIO) menghasilkan dua cluster mahasiswa dari total 233 item.
5. Clustering yang dilakukan pada data prodi Teknik Kimia Polimer (TKP). menghasilkan Enam cluster mahasiswa dari total 139 item.
5. REFERENSI
[1] I. Kurniawati, R. E. Indrajit, and M. Fauzi,
“Peran Bussines Intelligence Dalam Menentukan Strategi Promosi Penerimaan Mahasiswa Baru,” vol. 1, no. 2, pp. 70–79, 2017.
[2] A. Saifudin, “Metode Data Mining Untuk Seleksi Calon Mahasiswa,” J. Teknol. Univ.
Muhammadiyah Jakarta, vol. 10, no. 1, pp.
25–36, 2018.
[3] D. U. Setyawati, B. D. Korida, and B. R. A.
Febrilia, “Analisis Regresi Logistik Ordinal Faktor-Faktor yang Mempengaruhi IPK Mahasiswa,” J. Varian, vol. 3, no. 2, pp. 65–
72, 2020, doi: 10.30812/varian.v3i2.615.
[4] A. T. Purba, “Sistem Pendukung Keputusan Dalam Penerimaan Mahasiswa Baru Dengan Metode Analytical Hierarchy Process (AHP),” J. Tekinkom, vol. 1, no. 1, pp. 1–7, 2018.
[5] S. Aminah, S. Aminah, and S. P. Keputusan,
“PENGGUNAAN METODE ANALYTIC HIERARCHY PROCESS ( AHP ) DALAM SISTEM PENDUKUNG KEPUTUSAN KELULUSAN Seleksi Penerimaan Mahasiswa Baru pada,” J. Ilm. Betrik, vol.
11, no. 02, pp. 56–65, 2020.
[6] A. Faroby Falatehan, Analytical Hierarchy Process (AHP) Teknik Pengambilan Keputusan Untuk Pembangunan Daerah.
Yogyakarta: Indomedia Pustaka, 2017.
[7] D. D. Marsono, Penggunaan Hierarchy Process (AHP) dalam Penelitian. Bogor: IN MEDIA, 2020.
[8] F. Yunita, “Penerapan Data Mining Menggunkan Algoritma K-Means Clustring Pada Penerimaan Mahasiswa Baru,”
Sistemasi, vol. 7, no. 3, p. 238, 2018, doi:
10.32520/stmsi.v7i3.388.
[9] H. Muttaqien, M. Lutfi, M. KH, A. Muis, and H. Zainuddin, “Recommendation of Student Admission Priorities Using K- Means Clustering,” 2019, doi:
10.4108/eai.2-5-2019.2284614.
[10] E. Buulolo and R. Syahputra,
“Implementasi Algoritma Clustering K- Means Untuk Mengelompokkan Mahasiswa Baru Yang Berpotensi (Studi Kasus:
STMIK Budi Darma),” Pros. Semin. Nas.
Ris. Inf. Sci., vol. 1, no. September, p. 17, 2019, doi: 10.30645/senaris.v1i0.3.
[11] W. R. Izzati, M. Komarudin, H. D. Septama, and Y. Mulyani, “Analisis Potensi Asal Sekolah pada Jalur Penerimaan Mahasiswa Baru di Universitas Lampung menggunakan Algoritma K-Means,” Electrician, vol. 13, no. 1, p. 7, 2019, doi:
10.23960/elc.v13n1.2087.
[12] Y. Prastyo, “Pembagian Tingkat Kecanduan Game Online Menggunakan K-Means Clustering Serta Korelasinya Terhadap Prestasi Akademik,” Elinvo (Electronics, Informatics, Vocat. Educ., vol. 2, no. 2, pp.
138–148, 2017, doi:
10.21831/elinvo.v2i2.17307.
[13] R. J. Kasim, S. Bahri, and S. Amir,
“Implementasi Metode K-Means Untuk Clustering Data Penduduk Miskin Dengan Systematic Random Sampling,” Pros.
SISFOTEK, vol. 5, no. 1, pp. 95–101, 2021.
[14] E. Buulolo, Data Mining Untuk perguruan Tinggi. Sleman: DEEPUBLISH, 2020.
[15] W. Pradnyana, G.A. I.G.M., Darmawiguna, I.S.W., DATA MINING: Menemukan Pengetahuan dalam Data. Depok: PT. Raja Grafindo Persada, 2020.
[16] F. Martínez-Plumed et al, “CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories,”
Trans. Knowl. Data Eng., vol. 33, no. 8, pp.
3048–3061, 2021, doi:
10.1109/TKDE.2019.2962680.
[17] D. A. Nasution, H. H. Khotimah, and N.
Chamidah, “Perbandingan Normalisasi Data untuk Klasifikasi Wine Menggunakan Algoritma K-NN,” Comput. Eng. Sci. Syst.
J., vol. 4, no. 1, p. 78, 2019, doi:
10.24114/cess.v4i1.11458.
[18] N. Nofriansyah, D G.W., Algoritma Data Mining dan Pengujian. Sleman:
DEEPUBLISH, 2019.
[19] A. Badruttamam, S. Sudarno, and D. A. I.
Maruddani, “PENERAPAN ANALISIS
KLASTER K-MODES DENGAN
VALIDASI DAVIES BOULDIN INDEX
DALAM MENENTUKAN
KARAKTERISTIK KANAL YOUTUBE DI INDONESIA (Studi Kasus: 250 Kanal YouTube Indonesia Teratas Menurut Socialblade),” J. Gaussian, vol. 9, no. 3, pp.
263–272, 2020, doi:
10.14710/j.gauss.v9i3.28907.
[20] F. A. Hendajani, “Perbandingan Penggunaan Aplikasi Rapidminer Dengan Weka Untuk Penerapan Metode K-Means Clustering Pada Pengelompokan Penderita Demensia,” J. Ilm. Komputasi, vol. 18, no.
2, 2019, doi: 10.32409/jikstik.18.2.2584.