COLOUR HISTOGRAM DAN FITUR TEKSTUR MENGGUNAKAN METODE GREY LEVEL
CO-OCCURRENCE MATRICES
SKRIPSI
ANGGA ERIANSYAH S 111401053
PROGRAM STUDI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2015
GREY LEVEL CO-OCCURRENCE MATRICES
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Ilmu Komputer
ANGGA ERIANSYAH S 111401053
PROGRAM STUDI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2015
PERSETUJUAN
Judul : PERBANDINGAN CONTENT BASED IMAGE
RETRIEVAL MENGGUNAKAN FITUR WARNA DENGAN METODE COLOUR HISTOGRAM DAN FITUR TEKSTUR DENGAN METODE GREY LEVEL CO-OCCURRENCE MATRICES
Kategori : SKRIPSI
Nama : ANGGA ERIANSYAH S
NomorIndukMahasiswa : 111401053
Program Studi : SARJANA (S1) ILMU KOMPUTER
Departemen : ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI Diluluskan di Medan, Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Marihat Situmorang, M.Kom Dr. Poltak Sihombing, M.Kom NIP. 196312141989031001 NIP. 196203171991031001
Diketahui/Disetujui oleh
Program Studi S1 Ilmu Komputer Ketua,
Dr. Poltak Sihombing, M.Kom NIP.196203171991031001
PERNYATAAN
PERBANDINGAN CONTENT BASED IMAGE RETRIEVAL MENGGUNAKAN FITUR WARNA DENGAN METODE COLOUR HISTOGRAM DAN FITUR
TEKSTUR DENGAN METODE GREY LEVEL CO-OCCURRENCE MATRICES
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Juli 2015
ANGGA ERIANSYAH S NIM. 111401053
PENGHARGAAN
Puji dan syukur penulis ucapkan kepada Tuhan Yang Maha Kuasa atas segala berkat dan kasih karunia-Nya sehingga penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, pada Program Studi S1 Ilmu Komputer Fakultas Ilmu Komputer dan Teknologi Informasi, Universitas Sumatera Utara.
Ucapan terima kasih penulis sampaikan kepada :
1. Bapak Prof. Dr. Muhammad Zarlis selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
2. Bapak Dr. Poltak Sihombing, M.Kom, selaku Ketua Departemen Ilmu Komputer Universitas Sumatera Utara dan Dosen Pembimbing
3. Bapak Marihat Situmorang, S.Si, M.Kom, selaku Dosen Pembimbing.
4. Ibu Dian Rachmawati, S.Si, M.Kom dan Bapak Amer Syarif, S.Si, M.Kom, selaku Dosen Pembanding.
5. Semua dosen pada Departemen Ilmu Komputer Fasilkom-TI USU, dan pegawai di Ilmu Komputer Fasilkom-TI USU.
6. Papa saya Syahroel A.H, mama saya Erma Loewsita, dan adik saya Dwita Monica Putri, S.Ked yang memberikan motivasi dan dorongan kepada penulis selama menyelesaikan skripsi ini.
7. Rekan-rekan kuliah Ilmu Komputer Stambuk 2011, khususnya Rony, Agung, Misfar, Anhar, Prastia, Tio dan rekan-rekan asisten di IKLC khususnya Bang Arifin yang telah memberikan semangat dan dorongan kepada penulis.
8. Sahabat seperjuangan Jiwana Syahputra, S.Kom, Abdul Rahman Sosa, S.PdI, dan Luqmanul Hakim Muttaqien, S.Pd dan Isma Nur‟aini, Amd.Keb yang selalu menjadi penyemangat.
9. Teman-teman seperjuangan di Ikatan Pemuda Pelajar Mahasiswa Tanah Rencong khususnya Rony, Azirah, Sri Mulyati, Amar, dan Aulia Rahman yang telah memberikan semangat.
Semoga Tuhan Yang Maha Kuasa memberikan berkat yang berlimpah kepada semua pihak yang telah memberikan bantuan, perhatian, serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, Juli 2015
Penulis
ABSTRAK
Content Based Image Retrieval (CBIR) adalah salah satu aplikasi pengolahan citra yang dapat membantu pengguna menemukan suatu citra dari database citra secara cepat dengan menggunakan citra sebagai query. Dalam CBIR, fitur-fitur visual citra dalam database diekstraksi dan disimpan dalam vektor yang disebut vektor fitur. Fitur citra query juga diekstraksi dan diukur jaraknya dengan vektor fitur yang tersimpan di dalam database. Citra hasil temu kembali diurutkan berdasarkan jarak vektor fitur dari terkecil hingga terbesar. Metode pengukuran jarak vektor fitur yang digunakan adalah Euclidian Distance. Warna dan tekstur adalah dua fitur penting dari sebuah citra.
Dalam penelitian ini, fitur warna diekstraksi dengan metode Colour Histogram.
Colour Histogram menunjukkan probabilitas suatu intensitas warna. Model warna citra yang digunakan adalah RGB. Fitur tekstur diekstraksi dengan menggunakan metode Grey Level Co-Occurrence Matrices (GLCM). GLCM menunjukkan dua piksel berpasangan dengan level keabuan tertentu terpisah pada jarak d dan arah Ɵ.
Dalam penelitian ini, database citra yang digunakan adalah database Wang yang berisi 100 citra terbagi atas 10 kategori yaitu African, Beach, Building, Buses, Dinosaurus, Elephant, Flowers, Horses, Food, dan Mountain. Berdasarkan hasil pengujian yang dilakukan oleh 10 pengguna yang masing-masing menggunakan 2 citra query, CBIR dengan fitur warna memiliki nilai rata-rata precision dan recall yang lebih baik yaitu 33,75% dan 67,5% sedangkan dengan fitur tekstur memiliki nilai rata-rata precision dan recall 19% dan 38%. CBIR dengan fitur tekstur memiliki waktu temu kembali rata-rata lebih singkat dengan waktu 1,0951 detik sedangkan dengan fitur warna 1,63 detik.
Kata kunci : Content Based Image Retrieval, Citra, Colour Histogram, Grey Level Co-Occurrence Matrices, Euclidian Distance
COMPARISON OF CONTENT BASED IMAGE RETRIEVAL WITH COLOUR FEATURE USING COLOUR HISTOGRAM METHOD
AND TEXTURE FEATURE USING GREY LEVEL CO-OCCURRENCE MATRICES METHOD
ABSTRACT
Content Based Image Retrieval (CBIR) is one of image processing application that helps user to retrieve images from image database quickly using image as query. In CBIR, visual feature is extracted and saved in a vector called feature vector. The feature of query image is also extracted and measured the distance to feature vector saved in database. The retrieved images are sorted by the feature vector distance ascending. The distance measure method is Euclidian Distance. Colour and texture are two important feature of image. In this research, the colour feature is extracted using Colour Histogram method. Colour Histogram shows probability of colour intensity.
The colour model used is RGB. The texture features are extracted using Grey Level Co-Occurrence (GLCM) method. GLCM shows a pair of pixel with some grey level separated by d distance and Ɵo direction. In this research, the image database used is Wang database which consist 100 images classified by 10 categories : African, Beach, Building, Buses, Dinosaurus, Elephant, Flowers, Horses, Food, and Mountain. Based on testing by 10 users that every user use 2 query image, CBIR with colour feature has better precision and recall : 33,75% and 67,5% while CBIR with texture feature is 19% and 38%. CBIR with feature texture has shorter average retrieval time : 1,0961 s while CBIR with colour feature is 1,63 s.
Keyword : Content Based Image Retrieval, Image, Colour Histogram, Grey Level Co-Occurrence Matrices, Euclidian Distance
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii Penghargaan iv Abstrak vi Abstract vii Daftar Isi viii Daftar Tabel x Daftar Gambar xi Daftar Lampiran xii Bab I Pendahuluan 1.1 Latar Belakang 1
1.2 Perumusan Masalah 2
1.3 Batasan Masalah 2
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 3 1.7 Sistematika Penulisan 4
Bab II Landasan Teori 2.1 Citra Digital 5
2.1.1 Jenis Citra Digital 6
2.1.2 Format File Citra Digital 8
2.1.2.1 Format File Bitmap (BMP) 8
2.1.2.2 Format File JPEG (Joint Photographic Experts Group) 8
2.1.3 Elemen-Elemen Citra Digital 9
2.1.4 Warna 10 2.1.4.1 Model RGB (Red, Green, Blue) 11 2.1.4.2 Model HSV (Hue, Saturation, and Value) 12 2.1.4.3 Model HSL (Hue, Saturation, and Lightness) 12 2.1.4.4 Model CMYK (Cyan Magenta Yellow Key) 13
2.2 Content Based Image Retrieval (CBIR) 14
2.2.1 Ekstraksi Fitur 15 2.2.1.1 Colour Histogram 15 2.2.1.2 Grey Level Co-Occurrence Matrices 16 2.3 Metode Pengukuran Kemiripan 24
2.4 Efektifitas Information Retrieval System 28
Bab III Analisis dan Perancangan Sistem 3.1 Analisis 30
3.1.1 Analisis Masalah 30 3.1.2 Analisis Kebutuhan Sistem 31 3.1.2.1 Analisis Kebutuhan Fungsional 31
3.1.2.2 Analisis Kebutuhan non-Fungsional 32
3.2 Pemodelan 32
3.2.1 Pemodelan dengan Menggunakan Use Case Diagram 32
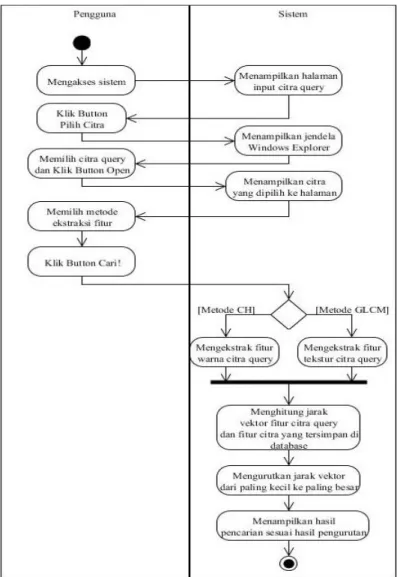
3.2.1.1 Use Case Temu Kembali Citra 33
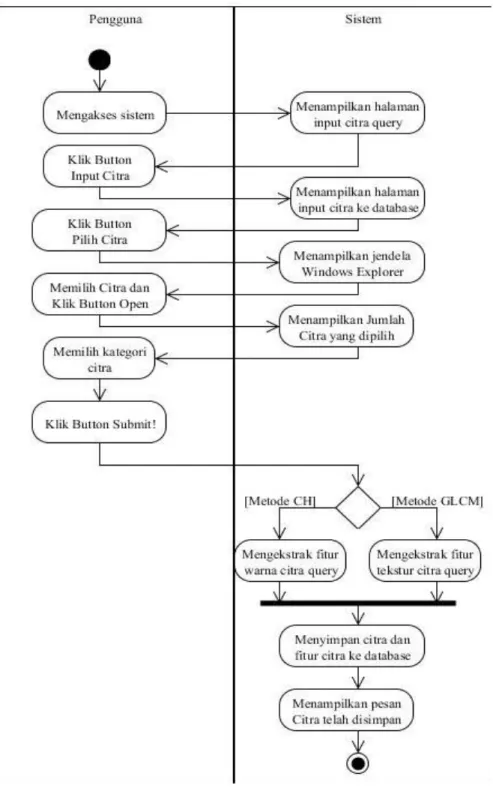
3.2.1.2 Use Case Input Citra ke Database 34 3.2.2 Pemodelan dengan Menggunakan Activity Diagram 35 3.2.2.1 Activity Diagram Temu Kembali Citra 35 3.2.2.2 Activity Diagram Input Citra ke Database 36 3.2.3 Pemodelan dengan Menggunakan Sequence Diagram 37 3.2.3.1 Sequence Diagram Temu Kembali Citra 37 3.2.3.2 Sequence Diagram Input Citra ke Database 37
3.3 Perancangan Sistem 38
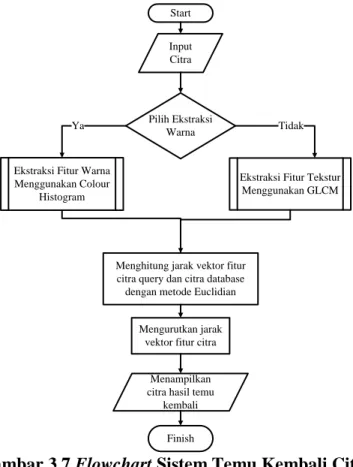
3.3.1 Flowchart 38
3.3.1.1Flowchart Sistem Temu Kembali Citra 38 3.3.1.2 Flowchart Metode Colour Histogram 39 3.3.1.3 Flowchart Metode Grey Level Co-Occurrence Matrices 40
3.3.2 Pseudocode 41
3.3.3 Kamus Data 47
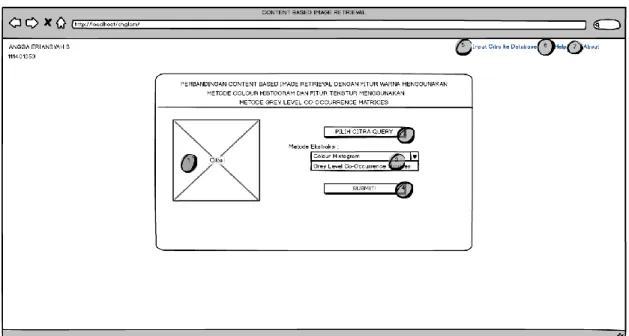
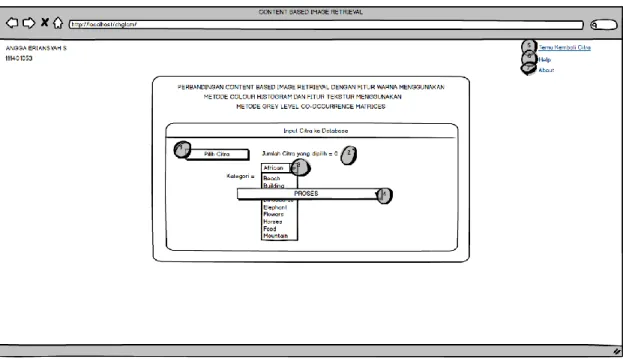
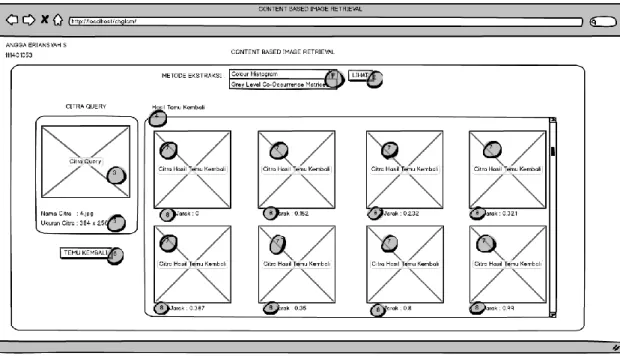
3.3.4 Perancangan Antarmuka 48
3.3.4.1 Antarmuka Halaman Temu Kembali Citra 49 3.3.4.2 Antarmuka Halaman Input Citra ke Database 50 3.3.4.3 Antarmuka Halaman Hasil Temu Kembali 51 3.3.4.4 Antarmuka Pop-up Detail Citra Hasil Colour Histogram 52 3.3.4.5 Antarmuka Pop-up Detail Citra Hasil Grey Level
Co-Occurrence Matrices 53
Bab IV Implementasi dan Pengujian
4.1 Implementasi 54
4.1.1 Halaman Temu Kembali Citra 54
4.1.2 Halaman Input Citra ke Database 55
4.1.3 Halaman Hasil Temu Kembali 55
4.1.4 Pop-up Detail Citra Hasil Colour Histogram 56 4.1.5 Pop-up Detail Citra Hasil Grey Level Co-Occurrence Matrices 56 4.1.6 Proses Kerja Temu Kembali Citra dengan Fitur Warna 57 4.1.6 Proses Kerja Temu Kembali Citra dengan Fitur Tekstur 60
4.2. Pengujian 64
4.2.1 Pengujian Metode Colour Histogram 65 4.2.2 Pengujian Metode Grey Level Co-Occurrence Matrices 71
4.2.3 Analisis Hasil Pengujian 77
Bab V Kesimpulan dan Saran
5.1 Kesimpulan 78
5.2. Saran 79
Daftar Pustaka 80
DAFTAR TABEL
Nomor
Tabel Nama Tabel Halaman
3.1 3.2 3.3 3.4 3.5 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 4.10 4.11 4.12 4.13 4.14 4.15 4.16 4.17 4.18 4.19
Spesifikasi Use Case Temu Kembali Citra Spesifikasi Use Case Input Citra ke Database Kamus Data Tabel CH
Kamus Data Tabel GLCM Kamus Data Tabel Kategori Piksel Citra 0.jpg
Nilai RGB setelah Kuantisasi
Probabilitas R,G, dan B tiap Level Warna dan Hasil Normalisasi
Normalisasi Nilai R,G, dan B pada Citra 0.jpg 200 x 200 piksel Piksel Citra 0.jpg
Piksel Citra 0.jpg Greyscale Elemen Matriks Co-Occurrence
Elemen Grey Level Co-Occurrence Matrices Identifikasi Pengguna dan Query
Penilaian Hasil Temu Kembali Citra oleh Pengguna Nilai Precision Citra Hasil Temu Kembali
Nilai Recall Citra Hasil Temu Kembali
Waktu Temu Kembali Menggunakan Colour Histogram Identifikasi Pengguna dan Query
Penilaian Hasil Temu Kembali Citra oleh Pengguna Nilai Precision Citra Hasil Temu Kembali
Nilai Recall Citra Hasil Temu Kembali
Waktu Temu Kembali Menggunakan Metode Grey Level Co- Occurrence Matrices
Rata-rata Nilai Precision, Recall dan Waktu Temu Kembali
33 34 47 48 48 57 58 59 59 61 62 62 63 65 67 68 69 70 71 73 74 75 76 77
DAFTAR GAMBAR
Nomor
Gambar Nama Gambar Halaman
2.1 2.2 2.3 2.4 2.5 2.6 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 3.10 3.11 3.12 3.13 3.14 4.1 4.2 4.3 4.4 4.5 4.6 4.7
Citra Biner Citra Grayscale Citra Warna
Struktur Warna RGB Model Warna HSV Diagram CBIR
Identifikasi Masalah Menggunakan Diagram Ihisikawa Use Case Diagram Sistem yang akan dikembangkan Activity Diagram untuk Temu Kembali Citra
Activity Diagram untuk Proses Input Citra ke Database Sequence Diagram Proses Temu Kembali Citra
Sequence Diagram Proses Input Citra ke Database Flowchart Sistem Temu Kembali Citra
Flowchart Metode Colour Histogram
Flowchart Metode Grey Level Co-Occurrence Matrices Rancangan Halaman Temu Kembali Citra
Rancangan Halaman Input Citra ke Database Rancangan Halaman Hasil Temu Kembali Citra
Rancangan Pop-up Detail Citra Hasil Colour Histogram Rancangan Pop-up Detail Citra Hasil Grey Level Co- Occurrence Matrices
Halaman Temu Kembali Citra Halaman Input Citra ke Database Halaman Hasil Temu Kembali
Pop-up Detail Citra Hasil Colour Histogram
Pop-up Detail Citra Hasil Grey Level Co-Occurrence Matrices Citra 0.jpg
Citra 0.jpg
6 7 7 11 12 15 31 33 35 36 37 37 38 39 40 49 50 51 52 53 54 55 55 56 56 57 61
DAFTAR LAMPIRAN
Halaman
A. Listing Program A-1
B. Penilaian Relevansi oleh Pengguna B-1
C. Curiculum Vitae C-1
PENDAHULUAN
1.1 Latar Belakang
Citra digital telah digunakan dalam berbagai bidang seperti dalam bidang kesehatan citra digunakan sebagai rekam medis pasien, dalam bidang kepolisian citra sidik jari digunakan untuk memeriksa identitas seseorang, dalam bidang perdagangan citra digunakan untuk mengetahui bentuk sebuah produk, dan bidang lainnya. Hal tersebut menyebabkan jumlah citra digital bertambah banyak jumlahnya. Salah satu solusi untuk mengatasi hal tersebut adalah penggunaan database citra. Seiring dengan digunakan database citra maka diperlukan metode untuk menemukan kembali citra yang diinginkan oleh pengguna.
Teknologi pencarian citra saat ini berkembang kearah pencarian citra berdasarkan isi visual dari citra yang dikenal dengan metode sistem temu kembali citra berbasis isi atau Content Based Image Retrieval (CBIR). Cara kerja CBIR berbeda dengan metode pencarian citra menggunakan kata kunci (keyword). Konsep dasar CBIR adalah mencari citra yang mirip berdasarkan fitur yang diekstraksi dari konten citra query dan konten sekumpulan citra yang ada pada database. Kelemahan metode pencarian citra menggunakan kata kunci adalah setiap citra dalam database harus dideskripsikan agar dapat ditemukan dengan kata kunci. Tentu hal ini akan membutuhkan sumber daya lebih yaitu, sumber daya manusia dan waktu. Terlebih persepsi tiap manusia terhadap citra berbeda-beda. Kelebihan CBIR adalah kemampuannya untuk mendukung query visual.
Pada CBIR umumnya digunakan deskripsi citra yang bersifat obyektif yaitu berupa fitur. Fitur adalah karakteristik atau atribut sebuah citra yang dapat membedakannya dengan citra lainnya. Fitur citra yang digunakan pada CBIR umumnya mencakup fitur komposisi warna, fitur tekstur dan fitur bentuk yang dimiliki citra. Fitur warna adalah fitur yang paling mudah diekstraksi. Fitur warna menyajikan informasi tentang komposisi warna-warna yang terdapat dalam sebuah citra. Tekstur sebagai fitur yang berisi informasi penting tentang struktur penyusunan
permukaan dan hubungannya dengan keadaan di sekitar gambar. Tekstur merupakan pola berulang dari hubungan (distribusi) spasial dari derajat keabuan pada piksel- piksel yang bertetangga. Pendekatan statistik mempertimbangkan parameter tekstur, distribusi intensitas pada piksel-piksel, serta hubungan antar piksel bertetangga.
1.2 Perumusan Masalah
Berdasarkan uraian dari latar belakang diatas, rumusan masalah yang akan dibahas adalah membandingkan fitur warna dengan metode Colour Histogram dengan fitur tekstur dengan metode Grey Level Co-Occurrence Matrices untuk Content Based Image Retrieval dengan parameter perbandingan recall, precision, dan waktu pencarian.
1.3 Batasan Masalah
Adapun batasan masalah dalam penelitian ini adalah :
1. Sample citra diinput berasal dari database Wang berjumlah 100 citra dan terbagi atas 10 kategori (African, Beach, Building, Buses, Dinosaurus, Elephants, Flowers, Horses, Food, dan Mountain).
(http://InfoLab.Stanford.EDU/~wangz/image.vary.jpg.tar).
2. Temu kembali citra diuji oleh 10 pengguna dan masing-masing pengguna menggunakan 2 citra query.
3. Temu kembali menggunakan citra sebagai query tanpa keyword.
4. File citra berekstensi .JPG
5. Parameter perbandingan antara lain waktu temu kembali citra dan tingkat keberhasilan CBIR menggunakan metode recall dan precision.
6. Model warna yang digunakan adalah RGB.
7. Fitur tekstur yang diekstraksi sebanyak 6 fitur yaitu, Energy, Entropy, Contrast, Variance, Correlation, dan Inverse Difference Moment.
8. Metode pengukuran kemiripan yang digunakan adalah Euclidian Distance.
9. Nilai koefisien yang digunakan dalam ekstraksi Grey Level Co-Occurrence Matrices adalah d = 1 dan Ɵ= 0o.
10. Menggunakan DBMS MySQL dan bahasa pemrograman PHP
1.4 Tujuan Penelitian
Adapun tujuan penelitian dalam tugas akhir ini adalah menunjukkan hasil perbandingan CBIR menggunakan fitur warna dengan metode Colour Histogram dan CBIR menggunakan fitur tekstur dengan metode Grey Level Co-Occurrence Matrices dengan menggunakan parameter perbandingan recall, precision, dan waktu temu kembali.
1.5 Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan informasi tentang Content Based Image Retrieval mana yang lebih baik diantara yang menggunakan fitur warna menggunakan metode Colour Histogram dengan yang menggunakan fitur tekstur menggunakan metode Grey Level Co-Occurrence Matrices.
1.6. Metodologi Penelitian
Metode penelitian yang dilakukan dalam penelitian ini adalah:
1. Studi literatur
Dilakukan peninjauan terhadap buku, jurnal, makalah, serta hasil penelitian yang membahas tentang Content Based Image Retrieval, Colour Histogram, Grey Level Co-Occurrence Matrices dan semua teori yang berkaitan.
2. Analisis dan Perancangan
Dengan adanya rumusan dan batasan masalah, permasalahan dan kebutuhan dianalisis disertai pembuatan flowchart, UML dan mockup dari sistem.
3. Implementasi
Hasil analisa dan perancangan diimplementasikan sebagai sebuah perangkat lunak.
4. Pengujian
Pengujian dilakukan terhadap keberhasilan proses yang dilakukan dalam Content Based Image Retrieval.
5. Dokumentasi
Selama pembuatan perangkat lunak hingga pengujian, dilakukan pendokumentasian berupa laporan.
1.6 Sistematika Penulisan
Agar pembahasan lebih sistematis, maka tulisan ini dibuat dalam lima bab, yaitu :
BAB I PENDAHULUAN
Berisi latar belakang, perumusan masalah, batasan masalah, tujuan dan manfaat penelitian dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Berisi tentang penjelasan singkat mengenai definisi citra digital, warna, Content Based Image Retrieval, ekstraksi fitur citra, fitur warna, fitur tekstur, dan metode pengukur kemiripan.
BAB III ANALISIS DAN PERANCANGAN
Berisi tentang analisis mengenai proses kerja Content Based Image Retrieval, Colour Histogram, Grey Level Co-Occurrence Matrices, dan perancangan tampilan halaman dari perangkat lunak.
BAB IV IMPLEMENTASI DAN PENGUJIAN
Berisi tentang algoritma, implementasi hasil perancangan, dan pengujian terhadap perangkat lunak.
BAB V KESIMPULAN DAN SARAN
Berisi tentang kesimpulan yang dapat ditarik setelah menyelesaikan tugas akhir ini dan saran-saran yang dapat diberikan untuk pengembangan perangkat lunak lebih lanjut.
TINJAUAN PUSTAKA
2.1 Citra Digital
Citra adalah suatu representasi (gambaran), kemiripan, atau imitasi dari suatu objek.
Citra merupakan salah satu komponen multimedia dimana memegang peranan yang sangat penting sebagai bentuk informasi visual. Citra mempunyai karakteristik yang tidak dimilki oleh data teks, yaitu citra kaya dengan informasi. Ditinjau dari sudut pandang matematis, citra merupakan fungsi berkelanjutan (continue) dari intensitas cahaya pada bidang dwimatra (dua dimensi).
Citra digital merupakan sebuah larik (array) yang berisi nilai-nilai riil maupun kompleks yang direpresentasikan dengan deretan bit tertentu. Pada umumnya citra digital berbentuk empat persegi panjang, dan dimensi ukurannya dinyatakan sebagai tinggi x lebar. Citra Digital merupakan suatu fungsi intensitas cahaya f(x,y), dimana harga x dan y merupakan koordinat spasial dan harga fungsi tersebut pada setiap titik (x,y) merupakan tingkat kecerahan citra pada titik tersebut. Citra digital yang tingginya N, lebarnya M, dan memiliki L derajat keabuan dapat dianggap sebagai fungsi:
f(x,y ) =
𝟎 ≤ 𝒙 ≤ 𝑴 𝟎 ≤ 𝒚 ≤ 𝑵
𝟎 ≤ 𝒇 ≤ 𝑳 ...(1)
Citra digital yang berukuran N x M lazim dinyatakan dengan matriks berukuran N baris dan M kolom sebagai berikut:
f(x,y) =
𝒇(𝟎, 𝟎) 𝒇(𝟏, 𝟎) ⋯ 𝒇(𝑴 − 𝟏, 𝟎)
𝒇(𝟎, 𝟏) 𝒇(𝟏, 𝟏) ⋯ 𝒇(𝑴 − 𝟏, 𝟎)
⋮ ⋮ ⋮ ⋮
𝒇(𝟎, 𝑵 − 𝟏) 𝒇(𝟏, 𝑵 − 𝟏) ⋯ 𝒇(𝑴 − 𝟏, 𝑵 − 𝟏)
...(2)
Keterangan:
N = jumlah baris,0 ≤ y ≤ N-1 M = jumlah kolom,0 ≤ x ≤ M-1
L = maksimal warna intensitas (derajat keabuan), 0 ≤ f(x,y) ≤ L-1
Masing-masing elemen pada citra digital disebut image element atau piksel.
Jadi, citra yang berukuran N x M mempunyai NM-buah piksel. Proses digitalisasi koordinat (x,y) dikenal sebagai pencuplikan citra (image sampling), sedangkan proses digitalisasi derajat keabuan f(x,y) disebut kuantisasi derajat keabuan (gray-level quantization)(Munir, 2004).
2.1.1 Jenis Citra Digital
Nilai suatu piksel memiliki nilai dalam rentang tertentu, dari nilai minimum sampai nilai maksimum, jangkauan yang digunakan berbeda-beda tergantung dari jenis warnanya. Secara umum jangkauannya adalah 0-255. Berikut adalah jenis-jenis citra berdasarkan nilai pikselnya.
Citra Biner merupakan citra digital yang hanya memiliki dua kemungkinan nilai piksel yaitu hitam dan putih. Citra biner hanya membutuhkan satu bit untuk mewakili nilai setiap piksel dari citra biner. Contoh citra biner dapat dilihat pada gambar 2.1
Gambar 2.1 Citra Biner .
Citra Grayscale adalah citra digital yang hanya memiliki satu nilai kanal pada setiap pikselnya, dengan kata lain nilai bagian red = green = blue. Citra grayscale memiliki kedalaman warna 8 bit (256 kombinasi warna keabuan). Contoh citra grayscale dapat dilihat pada gambar 2.2 (Putra, 2009).
Gambar 2.2 Citra Grayscale
Citra Warna (24 –Bit) adalah citra yang setiap piksel dari citra warna 24-bit diwakilidengan 24 –bit sehingga total 16.777.216 variasi warna. Variasi ini sudah lebih dari cukup untuk memvisualisasikan seluruh warna yang dapat dilihat penglihatan manusia. Setiap informasi warna disimpan ke dalam 1-byte data. 8-bit pertama menyimpan nilai biru, Kemudian diikuti dengan nilai hijau pada 8-bit kedua dan 8-bit terakhir merupakan nilai warna merah (Santoso, 2013). Contoh citra warna dapat dilihat pada gambar 2.3, dibawah ini:
Gambar 2.3 Citra Warna
2.1.2 Format File Citra Digital
File gambar berfungsi untuk menyimpan sebuah gambar yang dapat ditampilkan di layar ke dalam suatu media penyimpanan data. Untuk penyimpanan tersebut digunakan format gambar. Setiap format gambar memiliki karakteristik masing-
masing. Beberapa format umum saat ini, yaitu bitmap (.bmp), tagged image format (.tif, tiff), portable network graphics (.png), graphics interchange format (.gif), jpeg (.jpg), mpeg (.mpg), dan lain-lain.
2.1.2.1 Format File Bitmap (BMP)
Format file bitmap adalah sebuah format file citra standard untuk komputer-komputer yang menjalankan sistem operasi. Dasarnya format BMP tidak dikompresi sehingga ukuran filenya relatif lebih besar dari file JPG.
Kelebihan dari format file ini, yaitu mampu menyimpan gambar dalam model warna RGB, Grayscale, Indexed Color, dan Bitmap. Serta citra dalam format bitmap menghasilkan gambar yang lebih bagus daripada citra dalam format yang lainnya, karena citra dalam format bitmap umumnya tidak dimampatkan sehingga tidak ada informasi yang hilang. Format ini dapat menyimpan informasi dengan kualitas tingkat 1 bit sampai 24 bit. Terjemahan bebas bitmap adalah pemetaan bit. Artinya, nilai intensitas piksel di dalam citra dipetakan ke sejumlah bit tertentu. Peta bit yang umum adalah 8, artinya setiap piksel panjangnya 8 bit. Delapan bit ini merepresentasikan nilai intensitas piksel. Dengan demikian ada sebanyak 28= 256 derajat keabuan, mulai dari 0 sampai 255.
2.1.2.2 Format File JPEG (Joint Photographic Experts Group)
Format file JPEG dapat mengkompres objek dengan tingkat kualitas sesuai dengan pilihan yang disediakan dan dapat dimanfaatkan untuk menyimpan gambar yang akan digunakan untuk keperluan halaman web, multimedia, dan publikasi elektronik lainnya. Format file JPEG ini juga mampu menyimpan gambar dengan model warna RGB, CMYK, dan Grayscale serta mampu menyimpan alpha channel, namun karena orientasinya ke publikasi elektronik maka format ini berukuran relatif lebih kecil dibandingkan dengan format file lainnya(Dinata, 2014).
2.1.3 Elemen-Elemen Citra Digital
Citra digital mengandung sejumlah elemen-elemen dasar. Elemen-elemen dasar tersebut dimanipulasi dalam pengolahan citra dan dieksploitasi lebih lanjut dalam computer vision. Elemen-elemen dasar yang penting diantaranya adalah :
1. Kecerahan
Kecerahan adalah kata lain untuk intensitas cahaya. Sebagaimana telah dijelaskan pada bagian penerokan, kecerahan pada sebuah titik (piksel) di dalam citra bukanlah intensitas yang sebenarnya, tetapi sebenarnya adalah intensitas rata-rata dari suatu area yang melingkupinya. Sistem visual manusia mampu menyesuaikan dirinya dengan tingkat kecerahan (brightness level) mulai dari yang paling rendah sampai yang paling tinggi dengan jangkauan sebesar 1010.
2. Kontras
Kontras menyatakan sebaran terang (lightness) dan gelap (darkness) di dalam sebuah gambar. Citra dengan kontras rendah dicirikan oleh sebagian besar komposisi citranya adalah terang atau sebagian besar gelap. Pada citra dengan kontras yang baik, komposisi gelap dan terang tersebar secara merata.
3. Kontur (Countour)
Kontur adalah keadaan yang ditimbulkan oleh perubahan intensitas pada pixel- pixel yang bertetangga. Karena adanya perubahan intensitas inilah mata kita mampu mendeteksi tepi-tepi (edge) objek di dalam citra.
4. Warna
Warna adalah persepsi yang dirasakan oleh sistem visual manusia terhadap panjang gelombang cahaya yang dipantulkan oleh objek. Setiap warna mempunyai panjang gelombang (λ) yang berbeda. Warna merah mempunyai panjang gelombang paling tinggi, sedangkan warna ungu (violet) mempunyai panjang gelombang paling rendah. Warna-warna yang diterima oleh mata (sistem visual manusia) merupakan hasil kombinasi cahaya dengan panjang gelombang berbeda. Penelitian memperlihatkan bahwa kombinasi warna yang memberikan rentang warna yang paling lebar adalah red (R), green (G), dan blue (B).
5. Bentuk (Shape)
Shape adalah properti intrinsik dari objek tiga dimensi dengan pengertian bahwa
lebih sering mengasosiasikan objek dengan bentuknya ketimbang elemen lainnya (warna misalnya). Pada umumnya, citra yang dibentuk oleh mata merupakan citra dwimatra (2 dimensi), sedangkan objek yang dilihat umumnya berbentuk trimatra (3 dimensi). Informasi bentuk objek dapat diekstraksi dari citra pada permulaaan pra-pengolahan dan segmentasi citra. Salah satu tantangan utama pada computer vision adalah merepresentasikan bentuk, atau aspek-aspek penting dari bentuk.
6. Tekstur
Tekstur dicirikan sebagai distribusi spasial dari derajat keabuan di dalam sekumpulan piksel-piksel yang bertetangga. Jadi, tekstur tidak dapat didefinisikan untuk sebuah piksel. Sistem visual manusia pada hakikatnya tidak menerima informasi citra secara independen pada setiap pixel, melainkan suatu citra dianggap sebagai suatu kesatuan. Resolusi citra yang diamati ditentukan oleh skala pada mana tekstur tersebut dipersepsi(Sutoyo, 2009).
2.1.4 Warna
Isi dari sebuah citra digital adalah piksel atau kotak warna. Manusia dapat melihat radiasi elektromagnetik dengan panjang gelombang 400 sampai 700 nanometers(nm) sebagai warna. Hewan juga bisa melihat sisi yang berbeda dari spectrum elektromagnetik dan dapat melihat warna yang berbeda dari apa yang tidak dapat dilihat oleh manusia.
Pengalaman warna secara natural adalah proses kombinasi dari mata dan otak.
Mata bertindak sebagai penerima cahaya dan otak menginterpretasikan data dari mata sebagai informasi visual dan menerjemahkan data tersebut sebagai warna.
Penglihatan manusia didasarkan atas tiga penerima, satu untuk merah, yang lain untuk hijau , sisanya untuknya biru. Ada banyak representasi warna dari banyak perbedaan lingkup warna, atau model yang biasa memiliki tiga atau empat channel(Santoso, 2013).
2.1.4.1 Model RGB (Red, Green, Blue)
Model warna RGB adalah mode l warna berdasarkan konsep penambahan kuat cahaya primer yaitu Red, Green dan Blue. Struktur warna RGB dapat dilihat pada gambar 2.4
Gambar 2.4 Struktur Warna RGB
Dalam suatu ruang yang sama sekali tidak ada cahaya, maka ruangan tersebut adalah gelap total. Tidak ada signal gelombang cahaya yang diserap oleh mata kita atau RGB (0,0,0). Apabila kita menambahkan cahaya merah pada ruangan tersebut, maka ruangan akan berubah warna menjadi merah misalnya RGB (255,0,0), semua benda dalam ruangan tersebut hanya dapat terlihat berwarna merah. Demikian apabila cahaya kita ganti dengan hijau atau biru.
Berdasar pada tri-stimulus vision theory yang mengatakan bahwa manusia melihat warna dengan cara membandingkan cahaya yang datang dengan sensorsensor peka cahaya pada retina (yang berbentuk kerucut). Sensor-sensor tersebut paling peka terhadap cahaya dengan panjang gelombang 630 nm (merah), 530 nm (hijau) dan 450 nm (biru). Model ini dapat digambarkan dengan kubus dengan sumbu-sumbu R, G dan B(Santoso, 2013).
2.1.4.2 Model HSV (Hue, Saturation, and Value)
Model warna HSV mendefinisikan warna dalam terminologi Hue, Saturation dan Value. Hue menyatakan warna sebenarnya, seperti merah, violet, dan kuning. Hue digunakan untuk membedakan warna-warna dan menentukan kemerahan (redness),
kehijauan (greeness), dsb, dari cahaya. Hue berasosiasi dengan panjang gelombang cahaya.Saturation menyatakan tingkat kemurnian suatu warna, yaitu mengindikasikan seberapa banyak warna putih diberikan pada warna. Value adalah atribut yang menyatakan banyaknya cahaya yang diterima oleh mata tanpa memperdulikan warna.
Model warna HSV dapat dilihat pada gambar 2.5(Sutoyo, 2009).
Gambar 2.5 Model Warna HSV
2.1.4.3 Model HSL (Hue, saturation , and Lightness)
Pada dasarnya model warna HSL hampir sama dengan model warna HSV. Model warna HSL terdiri dari 3 komponen yaitu Hue, saturation , dan Lightness. Hue merupakan karakteristik warna berdasar cahaya yang dipantulkan oleh objek, dalam warna dilihat dari ukurannya mengikuti tingkatan 0 sampai 360.
Sebagai contoh, pada tingkat 0 adalah warna Merah, 60 adalah warna Kuning, untuk warna Hijau pada tingkatan 120, sedangkan pada 180 adalah warna Cyan.
Untuk tingkat 240 merupakan warna Biru, serta 300 adalah warna Magenta.
Saturation/Chroma adalah tingkatan warna berdasarkan ketajamannya berfungsi untuk mendefinisikan warna suatu objek cenderung murni atau cenderung kotor (gray). Saturation mengikuti persentase yang berkisar dari 0% sampai 100%
sebagai warna paling tajam.
Lightness adalah tingkatan warna berdasarkan pencampuran dengan unsur warna Putih sebagai unsur warna yang memunculkan kesan warna terang atau gelap. Nilai koreksi warna pada Lightness berkisar antara 0 untuk warna paling gelap dan 100 untuk warna paling terang(Santoso, 2013).
2.1.4.4 Model CMYK (Cyan Magenta Yellow Key)
Cyan Magenta Yellow Key (CMYK),atau sering disingkat sebagai CMYK adalah proses pencampuran pigmen yang lazim digunakan percetakan. Tinta process cyan, process magenta, process yellow, process black dicampurkan dengan komposisi tertentu dan akurat sehingga menghasilkan warna tepat seperti yang diinginkan.
Bahkan bila suatu saat diperlukan, warna ini dengan mudah bisa dibentuk kembali.
Sistem CMYK juga digunakan oleh banyak printer kelas bawah karena keekonomisannya.
CMYK (adalah kependekan dari cyan, magenta, yellow-kuning, dan warna utamanya (black-hitam), dan seringkali dijadikan referensi sebagai suatu proses pewarnaan dengan mempergunakan empat warna) adalah bagian dari model pewarnaan yang sering dipergunakan dalam pencetakan berwarna. Namun ia juga dipergunakan untuk menjelaskan proses pewarnaan itu sendiri. Meskipun berbeda- beda dari setiap tempat pencetakan, operator surat khabar, pabrik surat kabar dan pihak-pihak yang terkait, tinta untuk proses ini biasanya, diatur berdasarkan urutan dari singkatan tersebut.
Model ini, baik sebagian ataupun keseluruhan, biasanya ditimpakan dalam gambar dengan warna latar putih (warna ini dipilih, dikarenakan dia dapat menyerap panjang struktur cahaya tertentu). Model seperti ini sering dikenal dengan nama
“subtractive”, arena warna-warnanya mengurangi warna terang dari warna putih.
Dalam model yang lain “additive color”, seperti halnya RGB (Red-Merah, Green-Hijau, Blue-Biru), warna putih menjadi warna tambahan dari kombinasi warna- warna utama, sedangkan warna hitam dapat terjadi tanpa adanya suatu cahaya. Dalam model CMYK, berlaku sebaliknya: warna putih menjadi warna natural dari kertas atau warna latar, sedangkan warna hitam adalah warna kombinasi dari warna-warna utama.
Untuk menghemat biaya untuk membeli tinta, dan untuk menghasilkan warna hitam yang lebih gelap, dibuatlah satu warna hitam khusus yang menggantikan warna kombinasi dari cyan, magenta dan kuning(Santoso, 2013).
2.2 Content Based Image Retrieval (CBIR)
Content based image retrieval (Temu Kembali Citra Berbasis Isi) atau CBIR merupakan salah satu bentuk aplikasi pengolahan citra yang dapat membantu pengguna mengambil atau mencari dengan cepat suatu citra pada suatu database citra berdasarkan query atau permintaan pengguna(Putra, 2009).
Pada CBIR, ciri-ciri visual citra dalam basis data diekstraksi dan kemudian dideskripsikan sebagai vektor ciri multidimensional. Contoh fitur dalam citra adalah warna, bentuk, dan tekstur. Fitur – fitur tersebut kemudian disimpan dalam suatu basis data. Untuk melakukan temu kembali citra, pengguna memberikan citra query pada sistem pencarian kemudian dilakukan proses ekstraksi fitur terhadap citra query tersebut, sehingga diperoleh nilai vektor fitur-nya. Vektor yang diperoleh dari citra query akan dibandingkan kesamaannya dengan nilai vektor fitur yang terdapat dalam basis data. Diagram umum CBIR dapat dilihat pada gambar 2.6(Devireddy, 2009).
Gambar 2.6 Diagram CBIR
2.2.1 Ekstraksi Fitur
Ekstraksi fitur (konten) adalah dasar dari retrieval citra berbasis konten. Secara umum ada dua fitur citra yaitu visual dan semantic (tekstual). Fitur visual adalah fitur yang terdapat dalam citra itu sendiri. Fitur visual dibagi menjadi dua yaitu general dan domain spesifik. General visual content termasuk warna, bentuk, tekstur dan relasi spasial. Domain spesific content contohnya seperti fitur untuk wajah manusia, sidik
jari . Semantic content adalah penambahan deskripsi secara tekstual berdasarkan ekstraksi fitur citra. Ekstraksi fitur citra yang dapat dilakukan untuk citra digital adalah mengubah citra input a[m,n] menjadi sebuah citra output b[m,n](Rui & Huang, 1999).
2.2.1.1 Colour Histogram
Colour Histogram (Histogram Warna) adalah grafik yag menunjukkan frekuensi kemunculan setiap nilai gradiasi warna. Bila digambarkan pada koordinat kartesian maka sumbu X (absis) menunjukkan tingkat warna dan sumbu Y (ordinat) menunjukkan frekuensi kemunculan. Histogram warna(Colour Histogram) merupakan fitur warna yang paling banyak digunakan. Histogram warna sangat efektif mengkarakterisasikan distribusi global dari warna dalam sebuah citra digital(Sutoyo, 2009).
Fitur warna yang diekstraksi dengan menggunakan Colour histogram dimungkinkan dalam pengambilan gambar yang telah ditransformasi menjadi ukuran yang berbeda, namun memiliki kelemahan karena dapat menampilkan hasil gambar yang tidak relevan. Color histogram tersebut didefinisikan sebagai berikut:
HR,G,B[r,g,b]=N.Prob {R=r,G=g,B=b}...(3)
Masing-masing komponen RGB memiliki jangkauan nilai 0-255. Histogram dapat disederhanakan agar proses perhitungan lebih cepat dengan kuantisasi nilai masing-masing komponen. Masing-masing komponen dapat dikuantisasi menjadi beberapa bin. Bin adalah rentang nilai masing-masing komponen. Persamaan untuk mengkuantisasi histogram adalah sebagai berikut :
Nilai terkuantisasi = 𝑁𝑖𝑙𝑎𝑖 𝑙𝑒𝑣𝑒𝑙 𝑘𝑜𝑚𝑝𝑜𝑛𝑒𝑛 𝑅𝐺𝐵 𝑥 𝐽𝑢𝑚𝑙𝑎 𝐵𝑖𝑛
𝐽𝑢𝑚 𝑙𝑎 𝑙𝑒𝑣𝑒𝑙 𝐾𝑜𝑚𝑝𝑜𝑛𝑒𝑛 𝑅𝐺𝐵
...(4)
Jumlah piksel citra sangat beraga, maka histogram perlu dinormalisasi.
Normalisasi dilakukan dengan cara membagi jumlah piksel untuk masing-masing
piksel untuk masing-masing level dengan jumlah total piksel dalam citra sehingga didapatkan nilai minimum 0 dan maksimum 1 untuk tiap level warna.
2.2.1.2 Grey Level Co-Occurrence Matrices
Tekstur adalah fitur ekstraksi yang banyak digunakan tetapi tidak memiliki definisi yang tepat karena variabilitas nya luas. Tekstur merupakan keterangan tingkat rendah yang sangat baik untuk aplikasi pencarian dan pengambilan gambar. MPEG-7 sedang mempertimbangkan tiga deskriptor tekstur saat ini. Yang pertama disebuat sebagai texture browsing descriptors dan atribut ciri persepsi seperti arah, keteraturan, dan kekerasan dari tekstur. Yang kedua homogeneous texture descriptor (HTD).
Memberikan karakteristik kuantitatif daerah tekstur homogen untuk pengambilan kesamaan. Berdasarkan komputasi statik spasial frekuansi tekstur lokal. Yang terakhir edge histogram descriptors berguna ketika wilayah yang mendasari tidak homogen dalam sifat tekstur(Manjunath & Vinod, 2001).
Dalam analisis tekstur secara statistik, fitur ciri dikomputasi dari distribusi statistik kombinasi yang diobservasi dari intensitas pada posisi tertentu relatif terhadap satu sama lain dalam citra. Berdasarkan pada jumlah intensitas piksel dalam masing- masing kombinasi, statistik diklasifikasikan menjadi first-order, second-order, dan order statistik yang lebih tinggi.
Metode Grey Level Co-Occurrence Matrices (GLCM) adalah sebuah cara untuk mengekstraksi fitur tekstur statistik second-order. Pendekatan yang telah digunakan dalam sejumlah aplikasi, tekstur order ketiga dan yang lebih tinggi yang memperhitungkan hubungan antara tiga atau lebih piksel. Hal ini memungkinkan secara teori tetapi tidak umum diimplementasikan karena kalkulasi waktu dan kesulitan interpretasi.
Co-Occurrence didefinisikan sebagai distribusi gabungan dari level keabuan dua piksel yang terpisah jarak dan arah tertentu (∆x, ∆y)(referensi ke-5 identifikasi citra massa kistik). Sebuah GLCM adalah sebuah matriks dimana jumlah baris dan kolom sama dengan jumlah level keabuan, G, dalam citra. Elemen matriks P(i, j | ∆x,
∆y) adalah frekuensi relatif dengan dua piksel yang dipisahkan oleh jarak pixel (∆x,
∆y), terjadi di dalam ketetanggaan tertentu, yang satu dengan intensitas „i‟ dan yang lainnya dengan intensitas „j‟. Elemen matriks P(i, j | d, Ɵ) berisi nilai probabilitas statistik order kedua untuk perubahan antara level keabuan „i‟ dan „j‟ pada sebuah jarak perpindahan tertentu d dan pada sudut tertentu (Ɵ). Penggunaan jumlah yang besar tingkat intensitas G mengakibatkan besarnya penyimpanan data sementara, misalnya matriks G x G untuk tiap kombinasi dari (∆x, ∆y) atau (d, Ɵ). Karena besarnya dimensi, GLCM sangat sensitif terhadap ukuran sampel tekstur pada bagian yang diperiksa. Oleh karena itu, jumlah level keabuan sering direduksi(Mohanaiah, Sathyanarayana, & Gurukumar, 2013).
Langkah-langkah membuat GLCM simetris ternormalisasi adalah sebagai berikut:
1. Membuat framework matriks
2. Menentukan hubungan spasial antara piksel referensi dengan piksel tetangga, berupa sudut θ dan jarak d
3. Menghitung jumlah co-occurrence dan mengisikannya pada framework
4. Menjumlahkan matriks co-occurrence dengan transposnya untuk menjadikannya simetris
5. Normalisasi matriks untuk mengubahnya ke bentuk probabilitas.
Berikut ini adalah contoh matriks piksel dari sebuah citra dengan level keabuan adalah 4.
0 0 1 1 0 0 1 1 0 2 2 2 2 2 3 3
Untuk citra dengan tingkat keabuan 4 maka disiapkan matriks framework berukuran 4 x 4 sesuai dengan tingkat keabuan citra. Berikut ini adalah matriks framework yang disiapkan.
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Selanjutnya hubungan spasial untuk Ɵ = 0o dan d=1 pada matriks citra dapat diisi ke dalam matriks framework tersebut untuk membentuk matriks co-occurrence dari matriks citra asal. Indeks baris ke-0 dan indeks kolom ke-0 menunjukkan jumlah kemunculan dua piksel dengan masing-masing memiliki nilai level keabuan 0 pada jarak d = 1 dan Ɵ = 0o. Indeks kolom ke-0 dan indeks kolom ke-1 menunjukkan kemunculan dua piksel yang memiliki nilai keabuan masing-masing 0 dan 1 yang saling bertetangga pada jarak d=1 dan Ɵ = 0o. Berikut adalah matriks co-occurrence yang merupakan matriks framework yang telah diisi.
2 2 1 0 0 2 0 0 0 0 3 1 0 0 0 1
Selanjutnya matriks co-occurrence tersebut dijumlahkan dengan matriks transpose dari matriks tersebut untuk membuatnya menjadi simetris terhadap diagonal matriks tersebut.
2 2 1 0 0 2 0 0 0 0 3 1 0 0 0 1
+
2 0 0 0 2 2 0 0 1 0 3 0 0 0 1 1
=
4 2 1 0 2 4 0 0 1 0 6 1 0 0 1 1
Selanjutnya dilakukan normalisasi terhadap matriks co-occurence simetris tersebut. Nilai hasil penjumlahan seluruh elemen matriks diperlukan dalam normalisasi matriks. Selanjutnya normalisasi dilakukan dengan membagi seluruh elemen matriks co-occurence dengan nilai hasil penjumlahan seluruh elemen matriks.
𝑃𝑖,𝑗
3𝑖,𝑗 =0 = 4 + 2 + 1 + 0 + 2 + 4 + 0 + 0 + 1 + 0 + 6 + 1 + 0 + 0 + 1 + 1 = 23
1 23 𝑥
4 2 1 0 2 4 0 0 1 0 6 1 0 0 1 1
=
0.174 0.086 0.083 0
0.086 0.174 0 0
0.043 0 0.260 0.043
0 0 0.043 0.043
Setelah mendapatkan co-occurrence matrices ternormalisasi tersebut, maka ciri statistik orde dua dapat yang merepresntasikan citra yang diamati dapat dihitung.
Dalam tugas akhir ini digunakan 6 ciri statistik orde dua yaitu :
1. Energy
Parameter ini disebut juga dengan Angular Second Moment dan Uniformity.
Energy mengukur keseragaman tekstur yaitu perulangan pasangan piksel;
ketika potongan citra dianggap homogen (hanya ada level keabuan yang mirip) atau ketika terjadi keseragaman secara tekstur(pemindahan vektor selalu mengarah pada pasangan(i, j) level keabuan yang sama) , hanya sedikit (kemungkinan hanya satu) elemen GLCM yang akan lebih besar dari 0 dan mendekati 1, ketika banyak elemen yang mendekati 0. Pada kasus tersebut energy mencapai nilai yang mendekati maksimum, yaitu 1. Oleh karena itu, nilai energy yang tinggi terjadi ketika distribusi level keabuan pada citra bernilai konstan(Baraldi, 1995).
Energy =
𝑁−1𝑖,𝑗 =0
𝑃
𝑖,𝑗2...(5)Keterangan :
P : Elemen matriks GLCM N : Jumlah indeks matriks i : Indeks baris matriks j : Indeks kolom matriks
Parameter ini mengukur ketidakteraturan sebuah citra. Ketika sebuah citra tidak bertekstur seragam, banyak elemen GLCM mempunyai nilai yang sangat kecil yang mengakibatkan nilai entropy sangat besar. Dari sudut pandang konseptual, entropy sangat berhubungan secara terbalik dengan energy. Secara teori, hasil yang mirip diharapkan untuk pengelompokan energy dan entropy.
Sebuah keuntungan dengan menggunakan energy dibandingkan entropy terletak pada fakta bahwa energy mempunyai rentang yang ternormalisasi(Baraldi, 1995).
Entropy = 𝑁−1𝑖,𝑗 =0
𝑃
𝑖,𝑗− ln 𝑃
𝑖,𝑗 ...(6)Keterangan :
P : Elemen matriks GLCM N : Jumlah indeks matriks i : Indeks baris matriks j : Indeks kolom matriks
3. Contrast
Frekuensi spasial adalah perbedaan antara nilai tertinggi dan terendah dari sebuah kumpulan piksel yang berdekatan. Definisi ini juga berlaku untuk ekspresi contrast dalam GLCM, khususnya ketika modul vektor perpindahan sama dengan satu. Hal ini menunjukkan bahwa sebuah citra yang mempunyai nilai kontras yang rendah tidak selalu ditandai dengan distribusi level keabuan yang kecil, dengan kata lain tidak selalu disertai dengan sebuah nilai variansi yang rendah, tapi citra yang bernilai kontas rendah pasti mencirikan frekuensi spasial yang rendah. Kesimpulannya adalah contrast GLCM cenderung terhubung dengan frekuensi spasial sedangkan modul vektor perpindahan cenderung satu. Sebuah citra yang memiliki kontrast rendah menunjukkan susunan konsentrasi GLCM di sekitar diagonal utama dan akibatnya adalah nilai kontras yang rendah(Baraldi, 1995).
Contrast = 𝑁−1𝑖,𝑗 =0
𝑃
𝑖,𝑗𝑖 − 𝑗
2...(7)Keterangan :
P : Elemen matriks GLCM N : Jumlah indeks matriks i : Indeks baris matriks j : Indeks kolom matriks
4. Variance
Variance (Variansi) dalam GLCM adalah pengukuran terhadap keheterogenan dan sangat berkaitan dengan variabel statistik order pertama seperti standar deviasi. Khususnya, ketika sebuah daerah citra berbentuk persegi diinvestigasi teksturnya, variansi statistik order pertama sama dengan variansi GLCM jika perpindahan vektor GLCM adalah satu dan jika sudut yang digunakan dalam investigasi tersebut adalah 0o atau 90o. Variansi meningkat ketika nilai level keabuan berbeda dari rata-ratanya. Variansi tidak bergantung pada parameter kontras GLCM, khususnya ketika modul vektor perpindahan cenderung satu, karena sebuah daerah dapat mempunyai frekuensi spasial yang rendah dan nilai kontras yang rendah sementara variansi dapat memiliki nilai yang rendah maupun nilai yang tinggi(Baraldi, 1995).
𝜎
2=
𝑁−1𝑖,𝑗 =0𝑃
𝑖,𝑗𝑖 − 𝜇
2...(8)Keterangan : σ2 : Variansi
P : Elemen matriks GLCM N : Jumlah indeks matriks i : Indeks baris matriks
j : Indeks kolom matriks
5. Correlation
GLCM correlation diekspresikan oleh koefisien korelasi antara dua variabel acak i dan j, dimana i mewakili hasil yang mungkin dalam pengukuran level keabuan untuk elemen pertama dari vektor perpindahan, sementara j diasosiasikan dengan level keabuan dalam elemen kedua dari vektor perpindahan. Korelasi adalah sebuah pengukuran saling ketergantungan level keabuan secara linear dalam sebuah citra, secara khususnya arah investigasi sama dengan vektor perpindahan. Nilai korelasi yang tinggi (mendekati satu) menunjukkan sebuah hubungan linear antara level keabuan dari pasangan piksel. Sehingga, GLCM correlation tidak berkorelasi dengan GLCM energy dan entropy untuk pasangan piksel berulang, karena korelasi yang tinggi dapat diukur baik dalam keadaan energy yang rendah maupun tinggi. CLCM correlation juga tidak berkorelasi dengan kontras GLCM, karena prediktabilitas yang tinggi dari level keabuan dalam satu piksel dari piksel kedua dalam pasangan piksel sangat tidak bergantung kepada kontras(Baraldi, 1995).
Correlation =
𝑃
𝑖,𝑗 𝑖− 𝜇𝑖 𝑗 − 𝜇𝑗𝜎𝑖2 𝜎𝑗2
𝑁−1𝑖,𝑗 =0 ...(9)
Keterangan : σi2
: Nilai variance berdasarkan piksel referensi σi2
: Nilai variance berdasarkan piksel tetangga μi : Nilai mean berdasarkan piksel referensi μj : Nilai mean berdasarkan piksel tetangga P : Elemen matriks GLCM
N : Jumlah indeks matriks i : Indeks baris matriks j : Indeks kolom matriks
6. Inverse Difference Moment
Inverse Difference Moment biasa disebut juga dengan homogeneity yang mana mengukur kehomogenan sebuah citra, yang mengasumsikan semakin besar nilai untuk perbedaan level keabuan yang lebih kecil dalam elemen berpasangan. Berkaitan dengan hal tersebut, parameter ini lebih sensitif terhadap kehadiran elemen yang berada dekat diagonal dalam GLCM. GLCM contrast dan GLCM inverse difference moment berhubungan secara terbalik(Baraldi, 1995).
Inverse Difference Moment
=
𝑁−1𝑖,𝑗 =01+ 𝑖−𝑗 𝑃𝑖,𝑗 2...(10)Keterangan :
P : Elemen matriks GLCM N : Jumlah indeks matriks i : Indeks baris matriks j : Indeks kolom matriks
2.3 Metode Pengukuran Kemiripan (Similiarity Meassure)
Dalam proses CBIR terdapat sub proses matching (pencocokan) dan pengukuran kemiripan (similarity measure) merupakan salah satu proses penting yang harus diperhatikan. Pengukuran derajat kesamaan atau kecocokan pada dua atau lebih citra.
hal itu dilakukan dengan menghitung kemiripan (similarity) untuk mencari nilai-nilai kemiripan dari suatu citra dengan citra lainnya berdasarkan distance (jarak) vektor.
Distance (jarak) digunakan untuk menentukan kesamaan (similarity degree) atau ketidaksamaan (disimilarity degree) dua vektor fitur. Tingkat kesamaan berupa suatu nilai (score) dan berdasarkan nilai tersebut dua vektor fitur akan dikatakan mirip atau tidak. Semakin besar nilai distance (mendekati satu), maka kedua citra tersebut
semakin berbeda, sebaliknya semakin kecil nilai distance (mendekati nol), maka semakin mirip kedua citra tersebut(Putra, 2009).
Adapun beberapa metode yang dapat digunakan untuk mengukur tingkat kemiripan dua buah vektor fitur yaitu:
1. Euclidian Distance
Metrika yang paling sering digunakan untuk menghitung kesamaan dua vektor euclidean distance menghitung akar dari kuadrat perbedaan dua vektor (root of square differences between two vectors). Semakin kecil nilai jarak euclidian maka semakin mirip dua vektor tersebut dan sebaliknya semakin besar nilai jarak euclidian maka semakin tidak mirip kedua vektor tersebut(Zhang, 2002).
Adapun persamaan eucledian distance sebagai berikut:
d(A, B) =
𝑛𝑗 =1
𝐻
𝑗𝐴− 𝐻
𝑗𝐵 2...(11)Keterangan : A : Vektor A B : Vektor B
d(A,B) : Jarak Euclidian antara vektor A dan vektor B n : Jumlah elemen vektor
j : Indeks elemen vektor H : Elemen vektor
2. City Block Distance
City block distance biasanya disebut sebagai manhattan distance /boxcar distance/absolute value distance. City block distance menghitung nilai mutlak perbedaan dari 2 vektor(Putra, 2009). Adapun persamaan city block distance sebagai berikut
Dt (X2,X1) = || X2 – X1|| = 𝑃𝑓=1|𝑋2𝑓 − 𝑋1𝑓|...(12)
Dt : Jarak City Block X2 : Vektor kedua X1 : Vektor Pertama f : Indeks elemen vektor p : Jumlah elemen vektor
3. Chebyshe Distance
Chebyshev distance disebut juga maximum value distance yang mengukur jarak berdasarkan nilai mutlak atau sebuah magnitudo absolut perbedaan 2 vektor. Dari masing – masing nilai perbedaan akan dipilih nilai paling besar untuk dijadikan chebyshev distance)(Putra, 2009). Adapun persamaan chebyshev distance sebagai :
di,j = max (|𝑋𝑖𝑘 − 𝑋𝑗𝑘|)...(13)
Keterangan :
di,j : Jarak Chebyshe Xi :Vektor pertama Xj : Vektor kedua k : Indeks Matriks
4. Minkowski Distance
Minkowski distance dengan ordo λ ini menggeneralisasikan beberapa metrika sebelumnya, dimana λ=1 dinyatakan sebagai city block distance, λ=2 dinyatakan dengan euclidean distance dan λ=∞ (tak terhingga) dinyatakan dengan Chebyshev distance)(Putra, 2009). Adapun persamaan minkowski distance sebagai berikut :
dp (Q, T) =
𝑁−1𝑖=0
𝑄
𝑖− 𝑇
𝑖 λ 1λ...(14)Keterangan :
Dp : Jarak Minkowski Q : Vektor Q
T : Vektor T
N : Jumlah elemen vektor i : Indeks elemen vektor
5. Canberra Distance
Dalam canberra distance, untuk setiap nilai dari 2 vektor yang akan dicocokan, canberra distance membagi absolute selisih 2 nilai dengan jumlah dari absolute 2 nilai tersebut. Hasil dari setiap dua nilai dicocokkan lalu dijumlahkan untuk mendapatkan canberra distance. Jika kedua koordinat nol – nol kita memberikan definisi dengan 0/0 = 0. Canbera distance ini sangat peka terhadap sedikit perubahan dengan kedua koordinat mendekati nol)(Jurman, 2009). Adapun persamaan canberra distance sebagai berikut :
di,j = |𝑋𝑖𝑘− 𝑋𝑗𝑘| 𝑋𝑖𝑘|+|𝑋𝑗𝑘
𝑛𝑘=1 ...(15)
Keterangan :
di,j : Jarak Canberra Xi : Vektor i
Xj : Vektor j k : Indeks vektor
n : Jumlah elemen vektor
6. Bray Curtis Distance
Bray curtis distance sering disebut juga dengan sorensen distance. Metode normalisasi ini biasanya banyak digunakan dalam ilmu tumbuh-tumbuhan, ekologi dan ilmu lingkungan. The bray curtis distance mempunyai properti jika nilai yang dibandingkan positif dan nilai-nilainya akan berada diantara 0 dan 1. Bray curtis distance dirumuskan dengan jumlah dari absolute pengurangan dibagi jumlah 2 nilai yang dibandingkan. Zero bray curtis
distance menandakan kesamaan. Jika kedua objek sama nilainya nol akan menyebabkan pembagian dengan nol maka untuk kasus ini perlu didefinisikan sebelumnya)(Putra, 2009). Adapun persamaan Bray Curtis distance sebagai berikut :
d
i,j=
|𝑋𝑖𝑘−𝑋𝑗𝑘|𝑛𝑘=1
𝑋𝑖𝑘+𝑋𝑗𝑘
𝑛𝑘=1
...(16) Keterangan :
di,j : Jarak Bray Curtis Xi : Vektor i
Xj : Vektor j k : Indeks vektor
n : Jumlah elemen vektor
7. Correlation Coefficient
Correlation coefficient adalah standarisasi angular separation dengan pengurangan nilai koordinat dengan nilai mean. Nilainya di antara -1 dan +1.
Correlation coefficient juga lebih menghitung nilai kesamaan dibandingkan ketidaksamaan. Jadi semakin tinggi nilainya menunjukkan 2 vektor semakin mirip(Putra, 2009). Adapaun persamaan correlation coefficient sebagai :
r = 𝑋𝑖− 𝑋 𝑌𝑖− 𝑌
𝑛𝑖=1
𝑛𝑖=1 𝑋𝑖− 𝑋 2 𝑛𝑖=1 𝑌𝑖−𝑌 2
...(17)
Keterangan :
r : Correlation Coefficient n : Jumlah elemen vektor X : Elemen vektor X Y : Elemen vektor Y
𝑋 : Nilai rata-rata elemen vektor X 𝑌 : Nilai rata-rata elemen vektor Y i : Indeks elemen vektor
8. Hamming Distance untuk nilai biner
Urutan biner 0 dan 1 dinamakan word dalam teori coding. Jika dua word memiliki sama panjang, kita dapat menghitung jumlah dimana posisi word berbeda. Jumlah digit yang berlainan disebut hamming distance(Putra, 2009).
Adapun persamaan hamming distance sebagai berikut :
di,j = q + r ...(18)
2.4 Efektifitas Information Retrieval System
Lancaster (1980) menyatakan efektivitas dari suatu sistem temu kembali informasi adalah kemampuan dari sistem itu untuk memangil berbagai dokumen dari suatu basis data sesuai dengan permintaan pengguna. Ada dua parameter dasar yang digunakan dalam mengukur kemampuan suatu sistem temu kembali informasi yaitu rasio atau perbandingan dari perolehan (recall) dan ketepatan (precision).
Ukuran efektivitas pencarian pada dokumen yang ditampilkan oleh sistem temu balik dapat ditentukan oleh precision dan recall. Precision adalah rasio jumlah dokumen relevan yang ditemukan dengan total jumlah yang ditemukan oleh aplikasi.
Precision mengindikasikan kualitas himpunan jawaban, tetapi tidak memandang total jumlah dokumen yang relevan dalam kumpulan dokumen.
Precision = | 𝑅𝑒𝑙𝑒𝑣𝑎𝑛 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑠 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑠 𝑟𝑒𝑡𝑟𝑖 𝑒𝑣𝑒𝑑 |
| 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑠 𝑟𝑒𝑡𝑟𝑖𝑒𝑣𝑒𝑑 | ...(19)
Keterangan :
Precision : Nilai precision
Relevan documents : Jumlah dokumen yang relevan
Documents retrieved : Jumlah dokumen yang ditemukan kembali
Recall adalah rasio jumlah dokumen relevan yang ditemukan kembali dengan total jumlah dokumen dalam kumpulan yang dianggap relevan(Devireddy, 2009).
Recall = | 𝑅𝑒𝑙𝑒𝑣𝑎𝑛 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑠 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑠 𝑟𝑒𝑡𝑟𝑖𝑒𝑣𝑒𝑑 |
| 𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑡 𝑑𝑜𝑐𝑢𝑚𝑒𝑛 𝑡𝑠 | ...(20)
Keterangan :
Precision : Nilai recall
Relevan documents : Jumlah dokumen yang relevan
Documents retrieved : Jumlah dokumen yang ditemukan kembali
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1 Analisis
Sebelum memasuki tahap perancangan sistem, tahap yang harus dilakukan adalah analisis sistem. Analisis sistem merupakan tahapan yang dilakukan untuk menghasilkan pemahaman yang menyeluruh terhadap kebutuhan sistem sehingga diperoleh hal-hal yang harus dapat dilakukan oleh sistem. Fase awal dalam analisis sistem ini adalah fase analisis masalah yang bertujuan untuk mempelajari dan memahami masalah yang akan diselesaikan dengan menggunakan sistem ini.
Kemudian dilanjutkan dengan fase analitis kebutuhan yang akan memenuhi kebutuhan dan permintaan pengguna. Analisis selanjutnya dan yang terakhir adalah analisis proses yang akan dikerjakan oleh sistem.
3.1.1 Analisis Masalah
Masalah utama dalam penelitian ini adalah menemukan kembali citra dengan membandingkan isi (content) citra antara citra query dengan citra yang ada di dalam basis data. Isi citra yang dibandingkan adalah fitur yang dimiliki citra. Fitur yang digunakan untuk temu kembali citra dan dibandingkan hasil temu kembalinya adalah fitur warna dan fitur tekstur. Untuk mengekstraksi fitur warna pada citra digunakan metode Colour Histogram, sedangkan untuk mengekstraksi fitur tekstur pada citra digunakan metode Grey Level Co-Occurrence Matrices.
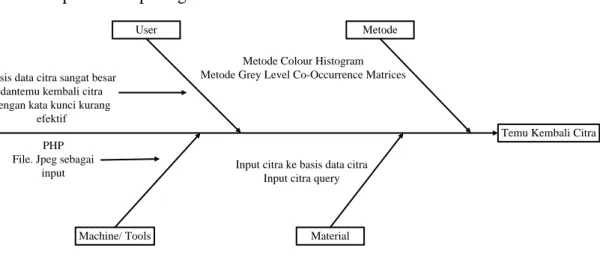
Diagram Ishikawa (fishbone diagram) digunakan untuk mengidentifikasi masalah. Diagram Ishikawa adalah sebuah alat grafis yang digunakan untuk mengidentifikasi, mengeksplorasi, dan menggambarkan suatu masalah serta sebab dan akibat masalah tersebut. Diagram Ishikawa yang digunakan untuk mengidentifikasi masalah dapat dilihat pada gambar 3.1
Temu Kembali Citra User
Machine/ Tools
Metode
Material PHP
File. Jpeg sebagai input
Basis data citra sangat besar dantemu kembali citra dengan kata kunci kurang
efektif
Metode Colour Histogram Metode Grey Level Co-Occurrence Matrices
Input citra ke basis data citra Input citra query
Gambar 3.1 Identifikasi Masalah menggunakan Diagram Ishikawa 3.1.2 Analisis Kebutuhan Sistem
Dalam pembangunan sebuah sistem, tahap analisis kebutuhan sistem perlu dilakukan dengan tujuan untuk mempermudah analisis sistem dalam menentukan keseluruhan kebutuhan secara lengkap. Analisis kebutuhan sistem dapat dikelompokkan menjadi 2 bagian yaitu kebutuhan fungsional dan kebutuhan non-fungsional.
3.1.2.1 Analisis Kebutuhan Fungsional
Dalam perancangan sebuah sistem diperlukan rekayasa kebutuhan yang merupakan sebuah proses untuk menemukan, menganalisis, mengdokumentasikan, dan memeriksa layanan serta batasan sistem. Berikut ini adalah kebutuhan-kebutuhan yang harus dapat dikerjakan oleh sistem.
1. Sistem dapat menyimpan file citra berekstensi .jpeg kedalam basis data.
2. Sistem dapat menyimpan fitur citra kedalam basis data.
3. Sistem dapat menerima input file citra query berekstensi .jpeg.
4. Sistem dapat melakukan temu kembali file citra dalam basis data citra berdasarkan fitur warna menggunakan metode Colour Histogram dan fitur tekstur menggunakan metode Grey Level Co-Occurrence Matrices.
3.1.2.2 Analisis Kebutuhan Non-Fungsional Sistem
Kebutuhan non-fungsional yang harus dapat dipenuhi oleh sistem yaitu:
1. Performa
Sistem yang akan dibangun dapat menunjukkan citra query dan citra hasil temu kembali.
2. Mudah digunakan dan dipelajari
Sistem yang dibangun harus sederhana agar pengguna dapat menggunakannya dengan mudah dan mudah dipelajari (user friendly).
3. Dokumentasi
Sistem yang akan dibangun terdapat fitur help untuk membantu pengguna dalam menggunakan sistem.
4. Hemat biaya.
Sistem yang dibangun akan mempermudah pengguna untuk efisiensi waktu, sehingga hemat biaya.
3.2 Pemodelan
Pada penelitian ini digunakan UML sebagai bahasa pemodelan untuk mendesain dan merancang sistem Content Based Image Retrieval dengan fitur warna menggunakan metode Colour Histogram dan fitur tekstur menggunakan metode Grey Level Co- Occurrence Matrices. Model UML yang digunakan adalah use case diagram, activity diagram, dan sequence diagram.
3.2.1 Pemodelan dengan Menggunakan Use Case Diagram
Sebuah use case diagram adalah sebuah diagram yang menunjukkan hubungan antara aktor dan kasus penggunaan dalam sistem.
Berdasarkan hasil analisis kebutuhan sistem, secara garis besar sistem melakukan temu kembali citra berbasis isi menggunakan fitur warna dengan metode Colour