Fakultas Ilmu Komputer
Universitas Brawijaya
312
Komparasi Metode K-Nearest Neighbors (K-NN) Dengan Support Vector
Machine (SVM) Untuk Klasifikasi Status Kualitas Air
Icha Gusti Vidiastanta1, Nurul Hidayat2, Ratih Kartika Dewi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Klasifikasi status kualitas air untuk masyarakat dibagi menjadi 2 kelas yaitu yang memenuhi
standar dan tidak memenuhi standar untuk dikonsumsi. Bidang penelitian klasifikasi objek
telah banyak dilakukan, sehingga memungkinkan diciptakan teknologi dalam bidang
klasifikasi objek dengan akurasi tinggi. Terdapat banyak metode klasifikasi, dalam penelitian
ini membahas komparasi antara algoritme K-Nearest-Neighbors (KNN) dengan Support
vector machine (SVM). Dilakukan penelitian terhadap variabel - variabel dalam algoritme
knn dan svm untuk menentukan variabel terbaik dalam melakukan klasifikasi. Pengujian
dilakukan dengan metode K-Fold dengan nilai K = 5 terhadap sebuah dataset status kualitas
air. Pengujian yang dilakukan mendapatkan nilai parameter optimal KNN dengan K = 7 dan
SVM dengan nilai iterasi maksimal = 300, nilai 𝜀 = 10
−12, nilai 𝜎 = 0.07, nilai 𝜆 = 3, nilai
𝛾 = 1.7, dan nilai 𝐶 = 1. Penelitian ini menghasilkan hasil akurasi KNN sebesar 88,94% dan
SVM sebesar 87,71%. Diamati bahwa algoritme K-Nearest-Neighbors (KNN) memiliki
akurasi lebih tinggi daripada algoritme Support vector machine (SVM).
Kata kunci: Pembelajaran Mesin, K-Nearest-Neighbors, Support Vector Machine
AbstractWater quality status classification for the community is divided into 2 classes namely those
that meet the standards and do not meet the standards for consumption. The field of object
classification research has been carried out, making it possible to create technology in the
field of object classification with high accuracy. There are many classification methods, in
this study discussing the comparison between K-Nearest-Neighbors (KNN) algorithm and
Support vector machine (SVM). Research on the variables in the KNN and SVM algorithm to
determine the best variable in classification. Testing is done by the K-Fold method with a
value of K = 5 on a dataset of water quality status. Tests carried out to get the optimal
parameter value KNN with K = 7 and SVM with value of the maximum iteration value
=
300, 𝜀 = 10
−12,
𝜎 = 0.07, 𝜆 = 3, 𝛾 = 1.7, and 𝐶 = 1. This research resulted in an
accuracy of KNN of 88.94% and SVM of 87.71%. It was observed that the
K-Nearest-Neighbors (KNN) algorithm had higher accuracy than the Support vector machine (SVM)
algorithm.`
Keywords: Machine Learning, K-Nearest-Neighbors, Support Vector Machine
1. PENDAHULUAN
Pembuangan sampah yang mengandung berbagai macam bakteri menjadi ancaman nyata bagi kehidupan masyarakat karena sebagian besar masyarakat bergantung pada air sungai ketika air sungainya digunakan untuk bahan
baku air minum PDAM. Sebagian besar air yang dikonsumsi manusia adalah air yang sudah dimurnikan. Air yang dikonsumsi oleh manusia banyak yang bersumber dari air dalam ledeng dan air dalam kemasan botol. Oleh karena itu diperlukan pengukuran kualitas air untuk menentukan kondisi air yang akan
dikonsumsi. Beberapa metode Indeks Kualitas Air (IKA) yang digunakan di Indonesia untuk melakukan penentuan status kualitas air adalah metode PI (Pollution Index), metode CCME (Canadian Council of Ministers of the Environment), dan metode STORET yang melakukan perbandingan data status kualitas air dengan baku mutu yang disesuaikan dengan indeksnya. Oleh karena itu, dilakukan penelitian untuk melakukan komparasi metode K-Nearest Neighbors dengan metode Support Vector Machines dalam mengklasifikasikan status kualitas air.
Penelitian tentang komparasi antar metode sudah sering dilakukan dalam beberapa waktu ini seperti pada penelitian sebelumnya yang dilakukan oleh M. Sakizadeh dan R. Mirzaei yang melakukan kopmparasi metode K-Nearest Neighbors dan Support Vector Machines mendapatkan hasil akurasi sebanyak 93% dan 94%. Penelitian lain yang telah dilakukan oleh Pathanjali C, Vimuktha E. Slis, Jalaja G., dan Latha A. yang mengkomparasi metode Support Vector Machines dengan K-Nearest Neighbors didapatkan kesimpulan hasil akurasi masing – masing sebesar 68,8383% dan 68.16%. Penelitian lain yang dilakukan oleh Shiela Novelia Dharma Pratiwi dan Brodjol Sutijo Suprih Ulama melakukan komparasi antara metode Support Vector Machines dengan K-Nearest Neighbors menghasilkan akurasi sebesar 96.6% dan 92.293%.
Berdasarkan pada penelitian sebelumnya, metode K-Nearest Neighbors (K-NN) dengan Support Vector Machine (SVM) merupakan metode dengan nilai akurasi yang cukup tinggi. Sehingga pada penelitian ini akan dilakukan penelitian tentang komparasi antara metode K-Nearest Neighbors (K-NN) dengan metode Support Vector Machine (SVM) yang bertujuan untuk mengetahui dan menentukan metode mana yang paling baik dalam melakukan klasifikasi terhadap kualitas air berdasarkan tingkat akurasinya.
2. METODE YANG DIGUNAKAN 2.1 Lazy Learners
Pada klasifikasi lazy learners pada saat diberikan tuple pelatihan maka hanya akan menyimpannya (atau hanya memproses kecil) dan menunggu sampai diberi tes tuple. Hanya ketika melihat tes tuple yang maka lazy learners akan melakukan generalisasi untuk mengklasifikasikan tuple berdasarkan
kesamaannya dengan pelatihan yang disimpan pada tuple (Han, et al., 2012).
2.1.1 Algoritme K-Nearest Neighbors (K-NN) Algoritma k-nearest neighbors pertama kali ditemukan pada awal tahun 1950-an.
K-nearest neighbors didasarkan pada
pembelajaran dengan analogi, yaitu dengan membandingkan tuple tes yang diberikan dengan tuple pelatihan yang serupa dengannya. Tuple pelatihan dijelaskan oleh n atribut (Han, et al., 2012).
Setiap tuple mewakili titik dalam ruang n-dimensi. Dengan cara ini, semua tuple pelatihan disimpan dalam ruang pola n-dimensi. Saat diberikan sebuah tuple yang tidak dikenal, sebuah k-terdekat-tetangga pengklasifikasi mencari ruang pola untuk k tuple pelatihan yang paling dekat dengan tuple yang tidak dikenal. Pelatihan k adalah k "Tetangga terdekat" dari tuple yang tidak dikenal (Han, et al., 2012).
"Kedekatan" didefinisikan dalam hal metrik jarak, seperti jarak Euclidean. Jarak Euclidean antara dua titik atau tuple, katakanlah, 𝑋1= (𝑥11, 𝑥12, … . , 𝑥1𝑛) dan 𝑋2=
(𝑥21, 𝑥22, … . , 𝑥2𝑛), adalah (Han, et al., 2012):
𝑑𝑖𝑠𝑡(𝑋1, 𝑋2) = √∑(𝑥1𝑖− 𝑥2𝑖)2 𝑛
𝑖=1
(1)
2.2 Metode Support Vector Machine (SVM) Support Vector Machine (SVM) adalah sistem pembelajaran dimana klasifikasi menggunakan ruang hipotesis dalam bentuk fungsi linear dalam ruang fitur dimensi tinggi, dilatih dengan algoritme pembelajaran berdasarkan teori optimasi dengan menerapkan bias pembelajaran yang berasal dari teori pembelajaran statistik (Cristiani & Taylor, 2000).
Gagasan dasarnya adalah menemukan hyperplane pemisah menjadi hyperplane tengah antara dua hyperplanes paralel, di mana dua hyperplane paralel ini dibangun mengikuti prinsip margin maksimum. SVM memiliki banyak keunggulan. Pertama, ia dapat memperoleh solusi optimal global dengan memecahkan masalah quadratic programming problem (QPP). Kedua, dapat meminimalkan batas atas kesalahan generalisasi dengan menerapkan prinsip minimalisasi risiko struktural, bukan prinsip minimalisasi risiko empiris. Keunggulan selanjutnya yaitu dapat mengubah case nonlinear menjadi case linier
Fakultas Ilmu Komputer, Universitas Brawijaya dengan memperkenalkan trik kernel ke dalam QPP ganda (Hou, et al., 2019).
2.2.1 SVM Non Linear
Gagasan perhitungan pada SVM non linear adalah memetakan data ruang input ke ruang dimensi yang lebih tinggi yang disebut dengan ruang fitur dan untuk mendefinisikan klasifikasi linear dalam ruang fitur. Pertimbangan pemetaan pada 𝜙 ∶ 𝑅𝑛→
𝐻 dimana 𝐻 adalah ruang Euclidean (ruang fitur) yang memiliki dimensi lebih besar dari 𝑛 (dimensi dapat bersifat infinite). Input vector training 𝑥𝑖 dipetakan dalam 𝜙(𝑥𝑖), dengan 𝑖 =
1, … , 𝑙.
Kita dapat berpikir untuk melakukan definisi SVM linear dalam ruang fitur dengan mengganti 𝑥𝑖 dengan 𝜙(𝑥𝑖). Kemudian kita
memiliki (Piccialli & Sciandrone, 2018):
Masalah tersebut diganti dengan Persamaan
2
min 𝜎 𝛤(𝜎) = 1 2∑ ∑ 𝑦 𝑖𝑦𝑗 𝑛 𝑗=1 𝑛 𝑖=1 𝜙(𝑥𝑖)𝑇𝜙(𝑥𝑗)𝜎 𝑖𝜎𝑗− ∑ 𝜎𝑖 𝑛 𝑖=1 𝑠. 𝑡 ∑ 𝜎𝑖𝑦𝑖= 0 𝑛 𝑖=1 0 ≤ 𝜎𝑖 ≤ 𝐶 𝑖 = 1, … , 𝑛 (2)Vector utama
𝑤
∗yang optimal diperoleh
dengan perhitungan Persamaan 3.
𝑤∗= ∑ 𝜎𝑖∗𝑦𝑖 𝑛
𝑖=1
𝜙(𝑥𝑖) (3)
Pemberian
𝑤
∗dan semua nilai dalam atas
0 < 𝜎
𝑖∗< 𝐶, b* dapat didefinisikan dengan
kondisi komplemen seperti pada Persamaan
4.
𝑦𝑖(∑ 𝜎 𝑗∗ 𝑛 𝑗=1 𝑦𝑗𝜙(𝑥𝑗)𝑇𝜙(𝑥𝑖) + 𝑏∗) − 1 = 0 (4)Diambil keputusan menggunakan fungsi
pada Persamaan 5.
𝑓𝑑(𝑥) = 𝑠𝑔𝑛((𝑤∗)𝑇𝜙(𝑥) + 𝑏∗) (5)
Dari persamaan 5 dapatkan permukaan
pemisah yaitu:
- Linear dalam ruang fitur - Non linear dalam ruang input
Penting untuk mengamati dala formulasi ganda persamaan 4 dan dalam rumus persamaan 5 tentang fungsi keputusan mengetahui pemetaan secara eksplisit tetapi cukup mengetahui dalam 𝜙(𝑥)𝑇𝜙(𝑧) dari ruang fitur.
Konsep ini mengarah pada konsep dasar fungsi kernel.
Fungsi kernel pada Persamaan 6
didefinisikan sebagai (Piccialli & Sciandrone, 2018)
𝐾(𝑥, 𝑦) = 𝜙(𝑥)𝑇𝜙(𝑦) ∀𝑥, 𝑦 ∈ 𝑋, (6) Masalah yang dialami dalam Persamaan 2.2 diatasi dengan mengganti perhitungan dengan Persamaan 2.7. min 𝜎 𝛤(𝜎) = 1 2∑ ∑ 𝑦 𝑖𝑦𝑗 𝑛 𝑗=1 𝑛 𝑖=1 𝐾(𝑥𝑖, 𝑥𝑗)𝜎 𝑖𝜎𝑗− ∑ 𝜎𝑖 𝑛 𝑖=1 𝑠. 𝑡 ∑ 𝜎𝑖𝑦𝑖= 0 𝑛 𝑖=1 0 ≤ 𝜎𝑖 ≤ 𝐶 𝑖 = 1, … , 𝑛 (7)
Permasalahan yang dialami pada persamaan 7 dapat disebut convex quadratic programming. Contoh fungsi kernel dapat dilihat pada Tabel 1 (Han, et al., 2012).
Tabel 1 Fungsi Kernel Kernel Linier 𝐾(𝑥, 𝑦) = 𝑥. 𝑦 Polymomial 𝐾(𝑥, 𝑦) = (𝑥. 𝑦 + 𝑐)𝑑 Radial Basis Function (RBF) 𝐾(𝑥⃑, 𝑦⃑) = exp (−‖𝑥⃑ − 𝑦⃑‖ 2 2𝜎2 ) Sigmoid 𝐾(𝑥, 𝑦) = tanh(𝑘〈𝑥⃑. 𝑦⃑〉 + 𝜗) Dengan melakukan penyelesaian pada QP Persamaan 7, didapatkan Persamaan 8 yang disebut sebagai fungsi bidang pemisah (Huang, et al., 2006).
𝑑(𝑥) = ∑ 𝑦𝑖𝛼𝑖𝐾(𝑥𝑖, 𝑥𝑗) + 𝑏 𝑛
𝑖=1
(8) Dimana persamaan 𝑏 dihitung dengan
Persamaan 9. 𝑏 = −1 2(𝑥 +. 𝑤 + 𝑥−. 𝑤) = −1 2(∑ 𝑦𝑖𝛼𝑖𝐾(𝑥𝑖, 𝑥 +) 𝑛 𝑖=1 + ∑ 𝑦𝑖𝛼𝑖𝐾(𝑥𝑖, 𝑥−) 𝑛 𝑖=1 ) (9)
Dengan menggunakan fungsi kernel, keputusan dari kelas diputusan menggunakan fungsi Persamaan 10 (Piccialli & Sciandrone, 2018). 𝑓𝑑(𝑥) = 𝑠𝑖𝑔𝑛(𝑑(𝑥))
= 𝑠𝑖𝑔𝑛 (∑ 𝑦𝑖𝛼𝑖𝐾(𝑥𝑖, 𝑥𝑗) + 𝑏 𝑛
𝑖=1
) (10)
2.3 Metode Sequential Learning SVM
Algoritme ini dapat menemukan bidang pemisah yang optimal lebih cepat dibandingkan quadratic programming. Algoritme sequential learing SVM dituliskan sebagai berikut (Vijakumar & Wu, 1999):
1. Semua data 𝑖 = 1, … , 𝑛 dan inisialisasi 𝛼𝑖= 0
2. Perhitungan matriks 𝐷𝑖𝑗
𝐷𝑖𝑗 = 𝑦𝑖𝑦𝑗(𝐾(𝑥𝑖, 𝑥𝑗) + 𝜆2) (11)
3. Melakukan perhitungan 𝐸𝑖, 𝛿𝛼𝑖, dan 𝛼𝑖
untuk setiap data training 𝑖 = 1, … , 𝑛 𝐸𝑖 = ∑ 𝛼𝑘𝐷𝑖𝑘 𝑛 𝑘=1 (12) 𝛿𝛼𝑖 = min {max[𝛾(1 − 𝐸𝑖), −𝛼𝑖], 𝐶 − 𝛼𝑖} (13) 𝛼𝑖= 𝛿𝛼𝑖+ 𝛼𝑖 (14)
Melakukan perulangan pada langkah 3 sampai syarat 𝑖𝑡𝑒𝑟𝑎𝑠𝑖 > 𝑖𝑡𝑒𝑟𝑎𝑠𝑖_𝑚𝑎𝑥 atau max(|𝛿𝛼|) < 𝜀 terpenuhi.
2.4 Metode Pengujian K-Fold
Pengujian ini mengumpulkan data secara acak kemudian dibagi menjadi k bagian terpisah dengan ukuran kira – kira sama dan setiap lipatan atau bagiannya digunakan secara giliran untuk menguji model yang diinduksi dari k-1 dan seterusnya. Setiap perkiraan akurasi yang dihasilkan dari validasi silang k-fold didapatkan dari hasil perhitungan akurasi dengan data acak pada tiap k-nya. Model yang diinduksi dalam iterasi k dalam validasi silang metode k-fold umumnya tidak semuanya sama (Wong & Yang, 2017).
Pemilihan nilai k dalam validasi silang metode k-fold biasanya bernilai 5 atau 10, tetapi tidak terdapat aturan formal. Saat nilai k bertambah besar, maka perbedaan ukuran antara data uji dan data latih menjadi lebih kecil (Brownlee, 2018). Adanya pertukaran bias-variance dalam pemilihan k dalam metode k-fold biasanya dengan pertimbangan ini maka dipilih nilai k=5 atau k=10, karena nilai – nilai ini telah dipilih secara empiris untuk menghasilkan perkiraan akurasi yang tidak menyebabkan bias yang terlalu tinggi maupun varian yang sangat tinggi (Kuhn & Johnson, 2013).
3. METODOLOGI PENELITIAN 3.1 Data Yang Digunakan
Teknik pengumpulan data pada penelitian ini menggunakan data yang diperoleh dari laboratorium PDAM Kota Malang tentang data kualitas air. Data hasil penjualan dimulai pada bulan juli 2018 sampai bulan januari 2019. Data yang digunakan adalah sebanyak 167 data
dengan parameter yang digunakan adalah derajat keasaman (pH), Total Dissolved Solids (TDS), Nitrit (NO2), Nitrat (NO3), kesadahan,
klorida, mangan. Kemudian akan diuji menggunakan metode k-fold dengan nilai k=5. 3.2 Diagram Alir Algoritme K-Nearest
Neighbors (K-NN)
Alur evaluasi menggunakan metode K-Nearest Neighbors (K-NN) dituliskan pada flowchat yang dapat diamati pada Gambar 1. Evaluasi ini bertujuan untuk mendapatkan hasil klasifikasi status kualitas air. Metode ini melakukan evaluasi terhadap masing – masing data uji untuk dibandingkan dengan seluruh data latih sistem. Algoritme ini menghitung jarak antara data tiap parameter data uji terhadap seluruh data latih yang ada dalam sistem menggunakan perhitungan jarak Euclidean. Setelah itu dilakukan pengurutan nilai jarak Euclidean dari terkecil hingga terbesar. Kemudian dipilih sebanyak 𝑘 data terkecil untuk kemudian ditentukan hasil kelasnya berdasarkan jumlah klas yang sering muncul. Kelas yang sering muncul ini merupakan hasil klasifikasi dari sistem evaluasi dengan algoritme K-NN.
Gambar 1. Diagram Alir Algoritme K-Nearest
Neighbors
3.3 Diagram Alir Algoritme Support Vector
Machine
3.3.1 Evaluasi dengan SVM
Alur evaluasi menggunakan metode Support Vector Machine (SVM) dituliskan pada flowchat yang dapat diamati pada Gambar 2. Pada evaluasi ini bertujuan untuk memperoleh hasil kelas dalam klasifikasi status kualitas air. Pada tahapan proses pada SVM Biner dapat diperoleh hasil dari pengklasifikasian sistem evaluasi dengan perhitungan algoritme Support Vector Machine (SVM).
Fakultas Ilmu Komputer, Universitas Brawijaya
Gambar 2. Diagram Alir Support Vector Machine (SVM)
3.3.2 SVM Biner
Proses SVM Biner adalah proses yang melakukan klasifikasi terhadap masing – masing data uji kemudian dikategorikan dalam kelas bertanda positif (1) atau kelas bertanda negatif (−1). Untuk memulai melakukan perhitungan rumus sequential learning, maka dilakukan langkah sebagai berikut:
1. Langkah pertama adalah dibentuknya matriks 𝐷𝑖𝑗 yang berisi nilai dari hasil
perhitungan menggunakan Persamaan 2.11 dengan nilai 𝑖 dan 𝑗 memiliki rentang 1 hingga jumlah data latih.
2. Langkah kedua adalah dilakukannya inisialisasi pada nilai parameter 𝛼𝑖 = 0.
3. Langkah ketiga adalah kemudian dihitung nilai dari parameter 𝐸𝑖 berdasarkan
Persamaan 2.12. Dari nilai 𝐸𝑖 selanjutnya
akan didapatkan perubahan nilai alpha 𝛿𝛼𝑖
sesuai dengan rumus pada Persamaan 2.13. 4. Langkah keempat kemudian dilakukan perbaruan nilai 𝛼𝑖 dengan cara
menambahkan nillai 𝛼𝑖 dan 𝛿𝛼𝑖. Proses
perbaruan nilai 𝛼𝑖 dilakukan secara
berulangkal dengan syarat yaitu jika 𝑖𝑡𝑒𝑟𝑎𝑠𝑖 < 𝑖𝑡𝑒𝑟𝑎𝑠𝑖_ max 𝑑𝑎𝑛 max(⌈𝛿𝛼⌉) < 𝜀.
5. Langkah kelima yaitu setelah didapatkan nilai akhir dari 𝛼𝑖 kemudian dicari nilai
Support Vectors (SV), yang merupakan data yang memiliki nilai 𝛼𝑖 > 𝑡ℎ𝑟𝑒𝑠ℎ𝑜𝑙𝑑.
Perhitungan nilai 𝑏 tersebut menggunakan rumus yang ada pada Persamaan 9. Kemudian hasil klasifikasi didapatkan berdasarkan perhitungan menggunakan Persamaan 10. Alur proses perhitungan SVM biner ini dapat dilihat dalam Gambar 3.
Gambar 3. Diagram Alir SVM Biner
4. HASIL DAN PEMBAHASAN
4.1 Pengujian Pengaruh Nilai Parameter Pengujian pengaruh nilai parameter yang dilakukan ini bertujuan untuk mengetahui seberapa berpengaruh atau tidaknya nilai parameter terhadap nilai error pada proses klasifikasi hasil status kualitas air ketika nilai parameter tersebut diubah-ubah.
4.1.1 Pengujian Pengaruh Nilai 𝒌 pada metode K-Nearest Neighbors
Hasil analisis dan pengujian nilai k pada algoritme K-Nearest Neighbors (KNN) dapat dilihat pada grafik pada Gambar 4. Pada pengujian tersebut nilai k dengan akurasi tertinggi adalah 7. Sehingga nilai parameter terbaik dan nilai yang akan digunakan selanjutnya adalah 𝑘 = 7.
Gambar 4. Grafik Pengaruh Nilai k Parameter Metode K-Nearest Neighbor
4.1.2 Pengujian Pengaruh Nilai Parameter Metode Support Vector Machine
4.1.2.1 Pengujian Pengaruh Nilai Parameter 𝜶 Pada Metode Support Vector Machine
Gambar 5. Grafik Pengaruh Nilai Parameter 𝛼 Metode Support Vector Machine
Hasil analisis dan pengujian pada nilai σ pada algoritme Support Vector Machine (SVM) dapat diamati grafiknya pada Gambar 5. Pada pengujian tersebut nilai σ dengan akurasi tertinggi adalah pada saat nilai σ = 0.07. Sehingga nilai parameter terbaik dan nilai yang akan digunakan selanjutnya adalah σ = 0.07. 4.1.2.2 Pengujian Pengaruh Nilai Parameter 𝝀 Pada Metode Support Vector Machine
Hasil analisis dan pengujian pada nilai λ pada algoritme Support Vector Machine (SVM) dapat diamati dalam grafiknya pada Gambar 6. Pada pengujian tersebut nilai λ dengan akurasi tertinggi adalah pada saat nilai λ = 3. Sehingga nilai parameter terbaik dan nilai yang akan digunakan selanjutnya adalah λ = 3.
Gambar 6. Grafik Pengaruh Nilai Parameter 𝜆
Metode Support Vector Machine
4.1.2.3 Pengujian Pengaruh Nilai Parameter 𝛄 Pada Metode Support Vector Machine
Gambar 7. Grafik Pengaruh Nilai Parameter γ Metode Support Vector Machine
Hasil analisis dan pengujian nilai γ pada
algoritme Support Vector Machine (SVM dapat diamati dalam grafiknya pada Gambar 7. Pada pengujian tersebut nilai γ dengan akurasi tertinggi adalah pada saat nilai γ = 1.7. Sehingga nilai parameter terbaik dan nilai yang akan digunakan selanjutnya adalah γ = 1.7. 4.1.2.4 Pengujian Pengaruh Nilai Parameter 𝑪 Pada Metode Support Vector Machine
Hasil analisis dan pengujian nilai C pada algoritme Support Vector Machine (SVM) dapat diamati dalam pada grafiknya pada Gambar 8. Pada pengujian tersebut nilai 𝐶 dengan akurasi tertinggi adalah pada saat nilai C = 1
.
Sehingga nilai parameter terbaik dan nilai yang akan digunakan selanjutnya adalah C = 1.Gambar 8. Grafik Pengaruh Nilai Parameter C Metode Support Vector Machine
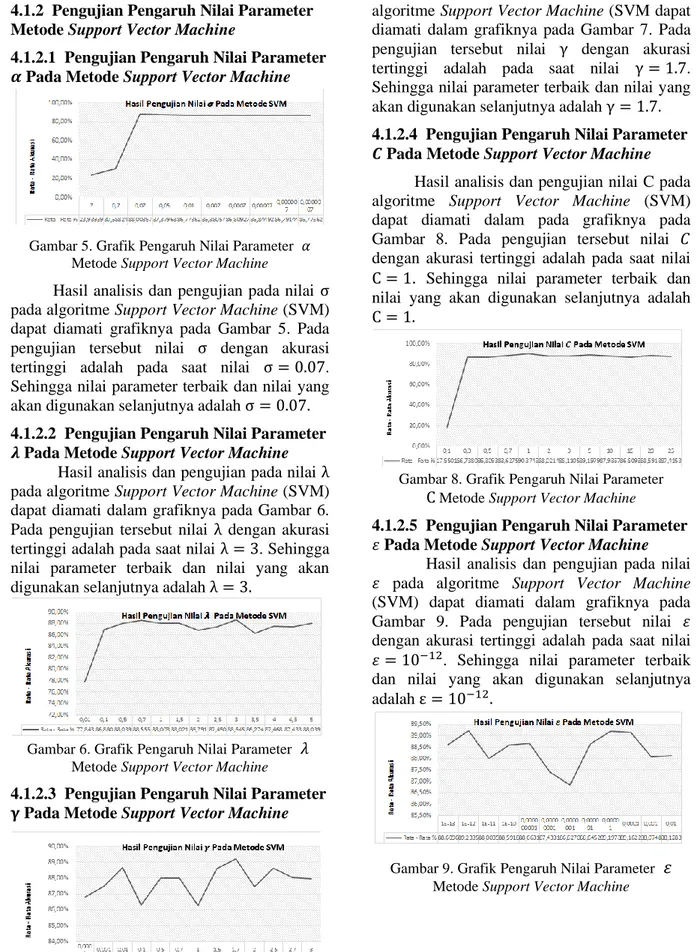
4.1.2.5 Pengujian Pengaruh Nilai Parameter 𝜀 Pada Metode Support Vector Machine
Hasil analisis dan pengujian pada nilai 𝜀 pada algoritme Support Vector Machine (SVM) dapat diamati dalam grafiknya pada Gambar 9. Pada pengujian tersebut nilai 𝜀 dengan akurasi tertinggi adalah pada saat nilai 𝜀 = 10−12. Sehingga nilai parameter terbaik dan nilai yang akan digunakan selanjutnya adalah ε = 10−12.
Gambar 9. Grafik Pengaruh Nilai Parameter
𝜀
Fakultas Ilmu Komputer, Universitas Brawijaya
4.1.2.6 Pengujian Pengaruh Nilai Parameter Iterasi Maksimal Pada Metode Support
Vector Machine
Gambar 10. Grafik Pengaruh Nilai Parameter C Metode Support Vector Machine
Hasil analisis dan pengujian terhadap nilai dari jumlah iterasi maksimal pada algoritme Support Vector Machine (SVM) dapat diamati dalam dan grafiknya pada Gambar 10. Pada pengujian tersebut nilai iterasi maksimal dengan akurasi tertinggi adalah 300. Sehingga nilai parameter terbaik dan nilai yang akan digunakan selanjutnya adalah iterasi maksimal = 300.
4.3 Pengujian Akhir
Berdasarkan hasil pengujian parameter – parameter KNN dan SVM, dapat disimpulkan didapatkan parameter – parameter terbaik. Pengujian sistem menggunakan parameter – parameter terbaik dalam Tabel 2 dilakukan sebanyak 15 kali untuk melihat kestabilan sistem dalam melakukan klasifikasi data. Pada Gambar 11 juga dapat diketahui grafik hasil nilai rata – rata akurasi algoritme K-Nearest Neighbors dan Support Vector Machine. Hasil akurasi rata – rata algoritme K-Nearest Neighbors dan Support Vector Machine adalah 91.57% dan 89.22%. Berdasarkan pengujian yang telah dilakukan dapat disimpulkan bahwa algoritme K-Nearest Neighbors dapat melakukan klasifikasi data stastus kualitas air lebih baik dibandingkan dengan algoritme Support Vector Machine.
Tabel 2. Pengujian Akhir Metode KNN dan SVM No Akurasi KNN SVM 1 88.59% 87.99% 2 89.80% 87.38% 3 91.03% 89.22% 4 86.27% 86.27% 5 88.02% 88.04% 6 89.23% 86.86% 7 89.23% 86.84% 8 89.20% 88.61% 9 87.40% 88.02% 10 89.18% 87.40% 11 91.57% 87.99% 12 90.43% 86.81% 13 87.45% 88.04% 14 89.25% 88.06% 15 87.49% 88.06% Rata - Rata 88.94% 87.71%
Gambar 9. Grafik Pengujian Akhir Metode KNN dan SVM
5. KESIMPULAN
Dari hasil yang didapatkan dalam penelitian tentang komparasi metode K-Nearest Neighbors dengan Support Vector Machine untuk melakukan klasifikasi status kualitas air didapatkan kesimpulan sebagai berikut:
1. Sistem ini diimplementasikan menggunakan bahasa pemrograman Phyton dan dijalankan menggunakan IDE Spyder. 2. Akurasi rata – rata yang didapatkan dengan
metode K-Nearest Neighbors dan Support Vector Machine adalah sebesar 88.94% dan 87.71%. Diketahui dari hasil tersebut metode K-Nearest Neighbors (KNN) merupakan metode yang lebih baik dalam melakukan klasifikasi status kualitas air dalam penelitian ini karena memiliki nilai rata – rata akurasi lebih tinggi dibandingkan dengan metode Support Vector Machine (SVM). Setelah dilakukan analisis pada penelitian ini diketahui bahwa data yang digunakan memiliki sifat imbalanced sehingga menyebabkan pada metode K-Nearest Neighbors (KNN) sebanyak 11.06% data diklasifikasikan salah dikarenakan saat data sebanyak 𝒌 tetangga terdekat diambil, hasilnya akan cenderung ke arah data mayoritas. Sedangkan pada metode Support Vector Machine (SVM) terdapat 12.29% data diklasifikasikan salah karena kurang dapat dihasilkan garis pemisah yang tepat.
3. Nilai – nilai terbaik untuk melakukan akurasi yang digunakan pada variabel di
dalam kedua metode yang digunakan adalah sebagai berikut:
I.
Parameter untuk Algoritme K-Nearest Neighbors (K-NN):a. Nilai 𝑘 = 7
II. Parameter untuk Algoritme Support Vector Machine (SVM):
a. Nilai Iterasi maksimal SVM = 300 b. Nilai 𝜀 = 10−12 c. Nilai 𝜎 = 0.07 d. Nilai 𝜆 = 3 e. Nilai 𝛾 = 1.7 f. Nilai 𝐶 = 1 6. DAFTAR REFERENSI
Brownlee, J., 2018. Machine Learning Mastery. [Online]
Available at:
https://machinelearningmastery.com/k-fold-cross-validation/
[Diakses 10 Desember 2019].
Han, J., Kamber, M. & Pei, J., 2012. Data Mining Concepts and Techniques. 3 penyunt. Waltham: Elsevier.
Hou, Q. et al., 2019. Discriminative
information-based nonparallel support vector machine. Elsevier, Volume 162, pp. 169 - 179. Huang, T., Kecman, V. & Kopriva, I., 2006. Kernel Based Algorithms for Mining Huge Data Sets. Heidelberg: Springer-Verlag Berlin Heidelberg .
Kuhn, M. & Johnson, K., 2013. Applied Predictive Modeling. Dalam: Applied Predictive Modeling. s.l.:Springer, p. 70. Piccialli, V. & Sciandrone, M., 2018. Nonlinear Optimization and Support Vector Machines, s.l.: ResearchGate.
Vijakumar, S. & Wu, S., 1999. Sequential Support Vector Classifiers and Regression. Wakoshi, ResearchGate.
Wong, T. T. & Yang, N. Y., 2017. Dependency Analysis of Accuracy Estimates in k-Fold Cross Validation. IEEE Transactions on Knowledge and Data Engineering, 29(11), pp. 2417 - 2427.