i
KLASIFIKASI STATUS GIZI BALITA MENGGUNAKAN METODE MODIFIED K-NEAREST NEIGHBORS (MKNN)
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
Oleh:
Ferdinandus Lembambang Sula 165314046
PROGRAM STUDI INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2021
ii
CLASSIFICATION OF NUTRITIONAL STATUS IN TODDLERS USING MODIFIED K-NEAREST NEIGHBORS METHOD (MKNN)
A THESIS
Present as Partial Fulfillment of the Requirement to Obtain Sarjana Komputer Degree
in Informatics Study Program
Written By:
Ferdinandus Lembambang Sula 165314046
INFORMATICS STUDY PROGRAM DEPARTMENT OF INFORMATICS FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
2021
iii
iv
v
HALAMAN PERSEMBAHAN
“Semakin jauh perjalanan, semakin berat tantangannya semakin mengubah orang yang terlibat di dalamnya.”
(SEE)
Skripsi ini saya persembahkan untuk:
Tuhan Yesus Kristus
Papa, Mama, Kakak dan Adik-adik serta seluruh anggota keluarga saya Bapak dan Ibu Dosen Informatika Sanata Dharma
Sahabat The Crips dan Sama Dihek serta seluruh teman-teman saya Terimakasih telah mendukung, mendoakan dan selalu memberikan semangat.
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak mengandung atau memuat hasil karya orang lain, kecuali yang telah disebutkan dalam daftar pustaka dan kutipan selayaknya karya ilmiah.
Yogyakarta, 04 Januari 2021 Penulis,
Ferdinandus Lembambang Sula
vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma:
Nama : Ferdinandus Lembambang Sula Nim : 165314046
Demi pengembangan pengetahuan, saya memberikan kepada perpustakaan Universitas Sanata Dharma karta ilmiah yang berjudul:
KLASIFIKASI STATUS GIZI BALITA MENGGUNAKAN METODE MODIFIED K-NEAREST NEIGHBORS (MKNN)
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan Kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengolah dalam bentuk pangkalan data, mendistribusikan secara terbatas dan mempublikasikan di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yogyakarta, 04 Januari 2021 Penulis,
Ferdinandus Lembambang Sula
viii ABSTRAK
Status gizi balita merupakan hal yang sangat penting untuk diketahui oleh para orang tua. Hanya dengan melihat perkembangan balita secara fisik saja tentu tidak cukup untuk mengetahui status gizi dari balita tersebut. Maka dilakukan penelitian untuk mengklasifikasi kategori status gizi menggunakan indeks berupa berat badan / umur, panjang badan / umur dan berat badan / panjang badan sesuai yang dipaparkan dalam buku Antropometri.
Penelitian ini menggunakan teknik data mining dengan menerapkan metode Modified K-Nearest Neighbors. Data yang digunakan adalah data pemantauan status gizi (PSG) tahun 2017 di Puskesmas Kebong, Kecamatan Kelam Permai oleh Dinas Kesehatan Kabupaten Sintang, Kalimantan Barat. Metode Modified K-Nearest Neighbors melakukan klasifikasi berdasarkan label yang memiliki jumlah weight voting terbesar pada k-tetangga terdekat dari data yang diklasifikasi.
Keluaran dari sistem ini adalah klasifikasi status gizi balita berdasarkan BB/U, PB/U dan PB/BB. Uji akurasi penelitian ini menggunakan cross validation dan confusion matrix. Dalam penelitian ini, dilakukan percobaan dengan membandingkan jumlah data, variasi k-fold dan knn serta penggunaan normalisasi min-max.
Data dibagi menjadi 4 dengan jumlah yang berbeda, yaitu 150, 250, 450 dan 850 menghasilkan nilai akurasi yang berbeda-beda, namun hal tersebut juga dipengaruhi oleh variasi k-fold dan knn yang digunakan. Percobaan dengan menerapkan normalisasi min-max dengan jumlah data 250, variasi k-fold = 9 dan knn = 3 menghasilkan nilai akurasi tertinggi yaitu 76.7196%. Pada percobaan yang dilakukan tanpa menerapkan normalisasi min-max nilai akurasi tertinggi didapat pada percobaan dengan jumlah data 850, variasi k-fold = 9 dan knn = 3 yaitu 81.5615%.
Kata Kunci: Modified K-Nearest Neighbors, Klasifikasi, Status Gizi
ix ABSTRACT
The nutritional status of children under five is very important for parents to know.
Just looking at a toddler’s physical development is of course not enough to see the nutritional status of these toddlers. For this reason, a study was made to classify the nutritional status category using the index of body weight / age, body length / age and body weight / length as described in the Anthropometry book.
This research uses data mining techniques by applying the Modified K-Nearest Neighbors method. The data used is nutritional status monitoring data in 2017 at Puskesmas Kebong, West Borneo. The Modified K-Nearest Neighbors method classifies based on the label that has the largest number of weight voting on the K- Nearest Neighbors from the classified data.
The output of this system it the classification of the nutritional status of children under five based on BB/U, PB/U and PB/BB. This research accuracy test uses Cross Validation and Confusion Matrix. In this study an experiment was carried out by comparing the amount of nutritional status monitoring data, the variation of k-fold and knn values and using the min-max normalization.
The data is divided into 4 with different amounts, 150, 250, 450, and 850 resulting in different accuracy values, but this is also influenced by the variation of k- fold and knn values. Experiments by applying min-max normalization with 250 data, k-fold = 9 and knn = 3 resulted in the highest accuracy, 76.7176%. In the experiment carried out without applying the min-max normalization, the highest accuracy value was obtained in the experiment with 850 data, k-fold = 9 and knn 3, namely 81.5615%.
Keywords: Modified K-Nearest Neighbors, Classification, Nutritional Status
x
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa karena berkat rahmat dan karunianya, penulis dapat menyelesaikan tugas akhir yang berjudul
“Klasifikasi Status Gizi Balita Menggunakan Metode Modified K-Nearest Neighbors”
dengan baik dan lancar.
Dalam proses penulisan tugas akhir ini penulis menyadari ada begitu banyak pihak yang turut memberikan dukungan, motivasi dan doa. Pada kesempatan ini, dengan segenap kerendahan hati penulis menghaturkan terimakasih kepada:
1. Tuhan Yang Maha Esa yang telah memberikan berkat dan rahmat melimpah kepada penulis.
2. Kedua orang tua serta kakak dan adik-adik penulis yang selalu memberikan doa restu, kasih sayang, dukungan dan perhatian serta nasihat yang memotivasi penulis dalam penyelesaian tugas akhir.
3. Ibu Agnes Maria Polina, S.Kom., M.Sc selaku dosen pembimbing yang telah bersedia meluangkan waktu, memberikan saran dan arahan kepada penulis selama menyelesaikan tugas akhir.
4. Seluruh Dosen Prodi Informatika Universitas Sanata Dharma yang telah mendidik dan memberi ilmu pengetahuan yang berguna dalam penulisan tugas akhir ini.
5. Teman-teman “The Crips” dan “Sama Dihek” yang selalu menghibur dan mendukung dalam pengerjaan tugas akhir ini.
6. Saudara Johan Satria Kesuma, Ricky Ferdian dan Yanuariu Basilius yang telah meluangkan waktu dan tenaga untuk membantu dan menemani penulis bertukar pikiran dalam pengerjaan tugas akhir ini.
7. Teman-teman Prodi Informatika Universitas Sanata Dharma khususnya angkatan 2016 yang telah berdinamika bersama selama proses perkuliahan.
xi
Penulis menyadari bahwa penulisan tugas akhir ini masih belum sempurna, maka penulis mengharapkan kritik dan saran yang bersifat membangun untuk perbaikan dimasa yang akan datang. Semoga penulisan tugas akhir ini dapat bermanfaat dan berguna bagi semua pihak yang membacanya khususnya saya sebagai penulis.
Yogyakarta, 4 Januari 2021
Penulis
xii DAFTAR ISI
HALAMAN PERSETUJUAN PEMBIMBING ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI... vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL ... xiv
DAFTAR GAMBAR ... xv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Tujuan Penelitian ... 3
1.4 Batasan Masalah ... 3
1.5 Metodologi Penelitian ... 3
1.6 Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 6
2.1 Status Gizi ... 6
2.2 Penilaian Status Gizi ... 6
2.3 Knowledge Discovery in Database ... 7
2.4 Data Mining ... 8
2.5 Klasifikasi Pada Data Mining ... 10
2.6 Metode K-Nearest Neighbor (KNN) ... 11
2.7 Metode Modified K-Nearest Neighbor (MKNN) ... 11
2.8 K-fold Cross Validation... 14
xiii
2.9 Confusion Matrix ... 16
BAB III METODE PENELITIAN... 17
3.1 Gambaran Umum Sistem ... 17
3.2 Dataset ... 18
3.3 Seleksi Data ... 20
3.4 Transformasi Data ... 21
3.5 K-fold Cross Validation... 24
3.6 Pemisahan Data ... 26
3.7 Klasifikasi Modified K-Nearest Neighbor ... 26
3.8 Evaluasi Menggunakan Confusion Matrix ... 36
3.9 Spesifikasi Sistem ... 37
3.10 Desain Interface Alat Uji ... 38
BAB IV IMPLEMENTASI SISTEM ... 40
4.1 Implementasi Sistem ... 40
BAB V ANALISA HASIL ... 48
5.1 Uji Validasi Sistem ... 48
5.2 Pengujian Sistem ... 50
5.2.1 Perbandingan Nilai Akurasi Pada 150 Data PSG ... 51
5.2.2 Perbandingan Nilai Akurasi Pada 250 Data PSG ... 53
5.2.3 Perbandingan Nilai Akurasi Pada 450 Data PSG ... 54
5.2.4 Perbandingan Nilai Akurasi Pada 850 Data PSG ... 56
BAB VI PENUTUP ... 60
6.1 Kesimpulan ... 60
6.2 Saran ... 61
DAFTAR PUSTAKA ... 62
xiv
DAFTAR TABEL
Tabel 2.1 Tabel Standar Penilaian Status Gizi ... 7
Tabel 2.2 Confusion Matrix ... 16
Tabel 3.1 Atribut Dataset PSG ... 18
Tabel 3.2 Contoh Dataset PSG... 19
Tabel 3.3 Atribut data yang dihapus ... 20
Tabel 3.4 Contoh Data Sebelum Normalisasi ... 21
Tabel 3.5 Normalisasi Kolom Berat B ... 23
Tabel 3.6 Normalisasi Semua Data ... 24
Tabel 3.7 Contoh data fold pertama ... 25
Tabel 3.8 Contoh data fold kedua ... 25
Tabel 3.9 Contoh data fold ketiga ... 26
Tabel 3.10 Data fold pertama ... 28
Tabel 3.11 Jarak Euclidean Data latih fold pertama ... 28
Tabel 3.12 Perbandingan label data training denganl label tetangga terdekat...29
Tabel 3.13 Nilai Validitas data latih ... 30
Tabel 3.14 Jarak Euclidean data latih dan data uji fold pertama ... 32
Tabel 3.15 Weight voting terhadap semua data uji fold pertama ... 33
Tabel 3.16 Ranking Weight voting ... 34
Tabel 3.17 Ranking Weight voting ... 34
Tabel 3.18 Ranking Weight voting ... 35
Tabel 3.19 Hasil Klasifikasi MKNN Data Uji fold Pertama ... 35
Tabel 3.20 Confusion Matrix fold Pertama ... 36
Tabel 3.21 Confusion Matrix fold Kedua ... 36
Tabel 3.22 Confusion Matrix fold Ketiga ... 37
Tabel 3.23 Penjelasan Desain Interface Alat Uji ... 39
Tabel 5.1 Nilai Akurasi Pada Percobaan dengan Normalisasi Min-max ... 59
Tabel 5.2 Nilai Akurasi Pada Percobaan tanpa Normalisasi Min-max ... 59
xv
DAFTAR GAMBAR
Gambar 3.1 Gambaran Umum Sistem ... 17
Gambar 3.2 Alur Proses Metode Modified K-Nearest Neighbors ... 27
Gambar 3.3 Desain Interface Alat Uji ... 38
Gambar 4.1 Halaman Utama ... 40
Gambar 4.2 Listing Program Integrasi file .Ui dengan python ... 41
Gambar 4.3 Sub Menu File ... 41
Gambar 4.4 Halaman Load Data ... 41
Gambar 4.5 Listing Program Load File ... 42
Gambar 4.6 Menu Test MKNN ... 42
Gambar 4.7 Halaman Test MKNN ... 42
Gambar 4.8 Listing Program Test MKNN ... 43
Gambar 4.9 Cek Status Gizi Berdasarkan BB/U ... 44
Gambar 4.10 Halaman Cek Status Gizi Berdasarkan BB/U ... 44
Gambar 4.11 Halaman Hasil Klasifikasi Status Gizi Berdasarkan BB/U ... 45
Gambar 4.12 Listing Program Lihat Hasil Klasifikasi Status Gizi BB/U ... 45
Gambar 4.13 Cek Status Gizi Berdasarkan PB/U ... 46
Gambar 4.14 Halaman Cek Status Gizi Berdasarkan PB/U ... 46
Gambar 4.15 Halaman Hasil Klasifikasi Status Gizi Berdasarkan PB/U ... 47
Gambar 4.16 Listing Program Lihat Hasil Klasifikasi Status Gizi PB/U... 47
Gambar 5.1 Hasil Perhitungan Manual Menggunakan Excel ... 48
Gambar 5.2 Hasil Perhitungan Oleh Sistem ... 49
Gambar 5.3 Percobaan dengan 150 Data ... 51
Gambar 5.4 Percobaan dengan 250 Data ... 53
Gambar 5.5 Percobaan dengan 450 Data ... 55
Gambar 5.6 Percobaan dengan 850 Data ... 57
1 BAB I PENDAHULUAN
1.1. Latar Belakang
Status gizi balita merupakan hal penting yang seharusnya diketahui oleh semua orang khususnya para orang tua. Hal ini perlu diperhatikan, karena hanya dengan mengetahui perkembangan balita berdasarkan fisik saja tentu tidak cukup untuk mengetahui status gizi dari balita tersebut. Semestinya orang tua perlu memperhatikan lebih jauh mengenai perkembangan balita. Berdasarkan bukti data hasil Riset Kesehatan Dasar (Riskesdas) 2018 oleh Kementrian Kesehatan Republik Indonesia, memperlihatkan status gizi balita mengalami perbaikan secara nasional. Pada prevalensi gizi kurang, perbaikan itu terjadi berturut-turut dari tahun 2013 sebesar 19,6% kemudian turun menjadi 17,7% pada tahun 2018.
Prevalensi stunting, dari 37,2% turun menjadi 30,8% dan prevalensi kurus dari 12,1% turun menjadi 10,2%. Meskipun data tersebut menunjukkan adanya perbaikan status gizi secara nasional, namun belum bisa dibanggakan bangga karena dalam masalah gizi khususnya stunting menurut data yang dikumpulkan World Health Organization (WHO) Indonesia berada pada posisi ketiga dengan prevalensi tertinggi di Regional Asia Tenggara atau South-East Asia Regional (SEAR), dengan rata-rata prevalensi balita stunting di Indonesia dari tahun 2005- 2017 adalah 36,4%. Oleh karena itu masalah gizi di Indonesia harus benar-benar di atasi dan menjadi perhatian khusus bagi pemerintah serta seluruh masyarakat Indonesia khususnya para orang tua.
Untuk mengatasi kasus gizi buruk di Indonesia perlu adanya pendeteksi status gizi balita yang terpantau. Status gizi perlu diperhatikan karena berkaitan dengan perkembangan tubuh. Dipaparkan dalam buku Antropometri mengenai pengklasifikasian kategori status gizi anak menggunakan indeks berupa berat badan berdasarkan umur (BB/U), tinggi badan berdasarkan umur (TB/U) dan berat badan berdasarkan tinggi badan (BB/TB). Indeks berat badan berdasarkan
umur (BB/U) merupakan indikator yang paling umum digunakan karena mempunyai kelebihan yaitu mudah dan lebih cepat dimengerti oleh masyarakat umum serta baik untuk mengatur gizi akut dan kronis. Berat badan dapat berfluktuasi, sangat sensitif terhadap perubahan-perubahan kecil dan dapat mendeteksi kegemukan (over weight). Namun diketahui bahwa berat badan laki- laki dan perempuan mempunyai selisih berat yang signifikan, sehingga untuk pengklasifikasian status gizi dibutuhkan 3 parameter yaitu berupa umur, jenis kelamin dan berat badan yang didasarkan sumber dari buku Antropometri (Kementerian Kesehatan Republik Indonesia, 2010).
Pada penelitian sebelumnya yang dilakukan oleh (Kusumadewi, 2019) dengan judul ”Klasifikasi Status Gizi Menggunakan Naive Bayesian Classification” digunakan data 47 orang mahasiswa Teknik Informatika UII sebagai data sampel dengan rentang usia 19 sampai 22 tahun. Penelitian ini menggunakan lima variabel yaitu tinggi badan, berat badan, jenis kelamin, lingkar pergelangan dan lingkar perut, sehingga diperoleh kinerja yang terbilang baik dengan akurasi 93,2%.
Dalam penentuan status gizi dibutuhkan metode yang tepat untuk melakukan proses pengklasifikasian. Metode Modified K-Nearest Neighbors adalah modifikasi dari metode K-Nearest Neighbors yang diberi tambahan beberapa proses, yaitu validasi data latih dan weight voting. Peneliti tertarik untuk mengambil topik ini dengan tujuan untuk mengetahui berapa presentase akurasi yang diperoleh dalam klasifikasi status gizi balita mengunakan metode Modified K-Nearest Neighbors.
1.2. Rumusan Masalah
Berdasarkan latar belakang yang dipaparkan di atas, maka dapat diketahui bahwa permasalahan yang diangkat pada penelitian ini adalah sebagai berikut:
1. Bagaimana implementasi metode Modified K-Nearest Neighbors dalam klasifikasi status gizi balita?
2. Berapa hasil akurasi dari metode Modified K-Nearest Neighbors dalam menentukan klasifikasi status gizi balita?
3. Apakah variasi k-fold, knn dan jumlah data mempengaruhi nilai akurasi?
4. Apakah normalisasi min-max dapat mempengaruhi nilai akurasi?
1.3. Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah sebagai berikut:
1. Menerapkan metode Modified K-Nearest Neighbors dalam sistem yang dapat melakukan klasifikasi status gizi balita.
2. Mengetahui hasil akurasi dari penerapan metode Modified K-Nearest Neighbors dalam menentukan klasifikasi status gizi balita.
1.4. Batasan Masalah
Batasan-batasan masalah dalam peneltian tugas akhir ini atara lain:
1. Data yang digunakan dibagi menjadi 4 dengan jumlah yang berbeda, yaitu 150 data, 250 data, 450 data dan 850 data.
2. Parameter yang digunakan adalah jenis kelamin, umur, berat badan, tinggi / panjang badan balita dan posisi ukur.
3. Penentuan status gizi menggunakan perhitungan berat badan/umur (BB/U), panjang badan / umur (PB/U) dan berat badan / panjang badan (BB/PB).
4. Perhitungan jarak menggunakan rumus Euclidean Distance.
5. Normalisasi data menggunakan rumus Min-max.
6. Data yang dapat diproses berupa data file excel (.xls) 1.5. Metodologi Penelitian
Dalam melakukan penelitian ini langkah-langkah yang dilakukan adalah sebagai berikut:
1. Studi pustaka
Pada langkah ini peneliti mempelajari teori-teori melalui buku, artikel, serta
jurnal yang berkatian dengan data mining, pengklasifikasian status gizi balita dan metode Modified K-Nearest Neighbors.
2. Pengumpulan Data
Data yang digunakan dalam penelitian ini bersumber dari Pemantauan Status Gizi (PSG) Balita di Puskesmas Kebong, Kabupaten Sintang.
3. Pembuatan Alat Uji
Pembuatan alat uji dalam penelitian ini menggunakan teknik data mining dengan tahapan proses sebagai berikut:
a. Seleksi Data: memilih atribut yang berperan dalam proses klasifikasi.
b. Transformasi Data: dalam penelitian ini data input perlu dinormalisasi terlebih dahulu agar data berada dalam range [0,1] sehingga sebaran datanya tidak terlalu jauh.
c. Implementasi proses klasifikasi menggunakan metode Modified K-Nearest Neighbor kedalam sistem.
d. Implementasi dan pengujian: sistem yang telah dibuat dijalankan, kemudian dilakukan pengujian akurasi sistem klasifikasi dengan menggunakan metode Modified K-Nearest Neighbor.
4. Evaluasi dan pengambilan kesimpulan, mengevaluasi implementasi sistem serta hasil pengujian sistem kemudian menarik kesimpulan terhadap penelitian tugas akhir yang telah dibuat.
1.6. Sistematika Penulisan
Dokumen ini tersusun dari beberapa bab, diantaranya:
1. Bab I Pendahuluan
Bab ini berisi tentang latar belakang masalah, rumusan masalah, tujuan penelitian, batasan masalah, metodologi penelitian, dan sistematika penulisan.
2. Bab II Landasan Teori
Bab ini menjelaskan mengenai penilaian status gizi, metode Modified K- Nearest Neighbors, akurasi Cross Validation dan teori-teori mengenai penambangan data lainnya.
3. Bab III Metode Penelitian
Bab ini menjelaskan mengenai perancangan sistem meliputi data yang digunakan, pengolahan data, pembuatan alat uji dan evaluasi, serta desain antar muka sistem.
4. Bab IV Implementasi Sistem
Bab ini membahas tentang implementasi sistem yang sudah dibuat dan menampilkan tahap-tahap pembuatan sistem.
5. Bab V Analisa Hasil
Bab ini berisi hal-hal yang berkaitan dengan uji validasi sistem, hasil dan analisis yang didapat dari pengujian-pengujian yang telah dilakukan.
6. Bab VI Penutup
Bab ini berisi kesimpulan serta saran dari penelitian mengenai penerapan metode Modified K-Nearest Neighbors pada klasifikasi status gizi balita.
6 BAB II LANDASAN TEORI
2.1. Status Gizi
Status gizi merupakan salah satu unsur penting dalam membentuk status kesehatan. Status gizi adalah keadaan yang diakibatkan oleh keseimbangan antara asupan zat gizi dari makanan dan kebutuhan zat gizi oleh tubuh. Status gizi sangat dipengaruhi oleh asupan gizi. Pemanfaatan zat gizi dalam tubuh dipengaruhi oleh dua faktor, yaitu primer dan sekunder. Faktor primer adalah keadaan yang mempengaruhi asupan gizi dikarenakan susunan makanan yang dikonsumsi tidak tepat, sedangkan faktor sekunder adalah zat gizi tidak mencukupi kebutuhan tubuh karena adanya gangguan pemanfaatan zat gizi di dalam tubuh.
2.2. Penilaian Status Gizi
Menilai status gizi dapat dilakukan melalui beberapa metode pengukuran, tergantung pada jenis kekurangan gizi. Hasil penilaian status gizi dapat menggambarkan tingkat kekurangan gizi, misalnya status gizi yang berhubungan dengan kesehatan atau berhubungan dengan penyakit tertentu. Antropometri adalah pengukuran tubuh manusia sebagai metode untuk menentukan status gizi.
Konsep dasar antropometri untuk mengukur status gizi adalah konsep pertumbuhan. Pertumbuhan adalah terjadinya perubahan sel-sel tubuh, terdapat dalam dua bentuk yaitu bertambah jumlah sel dan atau terjadinya pembelahan sel, secara akumulatif menyebabkan terjadinya perubahan tubuh. Jadi dasarnya menilai status gizi menggunakan metode antropometri adalah menilai pertumbuhan tubuh.
Pengkategorian parameter tinggi, berat dan BMI (body mass index) dalam penelitian ini berdasarkan pada Keputusan Menteri Kesehatan Republik Indonesia Nomor: 1995/Menkes/SK/XII/2010 tentang standar Antropometri
Penilaian Status Gizi anak. Kategori dan ambang batas status gizi anak dapat dilihat pada tabel 2.1 di bawah ini:
2.3. Knowledge Discovery in Database
Knowledge discovery in database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Data mining merupakan salah satu tahapan dalam keseluruhan proses KDD. Secara garis besar proses KDD adalah sebagai berikut:
1. Data Cleaning
Sebelum proses data mining dapat dilaksanakan perlu dilakukan proses cleaning pada data yang menjadi focus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi), selain itu juga dilakukan proses enrichment atau biasa dikatakan proses
“memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
Antropometri BB/U
Kategori Status Gizi Ambang Batas (Z-Score)
Gizi Buruk < -3 SD
Gizi Kurang >= -3 SD s.d <-2 SD Gizi Baik >= -2 SD s.d <=2 SD
Gizi Lebih > 2 SD
Antropometri BB/U atau PB/U Kategori Status Gizi Ambang Batas (Z-Score)
Sangat Pendek < -3 SD
Pendek >= -3 SD s.d <-2 SD
Normal >= -2 SD s.d <=2 SD
Tinggi > 2 SD
Antropometri BB/TB atau BB/PB Kategori Status Gizi Ambang Batas (Z-Score)
Sangat Kurus < -3 SD
Kurus >= -3 SD s.d <-2 SD
Normal >= -2 SD s.d <=2 SD
Gemuk > 2 SD
Tabel 2.1 Tabel Standar Penilaian Status Gizi
2. Data Selection
Pemilihan atau seleksi data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang digunakan untuk proses data mining disimpan dalam suatu berkas terpisah dari basisdata operasional.
3. Data Transformation
Data transformation merupakan proses untuk mengubah bentuk data ke bentuk yang sesuai untuk digunakan. Dalam penelitian ini metode transformasi data yang digunakan adalah metode min-max yang berfungsi untuk normalisasi.
4. Data Mining
Data Mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algortima yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation / Evaluation
Pada tahap ini, hasil data mining diperlihatkan kepada pengguna sehingga informasi yang diperoleh dapat digunakan. hasil ini dapat dijelaskan melalui visualisasi atau tampilan tertentu agar pengguna dapat memahaminya dengan lebih jelas. Tahap ini juga termasuk pengujian terhadap hasil yang ditemukan apakah sudah sesuai fakta sebelumnya.
2.4. Data Mining
Secara sederhana data mining merupakan penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang besar (Davies, 2004). Data mining biasa juga disebut dengan knowledge discovery atau menemukan pola tersembunyi pada data. Proses menganalisa data dari perspektif yang berbeda dan menyimpulkannya kedalam informasi yang
berguna, proses tersebut dapat dikatakan proses data mining (Segall et. All, 2008). Data mining juga sering dikatakan sebagai kegiatan menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya. Data mining berkaitan langsung dengan bidang ilmu-ilmu lain seperti database sistem, data warehousing, statistik, machine learning, information retrieval, dan komputasi tingkat tinggi. Selain itu, data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spattial data analysis, image database, signal processing (Han, 2006).
Menurut Gartner Group data mining merupakan suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti statistic dan matematika (Larose, 2005). Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwa data mining adalah proses menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data yang besar dengan menggunakan teknik pengenalan pola seperti statistic dan matematika sehingga ditemukan suatu pola menarik yang sebelumnya tidak diketahui. Terdapat dua pengelompokkan penambangan data berdasarkan bagaimana pembelajarannya, yaitu:
1. Supervised Learning merupakan pembelajaran menggunakan guru dan biasanya menggunakan kelas atau label pada himpunan datanya.
2. Unsupervised Learning merupakan pembelajaran tanpa guru dan biasanya tidak ada kelas atau label pada himpunan datanya.
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose, 2005):
1. Deskripsi
Deskripsi bertujuan untuk mengindetifikasi pola yang muncul secara berulang pada suatu data dan mengubah pola tersebut menjadi aturan dan kriteria yang mudah dimengerti oleh para ahli pada domain aplikasinya. Aturan yang dihasilkan harus mudah dimengerti agar dapat efektif meningkatkan pengetahuan pada sistem.
2. Prediksi
Prediksi memiliki kemiripan dengan klasifikasi, akan tetapi data diklasifikasikan berdasarkan perilaku atau nilai yang diperkirakan pada masa yang akan datang.
3. Estimasi
Estimasi hampir sama dengan prediksi, variabel target estimasi lebih ke arah numerik dari pada ke arah kategori.
4. Klasifikasi
Merupakan proses menemukan sebuah model atau fungsi yang mendeskripsikan dan membedakan data ke dalam kelas-kelas.
5. Klaster
Merupakan pengelompokan sejumlah data yang mempunyai kemiripan ke dalam kelompok-kelompok data.
6. Asosiasi
Teknik yang digunakan untuk mencari hubungan antara karakteristik tertentu dalam satu waktu.
2.5. Klasifikasi Pada Data Mining
Klasifikasi merupakan proses menemukan model atau fungsi yang menjelaskan dan membedakan kelas-kelas data, fungsi tersebut digunakan untuk memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. Proses klasifikasi ini terbagi menjadi dua tahapan, yaitu tahapan pelatihan (learning) dan tahap uji (testing). Pada tahap pelatihan, sebagian data yang telah diketahui kelas datanya diumpankan untuk membentuk model prediksi (Han dan Kamber, 2006).
2.6. Metode K-Nearest Neighbor (KNN)
Metode k-Nearest Neighbor merupakan salah satu metode yang digunakan dalam sistem klasifikasi yang menggunakan pendekatan Machine learning.
Menurut (Han dan Kamber, 2006), metode KNN memiliki sifat lazy learners dimana proses pembelajarannya menunggu hingga menit terakhir sebelum model yang dibangun dibutuhkan untuk mengklasifikasi data uji. KNN merupakan sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. Data pembelajaran diproyeksikan ke ruang berdimensi banyak, dimana masing- masing dimensi merepresentasikan fitur atau ciri dari data.
2.7. Metode Modified K-Nearest Neighbor (MKNN)
MKNN merupakan pengembangan dari metode KNN yang diberi tambahan beberapa proses, yaitu validasi data latih dan weight voting. Tujuan utamanya adalah menentukan referensi prediksi sistem terhadap kelas data yang akan diuji. Dalam MKNN dilakukan proses validitas data latih terlebih dahulu setelah menghitung jarak, kemudian dilakukan weighting untuk setiap data uji sebelum mengklasifikasi objek ke dalam kelas tertentu. Validasi dalam hal ini digunakan untuk mencari jumlah titik yang memiliki kategori atau label yang sama pada semua data latih, kemudian hasilnya digunakan sebagai informasi tambahan mengenai data tersebut. Karena adanya validasi pada data latih, metode
MKNN dapat menghasilkan akurasi yang lebih tinggi dibandingkan KNN.
Metode MKNN ini mengoptimalkan data latih yang memiliki validitas tinggi dan memiliki jarak terdekat dengan data uji, sehingga jika terdapat data yang tidak stabil, hal itu tidak banyak berpengaruh dalam pemberian label atau kelas pada objek (Parvin, 2008). Langkah-langkah metode Modified K-Nearest Neighbors adalah sebagai berikut:
1. Menentukan nilai k tetangga terdekat.
2. Menghitung jarak antar data latih menggunakan Euclidean distance.
Euclidean distance merupakan metode perhitungan jarak dari dua buah titik dalam Euclidean space. Euclidean ini berkaitan dengan Teorema Phytagoras dan biasanya diterapkan pada 1,2 dan 3 dimensi, tapi juga sederhana jika diterapkan pada dimensi yang lebih tinggi. Persamaan (2.1) mendefinisikan metode Euclidean distance yang digunakan dalam penelitian ini.
𝑑(𝑥, 𝑦) = √∑(𝑥𝑖 − 𝑦𝑖)2
𝑛
𝑖=1
(2.1)
dimana:
d: (distance) / jarak x : sampel data y : data uji / testing i : variable data n : dimensi data 3. Validasi Data Latih
Pada metode MKNN setiap data latih harus divalidasi. Validasi setiap data tergantung pada setiap tetangganya. Setelah dihitung validitas tiap data maka nilai validitas tersebut digunakan pada perhitungan weight voting.
Persamaan yang digunakan untuk menghitung validitas dari setiap data latih didefinisikan pada persamaan (2.2) berikut ini:
𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑎𝑠(𝑥)1
𝑘∑ 𝑆 (𝑙𝑎𝑏𝑒𝑙(𝑥), (𝑙𝑎𝑏𝑒𝑙(𝑁𝑖(𝑥))))
𝑘
𝑖=1
(2.2) dimana:
k : jumlah titik terdekat label(x) : kelas data x
label Ni(x) : label kelas titik terdekat data x
Fungsi S digunakan untuk menghitung kesamaan antara titik x dam data ke-I tetangga terdekat. Persamaan untuk mendefinisikan fungsi S terdapat pada persamaan (2.3).
𝑆(𝑎,𝑏)= {1 𝑎 = 𝑏 0 𝑎 ≠ 𝑏
(2.3) dimana:
a : kelas pada data latih
b : kelas selain a pada data latih
Persamaan (2.3) menunjukan bahwa a dan b adalah label kelas kategori suatu data latih. S bernilai 1 jika label kategori a sama dengan label kategori b. S bernilai 0 jika label kategori a tidak sama dengan label kategori b.
4. Menghitung jarak Euclidean antara data latih dengan data uji menggunakan Persamaan (2.1).
5. Menghitung Weight Voting
Weight voting merupakan salah satu variasi dari metode KNN yang menggunakan k tetangga terdekat dan hasil perhitungan dari jarak masing- masing data. Pada variasi metode KNN, weighted KNN, bobot setiap tetangganya dihitung menggunakan persamaan (2.4).
𝑊(𝑖) = 1 𝑑 + 𝑎
(2.4)
dimana:
W(i) : bobot setiap tetangga
d : jarak Euclidean data uji dengan data latih a : smoothing regulator, bernilai 0,5
Pembobotan ini kemudian dijumlahkan untuk setiap kelas dan yang dipilih adalah kelas dengan total terbesar. Validitas data latih dikalikan dengan bobot tersebut berdasarkan pada jarak Euclidean, sehingga didapatkan perhitungan weight voting pada MKNN yang didefinisikan oleh persamaan (2.5).
𝑊(𝑖) = 𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑎𝑠(𝑖)× 1 𝑑 + 0.5
(2.5) dimana:
W(i) :weight voting
Validitas(i) : nilai validitas
d : jarak data uji dengan data latih
Weight voting pada MKNN berpengaruh besar pada data yang memiliki nilai validitas lebih tinggi dan lebih dekat dengan data uji. Perkalian nilai validitas dengan bobot pada persamaan (2.5) dapat mengatasi kelemahan dalam hal outlier.
6. Menentukan kelas data uji
Untuk menentukan kelas data uji, diambil nilai weight voting terbesar. Kelas data dari nilai weight voting yang paling besar dijadikan kelas untuk data uji.
2.8. K-fold Cross Validation
Perhitungan akurasi dilakukan dengan menggunakan metode cross validation dan confusion Matrix. Pada metode ini, dilakukan pembagian data menjadi k subset atau fold yang saling bebas secara acak, yaitu S1, S2, …, Sk,
Tahap I
Tahap II
Tahap III
dengan ukuran setiap subset sama. Pelatihan dan pengujian dilakukan sebanyak k kali. Pada iterasi ke-i, subset S1 diperlakukan sebagai data pengujian, dan subset lainnya sebagai data pelatihan. Tingkat akurasi dihitung dengan membagi jumlah keseluruhan klasifikasi yang benar dengan jumlah instance pada awal (Han dan Kamber, 2006). Berikut contoh tahapan cross validation dengan 3-fold:
fold 1 fold 2 fold 3 Testing Training Training
Training Testing Training
Training Training Testing
Keterangan:
Tahap I
i. fold 1 sebagai data uji ii. fold 2 sebagai data latih iii. fold 3 sebagai data latih Tahap II
i. fold 1 sebagai data latih ii. fold 2 sebagai data uji iii. fold 3 sebagai data latih Tahap III
i. fold 1 sebagai data latih ii. fold 2 sebagai data latih iii. fold 3 sebagai data uji
2.9. Confusion Matrix
Confusion matrix adalah metode atau alat yang digunakan sebagai evaluasi model klasifikasi untuk memperkirakan objek yang benar atau salah. Sebuah matrix dari prediksi yang dibandingkan dengan kelas sebenarnya atau dengan kata lain berisi informasi nilai sebenarnya dan prediksi pada klasifikasi (Gorunescu, 2011: 319). Tabel 2.2 berikut merupakan contoh table confusion matrix 2 dimensi.
Accuracy dihitung menggunakan persamaan (2.6) di bawah ini:
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁𝑥 100%
(2.6) dimana:
TP : jumlah positive yang diklasifikasikan sebagai positive.
TN : jumlah negative yang diklasifikasikan sebagai negative.
FP : jumlah negative yang diklasifikasikan sebagai positive.
FN : jumlah positive yang diklasifikasikan sebagai negative.
Prediksi
Positive Negative
Nilai Aktual
Positive TP (True Positive) FN (False Negative)
Negative FP (False Positive) TN (True Negative) Tabel 2.2 Confusion Matrix
17 BAB III
METODE PENELITIAN
3.1. Gambaran Umum Sistem
Pada sistem ini terdapat 5 proses yang dijalankan yaitu proses input data, proses seleksi data, proses transformasi data, proses klasifikasi menggunakan metode Modified K-Nearest Neighbors dan proses perhitungan akurasi sistem.
Alur tahapan proses sistem secara umum dapat dilihat pada gambar 3.1 di atas.
Gambar 3.1 Gambaran Umum Sistem
3.2. Dataset
Data yang digunakan dalam penelitian ini adalah data Pemantauan Status Gizi (PSG) 2017 Dinas Kesehatan Kabupaten Sintang, Provinsi Kalimantan Barat. Data tersebut disajikan dalam bentuk file .xls. dengan total data sebanyak 850, data tersebut memiliki 19 atribut dan 3 klasifikasi yang memiliki 4 label yaitu “Buruk, Kurang, Baik, Lebih" untuk klasifikasi status gizi BB/U, 4 label yaitu “Sangat kurus, Kurus, Normal, Gemuk” untuk klasifikasi status gizi BB/PB dan 4 label yaitu “Sangat pendek, Pendek, Normal, Tinggi”untuk klasifikasi status gizi PB/U. Total atribut data yang digunakan dalam penelitian ini sebanyak 5 kemudian diklasifikasikan ke dalam 3 kelas yaitu BB/U, PB/U dan BB/PB.
Penjelasan atribut yang digunakan dapat dilihat pada tabel 3.1 dan contoh datanya dapat dilihat pada tabel 3.2 berikut ini:
No Atribut Keterangan
1 Js.L/P Jenis kelamin balita, untuk laki-laki = 1 dan perempuan = 2
2 Berat B Berat badan balita (Kg)
3 PB/TB Panjang badan atau tinggi badan balita (Cm)
4 Posisi Ukur Posisi ukur balita, terlentang = 3 dan berdiri = 4
5 Umur Umur balita (Bulan)
6 BB/U Kelompok kelas berdasarkan berat badan / umur, terdapat 4 label yang digunakan dalam kelas ini yaitu Buruk, Kurang, Baik dan Lebih.
Tabel 3.1 Atribut Dataset PSG
7 PB/U Kelompok kelas berdasarkan panjang badan / umur atau tinggi badan / umur, terdapat 4 label yang digunakan dalam kelas ini yaitu Sangat Pendek, Pendek, Normal dan Tinggi.
8 BB/PB Kelompok kelas berdasarkan berat badan / panjang badan atau berat badan / tinggi badan, terdapat 4 label yang digunakan dalam kelas ini yaitu Sangat Kurus, Kurus, Normal dan Gemuk.
Js.L/P Berat
B PB/TB Posisi
diukur Umur BB/U PB/U BB/PB
1 8 66,2 3 9 Baik Pendek Normal
1 7,8 63 3 8 Baik Sangat Pendek Normal
1 10,1 77 3 8 Baik Tinggi Normal
2 6,1 63 3 6 Baik Normal Normal
2 4,6 56,6 3 6 Buruk Sangat Pendek Normal
2 6,2 61 3 4 Baik Normal Normal
1 6,9 62 3 4 Baik Normal Normal
1 6,5 55 3 4 Baik Sangat Pendek Gemuk
2 4,8 58 3 3 Baik Normal Normal
2 5,4 59,9 3 3 Baik Normal Normal
1 7,2 65 3 10 Kurang Sangat Pendek Normal
1 5 57 3 2 Baik Normal Normal
2 4,6 55 3 2 Baik Normal Normal
1 4,7 57,2 3 2 Baik Normal Normal
1 3,4 50,5 3 0 Baik Normal Normal
2 61 61,5 3 3 Lebih Normal Gemuk
1 10,3 88 4 37 Kurang Pendek Kurus
1 10,4 84 4 27 Baik Normal Normal
1 14 92 4 27 Baik Normal Normal
Tabel 3.2 Contoh Dataset PSG
3.3. Seleksi Data
Pada tahap ini dilakukan proses seleksi data untuk memilih atribut relevan yang dibutuhkan dan menghapus atribut yang tidak relevan untuk penelitian.
Proses seleksi data ini dilakukan secara manual menggunakan aplikasi Microsoft Excel 2016. Atribut yang digunakan dalam sistem klasifikasi status gizi balita ini adalah atribut yang juga digunakan dalam rumus untuk menghitung status gizi pada data excel yang asli dan tidak diperoleh dari hasil hitungan atribut lain pada data excel. Atribut data yang dihapus dapat dilihat pada tabel 3.3 berikut:
No Atribut
1 Nama
2 Tanggal Lahir
3 Proses perhitungan umur 4 Konfersi TB/PB
5 Kelompok umur 6 Kode
7 Kode 2 8 Kode 3
9 Standart Gizi Buruk BB/U 10 Standart Gizi Baik BB/U
11 Standart Pendek PB/U atau TB/U 12 Standart Normal PB/U atau TB/U 13 Standart Kurus BB/PB atau BB/TB 14 Standart Normal BB/PB atau BB/TB
Tabel 3.3 Atribut data yang dihapus
3.4. Transformasi Data
Setelah proses seleksi data, kemudian dilakukan proses transformasi data.
Dalam penelitian ini proses transformasi data yang dilakukan adalah normalisasi menggunakan MinMaxScaler. Hal ini dilakukan agar data atribut dapat dikemas ke dalam skala yang lebih kecil yaitu min=0 dan max=1 sehingga rentang data tidak terlalu jauh berbeda. Contoh data sebelum dilakukan normalisasi dapat dilihat pada tabel 3.4 berikut:
No Js.L/P Berat B PB/TB Posisi diukur Umur
1 1 8 66,2 3 9
2 2 4,6 56,6 3 6
3 1 6,5 55 3 4
4 1 7,2 65 3 10
5 2 7,9 74,3 3 11
6 1 11,2 91,3 4 36
7 1 93 79,3 4 55
8 2 10 86,1 4 44
9 2 7,3 2,5 3 27
Sebagai contoh digunakan data pada kolom kedua yaitu Berat B untuk dilakukan normalisasi min-max. Persamaan 3.1 berikut merupakan persamaan yang digunakan untuk menghitung MinMaxScaler.
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 = 𝑋 − 𝑋𝑚𝑖𝑛 𝑋𝑚𝑎𝑥− 𝑋𝑚𝑖𝑛
(3.1) dimana:
Xscaled : Nilai hasil normalisasi
X : Nilai yang akan dinormalisasi Xmin : Nilai minimal dari kolom data X Xmax : Nilai maksimal dari kolom data X
Tabel 3.4 Contoh Data Sebelum Normalisasi
Maka langkah-langkah normalisasi menggunakan MinMaxScaler sebagai berikut:
1. Pertama cari nilai maksimum (Xmax) dan nilai minimum (Xmin) pada kolom data X yang dilakukan normalisasi, pada kasus ini kolom yang dinormalisasi sebagai contoh adalah kolom Berat B. Data kolom Berat B dapat dilihat pada tabel 3.4, berdasarkan data pada kolom Berat B diperoleh min= 4.6 dan max=93.
2. Kemudian hitung normalisasi setiap data pada kolom Berat B menggunakan persamaan 3.1.
Data ke 1 = 8
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 = 8 − 4.6
93 − 4.6 = 0.038
Data ke 2 = 4.6
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 =4.6 − 4.6 93 − 4.6 = 0
Data ke 3 = 6.5
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 =6.5 − 4.6
93 − 4.6 = 0.021
Data ke 4 = 7.2
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 =7.2 − 4.6
93 − 4.6 = 0.029
Data ke 5 = 7.9
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 =7.9 − 4.6
93 − 4.6 = 0.037
Data ke 6 = 11.2
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 =11.2 − 4.6
93 − 4.6 = 0.074
Data ke 7 = 93
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 =93 − 4.6 93 − 4.6 = 1
Data ke 8 = 10
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 =10 − 4.6
93 − 4.6 = 0.061
Data ke 9 = 7.3
𝑋𝑠𝑐𝑎𝑙𝑒𝑑 =7.3 − 4.6
93 − 4.6 = 0.030
3. Setelah perhitungan normalisasi MinMaxScaler dilakukan maka diperoleh hasil normalisasi kolom 2 yaitu Berat B yang dapat dilihat pada tabel 3.5 berikut:
No Berat B 1 0,038461538
2 0
3 0,021493213 4 0,029411765 5 0,037330317 6 0,074660633
7 1
8 0,061085973 9 0,030542986
Selanjutnya lakukan normalisasi untuk data pada kolom 1,3,4 dan 5 dengan cara yang sama seperti langkah 2 di atas. Hasil normalisasi untuk semua kolom data dapat dilihat pada tabel 3.6 berikut ini:
Tabel 3.5 Normalisasi Kolom Berat B
No Js.L/P Berat B PB/TB Posisi
diukur Umur
1 0 0,038461538 0,717342342 0 0,098039216
2 1 0 0,609234234 0 0,039215686
3 0 0,021493213 0,591216216 0 0
4 0 0,029411765 0,703828829 0 0,117647059
5 1 0,037330317 0,808558559 0 0,137254902
6 0 0,074660633 1 1 0,62745098
7 0 1 0,864864865 1 1
8 1 0,061085973 0,941441441 1 0,784313725
9 1 0,030542986 0 0 0,450980392
3.5. K-fold Cross Validation
Pada bagian ini data yang digunakan dibagi menjadi 2 yaitu data latih dan data uji sesuai dengan k-fold Cross Validation. Jumlah k dalam k-fold diinputkan oleh pengguna. Dalam penelitian ini dilakukan percobaan menggunakan 3-fold Cross Validation artinya dilakukan 3 kali percobaan dengan data latih dan uji yang berbeda disetiap percobaan. Data dipecah menjadi 3 bagian, 2/3 dari data dijadikan data latih dan 1/3 dijadikan data uji. Dalam pembagian data menggunakan fungsi k-fold pada library python, banyaknya fold wakili oleh parameter n_splits. Langkah-langkah pembagian data menggunakan k-fold adalah sebagai berikut:
1. Pertama tentukan jumlah n_folds = [int(self.K-fold.text())], n_folds yang digunakan sesuai dengan masukan pengguna pada kolom K-fold.
2. kf = K-fold(n_splits=n), menampung indeks data latih dan index data uji.
3. train_index, test_index in kf.split(attr), untuk setiap train_index dan test_index di dalam kf lakukan langkah 4 dan 5.
4. Masukan indeks data latih ke variabel x_train _index = train_index.
5. Masukan indeks data uji ke variabel x_test_index = test_index.
Tabel 3.6 Normalisasi Semua Data
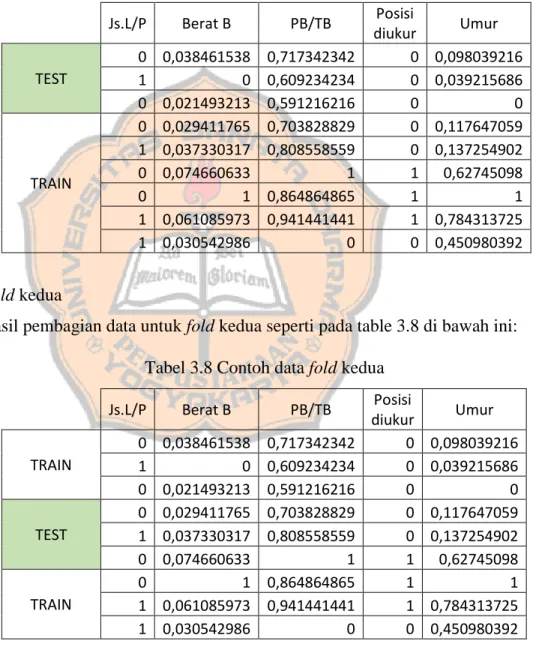
Berikut contoh pembagian data hasil normalisasi pada tabel 3.6 di atas menggunakan 3-fold Cross Validation:
a. Fold pertama
Hasil pembagian data untuk fold pertama seperti pada table 3.7 di bawah ini:
Js.L/P Berat B PB/TB Posisi
diukur Umur
TEST
0 0,038461538 0,717342342 0 0,098039216
1 0 0,609234234 0 0,039215686
0 0,021493213 0,591216216 0 0
TRAIN
0 0,029411765 0,703828829 0 0,117647059 1 0,037330317 0,808558559 0 0,137254902
0 0,074660633 1 1 0,62745098
0 1 0,864864865 1 1
1 0,061085973 0,941441441 1 0,784313725
1 0,030542986 0 0 0,450980392
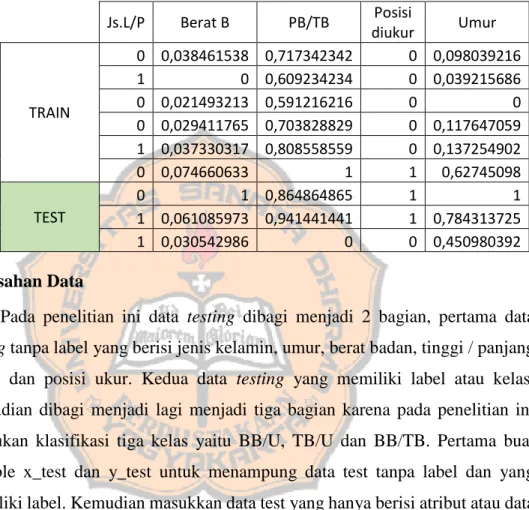
b. Fold kedua
Hasil pembagian data untuk fold kedua seperti pada table 3.8 di bawah ini:
Js.L/P Berat B PB/TB Posisi
diukur Umur
TRAIN
0 0,038461538 0,717342342 0 0,098039216
1 0 0,609234234 0 0,039215686
0 0,021493213 0,591216216 0 0
TEST
0 0,029411765 0,703828829 0 0,117647059 1 0,037330317 0,808558559 0 0,137254902
0 0,074660633 1 1 0,62745098
TRAIN
0 1 0,864864865 1 1
1 0,061085973 0,941441441 1 0,784313725
1 0,030542986 0 0 0,450980392
Tabel 3.7 Contoh data fold pertama
Tabel 3.8 Contoh data fold kedua
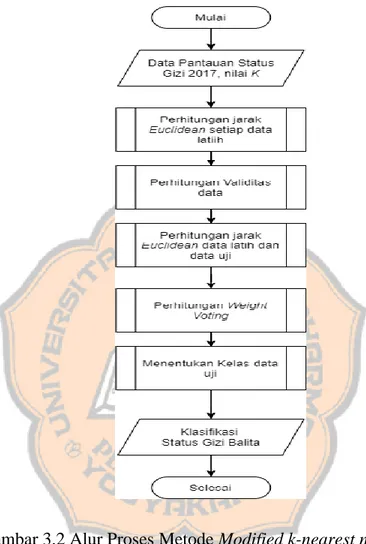
c. Fold ketiga
Hasil pembagian data untuk fold kedua seperti pada table 3.9 di bawah ini:
Js.L/P Berat B PB/TB Posisi
diukur Umur
TRAIN
0 0,038461538 0,717342342 0 0,098039216
1 0 0,609234234 0 0,039215686
0 0,021493213 0,591216216 0 0
0 0,029411765 0,703828829 0 0,117647059 1 0,037330317 0,808558559 0 0,137254902
0 0,074660633 1 1 0,62745098
TEST
0 1 0,864864865 1 1
1 0,061085973 0,941441441 1 0,784313725
1 0,030542986 0 0 0,450980392
3.6. Pemisahan Data
Pada penelitian ini data testing dibagi menjadi 2 bagian, pertama data testing tanpa label yang berisi jenis kelamin, umur, berat badan, tinggi / panjang badan dan posisi ukur. Kedua data testing yang memiliki label atau kelas.
Kemudian dibagi menjadi lagi menjadi tiga bagian karena pada penelitian ini dilakukan klasifikasi tiga kelas yaitu BB/U, TB/U dan BB/TB. Pertama buat variable x_test dan y_test untuk menampung data test tanpa label dan yang memiliki label. Kemudian masukkan data test yang hanya berisi atribut atau data test yang tidak memiliki label ke variabel x_test, selanjutnya masukkan data label ke variabel y_test.
3.7. Klasifikasi Modified K-Nearest Neighbors
Setelah data melalui tahap preprocessing, penambangan data menggunakan metode Modified K-Nearest Neighbors siap dilakukan. Dalam metode Modified K-Nearest Neighbors dilakukan proses perhitungan jarak Euclidean setiap data latih, proses validasi data latih, proses perhitungan jarak Euclidean data latih dan data uji, proses perhitungan Weight Voting serta
Tabel 3.9 Contoh data fold ketiga
menentukan kelas data uji. Alur proses metode Modified K-Nearest Neighbors dapat dilihat pada gambar 3.2.
Untuk memperjelas bagaimana metode Modified K-Nearest Neighbors bekerja dalam proses klasifikasi status gizi balita, berikut contoh perhitungan manual berdasarkan PB/U:
a. Data yang digunakan adalah data hasil normalisasi pada Tabel 3.6.
b. 3-fold Cross Validation.
c. Modified K-Nearest Neighbors menggunakan k = 3 (tetangga terdekat).
d. Hitung jarak euclidean setiap data training pada tabel 3.10 menggunakan persamaan 2.1.
Gambar 3.2 Alur Proses Metode Modified k-nearest neighbors
Js.L/P Berat B PB/TB Posisi
diukur Umur
TEST
0 0.038461538 0.717342342 0 0.098039216
1 0 0.609234234 0 0.039215686
0 0.021493213 0.591216216 0 0
TRAIN
0 0.029411765 0.703828829 0 0.117647059 1 0.037330317 0.808558559 0 0.137254902
0 0.074660633 1 1 0.62745098
0 1 0.864864865 1 1
1 0.061085973 0.941441441 1 0.784313725
1 0.030542986 0 0 0.450980392
Jarak Eulcidean data latih pertama:
𝑑(𝑥, 𝑦) =
√(0 − 0)2+ (0,0294 − 0,0294)2+ (0,7038 − 0,7038)2+ (0 − 0)2+ (0,1176 − 0,1176)2
Maka diperoleh jarak = 0 untuk data latih pertama dengan dirinya sendiri.
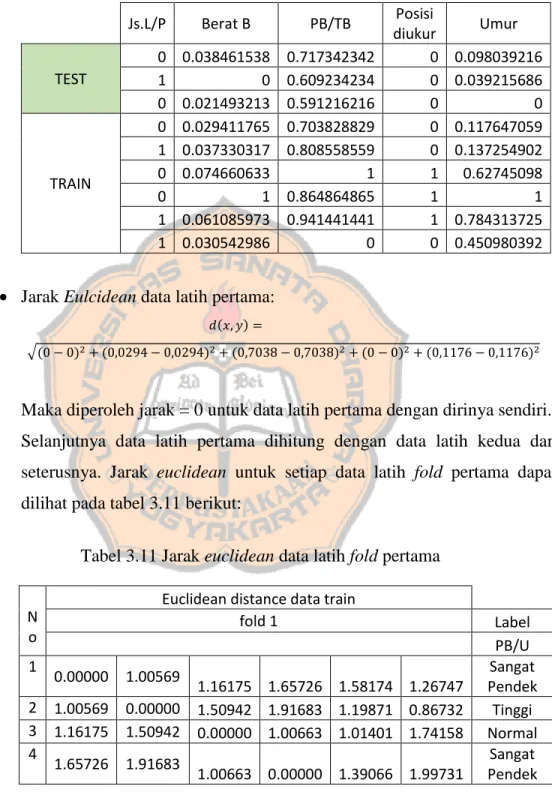
Selanjutnya data latih pertama dihitung dengan data latih kedua dan seterusnya. Jarak euclidean untuk setiap data latih fold pertama dapat dilihat pada tabel 3.11 berikut:
N o
Euclidean distance data train
fold 1 Label
PB/U
1 0.00000 1.00569
1.16175 1.65726 1.58174 1.26747
Sangat Pendek 2 1.00569 0.00000 1.50942 1.91683 1.19871 0.86732 Tinggi 3 1.16175 1.50942 0.00000 1.00663 1.01401 1.74158 Normal 4 1.65726 1.91683
1.00663 0.00000 1.39066 1.99731
Sangat Pendek Tabel 3.10 Data fold pertama
Tabel 3.11 Jarak euclidean data latih fold pertama
e. Setelah dilakukan perhitungan jarak selanjutnya cari tetangga terdekat data latih berdasarkan nilai k yang sudah ditentukan sebelumnya yaitu k = 3.
Kemudian bandingkan label dari 3 tetangga terdekat dengan label data training jika label tetangga terdekat = label data training maka nilainya adalah 1 dan jika label tetangga terdekat != label data training maka nilainya adalah 0. Dapat dilihat pada Tabel 3.10 bahwa label data training pertama adalah
“Sangat Pendek”, tetangga terdekat pertama adalah data ke-2 labelnya
“Tinggi” artinya tidak sama dengan label data training pertama, maka K1=0.
Selanjutnya tetangga terdekat kedua adalah data ke-3 labelnya “Normal”
artinya tidak sama dengan label data training pertama, maka K2=0. Kemudian yang terakhir tetangga terdekat ketiga adalah data ke-6 labelnya “Sangat Pendek” artinya sama dengan label data training pertama, maka K3=1.
Lakukan langkah yang sama untuk semua data training pada fold pertama.
Hasilnya dapat dilihat pada Tabel 3.12 berikut untuk semua data training:
No K3
K1 K2 K3
1 0 0 1
2 0 0 0
3 0 0 0
4 0 1 1
5 0 0 1
6 0 1 1
Tabel 3.12 Perbandingan Label Data Training dengan Label Tetangga Terdekat
f. Selanjutnya menghitung validitas data latih menggunakan Persamaan (2.2).
Validitas data latih pertama:
𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑎𝑠(𝑥)1
𝑘∑ 𝑆 (𝑙𝑎𝑏𝑒𝑙(𝑥), (𝑙𝑎𝑏𝑒𝑙(𝑁𝑖(𝑥))))
𝑘
𝑖=1
Sehingga,
= 1
3× (0 + 0 + 1) 𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑎𝑠(𝑥) = 0.3333
Untuk data latih pertama validitasnya = 0.3333, lakukan langkah perhitungan yang sama untuk mencari nilai validitas data latih kedua dan seterusnya. Hasil perhitungan validitas untuk semua data latih pada fold pertama dapat dilihat pada tabel 3.13 berikut:
g. Menghitung jarak Euclidean antar data latih dan data uji pada fold pertama menggunakan Persamaan (2.1), data yang digunakan adalah data pada tabel 3.10. berikut langkah-langkah menghitung jarak Euclidean semua data latih dengan data uji pertama:
Jarak Euclidean data latih pertama dengan data uji pertama:
𝑑(𝑥, 𝑦) =
√(0 − 0)2+ (0.0294 − 0.0384)2+ (0.7038 − 0.7173)2+ (0 − 0)2+ (0.1176 − 0.0980)2
Maka diperoleh jarak = 0.0254.
No K3
K1 K2 K3 VALIDITAS
1 0 0 1 0.3333
2 0 0 0 0.0000
3 0 0 0 0.0000
4 0 1 1 0.6667
5 0 0 1 0.3333
6 0 1 1 0.6667
Tabel 3.13 Nilai Validitas data latih
Jarak Euclidean data latih kedua dengan data uji pertama:
𝑑(𝑥, 𝑦) =
√(1 − 0)2+ (0.0373 − 0.0384)2+ (0.8085 − 0.7173)2+ (0 − 0)2+ (0.1372 − 0.0980)2
Maka diperoleh jarak = 1.0049.
Jarak Euclidean data latih ketiga dengan data uji pertama:
𝑑(𝑥, 𝑦) =
√(0 − 0)2+ (0.0746 − 0.0384)2+ (1 − 0.7173)2+ (1 − 0)2+ (0.6274 − 0.0980)2
Maka diperoleh jarak = 1.1668.
Jarak Euclidean data latih keempat dengan data uji pertama:
𝑑(𝑥, 𝑦) =
√(0 − 0)2+ (1 − 0.0384)2+ (0.8648 − 0.7173)2+ (1 − 0)2+ (1 − 0.0980)2
Maka diperoleh jarak = 1.6613.
Jarak Euclidean data latih kelima dengan data uji pertama:
𝑑(𝑥, 𝑦) =
√(1 − 0)2+ (0.0610 − 0.0384)2+ (0.9414 − 0.7173)2+ (1 − 0)2+ (0.7843 − 0.0980)2
Maka diperoleh jarak = 1.5879.
Jarak Euclidean data latih keenam dengan data uji pertama:
𝑑(𝑥, 𝑦) =
√(1 − 0)2+ (0.0305 − 0.0384)2+ (0 − 0.7173)2+ (0 − 0)2+ (0.4509 − 0.0980)2
Maka diperoleh jarak = 1.2803.
Lakukan perhitungan yang sama untuk semua data latih dengan data uji kedua dan ketiga. Hasil perhitungan jarak euclidean semua data latih dengan semua data uji dapat dilihat pada tabel 3.14 berikut:
Euclidean distance fold 1
d_test 1 d_test2 d_test3
0.0254 1.0079 0.1630
1.0049 0.2252 1.0326
1.1668 1.5824 1.2504
1.6612 1.9971 1.7413
1.5879 1.2920 1.6551
1.2803 0.7359 1.2461
h. Setelah jarak Euclidean antar data latih dengan data uji ditemukan, selanjutnya hitung weight voting menggunakan Persamaan (2.4).
Weight voting terhadap data uji pertama:
𝑊(𝑖) = 0.3333 × 1 0.0254+ 0.5 𝑊(𝑖) = 0.6343
Weight voting terhadap data uji kedua:
𝑊(𝑖) = 0.0000 × 1 1.0049+ 0.5 𝑊(𝑖) = 0
Weight voting terhadap data uji ketiga:
𝑊(𝑖) = 0.0000 × 1 1.1668+ 0.5 𝑊(𝑖) = 0
Weight voting terhadap data uji keempat:
𝑊(𝑖) = 0.6667 × 1 1.6612+ 0.5 𝑊(𝑖) = 0.3085
Tabel 3.14 Jarak Euclidean data latih dan data uji fold pertama