BAB II
TINJAUAN PUSTAKA
2.1. Image Preprocessing
Masalah umum pada tahap awal proses preprocessing OCR adalah menyesuaikan orientasi area teks. Baris teks seharusnya sejajar dengan batas
gambar. Pada bagian ini kami menyajikan sebuah algoritma memecahkan masalah
ini. Pentingnya tahap preprocessing dari sistem pengenalan karakter terletak pada kemampuannya. Untuk memperbaiki beberapa masalah yang mungkin terjadi
karena beberapa faktor. Tingkat pengenalan, penting untuk memiliki tahap
preprocessing yang efektif, menggunakan algoritma preprocessing yang efektif membuat sistem OCR lebih kuat terutama melalui peningkatan kualitas gambar
yang akurat, noise removal, thresholding gambar, condong deteksi/koreksi, segmentasi halaman, segmentasi karakter, normalisasi karakter (Bieniecky, et al., 2012).
Teknik preprocessing dibutuhkan pada gambar dokumen warna, abu-abu atau gambar biner berisi teks atau grafik. Dalam sistem pengenalan karakter
sebagian besar aplikasi gunakan gambar abu-abu atau biner karena memproses
gambar berwarna secara komputasi yang lebih sulit. Seperti itu gambar mungkin
juga mengandung latar belakang atau tanda air yang tidak seragam sehingga
menyulitkan ekstrak dokumen teks dari gambar tanpa melakukan beberapa
preprocessing, karena itu hasil yang diinginkan dari preprocessing adalah gambar biner yang hanya berisi teks (Alginahi, 2013).
Pada bagian image preprocessing dilakukan proses grayscalinge dan thresholding. Pada bagian ini diharapkan menghasilkan citra biner yang nantinya menjadi masukan pada tahap berikutnya tahap feature extraction.
2.1.1 Grayscaling
(kertas) dan mengubah menjadi citra biner. Proses Thresholding mengubah warna gambar menjadi citra biner (binary image) dimana ditentukan sebuah nilai level threshold kemudian piksel yang memiliki nilai di bawah level threshold diset menjadi warna putih (0 pada nilai biner) dan nilai di atas nilai threshold diset menjadi warna hitam (1 pada nilai biner).
Konversi citra berwarna menjadi grayscale merupakan tahapan awal dalam image preprocessing. Pada proses grayscaling, citra yang pada awalnya terdiri dari 3 layer matriks, yaitu R-layer, G-layer, dan B-layer akan diubah menjadi 1 layer matriks dan hasilnya adalah citra grayscale yang hanya memiliki derajat keabuan. Untuk mengubah citra berwarna, fungsi yang digunakan adalah ARGB_8888 yaitu mendefinisikan nilai alpha channel, merah, hijau, dan biru yang kemudian dapat dirumuskan dengan persamaan di bawah agar menjadi citra dengan derajat keabuan.
………..(1)
Dengan format warna ini dihasilkan citra grayscale dengan intensitas keabuan yang dipengaruhi oleh variabel warna merah hijau, dan biru.
2.1.2 Global Thresholding Metode Otsu
Threshold adalah proses membagi gambar ke background dan latar depan. Hasil lambang adalah hitam atau putih. Pada teknik pengolahan citra,
ambang batas dapat dikelompokkan menjadi lambang global dan lokal. Kinerja hasil ambang batas, ambang adaptif atau lokal menghasilkan hasil yang lebih baik
dibandingkan dengan global ambang batas. Nilai ambang T memainkan peran
penting, baik pixel yang diputarUntuk background atau foreground itu tergantung nilainya. Pengingat dari bagian ini dibahas tiga metode untuk menemukan nilai
threshold T (maksudnya, median dan OTSU) (Razali, et al., 2014)
Metode OTSU diperkenalkan oleh Nobuyuki Otsu. OTSU ambang
batas adalah keputusan tingkat binariasi otomatis berdasarkan Histogram. Tujuan
dari algoritma ini adalah untuk menemukan nilai threshold T yang meminimalkan
yang meminimalkan bobot di kelas varians dari dua kelas ini. Ini terbukti secara
matematis meminimalkan varians dalam kelas sama dengan memaksimalkan
antara varian kelas Metode OTSU telah diterapkan di percobaan sebelumnya,
namun hasil segmentasi ternyata tidak mampu untuk mengelompokkan seluruh
gigi.
Pada proses selanjutnya citra akan berubah menjadi citra biner yang hanya mempunyai dua kemungkinan nilai yaitu 0 untuk hitam dan 1 untuk putih. Pada proses ini tiap piksel pada citra akan diklasifikasikan berdasarkan ambang batas tertentu, jika nilai piksel kurang dari ambang batas, maka piksel tersebut akan bernilai 0. Namun, jika nilai piksel lebih dari atau sama dengan ambang batas, maka piksel tersebut akan bernilai 1. Dalam proses binerisasi citra ini menggunakan global thresholding metode Otsu dengan tujuan untuk membagi histogram citra gray ke dalam dua daerah yang berbeda secara otomatis tanpa membutuhkan masukan nilai ambang batas. Probabilitas setiap piksel pada level ke-i dapat dinyatakan sebagai berikut.
………(2) = jumlah piksel pada level ke-i
N = total piksel pada citra
Dalam menentukan nilai ambang batas pada metode Otsu, ada beberapa hal yang perlu diketahui, nilai zeroth cumulative moment, first cumulative moment, dan nilai mean berturut-turut dapat dinyatakan dengan rumus berikut (Putra, 2004).
∑ ∑ ∑ ... (3)
Nilai ambang k dapat ditentukan dengan memaksimumkan persamaan
dengan
……… (4)
2.2Optical Character Recognition ( OCR )
Optical Character Recognition atau yang biasa disebut dengan OCR adalah suatu proses pengkonversian dari scanned image menjadi editable text. Editable text didapatkan dari sebuah scanned image yang bisa saja diambil dari hasil pemotretan atau juga hasil scan gambar yang kemudian dimasukkan kedalam komputer. Scanned image ini terdiri dari satu kesatuan konten-konten yang nantinya akan dipilah menjadi konten-konten tersendiri. Teknologi ini membuat sebuah mesin dapat mengenali sebuah teks secara otomatis (Mithe, et al., 2012). OCR memungkinkan untuk mengedit teks, mencari kata atau frase, dan menerapkan teknik seperti mesin penerjemahan, text-to-speech dan text mining. OCR biasa digunakan untuk bidang penelitian dalam pengenalan pola, kecerdasan buatan (artificial intelligent) dan computer vision. Sistem OCR memerlukan kalibrasi untuk membaca font yang spesifik versi awal harus diprogram dengan gambar karakter masing-masing, dan bekerja pada satu font pada suatu waktu (Rakshit, et al., 2009).
Menurut Patel et.al (2012) hal ini dapat diumpamakan seperti kombinasi antara mata dan pikiran dari tubuh manusia. Sebuah mata yang dapat melihat teks yang terdapat pada suatu gambar dan secara langsung otak kita akan memproses mengekstrak teks tersebut dari gambar dan dibaca oleh mata. Konten-konten yang telah terkarakteristik kemudian dilakukan proses pengenalan dengan mengubahnya menjadi kode-kode karakter seperti ASCII atau Unicode lainnya. Setelah proses ini, konten-konten yang terdapat pada image tersebut yang sebelumnya tidak dapat di-edit akan menjadi karakter-karakter yang dapat di-edit ataupun juga di proses untuk keperluan selanjutnya seperti melakukan
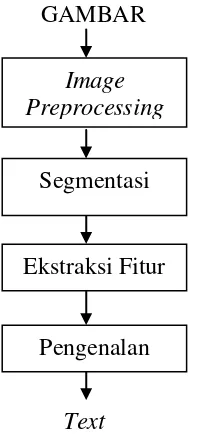
perhitungan pada karakter-karakter numerik. Secara garis besar proses OCR dapat dijelaskan pada gambar 2.2
GAMBAR
Gambar 2.2 Proses OCR (Aprilia 2012)
Didalam OCR, gambar yang berisi karakter yang ingin dikenali dilakukan preprocessing. Preprocessing adalah proses menghilangkan konten-konten yang tidak diinginkan seperti noise dan juga untuk memperbaiki kualitas gambar agar lebih mudah dikenali. Dalam tahap pertama preprocessing dilakukan grayscalling. Grayscalling adalah mengubah gambar yang berwarna menjadi gambar yang
hanya memiliki derajat keabuan saja. Selanjutnya dalam tahap kedua dilakukan noise filtering, yaitu proses mengurangi atau mereduksi noise yang ada pada
gambar. Noise yang terlalu banyak dapat mengurangi keakuratan dalam pengenalan karakter. Dan tahap terakhir dari preprocessing yaitu thresholding. Thresholding memisahkan konten yang akan dikenali dengan background dengan mengubah gambar menjadi hitam putih. Dengan berakhirnya tahap thresholding maka tahap preprocessing selesai dilakukan.
Tahap selanjutnya adalah segmentasi. Segmentasi melakukan pemisahan karakter yang berarea besar menjadi area yang lebih kecil seperti suatu kalimat menjadi kata-kata, dan kata menjadi karakter. Setelah dilakukan segmentasi maka dilakukan normalisasi. Normalisasi mengubah karakter karakter hasil segmentasi menjadi suatu karakter yang memiliki karakterisitik yang telah ditentukan, seperti dimensi region dan ketebalan karakter. Setelah proses normalisasi dilakukan maka
selanjutnya dilanjutkan pada tahap ekstraksi fitur. Ekstraksi fitur dilakukan untuk mendapatkan karakteristik khas yang dimiliki oleh tiap-tiap karakter. Dan tahap akhir dalam proses OCR ini adalah recognition, dimana dilakukannya pengenalan dengan cara membandingkan ciri-ciri fitur yang ingin dikenali dengan data yang telah tersimpan sebelumnya sesuai dengan algoritma pengenalan yang dipakai. Hasil perbandingan yang miriplah yang kemudian keluar menjadi suatu hasil pengenalan berupa teks.
2.2.1Tesseract OCR Engine
Mesin OCR Tesseract adalah salah satu dari 3 mesin teratas dalam Tes Akurasi UNLV 1995. Antara tahun 1995 dan 2006, hanya ada sedikit aktivitas di
Tesseract, sampai open-source oleh HP dan UNLV di tahun 2005.Mesin Tester Oter Tesseract awalnya dikembangkan untuk bahasa Inggris, sejak itu diperluas untuk mengenal Prancis, Italia, Jerman, Spanyol dan Belanda. Ini memiliki
kemampuan untuk melatih bahasa dan skrip lain juga. Algoritma yang digunakan
dalam berbagai tahap mesin sesuai dengan alfabet bahasa Inggris, yang
membuatnya lebih mudah untuk mendukung skrip lain yang secara struktural
serupa dengan hanya melatih kumpulan karakter dari skrip baru (Hasanat, 2013).
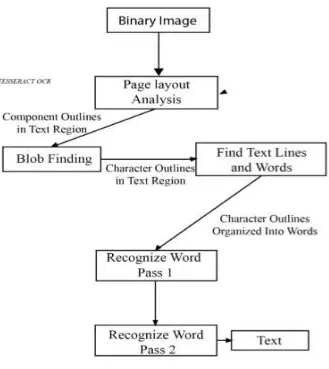
2.2.2. Arsitektur Tesseract OCR
Gambar 2.3Arsitektur Tesseract OCR
Kata-kata yang melewati pass pertama adalah kata-kata yang cocok dengan kamus dan diteruskan pada adaptif classifier untuk selanjutakan dipakai sebagai data pelatihan. Setelah sampel mencukupi, classifier adaptif ini juga dapat memberikan hasil klasifikasi bahkan pada pass pertama (Aprilia, 2012). Kata-kata yang mungkin kurang dikenali atau terlewat pada pass pertama akan dilanjutkan pada proses pass two. Pada kondisi ini classifier adaptif yang telah mendapatkan informasi lebih pada pass pertma akan lebih dapat mengenali kata yang terlewatkan atau kurang dikenali sebelumnya.
2.2.3 Pengenalan Karakter oleh Tesseract
Menurut Smith (2007) beberapa langkah yang dilakukan oleh Tesseract untuk pengenalan karakter adalah sebagai berikut :
2.2.3.1 Pencarian Teks line dan kata a. Line finding
Algoritma Line finding dirancang untuk dapat mengenali halaman miring tanpa harus melalui proses de-skew, hingga tidak menurunkan kualitas gambar (Smith, 2007). Kunci dari proses ini adalah filterisasi blob dan Line constructing mengasumsikan analisa tata letak halaman telah mendapatkan daerah teks yang memiliki ukuran teks yang seragam, filter presentasi ketinggian sederhana menghilangkan drop-caps dan garis vertikal yang menyentuh karakter. Rata tengah dari tinggi mendekati dari besar teks di dalam daerah tersebut, sehingga aman untuk menyaring blobs yang lebih kecil dari beberapa pecahan dari rata-rata tengah, seperti tanda baca dan juga noise.
Filterisasi blob lebih cocok kepada pemodelan non-overlapping, paralel, tetapi sloping lines (Smith, 2007). Penyortingan dan pemrosesan pada blob oleh kordinat-x memungkinkan untuk menentukan blob menjadi text line yang unik, sementara pelacakan kemiringan di sepanjang halaman, dengan sangat mengurangi kesalahan menempatkan text line yang salah didalam kemiringan. Setelah blob yang di filter disejajarkan pada garis, rata tengah terakhir dari squares fit digunakan untuk memperkirakan baselines, dan blob yang telah difilter akan dipasang kembali ke line yang tepat.
b. Baseline Fitting
Setelah text lines ditemukan, garis pangkal (baselines) dicocokkan dengan lebih tepat menggunakan quadratic splines. Hal inilah merupakan hal baru dalam sistem OCR, dimana tesseract memungkinkan dapat menangani halaman dengan baseline yang miring. Baseline dicocokkan dengan partisi blob kedalam sebuah kelompok perpindahan yang cukup berkelanjutan baseline lurus yang asli. Sebuah quadratic spline dicocokkan pada partisi yang paling padat (diasumsikan sebagai baseline). Kelebihan dari Quadratic Spline terletak dari kemampuan berhitungnya yang stabil, namun memiliki kelemahan yaitu diskonitinuitas dapat muncul pada beberapa saat segmen spline diperlukan.
Gambar 2.4Contoh fitted baseline
c. Chopping
akan dicari dulu ambang batas jarak antarkarakter untuk menentukan karakter yang terhubung dan karakter yang terpisah. Adapun contoh pemisahan karakter dapat dilihat pada gambar 2.5.
Gambar 2.5Contoh pemisahan karakter
2.2.3.2 Pengenalan Karakter dan Kata
Bagian dari proses pengenalan pada pengenalan segala karakter adalah dengan mengidentifikasi bagaimana sebuah kata atau karakter disegmentasi menjadi karakter atau simbol-simbol (Aprilia, 2012). Hasil akhir dari segmentasi awal akan diklasifikasikan sisa terakhir dari proses ini hanya dilakukan pada teks yang non fixed-pitch.
a. Pemisahan Karakter terhubung
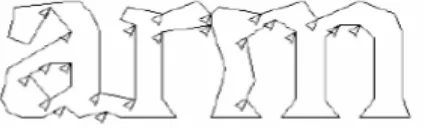
Apabila hasil dari pemisahan kata tidak memuaskan, Tesseract akan berusaha untuk memisahkan blob dengan kemugkinan terburuk dari classifier karakter (Smith, 2007). Kandidat dari titik potong di dapat dari simpul cekung dari pendekatan poligonal outline, dan dapat saja ditemukan simpul cekung lainnya dari titik yang berlawanan, atau garis segmen. Untuk karakter ASCII setidaknya menghabiskan sampai 3 pasang titik pemotongan untuk memisahkan karakter yang terhubung. Titik pemotongan dapat dilihat pada gambar 2.6.
Gambar 2.6 Titik Pemotongan Karakter(Smith 2007)
yang terpilih sebagai garis yang menelusuri outline dimana karakter ―r‖ bersentuhan dengan karakter ―m‖. Pemotongan dilakukan.
b. Menyatukan Karakter yang Rusak
Ketika pemotongan yang dilakukan tidak mendapatkan hasil yang tepat, kata atau karakter masih belum cukup, maka akan diberikan kepada associator. Associator ini membuat pencarian A* (terbaik pertama) dari graph segmentasi untuk kombinasi yang memungkinkan dari pemotongan blob maksimal menjadi kandidat karakter. Hasil pencarian A* dengan menarik kandidat state baru dari antrian prioritas dan mengevaluasi kandidat dengan mengklasifikan kombinasi fragmen yang belum terklasifikasi dapat dilihat pada Gambar 2.7.
Dengan segmentasi A* ini membuat tesseract dapat dengan mudah mengenali karakter yang rusak seperti pada gambar.
2.3 String Matching
2.3.1 Pengertian String Matching
String matching adalah pencarian sebuah pattern pada sebuah teks (Cormen, T.H. et al. 1994). String matching digunakan untuk menemukan suatu string yang disebut dengan pattern dalam string yang disebut dengan teks (Charras, C. & Lecroq, T. 1997). Prinsip kerja algoritma string matching (Effendi, D. et al. 2013) adalah sebagai berikut:
1. Memindai teks dengan bantuan sebuah window yang ukurannya sama dengan panjang pattern.
2. Menempatkan window pada awal teks.
3. Membandingkan karakter pada window dengan karakter dari pattern. Setelah pencocokan (baik hasilnya cocok atau tidak cocok) dilakukan pergeseran ke kanan pada window. Prosedur ini dilakukan berulang-ulang
sampai window berada pada akhir teks. Mekanisme ini disebut mekanisme sliding window.
Algoritma string matching mempunyai tiga komponen utama (Effendi, D. et al. 2013), yaitu:
1. Pattern, yaitu deretan karakter yang akan dicocokkan dengan teks, dinyatakan dengan [0… − 1], panjang pattern dinyatakan dengan . 2. Teks, yaitu tempat pencocokan pattern dilakukan. Dinyatakan dengan
[0… − 1], panjang teks dinyatakan dengan .
3. Alfabet, berisi semua simbol yang digunakan oleh bahasa pada teks dan pattern, dinyatakan dengan ∑ dengan ukuran dinyatakan ASIZE.
2.3.2 Cara kerja String Matching
2.3.3 Klasifikasi Algoritma String Matching
Algoritma string matching dapat diklasifikasikan menjadi tiga bagian menurut arah pencariannya (Charras, C. & Lecroq, T. 1997), yaitu:
1. From left to right dari arah yang paling alami, dari kiri ke kanan, yang merupakan arah untuk membaca. Algoritma yang termasuk dalam kategori ini adalah Algoritma Brute Force, Algoritma Morris dan Pratt yang kemudian dikembangkan menjadi Algoritma Knuth-Morris-Pratt.
2. From right to left dari arah kanan ke kiri, arah yang biasanya menghasilkan hasil terbaik secara partikal. Contoh algoritma ini adalah Algoritma Boyer-Moore, yang kemudian banyak dikembangkan menjadi Algoritma Tuned Boyer-Moore, algoritma Turbo Boyer-Moore, Algoritma Zhu Takaoka dan Algoritma Horspool
2.4.3 Algoritma Horspool
Algoritma Boyer-Moore (BM) memposisikan pola pada karakter paling kiri. Dalam teks dan mencoba untuk mencocokkannya dari kanan ke kiri. Jika
tidak terjadi ketidakcocokan, maka pola telah ditemukan. Jika tidak, algoritma
menghitung pergeseran, jumlah dengan yang polanya dipindahkan ke kanan
sebelum upaya pencocokan baru dilakukan.Pergeseran ini bisa dihitung dengan
dua heuristik. Pertandingan heuristik dan kemunculannya heuristis. Dalam tulisan
ini kami hanya mempertimbangkan yang kedua; Ini terdiri dari menyelaraskan
yang terakhir. Ketidakcocokan karakter dalam teks dengan karakter pertama dari
pola pencocokannya.Penyederhanaan diajukan pada tahun 1980 oleh Horspool. Untuk memaksimalkan rata-rata pergeseran setelah ketidakcocokan,
karakternya dibandingkan dengan karakter terakhir dari pola dipilih untuk
penyelarasan. Ini juga menyiratkan itu perbandingan dapat dilakukan dalam
urutan apapun (kiri-ke-kanan, kanan-ke-kiri, acak. Hasil empiris menunjukkan
bahwa versi yang lebih sederhana ini sama baiknya dengan algoritma
aslinya.Kode untuk Algoritma BayerMoore-Horspool sangat sederhana dan mudah
Algoritma Horspool mempunyai nilai pergeseran karakter yang paling kanan dari window. Pada tahap observasi awal (preprocessing), nilai shift akan dihitung untuk semua karakter. Pada tahap ini, dibandingkan pattern dari kanan ke kiri hingga kecocokan atau ketidakcocokan pattern terjadi. Karakter yang paling kanan pada window digunakan sebagai indeks dalam melakukan nilai shift. Dalam kasus ketidakcocokan (karakter tidak terdapat pada pattern) terjadi, window digeser oleh panjang dari sebuah pattern. Jika tidak, window digeser menurut karakter yang paling kanan pada pattern (Baeza-Yates, R.A. & Regnier, M. 1992).
2.4.3.1 Pencarian Dengan Algoritma Horspool
Terdapat dua tahap pada pencocokan string menggunakan algoritma Horspool (Singh, R. & Verma, H.N. 2011), yaitu:
Pada tahap ini, dilakukan observasi pattern terhadap teks untuk membangun sebuah tabel bad-match yang berisi nilai shift ketika ketidak cocokan antara pattern dan teks terjadi. Secara sistematis, langkah-langkah yang dilakukan algoritma Horspool pada tahap praproses adalah:
a. Algortima Horspool melakukan pencocokan karakter ter-kanan pada pattern. b. Setiap karakter pada pattern ditambah ke dalam tabel bad-match dan dihitung
nilai shift-nya.
c. Karakter yang berada pada ujung pattern tidak dihitung dan tidak dijadikan karakter ter-kanan dari karakter yang sama dengannya.
d. Apabila terdapat dua karakter yang sama dan salah satunya bukan karakter ter-kanan, maka karakter dengan indeks terbesar yang dihitung nilai shift-nya. e. Algoritma Horspool menyimpan panjang dari pattern sebagai panjang nilai
shift secara default apabila karakter pada teks tidak ditemukan dalam pattern. f. Nilai (value) shift yang akan digunakan dapat dicari dengan perhitungan
panjang dari pattern dikurang indeks terakhir karakter dikurang 1, untuk masing-masing karakter, � �= − −1.
2. Tahap pencarian
Secara sistematis, langkah-langkah yang dilakukan algoritma Horspool pada tahap praproses adalah:
a. Dilakukan perbandingan karakter paling kanan pattern terhadap window. b. Tabel bad-match digunakan untuk melewati karakter ketika ketidakcocokan
terjadi.
c. Ketika ada ketidakcocokan, maka karakter paling kanan pada window berfungsi sebagai landasan untuk menentukan jarak shift yang akan dilakukan.
d. Setelah melakukan pencocokan (baik hasilnya cocok atau tidak cocok) dilakukan pergeseran ke kanan pada window.
e. Prosedur ini dilakukan berulang-ulang sampai window berada pada akhir teks atau ketika pattern cocok dengan teks.
Untuk menggambarkan rincian algoritma, akan diberikan contoh kasus dimana pattern P = ―PRATAMA‖ dan teks T = ―DHIWA ARIEPRATAMA‖. Inisialisasi awal dan pembuatan bad-match terlihat pada Tabel 2.2 dan Tabel 2.3 berikut. dilakukan. Setiap teks dan pattern masing-masing diberi nilai m dan i, dimana m sebagai panjang pattern dan i sebagai indeks. Tabel 2.3 menunjukkan nilai pergeseran bad-match dengan menghitung nilai v seperti yang telah dilakukan pada Tabel 2.1. Pada tahap awal pencarian, dilakukan perbandingan karakter
m 1 2 3 4 5 6 7 8 9 10 11 1 1 1 1 1 1
T D H I W A A R I E P R A T A M A
P P R A T A M A
paling kanan pattern terhadap window. Apabila terjadi ketidak cocokan, akan dilakukan pergeseran ke kanan untuk melewati karakter yang tidak cocok dimana nilai pergeserannya terdapat pada tabel bad-match. Karakter paling kanan teks pada window berfungsi sebagai landasan untuk menentukan jarak geser yang akan dilakukan. Hal ini terlihat pada Tabel 2.4 berikut.
Tabel 2.4Iterasi Algoritma Horspool Pertama
Terdapat ketidakcocokan seperti yang terlihat pada Tabel 2.4. Karakter ―A‖ adalah karakter paling kanan teks pada window. Pada tabel bad-match, nilai geser karakter ―A‖ adalah 4. Maka, dilakukan pergeseran ke kanan pada window sebanyak 4 kali. Hal ini terlihat pada Tabel 2.5.
Tabel 2.5Iterasi Algoritma Horspool Kedua
Pada Tabel 2.5, terdapat ketidak cocokan kembali antara karakter ―P‖ dan ―A‖. Pada tabel bad-match, nilai geser karakter ―R‖ adalah 6. Maka, dilakukan pergeseran ke kanan pada window sebanyak 6 kali. Hal ini terlihat pada Tabel 2.6.
Tabel 2.6Iterasi Algoritma Horspool Ketiga
Pada Tabel 2.6, window telah berada pada akhir teks dan semua pattern cocok dengan teks. Seluruh pencocokan karakter menggunakan algoritma Horspool telah selesai dan berhenti pada iterasi ketiga.
2.4 Huruf Jepang Jenis Katakana
Huruf Jepang memiliki beberapa jenis huruf yaitu Hiragana, Katakana, Kanji dan Roomaji. Tentu saja ke semua jenis huruf itu memiliki perbedaan dalam bentuk huruf dan penggunaanya. Dalam penelitian ini menitik beratkan pada huruf Katakana saja.
2.4.1 Huruf Katakana
Di jaman dahulu huruf Katakana hanya digunakan oleh kaum lelaki, oleh karena itu bentuk hurufnya lurus-lurus. Digunakan untuk kata-kata yang berasal dari bahasa asing yang kemudian diserap menjadi bahasa Jepang. Misalnya nama orang asing, nama negara dan kota asing (kecuali China dan Korea) dan benda-benda dari negara asing. Selain itu juga digunakan untuk menulis onomatope (bentuk kata yang menirukan suatu bunyi/suara, baik dari manusia, hewan atau benda.
2.4.1.1Huruf Dasar Katakana
2.4.1.2 Huruf Tambahan Katakana
Huruf tambahan Katakana dapat dilihat pada gambar 2.9 di bawah ini :
2.4.1.3 Huruf Gabungan Katakana
Huruf gabungan Katakana dapat dilihat pada gambar 2.10 di bawah ini :