1
ESTIMASI
A. Dasar Teori
1. Penaksiran atau Estimasi
Penaksiran atau estimasi adalah metode untuk memperkirakan nilai populasi dengan menggunakan nilai sampel. Nilai penduga disebut estimator, estimator yang baik adalah tidak bias,memiliki varians minimum, efisien dan konsisten. Terdapat 3 penaksir parameter, yakni : estimasi rata-rata µ, estimasi proporsi, dan estimasi simpangan baku.
a. Penaksir
Simbol dari parameter populasi adalah (baca: tetha). bisa berupa rata-rata µ, proporsi π, simpangan baku σ, dll. Jika tidak diketahui, maka ditaksir dengan harga (baca: tetha topi) yang dinamakan penaksir. Maka dapat dikatakan bahwa = dan menunjukkan harga yang sebenarnya. Namun tidak menutup kemungkinan menaksir dengan terlalu tinggi atau sebaliknya.
Berikut adalah ciri penaksir yang baik :
1. Penaksir dikatakan takbias apabila rata-rata semua harga sama dengan .
2. Penaksir yang memiliki varians minimum adalah penaksir yang memiliki varians terkecil di antara seluruh penaksir untuk parameter yang sama. 3. Penaksir dikatakan konsisten apabila ukuran sampel n mendekati ukuran
populasi dan menyebabkan mendekati . b. Cara menaksir
Jika parameter ditaksir dengan harga tertentu, maka disebut penaksir. Secara umum adalah penaksir untuk µ.titik taksiran untuk suatu parameter µ harganya berlainan tergantung pada harga yang didapat dari sampel yang ada. Untuk lebih meyakinkan, dapat digunakan interval taksiran/selang taksiran untuk menaksir nilai parameter diantara batas dua nilai. Pada pelaksanaannya, terlebih dahulu harus mencari interval taksiran yang sempit dengan derajat kepercayaan yang memuaskan. Derajat kepercayaan menaksir disebut koefisien kepercayaan yang dinyatakan dalam bentuk peluang.
Pada umumnya koefisien kepercayaan dinyatakan dengan simbol (baca: gamma), dimana 0< < 1. Harga tergantung pada kebutuhan dan
2 seberapa besar keyakinan peneliti saat membuat pernyataan. Biasanya digunakan 0,95 atau 0,99, yang ditulis atau .
Dalam menentukan nilai interval taksiran parameter dengan koefisien kepercayaan , ambil sampel secara acak, kemudian hitung nilai statistik yang diperlukan. Rumus yang digunakan untuk menghitung peluang parameter antara A-B adalah sebagai berikut :
Dimana A dan B merupakan fungsi statistik berupa variabel acak namun bukan 0. Artinya, peluang berupa interval acak yang terbentang antara A-B berisikan . Apabila A-B dihitung harganya berdasarkan sampel, maka A-B merupakan bilangan tetap. Namun pernyataan tersebut harus dinyatakan sebagai berikut :
“seseorang hanya yakin 100 % bahwa terletak antara A-B”
Pernyataan diatas harus dipahami, karena peluang memang terletak atau tidak terletak diantara A-B adalah 1 atau 0.
c. Menaksir rata-rata µ
Dalam sebuah populasi N dengan rata-rata µ dan simpangan baku σ,parameter µ akan ditaksir dengan cara mengambil sampel acak berukuran n pada data, lalu hitung sebagai titik taksiran dari rata-rata µ dan hitung s.
Jika ingin mendapatkan taksiran yang lebih tinggi derajat kepercayaannya, maka dapat menggunakan interval taksiran/selang taksiran yang disertai dengan nilai koefisien kepercayaan yang diinginkan. Hal ini dibedakan menjadi 3, yakni :
1. Simpanan baku σ diketahui & populasinya berdistribusi normal. Dengan menggunakan rumus sebagai berikut :
Keterangan :
= koefisien kepercayaan
z1/2 = bilangan z didapat dari table normal baku untuk peluang .
Bentuk lain dari rumus di atas untuk memperoleh 100% interval kepercayaan parameter µ adalah sebagai berikut:
3 2. Simpanan baku σ tidak diketahui dan populasinya berdistribusi normal.
Kenyataannya, parameter σ sering tidak diketahui. Karena itu menggunakan rumus sebagai berikut :
Keterangan :
= koefisien kepercayaan
tp = nilai t didapat dari daftar distribusi student
dengan p = dan
Untuk interval kepercayaannya adalah sebagai berikut
Bilangan yang didapat dari dinamakan batas bawah dan dinamakan batas atas.
Jika ukuran sampel lebih besar daripada ukuran populasi N, rumus yabg digunakan adalah sebagai berikut :
Kemudian berubah menjadi :
3. Simpanan baku σ tidak diketahui dan populasinya tidak berdistribusi normal. Dalam hal ini jika distribusi populasi menyimpang dari normal & ukuran sampelnya terlalu kecil, maka harus menggunakan bentuk distribusi yang asli dari populas. Makin besar koefisien kepercayaan, makin lebar jarak interval kepercayaan dan sebaliknya. Jika batas selang kepercayaan menjadi satu, maka diperoleh titik taksiran dengan derajat kepercayaan terkecil.
d. Menaksir proporsi π
Merupakan suatu penelitian yang bertujuan untuk menggambarkan suatu variabel pada populasi tertentu. Misal pada suatu populasi binom berukuran N
4 terdapat proporsi π untuk sebuah peristiwa dalam populasi itu. Maka dapat diambil sebuah sampel secara acak -n dari populasi tersebut. Misal terdapat x peristiwa A, maka dapat dimisalkan proporsi sampel untuk sebuah peristiwa A = (x/n). Maka titik taksiran untuk sebuah π adalah (x/n). Jika 100 % interval kepercayaan untuk penaksiran π dikehendaki, maka rumusnya adalah sebagai berikut :
Keterangan : p = x/n, q= 1 –p,
adalah bilangan z yang didapat dari daftar normal yang baku untuk peluang .
e. Menaksir simpangan baku
Untuk menaksir varians 2 dari sebuah populasi, sampel varians s2 berdasarkan sampel acak berukuran n perlu dihitung. Variansi untuk data kelompok hampir sama dengan variansi data tunggal, namun dikalikan dengan frekuensi setiap kelas. Berikut adalah rumusnya :
Variansi Standar Deviasi data tunggal
Keterangan : = varian sampel
= jumlah frekuensi tiap kelas = nilai setiap data
= nilai rata – rata hitung dalam sampel n = jumlah total data
Variansi Standar Deviasi data kelompok :
5 varian s2 tersebut merupakan penaksir takbias untuk varians 2. Dengan kata lain simpangan baku s bukan penaksir takbias untuk simpangan baku . Jadi titik taksiran s untuk adalah bias.
Apabila populasinya berdistribusi normal dengan varians 2 maka dapat dirumuskan dengan menggunakan distribusi chi kuadrat, maka rumus yang digunakan adalah sebagia berikut :
Keterangan : n = ukuran sampel
dan didapat dari daftar chi kuadrat yang berurutan untuk p = 1⁄2(1+ γ) dan p = 1⁄2(1-γ) dengan dk = (n -1).
B. Permasalahan
Tugas 2, berdasarkan datanya sendiri – sendiri mahasiswa menghitung : 1. Mengestimasi mean
2. Standar deviasi 3. Proporsi
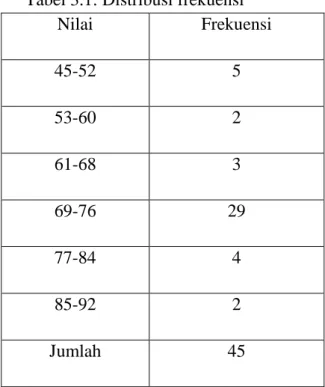
Tabel 3.1: Distribusi frekuensi
Nilai Frekuensi 45-52 5 53-60 2 61-68 3 69-76 29 77-84 4 85-92 2 Jumlah 45
6
C. Pembahasan
Pembahasan taksiran mean Analisis:
1. Menentukan sampel (n=45) dari 45 data.
2. Berdasarkan tugas 1b rata-rata hitung data individu didapat x 70,11. 3. Berdasarkan tugas 1c simpangan baku data individu didapat s9,41.
A. Kepercayaan 95%
dengan γ=95, maka α=1-γ=1-95%=0,05, diperoleh p=1-α/2=1-0,05/2=0,975, diperoleh tp=t(0,975) dengan derajat kebebasan dk=45 adalah 1,98.
B. Kepercayaan 99%
dengan γ=99, maka α=1-γ=1-99%=0,01, diperoleh p=1-α/2=1-0,01/2=0,995, diperoleh tp=t(0,995) dengan derajat kebebasan dk=45 adalah 2,69.
Pembahasan Standar Deviasi Analisis:
1. Menentukan sampel (n=45) dari 45 data.
2. Berdasarkan tugas 1b rata-rata hitung data individu didapat x 70,11. 3. Berdasarkan tugas 1c simpangan baku data individu didapat s9,41.
7 A. Kepercayaan 95% dengan γ=95%=0,95, dk= n-1= 45-1= 44, B. Kepercayaan 99% dengan γ=99%=0,99, dk= n-1= 45-1= 44,
8 Pembahasan Proporsi
Dimisalkan perbandingan komponen pasif dan komponen aktif dari sampel komponen elektronika sebanyak 450 buah ada 126 komponen aktif diperoleh:
dan A. Untuk kepercayaan 95%
9 D. Kesimpulan
Dari perhitungan manual diperoleh hasil akhir sebagai berikut: 1. Estimasi Mean :
Kepercayaan 95% = Kepercayaan 99% = 2. Estimasi Standar deviasi :
Kepercayaan 95% = Kepercayaan 99% = 3. Estimasi Proporsi : Kepercayaan 95% =
Kepercayaan 99% =
Sedangkan untuk perhitungan dengan menggunakan software SPSS diperoleh hasil sebagai berikut:
1. Estimasi mean :
Kepercayaan 95% = 66,78 < μ < 72,56 Kepercayaan 99% = 65,81 < μ < 73,52
Dari data diatas dapat disimpulkan bahwa perhitungan estimasi pada mean secara manual tidak jauh berbeda dibandingkan perhitungan menggunakan software SPSS. Namun dalam penggunaan perhitungan menggunakan software SPSS hanya dapat menghitung estimasi mean saja.
E. Daftar Pustaka
Basuki, Ismet. 2005. Handout 4 Mata Kuliah Statistika (Print Out Power Point). Sudjana. 1992. Metoda Statistika. Bandung: Tarsito.
10
F. Lampiran
Lampiran I: Hasil perhitungan dengan software SPSS. EXAMINE VARIABLES=Nilai
/PLOT BOXPLOT STEMLEAF
/COMPARE GROUPS
/MESTIMATORS HUBER(1.339) ANDREW(1.34) HAMPEL(1.7,3.4,8.5)
TUKEY(4.685)
/PERCENTILES(5,10,25,50,75,90,95) HAVERAGE
/STATISTICS DESCRIPTIVES EXTREME
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.
Explore
[DataSet1] D:\Document\TUgas Kuliah\SmtVIII\Statistika\Tugas\Data.sav
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
Nilai 45 100.0% 0 0.0% 45 100.0%
Descriptives
Statistic Std. Error
Nilai
Mean 69.6667 1.43372
95% Confidence Interval for Mean Lower Bound 66.7772 Upper Bound 72.5561 5% Trimmed Mean 70.0617 Median 70.0000 Variance 92.500 Std. Deviation 9.61769 Minimum 45.00 Maximum 85.00 Range 40.00 Interquartile Range 7.50 Skewness -1.044 .354 Kurtosis .558 .695
11 M-Estimators Huber's M-Estimatora Tukey's Biweightb Hampel's M-Estimatorc Andrews' Waved Nilai 71.4543 72.8233 71.5833 72.8490
a. The weighting constant is 1.339. b. The weighting constant is 4.685.
c. The weighting constants are 1.700, 3.400, and 8.500 d. The weighting constant is 1.340*pi.
Extreme Values
Case Number Value
Nilai Highest 1 16 85.00 2 22 85.00 3 12 80.00 4 14 80.00 5 32 80.00a Lowest 1 10 45.00 2 39 50.00 3 29 50.00 4 23 50.00 5 15 50.00
a. Only a partial list of cases with the value 80.00 are shown in the table of upper extremes.
Nilai
Nilai Stem-and-Leaf Plot
Frequency Stem & Leaf
8.00 Extremes (=<60) .00 6 . 3.00 6 . 555 13.00 7 . 0000000000000 15.00 7 . 555555555555555 4.00 8 . 0000 2.00 Extremes (>=85) Stem width: 10.00
12 GET
FILE='D:\Document\TUgas Kuliah\Smt VIII\Statistika\Tugas\Data.sav'.
DATASET NAME DataSet1 WINDOW=FRONT. EXAMINE VARIABLES=Nilai
/PLOT BOXPLOT STEMLEAF
/COMPARE GROUPS
/MESTIMATORS HUBER(1.339) ANDREW(1.34) HAMPEL(1.7,3.4,8.5)
TUKEY(4.685)
/PERCENTILES(5,10,25,50,75,90,95) HAVERAGE
/STATISTICS DESCRIPTIVES EXTREME
/CINTERVAL 99
/MISSING LISTWISE
/NOTOTAL.
Explore
13
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
Nilai 45 100.0% 0 0.0% 45 100.0%
Descriptives
Statistic Std. Error
Nilai
Mean 69.6667 1.43372
99% Confidence Interval for Mean Lower Bound 65.8067 Upper Bound 73.5266 5% Trimmed Mean 70.0617 Median 70.0000 Variance 92.500 Std. Deviation 9.61769 Minimum 45.00 Maximum 85.00 Range 40.00 Interquartile Range 7.50 Skewness -1.044 .354 Kurtosis .558 .695 M-Estimators Huber's M-Estimatora Tukey's Biweightb Hampel's M-Estimatorc Andrews' Waved Nilai 71.4543 72.8233 71.5833 72.8490
a. The weighting constant is 1.339. b. The weighting constant is 4.685.
c. The weighting constants are 1.700, 3.400, and 8.500 d. The weighting constant is 1.340*pi.
Percentiles
Percentiles
5 10 25 50 75 90 95
Weighted Average(Definition
1) Nilai 50.0000 50.0000 67.5000 70.0000 75.0000 80.0000 83.5000
14
Extreme Values
Case Number Value
Nilai Highest 1 16 85.00 2 22 85.00 3 12 80.00 4 14 80.00 5 32 80.00a Lowest 1 10 45.00 2 39 50.00 3 29 50.00 4 23 50.00 5 15 50.00
a. Only a partial list of cases with the value 80.00 are shown in the table of upper extremes.
Nilai
Nilai Stem-and-Leaf Plot Frequency Stem & Leaf 8.00 Extremes (=<60) .00 6 . 3.00 6 . 555 13.00 7 . 0000000000000 15.00 7 . 555555555555555 4.00 8 . 0000 2.00 Extremes (>=85) Stem width: 10.00
16 Lampiran II: Hasil software Plagiarsm Detector