MENGGUNAKAN JARINGAN SYARAF TIRUAN
M. Mahaputra Hidayat1, Diana Purwitasari2, Hari Ginardi3Jurusan Teknik Informatika Institut Teknologi Sepuluh Nopember
Surabaya, Indonesia
[email protected], [email protected]2, [email protected]3
ABSTRAK
Peningkatan kualitas pendidikan di perguruan tinggi dapat dilihat dari tingginya tingkat keberhasilan mahasiswa dan rendahnya tingkat kegagalan mahasiswa. Salah satu indikator kegagalan mahasiswa adalah kasus drop out (berhenti studi). Permasalahan drop out menjadi sesuatu yang menarik untuk diteliti, karena hal ini dapat dipengaruhi oleh bermacam faktor. Banyak peneliti yang mengkaji maupun melakukan prediksi
drop out berdasarkan faktor internal saja yaitu yang berasal dari dalam diri mahasiswa. Padahal selain faktor
tersebut banyak faktor lain yang juga dapat mempengaruhi terjadinya drop out, salah satunya perilaku sosial mahasiswa. Namun tidak mudah menentukan dan mempelajari classifier yang tepat berdasarkan perilaku sosial mahasiswa untuk memprediksi kemungkinan drop out ini. Untuk mengatasi permasalahan di atas, diusulkan model baru untuk mempelajari arsitektur Jaringan Syaraf Tiruan (JST) terbaik, agar menghasilkan
classifier yang tepat dalam melakukan prediksi drop out dengan memanfaatkan data mining pendidikan serta
pendekatan JST backpropagation pada penelitian ini. Hasil yang diperoleh dari analisis perilaku sosial dan model yang diusulkan, menunjukkan bahwa penggunaan data perilaku sosial mahasiswa dapat meningkatkan akurasi kemungkinan klasifikasi drop out sebesar 98,91% dengan tingkat signifikansi sensitivitas terbesar variabel perilaku sosial sebesar 4,737.
Kata Kunci: Prediksi drop-out, educational data mining, jaringan syaraf tiruan
ABSTRACT
Improvement of education quality in university can be seen by the highness rate of success student and the lowness rate of failed student. One indicator of failed student is drop out. The drop out problem is interesting to be studied, because it can be affected from many factors. Many researchers study and predict the drop out by internal factor only, which comes from the student themselves. Whereas there are many factors besides the internal factor that can trigger drop out, such as student social behavior. However, it is a non trivial task to determine and learn the correct classifier based on the student social behavior to predict drop out probability. To overcome that problem, a new model is proposed in this research to study the correct classifier that can predict drop out using educational data mining with neural network approach. The result from this analysis of social behavior and the proposed method is be able to show that the use of student behavior data can increase the drop out prediction accuracy of 98,91% and the sensitivity of social behaviour variable of 4,737.
Keywords: Drop out prediction, educational data mining, neural network.
PENDAHULUAN
Perguruan tinggi sering dijadikan tumpuan utama masyarakat dalam menilai berhasil tidaknya pendidikan tertinggi. Keberhasilan atau prestasi belajar mahasiswa hanya sering dilihat sebagai kesuksesan dan keunggulan pihak perguruan tinggi. Sebaliknya, kegagalan atau rendahnya kualitas mahasiswa sering dilihat sebagai ketidakmampuan pihak perguruan tinggi menyelenggarakan proses pendidikan tertinggi. Salah satu persoalan yang masih menjadi bahan pembicaraan adalah mengenai mahasiswa berhenti studi (drop out). Tingginya tingkat keberhasilan mahasiswa dan rendahnya tingkat kegagalan mahasiswa dapat mencerminkan kualitas dari suatu perguruan tinggi.
Banyaknya mahasiswa drop-out selain merugikan bagi pribadi/individu, juga merugikan institusi/perguruan tinggi pada khusus-nya dan negara pada umumnya. Oleh karena itu, perlu
dilakukan kajian maupun prediksi terhadap faktor-faktor yang mempengaruhi mahasiswa drop-out sehingga dapat dijadikan informasi yang bermanfaat bagi keberhasilan pendidikan di perguruan tinggi.
Salah satu teknik yang dapat digunakan untuk kasus prediksi adalah Jaringan Syaraf Tiruan (JST). JST akan melakukan pembelajaran untuk membentuk suatu model referensi berdasarkan data pelatihan, kemudian JST yang telah melakukan pembelajaran tersebut dapat digunakan untuk pencocokan pola [1]. Keunggulan dari JST adalah kemampuan klasifikasi terhadap data yang belum diberikan pada saat pembelajaran sebelumnya [2].
Permasalahan drop-out ini banyak menarik perhatian para peneliti untuk melakukan penelitian mengenai kegagalan siswa maupun kegagalan sekolah. Pada tahun 2009 telah dilakukan penelitian tentang komparasi algoritma Decision tree, Bayesian classifiers, logistic models, rule-based learner dan random forest dengan menggunakan 648 data set mahasiswa untuk melakukan prediksi drop-out [3]. Dalam penelitian tersebut decision tree menunjukkan tingkat akurasi yang paling tinggi. Pada tahun yang sama, penelitian mengenai faktor-faktor yang mempengaruhi drop-out mahasiswa UPN “Veteran” Jawa Timur juga dilakukan [4]. Hasil penelitian tersebut menunjukkan bahwa faktor intelegensia mahasiswa dan penghasilan orang tua memiliki pengaruh yang signifikan terhadap kasus drop-out di perguruan tinggi tersebut. Penelitian terbaru tentang analisis klasifikasi data mining untuk prediksi mahasiswa non-aktif di Universitas Dian Nuswantoro dilakukan dengan membandingkan empat algoritma yaitu logistic regression, decision tree, naive bayes, dan neural network [5]. Penelitian tersebut menunjukkan bahwa decision tree merupakan algoritma yang paling akurat, namun demikian decision tree tidak dominan terhadap algoritma yang lain. Berdasarkan hasil penelitian tersebut juga, logistic regression, decision tree, naïve bayes dan neural network masuk dalam kategori excellent classification.
Dari beberapa penelitian yang telah diuraikan sebelumnya, faktor yang banyak digunakan untuk memprediksi potensi drop-out mahasiswa adalah nilai akademis, kinerja mahasiswa, dan sosio-demographic mahasiswa, yang mana semua faktor tersebut berasal dari internal mahasiswa. Padahal faktor lainnya juga memiliki pengaruh yang signifikan terhadap prediksi potensi drop-out mahasiswa, salah satunya faktor perilaku sosial [6]. Oleh karena itu pada penelitian ini diusulkan model baru untuk mempelajari arsitektur Jaringan Syaraf Tiruan (JST) terbaik, agar menghasilkan classifier yang tepat dalam melakukan prediksi drop out berdasarkan perilaku sosial mahasiswa dengan memanfaatkan data mining pendidikan serta pendekatan JST backpropagation.
TINJAUAN PUSTAKA 1. Perilaku Sosial
Perilaku sosial seseorang itu tampak dalam pola respons antar orang yang dinyatakan dengan hubungan timbal balik antar pribadi. Perilaku sosial juga identik dengan reaksi seseorang terhadap orang lain [7]. Perilaku itu ditunjukkan dengan perasaan, tindakan, sikap keyakinan, kenangan, atau rasa hormat terhadap orang lain. Perilaku sosial seseorang merupakan sifat relatif untuk menanggapi orang lain dengan cara-cara yang berbeda-beda. Misalnya dalam melakukan kerja sama, ada orang yang melakukannya dengan tekun, sabar dan selalu mementingkan kepentingan bersama diatas kepentingan pribadinya. Sementara di pihak lain, ada orang yang bermalas-malasan, tidak sabaran dan hanya ingin mencari untung sendiri. Tabel 1 merupakan contoh perilaku sosial manusia.
Tabel 1. Contoh Perilaku Sosial Manusia [7]
Faktor pembentuk Contoh Perilaku sosial
Perilaku dan karakteristik Interaksi bergaul, kerja tim Proses kognitif Sharing ide, pendapat
Menjadi pemimpin bagi orang lain Lingkungan Logat bahasa, gaya hidup
2. Educational Data Mining
Educational Data Mining (EDM) adalah bidang ilmu baru yang mengeksploitasi statistik, machine-learning, dan algoritma data-mining (DM) pada berbagai jenis data pendidikan yang tujuan utamanya yaitu menganalisis jenis data dalam menyelesaikan masalah-masalah penelitian pendidikan [8]. EDM berkaitan dengan pengembangan metode untuk mengeksplorasi jenis data yang unik dalam pengaturan pendidikan. Metode ini digunakan untuk memahami siswa lebih baik dan pengaturan di mana mereka belajar [9]. Beberapa algoritma DM yang umum digunakan adalah Decision Tree, CART (Classification & Regression Trees), CHAID (Chi Square Automatic Interaction Detector), Neural Networks, KNN (K-Nearest Neighbors), Genetic Algorithm, dan sebagainya.
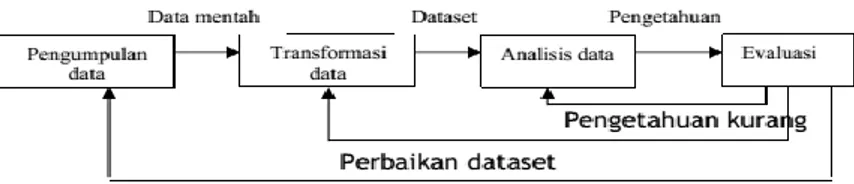
Pada Gambar 1 ditunjukkan diagram yang menggambarkan aliran informasi dalam proses data mining [10]. Proses data mining pada gambar tersebut ditunjukkan sebagai proses yang iteratif. Hasil evaluasi pengetahuan yang dihasilkan data mining dapat menimbulkan kebutuhan pengetahuan yang lebih lengkap, perbaikan kumpulan data (dataset) atau perubahan pada sistem.
Gambar 1. Aliran Informasi dalam Data Mining
. 3. Jaringan Syaraf Tiruan
Neural Networks (Artificial Neural Networks atau Jaringan Saraf Tiruan) merupakan sebuah metode softcomputing atau data mining yang banyak digunakan untuk melakukan pengklasifikasian dan prediksi. Artificial Neural Networks (ANN) pertama kali dikembangkan oleh McCulloch dan Pitts pada tahun 1943, dan sekarang ini telah banyak dikembangkan menjadi bentuk ANN yang bermacam-macam. Perubahan bentuk ini dapat berupa perubahan activation function, topology, learning algorithm dan lain-lain. Pada penelitian ini digunakan JST backpropagation.
3.1. Algoritma Backpropagation
Salah satu algoritma yang sering digunakan dalam melakukan learning terhadap ANN adalah backpropagation algorithm. Algoritma ini dikembangkan oleh Rumelhart dan McClelland pada tahun 1986. Sebuah neural networks umumnya terdiri dari input, output dan hidden layer. Dalam algoritma Backpropagation, proses learning dilaksanakan, pertama melakukan proses feed forward dengan mengirimkan sinyal ‘forward’. Adapun proses yang dilakukan dalam feed forward ini untuk sebuah neuron dijabarkan dalam gambar 2.
Gambar 2. Activation of single neuron
Algoritma backpropagation terdiri dari arah maju dan arah balik seperti berikut ini: Tahap 0 : pembobotan awal (set ke nilai random serendah mungkin), set harga error minimal. Tahap 1 : Ketika kondisi stop, false, lakukan tahap 2-9.
Tahap 2 : Untuk setiap pasangan training, lakukan tahap 3-8. Feedforward :
Tahap 3 : tiap unit masukan (𝑋𝑖, 𝑖 = 1, … , 𝑛), menerima sinyal 𝑥𝑖 dan menyebarkan sinyal ke
seluruh lapis tersembunyi (hidden layer).
Tahap 4 : tiap unit tersembunyi 𝑍𝑗, 𝑗 = 1, … , 𝑝), jumlahkan bobot sinyal inputnya,
𝑍𝑖𝑛𝑗 = 𝑣𝑜𝑗+ ∑ 𝑥𝑖𝑣𝑖𝑗
𝑝
𝑖=1 , (1)
Terapkan fungsi aktivasi untuk menghitung sinyal keluarannya, 𝑍𝑗= 𝑓(𝑧𝑖𝑛𝑗), dan mengirimkan sinyal ini ke seluruh unit lapis di atasnya (lapis output).
Tahap 5 : tiap unit keluaran (𝑌𝑘, 𝑘 = 1, … , 𝑚), jumlahkan bobot sinyal keluarannya,
𝑦𝑖𝑛𝑘 = 𝑤𝑜𝑘+ ∑𝑚𝑗=1𝑥𝑗𝑤𝑗𝑘, (2)
Sedangkan untuk cascade: 𝑌𝑖𝑛𝑘 = 𝑤𝑜𝑘+ ∑ 𝑥𝑗𝑤𝑗𝑘
𝑚
𝑗=1 + ∑𝑓𝑖=1𝑥𝑖𝑤𝑖𝑗 (3)
Terapkan fungsi aktivasi untuk menghitung sinyal keluarannya,
𝑦𝑘 = 𝑓(𝑧𝑖𝑛𝑘). (4)
Backpropagation Error:
Tahap 6 : tiap unit keluaran 𝑌𝑘, 𝑘 = 1, … , 𝑚), menerima pola target dan mengacu ke target
masukan, hitung kesalahannya
𝛿𝑘 = (𝑡𝑘− 𝑦𝑘)𝑓′(𝑦𝑖𝑛𝑘), (5) Hitung koreksi bobot,
∆𝑤𝑗𝑘= 𝛼𝛿𝑘𝑧𝑗, (6)
Hitung koreksi terhadap bias,
∆𝑤𝑜𝑘 = 𝛼𝛿𝑘, (7)
Dan mengirimkan sinyal tersebut ke lapis sebelumnya (mundur).
Tahap 7 : tiap unit tersembunyi (𝑍𝑗, 𝑗 = 1, … , 𝑝), menjumlahkan delta masukan dari lapis
diatasnya.
𝛿𝑖𝑛𝑗= ∑ 𝛿𝑘𝑤𝑗𝑘
𝑚
𝑘=1 , (8)
Dan hitung bobot koreksinya,
∆𝑣𝑖𝑗 = 𝛼𝛿𝑗𝑥𝑖, (9)
Dan hitung koreksi biasnya,
∆𝑣𝑜𝑗 = 𝛼𝛿𝑗, (10)
Update bobot dan bias:
Tahap 8 : tiap unit keluaran (𝑌𝑘, 𝑘 = 1, … , 𝑚), update bias dan bobot-bobotnya (𝑗 = 0, … , 𝑝):
𝑤𝑗𝑘(𝑛𝑒𝑤) = 𝑤𝑗𝑘(𝑜𝑙𝑑) + ∆𝑤𝑗𝑘, (11)
Tiap unit tersembunyi (𝑍𝑗, 𝑗 = 1, … , 𝑝), update bias dan bobotnya 𝑖 = 0, … , 𝑛):
𝑣𝑖𝑗(𝑛𝑒𝑤) = 𝑣𝑖𝑗(𝑜𝑙𝑑) + ∆𝑤𝑖𝑗, (12)
Tahap 9 : Uji kondisi berhenti.
𝑖𝑓 𝛿𝑘 < harga error set awal then “stop training”.
4. Generalisasi
Dalam penelitian ini digunakan parameter yang disebut generalisasi untuk mengukur tingkat pengenalan jaringan pada pola yang diberikan yaitu data validasi dan data testing. Generalisasi yang digunakan dalam [11] adalah sebagai berikut :
𝐺𝑒𝑛𝑒𝑟𝑎𝑙𝑖𝑠𝑎𝑠𝑖𝑡𝑒𝑠𝑡 =
𝑛𝑢𝑚𝑘𝑒𝑛𝑎𝑙𝑡𝑒𝑠𝑡
𝑗𝑢𝑚𝑝𝑜𝑙𝑎 𝑥100 (13)
dimana 𝑛𝑢𝑚𝑘𝑒𝑛𝑎𝑙𝑡𝑒𝑠𝑡 adalah jumlah pola yang dikenal dan 𝑗𝑢𝑚𝑝𝑜𝑙𝑎 adalah jumlah pola
keseluruhan. Jumlah 𝑛𝑢𝑚𝑘𝑒𝑛𝑎𝑙𝑡𝑒𝑠𝑡 dan 𝑗𝑢𝑚𝑝𝑜𝑙𝑎 yang ditunjukkan akan berbeda pada setiap
5. Analisis Sensitivitas
Analisis sensitivitas bertujuan untuk melihat perubahan output dari model yang didapatkan jika dilakukan perubahan terhadap input dari model. Selain itu analisis ini berguna untuk mengetahui variabel mana yang lebih berpengaruh atau sensitif untuk mencapai output akurat dari model yang dikembangkan [12].
Untuk mengetahui sensitivitas dari 𝑆𝑘𝑖𝑝 dimana JST yang digunakan memiliki 1 layer input 𝑍 = (𝑍1, … , 𝑍𝑖, … 𝑍𝐼), 1 layer tersembunyi 𝑌 = (𝑌1, … 𝑌𝑗, … 𝑌𝐽), dan 1 layer output 𝑂 =
(𝑂1, … 𝑂𝑘, … 𝑂𝐾) dan data training adalah 𝑃 = (𝑃1, … 𝑃𝑝, … 𝑃𝑃) digunakan :
𝑆𝑘𝑖𝑝 = 𝑂′𝑘+ ∑𝐽𝑗=1𝑤𝑘𝑗𝑦′𝑗𝑣𝑗𝑖 (14)
Untuk mendapatkan matrik sensitivitas dari semua data training terhadap output dapat digunakan :
𝑆𝑘𝑖𝑝𝑚𝑎𝑥 = max{𝑆𝑘𝑖𝑝} , 𝑝 = 1, … 𝑃 (15)
kemudian dilanjutkan dengan menghitung matrik sensitivitas dari input secara menyeluruh dapat digunakan :
∅𝑖 = max{𝑆𝑘𝑖} , 𝑘 = 1, … 𝐾 (16)
METODE PENELITIAN
Pada bagian ini akan dijelaskan mengenai tahap-tahap dalam penelitian untuk memperoleh model JST dengan arsitektur terbaik, yaitu preprocessing data, pengujian dan prediksi. Data pendidikan mahasiswa yang digunakan dalam penelitian ini diperoleh dari sistem akademik mahasiswa (SIAMIK) UPN “Veteran” Jawa Timur dan Universitas Bhayangkara (UBHARA) Surabaya, yaitu sebanyak 204 sampel mahasiswa teknik informatika semester 2 dan 6. Data perilaku sosial mahasiswa diperoleh dengan cara membagikan kuisioner kepada sampel mahasiswa tersebut untuk kemudian diisi sesuai dengan pilihan yang ada. Dataset yang digunakan dalam penelitian ini dikomposisikan dalam dua kelompok data (KD) yang dapat dilihat pada Tabel 2 dan Tabel 3.
Tabel 2. Kelompok Data Pertama
Kategori Data yang digunakan Data training (50%) Data validasi (25%) Data testing (25%) Jumlah Non DO 70 35 35 140 DO 32 16 16 64 Jumlah 102 51 51 204
Tabel 3. Kelompok data Kedua
Kategori Data yang digunakan Data training (70%) Data validasi (15%) Data testing (15%) Jumlah Non DO 98 21 21 140 DO 44 10 10 64 Jumlah 142 31 31 204 Preparation data
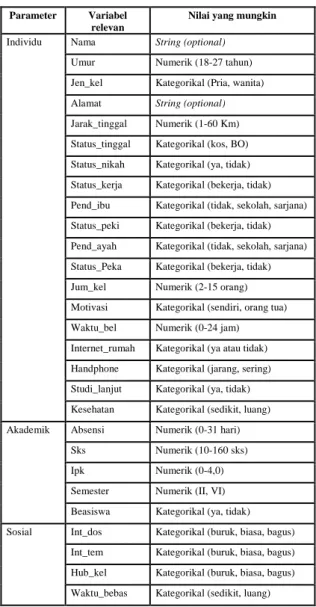
Pada langkah data preparation, pengolahan data terdiri dari 2 poin: seleksi data dan transformasi data. Seleksi data bertujuan untuk mengidentifikasi variabel-variabel relevan yang digunakan dalam penelitian ini. Transformasi data digunakan untuk mengubah dataset sehingga konten informasi terbaik diambil dan dimasukkan pada tool mining dalam format yang tepat. Pada langkah ini, ditentukan atribut-atribut yang akan mendukung variabel input. Tabel 4 menunjukkan hasil identifikasi variabel-variabel yang digunakan sebagai input data berdasarkan parameter individu, parameter akademik, dan parameter sosial mahasiswa.
Tabel 4. Variabel Input
Preprocessing data
Langkah berikutnya adalah preprocessing, yaitu untuk menangani data yang bersifat noise dan missing value data. Dengan pembersihan dan pengintegrasian, data noise dan informasi yang tidak relevan dari dataset akan berkurang. Di dalam preprocessing dilakukan cleaning data yaitu proses yang digunakan untuk menghapus data ganda, memeriksa data yang tidak konsisten, penanganan data missing dan merapikan data noise, dan transformasi data yaitu mengubah data ke dalam model analitik.
Unary Encoding merupakan metode transformasi data dengan mempresentasikan data kategorikal dalam bentuk kombinasi angka 1 dan 0 (numerical binary variable). Misalnya atribut jenis kelamin yang mempunyai 2 kategori maka akan diganti dengan 2 (dua) atribut bilangan biner yaitu pria dan wanita. Jika atribut jenis kelamin menunjukkan pria, maka nilai atribut pria 1 dan wanita 0. Dan jika atribut jenis kelamin menunjukkan menunjukkan wanita, maka nilai atribut pria 0 dan wanita 1. Tabel 5 dan 6 merupakan salah satu contoh atribut kategorikal, yaitu variabel jenis kelamin yang ditransformasi menjadi numerical binary variable.
Tabel 5. Atribut biner jenis kelamin Jenis Kelamin Biner Pria Biner Wanita
Pria 1 0 Wanita 0 1
Parameter Variabel relevan
Nilai yang mungkin Individu Nama String (optional)
Umur Numerik (18-27 tahun) Jen_kel Kategorikal (Pria, wanita) Alamat String (optional)
Jarak_tinggal Numerik (1-60 Km) Status_tinggal Kategorikal (kos, BO) Status_nikah Kategorikal (ya, tidak) Status_kerja Kategorikal (bekerja, tidak) Pend_ibu Kategorikal (tidak, sekolah, sarjana) Status_peki Kategorikal (bekerja, tidak) Pend_ayah Kategorikal (tidak, sekolah, sarjana) Status_Peka Kategorikal (bekerja, tidak) Jum_kel Numerik (2-15 orang) Motivasi Kategorikal (sendiri, orang tua) Waktu_bel Numerik (0-24 jam) Internet_rumah Kategorikal (ya atau tidak) Handphone Kategorikal (jarang, sering) Studi_lanjut Kategorikal (ya, tidak) Kesehatan Kategorikal (sedikit, luang) Akademik
Absensi Numerik (0-31 hari) Sks Numerik (10-160 sks)
Ipk Numerik (0-4,0)
Semester Numerik (II, VI) Beasiswa Kategorikal (ya, tidak) Sosial Int_dos Kategorikal (buruk, biasa, bagus)
Int_tem Kategorikal (buruk, biasa, bagus) Hub_kel Kategorikal (buruk, biasa, bagus) Waktu_bebas Kategorikal (sedikit, luang)
Tabel 6. Hasil transformasi
Jenis Kelamin Nilai
Pria 10 Wanita 01 Wanita 01 Wanita 01 Pria 10 Pria 10
Kemudian sebelum dilaksanakan input data dan data target ke dalam JST, pertama harus dilakukan normalisasi data untuk variabel numerik. Normalisasi adalah salah satu dari beberapa teknik dalam data transformasi, yang mengubah data asli ke dalam jangkauan datanya antara 0 dan 1 sesuai dengan fungsi aktivasi yang akan digunakan.
Dalam penelitian ini digunakan rumus normalisasi data max-min sebagai berikut : 𝑁𝑜𝑟𝑚𝑎𝑙𝑖𝑠𝑎𝑠𝑖 = 𝐴−𝐴𝑚𝑖𝑛
𝐴𝑚𝑎𝑥−𝐴𝑚𝑖𝑛 (17)
dimana:
𝐴 : atribut nilai input 𝐴𝑚𝑎𝑥 : bobot nilai maksimum
𝐴𝑚𝑖𝑛 : bobot nilai minimum
Pengujian
Pada tahap ini, setelah data siap untuk dimasukkan dalam JST, dilakukan pengujian dengan menggunakan variasi arsitektur yang ditentukan pada Tabel 7. Kemudian akan dibandingkan hasilnya dan dipilih arsitektur JST yang terbaik untuk sistem prediksi.
Tabel 7. Struktur JST yang Digunakan
Karakteristik Spesifikasi
Arsitektur 1 hidden layer
Neuron input Iterasi pertama 50 node, iterasi selanjutnya berdasarkan hasil proses seleksi variable input menggunakan analisis sensitivitas Hidden node 5, 10, 15
Fungsi pelatihan Resilent backpropagation, levenberg-marquardt
Neuron layer output 2 Toleransi galat 0,001
Learning rate 0.01, 0.05, 0.1, 0.5 Maksimum epoch 2000
Arsitektur JST yang telah diberi pembelajaran dan diuji kemudian dianalisis sensitivitas node-node inputnya menggunakan analisis sensitivitas yang telah dibahas pada subbab sebelumnya. Hasil yang diharapkan dari proses ini adalah didapatkan node-node input yang memiliki sensitivitas rendah, sehingga tidak akan digunakan kembali pada tahap pembelajaran selanjutnya. Proses ini akan berulang terus sampai didapatkan nilai sensitivitas dari masing-masing node yang cukup tinggi. Jaringan dengan arsitektur terbaik inilah yang siap untuk digunakan dalam sistem prediksi kemungkinan drop-out mahasiswa berdasarkan perilaku sosialnya.
HASIL DAN PEMBAHASAN
Serangkaian uji coba dilakukan untuk mengevaluasi sistem yang diusulkan. Digunakannya variasi parameter jaringan dalam proses pembelajaran dan pengujian dimaksudkan untuk mendapatkan parameter terbaik dari model JST yang kemudian digunakan untuk melakukan prediksi drop-out mahasiswa, dengan membandingkan hasil percobaan pelatihan dan pengujian pada dua kelompok data dan fungsi pelatihan yang berbeda, dimana pada masing-masing kelompok data, hasil percobaan memberikan informasi waktu pembelajaran tercepat, nilai MSE terkecil, dan generalisasi data validasi dan data testing tertinggi, parameter laju pembelajaran (lr) dan jumlah hidden-node.
Berdasarkan hasil pembelajaran dan pengujian berulang pada Tabel 8 terlihat bahwa waktu pembelajaran tercepat 0.06 detik, dihasilkan oleh pembelajaran pada kelompok data pertama dengan variasi fungsi pelatihan levenberg-marquardt pada laju pembelajaran 0.1 dan jumlah hidden-node 5. Nilai MSE terkecil dan tingkat generalisasi tertinggi dari data validasi dan data testing dihasilkan oleh pembelajaran kelompok data kedua dengan variasi fungsi pelatihan levenberg-marquardt, laju pembelajaran 0.1 dan jumlah hidden node 10.
Tabel 8. Hasil Pembelajaran dan Pengujian Terbaik
Variasi Kelompok data pertama Kelompok data kedua
waktu MSE Data
Validasi Data Testing
waktu MSE Data Validasi Data Testing Fungsi Pelatihan Resilent BP 0.08 0.0000103 98.86 98.88 0.14 0.0000038 98.48 98.64 lr 0.5 0.1 0.1 0.1 0.1 0.5 0.01 0.1 Hidden node 5 5 5 5 5 5 5 5 Fungsi Pelatihan levenberg-marquardt 0.06 0.0000106 98.86 98.77 0.06 0.00000026 98.89 98.91 lr 0.1 0.1 0.1 0.1 0.5 0.1 0.5 0.5 Hidden node 5 5 5 5 5 10 5 5
Hasil pembelajaran dan pengujian menunjukkan adanya perbaikan nilai yang dihasilkan oleh percobaan dengan menggunakan beberapa variasi fungsi pelatihan. Nilai waktu pembelajaran, MSE dan tingkat generalisasi dari data validasi dan data testing yang dihasilkan oleh percobaan dengan fungsi pelatihan resilent backpropagation terus diperbaiki bobotnya hingga menghasilkan waktu pembelajaran yang lebih cepat, nilai MSE yang lebih minimum dan tingkat akurasi yang lebih tinggi pada percobaan dengan fungsi levenberg-marquardt. Berdasarkan hasil generalisasi pada pengujian dengan mempertimbangkan beberapa variasi parameter jaringan, maka ditetapkan arsitektur terbaik yang dapat digunakan untuk melakukan prediksi tingkat kelulusan mahasiswa adalah sebagaimana yang ditunjukkan oleh Tabel 9.
Tabel 9. Parameter Jaringan Terbaik untuk Prediksi
Parameter Model JST untuk
prediksi
Kelompok Data Kedua
Fungsi Pelatihan Levenberg-marquardt
Learning rate 0.1
Jumlah hidden node 5 Generalisasi data validasi 98.89% Generalisasi data testing 98.91%
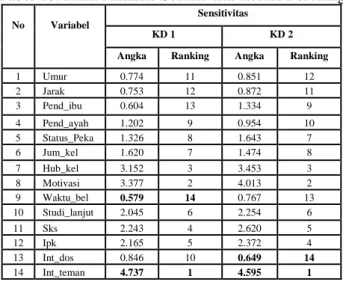
Selanjutnya dilakukan proses analisis sensitivitas terhadap JST dengan performa terbaik yang menghasilkan ranking variabel input dari yang terendah sampai yang tertinggi. Hasil analisis sensitivitas setelah dilakukan iterasi berulang dapat dilihat pada Tabel 10 yang menunjukkan bahwa variabel input yang memiliki tingkat sensitivitas paling tinggi untuk kelompok data pertama adalah ‘kualitas hubungan antar mahasiswa’ dengan skor 4.737 (ranking 1), dan terendah ‘waktu belajar’ dengan skor 0.579 (ranking 14). Sedangkan untuk kelompok data kedua, nilai sensitivitas tertinggi dicapai oleh variabel input ‘kualitas hubungan antar mahasiswa’ dengan skor 4.595 (ranking 1) dan terendah ‘interaksi dengan dosen’ dengan skor 0.649 (ranking 14). Sensitivitas pada semua variabel menunjukkan hasil yang cukup besar sehingga proses iterasi pembelajaran dihentikan.
Tabel 10. Hasil Analisis Sensitivitas Iterasi Berulang No Variabel Sensitivitas KD 1 KD 2
Angka Ranking Angka Ranking
1 Umur 0.774 11 0.851 12 2 Jarak 0.753 12 0.872 11 3 Pend_ibu 0.604 13 1.334 9 4 Pend_ayah 1.202 9 0.954 10 5 Status_Peka 1.326 8 1.643 7 6 Jum_kel 1.620 7 1.474 8 7 Hub_kel 3.152 3 3.453 3 8 Motivasi 3.377 2 4.013 2 9 Waktu_bel 0.579 14 0.767 13 10 Studi_lanjut 2.045 6 2.254 6 11 Sks 2.243 4 2.620 5 12 Ipk 2.165 5 2.372 4 13 Int_dos 0.846 10 0.649 14 14 Int_teman 4.737 1 4.595 1
Setelah semua proses uji coba dilakukan, didapatkan arsitektur JST terbaik yang siap untuk dikembangkan menjadi sistem prediksi drop-out mahasiswa yang handal. Sebagai tahap terakhir perlu dilakukan pengujian arsitektur terbaik terhadap sebagian data validasi dan data testing yang dimaksudkan untuk menguji ketepatan jaringan dalam melakukan prediksi sebelum digunakan untuk melakukan prediksi pada data baru yang akan diberikan. Data validasi dan data testing akan diuji tanpa memiliki data target, sehingga target hasil prediksi yang dihasilkan akan dibandingkan dengan data aktual. Hasil proses pengujian dengan menggunakan data validasi dan data testing pada model prediksi kemungkinan drop-out disajikan oleh Tabel 11.
Tabel 11. Pengujian dengan Menggunakan Arsitektur Terbaik untuk Prediksi
Data Data Validasi % Data testing % Jumlah data 31 31 Pengenalan data Dikenal Tidak dikenal 31 100 29 93.54 0 0 2 6.46
Data hasil prediksi
Drop-out Non drop-out 10 100 9 90 21 100 20 95.23 Data aktual Drop-out Non drop-out 10 100 10 100 21 100 21 100
Berdasarkan pengujian arsitektur terbaik terhadap data validasi dan data testing untuk model prediksi drop-out menunjukkan bahwa data dikenali 100% pada data validasi dan 93.54% pada data testing. Hasil prediksi menggunakan data validasi menyatakan bahwa mahasiswa yang diprediksi drop-out berjumlah 10 mahasiswa dan non drop-out 21 mahasiswa, dan data kategori aktual menunjukkan hal yang sama. Prediksi terhadap data testing menyatakan bahwa mahasiswa yang diprediksi non drop-out sebanyak 20 dan drop-out hanya 9 mahasiswa, berbeda dengan data aktual yang menyatakan bahwa mahasiswa yang out berjumlah 10 mahasiswa dan non drop-out 21 mahasiswa.
KESIMPULAN
Hasil uji coba menunjukkan bahwa, model yang diusulkan dapat digunakan untuk predikasi potensi drop-out mahasiswa. Arsitektur dan parameter jaringan terbaik yang diperoleh yaitu menggunakan komposisi kelompok data kedua, dengan fungsi pelatihan levenberg-marquardt, laju pembelajaran 0.1, 5 hidden node, generalisasi data validasi dan data testing sebesar
98.89% dan 98,91%. Hasil analisis sensitivitas menunjukkan variabel input untuk parameter sosial yang paling berpengaruh adalah kualitas interaksi dengan teman dan variabel hubungan keluarga. Sedangkan variabel input untuk parameter individu adalah studi_lanjut dan motivasi. Untuk parameter akademik, variabel input yang paling berpengaruh adalah SKS dan IPK.
DAFTAR PUSTAKA
[1]. Kusumadewi S and Hartati S, 2010, Neuro-Fuzzy. Integrasi Sistem Fuzzy & Jaringan Syaraf, Yogyakarta, Graha Ilmu.
[2]. Han J and Kamber M, 2001, Data Mining: Concepts and Techniques, USA : Academic Press.
[3]. G. W. Dekker et al., 2009, Predicting students drop out: A case study, In EDM: Proceedings of the 2nd International Conference On Educational Data Mining, Cordoba, Spain., pages 41-50.
[4]. Hertati, D, 2009, Faktor-Faktor Yang Mempengaruhi Putus Studi (Drop Out) Mahasiswa Universitas Pembangunan Nasional "Veteran" Jawa Timur (Tugas Akhir tidak dipublikasikan), Universitas Pembangunan Nasional “Veteran” Jawa timur.
[5]. Hastuti K, 2012, Analisis Komparasi Algoritma Klasifikasi Data Mining Untuk Prediksi Mahasiswa Non Aktif, Seminar Nasional Teknologi Informasi & Komunikasi Terapan 2012 (Semantik 2012).
[6]. B. Jaroslav et al., 2012, Predicting drop-out from social behaviour of students, EDM2012: Proceedings ofthe 5th International Conference on Educational Data Mining, Eindhoven, the Netherlands., pages 103-109, www.educationaldatamining.org.
[7]. Baron et al., 2006, Social Psychology, Erlangga.
[8]. C. Romero et al., 2010, Handbook of Educational Data Mining, New York: Taylor & Francis.
[9]. R. Baker and K. Yacef, 2010, The state of educational data mining in 2009: A review and future visions, Journal of Educational Data Mining, 1(1):3-17.
[10]. Nilakant, K, 2004, Applicationof Data Mining in Constraint Based Intelligent Tutoring System, www.cosc.canterbury.ac.nz/research/reports/HonsReps/2004/hons_0408.pdf, diakses tanggal 28 Juni 2013.
[11]. Agustini K, 2006, Perbandingan Metode Transformasi Wavelet Sebagai Praproses Pada Sistem Identifikasi Pembicara, [Thesis], Bogor: Program Pascasarjana, Institut Pertanian Bogor.
[12]. Engelbrecht AP, 2001, Sensitivity Analysis for Selective Learning by Feedforward Neural Networks, J Fundamental Informatics, Vol. XXI:1001-1028, IOS Press.
![Tabel 1. Contoh Perilaku Sosial Manusia [7]](https://thumb-ap.123doks.com/thumbv2/123dok/4598263.3354232/2.892.217.699.998.1110/tabel-contoh-perilaku-sosial-manusia.webp)