BAB 2
LANDASAN TEORI
2.1 Pembagian Ilmu Statistik
Secara garis besar ilmu statistik dibagi menjadi dua bagian yaitu:
1. Statistik Parametrik
Statistik parametrik adalah ilmu statistik yang digunakan untuk data – data yang memiliki distribusi normal. Jika data tidak berdistribusi normal maka statistik nonparametrik dapat digunakan. Apa yang dapat dilakukan jika data tidak berdistribusi secara normal, namum statistik parametrik tetap ingin digunakan?
Untuk kasus seperti ini data harus ditransformasikan terlebih dahulu. Transformasi data perlu dilakukan agar data mengikuti distribusi normal. Bagaimana cara melakukan tranformasi data tidak dibahas dalam tulisan ini.
2. Statistik nonparametrik
Statistik nonparametrik disebut juga statistik bebas distribusi. Statistik nonparametrik tidak mensyaratkan bentuk distribusi parameter populasi. Statistik nonparametrik dapat digunakan pada data yang memiliki distribusi normal atau tidak. Statistik nonparametrik biasanya digunakan untuk melakukan analisis pada data nominal atau ordinal.
Contoh metode statistik nonparametrik antara lain adalah Median test, Friedman test, korelasi rank Kendall, korelasi rank Spearman, dan lain – lain.
2.2 Langkah – Langkah Pemilihan Metode Statistik
Metode statistik nonparametrik digunakan bila salah satu syarat dalam statistik parametrik tidak terpenuhi. Syarat – syarat yang perlu diperhatikan untuk menentukan statistik apa yang digunakan dalam analisis, yaitu:
1. Apakah distribusi data diketahui?
Jika distribusi data tidak diketahui maka statistik yang sesuai adalah statistik nonparametrik. Jika distribusi data diketahui, maka kita harus melihat jenis distribusi data tersebut.
2. Apakah data berdistribusi normal?
Jika data tidak berdistribusi normal, maka statistik yang sesuai adalah statistik nonparametrik. Jika data berdistribusi normal, maka statistik yang sesuai adalah statistik parametrik.
3. Apakah sampel ditarik secara random?
Jika sampel tidak ditarik secara random maka statistik yang digunakan adalah statistik nonparametrik. Jika sampel ditarik secara random maka statistik yang digunakan adalah statistik parametrik.
4. Apakah varians kelompok sama?
Jika varians kelompok tidak sama, maka statistik yang sesuai adalah statistik nonparametrik. Jika varians kelompok sama, maka statistik yang sesuai adalah statistik parametrik.
5. Bagaimana jenis skala pengukuran data?
Jika skala pengukuran data nominal dan ordinal, maka statistik yang sesuai adalah statistik nonparametrik. Jika skala pengukuran data interval dan rasio, maka statistik yang sesuai adalah statistik parametrik.
Langkah – langkah pemilihan metode statistik dapat dilihat pada gambar berikut ini:
tidak
ya
tidak
ya
tidak
ya
tidak
ya
Distribusi populasi diketahui?
Distribusi populasi normal??
Skala pengukuran
??
Varians kelompok
sama ??
Sampel ditarik random ??
data
STATISTIK NONPARAMETRIK
STATISTIK PARAMETRIK
Interval dan rasio
Nominal dan ordinal
2.3 Klasifikasi Data
Secara umum dapat dikatakan bahwa tujuan diadakannya suatu observasi adalah memperoleh keterangan tentang bagaimana kondisi suatu objek pada berbagai keadaan yang ingin diperhatikan. Sebelum melakukan observasi terhadap variabel yang akan diukur, terlebih dahulu perlu ditentukan skala pengukurannya, karena akan mempengaruhi metode statistika yang akan digunakan.
Dergibson Siagian dan Sugiarto (2000, Hal: 19) menyatakan bahwa dalam statistika dibedakan empat macam skala pengukuran yang mungkin dihasilkan yaitu:
1. Skala Nominal
Skala nominal merupakan pengukuran yang paling sederhana. Nominal berasal dari kata ‘name’. Skala ini mengklasifikasikan (menggolongkan) setiap objek atau kejadian ke dalam kelompok yang menunjukkan kesamaan atau perbedaan ciri-ciri objek. Dengan skala nominal,hasil pengukuran bisa dibedakan tetapi tidak bisa diurutkan mana yang lebih tinggi, mana yang lebih rendah, mana yang utama dan mana yang bisa dikesampingkan. Setiap observasi harus dimasukkan pada satu kategori saja tidak boleh lebih. Sebagai contoh adalah variabel jenis kelamin (pria dan wanita).
2. Skala Ordinal
Dengan menggunakan skala ordinal,objek-objek juga dapat digolongkan dalam kategori tertentu. Ukuran pada skala ordinal tidak memberika nilai absolute pada objek, tetapi hanya urutan (ranking) relative saja sehingga kita dapat mementukan mana yang lebih besar atau kecil (secara umum mana yang lebih dan mana yang kurang). Sebagai contoh adalah status sosial (rendah, sedang, tinggi).
3. Skala Interval
Skala interval memberikan ciri angka kepada kelompok objek yang mempunyai skala nominal dan ordinal, ditambah dengan urutan yang sama pada urutan objeknya.
Data skala interval diberikan apabila kategori yang digunakan bisa dibedakan, diurutkan, mempnyai jarak tertentu, tetapi tidak bisa dibandingkan.
Data skala interval diperoleh sebagai hasil pengukuran dan biasanya mempunyai satuan pengukuran. Cirri penting dari skala interval adalah datanya bisa ditambahkan, dikurangi, digandakan, dan dibagi tanpa mempengaruhi jarak relatif skor-skornya. Sebagai contoh, dalam penilaian kinerja karyawan ( dengan skala 0 – 100 ), A mendapat penilaian 40 dan B mendapat penilaian 80 bukan berarti kinerja B dua kali kinerja A.
4. Skala Rasio
Skala rasio mempunyai semua sifat skala interval ditambah satu sifat lain, yaitu memberikan keterangan tentang nilai absolute dari objek yang diukur.
Skala rasio merupakan skala pengukuran yang ditujukan pada hasil pengukuran yang bisa dibedakan, diurutkan, mempunyai jarak tertentu, dan bisa dibandingkan. Sebagai contoh adalah umur, nilai uang, tinggi badan, dan lain sebagainya.
2.4 Statistik Nonparametrik
Istilah nonparametrik pertama kali digunakan oleh Wolfwitz pada tahun 1942. Metode statistik nonparametrik merupakan metode statistik yang dapat digunakan dengan mengabaikan asumsi – asumsi yang melandasi penggunaan metode statistik parametrik terutama yang berkaitan dengan distribusi normal. Istilah lain yang sering digunakan untuk statistik nonparametrik adalah statistik bebas distribusi (distribution- free statistic) dan uji bebas asumsi (assumption-free test). Statistik nonparametrik
banyak digunakan pada penelitian – penelitian sosial. Data yang diperoleh pada penelitian sosial pada umumnya berbentuk kategori atau berbentuk ranking.
Uji statistik nonparametrik adalah suatu uji statistik yang tidak memerlukan adanya asumsi – asumsi mengenai distribusi data populasi. Uji statistik ini disebut juga sebagai statistik bebas distribusi (distribution free). Statistik nonparametrik tidak mensyaratkan bentuk distribusi parameter populasi berdistribusi normal. Statistik nonparametrik dapat digunakan untuk menganalisis data yang berskala nominal atau ordinal karena pada umumnya data berjenis nominal dan ordinal tidak berdistribusi normal. Dari segi jumlah data, pada umumnya statistik nonparametrik digunakan untuk data berjumlah kecil (n < 30).
2.5 Keunggulan Statistik Nonparametrik
Keunggulan statistik nonparametrik diantaranya:
1. Jika pengujian data menunjukkan bahwa salah satu atau beberapa asumsi yang mendasari uji statistik parametrik (misalnya mengenai sifat distribusi data) tidak terpenuhi, maka statistik nonparametrik lebih sesuai diterapkan dibandingkan statistik parametrik.
2. Uji - ujinya lebih sederhana dan dapat dilaksanakan dengan cepat dan mudah, sehingga hasil penelitiannya segera dapat disampaikan.
3. Untuk memahami uji – uji dalam statistik nonparametrik tidak memerlukan dasar matematika serta statistika yang mendalam.
4. Uji – uji pada statistik nonparametrik dapat diterapkan jika kita menghadapi keterbatasan data yang tersedia, misalnya jika data telah diukur menggunakan skala pengukuran yang lemah (nominal atau ordinal).
5. Efisiensi statistik nonparametrik lebih tinggi dibandingkan dengan metode parametrik untuk ukuran jumlah sampel yang sedikit.
2.6 Keterbatasan Statistik Nonparametrik
Disamping keunggulan, statistik nonparametrik juga memiliki keterbatasan. Beberapa keterbatasan statistik nonparametrik antara lain:
1. Jika asumsi uji statistik parametrik terpenuhi, penggunaan uji nonparametrik meskipun lebih cepat dan sederhana akan menyebabkan pemborosan informasi.
2. Jika jumlah sampel besar, tingkat efisiensi statistik nonparametrik relatif lebih rendah dibandingkan dengan metode parametrik.
3. Statistik nonparametrik tidak dapat digunakan untuk membuat prediksi (peramalan).
2.7 Korelasi
2.7.1 Pengertian Korelasi
Korelasi adalah statistik yang menyatakan derajat hubungan antara dua variabel atau lebih tanpa memperlihatkan ada atau tidaknya hubungan kausal di antara variabel – variabel tersebut.
Dalam korelasi akan dijumpai bahwa dua variabel bernilai positif, negatif dan/atau nol. Dua variabel dikatakan berkorelasi positif jika kenaikan pada satu variabel diikuti oleh kenaikan variabel lainnya dan/atau penurunan pada satu variabel diikuti oleh penurunan variabel lainnya. Dengan kata lain dua variabel berkorelasi positif jika variabel – variabelnya cenderung berubah secara bersama. Dua variabel dikatakan berkorelasi negatif jika kenaikan pada satu variabel diikuti oleh penurunan pada variabel lainnya atau sebaliknya. Dengan kata lain variabel – variabelnya
cenderung berubah dalam arah yang berlawan. Dua variabel dikatakan berkorelasi nol jika perubahan satu variabel tidak ada hubungannya dengan variabel lainnya. Dengan kata lain dua variabel dikatakan tidak berkorelasi.
2.7.2 Koefisien Korelasi
Besarnya tingkat keeratan hubungan antara dua variabel dapat diketahui dengan mencari besarnya angka korelasi yang disebut koefisien korelasi. Koefisien korelasi dinyatakan dengan lambang . Jika yang diukur adalah korelasi antara variabel x dengan variabel y dinotasikan dengan .
Nilai dari koefisien korelasi berada diantara -1 dan +1. Jika dua variabel berkorelasi positif maka nilai koefisien korelasi akan mendekati +1, jika dua variabel berkorelasi negative maka nilai koefisien korelasi akan mendekati -1, jika dua variabel tidak berkorelasi maka nilai koefisien korelasi akan bernilai 0. Sehingga besarnya nilai koefisien korelasi dapat ditulis dalam pertidaksamaan .
2.7.3 Koefisien Determinasi
Koefisien determinasi merupakan pangkat dua dari koefisien korelasi, dinotasikan dengan . Koefisien determinasi yaitu koefisien yang menunjukkan/menentukan berapa besar peranan variabel x dalam menentukan besarnya y.
Apabila suatu variabel x mempunyai korelasi dengan variabel y dengan besarnya tingkat keeratan hubungan maka ditulis . Dengan demikian koefisien
determinasinya adalah yang menyatakan besarnya persentase x menjelaskan y.
2.7.4 Koefisien Rank Korelasi
Untuk data ; i = 1, 2, 3, …, n yang berskala ordinal maka koefisien korelasi antara x dan y dihitung berdasarkan statistika nonparametrik yang disebut dengan koefisien rank korelasi. Koefisien rank korelasi pada statistika nonparametrik antara lain koefisien rank korelasi Spearman, Kendall, Somer, Crammer dan sebagainya.
2.7.5 Koefisien Korelasi Rank Kendall
Koefisien korelasi rank kendall mempunyai kegunaan untuk mengukur derajat hubungan dari dua peubah yang pengukurannya minimal dalam skala ordinal. Metode ini dikemukakan untuk pertama kalinya oleh Maurice G. Kendall pada tahun 1938.
Koefisien korelasi rank kendall dinotasikan dengan .
2.7.6 Metode Perhitungan Koefisien Korelasi Rank Kendall ( )
Koefisien korelasi rank kendall ( ) dapat diperoleh dengan cara membandingkan score actual dengan score maximum yang mungkin dicapai. Atau dengan kata lain score actual adalah score +1 dan -1 yang sebenarnya. +1 diberikan untuk pasangan yang tersusun secara natural dan -1 diberikan untuk pasangan yang tidak tersusun secara natural. Sedangkan score maksimum yang mungkin dicapai ditentukan oleh susunan
yang dapat diuraikan menjadi . Sehingga koefisien korelasi rank Kendall ( ) dapat dirumuskan :
Selanjutnya score actual diberi symbol S, dan score maksimum ditentukan oleh susunan , dimana n adalah jumlah objek atau individu pada variabel random X dan Y. Secara matematis dapat ditulis:
Atau
Dimana : S = score actual (jumlah score +1 dan -1)
n = jumlah objek atau individu pada variabel random X dan Y
Ada kalanya pada variabel random X dan Y mempunyai objek yang sama atau sering disebut dengan rank kembar. Jika ada dua atau lebih nilai pengamatan (baik untuk variabel random X atau Y) yang sama, maka nilai – nilai tersebut diberi rank rata – rata. Pengaruh dari nilai rank kembar tersebut adalah merubah besarnyanilai penyebut pada rumus koefisien korelasi rank kendall ( ). Dalam hal ini rumus koefisien korelasi rank kendall ( ) menjadi:
Dimana : S = score actual (jumlah score +1 dan -1)
n = jumlah objek atau individu pada variabel random X dan Y
= ; t adalah jumlah rank kembaran tiap kelompok kembarnya untuk variabel X
= ; t adalah jumlah rank kembaran tiap kelompok kembarannya untuk variabel Y
2.8 Graph Theory
2.8.1 Konsep Dasar Graph Defenisi 2.1 Graph
Suatu graph G terdiri dari dua himpunan yang berhingga, yaitu himpunan titik – titik tidak kosong yang disebut dengan verteks yang disimbolkan dengan V(G) dan himpunan garis – garis yang disebut dengan edge yang disimbolkan dengan E(G).
Defenisi 2.2 Loop, Edge Paralel dan Simpel Graph
Sebuah edge yang menghubungkan pasangan verteks yang sama yakni disebut loop. Dua edge yang berbeda yang menghubungkan verteks yang sama disebut edge paralel. Dan jika ada suatu graph yang tidak memuat loop dan edge paralel disebut simple graph (graph sederhana).
V1 e6 V4
e1 e2 e3 e4
V2 e5 V3
Gambar 2.1 Simple Graph
Defenisi 2.3 incident dan adjacent
Suatu edge dalam suatu graph G dengan verteks – verteks ujung dan disebut saling insiden dengan dan sedangkan dan disebut dua buah verteks yang saling adjacent. Dua buah edge dan disebut saling adjacent jika kedua edge tersebut incident pada suatu verteks persekutuan. Sebagai contoh dapat dilihat pada gambar 2.2.
e7
V1 e5 V6 e8
e1 e4 e2 e6 V5
e9 e11
V2 e3 V3 e10 V4
Gambar 2.2 Graph G(6,11)
Dari graph diatas dapat dilihat bahwa dan adalah lima buah edge yang incident dengan verteks . Sedangkan dan merupakan dua buah edge yang adjacent dan dengan adalah dua buah verteks yang adjacent.
Defenisi 2.3 Degree
Degree dari sebuah verteks dalam graph G adalah jumlah edge yang incident dengan , dengan loop dihitung dua kali. Degree dari sebuah verteks dinotasikan dengan . Bila jumlah edge yang incident dengan jumlah verteks adalah n maka degree dari adalah n dan dinotasikan dengan .
Sebagai contoh, pada gambar 2.2dapat dilihat bahwa = = 3, = 5 , = = 2, dan = 6
Jika pada suatu graph ada suatu verteks yang tidak incident dengan suatu edge atau dengan kata lain degree dari verteks tersebut sama dengan nol. Verteks itu dinamakan isolated verteks (verteks terasing).
Defenisi 2.4 Graph Lengkap (Complete Graph)
Graph lengkap (complete graph) dengan n verteks (disimbolkan dengan ) adalah graph sederhana dengan n verteks, dimana setiap 2 verteks bebeda dihubungkan dengan suatu edge.
Teorema 2.4.1
Banyaknya edge dalam suatu graph lengkap dengan n verteks adalah atau buah.
Bukti
Misalkan G adalah suatu graph lengkap dengan n verteks . Ambil sembarang verteks (sebutlah ). Karena G merupakan graph lengkap, maka dihubungkan dengan verteks lainnya ). Jadi ada buah edge.
Selanjutnya, ambil sembarang verteks kedua (sebutlah ). Karena G adalah graph lengkap, maka juga dihubungkan dengan semua verteks sisanya
sehingga ada buah edge yang berhubungan dengan . Salah satu edge tersebut dihubungkan dengan . Garis ini sudah diperhitungkan pada waktu menghitung banyaknya edge yang berhubungan dengan . Jadi ada edge yang belum diperhitungkan.
Proses dilanjutkan dengan menghitung banyaknya edge yang berhubungan dengan dan yang belum diperhitungkan sebelumnya. Banyak edge yang didapat berturut – turut adalah : , , …, 3, 2, 1.
Jadi secara keseluruhan terdapat buah edge.
Sebagai contoh dapat dilihat gambar 2.3 dibawah ini:
K2 K3 K4 K5
Gambar 2.3 complete graph
2.8.2 Graph Tak Berarah ( undirected Graph )
Suatu graph tak berarah (undirected graph) merupakan kumpulan dari titik yang disebut verteks dan segmen garis yang menghubungkan dua verteks yang disebut edge. Secara matematis, sebuah graph G didefenisikan sebagai pasangan himpunan ( ).
Dimana: = himpunan tak kosong dari verteks – verteks (simpul atau titik) =
= himpunan tak terurut dari edge (sisi) yang menghubungkan sepasang verteks.
Atau dapat dinotasikan dengan
Defenisi diatas menyatakan bahwa dimana V tidak boleh kosong, sedangkan E mungkin kosong sehingga sebuah graph dimungkinkan tidak mempunyai edge satu buahpun tetapi harus memiliki verteks minimal satu.
2.8.3 Representasi Graph Tidak Berarah (Undirected graph) dalam Matriks
Matriks dapat digunakan untuk menyatakan suatu graph. Untuk menyelesaikan suatu permasalahan model graph dengan bantuan komputer maka graph tersebut dapat disajikan dalam bentuk matriks. Matriks – matriks yang dapat menyajikan model graph tersebut antara lain:
1. Matriks Ruas
Matriks ruas adalah matriks yang berukuran atau yang menyatakan ruas (edge) dari graph. Matriks ini tidak dapat mendeteksi adanya verteks terpencil.
2. Matriks adjacency
Matriks adjacency merupakan matriks simetri. Matriks adjacency digunakan untuk menyatakan graph dengan cara menyatakannya dalam jumlah edge yang menghubungkan verteks – verteksnya. Jumlah baris dan kolom matriks adjacency sama dengan jumlah verteks dalam graph. Sehingga matriks hubungnya berbentuk matriks bujur sangkar.
Defenisi matriks adjacency:
Misalkan G adalah graph tak berarah dengan verteks (n berhingga). Matriks hubung yang sesuai dengan graph G adalah matriks
dengan = jumlah edge yang menghubungkan verteks dengan
verteks ; .
Karena jumlah edge yang menghungkan verteks dengan verteks selalu sama dengan jumlah edge yang menghubungkan dengan verteks maka jelas bahwa matriks adjacency selalu merupakan matriks yang simetris
Notasi dari matiks adjacency yaitu:
1 jika ada edge dari verteks ke verteks =
0 jika tidak ada edge dari verteks ke verteks
3. Matriks Incidence
Matriks incidence adalah matriks yang menghubungkan verteks dengan edge.
Notasi dari matriks incidence yaitu:
1 jika verteks terhubung ke edge
= 2 jika edge menghubungkan verteks ke verteks 0 dalam hal lain
4. Matriks Connection
Matriks connection dapat mendeteksi suatu graph terhubung atau tidak. Graph terhubung jika dan hanya jika matriks tidak mengandung elemen nol. Tetapi matriks connection tidak ada mendeteksi adanya edge sejajar dan loop.
Notasi dari matriks connection yaitu:
1 bila atau ada edge dari verteks ke verteks =
0 Dalam hal lain
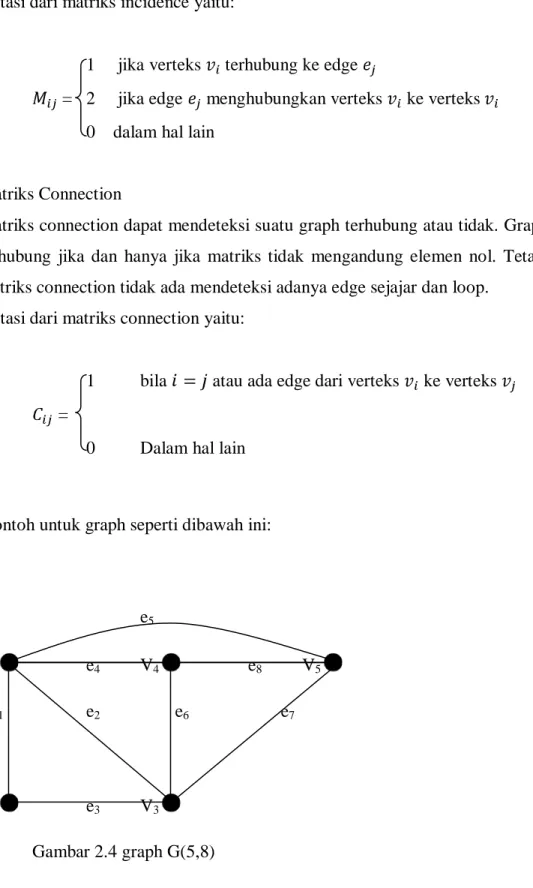
Sebagai contoh untuk graph seperti dibawah ini:
e5
V1 e4 V4 e8 V5
e1 e2 e6 e7
V2 e3 V3
Gambar 2.4 graph G(5,8)
Maka, Matriks ruas:
Atau
Matriks adjacency:
Matriks Incidence:
Matriks connection:
2.8.4 Graph Berarah ( Directed Graph )
Suatu graph berarah (digraph) D adalah merupakan suatu pasangan dari himpunan {V(D), A(D)} dimana V(D) = adalah himpunan berhingga yang tidak kosong yang elemennya disebut node/vertex dan A(D) = adalah suatu himpunan pasangan berurut dengan elemen – elemen yang disebut dengan arc.
Suatu vertex didalam digraph D disajikan dengan sebuah titik dan sebuah arc yang digambarkan berupa suatu penggalan garis dengan suatu anak panah dari vertex ke vertex . Sebagai contoh, gambar dibawah ini menampilkan suatu digraph yang terdiri dari empat verteks dan enam arcs.
V1 a1 a3
a2 V2
a4 a5
V3 a6 V4
Gambar 2.5 digraph dengan 4 verteks dan 6 arcs
2.8.4.1 Representasi Graph Berarah (Digraph) dalam Matriks
Cara menyatakan graph berarah dalam matris sebenarnya tidaklah jauh berbeda dengan cara menyatakan graph tak berarah dalam suatu matriks. Perbedaannya hanya terletak pada keikutsertaan informasi tentang arah garis yang terdapat dalam graph berarah. Sebuah graph berarah dapat juga dipersentasekan dalam matriks adjacency, matriks incidence dan matriks sirkuit. Adapun reorentase matriks dalam graph berarah yang dibahas dalam tulisan ini adalah matriks adjacency.
Defenisi dari Matriks Adjacency tersebut adalah sebagai berikut:
Misalkan G adalah graph berarah yang terdiri dari n verteks tanpa arc paralel. Matriks hubung yang sesuai dengan graph G adalah matriks bujursangkar
dengan notasi
1 jika ada arc dari verteks ke verteks =
0 jika tidak ada arc dari verteks ke verteks
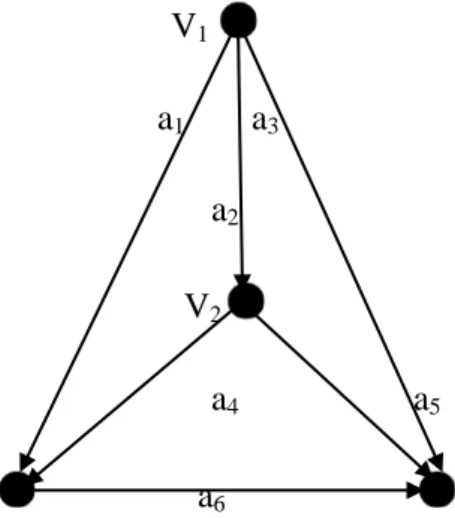
2.8.4.2 Complete Digraph
Digraph disebut sebagai complete digraph (graf berarah lengkap) jika setiap pasang vertex dihubungkan oleh sebuah arc. Atau sebuah graph adalah komplit jika setiap vertex terhubung ke setiap vertex yang lain. Pada gambar di bawah ini dapat dilihat suatu complete digraph.
V1
a1 a2 a3 a4
V2 a5 V3
a6 a7 a8 a9
V5 a10 V4 Gambar 2.6 complete digraph
2.8.4.3 Asymmetric Digraph
Suatu digraph dikatakan sebagai asymmetric digraph jika pada digraph yang terbentuk memiliki paling banyak satu arc antara sepasang vertex tanpa loop. Dengan kata lain tidak ada arc yang memiliki arc balik. Pada gambar dibawah ini dapat dilihat suatu asymmetric digraph.
V1
a1 a2
V2 V3
a3 a4
V4
Gambar 2.7 Asymmetric Digraph
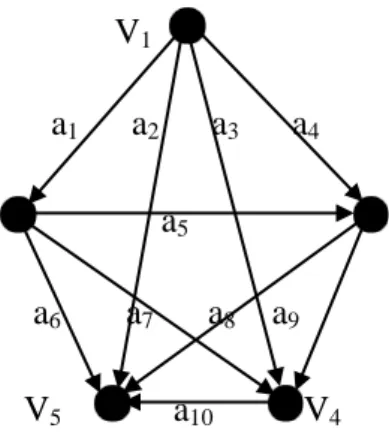
2.8.4.4 Complete Asymmetric Digraph
Complete asymmetric digraph adalah suatu asymmetric digraph dimana terdapat tepat satu antara setiap pasang vertex. Complete asymmetric digraph dengan vertices mengandung arcs.
Bukti
Misalkan D adalah suatu complete asymmetric digraph dengan n verteks . Ambil sembarang verteks (sebutlah ). Karena D merupakan complete asymmetric digraph, maka dihubungkan dengan verteks lainnya
). Jadi ada buah arc.
Selanjutnya, ambil sembarang verteks kedua (sebutlah ). Karena D adalah complete asymmetric digraph, maka juga dihubungkan dengan semua verteks sisanya
sehingga ada buah arc yang berhubungan dengan . Proses dilanjutkan dengan menghitung banyaknya arc yang berhubungan dengan
dan yang belum diperhitungkan sebelumnya. Banyak arc yang didapat berturut – turut adalah : , , …, 3, 2, 1.
Jadi secara keseluruhan terdapat buah arc
Pada gambar dibawah ini dapat dilihat suatu contoh dari complete asymmetric digraph.
V1 a1 V2
a2 a3 a4 a5
V3 a6 V4
Gambar 2.8 Complete Asymmetric Digraph
Complete asymmetric digraph dapat direpresentasikan dalam sebuah matriks adjacency. Jumlah baris dan kolom adjacency matrix sama dengan jumlah vertex dalam complete asymmetric digraph. Adjacency matrix yang sesuai adalah matrix bujur sangkar , yaitu matriks A = dengan:
+1 jika ada arc dari titik ke dan ( ) tersusun secara natural = -1 jika ada arc dari titik ke dan ( ) tidak tersusun secara natural
0 jika tidak ada arc titik ke