Penerapan Data Mining dalam Pembuatan
Rekomendasi Film Netflix Menggunakan Metode
Collaborative Filtering dan Korelasi Pearson
1Kevin Obert Richardo
2
Silvia Harlena, S.Kom, MMSI.
1
Jalan Kober No.10 Pondok Cina, Kecamatan Beji, Kota Depok. Email: kevinobertrichardo@student.gunadarma.ac.id
2
Jl. Margonda Raya No.100, Pondok Cina, Kecamatan Beji, Kota Depok. E-mail: silvia@staff.gunadarma.ac.id
Jurusan Teknik Informatika, Fakultas Teknologi Industri, Universitas Gunadarma
ABSTRAK
Perkembangan teknologi komputer, informasi dan komunikasi telah mengarahkan masyarakat ke era digital. Digitalisasi tersebut telah merambah ke sektor industry perfilman. Banyaknya film digital ari platform ditigal yang beredar akan membuat kesulitan kepada pelanggan dalam memilih film yang akan meraka tonton. Maka dari itu dibutuhkan adanya sistem rekomendasi yang tidak hanya akan membantu pelanggan dalam menentukan film yang akan ditonton namun juga dari sektor bisnis dapat menarik pelanggan untuk menambah pemasukan dari bertambahnya konsumsi fim oleh pelanggan. Salah satu cara untuk membuat sistem rekomendasi menurut perilaku user adalah menggunakan metode collaborative filtering. Metode collaborative filtering dapat dimanfaatkan untuk mendapatkan rekomendasi film untuk pelanggan berdasarkan preferensi pelaanggan lain yang memiliki selera film sejenis. Dari 51.031.355 data rating akan dihasilkan 10 rekomendasi film dengan prediksi score tertinggi. Berdasarkan hasil analisa, penerapan data mining dalam pembuatan rekomendasi film Netflix menggunakan metode collaborative filtering dan korelasi pearson dapat menghasilkan rekomendasi film yang akurat.
Kata kunci : Data Mining, Sistem Rekomendasi, Metode Collaborative Filtering, Korelasi Pearson.
ABSTRACT
The development of computer technology, information and communication has directed people to the digital age. The digitalization has penetrated into the film industry sector. The number of digital films in the digital platform that are circulating will make it difficult for customers to choose the films they will watch. Therefore, a recommendation system is needed that will not only help the customer in determining the film to be watched but also from the business sector can attract customers to increase revenue from increased film consumption by customers. One way to make a recommendation system according to user behavior is to use a collaborative filtering method. The collaborative filtering method can be utilized to obtain film
recommendations for customers based on the preferences of other customers who have similar film tastes. From 51,031,355 rating data 10 movie recommendations will be produced with the highest predicted score. Based on the analysis results, the application of data mining in making Netflix movie recommendations using collaborative filtering methods and Pearson correlation can produce accurate film recommendations.
Keywords: Data Mining, Recommendation System, Collaborative Filtering Method, Pearson Correlation.
PENDAHULUAN
Perkembangan teknologi
komputer, informasi dan
komunikasi telah mengarahkan
masyarakat ke era digital.
Digitalisasi bukan hanya
diterapkan dalam bidang ekonomi, pengetahuan dan sosial tapi juga sudah merambah ke dunia industri hiburan seperti industri musik dan perfilman. Digitalisasi tersebut menghasilkan data digital yang sangat besar baik berupa teks, audio, gambar, maupun video yang tersimpan dalam database masing masing perusahaan penyedia jasa. Pertumbuhan yang pesat dan integrasi dari sistem database memberikan sumber daya yang luas kepada para peneliti yang bertujuan untuk menganalisis data ilmiah, mengoptimalkan sistem industri, dan menemukan pola informasi yang berharga dalam
database tersebut. Banyak sekali informasi yang masih tersembunyi dalam database tersebut, yang mana informasi tersebut sangat penting namun masih belum
ditemukan atau belum
diartikulasikan. Maka dari itu, diperlukan suatu teknik dalam mengolah informasi yang berharga dan berguna dalam kumpulan data tersebut. Secara sederhana data
mining adalah teknik untuk
ekstrasi atau “menambang”
pengetahuan dari sekumpulan data yang jumlahnya besar.
Dalam dunia industri film,
pengolahan data juga tidak kalah pentingnya. Netflix contohnya, perusahaan jasa streaming film yang memiliki lebih dari 130 juta pelanggan di seluruh dunia dan lebih dari 2000 library film dan serial tv. Dengan jumlah film yang sangat banyak dan terus bertambah
tiap tahunnya, hal itu membuat
calon penonton menghadapi
kesulitan dalam mencari dan memilih film mana yang ingin ditonton sesuai dengan selera mereka masing masing. Oleh karena itu penulis tertarik untuk melakukan analisa data mining
menggunakan metode
collaborative filtering dan korelasi pearson yang berfungsi untuk menampilkan suatu rekomendasi film berdasarkan variabel tertentu. Sistem rekomendasi adalah suatu perangkat lunak dan teknik untuk memberikan saran rekomendasi terhadap item yang akan digunakan oleh pengguna dan bertujuan untuk membantu dalam berbagai macam proses pengambilan keputusan, seperti barang apa yang harus dibeli, musik apa yang harus didengar atau berita apa yang ingin dibaca.
Pada penelitian ini penulis
menggunakan metode
collaborative filtering dan korelasi
pearson untuk menentukan
prediksi film yang akan ditonton
oleh pelanggan. Collaborative
filtering, atau yang biasa disebut
dengan crowd-wisdom adalah
salah satu metode rekomendasi yang menggunakan data rating dari seorang pengguna, dan pengguna
lain untuk menghasilkan
rekomendasi. Collaborative
filtering menganggap bahwa selera pengguna terhadap suatu item atau barang akan cenderung sama dari waktu ke waktu. Ditambah lagi, pengguna yang menyukai suatu item biasanya juga akan menyukai item lain yang disukai oleh pengguna lain yang juga menyukai item yang sama dengan pengguna
tersebut. Sedangkan korelasi
pearson merupakan salah satu ukuran korelasi yang digunakan untuk mengukur kekuatan dan arah hubungan linier dari dua variabel. Dua variabel dikatakan berkorelasi apabila perubahan salah satu variabel disertai dengan perubahan variabel lainnya, baik dalam arah yang sama ataupun arah yang sebaliknya.
METODE PENELITIAN
penelitian ini adalah :
a. Studi Literatur
Tahapan ini dilakukan dengan
mengumpulkan dan mempelajari sumber seperti buku referensi, jurnal, makalah maupun dari artikel dari internet yang berkaitan dengan penelitian ini.
b. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap studi literatur yang telah dilakukan
sebelumnya untuk mengetahui dan
memahami mengenai metode data mining, khususnya metode collaborative filtering.
c. Pengambilan dan Pengenalan Data
Data yang digunakan diambil dari Netflix prize data. Dan pada tahap ini penulis juga mengumpulkan deskripsi data dan detail informasi mengenai atribut yang terdapat dalam data.
d. Pemuatan Libraries dan Package
Pada tahapan ini penulis melakuakan penginstalan dan pemuatan terhadap
libraries atau package yang akan
digunakan.
e. Pra-pemrosesan data
Pra-pemrosesan yang dilakukan terhadap
data adalah data cleaning, data slicing,
dan transformasi data, sehingga data lebih mudah dimuat dalam kernel.
f. Penerapan Metode Collaborative
Filtering dan Korelasi Pearson
Melakukan metode collaborative filtering
dan korelasi pearson untuk menentukan
tingkat similarity dari film maupun rating
user.
g. Visualisasi Hasil Rekomendasi
Menyajikan hasil rekomendasi kedalam bentuk visualisasi
PEMBAHASAN Gambaran Umum
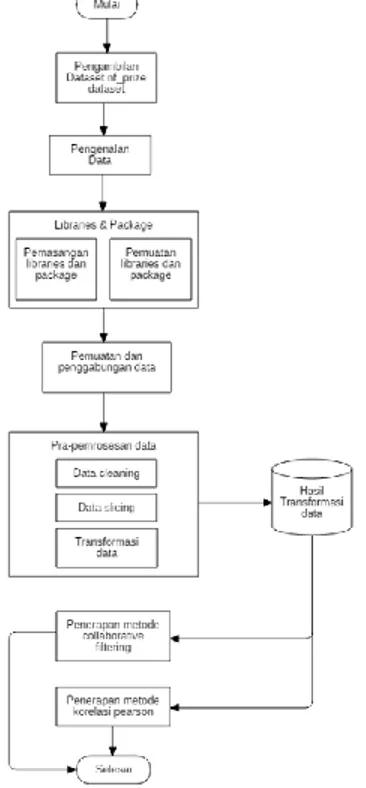
Analisa ini ditujukan sebagai sarana untuk membantu pengambilan keputusan perusahaan dalam merekomendasikan film yang akan ditonton oleh pelanggan Netflix berdasarkan riwayat rating film yang diberikan oleh pelanggan pada tiap film yang telah ditotonton sehingga dapat membantu pelanggan dalam memilih film yang akan ditonton. Analisa ini akan menghasilkan 10 rekomendasi film teratas kepada pelanggan disertai perkiraan rating berdasarakan metode collaborative filtering dan korelasi Pearson. Metodologi dalam penelitian ini terdiri dari
beberapa tahap yakni dimulai dari tahap untuk mendapatkan dataset riwayat rating pelanggan Netflix dan dataset film Netflix yang di dapat dari nf_prize dataset yang disediakan oleh netfix yang akan digunakan untuk analisa data mining. Kemudian tahap pengenalan data untuk mendapatkan detail informasi dari data yang nantinya akan diolah. Kemudian tahap selanjutnya adalah pemasangan package dan libraries yang akan digunakan dalam proses analisa. Lalu proses pemuatan dan penggabungan data. Kemudian tahap pra-pemrosesan data, pada tahap ini yang dilakukan adalah data cleaning, data slicing, dan transformasi data. Tahap terakhir adalah tahap analisa yakni menggunakan metode collaborative filtering dan korelasi Pearson untuk menghasilkan rekomendasi film.
Gambar 1 Gambaran Umum
Pengambilan Data
Tahap awal yang dilakukan pada
penelitian ini adalah pengambilan dataset
yang berupa riwayat rating film yang diberikan oleh pelanggan pada tiap film
netflix yang telah ditotonton dan dataset
berupa kumpulan judul film disertai tahun
rilis. Dataset ini didapat dari internet
archive di bawah lisensi dari Netflix, yang merupakan data yang disediakan oleh Netflix pada kompetisi Netflix prize event.
Dataset tersebut dapat diunduh di
https://archive.org/download/nf_prize_da
taset. Setelah pengunduhan dataset
selesai, dataset tersebut diletakan pada
direktori local tempat project python yaitu
home/Documents/PI/Data Mentah.
Pengenalan Data
Nf_prize dataset merupakan data
riwayat pemberian rating pada tiap film Netflix yang telah ditonton oleh
pelanggan dan data film beserta tahun rilis. Data terdiri dari 51.031.355 rating yang diambil dari 478.018 pelanggan secara acak dan 9.210 buah judul film disertai tahun rilis yang diambil dari
Oktober 1998 sampai Desember 2005 yang dibuat dalam bentuk 2 data terpisah
berformat .txt. Dataset rating pada tiap
film terdiri dari 3 buah atribut yaitu :
1. Id_Pelanggan : Nomor id
pelanggan yang memberikan
rating bertipe number yang terdiri dari 7 buah digit yang unik untuk tiap pelangganya.
2. Rating : Rating yang diberikan
oleh pelanggan pada film tersebut yang bertipe number dari rentang 1 - 5
3. Tanggal : Tanggal pemberian
rating oleh pelanggan yang bertipe date
Pemasangan dan Pemuatan Libraries
Sebelum masuk ke selanjutnya diperlukan pemasangan dan pemuatan
libraries serta package yang akan
digunakan pada analisis dengan metode
collaborative filtering dan korelasi
Pearson.
Penggabungan Data
Setelah proses pemasangan dan pemuatan libraries serta package selesai,
tahap selanjutnya adalah pemuatan dan penggabungan dataset yang telah di unduh. Dataset rating terdiri dari dua buah data berbentuk txt. Proses pemuatan data menggunakan fitur dataframe pada libraries pandas yang telah dimuat. Dataframe diarahkan ke direktori dimana dataset di simpan pada C:\Users\KEVIN\Documents\PI, kemudian diberi header sebagai judul kolom bernama Id_Pelanggan dan Rating, judul kolom pertama dibiarkan kosong karena merupakan nomor urutan record. Kemudian dilakukan pengubahan tipe data rating dari yang awalnya bertipe data string ke dalam bentuk float agar dapat diolah.
Pra-pemrosesan Data
Sebelum data dapat digunakan,
diperlukan adanya pra-pemrosesan
terlebih dahulu agar data siap pakai dan sesuai dengan model arsitektur yang dibangun. Pra- pemrosesan data yang
dilakukan yakni data cleaning, data
slicing, dan transformasi data menjadi tabel pivot dalam bentuk matriks dengan ukuran besar.
Data Cleaning
Data cleaning merupakan salah
cleaning biasa disebut dengan data
cleansing atau scrubbing. Proses data cleaning dilakukan untuk menghilangkan kesalahan informasi pada data. Sehingga
proses data cleaning dapat digunakan
untuk menentukan data yang tidak akurat, tidak lengkap atau tidak benar dan untuk
memperbaiki kualitas data melalui
pendeteksian kesalahan pada data. Data
cleaning diperlukan pada analisis ini dikarenakan Id_Film yang berulang pada
dataframe membuat kernel yang
digunakan kehabisan memori.
Data Slicing
Data slicing adalah proses
segmentasi pada data mining yang bertujuan agar memperoleh data yang
sesuai untuk analisis. Data slicing pada
analisis ini bertujuan untuk mengurangi jumlah data agar analisis dapat dilakukan secara efektif baik secara waktu proses maupun dalam penggunaan kernel. Data yang dikurangi pada dataset adalah film
dengan sedikit review dengan asumsi
bahwa film tersebut kurang popular, dan juga pelanggan yang memberikan sedikit
review dengan asusmsi bahwa pelanggan tersebut kurang aktif.
Transformasi Data
Transformasi data dalam proses data
mining berarti proses pengubahan bentuk data dengan format yang sesuai dengan tipe analisis. Pada analisis ini data diubah kedalam bentuk tabel pivot atau matriks
dengan ukuran besar. Id_Film menjadi
kolom pada tabel pivot sedangkan Id_Pelanggan menjadi baris pada tabel.
Pemuatan Data Judul Film
Setelah pra-pemrosesan data selesai dilakukan pemuatan data judul film yang diubah kedalam bentuk dataframe dengan mengunakan libraries pandas. Setelah itu dilakukan proses pembuatan dataframe baru bernama df_title dengan data film sebagai datasetnya. Dataset film diletakan pada direktori
C:\Users\KEVIN\Documents\PI\movie_titles. csv. Dataset dimuat dengan sistem encoding ISO-8859-1 yang mencakup 256 karakter Unicode. Dataset disusun dengan kolom Id_Film, Tahun, Judul dan kemudian diurutkan berdasarkan Id_film secara ascending. Setelah itu dilakukan pencetakan sampel dataframe berupa judul film dengan 10 indeks teratas.
Penerapan Metode Collaborative Filtering
Setelah pemuatan seluruh data selesai dan telah melalui pra-pemroesan data. Maka proses analisis untuk membuat rekomendasi siap dimulai. Sebelumnya dilakukan penghitungan tingkat akurasi
algoritma yang digunakan. Proses
penghitungan akurasi ini menggunakan fitur evaluate pada library SVD. Untuk menghitung akurasi analisis dengan
metode collaborative filtering ini
parameter yang digunakan adalah RMSE (Root Mean Square Error) dan MAE (Mean Absolute Error).
Visualisasi Rekomendasi Film dan Prediksi Rating
Setelah menampilkan film yang
disukai oleh pelanggan kemudian
dilakukan proses analisis rekomendasi film yang sesuai dengan pelanggan
tersebut menggunakan metode
collaborative filtering. Dilakukan terlebih dahulu pengosongan dataframe pelanggan yang sebelumnya berisi film favorit pelanggan tersebut. Kemudian membuat dataframe baru bernama data yang berisi
dataset rating dengan kolom
Id_Pelanggan, Id_Film, dan Rating.
Setelah itu menerapkan metode
collaborative filtering untuk menghasilkan 10 rekomendasi film teratas dengan mengunakan fungsi train pada library svd. Rekomendasi film juga disertai dengan prediksi rating fim terhadap pelanggan
PENUTUP Kesimpulan
Berdasarkan dari data dan
visualisasi ahkir rekomendasi film
menunjukan bahwa metode collaborarive
filtering dan korelasi pearson dapat
diterapkan untuk membuat sistem
rekomendasi film dengan hasil yang akurat dan nilai error dibawah 1 untuk 10 rekomendasi film teratas.
Berdasarkan penelitian yang telah dilakukan dapat dihasilkan rekomendasi yang spesifik pada selera film masing – masing user yang menjadikan sistem rekomendasi ini lebih cocok diterapkan
pada suatu platform film digital
dibandingkan dengan sistem rekomendasi film menurut rating yang dihimpun dari penonton secara global.
Film – film yang termasuk kedalam daftar 10 rekomendasi film
teratas berdasarkan metode collaborative
filtering dan korelasi pearson nantinya dapat disajikan atau ditawarkan kepada pelanggan setelah pelanggan selesai menonton atau ketika pelanggan masuk kedalam home aplikasi platform film digital mereka. Selain pada platform Netflix analisa ini juga dapat diterapkan pada platform film digital lainnya ataupun
situs – situs video streaming.
Peneerapan metode collaborative
filtering dan korelasi pearson dalam pembuatan rekomendasi film Netflix dan menghasilkan informasi 10 rekomendasi film teratas yang dapat dipakai dalam pengambilan keputusan film apa yang akan ditonton selanjutnya oleh user dapat menjawab latar belakang dan tujuan penulisan ilmiah ini.
Saran
Berikut adalah beberapa saran yang dapat
dilakukan untuk penelitian terkait
penerapan data mining dalam pembuatan rekomendasi film netflix menggunakan
metode Collaborative Filtering dan
korelasi pearson.
1. Menggunakan baris kode python
yang lebih efisien terkait
pembuatan array untuk
mendapatkan waktu pemrosesan yang lebih cepat.
2. Menggunakan data film maupun
rating dari user terbaru sehingga dapat menyajikan rekomendasi untuk film film terbaru
3. Mengembangkan analisa menjadi
model machine learning pada web
DAFTAR PUSTAKA
[1] Budi Santoso, dan Ardian Umam.
2018. Data Mining dan Big Data
Analytics. Edisi ke-2. Media Pustaka.Yogyakarta
[2] Suyanto. 2019. Data Mining untuk
Klasifikasi dan Klasterisasi Data. Informatika. Bandung.
[3] Totewar, Akansha. Introduction to
Data Mining.
https://www.slideshare.net/akanns hat/data-mining-153229899 (24 November 2012) (Diakses tanggal : 18 Juli 2019)
[4] P. Melville, R. J. Mooney, and R.
Nagarajan. Content-Boosted
Collaborative Filtering for
Improved Recommendations.
https://www.slideshare.net/Melvill
e/collaborative-filtering (26
Oktober 2014) (Diakses tanggal : 8 Agustus 2019)
[5] Gupta, Shivam . Python
Introduction.
https://www.slideshare.net/Shiva mGupta276/python-60414461. (3
April 2016) (Diakses tanggal : 20 Agustus 2019)
[6]mkkhttps://en.wikipedia.org/wiki/Proje
ct_Jupyter (Diakses tannggal 21 Agustus 2019)
[7] Chandra, Feri. Analisa Korelasi
Pearson.
https://www.slideshare.net/Ferich 18/makalah-analisa-korelasi-pearson-ppm. ( 5 Maret 2013) (Diakses tanggal : 21 Agustus 2019)
[8] H. Mase dan H. Ohwada, A
Collaborative Filtering
Incorporating Hybrid-Clustering Technologyi I , I, no. Icsai, 2012.