i
APLIKASI PENCARIAN DATA BUKU PADA
PERPUSTAKAAN
(Studi Kasus : Perpustakaan Daerah Wilayah Jawa Tengah)
Laporan ini disusun guna memenuhi salah satu syarat untuk menyelesaikan program studi Teknik Informatika S1 pada Fakultas Ilmu Komputer
Universitas Dian Nuswantoro Semarang
Disusun Oleh :
Nama : Anjar Bagus Triyadi
Nim : A11.2010.05413
Program Studi : Teknik Informatika – S1
FAKULTAS ILMU KOMPUTER
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2015
ii Nama Pelaksana : Anjar Bagus Triyadi
NIM : A11.2010.05413
Program Studi : Teknik Informatika – S1 Fakultas : Ilmu Komputer
Judul Tugas akhir : Aplikasi Pencarian Data Buku Pada Perpustakaan (Studi Kasus : Perpustakaan Daerah Wilayah Jawa Tengah)
Tugas akhir ini telah diperiksa dan disetujui, Semarang, 03 Maret 2015
Menyetujui : Mengetahui :
Pembimbing Dekan Fakultas Ilmu Komputer
iii
NIM : A11.2010.05413
Program Studi : Teknik informatika – S1 Fakultas : Ilmu Komputer
Judul Tugas akhir : Aplikasi Pencarian Data Buku Pada Perpustakaan (Studi Kasus : Perpustakaan Daerah Wilayah Jawa Tengah)
Tugas akhir ini telah diujikan dan dipertahankan dihadapan Dewan Penguji pada Sidang tugas akhir tanggal 03 Maret 2015. Menurut pandangan kami, tugas akhir ini memadai dari segi kualitas maupun kuantitas untuk tujuan penganugrahan gelar Sarjana Komputer (S.Kom).
Semarang, 03 Maret 2015 Dewan Penguji Anggota I Suprayogi, M.Kom Anggota II Sugiyanto, M.Kom Ketua Penguji
iv ini, saya :
Nama : Anjar Bagus Triyadi
NIM : A11.2010.05413
Menyatakan bahwa karya ilmiah saya yang berjudul :
Aplikasi Pencarian Data Buku Pada Perpustakaan
Merupakan karya asli saya (kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya). Apabila dikemudian hari, karya saya disinyalir bukan merupakan karya asli saya, yang disertai dengan bukti-bukti yang cukup, maka saya bersedia untuk dibatalkan gelar saya beserta hak dan kewajiban yang melekat pada gelar tersebut. Demikian surat pernyataan ini saya buat dengan sebenarnya,
Dibuat di : Semarang Pada Tanggal : 03 Maret 2015
Yang menyatakan
v
Sebagai mahasiswa Universitas Dian Nuswantoro, yang bertanda tangan di bawah ini, saya :
Nama Pelaksana : Anjar Bagus Triyadi
NIM : A11.2010.05413
Demi mengembangkan Ilmu Pengetahuan, menyetujui untuk memberikan kepada Universitas Dian Nuswantoro Hak Bebas Royalti Non Ekslusif (Non-exclusive Royalty-Free Right) atas karya ilmiah saya yang berjudul :
Aplikasi Pencarian Data Buku Pada Perpustakaan
beserta perangkat yang diperlukan (bila ada). Dengan Hak Bebas Royalti Non-Ekslusif ini Universitas Dian Nuswantoro berhak untuk menyimpan, mengkopi ulang (memperbanyak), menggunakan, mengelolanya dalam bentuk pangkalan data (database), mendistribusikannya dan menampilkan/ mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya selama tetap mencantumkan nama saya sebagai penulis/ pencipta.
Saya bersedia untuk menanggung secara pribadi, tanpa melibatkan pihak Universitas Dian Nuswantoro, segala bentuk tuntutan hukum yang timbul atas pelanggaran hak Cipta dalam karya ilmiah saya ini.
Demikian surat pernyataan ini saya buat dengan sebenarnya
Dibuat di : Semarang Pada Tanggal : 03 Maret 2015 Yang menyatakan
vi
yang telah dilimpahkan kepada penulis “Aplikasi Pencarian Data Buku Pada Perpustakaan (Studi Kasus : Perpustakaan Daerah Wilayah Jawa Tengah)”.
Laporan Tugas Akhir ini merupakan suatu kewajiban guna melengkapi syarat untuk menempuh ujian akhir di Universitas Dian Nuswantoro Semarang. Adapun penulis dalam membuat Laporan Tugas Akhir ini tidak luput dari kesulitan dan kesalahan, namun berkat bimbingan dan bantuan dari dosen pembimbing serta berbagai pihak yang tidak mungkin disebutkan disini maka laporan ini dapat penulis selesaikan. Dengan bekal pengetahuan yang penulis terima dengan segenap kemampuan terbaik yang bisa penulis lakukan.
Atas terselesainya Laporan Tugas Akhir ini penulis menyampaikan penghargaan dan ucapan terima kasih yang sangat mendalam kepada :
1. Bapak Dr. Ir. Edi Noersasongko, M.Kom, selaku Rektor Universitas Dian Nuswantoro Semarang.
2. Bapak Dr. Drs. Abdul Syukur, MM , selaku Dekan Fakultas Ilmu Komputer Universitas Dian Nuswantoro Semarang.
3. Bapak Dr. Heru Agus Santoso M.Kom, selaku Kaprogdi Sistem Informasi Fakultas Ilmu Komputer Universitas Dian Nuswantoro Semarang.
4. Bapak Wijanarto, M.Kom, selaku Dosen Pembimbing yang telah membantu dan memberikan bimbingan dan arahan dalam penyusunan Laporan Tugas Akhir ini.
5. Bapak dan Ibu selaku orangtua yang telah membantu secara moril maupun meteriil dalam penyelesaian Laporan Tugas Akhir ini, juga untuk doa dan kasih sayang yang tanpa henti.
6. Dosen-dosen Fasilkom Universitas Dian Nuswantoro Semarang yang telah memberikan ilmu sehingga penulis dapat mengimplementasikan ilmu yang telah disampaikan.
7. Desy Puspitasari, S.pd yang telah memberikan dukungan moral dan semangat kepada penulis.
vii
saran serta kritik yang membangun dalam kesempurnaan Laporan Tugas Akhir ini.
Akhirnya penulis berharap semoga Laporan Tugas Akhir ini dapat bermanfaat bagi semua pihak yang berkepentingan.
Semarang, 03 Maret 2015 Penulis
viii
Kebutuhan akan informasi dibidang pendidikan khususnya dinilai cenderung meningkat. Salah satunya adalah kebutuhan akan informasi dari koleksi buku yang ada di Perpustakaan Daerah Wilayah Jawa Tengah. Banyaknya buku yang masih tersimpan dalam bentuk fisik di dalam pencarian buku seringkali hanya dapat memberikan sepenggal informasi bagi pengunjung perpustakaan. Karena itu dibutuhkan suatu aplikasi yang dapat mengolah data buku tersebut menjadi informasi tambahan bagi user. Pembuatan aplikasi data mining ini akan mengolah data berupa database yaitu buku sehingga diperoleh keyword untuk masing-masing buku. Data mining sangat cocok digunakan untuk menganalisa data dalam jumlah yang besar. Dengan demikian jika diinputkan keyword dalam setiap pencarian maka akan dapat dicari itemsetnya atau kombinasi keywordnya dengan cara algoritma priori yang nantinya dapat digunakan untuk menentukan buku mana saja yang berhubungan dengan keyword yang berhubungan. Dengan menggunakan data mining, user akan lebih mudah melakukan pencarian dengan menginput kata-kata atau judul buku yang diinginkan. Dari inputan user tadi akan diperoleh keyword yang saling berasosiasi sehingga keyword yang dicari oleh user tidak hanya menapilkan sepenggal informasi berkenaan dengan keyword tersebut namun juga informasi lain berdasarkan keyword rekomendasi yang diperoleh dari association rules. Dengan aplikasi ini buku yang ditampilkan milai dari buku yang sangat berhubungan dengan keyword sampai buku yang sedikit hubungannya dengan keyword. Karena dalam pencariannya di cari kata perkata yang ada di judul dan sinopsis. Dengan aplikasi ini dapat mempermudah dan mempercepat pencarian data.
ix
Halaman Sampul Depan ... i
Halaman Persetujuan ... ii
Halaman Pengesahan ... iii
Halaman Pernyataan Keaslian Tugas Akhir ... iv
Halaman Pernyataan Persetujuan Publikasi ... v
Halaman Ucapan Terima Kasih ... vi
Halaman Abstrak ... viii
Halaman Daftar Isi ... ix
Halaman Daftar Tabel ... xi
Halaman Daftar Gambar ... xii
BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 3 1.3 Batasan Masalah ... 4 1.4 Tujuan Penelitian ... 4 1.5 Manfaat Penelitian ... 4
BAB II KAJIAN PUSTAKA ... 5
2.1 Pengertian Data Mining ... 5
2.2 Pengenalan Pola, Data Mining dan Machine Learning ... 6
2.3 Tahap-tahap Data Mining ... 7
2.4 Metode Bayes ... 10
2.5 Metode Data Mining ... 11
2.5.1 Association Rules ... 11
2.5.2 Decision Tree ... 15
2.5.3 Clustering ... 16
2.5.4 Software Aplikasi ... 17
2.5.5 Basis data dan sistem manajemen basis data ... 17
x
3.2 Prosedur Pengumpulan Data ... 25
3.3 Metodologi Penelitian ... 26
BAB IV ANALISIS DAN PERANCANGAN APLIKASI ... 33
4.1 Analisis Data Mining ... 33
4.2 Sumber Data ... 33
4.3 Integrasi Data ... 34
4.4 Transformasi Data ... 34
4.5 Perancangan Sistem ... 35
4.5.1 Use Case Diagram ... 35
4.5.2 Sequence Diagram ... 36
4.5.3 Class Diagram ... 40
4.5.4 Struktur File ... 40
4.5.5 Desain Input Output ... 42
4.5.6 Implementasi Sistem ... 46
4.5.7 Pengujian Sistem ... 52
4.5.8 Pengujian Data Mining ... 60
BAB V PENUTUP ... 62
5.1 Kesimpulan ... 62
5.2 Saran ... 62
xi
Tabel 4.2 : Tahap login ... 40
Tabel 4.3 : Tabel buku ... 40
Tabel 4.4 : Tabel kategori ... 41
xii
Gambar 2.2 : Tahap-tahap Data Mining ... 7
Gambar 2.3 : Clustering ... 16
Gambar 2.4 : Komponen DBMS ... 20
Gambar 2.5 : Waterfall model ... 22
Gambar 3.1 : Operasi pada dimensi waktu ... 29
Gambar 3.2 : Operasi pada dimensi buku ... 30
Gambar 3.3 : Metodologi Penelitian ... 32
Gambar 4.1 : Use Case diagram data mining perpustakaan... 35
Gambar 4.2 : Sequence diagram penambahan buku ... 36
Gambar 4.3 : Sequence diagram pencarian buku berdasarkan judul ... 37
Gambar 4.4 : Sequence diagram pencarian buku berdasarkan kategori ... 37
Gambar 4.5 : Sequence diagram pencarian buku berdasarkan deskripsi buku .. 38
Gambar 4.6 : Sequence diagram edit buku ... 39
Gambar 4.7 : Sequence diagram login ... 39
Gambar 4.8 : Class diagram aplikasi sistem perpustakaan ... 40
Gambar 4.9 : Desain menu utama ... 42
Gambar 4.10 : Desain form login ... 43
Gambar 4.11 : Desain form data buku ... 44
Gambar 4.12 : Desain form pencarian buku ... 45
Gambar 4.13 : List data buku ... 45
Gambar 4.14 : Tampilan Menu Utama ... 46
Gambar 4.15 : Tampilan Form Login ... 47
Gambar 4.16 : Tampilan Form Data Buku... 48
Gambar 4.17 : Tampilan Form Pencarian Buku ... 50
Gambar 4.18 : Pilihan cetak list buku ... 51
Gambar 4.19 : List Data Buku ... 51
Gambar 4.20 : Pengujian pada halaman login ... 52
xiii
Gambar 4.25 : Pengujian pengisian kode buku ... 59 Gambar 4.26 : Pengujian data mining ... 60
1 BAB I PENDAHULUAN
1.1 Latar Belakang
Dengan kemajuan teknologi informasi dewasa ini, kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kehidupan seari-hari, sehingga informasi akan menjadi suatu elemen penting dalam perkembangan masyarakat saat ini dan waktu mendatang. Namun kebutuhan informasi yang tinggi kadang tidak diimbangi dengan penyajian informasi yang memadai, seringkali informasi tersebut masih harus digali ulang dari data yang jumlahnya sangat besar. Metode tradisional untuk menganalisis data yang ada, tidak dapat menangani data dalam jumlah besar, sehingga membutuhkan teknologi informasi yang mampu mengumpulkan dan menyimpan berbagai tipe data serta dapat menganalisis, eringkas dan mengekstrak pengetahuan dari data.
Pemanfaatan data yang ada di dalam sistem informasi untuk menunjang kegiatan pengambilan keputusan, tidak cukup hanya mengandalkan data operasional saja, diperlukan suatu analisis data untuk menggali potensi-potensi informasi yang ada. Para pengambil keputusan berusaha untuk memanfaatkan gudang data yang sudah dimiliki untuk menggali informasi yang berguna membantu mengambil keputusan, hal ini mendorong munculnya cabang ilmu baru untuk mengatasi masalah penggalian informasi atau pola yang penting atau menarik dari data dalam jumlah besar, yang disebut dengan data mining. Penggunaan teknik data mining diharapkan dapat memberikan pengetahuan-pengetahuan yang sebelumnya tersembunyi di dalam gudang data sehingga menjadi informasi yang berharga.
Perpustakaan sebagaimana yang ada dan berkembang sekarang telah dipergunakan sebagai salah satu pusat informasi, sumber ilmu pengetahuan, penelitian, rekreasi, pelestarian khasanah budaya bangsa, serta memberikan
berbagai layanan jasa lainnya. Hal tersebut telah ada sejak dulu dan terus berproses secara alamiah menunjuk kepada suatu kondisi dan tingkat perbaikan yang signifikan meskipun belum memuaskan semua pihak.
Perpustakaan pada prinsipnya mempunyai tiga kegiatan pokok, yaitu pertama, mengumpulkan (to collect) semua informasi yang sesuai dengan bidang kegiatan dan misi organisasi dan masyarakat yang dilayaninya. Kedua, melestarikan, memelihara, dan merawat seluruh koleksi perpustakaan, agar tetap dalam keadaan baik, utuh, layak pakai, dan tidak lekas rusak baik karena pemakaian maupun karena usianya (to preserve). Ketiga, menyediakan dan menyajikan informasi untuk siap dipergunakan dan di berdayakan (to make availlable) seluruh koleksi yang dihimpun di perpustakaan untuk dipergunakan pemakainya.
“Informasi memegang peranan yang semakin besar dalam perkembangan ilmu pengetahuan (dalam arti luas). Informasi meningkatkan efisiensi ilmu pengetahuan yang merupakan kakas (force) produktif pada masyarakat modern. Ilmu pengetahuan dan sistem pemencaran pengetahuan berjalan dalam skala massal, namun mentalitas pemakai dalam memanfaatkan informasi masih mencerminkan tingkat awal pengembangan ilmu pengetahuan. Kini dengan banyaknya unit informasi serta berkembangnya teknologi informasi, pengumpulan dan pengolahan informasi dilakukan oleh berbagai unit informasi sementara emakain tinggal memanfaatkannya.
Perpustakaan Daerah Provinsi Jawa Tengah, atau yang sering disebut para penggunanya sebagai “Perwil” (Perpustakaan Wilayah), mempunyai visi mewujudkan masyarakat membaca dan belajar menuju masyarakat madani yang sadar akan informasi. Pemakai Perpustakaan tersebut tersebut adalah semua mahasiswa, dosen, sivitas akademik serta masyarakat umum daerah Semarang dan sekitarnya. Mahasiswa merupakan pemakai yang paling aktif dalam memanfaatkan sumber informasi yang ada di Perpustakaan.
Sejauh ini belum diketahui dengan jelas kebutuhan dan pola perilaku mahasiswa dalam pencarian informasi. Kebutuhan informasi pemakai dapat dilihat dari perilaku dalam pencarian informasi, maka perpustakaan perlu
memperhatikan hal tersebut guna mendapatkan umpan balik bagi perpustakaan untuk memberikan layanan informasi yang sesuai dengan kebutuhan pemakai. Ketepatan strategi yang diterapkan untuk mendapatkan informasi yang diperlukan sebagai penunjang kegiatan perkuliahan sangat menentukan dalam pencarian informasi.
Bayes memperkenalkan suatu metode yang diperlukan untuk mengetahui bentuk distribusi awal (prior) dari populasi yang dikenal dengan metode bayesian. Informasi ini kemudian digabungkan dengan informasi dari sampel untuk digunakan dalam mengestimasi parameter populasi. Pada metode bayesian, seorang peneliti harus menentukan distribusi prior dari parameter yang ditaksir. Distribusi prior ini dapat berasal dari data penelitian sebelumnya atau berdasarkan intuisi seorang peneliti.
Metode bayes memberikan cara yang mendasar dalam memasukkan informasi eksternal ke dalam proses analisa data. Proses ini diawali dengan distribusi probabilitas yang sudah ada diberikan untuk himpunan data yang dianalisa. Karena distribusi diberikan sebelum ada data yang dipertimbangkan, sehingga disebut distribusi priori. Himpunan data baru menjadikan distribusi priori ini menjadi distribusi posterior. Perubahan yang terjadi dari priori ke posterior merujuk pada Teorema Bayes.
Teorema Bayes merupakan latar belakang teoritis untuk pendekatan statistic terhadap masalah pengambilan kesimpulan induktif. Penulis akan terlebih dahulu menjelaskan konsep-konsep dasar yang didefinisikan dalam Teorem Bayes dan kemudian menggunakan teorema ini dalam penjelasan tentang proses Klasifikasi Bayes Naif, atau Klasifikator Bayes Sederhana.
Berdasarkan latar belakang tersebut diatas, dengan memanfaatkan data buku dengan metode bayes maka dapat diketahui informasi mengenai informasi detail tentang buku yang dicari.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan sebelumnya, hal yang menjadi rumusan masalah dalam penelitian ini adalah bagaimana
kebutuhan pencarian informasi data buku di Perpustakaan Daerah Provinsi Jawa Tengah dengan teknik data mining menggunakan metode bayes classifier.
1.3 Batasan Masalah
Pembatasan masalah pada penelitian ini antara lain : 1. Input data buku
2. Pencarian buku dengan menggunakan aplikasi data mining menggunakan metode bayes
3. Aplikasi dibuat menggunakan bahasa pemrograman Microsoft Visual Basic 6.0 dengan database MySql
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk mengetahui kebutuhan dan pencarian informasi data buku oleh anggota perpustakaan Perpustakaan Daerah Provinsi Jawa Tengah dengan teknik data mining menggunakan metode bayes classifier.
1.5 Manfaat Penelitian
Hasil penelitian ini diharapkan dapat memberikan manfaat terutama : 1. Sebagai masukan terhadap pihak Perpustakaan Daerah Provinsi Jawa
Tengah mengenai kebutuhan dan pencarian informasi data buku.
2. Dapat digunakan sebagai acuan bagi peneliti berikutnya, khususnya penelitian yang menyangkut masalah dan jenis yang sama dengan penelitian yang dilakukan ini.
5 BAB II
KAJIAN PUSTAKA
2.1 Pengertian Data Mining
Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar. Data mining juga disebut sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data. Data mining, sering juga disebut sebagai knowledge discovery in database (KDD). KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Data mining adalah kegiatan menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya. Data mining berkaitan dengan bidang ilmu-ilmu lain, seperti database system, data warehousing, statistik, machine learning, information retrieval, dan komputasi tingkat tinggi. Selain itu, data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image database, signal processing. Data mining didefinisikan sebagai proses menemukan pola-pola dalam data. Proses ini otomatis atau seringnya semiotomatis. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi. Data yang dibutuhkan dalam jumlah besar.
Karakteristik data mining sebagai berikut :
1. Data mining berhubungan dengan penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
2. Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dipercaya.
3. Data mining berguna untuk membuat keputusan yang kritis, terutama dalam strategi
Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwa data mining adalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui. Kata mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan database. Beberapa metode yang sering disebut-sebut dalam literatur data mining antara lain clustering, classification, association rules mining, neural network, genetic algorithm dan lain-lain.
2.2 Pengenalan Pola, Data Mining dan Machine Learning
Pengenalan pola adalah suatu disiplin ilmu yang mempelajari cara-cara mengklasifikasikan obyek ke beberapa kelas atau kategori dan mengenali kecenderungan data. Tergantung pada aplikasinya, obyek-obyek ini bisa berupa pasien, mahasiswa, pemohon kredit, image atau signal atau pengukuran lain yang perlu diklasifikasikan atau dicari fungsi regresinya.
Data mining, sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan. Sehingga istilah pattern recognition jarang digunakan karena termasuk bagian dari data mining.
Machine Learning adalah suatu area dalam artificial intelligence atau kecerdasan buatan yang berhubungan dengan pengembangan teknik-teknik yang bisa diprogramkan dan belajar dari data masa lalu. Pengenalan pola, data mining dan machine learning sering dipakai untuk menyebut sesuatu yang sama. Bidang ini bersinggungan dengan ilmu probabilitas dan
statistik kadang juga optimasi. Machine learning menjadi alat analisis dalam data mining.
Gambar 2.1
Data Mining merupakan irisan dari berbagai disiplin
2.3 Tahap-tahap Data Mining
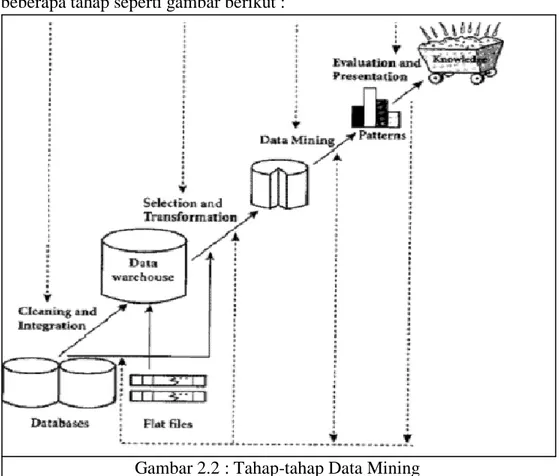
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap seperti gambar berikut :
Gambar 2.2 : Tahap-tahap Data Mining Sumber : Han, 2006
Tahap-tahap data mining ada 6 yaitu : Machine
Learning Visualisasi
Statistik Database Data mining
1. Pembersihan data (data cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Integrasi data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau file teks. Integrasi data dilakukan pada atribut-aribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis produk, nomor pelanggan dan lainnya. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Sebagai contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan produk dari kategori yang berbeda maka akan didapatkan korelasi antar produk yang sebenarnya tidak ada.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database. Sebagai contoh, sebuah kasus yang meneliti faktor kecenderungan orang membeli dalam kasus market basket analysis, tidak perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
4. Transformasi data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
5. Proses mining,
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi pola (pattern evaluation),
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7. Presentasi pengetahuan (knowledge presentation),
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining. Dalam presentasi
ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining.
2.4 Metode Bayes
Metode bayes memberikan cara yang mendasar dalam memasukkan informasi eksternal ke dalam proses analisa data. Proses ini diawali dengan distribusi probabilitas sudah ada diberikan untuk himpunan data yang dianalisa. Karena distribusi diberikan sebelum ada data yang dipertimbangkan, sehingga disebut distribusi priori. Himpunan data baru menjadikan distribusi priori ini menjadi distribusi posterior. Perubahan yang terjadi dari priori ke posterior merujuk pada Teorema Bayes.
Rumus bayes adalah sebagai berikut :
Dengan
Dengan :
-P(Hi|A) adalah peluang kejadian Hi dengan syarat A -i dimulai dari 1 hingga n
Persamaan bayes yang digunakan untuk menghitung nilai setiap alternatif disederhanakan menjadi :
Total Nilaii = ∑ Nilaiij (Kritj) Dimana :
Total nilai i = total nilai akhir dari alternatif ke-i Nilai ij = nilai dari alternatif ke-i pada kriteria ke-j Krit j = tingkat kepentingan (bobot) kriteria ke-j i = 1, 2, 3, ... n
n = jumlah alternatif j = 1, 2, 3, ... m m = jumlah kriteria
2.5 MetodeData mining
Dengan definisi data mining yang luas, ada banyak jenis metode analisis yang dapat digolongkan dalam data mining.
2.5.1 Association rules
Association rules (aturan asosiasi) atau affinity analysis (analisis afinitas) berkenaan dengan studi tentang “apa bersama apa”. Sebagai contoh dapat berupa berupa studi transaksi di supermarket, misalnya seseorang yang membeli susu bayi juga membeli sabun mandi. Pada kasus ini berarti susu bayi bersama dengan sabun mandi. Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan market basket analysis.
Aturan asosiasi ingin memberikan informasi tersebut dalam bentuk hubungan “if-then” atau “jika-maka”. Aturan ini dihitung dari data yang sifatnya probabilistik.
Analisis asosiasi dikenal juga sebagai salah satu metode data mining yang menjadi dasar dari berbagai metode data mining lainnya. Khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frekuensi tinggi (frequent pattern mining) menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efisien. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang) yaitu prosentase kombinasi item tersebut. dalam database dan confidence (nilai kepastian) yaitu kuatnya hubungan antar item dalam aturan assosiatif. Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan assosiatif yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum confidence).
Ada beberapa algoritma yang sudah dikembangkan mengenai aturan asosiasi, namun ada satu algoritma klasik yang sering dipakai yaitu algoritma apriori. Ide dasar dari algoritma ini adalah dengan mengembangkan frequent itemset. Dengan menggunakan satu item dan secara rekursif mengembangkan frequent itemset dengan dua item, tiga item dan seterusnya hingga frequent itemset dengan semua ukuran.
Untuk mengembangkan frequent set dengan dua item, dapat menggunakan frequent set item. Alasannya adalah bila set satu item tidak melebihi support minimum, maka sembarang ukuran itemset yang lebih besar tidak akan melebihi support minimum tersebut. Secara umum, mengembangkan set dengan fc-item menggunakan frequent set dengan k – 1 item yang dikembangkan dalam langkah sebelumnya. Setiap langkah memerlukan sekali pemeriksaan ke seluruh isi database.
Dalam asosiasi terdapat istilah antecedent dan consequent, antecedent untuk mewakili bagian “jika” dan consequent untuk mewakili bagian “maka”. Dalam analisis ini, antecedent dan consequent adalah sekelompok item yang tidak punya hubungan secara bersama.
Dari jumlah besar aturan yang mungkin dikembangkan, perlu memiliki aturan-aturan yang cukup kuat tingkat ketergantungan antar item dalam antecedent dan consequent. Untuk mengukur kekuatan aturan asosiasi ini, digunakan ukuran support dan confidence. Support adalah rasio antara jumlah transaksi yang memuat antecedent dan consequent dengan jumlah transaksi. Confidence adalah rasio antara jumah transaksi yang meliputi semua item dalam antecedent dan consequent dengan jumlah transaksi yang meliputi semua tem dalam antecedent.
Keterangan :
S = Support
∑(Ta+Tc) = Jumlah transaksi yang mengandung antecedent dan consequencent
∑(T) = Jumlah transaksi
Keterangan :
C = Confidence
∑(Ta+Tc) = Jumlah transaksi yang mengandung antecedent dan consequencent
∑(Ta) = Jumlah transaksi yang mengandung antecedent
Langkah pertama algoritma apriori adalah, support dari setiap item dihitung dengan men-scan database. Setelah support dari setiap item didapat, item yang memiliki support lebih besar dari minimum support dipilih sebagai pola frekuensi tinggi dengan panjang 1 atau sering disingkat 1-itemset. Singkatan k-itemset berarti satu set yang terdiri dari k item.
Iterasi kedua menghasilkan 2-itemset yang tiap set-nya memiliki dua item. Pertama dibuat kandidat 2-itemset dari kombinasi semua 1-itemset. Lalu untuk tiap kandidat 2-itemset ini dihitung support-nya dengan men-scan database. Support artinya jumlah transaksi dalam database yang mengandung kedua item dalam kandidat 2-itemset. Setelah support dari semua kandidat 2-itemset didapatkan, kandidat 2-itemset yang memenuhi syarat minimum
support dapat ditetapkan sebagai 2-itemset yang juga merupakan pola frekuensi tinggi dengan panjang 2.
Untuk selanjutnya iterasi-iterasi ke-k dapat dibagi lagi menjadi beberapa bagian :
1. Pembentukan kandidat itemset
Kandidat k-itemset dibentuk dari kombinasi (k-1)-itemset yang didapat dari iterasi sebelumnya. Satu ciri dari algoritma apriori adalah adanya pemangkasan kandidat k-itemset yang subset-nya yang berisi k-1 item tidak termasuk dalam pola frekuensi tinggi dengan panjang k-1.
2. Penghitungan support dari tiap kandidat k-itemset
Support dari tiap kandidat k-itemset didapat dengan men-scan database untuk menghitung jumlah transaksi yang memuat semua item di dalam kandidat k-item set tersebut. Ini adalah juga ciri dari algoritma apriori yaitu diperlukan penghitungan dengan scan seluruh database sebanyak k-itemset terpanjang.
3. Tetapkan pola frekuensi tinggi
Pola frekuensi tinggi yang memuat k item atau k-itemset ditetapkan dari kandidat k-itemset yang support-nya lebih besar dari minimum support. Kemudian dihitung confidence masing-masing kombinasi item. Iterasi berhenti ketika semua item telah dihitung sampai tidak ada kombinasi item lagi.
Secara ringkas algoritma apriori sebagai berikut : Create L1 = set of supported itemsets of cardinality one Set k to 2
while (Lk−1 _= ∅){
Create Ck from Lk−1
Prune all the itemsets in Ck that are not supported, to create Lk
Increase k by 1 }
The set of all supported itemsets is L1 ∪L2 ∪· · · ∪Lk Selain algoritma apriori, terdapat juga algoritma lain seperti FP-Grwoth. Perbedaan algoritma apriori dengan FP-Growth pada banyaknya scan database. Algoritma apriori melakukan scan database setiap kali iterasi sedangkan algoritma FP-Growth hanya melakukan sekali di awal.
2.5.2 Decision Tree
Dalam decision tree tidak menggunakan vector jarak untuk mengklasifikasikan obyek. Seringkali data observasi mempunyai atribut-atribut yang bernilai nominal.
Ada beberapa macam algoritma decision tree diantaranya CART dan C4.5. Beberapa isu utama dalam decision tree yang menjadi perhatian yaitu seberapa detail dalam mengembangkan decision tree, bagaimana mengatasi atribut yang bernilai continues, memilih ukuran yang cocok untuk penentuan atribut, menangani data training yang mempunyai data yang atributnya tidak mempunyai nilai, memperbaiki efisiensi perhitungan. Decision tree sesuai digunakan untuk kasus-kasus yang keluarannya bernilai diskrit. Walaupun banyak variasi model decision tree dengan tingkat kemampuan dan syarat yang berbeda, pada umumnya beberapa ciri yang cocok untuk diterapkannya decision tree adalah sebagai berikut :
1. Data dinyatakan dengan pasangan atribut dan nilainya 2. Label/keluaran data biasanya bernilai diskrit
3. Data mempunyai missing value (nilai dari suatu atribut tidak diketahui)
Dengan cara ini akan mudah mengelompokkan obyek ke dalam beberapa kelompok. Untuk membuat decision tree perlu memperhatikan hal-hal berikut ini :
1. Atribut mana yang akan dipilih untuk pemisahan obyek 2. Urutan atribut mana yang akan dipilih terlebih dahulu
3. Struktur tree
4. Kriteria pemberhentian 5. Pruning.
2.5.3 Clustering
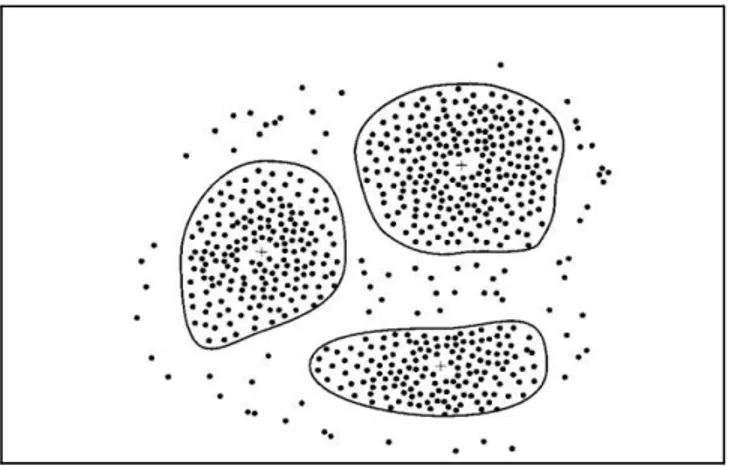
Clustering termasuk metode yang sudah cukup dikenal dan banyak dipakai dalam data mining. Sampai sekarang para ilmuwan dalam bidang data mining masih melakukan berbagai usaha untuk melakukan perbaikan model clustering karena metode yang dikembangkan sekarang masih bersifat heuristic. Usaha-usaha untuk menghitung jumlah cluster yang optimal dan pengklasteran yang paling baik masih terus dilakukan. Dengan demikian menggunakan metode yang sekarang, tidak bisa menjamin hasil pengklasteran sudah merupakan hasil yang optimal. Namun, hasil yang dicapai biasanya sudah cukup bagus dari segi praktis.
Gambar 2.3 : Clustering
Tujuan utama dari metode clustering adalah pengelompokan sejumlah data/obyek ke dalam cluster (group) sehingga dalam setiap cluster akan berisi data yang semirip mungkin seperti diilustrasikan pada gambar diatas. Dalam clustering metode ini berusaha untuk menempatkan obyek yang mirip (jaraknya dekat) dalam satu klaster dan membuat jarak antar klaster sejauh mungkin. Ini berarti obyek dalam satu cluster sangat mirip satu sama lain dan berbeda dengan
obyek dalam cluster-cluster yang lain. Dalam metode ini tidak diketahui sebelumnya berapa jumlah cluster dan bagaimana pengelompokannya.
2.5.4 Software Aplikasi
Software aplikasi terdiri atas program yang berdiri sendiri yang mampu mengatasi kebutuhan bisnis tertentu. Aplikasi memfasilitasi operasi bisnis atau pengambilan keputusan manajemen maupun teknik sebagai tambahan dalam aplikasi pemrosesan data konvensional. Sofware aplikasi digunakan untuk mengatur fungsi bisnis secara real time.
2.5.5 Basis Data dan Sistem Manajemen Basis Data (Database and Database Management System)
Database adalah sekumpulan data yang saling berelasi. Database didesain, dibuat, dan diisi dengan data untuk tujuan mendapatkan informasi tertentu. Pendekatan database memiliki beberapa keuntungan seperti keberadaan katalog, indepedensi program-data, mendukung view (tampilan) untuk banyak pengguna, dan sharing data pada sejumlah transaksi. Selain itu masih ada fleksibelitas, ketersediaan up-to-date informasi untuk semua pengguna, skala ekonomis.
Kategori utama pengguna database terbagi menjadi empat kategori, yakni Administrator, Designer, End user, System Analyst dan Application Programmers. Administrator atau Data Base Administrator (DBA) bertanggung jawab pada otoritas akses database, koordinasi dan monitoring penggunaan, dan pemilihan perangkat keras dan lunak yang dibutuhkan. Designer bertanggung jawab pada identifikasi data yang disimpan dalam database dan memilih struktur yang tepat untuk menggambarkan dan menyimpan data. End User adalah orang yang kegiatannya membutuhkan akses ke database untuk melakukan query, update, dan membuat laporan.
System Analysts menentukan kebutuhan End User. Application Programmers mengimplementasikan program sesuai spesifikasi.
Sistem Manajemen Basis Data (SMBD) adalah program yang digunakan pengguna untuk membuat dan memelihara database. SMBD memfasilitasi untuk mendefinisikan, mengkonstruksi, dan memanipulasi database untuk berbagai aplikasi. Pendefinisian database meliputi spesifikasi tipe data, struktur, dan constraint untuk data yang disimpan dalam database. Pengkonstruksian database adalah proses penyimpanan data itu sendiri pada media penyimpanan. Pemanipulasian database meliputi fungsi memanggil query database untuk mendapatkan data yang spesifik, update database, dan meng-generate laporan dari data tersebut.
Keuntungan yang diperoleh menggunakan SMBD meliputi mengontrol redudansi, membatasi akses yang tidak berwenang, menyediakan penyimpanan yang persisten, menghasilkan interface (antar muka) banyak pengguna, menjaga integritas constraint, menyediakan backup dan recovery.
Dalam SMBD menyediakan perintah yang digunakan untuk mengelola dan mengorganisasikan data, yakni Data Definition Language (DDL) dan Data Manipulation Language (DML). Data Definition Language adalah bahasa untuk medefinisikan skema atau dan database fisik ke SMBD. (DDL). Data Manipulation Language adalah bahasa untuk memanipulasi data yaitu pengambilan informasi yang telah disimpan, penyisipan informasi baru, penghapusan informasi, modifikasi informasi yang disimpan dalam database. Selanjutnya, query adalah statemen yang ditulis untuk mengambil informasi. Bagian dari DML yang menangani pengambilan informasi ini disebut bahasa query.
Ada lima komponen utama dalam lingkungan DBMS, yaitu :
a. Penyimpanan secondary (magnetic disk), I/O device seperti: disk drives), device controller, I/O channels dan lainnya. b. Hardware processor dan main memory, digunakan untuk
mendukung saat eksekusi system software database
2. Perangkat lunak, terdiri dari : DBMS, sistem operasi, software jaringan dan program aplikasinya
3. Data, digunakan oleh organisasi dan data ini digambarkan dalam bentuk skema
4. Prosedur adalah instruksi dan aturan yang harus diterapkan untuk mendesain dan menggunakan basis data dan DBMS
5. Orang, terdiri dari :
a. Application Programmers, bertanggungjawab untuk membuat aplikasi basis data dengan menggunakan bahasa pemrograman yang ada.
b. End Users, siapapun yang berinteraksi dengan system secara online melalui workstation/terminal.
c. DA (Data Administrator), seseorang yang berwenang untuk membuat keputusan strategis dan kebijakan mengenai data yang ada.
d. DBA (DataBase Administrator), menyediakan dukungan teknis untuk implementasi keputusan tersebut, dan bertanggungjawab atas keseluruhan kontrol system pada level teknis
Hardware Software Data Prosedur Orang
Mesin Jembatan Manusia
Gambar 2.4 : Komponen DBMS
SQL (dibaca "ess-que-el") singkatan dari Structured Query Language. SQL adalah bahasa yang digunakan untuk berkomunikasi
dengan database. Menurut ANSI (American National Standards Institute), bahasa ini merupakan standard untuk relational database management systems (RDBMS). Secara prinsip, perintah-perintah SQL (biasa disebut dengan pernyataan) dapat dibagi dalam tiga kelompok, yaitu :
1. DDL (Data Definition Language) atau bahasa penerjemah data Adalah perintah-perintah yang berkaitan dengan penciptaan atau penghapusan objek seperti tabel dan indek dalam database. Versi ANSI mencakup CREATE TABLE, CREATE INDEX, ALTER TABLE, DROP TABLE, DROP VIEW, dan DROP INDEX. Beberapa sistem database menambahkan pernyataan DDL seperti CREATE DATABASE dan CREATE SCHEMA.
2. DML (Data Manipulation Language) atau bahasa pemanipulasi data
Mencakup perintah-perintah yang digunakan untuk memanipulasi data. Misalnya untuk menambahkan data (INSERT), memperoleh data (SELECT), mengubah data (UPDATE), dan menghapus data (DELETE).
3. DCL (Data Control Language) atau bahasa pengendali data Merupakan kelompok perintah yang dipakai untuk melakukan otorisasi terhadap pengaksesan data dan pengalokasian ruang. Misalnya, suatu data bisa diakses si A, tetapi tidak bisa diakses oleh si B. Termasuk dalam kategori DCL yaitu pernyataan-pernyataan GRANT, REVOKE, COMMIT, dan ROLLBACK.[12]
2.6 Perancangan Perangkat Lunak
Proses perancangan sistem membagi persyaratan dalam sistem perangkat keras atau perangkat lunak. Kegiatan ini menentukan arsitektur sistem secara keseluruhan. Perancangan perangkat lunak melibatkan identifikasi dan deskripsi abstraksi sistem perangkat lunak yang mendasar dan hubungan-hubungannya.
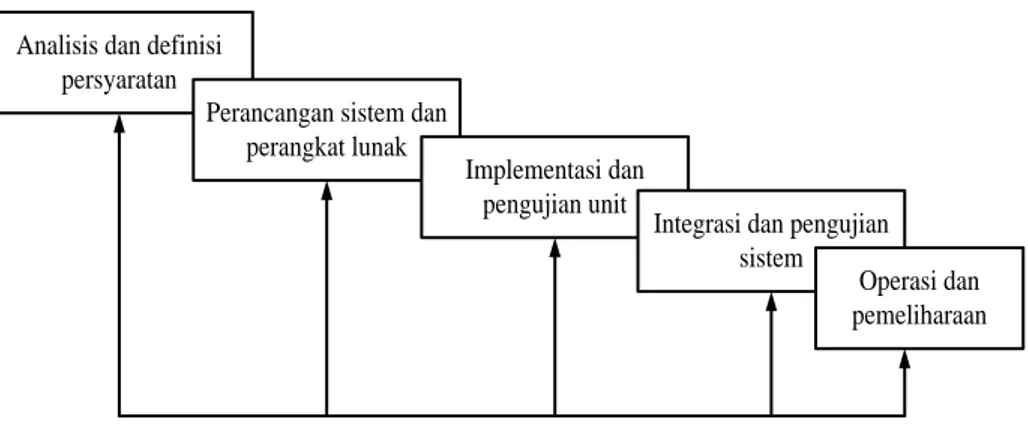
Sebagaimana persyaratan, desain didokumentasikan dan menjadi bagian dari konfigurasi software. Langkah penyelesaian dengan tahapan pengembangan perangkat lunak menggunakan model proses atau paradigma waterfall. Sebagai paradigma kehidupan klasik, waterfall model memiliki tempat penting dalam rekayasa perangkat lunak. Bahkan paradigma ini merupakan paradigma rekayasa perangkat lunak yang paling luas dipakai dan yang paling tua.
Waterfall model merupakan salah satu model proses perangkat lunak yang mengambil kegiatan proses dasar seperti spesifikasi, pengembangan, validasi dan evolusi, serta mempresentasikannya sebagai fase-fase proses yang berbeda seperti analisis dan definisi persyaratan, perancangan perangkat lunak, implementasi, pengujian unit, integrasi sistem, pengujian sistem, operasi dan pemeliharaan:
Tahap-tahap utama dari waterfall model pada gambar 2.4 memetakkan kegiatan-kegiatan pengembangan dasar, yaitu :
Analisis dan definisi persyaratan
Perancangan sistem dan perangkat lunak
Implementasi dan pengujian unit
Integrasi dan pengujian sistem
Operasi dan pemeliharaan
Gambar 2.5 : Waterfall model
Sumber : Ian Sommerville, Software Engineering (Rekayasa Perangkat Lunak), 2003
1. Analisis dan Definisi Persyaratan
Proses menumpulkan informasi kebutuhan sistem/perangkat lunak melalui konsultas dengan user system. Proses ini mendefinisikan secara rinci mengenai fungsi-fungsi, batasan dan tujuan dari perangkat lunak sebagai spesifikasi sistem yang akan dibuat.
2. Perancangan Sistem dan Perangkat Lunak
Proses perancangan sistem ini difokuskan pada empat atribut, yaitu struktur data, arsitektur perangkat lunak, representasi antarmuka, dan detail (algoritma) prosedural. Yang dimaksud struktur data adalah representasi dari hubungan logis antara elemen-elemen data individual.
3. Implementasi dan Pengujian Unit
Pada tahap ini, perancangan perangkat lunak direalisasikan sebagai serangkaian program atau unit program. Kemudian pengujian unit melibatkan verifikasi bahwa setiap unit program telah memenuhi spesifikasinya.
4. Integrasi dan Pengujian Sistem
Unit program/program individual diintegrasikan menjadi sebuah kesatuan sistem dan kemudian dilakukan pengujian. Dengan kata lain, pengujian ini ditujukan untuk menguji keterhubungan dari tiap-tiap fungsi perangkat lunak untuk menjamin bahwa persyaratan sistem telah terpenuhi. Setelah pengujian sistem selesai dilakukan, perangkat lunak dikirim ke pelanggan/user.
5. Operasi dan Pemeliharaan
Tahap ini biasanya memerlukan waktu yang paling lama. Sistem diterapkan (di-install) dan dipakai. Pemeliharaan mencakup koreksi dari beberapa kesalahan yang tidak diketemukan pada tahapan sebelumnya, perbaikan atas implementasi unit sistem dan pengembangan pelayanan sistem, sementara persyaratan-persyaratan baru ditambahkan.
2.7 Implementasi dan Pengujian Unit
Pada tahap ini, perancangan perangkat lunak direalisasikan sebagai serangkaian program atau unit program. Kemudian pengujian unit melibatkan verifikasi bahwa setiap unit program telah memenuhi spesifikasinya. Program sebaiknya dirilis setelah dikembangkan, diuji
untuk memperbaiki kesalahan yang ditemukan pada pengujian untuk menjamin kualitasnya. Terdapat dua metode pengujian yaitu :
1) Metode white box yaitu pengujian yang berfokus pada logika internal software (source code program).
2) Metode black box yaitu mengarahkan pengujian untuk menemukan kesalahan-kesalahan dan memastikan bahwa input yang dibatasi akan memberikan hasil aktual yang sesuai dengan hasil yang dibutuhkan.
Pada tahap pengujian, penulis melakukan metode black box yaitu menguji fungsionalitas dari perangkat lunak saja tanpa harus mengetahui struktur internal program (source code).
24 BAB III
METODOLOGI PENELITIAN
Pada bab ini akan dipaparkan langkah-langkah yang digunakan untuk membahas permasalahan yang diambil dalam penelitian. Dibagian ini juga dijelaskan alat dan metoda yang digunakan untuk melakukan perencanaan dan mendapatkan spesifikasi kebutuhan pengguna, dan dibagian akhir dituliskan rencana pengerjaan penelitian.
3.1 Instrumen Penelitian
1. Identifikasi Kebutuhan Software
Agar konsep bisa berfungsi sebagaimana mestinya perlu didukung oleh perangkat software yang memadai yaitu terdiri dari:
a. Bahasa Pemrograman (Human Made Sistem) dalam hal ini menggunakan bahasa Visual Basic 6.0 karena memiliki fasilitas fungsi perintah yang lengkap dan kecepatan eksekusi.
b. Software aplikasi yang lain digunakan untuk mendukung bagian– bagian yang lain diluar penanganan sistem misalnya Microsoft word, Microsoft excel, dan lain–lain.
2. Identifikasi Kebutuhan Hardware
Dengan mempertimbangkan kebutuhan pengguna sistem yang merupakan home industri, maka hardware yang dibutuhkan adalah sebagai berikut :
a. Laptop Asus K42F
Pertimbangan menggunakan laptop, karena harganya relatif murah dan fleksibel, dengan spesifikasi sbb, Processor Intel® Core™ i5 Processor 520M/430M : 2.4 GHz - 2.26 GHz, with Turbo Boost up to 2.93/2.53 GHz; Chipset Mobile Intel® HM55 Express Chipset, RAM Type 1066Mhz DDR3, RAM Slots 2, HDD 320
b. Printer Epson T13
Merupakan salah satu alat untuk mencetak proses dari komputer yang mempunyai hasil pengolahan sistem komputer. Pemilihan untuk jenis tersebut didasarkan pada petimbangan kebutuhan pencetakan dokumen, harga relatif murah, kecepatan tinggi serta kualitas cetakan yang lebih baik,dengan spesifikasi Ink System 4-colour, MAX PHOTO DRAFT – 10 x 15 cm / 4” x 6” Approx. 65 sec per photo (W/Border), Approx. 91 sec per photo (Borderless) Connectivity and Compatibility Interfaces Hi-speed USB 2.0, OS Support Windows® XP/XP Professional x64 Edition/VistaTM/7, Mac OS® 10.4.11 or later, Max. Paper Size 8.5" x 44", Max. Paper Capacity 100 sheets
c. UPS Power Link 650 W (Unitteruptible Power Supply )
Pertimbangan menggunakan UPS yaitu jika sewaktu–waktu listrik padam masih ada sisa arus listrik yang dapat digunakan untuk melakukan penyimpanan data yang baru saja dimasukkan sehingga data tidak hilang.
3.2 Prosedur Pengumpulan Data
Sesuai dengan sumber data dan tujuan penyusunan laporan penelitian ini, maka dalam pengumpulan data penulis menggunakan beberapa metode antara lain sebagai berikut :
1. Wawancara
Yaitu metode pengumpulan data dengan mengadakan wawancara secara langsung untuk mendapatkan data-data yang sudah dipersiapkan guna memperoleh informasi yang dibutuhkan. Dalam melakukan wawancara dijelaskan mengenai maksud dan tujuan dari penulis dalam melakukan penelitian. Wawancara dilakukan dengan pihak yang berkaitan langsung dengan data.
2. Observasi
Yaitu teknik pengumpulan data dengan cara mengadakan pengamatan dan peninjauan secara langsung terhadap objek penelitian. 3. Studi Kepustakaan
Yaitu metode pengumpulan data dengan cara membaca dan mempelajari literatur, majalah, buku yang berhubungan dengan pokok-pokok permasalahan, untuk mendapatkan dasar-dasar teori dari data yang dibutuhkan.
3.3 Metodologi Penelitian
Agar penelitian yang dilakukan lebih terarah maka akan digunakan suatu metode. Dalam penelitian ini, metode yang digunakan adalah waterfall. Langkah yang dilakukan dimulai dengan identifikasi dan analisis kebutuhan pengguna, yang dilakukan bersama-sama dengan mengamati kondisi sistem yang saat ini digunakan. Setelah itu dilanjutkan dengan menjelaskan desain aplikasi, kemudian dilanjutkan dengan desain data warehouse dan desain data mining. Desain-desain tersebut kemudian diaplikasikan dan dievaluasi agar didapatkan aplikasi yang benar-benar bermanfaat bagi pengguna.
Berikut dijelaskan secara lebih detail tahapan pengerjaan yang akan dilakukan :
1. Identifikasi dan analisi kebutuhan aplikasi
Tahap identifikasi dan analisis kebutuhan aplikasi dilakukan untuk mengetahui kebutuhan pengguna terhadap aplikasi yang akan dikembangkan. Hal ini perlu dilakukan agar aplikasi yang dikembangkan sesuai dengan kebutuhan pengguna.
Dibagian ini juga dijelaskan siapa saja yang akan menggunakan aplikasi ini, dan informasi apa saja yang bisa digunakan oleh mereka. Kegiatan yang dilakukan pada tahap identifikasi dan analisa kebutuhan ini antara lain :
b. Melakukan studi literatur atau studi pustaka untuk lebih menguasai dan memahami dasar-dasar teori dan konsep-konsep yang mendukung penelitian
c. Melakukan observasi permasalahan yang terjadi pada obyek penelitian dan dilanjutkan dengan mengidentifikasinya
Observasi dilakukan dengan beberapa langkah antara lain : a. Melakukan pengamatan dan menganalisa kondisi objek penelitian,
terutama pada sistem informasi yang saat ini digunakan. Dari sistem tersebut dilakukan pengamatan terhadap proses bisnis yang ada, alur transaksi pada masing-masing proses, model-model laporan yang dihasilkan, desain database yang digunakan, model penyimpanan data, serta hal-hal lain yang berhubungan dengan sistem yang ada.
b. Melakukan wawancara pada beberapa stakeholder sebagai pengambil keputusan, penggguna ditingkat operasional, staf teknologi informasi, dan staf-staf lain yang diperlukan. Skenario yang akan dilakukan untuk proses wawancara ini adalah sebagai berikut :
1) Menentukan orang-orang yang akan dijadikan sebagai sumber informasi, baik dari pihak manajemen, bagian teknologi informasi, bagian pelayanan dan bagian-bagian lain yang berhubungan
2) Membuat jadwal dan agenda dengan orang-orang yang akan diwawancarai
3) Menyiapkan pertanyaan baik yang bersifat strategis ataupun teknis untuk mengetahui kebutuhan pengguna pada aplikasi 4) Menyiapkan alat bantu wawancara seperti buku catatan atau
perekam suara
5) Melakukan wawancara dan mencatat semua hasil yang didapatkan
c. Melakukan analisa pada dokumen-dokumen yang dimiliki oleh Perpustakaan
2. Mendiskripsikan aplikasi yang akan dikembangkan
Setelah kebutuhan pengguna didapatkan, langkah selanjutnya adalah menggambarkan aplikasi yang akan dikembangkan. Gambaran aplikasi ini bertujuan agar pengguna mempunyai gambaran awal mengenai aplikasi dan fitur-fitur apa saja yang ada diaplikasi yang dikembangkan.
3. Mengumpulkan dan Menganalisa Data
Setelah mendeskripsikan aplikasi yang akan dikembangkan, langkah selanjutnya adalah mengumpulkan data. Data yang dibutuhkan adalah data transaksi peminjaman dan pengembalian buku. Setelah data tersebut didapatkan, langkah selanjutnya adalah menganalisa data. Langkah ini diperlukan agar karakteristik dari masing-masing data diketahui. Dengan mengetahui karakteristik data, bisa diketahui pula data mana yang dibutuhkan data mana yang tidak dibutuhkan.
4. Mendesain Data Warehouse
Untuk mendesain data warehouse, langkah yang akan dilakukan adalah :
a. Mendesain basis data logikal untuk data warehouse.
b. Menentukan skema data warehouse yang akan dipakai. Apakah akan memakai skema bintang, skema bola salju atau Fact constellations. Hasil akhir dari tahap ini berupa script untuk membangun tabel, script untuk pembuatan index.
c. Membersihkan data. Data transaksi peminjaman dan pengembalian buku tidak bisa langsung dimasukkan dalam data warehouse. Data tersebut harus dipersiapkan terlebih dahulu dengan cara meringkas dan membersihkan dari kemungkinan error dengan membuang record-record yang mengandung kesalahan atau diragukan validitasnya. Selain itu, data tersebut juga dipilih. Data tidak
berhubungan dengan penelitian tidak akan dimasukkan dalam data warehouse
d. Melakukan input data kedalam data warehouse 5. Membangun OLAP dan Analisa Data Multidimensi
Setelah data warehouse siap, data tersebut kemudian diolah dan dianalisa dengan menggunakan OLAP. Pengolahan data dengan OLAP dilakukan dengan membuat dimensi dan cube. Dimensi dan cube ini dibuat berdasarkan desain data warehouse yang dibuat pada tahap sebelumnya. Dengan menggunakan OLAP data dianalisa dengan melakukan operasi slicing, dicing, roll up, dan drill down pada warehouse. Salah satu contoh operasi drill-down dan roll up yang akan dilakukan pada OLAP terlihat pada gambar 3.1 dan gambar 3.2
6. Market Basket Analysis pada transaksi peminjaman buku
Untuk mendapatkan informasi yang berhubungan dengan keterkaitan buku yang dipinjam oleh anggota, dilakukan proses data mining pada data warehouse yang sudah dibuat. Proses data mining dilakukan dengan menggunakan SQL Server 2005 dan menggunakan metode Association Rule Mining
Shift
Harian
Minggu
Bulanan
Tahunan
Buku
Kategori
Gambar 3.2 : Operasi pada dimensi buku
Sebelum melakukan data mining, beberapa hal yang harus dilakukan adalah :
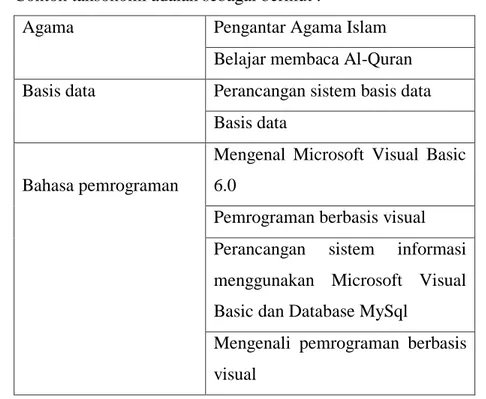
a. Menyusun taksonomi buku
Contoh taksonomi adalah sebagai berikut :
Agama Pengantar Agama Islam
Belajar membaca Al-Quran Basis data Perancangan sistem basis data
Basis data
Bahasa pemrograman
Mengenal Microsoft Visual Basic 6.0
Pemrograman berbasis visual Perancangan sistem informasi menggunakan Microsoft Visual Basic dan Database MySql
Mengenali pemrograman berbasis visual
b. Menyusun nilai support dan cofidence yang diinginkan c. Melakukan proses data mining
d. Mengolah rule yang didapatkan dan merumuskannya sehingga didapatkan informasi mengenai keterkaitan barang yang dibeli oleh konsumen.
7. Uji Coba Aplikasi dan Evaluasi
Untuk memastikan bahwa aplikasi yang dikembangkan bebas dari kesalahan, dilakukan testing (uji coba) pada aplikasi tersebut. Uji coba
yang dilakukan mencakup uji coba pada desain data warehouse, proses ekstraksi, transformasi, dan load data ke data warehouse, ujicoba pada OLAP, dan yang terakhir uji coba pada hasil data mining. Pada tahap ini juga akan dilakukan evaluasi terhadap hasil penelitian yang dilakukan. Evaluasi dilakukan mencakup evaluasi hasil dan manfaat cara dengan membandingkan hasil yang didapatkan dengan kebutuhan pengguna saat survey kebutuhan pengguna.
8. Menyusun Laporan Penelitian
Langkah terakhir dari penelitian ini adalah membuat laporan penelitian. Laporan ini berisi hal-hal yang dikerjakan selama melakukan penelitin dan hasil-hasil yang didapatkan ketika melakukan penelitian.
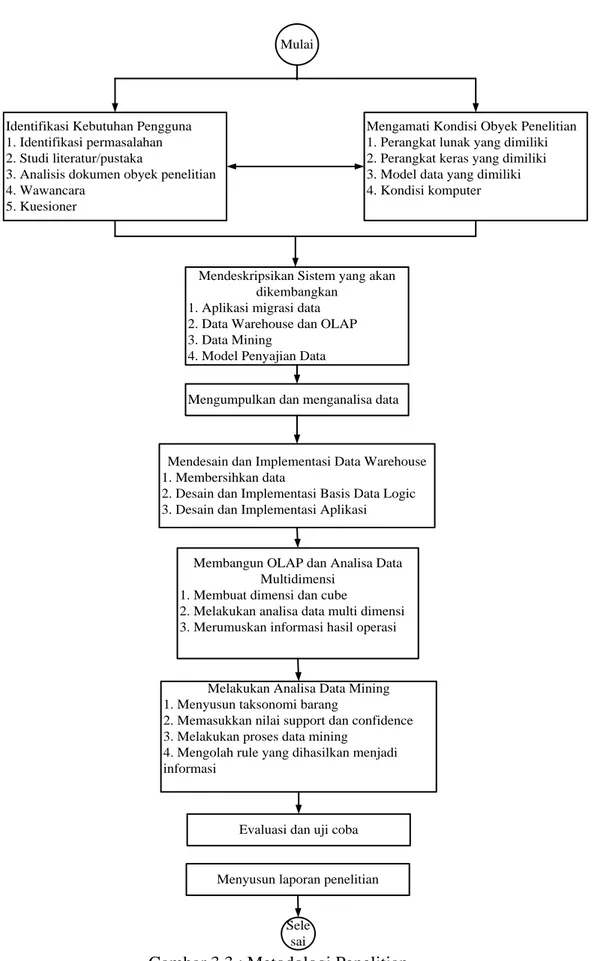
Dari uraian diatas, dapat digambarkan langkah-langkah yang digunakan pada penelitian ini adalah sebagai berikut :
Mulai
Identifikasi Kebutuhan Pengguna 1. Identifikasi permasalahan 2. Studi literatur/pustaka
3. Analisis dokumen obyek penelitian 4. Wawancara
5. Kuesioner
Mengamati Kondisi Obyek Penelitian 1. Perangkat lunak yang dimiliki 2. Perangkat keras yang dimiliki 3. Model data yang dimiliki 4. Kondisi komputer
Mendeskripsikan Sistem yang akan dikembangkan
1. Aplikasi migrasi data 2. Data Warehouse dan OLAP 3. Data Mining
4. Model Penyajian Data
Mengumpulkan dan menganalisa data
Mendesain dan Implementasi Data Warehouse 1. Membersihkan data
2. Desain dan Implementasi Basis Data Logic 3. Desain dan Implementasi Aplikasi
Membangun OLAP dan Analisa Data Multidimensi
1. Membuat dimensi dan cube
2. Melakukan analisa data multi dimensi 3. Merumuskan informasi hasil operasi
Melakukan Analisa Data Mining 1. Menyusun taksonomi barang
2. Memasukkan nilai support dan confidence 3. Melakukan proses data mining
4. Mengolah rule yang dihasilkan menjadi informasi
Evaluasi dan uji coba Menyusun laporan penelitian
Sele sai
33 BAB IV
ANALISIS DAN PERANCANGAN APLIKASI
Bab ini menjelaskan tentang analisis dan perancangan dalam membangun Aplikasi Data Mining. Analisis meliputi analisis data mining, analisis lingkungan sistem serta analisis dalam membangun aplikasi.
4.1 Analisis Data Mining
Aplikasi data mining yang dihasilkan akan melakukan pem-filter-an, penyimpanan kata penting pada tiap sinopsis, menemukan dan menganalisa relasi antar sinopsis, dan kemudian menampilkan hasil analisa tersebut kepada user. Dengan aplikasi ini nantinya diperoleh list judul buku dari yang paling berhubungan dengan keyword yang diinputkan oleh user sampai dengan yang paling sedikit hubungannya dengan keyword yang dientrikan. 4.2 Sumber Data
Data yang digunakan dalam penulisan tugas akhir ini terdiri dari satu sumber data yaitu data master buku.
Data master buku adalah data buku yang didata oleh pihak Perpustakaan ketika dilakukan penambahan atau perubahan data buku. Data yang dicatat adalaha identitas buku dengan atribut sebagai berikut :
Tabel 4.1 : Tabel data master buku
Atribut Keterangan
Kode buku Kode buku adalah kode yang dimiliki buku sebagai kode unik identitas buku
Judul buku Merupakan judul buku yang bersangkutan Anak judul Merupakan judul spesifik buku
Pengarang Merupakan nama pengarang buku
Pengarang tambahan Merupakan nama pengarang, jika pengarang lebih dari satu
Tempat terbit Merupakan tempat buku diterbitkan Tahun terbit Merupakan tahun buku diterbitkan
Cetakan/edisi Merupakan edisi buku (Kesatu|kedua|ketiga) No. Kelas Merupakan kelas buku (fiksi|non fiksi) Deskripsi fisik Merupakan ukuran dan ketebalan buku Penempatan Merupakan penempatan rak buku ISBN/ISSN Merupakan nomor ISBN
Data buku yang diambil dalam sampel adalah semua data buku yang ada di Perpustakaan Daerah Wilayah Jawa Tengah sejak tahun 2010. Data tersebut diperoleh langsung oleh peneliti dari bagian sirkulasi Perpustakaan Daerah Wilayah Jawa Tengah.
4.3 Intergrasi Data
Dalam penelitian ini diasumsikan bahwa semua data yang diambil sudah berupa tabel-tabel dalam satu server. Untuk proses mining data buku digunakan judul buku, pengarang, deskripsi dan kategori sebagai keyword. Proses integrasi data dilakukan ketika proses ETL (ekstract, transform, and load)
4.4 Transformasi Data
Transformasi data merupakan proses pengubahan atau penggabungan data ke dalam format yang sesuai untuk diproses dalam data mining. Seringkali data yang akan digunakan dalam proses data mining mempunyai format yang belum langsung dapat digunakan, oleh karena itu perlu dirubah formatnya.
4.5 Perancangan Sistem
Rancangan aplikasi pencarian buku ini akan dilakukan lebih mendalam dengan mendeskripsikan buku-buku tersebut dan akan dilakukan pengklasifikasian dengan menggunakan metode naive bayes clasiffier (NBC) sehingga akan mendapatkan hasil yang lebih optimal dikarenakan user mendapatkan referensi buku yang lebih banyak.
Pada proses pencarian dengan menggunakan metode naive bayes clasiffier (NBC) akan melalui dua tahap, yaitu proses learning dan proses clasiffier. Dimana proses learning akan membentuk vocabulary pada setiap dokumen data training, yaitu berupa kamus kata dasar yang nantinya akan menjadi perbandingan antarasatu kata dengan kata yang lainnya. Kemudian proses learning akan akan menghitung probabilitas pada setiap kategori tersebut untuk nantinya di klasifikasikan. Sedangkan pada proses clasiiffier langkahnya yaitu menghitung probabilitas pada setiap dokumen terhadap sekumpulan dokumen dan kemudian menentukan probabilitas kemunculan kata yang terbesar pada suatu dokumen dengan kategori class tersebut. Sehingga kata yang memiliki presentasi terbesarlah yang akan dimunculkan pada hasil pencarian.
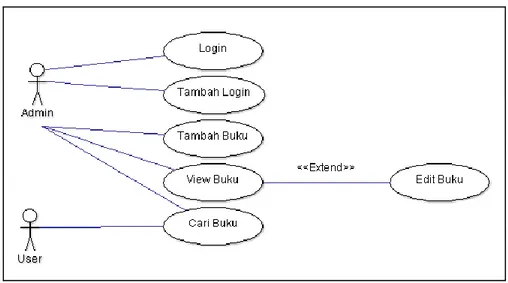
4.5.1 Use Case Diagram
Perancangan sistem dapat dilihat dari use case diagram dibawah ini :
Gambar diatas menjelaskan bahwa dalam aplikasi data mining pada Perpustakaan Daerah Wilayah Jawa Tengah terdapat 2 actor yaitu :
1. Admin
Dapat menjalankan sistem pada bagian login dan masuk ke menu utama untuk melakukan tambah buku dan edit buku.
2. User
Dapat melakukan pencarian buku dengan memasukkan keyword yang diinginkan dengan mengacu pada judul, pengarang, deskripsi atau kategori dari buku yang dicari.
4.5.2 Sequence Diagram
Penjelasan antar proses akan digambarkan dengan sequence diagram berikut :
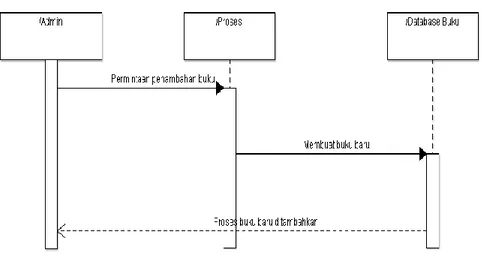
1. Sequence diagram penambahan buku
Gambar 4.2 : Sequence diagram penambahan buku
Penambahan buku dilakukan oleh admin jika ada buku baru yang masuk.
2. Sequence diagram pencarian buku berdasarkan judul
Gambar 4.3 : Sequence diagram pencarian buku berdasarkan judul
Untuk melakukan pencarian buku, dapat dilakukan berdasarkan judul, kategori maupun deskripsi dari buku yang ingin dicari. Gambar diatas menjelaskan alur sequence diagram pencarian buku berdasarkan judul buku.
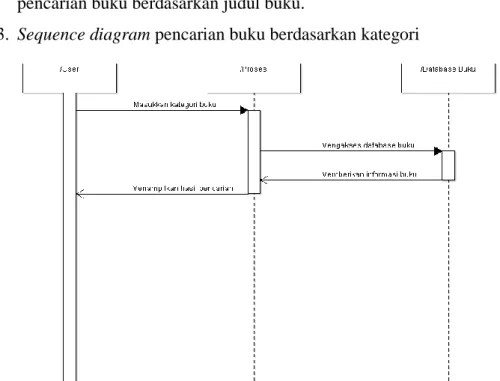
3. Sequence diagram pencarian buku berdasarkan kategori
Gambar 4.4 : Sequence diagram pencarian buku berdasarkan kategori
Gambar tersebut menjelaskan alur pencarian buku berdasarkan kategori buku.
4. Sequence diagram pencarian buku berdasarkan deskripsi buku
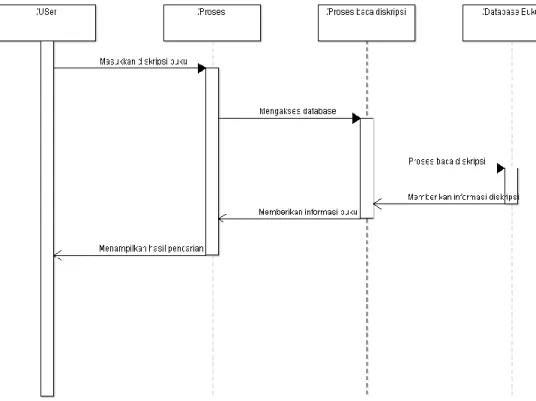
Gambar 4.5 : Sequence diagram pencarian buku berdasarkan deskripsi buku
Gambar tersebut menjelaskan alur sequence diagram pencarian buku berdasarkan deskripsi buku.
5. Sequence diagram edit buku
Gambar 4.6 : Sequence diagram edit buku
Admin dapat juga melakukan edit buku untuk mengedit kesalahan ketika memasukkan data buku dan sudah disimpam dalam database.
6. Sequence diagram login
4.5.3 Class Diagram
Gambar 4.8 : Class diagram aplikasi sistem perpustakaan
Dari kelas diagram diatas dapat dilihat bagaimana relasi antar tabel dan atribut yang terdapat pada tabel. Data buku menjadi inti dari proses pencarian, yang nantinya akan dikelompokkan berdasarkan pencarian judul, kategori maupun deskripsi yang dimasukkan oleh user.
4.5.4 Struktur File 1. File Login
Nama tabel = Login Kunci field = username
Tabel 4.1 : Tabel Login
No Nama field Type Width Dec Keterangan 1 Username String 10 Nama user 2 Password String 10 Password
2. File Buku
Nama tabel = buku Kunci field = kode_buku
Tabel 4.2 : Tabel Buku
No Nama field Type Width Dec Keterangan 1 Kode_buku Integer 15 Kode buku
No Nama field Type Width Dec Keterangan
2 Judul String 30 Judul buku
3 Anak_judul String
30 Anak judul (bila ada) 4 Pengarang String 20 Nama pengarang buku 5 Pengarang_t ambahan String 20 Nama pengarang tambahan (bila ada)
6 Penerbit String 30 Penerbit buku 7 Tempat_terb it String 30 Tempat buku diterbitkan 8 Tahun_terbi t String 4 Tahun diterbitkannya buku
9 Cetakan String 10 Cetakan buku 10 No_kelas String
5 Nomor kelas
penempatan 11 Deskripsi String 100 Deskripsi buku 12 Penempatan String 10 Penempatan buku
13 ISBN String 10 Nomor ISBN
3. File Kategori
Nama tabel = Kategori Kunci field = id_kategori
Tabel 4.3 : Tabel Kategori
No Nama field Type Width Dec Keterangan 1 Id_kategori Integer 5 Id kategori 2 Kategori String 30 Kategori buku