BAB 3
METODE PENELITIAN
3.1 Desain Penelitian
Penelitian yang dilaksanakan di Kantor Notaris dan PPAT Buntario Tigris ini merupakan penelitian yang memiliki tujuan sekedar untuk memahami masalah secara mendalam dalam organisasi yang berguna untuk pengembangan ilmu manajemen (tanpa ingin menerapkan hasilnya), maka penelitian ini dinamakan penelitian dasar (murni). Penelitian ini dapat dikategorikan sebagai penelitian asosiatif atau hubungan kuantitatif dengan statistik karena bertujuan untuk mengetahui hubungan antara variabel kualitas pelayanan jasa, sikap konsumen, dan loyalitas pelanggan. Data yang diperoleh dibuat skala pengukurannya yang kemudian diolah untuk dianalisis. Penggunaan metode Survey dilakukan karena penelitian dilakukan pada populasi besar, tetapi data yang dipelajari adalah data dari sampel yang diambil dari populasi tersebut, sehingga ditemukan kejadian-kejadian relatif, distribusi, dan hubungan-hubungan antarvariabel sosiologis maupun psikologis. (Sugiyono, 2006, p5-7)
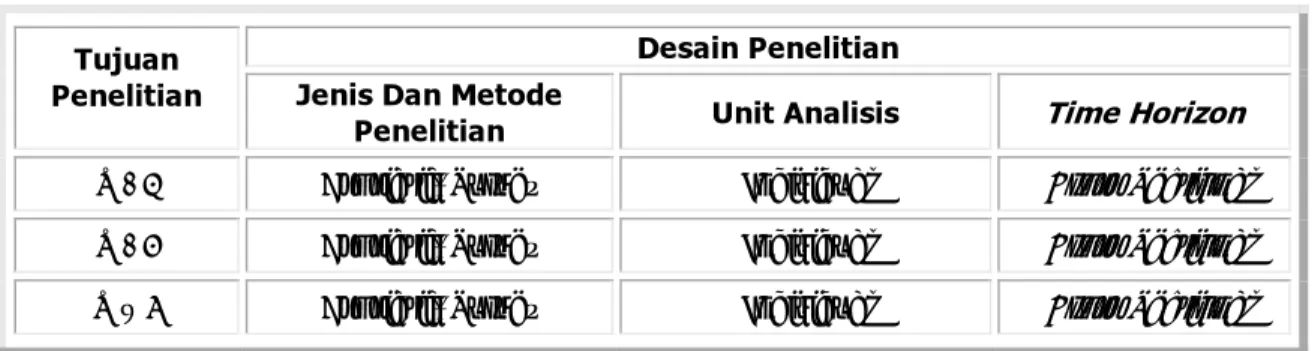
Unit analisis berupa individu, yaitu para pengguna (konsumen) jasa hukum Kantor Notaris dan PPAT Buntario Tigris SH., SE., MH. Time Horizon yang digunakan adalah cross sectional, yaitu suatu penelitian yang dilakukan dalam kurun waktu tertentu. Untuk lebih ringkasnya, desain penelitian dijabarkan dalam Tabel 3.1 berikut.
Tabel 3.1 Desain Penelitian Desain Penelitian Tujuan
Penelitian Jenis Dan Metode
Penelitian Unit Analisis Time Horizon
T - 1 Asosiatif, Survey Individual Cross Sectional
T - 2 Asosiatif, Survey Individual Cross Sectional
T – 3 Asosiatif, Survey Individual Cross Sectional
Sumber : Hasil Penelitian (2008)
T-1 : Untuk mengetahui pengaruh kualitas pelayanan jasa terhadap sikap konsumen di Kantor Notaris dan PPAT Buntario Tigris.
T-2 : Untuk mengetahui pengaruh sikap konsumen terhadap loyalitas pelanggan di Kantor Notaris dan PPAT Buntario Tigris.
T-3 : Untuk mengetahui pengaruh kualitas pelayanan jasa terhadap loyalitas pelanggan di Kantor Notaris dan PPAT Buntario Tigris melalui sikap konsumen.
3.2 Operasionalisasi Variabel Penelitian
Variabel penelitian adalah suatu atribut atau sifat atau nilai dari orang, obyek, atau kegiatan yang mempunyai variasi tertentu yang ditetapkan oleh peneliti untuk dipelajari dan ditarik kesimpulannya (Sugiyono, 2006, p32).
Variabel independen atau yang dalam Structural Equations Modeling disebut variabel eksogen berupa kualitas pelayanan jasa di Kantor Notaris dan PPAT Buntario Tigris, sedangkan variabel dependen atau variabel endogen yaitu sikap konsumen dan loyalitas pelanggan di Kantor Notaris dan PPAT Buntario Tigris. Sikap konsumen yang dihipotesiskan mempengaruhi loyalitas pelanggan di Kantor Notaris dan PPAT Buntario Tigris dalam hal ini disebut juga variabel intervening, karena merupakan variabel endogen yang dapat
mempengaruhi variabel endogen lainnya. Adapun pelanggan yang dimaksudkan dalam penelitian ini adalah pihak-pihak yang menggunakan jasa hukum yang ditawarkan oleh Kantor Notaris dan PPAT Buntario Tigris, yaitu klien-klien kantor notaris tersebut.
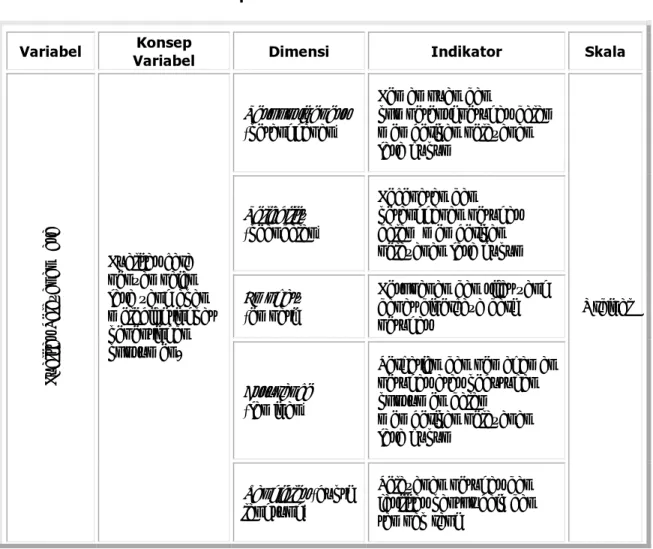
Variabel tersebut diatas merupakan variabel laten. Dari variabel laten tersebut kemudian dikembangkan menjadi beberapa variabel penelitian yang dapat digunakan sebagai indikator penelitian. Variabel-variabel ini disebut dengan variabel manifest, yang merupakan variabel dasar yang dapat memrepresentasikan kualitas pelayanan jasa , sikap konsumen, dan loyalitas pelanggan.
Tabel 3.2 Operasionalisasi Variabel Penelitian
Variabel Variabel Konsep Dimensi Indikator Skala
Responsiveness (ketanggapan)
Kemampuan dan
kompetensi petugas dalam memberikan pelayanan jasa hukum Reliability (keandalan) Kecepatan dan ketanggapan petugas dalam memberikan pelayanan jasa hukum Emphaty
(empati)
Kesopanan dan sifat yang dapat dipercaya dari petugas
Assurance (jaminan)
Perhatian dan pemahaman petugas atas kebutuhan konsumen dalam memberikan pelayanan jasa hukum Ku al itas P ela ya na n Ja sa Kualitas cara penyampaian jasa yang akan melebihi tingkat kepentingan konsumen.
Tangibles (bukti langsung)
Pelayanan petugas dan fasilitas kantor baik dan tampak rapi
Kualitas jasa hukum yang diberikan
Komponen Kognitif
Kesesuaian jasa yang diberikan terhadap ekspektasi konsumen Rasa senang dan kepuasan konsumen terhadap jasa hukum yang diberikan
Komponen Afektif
Rasa percaya konsumen terhadap jasa yang diberikan Si ka p K ons um
en Evaluasi konsumen atas
jasa yang diberikan dalam memenuhi kebutuhan konsumen. Komponen Konatif Konsumen ingin
menggunakan jasa hukum yang ditawarkan Ordinal Membeli tanpa beralih Pelanggan bersedia melakukan pembelian kembali dan tidak beralih ke pesaing
Rekomendasi Pelanggan merekomendasikan kepada orang lain
Membicarakan hal-hal baik
Pelanggan menceritakan hal-hal yang positif kepada orang lain
Membeli lebih banyak
Pelanggan bersedia menggunakan jasa hukum tambahan lain yang ditawarkan Loyalitas P elanggan Suatu perilaku pembelian yang dilakukan berulang kali dan bukan merupakan pembelian acak. Memberi saran dan kurang peka terhadap harga
Pelanggan memberikan saran dan bersedia membayar biaya yang lebih tinggi sesuai dengan kualitas jasa yang
diberikan
Ordinal
3.3 Jenis dan Sumber Data Penelitian
Untuk mendapatkan data yang valid untuk penelitian, yang pertama perlu diketahui adalah mengenai jenis-jenis data. Data dapat dikelompokkan sebagai berikut :
1) Menurut Sifat
• Data Kualitatif, yaitu data yang tidak berbentuk angka (nonnumeris).
• Data Kuantitatif, yaitu data yang dinyatakan dalam bentuk angka. 2) Menurut Sumber
• Data internal, yaitu data yang bersumber dari keadaan atau kegiatan suatu organisasi atau kelompok.
• Data eksternal, yaitu data yang bersumber dari luar suatu organisasi atau kelompok.
3) Menurut Cara Memperoleh
• Data primer, yaitu data yang dikumpulkan dan diolah sendiri oleh suatu organisasi atau perorangan langsung dari objeknya.
• Data sekunder, yaitu data yang diperoleh dalam bentuk jadi dan telah diolah oleh pihak lain, yang biasanya dalam bentuk publikasi.
4) Menurut Waktu Pengumpulannya
• Data cross section, yaitu data yang dikumpulkan dalam suatu periode tertentu, biasanya menggambarkan keadaan atau kegiatan dalam periode tersebut.
• Data time series (berkala), yaitu data yang dikumpulkan dari waktu ke waktu dengan tujuan untuk menggambarkan perkembangan suatu kegiatan dari waktu ke waktu. Data ini sering juga disebut sebagai data historis.
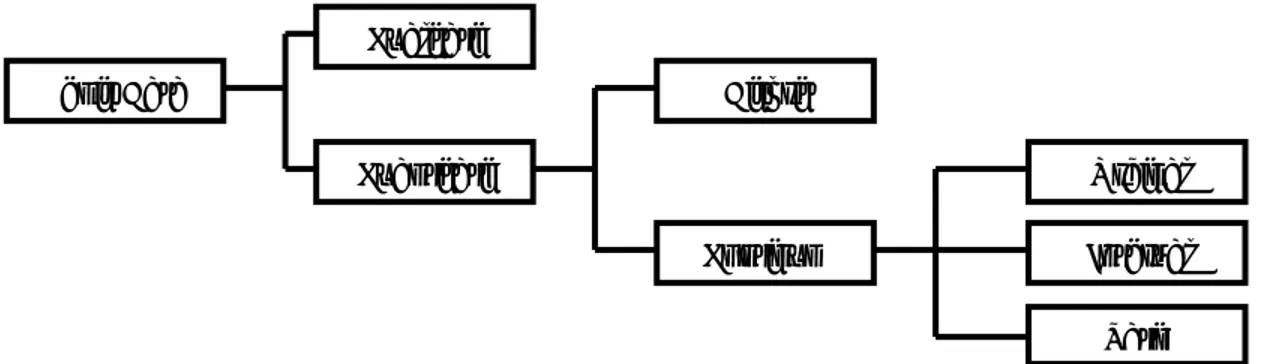
Sumber : Sugiyono (2006, p14)
Gambar 3.1 Jenis-jenis Data
Berdasarkan pembagian tersebut, jenis data yang dikumpulkan adalah data primer dan sekunder yang bersifat kualitatif maupun kuantitatif. Data-data yang diperoleh dalam penelitian ini berupa data dengan skala ukur ordinal. Menurut pendapat Sitinjak dan Sugiarto (2006, p12), skala ordinal adalah skala yang mengelompokkan (kategori) obyek-obyek dan mengandung tingkatan sehingga dari kelompok yang terbentuk dapat dibuat sesuatu urutan peringkat yang menyatakan hubungan lebih dari atau kurang dari menurut suatu aturan penataan tertentu.
Data yang diperlukan dalam penelitian ini terdiri dari data profil Kantor Notaris dan PPAT Buntario Tigris, struktur organisasi Kantor Notaris dan PPAT Buntario Tigris, sistem pelayanan jasa di Kantor Notaris dan PPAT Buntario Tigris, tingkat kualitas pelayanan jasa, sikap konsumen, dan tingkat loyalitas pelanggan di Kantor Notaris dan PPAT Buntario Tigris. (dalam hal ini yaitu pengguna atau konsumen jasa hukum di Kantor Notaris dan PPAT Buntario Tigris). Jenis Data Kualitatif Kuantitatif Diskrit Kontinum Ordinal Interval Ratio
3.4 Teknik Pengumpulan Data
Untuk memperoleh data-data yang berguna bagi penelitian yang dilakukan, maka digunakan metode pengumpulan data penelitian lapangan (field research) untuk memperoleh data primer. Penelitian lapangan dilakukan dengan melakukan peninjauan ke Kantor Notaris dan PPAT Buntario Tigris yang menjadi subyek penelitian.
Untuk mendapatkan data primer, dilakukan dengan menyebarkan kuesioner (angket) kepada pengguna (konsumen) jasa hukum di Kantor Notaris dan PPAT Buntario Tigris yang dilakukan mulai sejak tanggal 20 Desember 2007 sampai 4 Januari 2008. Kuesioner merupakan teknik pengumpulan data yang dilakukan dengan cara memberi seperangkat pertanyaan atau pernyataan tertulis kepada responden untuk dijawabnya (Sugiyono, 2006, p135). Untuk memperoleh data-data yang dibutuhkan, penulis menggunakan kuesioner sebagai instrumen utama dan menghubungkan bahan-bahan kepustakaan serta mempelajari buku-buku, literatur-literatur, observasi, wawancara, serta pencarian melalui situs-situs internet.
Dalam penelitian ini kuesioner dibuat menggunakan skala pengukuran Likert, yaitu skala pengukuran yang menyatakan setuju atau ketidaksetujuan terhadap subyek, obyek atau kejadian tertentu. Setiap pertanyaan disusun sedemikian rupa agar bisa dijawab dalam lima tingkatan jawaban pertanyaan atau pernyataan yang diajukan. Urutan untuk skala ini menggunakan lima angka penilaian yaitu :
1) Sangat tidak setuju 2) Tidak Setuju 3) Ragu-ragu 4) Setuju 5) Sangat Setuju
3.5 Teknik Pengambilan Sampel
Populasi adalah keseluruhan dari karakteristik atau unit hasil pengukuran yang menjadi objek penelitian atau populasi merupakan objek atau subjek yang berada pada suatu wilayah dan memenuhi syarat tertentu berkaitan dengan masalah penelitian. (Riduwan dan Kuncoro (2007, p37).
Berdasarkan pendapat Sugiyono (2006, p72), populasi adalah wilayah generalisasi yang terdiri atas : obyek atau subyek yang mempunyai kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya. Sedangkan sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut.
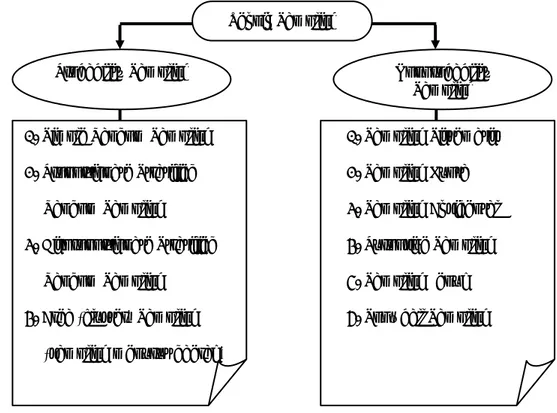
Sumber : Sugiyono (2006, p72)
Gambar 3.2 Teknik Pengambilan Sampel
1. Simple Random Sampling 2. Proportionate Stratified Random Sampling
3. Disproportionate Stratified Random Sampling
4. Area (cluster) Sampling (sampling menurut daerah)
1. Sampling Sistematis 2. Sampling Kuota 3. Sampling Aksidental 4. Purposive Sampling 5. Sampling Jenuh 6. Snowball Sampling
Probability Sampling Nonprobability
Sampling Teknik Sampling
Teknik sampling atau teknik pengambilan sampel adalah suatu cara mengambil sampel yang representatif dari populasi dimana pengambilan sampel harus dilakukan sedemikian rupa sehingga diperoleh sampel yang benar-benar dapat mewakili dan dapat menggambarkan keadaan populasi yang sebenarnya (Riduwan dan Kuncoro, 2007, p40). Terdapat berbagai teknik pengambilan sampel yang dapat digunakan yang digambarkan secara skematis seperti pada Gambar 3.2.
Dalam melakukan identifikasi sampel diperlukan teknik pengambilan sampel. Teknik pengambilan sampel yang diterapkan dalam penelitian ini adalah Probability Sampling. Probability sampling adalah teknik pengambilan sampel (teknik sampling) yang memberikan peluang yang sama bagi setiap unsur (anggota) populasi untuk dipilih menjadi anggota sampel. Metode yang digunakan dalam penelitian ini adalah Simple Random Sampling, karena pengambilan sampel anggota populasi dilakukan secara acak tanpa memperhatikan strata yang ada dalam populasi.
3.6 Teknik Pengolahan Sampel
Karena populasi pengguna (konsumen) jasa hukum di Kantor Notaris dan PPAT Buntario Tigris besar, dan penulis tidak mungkin mempelajari semua yang ada pada populasi karena keterbatasan dana, tenaga, dan waktu, maka penulis menggunakan sampel yang diambil dari populasi pengguna (konsumen) jasa hukum di kantor notaris dan PPAT tersebut.
Untuk menentukan berapa banyak sampel minimal yang perlu diambil untuk melakukan penelitian, dapat menggunakan rumus dari Taro Yamane atau Slovin sebagai berikut (Riduwan dan Kuncoro, 2006, p49) :
n = N N.d2 + 1
Dimana : n = jumlah sampel N = jumlah populasi
d2 = Presisi (ditetapkan 10% dengan tingkat kepercayaan 95%)
Berdasarkan rumus tersebut diperoleh jumlah sampel minimal adalah sebagai berikut :
n = 3250
(3250) 0,12 + 1
= 97.0149 ≈ 98 responden
Sampel penelitian yang digunakan adalah kuesioner yang telah diisi oleh para pengguna (konsumen) jasa hukum di Kantor Notaris dan PPAT Buntario Tigris. Jumlah kuesioner yang dibagikan adalah 130, dan dari 130 kuesioner yang dibagikan jumlah yang kembali adalah 110. Berdasarkan pendapat Ghozali dan Fuad (2005, p36), jumlah sampel yang disarankan untuk penelitian Structural Equation Modeling menggunakan metode estimasi Maximum Likelihood adalah antara 100 sampai 200 sampel. Oleh karena itu jumlah sampel yang diperoleh, yaitu 110 sampel dapat digunakan untuk penelitian.
3.7 Metode Analisis
Metode analisis yang digunakan adalah Model Persamaan Struktural (Structural Equation Modeling) yang mengacu pada hubungan antara variabel manifest dengan variabel laten (Model Pengukuran) dan hubungan antarvariabel laten (Model Jalur) baik hubungan langsung maupun tidak langsung. Dalam Structural Equation Modeling, seluruh tahap-tahap analisis menggunakan program LISREL 8.54.
3.7.1 Konseptualisasi Model
Konseptualisasi model mengharuskan dua hal yang harus dilakukan, yaitu :
• Hubungan yang dihipotesiskan antara variabel laten harus ditentukan, dengan menentukan mana variabel eksogen, endogen, intervening, manifest, dan error term masing-masing variabel.
• Menentukan arah (positif atau negatif) dan jumlah hubungan antarvariabel-variabel eksogen dan antara variabel eksogen dengan variabel endogen.
Model pengukuran dalam LISREL mengasumsikan bahwa variabel manifest merupakan indikator reflektif dari variabel laten, bukan indikator formatif. Variabel manifest dalam LISREL biasanya menggunakan reflective indicators dimana variabel laten dianggap mempengaruhi variabel manifest, karena beberapa program Structural Equation Modeling termasuk LISREL hanya dapat menggunakan indikator reflektif.
3.7.2 Spesifikasi Model
Spesifikasi model dilakukan terhadap permasalahan yang diteliti. Secara garis besar, spesifikasi model dijalankan dengan menspesifikasi model pengukuran serta model struktural. Spesifikasi model pengukuran meliputi definisi variabel-variabel laten dan variabel manifest (observed), dan definisi hubungan antara variabel laten dengan variabel manifest. Spesifikasi model struktural dilakukan dengan mendefinisikan hubungan kausal di antara variabel-variabel laten (Sitinjak dan Sugiarto, 2006, p64).
3.7.3 Identifikasi Model
Identifikasi model dimaksudkan untuk menjaga agar model yang dispesifikasikan bukan merupakan model yang under-identified atau unidentified. Model struktural dapat dikatakan baik apabila memiliki satu solusi yang unik untuk estimasi parameter. Jika solusi
unik tidak dapat terpenuhi maka mungkin diperlukan modifikasi model untuk dapat diidentifikasi sebelum melakukan estimasi. Untuk menentukan apakah suatu model memiliki solusi yang unik, maka harus memenuhi keadaan berikut (Ghozali dan Fuad, 2005, p46) :
t ≤ s/2
Dimana :
t = jumlah parameter yang diestimasi
s = jumlah varians dan kovarians antara variabel manifest yang merupakan (p+q)(p+q+1) p = jumlah variabel y (indikator variabel endogen)
q = jumlah variabel x (indikator variabel eksogen)
Jika t ≥ s/2 maka model tersebut adalah unidentified. Masalah unidentified dapat diatasi dengan mengkonstraint model. Jika t = s/2 maka model tersebut adalah just-identified, sehingga solusi yang unik, tunggal, dapat diestimasi untuk mengestimasi parameter. Namun pada model yang just-identified, seluruh informasi yang tersedia telah digunakan untuk mengestimasi parameter, sehingga tidak ada informasi yang tersedia untuk menguji model (derajat kepercayaan adalah 0). Jika t < s/2 maka model tersebut adalah over-identified. Berbeda dengan model yang just-identified, model ini dapat menggunakan informasi yang tersisa untuk menguji fit atau tidaknya suatu model.
3.7.4 Estimasi Parameter
Dalam program LISREL 8.54, data dibagi menjadi dua, yaitu Data Continuous dan Data Ordinal. Jenis data yang digunakan dalam penelitian ini adalah data ordinal, karena data memiliki kategori berurutan dan menggunakan skala Likert (1 sampai 5). Akan tetapi
data ordinal yang mengharuskan penggunaan metode estimasi Weighted Least Square sulit untuk dilakukan karena memerlukan jumlah data yang sangat besar (lebih besar dari 1000). Chou et al (1991) dan Hu et al (1992) berpendapat bahwa lebih masuk akal jika memperlakukan data ordinal sebagai data continuous dan mengkoreksi uji statistik. Beberapa peneliti membolehkan penggunaan data ordinal sebagai data continuous sehingga dapat langsung dianalisis dengan menggunakan metode Maximum Likelihood dan melakukan koreksi atas beberapa bias yang mungkin timbul (Chou et al. 1991; Hu et al. 1992). Penggunaan data ordinal sebagai data continuous dan diestimasi menggunakan metode Maximum Likelihood dengan menggunakan ukuran data yang kecil dan jumlah kategori yang lebih dari tiga akan menghasilkan kemungkinan bias yang kecil.
Metode estimasi Maximum Likelihood (ML) adalah metode yang paling populer digunakan pada penelitian Structural Equation Modeling. Maximum Likelihood akan menghasilkan estimasi parameter yang valid, efisien, dan reliabel apabila data yang digunakan adalah multivariate normality dan tidak terpengaruh/kuat terhadap penyimpangan multivariate normality yang sedang (moderate). Tetapi estimasi akan bias apabila pelanggaran terhadap multivariate normality sangat besar (Ghozali dan Fuad, 2005, p35-36). Oleh karena itu metode Maximum Likelihood perlu disertai dengan melakukan koreksi terhadap bias pada nilai standar error dan chi-square atas dilanggarnya normalitas dengan menggunakan asymptotic covariance matrix. Penggunaan metode estimasi Maximum Likelihood akan menghasilkan output yang menunjukkan nilai loading yang sama dengan apabila menggunakan metode estimasi Weighted Least Square. Ukuran sampel yang disarankan Hair et al. (1998) untuk penggunaan estimasi Maximum Likelihood adalah sebesar 100-200. Kelemahan metode Maximum Likelihood adalah metode ini akan menjadi sangat sensitif dan menghasilkan indeks goodness of fit yang buruk apabila data yang digunakan adalah besar (antara 400-500).
3.7.4.1 PRELIS
Alasan utama adanya PRELIS adalah untuk membantu peneliti melakukan screening data dengan menyediakan program yang mampu mengatasi berbagai permasalahan yang timbul dalam pengumpulan data. PRELIS memiliki berbagai fungsi berikut :
• Menyimpan data mentah yang sebelumnya disimpan pada berbagai macam program seperti SPSS, Ms. EXCEL, SAS, data text, dan lain sebagainya.
• Menyajikan statistik deskriptif dan analisis grafis mengenai data.
• Menghasilkan berbagai macam matriks (covariance, correlation, atau asymptotic covariance matrix).
• Memperlakukan dua jenis data yang berbeda seperti continuous ataupun ordinal.
• Dapat menghasilkan matriks pada data yang mengandung missing values (nilai-nilai observasi hilang).
• Dapat melakukan manipulasi data dan manajemen data, seperti menghilangkan outliers, transformasi data, dan lain sebagainya.
3.7.4.2 Model Pengukuran (Measurement Model)
Tujuan dari model pengukuran (measurement model) adalah untuk menggambarkan sebaik apa variabel-variabel manifest dapat digunakan sebagai instrumen pengukuran variabel laten. Dalam hal ini, konsep utama yang digunakan adalah pengukuran, validitas, dan reliabilitas. Dalam metode analisisnya, yaitu Confirmatory Factor Analysis (CFA), dianggap bahwa variabel laten sebagai variabel penyebab atau variabel yang mendasari variabel-variabel manifest (observed).
Pada masing-masing persamaan yang dihasilkan mengandung tiga jenis informasi, yaitu (Ghozali dan Fuad, 2005, p285) :
• Unstandardized Parameter Estimate
Menunjukkan pengaruh estimate value suatu variabel laten terhadap variabel manifest.
• Standard Error
Menginformasikan seberapa tepat bila suatu parameter tersebut diestimasi. Semakin kecil standard error, semakin baik estimasi yang dimiliki.
• Nilai t
Menentukan apakah suatu parameter secara signifikan berbeda dari nol dalam suatu populasi. Nilai t antara -1,979 sampai 1,979 mengindikasikan bahwa parameter secara signifikan tidak berbeda dari nol (pada taraf signifikansi 5%).
3.7.4.3 Uji Validitas dan Reliabilitas
Menurut Ghozali dan Fuad (2005, p.317), tujuan dalam mengevaluasi model pengukuran (measurement model) adalah untuk menentukan validitas dan reliabilitas variabel-variabel manifest dari suatu variabel laten. Uji validitas merupakan suatu uji yang bertujuan untuk menentukan kemampuan suatu indikator dalam mengukur variabel laten tersebut. Sedangkan uji reliabilitas adalah suatu pengujian untuk menentukan konsistensi pengukuran indikator-indikator dari variabel suatu variabel laten.
Validitas suatu variabel manifest dapat dievaluasi dengan tingkat signifikansi pengaruh antara suatu variabel laten dengan variabel manifestnya. Model penelitian dikatakan tidak valid ditunjukkan dengan tidak signifikannya hubungan antara variabel manifest (observed) dengan variabel laten. Apabila model pengukuran adalah fit, maka nilai estimasi unstandardized loading dapat digunakan sebagai koefisien validitas. Indikator yang paling kurang valid ditunjukkan dengan nilai unstandardized loading variabel manifest yang paling rendah. Namun karena variabel-variabel manifest dari suatu variabel laten yang sama
dapat diukur dengan skala yang sangat berbeda antara variabel manifest yang satu dan yang lainnya, maka perbandingan dengan menggunakan unstandardized loading adalah tidak sesuai. Oleh karena itu disarankan untuk mengevaluasi nilai standardized loading pada output Completely Standardized Solutions.
Sedangkan reliabilitas suatu variabel manifest diinterpretasikan dengan nilai Squared Multiple Correlations (R2) dari masing-masing variabel manifest yang ditampilkan pada ouput Measurement Equations. R2 menjelaskan mengenai seberapa besar proporsi varians variabel manifest yang dijelaskan oleh variabel laten, sedangkan sisanya dijelaskan oleh measurement error. Variabel manifest yang paling kurang reliable ditunjukkan dengan nilai R2 yang paling rendah pada persamaan pengukuran (measurement equations) antara indikator dengan variabel latennya.
Disamping menguji reliabilitas variabel manifest individual, dapat pula dinilai reliabilitas gabungan (Composite Reliability) untuk tiap-tiap variabel laten. Composite Reliability sering juga disebut Construct Reliability. Dengan menggunakan informasi pada loading variabel manifest dan error variance yang diperoleh pada output SIMPLIS Completely Standardized Solutions, perhitungan Composite Reliability dapat menggunakan rumus berikut ini :
ρc = (Σλ)2 / [(Σλ)2 + (Σθ)]
Dimana :
ρc = Composite Reliability
λ = loading variabel manifest
Menurut Bagozzi dan Yi (1988) tingkat cut-off untuk dapat mengatakan bahwa Composite Reliability cukup bagus adalah 0,6. Metode lain yang dapat mengukur Composite Reliability adalah dengan menggunakan metode Average Variance Extracted yang mengukur secara langsung jumlah varians yang diperoleh melalui suatu variabel laten dibandingkan dengan jumlah varians yang diperoleh melalui measurement error. Diharapkan nilai ρc lebih daripada 0,5 karena apabila ρc kurang daripada 0,5 menunjukkan bahwa measurement error lebih banyak memiliki kontribusi kepada variabel manifest daripada variabel laten. Informasi yang digunakan sama dengan yang digunakan dalam perhitungan Composite Reliability. Rumus untuk menilai Average Variance Extracted adalah sebagai berikut :
ρc = (Σλ2) / [(Σλ2)+ (Σθ)]
3.7.4.4 Penilaian Model Struktural
Evaluasi model struktural berfokus pada hubungan-hubungan antara variabel laten eksogen (ξ) dan endogen (η) serta hubungan antarvariabel endogen (η). Tujuan dalam menilai model struktural adalah untuk memastikan apakah hubungan-hubungan yang dihipotesiskan pada model konseptualisasi didukung oleh data empiris yang diperoleh melalui survey. Pada masing-masing persamaan akan menghasilkan unstandardized parameter estimate, standar error, dan nilai t. Terdapat tiga hal yang harus diperhatikan dalam hal ini, yaitu :
1. Tanda (arah) hubungan antara variabel-variabel laten yang mengindikasikan apakah hasil hubungan antara variabel-variabel tersebut memiliki pengaruh yang sesuai dengan yang dihipotesiskan.
2. Signifikansi parameter yang diestimasi memberikan informasi yang sangat berguna mengenai hubungan antara variabel-variabel laten. Signifikansi tersebut dapat dilihat
pada baris ketiga dibawah nilai estimasi parameter. Batas untuk menolak atau menerima suatu hubungan dengan tingkat signifikansi 5% adalah 1,979 (mutlak) yang diperoleh dari nilai t tabel dengan tingkat signifikansi 5% pada df = 125 (karena jumlah sampel 110). Apabila nilai t terletak diantara -1,979 dan 1,979 maka hipotesis yang menyatakan adanya pengaruh harus ditolak, sedangkan apabila nilai t lebih besar daripada 1,979 atau lebih kecil daripada -1,979 maka hipotesis yang menyatakan adanya pengaruh harus diterima dengan taraf signifikansi 5%.
3. Koefisien determinasi (R2) mengindikasikan jumlah varians pada variabel laten endogen yang dapat dijelaskan secara simultan oleh variabel-variabel laten eksogen. Semakin tinggi nilai R2, maka semakin besar variabel-variabel eksogen tersebut dapat menjelaskan variabel endogen, sehingga semakin baik persamaan struktural. Informasi mengenai koefisien determinasi R2 diperoleh melalui matriks PSI pada format LISREL dan juga di sebelah kanan persamaan struktural. Untuk mengetahui variabel mana yang memiliki pengaruh terbesar, maka sangat disarankan untuk melihat pada standardized estimates daripada unstandardized estimates.
3.7.4.5 Standardized Solutions Dan Completely Standardized Solutions
Standardized Solutions dan Completely Standardized Solutions yang dihasilkan LISREL dengan memasukkan perintah ‘Options: SS SC’ merupakan output nilai estimasi parameter-parameter yang sudah distandarisasi. Pada hubungan-hubungan langsung, estimasi parameter yang terstandarisasi menunjukkan tingkat perubahan variabel endogen akibat berubahnya standar deviasi variabel eksogen. Sedangkan pada hubungan tidak langsung (covariance), parameter yang terstandarisasi mengestimasi korelasi antara variabel-variabel yang bersangkutan. Manfaat dari metode yang distandarisasi ini adalah memudahkan interpretasi hubungan-hubungan bivariate antara variabel-variabel laten.
Karena hubungan-hubungan antara variabel tersebut dirubah dalam bentuk korelasi, sehingga hubungan antara dua variabel tersebut menjadi jelas. Korelasi yang memiliki nilai mendekati 1 menunjukkan hubungan yang kuat, sedangkan nilai yang mendekati nol memiliki hubungan yang semakin lemah.
Sebenarnya Standardized Solutions dan Completely Standardized Solutions adalah sama, kecuali pada bagian LAMBDA-Y dan LAMBDA-X. Perbedaannya, pada bagian Standardized Solutions hanya terdapat standarisasi nilai estimasi variabel laten. Sedangkan Completely Standardized Solutions menampilkan baik standarisasi variabel laten maupun variabel manifest. Perintah Standardized Solutions dan Completely Standardized Solutions akan menghasilkan matriks-matriks berikut :
• Matriks LAMBDA-Y menghubungkan variabel laten endogen dengan variabel-variabel manifestnya.
• Matriks LAMBDA-X menginformasikan mengenai estimasi parameter yang
menghubungkan variabel laten eksogen dengan variabel-variabel manifestnya.
• Matriks BETA menunjukkan hubungan antara sesama variabel laten endogen.
• Matriks GAMMA menunjukkan pengaruh antara variabel laten eksogen terhadap variabel laten endogen.
• Correlation Matrix of ETA and KSI, yaitu matriks korelasi antara variabel-variabel laten yang dianalisis.
• Matriks PSI menunjukkan error model struktural dimana error tersebut telah distandarisasi.
• Regression Matrix ETA on KSI (Standardized) menunjukkan pengaruh variabel laten eksogen terhadap variabel laten endogen.
• Matriks THETA-EPS (hanya terdapat dalam Completely Standardized Solutions)
3.7.4.6 Effect Decomposition
Effect decomposition merupakan salah satu output dalam LISREL yang menampilkan estimasi pengaruh langsung, tidak langsung, dan pengaruh total antara satu variabel dengan variabel lainnya. Komposisi pengaruh variabel eksogen terhadap variabel endogen tersebut terdiri dari total pengaruh langsung dan pengaruh tidak langsung. Pengaruh tidak langsung diperoleh dari perkalian antara estimasi unstandardized antara variabel-variabel perantara (intervening). Sedangkan pengaruh total (total effects) diperoleh melalui penjumlahan pengaruh tidak langsung dan pengaruh langsung antara suatu variabel terhadap variabel lainnya. Perintah effect decomposition diperoleh dengan menuliskan perintah Options : EF.
Total effect dan indirect effect terdiri dari beberapa matriks yang terbagi dalam empat bagian berikut :
• Total Effects of KSI on ETA dan Indirect Effects of KSI on ETA, menginformasikan mengenai bagaimana pengaruh antara variabel laten eksogen (ξ/KSI) terhadap variabel laten endogen (η
/
ETA), baik pengaruh tidak langsung maupun pengaruh total.• Total Effects of ETA on ETA, menggambarkan total pengaruh variabel laten endogen terhadap variabel laten endogen lainnya.
• Total Effects of ETA on Y dan Indirect Effects of ETA on Y, menjelaskan pengaruh variabel laten endogen terhadap variabel-variabel manifestnya (Y).
• Total Effects of KSI on Y, menginformasikan pengaruh variabel laten eksogen terhadap variabel-variabel manifest dari variabel laten endogen.
3.7.4.7 Residual Analysis
Analisis Residual merupakan salah satu output LISREL yang dihasilkan dengan menambahkan perintah ‘Options: RS’. Residual Analysis menampilkan Fitted Residual Matrix yang merupakan hasil perbandingan antara Fitted Covariance Matrix dengan Sample Covariance Matrix.
Fitted Residual = Covariance Matrix – Fitted Covariance Matrix
Apabila Fitted Residual bernilai positif, maka disebut Underfitting. Yang berarti model penelitian yang diajukan merendahkan nilai kovarians matriks aktual (berdasarkan data). Demikian pula dengan Fitted Residual yang bernilai negatif disebut Overfitting, karena kovarians matriks sesungguhnya lebih tinggi daripada fitted covariance matrix.
Standardized Residuals menunjukkan nilai residual yang tidak dipengaruhi oleh bedanya pengukuran variabel manifest lainnya. Standardized Residuals dapat diinterpretasikan dengan penyimpangan normal standarnya (z-score) dimana nilai absolut yang lebih besar daripada 2,58 dianggap memiliki penyimpangan yang besar. Jumlah nilai Standardized Residuals terbesar dapat menunjukkan apakah model penelitian me-underestimate atau me-overestimate kovarians antara variabel manifest pada data empiris. Apabila jumlah Largest Negative Standardized Residuals lebih banyak daripada Largest Positif Standardized Residuals, maka dapat dikatakan bahwa model me-overestimate kovarians antara variabel manifest pada data empiris, begitu pula sebaliknya.
Stem-Leaf Residual Plot seperti yang ditampilkan berikut merupakan output yang menunjukkan nilai residual individual. Dikatakan stem-leaf residual plots karena nilai-nilai pada sebelah kiri garis vertikal (|) disebut stem, sedangkan yang terdapat pada sebelah
kanan garis vertikal disebut leaf, yang merupakan digit kedua nilai residual. (Ghozali dan Fuad, 2005, p330) -10|4 - 8|2 - 6|96 - 4|96654218642 - 2|98663186652210 - 0|998765533111109988750000000000000000 0|11345789900023345567999 2|0335699056 4|378816 6|1779145 8|12384 10|016 12| 14| 16|5
Jika model adalah fit, maka stem-leaf plots akan memiliki residual yang akan mengelompok secara simetris sekitar nilai nol, dimana nilai residual paling banyak terdapat pada tengah distribusi dan akan semakin sedikit pada bagian bawah dan atas. Kelebihan residual pada bagian bawah stem-leaf plots seperti contoh tersebut berarti bahwa kovarians secara sistematis dinilai rendah (underestimated) oleh suatu model. Apabila kelebihan residual pada bagian atas berarti kovarians secara sistematis dinilai tinggi (overestimated) oleh suatu model.
Untuk mengatasi adanya underestimated tersebut, model seharusnya dimodifikasi dengan menambahkan jumlah path (dengan membebaskan parameter). Sebaliknya, residual negatif berarti bahwa model menilai lebih (overestimated) kovarians matriks pada data empiris yang dimiliki. Sehingga modifikasi pada keadaan tersebut seharusnya dilakukan dengan menghilangkan path yang berhubungan dengan kovarians tersebut.
Sumber : Ghozali dan Fuad (2005, p336)
Gambar 3.3 disebut Normal Probability (Q-plots), yang menunjukkan terpenuhi tidaknya asumsi normalitas dan juga kemungkinan model fit. Suatu model dapat dikatakan memiliki kemungkinan fit terbaik apabila garis residual sejajar dengan garis diagonal. Sedangkan model memiliki kemungkinan acceptable fit apabila garis residual memiliki kecuraman lebih besar daripada 45 derajat. Sedangkan model yang paling buruk adalah model yang residualnya terletak pada garis horizontal.
Jika pola residual tersebut tidak linear, maka terdapat indikasi bahwa data menyimpang dari asumsi normalitas, linearitas, atau bahkan adanya specification errors, yaitu model yang tidak sempurna yang timbul akibat dimasukkan variabel atau indikator yang tidak relevan dan/atau dihilangkannya variabel atau indikator yang relevan.
3.7.5 Penilaian Model Fit
Salah satu tujuan utama Structural Equation Modeling adalah untuk menentukan apakah model plausible (masuk akal) atau fit, yaitu apakah model adalah benar berdasarkan suatu data yang dimiliki. Suatu model dapat dikatakan fit apabila kovarians matriks suatu model (implied covariance matrix) adalah sama dengan kovarians matriks data (observed). Sample covariance matrix adalah matriks kovarians yang diperoleh melalui observasi (data), sedangkan implied (fitted) covariance matrix adalah matriks kovarians yang diperoleh berdasarkan model. Analisis Structural Equation Modeling menentukan apakah estimasi nilai-nilai parameter memiliki perbedaan antara sample covariance matrix dengan implied (fitted) covariance matrix. Idealnya elemen perbedaan-perbedaan tersebut yang disebut sebagai matriks residual adalah nol. Suatu model penelitian dikatakan baik apabila memiliki model fit yang baik pula. (Ghozali dan Fuad, 2005, p25-29)
Dalam Structural Equation Modeling, penilaian model fit tidak sejelas pendekatan statistik berdasarkan pengukuran variabel tanpa error. Karena belum ada tes signifikansi statistik tunggal dalam mengidentifikasi model yang benar dalam mewakili data sampel. Oleh karena itu diperlukan beberapa kriteria untuk penilaian model fit.
Secara keseluruhan Goodness of Fit dari suatu model dapat dinilai berdasarkan beberapa ukuran fit berikut (Ghozali dan Fuad, 2005, p29-34) :
1. Chi-Square dan Probabilitas
Nilai Chi-Square menunjukkan adanya penyimpangan antara sample covariance matrix dan model (fitted) covariance matrix. Namun nilai Chi-Square hanya akan valid apabila asumsi normalitas data terpenuhi dan ukuran sampel adalah besar. Nilai Chi-Square sebesar 0 menunjukkan bahwa model memiliki fit yang sempurna (perfect fit). P adalah probabilitas untuk memperoleh penyimpangan (deviasi) besar sebagaimana ditunjukkan oleh nilai Chi-Square. Nilai probabilitas Chi-Square yang tidak signifikan (lebih daripada 0,05) adalah yang diharapkan, karena menunjukkan bahwa data empiris yang diperoleh sesuai dengan model yang telah dibangun berdasarkan Structural Equation Modeling.
LISREL dapat menghasilkan empat jenis Chi-Square beserta probabilitasnya yang berbeda, yaitu Minimum Fit Function Chi-Square (C1), Normal Theory Weighted Least Square (C2), Satorra-Bentler Scaled Chi-Square (C3), dan Chi Square Corrected for Non-normality (C4). Estimasi model berdasarkan asumsi normalitas yang terpenuhi akan menghasilkan dua jenis Chi-Square, yaitu C1 dan C2. Sedangkan jika asumsi model diestimasi dengan data yang tidak normal, dengan memberikan asymptotic covarince matrix, akan menghasilkan empat jenis Chi-Square tersebut.
2. Goodness of Fit Indices
Goodness of Fit Indices (GFI) merupakan suatu ukuran mengenai ketepatan model dalam menghasilkan observed matriks kovarians. Nilai GFI harus berkisar antara 0 dan 1. Model yang memiliki nilai GFI negatif adalah model yang paling buruk dari seluruh model yang ada. Nilai GFI yang lebih besar daripada 0,9 menunjukkan fit suatu model yang baik.
3. Adjusted Goodness of Fit Index
Adjusted Goodness of Fit Index (AGFI) adalah sama seperti GFI, tetapi telah menyesuaikan pengaruh degrees of freedom pada suatu model. Model yang fit adalah model yang memiliki nilai AGFI 0,9. Ukuran yang hampir sama dengan GFI dan AGFI adalah Parsimony Goodness of Fit Index (PGFI) yang diperkenalkan oleh Mulaik et al (1989) yang juga telah menyesuaikan adanya dampak dari degrees of freedom dan kompleksitas model. Model yang baik apabila memiliki nilai PGFI jauh lebih besar daripada 0,6.
4. Root Mean Square Error of Approximation
Root Mean Square Error of Approximation (RMSEA) yang diperkenalkan oleh Steiger dan Lind pada tahun 1980 ini merupakan indikator model fit yang paling informatif. RMSEA mengukur penyimpangan nilai parameter pada suatu model dengan matriks kovarians populasinya. Suatu model dikatakan fit apabila nilai RMSEA kurang daripada 0,05, dan nilai RMSEA yang berkisar antara 0,08-0,1 mengindikasikan model memiliki fit yang cukup (mediocre), sedangkan RMSEA yang lebih besar daripada 0,1 mengindikasikan model fit yang sangat jelek. Steiger (1990) dan MacCallum (1996) menganjurkan penggunaan confidence intervals untuk menilai ketetapan estimasi RMSEA. LISREL 8.54 menyajikan 90% interval atas nilai RMSEA yang diharapkan, sehingga RMSEA memiliki ketepatan yang baik. Joreskog (1996)
menganjurkan bahwa nilai P-value for test of close fit (RMSEA < 0,05) haruslah lebih besar daripada 0,5.
5. Expected Cross Validation Index
Menurut Byrne (1998), Expected Cross Validation Index (ECVI) mengukur penyimpangan antara fitted (model) covariance matrix pada sampel yang dianalisis dan kovarians matriks yang akan diperoleh pada sampel lain tetapi yang memiliki ukuran sampel yang sama besar. Model yang memiliki ECVI terendah berarti model tersebut sangat potensial untuk direplikasi. Nilai ECVI model yang lebih rendah daripada ECVI yang diperoleh pada saturated model dan independence model mengindikasikan bahwa model adalah fit.
6. Akaike’s Information Criterion (AIC) dan CAIC
AIC dan CAIC digunakan untuk menilai mengenai masalah parsimony dalam penilaian model fit. Meskipun nilai AIC dan CAIC tidak sensitif terhadap kompleksitas model, namun AIC lebih sensitif dan dipengaruhi oleh banyaknya jumlah sampel yang digunakan. AIC dan CAIC membandingkan dua atau lebih model, dimana nilai AIC dan CAIC yang lebih kecil dari AIC dan CAIC model saturated maupun independence berarti memiliki model fit yang lebih baik.
7. Fit Index
Normed Fit Index (NFI) yang ditemukan oleh Bentler dan Bonens (1980), merupakan salah satu alternatif untuk menentukan model fit. Namun karena NFI memiliki tendensi untuk merendahkan fit pada sampel yang kecil, Bentler (1990) merevisi indeks ini dengan nama Comparative Fit Index (CFI). Nilai NFI dan CFI berkisar antara 0 dan 1. Suatu model dikatakan fit apabila nilai NFI dan CFI lebih besar daripada 0,9. Sedangkan Non-Normed Fit Index (NNFI) digunakan untuk mengatasi permasalahan yang timbul akibat kompleksitas model. Tetapi karena NNFI adalah
“non-normed”, nilainya dapat lebih besar daripada 1, sehingga susah untuk diinterpretasikan. Meskipun ketiga indeks tersebut dihasilkan pada output LISREL, tetapi Bentler (1990) menganjurkan penggunaan CFI sebagai ukuran fit. Incremental Fit Index (IFI), yang diperkenalkan oleh Bollen (1990) digunakan untuk mengatasi masalah parsimony dan ukuran sampel, dimana hal tersebut berhubungan dengan NFI. Menurut Byrne (1998), batas cut-off IFI adalah 0,9. Sedangkan Relative Fit Index (RFI) digunakan untuk mengukur fit dimana nilainya adalah 0 sampai 1. Nilai yang lebih besar menunjukkan adanya superior fit.
3.7.6 Modifikasi Model
Modifikasi model biasanya dilakukan pada dua keadaan berikut (Ghozali dan Fuad, 2005, p327-328) :
1. Meningkatkan model fit pada model penelitian yang telah memiliki fit yang bagus. Masalahnya adalah modifikasi pada model yang telah menunjukkan fit yang baik belum tentu akan memberikan hasil penelitian yang sama apabila digunakan pada sampel yang berbeda. Sehingga opsi ini seharusnya dihindari.
2. Modifikasi model yang dilakukan untuk meningkatkan model fit yang sebelumnya sangat buruk. Modifikasi model sendiri hanya berlaku untuk internal specification errors, yaitu dihilangkannya (atau dimasukkannya) parameter-parameter yang penting (tidak relevan) pada variabel-variabel dalam suatu model.
Output Modification Indices yang terdiri dari Modification Indices, Expected Change, dan Completely Standardized Expected Change for THETA-DELTA-EPS adalah output mengenai modifikasi dan nilai estimasi yang akan diperoleh apabila menambah parameter yang berhubungan dengan error indikator-indikator dari variabel laten endogen. Untuk menampilkan Modification Indices, cukup menambahkan perintah ‘Options: MI’
Output THETA-DELTA-EPS adalah output mengenai hubungan antara error indikator variabel laten eksogen (DELTA) dengan error indikator variabel endogen (EPS). Output ini menjelaskan penurunan chi-square yang diharapkan dengan mengkovarianskan error indikator endogen terhadap error indikator eksogen dan estimasi parameter yang diharapkan atas penambahan parameter tersebut. Output THETA-DELTA memberikan informasi yang hampir sama dengan THETA-DELTA-EPS, hanya saja yang dikovarianskan adalah hubungan antara error variance indikator-indikator variabel laten eksogen.
3.8 Rancangan Uji Hipotesis
Hipotesis merupakan suatu proposisi atau anggapan yang mungkin benar, dan sering digunakan sebagai dasar pembuatan keputusan atau pemecahan persoalan ataupun untuk dasar penelitian lebih lanjut. (J. Supranto 2001, p124)
Dari penelitian ini hipotesis yang telah disusun adalah sebagai berikut :
H0 : Tidak ada pengaruh antara Kualitas Pelayanan Jasa, Sikap Konsumen, dan Loyalitas Pelanggan.
H1 : Kualitas Pelayanan Jasa berpengaruh positif terhadap Sikap Konsumen. H2 : Kualitas Pelayanan Jasa berpengaruh positif terhadap Loyalitas Pelanggan.
H3 : Kualitas Pelayanan Jasa berpengaruh positif terhadap Loyalitas Pelanggan melalui Sikap Konsumen.
Pengujian hipotesis dilakukan dengan menilai hasil analisis menggunakan program LISREL, yaitu pada output Structural Equations. Batas untuk menerima atau menolak hubungan adalah 1,979 (mutlak) yang diperoleh dari nilai t tabel dengan tingkat signifikansi 5% pada df = 125 (karena jumlah sampel 110). Apabila nilai t yang terdapat pada setiap nilai estimasi parameter dalam output Structural Equations terletak antara -1,979 dan 1,979
maka hipotesis yang menyatakan adanya pengaruh harus ditolak, sedangkan apabila nilai t lebih besar daripada 1,979 atau lebih kecil dari -1,979 maka hipotesis yang menyatakan adanya pengaruh harus diterima. Oleh karena itu rancangan uji hipotesis dapat dinyatakan sebagai berikut :
Terima H0 : Jika hubungan yang dinyatakan tidak signifikan, dimana nilai t antara -1,979 dan 1,979.
Terima H1 : Jika pengaruh Kualitas Pelayanan Jasa terhadap Sikap Konsumen menunjukkan hubungan yang signifikan dan positif, dimana nilai t lebih besar dari 1,979.
Terima H2 : Jika pengaruh Kualitas Pelayanan Jasa terhadap Loyalitas Pelanggan menunjukkan hubungan yang signifikan dan positif, dimana nilai t lebih besar dari 1,979.
Terima H3 : Jika pengaruh Kualitas Pelayanan Jasa terhadap Loyalitas Pelanggan melalui Sikap Konsumen menunjukkan hubungan yang signifikan dan positif, dimana nilai t lebih besar dari 1,979.
3.9 Rancangan Implikasi Hasil Penelitian
Hasil penelitian Structural Equation Modeling dengan menggunakan program LISREL akan menghasilkan output yang sangat berguna untuk mengetahui hubungan antara kualitas pelayanan jasa, sikap konsumen, dan loyalitas pelanggan di Kantor Notaris dan PPAT Buntario Tigris. Dengan begitu mereka dapat mengetahui apakah kualitas pelayanan jasa mereka memberikan pengaruh yang positif terhadap sikap konsumen dan loyalitas pelanggan mereka.
Hasil penelitian juga akan memberikan informasi mengenai indikator manakah yang memiliki kontribusi terbesar dalam merepresentasikan kualitas pelayanan jasa, sikap konsumen, dan loyalitas pelanggan mereka. Dengan begitu Kantor Notaris dan PPAT Buntario Tigris dapat lebih berfokus kepada indikator tersebut dalam melakukan pengambilan keputusan strategik untuk meningkatkan kualitas pelayanan jasa, sikap konsumen dan loyalitas pelanggan mereka.