243
PREDIKSI USIA ABALONE DENGAN MENGGUNAKAN
ALGORITMA K-MEANS DAN DECISION TREE (SLIQ)
Luthfia Rahmi
Prodi Ilmu Komputer FMIPA ULM
Jl. A. Yani Km 36 Banjarbaru, Kalimantan selatan
Email:[email protected]
Abstract
Prediction is one method of classification for the determination of a decision if the data
is own group, and decision tree algorithms is very good to make a prediction data. The
objective of this research is to find the class prediction by developing a classification method
that uses an algorithm SLIQ (supervision Learning Quest) and K-Means as the initial stage of
group formation. In this research the data amounted to 3677 the data as training data for the
calculation of the K-Means and SLIQ and 500 data to be testing for testing predictions. The
final conclusion when calculating K-Means the data yielded three clusters and presentations
on testing predictions with SLIQ which 157 (31.4%) at the age of short, 284 (56.8%) at the age
of medium and 59 (11.8%) at the age of long. We conducted trials back, with 3677 the data on
the predicted results to determine the similarity hasi Means and results of similarity
K-Means and SLIQ obtain an accuracy of 99.83%, and is an excellent accuracy.
Keyword : K-Means, SLIQ, Unsupervised, Klasification, Prediction
Abstrak
Prediksi adalah salah satu metode dalam klasifikasi untuk penentuan sebuah
keputusan jika data tersebut sudah memiliki kelompok, dan decision tree adalah algoritma
yang sangat baik untuk melakukan sebuah prediksi data. Pada penelitian ini bertujuan untuk
menemukan sebuah prediksi kelas dengan mengembangkan metode klasifikasi yaitu
menggunakan algortima SLIQ (Supervised Learning In Quest) dan K-Means sebagai fase awal
pembentukan kelompok. Pada penelitian ini data berjumlah 3677 data sebagai data training
untuk perhitungan K-Means dan SLIQ dan 500 data sebagai data testing untuk pengujian
prediksi. Kesimpulan akhir saat perhitungan K-Means data menghasilkan 3 cluster dan
presentasi pada pengujian prediksi dengan SLIQ yaitu 157(31,4%) pada usia singkat, 284
(56,8%) pada usia sedang dan 59 (11,8%) pada usia lama. Saat dilakukan uji coba kembali
dengan data 3677 pada hasil prediksi untuk mengetahui kesamaan hasi K-Means dan hasil
kesamaan K-Means dan SLIQ memperoleh akurasi 99,83%, dan merupakan akurasi yang
sangat baik.
Kata kunci : K-Means, SLIQ, Unsupervised, Klasifikasi, Prediksi
1. PENDAHULUAN
Teknik klasifikasi yaitu memprediksi kelas pada setiap data dan dataset dipartisi menjadi dua yaitu, sebagai pelatihan dan pengujian. Dataset pelatihan akan dilatih untuk menjadi pembentukan kelas. Kebenaran dari kelas tersebut dapat diuji
dengan menggunakan dataset pengujian. Salah satu algoritma terbaik dalam klasifikasi yaitu Desicion Tree karena memberikan akurasi yang baik pada saat data yang digunakan sangat banyak.
Salah satu algoritma decision tree yaitu SLIQ (Supervised Learning In Quest), SLIQ
244
mampu menangani untuk dataset yang besar tanpa kehilangan tingkat akurasinya. SLIQ juga mempunyai kelebihan yaitu, bisa digunakan untuk perhitungan data yang bertipe numerik dan katergorikal. SLIQ menggunakan teknik presorting dalam tahap
decision tree yang sangat berpengaruh
menemukan perpecahan yang baik dalam simpul . SLIQ merupakan algoritma yang digunakan untuk supervised dataset atau data yang memiliki pembelajaran, sehinggan saat
dataset yang digunakan belum memiliki
pembelajaran atau unsupervised dataset maka harus melakukan pembelajaran terlebih dahulu dengan mengelompokkan data untuk melakukan fase awal sehingga bisa dilakukan klasifikasi dengan menggunakan SLIQ.
Clustering digunakan untuk melakukan
pengelompokan data, salah satu algortima dalam Clustering yaitu K-Means. K-Means adalah salah satu algoritma clustering yang paling umum digunakan yang dikembangkan oleh Mac Ratu pada tahun 1967 [1]. Algoritma K-Means bisa digunakan untuk
clustering data tanpa adanya data pembelajaran tetapi, K-Means sangat
sensitive terhadap pemilihan centroid awal,
dengan kata lain, centroid yang berbeda dapat menghasilkan perbedaan yang signifikan dari hasil clustering. Karena K-Means dapat digunakan tanpa data pembelajaran sehingga untuk penggunaan tahap pertama pembuatan decision tree pada
dataset unsupervised menggunakan
clustering untuk melakukan pengelompokan
sebagai fase awal pembentukan dan akan dilakukan klasifikasi untuk tahap selanjutnya. Oleh karena itu peneliti ini ingin menggabungkan dua metode untuk melakukan klasifikasi untuk prediksi terhadap dataset yang unsupervised dengan menggunakan K-Means sebagai fase awal melakukan pengelompokan data dan akan dilanjutkan tahap Klaisifikasi dengan menggunakan SLIQ.
Dataset abalone didapat dalam website http://archive.ics.uci.edu perhitungan akan di implementasikan untuk dataset
unsupervised, dan data yang digunakan yaitu
data abalone, Abalone sendiri adalah salah satu jenis kekarangan yang hidup diperairan pantai, dan termasuk salah satu komoditas perikanan yang langka dan memiliki nilai ekonomi yang sangat tinggi. Seekor abalone mampu bertahan hidup 10 hingga 20 tahun ,
karena usianya yang relatif lebih panjang inilah maka abalone memiliki harga yang tinggi. abalone mempunyai siklus pertumbuhan musiman akibat pengaruh peroses reproduksi dan ini merupakan salah satu faktor untuk mempengaruhi pengukuran fisik abalone., Oleh karena itu dari dataset yang didapat tersebut, peneliti akan menentukan prediksi usia abalone denga menggunakan K-Means sebagai tahap awal pembentukan kelas dan SLIQ sebagai algoritma klasifikasi untuk perhitungan prediksi.
2. METODE PENELITIAN
Metode yang digunakan pada proses perhitungan data mining ini yaitu : penentuan dataset, preposes data,
Pemprosesan data dan analisis hasil [2]. Dataset yang digunakan untuk penelitian ini yaitu Dataset Abalone yang telah di dapat dari website http://archive.ics.uci.edu dengan jumlah data 4177 yang akan dibuat data pembelajarannya yaitu 3677 record dan 500 record menjadi data baru yang akan di uji klasifikasinya. Setelah didapat dataset tersebut akan masuk pada tahap preproses data yaitu, untuk mempersiapkan data dengan melakukan pembersihan pada data. Setelah selesai tahap preproses data, dataset dapat melakukan perhitungan dengan
K-Means untuk mendapatkan jumlah kelasnya,
dengan menguji beberapa jumlah kelasnya nanti dari dua sampai tujuh dengan menggunakan 3677 record dan perhitungan dengan SLIQ dari data pembelajaran sebanyak 3677 tersebut setelah perhitungan berhasil kemudian mencoba memasukkan data baru dengan jumlah 500 record.
2.1. Penentuan dataset
Data yang digunakan dalam penelitian ini adalah dengan menggunakan data
abalone yang diambil pada website
http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone/, yang dikeluarkan dari Divisi Sumber Daya Kelautan, Depertemen Industri Primer dan Perikanan, Tasmania daerah Australia dengan nomor 48 pada ISSN 1034-3288. Dengan dataset ini akan memprediksi usia abalone dari pengukuran fisik[3]. Usia abalone ditentukan dengan memotong cangkang melalui kerucutan, pewarnaan, dan menghitung ring melalui mikroskop.
245
Tabel 1. Nama dan satuan atribut dataset
Nama Tipe data Satuan
Jenis Kelamin Nominal
Panjang Kontinu mm
Diameter Kontinu mm
Tinggi Kontinu mm
Berat
Keseluruhan Kontinu gram
Berat Daging Kontinu gram Berat Jeroan Kontinu gram
Berat
Cangkang Kontinu gram
Cincin ineteger mm
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest)
untuk Memprediksi Unsupervised
Dataset.2016
2.2. Preproses data
Dilakukan pemeriksaan terhadap data set apakah sudah sesuai untuk dilanjutkan ke dalam proses pembentukan model. Dataset yang digunakan dari website http://archive.ics.uci.edu/ adalah kumpulan dataset yang digunakan hanya untuk penelitian ini memiliki data yang sudah siap digunakan karena sudah di bersihkan dan di seleksi dari data yang nois sehingga satu atribut yang tidak digunakan untuk proses perhitungan dataset nanti yaitu atribut jenis kelamin, karena atribut jenis kelamin tidak berpengaruh dalam perhitungan, oleh karenanya hanya delapan atribut yang bisa digunakan dalam perhitungan nantinya yaitu atribut panjang abalone, diameter abalone, tinggi abalone, berat abalone, berat daging abalone, berat jeroan abalone, berat luaran abalone dan cincin abalone.
2.3. Pemprosesan data
Data Mining yang dibuat untuk perhitungan K-Means dan SLIQ dengan data yang digunakan menggunakan dataset
unsupervised sehingga tahapan perhitungan
di sini adalah:
a. Perhitungan K-Means
Tahapan dalam perhitungan K-Means adalah :
1) Penentuan jumlah K
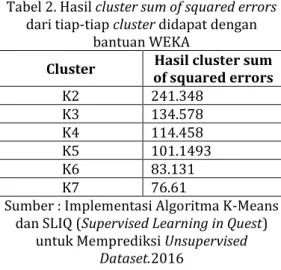
Telah dilakukan beberapa pengujian untuk penentuan centroid awal dengan menggunakan WEKA untuk melihat beberapa hasil SSE (Sum of Square Error) dari masing-masing nilai cluster dengan menggunakan jenis K yang berbeda-beda.
jumlah cluster yang dilihat dari K=2 sampai dengan K=7 .
Tabel 2. Hasil cluster sum of squared errors dari tiap-tiap cluster didapat dengan
bantuan WEKA
Cluster of squared errors Hasil cluster sum
K2 241.348 K3 134.578 K4 114.458 K5 101.1493 K6 83.131 K7 76.61
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest)
untuk Memprediksi Unsupervised
Dataset.2016
Kemudian menggunakan metode elbow untuk melihat nilai K yang paling baik untuk digunakan dengan cara melihat persentase hasil perbandingan antara jumlah
cluster yang akan membentuk siku pada
suatu titik [4]. Setelah dilihat akan ada beberapa nilai K yang mengalami penurunan paling besar dan selanjutnya hasil dari nilai K akan turun secara perlahan sampai hasil dari nilai K tersebut stabil.
Gambar 1. Grafik cluster sum of squared
errors dari tiap-tiap cluster
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest)
untuk Memprediksi Unsupervised
Dataset.2016
Dari hasil SSE yang didapat sebelumnya jika dijadikan sebuah grafik maka K=2 akan mengalami penurunan secara drastis ke K=3 dan K=3 ke K=4 mengalami penurunan scara perlahan karena nilai pada SSE tidak terlalu jauh sehingga pada K=3 ke K=4 akan membentuk seperti siku yang menjadikan seperti sebuah titik pada ujung siku, sehingga K yang baik menut metode elbow adalah K=3. 2) Penentuan pusat awal cluster
Penggunaan jumlah cluster pada dataset yang digunakan adalah 3 cluster, karena
246
sebelumnya sudah dilakukan perhitungan terhadap jumlah cluster yang baik, untuk pusat cluster dibuat secara statis. berikut merupakan nilai centroid untuk cluster yang digunakan.
3) Hasil pusat cluster akhir
Sebelumnya telah melakukan
perhitungan dengan jarak pusat cluster dan melakukan pengelompokan data dengan perbandingan dan dipilih jarak terdekat antara data dengan pusat cluster. Setelah diketahui anggota tiap-tiap cluster kemudian pusat cluster baru dihitung berdasarkan data anggota tiap-tiap cluster sesuai dengan rumus pusat anggota cluster. Kemudian pada perhitungan selanjutnya berhenti pada iterasi ke 4 karena pengelompokan data ke 4 = kelompok data ke 3.
4) Pemberian label hasil pengelompokan Dilihat dari nilai centroid akhir karakteristik bisa terlihat dengan variasi rentang angka antara kecil ke sedang dan sedang ke besar. Yang lebih terlihat jelas dalam rentangan angka pada cincinan karena
cluster yang satu pasti tidak sama dengan cluster yang lain.
ukuran fisik abalone pada cluster 1 memiliki ukuran yang lebih kecil dibanding dengan ukuran fisik abalone pada cluster 2 dan 3, yang sangat terlihat jelas pada ukuran cincinnya jika abalone memiliki cincinan +1,5 mm dia memiliki usia yang lebih dari setahun. karena semakin besar fisik abalone dia mampu bertahan hidup lebih lama. Tabel 6. Evaluasi pelabelan masing-masing
cluster
Cluster Label / Class Instance
1 Usia yang singkat 1.250 (34%) 2 Usia yang sedang 1.793
(48,76%)
3 Usia yang lama 634
(17,24%) Sumber : Implementasi Algoritma K-Means
dan SLIQ (Supervised Learning in Quest) untuk Memprediksi Unsupervised
Dataset.2016
Tabel 3. Penentuan Nilai Centroid awal
Atri
but Panjang Diame-ter Ting- gi Berat Keseluruha n
Berat
Daging Berat Jeroan Berat Cangkang Cincin
C1 0,25 0,2 0,05 0,4 0,1 0,05 0,12 4
C2 0,45 0,4 0,1 0,83 0,4 0,2 0,24 10
C3 0,64 0,5 0,18 1,66 0,8 0,4 0,4 16
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest) untuk Memprediksi Unsupervised Dataset.2016
Tabel 4. Hasil pusat centroid akhir
Atribut Panjan
g Diame-ter Ting- gi Berat Keseluruh an
Berat
Daging Berat Jeroan Berat Cangkang Cincin
C1 0.374 0.2857 0.096 0.3329 0.1468 0.0736 0.0939 6
C2 0.516 0.4060 0.140 0.7545 0.3057 0.1687 0.2285 10
C3 0.584 0.4649 0.165 1.1171 0.4210 0.2326 0.3568 16
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest) untuk Memprediksi Unsupervised Dataset.2016
Tabel 5. Karakteristik pada setiap pusat cluster
Atribut Kelompok 1 Kelompok 2 Kelompok 3
Panjang (ukuran paling kecil) 0,3740 (ukuran sedang) 0,5168 (ukuran cukup 0,5843 besar)
247
Diameter (ukuran paling kecil) 0,2857 (ukuran sedang) 0,4060 (ukuran cukup 0,245 – 0,65 besar) Tinggi (ukuran paling kecil) 0,0962 (ukuran sedang) 0,1404 (ukuran paling 0,1658
besar) Berat Keseluruhan (ukuran paling kecil) 0,3329 (ukuran sedang) 0,7545 (ukuran besar) 1.1171
Berat Daging (ukuran paling kecil) 0,1468 (ukuran sedang) 0,3057 (ukuran besar) 0,4210 Berat Jeroan (ukuran paling kecil) 0,0736 (ukuran sedang) 0,1687 (ukuran besar) 0,2326 Berat Luaran /
Cangkang (ukuran paling kecil) 0,0939 (ukuran sedang) 0,2285 (ukuran besar) 0,3568 Cincinan (ukuran kecil) 6,5714 (ukuran sedang) 10,7564 (ukuran besar) 16,7273 Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest) untuk
Memprediksi Unsupervised Dataset.2016
Tabel 7. Contoh presorting untuk atribut panjang, diameter dan tinggi
Panjang Daftar Indeks kelas Diameter Indeks Daftar
Kelas Tinggi Daftar Indeks Kelas 0.33 5 0.255 5 0.08 5 0.35 2 0.265 2 0.08 19 0.355 17 0.28 17 0.085 17 0.365 19 0.295 19 0.09 2 0.425 6 0.3 6 0.095 1 0.43 12 0.32 20 0.095 6 0.44 4 0.34 18 0.1 15 0.44 18 0.35 12 0.1 18 0.45 20 0.355 15 0.1 20 0.455 1 0.365 1 0.11 12 0.47 15 0.365 4 0.125 4 0.475 9 0.37 9 0.125 8 0.49 13 0.38 11 0.125 9 0.5 16 0.38 13 0.13 16 0.525 11 0.4 16 0.135 3 0.53 3 0.405 14 0.135 13 0.53 7 0.415 7 0.14 11 0.535 14 0.42 3 0.145 14 0.545 8 0.425 8 0.15 7 0.55 10 0.44 10 0.15 10 … … … … … … 0,815 1430 0,65 1430 1,13 1280
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest) untuk Memprediksi Unsupervised Dataset.2016
248
b. Perhitungan SLIQ 1) Proses Presorting
Proses presorting yaitu data akan di urutkan dari nilai yang paling besar ke nilai yang paling kecil, karena tahap tersebut strategi agar hasil algortima akan menghasilkan akurasi yang tinggi meskipun data tersebut berjumlah banyak[5]. Sebelumnya data hasil perhitungan dengan K-Means akan dijadikan data training untuk perhitungan algortima SLIQ.
2) Proses titik split
Adapun prosedur dari penentuan titik split sendiri pertama yaitu menghitung gini index yaitu kriteria yang digunakan untuk menentukan titik pemecahan terbaik dari sebuah atribut, dengan rumus :
𝑔𝑖𝑛𝑖(𝑇) = 1 − ∑ 𝑃𝑗2………. (1)
Kemudian untuk menentukan titik split tersebut menggunakan rumus
𝑔𝑖𝑛𝑖 𝑠𝑝𝑙𝑖𝑡 (𝑇) = 𝑛1
𝑛 × 𝑔𝑖𝑛𝑖(𝑇1) + 𝑛2
𝑛 × 𝑔𝑖𝑛𝑖(𝑇2)
………… (2)
Sebagai contoh pada salah satu atribut panjang untuk menentukan split terbaik maka disini akan melakukan pemotongan dengan 3 titik potong yaitu panjang ≤ 0.3, panjang ≤ 0.4, dan panjang ≤ 0.5 dan hasil index dan split yang di dapat :
Tabel 8. Titik split pada atribut panjang
Panjang Gini Index Gini Split
≤ 0.3 0 0.570213 0.606609 ≤ 0.4 0.375 0.511053 0.554017 ≤ 0.5 0.534979 0.518454 0.499055
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest)
untuk Memprediksi Unsupervised
Dataset.2016
Dan menjadi split terbaik yaitu jika perhitungannya memiliki hasil nilai split terendah maka yang memenuhi syarat untuk percabangan pohon yaitu jika panjang ≤ 0.4, jika nilai atribut memenuhi syarat maka masuk cabang yang sebelah kiri dan jika nilai atribut tidak memenuhi syarat atau panjangnya > 0.4 maka masuk cabang sebelah kanan.
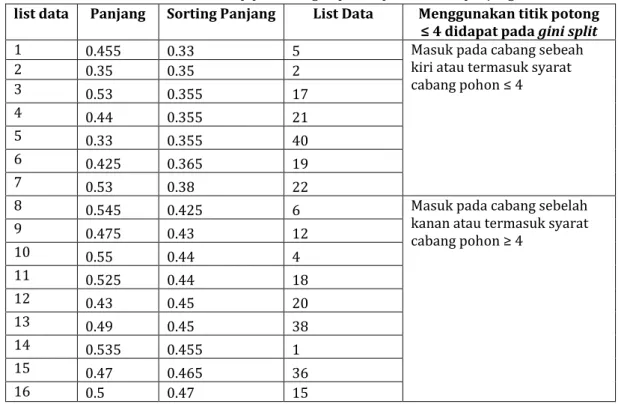
Tabel 9. Tahap percabangan pohon pada atribut panjang
list data Panjang Sorting Panjang List Data Menggunakan titik potong ≤ 4 didapat pada gini split
1 0.455 0.33 5 Masuk pada cabang sebeah
kiri atau termasuk syarat cabang pohon ≤ 4 2 0.35 0.35 2 3 0.53 0.355 17 4 0.44 0.355 21 5 0.33 0.355 40 6 0.425 0.365 19 7 0.53 0.38 22
8 0.545 0.425 6 Masuk pada cabang sebelah
kanan atau termasuk syarat cabang pohon ≥ 4 9 0.475 0.43 12 10 0.55 0.44 4 11 0.525 0.44 18 12 0.43 0.45 20 13 0.49 0.45 38 14 0.535 0.455 1 15 0.47 0.465 36 16 0.5 0.47 15
249
17 0.355 0.475 9
18 0.45 0.525 11
3) Mengulangi langkah tersebut sampai pembentukan pohon bisa dikatakan selesai jika gini dan split menghasilkan angka 0. Banyaknya variasi data setiap atribut sehingga pembentukan pohon akan semakin panjang
3. HASIL DAN PEMBAHASAN
Pada penelitian ini peneliti menggunakan dataset yang didapat berupa
dataset Abalone (salah satu jenis kekerangan
yang hidup diperairan pantai) yang didapat pada salah satu website penyedia dataset dan
dataset tersebut sudah bisa digunakan
langsung untuk perhitungan data mining karena data sudah dibersihkan dan di seleksi dari data yang noise. Jumlah data tersebut adalah 4177 record dan tidak mempunyai kelas, sehingga data sebanyak tadi dilakukan pembagian untuk 3677 record digunakan untuk clustering dengan K-Means dan 500
record sisa data digunakan untuk data uji
pada klasifikasi dengan SLIQ (Supervised
Learning In Quest).
Pada penelitian ini data yang disajikan langsung bisa dilanjutkan untuk proses data mining, yaitu langsung pada proses perhitungan K-Means, 3677 data yang telah di clustering mempunyai karakteristik yang sama pada kelompok pertama, kedua dan ketiga. Pada data yang digunakan lebih susah dibuat karakteristik karena banyaknya variasi setiap data, dan mempunyai atribut yang banyak. Karakteristik bisa terlihat dengan variasi rentang angka antara kecil ke sedang dan sedang ke besar. Yang lebih terlihat jelas dalam rentangan angka pada cincinan karena cluster yang satu pasti tidak sama dengan cluster yang lain.
Berdasarkan hasil clustering pada masing-masing atribut pada kelompok pertama memiliki nilai ukuran fisik paling kecil, sangan tampak pada range nilai pada cincinan atau yang bisa disebut dengan
lingkarannya yang memiliki ukuran yang lebih kecil dibanding dengan kelompok kedua dan ketiga. Karena usia abalone dapat ditentukan dengan ukuran fisiknya dimana semakin besar ukuran pada abalone maka dia memungkinkan untuk bisa bertahan hidup lebih lama, oleh karena itu pada kelompok pertama dapat diberikan label kelas “usia singkat”. Kelompok kedua memiliki ukuran fisik rentang yang sedang, atau nilai yang tidak terlalu kecil dan tidak terlalu besar. Nilai pada cincinan juga memiliki angka yang berada ditengah-tengah kelompok pertama dan kelompok ketiga, sehingga pada kelompok kedua dapat diberikan label kelas “usia sedang”. Terakhir pada kelompok ketiga memiliki ukuran fisik dengan rentangan yang lebih besar dibanding dengan kelompok sebelumnya, sehingga pada kelompok ketiga dapat diberikan label kelas “usia lama”.
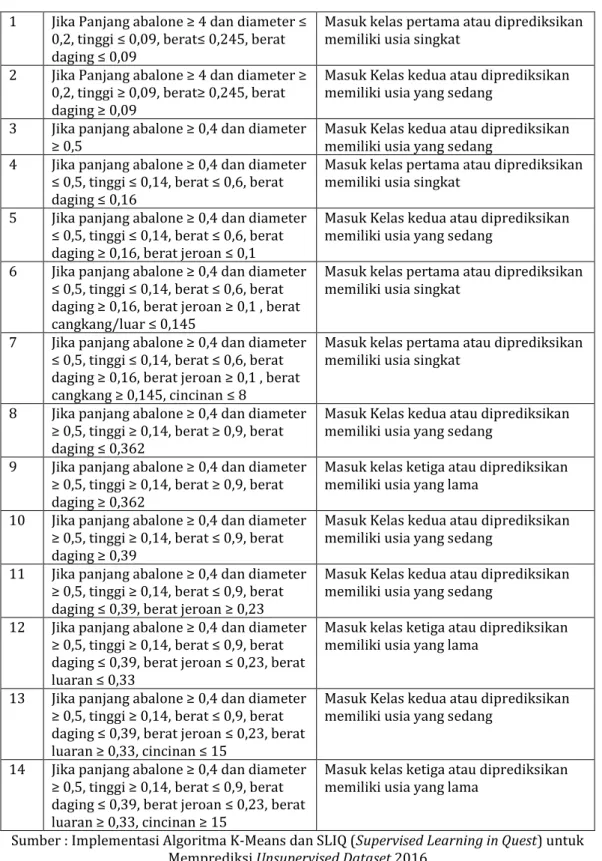
Tahapan selanjutnya yaitu perhitungan klasifikasi dengan SLIQ (Supervised Learning In Quest) menggunakan 500 data uji. Data training yang sudah mempunyai kelas dilakukan pengurutan setiap atributnya dari angka yang terkecil ke terbesar, kemudian dilakukan pembentukan pohon setiap atribut satu persatu dengan gini dan split. Pembentukan pohon bisa dikatakan selesai jika gini dan split menghasilkan angka 0. Banyaknya variasi data setiap atribut sehingga pembentukan pohon akan semakin panjang, oleh karena itu pada tabel 24 akan disajikan pola prediksi untuk melihat hasil pembentukan cabang-cabang pohon.
Saat dilakukan pembandingan hasil kelas pada perhitungan algoritma SLIQ dengan data yang sama digunakan dalam K-Means tetapi belum dilakukan perhitungan yaitu menggunakan 3677 data dan peneliti melihat hasil tersebut, akhirnya hasil yang didapat yaitu data yang dimasukkan dalam algoritma SLIQ mampu memliki kesamaan kelas, tetapi ada beberapa pertukaraan kelas pada data sehingga akan memiliki akurasi tidak 100 %, atau ada pengurangan kesamaan pada data K-Means dan data K-Means dan SLIQ.
Tabel 10. Pola prediksi pada hasil percabangan pohon
250
1 Jika Panjang abalone ≥ 4 dan diameter ≤ 0,2, tinggi ≤ 0,09, berat≤ 0,245, berat daging ≤ 0,09
Masuk kelas pertama atau diprediksikan memiliki usia singkat
2 Jika Panjang abalone ≥ 4 dan diameter ≥ 0,2, tinggi ≥ 0,09, berat≥ 0,245, berat daging ≥ 0,09
Masuk Kelas kedua atau diprediksikan memiliki usia yang sedang
3 Jika panjang abalone ≥ 0,4 dan diameter
≥ 0,5 Masuk Kelas kedua atau diprediksikan memiliki usia yang sedang 4 Jika panjang abalone ≥ 0,4 dan diameter
≤ 0,5, tinggi ≤ 0,14, berat ≤ 0,6, berat daging ≤ 0,16
Masuk kelas pertama atau diprediksikan memiliki usia singkat
5 Jika panjang abalone ≥ 0,4 dan diameter ≤ 0,5, tinggi ≤ 0,14, berat ≤ 0,6, berat daging ≥ 0,16, berat jeroan ≤ 0,1
Masuk Kelas kedua atau diprediksikan memiliki usia yang sedang
6 Jika panjang abalone ≥ 0,4 dan diameter ≤ 0,5, tinggi ≤ 0,14, berat ≤ 0,6, berat daging ≥ 0,16, berat jeroan ≥ 0,1 , berat cangkang/luar ≤ 0,145
Masuk kelas pertama atau diprediksikan memiliki usia singkat
7 Jika panjang abalone ≥ 0,4 dan diameter ≤ 0,5, tinggi ≤ 0,14, berat ≤ 0,6, berat daging ≥ 0,16, berat jeroan ≥ 0,1 , berat cangkang ≥ 0,145, cincinan ≤ 8
Masuk kelas pertama atau diprediksikan memiliki usia singkat
8 Jika panjang abalone ≥ 0,4 dan diameter ≥ 0,5, tinggi ≥ 0,14, berat ≥ 0,9, berat daging ≤ 0,362
Masuk Kelas kedua atau diprediksikan memiliki usia yang sedang
9 Jika panjang abalone ≥ 0,4 dan diameter ≥ 0,5, tinggi ≥ 0,14, berat ≥ 0,9, berat daging ≥ 0,362
Masuk kelas ketiga atau diprediksikan memiliki usia yang lama
10 Jika panjang abalone ≥ 0,4 dan diameter ≥ 0,5, tinggi ≥ 0,14, berat ≤ 0,9, berat daging ≥ 0,39
Masuk Kelas kedua atau diprediksikan memiliki usia yang sedang
11 Jika panjang abalone ≥ 0,4 dan diameter ≥ 0,5, tinggi ≥ 0,14, berat ≤ 0,9, berat daging ≤ 0,39, berat jeroan ≥ 0,23
Masuk Kelas kedua atau diprediksikan memiliki usia yang sedang
12 Jika panjang abalone ≥ 0,4 dan diameter ≥ 0,5, tinggi ≥ 0,14, berat ≤ 0,9, berat daging ≤ 0,39, berat jeroan ≤ 0,23, berat luaran ≤ 0,33
Masuk kelas ketiga atau diprediksikan memiliki usia yang lama
13 Jika panjang abalone ≥ 0,4 dan diameter ≥ 0,5, tinggi ≥ 0,14, berat ≤ 0,9, berat daging ≤ 0,39, berat jeroan ≤ 0,23, berat luaran ≥ 0,33, cincinan ≤ 15
Masuk Kelas kedua atau diprediksikan memiliki usia yang sedang
14 Jika panjang abalone ≥ 0,4 dan diameter ≥ 0,5, tinggi ≥ 0,14, berat ≤ 0,9, berat daging ≤ 0,39, berat jeroan ≤ 0,23, berat luaran ≥ 0,33, cincinan ≥ 15
Masuk kelas ketiga atau diprediksikan memiliki usia yang lama
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest) untuk Memprediksi Unsupervised Dataset.2016
Tabel 11. Jumlah akurasi pada hasil perhitungan kembali 3677 data untuk membandingkan hasil kelas pada SLIQ dengan hasil kelas pada K-Means
K-Means Kelas 1 Perhitungan K-means dan SLIQ Kelas 2 Kelas 3 Total
Kelas 1 1250 0 0 1250
251
Kelas 3 0 1 633 634
Total 1252 1789 636 3677
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest) untuk Memprediksi Unsupervised Dataset.2016
Gambar 2. Pola Pembentukan Pohon pada Algoritma SLIQ
Sumber : Implementasi Algoritma K-Means dan SLIQ (Supervised Learning in Quest) untuk Memprediksi Unsupervised Dataset.2016
Untuk menghitung akurasi menggunakan rumus :
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝐽𝑢𝑚𝑙𝑎ℎ 𝑘𝑙𝑎𝑠𝑖𝑓𝑖𝑘𝑎𝑠𝑖 𝑏𝑒𝑛𝑎𝑟
𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎 𝑢𝑗𝑖 × 100%
…(3)
Oleh karena itu didapat dengah hasil akurasi sebagai berikut :
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =1250 + 1788 + 633
3677 × 100%
= 99,83%
Sehingga hasil akhir untuk kesamaan pada K-Means dan Perhitungan K-K-Means dan SLIQ adalah 99,83 %, disebabkan adanya beberapa data yang lepas dari kelasnya.
4. KESIMPULAN
Dari penelitian yang sudah dilakukan, maka kesimpulan yang dapat diambil adalah sebagai berikut:
a. Jumlah pengelompokan data pada algoritma k-means adalah 3 kelompok, dari 3677 data 7,24% pada kelompok ke 1; 48,76% pada kelompok ke 2 dan 34 % pada kelompok ke 3. Dari 3 kelompok yang didapat, ditentukan pelabelan yaitu: Kelompok pertama memiliki usia yang singkat, kelompok kedua memiliki usia yang sedang, dan kelompok ketiga meiliki usia yang lama
b. Persentase hasil klasifikasi dengan algoritma SLIQ (Supervised Learning In
Quest) dengan menggunakan jumlah
data uji 500 yaitu, 157(31,4%) data masuk kedalam klasifikai usia yang singkat, 284 (56,8%) masuk kedalam klasifikasi usia yang sedang dan 59 (11,8%) masuk kedalam klasifikasi usia yang lama.
c. Saat dilakukan pembandingan hasil kelas pada perhitungan algoritma SLIQ dengan data yang sama digunakan
252
dalam K-Means tetapi belum dilakukan perhitungan yaitu menggunakan 3677 data menghasilkan akurasi 99,83%
DAFTAR PUSTAKA
[1] Alnazi, Khaled W dan Wesam M. Ashour, “A Novel Clustering Algorithm Using K-Means (CUK).
International Journal of Computer Applicationr”, (0975 – 8887)
Volume 25-No.1, 2011.
[2] Shaufiah, “Klasifikasi dalam Data Mining Menggunakan Algoritma SLIQ”, Teknik Informatika, Fakultas Teknik Informatika, Universitas Telkom, 2005.
[3] K. Henning, “Abalone (Haliotis tuberculata) hemocyanin type 1
(HtH1)”. Institute of Zoology,
Johannes Gutenberg University of Mainz, Germany, 2014.
[4] Merliana, Ni Putu Eka, “ Analisa Penentuan Jumlah Cluster Terbaik pada Metode K-Means Clustering”. Program Studi Magister Teknik Informatika, Fakultas Teknik Industri, Universitas Atma Jaya, Prosiding Seminar Nasional Multi Disiplin Ilmu & Call For Papers Unisbank (Sendi_U), ISBN: 978-979-3649-81-8, 2015.
[5] Prasad, Narasimha, et. al “CC-SLIQ: Performance Enhancement with 2k Split Points in SLIQ Decision Tree Algorithm”, IAENG International Journal of Computer Science, 41:3, IJCS_41_3_02, 2014.
[6] Rahmi, Luthfia, “Implementasi
Algortima K-Means dan Sliq
(Supervised Learning In Quest) untuk Memprediksi Unsupervised Dataset”, Skripsi Program Studi Ilmu Komputer, Universitas Lambung Mangkurat, Banjarbaru, 2017.