Penerapan Data Mining Dalam Mengelompokkan Data Impor
Tembaga Menurut Negara Asal Menggunakan
Algoritma K-Means
Lise Pujiastuti1, Mochamad Wahyudi2 , , Solikhun3
1
Program Studi S1 Sistem Informasi, STMIK Antar Bangsa, Tangerang, Indonesia
2
Program Studi S1 Sistem Informasi, Universitas Bina Sarana Informatika, Jakarta, Indonesia
3*
Program Studi D3 Manajemen Informatika, AMIK Tunas Bangsa, Pematangsiantar, Indonesia
1
[email protected],[email protected], 3* [email protected]
Abstract
Import is an activity of transportation of goods or commodities from country to country. The import process is generally the activity of entering goods or commodities from other countries into the country. Copper is one of the most important metals and plays a major role in human history and is among the first mined metals. Copper is a good conductor of heat and electricity. In addition this element has a very fast corrosion. Pure copper is smooth and soft, with a reddish orange surface. Copper import activity from year to year continues to increase. There needs to be a deep presentation regarding copper imports. In this study, the authors use the data mining technique k-means clustering method to classify copper import data according to the original destination. The results of this study are a copper import data cluster. Copper import clusters consist of two clusters namely high and low clusters. High clusters are from Japan and China, while low clusters consist of South Korea, Thailand, the Philippines, Australia, Malaysia, Singapore, Myanmar and Chile.
Keywords: Data Mining, K-Means, Copper
1. Introduction
Perdagangan Internasional memiliki berbagai manfaat nyata yang terdiri dari ekspor dan impor yaitu dapat berupa kenaikan pendapatan, kenaikan devisa, transfer modal, dan makin luasnya kesempatan kerja apabila dilihat dari kegiatan ekspor. Sedangkan dari sudut impor memberikan lebih banyak alternatif barang yang dapat dikonsumsi dan terpenuhinya barang-barang yang belum bisa dibuat di dalam negeri[1].
Impor adalah sebuah kegiatan transportasi barang atau komoditas dari suatu
negara ke negara. Proses impor umumnya adalah kegiatan memasukan barang atau
komoditas dari negara lain ke dalam negeri. Kegiatan impor memiliki manfaat
yang besar yaitu mendapatkan bahan baku yang tidak di dapatkan di negara
importir tersebut
. Kegiatan impor tembaga dari tahun ke tahun mengalami peningkatan. Perlu adanya kajian yang mendalam mengenai data impor tembaga dari negara asal. Pemerintah membutuhkan sebuah informasi yang akurat mengenai pengelompokkan data impor tembaga dari negara asal. Ada 10 negara pengimpor tembaga ke negara Indonesia. Negara pengimpor tembaga ke Indonesia adalah Jepag, Cina, Korea Selatan, Tahiland, Philipihina, Asutralia, Malaysia, Singapura, Myanmar dan Chili. Penelitian ini menggunakan teknik data mining metode k-means Clustering. Data di kelompokkan ke dalam 2 cluster, yaitu cluster tinggi dan cluster rendah. Data diambil dari badan pusat statistik Indonesia yaitu data impor tembaga menurut negara asala dari tahun 2010 sampai tahun 2019. Hasil penilitian ini nantinya menjadi masukan kepada pemerintah untuk menentukan kebijakan selanjutnya mengenai kegiatan impor tembaga ke Indonesia.2. Metode Penelitian
2.1. Data Mining
Data mining merupakan proses iteratif dan interaktif untuk menemukan pola -pola atau model baru yang shahih (sempurna), bermanfaat dan dapat dimengerti dalam suatu database yang sangat besar (massive databases). Data mining berisi pencarian trend atau pola yang diinginkan dalam database besar untuk membantu pengambilan keputusan di waktu yang akan datang[2][3].
2.2. K-Means
Algoritma K-Means merupakan algoritma klasterisasi yang mengelompokkan data berdasarkan titik pusat klaster (centroid) terdekat dengan data. Tujuan dari K-Means adalah pengelompokkan data dengan memaksimalkan kemiripan data dalam satu klaster dan meminimalkan kemiripan data antar klaster. Ukuran kemiripan yang digunakan dalam klaster adalah fungsi jarak. Sehingga pemaksimalan kemiripan data didapatkan berdasarkan jarak terpendek antara data terhadap titik centroid[4][5].
2.3. Clustering
Menurut Baskoro cluster atau klusterisasi adalah salah satu alat bantu pada data mining yang bertujuan mengelompokkan objek-objek ke dalam cluster - cluster. Cluster
adalah metode penganalisaan data, yang sering dimasukkan sebagai salah satu metode
Data mining, yang tujuannya adalah untuk mengelompokkan data dengan karakteristik yang sama ke suatu wilayah yang sama dan data dengan karakteristik yang berbeda ke wilayah yang lain. Cluster berbeda dari klasifikasi karena cluster tidak memiliki variabel target. Tujuan cluster bukan untuk mengklasifikasikan, memperkirakan, atau memprediksi nilai variabel taget [6]. Metode K-Meansdapat digunakan untuk menjelaskan algoritma dalam penentuan suatu objek kedalam klaster tertentu berdasarkan rataan terdekat. Dalam prosedur pembentukan K-Means Cluster terdapat langkah-langkah yang dapat
dilakukan, antara lain:
1. Tentukan banyaknya klaster (k) yang akan dibentuk. 2. Bangkitkan k centroidawal (rata-rata setiap klaster).
3. Hitung jarak antara setiap objek dengan setiap centroid dan masukan objek tersebut ke dalam klaster yang sesuai berdasarkan jarak terdekat.
4. Tentukan centroid dari klaster yang baru.
5. Ulangi langkah 3 dan 4 sampai tidak ada lagi pemindahan objek antarklaster[7].
2.4. Rapid Miner
Rapid Miner merupakan perangkat lunak yang dibuat oleh Dr. Markus Hofman dari Institute of Technologi Blanchardstown dan Ralf Klinkenberg dari
rapid-i.com dengan tampilan GUI (Graphical User Interface) sehingga memudahkan pengguna dalam menggunakan perangkat lunak ini. Perangkat lunak ini bersifat open source dan dibuat dengan menggunakan program Java di bawah lisensi GNU Public Licence dan Rapid Miner dapat dijalankan di sistem operasi manapun. Dengan menggunakan Rapid Miner, tidak dibutuhkan kemampuan koding khusus, karena semua fasilits sudah disediakan. Rapid Miner dikhususkan untuk penggunaan data mining. Model yang disediakan juga cukup banyak dan lengkap, seperti Model Bayesian, Modelling, Tree Induction, Neural Network dan lain-lain [8].
3. Hasil Dan Pembahasan
Untuk mendapatkan hasil dari penelitian yang dilakukan, berikut uraian perhitungan manual proses algoritma k-means clustering pada data impor tembaga
menurut negara asal dengan menggunakan sebuah konsep data mining.
Pengolahan
Data Manual:
Tabel 1. Data Impor Tembaga Menurut Negara Asal
Negara Asal 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 Berat Bersih : 000 Kg Jepang 56 227.0 39 468.5 55 112.4 57 725.3 55 886.6 44 059.6 42 399.3 35 637.2 48 759.2 40 292.3 Cina 25 632.0 16 352.1 34 349.5 26 936.6 36 744.9 34 958.6 36 505.9 66 126.6 67 161.0 68 428.9 Korea Selatan 12 340.5 9 258.7 9 002.1 16 035.8 14 815.7 17 448.0 11 785.8 13 265.1 8 164.0 9 722.5 Thailand 10 319.7 13 590.1 8 383.8 9 867.2 10 312.9 10 613.8 2 795.9 16 229.4 15 458.5 18 427.8 Philipina 6 223.0 3 734.7 2 362.7 6 370.0 2 176.0 11 711.4 4 226.0 23 565.9 14 686.1 17 590.0 Australia 19 729.9 24 910.4 31 924.5 9 882.3 15 899.5 21 032.1 31 953.5 7 396.5 5 077.3 4 084.9 Malaysia 11 332.6 9 929.4 11 461.7 9 896.6 10 725.8 12 128.4 11 069.7 8 804.5 7 408.5 8 952.1 Singapura 9 575.9 25 536.6 14 543.5 11 750.8 8 315.5 12 534.3 11 131.8 9 239.6 6 458.6 5 115.8 Myanmar 0.1 0.0 502.0 1 800.4 6 802.3 20 097.0 14 887.2 8 212.5 9 432.8 8 257.0 Chili 149.7 10 389.0 8 988.1 6 640.4 17 049.8 16 390.5 11 409.8 1 019.4 2 316.8 5 547.3
1.
Menentukan jumlah data yang akan di cluster, dengan sampel data impor
tembaga menurut negara asal utama dari tahun 2010-2019 dengan jumlah
data sebanyak 10 Negara. Berikut yaitu cara mencari nilai rata-rata :
R1 = (56227,0 + 39468,5 + 55112,4 + 57725,3 + 55886,6 + 44059,6 +
44059,6+ 42399,3 + 35637,2 + 48759,2 + 40292,3)/10 = 47556,7
R2 = (25632 + 16352,1 + 34349,5 + 26936,6 + 36744,9 + 34958,6 +
36505,9+66126,6 + 67161 + 68428,9)/10 = 41319,6
R3 = (12340,5 + 9258,7 + 9002,1 + 16035,8 + 14815,7 + 17448 + 11785,8
+13265,1+ 8164 + 9722,5)/10 = 12183,8
Lakukan pencarian rata-rata sampai R10, berikut adalah hasil dari rata-rata
yang telah didapat :
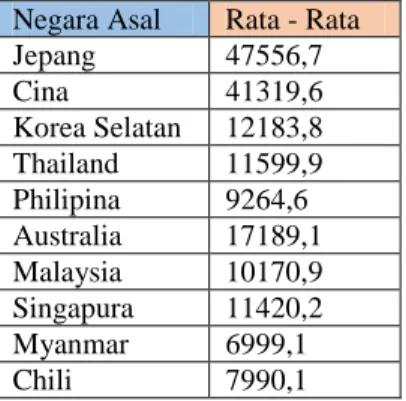
Tabel 2. Data Hasil Nilai Rata-Rata
Negara Asal Rata - Rata
Jepang 47556,7 Cina 41319,6 Korea Selatan 12183,8 Thailand 11599,9 Philipina 9264,6 Australia 17189,1 Malaysia 10170,9 Singapura 11420,2 Myanmar 6999,1 Chili 7990,1
2.
Menentukan nilai k jumlah
cluster
sebanyak 2
cluster
yaitu
cluster
tinggi
dan
cluster
rendah.
3.
Menentukan nilai
centroid
awal yang telah ditentukan secara random,
cluster
tinggi (C1) diperoleh dari nilai maximum pada rata-rata data,
Berikut adalah nilai
centroid
data awal pada iterasi 1:
Tabel 3.
Centroid
Awal Iterasi 1
C1 Maximum 47556,7 C2 Minimum 6999,1
4.
Setelah data niai pusat
cluster
ditentukan, selanjutnya menghitung jarak
setiap data terhadap pusat
cluster
yang dilakukan dengan titik pusan pada
cluster
pertama. Berikut adalah perhitungannya:
D (1.1) =
2= 0
D (1.2) =
2= 6237,1
Perhitungan dilakukan sampai D(1.10).
Selanjutnya perhitunggan pada
cluster
2 rata-rata dengan titik pusat
centroid:
D (2.1) =
2= 40557,6
D (2.1) =
2= 41319,6
Perhitungan dilakukan sampai D (2.10).
Sehingga diperoleh hasil dari perhitungan rata-rata data dengan titik pusat
centroid
setiap
cluster
sebgai berikut:
Tabel 4. Perhitungan
Centroid
Pada Setiap
Cluster (
Iterasi 1)
Negara Asal Rata-Rata C1 C1
Jepang 47556,7 0 40557,6 Cina 41319,6 6237,1 41319,6 Korea Selatan 12183,8 35372,9 12183,8 Thailand 11599,9 35956,8 11599,9 Philipina 9264,6 38292,1 9264,6 Australia 17189,1 30367,6 17189,1 Malaysia 10170,9 37385,8 10170,9 Singapura 11420,2 36136,5 11420,2 Myanmar 6999,1 40557,6 6999,1 Chili 7990,1 39566,6 7990,1
Lalu hitung jarak terdekat dari
cluster
dengan menggunakan Euclidean
Distance, seperti hasil dibawah ini:
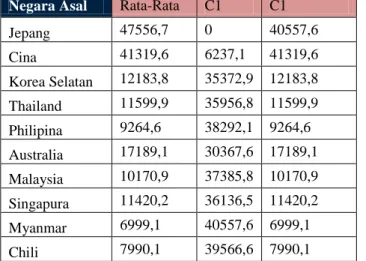
Tabel 5. Jarak Terdekat (Iterasi 1)
Jarak Terdekat Hasil C1 C2
0 C1 1
6237,1 C1 1
12183,8 C2 1
9264,6 C2 1 17189,1 C2 1 10170,9 C2 1 11420,2 C2 1 6999,1 C2 1 7990,1 C2 1
Sehingga hasil dari perhitungan jarak data ke titik pusat
cluster
pada iterasi
1 yaitu:
Tabel 6. Hasil
Cluster
Pada Iterasi 1
Cluster
Hasil
C1
2
C2
8
5.
Selanjutnya lakukan kembali langkah 4 – 5 jika nilai hasil
centroid
dari
iterasi 1 dengan nilai
centroid
selanjutnya bernilai sama ataupun nilai
centroid
sudah optimal dan posisi
cluster
tidak mengalami perubahan lagi
maka proses iterasi berhenti. Akan tetapi jika posisi
cluster
masih
berubah-ubah maka proses iterasi terus berlanjut sampai hasil bernilai
sama.
6.
Menghitung titik pusat terbaru dengan menggunakan hasil dari setiap
cluster
pada iterasi 1. Berikut adalah contoh perhitungan titik pusat
cluster
baru pada iterasi 2:
C1 =
=
44438,15
C2 =
=
12302,2
Sehingga diperoleh hasil nilai
centroid
baru pada iterasi 2 sebagai berikut:
Tabel 7. Nilai
Centroid
Baru(Iterasi 2)
C1 Maximum 44438,15 C2 Minimum 12302,2
Dengan menggunakan langkah – langkah yang sama seperti iterasi 1 sebelumnya
untuk menentukan hasil
cluster
1,
cluster
2 dan jarak terdekat diperoleh hasil
sebagai berikut:
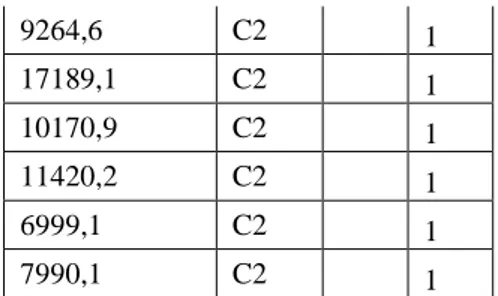
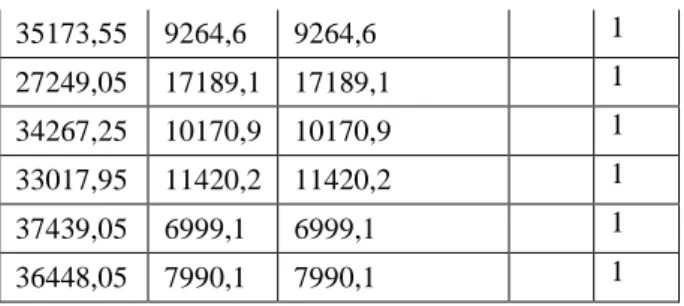
Tabel 8. Hasil
cluster
dan Jarak Terdekat (Iterasi 2)
C1 C1 Jarak Terpendek C1 C2 3118,55 35254,5 3118,55 1 3118,55 41319,6 3118,55 1 32254,35 12183,8 12183,8 1 32838,25 11599,9 11599,9 1
35173,55 9264,6 9264,6 1 27249,05 17189,1 17189,1 1 34267,25 10170,9 10170,9 1 33017,95 11420,2 11420,2 1 37439,05 6999,1 6999,1 1 36448,05 7990,1 7990,1 1
Sehingga diperoleh hasil dari perhitungan jarak data ke titik pusat
cluster
pada
iterasi 2 yaitu bernilai sama dengan hasil dari iterasi 1, maka proses dalam
pencarian data yang telah bernilai sama terhenti pada iterasi 2 berikut:
Tabel 9. Hasil
Cluster
Pada Iterasi 1
Cluster Hasil
C1 2
C2 8
Untuk mendapatkan hasil dari pengelompokan pada tahap selanjutnya dilakukan
proses pengelompokkan dengan menggunakan aplikasi
Rapidminer
. Berikut hasil
dan langkah terakhir dari penggunaan tools
rapidminer
. adapun tampilan pertama
pada
rapidminer
yaitu:
Gambar 1. Tampilan Data View Rapidminer
Tampilan kedua dari
rapidminer
yaitu
Clustering
Model Rapidminer seperti
berikut:
Gambar 2. Tampilan
Clustering
Model Rapidminer
Keterangan:
1.
Jumlah
cluster
0 (Tinggi) berjumlah 2
items
2.
Jumlah
cluster
1 (Rendah) berjumlah 8
items
Selanjutnya tampilan ketiga hasil akhir dari
rapirminer
yaitu tampilan
Plot View
:
Gambar 3. Tampilan Akhir
Rapidminer
4.
Kesimpulan
Hasil akhir dari penelitian yang menggunakan data sebanyak 10 negara ini, dapat disimpulkan bahwa telah didapatkan masing-masing nilai cluster yakni :
1.
Cluster
tinggi (C1) dengan jumlah sebanyak 2 negara yaitu : Jepang dan
China.
2.
Cluster
rendah (C2) dengan jumlah sebanyak 8 negara selain dari
cluster
tinggi, yaitu : Korea Selatan, Tahiland, Philipihina, Asutralia, Malaysia,
Singapura, Myanmar dan Chili.
3. Proses pemberhentian iterasi pada pengujian yang dilakukan pada penelitian ini yaitu terjadi pada iterasi ke 2.
4. Nilai hasil akurasi yang dilakukan dengan perhitungan manual dan dengan aplikasi rapidminer bernilai sama.
Daftar Pustaka
[1] A. J. Nathan and A. Scobell, “How China sees America,” Foreign Aff., vol. 91, no. 5, pp. 1689–1699,
2012.
[2] S. Al Syahdan and A. Sindar, “Data Mining Penjualan Produk Dengan Metode Apriori Pada
Indomaret Galang Kota,” J. Nas. Komputasi dan Teknol. Inf., vol. 1, no. 2, 2018.
[3] Y. Darmi and A. Setiawan, “Penerapan Metode Clustering K-Means Dalam,” Y. Darmi, A. Setiawan,
vol. 12, no. 2, pp. 148–157, 2016.
[4] M. Robani and A. Widodo, “Algoritma K-Means Clustering Untuk Pengelompokan Ayat Al Quran
Pada Terjemahan Bahasa Indonesia,” J. Sist. Inf. Bisnis, vol. 6, no. 2, p. 164, 2016.
[5] R. A. Asroni, “Penerapan Metode K-Means Untuk Clustering Mahasiswa Berdasarkan Nilai
Akademik Dengan Weka Interface Studi Kasus Pada Jurusan Teknik Informatika UMM Magelang,”
Ilm. Semesta Tek., vol. 18, no. 1, pp. 76–82, 2015.
[6] D. Retno and S. Mayangsari, “PENGELOMPOKKAN JUMLAH DESA / KELURAHAN YANG
MEMILIKI DENGAN MENGGUNAKAN METODE K-MEANS CLUSTER,” vol. 3, pp. 370–377, 2019.
[7] F. Ramdhani and A. Hoyyi, “Pengelompokan Provinsi Di Indonesia Berdasarkan Karakteristik
Kesejahteraan Rakyat Menggunakan Metode K-Means Cluster,” J. Gaussian, vol. 4, no. 4, pp. 875–
884, 2015.
[8] S. Kasus, U. Dehasen, S. Haryati, A. Sudarsono, and E. Suryana, “IMPLEMENTASI DATA
MINING UNTUK MEMPREDIKSI MASA STUDI MAHASISWA MENGGUNAKAN