IV. METODOLOGI
Dalam bagian IV ini akan dikemukakan berturut-turut kerangka pemikiran, spesifikasi model, prosedur estimasi, serta data yang digunakan dalam penelitian ini.
4.1. Kerangka Pemikiran
Berdasarkan permasalahan dan tujuan penelitian, studi pustaka dan kerangka teoritis yang telah dikemukakan sebelumnya, maka dibangunlah sebuah kerangka berpikir sebagai berikut :
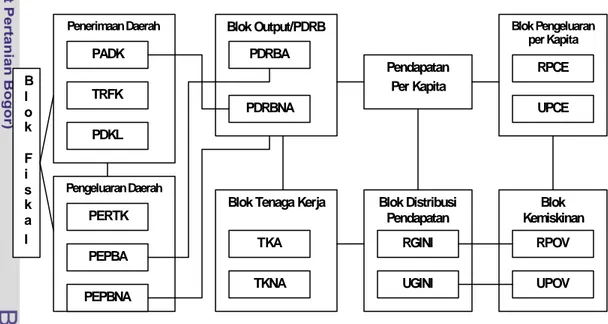
Dalam Gambar 5 ditunjukkan bahwa kemiskinan dengan berbagai indikator-nya akan dipengaruhi oleh perubahan dalam instrumen kebijakan yaitu transfer fiskal (blok fiskal) melalui jalur (channel) blok output (PDRB) dan blok tenaga kerja,
Blok Tenaga Kerja Blok Distribusi Pendapatan Blok Kemiskinan Pendapatan Per Kapita Blok Pengeluaran per Kapita
Gambar 5. Kerangka Pemikiran Penerimaan Daerah Pengeluaran Daerah Blok Output/PDRB PDRBA PDRBNA TKA TKNA RGINI UGINI RPOV UPOV PADK TRFK PDKL PERTK PEPBA PEPBNA RPCE UPCE B l o k F i s k a l
dimana kedua blok tersebut pada gilirannya akan mempengaruhi blok distribusi pendapatan, dan akhirnya blok kemiskinan.
4.2. Spesifikasi Model
Spesifikasi model merupakan tahap yang amat penting, sebab dalam tahap inilah akan dilakukan pengkajian mengenai hubungan diantara berbagai peubah dan diekspresikan ke dalam model kuantitatif, dimana fenomena ekonomi yang bersang-kutan selanjutnya akan diselidiki secara empirik (Koutsoyiannis, 1977). Termasuk di dalamnya adalah melakukan identifikasi peubah-peubah yang akan dimasukkan ke dalam model yang dikembangkan.
Spesifikasi model transfer fiskal dan kemiskinan yang dibangun ini terkait erat dengan tujuan penelitian, tinjauan pustaka dan kerangka teoritis yang telah di-kemukakan sebelumnya. Dalam studi ini digunakan pendekatan ekonometrik dalam model sistem persamaan simultan. Model dipilah ke dalam beberapa blok yaitu fiskal, output, tenaga kerja, pengeluaran per kapita, disrtibusi, dan kemiskinan, terdiri atas 20 persamaan struktural dan 7 persamaan identitas, sebagai berikut :
4.2.1. Blok Fiskal Daerah 4.2.1.1. Penerimaan Daerah
Persamaan untuk sisi penerimaan dari blok fiskal terdiri dari 3 persamaan struktural dan 2 persamaan identitas. Ketiga persamaan struktural tersebut adalah persamaan untuk pajak daerah (PJKK), persamaan untuk retribusi daerah (RETRK), dan persamaan untuk jenis PAD lainnya (PADL), sebagai berikut :
RETRK = b0 + b1*PDRBNA + b2*DDF + u2 ……… (2)
PADL = c0 + c1*PDRBNA + c2*DDF + u3 ……… (3)
Tanda yang diharapkan dari parameter a1, a2, b1, b2, c1, dan c2 > 0.
Sedangkan persamaan identitas untuk sisi penerimaan dari blok fiskal adalah identitas untuk penerimaan asli daerah (PADK), dan identitas untuk total penerimaan daerah kabupaten/kota, sebagai berikut :
PADK = PJKK + RETRK + PADL ……….. (4) TPDK = PADK + BHPJK + BHBPJK + DAUK + PDKL ………. (5) dimana :
PJKK = pajak daerah (Rp jutaan) RETRK = retribusi daerah (Rp jutaan)
PADL = penerimaan asli daerah lain- lainnya (Rp jutaan) PADK = penerimaan asli daerah Kabupaten/Kota (Rp jutaan)
BHPJK = bagi hasil pajak (Rp jutaan)
BHBPJK= bagi hasil bukan pajak (Rp jutaan)) DAUK = Dana Alokasi Umum (Rp jutaan) PDKL = penerimaan daerah lain- lain (Rp jutaan)
TPDK = total penerimaan daerah Kabupaten/Kota (Rp jutaan)
DDF = peubah dummy desentralisasi fiskal (sebelum desentralisasi fiskal diberi angka 0 dan setelah desentralisasi fiskal diberi angka 1) u = faktor pengganggu (disturbance error)
4.2.1.2. Pengeluaran Daerah
Adapun persamaan struktural untuk sisi pengeluaran dari blok fiskal daerah terdiri dari 3 persamaan, yaitu persamaan untuk pengeluaran rutin (PERTK), persa-maan pengeluaran pembangunan sektor pertanian (PEPBA), dan persapersa-maan penge-luaran pembangunan sektor non pertanian (PEPBNA).
PERTK = d0 + d1*PADK + d2*BHPJK + d3*BHBPJK + d4*DAUK
PEPBA = e0 + e1*PADK + e2*BHPJK + e3*BHBPJK + e4*DAUK
+ e5*AREA + e6*DDF + u5 ... (7)
PEPBNA = fo + f1*PADK + f2*BHPJK + f3*BHBPJK + f4*DAUK
+ f5*AREA + f6*DDF + u6 ... (8)
Tanda yang diharapkan dari parameter d1, d2, d3, d4, d5, d6, e1, e2, e3, e4, e4, e5, e6, f1,
f2, f3, f4, f5, dan f6 > 0
Sedangkan persamaan identitas dari sisi pengeluaran terdiri dari 2 persamaan identitas yaitu persamaaan identitas untuk total pengeluaran pembangunan (PEPBK), dan persamaan identitas untuk total pengeluaran daerah (TPEK), sebagai berikut :
PEPBK = PEPBA + PEPBNA ... (9) TPEK = PERTK + PEPBK ... (10) dimana :
PERTK = pengeluaran rutin pemerintah daerah (Rp jutaan)
PEPBA = pengeluaran pembangunan untuk sektor pertanian (Rp jutaan) PEPBNA= penge luaran pembangunan untuk sektor non pertanian (Rp jutaan) PEPBK = pengeluaran pembangunan daerah kabupaten/kota (Rp jutaan) TPEK = total pengeluaran daerah kabupaten/kota (Rp jutaan)
PNS = jumlah pegawai negeri sipil per Provinsi (Rp jutaan) AREA = luas wilayah masing- masing Provinsi (Km2)
4.2.2. Blok Output
Persamaan untuk blok output atau produk domestik regional bruto (PDRB) terdiri dari 2 persamaan struktural yaitu persamaan untuk produk domestik regional bruto sektor pertanian (PDRBA), dan persamaan untuk produk domestik regional bruto sektor non pertanian (PDRBNA); dan 2 persamaan identitas yaitu persamaan identitas PDRB dan pesamaan identitas pendapatan (PDRB) per kapita.
PDRBA = g0 + g1*TKA + g2*PEPBA + g3*DDF + u7 ………... (11)
PDRBNA = h0 + h1*TKNA + h2*PEPBNA + h3*DDF + u8 …….. (12)
PDRB = PDRBA + PDRBNA ………..… (13) YCAP = PDRB/POP ... (14) dimana :
PDRB = produk domestik regional bruto total (Rp jutaan) YCAP = pendapatan (PDRB) per kapita (Rp)
PEPBA = pengeluaran pembangunan untuk sektor pertanian (Rp jutaan) PEPBNA = pengeluaran pembangunan untuk sektor non pertanian (Rp jutaan) Tanda yang diharapkan dari parameter g1, g2, g3, h1, h2, h3 > 0.
4.2.3. Blok Tenaga Kerja
Persamaan untuk blok tenaga kerja terdiri dari 2 persamaan struktural, yaitu persamaan penyerapan tenaga kerja sektor pertanian (TKA), dan persamaan penye-rapan tenaga kerja sektor non pertanian (TKNA), serta 1 persamaan identitas yaitu persamaan identitas penyerapan tenaga kerja total (TKT)
TKA = i0 + i1*PDRBA + i2*UPHA + i3*DDF + u9 ... (15)
TKNA = j0 + j1*PDRBNA + j2*UPHR + j3*DDF + u10 ... (16)
TKT = TKA + TKNA ... (17) dimana :
TKA = penyerapan tenaga kerja di sektor pertanian (Orang) TKNA = penyerapan tenaga kerja sektor di luar pertanian (Orang) TKT = penyerapan tenaga kerja total di daerah (Orang)
PDRBA = produk domestik regional bruto sektor pertanian (Rp jutaan) PDRBNA= produk domestik regional bruto sektor industri (Rp jutaan) UPHA = upah tenaga kerja di sektor pertanian (Rp)
UPHR = upah rata-rata karyawan/tenaga kerja (Rp)
4.2.4. Blok Pengeluaran Per Kapita Rumahtangga
Persamaan untuk pengeluaran per kapita rumahtangga terdiri dari 2 persamaan, yaitu persamaan pengeluaran per kapita rumahtangga perdesaan (RPCE) dan persamaan pengeluaran per kapita rumahtangga perkotaan (UPCE), sebagai berikut :
RPCE = k0+k1*YCAP+k2*AMH +k3*UMPR + k4*INFL+ k5*DDF + u11 (18)
UPCE = l0 +l1*YCAP + l2*AMH + l3*UMPR + l4*INFL + l5*DDF + u12 (19)
dimana :
RPCE = pengeluaran per kapita rumahtangga perdesaan (Rp jutaan/bulan) UPCE = pengeluaran per kapita rumahtangga perkotaan (Rp jutaan/bulan) AMH = angka melek huruf orang dewasa (Persen)
UMPR = upah minimum provinsi riil per bulan (Rp/bulan) INFL = tingkat inflasi (Persen)
Tanda yang diharapkan dari parameter k1, l1, k2, l2, k3, l3, dan k5, l5 > 0, dan k4, k4< 0
4.2.5. Blok Distribusi Pendapatan
Persamaan untuk blok distribusi pendapatan terdiri dari 2 persamaan, yaitu persamaan untuk indeks Gini perdesaan (RGINI) dan persamaan untuk indeks Gini perkotaan (UGINI), sebagai berikut :
RGINI = m0 + m1*YCAP + m2*TKASH + m3*URBP + m4*AMH +
m5*RURUN + m6*DDF + u13 ………. (20)
UGINI = n0 + n1*YCAP + n2*TKASH + n3*URBP + n4*AMH + n5*URBUN
+ n6*DDF + u14 ………..………. (21)
RGINI = indeks Gini untuk daerah perdesaan UGINI = indeks Gini untuk daerah perkotaan URBP = derajat urbanisasi (Persen)
TKASH = pangsa tenaga kerja pertanian terhadap total tenaga kerja (Persen) URBUN = tingkat pengangguran di perkotaan (Persen)
RURUN = tingkat pengangguran di perdesaan (Persen)
Adapun tanda yang diharapkan dari parameter m1, m4, m6, n2, n4, n6 > 0 dan m2, m3,
n1, n3 < 0.
4.2.6. Blok Kemiskinan
Persamaan untuk blok kemiskinan terdiri dari 6 persamaan, yaitu persamaan tingkat kemiskinan perdesaan (RHCI), persamaan indeks kedalaman kemiskinan perdesaan (RPGI), persamaan indeks keparahan kemiskinan perdesaan (RPSI), persa-maan tingkat kemiskinan perkotaan (UHCI), persapersa-maan indeks kedalaman kemis-kinan perkotaan (UPGI), dan persamaan indeks keparahan kemiskemis-kinan perkotaan (UPSI).
RHCI = o0 + o1*RPCE + o2*RGINI + o3*RPL + o4*DDF + u15 ... (22)
RPGI = p0 + p1*RPCE + p2*RGINI + p3*RPL + p4*DDF + u16 ... (23)
RPSI = q0 + q1*RPCE + q2*RGINI + q3*RPL + q4*DDF + u17 ... (24)
UHCI = r0 + r1*UPCE + r2*UGINI + r3*UPL + r4*DFF + u18 ... (25)
UPGI = s0 + s1*UPCE + s2*UGINI + s3*UPL + s4*DDF + u19 ….. (26)
UPSI = t0 + t1*UPCE + t2*UGINI + t3*UPL + t4*DDF + u20 ….. (27)
dimana :
RHCI = tingkat kemiskinan perdesaan (Persen)
RPGI = indeks kedalaman kemiskinan perdesaan (Persen) RPSI = indeks keparahan kemiskinan (Persen)
UPGI = indeks kedalaman kemiskinan perkotaan (Persen) UPSI = indeks keparahan kemiskinan perkotaan (Persen) RPL = garis kemiskinan daerah perdesaan (Rp)
UPL = garis kemiskinan daerah perkotaan (Rp)
Tanda yang diharapkan dari parameter-parameter adalah o1, o4, p1 , p4, q1, q4, r1, r4,
s1, s4,t1 dan t4 < 0, dan o2, o3, p2, p3, q2, q3, r2, r3, s2, s3, t2, dan t3 > 0.
4.3. Prosedur Estimasi Model
Dalam bagian ini diuraikan mengenai masalah identifikasi, metode estimasi, validasi model dan simulasi model kemiskinan regional.
4.3.1. Identifikasi Model
Indentifikasi pada dasarnya persoalan formulasi model (model formulation
problem). Model ekonometrik yang dirumuskan dalam bentuk sistem persamaan
simultan mensyaratkan bahwa jumlah persamaan harus sama dengan jumlah peubah endogen (Koutsoyiannis, 1977). Sebagai suatu aturan (rule), maka adalah tidak mungkin untuk mengestimasi parameter dari sistem yang tidak lengkap (Greene, 2001). Supaya suatu persamaan menjadi teridentifikasi (identified), maka syaratnya harus memenuhi apa yang dinamakan sebagai “order condition of identification”, yaitu bahwa jumlah peubah (endogen dan eksogen) yang tidak termasuk dalam persa-maan tersebut tetapi masuk dalam persapersa-maan lain dalam sistem persapersa-maan simultan harus sama dengan atau lebih besar dari jumlah peubah endogen di dalam model dikurangi satu (Gujarati, 2003), atau dapat diformulasikan sebagai berikut :
(K – M) (G – 1) ... (28) dimana :
M= jumlah peubah endogen dan eksogen yang terdapat dalam persamaan tertentu dalam model, dan
G = jumlah persamaan dalam model, yaitu sama dengan jumlah peubah endogen dalam model.
Berdasarkan “order condition” tersebut, jika (K–M) > (G–1), maka persa-maan dikatakan teridentifikasi secara berlebih (overidentified). Jika (K-M) = (G-1), maka persamaan dikatakan teridentifikasi secara tepat (just or exactly identified); dan jika (K-M) < (G-1), maka persamaan dikatakan tidak teridentifikasi (unidentified). Hanya persamaan yang “exactly” atau “overidentified” saja yang parameternya dapat diestimasi berdasarkan kriteria “order condition” tersebut.
Namun harus diingat bahwa suatu persamaan yang dapat diidentifikasi dengan “order condition” belum tentu parameter-parameternya dapat diestimasi. Agar suatu persamaan betul-betul dapat diidentifikasi, selain “order condition”, masih diperlukan syarat lain yang sekaligus merupakan syarat cukup yaitu “rank condition”, yang menyatakan jika nilai determinant order (G-1) dari suatu persamaan paling sedikit ada satu yang nilainya tidak sama dengan nol, maka persamaan tersebut memenuhi syarat cukup untuk identifikasi (Koutsoyiannis, 1977).
Dalam penelitian ini, model kemiskinan regional yang diformulasikan terdiri dari 27 persamaan atau 27 peubah endogen (G), dan 17 peubah predetermined, sehingga total peubah di dalam model (K) adalah 44 peubah. Berdasarkan hasil identifikasi yang dilakukan diketahui bahwa persamaan yang ada dalam model ini seluruhnya teridentifikasi secara berlebih (overidentified).
Oleh karena identifikasi terhadap model menunjukkan bahwa seluruh per-samaan teridentifikasi secara berlebih (overidentified), maka metode estimasi yang tepat digunakan 2SLS (Two Stages Least Squares). Pyndick dan Rubinfeld(1991) menulis sebagai berikut : “Two-stage least squares (2SLS) provides a very useful
estimation procedure for obtaining the values of structural parameters in over-identified equations”. Dengan kata lain, penerapan metode 2SLS dapat
menghasil-kan estimasi yang konsisten, lebih sederhana, dan lebih mudah, dibandingmenghasil-kan misal-nya dengan metode 3SLS ataupun FILM yang menggunakan lebih bamisal-nyak informasi dan lebih sensitif terhadap kesalahan pengukuran (measurement error) maupun ke-salahan dalam spesifikasi model (Gujarati, 2003).
Dalam rangka untuk mengetahui apakah pengaruh secara bersama-sama dari peubah penjelas itu signifikan atau tidak, maka dilakukan pengujian dengan meng-gunakan uji F. Sedangkan untuk mengetahui signifikan atau tidaknya pengaruh secara sendiri-sendiri dari masing- masing peubah penjelas terhadap peubah endogennya diuji dengan menggunakan uji t pada tingkat signifikansi tertentu, dimana dalam studi ini digunakan á sebesar 0.15, 0.10, 0.05, dan 0.01.
4.3.3. Validasi Model
Validasi model dimaksudkan untuk mengetahui apakah model yang dirumus-kan itu cukup sahih (valid) untuk digunadirumus-kan dalam menganalisis dampak transfer fiskal terhadap kemiskinan di Indonesia. Ada beberapa kriteria statistik yang biasanya digunakan para peneliti dalam menilai sahih atau tidaknya suatu model ekonometrik, diantaranya adalah “root mean square error” (RMSE), “root mean squares percent
error” (RMSPE), dan “Theil Inequality coefficient” (U) (Pyndick dan Rubinfeld,
1991), yang masing- masing dapat dituliskan sebagai berikut :
∑
(
)
− − = T i a t s t Y Y T RMSE 1 2 1 ... (29) 2 1 1∑
− − = T i a t a t s t Y Y Y T RMSPE ... (30) dimana : = s t Y nilai Yt simulasi/prediksi = a t Y nilai aktualT = jumlah observasi di dalam simulasi
∑
∑
∑
− − − + − = T i T i a t s t T i a t s t Y T Y T Y Y T U 1 1 2 2 1 2 ) ( 1 ) ( 1 ) ( 1 ... (31)U dapat didekomposisi menjadi :
a s a s a s a t s t Y Y Y Y N ( ) ( ) (σ σ ) 2(1 ρ)σσ 1
∑
− 2 = − 2+ − 2+ − − − ... (32) dimana : = − − a dan pY
Y
rata-rata untuk nilai prediksi dan nilai aktual=
a
pdanσ
σ standar deviasi untuk nilai prediksi dan nilai actual
=
ρ koefisien korelasi.
∑
− − = − − 2 2 ) ( ) / 1 ( ) ( a t p t a p M Y Y N Y Y U∑
− − = 2 2 ) ( ) / 1 ( ) ( a t p t a p S Y Y N U σ σ∑
− − = 2 ) ( ) / 1 ( ) 1 ( 2 a t p t a p C Y Y N U ρσσdimana UM adalah proporsi bias yang menjelaskan seberapa jauh rata-rata nilai prediksi menyimpang dari rata-rata nilai aktual dan nilai UM yang diharapkan adalah yang mendekati nol; US adalah proporsi varians yang menjelaskan seberapa jauh variasi nilai prediksi menyimpang dari nilai variasi nilai aktual, dan nilai US yang diharapkan adalah yang mendekati nol. Sedangkan UC adalah proporsi kovarians yang mengukur kesalahan peramalan yang tidak sistematis (unsystematic error).
Distribusi ketimpangan (U) yang ideal atas ketiga sumber tersebut adalah UM = US = 0dan UC = 1 (Pyndick dan Rubinfeld,1991). Apabila persamaan (32) dibagi dengan sisi kirinya, maka akan diperoleh 1 = UM + US + UC.
4.3.4. Simulasi Model
Simulasi pada dasarnya merupakan solusi matematis (mathematical solution) dari suatu kumpulan berbagai persamaan secara simultan. Simulasi model dengan demikian menunjuk kepada sekumpulan persamaan (set of equations) tersebut. Simulasi model dilakukan dengan berbagai alasan, misalnya untuk pengujian dan evaluasi model, analisis kebijakan historis dan untuk peramalan (Pindyck dan Rubinfeld, 1991).
Dalam studi, simulasi terutama ditujukan untuk keperluan analisis kebijakan historis (historical policy analysis). Analisis simulasi kebijakan yang dimaksudkan untuk melihat dampak transfer fiskal terhadap kemiskinan di Indonesia. Berbagai skenario kebijakan transfer fiskal dilakukan baik secara parsial maupun kombinasi, dan terdiri atas 7 skenario sebagai berikut :
1. Menaikkan bagian bagi hasil pajak (BHPJK) sebesar 10 persen
2. Menaikkan bagian bagi hasil bukan pajak (BHBPJK) sebesar 10 persen 3. Menaikkan dana alokasi umum (DAUK) sebesar 1.25 persen
4. Menaikkan bagian bagi hasil pajak (BHPJK) dan bagian bagi hasil bukan pajak (BHBPJK) secara serentak dengan besaran masing- masing sebesar 10 persen. 5. Menaikkan bagian bagi hasil pajak (BHPJK) dan DAUK secara serentak dengan
besaran masing- masing 10 persen dan 1.25 persen.
6. Menaikkan bagian bagi hasil bukan pajak (BHBPJK) dan DAUK secara serentak dengan besaran masing- masing 10 persen dan 1.25 persen.
7. Menaikkan bagian bagi hasil pajak (BHPJK), bagian bagi hasil bukan pajak (BHBPJK) dan DAUK secara serentak dengan besaran masing- masing 10 persen, 10 persen dan 1.25 persen.
Adapun ya ng menjadi pertimbangan mengapa menggunakan kenaikan sebesar 10 persen untuk bagi hasil pajak (BHPJK) dan bukan pajak (BHBPJK), bertitik tolak dari pengalaman dimana dalam 4 tahun terakhir ini kedua peubah tersebut mengalami kenaikan rata-rata sebesar 10 persen per tahun. Sedangkan penggunaan angka 1.25 persen untuk dana alokasi umum (DAUK) lebih didasarkan atas perimbangannya dengan jumlah dari bagi hasil pajak dan bukan pajak, dimana rata-rata dana alokasi
umum (DAUK) adalah sekitar 8 kali rata-rata bagi hasil pajak (BHPJK) atau rata-rata bagi hasil bukan pajak (BHBPJK).
4.4. Data dan Sumber
Data yang digunakan dalam estimasi dan simulasi adalah data panel yang merupakan gabungan antara data runtut waktu (time series) tahun 1999-2002 dan data “cross-section” 25 Provinsi di Indonesia. Dalam studi ini, Provinsi DKI Jakarta tidak diikutsertakan karena dianggap memiliki karakteristik yang sangat berbeda dengan Provinsi-provinsi lainnya. Sedangkan beberapa Provinsi yang baru terbentuk seperti Provinsi Maluku Utara, Bangka Belitung, Banten, dan Gorontalo, dalam studi ini datanya masih digabungkan dengan data Provinsi induknya.
Data fiskal yang digunakan merupakan data gabungan (consolidated) dari data fiskal atau APBD Kabupaten/Kota di masing- masing Provinsi, yang mencakup baik data penerimaan maupun pengeluaran kabupaten/kota per Provinsi. Data fiskal Kabupaten/Kota tersebut diperoleh antara lain dari (1) Statistik Keuangan Pemerintah Kabupaten/Kota tahun 1999-2002 yang dikeluarkan Badan Pusat Statistik, dan (2) Nota Keuangan dan RAPBN tahun 1999-2002 yang dikeluarkan Departemen Keuangan.
Data produk domestik regional bruto (PDRB) yang digunakan adalah data produk domestik regional bruto (PDRB) Provinsi menurut lapangan usaha, yang diperoleh dari (1) Produk Domestik Regiona Bruto Provinsi-Provinsi di Indonesia tahun 1999-2002, dan (2) Statistik Indonesia tahun 1999-2002 yang diterbitkan
Badan Pusat Statistik. Data pendapatan per kapita (PDRB) diperoleh dengan mem-bagi PDRB dengan jumlah penduduk dari masing- masing Provinsi.
Data pengeluaran rumahtangga per kapita yang digunakan diperoleh dari sumber-sumber antara lain (1) Indikator Kesejahteraan Rakyat tahun 1999-2002, dan (2) Data dan Informasi Kemiskinan tahun 1999-2002 yang diterbitkan Badan Pusat Statistik. Dari data hasil SUSENAS ini pula kemudian dihitung indeks Gini, tingkat kemiskinan (P0), indeks kedalaman kemiskinan (P1), dan indeks keparahan kemis-kinan (P2), baik untuk daerah perdesaan maupun perkotaan3.
Data penyerapan tenaga kerja per Provinsi yang digunakan diperoleh antara lain dari (1) Keadaan Angkatan Kerja Indonesia Tahun 1999-2002, dan (2) Statistik Indonesia tahun 1999-2002 yang diterbitkan Badan Pusat Satistik Jakarata. Namun perlu dikemukakan bahwa data penyerapan tenaga kerja menurut Provinsi hasil SAKERNAS hanya tersedia untuk tahun 1999 dan 2002. Sedangkan untuk tahun 2000 dan 2001, data penyerapan tenaga kerja hanya disajikan berdasarkan Pulau dan Indonesia. Untuk mendapatkan data penyerapan tenaga kerja menurut Provinsi yang dibutuhkan, penulis terpaksa melakukan estimasi dengan metode alokasi berdasarkan data penyerapan tenaga kerja tahun 1999. Dengan menggunakan data penyerapan tenaga kerja tahun 1999, penulis pertama-tama menghitung pangsa (share) penye-rapan tenaga kerja masing- masing Provinsi terhadap total penyepenye-rapan tenaga kerja secara nasional. Selanjutnya pangsa penyerapan kerja masing- masing Provinsi itu dikalikan dengan jumlah penyerapan tenaga kerja secara nasional untuk tahun dimana data penyerapan tenaga kerja per Provinsi tidak tersedia, misalnya tahun 2000 untuk
3
Perhitungan untuk memperoleh indeks Gini, tingkat kemiskinan (P0), indeks kedalaman kemiskinan (P1), dan indeks keparahan kemiskinan (P2), baik untuk perdesaan maupun perkotaan dilakukan dengan bantuan staff dari SMERU Research Institute Jakarta.
mendapatkan besarnya penyerapan tenaga kerja per Provinsi untuk tahun 2000 yang bersangkutan. Dengan cara yang sama, data penye-rapan tenaga kerja per Provinsi untuk tahun 2001 dapat diperoleh.
Data jumlah pegawai ne geri sipil (PNS), jumlah penduduk, dan luas wilayah per Provinsi diambil antara dari Statistik Indonesia tahun 1999-2002 yang diterbitkan Badan Pusat Statistik.
Data tingkat pengangguran dan upah tenaga kerja per Provinsi diperoleh dari sumber-sumber seperti (1) Keadaan Angkatan Kerja Indonesia tahun 1999-2002, dan (2) Keadaan Pengangguran di Indonesia tahun 1999-2000, dan (3) Statistik Indonesia tahun 1999-2002 yang diterbitkan Badan Pusat Statistik. Data tingkat inflasi per Provinsi diambil dari sumber-sumber antara lain : (1) Laporan Perekonomian Indonesia tahun 1999-2002 yang dikeluarkan oleh Bank Indonesia, dan (2) Statistik Indonesia tahun 1999-2002 yang diterbitkan Badan Pusat Statistik (lihat Lampiran 2).