ANALISIS PERBANDINGAN METODE MACHINE
LEARNING PADA PREDIKSI KHASIAT JAMU
DENI SUSWANTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2016
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Analisis Perbandingan Metode Machine Learning pada Prediksi Khasiat Jamu adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2016
Deni Suswanto
ABSTRAK
DENI SUSWANTO. Analisis Perbandingan Metode Machine Learning Pada Prediksi Khasiat Jamu. Dibimbing oleh WISNU ANANTA KUSUMA dan VEKTOR DEWANTO.
Jamu adalah bahan berupa tumbuhan, bahan hewan, bahan mineral, sediaan sarian (galenik) atau campuran dari bahan tersebut yang secara turun temurun telah digunakan untuk pengobatan. Jamu telah terbukti secara empiris dapat menyembuhkan beberapa penyakit namun belum ada bukti ilmiah yang menjelaskan keterkaitan antar formula dan komposisi bahan-bahan alami dengan khasiatnya sehingga masih menjadi permasalahan yang menarik untuk diteliti. Tujuan penelitian ini adalah menganalisis metode machine learning dalam mengklasifikasi khasiat jamu berdasarkan komposisi tanaman dan mencari metode yang paling cocok untuk klasifikasi khasiat formula jamu. Hasil penelitian ini dibandingkan dengan penelitian sebelumnya yang menggunakan metode Partial
Least Square Discriminant Anaysis (PLS-DA), metode Support Vector Machine
(SVM), dan metode Voting Feature Intervals 5 (VFI5). Metode PLS-DA memiliki akurasi 71.60%, SVM memiliki akurasi 71%, dan metode VFI5 memiliki akurasi 54.91%. Metode machine learning yang paling cocok dengan data jamu adalah
random forest dengan akurasi sebesar 71.77% dengan waktu training yang tidak
jauh berbeda dengan metode machine learning lainnya. Kata kunci: jamu, machine learning, random forest
ABSTRACT
DENI SUSWANTO. Comparison Analysis of Machine Learning Methods for Jamu Efficacy Prediction. Supervised by WISNU ANANTA KUSUMA and VEKTOR DEWANTO.
Jamu is a materials consisting of plant material, animal material, mineral materials, preparation sarian (galenic) or mixtures of these materials that have historically been used for treatment. Jamu has been empirically proven to cure some diseases, However there is no scientific evidence that explains linkages between the formula and the composition of natural ingredients with efficacy that still be an insteresting problem to study. The purpose of this study is to analyze methods of machine learning in classifying the efficacy of jamu based composition of plants and to look for the most suitable method for jamu data. The results of this research was compared to the previous study of using Partial Least Square Discriminant Anaysis (PLS - DA) method, Support Vector Machine (SVM) method, and Voting Feature Intervals 5 (VFI5) method. PLS - DA method has an accuracy of 71.60%, SVM has an accuracy of 71%, and VFI5 method has a 54.91% accuracy. The method of machine learning that be the best fits with the jamu data is random forest with an accuracy of 71.77% with a training time that is comparable to other methods of machine learning.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
ANALISIS PERBANDINGAN METODE MACHINE
LEARNING PADA PREDIKSI KHASIAT JAMU
DENI SUSWANTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2016
Penguji :
Judul Skripsi : Analisis Perbandingan Metode Machine Learning Pada Prediksi Khasiat Jamu
Nama : Deni Suswanto NIM : G64134010
Disetujui oleh
Dr Eng Wisnu Ananta Kusuma, ST MT Pembimbing I
Vektor Dewanto, ST M Eng Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juni 2015 ini ialah mengenai obat tradisional Indonesia jamu, dengan judul Analisis Perbandingan Metode
Machine Learning Pada Prediksi Khasiat Jamu.
Penulis mengucapkan terima kasih dan memberikan penghargaan setinggi-tingginya kepada:
Bapak Dr Eng Wisnu Ananta Kusuma, ST MT dan Bapak Vektor Dewanto, ST MEng selaku pembimbing dan Ibu Husnul Khotimah, SKomp MKom selaku penguji yang telah memberi saran, masukan dan ide-ide dalam penelitian ini. Kepada ayahanda Dedi Iswanto, ibunda Heni Sunarni, serta seluruh keluarga
atas doa, semangat, nasihat, dan dukungannya.
Teman seperjuangan: Ferry, Randa, Ria, Rizky, dan Rozi yang telah memberikan semangat dan masukan.
Teh Syeiva Nurul Desylvia atas segala masukan dan bantuannya dalam pemahaman algoritme dalam penelitian ini serta Novasari Hartini atas dukungan dan semangatnya.
Para pejantan tangguh Bayu, Fahmi, dan Nino atas semangat dan dukungannya. Penjaga Lab Baranangsiang Bapak Dayat dan Bapak Yuda yang membantu
penulis untuk menggunakan komputer lab.
Departemen Ilmu Komputer IPB, staf, dan dosen yang telah banyak membantu selama masa perkuliahan hingga penelitian.
Teman-teman ekstensi angkatan 8 dan angkatan 9 atas segala doa dan dukungannya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2016
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE 3 Data Penelitian 3 Data 5 Pemodelan Algoritme 5 Perhitungan Akurasi 12 Peralatan Penelitian 13
HASIL DAN PEMBAHASAN 14
Hasil 14
Pembahasan 23
SIMPULAN DAN SARAN 23
Simpulan 23
Saran 24
DAFTAR PUSTAKA 24
LAMPIRAN 13
DAFTAR TABEL
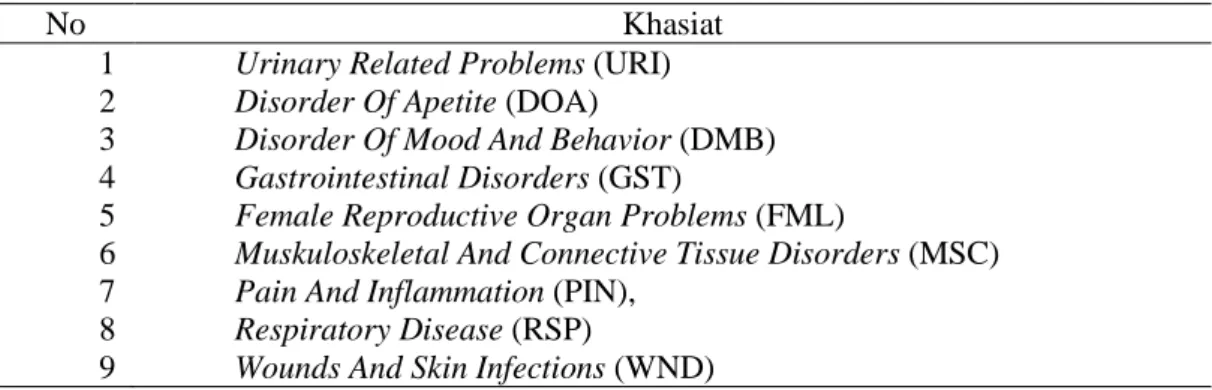
1 Khasiat jamu 5
2 Selang kepercayaan setiap metode machine learning 14 3 Rata-rata waktu training setiap metode machine learning 14 4 Confusion matrix algoritme Random Forest 17 5 Precision dan recall dari confusion matrix algoritme Random Forest 18 6 Confusion matrix algoritme AdaBoost 19 7 Precision dan recall dari confusion matrix algoritme Adaptive
Boosting 19
8 Confusion matrix algoritme Gradient Boost 19 9 Precision dan recall dari confusion matrix algoritme Gradient
Boosting 20
10 Confusion matrix algoritme SVM 20 11 Precision dan recall dari confusion matrix algoritme SVM 21 12 Confusion matrix algoritme KNN 22 13 Precision dan recall dari confusion matrix algoritme KNN 22 14 Hasil rata-rata akurasi, precision, dan recall dari setiap metode 23
DAFTAR GAMBAR
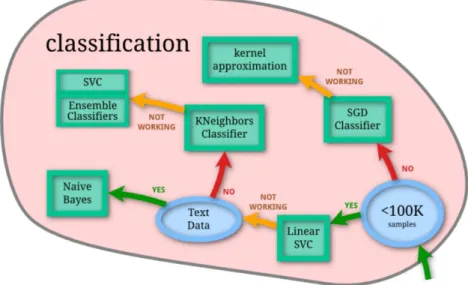
1 Flowchart metode machine learning (Scikit-Learn.org) 3
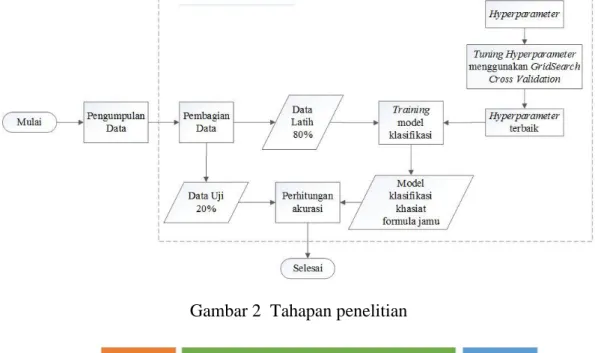
2 Tahapan penelitian 4
3 Illustrasi data jamu 4
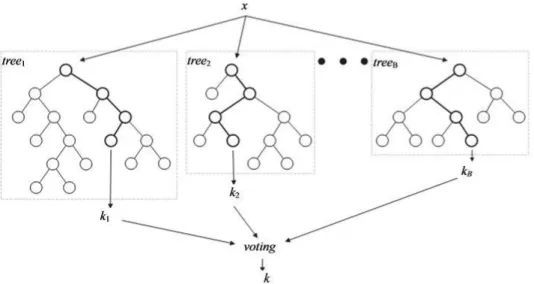
4 Arsitektur umum Random Forest (Verikas et al. 2011) 6 5 Cara kerja algoritme AdaBoost (Schapire and Freund 2012) 8
6 Illustrasi hyperplane 10
7 Contoh illustrasi pemodelan SVM yang bersifat linear 11 8 Selang kepercayaan dari setiap metode machine learning 15 9 Rataan waktu training setiap metode machine learning 15
10 Contoh Class Noise dan Attribute Noise 16
11 Contoh contradictory noise pada data jamu 17
DAFTAR LAMPIRAN
1 Karakteristik data 26
2 Hyperparameter value dalam format json 36 3 Hyperparameter terbaik dari setiap metode machine learning 38 4 Parameter dari setiap metode machine learning 40
PENDAHULUAN
Latar BelakangJamu adalah bahan yang berupa tumbuhan, bahan hewan, bahan mineral, sediaan sarian (galenik) atau campuan dari bahan tersebut yang secara turun temurun telah digunakan untuk pengobatan dan dapat diterapkan sesuai dengan norma yang berlaku di masyarakat (Kemenkes 2010). Menurut WHO, sekitar 80% dari penduduk di beberapa negara Asia dan Afrika menggunakan obat tradisional untuk mengatasi masalah kesehatannya.
Secara umum jamu dianggap tidak beracun dan telah terbukti secara empiris dapat menyembuhkan beberapa penyakit. Namun demikian belum ada bukti ilmiah yang menjelaskan keterkaitan antar komposisi bahan-bahan alami penyusun jamu dengan khasiatnya. Saat ini, banyak obat jamu yang diproduksi secara komersial pada skala industri di Indonesia. Meskipun masing-masing produsen memiliki formula jamu mereka sendiri, jelas bahwa keberhasilan jamu ditentukan oleh komposisi tanaman yang digunakan (Afendi et al. 2013). Tanaman jamu sendiri sangat beragam dan banyak. Jika diuji secara ilmiah satu per satu akan memakan waktu yang lama dan biaya yang besar. Oleh karena itu dibutuhkan suatu sistem atau metode yang dapat memprediksi antara ramuan jamu berdasarkan komposisi tanaman jamu dengan khasiatnya.
Afendi et al. (2013) telah melakukan suatu upaya sistematis untuk menemukan hubungan antara komposisi dan khasiat jamu dengan menggunakan pendekatan statistika. Hasil penelitian ini menunjukkan bahwa tanaman jamu dengan khasiatnya memiliki aktivitas farmakologi tertentu. Afendi et al. (2013) juga mengembangkan hipotesis bahwa jamu terdiri atas tanaman utama dan tanaman pendukung. Tanaman utama memiliki efek langsung terhadap penyakit dan tanaman pendukung ditentukan memiliki tiga karakteristik, yaitu analgesik, antimikroba, dan antiperadangan. Afendi et al. (2013) menggunakan Partial Least
Squares Dyscriminant Analysis (PLS-DA) untuk mengembangkan sebuah model
klasifikasi formula jamu. Penelitian ini menggunakan banyak tanaman yang berfungsi sebagai prediktor sehingga PLS-DA cocok untuk analisis ini. Penelitian tersebut difokuskan pada pengamatan 3138 sampel jamu yang diklasifikasikan ke dalam 9 jenis khasiat.
Dalam penelitian lain oleh Fitriawan (2013) dilakukan klasifikasi formula jamu dengan khasiatnya menggunakan teknik Support Vector Machine (SVM). SVM adalah salah satu teknik machine learning yang mampu mengklasifikasikan masalah di dunia nyata dengan hasil akurasi yang tinggi (Byun dan Lee 2003). Berdasarkan penelitian yang telah dilakukan, SVM juga mampu menghasilkan akurasi tinggi untuk mengklasifikasikan potongan metagenome dari komunitas kecil mikroba (Kusuma dan Akiyama 2011). Oleh karena itu, SVM dipilih oleh Fitriawan (2013) sebagai algoritme untuk mengembangkan model klasifikasi formula jamu.
Penelitian lain yang dilakukan oleh Ristyawan (2014) menggunakan metode
Voting Feature Interval 5 (VFI5). VFI5 dipilih karena algoritme ini merupakan
2
memberikan hasil yang baik. Algoritme klasifikasi VFI5 merepresentasikan sebuah konsep yang mendeskripsikan konsep selang antar fitur.
Perbandingan hasil akurasi metode yang dilakukan Afendi et al. (2013) menggunakan PLS-DA, Fitriawan (2013) menggunakan metode SVM, dan Ristyawan (2014) menggunakan metode VFI5 dengan menggunakan data 3138 formula jamu dan 465 komposisi tanaman jamu menunjukan hasil yang tidak jauh berbeda antara PLS-DA dan SVM. metode PLS-DA memiliki akurasi 71.60% dan SVM memiliki akurasi 71%. Adapun metode VFI5 memiliki akurasi 54.91%.
Dalam bidang ilmu komputer, masalah klasifikasi dapat diselesaikan dengan berbagai cara, salah satunya menggunakan teknik machine learning yang sudah diaplikasikan pada data jamu oleh Fitriawan (2013) dan Ristyawan (2014). Saat ini terdapat pendekatan yang lebih baru dibandingkan dengan SVM, yaitu Ensemble
Method. Ensemble Method adalah metode yang menggabungkan beberapa model
menjadi satu yang lebih akurat dari komponen-komponennya (Seni dan Elder 2010). Oleh karena itu, penelitian ini mengelaborasi beberapa metode ensemble dalam memprediksi khasiat dari formula jamu dan membandingkannya dengan metode
machine learning yang lainnya sehingga bisa dilakukan analisis metode machine learning yang paling sesuai dalam memprediksi komposisi tanaman jamu dan
khasiatnya.
Perumusan Masalah
Perumusan masalah pada penelitian ini adalah menganalisis metode machine
learning (KNN, SVM) dan metode Ensemble (AdaBoost, Gradient Boost, dan
Random Forest) dalam memprediksi komposisi formula jamu dan khasiatnya, juga mengetahui metode machine learning atau metode ensemble yang paling sesuai dalam memprediksi khasiat formula jamu.
Tujuan Penelitian Tujuan dari penelitian ini adalah:
1 Menerapkan dan menganalisis metode KNN, SVM, AdaBoost, Gradient Boost, dan Random Forest dalam memprediksi data jamu.
2 Mendapatkan metode machine learning atau metode ensemble yang paling sesuai untuk memprediksi komposisi formula jamu dan khasiatnya.
Manfaat Penelitian
Manfaat dari penelitian ini adalah dapat menjadi acuan bagi penelitian lainnya dalam memprediksi suatu kelas untuk mendapatkan hasil yang akurat dan menjadi dasar dalam menangani solusi permasalahan klasifikasi data jamu beserta khasiatnya di Indonesia.
Ruang Lingkup Penelitian Ruang lingkup penelitian adalah:
1 Tanaman yang dikenali terbatas pada 465 jenis tanaman dari 3138 jamu hasil praproses dari penelitian Afendi et al. (2010).
3 2 Metode machine learning yang diterapkan dan dianalisis adalah metode KNN, SVM, dan metode ensemble (AdaBoost, Gradient Boost, dan Random Forest). 3 Implementasi metode machine learning yang dianalisis menggunakan library
Scikit-learn versi 0.17, dengan menggunakan bahasa pemograman Python versi 2.7.10.
METODE
Penelitian ini melakukan klasifikasi dengan menggunakan metode machine
learning atau metode ensemble untuk memprediksi komposisi formula jamu dan
khasiatnya. Metode yang digunakan adalah metode K-Nearest Neighbors (KNN),
Support Vector Machines (SVM), Adaptive Boosting (AdaBoost), Gradient Boost,
dan Random Forest. Metode tersebut dipilih merujuk pada flowchart dari dokumentasi Scikit-Learn. Flowchart dapat dilihat pada Gambar 1. Tahapan yang dilakukan pada penelitian ini bisa dilihat pada Gambar 2.
Gambar 1 Flowchart metode machine learning (Scikit-Learn 2014) Data Penelitian
Penelitian ini menggunakan data yang sama seperti yang digunakan pada penelitian Afendi et al. (2010) dan Fitriawan (2013) yaitu 3138 formula jamu yang terdaftar di Badan Pengawas obat dan Makanan (Badan POM sampai tahun 2010) dan 465 jenis tanaman yang menyusun data formula jamu yang dianggap mewakil data yang dibutuhkan untuk dianalisis. Data ini telah melalui praproses data dari jumlah awal 6533 formula jamu. Praproses data terdiri atas penghapusan redudansi data jamu sebanyak 1223 formula jamu. Dari sisa 5310 formula jamu hanya diambil sebanyak 3138 formula jamu yang dianggap dapat mewakili data yang dibutuhkan untuk analisis (Afendi et al. 2010). Illustrasi data dapat dilihat pada Gambar 3.
4
Data yang digunakan pada penelitian ini merupakan hasil representasi data dari jamu yang beredar di Indonesia. Data yang digunakan berupa hubungan antara jamu, tanaman yang digunakan dalam komposisi jamu, dan khasiat dari jamu tersebut. Komposisi tanaman jamu didefinisikan dengan menetapkan nilai biner untuk masing-masing tanaman. Karakteristik data dapat dilihat pada Lampiran 1.
Gambar 2 Tahapan penelitian
Gambar 3 Illustrasi data jamu
Kolom jamu merepresentasikan indeks jamu atau formula dari jamu. Kolom komposisi tanaman merepresentasikan 465 tanaman yang menyusun formula dari jamu. Jika tanaman tertentu dimasukkan ke dalam sampel komposisi tanaman penyusun jamu, nilai pada tanaman ini ditetapkan sebagai 1, sebaliknya jika tanaman tertentu tidak termasuk ke dalam komposisi tanaman penyusun jamu penetapan nilainya adalah 0. Kolom khasiat merepresentasikan khasiat atau kelas dari komposisi tanaman penyusun jamu.
5 Penelitian ini difokuskan pada pengamatan 3138 sampel jamu yang diklasifikasikan ke dalam 9 jenis khasiat. Khasiat yang dapat diprediksi oleh metode ini direpresentasikan pada Tabel 1.
Tabel 1 Khasiat jamu
No Khasiat
1 Urinary Related Problems (URI)
2 Disorder Of Apetite (DOA)
3 Disorder Of Mood And Behavior (DMB)
4 Gastrointestinal Disorders (GST)
5 Female Reproductive Organ Problems (FML)
6 Muskuloskeletal And Connective Tissue Disorders (MSC)
7 Pain And Inflammation (PIN),
8 Respiratory Disease (RSP)
9 Wounds And Skin Infections (WND)
Pembagian Data
Data jamu yang sudah direduksi sebanyak 3138 formula jamu dibagi menjadi dua, yaitu 80% menjadi data latih dan 20% menjadi data uji. Tahap selanjutnya adalah tuning untuk mencari hyperparameter terbaik dilakukan dengan menggunakan fungsi Grid Search Cross Validation dari library Scikit-learn. Format hyperparameter value yang di import dalam format json dapat dilihat pada Lampiran 2 dan hyperparameter terbaik dapat dilihat pada Lampiran 3. Proses
tuning adalah metode untuk mendapatkan nilai yang optimal untuk nilai parameter
untuk menghindari overfitting. Parameter dari setiap metode machine learning dapat dilihat pada Lampiran 4. Overfitting adalah model yang terlalu rumit sehingga data mengikuti pola dari sampel pelatihan, tidak memberikan klasifikasi yang baik dari pola baru (Duda et al. 2001).
Selanjutnya dilakukan training untuk mendapatkan model dari setiap metode
machine learning (KNN, SVM, Gradient Boost, AdaBoost, dan Random Forest)
dan dilakukan pengujian untuk evaluasi menggunakan data uji. Setelah dilakukan tahap tuning, training, dan testing, dilakukan juga pengulangan dari setiap proses tersebut mulai pembagian data hingga pengujian. Proses ini dinamakan cloning yang bertujuan untuk menghindari bias dari data. Proses cloning pada penelitian ini dilakukan sebanyak seratus kali.
Pemodelan Algoritme
Pada pemodelan algoritme proses pelatihan dilakukan untuk mendapatkan model klasifikasi untuk setiap algoritme yang dibandingkan. Pada setiap base
learner dari metode ensemble terdapat juga proses boosting dan bagging.
Boosting adalah metode umum untuk meningkatkan kinerja setiap algoritma
pembelajaran (Schapire dan Freund 1996). Boosting meningkatkan prediksi dengan secara berulang menjalankan learning algorithm pada berbagai jenis distribusi data dan menggabungkan classifier yang dihasilkan oleh base learner menjadi classifier tunggal gabungan. Adapun bagging atau bootstrap aggregating meningkatkan prediksi dengan cara berulang kali menjalankan learning algorithm dan
6
menggabungkan hasil perhitungan dari setiap classifier dan menentukan hasil kelas prediksi dengan voting sederhana.
Algoritme Random Forest
Algoritme Random Forest (RF) merupakan pengembangan dari metode
Classification and Regression Tree (CART) dengan menerapkan metode bootstrap aggregating (bagging) dan random feature selection (Breiman 2001). Algoritme
RF merupakan algoritme yang sesuai digunakan untuk klasifikasi data yang besar dan pada algoritme RF tidak terdapat pruning atau pemangkasan variabel seperti pada algoritme decision tree. Metode RF menggabungkan banyak pohon (tree) tidak seperti single tree yang hanya terdiri atas satu pohon untuk membuat klasifikasi dan prediction class. Pada RF pembentukan tree dilakukan dengan cara melakukan training sample data. Pemilihan variabel yang digunakan untuk split diambil secara acak. Klasifikasi dijalankan setelah semua tree terbentuk. Penentuan klasifikasi pada RF ini diambil berdasarkan vote dari masing-masing tree dan vote terbanyak yang menjadi pemenang. Arsitektur umum dari RF dapat dilihat pada Gambar 4.
Gambar 4 Arsitektur umum Random Forest (Verikas et al. 2011)
Berikut ini adalah prosedur atau algoritme untuk membangun Random Forest pada gugus data yang terdiri atas n amatan dan p peubah penjelas (Breiman 2001; Breiman dan Cutler 2003):
1 Lakukan penarikan contoh acak berukuran n dengan pemulihan pada gugus data. Langkah ini dinamakan dengan bootstrap.
2 Dengan menggunakan contoh bootstrap, pohon dibangun sampai mencapai ukuran maksimum yaitu tanpa pemangkasan (pruning). Pruning atau condensing adalah sebuah metode sederhana untuk mengurangi O (n) kompleksitas ruang untuk menghilangkan prototipe yang dikelilingi oleh poin pelatihan dari label kategori yang sama (Duda et al. 2001). Pembangunan pohon dilakukan dengan menerapkan random feature selection yaitu m peubah penjelas dipilih secara acak di mana m << p, selanjutnya pemilah terbaik dipilih berdasarkan m peubah penjelas.
7 Ulangi langkah 1 dan 2 sebanyak t kali untuk membuat sebuah forest yang terdiri atas t pohon. Ukuran random forest (t) ditentukan oleh nilai yang tepat (Breiman 2001).
Tahapan pembuatan model klasifikasi menggunakan algoritme Random
Forest dilakukan setelah membuat pemodelan data latih menggunakan package random forest dari Scikit-learn. Pembentukan tree pada algoritme Random Forest
dilakukan dengan cara melakukan training pada sampel. Variabel yang digunakan untuk split diambil secara acak dan klasifikasi dijalankan setelah semua tree terbentuk. Penentuan klasifikasi pada Random Forest ini diambil berdasarkan vote dari masing-masing tree dan vote terbanyak yang menjadi pemenang.
Pada pembentukan Random Forest menggunakan nilai Gini Index untuk menentukan split yang akan dijadikan root/node. Berikut ini adalah rumus-rumus untuk mencari nilai Gini Index:
Gini(S)=1- ∑ pi2
k
i=1
(1)
Nilai pi adalah probabilitas dari Gini Index (S) milik class i. Adapun k adalah banyaknya nilai atribut yang termasuk ke dalam suatu kelas berdasarkan atribut data. Setelah menghitung nilai Gini Index (S), langkah berikutnya adalah menghitung nilai GiniGain. Fungsi Si adalah partisi dari S yang disebabkan oleh atribut A.
GiniGain(S)=Gini(S)-Gini(A, S)=Gini(S)- ∑|Si|
|S| Gini(Si) (2) n
i=1 Algoritme Adaptive Boosting (AdaBoost)
Prinsip inti AdaBoost adalah menyesuaikan serangkaian weak learner pada versi berulang modifikasi data. Semua prediksi kemudian digabungkan melalui
weighted majority vote (atau sum) untuk menghasilkan prediksi final. Modifikasi
data pada setiap disebut boosting iteration terdiri atas penerapan bobot t = 1,. . ., T untuk setiap sampel pelatihan (Schapire dan Freund 1999).
Diberikan: (x1,y1), …,(xm,ym) Dimana xi ϵ X, yi ϵ Y={-1, +1} Inisialisasi D1(i)=m1
Untuk t = 1, . . ., T:
Train base learner menggunakan distribusi Dt.
Dapatkan weak hypothesis ℎ𝑡: X → {-1, +1} dengan error
ϵt=Pri~Dt[ht(xi)≠yi] (3) Pilih αt= 1 2ln( 1-ϵt ϵt) Update:
8 Dt+1(i)=Dt(i) Zt × { e−𝛼𝑡 jika h t(xi)= yi eαt jika h t(xi)≠ yi (4) =Dt(i) exp (-αtyiht(xi)) Zt
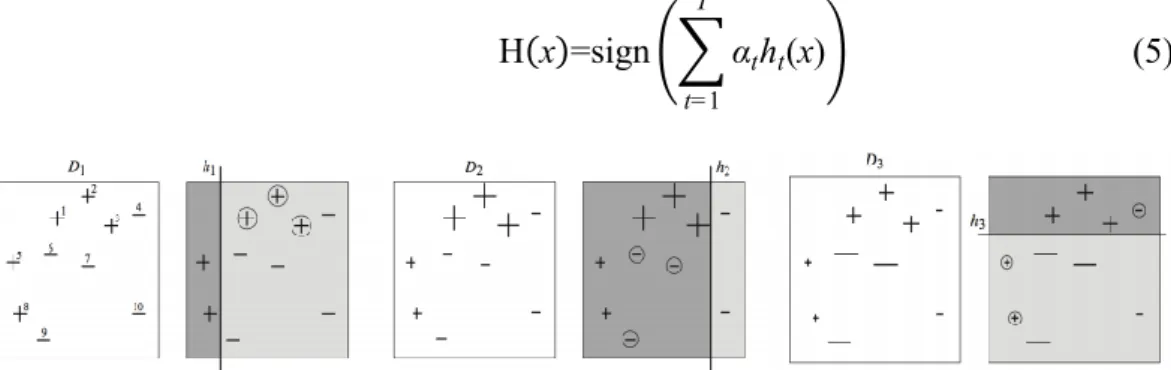
Fungsi 𝑍𝑡 adalah faktor normalisasi (dipilih sehingga Dt+1 akan menjadi distribusi), sehingga didapatkan output akhir pada Persamaan 5. Illustrasi adaboost dapat dilihat pada Gambar 5.
H(x)=sign (∑ αtht(x) T
t=1
) (5)
Gambar 5 Cara kerja algoritme AdaBoost (Schapire dan Freund 2012) Langkah pertama hanya melatih weak learner pada data asli. Untuk setiap iterasi berturut-turut, bobot sampel secara individual dimodifikasi dan algoritme pembelajaran yang diaplikasikan ulang pada data yang bobotnya sudah diatur ulang. Pada setiap langkah, sampel pelatihan yang diprediksi secara keliru oleh boosted
model diinduksi pada langkah sebelumnya dan ditingkatkan bobotnya, sedangkan
bobot diturunkan bagi sampel yang diprediksi dengan benar. Pada proses iterasi, sampel yang sulit untuk diprediksi mendapatkan ever-increasing influence setiap
subsequent weak learner.
Algoritme Gradient Boosting
Gradient Tree Boosting atau Gradient Boosted Regression Trees (GBRT)
adalah generalisasi dari boosting untuk membedakan loss function secara sembarang. GBRT adalah prosedur ‘off-the-shelf’ yang akurat dan efektif yang bisa digunakan untuk permasalahan regresi dan klasifikasi. Model Gradient Tree
Boosting digunakan dalam berbagai macam area termasuk rangking web search dan ecology. GBRT mempertimbangkan model aditif dari Persamaan 6:
F(x)= ∑ γmhm(x) M
m=1
(6)
Fungsi hm(x) adalah fungsi dasar yang biasanya disebut base learner dalam konteks boosting. Gradient Tree Boosting menggunakan decision trees dari ukuran yang tetap sebagai weak learner. Decision trees mempunyai sejumlah kemampuan yang membuatnya bernilai untuk boosting, yaitu kemampuan untuk menangani jenis data campuran dan kemampuan untuk memodelkan fungsi yang kompleks.
9 Input: training set {(xi,yi)}i=1
n
, loss function terdiferensiasi L(y,F(x)), jumlah iterasi M. Algoritme untuk regresi dan klasifikasi hanya berbeda dalam loss
function konkrit yang digunakan.
Algoritme:
1 Inisialisasi model dengan nilai konstan: F0(x)= arg min ∑ L(yi,γ)
n
i=1
(7) 2 Untuk m=1 hingga M,
Hitunglah nilai yang disebut pseudo-residual: rim=- [
∂L (yi,F(xi)) ∂F(xi) ]
F(x)=Fm-1(x)
untuk i=1, …., n. (8) Fit base learner hm(x) untuk pseudo-residual, misal melatih
dengan menggunakan training set {(xi,yi)}i=1 n
Hitung perkalian γm dengan pendekatan one dimensional
optimization:
γm= arg min ∑ L(yi,Fm-1(xi) n i=1 +γhm(xi)) (9) Update model: Fm(x)=Fm-1(x)+γmhm(x) (10) 3 Output FM(x)
Algoritme Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah suatu metode pembelajaran
menggunakan ruang hipotesis dari suatu fungsi linear dalam suatu ruang dimensi berfitur tinggi. Tujuan utama SVM ialah menemukan fungsi pemisah pada suatu subruang (hyperplane) yang terbaik untuk memisahkan dua buah kelas sesuai dengan label kelasnya. Contoh hyperplane ditampilkan pada Gambar 7.
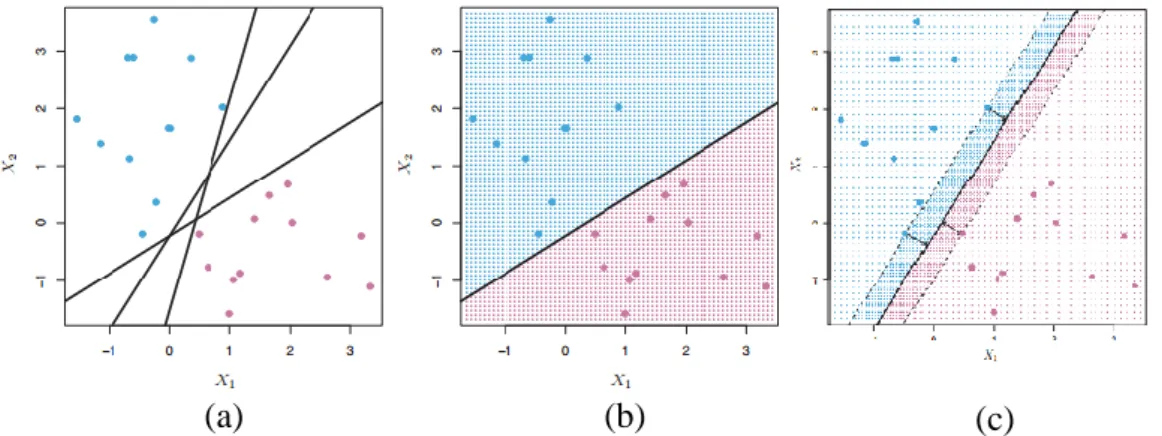
Pada Gambar 6 (a) menunjukan dua kelas amatan, yang digambarkan dengan warna biru dan ungu, yang masing-masing memiliki pengukuran pada dua variabel. Tiga hyperplanes pemisah, dari banyak kemungkinan, ditampilkan dalam warna hitam. Gambar 6 (b) menunjukan sebuah hyperplane pemisah yang terbaik dipilih dan ditampilkan dengan warna hitam. Grid biru dan ungu menunjukkan decision
rule yang dibuat oleh classifier berdasarkan hyperplane pemisah dan tes
pengamatan yang jatuh di bagian berwarna biru dari grid akan diklasifikasikan ke kelas biru, dan pengamatan tes yang jatuh ke bagian berwarna ungu akan diklasifikasikan ke kelas ungu. Gambar 6 (c) menunjukkan dua titik biru dan titik ungu yang terletak pada garis putus-putus adalah support vector, dan jarak dari titik-titik ke hyperplane yang ditunjukkan oleh anak panah. Grid ungu dan biru menunjukkan decision rule yang dibuat oleh classifier berdasarkan hyperplane pemisah.
10
Gambar 6 Illustrasi hyperplane
Hyperplane terbaik antara dua kelas dapat ditemukan dengan pengukuran margin hyperplane yang maksimal antara ruang input non-linear dengan ruang ciri
menggunakan fungsi kernel (Cortes dan Vapnik 1995). Menurut Byun dan Lee (2003), fungsi kernel yang umum digunakan adalah:
1. linear kernel K(xi,x)=xTx i (11) 2. polynomial kernel K(xi,x)=(xTxi+1) d (12) 3. Radial Basis Function (RBF) kernel
K(xi,x)=exp (-γ ||xi-x||
2
) , dengan γ=1
2σ2 (13) Dari ketiga fungsi kernel tersebut ximerepresentasikan vektor dari setiap data,
d merepresentasikan jumlah derajat dari fungsi polinomial, dan γ
merepresentasikan ukuran rentangan pada kurva gaussian. SVM menerapkan
kernel yang digunakan untuk merepresentasikan data ke dimensi yang lebih tinggi.
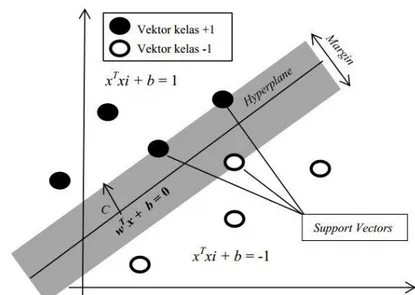
Data yang sudah berada di dimensi lebih tinggi tersebut dapat dengan mudah dipisahkan dengan hyperplane yang linear (Boswell 2002). Hyperplane yang baik adalah hyperplane yang dapat memaksimumkan jarak antara geometri hyperplane dengan support vector. Jarak tersebut diistilahkan dengan margin seperti diilustrasikan pada contoh pemodelan SVM yang bersifat linear (Gambar 7). Pelatihan data dilakukan dengan Scikit-learn 0.17 menggunakan 3 kernel, yaitu
linear kernel, polynomial kernel, dan RBF kernel yang didapatkan setelah proses tuning.
11
Gambar 7 Contoh illustrasi pemodelan SVM yang bersifat linear Algoritme K-Nearest Neighbor (KNN)
K-Nearest Neighbor (KNN) adalah suatu metode yang menggunakan
algoritme supervised learning. Hasil dari query instance yang baru diklasifikasikan berdasarkan mayoritas dari kategori pada KNN. Tujuan dari algoritme ini adalah mengklasifikasikan objek baru berdasarkan atribut dan training sample (Saputra 2015). Pada penelitian nilai k atau jumlah tetangga yang digunakan tergantung dari hasil tuning. Nilai k yang digunakan pada penelitian ini adalah 300, 400, atau 1000. Jika terjadi dua kelas atau lebih memiliki jumlah nilai k yang sama maka kelas yang dipilih merupakan kelas yang memiliki nilai jarak yang terdekat. Persamaan jarak pada KNN adalah: 1. Euclidian: d(x,y)= √∑(xi- yi)2 n i=1 (14) 2. Minkowski: d(x,y)= ( ∑ |xi- yi|c n i=1 ) 1/c (15) 3. Manhattan: d(x,y)= ∑ |xi-yi| n i=1 (16)
d : jarak data uji ke data pembelajaran xi : data uji ke-i
yi : data pembelajaran ke-i
12
Perhitungan Akurasi
Perhitungan akurasi dilakukan setelah proses klasifikasi selesai dilakukan pada setiap clone-dataset. Perhitungan ini berfungsi untuk menunjukkan tingkat kebenaran klasifikasi data terhadap data yang sebenarnya. Perhitungan akurasi dilakukan dengan menggunakan rumus sebagai berikut:
Akurasi= Σ data uji benar klasifikasi
Σ jumlah total data uji x 100% (17) Setelah menghitung nilai akurasi dari setiap clone-dataset maka dilakukan penghitungan nilai precision atau nilai presisi. Dalam Information Retrieval,
precision adalah ukuran dari hasil yang relevan, di mana precision merupakan
ukuran ketepatan dari tuple yang dilabeli dengan benar sesuai kelasnya, sedangkan
recall adalah ukuran dari berapa banyak hasil yang benar-benar relevan yang
dikembalikan. Recall adalah ukuran sensitivitas dari system untuk menemukan kembali suatu informasi. Meskipun classifier memiliki akurasi yang tinggi, kemampuan classifier tersebut untuk melakukan klasifikasi data ke kelas yang benar memiliki sensitivitas yang rendah (Han et al. 2012). Rumus untuk menghitung nilai presisi (Manning et al. 2008) sebagai berikut:
Precision= tp
tp+fp x 100% (18)
Dengan tp adalah nilai true positive dan fp adalah nilai false positif. Nilai tp merupakan nilai tuple yang dilabeli oleh classifier dengan benar (Han et al. 2012). Nilai tp + fp pada Persamaan 18 merupakan jumlah keseluruhan data yang terprediksi ke dalam data tertentu. Setelah mengetahui akurasi dari setiap clone, dihitung selang kepercayaan dari semua clone-dataset dari setiap metode yang diujikan untuk analisis.
Selang kepercayaan (confidence interval) adalah sebuah interval antara dua angka, nilai parameter sebuah populasi dipercaya terletak di dalam interval tersebut. Pertama dihitung nilai rata-rata dari jumlah semua clone-dataset dalam penelitian ini jumlah cloning atau perulangan proses dari setiap clone-dataset yang dilakukan adalah seratus kali. Langkah pertama adalah menghitung rata-rata dari semua
clone-dataset dengan menggunakan rumus sebagai berikut:
x̅= ∑x
n (19)
Di mana x̅ adalah rata-rata dari hasil akurasi setiap metode, ∑x adalah nilai semua hasil akurasi dan n adalah jumlah total clone-dataset. Kemudian hitung standar deviasi dari dari sampel. Dengan menggunakan rumus sebagai berikut:
σ= √∑(x-x̅)
2
13 Setelah didapatkan standar deviasi (𝜎) di mana ∑ (x-x̅)2 adalah jumlah dari sampel dikurangi dengan jumlah rata-rata sampel kemudian dibagi dengan jumlah
clone-dataset dikurangi 1. Tingkat kepercayaan yang digunakan pada penelitian ini
adalah 95%. Kemudian hitung margin kesalahan (margin of error) dari data dengan rumus sebagai berikut:
zα 2 ⁄ × σ √(n) (21) Fungsi zα 2
⁄ adalah koefisien kepercayaan, di mana α adalah tingkat
kepercayaan, σ adalah standar deviasi, dan n adalah ukuran sampel (clone-dataset). Kemudian hitung selang kepercayaan dengan rumus sebagai berikut:
x̅ ± zα 2
⁄ ×
σ
√(n) (22) Selang kepercayaan untuk batas atas didapatkan dari hasil penjumlahan mean atau rata-rata dengan koefisien kepercayaan dikalikan dengan standar deviasi yang dibagi akar dari jumlah total clone-dataset. Sedangkan batas bawah didapatkan dari hasil pengurangan rata-rata dengan koefisien kepercayaan dikalikan dengan standar deviasi yang dibagi akar dari jumlah total clone-dataset.
Peralatan Penelitian
Spesifikasi perangkat lunak dan perangkat keras yang digunakan pada penelitian ini yaitu:
1. Perangkat lunak:
Sistem Operasi : Windows 8.1 x64 Bahasa Pemrograman : Python
Antarmuka Bahasa pemrograman : Idle Python dan Sublime Text 3 Library : Scikit Learn, Matplotlib, Numpy,
Scipy
2. Perangkat keras berupa komputer personal dengan spesifikasi sebagai berikut:
Processors : Intel Core i7-4510U CPU @2.00 GHz Memory : 12 Gb DDR3
System type : 64-bit operating system VGA : AMD Radeon R5 M230
14
HASIL DAN PEMBAHASAN
HasilLangkah awal dalam penelitian ini ialah import data agar dapat digunakan untuk proses komputasi dengan menggunakan library numpy. Data yang digunakan ialah data 3138 buah jamu yang terdaftar di Badan Pengawas obat dan Makanan (Badan POM) dan 465 jenis tanaman yang menyusun data formula jamu.
Setelah data jamu di import, data tersebut kemudian dibagi menjadi 2 bagian, 80% data latih dan 20% data uji. Kemudian untuk menghindari overfitting dilakukan tuning hyperparameter untuk mendapatkan hyperparameter terbaik dari setiap parameter yang digunakan oleh setiap metode dengan menggunakan function
gridSearchCV dari Scikit-learn.
Pada proses training dilakukan pelatihan data dengan menggunakan
hyperparameter terbaik yang didapat saat proses tuning untuk mendapatkan model
yang akan diuji menggunakan data uji 20%. Hasil rataan klasifikasi dari data yang telah dilakukan cloning dan selang kepercayaan (data uji) dataset jamu dapat dilihat pada Gambar 8. Nilai akurasi rata-rata model klasifikasi dataset tertinggi untuk khasiat formula jamu adalah algoritme Random Forest sebesar 71.77% dan Algoritme dengan hasil rata-rata klasifikasi terkecil adalah algoritme KNN sebesar 44.84%.
Berdasarkan Gambar 8 dapat diketahui bahwa rata-rata hasil klasfikasi tidak terlalu besar perbedaannya pada 4 algoritme yang diuji yaitu SVM, AdaBoost,
Gradient Boost, dan Random Forest serta rata-rata hasil klasifikasi terendah adalah
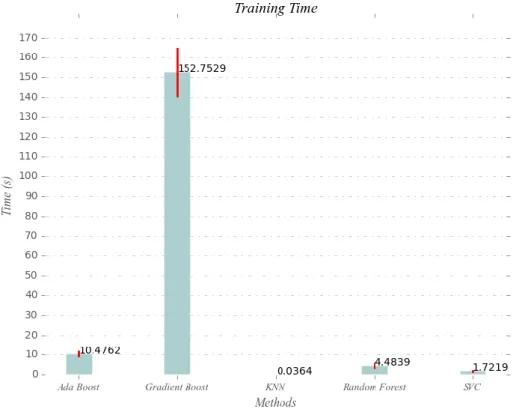
algoritme KNN. Hasil perhitungan selang kepercayaan pada setiap metode pada Tabel 2. Selain rataan hasil akurasi, dihitung pula rataan dari waktu klasifikasi yang dapat dilihat pada Gambar 9.
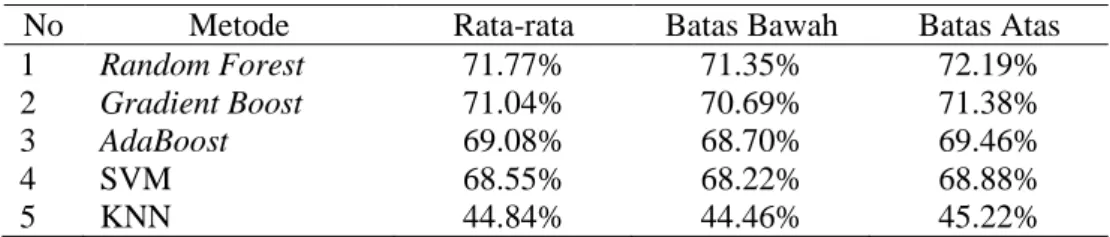
Tabel 2 Selang kepercayaan setiap metode machine learning
No Metode Rata-rata Batas Bawah Batas Atas
1 Random Forest 71.77% 71.35% 72.19%
2 Gradient Boost 71.04% 70.69% 71.38%
3 AdaBoost 69.08% 68.70% 69.46%
4 SVM 68.55% 68.22% 68.88% 5 KNN 44.84% 44.46% 45.22%
Tabel 3 Rata-rata waktu training setiap metode machine learning
Pada Gambar 10 rata-rata waktu klasifikasi dataset tertinggi untuk khasiat formula jamu adalah algoritme Gradient Boost dengan 152 detik dan algoritme dengan hasil rata-rata waktu klasifikasi tercepat adalah algoritme KNN selama 0.03 detik, sedangkan rata-rata waktu training algoritme lainnya berada pada selang 1
No Metode Rata-rata (s) 1 Gradient Boost 152.7529 2 AdaBoost 10.4762 3 Random Forest 4.4839 4 SVM 1.7219 5 KNN 0.0364
15 hingga 10 detik. Hasil perhitungan selang kepercayaan pada waktu setiap metode pada Tabel 3.
Gambar 8 Selang kepercayaan dari setiap metode machine learning
16
Hasil klasifikasi pada semua metode tidak memberikan hasil yang maksimal dikarenakan adanya noise pada data yang digunakan. Kualitas dari data biasanya dikarakterisasikan oleh dua sumber informasi, yaitu atribut dan label kelas (Zhu and Wu 2004). Kualitas atribut mengindikasikan seberapa baik instance dari karakterisasi atribut untuk klasifikasi. Kualitas dari label kelas merepresentasikan kelas dari setiap instance yang dilabeli dengan benar.
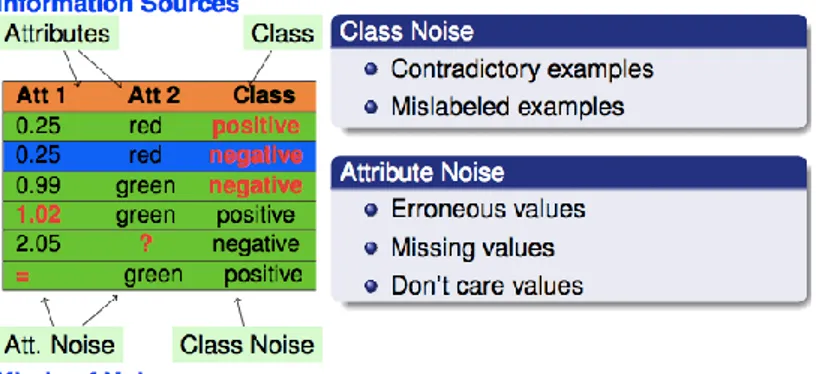
Class Noise (label noise) terjadi ketika sebuah contoh yang
diklasifikasikan/dilabeli dengan salah. Class noise dapat disebabkan oleh beberapa sebab, seperti subjektivitas selama proses pelabelan, kesalahan entri data, atau kurangnya informasi yang digunakan memberi label pada setiap contoh, lebih jelas mengenai noise dapat dilihat pada Gambar 10. Dua jenis class noise dapat dibedakan menjadi:
1 Contradictory examples duplikat examples memiliki label kelas yang berbeda. Pada gambar 10 dua contoh (0,25, merah, kelas = positif) dan (0,25, merah, kelas = negatif) adalah contoh Contradictory examples, karena mereka memiliki nilai atribut yang sama tetapi dilabeli pada kelas yang berbeda. 2 Misclassifications contoh yang diberi label sebagai kelas yang berbeda dari
yang asli. Pada gambar ditempatkan di atas contoh (0.99, hijau, kelas = negatif) adalah contoh mislabeled, karena label kelasnya yang salah, karena kelas seharusnya adalah positif.
Attribute noise mengacu pada corrupt dalam nilai-nilai dari satu atau lebih
atribut. Contoh Attribute noise:
1 nilai atribut yang keliru (erroneous values). Pada gambar 10, contoh (1.02, hijau, kelas = positif) memiliki atribut dengan noise, karena memiliki nilai yang salah. 2 Hilang (missing) atau nilai atribut yang tidak diketahui (missing values). Pada gambar ditempatkan di atas, contoh (Att 1 = 2.05, Att 2 = ?, kelas = negatif) memiliki atribut noise, karena kita tidak tahu nilai dari atribut kedua.
3 atribut tidak lengkap (incomplete attributes) atau “do not care” values. Pada gambar ditempatkan di atas, contoh (Att 1 = ‘=’, Att 2 = green, kelas = positif) memiliki noise atribut, karena nilai atribut pertama tidak mempengaruhi sisa nilai-nilai contoh, termasuk kelas example.
Gambar 10 Contoh Class Noise dan Attribute Noise
Pada penelitian ini ditemukan banyak sekali data yang memiliki
contradictory noise atau data yang memiliki atribut yang sama tetapi dilabeli pada
17 duplikasi. Dari noise yang ada pada data menyebabkan khasiat formula jamu tidak terklasifikasi dengan optimal dengan menggunakan metode yang diujikan. Terbukti oleh penelitian yang dilakukan Fitriawan (2013) yang melakukan reduksi data jamu yang menjadi noise.
Gambar 11 Contoh contradictory noise pada data jamu
Data yang telah direduksi menjadi 231 jenis tanaman dari 2748 khasiat jamu menghasilkan klasifikasi yang maksimal menggunakan metode SVM yaitu sebesar 95.34% dibandingkan dengan menggunakan data yang belum direduksi yang hanya menghasilkan klasifikasi sebesar 71%. Pada penelitian ini metode yang diujikan menghasilkan data yang tidak jauh berbeda dengan penelitian yang dilakukan oleh Fitriawan (2013) menggunakan data yang belum dilakukan reduksi. Hal ini membuktikan bahwa noise mempengaruhi klasifikasi pada metode machine
learning yang diujikan termasuk ensemble method.
Algoritme Random Forest
Nilai akurasi rata-rata model klasifikasi dataset tertinggi untuk khasiat formula jamu adalah algoritme Random Forest sebesar 71.77%. Hal ini dikarenakan data yang digunakan berupa data yang bersifat biner atau hanya terdiri atas 1 dan 0 untuk representasi datanya. Selain itu, base learner yang digunakan adalah decision tree yang cukup baik jika digunakan untuk mengklasifikasikan data dengan tipe biner sehingga hasil rata-rata akurasinya cukup baik walaupun masih terdapat banyak noise pada data yang digunakan. Tabel 4 menunjukkan confusion
matrix dari algoritme Random Forest dalam mengklasifikasikan data formula jamu.
Tabel 4 Confusion matrix algoritme Random Forest
Aktual Prediksi Kelas 1 Kelas 2 Kelas 3 Kelas 4 Kelas 5 Kelas 6 Kelas 7 Kelas 8 Kelas 9 Kelas 1 10 0 0 3 1 1 0 0 0 Kelas 2 0 28 0 5 5 6 0 0 1 Kelas 3 0 0 0 0 0 3 0 1 0 Kelas 4 2 0 0 171 4 14 5 0 2 Kelas 5 1 5 0 15 62 13 0 0 1 Kelas 6 1 4 0 7 9 133 3 1 0 Kelas 7 0 0 0 9 1 13 35 0 0 Kelas 8 0 0 0 3 1 2 3 7 1 Kelas 9 0 0 0 4 0 0 2 0 24
18
Tabel 4 menjelaskan confusion matrix dari hasil klasifikasi terbaik dari algoritme Random Forest. Pada algoritme random forest data terklasifikasi secara merata. Namun, pada beberapa kelas data tidak terklasifikasi dengan tepat. Pada kelas 4 data menyebar kelas lainnya dan paling banyak terklasifikasi ke kelas 5 yaitu berkhasiat untuk mengobati Female Reproductive Organ Problems (FML) sebanyak 15 data. Data pada kelas 5 juga menyebar ke kelas 6 yang berkhasiat mengobati Muskuloskeletal and Connective Tissue Disorders (MSC) sebanyak 9 data. Pada kelas 6 menyebar hampir merata ke 3 kelas, yaitu kelas 4, 5 dan 7. Pada kelas 6 data yang salah terklasifikasi paling banyak ke kelas 4 yang berkhasiat mengobati Gastrointestinal Disorders (GST) sebanyak 14 data. Dari data ini dapat dihitung jumlah dari precision dan recall dari algoritme Random Forest yang diperlihatkan pada Tabel 5.
Tabel 5 Precision dan recall dari confusion matrix algoritme Random Forest
Precision Recall Kelas 1 0.71 0.67 Kelas 2 0.76 0.62 Kelas 3 0 0 Kelas 4 0.79 0.86 Kelas 5 0.75 0.64 Kelas 6 0.72 0.84 Kelas 7 0.73 0.6 Kelas 8 0.78 0.41 Kelas 9 0.83 0.8 Average 0.75 0.76 Algoritme AdaBoost
Nilai akurasi rata-rata model klasifikasi khasiat formula jamu pada algoritme
Adaptive Boosting atau AdaBoost sebesar 69.08%. Selain data yang bersifat biner
atau hanya terdiri dari 1 dan 0 untuk representasi datanya, base learner yang digunakan sama dengan Random Forest yaitu decision tree. Namun digabungkan dengan metode boosting untuk memperkuat hasil klasifikasinya, sehingga hasilnya masih tergolong cukup baik mengingat tipe data yang digunakan adalah biner dan masih terdapat noise dari data.
Tabel 6 menjelaskan confusion matrix dari hasil klasifikasi terbaik dari algoritme AdaBoost. Pada algoritme adaboost data terklasifikasi secara merata. Namun, pada beberapa kelas data tidak terklasifikasi dengan tepat. Pada kelas 4 data menyebar hampir merata ke kelas 5 dan 6. Namun, paling banyak terklasifikasi ke kelas 6 yaitu untuk khasiat untuk mengobati Muskuloskeletal and Connective
Tissue Disorders (MSC) sebanyak 12 data. Data pada kelas 5 juga menyebar paling
banyak ke kelas 6 yang berkhasiat mengobati Muskuloskeletal and Connective
Tissue Disorders (MSC) sebanyak 7 data. Pada kelas 6 menyebar hampir merata.
Namun, data yang salah terklasifikasi paling banyak ke kelas 4 yang berkhasiat mengobati Gastrointestinal Disorders (GST) sebanyak 25 data. Dari data ini dapat dihitung jumlah dari precision dan recall dari algoritme adaptive boosting yang diperlihatkan pada Tabel 7.
19 Tabel 6 Confusion matrix algoritme AdaBoost
Aktual Prediksi Kelas 1 Kelas 2 Kelas 3 Kelas 4 Kelas 5 Kelas 6 Kelas 7 Kelas 8 Kelas 9 Kelas 1 6 0 0 2 1 2 0 0 0 Kelas 2 0 39 1 2 7 4 0 0 0 Kelas 3 0 0 0 0 1 0 0 0 0 Kelas 4 1 4 0 179 4 25 8 2 0 Kelas 5 0 4 0 11 50 17 1 0 1 Kelas 6 0 1 1 12 7 126 1 1 0 Kelas 7 0 0 0 7 1 9 38 0 0 Kelas 8 0 0 0 2 2 6 4 5 0 Kelas 9 1 0 0 6 1 1 3 1 14
Tabel 7 Precision dan recall dari confusion matrix algoritme Adaptive Boosting
Precision Recall Kelas 1 0.75 0.55 Kelas 2 0.81 0.74 Kelas 3 0 0 Kelas 4 0.81 0.8 Kelas 5 0.68 0.6 Kelas 6 0.66 0.85 Kelas 7 0.69 0.69 Kelas 8 0.56 0.26 Kelas 9 0.93 0.52 Average 0.74 0.73
Algoritme Gradient Boosting
Nilai akurasi rata-rata model klasifikasi khasiat formula jamu pada algoritme
Gradient Boosting sebesar 71.04%. Metode Gradient Boosting merupakan
gabungan antara metode Gradient Descent dengan metode boosting untuk memperkuat hasil klasifikasinya sehingga hasilnya masih tergolong cukup baik mengingat tipe data yang digunakan adalah biner dan masih terdapat noise dari data. Tabel 8 menunjukkan confusion matrix dari algoritme Gradient Boost dalam mengklasifikasikan data formula jamu. Tabel 8 menjelaskan confusion matrix dari hasil klasifikasi terbaik dari algoritme Gradient Boosting. Pada algoritme gradient
boost data terklasifikasi secara merata. Namun, pada beberapa kelas data tidak
terklasifikasi dengan tepat.
Tabel 8 Confusion matrix algoritme Gradient Boost
Aktual Prediksi Kelas 1 Kelas 2 Kelas 3 Kelas 4 Kelas 5 Kelas 6 Kelas 7 Kelas 8 Kelas 9 Kelas 1 11 0 0 1 1 1 0 1 0 Kelas 2 1 31 0 5 5 1 1 0 0 Kelas 3 0 1 1 2 0 0 0 0 0 Kelas 4 1 4 0 171 4 12 8 1 2 Kelas 5 0 9 0 10 59 10 1 1 0 Kelas 6 0 4 1 11 7 118 5 2 0 Kelas 7 1 0 0 7 2 12 53 1 0 Kelas 8 0 0 0 2 1 0 2 12 1 Kelas 9 0 0 0 6 2 1 0 0 15
20
Pada kelas 4 data menyebar hampir merata ke kelas 5 dan 6. Namun, paling banyak terklasifikasi ke kelas 6 yaitu untuk khasiat untuk mengobati
Muskuloskeletal and Connective Tissue Disorders (MSC) sebanyak 11 data. Data
pada kelas 5 juga menyebar paling banyak ke kelas 6 yang berkhasiat mengobati
Muskuloskeletal and Connective Tissue Disorders (MSC) sebanyak 7 data. Pada
kelas 6 menyebar hampir merata. Namun, data yang salah terklasifikasi paling banyak ke kelas 4 yang berkhasiat mengobati Gastrointestinal Disorders (GST) dan 7 yang berkhasiat mengobati Pain and Inflammation (PIN) sebanyak 12 data. Dari data ini dapat dihitung jumlah dari precision dan recall dari algoritme gradient
boosting yang diperlihatkan pada Tabel 9.
Tabel 9 Precision dan recall dari confusion matrix algoritme Gradient Boosting
Precision Recall Kelas 1 0.79 0.73 Kelas 2 0.63 0.7 Kelas 3 0.5 0.25 Kelas 4 0.8 0.84 Kelas 5 0.73 0.66 Kelas 6 0.76 0.8 Kelas 7 0.76 0.7 Kelas 8 0.67 0.67 Kelas 9 0.83 0.62 Average 0.76 0.76
Algoritme Support Vector Machine (SVM)
Nilai akurasi rata-rata model klasifikasi khasiat formula jamu pada algoritme SVM sebesar 68.55%. SVM membagi data menjadi 2 kelas {+1, -1} dan ada 2 metode pembagian data pada SVM yaitu one vs one dan one vs rest. Metode one vs
one adalah metode klasifikasi yang membandingkan data hanya dengan 2 kelas saja,
contoh: kelas 1 vs kelas 2, kelas 1 vs kelas 3, …, kelas 8 vs kelas 9. Metode one vs
rest adalah metode yang membandingkan 1 kelas dengan kelas sisanya, contoh
kelas 1 vs kelas 2,3,4,5,6,7,8,9, …, kelas 9 vs kelas 1,2,3,4,5,6,7,8. Prinsip dasar SVM adalah linear classifier dan selanjutnya dikembangkan agar dapat bekerja pada problem non-linear. Dengan memasukkan konsep kernel trick pada ruang kerja berdimensi tinggi.
Tabel 10 Confusion matrix algoritme SVM
Aktual Prediksi Kelas 1 Kelas 2 Kelas 3 Kelas 4 Kelas 5 Kelas 6 Kelas 7 Kelas 8 Kelas 9 Kelas 1 6 0 0 2 0 1 0 0 0 Kelas 2 0 37 0 3 9 3 1 0 1 Kelas 3 0 1 0 0 0 0 0 0 0 Kelas 4 2 2 1 177 5 11 5 2 6 Kelas 5 1 4 0 13 50 13 2 0 2 Kelas 6 7 4 2 15 5 117 9 1 1 Kelas 7 0 0 1 7 1 7 31 2 1 Kelas 8 0 0 0 2 0 3 7 11 0 Kelas 9 0 0 0 3 1 0 3 0 21
21 Vapnik (2000) menjelaskan bahwa generalization error dipengaruhi oleh dua faktor: error terhadap training set dan satu faktor lainnya dipengaruhi oleh dimensi VC (Vapnik-Chervokinensis). Strategi pembelajaran metode machine learning pada umumnya difokuskan pada usaha untuk meminimimalkan error pada
training-set (Nugroho et al. 2003). Strategi ini disebut Empirical Risk Minimization (ERM).
Pada SVM selain meminimalkan error pada training set juga meminimalkan
Structural Risk Minimization (SRM) sehingga hasil klasifikasinya masih tergolong
cukup baik mengingat tipe data yang digunakan adalah biner dan masih terdapat
noise dari data. Tabel 6 menunjukkan confusion matrix dari algoritme SVM dalam
mengklasifikasikan data formula jamu.
Tabel 10 menjelaskan confusion matrix dari hasil klasifikasi terbaik dari algoritme SVM. Pada algoritme SVM data terklasifikasi secara merata. Namun, pada beberapa kelas data tidak terklasifikasi dengan tepat. Pada kelas 4 data menyebar hampir merata ke kelas 5 dan 6. Namun, paling banyak terklasifikasi ke kelas 6 yaitu untuk khasiat untuk mengobati Muskuloskeletal and Connective
Tissue Disorders (MSC) sebanyak 15 data.
Tabel 11 Precision dan recall dari confusion matrix algoritme SVM
Precision Recall Kelas 1 0.38 0.67 Kelas 2 0.77 0.69 Kelas 3 0 0 Kelas 4 0.8 0.84 Kelas 5 0.7 0.59 Kelas 6 0.75 0.73 Kelas 7 0.53 0.62 Kelas 8 0.69 0.48 Kelas 9 0.66 0.75 Average 0.73 0.72
Data pada kelas 5 juga menyebar paling banyak ke kelas 2 sebanyak 9 data. Pada kelas 6 data yang salah terklasifikasi paling banyak ke kelas 5 yang berkhasiat mengobati Female Reproductive Organ Problems (FML) sebanyak 13 data. Pada kelas 7 data yang salah terklasifikasi paling banyak ke kelas 6 yaitu untuk khasiat untuk mengobati Muskuloskeletal and Connective Tissue Disorders (MSC) sebanyak 9 data. Dari data confusion matrix ini dapat dihitung jumlah dari precision dan recall dari algoritme SVM yang diperlihatkan pada tabel 11.
Algoritme KNN
Algoritme KNN merupakan algoritme dengan cara kerja menghitung jarak antar tetangga nya sesuai dengan jumlah K yang didefinisikan oleh pengguna untuk mencari kelas pada dataset baru. Tabel 12 menunjukkan confusion matrix dari algoritme KNN dalam mengklasifikasikan data formula jamu. Pada penelitian ini perhitungan jarak algoritme KNN dengan data tetangga dihitung dengan menggunakan jarak minkowski, manhattan atau euclidean tergantung hasil tuning dan hasil tuning pada penelitian ini semuanya menggunakan jarak manhattan. Namun untuk data jamu yang bertipe biner jarak manhattan kurang cocok digunakan karena perhitungan jaraknya menjadi tidak optimal karena nilai yang
22
digunakan hanya 0 dan 1 dan perhitungan jarak manhattan algoritme KNN hanya cocok menggunakan data desimal.
Tabel 12 menjelaskan confusion matrix dari hasil klasifikasi terbaik dari algoritme KNN. Pada algoritme KNN data tidak terklasifikasi secara merata dan data yang tidak terklasifikasi dengan tepat paling banyak terjadi pada kelas 4 dan banyak terklasifikasi ke kelas 6 yaitu untuk khasiat untuk mengobati
Muskuloskeletal and Connective Tissue Disorders (MSC) sebanyak 103 data. Dari
data confusion matrix ini dapat dihitung jumlah dari precision dan recall dari algoritme KNN yang diperlihatkan pada Tabel 13.
Tabel 12 Confusion matrix algoritme KNN
Aktual Prediksi Kelas 1 Kelas 2 Kelas 3 Kelas 4 Kelas 5 Kelas 6 Kelas 7 Kelas 8 Kelas 9 Kelas 1 4 0 0 7 0 0 0 0 0 Kelas 2 0 5 1 46 0 1 0 0 0 Kelas 3 0 0 0 1 0 0 0 0 0 Kelas 4 0 0 0 217 1 4 1 0 0 Kelas 5 0 0 0 70 12 2 0 0 0 Kelas 6 0 0 1 103 0 45 0 0 0 Kelas 7 0 0 0 35 0 0 20 0 0 Kelas 8 0 0 0 14 0 1 1 3 0 Kelas 9 0 0 0 21 0 0 0 0 6
Tabel 13 Precision dan recall dari confusion matrix algoritme KNN
Precision Recall Kelas 1 1 0.36 Kelas 2 1 0.09 Kelas 3 0 0 Kelas 4 0.42 0.97 Kelas 5 0.92 0.14 Kelas 6 0.85 0.3 Kelas 7 0.91 0.36 Kelas 8 1 0.16 Kelas 9 1 0.22 Average 0.74 0.5
Dari hasil perhitungan precision dan recall didapatkan bahwa Random Forest memiliki hasil precision yang paling tinggi dibanding metode lainnya, yaitu sebesar 71.85% atau lebih banyak 0.08% dibanding dengan akurasi. Hal ini menunjukkan bahwa ketepatan klasifikasi data jamu dari kelas lain namun diklasifikasikan ke kelas positif sebanyak 0.08%, sedangkan hasil perhitungan recall dari random forest yaitu data yang seharusnya terklasifikasi ke kelas lain namun terklasifikasi ke kelas positif sebesar 71.7%. hasil perhitungan precision dan recall yang terendah adalah SVM dengan hasil precision sebesar 68.88% dan hasil recall terendah adalah metode KNN dengan hasil sebesar 44.84%. Hasil perhitungan rata-rata akurasi, precision, dan recall dari total semua clone-dataset pada setiap metode dapat dilihat pada Tabel 14.
23 Tabel 14 Hasil rata-rata akurasi, precision, dan recall dari setiap metode
No Metode Akurasi Precision Recall
1 Random Forest 71.77% 0.7185 0.717 2 Gradient Boost 71.04% 0.7104 0.7102 3 AdaBoost 69.08% 0.6918 0.6909 4 SVM 68.55% 0.6888 0.6854 5 KNN 44.84% 0.6992 0.4484 Pembahasan
Rata-rata hasil klasifikasi pada selang kepercayaan pada setiap metode tidak terlalu besar dan berada di selang 68% hingga 71%. Karena data yang digunakan masih memiliki duplikasi dan diantara data duplikasi tersebut ada data yang terklasifikasi pada kelas yang berbeda.
KNN menghasilkan rata-rata terendah, karena algoritme KNN pada penelitian ini menggunakan jarak manhattan sehingga tidak cocok untuk data yang bersifat biner. Dari 6 metode yang dicoba, algoritme yang menghasilkan klasifikasi terbaik adalah metode Random Forest. Hal ini disebabkan karena tipe data yang digunakan pada penelitian ini lebih cocok dimodelkan dengan tree, karena atribut atau komposisi tanaman yang memilliki tipe data biner dianggap label oleh decision
tree sehingga algoritme dengan base estimator decision tree tidak terlalu
terpengaruh oleh data jamu dan Random Forest menghasilkan klasifikasi yang tinggi karena base estimator dari Random Forest adalah decision tree.
Rata-rata waktu Gradient Boost menjadi yang paling lama dikarenakan perhitungan algoritmenya yang membutuhkan fiting atau pembobotan yang berulang sehingga membutuhkan waktu yang lama hingga data diklasifikasikan dengan benar, sedangkan KNN menjadi yang tercepat karena menggunakan perhitungan jarak manhattan sehingga klasifikasinya menjadi lebih cepat.
SIMPULAN DAN SARAN
SimpulanPenelitian ini menerapkan algoritme KNN, SVM, AdaBoost, Gradient Boost, dan Random Forest untuk klasifikasi khasiat dari formula jamu dan menghasilkan metode yang paling cocok untuk klasifikasi khasiat formula jamu yaitu metode random forest dengan rata-rata hasil akurasinya mencapai 71.77%. Hal ini disebabkan karena tipe data yang digunakan pada penelitian ini lebih cocok dimodelkan dengan tree, karena data dari jamu yang hanya terdiri dari angka 0 dan 1 dianggap label oleh algoritme decision tree sehingga pengklasifikasiannya tidak terpengaruh oleh data tersebut, sehingga Random Forest menghasilkan klasifikasi yang tinggi karena base estimator atau base learner dari Random Forest adalah
decision tree.
Rata-rata hasil dari klasifikasi metode SVM, AdaBoost, Gradient Boost, dan
24
hingga 71%. Hal ini dikarenakan banyaknya data yang memiliki duplikasi dan data yang memiliki duplikasi tersebut terklasifikasi pada kelas yang berbeda.
Saran
Saran untuk penelitian selanjutnya yaitu penggunaan data yang sudah dihilangkan duplikasi datanya dan disesuaikan dengan aturan dari komposisi formula jamu seperti reduksi data formula jamu yang komposisi tanamannya kurang dari empat tanaman sesuai dengan hipotesis dari (Afendi et al. 2013) yang menerangkan bahwa sebuah formula jamu harus terdiri atas 4 tanaman, yaitu 3 tanaman pendukung (tanaman yang masing masing memiliki karakteristik analgesik, antimikroba, dan anti-peradangan) dan tanaman utama yang memiliki efek langsung dengan penyakit sehingga harus memiliki khasiat tertentu.
DAFTAR PUSTAKA
Afendi FM, Darusman LK, Hirai A, Amin MA, Takahashi H, Nakamura K, Kanaya S. 2010. System biology approach for elucidating the relationship between Indonesia herbal plants and the efficacy of jamu. Di dalam: Fan W, Hsu W, Webb GI, Liu B, Zhang C, Gunopulos D, Wu X, editor. 2010 IEEE
International Conference on Data Mining Workshops; 2010 Des 14; Sydney,
Australia. Sydney (AU): Conference Publishing Services.
Afendi FM, Darusman LK, Morita AH, Altaf-Ul-Amin M, Takahashi H, Nakamura K, Tanaka K, Kanaya S. 2013. Efficacy prediction of jamu formulations by PLS modeling. Current Computer-Aided Drug Design. 9:46-59.
Breiman L. 2001. Random Forests. Statistics Departement, University of California [internet]. [diacu 2016 Maret 05]. Tersedia dari: https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf.
Breiman, L dan A Cutler. 2003. Manual–Setting Up, Using, And Understanding
Random Forests V4.0 [internet]. [diacu 2016 Mei 21]. Tersedia dari:
https://www.stat.berkeley.edu/~breiman/Using_random_forests_V3.1.pdf.
Byun H, Lee SW. 2003. Applications of support vector machines for pattern
recognition: A survey. Int J Patt Recogn Artif Intell. 17(3):459–486.
doi:10.1.1.723.5893.
Duda RO, Stork DG, Hart PE. 2001. Pattern Classification. Ed ke-2. New York (US): Wiley.
Fitriawan A. 2013. Sistem klasifikasi khasiat formula jamu dengan metode Support Vector Machine [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Freund Y, Schapire RE. 1999. A short introduction to boosting. Journal of Japanese
Society for Artificial Intelligence. 14(5):771-780.
Freund Y, Schapire RE. 1996. Experiments with a new boosting algorithm. Di dalam: Saitta, Lorenza, editor. Proceedings of the Thirteenth International
Conference on Machine Learning (ICML 1996). 13:148-156. Bari, Italy.
Freund Y, Schapire RE. 2012. Boosting: Foundations and Algorithms. Cambridge (CA) : MIT Press.
Hackeling G. 2014. Mastering Machine Learning with Scikit-Learn. Birmingham (GB): Packt Publishing Ltd.
25 Han J, Kamber M, Pei J. 2012. Data Mining: Concepts and Techniques. Ed ke-3.
Amsterdam (NL): Elsevier, Morgan Kaufmann.
Nugroho AS, Witarto AB, Handoko D. 2003. Support Vector Machine: Teori dan Aplikasinya dalam Bioinformatika [internet]. [diacu 2016 Mei 19]. Tersedia dari: http://asnugroho.net/papers/ikcsvm.pdf
Peraturan Menteri Kesehatan Republik Indonesia. 2010. Saintifikasi jamu dalam penelitian berbasis pelayanan kesehatan. Nomor : 003/MENKES/PER/I/2010. Ristyawan Y. 2014. Sistem klasifikasi khasiat formula jamu dengan metode Voting
Feature Interval 5 [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Seni G, Elder JF. 2010. Ensemble Methods in Data Mining: Improving Accuracy
Through Combining Predictions. San Rafael (DO): Morgan & Claypool
Publishers.
Saputra JH. 2015. Klasifikasi enzim protein menggunakan metode k-nearest
neighbor dan analisis komponen utama sebagai pereduksi ciri [skripsi]. Bogor
(ID): Institut Pertanian Bogor.
Zhu X, Wu X. 2004. Class Noise vs. Attribute Noise: A Quantitative Study
26
Lampiran 1 Karakteristik data
27 Lampiran 1 Karakteristik data (Lanjutan)
28
Lampiran 1 Karakteristik data (Lanjutan)
29 Lampiran 1 Karakteristik data (Lanjutan)
30
Lampiran 1 Karakteristik data (Lanjutan)
31 Lampiran 1 Karakteristik data (Lanjutan)
31
32
Lampiran 1 Karakteristik data (Lanjutan)
33 Lampiran 1 Karakteristik data (Lanjutan)
34
Lampiran 1 Karakteristik data (Lanjutan)
35 Lampiran 1 Karakteristik data (Lanjutan)
36
Lampiran 2 Hyperparameter value dalam format json { "rf":{ "name":"Random Forest", "method":"RandomForestClassifier()", "base_estimator":[{"model":"ET = ExtraTreesClassifier()"},{"model":"DecisionTreeClassifi er()"}], "params":{ "n_estimators": [300, 1000, 400], "n_jobs":[-1], "max_features": ["auto","sqrt","log2", "None"],
"oob_score": [true, false],
"class_weight":["auto", "balanced", "balanced_subsample"],
"criterion": ["gini", "entropy"] } }, "knn":{ "name":"KNN", "method":"KNeighborsClassifier()", "params":{ "n_neighbors": [300, 400, 1000], "weights":["uniform", "distance"], "algorithm":["auto","ball_tree","kd_tree", "brute"], "leaf_size":[30, 300,400], "metric":["minkowski","manhattan", "euclidean"], "n_jobs":[-1] } }, "gbc":{ "name":"Gradient Boost", "method":"GradientBoostingClassifier()", "params":{ "n_estimators":[1000, 300, 400], "max_depth":["None"], "loss":["deviance","exponential"],
"max_features": ["auto", "sqrt", "log2", "None"]
37 Lampiran 2 Hyperparameter value dalam format json (Lanjutan)
} }, "svc":{ "name":"SVC", "method":"svm.SVC()", "params":{ "C":[0.1, 2.0, 1.0], "kernel":["linear", "poly", "rbf"], "decision_function_shape":["ovo","ovr"] } }, "ada":{ "name":"Ada Boost", "method":"AdaBoostClassifier()", "params":{ "base_estimator__criterion" :["gini", "entropy"], "base_estimator__splitter" :["best", "random"], "n_estimators":[300, 1000, 400], "algorithm":["SAMME","SAMME.R"] } } }
38
Lampiran 3 Hyperparameter terbaik dari setiap metode machine learning
No Metode Best hyperparameter
1 Random Forest warm_start : FALSE,
oob_score : FALSE, n_jobs : -1, verbose : 0, max_leaf_nodes : None, bootstrap : True, min_samples_leaf : 1, n_estimators : 1000, max_features : log2, min_weight_fraction_leaf : 0.0, criterion : gini, random_state : None, min_samples_split : 2, max_depth : None, class_weight : balanced 2 Gradient Boost presort : auto,
loss : deviance, verbose : 0, max_features : log2, max_leaf_nodes : None, learning_rate : 0.1, warm_start : FALSE, min_samples_leaf : 1, n_estimators : 1000, subsample : 1.0, init : None, min_weight_fraction_leaf : 0.0, random_state : None, min_samples_split : 2, max_depth : 3 3 KNN n_neighbors : 300, n_jobs : -1, algorithm : auto, metric : manhattan, metric_params : None, p : 2, weights : distance, leaf_size : 30
39 Lampiran 4 Hyperparameter terbaik dari setiap metode machine learning (Lanjutan)
No Metode Best hyperparameter
4 AdaBoost presort : FALSE,
splitter : best, learning_rate : 1.0, algorithm : SAMME.R, base_estimator : DecisionTreeClassifier, min_samples_leaf : 1, n_estimators : 300, max_features : auto, min_weight_fraction_leaf : 0.0, criterion : gini, random_state : None, max_leaf_nodes : None, min_samples_split : 2, max_depth : None 5 SVM kernel : linear, C : 0.1, verbose : FALSE, degree : 3, coef0 : 0.0, shrinking : TRUE, decision_function_shape : ovo, probability : FALSE, random_state : None, cache_size : 200, tol : 0.001, max_iter : -1, gamma : auto, class_weight : None