________________________________________________________________________________________________
LW/Basic Biostatitics_2005/HKI/module
II. MENDESKRIPSIKAN DATA
13 Desember 2005
Analisis Deskriptif
Tujuan dari analisis deskritif adalah memberikan gambaran ringkas tentang suatu data. Data bisa berupa data categorical atau data non-categorical. Meringkas data dalam bentuk angka statistik (Statistics) dapat dilakukan dengan beberapa cara berdasarkan:
1. Letak pusat data: persentase, mean, median, mode 2. Variasi data: rentang (range), standar deviasi, percentile
Untuk mendapatkan angka statistik (Statistics) seperti yang disebutkan diatas, kita dapat menggunakan fungsi Analyze – Descriptive Statistics – Frequencies (lihat gambar 2.1a.).
Gambar 2.1a. Menu Frequencies
Dalam kotak dialog Frequencies, kita dapat membuat pilihan Statistics dengan langkah-langkah sebagai berikut:
1. Sorot variabel yang akan dideskripsikan, lalu klik pada tanda í untuk memasukkan variabel tersebut ke dalam kotak dibawah Variable(s): (lihat gambar 2.1b.)
2. Pilih Display frequency tables di kotak dialog Frequencies untuk menampilkan persentase dari suatu kategori untuk data categorical, misalnya persentase jumlah responden di setiap kabupaten (var: kab), persentase ibu nifas yang menerima kapsul vitamin A (var: vaprogpp). Biasanya command/perintah ini sudah aktif secara otomatis (set as a default) pada saat kita menggunakan menu Frequencies (lihat
________________________________________________________________________________________________
LW/Basic Biostatitics_2005/HKI/module
gambar 2.1b.). Kemudian klik OK. Hasil analisis atau output SPSS berupa tabel frekuensi dapat dilihat pada output 2.1.
Gambar 2.1b. Menampilkan Tabel Frekuensi
Output 2.1. Frequency Table
Statistics 980 988 8 0 Valid Missing N Program of giving VA capsule to postpartum mother Code of district
Program of giving VA capsule to postpartum mother
205 20.7 20.9 20.9 730 73.9 74.5 95.4 45 4.6 4.6 100.0 980 99.2 100.0 8 .8 988 100.0 No Yes Sometimes Total Valid 9 Missing Total
Frequency Percent Valid Percent
Cumulative Percent
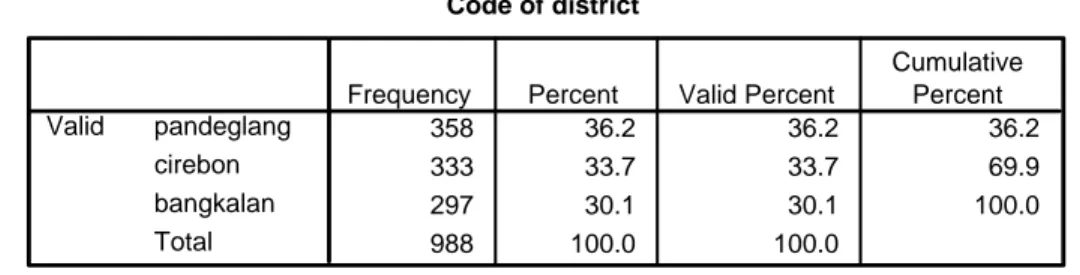
________________________________________________________________________________________________ LW/Basic Biostatitics_2005/HKI/module Code of district 358 36.2 36.2 36.2 333 33.7 33.7 69.9 297 30.1 30.1 100.0 988 100.0 100.0 pandeglang cirebon bangkalan Total Valid
Frequency Percent Valid Percent
Cumulative Percent
Interpretasi output 2.1:
Table Statistics menjelaskan tentang jumlah data point (N) yang ada/valid untuk diproses pada variabel vaprogpp (N = 980) dan kab (N= 988). Sedangkan jumlah data point yang hilang (missing value) adalah delapan (8) pada variabel vaprogpp dan nol (0) pada variabel kab.
Tabel Program of Giving Vitamin A capsule to Postpartum mother dan tabel Code of district merupakan tabel frekuensi. Cara menginterprestasikan isi tabel: ¾ Kolom pertama berisi kategori dari variabel categorical.
Contoh untuk variabel kabupaten, terdiri dari 3 kategori: Pandeglang, Cirebon dan Bangkalan.
¾ Kolom kedua (Frequency): menunjukkan jumlah data yang valid (N) dari tiap kategori.
Contoh: jumlah responden di kabupaten Pandeglang = 358.
¾ Kolom ketiga (Percent): menunjukkan persentase dari jumlah data valid per kategori dibagi dengan jumlah total data.
Contoh: pada tabel Program of Giving Vitamin A capsule to Postpartum mother, jumlah ibu yang tidak menerima program vitamin A postpartum adalah 205/988 x 100% = 20,7%
¾ Kolom keempat (Valid Percent): menunjukkan hal yang sama dengan Percent jika tidak ada data yang hilang (missing value), seperti di tabel Code of district. Jika ada data yang hilang, maka Valid Percent menunjukkan persentase jumlah data valid per kategori dibagi dengan jumlah total data valid.
Contoh: pada tabel Program of Giving Vitamin A capsule to Postpartum mother, valid percent dari ibu yang tidak menerima program vitamin A postpartum adalah 205/980 x 100% = 20,9%
¾ Kolom kelima (Cumulative Percent): baris pertama menunjukkan Valid Percent dari kategori pertama, baris kedua menunjukkan kumulatif dari Valid Percent kategori pertama dengan Valid Percent kategori kedua dan seterusnya hingga pada akhirnya mencapai jumlah 100%.
Contoh: pada tabel Program of Giving Vitamin A capsule to Postpartum mother, Cumulative Percent di baris pertama adalah 20.9 dan pada baris kedua adalah 20.9 + 74.5 = 95.4 dan pada baris terakhir adalah 95.4 + 4.6 = 100%.
________________________________________________________________________________________________
LW/Basic Biostatitics_2005/HKI/module
3. Untuk mendeskripsikan data non-categorical berdasarkan letak pusat data (mean, median, mode) dan variasi data (standar deviasi, percentile, maksimum, minimum), klik Statistics dalam kotak dialog Frequencies. Dalam kotak dialog Statistics pilih angka statistik yang diperlukan untuk mendeskripsikan data. (lihat gambar 2.1c.), kemudian klik Continue – OK. Hasil analisis dapat dilihat pada output 2.2.
Gambar 2.1c. Kotak Dialog Statistics Output 2.2. Ringkasan dari data non-categorical
Statistics 961 988 27 0 -1.2976 28.06 -1.3600 27.00 1.30968 6.499 8.04 33 -5.18 17 2.86 50 -2.8880 20.00 .3500 37.00 Valid Missing N Mean Median Std. Deviation Range Minimum Maximum 10 90 Percentiles Nilai HAZ (tinggi menurut umur) anak Umur ibu (dalam tahun)
________________________________________________________________________________________________
LW/Basic Biostatitics_2005/HKI/module
Interpretasi output 2.2:
Dalam table Statistics terdapat deskripsi data HAZ (tinggi menurut umur) anak dan umur ibu (dalam tahun).
¾ N menunjukkan jumlah data valid pada masing-masing variabel mage dan chaz. Pada variabel chaz terdapat 27 data yang hilang (missing value) dan pada variabel mage tidak ada data yang hilang.
¾ Mean menerangkan nilai rata-rata dari HAZ (tinggi menurut umur) anak dan umur ibu (dalam tahun). Jadi nilai rata-rata HAZ anak = -1,2976 SD dan nilai rata-rata umur ibu = 28,06 tahun.
¾ Median menerangkan data point yang letaknya tepat di tengah-tengah setelah data point dalam suatu variabel diurutkan (dari terbesar ke yang terkecil atau sebaliknya). Jadi angka median ini akan membagi data set dalam satu variabel menjadi 2 bagian sama besar. Contohnya: median -1,3600 SD menerangkan bahwa 50% dari anak yang menjadi subyek survei mempunyai HAZ -1,3600 SD ke atas dan 50% yang lainnya mempunyai HAZ 1,3600 SD ke bawah. Median usia ibu 27 tahun menunjukkan 50% dari ibu yang menjadi subyek survei berumur 27 tahun ke atas dan 50% yang lainnya berusia 27 tahun ke bawah.
¾ Standar deviasi (SD) menunjukkan sebaran/rentang/variasi data. Jika diasumsikan rentang usia ibu terletak pada 2 SD dari mean, dan nilai SD = 6,499, maka rentang usia ibu adalah: 28,06 ± (2 x 6,499) = 15,06 sampai 41,06 tahun. ¾ Maximum menunjukkan data point dengan nilai terbesar dalam suatu variabel.
Dan Minimum menunjukkan data point dengan nilai terkecil dalam suatu variabel. Kedua nilai ini, sama halnya dengan SD, bisa digunakan untuk mendeskripsikan rentang data. Jika kita perhatikan rentang data yang dideskripsikan dengan angka minimum dan angka maksimum masih berada dalam rentang data yang dihitung dengan menggunakan mean ± 2 SD. Range data dapat dihitung dengan adalah data maksimum – data minimum. Jika umur ibu termuda yang menjadi subyek survei adalah 17 tahun dan umur ibu tertua adalah 50 tahun, maka range umur ibu = 50-17 = 33 tahun.
¾ Percentile menunjukkan persentase subyek yang mempunyai nilai data point lebih kecil dari nilai percentile itu sendiri. Contohnya: jika 10 percentile dari data usia ibu adalah = 20, berarti ada 10% ibu berusia di bawah 20 tahun. Dan jika 90 percetile-nya = 37, berarti ada 90% ibu berusia di bawah 37 tahun.
Split File
Pada beberapa kondisi, jika kita ingin mendeskripsikan suatu data tetapi analisisnya dibagi dalam kelompok tertentu, misalnya kita ingin mendeskripsikan usia ibu dalam bentuk mean, median, standar deviasi, maximum, minimum, percentile di setiap kabupaten. Hal ini dapat dilakukan dengan menggunakan fungsi Split File. Tekan tombol Data yang ada di layar tampilan Variable View, kemudian klik Split File. Di dalam kotak dialog Split File, pilih Compare groups, lalu sorot variabel yang akan digunakan untuk mengelompokkan hasil analisis (dalam hal ini variabel kab), klik tanda í untuk memasukkan variabel tersebut ke dalam box di bawah Group based on:. Untuk meniadakan fungsi Split File, pilih analyze all cases, do not create groups yang ada di
________________________________________________________________________________________________
LW/Basic Biostatitics_2005/HKI/module
kotak dialog Split File. (lihat gambar 2.2a. dan gambar 2.2b.). Hasil analisis, setelah dilakukan split file, akan terpisah berdasarkan kabupaten seperti pada output 2.3.
Gambar 2.2a. Fungsi Split File
________________________________________________________________________________________________
LW/Basic Biostatitics_2005/HKI/module
Output 2.3. Hasil analisis setelah split file
Statistics
Umur ibu (dalam tahun)
358 0 28.71 28.00 7.107 33 17 50 20.00 39.00 333 0 27.85 27.00 6.128 27 18 45 20.00 36.00 297 0 27.51 26.00 6.078 30 18 48 20.00 35.00 Valid Missing N Mean Median Std. Deviation Range Minimum Maximum 10 90 Percentiles Valid Missing N Mean Median Std. Deviation Range Minimum Maximum 10 90 Percentiles Valid Missing N Mean Median Std. Deviation Range Minimum Maximum 10 90 Percentiles pandeglang cirebon bangkalan Select Cases
Adakalanya pula kita ingin mendeskripsikan suatu data hanya dalam kelompok tertentu saja, misalnya kita ingin mendeskripsikan usia ibu dalam bentuk mean, median, standar deviasi, maximum, minimum, percentile hanya di kabupaten Pandeglang. Hal ini dapat dilakukan dengan menggunakan fungsi Select Cases. Tekan tombol Data yang ada di layar tampilan Variable View, kemudian klik Select Cases (letaknya tepat dibawah menu Split File). Di dalam kotak dialog Select Cases, pilih if condition is satified, lalu tekan tombol If… (lihat gambar 2.3a.) untuk membuka kotak dialog berikutnya.
________________________________________________________________________________________________
LW/Basic Biostatitics_2005/HKI/module
Gambar 2.3a. Fungsi Select Cases
Sorot variabel yang akan digunakan untuk memilih kelompok hasil analisis (dalam hal ini variabel kab), klik tanda í untuk memasukkan variabel tersebut ke dalam box di sebelah kanannya, lalu tekan tombol =, setelah itu tekan tombol 1 jika hasil analisis yang akan kita tampilkan hanya data dari kabupaten Pandenglang saja. Klik Continue – OK (lihat gambar 2.3b.).
________________________________________________________________________________________________
LW/Basic Biostatitics_2005/HKI/module
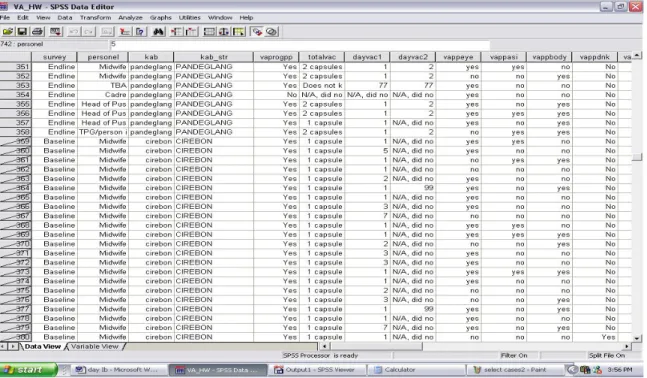
Tampilan di layar Data View setelah fungsi Select Cases diaktifkan dapat dilihat pada gambar 2.4. Dalam hal ini hanya data dari kabupaten Pandeglang saja yang dapat dianalisa nantinya, sementara data dari kabupaten lain akan “dikeluarkan” dari analisa sampai fungsi Select Cases ditiadakan atau diubah. Untuk meniadakan fungsi Select Cases, pilih All Cases yang ada di kotak dialog Select Cases.
Gambar 2.4. Tampilan pada Data View saat fungsi Select Cases diaktifkan
Hasil analisis data setelah fungsi Select Cases diaktifkan dapat dilihat di Output 2.4. Output 2.4. Hasil analisis jika fungsi Select Cases diaktifkan
Statistics
Umur ibu (dalam tahun)
358 0 28.71 28.00 7.107 33 17 50 20.00 39.00 Valid Missing N Mean Median Std. Deviation Range Minimum Maximum 10 90 Percentiles pandeglang