Pendahuluan Datamining
Ketika kita disodori sejumlah data dari suatu subjek atau kejadian, apa yang bisa kita lakukan Untuk menindak lanjutinya? Kita perlu mengolahnya untuk mendapatkan kecenderungan tertentu dari data tersebut. Misalkan data itu tentang mahasiswa baru, mungkin bisa kita kelompokkan berdasarkan asal SMU atau tingginya nilai tes masuk atau berdasarkan kedua – duanya. Setelah proses pengelompokan ini mungkin akan kita dapatkan mahasiswa berdasarkan kategori dari SMU swasta dengan nilai tertentu. Kemudian kita bisa melakukan analisis lebih jauh, mengenali pola data mahasiswa tersebut. Misalnya kecenderungan jika mahasiswa berasal dari negeri akan menapatkan indeks prestasi tinggi di semester pertama atau kecenderungan yang lain.
Kemudian kita juga bisa melakukan pekerjaan prediksi atas apa yang akan terjadi pada seorang mahasiswa berasarkan data masa sebelumnya berkaitan dengan indeks prestasi yang akan dicapainya pada semester satu. Pekerjaan – pekerjaan seperti ini dalam dunia ilmiah sering disebut dengan pattern recognition atau pengenalan pola. Pengenalan pola adalah bagian dari data mining. Jadi pengenalan pola adalah suatu disiplin ilmu yang mempelajari bagaimana kita mengelompokkan obyek ke berbagai kelas dan bagaimana dari data bisa kita temukan kecenderungannya. Yang pertama mengacu pada kasus klasifikasi dan yang kedua mengacu pada regresi. Data mining juga meliputi langkah – langkah menentukan varibel atau fitur yang penting untuk di pakai dalam klasifikasi dan regresi. Data mining memegang peran penting dalam bidang industry, keuangan, cuaca, ilmu dan teknologi. Data mining berkenaan dengan pengolahan data dalam skala besar. Berikut ini adalah contoh – contoh data volume besar yang sekarang tersedia di dunia.
• Very Long Baseline Interferometry (VLBI) milik Eropa mempunyai 16 teleskop, dimana setiap satunya
menghasilkan data sebesar 1 Gigabit / detik data astronomi . Ini membawa konsekuensi penyimpanan
anilisis suatu problem skala besar.
• AT- T menangani milyaran panggilan telepon per hari
• Berdasarkan survey Winter Corp .2003: france telecom mempunyai decision – support DB , 30 TB
(tera bit) ; AT & T 26 TB
• UC Berkeley 2003 mengestimasi 5 exabytes ( 5 juta terabytes) data baru dihasilkan pada tahun 2002
Winter Corp melakukan survei mengenai ukuran data paling besar dalam beberapa tahun terakhir.
Dalam dua tahun terakhir ukuran ini menjadi 3 kali lipat ( Piatetsky and Shapiro, 2006).
Banyak kasus dalam kehidupan sehari – hari yang memakai teknik – teknik data mining yang
dipelajari dalam buku ini. Istilah ini mungkin belum begitu di kenal di kalangan mahasiswa maupun
dosen atau kalangan umum termasuk industry. Contoh – contoh berikut ini memperlihatkan masalah –
masalah dalam data mining :
1. Memprediksi harga suatu saham dalam beberapa bulan ke depan berdasarkan performansi perusahaan dan data – data ekonomi. 2. Memprediksi apakah seorang pasien yang diopname akan
mendapatkan serangan jantung berikutnya berdasarkan catatan kesehatan sebelumnya dan pola makananya.
3. Memprediksi permintaan semen dalam beberapa tahun mndatang berdasarkan data permintaan semen di tahun - tahun sebelumnya. 4. Memprediksi apakah akan terjadi tornado berdasarkan informasi dari
sebuah radar tentang kondisi angin dan atmosfir yang lain.
5. Identifikasi apakah sudah trjadi penipuan terhadap pengguna kartu kredit dengan melihat catatan transaksi yang tersimpan dalam database perusahaan kredit.
6. Barang apa yang biasanya dibeli oleh customer supermarket ketika dia membeli diaper bayi? bagaimana manajemen supermarket member respon stelah mengetahui pola pembelian customer.
7. Berapa persen kira – kira customer yang akan lari dari service atau produk kita? Bagaimana mencegahnya?
8. Dalam hal orang meminta hutang ke suatu bank. Haruskah suatu bank menyetujui hutang tersebut? Orang yang punya sejarah paling bagus biasanya tidak perlu hutang, dan orang yang mempunyai sejarah paling buruk biasanya tidak akan membayar hutang. Customer bank yang terbaik adalah yang ditengah –tengah.
9. Dalam e-commerce, misalkan seseorang membeli buku lewat
Amazon.com. Kita bisa menyarankan buku lain apa yang seharusnya dibeli oleh customer yang sama. Amazon bisa melakukan klastering data buku – buku yang dibeli. Misalnya customer yang membeli Data Mining : Teknik memanfaatkan data , juga membeli Data Mining dengan Matlab.
10. Diberikan data microarray untuk sejumlah sampel (pasien),
Prediksi hasil dari suatu treatment terhadap pasien ? Rekomendasikan treatment terbaik?
11. Dalam marketing : menemukan kelompok customer dan
mempergunakan untuk target pemasaran dan re-organization.
12. Dalam Astronomi: menemukan kelompok bintang yang mirip dan
galaksi.
13. Gemomics : menemukan kelompok gen dengan tingkat ekspresi
yang mirip.
Tentu saja masih banyak lagi contoh – contoh dari berbagai bidang yang bisa dimasukkan atau bisa diselesaikan dengan teknik – teknik data mining. Teknik – teknik belajar (learning) memegang peran kunci dalam masalah - masalah di atas. Masalah – masalah yang sesuai untuk
diselesaikan dengan teknik data mining bila dicirikan dengan (Piatetsky and Shapiro, 2006)
• Memerlukan keputusan yang bersifat knowledge – based • Mempunyai lingkungan yang berubah
• Metode yang ada sekarang bersifat sub – optimal • Tersedia data yang bisa diakses, cukup dan relevan
• Memberikan keuntungan yang tinggi jika keputusan yang diambil tepat
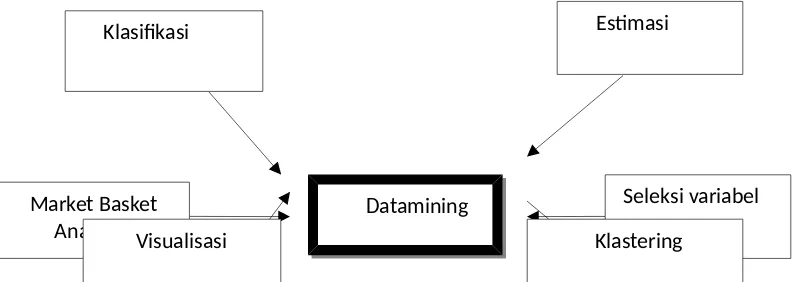
Secara umum kajian data mining meliputi hal – hal seperti dalam Gambar 1.1
Buku ini memperkenalkan dan membahas metode – metode yang sering dipaki dalam data mining. bahasan terutama ditujukan untuk klastering,klasifikasi,regresi, seleksi variabel dan market basket analisis atau aturan asosiasi. Dalam contoh di atas, harga aham masuk dalam variabel kuantitatif yang nilainya kontinyu. Sedangkan output dari
prediksi kita terhadap tornado berupa variabel diskrit atau kategori yaitu ada tornado atau tidak. Untuk masalah harga saham kita menggunakan teknik prediksi yang sering di sebut regresi. Dalam prediksi tornado kita gunakan teknik klasifikasi. Apa yang akan kita lalukan terhadap data yang kita miliki secara umum dan urutan langkahnya digambarkan dalam Gambar 1.2.
Datamining Klasifikasi
Market Basket Analisis
Estimasi
Gambar 1.1 Beberapa kajian yang masuk dalam Data Mining
Untuk ilustrasi lebih jauh, lihat sebagian data Iris Fisher (1936) dalam Tabel 1.1 berikut yang
menandakan jenis bunga berdasarkan panjang sepal, lebar sepal, panjang petal dan lebar petal.
Sedangkan jenis bunga bisa di kelompokkan alam Virginica, Setosa dan Versicolor . Jenis - jenis bunga
iris ini bisa diubah ke dalam nilai numeric, misalkan 1 untuk Virginica, 2 untuk Setosa dan 3 untuk
Versicolor. Dalam hal ini, panjang panjang sepal, lebar sepal, panjang petal dan lebar petal kita sebut
Sebagai atribut atau variabel. Nilai dari variabel ini kita sebut input. Sedangkan jenis bunga kita namakan
sebagai output.