NAÏVE BAYES
Diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Teknik Informatika
Disusun Oleh : NANDA IRWANSYAH
311410187
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA CIKARANG
iv
Tuberculosis (TBC) Menggunakan Algoritma Naïve Bayes”. Yang merupakan syarat dalam menyelesaikan Program Studi Sl pada Program Studi Teknik Informatika, Sekolah Tinggi Teknologi Pelita Bangsa.
Selama penulisan skripsi ini penulis mendapat banyak bantuan dan bimbingan dari berbagai pihak, untuk itu pada kesempatan ini penulis mengucapkan terima kasih yang sebesar-besarnya. pada :
1. Dr. Ir. Supriyanto, M.P., selaku Ketua Sekolah Tinggi Teknologi Pelita Bangsa.
2. Aswan Supriyadi Sunge, S.E, M.Kom., selaku Ketua Program Studi Teknik Informatika Sekolah Tinggi Teknologi Pelita Bangsa.
3. Bapak Makmum Effendi S.Kom.,M.Kom. selaku Dosen Pembimbing I 4. Bapak Rosi’in M.Pd selaku Dosen Pembimbing II.
5. Seluruh Dosen Teknik Informatika.
6. Rekan-rekan mahasiswa STT Pelita Bangsa angkatan 2014.
7. Ayah dan Ibu saya telah banyak memberikan dukungan maupun do'a kepada saya sehingga semua dapat berjalan dengan lancar.
8. Seluruh keluarga yang ada di bekasi
9. Semua pihak yang telah menbantu penulis dalam menyelesaikan Skripsi. Penulis sadar bahwa tentunya dalam penulisan skripsi ini masih banyak terdapat kekurangan untuk itu saran dan kritik dari pembaca yang sifatnya membangun sangat diharapkan, demi pengembangan kemampuan penulis ke depan.
v
estimasi, assosiasi, clustering, dan deskripsi. Sekumpulan data yang ada di laboratorium klinik belum difungsikan secara efektif dan hanya di fungsikan sebagai arsip untuk riwayat penyakit pasien. Tuberculosis (TBC) adalah penyakit menular paru-paru yang disebabkan oleh basil Mycobacterium tuberculosis. Penyakit ini ditularkan dari penderita TBC aktif yang batuk dan mengeluarkan titik-titik kecil air liur dan terinhalasi oleh orang sehat yang tidak memiliki kekebalan tubuh terhadap penyakit ini. TBC termasuk dalam 10 besar penyakit yang menyebabkan kematian di dunia menurut World Health Organization. Pada penelitian ini akan memprediksi penyakit tuberculosis dengan algoritma klasifikasi data mining Naive Bayes menggunakan aplikasi Rapidminer. Pengukuran dengan Naives Bayes menghasilkan akurasi 89,74%. Kata Kunci: Data Mining, Penyakit Tuberculosis, Naive Bayes.
vi
1.1 Latar Belakang ... 1
1.2 Identifikasi Masalah ... 4
1.3 Rumusan Masalah ... 4
1.4 Batasan Masalah ... 4
1.5 Tujuan dan Manfaat ... 4
1.5.1 Tujuan ... 4
1.5.2 Manfaat ... 4
1.6 Metode Pengumpulan Data ... 5
1.7 Sistematika Penulisan ... 6
BAB II ... 9
LANDASAN TEORI ... 9
2.1 Pengertian Implementasi ... 9
2.2 Pengertian Diagnosis ... 9
2.3 Pengertian Penyakit Tuberculosis ... 10
2.4 Data Mining ... 10
2.4.1 Pengertian Data Mining ... 10
2.4.2 Tugas – Tugas Data Mining ... 12
2.5 Arsitektur Sistem Data Mining ... 14
2.6 Penyimpanan Data dalam Data Mining ... 16
2.7 Tahap – Tahap Data Mining ... 17
2.8 Teknik – Teknik Data Mining ... 19
2.8.1 Macam – macam Tekhnik Data Mining ... 19
2.8.2 Teknik Classification menggunakan Naïve Bayes ... 21
2.9 Implementasi (Penerapan Data Mining) ... 23
2.10 Metode Penelitian Data Mining ... 24
vii
2.13 Penelitian Terdahulu ... 33
2.14 Spesifikasi Kebutuhan Software dan Hardware ... 33
BAB III ... 36
METODE PENELITIAN ... 36
3.1 Kerangka Pemikiran ... 36
3.2 Sekilas Tentang Rumah Sakit Umum Daerah Padangan ... 37
3.2.1 Waktu dan Tempat Penelitian ... 38
3.3 Metode Pengumpulan Data ... 38
3.3.1 Hasil Wawancara ... 39
3.4 Desain Penelitian ... 40
3.5 Analisis metode yang berjalan ... 40
3.6 Akuisisi Pengetahuan ... 41
3.7 Analisa Sistem ... 42
3.8 Perancangan Sistem ... 43
3.8.1 Metode Algoritma Naïve Bayes ... 43
3.8.2 Pengumpulan Data ... 44
3.8.3 Model yang diusulkan ... 45
BAB IV ... 48
HASIL DAN PEMBAHASAN ... 48
4.1 Langkah Perhitungan ... 48
4.2 Seleksi Data ... 49
4.3 Metode yang diusulkan ... 52
4.4 Hasil Pengujian Prediksi Diagnosa ... 52
4.4.1 Prediksi Menggunakan Perhitungan Manual ... 52
4.4.2 Prediksi Menggunakan Rapid Miner ... 56
viii BAB V ... 68 PENUTUP ... 68 a. Kesimpulan ... 68 b. Saran ... 68 DAFTAR PUSTAKA ... 69
ix
Gambar 2.4 Intrface Rapid Miner Pada Data Mining Naïve Bayes ... 35
Gambar 3.1 Kerangka Pemikiran ... 37
Gambar 3.2 Activity Diagram Diagnosa Prediksi Penyakit Tuberculosis ... 41
Gambar 3.3 Model Pengujian ... 46
Gambar 4.1 Model Agoritma Naïve Bayes ... 47
Gambar 4.2 Metode Untuk Menentukan Performance Algoritma ... 52
Gambar 4.3 Design Rapid Miner Prediksi Data Testing ... 58
Gambar 4.4 Hasil Prediksi Data Testing Di Rapid Miner ... 59
Gambar 4.5 Simple Distribution Model ... 60
Gambar 4.6 Grafik Ditribusi Label ... 62
Gambar 4.7 Accuracy ... 63
Gambar 4.8 Precision ... 64
Gambar 4.9 Recall ... 65
Gambar 4.10 Kurva ROC ... 67
x
Tabel 4.1 Seleksi Data ... 50
Tabel 4.2 Setelah Proses Seleksi Data ... 51
Tabel 4.3 Data Training ... 53
Tabel 4.4 Data Testing ... 54
Tabel 4.5 Data Distribusi ... 61
1 BAB 1 PENDAHULUAN
1.1 Latar Belakang
Rumah Sakit Umum Daerah Padangan merupakan unit pelayanan teknis dinas kesehatan Kabupaten Bojonegoro yang bertanggung jawab menyelenggarakan pembangunan kesehatan di wilayah Kecamatan Padangan. Rumah Sakit Umum Daerah Padangan mempunyai wewenang dan tanggungjawab atas pemeliharaan kesehatan masyarakat dalam wilayah kerja di seluruh Kecamatan Padangan dan sekitarnya.
Rumah Sakit Umum Daerah Padangan telah menerima dan mengobati beragam jenis penyakit dari masyarakat di Daerah Bojonegoro khususnya di Kecamatan Padangan. Penyakit tersebut antara lain adalah typhoid fever, Diabetes Melitus, Demam berdarah dengue (DBD), Malaria, liver, dan Tuberculosis (TBC). Dalam beberapa penyakit diatas, penyakit Tuberculosis (TBC) adalah yang paling melakukan peningkatan dari tahun ke tahun yaitu sebesar 30%. Hal ini sangat mengejutkan karena begitu membahayakannya penyakit ini.
Tuberculosis (TBC) adalah penyakit menular paru-paru yang disebabkan oleh basil Mycobacterium tuberculosis. Penyakit ini ditularkan dari penderita TBC aktif yang batuk dan mengeluarkan titik-titik kecil air liur dan terinhalasi oleh orang sehat yang tidak memiliki kekebalan tubuh terhadap penyakit ini. TBC termasuk dalam 10 besar penyakit yang menyebabkan kematian di dunia. Data WHO menunjukkan bahwa
pada tahun 2015, Indonesia termasuk dalam 6 besar negara dengan kasus baru TB terbanyak.
Teknologi informasi di bidang kesehatan atau kedokteran komputer juga telah memperlihatkan peran yang sangat signifikan untuk menolong jiwa manusia dan riset di bidang kedokteran. Komputer digunakan untuk mendiagnosis penyakit, menemukan obat yang tepat serta menganalisis organ tubuh manusia bagian dalam yang sulit untuk dilihat. Saat ini telah ada temuan baru yaitu komputer DNA yang mampu mendiagnosis penyakit sekaligus memberi obat.
Oleh Karena itu kemajuan teknologi mendorong setiap instansi – instansi dalam dunia kesehatan yaitu Rumah Sakit untuk meningkatkan mutu pelayanan terhadap pasien melalui cara melibatkan kemajuan teknologi dalam dunia kesehatan. Dimana nantinya pihak Rumah Sakit Umum Daerah Padangan mampu mendiagnosa penyakit menggunakan teknologi.
Rumah Sakit Umum Daerah Padangan mengidentifikasi penyakit Tuberculosis secara manual terhadap pasien dengan keluhan awal yaitu antara lain batuk berkepanjangan, batuk disertai bercak darah, penurunan berat badan drastis, berkeringat pada malam hari, infeksi tidak kunjung sembuh, tidak nafsu makan, nyeri dada, sesak nafas dan fisik lemah. Tahap diagnosa awal untuk mengetahui positif atau negatif nya penyakit tuberculosis memerlukan waktu yang tidak singkat. Perlu setidaknya beberapa minggu hanya untuk mengetahui diagnosa awal penyakit tuberculosis. Setelah mengikuti kemajuan teknologi, diharapkan Rumah Sakit Umum Daerah Padangan menggunakan data mining untuk mendiagnosa penyakit tuberculosis
sehingga tidak memerlukan waktu beberapa hari untuk mengetahui pasien tersebut positif penyakit tuberculosis atau negatif.
Data mining juga sering disebut sebagai kegiatan mengeksplorasi dan menganalisis data dalam jumlah yang besar untuk menemukan pattern dan rule yang berarti (Berry, 2004). Data mining digunakan untuk mencari informasi bisnis berharga dari basis data yang sangat besar, yang dipakai untuk memprediksi tren dan sifat – sifat bisnis serta menemukan pola - pola yang tidak diketahui sebelumnya.
Dengan adanya masalah tersebut serta ada solusi untuk mengatasi dan penerapan metode penelitian menggunakan data mining terhadap pasien untuk mendiagnosa penyakit tersebut maka penulis akan mengusulkan judul skripsi “Implementasi Data Mining Untuk Diagnosa Prediksi Penyakit Tuberculosis (TBC) Menggunakan Algoritma Naïve Bayes”.
1.2 Identifikasi Masalah
Adapun identifikasi masalah dari latar belakang diatas adalah karena sering terjadi di masyarakat sulitnya dalam melakukan diagnosa awal dari penyakit tuberculosis (TBC). Dikarenakan penyakit Tuberculosis (TBC) mempunyai gejala – gejala yang berjumlah cukup banyak dan terdapat kesamaan gejala yang dimiliki penyakit lain serta memerlukan waktu yang lama untuk mendiagnosa awal penyakit tersebut.
1.3 Rumusan Masalah
Dari identifikasi masalah yang terjadi, maka perumusan masalah yang akan dibahas dalam penulisan ini adalah bagaimana melakukan prediksi data mining untuk jenis data penyakit tuberculosis di Rumah Sakit Umum Daerah Padangan sehingga pasien dapat melihat hasil diagnosa awal dari gejala dengan cepat dan cukup akurat ?
1.4 Batasan Masalah
Penulis membatasi masalah dalam penelitian ini, agar dalam pembahasan dilaporan penelitian dapat terarah dan mencapai tujuan. Batasan masalah membahas pendataan dalam kurun waktu 3 tahun ke belakang mengenai gejala – gejala yang di derita oleh pasien penyakit Tuberculosis (TBC) menggunakan data mining dengan metode naïve bayes classifier.
1.5 Tujuan dan Manfaat 1.5.1 Tujuan
Berdasarkan latar belakang dan rumusan masalah yang telah diuraikan diatas maka tujuan dari penelitian ini adalah tentang penerapan data mining menggunakan metode naïve bayes untuk memprediksi penyakit Tuberculosis (TBC).
1.5.2 Manfaat
Adapun manfaat dari penulisan tugas akhir ini dibagi menjadi beberapa bagian yaitu :
a. Bagi Penulis
Manfaat bagi penulis yaitu dapat mengimplementasikan ilmu pengetahuan yang telah didapatkan penulis selama masa perkuliahan dan dapat memahami penerapan data mining serta metode naïve bayes.
b. Bagi Institusi
Manfaat bagi institusi yaitu dengan adanya penerapan data mining ini dapat membantu dpkter dalam mendiagnosa penyakit Tuberculosis (TBC) tersebut.
c. Bagi Instansi
Manfaat bagi instansi yaitu diharapkan dapat menjadi tambahan bagi peneliti selanjutnya untuk meneliti variable yang lain yang berkaitan dengan diagnosa penyakit Tuberculosis (TBC) menggunakan data mining dengan metode naïve bayes classifier.
1.6 Metode Pengumpulan Data
Pada tahap ini penulis juga melakukan pengumpulan data yang dilakukan melalui : 1. Studi Lapangan (Field Research)
Penelitian lapangan adalah salah satu cara untuk mendapatkan data, yang dilakukan dengan cara melakukan penelitian langsung ke lokasi studi. Adapun Teknik pengumpulan data yang dilakukan adalah :
a. Metode Observasi (Pengamatan)
Merupakan salah satu metode pengumpulan data yang cukup efektif untuk mempelajari suatu sistem. Penulis melakukan pengamatan langsung pada Dokter agar data yang di dapatkan lebih akurat.
b. Metode Wawancara (Interview)
Merupakan metode yang Teknik pengumpulan data dengan cara tanya jawab secara langsung dengan narasumber yang terkait.
2. Studi Pustaka (Library Research)
Metode ini memperoleh data – data yang berhubungan dengan penulisan skripsi dari berbagai sumber bacaan seperti buku, jurnal, majalah dan lain sebagainya sebagai acuan.
3. Internet (Browsing)
Melakukan pengumpulan jurnal yang bersumber dari internet.
1.7 Sistematika Penulisan
Untuk dapat mengetahui secara ringkas permasalahan dalam penulisan laporan ini maka digunakan sistematika penulisan yang bertujuan untuk mempermudah pembaca dalam menelusuri dan memahami isi laporan. Sistematika penulisan dalam penyusunan laporan dengan judul skripsi “Implementasi Data Mining Untuk Diagnosa Prediksi Penyakit Tuberculosis (TBC) Menggunakan Algoritma Naïve Bayes Classifier” sebagai berikut :
BAB I PENDAHULUAN
Pada bab ini berisi tentang beberapa hal umum tentang maksud dan tujuan penulisan serta pelaksanaan penelitian pada Rumah Sakit Umum Daerah Padangan sebagai acuan yang terdiri dari latar belakang, identifikasi masalah, rumusan masalah, batasan masalah, tujuan dan manfaat, metode pengumpulan data serta sistematika penulisan dalam penyusunan skripsi ini.
BAB II LANDASAN TEORI
Pada bab ini menjelaskan konsep tentang Data Mining dan Metode Naïve Bayes untuk pemecahan masalah mengenai identifikasi gejala penyakit Tuberculosis (TBC) pada pasien Rumah Sakit Umum Daerah Padangan, Metode – Metode Pilihan dan Klasifikasi, definisi Unified Modelling Language (UML) serta jenis – jenis diagram UML.
BAB III METODE PENELITIAN
Pada bab ini merupakan penjabaran lebih rinci tentang metode penelitian yang digunakan dalam pencarian data yang dilakukan pada penelitian. secara garis besar telah disinggung dalam bab pendahuluan. Batasan istilah yang ada pada judul dan variable yang dilibatkan dalam pencarian data juga dijelaskan dalam bab ini. Semua prosedur, proses dan hasil penelitian sejak persiapan hingga penelitiaan berakhir akan dibahas di bab ini.
BAB IV HASIL DAN PEMBAHASAN
Pada bab ini membahas diagnosa prediksi penyakit Tuberculosis (TBC) menggunakan data mining dengan metode naïve bayes terhadap hasil penelitian yang telah dibahas di bab sebelumnya. Dan yang akan menghasilkan prediksi data mining untuk jenis data penyakit Tuberculosis (TBC), tolak ukurnya dapat dikembalikan pada persiapan, asumsi, hipotesis, metode penelitian, tolak ukur penafsiran data dan komponen – komponen yang lain.
BAB V PENUTUP
Pada bab ini berisi tentang kesimpulan dari penelitian dan hasil akhir dari pemecahan masalah setelah diteliti serta saran yang dianggap penting atau dijalankan pada masa yang akan datang untuk kesempurnaan hasil penelitian atau pemecahan masalah dimana penulisan laporan skripsi ini dilakukan.
9 BAB II
LANDASAN TEORI
2.1 Pengertian Implementasi
Pandangan Implementasi menurut Solichin Abdul Wahab adalah tindakan-tindakan yang dilakukan baik oleh individu-individu, pejabat-pejabat, atau kelompok – kelompok pemerintah atau swasta yang diarahkan pada tercapainya tujuan – tujuan yang telah digariskan dalam keputusan kebijakan (Solichin Abdul Wahab, 1997)
Nurdin Usman berpendapat bahwa implementasi bermuara pada aktivitas, aksi, tindakan, atau adanya mekanisme suatu sistem. Implementasi bukan sekedar aktivitas, tetapi suatu kegiatan yang terencana dan untuk mencapai tujuan kegiatan (Nurdin Usman, 2002 )
2.2 Pengertian Diagnosis
Diagnosa adalah identifikasi sifat – sifat penyakit atau kondisi atau membedakan satu penyakit atau kondisi dari yang lainnya. Penilaian dapat dilakukan melalui pemeriksaan fisik, tes laboratorium atau sejenisnya. Dan dapat dibantu oleh program komputer yang dirancang untuk memperbaiki proses pengambil keputusan (Carpenito, 2008).
2.3 Pengertian Penyakit Tuberculosis
Penyakit Tuberculosis adalah penyakit infeksius yang menyerang perenkim paru. Agen infeksiusnya adalah Mycobacterium tuberculosis yang merupakan batang aerobik yang tahan asam, tumbuhnya lambat dan agak sensitif dengan panas dan sinar ultraviolet. Penyakit tuberkulosis bisa ditularkan ke bagian tubuh lainnya seperti meninges, tulang, ginjal, dan nodus limfe. (Brunner & Suddarth, 2001).
Tuberculosis (TBC) adalah suatu penyakit menular langsung yang disebabkan oleh kuman TB yaitu Mycobacterium tuberculosis. Mayoritas kuman TB akan menyerang paru, akan tetapi kuman TB bisa juga menyerang organ tubuh yang lainnya. (Departemen kesehatan, 2007)
Tuberculosis merupakan jenis penyakit infeksius yang menyerang paru-paru, ditandai dengan pembentukan granuloma dan timbulnya nekrosis jaringan. Penyakit tuberkulosis ini bersifat menahun dan bisa menular dari si penderita ke orang lainnya. (Santa dkk,2009)
2.4 Data Mining
2.4.1 Pengertian Data Mining
Data Mining merupakan istilah yang sering dikatakan sebagai suatu cara untuk menguraikan serta mencari penemuan berupa pengetahuan di dalam suatu database. Data mining adalah proses pemilihan atau “menambang” pengetahuan dari sekumpulan
Data Mining adalah langkah analisis terhadap proses penemuan pengetahuan di dalam basisdata atau knowledge discovery in database atau biasa disingkat menjadi KDD (fayyed et al, 1996)
Data mining digunakan untuk mencari informasi bisnis yang berharga dari basis data yang sangat besar, yang dipakai untuk memprediksi trend dan sifat – sifat bisnis serta menemukan pola – pola yang tidak diketahui sebelumnya.
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Data mining adalah analisis otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya.
Data mining didefinisikan sebagai proses menemukan pola – pola dalam data. Proses ini otomatis atau seringnya semi otomatis. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi. Data yang dibutuhkan dalam jumlah besar.
Data mining adalah proses pengumpulan informasi penting dari sejumlah data besar yang tersimpan di dalam basis data, gudang data, atau tempat penyimpanan lainnya. Data mining merupakan proses yang tidak dapat dipisahkan dengan Knowledge Discovery in Database (KDD), Karena penambangan data adalah salah satu dari tahap dalam proses KDD. (Han & Kamber, 2006)
2.4.2 Tugas – Tugas Data Mining
Menurut Larose (2005) tugas – tugas dalam data mining secara umum dibagi ke dalam beberapa kategori yaitu :
a. Prediktif
Tujuan dari tugas prediktif adalah untuk memprediksi nilai dari atribut tertentu berdasarkan pada nilai dari atribut – atribut lain. Atribut yang diprediksi umumnya dikenal sebagai target atau variabel tak bebas, sedangkan atribut – atribut yang digunakan untuk membuat prediksi dikenal sebagai explanatory atau variabel bebas. b. Deskriptif
Tujuan dari tugas deskriptif adalah untuk menurunkan pola - pola (korelasi, trend, cluster, trayektori dan anomali) yang meringkas hubungan yang pokok dalam data. Tugas data mining deskriptif sering merupakan penyelidikan dan seringkali memerlukan Teknik post processing untuk validasi dan penjelasan hasil.
Berikut adalah tugas – tugas dalam data mining (Larose, 2006) : a. Analisis Asosiasi (Korelasi dan Kausalitas)
Analisis Asosiasi adalah pencarian aturan – aturan asosiasi yang menunjukkan kondisi – kondisi nilai atribut yang sering terjadi bersama – sama dalam sekumpulan data. Analisis asosiasi sering digunakan untuk menganalisa market basket dan data transaksi.
b. Klasifikasi dan Prediksi
Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas – kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk memprediksi kelas atau objek yang memiliki label kelas tidak diketahui. Model yang diturunkan didasarkan pada analisis dari training data (yaitu objek data yang memiliki label kelas yang diketahui). Model yang diturunkan dapat direpresentasikan dalam berbagai bentuk seperti aturan IF – THEN klasifikasi, pohon keputusan, formula matematika atau jaringan syaraf tiruan. Dalam banyak kasus, pengguna ingin memprediksi nilai – nilai data yang tidak tersedia atau hilang (bukan label dari kelas). Dalam kasus ini biasanya nilai data yang akan diprediksi merupakan data numeric. Kasus ini seringkali dirujuk sebagai prediksi.
c. Analisis Cluster
Tidak seperti klasifikasi dan prediksi, yang menganalisis objek data yang diberi label kelas, clustering menganalisis objek data dimana label kelas tidak diketahui. Clustering dapat digunakan untuk menentukan label kelas tidak diketahui dengan cara mengkelompokkan data untuk membentuk kelas baru. Sebagai contoh Clutering rumah untuk menemukan pola distribusinya. Prinsip dalam clustering adalah memaksimumkan kemiripan intra – class dan meminimumkan kemiripan interclass.
d. Analisis Outlier
Outlier merupakan objek data yang tidak mengikuti perilaku umum dari data. Outlier dapat dianggap sebagai noise atau pengecualian. Analisis data outlier dinamakan outlier mining. Teknik ini berguna dalam fraud detection dan rare event analysis.
e. Analisis Trend dan Evolusi
Analisis evolusi data menjelaskan dan memodelkan trend dari objek yang memiliki perilaku yang berubah setiap waktu. Teknik ini dapat meliputi karakterisasi, deskriminasi, asosiasi, klasifikassi atau clustering dari data yang berkaitan dengan waktu.
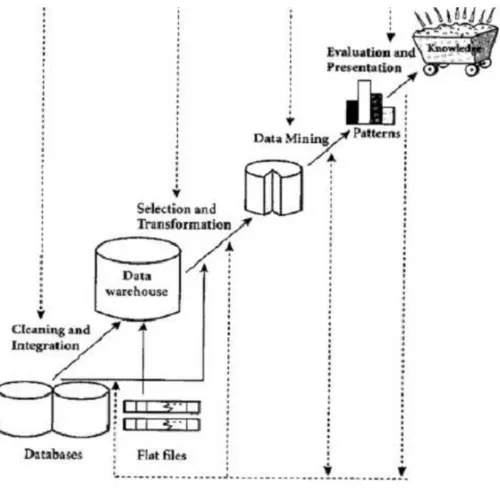
2.5 Arsitektur Sistem Data Mining
Data mining merupakan proses pencarian pengetahuan yang menarik dari data berukuran besar yang disimpan dalam basis data, data warehouse atau tempat penyimpanan informasi lainnya. Dengan demikian menurut Connoly. T & Begg. C arsitektur sistem data mining memiliki komponen – komponen utama yaitu : - Basis data, data warehouse atau tempat penyimpanan informasi lainnya. - Basis data dan data warehouse server. Komponen ini bertanggung jawab dalam
pengambilan relevan data, berdasarkan permintaan pengguna.
- Basis pengetahuan. Komponen ini merupakan domain knowledge yang digunakan untuk memandu pencarian atau mengevaluasi pola – pola yang dihasilkan. Pengetahuan tersebut meliputi hirarki konsep yang digunakan
untuk mengorganisasikan atribut atau nilai atribut ke dalam level abstraksi yang berbeda. Pengetahuan tersebut juga dapat berupa kepercayaan pengguna (user belief) yang dapat digunakan untuk menentukan kemenarikan pola yang diperoleh.
- Data Mining Engine. Bagian ini merupakan komponen penting dalam arsitektur sistem data mining. Komponen ini terdiri modul – modul fungsional data mining seperti karakterisasi, asosiasi, klasifikasi dan analisis cluster. - Modul Evaluasi Pola. Komponen ini menggunakan ukuran – ukuran
kemenarikan dan berinteraksi dengan modul data mining dalam pencarian pola – pola menarik. Modul evaluasi pola dapat menggunakan threshold
kemenaikan untuk memfilter pola – pola yang diperoleh.
- Antarmuka Pengguna Grafis. Modul ini berkomunikasi dengan pengguna dan sistem data mining. Melalui modul ini, pengguna berinteraksi dengan sistem menentukan query atau task data mining. Antarmuka juga menyediakan informasi untuk memfokuskan pencarian dan melakukan eksplorasi data mining berdasarkan hasil data mining. Komponen ini juga memungkinkan pengguna untuk mencari (browser) basis data dan skema data warehouse atau struktur data, evaluasi pola yang diperoleh dan visualisasi pola dalam berbagai bentuk.
2.6 Penyimpanan Data dalam Data Mining
Data mining dapat diaplikasikan pada berbagai jenis penyimpanan data seperti basis data relational, data warehouse, transactional database, object – oriented and object – relational databases, spatial databases, time – series data and temporal data, text databases and multimedia databases, heterogeneous and legacy databases dan WWW.
a. Basis Data Relasional
Merupakan kolekssi dari table. Setiap table berisi atribut (field) dan biasanya menyimpan sejumlah besar tuple (record). Setiap tuple dalam table relasional merepresentasikan sebuah objek yang diidentifikasikan oleh kunci unik dan dideskripsikan oleh sekumpulan nilai atribut. Data relasional dapat diakses oleh query basis data yang ditulis dalam bahasa query relasional seperti SQL atau dengan bantuan antarmuka pengguna grafis.
b. Data Warehouse
Merupakan tempat penyimpanan informasi yang dikumpulkan dari berbagai sumber, disimpan dalam skema yang dipersatukan (unified schema) dan biasanya bertempat pada tempat penyimpanan tunggal. Data warehouse dikonstruksi melalui sebuah proses data cleaning, data transformation, data integration, data loading dan periodic data refreshing. Selain data warehouse, terdapat istilah penyimpanan data yang lain yaitu datamart. Sebuah data warehouse mengumpulkan informasi mengenai subjek – subjek yang menjangkau seluruh organisasi, dengan demikian cakupannya enterprise-wide. Sedangkan datamart merupakan sub bagian dari data
warehouse. Fokus datamart adalah pada subjek yang dipilih dan dengan demikian cakupannya adalah department-wide.
c. Basis Data Transaksional
Secara umum, basis data transaksional terdiri dari sebuah file dimana setiap record merepresentasikan transaksi.
2.7 Tahap – Tahap Data Mining
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Menurut Fayyad proses KDD secara garis besar dapat dijelaskan sebagai berikut :
1. Data Selection
Pemilihan (seleksi) dari data sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan suatu berkas, terpisah dari basis data operasional.
2. Pre – Processing (Cleaning)
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi focus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, memperbaiki kesalahan pada data,
seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode atau algoritma dalam data mining sangat bervariasi pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation (Evaluation)
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
Gambar 2.1 Tahapan Proses Data Mining
2.8 Teknik – Teknik Data Mining
2.8.1 Macam – macam Tekhnik Data Mining
Dengan definisi data mining yang luas, ada banyak jenis teknik analisa yang dapat digolongkan dalam data mining. Karena keterbatasan tempat, disini penulis akan memberikan sedikit gambaran tentang tiga teknik data mining yang paling banyak digunakan menurut Larose Daniel T (2005) :
a. Association Rule Mining
Association rules (aturan asosiasi) atau affinity analysis (analisis afinitas) berkenaan dengan studi tentang “apa bersama apa”. Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan market basket analysis. Analisis asosiasi dikenal juga sebagai salah satu metode data mining yang menjadi dasar dari berbagai metode data mining lainnya.
b. Classification
Dalam klasifikasi, terdapat target variable kategori. Sebagai contoh penggolongan pendapatan dapat dipisahkan dalam tiga kategori yaitu pendapatan tinggi, pendapatan sedang dan pendapatan rendah.
c. Clustering
Termasuk metode yang sudah cukup dikenal dan banyak dipakai dalam data mining. Sampai sekarang para ilmuwan dalam bidang data mining masih melakukan berbagai usaha untuk melakukan perbaikan model clustering karena metode yang dikembangankan sekarang masih bersifat heuristic. Tujuan utama dari metode clustering adalah pengelompokkan sejumlah data / objek ke dalam cluster (group) sehingga dalam setiap cluster akan berisi data yang semirip mungkin. Dalam metode ini tidak diketahui sebelumnya berapa jumlah cluster dan bagaimana pengelompokannya.
Berikut ini adalah 9 algoritma penggalian data yang paling sering digunakan berdasarkan konferensi ICDM ’06 :
1. C4.5 2. K-Means 3. SVM 4. Apriori 5. EM 6. PageRank 7. AdaBoost 8. kNN 9. Naïve Bayes
2.8.2 Teknik Classification menggunakan Naïve Bayes
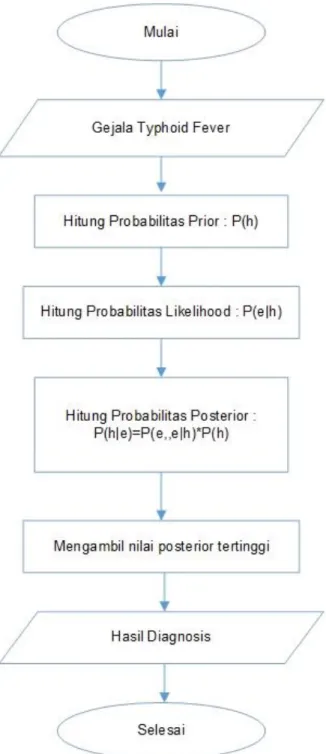
Naïve Bayes merupakan sebuah metoda klasifikasi menggunakan metode probabilitas dan statistic yang dikemukakan oleh ilmuwan Inggris Thomas Bayes. Naïve Bayes memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai Teorema Bayes.
Gambar 2.2 Diagram Alir Naïve Bayes (Jurnal PPTIK Vol.2, No.8, Agustus 2018)
2.9 Implementasi (Penerapan Data Mining) Beberapa contoh bidang penerapan data mining : 1. Analisa pasar dan manajemen
Solusi yang dapat diselesaikan dengan data mining, diantaranya : menembak target pasar, melihat pola beli pemakai dari waktu ke waktu, cross-market analysis, profil customer, identifikasi kebutuhan customer, menilai loyalitas customer, informasi summary.
2. Analisa perusahaan dan manajemen resiko
Solusi yang dapat diselesaikan dengan data mining, diantaranya : perencanaan dan evaluasi aset, perencanaan sumber daya (resource planning), persaingan (competition).
3. Telekomunikasi
Menerapkan data mining untuk melihat dari jutaan transaksi yang masuk dan transaksi mana sajakah yang harus ditangani secara manual.
4. Keuangan
Menggunakan data mining untuk menambang berbagai subyek seperti property, rekening bank dan transaksi keuangan lainnya untuk mendeteksi transaksi – transaksi keuangan yang mencurigakan seperti money laundry.
5. Asuransi
Menggunakan data mining untuk mengidentifikasi layanan kesehatan yang sebenarnya tidak perlu tetapi tetap dilakukan oleh peserta asuransi.
6. Olahraga
Menggunakan data mining untuk menganalisis statistic permainan NBA dalam rangka mecapai keunggulan bersaing.
2.10 Metode Penelitian Data Mining 2.10.1 Teori Naïve Bayes Classifier
Naïve Bayes merupakan sebuah pengklasifikasian probalistik sederhana yang menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan kombinasi nilai dari dataset yang diberikan. Algoritma menggunakan Teorema Bayes dan mengasumsikan semua atribut independen atau tidak saling ketergantungan yang diberikan oleh nilai pada variable kelas. Naïve Bayes juga didefinisikan sebagai pengklasifikasian dengan metode probabilitas dan statistik yang dikemukakan oleh ilmuan inggris Thomas Bayes yaitu memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya (Saleh, 2015).
Naïve Bayes didasarkan pada asumsi penyederhanaan bahwa nilai atribut secara kondisional saling bebas jika diberikan nilai output. Dengan kata lain diberikan nilai output, probabilitas mengamati secara bersama adalah produk dari probabilitas individu. Keuntungan penggunaan Naïve Bayes adalah bahwa metode ini hanya membutuhkan jumlah data pelatihan (Training Data) yang kecil untuk menentukan estimasi parameter yang diperlukan dalam proses pengklasifikasian. Naïve Bayes
sering bekerja jauh lebih baik dalam kebanyakan situasi dunia nyata yang kompleks daripada yang diharapkan (Saleh, 2015).
Persamaan dari Teorema Bayes dapat dilihat dibawah ini :
𝑃 (𝐻 | 𝑋) =P(X|H). P(H) P(H)
Dimana :
X : Data dengan class yang belum diketahui
H : Hipotesis data menggunakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X (parteriori probabilitas) P(H) : Probabilitas hipotesis H (prior probabilitas)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H P(X) : Probabilitas H
2.10.2 Naïve Bayes Untuk Klasifikasi
Kaitan antara naïve bayes dengan klasifikasi, korelasi hipotesis dan bukti klasifikasi adalah bahwa hipotesis dalam teorema bayes merupakan label kelas yang menjadi target pemetaan dalam klasifikasi, sedangkan bukti merupakan fitur – fitur yang menjadikan masukkan dalam model klasifikasi. Jika X adalah vector masukkan yang berisi fitur dan Y adalah label kelas, naïve bayes dituliskan dengan P(X|Y). Notasi tersebut berarti probabilitas label kelas Y didapatkan setelah fitur – fitur X diamati. Notasi ini disebut juga probabilitas akhir (posterior probability) untuk Y, sedangkan P(Y) disebut probabilitas awal (prior probability) Y.
Konsep Klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan utama yang dilakukan, yaitu :
1. Pembangunan model seperti prototype untuk disimpan sebagai memori.
2. Penggunaan model tersebut untuk melakukan pengenalan / klasifikasi / prediksi pada suatu objek data lain agar diketahui di kelas mana objek data tersebut dalam model yang mudah disimpan.
Contohnya adalah bagaimana melakukan diagnosis penyakit kulit kanker melanoma (Amaliyah, 2011) yaitu dengan melakukan pembangunan model berdasarkan data latih yang ada, kemudian menggunakan model tersebut untuk mengidentifikasi penyakit pasien baru sehingga diketahui apakah pasien tersebut menderita kanker atau tidak. 2.10.3 Model Klasifikasi
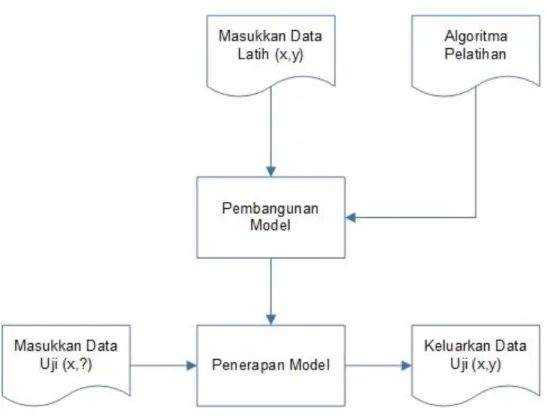
Model dalam klasifikasi mempunyai arti yang sama dengan kotak hitam, dimana ada suatu model yang menerima masukan, kemudian mampu melakukan pemikiran terhadap masukan tersebut dan memberikan jawaban sebagai keluaran dari hasil pemikirannya. Kerangka kerja (framework) klasifikasi ditunjukkan pada gambar 2.1, pada gambar tersebut disediakan sejumlah data latih (x,y) untuk digunakan sebagai data pembangunan model. Model tersebut kemudian dipakai untuk memprediksi kelas dari data uji (x,y) sehingga diketahui kelas y yang sesungguhnya. Menurut Amaliyah (2011) berikut adalah contoh proses klasifikasi data latih
Gambar 2.3 Proses Klasifikasi (Amaliyah, 2011)
Model yang sudah dibangun pada saat pelatihan kemudian dapat digunakan untuk memprediksi label kelas baru yang belum diketahui. Dalam pembangunan model selama proses pelatihan tersebut diperlukan suatu algoritma untuk membangunnya, yang disebut algoritma pelatihan (learning algorithm). Ada banyak algoritma pelatihan yang sudah dikembangkan oleh para peneliti seperti K-Nearest Neighbor, Artificial Neural Network, Support Vector Machine dsb. Setiap algoritma mempunyai kelebihan dan kekurangan, tetapi semua algoritma berprinsip sama yaitu melakukan suatu pelatihan sehingga di akhir pelatihan model dapat memetakan (memprediksi) setiap vektor masukan ke label kelas keluaran dengan benar.
Contoh studi kasus hasil pengujian akurasi :
Hasil dari pengujian akurasi dengan sampel 40 data uji mendapat 35 hasil yang akurat dan 5 hasil tidak akurat. Untuk mencari nilai persentase akurasi sistem diperoleh dari menghitung jumlah data yang akurat dibagi jumlah seluruh data uji, setelah mendapat hasil pembagian kemudian dikali 100. Nilai akurasi dihitung dengan menggunakan persamaan 2 (Gardenia dkk, 2015) dan memperoleh hasil seperti berikut :
𝑎𝑘𝑢𝑟𝑎𝑠𝑖 =𝑗𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎 𝑦𝑎𝑛𝑔 𝑎𝑘𝑢𝑟𝑎𝑡
𝑗𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎 𝑥 100
= 35
40 𝑥 100 = 87,5%
Dari hasil perhitungan akurasi di dapatkan persentase sebesar 87,5%. Terdapat 5 kesalahan hasil diagnosis sistem, kesalahan terjadi disebabkan karena gejala dimiliki oleh dua penyakit sedangkan sistem hanya dapat menghasilkan satu output penyakit. Dapat dikatakan semakin banyak gejala spesifik yang digunakan maka akurasi semakin tinggi, semakin banyak gejala umum yang digunakan maka akurasi semakin rendah.
2.11 Metode – metode Pilihan dan Klasifikasi
Berikut merupakan beberapa metode yang digunakan pada klasifikasi secara umum, diantaranya adalah :
1. Klasifikasi berdasarkan pohon keputusan (Decission Tree)
Pohon keputusan atau decission tree merupakan proses pelatihan data set yang memiliki atribut dengan dasaran nominal, yaitu bersifat kategoris dan setiap nilai
tidak bisa dijumlahkan atau dikurangkan. Pada umumnya, ciri khusus berikut cocok untuk diterapkan pada decission tree :
a. Data / example dinyatakan dengan pasangan atribut dan nilainya b. Label / output data biasanya bernilai diskrit
c. Data mempunyai missing value 2. Klasifikasi Bayesian
Klasifikasi Bayesian merupakan klasifikasi berdasarkan statistic classifier. Ini dapat mengklasifikasikan sebuah kelas dengan probabilitas dari setiap klasifikasi Bayesian didasarkan pada Bayes Theorem. Beberapa penelitian yang membandingkan algoritma klasifikasi telah menemukan sebuah klasifikasi Bayesian sederhana yang dikenal dengan nama Naïve Bayes Classifier. Algoritma ini telah dibandingkan dengan decission tree dan selektif Neoral Network secara performansi. Klasifikasi Bayesian juga memiliki tingkat akurasi yang tinggi dan cepat jika diterapkan pada database yang besar. Naïve Bayes Classifier mengenali setiap atribut pada data set sebagai atribut yang independen, sehingga disebut algoritma yang naïve.
3. Klasifikasi berdasarkan Propagasi Balik (Back Propagation)
Propagasi Balik atau Back Propagation merupakan sebuah algoritma pembelajaran dari Neural Network. Secara umum, neural network merupakan satu set input / output yang terhubung pada setiap koneksi memiliki weight. Input / Output yang terhubung tersebut mengadopsi system syaraf manusia, yang pemrosesan utamanya adalah di otak. Bagian terkecil dari otak manusia adalah sel syaraf yang disebut
Unit Dasar pemroses informasi atau neuron. Ada sekitar 10 miliar neuron dalam otak manusia dan sekitar 60 triliun koneksi dengan menggunakan neuron tersebut secara simultan, otak manusia dapat memproses informasi secara parallel dan cepat, bahkan lebih cepat dari komputer tercepat saat ini. Dengan analogi system kinerja otak tersebut, neural network terdiri dari unit proses yang disebut neuron yang berisi penambah dan fungsi aktivasi, sejumlah bobot, sejumlah vector masukan. Fungsi aktivasi berguna untuk mengatur keluaran yang diberikan oleh neuron. Propagasi Balik mempelajari data dengan memprediksi setiap jaringan pada setiap atribut dan kemudian mengklasifikasikannya kedalam kelas target. Kelas target dapat diketahui melalui training pada data set.
4. Support Vector Machine (SVM)
SVM merupakan metode klasifikasi yang berakar dari teori pembelajaran statistik yang hasilnya sangat menjanjikan untuk memberikan hasil yang lebih baik daripada metode yang lain. SVM juga bekerja dengan baik pada set data berdimensi tinggi, bahkan SVM yang menggunakan teknik kernel yang harus memetakan data asli dari dimensi asalnya menjadi dimensi lain yang relative lebih tinggi. Pada SVM, data latih yang akan dipelajari hanya data terpilih saja yang berkontribusi untuk membentuk model yang digunakan dalam klasifikasi yang akan dipelajari. Hal ini menjadi kelebihan SVM karena tidak semua data latih akan dipandang untuk dilibatkan dalam setiap iterasi pelatihannya. Data yang berkontribusi tersebut disebut Support Vector sehingga metodenya disebut Support Vector Machine.
2.12 UML (Unified Modelling Language)
Unified Modelling Language (UML) adalah salah satu standar bahasa yang banyak digunakan untuk mengkombinasikan, membuat analisis dan desain, serta menggambarkan arsitektur dalam pemograman berorientasi objek. UML merupakan bahasa visual untuk pemodelan dan komunikasi mengenai sebuah sistem dengan menggunakan diagram dan teks – teks pendukung. UML muncul karena adanya kebutuhan pemodelan visual untuk menspesifikasikan, menggambarkan, membangun, dan dokumentasi dari sistem perangkat lunak. UML hanya berfungsi untuk melakukan permodelan. Jadi penggunaan UML tidak terbatas pada metodologi tertentu, meskipun pada kenyataannya UML paling banyak digunakan pada metodologi berorientasi objek (Rosa A.S dan M. Shalahudin, 2014:133)
UML adalah bahasa yang telah menjadi standar untuk visualisasi, menetapkan, membangun dan mendokumentasikan suatu sistem perangkat lunak (Hend, 2006:5).
UML adalah alat bantu analis serta perancangan perangkat lunak berbasis objek (Adi Nugroho, 2005:3).
UML adalah keluarga notasi grafis yang di dukung oleh meta-model 28 tunggal yang membantu pendeskripsian dan desain sistem perangkat lunak khususnya sistem yang dibangun menggunakan pemograman berorientasi objek (Martin Fowler, 2005:1). UML adalah bahasa standar untuk membuat rancangan software. UML biasanya digunakan untuk menggambarkan dan membangun dokumen dari software – intensive system (Booch, 2005:7).
UML adalah bahasa pemodelan untuk sistem atau perangkat lunak yang berparadigma “berorientasi objek”. Pemodelan (modelling) sesungguhnya digunakan untuk penyederhanaan permasalahan – permasalahan yang kompleks sedemikian rupa sehingga lebih mudah dipelajari dan dipahami (Nugroho, 2010:6).
UML adalah metodologi kolaborasi antara metoda – metoda Booch, OMT (Object Modelling Technique) serta OOSE (Object Oriented Software Enginering) dan beberapa metoda lainnya merupakan metodologi yang paling sering digunakan saat ini untuk analisa dan perancangan sistem dengan metodologi berorientasi objek mengadaptasi maraknya pengguna Bahasa pemograman berorientasi objek (OOP) (Nugroho, 2009:4).
Beberapa literature menyebutkan bahwa UML menyediakan 9 diagram, yang lainnya menyebutkan 8 diagram karena ada beberapa diagram yang digabung misalnya diagram komunikasi, diagram urutan dan diagram perwaktuan digabung menjadi diagram interaksi (Heriawati, 2011)
UML adalah Bahasa pemodelan standar yang memiliki sintak dan semantik (Widodo, 2011)
Berdasarkan beberapa pendapat yang dikemukakan dapat ditarik kesimpulan bahwa Unified Modelling Language (UML) adalah Bahasa grafis untuk mendokumentasikan, mengspesifikasikan dan membangun system perangkat lunak.
2.13 Penelitian Terdahulu
Sistem Diagnosis Penyakit Hati menggunakan metode Naïve Bayes merupakan aplikasi yang bertujuan membantu masyarakat dalam mendiagnosis penyakit hati secara dini. Sistem ini dibangun berdasarkan masalah yang terjadi di masyarakat yaitu sulitnya dalam mengenali jenis penyakit hati. Dikarenakan penyakit hati mempunyai gejala – gejala yang berjumlah cukup banyak serta terdapat kesamaan gejala yang dimiliki beberapa penyakit hati. Hal ini termasuk salah satu penyebab tingginya tingkat presentase penyakit hati di Indonesia, tercatat dari Riset Kesehatan Dasar tahun 2013, salah satu jenis penyakit hati yaitu Hepatitis B secara nasional prevalensinya mencapai 21,8% dan menduduiki peringkat tertinggi ketiga di Indonesia. Metode naïve bayes dipilih pada penelitian ini karena naïve bayes memperhatikan seluruh fitur pada data latih sehingga membuat metode ini optimal dalam melakukan proses klasifikasi. Sistem ini menggunakan system operasi Android, karena android cukup konsisten kepopulerannya di pasar smartphone Indonesia hingga sekarang. Data yang digunakan pada penelitian ini diperoleh dari dokter yang sudah divalidasi oleh instansi Rumah Sakit Universitas Brawijaya, Malang. Hasil penelitian ini menunjukkan bahwa pada pengujian akurasi dari 40 data uji mendapatkan tingkat akurasi sebesar 87,5%.
2.14 Spesifikasi Kebutuhan Software dan Hardware
Suatu sistem yang baik tidak akan berhasil dengan baik apabila tidak didukung oleh sarana pendukung yang baik pula. Sarana pendukung yang dimaksud bukan harus menggunakan suatu unit komputer dengan merek tertentu dan harga yang mahal tetapi
harus berintegrasi dengan baik antara satu dengan yang lainnya. Sistem dikatakan baik dan akan berhasil digunakan atau diterapkan jika didiukung dengan beberapa unsur atau beberapa aspek antara lain perangkay keras (Hardware), perangkat lunak (Software) dan pemakai (Brainware). Diantara unsur tersebut yaitu prasarana atau peralatan pendukung yang dibutuhkan harus sesuai dengan spesifikasi sistem yang diusulkan untuk itu penulis menguraikan prasarana atau perangkat komputer yang harus tersedia pada sistem yang diusulkan. Adapun spsesifikasinya adalah sebagai berikut :
Perangkat lunak (Software) yang digunakan pada sistem usulan ini yaitu menggunakan :
a. Operating Sistem : Microsoft Windows 10
b. Menggunakan Rapidminer untuk data mining dengan metode algoritma naïve bayes classifier.
Rapidminer adalah aplikasi data mining berbasis sistem open-source yang berguna untuk analisis data dan sebagai mesin data mining untuk integrasi ke dalam produk.
Contoh interface Rapidminer pada data mining naïve bayes classifier
Gambar 2.4 Interface Rapidminer pada data mining naïve bayes classifier Adapun perangkat keras yang digunakan sebagai berikut :
a. Micro Processor : Intel CORE i5 7th Generation
b. Memori : 8 GB DDR4
c. Hardisk : 1 TB HDD
d. Monitor : 14”
e. Keyboard / Mouse : Serial / PS2 / USB
36 BAB III
METODE PENELITIAN
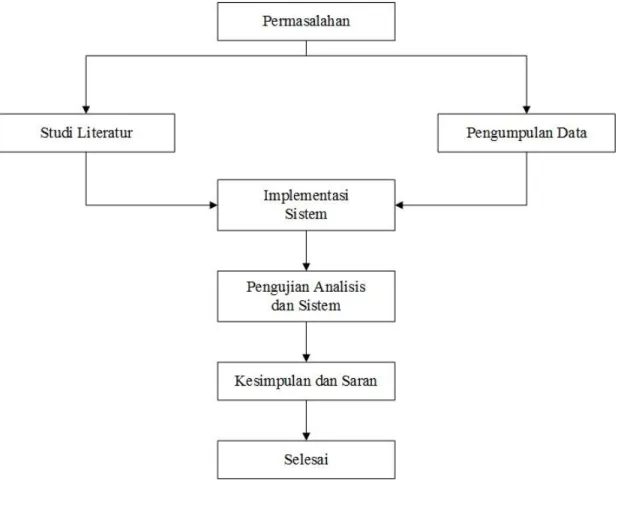
3.1 Kerangka Pemikiran
Kerangka pikir merupakan garis besar dari langkah – langkah penelitian yang dilakukan. Langkah – langkah tersebut disusun sedemikian rupa sebagai acuan untuk tahap – tahap yang dilakukan dalam proses penelitian. Kerangka pemikiran dalam penelitian ini berisi landasan teori yang menjadi dasar dalam menjawab tujuan penelitian. Teori yang diuraikan meliputi konsep dasar dari metode naïve bayes beserta Teknik yang digunakan untuk mengetahui diagnosa penyakit Tuberculosis yang dialami oleh pasien akibat terinfeksi virus. Dan menggunakan rapid miner untuk mengetahui akurasi prediksi penyakit tuberculosis.
Berdasarkan kerangka teori yang telah dijelaskan pada gambaran umum objek, maka dikembangkan kerangka pemikiran penelitian diagnosa penyakit typhoid fever yang dipengaruhi oleh gejala yang ada pada penyakit tuberculosis. Berikut ini gambar kerangka pemikiran.
Gambar 3.1 Kerangka Pemikiran
3.2 Sekilas Tentang Rumah Sakit Umum Daerah Padangan
Rumah Sakit Umum Daerah (RSUD) Padangan yang beralamat di Jl. Dr. Soetomo No. 02 Padangan Bojonegoro adalah sebuah rumah sakit milik Pemerintah Kabupaten Bojonegoro, yang merupakan perubahan status dari Puskesmas Perawatan menjadi Rumah Sakit Kelas D pada tahun 2011.
Perubahan status dari Puskesmas Perawatan menjadi Rumah Sakit Kelas D bertujuan untuk meningkatkan pelayanan kesehatan kepada masyarakat khususnya masyarakat wilayah barat Kabupaten Bojonegoro. Dengan didirikannya RSUD Padangan sebagai fasilitas kesehatan rujukan, diharapkan dapat memberikan pelayanan kesehatan yang lebih lengkap disbanding Puskesmas.
Selama tujuh tahun secara resmi RSUD Padangan berdiri telah menunjukkan adanya perkembangan yang signifikan, baik dari kuantitas maupun kualitas pelayanan, dalam arti jumlah kunjungan pasienada peningkatan dari tahun ke tahun baik pasien rawat jalan maupun pasien rawat inap.
3.2.1 Waktu dan Tempat Penelitian
Penelitian dilakukan pada tanggal 15 Agustus 2018 sampai tanggal 25 Agustus 2018 di Rumah Sakit Umum Daerah (RSUD) Padangan yang beralamat di Jl. Dr. Soetomo No. 02 Padangan, Bojonegoro, Jawa Timur.
3.3 Metode Pengumpulan Data
Metode yang digunakan dalam penyusunan laporan skripsi ini adalah : 1. Metode Wawancara
Dilakukan terhadap narasumber yang mengerti konsep kesehatan khususnya mengenai gejala penyakit tuberculosis dan jenisnya.
2. Observasi
Merupakan salah satu metode pengumpulan data yang cukup efektif untuk mempelajari suatu sistem. Penulis melakukan pengamatan langsung pada Dokter agar data yang di dapatkan lebih akurat.
3. Studi Pustaka (Library Research)
Metode ini memperoleh data – data yang berhubungan dengan penulisan skripsi dari berbagai sumber bacaan seperti buku, jurnal dan lain sebagainya sebagai acuan. 4. Searching (Browsing)
Melakukan pengumpulan jurnal yang bersumber dari internet. 3.3.1 Hasil Wawancara
Setelah melakukan penelitian dan wawancara dengan seorang pakar yang ahli di bidang kesahatan dan cara penanganan dapat disimpulkan bahwa penyakit tuberculosis dapat berakibat fatal jika tidak segera ditangani. Gejala penyakit tuberculosis bermacam – macam seperti batuk lebih dari 2 minggu, batuk disertai bercak darah, penurunan berat badan drastis, berkeringat pada malam hari, demam, tidak nafsu makan, nyeri dada, dan fisik lemah yang akan berakibat fatal apabila tidak segera ditangani. Cara penanganannya dengan rawat inap di rumah sakit tertentu dan melakukan serangkaian tes laboratorium.
3.4 Desain Penelitian
Dalam melakukan suatu penelitian ini sangat perlu dilakukan perencanaan agar penelitian yang dilakukan dapat berjalan dengan baik dan sistematis. Desain penelitian
menurut Moh. Nazir (2003:84) memaparkan bahwa desain penelitian adalah semua proses yang dilakukan dalam perencanaan dan pelaksanaan penelitian. Dari definisi diatas maka dapat disimpulkan bahwa desain penelitian merupakan semua proses penelitian yang dilakukan oleh penulis dalam melaksanakan penelitian mulai dari perencanaan sampai dengan pelaksanaan penelitian yang dilakukan pada waktu tertentu
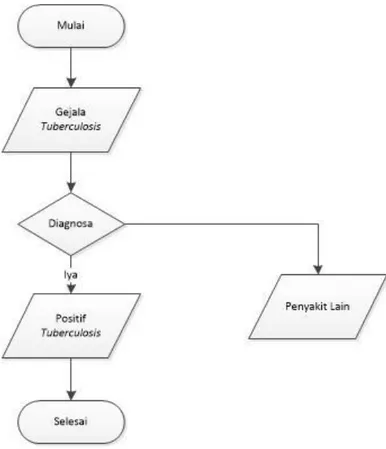
3.5 Analisis metode yang berjalan
Sebelum melakukan penelitian sistem, terlebih dahulu dilakukan analisa sistem berjalan. Arus data pada sistem kerja dilihat pada gambar flowchart Diagnosa Prediksi Penyakit Tuberculosis berikut
Gambar 3.2 Activity Diagram Diagnosa Prediksi Penyakit Tuberculosis
3.6 Akuisisi Pengetahuan
Selanjutnya setelah penyusunan basis pengetahuan dengan tabel keputusan diagnosa penyakit sesuai pengamatan pada penyakit Tuberculosis. Hanya beberapa gejala yang paling nampak yang digunakan dalam tabel keputusan diagnosa, kemudian ditentukan hasil diagnosanya. Representasi pengetahuan dibuat dalam bentuk tabel yang akan digunakan dalam pembuatan aturan – aturan untuk melakukan pengambilan keputusan diagnosa pada penyakit Tuberculosis.
Tabel 3.1 Akuisisi Pengetahuan
Penyakit Gejala Penyakit Penyebab Gejala Penyakit
Tuberculosis
- Batuk
berkepanjangan - Batuk disertai bercak
Darah - Penurunan berat badan drastis - Berkeringat pada malam hari - Nyeri dada - Sesak nafas
- Infeksi virus flu
- Kurang menjaga kesehatan paru – paru dan tenggorokan - Tidak nafsu makan
- Perubahan suhu tubuh karena demam
- Infeksi pada saraf yang menimbulkan ruam
- Tamponade jantung
(kelebihan cairan di sekitar jantung)
3.7 Analisa Sistem
Pada bagian ini analisa dilakukan terhadap data dan permasalahan yang telah dirumuskan yang dapat menjawab permasalahan dan kendala yang ada. Adapun analisa yang dilakukan adalah :
a. Analisa kebetuhan sistem
Tahap ini dilakukan berdasarkan data yang diperoleh dari pakar kemudian data tersebut digunakan dalam membangun sistem.
Pada tahap ini dibangun basis pengetahuan berupa data gejala. Pada tahap ini digunakan table relasi gejala penyakit dengan memanfaatkan pengetahuan dari pakar yang bersangkutan.
c. Mesin inferensi
Pada tahap ini dilakukan proses penggabungan banyak aturan berdasarkan data yang tersedia dari pakar yang merujuk kepada table relasi untuk mempertimbangkan informasi dalam basis pengetahuan dan merumuskan kesimpulan. Mesin inferensi yang digunakan adalah forward chaining (runut maju).
d. Analisa fungsional
Analisa fungsional berisikan Analisa data kedalam bentuk UML (Unifield Modelling Language).
Dengan adanya analisa di atas, dapat diketahui kebutuhan sistem dengan meneliti dari mana data berasal, bagaimana aliran data menuju sistem, bagaimana operasi sistem yang ada dan hasil akhirnya.
3.8 Perancangan Sistem
3.8.1 Metode Algoritma Naïve Bayes
Naïve Bayes merupakan sebuah pengklasifikasian probalistik sederhana yang menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan kombinasi nilai dari data set yang diberikan. Algoritma menggunakan Teorema Bayes dan mengasumsikan semua atribut independen atau tidak saling ketergantungan yang diberikan oleh nilai pada variable kelas. Naïve Bayes juga didefinisikan sebagai pengklasifikasian dengan metode probabilitas dan statistic yang dikemukakan oleh
Thomas Bayes yaitu memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya.
Naïve Bayes didasarkan pada asumsi penyederhanaan bahwa nilai atribut secara kondisonal saling bebas jika diberikan nilai output. Dengan kata lain diberikan nilai output, probabilitas mengamati secara bersama adalah produk dari probabilitas individu. Keuntungan penggunaan naïve bayes adalah bahwa metode ini hanya membutuhkan jumlah data pelatihan (Training Data) yang kecil untuk menentukan estimasi parameter yang diperlukan dalam proses pengklasifikasian. Naïve Bayes sering bekerja jauh lebih baik dalam kebanyakan situasi dunia nyata yang kompleks daripada yang diharapkan (Saleh, 2015).
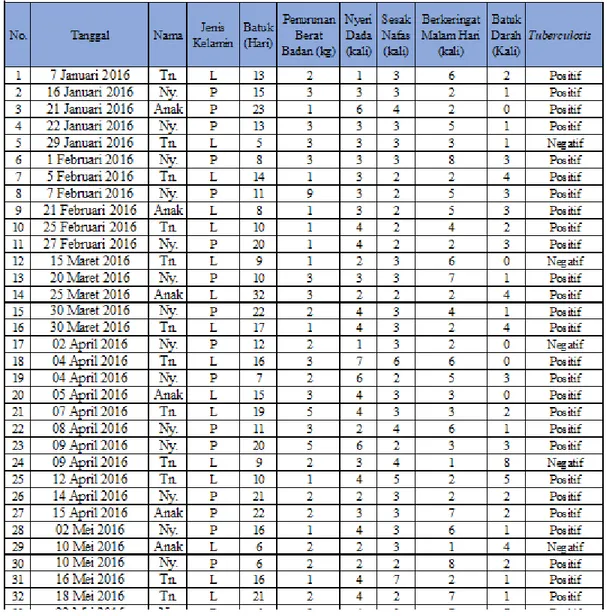
3.8.2 Pengumpulan Data
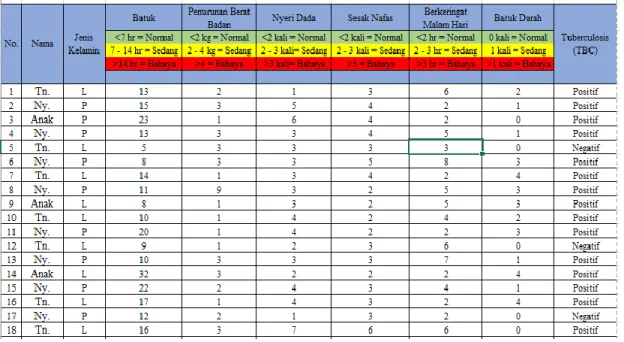
Penulis mendapatkan data dari Rumah Sakit Umum Daerah (RSUD) Padangan Data berupa hard copy file rekam medis pasien. Data rekam medis tersebut kemudian dianalisis guna mendapatkan data yang spesifik dan menuangkan data yang didapatkan dalam bentuk excel, guna mempermudah pengolahan data. Total data yang diambil sebanyak 199 kasus, pasien terdiagnosa positif tuberculosis sebanyak 172 orang dan pasien terdiagnosa negatif tuberculosis sebanyak 27 orang.
Tabel 3.2 Data Pasien
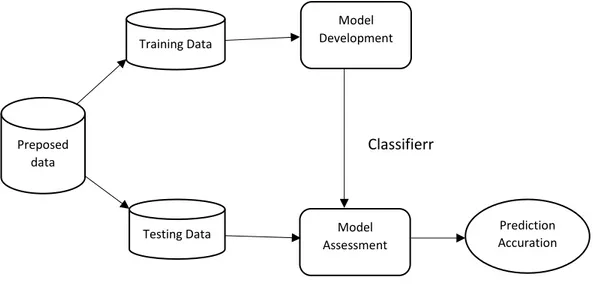
3.8.3 Model yang diusulkan
Model yang diusulkan untuk klasifikasi menggunakan algoritma Naïve bayes adalah menggunakan model split validation. Split validation membagi data menjadi
dua subset data yaitu data trainning dan data testing. Data trainning merupakan data yang digunakan untuk pelatihan, sedangkan data testing akan digunakan untuk pengujian. Adapaun untuk melihat secara lebih jelas dari model split validation dapat dilihat pada gambar 3.1
Gambar 3.3 Model pengujian
Pada gambar 3.3 akan digunakan untuk melakukan pengujian dengan masing-masing proporsi pembagian datanya dapat dilihat tabel 3.3.
Tabel 3.3 Pembagian Data
Training Testing 60% 40% 70% 30% 80% 20% 90% 10% Preposed data Testing Data Training Data Model Development Model Assessment Prediction Accuration Classifierr
Dari empat kali percobaan yang dilakukan berdasarkan proporsi dari tabel 3.2 setiap hasil yang diperoleh akan ditentukan jumlahnya.
48 BAB IV
HASIL DAN PEMBAHASAN
4.1 Langkah Perhitungan
Pada tahap ini metode yang digunakan dalam perhitungan tingkat akurasi adalah algoritma naive bayes dengan melakukan pengujian akurasi data set dan perhitungan manual. Berikut langkah metode algoritma naive bayes :
Gambar4.1 Model Algoritma Naive bayes
Pada gambar 4.1 mulai identifikasi sampel dari data set baca data. selanjutnya P(Xi|Ci) menghitung jumlah class dari klasifikasi yang sudah terbentuk yaitu class
Proses Naive bayes Menghitung
probabilitas awal untuk klasifikasi yg terbentuk positif dan
negatif P(𝑋𝑖|𝐶𝑖) dari
setiap Class i
Hitung setiap class yang sama untuk probabilitas class X P(𝑋𝑖|𝐶𝑖) dari setiap Class Perkalian dari semua Class yang sudah dihitung probabilitasnya P(𝑋𝑖|𝐶𝑖) * P(𝐶𝑖)
Membandingkan hasil tiap class probabilitas 𝐶+untuk class positif
𝐶− untuk class negatif
diterima P(X|𝐶+)>P(X|𝐶−) Prediksi positif 𝐶+ Prediksi negatif 𝐶− Mulai Input dataset selesai
positif dan negatif untuk setiap class. Kemudian P(X|Ci) menghitung jumlah kasus yang sama dari kelas yang sama X, dalam kasus data set pada penelitian ini terdiri dari 2 class yaitu positif yang dinyatakan dengan simbul (+) dan negatif yang dinyatakan dengan simbul (-). Kemudian hitung P(X|𝐶+),i=+,- untuk setiap kelas atau atribut. Setelah itu dibandingkan, jika P(X|𝐶+)>P(X|𝐶−) maka kesimpulannya adalah 𝐶+ atau pada penelitian ini berarti diagnosa penyakit positif. Jika P(X|𝐶+)<P(X|𝐶−) maka kesimpulannya 𝐶− atau negatif.
4.2 Seleksi Data
Proses seleksi data yaitu dengan cara mengelompokkan data yang berupa angka menjadi keterangan tingkat gejala normal, sedang dan bahaya. Berikut ini adalah tabel klasifikasinya.
Tabel 4.1 Seleksi Data
Pada tabel 4.1 menerangkan tentang proses penyeleksian data ke dalam klasifikasi gejala Normal, Sedang dan Bahaya.
Tabel 4.2 Setelah Proses Seleksi Data
Tabel 4.2 merupakan tampilan setelah di lakukan proses seleksi data. Pada semua tabel gejala telah dikelompokkan menjadi normal, sedang, dan bahaya berdasarkan tabel seleksi data.
4.3 Metode yang diusulkan
Metode yang akan digunakan dalam penelitian ini adalah algoritma naive bayes. Dalam pemodelan ini algoritma naive bayes akan dicari performance Vektor(accuracy) dan confusion matrix.
4.4 Hasil Pengujian Prediksi Diagnosa
Tabel 4.3 Data training
Data training adalah data yang akan di latih untuk menentukan hasil dari data testing.
Tabel 4.4 Data Testing
Tabel 4.4 berisi tentang data diagnosa dari rumah sakit yang kemudian akan di testing menggunakan hitung manual dan rapid miner.
4.4.1 Prediksi Menggunakan Perhitungan Manual
Berikut ini perhitungan dalam penelitian ini menggunakan 199 data training terdiri dari 10 atribut untuk menentukan sebuah class, yang mana dari 199 data
training tersebut akan digunakan untuk melakukan perhitungan algoritma Naive bayes. Adapun data training tersebut dapat dilihat pada tabel 4.1.
Data testing 1 : X = (Nama=”Tn”, Jenis kelamin=”L”, Batuk= “Bahaya”, Penurunan Berat Badan=”Sedang”, Nyeri Dada= “Normal”, Sesak Nafas= “Sedang”, Berkeringat Malam Hari=”Bahaya”, Batuk Darah=”Bahaya”)
Tahap 1 menghitung jumlah kelas atau prediksi data testing
P(Ci)
P(Positif) = 172
199 = 0,864 P(Negatif) = 27
Tahap 2 menghitung jumlah kasus yang sama dengan kelas yang sama. P(X | Ci) Batuk(Bahaya | Positif) = 87 172 = 0,5058 Batuk(Bahaya | Negatif) = 1 27 = 0,0370 Penurunan BB(Sedang | Positif) = 111
172 = 0,6453 Penurunan BB(Sedang | Negatif) = 17
27 = 0,6296 Nyeri dada(Normal | Positif) = 27
172 = 0,1569 Nyeri dada(Normal | Negatif) = 4
27 = 0,1481 Sesak nafas(Sedang | Positif) = 80
172 = 0,4651 Sesak nafas(Sedang | Negatif) = 24
27 = 0,8888 Berkeringat MH(Bahaya | Positif) = 61
172 = 0,3546 Berkeringat MH(Bahaya | Negatif) = 2
27 = 0,0740 Batuk darah(Bahaya | Positif) = 84
172 = 0,4883 Batuk darah(Bahaya | Negatif) = 4
Tahap 3 mengkalikan semua hasil dari atribut Positif dan Negatif.
Tahap 4 membandingkan nilai kelas Positif dan Negatif.
Jadi untuk (Nama=”Tn”, Jenis kelamin=”L”, Batuk= “Bahaya”, Penurunan Berat Badan=”Sedang”, Nyeri Dada= “Normal”, Sesak Nafas= “Sedang”, Berkeringat Malam Hari=”Bahaya”, Batuk Darah=”Bahaya”, hasilnya “Positif” Tuberculosis. 4.4.2 Prediksi Menggunakan Rapid Miner
Uji coba ini dilakukan untuk mengetahui apakah perhitungan yang telah dilakukan diatas sesuai dengan klasifikasi diagnosa penyakit tuberculosis dengan metode naive bayes menggunakan Rapid Miner 9.0.
P(X | Positif)= 0,5058*0,6453*0,1569*0,4651*0,3546*0,4883 = 0,004124 P(X | Negatif)= 0,0370*0,6296*0,1481*0,8888*0,0740*0,1481 = 0,0000336
P(X | Ci * P(Ci)
P(X | Positif) * P(Positif) = 0,004124 * 0,864 = 0,003563136 P(X | Negatif) * P(Negatif) = 0,0000336 * 0,135 = 0,000004536
Gambar 4.3 Design Rapid Miner Prediksi Data Tesing
Gambar 4.3 berisi tentang design model rapid miner yang terdiri dari dua read excel, select attributes, naïve bayes dan apply mode yang saling terkoneksi. Pada read excel pertama berisi data training dan read excel yang kedua berisi data testing.
Gambar 4.4 Hasil Prediksi Data Testing di Rapid Miner
Dari keterangan gambar 4.4 hasil testing data pada nomor 1 dengan klasifikasi Nama=”Tn”, Jenis kelamin=”L”, Batuk=“Bahaya”, Penurunan Berat Badan=”Sedang”, Nyeri Dada= “Normal”, Sesak Nafas= “Sedang”, Berkeringat Malam Hari=”Bahaya”, Batuk Darah=”Bahaya” yang dilakukan dengan menggunakan Rapid miner menghasilkan prediksi yang sama dengan kasus perhitungan manual yaitu “Positif” Tuberculosis.
4.5 Hasil Klasifikasi Class 4.5.1 Simple Distribution Model
Menganalisa tabel data pasien dalam memprediksi diagnosa penyakit typhoid fever dengan metode naive bayes dapat menghasilkan 2 class utama.
Gambar 4.5 Simple Distribution Model
Hasil dari klasifikasi dari data pasien dengan menggunakan metode naive bayes membagi 2 kelas klasifikasi yaitu class POSITIF dan class NEGATIF.Untuk nilai class POSITIF yaitu 0.864 dan nilai class NEGATIF 0.136
4.5.2 Distribution Table
Tabel distribusi hasil analisa dengan metode naive bayes terhadap tabel data pasien dalam memprediksi diagnosa penyakit dapat dilihat di tabel berikut.
Tabel 4.5 Tabel Distribusi
Atribut Value Probabilitas
Positif Negatif Batuk Biasa 0,04651163 0,29629630 Sedang 0,45348837 0,66666667 Bahaya 0,50000000 0,03703704 Penurunan Berat Badan Biasa 0,29651163 0,29629630 Sedang 0,64534884 0,62962963 Bahaya 0,05813953 0,07407407 Nyeri Dada Biasa 0,15697674 0,14814815 Sedang 0,36046512 0,55555556 Bahaya 0,48255814 0,29629630 Sesak Nafas Biasa 0,10465116 0,03703704 Sedang 0,46511628 0,88888889 Bahaya 0,43023256 0,07407407 Berkeringat Malam Hari Biasa 0,20348837 0,37037037 Sedang 0,44186047 0,55555556 Bahaya 0,35465116 0,07407407 Batuk Darah Biasa 0,04069767 0,40740741 Sedang 0,47674419 0,44444444 Bahaya 0,48255814 0,14814815
Pada tabel 4.5 adalah tabel distribusi yang mempunyai nilai yang besar terhadap probabilitasnya, dapat diketahui bahwa atribut tersebut mempunyai nilai yang hampir sempurna. Atribut tersebut dapat mempengaruhi pola dari prediksi diagnosa penyakit tuberculosis.
Gambar 4.6 Grafik Distribusi Label
4.6 Hasil Performance Vektor
Proses klasifikasi dengan rapidminer dengan metode naive bayes yang digunakan mengklasifikasi data pasien sebanyak 199 data pada penelitian ini sehingga diperoleh nilai Accuracy, Precision dan Recall dengan menggunakan Split validation 80 : 20 . 0,00000000 0,20000000 0,40000000 0,60000000 0,80000000 1,00000000 N o rmal Se d an g Ba h aya N o rmal Se d an g Ba h aya N o rmal Se d an g Ba h aya N o rmal Se d an g Ba h aya N o rmal Se d an g Ba h aya N o rmal Se d an g Ba h aya Batuk Penurunan Berat Badan
Nyeri Dada Sesak Nafas Berkeringat Malam Hari
Batuk Darah
Grafik Distribusi Label
1. Accuracy / akurasi
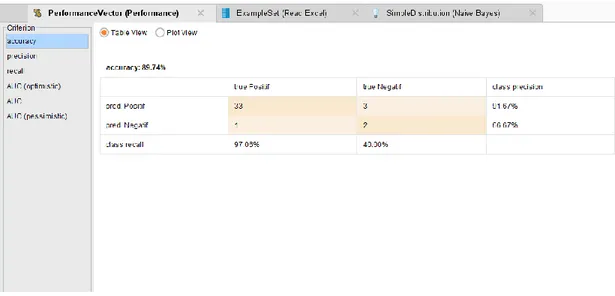
Dengan mengetahui jumlah data yang di klasifikasikan secara benar maka dapat diketahui akurasi hasil prediksi yaitu 89,74% dari hasil data pasien. Di bawah ini merupakan hasil dari testing menggunakan rapidminer 9.0.
Berikut ini perhitungan manual untuk menentukan accuracy.
2. Precision
Precision adalah jumlah data yang true positive (jumlah data positif yang dikenali secara benar sebagai positif) dibagi dengan jumlah data dikenali sebagai positif. Dari hasil pengujian nilai precision yaitu 91,67% untuk class Positif dan nilai precision 66,67% untuk class Negatif.
Gambar 4.8 Precision Accuracy = (𝑇𝑃+𝑇𝑁) (𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁)𝑥100% = (33 + 2) (33 + 2 + 33 + 1)𝑥100% = (35) (39)𝑥100% = 0.897 𝑥 100% = 89.74%
Berikut ini perhitungan manual untuk menentukan Precision.
3. Recall
Recall merupakan jumlah data yang true positive dibagi dengan jumlah data yang sebenarnya positive (true positive + true negative). Untuk nilai recall yaitu 97,06% pada class positif dan nilai recall 40% pada class negatif.
Gambar 4.9 Recall Precision positive = 𝑇𝑃 (𝑇𝑃+𝐹𝑃)𝑥100% = 33 (33 + 3)𝑥100% = 33 36𝑥100% = 0.9166 𝑥 100% = 91.66% Precision negative = 𝑇𝑁 (𝑇𝑁+𝐹𝑃)𝑥100% = 2 (2 + 3)𝑥100% = 2 5𝑥100% = 0.4 𝑥 100% = 40.00%