LOGO
PERTEMUAN 1
Sensus vs Survei Alasan Penggunaan Sampling Konsep-konsep dalam Sampling Kerangka sampel Keuntungan dan kelemahan Sampling Probability dan Nonprobability Sampling
LOGO
Tidak menggunakan kaidah peluang dalam pemilihan sampel
Hasil surveinya tidak dapat digunakan untuk melakukan pendugaan
(estimasi) terhadap karakteristik populasi
Menggunakan kaidah peluang
(probability) dalam pemilihan sampel Hasil surveinya dapat digunakan
untuk melakukan pendugaan (estimasi) terhadap karakteristik populasi
Mengumpulkan data dari sebagian elemen populasi
Mengumpulkan data dari seluruh elemen dalam populasi
Metode Pegumpulan Data
Probability
sampling Nonprobability Sampling
Pengumpulan data
Sensus (sampling) Survei
Catatan administrasi (registrasi)
Sensus
Pengumpulan data untuk mendapatkan informasi
dari semua elemen dalam populasi
Undang-undang No.16 Tahun 1997, tentang
Statistik:
Sensus Penduduk (tahun berakhiran-0) Sensus Pertanian (tahun berakhiran-3) Sensus Ekonomi (tahun berakhiran-6)
Dalam sensus biasanya dikumpulkan data dasar /
pokok
Karakteristik yang dicakup terbatas
Penyajian sampai wilayah satuan unit kecil seperti
LOGO
Keuntungan dan Kelemahan Sensus
Keuntungan
1. Dapat menyajikan data wilayah kecil
2. Dapat dijadikan kerangka sampel (frame)
Kelemahan
1. Cakupan variabel terbatas
2. Waktu lama
3. Biaya besar
4. Ketelitian kurang
Mengapa Sampling?
1. Sumber daya terbatas
2. Waktu yang tersedia terbatas 3. Pengamatan kadang bersifat merusak 4. Mustahil mengamati seluruh anggota populasi
bagaimana caranya dengan mengambil dan menggunakan data sampel kita dapat mengambil
LOGO
Prinsip-Prinsip Sampling Theory
1. Prinsip validitas
Design sampling harus menjamin adanya estimasi yang valid dari parameter-parameter populasi.
2. Prinsip “Statistical Regularity”
Jumlah sampel yang diambil secara random dari populasi secara rata-rata akan mempunyai karakteristik yang
sama/menyerupai karakteristik populasi.
3. Prinsip optimisasi.
Desain sampling (metode penarikan sampel dan estimasi): a. Dengan tingkat ketelitian tertentu, diperlukan sumber
daya yang minimum, atau
b. Dengan biaya tertentu, memberikan ketelitian yang optimum
LOGO
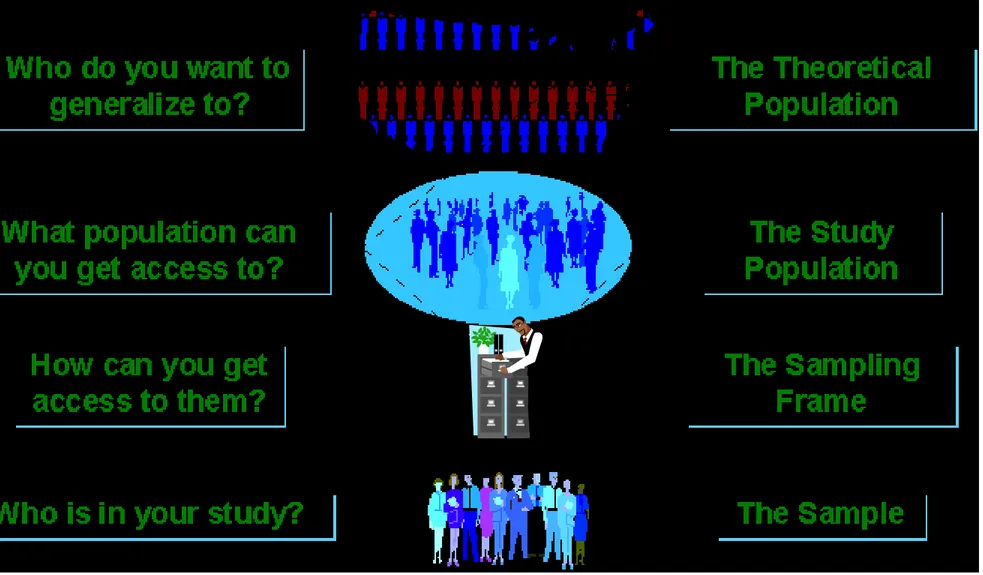
Konsep dan Definisi
Populasi
Populasi merupakan agregasi dari seluruh elemen yang perlu ditentukan berikut isi, unit, cakupan, dan waktu.
Contoh populasi: semua penduduk yang bertempat tinggal dalam rumahtangga biasa di Kecamatan Polobangkang Selatan,
Kabupaten Takalar, pada bulan September tahun 2012
Populasi dibedakan menjadi finite populaton dan infinite
population, tergantung dari jumlah unitnya terbatas atau tidak
terbatas
Continous population: populasi yang terdiri dari zat/benda
(mass of matter) yang tidak bisa diidentifikasi/dibedakan dengan mudah dan unit atau kumpulan unitnya terbentuk secara alami. Contoh: Populasi air di danau.
Dalam praktiknya, kita akan memfokuskan hanya pada finite population saja MPC1
LOGO
Konsep dan Definisi
Populasi Target
Target populasi merupakan sub populasi dari
elemen yang ada pada populasi yang berbagai
indikatornya akan dicari, seperti penduduk usia
7-12 tahun.
Karakteristik
Ciri, sifat atau hal-hal yang dimiliki elemen,
seperti penghasilan, pengeluaran, biaya, jumlah
anggota rumahtangga.
Nilai karakteristik yang dihitung (diestimasi) dapat
berupa rata-rata, total, rasio, proporsi, persentase, dan sebagainya
LOGO
Konsep dan Definisi
Elemen (elementary unit)
Elemen adalah unit yang digunakan untuk mendapatkan
informasi, misalnya individu, rumah tangga, perusahaan, dsb. Unit observasi
Unit observasi adalah unit dimana informasinya diperoleh baik secara langsung maupun melalui responden tertentu. Elemen sangat erat kaitannya dengan unit observasi.
Elemen bisa sama dengan unit observasi, sebagai contoh
rumahtangga adalah selain sebagai elemen juga dapat sebagai unit observasi, misal pengumpulan data keadaan tempat
tinggal.
Unit observasi bisa individu dari elemen yang mewakili sekumpulan elemen, misalnya kepala rumah tangga yang memberikan informasi mengenai anggota rumah tangganya.
Konsep dan Definisi
Unit sampling (sampling unit)
Unit sampling adalah unit yang dijadikan dasar penarikan sampel baik berupa elemen maupun kumpulan elemen (klaster).
Contoh:
1. Unit sampling elemen: rumah tangga
2. Unit sampling klaster: kumpulan rumahtangga pada wilayah tertentu seperti blok sensus, RT/RW, bahkan desa.
Selain rumahtangga, cukup banyak unit yang bisa dijadikan unit sampling sesuai dengan tujuan survei seperti sekolah, kelas, perusahaan, dsb.
Unit analisis
Unit yang digunakan pada tahap tabulasi data, bisa berupa elemen atau kumpulan elemen.
Unit analisis tidak selalu sama dengan unit observasi
Misal: unit observasi adalah rumah tangga (atau lebih spesifik kepala
rumah tangga). Unit analisisnya bisa rumah tangga itu sendiri atau anggota rumah tangga
LOGO
Konsep dan Definisi
Kerangka Sampel
Kerangka sampel adalah daftar semua unit yang akan dijadikan
sampling unit (sebagai dasar penarikan sampel) dan harus
memenuhi persyaratan kerangka sampel yang dibentuk dari master
file.
Survey period: the time period during which the required data are collected.
Reference period: the time period to which the data information should refer. It depends on the objective of the survey
Konsep dan Definisi
Prasyarat yang harus diperhatikan:
Desain probability sampling baru dapat
diaplikasikan
bila tersedia kerangka sampel
sesuai metode sampling yang ditetapkan.
Metode sampling yang dipilih harus
dapat
diaplikasikan di lapangan
ditinjau dari segi unit
sampling dan biaya.
Metode yang telah ditentukan harus
benar-benar
LOGO
Contoh Kasus 1:
Populasi:
semua mahasiswa STIS tahun 2012
Populasi target:
semua mahasiswa STIS tahun 2012
Kerangka sampel:
daftar mahasiswa STIS tahun 2012
Unit sampling:
mahasiswa STIS
Unit observasi:
mahasiswa STIS
Karakteristik yang diteliti:
pengeluaran sebulan
Nilai karakteristik yang diestimasi:
rata-rata
Unit analisis:
mahasiswa STIS
MPC1
Suatu survei dilakukan dengan tujuan untuk mengetahui rata-rata pengeluaran sebulan mahasiswa STIS tahun 2012. Definisikan apa yang menjadi populasi, populasi target, kerangka sampel, unit
sampling, unit observasi, karakteristik yang diteliti, nilai karakteristik yang diestimasi, dan unit analisnya!
Contoh Kasus 2:
Suatu survei bertujuan untuk memperkirakan total biaya produksi dari rumah tangga yang mengusahakan tanaman hortikultura di Desa Kayuwangi Mei 2012.
Populasi: semua rumah tangga di Desa Kayuwangi Mei 2012
Populasi target: semua rumah tangga yang mengusahakan
tanaman hortikultura Mei 2012
Kerangka sampel: Daftar rumah tangga yang mengusahakan
tanaman hortikultura di Desa Kayuwangi Mei 2012
Unit sampling: rumah tangga yang mengusahakan tanaman
hortikultura
Unit observasi: rumah tangga yang mengusahakan tanaman
hortikultura (kepala rumah tangga)
Karakteristik yang diteliti: biaya produksi
Nilai karakteristik yang diestimasi: total
Unit analisis: rumah tangga yang mengusahakan tanaman
LOGO
MPC1
Contoh Kasus 3:
Suatu survei bertujuan untuk memperkirakan rasio murid-guru Sekolah Dasar di Provinsi DIY bulan September 2012.
Populasi: semua Sekolah Dasar di Provinsi DIY September
2012
Populasi target: semua Sekolah Dasar di Provinsi DIY
September 2012
Kerangka sampel: Daftar Sekolah Dasar di Provinsi DIY
September 2012
Unit sampling: Sekolah Dasar
Unit observasi: Sekolah Dasar
Karakteristik yang diteliti: jumlah murid, jumlah guru
Nilai karakteristik yang diestimasi: rasio
Contoh Kasus 4:
Suatu survei bertujuan di Kelurahan Rawajati Mei 2012 bertujuan untuk:
1. Memperkirakan proporsi balita dengan gizi buruk.
2. Memperkirakan rata-rata pengeluaran rumah tangga yang mempunyai balita dengan status gizi buruk
Populasi: semua rumah tangga di Kelurahan Rawajati Mei 2012
Populasi target: semua rumah tangga yang mempunyai balita di
Kelurahan Rawajati Mei 2012
Kerangka sampel: Daftar rumah tangga yang mempunyai balita di
Kelurahan Rawajati Mei 2012
Unit sampling: rumah tangga yang mempunyai balita
Unit observasi: rumah tangga yang mempunyai balita
Karakteristik
yang diteliti Nilai karakteristik yang diestimasi Unit analisis
LOGO
Kerangka Sampel
Kerangka sampel harus memenuhi persyaratan: 1. Tersedia sampai dengan unit sampling
2. Batas jelas
3. Tidak tumpang tindih atau terlewat 4. Ada korelasi dengan data yang diteliti 5. Mutakhir
Persyaratan tsb diperlukan agar tidak terjadi:
1. Unit sampling yang tidak dijumpai 2. Unit sampling yang duplikasi
3. Unit sampling yang terpecah 4. Unit sampling yang tergabung
5. Unit sampling baru yang belum tercakup
Kerangka Sampel
Dalam bentuk daftar sampling unit/list frame (seperti daftar rumah tangga, daftar perusahaan industri
besar/sedang, diretori perusahaan pertanian dsb)
Dalam bentuk peta/area frame/map frame (peta blok sensus, peta desa,dsb) menunjukkan batas geografis dari sampling unit atau kumpulan sampling unit.
Bentuk Kerangka Sampel
Konsep dan Definisi Blok Sensus:
Blok sensus biasa (B) adalah blok sensus yang sebagian besar muatannya antara 80 sampai 120 rumahtangga atau bangunan tempat tinggal atau bangunan bukan tempat tinggal atau gabungan keduanya.
Blok sensus khusus (K) adalah blok sensus yang tertutup untuk umum. Tempat-tempat yang biasa dijadikan blok sensus khusus antara lain asrama/barak militer, asrama perawat, panti asuhan dengan 100 penghuni atau lebih dan lembaga pemasyarakatan (tidak ada batasan jumlah penghuni).
LOGO
Keuntungan Survei Sampel
1. Menghemat biaya
2. Mempercepat penyajian hasil survei
3. Cakupan materi lebih luas
4. Akurasi data lebih tinggi
Kelemahan Survei Sampel
Penyajian sampai wilayah kecil (seperti kecamatan
atau desa) dengan sampel yang terbatas tidak akan
dapat dipenuhi
Penyajian variabel langka/jarang terjadi/proporsi
kecil tidak dapat dipenuhi
Bila diperlukan trend data untuk mengukur
perubahan yang sangat kecil, survei sampel dari satu
periode ke periode berikutnya kemungkinan tidak
dapat digunakan, kecuali bila digunakan panel (sampel
sama untuk beberapa periode)
Apabila tidak tersedia kerangka sampel maka
LOGO
Probability Sampling
Metode pemilihan sampelnya berdasarkan teori peluang Setiap unit dari populasi memiliki peluang untuk terpilih
sebagai sampel (besarnya peluang tidak boleh sama dengan nol)
Besarnya peluang dapat sama (equal probability) atau tidak sama (unequal probability) tergantung dari metode sampling yang digunakan
Untuk keperluan penarikan sampel diperlukan kerangka sampel
Oleh karena setiap unit dalam populasi mempunyai peluang untuk terpilih dalam sampel dan besarnya juga telah
diperhitungkan, maka dimungkinkan untuk menghasilkan estimasi parameter dari populasi seperti total, rata-rata, proporsi, dan sebagainya.
Probability Sampling harus memenuhi 4 kriteria
1. Kita bisa mendefinisikan “the set of distinct samples” yang bisa dipilih
2. Setiap sampel mempunyai probability untuk dipilih, dan besarnya probability diketahui
3. Terpilihnya sampel dengan proses automatic randomization, konsisten dengan probability-nya
4. Metode untuk menghitung estimasinya harus
menggunakan sampling weight dan menghasilkan nilai estimasi yang unik.
LOGO
Probability Sampling
Probability Sampling Sampling Elemen Simple Random Sampling (SRS) Systematic sampling PPS Sampling Stratified Sampling Sampling Klaster Single Stage Cluster Sampling Multistage Sampling Dipelajari di MPC 1 Dipelajari di MPC 2 MPC1LOGO
Nonprobability Sampling
Sampel dipilih dengan sebuah metode
non-random
Dalam memilih sampel sangat tergantung pada
kebijaksanaan atau pertimbangan dari peneliti
Dapat digunakan tanpa menggunakan kerangka
sampel
Kelemahan:
1. Tidak dapat melakukan generalisasi populasi
berdasarkan data sampel
2. Tidak mungkin untuk mengukur tingkat
ketelitian (presisi) data dari sampelnya
3. Kesalahan frame atau nonrespon tidak dapat
LOGO
Nonprobability Sampling
Convenience sampling
Prosedur untuk mendapatkan unit sampel
menurut keinginan peneliti dengan
menggunakan sampel yang paling sederhana dan
ekonomis
Tidak memerlukan daftar populasi yang panjang
Seringkali menghasilkan output penelitian
dengan tingkat objektivitas yang rendah
Variabilitas dan bias tidak dapat diukur atau
dikontrol
Nonprobability Sampling
Judgement (purposive) sampling
Peneliti memilih sampel berdasarkan
penilaian
terhadap beberapa karakteristik anggota sampel
yang disesuaikan dengan tujuan penelitian
Peneliti ahli memilih sampel untuk memenuhi
tujuannya, seperti meyakinkan bahwa semua
populasi mempunyai karakteristik tertentu
Biasanya dilakuakn bila unit yang dipilih sedikit,
misalnya melakukan studi kasus di daerah kecil
Biaya moderat, namun hasilnya bias karena sampel
tidak representatif
LOGO
Nonprobability Sampling
Contoh Judgement (Purposive) Sampling:
Sebuah penelitian mengenai pengaruh
pengumuman merger dan akuisisi terhadap return
saham perusahaan target di Bursa Efek Jakarta.
Sampel penelitiannya adalah semua perusahaan
yang dijadikan target merger dan akuisisi pada
tahun 1991-1997, dengan alasan pada akhir 1997
Indonesia
dilanda
krisis
ekonomi
yang
mengakibatkan kesulitan likuiditas. Dari kriteria tsb,
diperoleh 36 perusahaan yang dijadikan sampel
penelitian.
Nonprobability Sampling
Quota sampling
Peneliti mengklasifikasikan populasi menurut
kriteria tertentu (partinent properties), menentukan
proporsi sampel yang
dikehendaki
untuk tiap kelas,
menetapkan kuota untuk setiap pewawancara
Tidak memerlukan daftar populasi lagi
Memberikan hasil klasifikasi yang bias
Penyimpangan hasil populasi tidak dapat
diperkirakan karena penggunaan seleksi yang
LOGO
Nonprobability Sampling
Haphazard sampling
Peneliti memilih sampel tanpa prosedur khusus atau
tanpa mengontrol dalam pemilihan sampel
Misal: menanyakan sukarelawan untuk
berpartisipasi dalam pendidikan
Cara ini mudah, murah, dan berguna hanya untuk
bentuk yang kesannya umum atau secara garis besar
saja
Hasilnya bias dan tidak dapat menduga nilai
populasi
LOGO
Nonprobability Sampling
Snowball sampling
Peneliti memilih sampel di mana responden awal
(pertama) dipilih dengan metode probabilitas,
kemudian responden selanjutnya diperoleh dari
informasi yang diberikan oleh responden yang
pertama
Keuntungan: memungkinkan ditekannya ukuran
sampel dan biaya, bermanfaat untuk pengalokasian
anggota populasi yang jumlahnya sedikit
Kelemahan: hasilnya bias karena jumlah sampel
tidak independen (orang yang direkomendasikan
oleh responden terdahulu untuk diwawancarai
memiliki kemungkinan kemiripan)
LOGO
Nonprobability Sampling
Identifikasi Responden Snowball
LOGO
PERTEMUAN 2
Sampling Error dan Nonsampling Error Parameter dan Statistik All Possible Sample Expected Value dan Bias Mean Square Error Distribusi sampling
LOGO
Error
Sampling error
Kesalahan karena
faktor sampling
Non-sampling error
Kesalahan bukan
karena faktor sampling
Kesalahan (Error) dalam Pengumpulan Data
Setiap pengukuran tidak akan terlepas dari kemungkinan
adanya kesalahan (error)
Kesalahan dalam pengumpulan data ada 2, yaitu sampling
error dan nonsampling error
Total Error
A
B
C
Besar kesalahan (error) Sampling errorNon sampling error
Ukuran sampel (n)
LOGO
Sampling Error
Kesalahan (error) timbul berkenaan dengan penarikan kesimpulan tentang populasi berdasarkan observasi terhadap sebagian unit populasi (sampel)
Error ini tidak akan muncul pada pencacahan
lengkap/complete enumeration/sensus
Sampel dengan sampling error terkecil selalu
dipertimbangkan sebagai representasi yang baik dari populasi
Nilai sampling error akan menurun dengan peningkatan ukuran sampel (sample size)
Penurunan nilai sampling error akan berbanding terbalik terhadap akar kuadrat dari sample size
Cara Mengurangi Sampling Error
Memperbesar ukuran sampel (sample size)
Tetapi cara ini bisa meningkatkan nonsampling error
Sampling design yang tepat
Misalnya tanpa menambah jumlah sampel, sampling
error bisa ditekan dengan menggunakan stratified
random sampling
LOGO
Nonsampling Error
Kesalahan (error) yang timbul terutama pada
tahap pengumpulan dan pengolahan data.
Error ini muncul di dalam pencacahan lengkap
(sensus) dan survei sampel
Error ini akan meningkat seiring dengan
peningkatan ukuran sampel
Error ini akan lebih besar pada pencacahan
lengkap (sensus) daripada survei
Nonsampling Error
1. Conceptual Error
a. Error dalam penggunaan konsep, definisi , dan
klasifikasi.
b. Error dalam perencanaan (kuesioner desain,
frame, pelatihan petugas, instruksi dalam
manual)
2. Error karena penggantian sampel
a. Kesalahan identifikasi unit sampling
b. Unit sampling tidak ditemukan
c. Unit sampling sulit dijangkau (bencana alam,
faktor keamanan, faktor alam, dsb)
LOGO
Nonsampling Error
4. Kesalahan Petugas
a. Tidak dipahaminya konsep dan definisi
b. Under/over coverage
c. Petugas kurang gigih menggali informasi
responden
Dishonest Interviewer
Daripada capek cari responden, aku berburu saja. Nanti
kuesioner aku isi sendiri
Nonsampling Error
5. Error karena responden
a. Kurangnya penjelasan petugas kepada
responden tentang tujuan/maksud dari survei
dan maksud dari item-item pertanyaan
b. Responden tidak bisa menjawab atau menolak
c. Responden terlalu reaktif dan menghubungkan
dengan hal-hal lain yang tak terkait dengan
survei
LOGO
Nonsampling Error
6. Error Pengolahan Data
a. Error Receiving dan batching
b. Error Editing dan coding
c. Error Entry data
d. Error Validasi data
e. Error Cross-check table
Cara Mengurangi Nonsampling Error
Callback
Rewards and incentive
Trained interviewers
Data check (monitoring)
LOGO
Parameter vs Statistik
data populasi pengolahan/analisis parameter
data sampel pengolahan/analisis statistik
Statistik merupakan nilai yg dihitung dari hasil survei sample mengenai
karakteristik, biasanya untuk tujuan membuat estimasi populasi.
Jika digunakan untuk membuat estimasi nilai karakteristik populasi akan disebut sebagai penduga (estimator).
MPC1 Parameter : sebuah fungsi nilai frekuensi dari seluruh N unit (populasi)
Contoh:
Total: 𝑌1 + 𝑌2 + ⋯ + 𝑌𝑁 = 𝑁𝑖=1𝑌𝑖 = 𝑌 Rata-rata: total dibagi jumlah unit, 𝑌 = 1
𝑁 𝑌𝑖 = 𝑌 𝑁 𝑁
Estimator vs Estimate
Estimator
is a statistics obtained by specified
procedure for estimating a population parameter.
The estimator is a random variable as its value differs
from sample to sample and the samples are selected
with specified probability.
The particular value, which the estimator takes for a
given sample, is known as an
estimate
LOGO
Notasi
Pada metode sampling telah disepakati adanya notasi dengan “huruf besar” menyatakan data populasi dan “huruf kecil”
menyatakan nilai sampel
No Rincian Populasi Sampel
1 Nilai karakteristik unit ke-i 𝑌𝑖 𝑦𝑖
2 Rata-rata nilai karakteristik 𝑌 𝑦 = 𝑌
3 Total nilai karakteristik 𝑌 𝑌
4 Banyaknya unit sampling 𝑁 𝑛
5 Varians 𝑆2 𝑠2
6 Proporsi 𝑃 𝑝 = 𝑃
7 Rasio 𝑅 𝑟 = 𝑅
Varians dan Varians Sampling
Varians (𝑠2) menunjukkan bagaimana tingkat
homegenitas/heterogenitas nilai karakteristik unit dalam populasi.
Akar dari varians (𝑠2) disebut standar deviasi. Varians sampling 𝑣(𝜃 ) , varians ini berbeda dengan
varians yang dinyatakan dengan 𝑠2. Varians sampling
menunjukkan tingkat keragaman dari nilai-nilai estimasi Akar dari varians sampling disebut standard error atau
sampling error 𝑠𝑒(𝜃 ).
Standar error dibagi nilai estimasi karakteristik disebut relative standar error (rse), biasanya dinyatakan dalam
LOGO
All Possible Samples
Misalkan, kita ingin memilih sebanyak 𝑛 sampel dari
populasi sebanyak 𝑁 unit .
Dalam pemilihan sampel, terdapat 2 cara yaitu dengan
pengembalian (with replacement/wr) dan tanpa
pengembalian (without replacement/wor).
All posible sample:
With replacement (wr)--- > terdapat 𝑁
𝑛possible sample
Without replacement (wor)--- > terdapat 𝑁
𝑛
=
𝑁! 𝑛! 𝑁−𝑛 !
possible sample
All Posible Sample
Misal, kita akan memilih 2 orang sampel dari populasi
3 orang yaitu A, B, C.
Jika pemilihan dilakukan dengan with replacement
(wr) akan terdapat 3
2= 9 kemungkinan sampel yaitu:
Jika pemilihan dilakukan dengan without replacement
(wor) akan terdapat 3
2
=
3! 2!(3−2)!= 3 kemungkinan
sampel yaitu:
1. AA 2. AB 3. AC 4. BA 5. BB 6. BC 7. CA 8. CB 9. CC 1. AB 2. AC 3. BCLOGO
Expected Value dan Bias
Misalkan, peluang terpilihnya gugus sampel ke-i adalah 𝑃𝑖 dan 𝜃 𝑖 adalah estimasi dari gugus sampel ke-i, yang
merupakan penduga 𝜃 dari parameter 𝜃 (i=1,2,…,M), M adalah total dari gugus sampel yang mungkin.
Nilai harapan (expected value) atau rata-rata dari penduga 𝜃 adalah
𝐸 𝜃 = 𝑃𝑖𝜃 𝑖 𝑀
𝑖=1
Jika peluang terpilihnya tiap gugus sampel sama 𝑃𝑖 = 𝑀1 , maka 𝐸 𝜃 = 1 𝑀 𝜃 𝑖 𝑀 𝑖=1 MPC1
Expected Value, Bias, dan Consistent Estimator
Penduga 𝜃 dikatakan unbiased estimator (penduga
yang tidak bias) dari parameter 𝜃 jika expected
value-nya sama dengan 𝜃.
𝐸 𝜃 = 𝜃
Jika 𝐸 𝜃 ≠ 𝜃 , maka penduga 𝜃 dikatakan biased
estimator (penduga yang bias) dari 𝜃.
Bias dari 𝜃 adalah
𝐵 𝜃 = 𝐸 𝜃 − 𝜃
Penduga 𝜃 dikatakan consistent estimator dari
parameter 𝜃 jika nilai 𝜃 akan mendekati 𝜃 seiring
dengan peningkatan jumlah sampel
LOGO
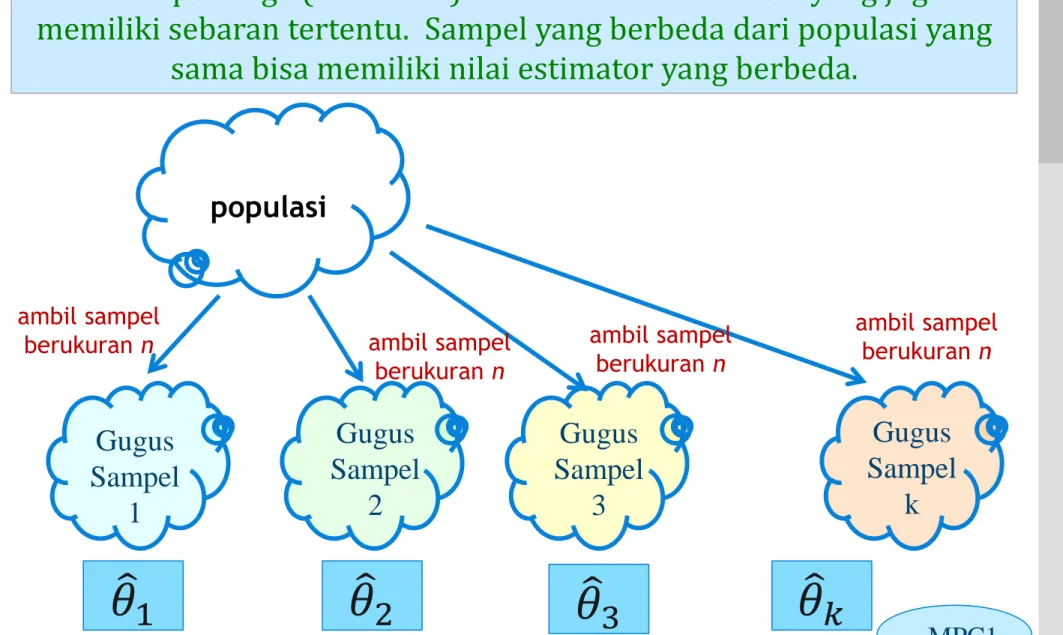
Suatu penduga (estimator) adalah random variabel yang juga memiliki sebaran tertentu. Sampel yang berbeda dari populasi yang
sama bisa memiliki nilai estimator yang berbeda.
Ilustrasi Gugus Sampel
populasi
ambil sampel berukuran n ambil sampel
berukuran n ambil sampel
berukuran n ambil sampel berukuran n Gugus Sampel 1 Gugus Sampel 2 Gugus Sampel 3 Gugus Sampel k
𝜃
1𝜃
2𝜃
3𝜃
𝑘 MPC1LOGO
Mean Square Error (MSE)
Nilai estimasi berdasarkan pada observasi terhadap suatu gugus sampel akan berbeda dengan nilai estimasi dari gugus sampel lainnya
Perbedaan antara estimasi 𝜃 𝑖 berdasarkan gugus sampel ke-i dengan parameter 𝜃 disebut kesalahan estimasi 𝜃 𝑖 − 𝜃
Kesalahan estimasi bervariasi antara gugus sampel yang satu dengan gugus sampel yang lainnya.
Rata-rata ukuran perbedaan dari estimasi-estimasi yang
berbeda dari nilai parameternya disebut Mean Square Error (MSE) yang dihitung berdasarkan nilai harapan (expected
value) dari kuadrat kesalahan estimasi, yaitu
𝑀𝑆𝐸 𝜃 = 𝐸 𝜃 − 𝜃 2 = 𝑃𝑖 𝑀 𝑖=1
𝜃 𝑖 − 𝜃 2
LOGO
Varians Sampling
Varians sampling dihitung berdasarkan nilai
harapan (expected value) dari deviasi nilai estimasi
dengan nilai harapannya
𝑉 𝜃 = 𝐸 𝜃 − 𝐸 𝜃
2= 𝐸 𝜃
2− 𝐸 𝜃
2
Varians sampling mengukur keragaman atau
ketepatan dari penduga (estimator)
Hubungan Antara MSE dan Varians Sampling
MSE adalah jumlah dari varians sampling dan bias
kuadrat, hal ini bisa dibuktikan:
𝑀𝑆𝐸 𝜃 = 𝐸 𝜃 − 𝜃
2= 𝐸 𝜃 − 𝐸 𝜃 + 𝐸 𝜃 − 𝜃
2= 𝐸 𝜃 − 𝐸 𝜃
2+ 𝐸 𝐸 𝜃 − 𝜃
2= 𝑉 𝜃 + 𝐵 𝜃
2
Untuk unbiased estimator, MSE sama dengan
LOGO
All Posible Sample
Berikut ini adalah data jumlah populasi siswa
laki-laki dan perempuan di suatu kelas
No Kelas Laki-laki (X) Perempuan (Y)
1 A 5 2 2 B 10 5 3 C 15 3 4 D 5 2 5 E 10 4 MPC1
All Possible Sample
No Kelas (Xi) (Yi)
1 A 5 2 2 B 10 5 3 C 15 3 4 D 5 2 5 E 10 4 Total 𝑋 = 𝑋𝑖 = 45 𝑌 = 𝑌𝑖 = 16 Rata-rata 𝑋 = 𝑁1 𝑋𝑖 = 1 5 × 45 = 9 𝑌 = 1 𝑁 𝑌𝑖 = 1 5 × 16 = 3.2 Rasio 𝑅 = 𝑋 𝑌 = 9 3.2 = 2.8125
LOGO
Jika dari 5 kelas tersebut, diambil 2 kelas sebagai
sampel secara wor, maka akan terdapat 5
2
=10
kemungkinan sampel.
MPC1
All Possible Sample
No Sampel
Laki-laki (x) Perempuan (y) Rasio
𝑹𝒊 = 𝒙 𝒊 𝒚 𝒊 𝑥𝑖1 𝑥𝑖2 𝑥 𝑖 𝑦𝑖1 𝑦𝑖2 𝑦 𝑖 1 A,B 5 10 7.5 2 5 3.5 2.1 2 A,C 5 15 10 2 3 2.5 4 3 A,D 5 5 5 2 2 2 2.5 4 A,E 5 10 7.5 2 4 3 2.5 5 B,C 10 15 12.5 5 3 4 3.1 6 B,D 10 5 7.5 5 2 3.5 2.1 7 B,E 10 10 10 5 4 4.5 2.2 8 C,D 15 5 10 3 2 2.5 4 9 C,E 15 10 12.5 3 4 3.5 3.6 10 D,E 5 10 7.5 2 4 3 2.5 Jumlah 90 32 28.7
LOGO
All Possible Sample
Expected value dari estimator vs parameter
𝐸 𝑥 = 𝑀1 𝑀𝑖=1 𝑥 𝑖 = 101 × 90 = 9 , 𝑋 = 9 (unbiased) 𝐸 𝑦 = 𝑀1 𝑀𝑖=1 𝑦 𝑖 = 101 × 32 = 3.2 , 𝑌 = 3.2 (unbiased) 𝐸 𝑅 = 1 𝑀 𝑅 𝑖 𝑀 𝑖=1 = 101 × 28.7 = 2.87 , 𝑅 = 2.8125 (biased)
Dari hasil di atas, dapat disimpulkan bahwa estimator rata-rata adalah estimator yang unbiased, sedangkan estimator rasio
adalah estimator yang biased.
Besarnya bias untuk estimator rasio adalah
All Possible Sample
Jika diketahui populasi berukuran N=6 yaitu A, B, C, D, E, dan F dengan nilai variabel X berturut-turut adalah 6,2,8,4,2, dan 4. Sampel berukuran n=4 dipilih secara acak tanpa
pengembalian (wor) dari populasi tsb. a. Hitunglah nilai 𝐸 𝑥 , 𝐸 𝑋 dan 𝐸 𝑠2
b. Bandingkan hasil pada point (a) dengan nilai
parameternya. Kesimpulan apa yang bisa diambil ?
Petunjuk:
Untuk gugus sampel ke-i: 𝑋 𝑖 = 𝑁𝑥 𝑖
LOGO
Koefisien Korelasi
Mengukur keeratan/kekuatan hubungan antara
dua variabel
Korelasi bisa bernilai positif atau negatif
Semakin besar nilai koefisien korelasi
menandakan bahwa hubungan dua variabel
tersebut semakin kuat
Rumus:
𝜌 =
𝑐𝑜𝑣 𝜃
1, 𝜃
2𝑣 𝜃
1× 𝑣 𝜃
2=
𝐸 𝜃
1− 𝜃
1𝜃
2− 𝜃
2𝐸 𝜃
1− 𝜃
1 2× 𝐸 𝜃
2− 𝜃
2 2 MPC1Distribusi Sampling
Dari hasil estimasi yang didapat dari satu gugus sampel akan menghasilkan suatu estimasi titik (point estimate).
Sebenarnya setiap gugus sampel dari seluruh kemungkinan gugus sampel mempunyai nilai estimasi yang kemungkinan akan berbeda dengan nilai sebenarnya (true value).
Seluruh nilai point estimate dari setiap gugus sampel dapat diperkirakan dengan menggunakan estimasi selang (interval
estimate) atau confidence interval (1-𝛼)%, dengan rumus:
𝜃 − 𝑍𝛼/2 ∙ 𝑠𝑒 𝜃 < 𝜃 < 𝜃 + 𝑍𝛼/2 ∙ 𝑠𝑒 𝜃
Interpretasi confidence interval (1-𝛼)%: jika kita melakukan pemilihan n sampel secara berulang sebayak 100 kali maka kita akan terdapat 100 selang kepercayaan dan harapannya sebanyak (1-𝛼) selang kepercayaan akan memuat nilai
LOGO
Distribusi Sampling
𝐸(𝑦 )
-2se(𝑦 ) -se(𝑦 ) +se(𝑦 ) +2se(𝑦 ) 𝑦 𝑌 𝑌 𝑡𝑟𝑢𝑒 SB NSB TB Total Error Peluang Keterangan:
SE: sampling error SB: sampling bias
NSB: nonsampling bias TB: total bias
MPC1 SE
Akurasi, Efisiensi, dan Presisi
Akurasi diukur dari nilai
total error
, yaitu
perbedaan antara nilai estimasi dengan nilai
sebenarnya (true value). Semakin kecil nilai total
error, suatu estimator dikatakan semakin akurat.
Efisiensi diukur dari besarnya
mean square error
(MSE)
. Semakin kecil nilai MSE, suatu estimator
akan semakin efisien.
Presisi diukur dari besarnya
varians sampling
.
Semakin kecil nilai varians sampling, suatu
LOGO
𝑅𝐸𝑐 𝜃 1|𝜃 2 = 𝑀𝑆𝐸 𝜃 1 × 𝐶 𝜃 1 𝑀𝑆𝐸 𝜃 2 × 𝐶 𝜃 2
Estimator 𝜃 1 dikatakan lebih efisien daripada estimator 𝜃 2 jika 𝑀𝑆𝐸 𝜃 1 < 𝑀𝑆𝐸 𝜃 2 , besarnya Relative Efficiency (RE) dirumuskan:
𝑅𝐸𝑠 𝜃 1|𝜃 2 = 𝑀𝑆𝐸 𝜃 1 𝑀𝑆𝐸 𝜃 2
Estimator 𝜃 1 dikatakan lebih precise daripada estimator 𝜃 2 jika V 𝜃 1 < 𝑉 𝜃 2
Relative Efficiency
Efficiency
Sampling efficiency Cost efficiency MPC1LOGO
PERTEMUAN 3
Pengertian Keuntungan dan Kelemahan SRS WR dan SRS WOR All Possible Sample Estimasi Rata-rata, Total Estimasi Varians
LOGO
Pengertian
Simple Random Sampling/SRS (Penarikan Sampel Acak
Sederhana/PSAS) adalah suatu metode memilih sampel dengan peluang setiap unit populasi untuk terpilih di dalam sampel adalah sama.
Keuntungan: cara pengambilan sampel dan teknik estimasi parameternya sederhana
Kelemahan:
hanya cocok untuk populasi yang relatif homogen, hanya cocok untuk cakupan survei yang tidak terlalu
luas, karena membutuhkan kerangka sampel sampai elemen,
biaya tinggi untuk populasi yang besar
SRS WR dan SRS WOR
Ada 2 tipe penarikan sampel secara SRS:
SRS WR
Setiap unit yang sudah terpilih sebagai sampel,
dikembalikan lagi ke dalam populasi, sehingga terjadi
kemungkinan terpilih kembali pada pengambilan
sampel berikutnya
SRS WOR
Suatu unit hanya terpilih satu kali sebagai sampel, unit
yang sudah terpilih tidak dikembalikan ke dalam
LOGO
All Possible Samples
Misalkan, kita ingin memilih sebanyak 𝑛 sampel dari
populasi sebanyak 𝑁 unit .
All posible sample:
SRS with replacement (wr)--- > terdapat 𝑁
𝑛possible
sample
SRS without replacement (wor)--- > terdapat
𝑁
𝑛
=
𝑁!
𝑛! 𝑁−𝑛 !
possible sample
All Posible Sample
Misal, kita akan memilih 2 orang sampel dari populasi 3 orang yaitu A, B, C.
Jika pemilihan dilakukan dengan with replacement (wr) akan terdapat 32 = 9 kemungkinan sampel yaitu:
Jika pemilihan dilakukan dengan without replacement (wor) akan terdapat 3
2 = 3! 2!(3−2)! = 3 kemungkinan sampel yaitu: 1. AA 2. AB 3. AC 4. BA 5. BB 6. BC 7. CA 8. CB 9. CC 1. AB 2. AC 3. BC
LOGO
Inclusion Probability 𝝅
𝒊MPC1
Ketika mengambil satu unit sebagai sampel, peluang unit ke-i untuk terpilih sebagai sampel adalah 𝑝𝑖 = 1
𝑁
Misalkan kita mengambil sampel sebanyak n kali, maka peluang unit ke-i untuk terpilih dalam sampel (inclusion
probability) adalah penjumlahan dari peluang terpilihnya
unit tersebut pada pengambilan yang pertama, kedua, ketiga, dst sampai dengan pengambilan ke-n.
Pada SRS WR 𝜋𝑖 = 1 𝑁 + 1 𝑁 + ⋯ + 1 𝑁 = 1 𝑁 = 𝑛 𝑁 𝑛 𝑖=1 Pada SRS WOR 𝜋𝑖 = 1 𝑁 + 𝑁 − 1 𝑁 ∙ 1 𝑁 − 1 + ⋯ + 𝑁 − 𝑛 𝑁 ∙ 1 𝑁 − 𝑛 = 𝑛 𝑁
Prosedur Pemilihan Sampel
Lottery Method
Menggunakan tabel angka random
1. Independent Choice Of Digits
2. Pendekatan Sisa (Remainder Approach)
3. Pendekatan hasil bagi (Quotient Approach)
Menggunakan angka random yang di-generate
LOGO
Independent Choice Of Digits
Tentukan baris, kolom, dan halaman Tabel Angka Random (TAR) yang digunakan untuk memulai penelusuran angka random
Jika jumlah populasi sebanyak N unit dan jumlah digits dari N adalah sebanyak 𝑟 digit, maka telusuri 𝑟 digit angka dari baris dan kolom permulaan.
Jika angka random (AR)≤ N, maka unit yang nomor urutnya sama dengan AR tsb terpilih sebagai sampel.
Jika angka random (AR)=0, maka unit ke-N (terakhir) terpilih sampel Jika angka random (AR)>N, maka lanjutkan penelusuran ke angka
random di baris selanjutnya pada kolom yang sama.
Lakukan pengambilan AR sampai jumlah sampel terpenuhi
Jika sudah sampai pada kolom terakhir dan belum mendapatkan angka random sebanyak sampel, lanjutkan ke kolom berikutnya baris
pertama
Independent Choice Of Digits
Misalkan kita ingin mengambil sampel SRS n=6 dari populasi N=60. Pembacaan TAR dimulai dari halaman 1, baris 1, kolom 1. N=60, 𝑟=2 (jumlah digit populasi) Sampel terpilih: SRS WR: 57, 57, 26, 48, 22,19 SRS WOR: 57, 26, 48, 22,19, 46 Baris Kolom (1-5) 1 88347 2 57140 3 74686 4 68013 5 57477 6 89127 7 26519 8 48045 9 22531 10 84887 11 72047 12 19645 13 46884 14 92289 Baris Kolom (1-5) 1 88347 2 57140 3 74686 4 68013 5 57477 6 89127 7 26519 8 48045 9 22531 10 84887 11 72047 12 19645 13 46884 14 92289 SRS WR SRS WOR
LOGO
Remainder Approach
Dari N unit populasi dan jumlah digits dari N adalah sebanyak 𝑟 digit, maka tentukan nilai 𝑁′ yaitu kelipatan terbesar dari N dengan jumlah digit yang sama. 𝑁′ adalah batas atas dari angka random yang akan dipilih.
Misal: N=32, 𝑟=2, 𝑁′=96
Jika AR≤ N, maka unit yang nomor urutnya sama dengan AR tsb terpilih sebagai sampel.
Jika AR=0, maka unit ke-N (terakhir) terpilih sampel Jika N<AR≤ 𝑁′, maka lakukan operasi pembagian:
𝐴𝑅
𝑁 = 𝑘 (𝑠𝑖𝑠𝑎 𝑠)
Unit dengan nomor urut=s terpilih sebagai sampel. Jika s=0, unit ke-N (terakhir) terpilih sampel
Jika AR > 𝑁′, maka lanjutkan penelusuran ke angka random di baris selanjutnya pada kolom yang sama.
Lakukan pengambilan AR sampai jumlah sampel terpenuhi
Jika sudah sampai kolom terakhir dan belum mendapatkan AR sebanyak sampel, lanjutkan ke kolom berikutnya baris pertama
LOGO
Remainder Approach
Misalkan kita ingin mengambil sampel SRS WOR n=3 dari populasi N=36 dengan remainder
approach. Pembacaan TAR dimulai dari halaman
1, baris 1, kolom 2.
N=36, 𝑟=2, 𝑁′ = 72 Angka random:
• 83 tolak, karena lebih dari 𝑁′
• 71 71
36 = 1, 𝑠𝑖𝑠𝑎 35 (unit ke-35 terpilih sampel) • 46 4636 = 1, 𝑠𝑖𝑠𝑎 10 (unit ke-10 terpilih sampel)
• 80 tolak, karena lebih dari 𝑁′ • 74 tolak, karena lebih dari 𝑁′ • 91 tolak, karena lebih dari 𝑁′ • 65 65
36 = 1, 𝑠𝑖𝑠𝑎 29 (unit ke-29 terpilih sampel)
Sampel terpilih: 35, 10, 29 Baris Kolom (1-5) 1 88347 2 57140 3 74686 4 68013 5 57477 6 89127 7 26519 8 48045 9 22531 10 84887 11 72047 12 19645 13 46884 14 92289 MPC1
LOGO
Quotient Approach
Dari N unit populasi dan jumlah digits dari N adalah sebanyak 𝑟 digit, maka tentukan nilai 𝑁′ yaitu kelipatan terbesar dari N dengan jumlah digit yang sama.
Misal: N=32, 𝑟=2, 𝑁′=96 Hitung nilai 𝑞 = 𝑁′
𝑁
Angka random (AR) yang diambil adalah mulai dari 0 sampai (𝑁′ − 1) Hitung 𝑡 = 𝐴𝑅
𝑞 (pembulatan ke bawah)
Sampel terpilih=unit dengan nomor urut (t-1)
Lakukan pengambilan AR sampai jumlah sampel terpenuhi
Jika sudah sampai kolom terakhir dan belum mendapatkan AR sebanyak sampel, lanjutkan ke kolom berikutnya baris pertama
LOGO
Quotient Approach
Misalkan kita ingin mengambil sampel SRS WOR n=3 dari populasi N=36 dengan quotient approach.
Pembacaan TAR dimulai dari halaman 1, baris 1, kolom 2.
N=36, 𝑟=2, 𝑁′ = 72, (𝑁′−1) = 71, 𝑞 = 72
36 = 2
Angka random:
• 83 tolak, karena lebih dari 𝑁′ − 1 • 71 t = 71
𝑞 = 71
2 = 35 (unit ke-34 terpilih sampel) • 46 t = 46
𝑞 = 46
2 = 23 (unit ke-22 terpilih sampel)
• 80 tolak, karena lebih dari 𝑁′ − 1 • 74 tolak, karena lebih dari 𝑁′ − 1 • 91 tolak, karena lebih dari 𝑁′ − 1 • 65 t = 65
𝑞 = 65
2 = 32 (unit ke-31 terpilih sampel)
Sampel terpilih: 34, 22, 31 Baris Kolom (1-5) 1 88347 2 57140 3 74686 4 68013 5 57477 6 89127 7 26519 8 48045 9 22531 10 84887 11 72047 12 19645 13 46884 14 92289 MPC1
LOGO
Estimasi
Nilai yang diestimasi SRS WR WOR Rata-rata 𝑦 = 1 𝑛 𝑦𝑖 𝑛 𝑖=1 Varians rata-rata 𝑣 𝑦 = 𝑠2 𝑛 𝑣 𝑦 = 𝑁 − 𝑛 𝑁 ∙ 𝑠2 𝑛 Total 𝑌 = 𝑁 𝑛 𝑦𝑖 = 𝑁𝑦 𝑛 𝑖=1 Varians Total 𝑣 𝑌 = 𝑁2 ∙ 𝑠2 𝑛 = 𝑁2 ∙ 𝑣 𝑦 𝑣 𝑌 = 𝑁2 ∙ 𝑁 − 𝑛 𝑁 ∙ 𝑠2 𝑛 = 𝑁2 ∙ 𝑣 𝑦 MPC1Estimasi Rata-rata
Estimasi rata-rata 𝑦 adalah estimasi yang unbiased dari parameter 𝑌 . Bukti: 𝐸 𝑦 = 𝐸 1 𝑛 𝑦𝑖 𝑛 𝑖=1 = 1 𝑛 𝐸 𝑦𝑖 𝑛 𝑖=1 = 1 𝑛 𝑝𝑖𝑌𝑖 𝑁 𝑖=1 𝑛 𝑖=1 = 1 𝑛 𝑌𝑖 𝑁 𝑁 𝑖=1 𝑛 𝑖=1 = 1 𝑛 𝑌 = 1 𝑛 𝑛𝑌 𝑛 𝑖=1 = 𝑌
LOGO
Varians Rata-rata (1)
Varians rata-rata adalah:
𝑉 𝑦 =
𝑁−𝑛 𝑁∙
𝑆2 𝑛 Bukti: 𝑉 𝑦 = 𝐸 𝑦 − 𝑌 2 = 𝐸 1 𝑛 𝑦𝑖 − 𝑌 𝑛 𝑖=1 2 = 1 𝑛2 𝐸 𝑦𝑖 − 𝑌 𝑛 𝑖=1 2 = 1 𝑛2 𝐸 𝑦𝑖 − 𝑌 2 + 𝑦𝑖 − 𝑌 𝑦𝑗 − 𝑌 𝑛 𝑖≠𝑗 𝑛 𝑖=1 MPC1Varians Rata-rata (2)
𝑉 𝑦 = 1 𝑛2 𝐸 𝑦𝑖 − 𝑌 2 + 1 𝑛2 𝐸 𝑦𝑖 − 𝑌 𝑦𝑗 − 𝑌 𝑛 𝑖≠𝑗 𝑛 𝑖=1 = 1 𝑛2 1 𝑁 𝑦𝑖 − 𝑌 2 𝑁 𝑖=1 + 1 𝑛2 1 𝑁 ∙ 1 𝑁 − 1 ∙ 𝑦𝑖 − 𝑌 𝑦𝑗 − 𝑌 𝑁 𝑖≠𝑗 𝑛 𝑖≠𝑗 𝑛 𝑖=1 = 1 𝑛2 𝜎2 𝑛 𝑖=1 + 1 𝑛2 ∙ 1 𝑁 ∙ 1 𝑁 − 1 ∙ 𝑦𝑖 − 𝑌 𝑁 𝑖=1 2 − 𝑦𝑖 − 𝑌 2 𝑁 𝑖=1` 𝑛 𝑖≠𝑗 = 1 𝑛2 𝑛𝜎2 + 1 𝑛2 ∙ 1 𝑁 ∙ 1 𝑁 − 1 ∙ − 𝑦𝑖 − 𝑌 2 𝑁 𝑖=1 𝑛 𝑖≠𝑗 = 𝜎 2 𝑛 − 1 𝑛2 ∙ 1 𝑁 ∙ 1 𝑁 − 1 ∙ 𝜎2 𝑛 𝑖≠𝑗 = 𝜎2 𝑛 − 1 𝑛2 ∙ 1 𝑁 ∙ 1 𝑁 − 1 ∙ 𝑛 𝑛 − 1 𝜎2 = 𝑁 − 𝑛 𝑁 − 1 ∙ 𝜎2 𝑛 𝑵 − 𝒏 𝑺𝟐LOGO
Varians Rata-rata (3)
Rumus Varians Untuk SRS WOR 𝑉 𝑦 = 𝑁 − 𝑛 𝑁 ∙ 𝑆2 𝑛 = 1 − 𝑛 𝑁 ∙ 𝑆2 𝑛 = 1 − 𝑓 ∙ 𝑆 2 𝑛 Keterangan: 𝑁−𝑛 𝑁 𝑑𝑖𝑠𝑒𝑏𝑢𝑡 𝑓𝑖𝑛𝑖𝑡𝑒 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑖𝑜𝑛𝑠 (𝑓𝑝𝑐) 𝑓 = 𝑁𝑛 𝑑𝑖𝑠𝑒𝑏𝑢𝑡 𝑠𝑎𝑚𝑝𝑙𝑖𝑛𝑔 𝑓𝑟𝑎𝑐𝑡𝑖𝑜𝑛
Jika sampel diambil dengan SRS WR, 𝑦𝑖 dan 𝑦𝑗 saling statistically
independent, sehingga 𝐸 𝑦𝑖 − 𝑌 𝑦𝑗 − 𝑌 = 0 dan 𝑉 𝑦 = 1
𝑛2 ∙ 𝑛𝜎2
= 𝜎
2
Sample Varians 𝒔
𝟐𝑠2 adalah unbiased estimator dari parameter 𝑆2 dan 𝜎2. 𝐸 𝑠2 = 𝜎2 jika sampel diambil secara SRS WR
𝐸 𝑠2 = 𝑆2 jika sampel diambil secara SRS WOR Bukti: 𝑠2 = 1 𝑛 − 1 𝑦𝑖 − 𝑦 2 𝑛 𝑖=1 = 1 𝑛 − 1 𝑦𝑖 − 𝑌 2 − 𝑛 𝑦 − 𝑌 2 𝑛 𝑖=1 𝐸 𝑠2 = 1 𝑛 − 1 𝐸 𝑦𝑖 − 𝑌 2 𝑛 𝑖=1 − 𝐸 𝑛 𝑦 − 𝑌 2
LOGO
Sample Varians 𝒔
𝟐 𝐸 𝑠2 = 1 𝑛 − 1 𝐸 𝑦𝑖 − 𝑌 2 𝑛 𝑖=1 − 𝑬 𝒏 𝒚 − 𝒀 𝟐 MPC1 𝑬 𝒏 𝒚 − 𝒀 𝟐 𝑺𝑹𝑺 𝑾𝑹: 𝑬 𝒏 𝒚 − 𝒀 𝟐 = 𝒏 ∙ 𝝈𝟐 𝒏 = 𝝈𝟐 … (𝟐𝒂) 𝑺𝑹𝑺 𝑾𝑶𝑹: 𝑬 𝒏 𝒚 − 𝒀 𝟐 = 𝒏 ∙ 𝑵 − 𝒏 𝑵 ∙ 𝑺𝟐 𝒏 = 𝑵 − 𝒏 𝒏 ∙ 𝑺𝟐 … (𝟐𝒃) 𝑬 𝒚𝒊 − 𝒀 𝟐 𝒏 𝒊=𝟏 = 𝑬 𝒚𝒊 − 𝒀 𝟐 = 𝟏 𝑵 𝒚𝒊 − 𝒀 𝟐 𝑵 𝒊=𝟏 𝒏 𝒊=𝟏 𝒏 𝒊=𝟏 = 𝟏 𝑵 ∙ 𝒏 ∙ 𝑵 − 𝟏 ∙ 𝑺𝟐 … (𝟏)
SRS WR
Dari persamaan (1) dan (2a) diperoleh:
𝐸 𝑠
2=
1 𝑛−1 𝑛(𝑁−1) 𝑁𝑆
2− 𝜎
2= 𝜎
2(terbukti)
SRS WOR
Dari persamaan (1) dan (2b) diperoleh:
𝐸 𝑠
2=
1 𝑛−1 𝑛(𝑁−1) 𝑁𝑆
2−
𝑁−𝑛 𝑁𝑆
2= 𝑆
2(terbukti)
Sample Varians 𝒔
𝟐LOGO
Varians Sampling Untuk penduga Rata-rata 𝒗 𝒚
Dengan men-substitusikan 𝑠
2untuk 𝜎
2(SRS WR)
dan 𝑆
2(SRS WOR), kita akan memperoleh unbiased
estimasi varians sampling untuk penduga rata-rata,
yaitu:
𝑣 𝑦 =
𝑠2 𝑛(SRS WR)
𝑣 𝑦 =
𝑁−𝑛 𝑁∙
𝑠2 𝑛(SRS WOR)
MPC1Estimasi Total Karakteristik (𝒀
)
Estimasi total karakteristik
𝑌 = 𝑁𝑦
Penduga total di atas adalah unbiased estimator untuk
parameter 𝑌, dapat dibuktikan:
𝐸 𝑌 = 𝐸 𝑁𝑦 = 𝑁 ∙ 𝐸 𝑦 = 𝑁𝑌 = 𝑌
Estimasi varians dari penduga total karakteristik:
𝑣 𝑌 = 𝑣 𝑁𝑦 = 𝑁
2∙ 𝑦
SRS WR: 𝑣( 𝑌 = 𝑁
2∙
𝑠𝑛2LOGO
Estimasi Rata-rata
Nilai yang diestimasi SRS WR WOR Rata-rata 𝑦 = 1 𝑛 𝑦𝑖 𝑛 𝑖=1 Varians rata-rata 𝑣 𝑦 = 𝑠2 𝑛 𝑣 𝑦 = 𝑁 − 𝑛 𝑁 ∙ 𝑠2 𝑛 Standar error 𝑠𝑒 𝑦 = 𝑣 𝑦 Relative standar error (RSE) 𝑟𝑠𝑒 𝑦 = 𝑠𝑒(𝑦 ) 𝑦 × 100% 1 − 𝛼 % Confidence Interval 𝑦 − 𝑍𝛼/2 ∙ 𝑠𝑒 𝑦 < 𝑌 < 𝑦 + 𝑍𝛼/2 ∙ 𝑠𝑒 𝑦 MPC1 𝑠2 = 1 𝑛 − 1 𝑦𝑖 − 𝑦 2 𝑛 𝑖=1 Catatan: 𝑁−𝑛 𝑁 𝑑𝑖𝑠𝑒𝑏𝑢𝑡 𝑓𝑖𝑛𝑖𝑡𝑒 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑖𝑜𝑛𝑠 (𝑓𝑝𝑐) 𝑓 = 𝑁𝑛 𝑑𝑖𝑠𝑒𝑏𝑢𝑡 𝑠𝑎𝑚𝑝𝑙𝑖𝑛𝑔 𝑓𝑟𝑎𝑐𝑡𝑖𝑜𝑛Estimasi Total
Nilai yang diestimasi SRS WR WOR Total 𝑌 = 𝑁 𝑛 𝑦𝑖 = 𝑁𝑦 𝑛 𝑖=1 Varians total 𝑣 𝑌 = 𝑁2 ∙ 𝑠 2 𝑛 = 𝑁2 ∙ 𝑣 𝑦 𝑣 𝑌 = 𝑁2 ∙ 𝑁 − 𝑛 𝑁 ∙ 𝑠2 𝑛 = 𝑁2 ∙ 𝑣 𝑦 Standar error 𝑠𝑒 𝑌 = 𝑣 𝑌 Relative standar error (RSE) 𝑟𝑠𝑒 𝑌 = 𝑠𝑒(𝑌 ) 𝑌 × 100% 1 − 𝛼 % Confidence Interval 𝑌 − 𝑍𝛼/2 ∙ 𝑠𝑒 𝑌 < 𝑌 < 𝑌 + 𝑍𝛼/2 ∙ 𝑠𝑒 𝑌LOGO
Contoh 1
Sebuah sampel acak sederhana yang terdiri dari 20 rumah tangga dipilih dari blok sensus X yang mempunyai muatan sebanyak 150
rumah tangga. Jumlah ART dari rumah tangga sampel sebagai berikut:
a. Perkirakan rata-rata jumlah ART dan total penduduk di blok sensus tersebut beserta standar error dan rse-nya !
b. Dengan tingkat kepercayaan 95%, buatlah selang kepercayaan untuk estimasi rata-rata jumlah ART dan total penduduk !
c. Interpretasikan hasil penghitungan di atas !
No ruta sampel 1 2 3 4 5 6 7 8 9 10
Jumlah ART 4 2 3 5 4 6 3 4 5 7
No ruta sampel 11 12 13 14 15 16 17 18 19 20
Jumlah ART 3 4 6 2 1 2 3 4 6 4
LOGO
Penyelesaian (1)
Diketahui: 𝑁 = 150, 𝑛 = 20 Estimasi rata-rata: 𝑦 = 1 𝑛 𝑦𝑖 = 1 20 4 + 2 + 3 + ⋯ + 6 + 4 = 1 20 ∙ 78 = 3,9 𝑛 𝑖=1Varians dari estimasi rata-rata: 𝑣 𝑦 = 𝑁 − 𝑛 𝑁 ∙ 𝑠2 𝑛 = 150 − 20 150 ∙ 2,515 20 = 0,109
Standar error dari estimasi rata-rata:
𝑠𝑒 𝑦 = 𝑣 𝑦 = 0,109 = 0,330
Relative standar error (RSE):
𝑟𝑠𝑒 𝑦 = 𝑠𝑒(𝑦 )
𝑦 ∙ 100% =
0,330
3,9 ∙ 100% = 8,46% Selang Kepercayaan (Confidence Interval) 95%:
𝑦 − 𝑍𝛼/2 ∙ 𝑠𝑒 𝑦 < 𝑌 < 𝑦 + 𝑍𝛼/2 ∙ 𝑠𝑒 𝑦 3,9 − 1,96 ∙ 0,330 < 𝑌 < 3,9 + 1,96 ∙ 0,330
3,253 < 𝑌 < 4,547
LOGO
Interpretasi:
Estimasi rata-rata anggota rumah tangga di blok
sensus X adalah 3,9 orang per rumah tangga dengan
perkiraan rata-rata penyimpangan (standar error)
sebesar 0,33 dan relative standar error sebesar
8,46%. Dengan tingkat kepercayaan 95%, dapat
dinyatakan bahwa nilai populasi rata-rata anggota
rumah tangga akan berada pada interval antara
3,253 sampai 4,547 orang per rumah tangga.
MPC1
Penyelesaian (3)
Estimasi total:
𝑌 = 𝑁𝑦 = 150 ∙ 3,9 = 585 Varians dari estimasi rata-rata:
𝑣 𝑌 = 𝑁2 ∙ 𝑣 𝑦 = 1502 ∙ 0,109 = 2452,895
Standar error dari estimasi rata-rata:
𝑠𝑒 𝑌 = 𝑣 𝑌 = 2452,895 = 49,526
Relative standar error (RSE):
𝑟𝑠𝑒 𝑌 = 𝑠𝑒(𝑌 )
𝑌 ∙ 100% =
49,526
585 ∙ 100% = 8,46% Selang Kepercayaan (Confidence Interval) 95%:
𝑌 − 𝑍𝛼/2 ∙ 𝑠𝑒 𝑌 < 𝑌 < 𝑌 + 𝑍𝛼/2 ∙ 𝑠𝑒 𝑌
585 − 1,96 ∙ 49,526 < 𝑌 < 585 + 1,96 ∙ 49,526 487,92 < 𝑌 < 682,07
LOGO
Interpretasi:
Estimasi total penduduk di blok sensus X adalah 585
orang dengan perkiraan rata-rata penyimpangan
(standar error) sebesar 49,526 orang dan relative
standar error sebesar 8,46%. Dengan tingkat
kepercayaan 95%, dapat dinyatakan bahwa nilai
populasi total penduduk akan berada pada interval
antara 487,92 sampai 682,07 orang.
MPC1
LOGO
PERTEMUAN 4
Proporsi Presisi Penentuan Ukuran Sampel All Possible Sample
LOGO
Proporsi Populasi 𝑷
Proporsi adalah special case dari rata-rata ketika
variabel/karakteristik yang diteliti 𝑌
𝑖hanya bernilai 0
dan 1.
Misalkan, kita ingin mengetahui proporsi mahasiswa
yang suka terhadap mata kuliah MPC di kelas 2KS1, maka
𝑌
𝑖= 0 untuk seorang mahasiswa yang tidak suka MPC
𝑌
𝑖= 1 untuk seorang mahasiswa yang suka MPC
Maka proporsi populasi mahasiswa yang suka MPC di 2KS1:
𝑃 =
1
𝑁
𝑌
𝑖 𝑁𝑖=1
Estimasi Proporsi (𝒑)
Jika 𝑦1, 𝑦2, … , 𝑦𝑛 adalah random sampel dengan ukuran 𝑛 yang diambil dari populasi sebanyak N, maka estimasi proporsi: 𝑝 = 1 𝑛 𝑦𝑖 𝑛 𝑖=1 Keterangan:
𝑦𝑖 harus bernilai 0 atau 1
Estimasi proporsi 𝑝 adalah unbiased estimator untuk parameter 𝑃, hal ini dibuktikan:
𝐸 𝑝 = 𝐸 1 𝑛 𝑦𝑖 𝑛 𝑖=1 = 1 𝑛 𝐸 𝑦𝑖 𝑛 𝑖=1 = 1 𝑛 ∙ 𝑛 ∙ 𝑌𝑖 𝑁 𝑛 𝑖=1 = 𝑃
LOGO
Varians Populasi dari 𝒀
𝒊(𝒀
𝒊=0 atau 1)
Misalkan dari sebanyak N populasi mahasiswa, terdapat A mahasiswa yang suka mata kuliah MPC, sehingga:
𝑌𝑖 = 0 untuk seorang mahasiswa yang tidak suka MPC 𝑌𝑖 = 1 untuk seorang mahasiswa yang suka MPC
Dari keterangan di atas, secara matematis dapat dituliskan: 𝑌𝑖 = 𝐴
𝑁 𝑖=1
dan 𝑃 = 𝐴
𝑁 , 𝑄 = 1 − 𝑃 Varians dari 𝑌𝑖 dapat dirumuskan:
𝑆2 = 1 𝑁 − 1 𝑌𝑖 − 𝑌 2 = 1 𝑁 − 1 𝑌𝑖2 − 𝑁𝑌 2 𝑁 𝑖=1 𝑁 𝑖=1 Karena 𝑌𝑖 = 0 𝑎𝑡𝑎𝑢 1, maka: 𝑌𝑖2 = 𝐴 = 𝑁𝑃 𝑁 𝑖=1 𝑑𝑎𝑛 𝑌 2 = 𝑃2 𝑆2 = 1 𝑁 − 1 𝑁𝑃 − 𝑁𝑃2 = 𝑁 𝑁 − 1𝑃𝑄 MPC1
LOGO
Varians Sampel dari 𝒚
𝒊(𝒚
𝒊=0 atau 1)
Misalkan dari sebanyak n sampel mahasiswa, terdapat a mahasiswa yang suka mata kuliah MPC, sehingga:
𝑦𝑖 = 0 untuk seorang mahasiswa yang tidak suka MPC 𝑦𝑖 = 1 untuk seorang mahasiswa yang suka MPC
Dari keterangan di atas, secara matematis dapat dituliskan: 𝑦𝑖 = 𝑎
𝑛 𝑖=1
dan 𝑝 = 𝑎
𝑛 , 𝑞 = 1 − 𝑝 Varians dari 𝑦𝑖 dapat dirumuskan:
𝑠2 = 1 𝑛 − 1 𝑦𝑖 − 𝑦 2 = 1 𝑛 − 1 𝑦𝑖2 − 𝑛𝑦 2 𝑛 𝑖=1 𝑛 𝑖=1 Karena 𝑦𝑖 = 0 𝑎𝑡𝑎𝑢 1, maka: 𝑦𝑖2 = 𝑎 = 𝑛𝑝 𝑛 𝑖=1 𝑑𝑎𝑛 𝑦 2 = 𝑝2 𝑠2 = 1 𝑛 − 1 𝑛𝑝 − 𝑛𝑝2 = 𝑛 𝑛 − 1𝑝𝑞 MPC1
LOGO
Varians Sampling dari Estimasi Proporsi
Untuk SRS WR
𝑣 𝑝 =
𝑠
2𝑛
=
1
𝑛
∙
𝑛
𝑛 − 1
𝑝𝑞
=
𝑝𝑞
𝑛 − 1
Untuk SRS WOR
𝑣 𝑝 =
𝑁 − 𝑛
𝑁
∙
𝑠
2𝑛
=
𝑁 − 𝑛
𝑁
∙
1
𝑛
∙
𝑛
𝑛 − 1
𝑝𝑞
=
𝑁 − 𝑛
𝑁
∙
𝑝𝑞
𝑛 − 1
MPC1LOGO
Estimasi Total dari Proporsi
Misalkan dari populasi sebanyak N mahasiswa diambil sampel sebanyak n mahasiswa. Dari sampel tersebut, terdapat
sebanyak 𝒂 mahasiswa yang suka MPC.
𝑦𝑖 = 0 untuk seorang mahasiswa yang tidak suka MPC 𝑦𝑖 = 1 untuk seorang mahasiswa yang suka MPC
Dari keterangan di atas, secara matematis dapat dituliskan: 𝑦𝑖 = 𝒂
𝑛
𝑖=1
Estimasi proporsi mahasiswa yang suka MPC: 𝑝 = 𝒂
𝑛
Estimasi total mahasiswa yang suka MPC:
𝐴 = 𝑁𝑝 Estimasi varians total:
𝑣 𝐴 = 𝑁2 ∙ 𝑣 𝑝
LOGO
Estimasi Proporsi
Nilai yang diestimasi SRS WR WOR Rata-rata 𝑝 = 1 𝑛 𝑦𝑖 𝑛 𝑖=1 Varians rata-rata 𝑣 𝑝 = 𝑛 − 1𝑝𝑞 𝑣 𝑝 = 𝑁 − 𝑛 𝑁 ∙ 𝑝𝑞 𝑛 − 1 Standar error 𝑠𝑒 𝑝 = 𝑣 𝑝 Relative standar error (RSE) 𝑟𝑠𝑒 𝑝 = 𝑠𝑒(𝑝) 𝑝 × 100% 1 − 𝛼 % Confidence Interval 𝑝 − 𝑍𝛼/2 ∙ 𝑠𝑒 𝑝 < 𝑃 < 𝑝 + 𝑍𝛼/2 ∙ 𝑠𝑒 𝑝 MPC1 Catatan: 𝑦𝑖 = 0 atau 1 𝑞 = 1 − 𝑝 𝑁−𝑛𝑁 𝑑𝑖𝑠𝑒𝑏𝑢𝑡 𝑓𝑖𝑛𝑖𝑡𝑒 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑖𝑜𝑛𝑠 (𝑓𝑝𝑐) 𝑓 = 𝑁𝑛 𝑑𝑖𝑠𝑒𝑏𝑢𝑡 𝑠𝑎𝑚𝑝𝑙𝑖𝑛𝑔 𝑓𝑟𝑎𝑐𝑡𝑖𝑜𝑛Estimasi Total
Nilai yang diestimasi SRS WR WOR Total 𝐴 = 𝑁𝑝 Varians total 𝑣 𝐴 = 𝑁2 ∙ 𝑛 − 1𝑝𝑞 𝑣 𝐴 = 𝑁2 ∙ 𝑁 − 𝑛 𝑁 ∙ 𝑝𝑞 𝑛 − 1 Standar error 𝑠𝑒 𝐴 = 𝑣 𝐴 Relative standar error (RSE) 𝑟𝑠𝑒 𝐴 = 𝑠𝑒(𝐴 ) 𝐴 × 100% 1 − 𝛼 % Confidence Interval 𝐴 − 𝑍𝛼/2 ∙ 𝑠𝑒 𝐴 < 𝐴 < 𝐴 + 𝑍𝛼/2 ∙ 𝑠𝑒 𝐴LOGO
Contoh 1:
Dari populasi sebanyak 50 pegawai di perusahaan X, dipilih 10 orang sebagai sampel secara SRS WOR. Data yang diperoleh sebagai berikut:
Tentukan:
a. Estimasi proporsi pegawai yang berumur kurang dari 30 tahun b. Estimasi total/jumlah pegawai yang berumur kurang dari 30
tahun
c. Estimasi proporsi pegawai yang pendidikan terakhir S1
d. Estimasi jumlah pegawai yang pendidikan terakhir S1 MPC1 No Umur Pendidikan
terakhir No Umur Pendidikan terakhir
1 24 S1 6 50 D3
2 35 D3 7 27 SMA
3 42 SMA 8 52 SMA
4 31 S1 9 46 S2
Penyelesaian:
No Umur Pendidikan
terakhir Kode Umur (<30=1, 30 ke atas=0) Kode Pendidikan Terakhir (S1=1, bukan S1=0) 1 24 S1 1 1 2 35 D3 0 0 3 42 SMA 0 0 4 31 S1 0 1 5 29 S1 1 1 6 50 D3 0 0 7 27 SMA 1 0 8 52 SMA 0 0 9 46 S2 0 0 10 39 S1 0 1