3.
METODOLOGI
3.1 Waktu dan Tempat
Penelitian dilaksanakan di laboratorium Klimatologi, CCROM. Seluruh rangkaian kegiatan penelitian dilaksanakan meliputi studi pustaka atau literatur, pengumpulan data penelitian, pengolahan data dan perbaikan hasil penelitian.
3.2 Data Penelitian
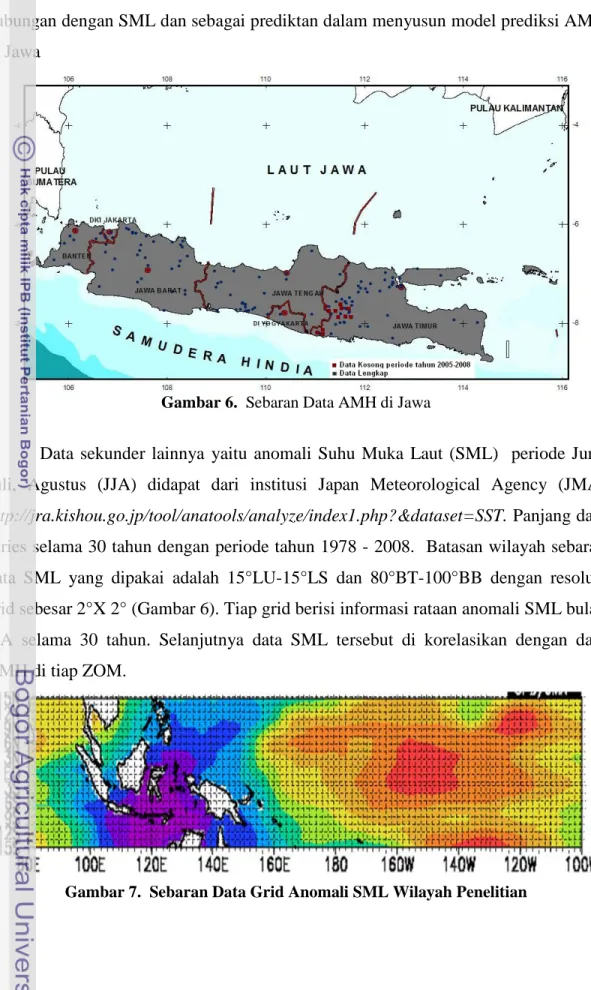
Data yang digunakan dalam penelitian ini berupa data sekunder, yaitu data hujan dasarian dan data Suhu Muka laut (SML). Wilayah penelitian meliputi seluruh kabupaten di Jawa yang diwakili oleh beberapa pos pencatat data hujan didalamnya. Dari catatan data hujan harian, selanjutnya disusun akumulasi curah hujan sepuluh harian (dasarian) dengan periode data 1979-2008. Sebaran data hujan di Jawa terdiri dari 188 pos hujan mulai dari Propinsi Banten hingga Pulau Madura (Gambar 5). Tingkat kelengkapan data selama 30 tahun di tiap pos hujan bervariasi, namun pada umumnya untuk wilayah Banten, Jawa Barat dan Jawa Tengah relatif lengkap. Sedangkan wilayah Jawa Timur terdapat beberapa pos hujan mulai 2005-2008 tidak ada data. Untuk mengatasi kekosongan data tersebut dilakukan rataan untuk data curah hujan tahun yang ada kemudian dipakai untuk mengisi tahun yang kosong.
Berdasarkan akumulasi curah hujan dasarian maka ditentukan terjadinya Awal Musim Hujan (AMH) dengan menggunakan kriteria yang telah di lakukkan BMKG. Hasil yang di dapatkan yaitu informasi kejadian AMH di tiap titik selama periode 30 tahun (Lampiran 1). Tiap titik pos pengamatan berisi informasi posisi stasiun (Lampiran 2) dan catatan curah hujan harian. Langkah selanjutnya data ini akan di kelompokkan menurut kejadian AMH yang mirip sehingga didapatkan zona musim (ZOM) di Jawa. ZOM merupakan gambaran satu atau beberapa wilayah kabupaten yang mempunyai kejadian AMH serupa, namun ZOM bukan mewakili wilayah administrasi. Dalam satu ZOM dapat terdiri dari satu atau beberapa pos pencatat hujan didalamnya sehingga ZOM yang dipakai merupakan nilai AMH rataan dari
beberapa pos hujan. Nilai rataan inilah yang selanjutnya akan di pakai untuk mencari hubungan dengan SML dan sebagai prediktan dalam menyusun model prediksi AMH di Jawa
Gambar 6. Sebaran Data AMH di Jawa
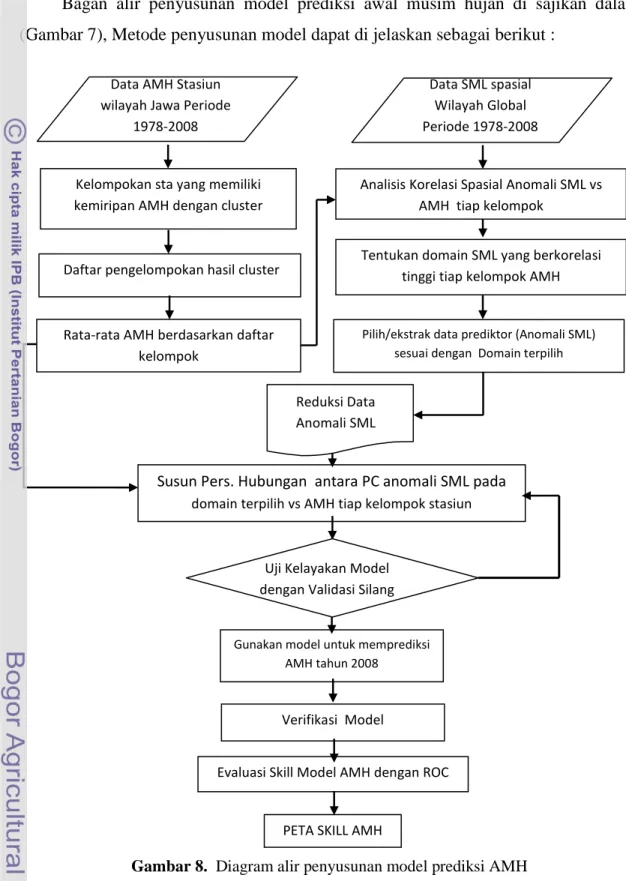
Data sekunder lainnya yaitu anomali Suhu Muka Laut (SML) periode Juni, Juli, Agustus (JJA) didapat dari institusi Japan Meteorological Agency (JMA) http://jra.kishou.go.jp/tool/anatools/analyze/index1.php?&dataset=SST. Panjang data series selama 30 tahun dengan periode tahun 1978 - 2008. Batasan wilayah sebaran data SML yang dipakai adalah 15°LU-15°LS dan 80°BT-100°BB dengan resolusi grid sebesar 2°X 2° (Gambar 6). Tiap grid berisi informasi rataan anomali SML bulan JJA selama 30 tahun. Selanjutnya data SML tersebut di korelasikan dengan data AMH di tiap ZOM.
3.3 Prosedur Pengolahan Data
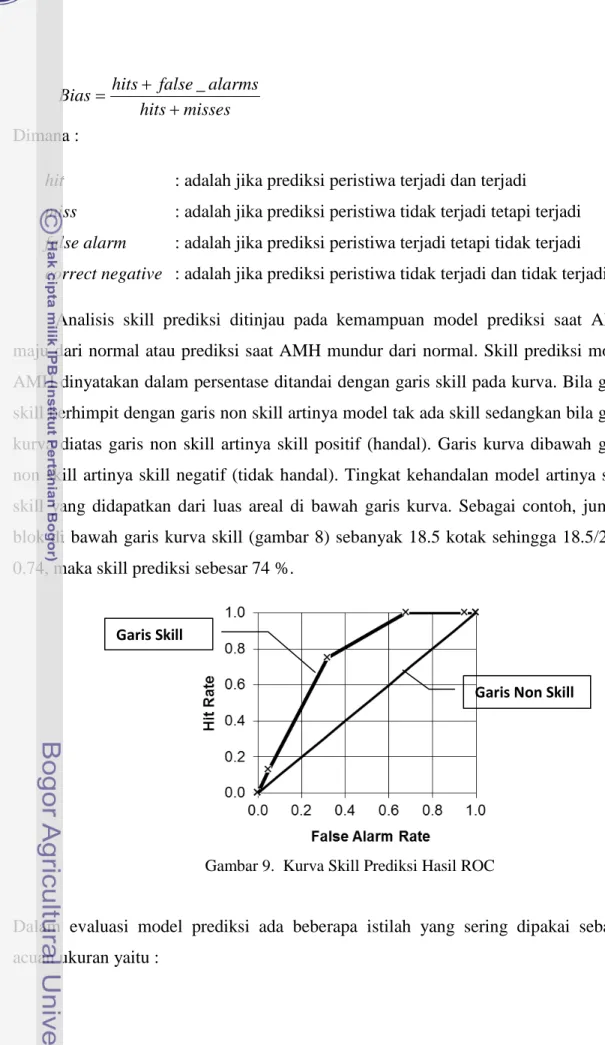
Bagan alir penyusunan model prediksi awal musim hujan di sajikan dalam (Gambar 7), Metode penyusunan model dapat di jelaskan sebagai berikut :
Gambar 8. Diagram alir penyusunan model prediksi AMH Kelompokan sta yang memiliki
kemiripan AMH dengan cluster
Tentukan domain SML yang berkorelasi tinggi tiap kelompok AMH
Susun Pers. Hubungan antara PC anomali SML pada domain terpilih vs AMH tiap kelompok stasiun Daftar pengelompokan hasil cluster
Rata-rata AMH berdasarkan daftar kelompok
Analisis Korelasi Spasial Anomali SML vs AMH tiap kelompok
Gunakan model untuk memprediksi AMH tahun 2008
Verifikasi Model
PETA SKILL AMH
Evaluasi Skill Model AMH dengan ROC
Pilih/ekstrak data prediktor (Anomali SML) sesuai dengan Domain terpilih
Reduksi Data Anomali SML
Uji Kelayakan Model dengan Validasi Silang Data AMH Stasiun
wilayah Jawa Periode 1978-2008
Data SML spasial Wilayah Global Periode 1978-2008
3.4 Analisis Cluster
Analisis cluster merupakan teknik multivariat
∑∑ −
= ==
G g n i gx
x
i
W
1 1 2yang mempunyai tujuan utama untuk mengelompokkan beberapa objek berdasarkan karakteristik yang dimilikinya. Analisis cluster mengklasifikasi objek sehingga setiap objek yang paling dekat kesamaannya dengan objek lain berada dalam kelompok yang sama. Kelompok yang terbentuk memiliki homogenitas internal yang tinggi dan heterogenitas eksternal yang tinggi. Banyaknya cluster ditentukan dengan plot jarak antar data sebagai fungsi dari jumlah cluster. Bila terjadi lompatan signifikan jarak antar data maka dapat di tetapkan sebagai referensi jumlah cluster. Metode pemecahan dimulai dari satu kelompok besar yang mengandung seluruh observasi, selanjutnya observasi yang paling tidak sama dipisah dan dibentuk kelompok yang lebih kecil. Proses ini dilakukan hingga tiap observasi menjadi beberapa kelompok kecil (objek). Kesamaan antar objek merupakan ukuran korespodensi antar objek. Teknik untuk mengukur jarak dalam metode ini yaitu metode ward’s, dengan menghitung jumlah kuadrat antara dua kelompok untuk seluruh variabel, formulasinya adalah :
Dimana ;
W : Jarak
G : Kelompok Besar g : Objek (kelompok kecil)
3.5 Menghitung PCA (Principal Componen Analysis)
PCA telah mulai dilakukan oleh Pearson (1901) dan kemudian dikembangkan oleh Hotelling (1933). Aplikasi dari PCA didiskusikan oleh Rao (1964), Cooley dan Lohnes (1971), dan Gnanadesikan (1977). Perlakuan statistik yang menakjubkan dengan PCA ditemukan oleh Kshirsagar (1972), Morrison (1976), dan Mardia, Kent, dan Bibby (1979). Tujuan utama metode PCA adalah mereduksi sejumlah data
dengan variasi yang besar ke dalam bentuk variabel baru. Data yang dihitung dalam PCA merupakan anomali yaitu dengan mengurangi tiap variable dengan rata-ratanya.
− = k k x x x x x x x x x 3 2 1 3 2 1 ' Variabel baru um
'
x
e
u
m=
mTmenunjukan jumlah maksimum variasi dengan sebelumnya menghitung eigenvector. Sehingga komponen utama dapat dihitung dengan formula :
Elemen eigen vector adalah bobot aij dan biasanya disebut sebagai loading. Elemen
diagonal matrik Sy,varian-covarian matrik komponen utama atau sering disebut eigen
values. Eigen value adalah variasi yang dijelaskan oleh komponen utama. Posisi data awal observasi pada sistim koordinat baru komponen utama disebut skor dan dihitung sebagai kombinasi linier antara data awal (asli) dan nilai bobot aij. Sebagai contoh,
bila skor untuk rth sample pada kth
kp kp k k k k kr a x a x a x Y = 1 1+ 2 2 ++
komponen utama maka dapat di hitung dengan :
3.6 Analisis Korelasi
Dengan memperhatikan korelasi antara komponen satuan grid SML dan PC-1 AMH selanjutnya dapat dianalisis keeratan hubungan antara AMH dan SML di suatu wilayah (15°S – 15°N; 80°E- 100°W). Nilai korelasi tiap grid di petakan, sehingga dapat diketahui pola keeratan hubungan kedua variabel. Tingkat hubungan SML dan AMH di satu grid dinyatakan dengan formulasi :
∑
∑
∑
∑
∑
∑
∑
= = = = = = = − − − = n t n t j j i j j i n t n t t t n t n t t j i n t t t j i tY
Y
X
X
Y
X
Y
X
n n n r 1 2 1 , , 2 , , 2 1 1 2 1 1 , , 1 , , ) (Dimana :
r = besarnya korelasi antara AMH dengan SST Xt = AMH bulan ke t
Yi,j,t
3.7 Principal Componen Regression (PCR)
= Rata-rata SML pada lintang ke (i) bujur ke (j), bulan ke t n = Banyaknya bulan
r = Nilai korelasi pada rentang -1 ≤ r ≤ 1
Analisis korelasi, di gunakan untuk menentukan keeratan hubungan antara AMH tiap kelompok dan wilayah grid SML yang ditandai dengan nilai korelasi signifikan (-0.5 ≥ r ≥ 0.5). Nilai korelasi signifikan dari tiap grid akan membentuk suatu pola spasial, kemudian di ambil sebagai domain prediktor untuk menyusun model prediksi AMH di Jawa. Dalam mempetakan hubungan korelasi spasial antara SML dan AMH di Jawa digunakan software Interactive Tool for Analysis of Climate System (ITACS) yang di dikembangkan oleh Japan Meteorological Administration (JMA) tahun 2008. Peta korelasi spasial ini menunjukan korelasi lokasi spesifik antara series data kelompok AMH di Jawa dan tiap grid wilayah SML. Korelasi AMH tiap kelompok di Jawa dengan wilayah SML Perairan India, Indonesia dan Pasifik mengindikasikan wilayah SML potensial menjadi prediktor model AMH. Ketiga perairan tersebut merupakan lokasi dimana kejadian fenomena iklim regional dan global serta berasosiasi dengan kondisi iklim wilayah Jawa. Kesimpulan tersebut menguatkan alasan teknik korelasi yang digunakan dalam penelitian ini untuk menentukan prediktor.
Model regresi statistik dalam prosesnya adalah mengolah data histori dan mengidentifikasi hubungan sebab akibat. Dalam menyusun model prediksi penelitian ini, digunakan teknik analisis Principal Component Regression (PCR) dengan variable bebas sebagai prediktor adalah SML pada suatu wilayah grid dan variable tak bebas sebagai prediktan adalah AMH di Jawa. Metoda Principal Component Regression (PCR) merupakan teknik analisis multivariat yang dilakukan dengan
terlebih dahulu mereduksi komponen data awal dengan teknik Principal Component Analysis (PCA) dilanjutkan dengan teknik analisis regresi antara komponen utama yang baru (PC1,PC2...PCn) terhadap respon (Prediktan). PCR secara khas digunakan
untuk model regresi linier, dimana jumlah variabel bebas (prediktor) adalah sangat banyak. Metoda ini telah dioperasionalkan untuk prediksi musim hujan oleh India Meteorological Departement (Rajeevan 2009). Selain itu dengan teknik PCR ini juga diaplikasikan untuk model penentu datangnya monsun untuk wilayah Kerala India dengan performa yang baik (Pai & Rejeevan 2009). Prediktor model PCR dalam model AMH di Jawa, menggunakan komponen utama (PC) hasil reduksi SML pada suatu domain terpilih. Prosedur model yang diduga dari nilai PC1,PC2,….PCn
e Z b Z b Z b Z b b Yˆ = 0 + 1 1+ 2 2 + 3 3+...+ n n + , ditunjukkan sebagai berikut :
(9) Dimana : Y : Respon (data AMH/LMH tiap stasiun)
b0 : Nilai intersepsi
b1
3.8 Analisis Validasi Silang (Cross validation)
: Koefisien regressi Z : Komponen utama (PC) e : Nilai Error
Untuk menilai model regresi yang dihasilkan merupakan model yang paling sesuai (memiliki error terkecil), ditetapkan beberapa asumsi kenormalan.
Validasi model pada dasarnya merupakan cara untuk menyimpulkan apakah model sistem tersebut di atas merupakan perwakilan yang valid dari realitas yang dikaji sehingga dapat dihasilkan kesimpulan yang meyakinkan. Validasi merupakan proses iteratif yang berupa pengujian berturut-turut sebagai proses penyempurnaan model. Teknik validasi silang pada dasarnya membagi data sebagai data training dan data testing secara berurutan dan terus menerus Efron, 1982; Gong, 1983 dan Michaelson, 1987 (Wilks 1995). Model prakiraan awal musim hujan dengan data periode 1978-2007, di validasi dengan validasi silang untuk menguji stabilitas model
tersusun. Leave One Out Cross Validation (LOOCV) yaitu teknik validasi dengan mengeluarkan satu data untuk testing dari kumpulan data training (n-1), selanjutnya
menghitung nilai Root Mean Square Error (RMSE). Hal tersebut dilakukan berurutan dan seterusnya sehingga setiap satu data prediktan teruji sebagai data testing (independen data) dan menghasilkan sejumlah (n) nilai RMSE, dihitung menggunakan persamaan : RMSE =
∑
−
= n jY
oiY
pi n 1 2)
(
1 Dimana :Yoi = Observasi pada periode ke-i (i=1,2, ... , n)
Ypi = Hasil prakiraan pada periode ke-i (i=1,2, ... , n)
n = Panjang periode prakiraan
Semakin kecil nilai RMSE mengindikasikan model memiliki tingkat kesalahan prediksi (error) yang kecil. Nilai RMSE rata-rata seluruh hasil testing validasi menggunakan persamaan berikut :
RMSErata-rata RMSE j RMSE k
j − + ...+ − 1 = Dimana : RMSErata-rata 3.9 Verifikasi
= Rata-rata RMSE validasi
RMSE ke-j = Testing ke-j dengan data training (n- data ke-j) RMSE ke-j = Testing ke-k dengan data training (n- data ke-k) j,k = urutan data ke-
n = Jumlah seluruh data
Langkah verifikasi yaitu dengan memasukkan prediktor ke dalam model untuk tahun data yang tidak dilibatkan dalam training. Prediktor verifikasi model AMH adalah hasil reduksi anomali SML bulan JJA tahun 2008 di domain terpilih. Tingkat akurasi model dalam memprakirakan awal musim hujan Tahun 2008 ditentukan dengan menilai tingkat kesalahan prediksi terhadap observasi (error) di tiap cluster.
Sehingga dengan verifikasi model merupakan perwakilan yang benar dari suatu fakta di lapangan (observasi). Alasan penting suatu model perlu di verifikasi, adalah :
Memonitor kualitas prediksi, seberapa akurat model prediksi dan kaitanya dengan waktu kedepan.
Meningkatkan kualitas prediksi, sebagai langkah lanjutan dalam menemukan kesalahan hasil prediksi.
Membandingkan kualitas prediksi dari model lainnya.
3.10 Evaluasi
Karena hasil prediksi AMH mengandung elemen yang mengikut sertakan faktor kemungkinan, maka digunakan simulasi Monte Carlo. Dasar dari simulasi Monte Carlo adalah percobaan elemen kemungkinan dengan menggunakan sampel random (acak). Prinsip kerja simulasi Monte Carlo yaitu membangkitkan angka acak atau sampel dari suatu variabel yang telah diketahui distribusinya. Oleh karena itu, dengan simulasi seolah-olah data diperoleh dari pengamatan. Simulasi ini merupakan alat rekayasa untuk menyelesaikan berbagai persoalan ketidapastian. Simulasi tidak memberikan hasil yang eksak namun dalam bentuk peluang kejadian suatu persoalan.
Tujuan digunakan teknik peluang pada penelitian ini adalah mengetahui besarnya kemungkinan AMH pada kondisi kejadian maju atau mundur dari normalnya. Untuk mengetahui skill prediksi model, uji kehandalan model prediksi menggunakan metode Relative Operating Characteristics (ROC) yang disusun dengan melakukan simulasi hasil prediksi berdasarkan kejadian AMH bawah normal dan atas normal. Selanjutnya memplot nilai False Alarm Rate dan Hit Rate dari tabel kontigensi. Formulasi umum yang digunakan dalam mencari nilai sebagai dasar penyusunan table kontigensi adalah sebagai berikut :
misses hits hits Rate Hit + = _ alarms false negatives correct alarms false Rate Alarm False _ _ _ _ _ + =
misses hits alarms false hits Bias + + = _ Dimana :
hit : adalah jika prediksi peristiwa terjadi dan terjadi
miss : adalah jika prediksi peristiwa tidak terjadi tetapi terjadi false alarm : adalah jika prediksi peristiwa terjadi tetapi tidak terjadi
correct negative : adalah jika prediksi peristiwa tidak terjadi dan tidak terjadi Analisis skill prediksi ditinjau pada kemampuan model prediksi saat AMH maju dari normal atau prediksi saat AMH mundur dari normal. Skill prediksi model AMH dinyatakan dalam persentase ditandai dengan garis skill pada kurva. Bila garis skill berhimpit dengan garis non skill artinya model tak ada skill sedangkan bila garis kurva diatas garis non skill artinya skill positif (handal). Garis kurva dibawah garis non skill artinya skill negatif (tidak handal). Tingkat kehandalan model artinya skor skill yang didapatkan dari luas areal di bawah garis kurva. Sebagai contoh, jumlah blok di bawah garis kurva skill (gambar 8) sebanyak 18.5 kotak sehingga 18.5/25 = 0.74, maka skill prediksi sebesar 74 %.
Gambar 9. Kurva Skill Prediksi Hasil ROC
Dalam evaluasi model prediksi ada beberapa istilah yang sering dipakai sebagai acuan ukuran yaitu :
Garis Non Skill Garis Skill
• Kehandalan: adalah tingkat kesesuaian atau kemiripan rata-rata antara hasil prediksi dengan observasi.
• Skill : adalah ketepatan relatif suatu model prediksi terhadap refrensi. Referensi umumnya prakiraan yang tidak memiliki skill (unskill forecast) misalnya peluang acak atau klimatologi. Jadi skill dapat dikatakan sebagai peningkatan ketepatan (acuracy) prakiraan karena membaiknya sistem prakiraan tersebut.
• Bias : adalah penyimpangan antara nilai rata prediksi dengan nilai rata-rata observasi