DATA MINING DENGAN METODE CLUSTERING K-MEAN UNTUK
PENGELOMPOKAN MAHASISWA POTENSIAL DROP OUT PADA PROGRAM
STUDI TEKNIK INFORMATIKA UNIVERSITAS SILIWANGI
Adi Firmansyah, Acep Irham Gufroni, Andy Nur Rachman Teknik Informatika Universitas Siliwangi Tasikmalaya
Email: [email protected]
ABSTRACT
The College is one of an institution that has many data volumes. Database’scollege save the academic data, administration and data’s students. One of the data that found is the student’s comprehension information who has a drop out potential. This problem is important to know and understanding. The understanding can be done by analysis of possessing data to cluster and understanding of drop out potential students. It is important to keep failure’s students of the collage management. The measure of success or achievement of students can be seen from the Achievement Index (IP), which reflects all the values obtained student until the current semester. In this survey technique data mining in the method of clustering k-mean will be implementation to be a number of students cluster who have drop out potential of the strata 1 study program of Siliwangi University Informatics Engineering.
Keywords :Data Mining, Clustering, Potenential Drop Out, K-mean
ABSTRAK
Perguruan tinggi adalah salah satu institusi yang sudah pasti memiliki data yang tidak kecil volumenya. Database perguruan tinggi menyimpan data akademik, administrasi dan data mahasiswa. Salah satu data yang dapat digali adalah informasi mahasiswa yang potensial drop out. Hal ini penting untuk diketahui dan dipahami, serta dapat dilakukan dengan menganalisis data yang dimiliki untuk memahami dan mengelompokkan mahasiswa yang potensial drop out. Pencegahan kegagalan mahasiswa sangat penting bagi manajemen perguruan tinggi. Ukuran keberhasilan atau prestasi mahasiswa dapat dilihat dari Indeks Prestasi (IP) yang mencerminkan seluruh nilai yang diperoleh mahasiswa sampai semester yang sedang berjalan Pada penelitian ini teknik data mining dalam metode clustering k-mean akan di implementasikan untuk mengelompokkan jumlah mahasiswa-mahasiswa yang di potensial drop out pada program Studi Strata 1 Teknik Informatika Universitas Siliwangi.
Kata Kunci: Data Mining, Clustering, Potensial Drop Out, K-mean
1. PENDAHULUAN
Beberapa institusi yang memanfaatkan sistem informasi berbasis komputer selama bertahun-tahun sudah pasti memiliki jumlah data yang cukup besar pula. Data yang dihasilkan dan disimpan dalam sistem komputer dirancang agar cepat dan akurat baik dalam mengoperasikan maupun administrasinya. Data ini dirancang untuk pelaporan dan analisa yang menggunakan data. Data tersedia secara luar biasa melimpah. Sedemikian melimpahnya data, sehingga membuat kita semakin tertantang untuk bertanya “Pengetahuan apakah yang dapat dihasilkan dari data tersebut”. (Guchi, 2010)
Perguruan tinggi adalah salah satu institusi yang sudah pasti memiliki data yang tidak kecil volumenya. Database perguruan tinggi menyimpan data akademik, administrasi dan data mahasiswa. Data tersebut apabila digali dengan tepat maka dapat diketahui pola atau pengetahuan untuk mengambil keputusan.
Salah satu data yang dapat digali adalah pemahaman informasi mahasiswa yang potensial
drop out. Hal ini penting untuk diketahui dan dipahami. Pemahaman dapat dilakukan dengan mengungkapkan pengetahuan yang dimiliki untuk memahami dan mengelompokkan. Pencegahan kegagalan adalah sangat penting bagi manajemen perguruan tinggi. Pengetahuan ini dapat digunakan dalam membantu pihak perguruan tinggi untuk lebih mengenal situasi para mahasiswanya dan dapat dijadikan sebagai pengetahuan dini dalam proses pengambilan keputusan untuk tindakan preventif dalam hal mengantisipasi mahasiswa drop-out, untuk meningkatkan prestasi mahasiswa, untuk meningkatkan kurikulum, meningkatkan proses kegiatan belajar dan mengajar dan banyak lagi keuntungan lain yang bisa diperoleh dari hasil penambangan data tersebut. (Guchi, 2010).
lantaran mahasiswa yang bersangkutan memiliki aktivitas lain di luar jam kuliah, yaitu seperti kerja atau yang lainnya. Saat mahasiswa bekerja konsentrasinya akan terpecah dengan kuliah, akibatnya tidak bisa fokus dan kuliah jadi terbengkalai.
Ukuran keberhasilan atau prestasi mahasiswa dapat dilihat dari Indeks Prestasi (IP) yang mencerminkan seluruh nilai yang diperoleh mahasiswa sampai semester yang sedang berjalan. IP diperoleh dengan cara menjumlahkan seluruh menggunakan implementasi algoritma K-Mean dengan data training yang bersumber dari data Mahasiswa Teknik Informatika Universitas Siliwangi.
1.3 Batasan Masalah
Agar penelitian ini lebih terarah dan tepat dalam penyampaian tujuannya, serta untuk menghindari penyimpangan pembahasan dari tujuan awal maka diperlukan batasan masalah penelitian ini adalah sebagai berikut:
1.
Penelitian ini hanya mengelompokkan mahasiswa drop out di program studi S1 Teknik Informatika Universitas Siliwangi.2.
Objek yang dikelompokkan drop out adalah berdasarkan IP Semester awal sampai ip semester akhir.3.
Data yang digunakan Data Mahasiswa Angkatan 2010-2013.4.
Algoritma yang digunakan dalam melakukan clustering adalahalgoritma K-Means.1.4 Tujuan Penelitian
Adapun tujuan penelitian ini adalah untuk melakukan pengelompokan mahasiswa yang potensial drop out menggunakan implementasi algoritma K-Mean dengan data training yang bersumber dari data Mahasiswa Teknik Informatika Universitas Siliwangi. Discovery from Data, merupakan proses terstruktur, yaitu sebagai berikut:
1.
Data Cleaning adalah proses membersihkan data dari data noise dan missing value.2.
DataIntegration adalah proses untuk menggabungkan data dari beberapa sumber yang berbeda.3.
DataSelection adalah proses untuk memilih data dari database yang sesuai dengan tujuan analisis.4.
Data Transformation adalah proses mengubah bentuk data menjadi data yang sesuai untuk proses mining.5.
Data Mining adalah proses penting yang menggunakan sebuah metode tertentu untuk memperoleh sebuah pola dari data.2.2 Clustering
Clustering merupakan pekerjaan yang memisahkan data/vector ke dalam sejumlah kelompok (cluster) menurut karakteristiknya masing-masing. Data-data yang mempunyai kemiripan karakteristik akan berkumpul dalam cluster yang sama, dan data-data dengan karakteristik berbeda akan terpisah dalam cluster yang berbeda. (Teguh, 2009)
2.3 Metode K-Mean
Salah satu algoritma pengelompokan data adalah algoritma K-Means. Algoritma K-Means adalah algoritma klastering yang paling sederhana dibanding algoritma
klastering yang lain. Algoritma ini mempunyai kelebihan mudah diterapkan dan dijalankan, relatif cepat, mudah untuk diadaptasi, dan paling banyak dipraktekkan dalam tugas data mining. (Teguh,2009)
Berdasarkan perbandingan kemampuan prediktif algoritma non-hierarki dengan menggunakan data sel ragi, maka disimpulkan bahwa Algoritma K-Means bagus digunakan untuk mengelompokkan data ke dalam jumlah cluster. (Rosni,2014)
Adapunl angkah-langkah pada algoritma K-Means adalah sebagai berikut :
1. Tentukan K.
2. Pilih K buat catatan dari sekianc atatan yang ada sebagai pusat kelompok awal (mi)
3. Untuk langkah ke – 3 ini lakukan :
1.
Untuk setiap catatan, tentukan pusat kelompok terdekatnya dan tetapkan catatan tersebut sebagai kelompok anggota dari kelompok yang terdekat pusat kelompoknya. Dengan menggunakan rumus Ecluidien Distance.3.
Hitung WCV( Within cluster Variation ) = Jarak antara anggota dalam Cluster.4.
Rasio = BCV/WCV (bedasarkan kelompok yang di dapat dari langkah ke – 3) dan kembalilah kelangkah ke-3. Badan Administrasi Akademik Universitas Siliwangi dengan, yang dijadikan sampel dalam penelitian ini adalah data mahasiswa dan data Nilai Indeks Prestasi Mahasiswa Program Studi Teknik Informatika. Dengan total jumlah data mahasiswa Teknik Informatika Angkatan 2010-2013 sebanyak data dengan rincian sebagai berikut:Tabel 1. Data Penelitian
Sumber teori dan data yang digunakan dalam penelitian ini didapatkan dari beberapa cara, diantaranya:
a.
Studi LiteraturStudi literatur dilakukan dengan mengumpulkan bahan-bahan refrensi baik dari buku, artikel, paper, jurnal, makalah, maupun situs-situs internet yang berhubungan dengan konsep dan algoritma data mining.
b.
Analisis PermasalahanPada tahap ini dilakukan analisis terhadap studi literatur untuk mengetahui dan mendapatkan pemahaman mengenai masalah yang di teliti.
c.
WawancaraWawancara dilakukan untuk memperoleh sumber data berdasarkan keterangan dan penulisan secara langsung dari pihak yang terkait atau dengan pembimbing lapangan.
d.
Studi PustakaMelakukan pengumpulan dan penyusunan data dengan membaca buku literature, serta
bahan-bahan perkuliahan yang sesuai dengan masalah yang diteliti.
3.2 Proses Persiapan Data Mining
1. Data Cleaning
Data Cleaning merupakan proses untuk dapat mengatasi nilai yang hilang, noise dan data yang tidak konsisten. (Han, Kamber, and Pei 2012) Dari data set yang didapatkan dari data mahasiswa Teknik Informatika sebanyak 314 Mahasiswa Angkatan 2010, 340 Mahasiswa Angkatan 2011, 320 Mahasiswa Angkatan 2012 dan Mahasiswa Angkatan 2013, seperti terlihat pada lampiran. Data tersebut kemudian masuk ke proses Cleaning dan beberapa mahasiswa yang sudah lulus dan mahasiswa yang sudah keluar dalam proses cleaning akan dihilangkan. Berikut ini adalah kolom-kolom yang di cleaning beserta alasan kolom tersebut mengalami proses cleaning.
Tabel 2. Data Cleaning dilakukan penghapusan data karena data mahasiswa yang sudah lulus tidak dapat diproses.
b.
Data Mahasiswa yang sudah keluar, dilakukan penghapusan data karena tidak dapat diproses, baik yang keluar, ataupun yang sudah di DO.Setelah dilakukan proses Data Cleaning maka data penelitian menjadi berkurang.
Tabel 3. Data Penelitian yang sudah di Cleaning
No Angkatan Jumlah Data
1 2010 100
3 2012 248
4 2013 258
Total 871
2. Data Integration
Data Integration merupakan proses menggabungkan data dari banyak database atau data warehouse. Proses ini dapat membantu mengurangi data redundan dan data yang tidak konsisten yang disebabkan pengambilan data dari banyak sumber data. Hal ini tentu saja akan berpengaruh terhadap kecepatan dan akurasi saat melakukan Data mining(Han, Kamber, and Pei 2012).
Data set yang telah melalui proses celeaning perlu di integrasikan karena data yang digunakan secara terpisah, maka data tersebut digabungkan.
3. Data Selection
Data Selection atau Data Reduction merupakan proses meminimalkan jumlah data yang digunakan untuk proses mining dengan tetap merepresentasikan data aslinya. Mengurangi jumlah data yang digunakan untuk proses mining akan lebih efisien mengingat hasil yang didapatkan sama (atau hampir sama) secara analitikal.
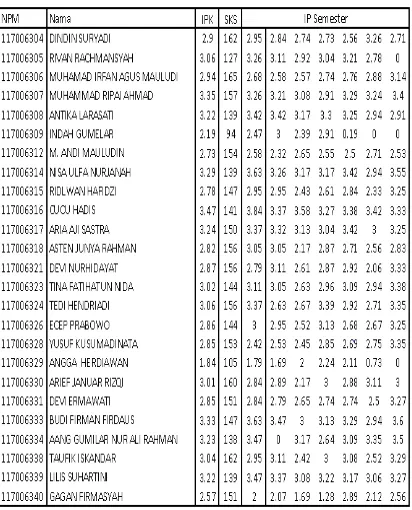
Dari 871 data set yang merupakan gabungan dari 4 Angkatan, dipilih 25 data set secara acak angkatan 2011 sebagaisampelyang dapat merepresentasikan data tersebut. Data set tersebut dapat dilihat pada tabel dibawah.
Tabel 4. Data Selection
3.3 Data Mining
Untuk melakukan Proses pengclusteran maka langkah-langkah yang dilakukan sebagai berikut:
1.
InisialisasiMenentukan Jumlah Cluster K=3 (C1,C2,C3) Ket:
C1= Cluster ke-1 C2= Cluster ke-2 C3= Cluster Ke-3
2.
Dilakukan pemilihan K data sebagai centeroid awal, maka dengan data yang banyak perlu dilakukan normalisasi data. Yaitu dengan mencari nilai m1,m2 dan m3.Maka didapat nilai m1,m2 dan m3.m1 = 0.707142857 m2 = 2,803028571 m3 = 3.531428571
3. Baca data IP Mahasiswa, Fakultas Teknik Informatika Universitas Siliwangi untuk angkatan 2011.
4. Hitung jarak setiap data dengan masing-masing centroid, Untuk mendapatkan jarak dari masing-masing IP mahasiswa ke C1, C2, dan C3digunakan rumus euclidean distance.
Tabel 5.Literasi 1
5. Menghitung Nilai BCV
BCV = d (m1, m2) + d (m2, m3) + d (m1,m3) Didapat BCV = 3.5916
DidapatNilai WCV = 62.1072 7. MenghitungNilai Ratio
Ratio = = = 0.0578 8. Menghitung Iterasi ke-2
mi =
mi =
m1 = = 5.752611
m2 = = 1.450244 m3 = = 2.22953
Lakukanlangkah 1-8 untukmencarihasilLiterasike 2. Setelah dibandingkan rasio ke 2 Iterasi tersebut, jika rasio tersebut nilainya semakin besar maka lanjutkan ke langkah berikutnya namun jika tidak hentikan prosesnya.
4. HasildanPembahasan
Hasil dari proses Data Mining menggunakan Metode Clustering K-mean sesuai dengan tujuan yang telah ditetapkan, seperti dijelaskan dibawah ini. Setelah proses perhitungan 25 data mahasiswa menggunakan metode clustering dengan Algoritma K-mean, hasil dari perhitungan 4 angkatan adalah sebagai berikut:
4.1. Angkatan 2010
Setelah dibandingkan rasio ke 2 Iterasi tersebut, jika rasio tersebut nilainya semakin besar maka lanjutkan ke langkah berikutnya namun jika tidak hentikan prosesnya
Rasio ke 2 literasi: R1= 0.061121 R2= 0.058682
Tabel 6.Hasil Pengclusteran Mahasiswa Potensial Drop Out Angkatan 2010
4.2 Angkatan 2011
Setelah dibandingkan rasio ke 2 Iterasi tersebut, jika rasio tersebut nilainya semakin besar maka lanjutkan ke langkah berikutnya namun jika tidak hentikan prosesnya
Rasio ke 2 literasi: R1= 0.0578297 R2= 0.042101
Karena nilainya tidak bertambah maka proses dihentikan. Maka didapat Hasil dari Proses Clustering Mahasiswa Potensial Drop Out adalah Pada table dibawahini.
Tabel 7.Hasil Pengclusteran Mahasiswa Potensial Drop Out Angkatan 2011
4.3 Angkatan 2012
Setelah dibandingkan rasio ke 2 Iterasi tersebut, jika rasio tersebut nilainya semakin besar maka lanjutkan ke langkah berikutnya namun jika tidak hentikan prosesnya
Rasio ke 2 literasi: R1= 0.083743912 R2= 0.076195584
Karena nilainya tidak bertambah maka proses dihentikan. Maka didapat Hasil dari Proses Clustering Mahasiswa Potensial Drop Out adalah Pada table dibawahini.
Tabel 8.Hasil Pengclusteran Mahasiswa Potensial Drop Out Angkatan 2012
4.4 Angkatan 2013
Setelah dibandingkan rasio ke 2 Iterasi tersebut, jika rasio tersebut nilainya semakin besar maka lanjutkan ke langkah berikutnya namun jika tidak hentikan prosesnya
Rasioke 2 literasi: R1= 0.104172 R2= 0.073581
Karena nilainya tidak bertambah maka proses dihentikan. Maka didapat Hasil dari Proses Clustering Mahasiswa Potensial Drop Out adalah Pada table dibawahini.
Tabel 9.Hasil Pengclusteran Mahasiswa Potensial Drop Out Angkatan 2013
5. Kesimpulandan Saran 5.1 Kesimpulan
kesimpulan yang dapat diambil adalah sebagai berikut:
Dengan bantuan teknik data mining, seperti algoritma clustering, memungkinkan untuk menemukan karakteristik-karakteristik dari mahasiswa dan menggunakan karakteristik mereka dalam memprediksi prestasi dimasa depan. Hasilyang diperoleh merupakan kelompok mahasiswa yang berpotensi untuk drop out, artinya mahasiswa-mahasiswa yang termasuk dalam data merupakan acuan untuk mempermudah pengambilan keputusan terhadap mahasiswa yang akan di drop out.
5.2 Saran
Untuk pengembangan penelitian lebih lanjut terhadap sistem Aplikasi Prediksi Mahasiswa Drop Out Akademik Dengan Menggunakan Metode Clustering Pada Program Studi Teknik Informatika Universitas Siliwangi.
sebagai berikut:
1. Untuk mendapatkan hasil yang lebih variatif penelitian ini dapat juga dikembangkan dengan menggunakan algoritma pengelompokkan lain seperti hierarchical clustering, partitional clustering, single linkage, complete linkage, average linkage, DBSCAN, Fuzzy C-Means, Self-Organizing Map, K-Modes dan lain-lain.
2. Untuk memperoleh akurasi sistem yang lebih tinggi dalam mengelompokkandata mahasiswa yang potensial DO, algoritma clusterring ini dapat dikombinasikan dengan algoritma data mining pada fungsi mayor yang lain, misalnya dengan fungsi mayor klasifikasi, deteksi anomali, maupun analisa asosiasi.
DaftarPustaka
Agusta, Yudi, 2007.
K-Means-Penerapan,Permasalahan,
danMetodeTerkait. Jurnal Sistem dan Informatika Vol. 3 (Pebruari 2007), 47-60 Akbar, Rizal. 2011. Penerapan Data Mining
denganMenggunakanMetode Clustering K-Mean UntukMengukur Tingkat KetepatanKelulusanMahasiswa Program
TeknikInformatika S1. JurnalInformatika 2011.
EkoPrasetyo. 2012. Datamining
KonsepdanAplikasimenggunakanMatlab Yogyakarta: 2012.
Etandalan, Website
http://ihsaned.blogspot.com/2013/02/do-drop-out-perkuliahan.html.
DiaksesPadatanggal 2 Agustus 2015. Guchi, NurulMasithah., 2010. Pengelompokan
Mahasiswa Potensial Drop Out Menggunakan Metode Clustering Pada Program Studi Strata 1 Ilmu Komputer Dan Teknologi Informasi Universitas Sumatera Utara. 2010.
Hamimi, Hafillah. 2014. Analisis Data AnggaranPendapatanBelanja Daerah Menggunakan Clustering K-Means danForecasting (StudiKasuspada DPKA Kota Padang) Jurnal 2014.
Herawati, Rosita. 2012.
RekomendaisiPenjurusan di SMU YSKI denganAlgoritma K-Means.2012
Heryadi.Teguh. 2009. Penerapan Algoritma K-Means Untuk Pengelompokan Data Nilai Siswa.Jurnal A21 2009. Jananto, Arief. 2010. Memprediksi Kinerja Mahasiswa Menggunakan Teknik Data Mining (Studi kasus data akademik mahasiswa UNISBANK. Tesis Tidak Terpublikasi. Yogyakarta: Universitas Gajah Mada.
Lumbantoruan, Rosni. 2014.
ANDI.PENGUKURAN KEMAMPUAN PREDIKTIF TEKNIK
CLUSTERINGDENGAN FIGURE OF MERIT. Institute Teknologi Bandung. 2014. Larose, D., T., 2005, Discovering Knowledge In
Data An Introduction to Data Mining, Jhon Willey & Sons Inc, New Jersey
Narwati,2011.
PengelompokkanMahasiswaMenggunakanAl goritma K-Means. JurnalInformatika 2011. Safitri, HabibRamdani., Penerapan Teknik Data