DATA MINING MENGGUNAKAN ALGORITMA KMEANS CLUSTERING UNTUK MENENTUKAN STRATEGI TINGKAT KELULUSAN SMA
STUDI KASUS DATA SEKOLAH KOTA SMA BANDA ACEH Sofyan Saputra
5520111189
Jurusan Tehnik Informatika
Sekolah Tinggi Manajemen Informasi Dan Komputer Adhi Guna
ABSTRAK
Abstrak Abstrak Abstrak Abstrak Abstrak (maks 250 kata)
Keyword: Abstrak, Abstrak (3-5 kata)
1 Pendahuluan
Kemajuan teknologi informasi sudah semakin berkembang pesat disegala bidang kehidupan. Banyak sekali data yang dihasilkan oleh teknologi informasi yang canggih, mulai dari bidang industri, ekonomi, ilmu dan teknologi serta berbagai bidang kehidupan lainnya. Penerapan teknologi informasi dalam dunia pendidikan juga dapat menghasilkan data yang berlimpah mengenai siswa dan proses pembelajaran yang dihasilkan.
Tingginya kasus tidak lulus siswa SMA dan SMK dalam menempuh Ujian Akhir Nasional membuat para guru ataupun staf dari sekolah berusaha untuk mencari cari cara agar para siswa mampu menghadapi Ujian Akhir Nasional dengan baik.
Berdasarkan melimpahnya data siswa
SMA dan SMK, informasi yang
tersembunyi dapat diketahui dengan mengolah data tersebut hingga berguna bagi pihak sekolah. Pengolahan data tersebut perlu dilakukan guna untuk mengetahui pengetahuan baru (Knowledge Discovery) misalnya informasi mengenai pengelompokan data mahasiswa berpotensi
berdasarkan sekolah asal siswa [1].
Berdasarkan data yang diperoleh dari database website dinas pendidikan kota banda terdapat terdapat 54 sekolah SMA dan 10 sekolah SMK dimana terdapat 26 siswa yang tidak lulus sedangkan pada tahun 2013 terdapat 49 SMA dan 8 SMK terdapat 12 siswa yang tidak lulus. Peningkatan ini terjadi karena kurangnya pengolahan data secara tepat berdasarkan data historis yang dimana hal tersebut dapat mempengaruhi pengambilan keputusan dalam menentukan strategi menghadapi ujian nasional.
2 Landasan Teori
2.1 Definisi Data Mining
Jika dilihat sudut pandang bahwa data mining merupakan data yang menggali data yang telah lama dari beberapa serangkaian kegiatan. Menurut Giudici & Figini (2009) data mining merupakan proses terpadu dari analisis data yang terdiri dari serangkaian kegiatan yang berjalan berdasarkan definisi tujuan yang akan dianalisis, dengan analisis datanya sampai interpretasi dan evaluasi hasil.
1. Definisi tujuan untuk analisa Suatu pernyataan yang jelas tentang masalah dan tujuan yang akan dicapai merupakan hal yang paling penting dalam membentuk analisa dengan benar. Hal ini menjadi salah satu bagian paling sulit dari proses karena menentukan metode yang akan digunakan. Oleh karena itu tujuan harus jelas dan tidak boleh ada ruang untuk keraguan atau ketidakpastian.
2. Seleksi, organisasi, dan pra-perawatan data
Setelah tujuan dianalisa dan diidentifikasi perlu adanya pengumpulan atau pemilihan data yang diperlukan untuk analisa. Sumber data yang ideal adalah data warehouse perusahaan, sebuah “store room” data histori yang sudah tidak lagi digunakan. Jika tidak ada data warehouse maka pasar data dapat diciptakan dari overlapping dari berbagai sumber data perusahaan.
3. Eksplorasi analisis data dan mentransformasinya
Pada tahap ini melibatkan analisa eksplorasi awal dari data, yang sangat serupa dengan teknik Online Analytical Process (OLAP). Tahap ini dapat mengakibatkan transformasi dari variabel asli dalam rangka lebih memahami fenomena atau metode statistik yang digunakan. Analisis eksplorasi dapat menyoroti data anomaly, data yang berbeda dari data yang lain.
4. Spesifikasi dari metode statistik Berbagai macam metode statistik yang dapat digunakan dan juga banyak algoritma yang tersedia, sehingga sangat penting membuat klasifikasi dari metode yang sudah tersedia. Pemilihan metode yang akan digunakan dalam membuat analisa tergantung dari masalah yang sedang dipelajari atau pada jenis data yang tersedia. Berbagai macam metode tersebut dikelompokkan menjadi dua kelas utama
sesuai dengan tahap yang berbeda dari analisis data yaitu:
a. Metode Deskriptif
Tujuan utama dari metode di kelas ini adalah untuk menggambarkan kelompok data dengan cara yang ringkas. Dalam metode deskriptif tidak ada hipotesis sebab akibat antara variabel-variabel yang tersedia. Yang termasuk dalam kelompok ini misalnya metode asosiasi, model log-linear, model grafis).
b. Metode Prediksi
Metode dalam kelas ini mempunyai tujuan untuk menggambarkan satu atau lebih variabel yang dilakukan dengan mencari aturan klasifikasi atau prediksi berdasarkan data. Aturan-aturan ini
membantu memprediksi atau
mengklasifikasikan hasil masa depan salah satu atau lebih variabel respon atau target dalam kaitannya dengan apa yang terjadi pada variabel penjelas atau masukan. Yang termasuk dalam metode ini antara lain neural network dan decision tree dan termasuk juga model regresi linear dan logistik.
5. Analisis data berdasarkan metode yang dipilih Setelah menentukan metode statistik yang akan digunakan selanjutnya menerjemahkan ke dalam algoritma yang sesuai untuk mendapatkan hasil yang dibutuhkan berdasarkan data yang tersedia. 6. Evaluasi dan perbandingan dari metode yang digunakan dan pilihan model akhir untuk analisis Interpretasi dari model yang dipilih dan penggunaannya dalam decision process
2.2 Algoritma K-Means
1. Euclidean distance
Formula jarak antar dua titik dalam satu, dua dan tiga dimensi secara berurutan ditunjukkan pada formula 1, 2, 3 berikut ini :
2. Manhattan Distance
Manhattan distance disebut juga taxicab distance.
3. Chebichev Distance
Di dalam Chebichev distance atau Maximum Metric jarak antar titik didefinisikan dengan cara mengambil nilai selisih terbesar dari tiap koordinat dimensinya.
2.3 Rapidminer
RapidMiner adalah sebuah lingkungan machine learning data mining, text mining dan predictive analytics [5].
3 Hasil Dan Pembahasan 3.1 Pemahaman Data
Datasets siswa didapatkan melalui sumber bank data terbuka pada alamat
http://data.bandaacehkota.info/dataset/dafta r-kelulusan-sma-kota-banda-aceh untuk
data siswa SMA dan
http://data.bandaacehkota.info/dataset/dafta r-kelulusan-smk-kota-banda-aceh untuk data siswa SMK yang telah menempuh ujian.
3.2 Deskripsi Data
Datasets siswa terdiri atas atribut kode-sekolah,nama sekolah, status, jumlah tidak lulus, jurusan, jumlah peserta laki-laki,jumlah peserta perempuan, rerata
nilai bahasa inggris, rerata nilai bahasa indonesia, rerata nilai fisika dan ekonomi, rerata nilai kimia dan sosiologi, rerata nilai biologi dan geografi, serta total nilai rerata untuk semua mata pelajaran. Dalam kasusnya rerata nilai menjadi patoka terhadap jurusan dihilangkan karena strategi yang sama akan diterapkan pada semua jurusan.
3.3 Pemilihan Atribut Data
Atribut yang digunakan adalah semua rerata nilai masing-masing mata pelajaran yang diujiankan oleh para siswa dan Kode Sekolah. Data yang tidak menjadi atribut akan dihilangkan sedangkan atribut Kode sekolah yang bertipe nominal akan di transformasi menjadi data integer agar dapat dijadikan sebagai kode unik untuk pemanfaatan performansi data.
3.4 Penetapan Jumlah Cluster
Jumlah cluster (K) yang digunakan dalam penelitian ini adalah berjumlah 3.
3.5 Transformasi Data
Atribut dengan jenis nominal seperti kode sekolah akan di inisialisasi terlebih dahulu kedalam bentuk angka. Proses inisial dilakukan seperti pada Tabel 1.
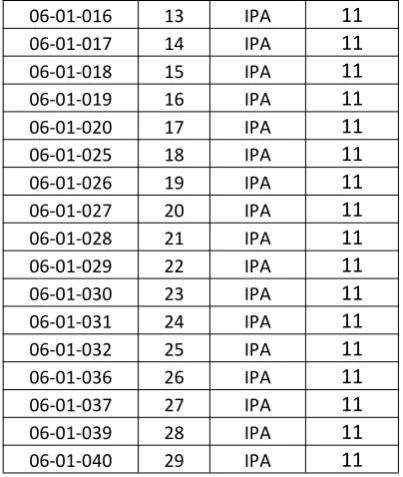
Tabel 1 Inisialisasi Kode Sekolah Jurusan IPA
Kode Sekolah Inisial Jurusan Inisial
06-01-001 1 IPA 11
06-01-002 2 IPA 11
06-01-003 3 IPA 11
06-01-004 4 IPA 11
06-01-005 5 IPA 11
06-01-006 6 IPA 11
06-01-007 7 IPA 11
06-01-008 8 IPA 11
06-01-009 9 IPA 11
06-01-010 10 IPA 11
06-01-011 11 IPA 11
06-01-016 13 IPA 11 06-01-017 14 IPA 11 06-01-018 15 IPA 11 06-01-019 16 IPA 11 06-01-020 17 IPA 11 06-01-025 18 IPA 11 06-01-026 19 IPA 11 06-01-027 20 IPA 11 06-01-028 21 IPA 11 06-01-029 22 IPA 11 06-01-030 23 IPA 11 06-01-031 24 IPA 11 06-01-032 25 IPA 11 06-01-036 26 IPA 11 06-01-037 27 IPA 11 06-01-039 28 IPA 11 06-01-040 29 IPA 11
Tabel 2 Inisialisasi Kode Sekolah Jurusan IPS
Kode Sekolah Inisial Jurusan Inisial
06-01-001 1 IPS 12
06-01-002 2 IPS 12
06-01-003 3 IPS 12
06-01-004 4 IPS 12
06-01-008 5 IPS 12
06-01-009 6 IPS 12
06-01-011 7 IPS 12
06-01-015 8 IPS 12
06-01-016 9 IPS 12
06-01-017 10 IPS 12 06-01-018 11 IPS 12 06-01-019 12 IPS 12 06-01-020 13 IPS 12 06-01-025 14 IPS 12 06-01-026 15 IPS 12 06-01-027 16 IPS 12 06-01-028 17 IPS 12 06-01-029 18 IPS 12 06-01-030 19 IPS 12 06-01-031 20 IPS 12 06-01-032 21 IPS 12 06-01-036 22 IPS 12 06-01-039 23 IPS 12 06-01-040 24 IPS 12
Selain pada atribut kode sekolah proses transformasi data juga dilakukan
pada urutan tertinggi nilai total rerata masing-masing mata pelajaran. Sekolah yang mendapat rerata tinggi namun mempunyai tingkat siswa tidak lulus akan disortingpaling atas.
3.6 Pemodelan Rapid Miner
Berikut adalah pengolahan data dengan menggunakan algoritma K-Means pada
Rapidminer.
Gambar 1 Implementasi Rapid Miner
Dengan menggunakan pemodelan
k-means clustering seperti Gambar 1, dengan inisialisasi jumlah cluster sebanyak 3 buah, maka didapatkan hasil dengan cluster yang terbentuk adalah 3, sesuai dengan pendefinisian bahwa cluster berjumlah 3 dimana nilai k pada dataset SMA IPA dapat dilihat pada Tabel 3.
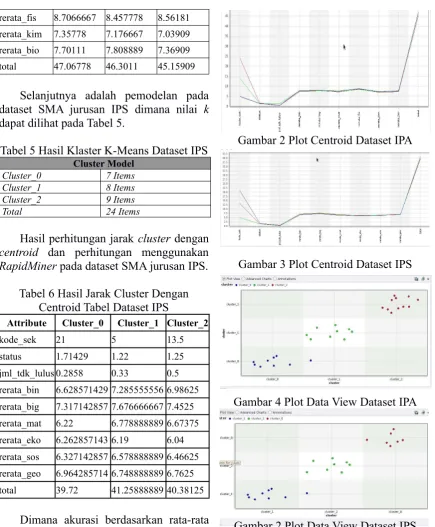
Tabel 3 Hasil Klaster K-Means Dataset IPA
Cluster Model Cluster_0 9 Items Cluster_1 9 Items Cluster_2 11 Items
Total 29 Items
Hasil perhitungan jarak cluster dengan
centroid dan perhitungan menggunakan
RapidMinerpada dataset SMA jurusan IPA. Tabel 4 Hasil Jarak Cluster Dengan
Centroid Tabel Dataset IPA
Attribute Cluster_0 Cluster_1 Cluster_2
kode_sek 5 14 24
status 1.4444 1.3333 1.5454
rerata_fis 8.7066667 8.457778 8.56181 rerata_kim 7.35778 7.176667 7.03909 rerata_bio 7.70111 7.808889 7.36909 total 47.06778 46.3011 45.15909
Selanjutnya adalah pemodelan pada dataset SMA jurusan IPS dimana nilai k
dapat dilihat pada Tabel 5.
Tabel 5 Hasil Klaster K-Means Dataset IPS
Cluster Model Cluster_0 7 Items Cluster_1 8 Items Cluster_2 9 Items
Total 24 Items
Hasil perhitungan jarak cluster dengan
centroid dan perhitungan menggunakan
RapidMinerpada dataset SMA jurusan IPS. Tabel 6 Hasil Jarak Cluster Dengan
Centroid Tabel Dataset IPS
Attribute Cluster_0 Cluster_1 Cluster_2
kode_sek 21 5 13.5
status 1.71429 1.22 1.25
jml_tdk_lulus 0.2858 0.33 0.5 rerata_bin 6.628571429 7.285555556 6.98625 rerata_big 7.317142857 7.676666667 7.4525 rerata_mat 6.22 6.778888889 6.67375 rerata_eko 6.262857143 6.19 6.04 rerata_sos 6.327142857 6.578888889 6.46625 rerata_geo 6.964285714 6.748888889 6.7625 total 39.72 41.25888889 40.38125
Dimana akurasi berdasarkan rata-rata
within centroid distance.
Tabel 7 Rata-Rata Centroid Distance
Average Within IPA dan IPS
Cluster_0 Cluster_1 Cluster_2 Rata-Rata
-22.537 -17.765 -16.171 -18.641
-12.676 -15.244 -11.142 -13.128
Gambar 2 Plot Centroid Dataset IPA
Gambar 3 Plot Centroid Dataset IPS
Gambar 4 Plot Data View Dataset IPA
Gambar 2 Plot Data View Dataset IPS
3.7 Evaluasi (Evaluation)
3.7.1 Evaluasi Hasil (Evaluation Results)
Tahap ini menilai sejauh mana hasil pemodelan data mining memenuhi tujuan data mining yang telah ditentukan pada tahap business understanding.
3.7.2 Pengecekan Ulang Proses (Review Process)
Pada tahapan ini penulis memastikan bahwa semua tahapan / faktor penting yang telah dilakukan dalam pengolahan data tidak ada yang terlewatkan.
3.7.3 Menentukan Langkah Selanjutnya (Determine Next Steps)
Pada tahap ini adalah tahapan dalam menentukan langkah selanjutnya yang dilakukan. Terdapat 2 pilihan yaitu kembali pada tahap awal (predict understanding) atau melanjutkan ke tahap akhir (deployment).
3.8 Persebaran (Deployment)
Berdasarkan hasil analisa klaster masing-masing jurusan maka hasil analisis untuk evaluasi tahap akhir untuk menentukan strategi kelulusan dapat dilihat pada Tabel 8 dan seterusnya.
Tabel 8 Hasil Analisa Pada Cluster 0 Jurusan IPA
Tidak Lulus Berasal Dari
3 A. Negeri = 2
B. Swasta = 1 Jumlah Sekolah = 9 Rerata Nilai = 47.067
Tabel 9 Hasil Analisa Pada Cluster 1 Jurusan IPA
Tidak Lulus Berasal Dari
13 A. Negeri = 10
B. Swasta = 3 Jumlah Sekolah = 9 Rerata Nilai = 46.301
Tabel 10 Hasil Analisa Pada Cluster 2 Jurusan IPA
Tidak Lulus Berasal Dari
5 A. Negeri = 2
B. Swasta = 3 Jumlah Sekolah = 11 Rerata Nilai = 45.159
Selanjutnya analisa dilakukan pada dataset SMA jurusan ips, dapat dilihat pada Tabel 11 dan seterusnya.
Tabel 11 Hasil Analisa Pada Cluster 0 Jurusan IPA
Tidak Lulus Berasal Dari
2 A. Negeri = 0
B. Swasta = 2 Jumlah Sekolah = 7 Rerata Nilai = 39.72
Tabel 12 Hasil Analisa Pada Cluster 1 Jurusan IPA
Tidak Lulus Berasal Dari
3 A. Negeri = 1
B. Swasta = 2 Jumlah Sekolah = 9 Rerata Nilai = 41.258
Tabel 13 Hasil Analisa Pada Cluster 2 Jurusan IPA
Tidak Lulus Berasal Dari A. Negeri = B. Swasta = Jumlah Sekolah = 7 Rerata Nilai = 40.381
Tabel 14. Strategi Yang Diajukan Pada Jurusan IPA
No Strategi 0 1 2 0 1 2Negeri Swasta
1 Meningkatkan NilaiRerata UAN/UAS y y y y y y
2 Pengawasan Yang Lebihbaik y y y
Tabel 15 Strategi Yang Diajukan Pada Jurusan IPS
No Strategi 0 1 2 0 1 2Negeri Swasta
1 Meningkatkan NilaiRerata UAN/UAS y y y y y y
2 Pengawasan Yang Lebihbaik y y y
3 Ekstrakurikuler IntensifMelakukan Jadwal y y y y y y
4 Kesimpulan Dan Saran 4.1 Kesimpulan
Algoritma k-means merupakan algoritma yang mampu mengetahui dengan evaluasi pada data yang random ini terbukti bahwa hasil yang didapat terhadap strategi yang akan dilaksanakan oleh sekolah sangat baik bagi penerapannya untuk sekolah tersebut.
Daftar Pustaka
[1] Johan Oscar Ong, "IMPLEMENTASI
ALGORITMA K-MEANS
CLUSTERING UNTUK
MENENTUKAN STRATEGI
MARKETING PRESIDENT
UNIVERSITY," Jurnal Ilmiah Teknik Industri, vol. 12, no. 1, pp. 10-13, Juni 2013
[2] Giudici & Figini (2009). Applied Data
Mining for Business and Industry, 2ndEdition
[3] Larose, Daniel T, Discovering
Knowledge in Data: An
Introduction to Data Mining.: John Willey &Sons. Inc, 2005. [4] Han,J. and Kamber,M. “Data mining:
Concepts and Techniques”, 2nd
[5] Rima Dias Ramadhani, DATA MINING MENGGUNAKAN
ALGORITMA K-MEANS
CLUSTERING UNTUK
MENENTUKAN STRATEGI
PROMOSI UNIVERSITAS