PEMANFAATAN SISTEM QUESTION ANSWERING
SEDERHANA BERBASIS ONTOLOGI PADA
APLIKASI WEB SEMANTIK
Usulan Penelitian Untuk Tesis S2
Program Magister Ilmu Komputer Fakultas MIPA
Diajukan Oleh:
Reginaldus Kristoforus Jawa Bendi NIM : 07/259608/PPA/2252
Kepada
Program Pasca Sarjana
Universitas Gadjah Mada
Usulan Penelitian Tesis
PEMANFAATAN SISTEM QUESTION ANSWERING
SEDERHANA BERBASIS ONTOLOGI PADA
APLIKASI WEB SEMANTIK
Diajukan Oleh:
Reginaldus Kristoforus Jawa Bendi NIM : 07/259608/PPA/2252
Telah disetujui oleh:
DAFTAR ISI
LATAR BELAKANG 1
RUMUSAN MASALAH 5
BATASAN MASALAH 6
KEASLIAN PENELITIAN 7
TUJUAN PENELITIAN 8
MANFAAT PENELITIAN 8
TINJAUAN PUSTAKA 9
METODA PENELITIAN 12
JADWAAL PENELITIAN 14
PEMANFAATAN SISTEM QUESTION ANSWERING SEDERHANA BERBASIS ONTOLOGI PADA APLIKASI WEB SEMANTIK
(USULAN TESIS)
A. LATAR BELAKANG
Informasi telah menjadi bagian terpenting dari berbagai aktivitas masyarakat
modern. Bagi kalangan bisnis saat ini, informasi adalah aset perusahaan yang
harus dikelola dan dimanfaatkan untuk mencapai keunggulan kompetitif
[MCL2004;OBR2005]. Perkembangan teknologi Internet dan Web yang demikian
pesat mengakibatkan sumber-sumber informasi menjadi semakin banyak dan
beragam. Bahkan saat ini Web telah menjadi suatu kebutuhan, baik itu digunakan
untuk melakukan transaksi bisnis, komunikasi, penyebaran informasi, maupun
pencarian informasi [ANT2003].
Kehadiran mesin-mesin pencari (search engines) seperti Google
(www.google.com), Yahoo (www.yahoo.com), Altavista (www.altavista.com) dan
sebagainya, memberikan kemudahan untuk mencari dan menemukan informasi di
Web. Namun seiring perkembangannya yang sangat pesat, saat ini terdapat
milyaran dokumen Web. Peningkatan volume informasi yang sangat besar ini
justru menambah kesulitan untuk menemukan, mengelola, mengakses dan
memelihara informasi yang dibutuhkan [DAV2003]. Setidaknya terdapat dua
Pertama, makna informasi yang terdapat dalam dokumen web (web content) ,
hanya dapat dipahami oleh manusia namun tidak dapat dipahami oleh mesin.
Akibatnya, mesin tidak mampu menginterpretasikan informasi apa yang
dibutuhkan atau dicari oleh manusia [ANT2003].
Kedua, mesin-mesin pencari saat ini merupakan mesin pencari berbasis kata
kunci (keyword-based search engine). Mesin-mesin ini mencari dokumen
berdasarkan kata (the spelling of the word) dan bukan berdasarkan makna (the
meaning of the word) [ANT2003]. Hal ini mengakibatkan dokumen-dokumen
yang tidak relevan pun disertakan sebagai hasil pencarian (search result). Dan
seringkali terjadi bahwa dokumen-dokumen yang relevan justru tidak terindeks
oleh mensin pencari. Sehingga campur tangan manusia untuk memilah
informasi-informasi tersebut tetap dibutuhkan.
Untuk mengatasi kesulitan tersebut, dibutuhkan suatu mekanisme yang
memampukan komputer memahami makna informasi yang dicari. Dengan kata
lain, dibutuhkan suatu cara agar informasi dalam suatu dokumen Web dapat
dibaca dan dipahami oleh mesin (machine understandable). Web dengan
kemampuan demikian, seolah-olah memiliki kecerdasan buatan yang sanggup
memberikan jawaban yang tepat terhadap pertanyaan atau kebutuhan para
penggunanya.
Salah satu cara untuk menemukan informasi yang diinginkan adalah dengan
memanfaatkan sistem Question Answering (QA) [KAT2002; MOL2003;
pertanyaan dengan bahasa alami, mencari jawaban pada sekumpulan dokumen
atau pada sebuah domain basis pengetahuan, mengekstraknya dan kemudian
memformulasikan jawaban yang ringkas. Salah satu cara untuk meningkatkan
kualitas sistem QA adalah dengan manipulasi konten (content manipulation
approach) yang dilakukan dengan menambahkan meta-information pada
dokumen web sehingga sistem QA tersebut dapat menemukan jawaban yang
sesuai [MCG2004].
Web semantik yang dipelopori oleh Tim Berners-Lee, merupakan suatu cara
untuk merepresentasikan web content dalam bentuk yang dapat dipahami dan
diproses oleh mesin [ANT2003]. Dengan kata lain, web semantik
mengindikasikan bahwa makna data (the meaning of data) pada web dapat
dipahami, baik oleh manusia maupun oleh komputer [PAS2004]. Agar dapat
diproses oleh mesin, dokumen web dianotasikan dengan meta-information
(metadata). Meta-information mendefinisikan informasi mengenai sebuah
dokumen web atau entitas-entitas dalam dokumen tersebut dalam suatu cara yang
dapat diproses oleh mesin [DAV2003; DAV2006]. Dengan demikian proses
pencarian informasi pada dokumen web yang semantis mampu memberikan hasil
yang diharapkan oleh pengguna.
Inti dari sebuah aplikasi web semantik adalah pemanfaatan ontologi untuk
merepresentasikan basis pengetahuan dan sumberdaya web. Ontologi
menghubungkan simbol-simbol yang dipahami manusia dengan bentuknya yang
antara manusia dan mesin [DAV2003; BRE2007]. Dalam kaitannya dengan
pencarian informasi pada web, ontologi bermanfaat untuk meningkatkan akurasi
pencarian. Mesin pencari dapat mencari halaman yang merujuk pada konsep yang
tepat dalam sebuah ontologi. Mesin pencari dapat mengeksploitasi informasi
secara umum atau spesifik. Jika sebuah query gagal menemukan dokumen yang
relevan, mesin pencari dapat menyarankan pengguna untuk memberikan query
yang lebih umum. Jika terlalu banyak dokumen yang ditemukan, mesin pencari
dapat menyarankan query yang lebih spesifik [ANT2003].
Kasus yang diangkat dalam penelitian ini adalah pencarian informasi film.
Film merupakan produk seni dan budaya yang mempunyai peranan penting bagi
pengembangan budaya bangsa sebagai salah satu aspek peningkatan ketahanan
nasional [UND1992]. Secara ekonomis, film merupakan bagian dari industri
konten yang memberikan memberikan andil cukup besar dalam pembangunan
ekonomi nasional dalam bentuk pajak hiburan [KOM2008]. Selain sebagai media
hiburan, film dapat juga dijadikan sebagai media diseminasi pemikiran kritis,
media komunitas, media dokumentasi, media silaturahmi sosial dan budaya dan
bahkan sebagai bahan kajian ilmiah [TAS2007]. Karena itu, tersedianya informasi
film yang berkualitas dan mudah diakses tidak hanya bermanfaat bagi para
penikmat film semata, tetapi juga bagi berbagai kalangan di bidang budaya, seni,
industri maupun akademis. Informasi-informasi tersebut dapat digunakan untuk
mengembangkan dan mempelajari film sebagai baik produk budaya dan seni
Situs-situs web yang berisi informasi film sangat beragam, diantaranya: The
Internet Movie Database (www.imdb.com), Rotten Tomatoes
(www.rottentomatoes.com), Cineplex21 (www.21cineplex.com), dan Yahoo
Movies (www.movies.yahoo.com). Setiap situs web menawarkan informasi film
yang sangat beragam dan banyak. Kondisi ini mengakibatkan proses pencarian
informasi tertentu yang berkaitan dengan film menjadi tidak mudah. Pemanfaatan
teknologi web semantik yang dikombinasikan dengan teknologi QA diharapkan
dapat mengatasi masalah tersebut.
B. RUMUSAN MASALAH
Berdasarkan latar belakang yang telah dikemukakan, permasalahan yang
menjadi fokus penelitian ini adalah:
1. bagaimana membangun sebuah ontologi sebagai basis pengetahuan untuk
informasi film,
2. bagaimana membangun sebuah sistem QA sederhana untuk memanipulasi
informasi pada ontologi yang telah dibangun, dan
3. bagaimana memanfaatkan ontologi dan sistem QA sederhana yang telah
C. BATASAN MASALAH
Mengingat adanya berbagai keterbatasan dan untuk menghindari kompleksitas
yang mungkin timbul selama penelitian berlangsung, diberikan
batasan-batasan dalam penelitian ini, yakni:
1. Domain masalah dalam penelitian ini dibatasi pada informasi film.
2. Informasi film yang dimaksud adalah artibut-atribut yang terkait dengan
sebuah film, misalnya judul film, sudtradara, aktor, dan sebagainya
3. Informasi film yang digunakan bersumber pada Internet Movie Database
(www.imdb.com).
4. Model ontologi informasi film dibangun dengan menggunakan bahasa
OWL (Web Ontology Language) dan Protégé (ontology editor).
5. Sistem QA sederhana dibangun berbasis kalimat bahasa indonesia yang
terstruktur.
6. Klasifikasi kalimat pertanyaan dibatasi pada pertanyaan: Siapa, Kapan,
dan Dimana.
7. Aplikasi web semantik yang dikembang berupa aplikasi pencarian
D. KEASLIAN PENELITIAN
Penelitian-penelitian yang terkait dengan teknologi web semantik dan
teknologi QA telah banyak dilakukan. Untuk memastikan keaslian penelitian ini,
telah dilakukan serangkaian penelusuran terhadap penelitian-penelitian
sebelumnya yang terkait dengan topik penelitian ini. Penelusuran secara manual
dilakukan pada perpustakaan Magister Ilmu Komputer UGM dan perpustakaan S1
Ilmu Komputer UGM. Penelusuran secara online dilakukan melalui Google
(www.google.com), Google Scholar (scholar.google.com), CiteSeer
(citeseerx.ist.psu.edu) dan IEEE Computing Society (www.computer.org). Dari
hasil penelusuran ditemukan beberapa penelitian yang terkait dengan topik
penelitian ini (Tabel 1).
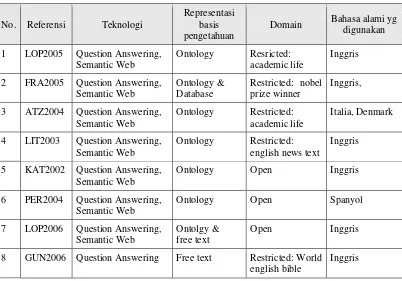
Tabel 1. Penelitian-penelitian yang terkait
No. Referensi Teknologi
1 LOP2005 Question Answering, Semantic Web
Ontology Resricted:
academic life
Inggris
2 FRA2005 Question Answering, Semantic Web
3 ATZ2004 Question Answering, Semantic Web
Ontology Restricted:
academic life
Italia, Denmark
4 LIT2003 Question Answering, Semantic Web
Ontology Restricted:
english news text
Inggris
5 KAT2002 Question Answering, Semantic Web
Ontology Open Inggris
6 PER2004 Question Answering, Semantic Web
Ontology Open Spanyol
7 LOP2006 Question Answering, Semantic Web
Ontolgy & free text
Open Inggris
8 GUN2006 Question Answering Free text Restricted: World
english bible
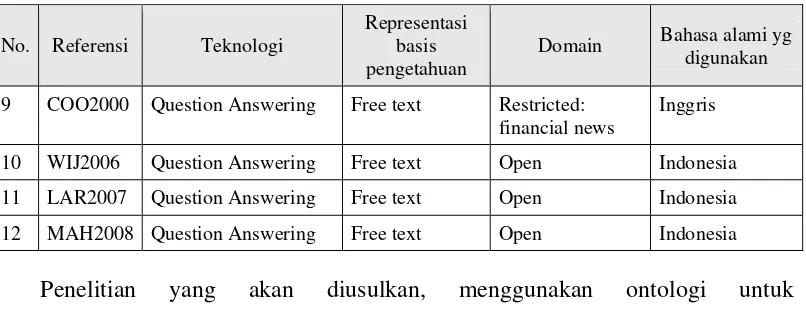
Tabel 1 (lanjutan). Penelitian-penelitian yang terkait
9 COO2000 Question Answering Free text Restricted:
financial news
Inggris
10 WIJ2006 Question Answering Free text Open Indonesia
11 LAR2007 Question Answering Free text Open Indonesia
12 MAH2008 Question Answering Free text Open Indonesia
Penelitian yang akan diusulkan, menggunakan ontologi untuk
merepresentasikan basis pengetahuan dari sistem QA berbahasa Indonesia pada
sebuah domain yang terbatas (informasi film). Dengan membandingkan
penelitian-penelitian sebelumnya dan penelitian yang akan diusulkan, dapat
disimpulkan bahwa penelitian ini belum pernah dilakukan.
E. TUJUAN PENELITIAN
Penelitian ini bertujuan untuk menjawab permasalahan yang telah
dikemukakan pada rumusan masalah, yakni membangun sebuah aplikasi
pencarian informasi film berbasis web semantik yang memanfaatkan teknik QA
sederhana untuk menemukan informasi pada ontologi sebagai basis pengetahuan
dari domain informasi film tersebut.
F. MANFAAT PENELITIAN
Beberapa manfaat yang diharapkan dari hasil penelitian ini adalah sebagai
berikut.
1. Bagi perkembangan ilmu, khususnya di bidang teknologi web semantik dan
mengenai bagaimana membangun dan mengembangkan sistem QA sederhana
dan ontologi untuk sebuah domain tertentu, dan bagaimana membangun
sebuah aplikasi pencarian berbasis web semantik.
2. Bagi para pengembang web dan pengembang sistem, penelitian ini diharapkan
memberikan wawasan tentang pemanfaatan teknologi web semantik dan
teknologi QA untuk mengembangkan sebuah sistem berbasis web.
3. Bagi para peneliti di bidang web semantik dan teknologi QA, penelitian ini
diharapkan dapat menjadi acuan bagi penelitian lanjutan yang lebih kompleks.
G. TINJAUAN PUSTAKA
Sebuah sistem QA, menerima query dalam bentuk pertanyaan dengan bahasa
alami, mencari jawaban pada sekumpulan dokumen atau pada sebuah domain
basis pengetahuan, mengekstraknya dan kemudian memformulasikan jawaban
yang ringkas [MOL2003]. Umumnya sistem QA terdiri atas tiga modul utama,
yakni question processing, document retrieval dan answer processing.
Kebanyakan sistem QA mengelompokan pertanyaan berdasarkan jenis
pertanyaannya [COO2000; MOL2003; PER2004; GUN2006; WIJ2006]. Jika
jenis pertanyaan dapat ditentukan maka jenis jawabannya dapat ditentukan pula.
Dimisalkan, jenis pertanyaannya adalah ”Siapa…” , maka jawaban yang
diinginkan adalah orang atau organisasi. Jika pertanyaannya “Kapan…” jawaban
Web dengan milyaran informasi yang sangat beragam dan tak terstruktur
dipandang sebagai sumber informasi yang bernilai [MOL2003]. Walaupun saat ini
tersedia banyak mesin pencari, namun mereka tidak mampu memberikan
informasi yang spesifik yang diinginkan pengguna [MOL2003; PER2004].
Pemanfaatan teknologi QA pada web bertujuan untuk mengatasi masalah tersebut.
Teknologi QA diharapkan dapat menjadi antarmuka yang lebih intuitif untuk
memformulasikan pertanyaan dan memberikan jawaban dalam bahasa alami
daripada mengembalikan sekumpulan dokumen web yang terurut berdasarkan
ranking [MOL2003; MCG2004; LOP2005].
Seperti yang telah dijelaskan sepintas pada subbagian D, penelitian-pelitian
yang terkait dengan sistem QA pada web semantik telah banyak dilakukan. Katz
[KAT2002] menyebutkan bahwa terdapat peluang sinerjik antara teknologi bahasa
alami dan web semantik, yakni sebuah sistem QA yang mampu memberikan
informasi yang relevan dari sebuah basis pengetahuan berbasis ontologi dalam
menanggapi query yang berikan oleh pengguna dalam bahasa alami.
Ide ini diwujudkan dengan mengadopsi triple-based data model (misalnya
RDF) sebagai basis pengetahuan pada sistem QA [KAT2002; LOP2005;
LOP2006; LIT2003]. Hal ini didasarkan pada pertimbangan bahwa terdapat
kemungkinan untuk merepresentasikan sebuah query berbasis bahasa alami ke
dalam bentuk triple, yang dalam hal ini berbentuk subyek, predikat dan obyek dari
menggunakan RDF (Resource Description Framework) juga menyatakan sebuah
statement dalam bentuk triple: resources, properties, value.
Beberapa penelitian lain melakukannya dengan cara pengenalan Named
Entities (NE) dan relasi antar entitas dalam bahasa alami [FRA2005; PER2004].
Metoda ini diadopsi dari teknologi Information Extraction. NE mengacu pada
sebuah konsep atau instance dalam ontologi.
Kecenderungan penelitian-penelitan QA yang dilakukan saat ini mengarah
pada open domain QA yang berbasis pada sejumlah besar dokumen pada web.
Berbeda dengan kecenderungan tersebut, beberapa penelitian berfokus pada
restricted domain [LOP2005; FRA2004; ATZ2004]. Pemilihan restricted domain
didasarkan pada beberapa alasan, antara lain, pertama, eksploitasi informasi pada
dokumen web sering dihadapkan pada masalah reliabilitas informasi tersebut.
Dapat saja terjadi bahwa informasi yang diberikan telah kadaluwarsa atau bahkan
sepenuhnya salah. Kedua, pemanfaatan pengetahuan formal pada restricted
domain dapat meningkatkan keakuratan sistem QA, karena baik pertanyaan
maupun jawabannya dianalisis berdasarkan basis pengetahuan tersebut. Ketiga,
sangat dimungkinkan bahwa sebuah institusi memiliki dan mengelola basis
pengetahuan yang sifatnya terbatas dan hanya dipergunakan dalam lingkup
institusi tersebut.
Dalam sebuah essay, McGuinness [MCG2004] menyebutkan bahwa
pengetahuan), memanipulasi query atau memanipulasi jawaban. Pada umumnya
sistem QA pada web, mengekstrak jawaban dari sekumpulan dokumen yang tidak
terstruktur. Pada restricted domain, penggunaan basis pengetahuan yang
terstruktur sangat dimungkinkan karena ukuran basis pengetahuannya yang
cenderung lebih kecil dan stabil [FRA2004] dibandingkan dengan basis
pengetahuan pada open domain. Dengan basis pengetahuan yang terstruktur
(misalnya ontologi), sistem dapat menurunkan lebih banyak makna dan dapat
memanfaatkan domain dan range pada slot untuk mengecek konsistensi informasi
[MCG2004].
Sejauh ini terdapat sejumlah penelitian mengenai sistem QA yang
menggunakan bahasa Indonesia [WIJ2006; LAR2007; MAH2008]. Sebagai
bahasa kenegaraan yang resmi bahasa Indonesia digunakan oleh lebih dari seratus
juta orang. Berdasarkan fakta tersebut, penggunaan bahasa Indonesia sebagai
bahasa alami dalam sebuah sistem QA patut dipertimbangkan.
H. METODA PENELITIAN
Metoda yang digunakan untuk pengembangan sistem ini adalah waterfall
model atau Classic Life Cycle model. Model inimengusulkan sebuah pendekatan
yang sistematik dan sekuensial dalam mengembangkan sistem. Model ini
membagi pengembangan sistem dalam lima tahap, yakni: tahap analisis, tahap
desain, tahap pengkodean, tahap pengujian, dan tahap pemeliharaan [PRE2001;
MCL2004]. Sementara [WHI2004] menyebutnya sebagai strategi pengembangan
definisi lingkup, fase analisis masalah, fase analisis persyaratan, fase desain logis,
fase analisis keputusan, fase desain dan integrasi fisik, fase konstruksi dan
pengujian, dan terakhir adalah fase instalasi dan delivery.
Berdasarkan uraian di atas, tahapan-tahapan penelitian ini terbagi atas:
a. Tahap Definisi Lingkup Sistem
Pada tahapan ini, seluruh masalah, kesempatan dan arahan yang mendasari
pengembangan sistem ini didefinisikan. Termasuk di dalammya adalah
mendefinisikan batasan sistem dan strategi pengembangan yang digunakan.
b. Tahap Analisis Persyaratan
Pada tahapan ini, seluruh informasi yang terkait dengan pengembangan sistem
dikumpulkan dan dianalisis. Informasi-informasi tersebut merupakan dasar
untuk menetapkan persyaratan bisnis dari sistem yang akan dikembangkan.
Penemuan fakta dilakukan dengan cara studi literatur dan site visit.
c. Tahap Analisis
Pada tahapan ini, sistem dimodelkan secara logis berdasarkan
persyaratan-persyaratan bisnis yang telah ditentukan.
d. Tahap Desain
Pada tahapan ini persyaratan-persyaratan bisnis yang telah dimodelkan dalam
tahap analisis ditransformasikan dalam spesifikasi desain fisik yang akan
menjadi dasar konstruksi sistem.
Pada tahapan ini, sistem dibangun dengan menggunakan bahasa pemrograman
dan tools yang telah ditentukan sebelumnya. Setelah itu akan dilakukan pengujian
terhadap komponen-komponen sistem.
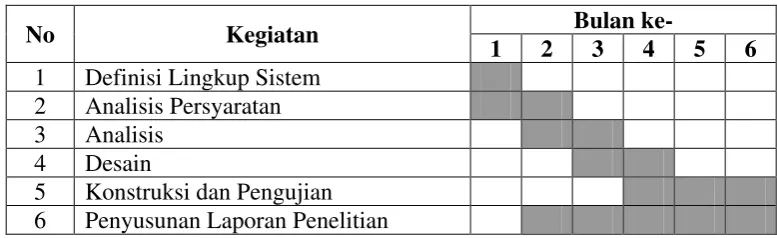
I. JADWAL PENELITIAN
Mengingat adanya keterbatasan waktu, kegiatan penelitian ini terbagi atas
beberapa tahap yang dilakukan secara terjadwal. Secara umum jadwal yang
diusulkan sebagai berikut.
Tabel 2. Jadwal Penelitian
No Kegiatan Bulan ke-
1 2 3 4 5 6
1 Definisi Lingkup Sistem 2 Analisis Persyaratan 3 Analisis
4 Desain
J. DAFTAR PUSTAKA
[ANT2003] Antoniou, G., dan F. van Harmelen. (2003). A Semantic Web Primer. MIT Press.
[ATZ2004] Atzeni, P., dkk. (2004). Ontology-based Question Answering In A Federation of University Site: The MOSES Case Study. Natural Language Processing and Information Systems. LNCS 3136. Springer-Berlin.
[BRE2007] Breitman, K. K., M. A. Casanova, dan W. Truszkowski. (2007).
Semantic Web: Concepts, Technologies and Applications. Springer.
[COO2000] Cooper, R. J., dan S. M. Ruger (2000). A Simple Question Answering System. Proceedings of the 9th Text REtrieval Conference.
[DAV2003] Davies, J., D. Fensel., dan F. van Harmelen. (2003). Towards The Semantic Web Ontology-driven Knowledge Management. John Wiley & Sons.
[DAV2006] Davies, J., R. Studer, dan P. Warren. (2006). Semantic Web Technologies Trends and Research in Ontology-based Systems.
John Wiley & Sons.
[FRA2005] Frank, A., dkk. (2005). Querying Structured Knowledge Sources.
Proceedings of AAAI-05 and Workshop on Question Answering in Restricted Domains.
[GUN2006] Gunawan dan G. Lovina (2006). Question Answering System dan Penerapannya pada Alkitab. Jurnal Informatika. Vol 7(1).
[KAT2002] Katz, B., J. Lin dan D. Quan. (2002). Natural Language Annotations for the Semantic Web. Proceedings of the
International Conferences on Ontology, Databases, and
Applications of Semantics.
[KOM2008] ---. (2008). Masyarakat Perfilman Berharap Kontribusi dari Pajak Hiburan. Diakses di: www.kompas.com. Tanggal: 4/12/2008.
[LAR2007] Larasati, S.D. dan R. Manurung. (2007). Towards a Semantic Analysis of Bahasa Indonesia for Question Answering. Proceedings of the 10th Conference of the Pacific Association for Computational Linguistics (PACLING 2007).
[LIT2003] Litkowski, K. C., (2003). Question Answering Using XML-Tagged Documents. Proceedings of the 11th TREC.
[LOP2005] Lopez, V., M. Pasin, dan E. Motta. (2005). AquaLog: An Ontology-Portable Question Answering for the Semantic Web.
[LOP2006] Lopez, V., E. Motta, dan V. Uren (2006). PowerAqua: Fishing the Semantic Web. Proceedings of European Semantic Web Conference 2006.
[MAH2008] Mahendra, R., S. D. Larasati dan R. Manurung. (2008). Extending an Indonesian Semantic Analysis-based Question Answering System with Based Linguistic and World Knowledge Axioms. The 22nd Pacific Asia Conferences on Language Information and Computation (PACLIC22).
[MCG2004] McGuinness, D. L. (2004). Question Answering on the Semantic Web. IEEE Inteligent Systems .Vol 19(1).
[MCL2004] McLeod, R., dan G. P. Schell. (2004). Management Information System 9th edition. Prentice Hall.
[MOL2003] Moldovan, D. dan M. Surdeanu. (2003). On The Role of Information Retrieval dan Information Extraction in Question Answering Systems. Information Extraction in the Web Era. LNAI 2700. Springer-Verlag. Question Answering Systems. Advances in Web Intelligence. LNCS 3034. Springer-Verlag.
[PRE2001] Pressman, R. R., (2001), Software Engineering: A Practitioner’s
Approach, 5th Edition, McGraw-Hill.
[TAS2007] Taslim, T. (2007). Memberdayakan Sinema di Indonesia. Diakses di: http://milisi.org/forum/viewtopic.php?id=6 04/11/08 Tanggal: 4/12/2008 Analysis and Design Methods, Terjemahan, Penerbit Andi.
[WIJ2006] Wijono, S.H., I. Budi, L. Fitria dan M. Adriani. (2006). Finding Answers to Indonesian Questions from English Documents.