APLIKASI DATA MINING UNTUK
PREDIKSI PEMUSNAHAN BARANG
SCRAP DENGAN MENGGUNAKAN
METODE ALGORITMA C4.5
SKRIPSI
Diajukan Sebagai Salah Satu Syarat Untuk Menyelesaikan Program Strata Satu (S1) pada Program Studi Teknik Informatika
Oleh :
MEI KURNIA
311410549
PROGRAM STUDI TEKNOLOGI INFORMASI
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI
2018
iv ABSTRAK
Dalam proses produksi di suatu perusahaan tentu akan ada barang yang dimusnahkan dengan berbagai alasan. Salah satu faktor penyebab barang yang dimusnahkan adalah kurangnya parameter/prediksi dalam pemusnahan barang. Tujuan penelitian ini adalah membuat prediksi klasifikasi barang musnah dengan menggunakan data mining algoritma C4.5 hitungan manual dan aplikasi RapidMiner sebagai acuan dalam mengambil tindakan untuk proses pemusnahan barang. Hasil klasifikasi dari algoritma C4.5 dievaluasi dan divalidasi dengan confusion matrix dan kurva Receiver Operating Characteristic (ROC) untuk mengetahui tingkat akurasi algoritma C4.5 dalam membuat klasifikasi barang musnah. Dengan hasil akurasi yang diperoleh sebesar 91,25% pada penelitian ini maka status barang dapat diprediksi antara musnah atau tidak, dengan begitu tujuan penelitian tercapai karena proses penjualan barang scrap/NG lebih cepat sehingga tempat penyimpanan barang scrap lebih efisien dan tidak menumpuk. Kata Kunci : Algoritma C4.5, Data Mining, RapidMiner, Prediksi barang scrap.
v ABSTRACT
In the production process in a company, of course there will be goods that are destroyed for various reasons. One of the factors that causes the goods to be destroyed is the lack of parameters / predictions in the destruction of goods. The purpose of this study is to make the classification of goods predictions destroyed by using the C4.5 data mining algorithm manual count and RapidMiner application as a reference in taking action for the destruction of goods. The classification results of the C4.5 algorithm are evaluated and validated with the confusion matrix and Receiver Operating Characteristic (ROC) curve to determine the accuracy of the C4.5 algorithm in classifying destroyed items. With the results of accuracy obtained at 91.25% in this study, the status of goods can be predicted to be destroyed or not, so the research objectives are achieved because the process of selling scrap / NG goods is faster so that the scrap goods storage is more efficient and does not accumulate.
vi
KATA PENGANTAR
Puji dan syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan kemudahan dalam penyelesaian skripsi. Skripsi ini disusun sebagai salah satu persyaratan akademik di STT Pelita Bangsa Bekasi, Program Studi Teknologi Informasi untuk mendapatkan gelar Sarjana (S1). Adapun judul skripsi ini adalah “Aplikasi Data Mining untuk Prediksi Pemusnahan Barang Scrap
dengan Menggunakan Metode Algoritma C4.5”.
Penelitian ini membahas tentang prediksi pemusnahan barang dengan menggunakan data mining algoritma C4.5. Tujuannya supaya proses pemusnahan barang lebih akurat dengan harapan dapat membantu proses penentuan material yang musnah atau tidak.
Pada kesempatan ini penulis menyampaikan terima kasih kepada pihak-pihak yang telah membantu sehingga terselesaikannya penelitian.
1. Bpk. Dr. Ir. Supriyanto, M.P selaku Ketua STT Pelita Bangsa.
2. Bpk. Aswan S. Sunge, S.E,M.Kom selaku Ketua Program Studi Teknologi Informasi.
3. Bpk. Ir. U. Darmanto Soer, M.Kom selaku dosen pembimbing I (pertama) yang banyak memberikan pengarahan dan masukan selama pengerjaan skripsi ini.
4. Ibu Arvita Emarilis Intani, S.T., M.T selaku dosen pembimbing II (kedua) yang memberikan bimbingan dan kemudahan selama penulisan skripsi ini.
vii
5. Orang tua tercinta dan keluarga yang telah banyak memberikan do’a dan dukungan kepada penulis secara moril maupun materil hingga skripsi ini dapat selesai.
6. Sahabat dan rekan seperjuangan yang tiada henti memberi dukungan dan motivasi kepada penulis.
7. Semua pihak yang telah banyak membantu dalam penyusunan skripsi ini yang tidak bisa penulis sebutkan semuanya.
Saya menyadari laporan skripsi ini masih jauh dari kata sempurna. Oleh sebab itu, dengan hati yang terbuka Saya mengharapkan kritik serta saran yang membangun guna kesempurnaan laporan skripsi ini. Semoga laporan skripsi ini bermanfaat bagi Kita semua, Aamiin.
Cikarang, 07 November 2018
viii DAFTAR ISI
PERSETUJUAN ... i
PENGESAHAN ... ii
PERNYATAAN KEASLIAN PENELITIAN ... Error! Bookmark not defined. ABSTRAK ... iv
ABSTRACT ... v
KATA PENGANTAR ... vi
BAB 1 ... 1
PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 9 1.3 Batasan Masalah ... 10 1.4 Rumusan Masalah ... 10 1.5 Tujuan Penelitian ... 10 1.6 Manfaat Penelitian ... 10 1.7 Metodologi Penulisan ... 11 1.8 Sistematika Penulisan ... 12 BAB II ... 14 TINJAUAN PUSTAKA ... 14 2.1 Tinjauan Pustaka ... 14 2.2 Prediksi ... 28 2.3 Barang Scrap ... 29
2.3.1 Manfaat Barang Scrap ... 29
2.4 Data Mining ... 29
2.4.1 Kategori Data Mining ... 30
2.4.2 Proses Tahapan Data Mining ... 31
2.4.3 Fungsi Data Mining ... 34
2.4.4 Teknik Data Mining ... 34
2.4.5 Cross-Industry Standard Process for Data Mining ( CRISP-DM ) 36 2.5 Algoritma C4.5 ... 38
ix 2.6 Decision Tree ... 43 2.7 RapidMiner ... 43 BAB III ... 47 METODE PENELITIAN ... 47 3.1 Kerangka Berfikir ... 47 3.2 Analisa Data ... 47
3.3 Alat dan Bahan ... 48
3.3.1 Perangkat Lunak ... 48
3.3.2 Perangkat Keras ... 49
3.3.3 Jenis Data ... 49
3.4 Metode Pengumpulan Data ... 49
3.5 Sejarah Perusahaan ... 50
3.5.1 Sasaran Mutu ... 51
3.5.2 Struktur Organisasi ... 51
3.5.3 Visi dan Misi ... 52
3.6 Deskripsi Sistem ... 53
3.6.1 Menentukan Root ... 53
3.6.2 Menentukan Cabang ... 54
3.1.1 Menentukan Node ... 54
3.7 Tahap Penelitian ... 54
3.8 Tahap Pengujian Menggunakan RapidMiner Studio 8.1.0 ... 64
BAB IV ... 65
HASIL DAN PEMBAHASAN ... 65
4.1 HASIL ... 65
4.1.1 Jumlah Kasus Data Keseluruhan, Data Training Dan Data Testing 65 4.1.2 Pemodelan Klasifikasi Algoritma C4.5 ... 69
4.1.3 Pengujian Hasil Menggunakan Aplikasi RapidMiner ... 77
4.2 Kurva ROC/AUC (Area Under Curve) ... 83
BAB V... 86
x
5.1 Kesimpulan ... 86
5.2 Saran ... 86
DAFTAR PUSTAKA ... 87
xi
DAFTAR TABEL
Tabel 2.1 Contoh Kasus Keputusan Bermain Tenis ...21
Tabel 2.2 Contoh Kasus Perhitungan Bermain Tenis ...22
Tabel 3.1 Data Pemusnahan Barang Jan s/d Mar 2018...37
Tabel 3.2 Pemilihan Data ...39
Tabel 3.3 Proses Cleaning Data ...40
Tabel 3.4 Keterangan Warna Bagus ...41
Tabel 3.5 Data Training ...43
Tabel 3.6 Data Testing ...44
Tabel 4.1 Jumlah Nilai Atribut Keseluruhan ...47
Tabel 4.2 Jumlah Kasus Data Training ...48
Tabel 4.3 Jumlah Kasus Data Testing ...49
Tabel 4.4 Perhitungan Node 1 Root ...51
Tabel 4.5 Perhitungan Node 1.1 ...53
Tabel 4.6 Perhitungan Node 1.1.1 ...55
xii
DAFTAR GAMBAR
Gambar 2.1 Tahap Tahap Data Mining ...13
Gambar 2.2 Tahapan CRISP-DM ...17
Gambar 2.3 Contoh Kasus Pohon Keputusan Sementara ...24
Gambar 2.4 Menu Aplikasi RapidMiner ...27
Gambar 3.1 Kerangka Berpikir ... 28
Gambar 3.2 Metode yang diusulkan ...29
Gambar 3.3 Struktur Organisasi ...34
Gambar 3.4 Model Penelitian yang diusulkan ...45
Gambar 3.5 Tampilan Awal Aplikasi RapidMiner ...47
Gambar 4.1 Pohon Keputusan Node 1 ...53
Gambar 4.2 Pohon Keputusan Node 1.1 ...54
Gambar 4.3 Pohon Keputusan Node 1.1.1 ...56
Gambar 4.4 Pohon Keputusan Node 1.1.1.1 ...57
Gambar 4.5 Tampilan Awal Aplikasi RapidMiner ... 58
Gambar 4.6 Import Data Training ...59
Gambar 4.7 Proses Validasi ...60
Gambar 4.8 Proses Training Dan Testing ...61
Gambar 4.9 Pohon Keputusan Hasil RapidMiner ...61
Gambar 4.10 Rule Model Data Training ...62
Gambar 4.11 Rule Model Data Testing ...62
Gambar 4.12 Hasil Evaluasi Nilai Accurasy ...62
Gambar 4.13 Hasil Evaluasi Nilai Precision ...63
Gambar 4.14 Hasil Evaluasi Nilai Recall ...64
Gambar 4.15 Hasil Evaluasi Kurva ROC/AUC ... 65
1 BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
PT.Inabata Creation Indonesia adalah perusahaan yang memproduksi grip tape. Bahan yang diguanakn untuk pembuatan grip tape adalah SPLS (Synthetic Polyurethane Leather Sheet), barang tersebut ada berbagai jenis. Sebelum SPLS (Synthetic Polyurethane Leather Sheet) masuk kedalam proses produksi tentu harus sudah lulus seleksi QC (Quality Control) sebagai barang yang OK. Setelah melalui berbagai macam proses didalam produksi, ada barang yang rusak dan barang sisa yang dihasilkan.
Barang yang sudah rusak dan barang sisa merupakan unit yang tidak dapat diterima sehingga harus dibuang atau dijual dengan nilai yang lebih rendah. Sebagaimana yang telah diketahui dalam perusahaan pasti akan ada barang scrap. Scrap merupakan masukan yang tidak menjadi bagian keluaran tetapi masih mempunyai nilai ekonomi yang relatif kecil, barang sisa dapat dijual atau digunakan kembali (Charies dan Foster,2001:150 dalam Jurnal Yentifa, A., Maryati, U., & Putri, S. Y. A, 2015). Dari uraian pengertian tersebut dapat ditarik kesimpulan bahwa sisa bahan baku merupakan bahan yang tersisa atau bahan yang rusak dari proses produksi yang tidak dapat dimasukan lagi ke dalam produksi dengan kegunaan seperti sebelumnya, tetapi mempunyai nilai ekonomi yang relatif kecil dan bahan tersebut mungkin dapat dipakai untuk kegunaan lain atau proses produksi lain atau bahan tersebut dapat dijual kepada pihak luar
8
(Yentifa, A., Maryati, U., & Putri, S. Y. A, 2015). Biasanyan produk rusak ditemukan pada akhir proses dengan demikian ia telah menyerap biaya produksi.
PT.Inabata Creation Indonesia adalah perusahaan manufacturing jepang yang fokus bergerak dalam bidang grip tape. Barang utama yang digunakan untuk pembuatan grip tape adalah material SPLS (Synthetic Polyurethane Leather Sheet). Material yang akan dibahas sebagai barang sisa dan rusak yaitu material SPLS (Synthetic Polyurethane Leather Sheet).
Permasalahan yang saat ini masih terjadi adalah :
a) Barang scrap masih menumpuk didalam area warehouse. Hal ini dikarenakan oleh faktor pendataan barang yang masih ditangani secara manual.
b) Tingkat terjadinya kesalahan dalam prediksi pemusnahan barang scrap masih tinggi yaitu 6,6%. Dari Total 30 form, ada sebanyak 2 kali revisi data barang yang akan dimusnahkan.
jika masalah seperti ini tidak ditangani maka bukan tidak mungkin juga barang yang seharusnya masih bisa digunakan tetapi masuk ke dalam data barang yang harus di musnahkan. Kesalahan prediksi tersebut tentunya dapat mempengaruhi proses produksi, misalnya produksi akan mengalami kekurangan barang karena barang yang seharusnya diproduksi tidak ada / sudah dimusnahkan. Semua kesalahan tersebut akan mengakibatkan gagalnya penjualan produk, dan profit perusahaan akan menurun.
8
Oleh karena itu proses prediksi untuk pemusnahan barang scrap sangat penting, manfaat yang bisa didapatkan adalah :
a) Barang sisa dari produksi atau barang yang memang tidak layak pakai (scrap) masih mempunyai nilai jual, dengan menjualnya maka tentu perusahaan akan tetap mendapatkan pemasukan dari barang scrap.
b) Tempat penyimpanan barang (Warehouse) akan mempunyai kapasitas penyimpanan yang lebih luas karena tidak dipenuhi dengan barang scrap. Salah satu cara mengatasi masalah ini adalah dengan menggunakan Data Mining (DM) dengan teknik klasifikasi algoritma C4.5. Data mining dapat digunakan untuk menangani meledaknya volume data. Data mining merupakan serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu basis data.
Menimbang dari latar belakang masalah diatas maka Saya mengambil penelitian skripsi dengan judul “ Aplikasi Data Mining Untuk Prediksi
Pemusnahan Barang Scrap Dengan Menggunakan Metode Algoritma C4.5 “.
1.2 Identifikasi Masalah
Tingkat terjadinya kesalahan dalam prediksi pemusnahan barang scrap masih tinggi yaitu 6,6%, tempat penyimpanan barang scrap penuh dan proses penjualan barang scrap membutuhkan waktu yang lama. Hal tersebut terjadi karena salah informasi mengenai barang yang reject.
8
1.3 Batasan Masalah
Pembatasan masalah dalam pembahasan skripsi ini adalah :
1. Memprediksi barang scrap menggunakan metode data mining Algoritma C4.5
2. Menggambarkan pohon keputusan dengan Algoritma C4.5 yang bertujuan untuk menganalisa nilai resiko dan efisiensi penyimpanan barang musnah di warehouse serta mempercepat proses penjualan barang musnah.
1.4 Rumusan Masalah
Bagaimana caranya memprediksi pemusnahan barang-barang scrap menggunakan data mining dengan metode algoritma C4.5 ?
1.5 Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1) memprediksi barang scrap yang harus dimusnahkan dengan menggunakan metode Algoritma C4.5.
2) Efisiensi tempat penyimpanan barang scrap 3) Mempercepat proses penjualan barang scrap
1.6 Manfaat Penelitian
1.) Manfaat penelitian bagi Penulis (Mahasiswa) adalah :
a.) Dapat memenuhi tugas skripsi yang diberikan oleh pihak Kampus sebagai syarat untuk lulus Strata 1 bidang Teknik Informatika.
8 2.) Manfaat penelitian bagi Institusi adalah :
a.) Hasil penelitian ini diharapkan dapat memberi manfaat dan menambah perbendaharaan bacaan bahan bagi mahasiswa/mahasiswi Sekolah Tinggi Teknologi Pelita Bangsa program studi Teknik Informasi untuk penelitian selanjutnya.
3.) Manfaat penelitian bagi Perusahaan adalah :
a.) Pihak perusahaan mendapatkan data prediksi barang-barang yang dimusnahkan secara lebih akurat.
1.7 Metodologi Penulisan
Metodologi penulisan merupakan langkah penting dalam penyusunan laporan skripsi. Dalam kegiatan metodologi penulisan, penulis melakukan pengumpulan data melalui cara :
1.) Wawancara
Wawancara dilakukan dengan orang yang menangani bagian tersebut secara langsung, untuk mengetahui bagaimana proses yang terjadi dan apa saja faktor-faktor yang dapat mempengaruhi pengambilan keputusan pemusnahan material.
2.) Observasi
Melalui observasi ke bagian yang berhubungan dengan kegiatan pemusnahan material untuk mendapatkan gambaran yang jelas. Kegiatan ini diperlukan untuk mencari dan mengumpulkan data yang dibutuhkan langsung dari sumbernya.
8 3.) Studi Kepustakaan
Mengumpulkan data yang diperoleh dari buku-buku atau literatur lain yang dapat dijadikan acuan untuk membahas penelitian ini.
4.) Browsing
Mencari informasi tentang jurnal, skripsi dan pembahasan lain mengenai algoritma C4.5
1.8 Sistematika Penulisan
Untuk mengetahui secara ringkas permasalahan dalam penulisan laporan tugas akhir ini, maka digunakan sistematika penulisan yang bertujuan untuk mempermudah pembaca menelusuri dan memahami laporan tugas akhir ini. BAB 1 PENDAHULUAN
Pada bab ini penulis menguraikan tentang Latar Belakang Masalah, Identifikasi Masalah, Batasan Masalah, Rumusan Masalah, Tujuan Penelitian, Manfaat Penelitian, Metodologi Penulisan dan Sistematika Penulisan.
BAB II LANDASAN TEORI
Dalam bab ini menguraikan tentang dasar-dasar teori tentang pemusnahan barang scrap, data mining dan teori tentang prediksi menggunakan algoritma C4.5 yang dipakai dalam mendukung penelitian ini agar dapat di jadikan dasar untuk memecahkan masalah dan dilakukan studi pustaka sebagai landasan dalam melakukan penelitian.
8 BAB II I METODE PENELITIAN
Dalam Bab ini berisi tentang kerangka pikir, sejarah PT.Inabata Creation Indonesia, struktur organisasi, dan metode penelitian.
BAB IV HASIL DAN PEMBAHASAN
Dalam Bab ini berisi tentang permasalahan, hasil penelitian dan pembahasan.
BAB V PENUTUP
Pada Bab ini merupakan bab terakhir berisi kesimpulan dari apa yang di bahas dalam laporan ini, dilanjutkan dengan saran-saran untuk mencapai suatu hasil akhir yang baik.
8 BAB II
TINJAUAN PUSTAKA
2.1 Tinjauan Pustaka
Contoh penelitian yang membahas mengenai prediksi menggunakan algoritma C4.5 yaitu :
Penerapan Algoritma C4.5 pada Analisis Kerusakan Barang Jadi (Oktana, I. & Hansun, S., 2015).
PT.Kayu Lapis Asli Murni merupakan perusahaan yang bergerak dalam bidang industri plywood. Perusahaan ini memiliki database yang berukuran sangat besar pada bagian data kerusakan barang dan dapat terus bertambah. Dalam menghadapi persaingan bisnis dan meningkatkan pendapatan perusahaan, pihak terkait dalam perusahaan dituntut untuk dapat mengambil keputusan yang tepat dalam menentukan strategi produk yang dijual. Ketersediaan data yang melimpah akan mendukung pengambilan keputusan untuk membuat solusi bisnis dibidang teknologi informasi yang melatarbelakangi lahirnya teknologi data mining. Dengan data mining perusahaan dapat menganalisis data perusahaan dan mengambil keputusan dengan tepat yang pada akhirnya bisa meningkatkan keuntungan atau mengurangi kerugian perusahaan.
PT.Kayu Lapis Asli Murni melakukan penelitian menggunakan Algoritma C4.5. Dari hasil uji yang dilakukan dari seratus data testing maka didapat 85% hasil grade dari data testing sama dengan hasil grade dari pohon keputusan. Karena
28
data yang diuji adalah seratus data, maka data dengan hasil yang sama adalah 85 data dan data dengan hasil yang berbeda adalah 15 data.
Kesimpulannya dengan adanya analisis menggunakan data mining ini adalah menampilkan informasi mengenai hubungan data kerusakan barang jadi dengan menggunakan pohon keputusan. Aplikasi data mining ini dapat memberikan hasil grade plywood berdasarkan atribut-atribut kerusakan plywood dengan algoritma C4.5 untuk melihat keakuratan. Semakin tinggi nilai presentasi dari data grade plywood yang ada dengan grade dari pohon keputusan, maka menandakan bahwa pola kerusakan barang jadi dari hari ke hari tidak terlalu banyak berubah, akan tetapi bila presentasenya kecil, pola kerusakan barang jadi berubah sangat besar dari hari sebelumnya.
Hasil dari proses data mining ini dapat berguna untuk mempertimbangkan pengambilan keputusan lebih lanjut untuk meminimalisir kerusakan plywood dengan melihat tipe kerusakan plywood pada PT.Kayu Lapis Asli Murni.
2.2 Prediksi
Prediksi adalah sama dengan ramalan atau perkiraan. Menurut kamus besar bahasa Indonesia, prediksi adalah hasil dari kegiatan memprediksi atau meramal atau memperkirakan. Prediksi bisa berdasarkan metode ilmiah ataupun subjektif belaka. Sebagai contoh, prediksi cuaca selalu berdasarkan data dan informasi terbaru yang didasarkan pengamatan termasuk oleh satelit. Begitupun prediksi gempa, gunung meletus ataupun bencana secara umum. Namun, prediksi seperti
28
pertandingan sepakbola, olahraga, dll umumnya berdasarkan pandangan subjektif dengan sudut pandang sendiri yang memprediksinya (Ririanti, 2014:140).
2.3 Barang Scrap
Scrap merupakan masukan yang tidak menjadi bagian keluaran tetapi masih mempunyai nilai ekonomi yang relatif kecil, barang sisa dapat dijual atau digunakan kembali ( Charies dan Foster,2001:150 dalam Jurnal Yentifa, A., Maryati, U., & Putri, S. Y. A, 2015 ).
Scrap adalah limbah yang baik, tidak memiliki nilai ekonomi atau hanya nilai kandungan bahan dasarnya yang dapat dipulihkan melalui daur ulang. (SKF Indonesia) (Budiningtyas, A., Fahma, F., & Laksono, P. W. 2017).
Unsur atau atribut barang scrap pada PT.Inabata Creation Indonesia adalah masa simpan, warna, dan suhu.
2.3.1 Manfaat Barang Scrap
Sisa bahan baku (Scrap) merupakan bahan yang tersisa atau bahan yang rusak dari proses produksi yang tidak dapat dimasukan lagi ke dalam produksi dengan kegunaan seperti sebelumnya, tetapi mempunyai nilai ekonomi yang relatif kecil dan bahan tersebut mungkin dapat dipakai untuk kegunaan lain atau proses produksi lain atau bahan tersebut dapat dijual kepada pihak luar Yentifa, A., Maryati, U., & Putri, S. Y. A, 2015 ).
2.4 Data Mining
Data Mining adalah serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu basis data. Informasi yang dihasilkan diperoleh dengan cara mengekstraksi dan mengenali
28
pola yang penting atau menarik dari data yang terdapat pada basis data. Data mining terutama digunakan untuk mencari pengetahuan yang terdapat dalam basis data yang besar sehingga sering disebut Knowledge Discovery Databases (KDD) (Vulandari, Retno Tri 2017).
Menurut Larose dalam (Wahyono, 2017 )Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor, antara lain :
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang handal.
3. Adanya peningkatan akses data melalui navigasi web dan internet.
4. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
2.4.1 Kategori Data Mining
Data mining dibagi menjadi dua kategori utama menurut Han dan Kamber dalam (Vulandari, Retno Tri 2017).
1. Prediktif
Tujuan dari tugas prediktif adalah untuk memprediksi nilai dari atribut tertentu berdasarkan pada nilai atribut-atribut lain. Atribut yang diprediksi
28
umumnya dikenal sebagai target atau variabel tak bebas, sedangkan atribut-atribut yang digunakan untuk membuat prediksi dikenal sebagai explanatory atau variabel bebas.
2. Deskriptif
Tujuan dari tugas deskriptif adalah untuk menurunkan pola-pola (korelasi, trend, cluster, teritori, dan anomali) yang meringkas hubungan yang pokok dalam data. Tugas data mining deskriptif sering merupakan penyelidikan dan seringkali memerlukan teknik post-processing untuk validasi dan penjelasan hasil.
2.4.2 Proses Tahapan Data Mining
Data mining merupakan salah satu dari rangkaian Knowledge Discovery Databases (KDD). Istilah data mining dan Knowledge Discovery Databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Beberapa tahapan data mining dijelaskan pada Gambar 2.1.
28
Gambar 2.1 Tahap-tahap data mining
Sumber : Han&Kamber (2006) dalam (Segara, 2017)
Proses KDD secara garis besar dapat dijelaskan sebagai berikut menurut Fayyad dalam (Wahyono, 2017) :
1. Data selection
Pemilihan (seleksi) data dan sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas terpisah dan basis data operasional.
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan ing pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Kemudian dilakukan juga proses enrichment, yaitu proses “memperkaya”
28
data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Data Mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation / Evaluation
Pola informasi yang dihasilkan dan proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dan proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
28 2.4.3 Fungsi Data Mining
Fungsi-fungsi yang umum diterapkan dalam data mining menurut Haskett dalam (Vulandari, Retno Tri., 2017)
1. Assosiation, adalah proses untuk menemukan aturan asosiasi antara suatu kombinasi item dalam suatu waktu.
2. Sequence, proses untuk menemukan aturan asosiasi antara suatu kombinasi item dalam suatu waktu dan diterapkan lebih dari suatu periode.
3. Clustering, adalah proses pengelompokan sejumlah data/obyek ke dalam kelompok data sehingga setiap kelompok berisi data yang mirip. 4. Classification, peoses penemuan model atau fungsi yang menjelaskan
atau membedakan konsep atau kelas data dengan tujuan untuk memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. 5. Regression adalah proses pemetaan data dalam suatu nilai prediksi. 6. Forecasting adalah proses pengestimasian nilai prediksi berdasarkan
pola-pola di dalam sekumpulan data.
7. Solution adalah proses penemuan akar masalah dan problem solving dari persoalan bisnis yang dihadapi atau paling tidak sebagai informasi dalam pengambilan keputusan.
2.4.4 Teknik Data Mining
Teknik pendekatan dasar data mining terbagi menjadi Association Rule Mining, Classification, Clustering dan Regretion menurut Rodpysh dalam dalam (Segara, Dwi W. B., 2017) :
28 1. Klasifikasi (Classification)
Pendekatan ini untuk memprediksi perilaku catatan database pelanggan dengan klasifikasi berdasarkan yang telah ditetapkan. Melalui variabel-variabel yang mungkin dipetakan berdasarkan karakteristik komposisi perbedaan kategori. Dengan menggunakan decision tree pendekatan ini dapat digunakan dan untuk melakukan evaluasi dapat menggunakan metode Algoritma C4.5.
2. Regresi (Regretion)
Model ini memungkinkan untuk memperoleh model tertentu secara beraturan dalam data mining. Model ini menyediakan laporan bagi manajemen dari tools yang digunakan berdasarkan teori statistik untuk mengatur data yang dihasilkan secara berurutan.
3. Clustering
Dalam pendekatan ini sejumlah sampel data heterogen yang besar dengan bantuan aplikasi akan dipecah-pecah berdasarkan pola yang sesuai.
4. Asosiasi (Association Rule Mining)
Tujuan dari pendekatan ini menemukan keterkaitan antara item yang berbeda dari informasi yang masuk dan akhirnya menghasilkan suatu pengetahuan yang dapat dipercaya.
28
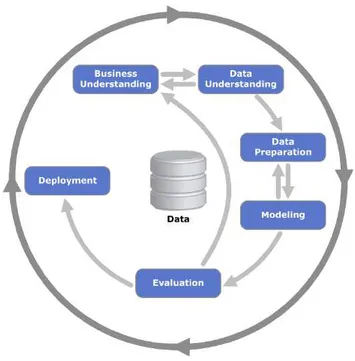
2.4.5 Cross-Industry Standard Process for Data Mining ( CRISP-DM )
Cross-Industry Standard Process for Data Mining ( CRISP-DM ) adalah standarisasi data mining yang disusun oleh tiga penggagas data mining market yaitu Daimler Chrysler ( Daimler-Benz ), SPSS (ISL), NCR. Kemudian dikembangkan pada berbagai workshops ( antara 1997-1999 ). Lebih dari 300 organisasi yang berkontribusi dalam proses modeling ini dan akhirnya CRISP-DM 1.0 dipublikasikan pada 1999.
Menurut Larose dalam (Segara, Dwi W. B., 2017), proses data mining berdasarkan CRISP-DM terdiri dari 6 fase.
Gambar 2.2 Tahapan CRISP-DM 1. Business/Research Understanding Phase
Dalam hal ini dilakukan pemahaman terhadap penelitian yang dilakukan. Perlunya pemahaman terhadap subtansi atau inti dari penelitian yang dilakukan dimulai dari kebutuhan dan perspektif
28
bisnis yang dilakukan. Terdapat beberapa kegiatan pada tahapan ini diantaranya adalah ditentukannya sasaran dan tujuan dari penelitian, pemahaman kondisi atau situasi bisnis, menentukan tujuan dari data mining dan melakukan penjadwalan atau perencanaan strategi penelitian.
2. Data Understanding Phase ( Fase Pemahaman Data )
Fase ini dikenal sebagai fase pemahaman terhadap data yang diperoleh dan kemudian data awal yang dikumpulkan melalui observasi langsung.
3. Data Preparation Phase ( Fase Pengolahan Data )
Tahapan ini merupakan pengolahan data atau dapat juga dikatakan sebagai tahapan persiapan data. Banyak persiapan yang dilakukan pada tahapan ini sehingga tak jarang fase ini juga disebut sebagai fase padat karya. Beberapakegiatan seperti pemilihan tabel dan field terjadi pada fase ini.Pemilihan tabel dan field tersebut akan dimasukan atau ditransformasikan kedalam database yang lain atau database baru sebagai bahan atau data mining mentah.
4. Modelling Phase ( Fase Pemodelan )
Pada fase pemodelan dilakukan dengan penggunaan aplikasi seperti RapidMiner, aplikasi pengolah data mining mentah, dan dimasukan juga algoritma C4.5. Dari data tersebut dipilih atribut yang menjadi label. Kemudian seluruh parameter dipilih dengan penentuan nilai yang optimal.
28
5. Evaluation Phase ( Fase Evaluasi )
Fase ini merupakan tahapan analisa dari hasil pengolahan fase sebelumnya dengan menginterpretasikan data yang kemudian diperoleh nilai perbandingan dengan proses model yang sebelumnya. Perlunya kajian mendalam pada tahapan ini adalah untuk menentukan nilai akurasi pada data model yang dihasilkan. Hal tersebut bertujuan agar dapat digunakan oleh sasaran sesuai rencana pada domain goal pada fase pertama.
6. Deployment Phase ( Fase Penyebaran )
Fase ini merupakan tahapan pembuatan laporan atau implementasi knowledge yang diperoleh dari fase sebelumnya.
2.5 Algoritma C4.5
Algoritma C4.5 merupakan algoritma klasifikasi dengan teknik Decision tree (pohon keputusan) yang terkenal dan disukai karena memiliki kelebihan-kelebihan. Kelebihannya adalah dapat mengolah data numerik (kontinyu) dan diskret, dapat menangani nilai atribut yang hilang, dapat menghasilkan aturan-aturan yang mudah diinterpretasikan dan tercepat diantara algoritma-algoritma yang lain.
Pada akhir tahun 1970 sampai awal tahun 1980 J.Ross Quinlan, seorang peneliti di bidang machine learning, membuat sebuah algoritma desision tree yang dikenal dengan ID3 (Iterative Dichotomiser). Quinlan kemudian mengembangkan algoritma ID3 menjadi algoritma C4.5 yang merupakan penyempurnaan algoritma sebelumnya.
28
Menurut Kusrini & Luthfi dalam (Segara, Dwi W. B., 2017), ada beberapa tahap dalam membuat sebuah pohon keputusan dengan algoritma C4.5 yaitu :
1. Menyiapkan data training. Data training biasanya diambil dari data history yang pernah terjadi sebelumnya dan sudah dikelompokan ke dalam kelas-kelas tertentu.
2. Menentukan akar dari pohon. Akar akan diambil dari atribut yang terpilih, dengan cara menghitung nilai gain dari masing-masing atribut. Nilai gain yang paling tinggi akan menjadi akar pertama. Sebelum menghitung nilai gain dari atribut, hitung dahulu nilai entropy. Untuk menghitung nilai entropy digunakan rumus :
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆 = −𝑝𝑖 𝑛
𝑖=1
× log2𝑝𝑖
n : jumlah partisi S
pi : Proporsi dari Si terhadap S
3. Kemudian hitung nilai gain dengan menggunakan rumus :
𝐺𝑎𝑖𝑛 𝑆,𝐴 =𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆 − 𝑆𝑖 𝑆 𝑛 𝑖=1 ×𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆1 S : Himpunan kasus A : Atribut
n : Jumlah partisi atribut A
|Si| : Jumlah kasus pada partisi ke-i |S| : Jumlah kasus dalam S
28
5. Proses partisi pohon keputusan akan berhenti saat :
Semua record dalam simpul N mendapat kelas yang sama. Tidak ada atribut di dalam record yang dipartisi lagi. Tidak ada record di dalam cabang yang kosong.
a. Contoh Kasus
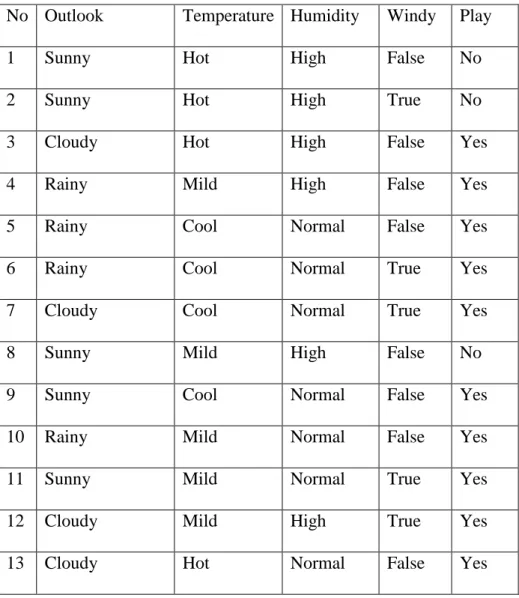
Untuk memudahkan penjelasan mengenai algoritma C4.5 berikut ini disertakan contoh kasus yang dituangkan dalam Tabel 2.1
Tabel 2.1 Contoh Kasus Keputusan Bermain Tenis
No Outlook Temperature Humidity Windy Play
1 Sunny Hot High False No
2 Sunny Hot High True No
3 Cloudy Hot High False Yes
4 Rainy Mild High False Yes
5 Rainy Cool Normal False Yes
6 Rainy Cool Normal True Yes
7 Cloudy Cool Normal True Yes
8 Sunny Mild High False No
9 Sunny Cool Normal False Yes
10 Rainy Mild Normal False Yes
11 Sunny Mild Normal True Yes
12 Cloudy Mild High True Yes
28
No Outlook Temperature Humidity Windy Play
14 Rainy Mild High True No
b. Contoh perhitungan
Perhitungan Entropy(Total) dan Gain (Total, Outlook) pada kasus yang tertera pada tabel 2.1 yaitu
𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑇𝑜𝑡𝑎𝑙) = − 4 14 × log2 4 14 + − 10 14 × log2 10 14 = 0,863120569 𝐺𝑎𝑖𝑛 𝑆,𝐴 =𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑇𝑜𝑡𝑎𝑙 − 𝑂𝑢𝑡𝑙𝑜𝑜𝑘1 𝑇𝑜𝑡𝑎𝑙 𝑛 𝑖=1 ×𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑂𝑢𝑡𝑙𝑜𝑜𝑘1 𝐺𝑎𝑖𝑛 𝑆,𝐴 = 0,863120569 − 4 14× 10 + 5 14× 0,721928095 + 5 14× 0,970950594 = 0,258521037
Tabel 2.2 Contoh Kasus Perhitungan Bermain Tenis S No (S1) Yes (S2) Entropy Gain Total 14 4 10 0,863120569 Outlook 0,258521037 Cloudy 4 0 4 0 Rainy 5 1 4 0,721928095
28 S No (S1) Yes (S2) Entropy Gain Sunny 5 3 2 0,970950594 Temperature 0,183850925 Cool 4 0 4 0 Hot 4 2 2 1 Mild 6 2 4 0,918295834 Humidity 0,370506501 High 7 4 3 0,985228136 Normal 7 0 7 0 Windy 0,005977711 False 8 2 6 0,811278124 True 6 4 2 0,918295834
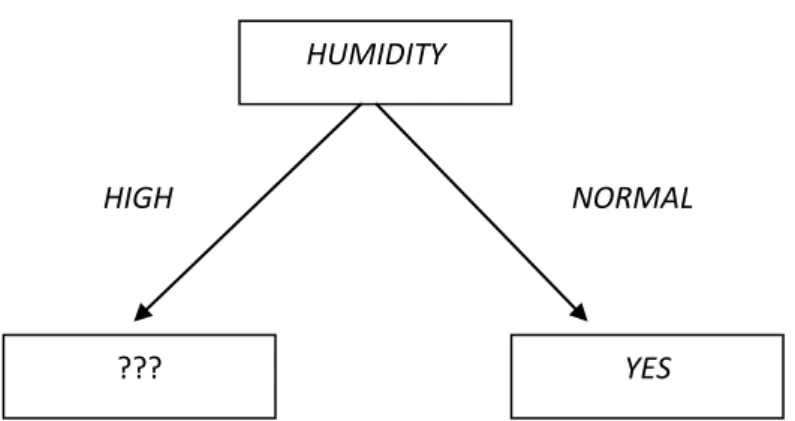
Dari perhitungan tersebut Gain tertinggi adalah Humidity = 0,37 maka Humidity menjadi node akar. Ada 2 nilai atribut dari Humidity yaitu High dan Normal. Dari kedua nilai atribut tersebut, nilai atribut Normal sudah mengklasifikasikan kasus menjadi 1 yaitu keputusannya Yes, sehingga tidak perlu dilakukan perhitungan lebih lanjut. Tetapi untuk hasil nilai atribut High masih perlu dilakukan
perhitungan lagi. Dari hasil tersebut dapat digambarkan pohon keputusan sementara seperti Gambar 2.3 dibawah ini.
28
Gambar 2.3 Contoh Kasus Pohon Keputusan Sementara
2.6 Decision Tree
Pohon dalam analisis pemecahan masalah pengambilan keputusan adalah pemetaan mengenai alternatif-alternatif pemecahan masalah yang dapat diambil dari masalah tersebut. Pohon tersebut juga memperlihatkan faktor-faktor kemungkinan yang akan mempengaruhi alternatif-alternatif keputusan tersebut, disertai dengan estimasi hasil akhir yang akan didapat bila Kita mengambil alternatif keputusan tersebut.
2.7 RapidMiner
a. Penjelasan RapidMiner
RapidMiner adalah perangkat lunak yang bersifat terbuka (open source). RapidMiner merupakan solusi untuk melakukan suatu analisis terhadap data mining, text mining dan analisis prediksi. RapidMiner menggunakan berbagai teknik deskriptif dan prediksi dalam memberikan wawasan kepada pengguna sehingga dapat membuat keputusan yang paling baik. RapidMiner memiliki kurang lebih 500 operator data mining, termasuk operator untuk input, output,
HUMIDITY
??? YES
28
data preprocessing dan visualisasi. RapidMiner merupakan software yang berdiri sendiri untuk analisis data dan sebagai mesin data mining yang dapat diintegrasikan pada produknya sendiri. RapidMiner ditulis dengan menggunakan bahasa java sehingga dapat bekerja di semua sistem operasi (Apprilla Dennis, 2013).
RapidMiner sebelumnya bernama YALE (Yet Another Learning Environment), dimana versi awalnya mulai dikembangkan pada tahun 2001 oleh RalfKlinkenberg, Ingo Mierswa, dan Simon Fischer di Artificial Intelligence Unit dari University of Dortmund. RapidMiner didistribusikan di bawah lisensi AGPL (GNU Affero General Public License) versi 3. Hingga saat ini telah ribuan aplikasi yang dikembangkan menggunakan RapidMiner di lebih dari 40 Negara. RapidMiner sebagai software open source untuk data mining tidak perlu diragukan lagi karena software ini sudah terkemuka di dunia. RapidMinermenempati peringkat pertama sebagai software data mining pada polling oleh Kdnuggets, sebuah portal data mining pada 2010-2011.
Sifat – sifat RapidMiner yaitu sebagai berikut :
1. Ditulis dengan bahasa pemrograman Java sehingga dapat dijalankan di berbagai sistem operasi.
2. Proses penemuan pengetahuan dimodelkan sebagai operator trees. 3. Representasi XML internal untuk memastikan format standar pertukaran data.
28
4. Bahasa scripting memungkinkan untuk eksperimen skala besar dan otomatisasi eksperimen.
5. Konsep multi-layer untuk menjamin tampilan data yang efisien dan menjamin penanganan data.
6. Memiliki GUI, command line mode, dan Java API yang dapat dipanggil dari program lain.
Beberapa Fitur dari RapidMiner yaitu :
1. Banyaknya algoritma data mining, seperti decision tree dan self organization map.
2. Bentuk grafis yang canggih, seperti tumpang tindih diagram histogram, tree chart dan 3Dscatter plots.
3. Banyaknya variasi plugin, seperti text plugin untuk melakukan analisis teks.
4. Menyediakan prosedur data mining dan machine learning termasuk : ETL (extraction, transformation, loading), data preprocessing, visualisasi, modelling dan evaluasi.
5. Proses data mining tersusun atas operator operator yang nestable, dideskripsikan dengan XML, dan dibuat dengan GUI.
6. Mengintegrasikan proyek data mining Weka dan statistika R.
b. Proses Kerja RapidMiner
RapidMiner menyediakan GUI (Graphic User Interface) untuk merancang sebuah pipeline analitis. GUI ini akan menghasilkan file XML (Extensible Markup Language) yang mendefinisikan proses analitis keinginan pengguna
28
untuk diterapkan ke data. File ini kemudian dibaca oleh RapidMiner untuk menjalankan analisa secara otomatis.
28 BAB III
METODE PENELITIAN
3.1 Kerangka Berfikir
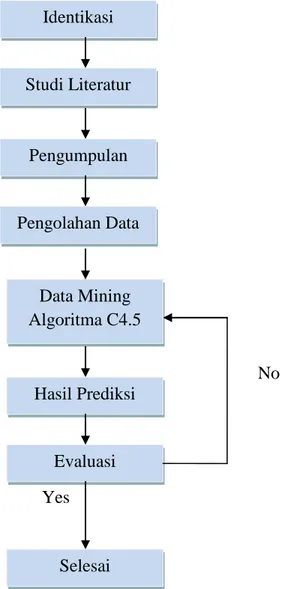
Berikut adalah gambaran keseluruhan langkah-langkah yang akan dilakukan pada penelitian ini :
No
Yes
Gambar 3.1 Kerangka Berfikir Identikasi Masalah Studi Literatur Pengumpulan Data Pengolahan Data Data Mining Algoritma C4.5 Hasil Prediksi Evaluasi Selesai
47
3.2 Analisa Data
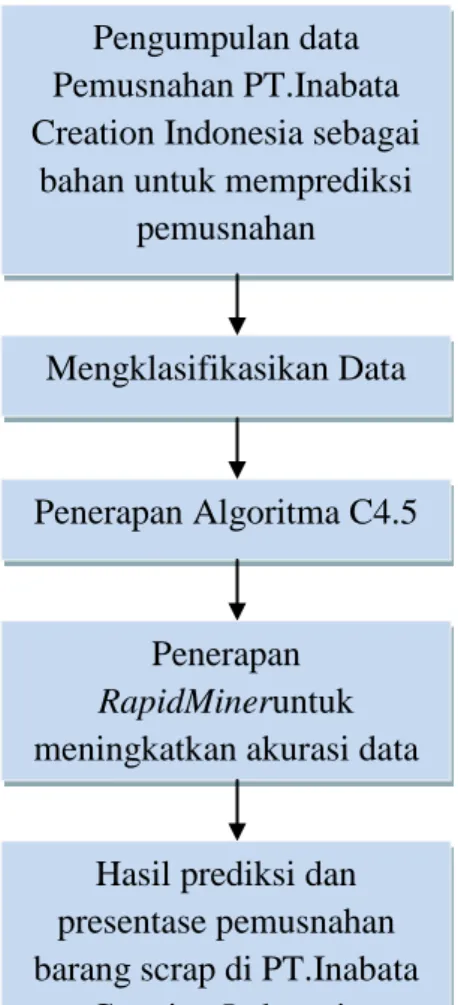
Metode yang diusulkan untuk proses prediksi pemusnahan barang di PT.Inabata Creation Indonesia adalah :
Gambar 3.2 Metode yang diusulkan Uraian metode diatas adalah sebagai berikut :
1 Pengumpulan data dari laporan masa simpan barang dan laporan barang musnah PT Inabata Creation Indonesia dari bulan Januari 2018 sampai Maret 2018.
Pengumpulan data Pemusnahan PT.Inabata Creation Indonesia sebagai
bahan untuk memprediksi pemusnahan
Mengklasifikasikan Data
Penerapan Algoritma C4.5
Penerapan RapidMineruntuk meningkatkan akurasi data
Hasil prediksi dan presentase pemusnahan barang scrap di PT.Inabata
47
2 Mengklasifikasikan data, data yang terkumpul dikelompokan sesuai atribut, kemudian menentukan data training berdasarkan atribut yang paling mendekati untuk hasil keputusan.
3 Penerapan Algoritma C4.5, dilakukan perhitungan dengan metode Algoritma C4.5 secara manual.
4 Penerapan RapidMiner bertujuan untuk meningkatkan akurasi data. Setelah perhitungan manual selesai kemudian hasil akan dibandingkan dengan hasil pengujian data pada RapidMiner.
5 Hasil prediksi dan presentase pemusnahan barang PT Inabata Creation Indonesia terhadap layak atau tidak nya barang untuk dimusnahkan. Hasil perhitungan algoritma tersebut menghasilkan node, root, dan class (leaf) dan perhitungan performance atau presentasi data.
3.3 Alat dan Bahan
Pada penelitian ini membutuhkan beberapa hal sebagai penunjang penelitian, yaitu sebagai berikut :
3.3.1 Perangkat Lunak
Perangkat lunak yang dibutuhkan dalam membantu proses analisa data mining adalah sebagai berikut :
1 Microsoft Office Word 2007 untuk membuat laporan penelitian tugas akhir 2 Microsoft Office Excel 2007, untuk perhitungan algoritma C4.5
menggunakan rumus formula pada Microsoft Office Excel 2007
3 Sistem Operasi Windows 7-64 bit untuk mendukung laporan penelitian dan pengujian sistem
47
4 RapidMinerStudio 8.1.0 untuk proses pengujian akurasi data mining
3.3.2 Perangkat Keras
Beberapa perangkat keras yang digunakan untuk membantu proses penelitian yaitu sebagai berikut :
1 Laptop ASUS intel core i3 2 RAM 2 GB
3 Mouse 4 Printer
3.3.3 Jenis Data
Jenis data yang digunakan dalam penelitian ini adalah sebagai berikut :
1. Data Kuantitatif, yaitu data yang diperoleh dari departement Sales PT.Inabata Creation Indonesia, berupa data yang masih perlu dianalisis kembali. Seperti data pemusnahan barang serta data lainnya yang menunjang penelitian ini.
2. Data Kualitatif, yaitu data yang diperoleh dari PT.Inabata Creation Indonesia dalam bentuk informasi baik secara lisan maupun tulisan, yang berfungsi sebagai data pendukung dalam penelitian ini.
47
Metode pengumpulan data pada penelitian ini adalah sebagai berikut :
a. Metode Wawancara
Wawancara dilakukan dengan orang yang menangani bagian tersebut secara langsung, untuk mengetahui bagaimana proses yang terjadi dan apa saja faktor-faktor yang dapat mempengaruhi pemusnahan material.
b. Metode Observasi
Melalui observasi ke bagian yang berhubungan dengan kegiatan pemusnahan material untuk mendapatkan gambaran yang jelas. Kegiatan ini diperlukan untuk mencari dan mengumpulkan data yang dibutuhkan langsung dari sumbernya.
c. Studi Kepustakaan
Penelitian yang dilakukan dengan mengumpulkan bahan-bahan pustaka, literature, dan karangan ilmiah yang ada kaitannya dengan penelitian ini. Metode ini dibutuhkan untuk membahas permasalahan yang bersifat teori.
d. Browsing
Proses inimencari informasi tentang jurnal, skripsi dan pembahasan lain mengenai algoritma C4.5 melalui browsing di Website.
47
PT.Inabata Creation Indonesia berdiri sejak 30 April 2009, awal berdiri beralamat di Jl.Angsana II Blok AE-27 Delta Silicon Industrial Park Lippo Cikarang Bekasi 17550 Indonesia. Pada 27 Februari 2017 kemudian PT.Inabata Creation Indonesia pindah lokasi ke alamat Jl.Serui Blok AE 5 Kawasan Industri MM2100 Desa Jatiwangi Kecamatan Cikarang - Barat Kabupaten Bekasi 17845, Indonesia. Luas tanah 4,990.00 m² dan luas bangunan 3,172.50 m². Perusahaan ini merupakan salah satu grup dari perusahaan jepang yaitu Inabata & Co,.Ltd.
Perusahaan ini bergerak di bidang Sport yaitu membuat Grip Tape yang diaplikasikan sebagai aksesoris olahraga Bulutangkis. Produk yang dihasilkan akan diekspor ke berbagai negara, contohnya : Jepang, China, India, daerah Eropa dll.
3.5.1 Sasaran Mutu
Adapun sasaran mutu PT.Inabata Creation Indonesia yaitu :
1. Menerapkan sistem manajemen mutu ISO 9001:2015 100% efektif dan konsisten.
2. Mengurangi keluhan dari pelanggan, maksimal 2 kasus per tahun. 3. Mengurangi reject proses maksimal 1%
4. Meningkatkan sumber daya manusia dengan memberikan pendidikan dan pelatihan minimal 1 kali dalam setahun.
5. Pengiriman tepat waktu, 100% sesuai tanggal permintaan.
47
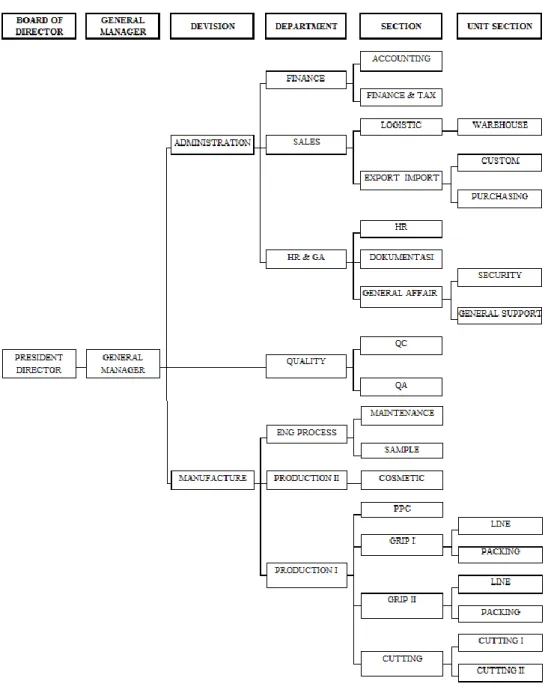
Struktur organisasi merupakan pengelompokan serta pengaturan dari berbagai macam aktivitas untuk mencapai tujuan tertentu. Berikut struktur organisasi PT.Inabata Creation Indonesia yang tertera pada gambar 3.3.
Gambar 3.3 Struktur Organisasi PT.Inabata Creation Indonesia
47 Visi PT.Inabata Creation Indonesia yaitu :
PT. Inabata Creation Indonesia bertekad untuk memenuhi kepuasan pelanggan, pengiriman tepat waktu dan perbaikan secara berkelanjutan.
Misi PT.Inabata Creation Indonesia yaitu :
1. PT Inabata Creation Indonesia akan menyiapkan tenaga kerja yang terlatih dan menerapkan sistem manajemen mutu dalam menjalankan pekerjaannya serta melakukan perbaikkan secara berkesinambungan.
2. Kami akan menggunakan teknologi yang berkualitas untuk dapat memenuhi kebutuhan dan kepuasan pelanggan
3. PT Inabata Creation Indonesia berkomitmen untuk melakukan pengiriman sesuai permintaan pelanggan.
3.6 Deskripsi Sistem
Dibawah ini adalah deskripsi sistem berjalan yang diterapkan pada penelitian yaitu :
3.6.1 Menentukan Root
Uraian sistem algoritma C4.5 atau decision tree dalam menentukan root, yaitu :
1. Sistem akan memasukan data training
2. Sistem akan menghitung total kasus keseluruhan, total keseluruhan Ya dan total keseluruhan Tidak pada atribut label hasil pemusnahan.
3. Setelah menghitung total kasus, kemudian menghitung nilai entropy total dari kasus keseluruhan
47
5. Sistem menghitung nilai entropy pada masing-masing value pada atribut 6. Sistem menghitung semua nilai info gain dari seluruh entropy pada tiap
atribut.
7. Sistem menghitung semua nilai gain ratio pada setiap atribut. Nilai gain tertinggi ditentukan sebagai akar atau root.
3.6.2 Menentukan Cabang
Uraian sistem algoritma C4.5 atau decision tree dalam menentukan cabang, yaitu :
1. Pi adalah hasil dari pencarian akar sebelumnya. Kemudian hitung nilai entropy pada tiap atribut tersebut.
2. Hitung nilai gain dari seluruh entropy pada tiap atribut.
3. Sistem mencari nilai tertinggi pada gain ratio untuk menentukan cabangnya.
3.1.1 Menentukan Node
Uraian sistem algoritma C4.5 atau decision tree dalam menentukan node, yaitu :
1. P2 adalah hasil dari pencarian akar sebelumnya. Kemudian hitung nilai entropy pada tiap atribut tersebut.
2. Hitung nilai gain dari seluruh entropy pada tiap atribut.
3. Sistem mencari nilai tertinggi pada gain ratio untuk menentukan cabangnya atau keputusan.
47
Penelitian menggunakan model CRISP-DM (Cross Industry Standart Process ForData Mining ) dengan langkah berikut ini :
A. Fase Pemahaman Bisnis (Bussines Undestanding)
Penelitian ini memiliki tujuan bisnis untuk menentukan aturan prediksi pemusnahan barang scrap di PT Inabata Creation Indonesia supaya memberikan manfaat bagi perusahaan khususnya pada bidang teknologi dan bisnis.
B. Fase Pemahaman Data ( Data Understanding Phase )
Penelitian ini mengumpulkan data dengan metode observasi dan melihat rekapan laporan pemusnahan barang PT Inabata Creation Indonesia.
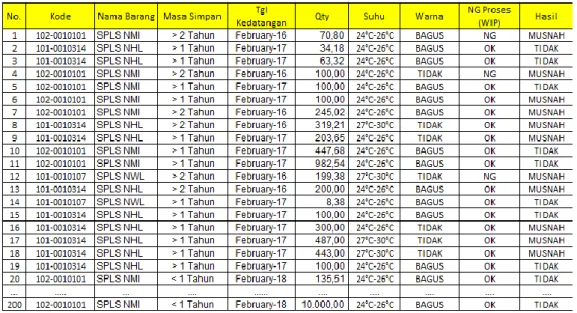
Laporan pemusnahan barang terdiri dari atribut Kode barang, nama barang, masa simpan, tgl kedatangan, Qty, Suhu, NG proses. Data tersebut akan melalui proses training untuk pembentukan tree dan menguji hasil tree.
Tabel 3.1 Data Pemusnahan Barang Januari s/d Maret 2018
Seluruh data ini berjumlah 200 record. Dari sumber data tersebut maka dapat menganalisis dan memprediksi data pemusnahan barang dengan algoritma C4.5.
47 C. Pengolahaan Data (Data Preparation)
Pada tahap ini menjelaskan tahap awal data mining. Data yang telah didapatkan akan diolah keformat yang dibutuhkan, pengelompokan data dan penentuan atribut data. Dalam melakukan pengolahan data awal, akan dilakukan beberapa tahapan agar didapatkan data yang bisa digunakan untuk tahap selanjutnya. Beberapa tahapan tersebut yaitu : Select data, Pre-processing serta akan dilakukan split validation.
a) Select Data
Data yang ada akan dipilih untuk menjadi atribut /variabel yang nantinya akan digunakan menjadi masukan atau variabel input.
Dari data 200 recorddengan 9 atribut hanya diambil 6 atribut saja, yaitu nama material/barang, masa simpan, suhu, warna, NG proses dan hasil. Data hasil seleksi akan digunakan dalam proses data mining. Pemilihan data seleksi dijelaskan pada tabel dibawah ini :
Tabel 3.2 Pemilihan Data
47
Kode X -
Nama Barang √ ID
Masa Simpan √ Nilai Model
Tgl Kedatangan X -
Qty X -
Unit X -
Suhu √ Nilai Model
Warna √ Nilai Model
NG Proses
(WIP) √ Nilai Model
Hasil √ Label Target
Pada Tabel 3.2 menerangkan atribut/variabel yang akan digunakan dan tidak digunakan dalam penelitian ini. Indikator “√” menandakan bahwa
atribut tersebut akan digunakan, sedangkan indikator “X” menandakan bahwa atribut tersebut dieliminasi pada tahap pengolahan data awal. Proses eliminasi atribut/variabel tersebut berdasarkan nilai model yang relatif sama dan tidak mempengaruhi hasil dari proses penilaian.
b) Pre-processing
Pada proses ini akan dilakukan pembersihan data untuk membuang data yang tidak konsisten dan juga memperbaiki data yang rusak. Proses ini berfungsi untuk memastikan bahwa data yang telah dipilih layak untuk dilakukan proses pemodelan. Pada tahap ini dilakukan proses
47
menghilangkan atribut/variabel Nama Barang sebagai ID karena tidak akan digunakan pada proses pemodelan.
Tabel 3.3 Proses Cleaning Data
Masa Simpan Suhu Warna NG Proses
(WIP) Hasil
> 2 Tahun 24°C-26°C BAGUS NG MUSNAH
> 1 Tahun 24°C-26°C BAGUS OK TIDAK
> 1 Tahun 24°C-26°C BAGUS OK TIDAK
> 2 Tahun 24°C-26°C TIDAK NG MUSNAH
> 1 Tahun 24°C-26°C BAGUS OK TIDAK
> 1 Tahun 24°C-26°C BAGUS OK MUSNAH
> 2 Tahun 24°C-26°C BAGUS OK MUSNAH
> 2 Tahun 27°C-30°C TIDAK OK MUSNAH
> 1 Tahun 24°C-26°C TIDAK OK MUSNAH
> 1 Tahun 24°C-26°C BAGUS OK TIDAK
> 1 Tahun 24°C-26°C BAGUS OK TIDAK
> 2 Tahun 27°C-30°C TIDAK NG MUSNAH
> 2 Tahun 24°C-26°C BAGUS OK MUSNAH
> 1 Tahun 24°C-26°C BAGUS OK TIDAK
> 1 Tahun 24°C-26°C BAGUS OK TIDAK
> 1 Tahun 24°C-26°C TIDAK OK MUSNAH
> 1 Tahun 27°C-30°C TIDAK OK MUSNAH
> 1 Tahun 27°C-30°C TIDAK OK MUSNAH
> 1 Tahun 24°C-26°C BAGUS OK TIDAK
< 1 Tahun 24°C-26°C BAGUS OK TIDAK
Keterangan attribut pada tabel diatas (Tabel 3.3) adalah sebagai berikut : a. Keterangan suhu
24℃ −26℃ = Normal
27℃ −30℃ = Tidak Normal
47
Pada Tabel 3.4 dibawah ini akan dijelaskan mengenai gambaran warna SPLS yang bagus. Jika tidak sesuai dengan warna standar maka barang tersebut dikategorikan warnanya tidak bagus.
Tabel 3.4 Keterangan Warna Bagus
Nama
Barang Warna Bagus
SPLS NHL
SPLS NMI
SPLS NWL
c) Split Validation
Pada proses ini yaitu membagi data menjadi dua bagian secara acak yaitu sebagian sebagai data training dan sebagian lagi data testing dengan menggunakan teknik sampling random sistematik (Systematic Random Sampling). Cara penggunaan teknik sampling random sistematik ini
47
dilakukan hanya satu kali perandoman atau pengundian. Penentuan unsur sampling selanjutnya ditempuh dengan cara memanfaatkan interval sampel.
Interval sampel (sampling ratio) diperoleh dengan cara membagi ukuran populasi dengan ukuran sampel yang dikehendaki (N/n). Hasil perhitungan untuk mengambil data testing adalah sebagai berikut :
Jumlah populasi (N) = 200
Jumlah data testing = 20% x 200 = 40 Jumlah sampel (n) = 40
Interval sampling (k) = 𝑁 𝑛 =
200 40 = 5
Unsur pertama yang diambil untuk data testing (s) = 1 Unsur kedua = s + k
Unsur Ketiga = s + 2k
Unsur Keempat = s + 3k, dan seterusnya hingga unsur ke-n
Pembagian data menjadi data training dan data testing pada penelitian ini menggunakan split ratio 80% untuk data training dan 20% untuk data testing.
Dari hasil diatas diperoleh data testing sebanyak 40 data barang, maka sisanya yaitu 160 data barang dijadikan data training.
47
No Masa
Simpan Suhu Warna
NG Proses
(WIP) Hasil
1 > 2 Tahun 24°C-26°C BAGUS NG MUSNAH
2 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
3 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
4 > 2 Tahun 24°C-26°C TIDAK NG MUSNAH
5 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
6 > 1 Tahun 24°C-26°C BAGUS OK MUSNAH
7 > 2 Tahun 24°C-26°C BAGUS OK MUSNAH
8 > 2 Tahun 27°C-30°C TIDAK OK MUSNAH
9 > 1 Tahun 24°C-26°C TIDAK OK MUSNAH
10 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
11 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
12 > 2 Tahun 27°C-30°C TIDAK NG MUSNAH
13 > 2 Tahun 24°C-26°C BAGUS OK MUSNAH
14 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
15 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
16 > 1 Tahun 24°C-26°C TIDAK OK MUSNAH
17 > 1 Tahun 27°C-30°C TIDAK OK MUSNAH
18 > 1 Tahun 27°C-30°C TIDAK OK MUSNAH
19 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
20 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
.... ... .... .... .... ....
160 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
47
No Masa
Simpan Suhu Warna
NG Proses
(WIP) Hasil
1 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
2 < 1 Tahun 24°C-26°C BAGUS NG MUSNAH
3 > 2 Tahun 24°C-26°C BAGUS OK TIDAK
4 > 2 Tahun 24°C-26°C BAGUS OK TIDAK
5 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
6 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
7 > 2 Tahun 24°C-26°C TIDAK NG MUSNAH
8 > 1 Tahun 24°C-26°C BAGUS OK TIDAK
9 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
10 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
11 > 2 Tahun 24°C-26°C BAGUS OK TIDAK
12 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
13 > 2 Tahun 24°C-26°C BAGUS OK TIDAK
14 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
15 > 2 Tahun 24°C-26°C BAGUS NG MUSNAH
16 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
17 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
18 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
19 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
20 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
.... .... .... .... .... ....
40 < 1 Tahun 24°C-26°C BAGUS OK TIDAK
D. Fase Pemodelan (Modelling Phase)
Metode yang diusulkan dalam proses pemodelan penelitian tugas akhir ini adalah algoritma C4.5. Pengukuran akurasi dalam penelitian ini akan menggunakan aplikasi RapidMiner.
Processing Menentukan atribut data set Data Set New Data Modelling Menggunakan data mining klasifikasi algoritma C4.5 Training Evaluation Menggunakan RapidMiner dengan confusion matrix & kurva ROC/AUC
47
Gambar 3.4 Model penelitian yang diusulkan
Metode Algoritma C4.5 dipilih karena salah satu kelebihannya adalah dapat menangani data numerik dan diskret, menggunakan rasio perolehan (gain ratio). Ada beberapa tahap dalam membentuk pohon keputusan dengan algoritma C4.5 antara lain :
a) Pilih data training, dimana data tersebut akan diklasifikasikan.
b) Menentukan akar pohon, akar akan diperoleh dari penghitungan nilai gaindari masing masing atribut yang sudah terpilih. Nilai gain tertinggi akan dijadikan sebagai akar pertama dalam pohon keputusan. Sebelum menghitung nilai gain, hitung dulu nilai entropy dengan rumus sebagai berikut :
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆 = −𝑝𝑖
𝑛
𝑖=1
× log2𝑝𝑖
c) Hitung nilai gain dengan rumus sebagai berikut :
𝐺𝑎𝑖𝑛 𝑆,𝐴 =𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆 − 𝑆𝑖 𝑆
𝑛
𝑖=1
×𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆1
d) Ulangi langkah 2 hingga semua record terpartisi e) Proses perhitungan akan berhenti saat :
47
Semua record pada simpul N mendapat kelas yang sama Tidak ada atribut didalam record yang akan dipartisi lagi Tidak ada record didalam cabang yang kosong.
E. Fase Validasi dan Evaluasi ( Evaluation Phase )
Dalam tahapan ini akan dilakukan validasi serta pengukuran keakuratan hasil yang dicapai dengan menggunakan perhitungan manual dan aplikasi RapidMiner.
F. Fase Penyebaran ( Deployment Phase )
Hasil dari proses penyebaran adalah adanya pohon keputusan dengan hasil yang akurat dan memiliki fungsi sebagai pembuktian sebuah kasus.
3.8 Tahap Pengujian Menggunakan RapidMiner Studio 8.1.0
Tahap ini adalah proses pengujian akurasi perhitungan manual Algoritma C4.5 kedalam aplikasi RapidMiner. Gambar 3.5 dibawah ini adalah tampilan menu awal aplikasi RapidMiner Studio 8.1.0.
47 BAB IV
HASIL DAN PEMBAHASAN
4.1 HASIL
4.1.1 Jumlah Kasus Data Keseluruhan, Data Training Dan Data Testing
Data keseluruhan yang digunakan pada penelitian ini sejumlah 200 kasus, kemudian dilakukan pembagian data yaitu data training 160 kasus dan data testing 40 kasus. Beikut ini hasil perhitungan kasus pada keseluruhan data.
Tabel 4.1 Jumlah Nilai Atribut Keseluruhan
No Atribut Value Jumlah Kasus
( S ) MUSNAH (S₁) TIDAK (S₂) Total 200 75 125 1 Masa Simpan > 2 Tahun 51 45 6 > 1 Tahun 53 28 25 < 1 Tahun 96 2 94 2 Suhu 24°C - 26°C 179 58 121 27°C - 30°C 21 17 4 3 Warna Bagus 176 51 125 Tidak 24 24 0 4 NG Proses ( WIP ) NG 28 28 0 OK 172 47 125
67
Pada Tabel 4.1 menjelaskan semua kasus pada data keseluruhan yang berjumlah 200 dengan keputusan Musnah sebanyak 75 dan keputusan Tidak sebanyak 125.
Data keseluruhan yang telah dibagi menjadi data training dan data testing kemudian dihitung kembali jumlah kasusnya. Pada Tabel 4.2 dibawah ini adalah jumlah kasus pada data training dan data ini akan dijadikan sebagai data sekunder dalam pembuatan pohon keputusan prediksi pemusnahan barang dan pengujian dalam RapidMiner dengan menggunakan metode confusion matrix dan kurva ROC/AUC
Tabel 4.2 Jumlah Kasus Data Training
No Atribut Value Jumlah Kasus
( S ) Musnah (S₁) Tidak (S₂) Total 160 65 95 1 Masa Simpan > 2 Tahun 41 39 2 > 1 Tahun 50 26 24 < 1 Tahun 69 0 69 2 Suhu 24°C - 26°C 140 49 91 27°C - 30°C 20 16 4 3 Warna Bagus 141 46 95 Tidak 19 19 0 4 NG Proses ( WIP ) NG 18 18 0 OK 142 47 95
67
Tabel 4.3 di bawah ini adalah jumlah kasus pada data testing. Data testing akan digunakan untuk menguji data yang dihasilkan dari rule Algoritma C4.5 pada aplikasi RapidMiner.
Tabel 4.3 Jumlah Kasus Data Testing
No Atribut Value Jumlah
Kasus ( S ) Musnah (S₁) Tidak (S₂)
Total 40 10 30 1 Masa Simpan > 2 Tahun 10 6 4 > 1 Tahun 3 2 1 < 1 Tahun 27 2 25 2 Suhu 24°C - 26°C 39 9 30 27°C - 30°C 1 1 0 3 Warna Bagus 35 5 30 Tidak 5 5 0 4 NG Proses ( WIP ) NG 10 10 0 OK 10 0 30
Berdasarkan hasil pengelompokan dan pengolahan data di atas, maka dapat dijelaskan sebagai berikut :
Total data keseluruhan ada 200 kasus yang kemudian digunakan untuk data training sebanyak 160 kasus dan untuk data testing 40 kasus. Pada data pemusnahan jumlah nilai keseluruhan dengan keputusan Musnah sebanyak 75 kasus dan keputusan Tidak sebanyak 125 kasus.
67
Pada data training keputusan Musnah berjumlah 65 kasus dan keputusan Tidak berjumlah 95 kasus, sedangkan pada data testing keputusan Musnah berjumlah 10 kasus dan keputusan Tidak berjumlah 30 kasus.
Keputusan yang telah dihasilkan dapat disimpulkan bahwa pada penelitian ini lebih banyak keputusan Tidak daripada keputusan Musnah.
4.1.2 Pemodelan Klasifikasi Algoritma C4.5
Penelitian klasifikasi barang Scrap/NG ini menggunakan Algoritma C4.5, pohon keputusan dibuat berdasarkan hasil perhitungan Entropy dan Gain, setelah pohon keputusan dibentuk kemudian mencari Rule berdasarkan cabang pohon keputusan.
Berdasarkan Tabel 4.1 jumlah kasus untuk keputusan Musnahberjumlah 75 dan keputusan Tidak berjumlah 125, dan total keseluruhan kasus adalah 200. Setelah Kita ketahui jumlah kasus yang perlu dihitung, langkah selanjutnya menghitung Entropy dan Gain dari atribut masa simpan, suhu, warna, dan NG proses (WIP).
A. Node 1 (Root) Atribut Total
Prosesnya adalah dengan menghitung jumlah kasus, jumlah kasus untuk keputusan Musnah, jumlah kasus untuk keputusan Tidak, dan entropy dari semua kasus. Setelah itu melakukan perhitungan gain untuk setiap atribut.
67
Tabel 4.4 Perhitungan Node 1(Root)
No Atribut Value Jumlah Kasus ( S ) Musnah (S₁) Tidak (S₂) Entropy Gain Total 160 65 95 0,9744894 1 Masa Simpan > 2 Tahun 41 39 2 0,2811938 0,5902943 > 1 Tahun 50 26 24 0,9988455 < 1 Tahun 69 0 69 0 2 Suhu 24°C - 26°C 140 49 91 0,9340681 0,0669388 27°C - 30°C 20 16 4 0,7219281 3 Warna Bagus 141 46 95 0,9110398 0,1716356 Tidak 19 19 0 0 4 NG Proses ( WIP ) NG 18 18 0 0,0000000 0,1616011 OK 142 47 95 0,9159305
Dari Tabel 4.4menunjukan bahwa jumlah kasus (S) adalah 160, jumlah keputusan Musnah(S₁) adalah 65, dan jumlah kasus keputusan Tidak(S₂) adalah 95. Perhitungan entropy total pada Tabel 4.4 dapat dihitung dengan menggunakan persamaan sebagai berikut :
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑇𝑜𝑡𝑎𝑙 = − 65 160× log2 65 160 + − 95 160× log2 95 160 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑇𝑜𝑡𝑎𝑙) =0,9744894
67
Kemudian, nilai gain pada baris nama barang dihitung dengan menggunakan persamaan sebagai berikut :
𝐺𝑎𝑖𝑛 𝑇𝑜𝑡𝑎𝑙 ,𝑁𝑎𝑚𝑎𝐵𝑎𝑟𝑎𝑛𝑔 = 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑇𝑜𝑡𝑎𝑙 − 𝑁𝑎𝑚𝑎𝐵𝑎𝑟𝑎𝑛𝑔 𝑇𝑜𝑡𝑎𝑙 𝑛 𝑖=1 ×𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑁𝑎𝑚𝑎𝐵𝑎𝑟𝑎𝑛𝑔 𝐺𝑎𝑖𝑛 𝑇𝑜𝑡𝑎𝑙 ,𝑁𝑎𝑚𝑎𝐵𝑎𝑟𝑎𝑛𝑔 = 0,9744894 − 41 160× 0,2811938 + 50 160× 0,9988455 + 69 160× 0 = 0,5902943
Untuk perhitungan pada atribut entropy dan gain berikutnya sama seperti perhitungan pada nama barang. Sehingga diperoleh hasil perhitungan yang ditunjukan pada Tabel 4.4. Dari Tabel 4.4 diketahui bahwa atribut dengan nilai gain tertinggi adalah masa simpan dengan nilai sebesar 0,5902943, maka dengan demikian masa simpan ini menjadi node akar. Pada atribut masa simpan ini ada tiga nilai yaitu >2 tahun, <1 tahun dan >1 tahun. Nilai >1 tahun masih memerlukan perhitungan lebih lanjut. Dan hasil perhitungan tersebut dapat digambarkan dengan pohon keputusan seberi pada Gambar 4.1.