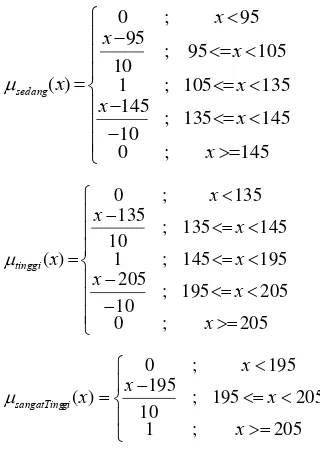NURDIATI.
Teknologi pengumpulan dan penyimpanan data telah memudahkan suatu organisasi untuk mengumpulkan data berukuran besar, salah satu contohnya adalah basis data untuk sebuah rumah sakit. Data yang dikumpulkan oleh rumah sakit sangat banyak dan bervariasi, termasuk juga data pasien yang berkaitan dengan penyakit diabetes, akan tetapi data tersebut banyak yang belum dimanfaatkan secara optimal. Diperlukan suatu sistem data mining yang bisa memanfaatkan data tersebut menjadi suatu informasi yang berguna. Dalam penelitian ini dipelajari bagaimana data bisa digunakan untuk membantu mengetahui potensi suatu penyakit, khususnya penyakit diabetes. Salah satu teknik data mining yang dapat digunakan untuk mengetahui label kelas dari suatu record dalam data adalah klasifikasi.
Decision tree adalah salah satu metode yang umum digunakan untuk melakukan klasifikasi. Untuk menangani ketidakpastian dan ketidaktepatan, pendekatan fuzzy digunakan. Pada penelitian ini dilakukan salah satu teknik data mining yaitu klasifikasi menggunakan metode fuzzy decision tree pada data diabetes agar diperoleh suatu aturan klasifikasi yang dapat dipergunakan untuk mengetahui label kelas data yang baru. Algoritma sederhana untuk membangun sebuah fuzzy decision tree dengan akurasi yang cukup tinggi adalah fuzzy ID3 (fuzzy Iterative Dichotomiser 3).
Dari penelitian yang telah dilakukan jumlah aturan yang diperoleh adalah 30 buah aturan dengan akurasi 90.69%, pada nilai fuzziness control threshold sebesar 98% dan leaf decision threshold sebesar 3%. Aturan klasifikasi yang mengandung kelas target negatif diabetes sebanyak 29 aturan, sedangkan untuk kelas target positif diabetes sebanyak 1 aturan. Klasifikasi dengan 30 aturan tersebut dapat digunakan untuk mengetahui potensi seseorang terserang diabetes.
FIRAT ROMANSYAH
G64103006
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
FIRAT ROMANSYAH
G64103006
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
FIRAT ROMANSYAH
G64103006
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
NURDIATI.
Teknologi pengumpulan dan penyimpanan data telah memudahkan suatu organisasi untuk mengumpulkan data berukuran besar, salah satu contohnya adalah basis data untuk sebuah rumah sakit. Data yang dikumpulkan oleh rumah sakit sangat banyak dan bervariasi, termasuk juga data pasien yang berkaitan dengan penyakit diabetes, akan tetapi data tersebut banyak yang belum dimanfaatkan secara optimal. Diperlukan suatu sistem data mining yang bisa memanfaatkan data tersebut menjadi suatu informasi yang berguna. Dalam penelitian ini dipelajari bagaimana data bisa digunakan untuk membantu mengetahui potensi suatu penyakit, khususnya penyakit diabetes. Salah satu teknik data mining yang dapat digunakan untuk mengetahui label kelas dari suatu record dalam data adalah klasifikasi.
Decision tree adalah salah satu metode yang umum digunakan untuk melakukan klasifikasi. Untuk menangani ketidakpastian dan ketidaktepatan, pendekatan fuzzy digunakan. Pada penelitian ini dilakukan salah satu teknik data mining yaitu klasifikasi menggunakan metode fuzzy decision tree pada data diabetes agar diperoleh suatu aturan klasifikasi yang dapat dipergunakan untuk mengetahui label kelas data yang baru. Algoritma sederhana untuk membangun sebuah fuzzy decision tree dengan akurasi yang cukup tinggi adalah fuzzy ID3 (fuzzy Iterative Dichotomiser 3).
Dari penelitian yang telah dilakukan jumlah aturan yang diperoleh adalah 30 buah aturan dengan akurasi 90.69%, pada nilai fuzziness control threshold sebesar 98% dan leaf decision threshold sebesar 3%. Aturan klasifikasi yang mengandung kelas target negatif diabetes sebanyak 29 aturan, sedangkan untuk kelas target positif diabetes sebanyak 1 aturan. Klasifikasi dengan 30 aturan tersebut dapat digunakan untuk mengetahui potensi seseorang terserang diabetes.
NRP :
G64103006
Menyetujui:
Pembimbing I,
Pembimbing II
Imas S. Sitanggang, S.Si., M.Kom.
Dr. Ir. Sri Nurdiati, M.Sc.
NIP 132 206 235
NIP 131 578 805
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP 131 473 999
menengah atas di SMUN 1 Sumbawa Besar dan lulus pada tahun 2003.
senantiasa tercurah kepada nabi besar Muhammad SAW, keluarganya, para sahabat, serta para pengikutnya yang tetap istiqomah mengemban risalah-Nya.
Melalui lembar ini, penulis ingin menyampaikan penghargaan dan terima kasih kepada semua pihak atas bantuan, dorongan, saran, kritik, serta koreksi selama penulisan karya ilmiah ini. Ucapan terima kasih penulis ucapkan kepada:
1. Ibu, Abah, ka’ Maya, ka’ Rian, Robi, ade’ Mala, dan seluruh keluargaku atas doa, kasih sayang, dan pengorbanan yang telah diberikan selama ini.
2. Ibu Imas S. Sitanggang, S.Si., M.Kom. selaku pembimbing I, Ibu Dr. Ir. Sri Nurdiati, M.Sc. selaku pembimbing II dan Bapak Hari Agung A., S.Kom. selaku dosen penguji. 3. Pandi, Meynar, dan Arum yang telah bersedia menjadi pembahas.
4. Ratih sebagai teman senasib seperjuangan dalam melakukan penelitian dan Sofi yang banyak membantu peneliti di awal-awal penelitian.
5. Bapak Herwanto yang telah bersedia memberikan data sebagai bahan penelitian. 6. Meynar selaku “Emak” yang selalu memberi dukungan pada peneliti selama di IPB. 7. Jemi, Pandi, PIS, Dhiku, dan anggota “Geng Cinta” lainnya yang telah banyak memberi
inspirasi dan kegembiraan pada peneliti.
8. Gibtha sekeluarga atas dukungan dan bantuannya pada peneliti selama di IPB. 9. Yayan yang telah meminjamkan installer Matlab 7.0.
10. Seluruh staf pengajar yang telah memberikan bekal ilmu dan wawasan selama penulis menuntut ilmu di Departemen Ilmu Komputer.
11. Seluruh staf administrasi dan perpustakaan Departemen Ilmu Komputer atas bantuannya.
12. Rekan-rekan Departemen Ilmu Komputer angkatan 40.
Sebagaimana manusia yang tidak luput dari kesalahan, penulis menyadari bahwa karya ilmiah ini jauh dari sempurna. Namun penulis berharap semoga karya ilmiah ini dapat bermanfaat bagi siapapun yang membacanya.
Bogor, Mei 2007
DAFTAR ISI
Halaman
DAFTAR TABEL...vi
DAFTAR GAMBAR ...vi
DAFTAR LAMPIRAN...vi
PENDAHULUAN ... 1
Latar Belakang ...1
Tujuan Penelitian ...1
Ruang Lingkup Penelitian ...1
Manfaat Penelitian...1
TINJAUAN PUSTAKA... 1
Knowledge Data Discovery (KDD) ...1
Data Mining...2
Klasifikasi ...2
Himpunan Fuzzy...2
Linguistic Variable (Peubah Linguistik) ...3
Linguistic Term...3
Fuzzy Decision Tree (FDT)...3
Fuzzy ID3 Decision Tree...4
Fuzzy Entropy dan Information Gain...4
Threshold...5
K-fold Cross Validation...5
Sistem Inferensi Fuzzy...5
METODE PENELITIAN... 5
Lingkungan Pengembangan ...6
HASIL DAN PEMBAHASAN... 6
Pembersihan Data...7
Transformasi Data ...7
Data Mining...9
Training...9
Testing...12
Representasi Pengetahuan ...13
Evaluasi Kinerja FID3...13
KESIMPULAN DAN SARAN... 14
Kesimpulan ...14
Saran...14
DAFTAR PUSTAKA ... 14
DAFTAR TABEL
Halaman
1 Nilai referensi hasil laboratorium...7
2 Aturan klasifikasi contoh training set...10
3 Rata-rata jumlah aturan ...11
4 Rata-rata waktu eksekusi dalam satuan detik ...11
5 Model untuk training set pertama dengan θr (75%) dan θn (3%) ...12
6 Model untuk training set pertama dengan θr (85%) dan θn (3%) ...12
7 Evaluasi kinerja FID3...13
DAFTAR GAMBAR
Halaman 1 Tahapan proses KDD (Han & Kamber 2001) ...22 Diagram alur proses klasifikasi ...6
3 Himpunan fuzzy atribut GLUN ...7
4 Himpunan fuzzy atribut GPOST ...8
5 Himpunan fuzzy atribut HDL ...8
6 Himpunan fuzzy atribut TG ...8
7 Hasil ekspansi training set berdasarkan atribut GPOST ...9
8 Fuzzy decision tree untuk contoh training set...10
9 Perbandingan rata-rata jumlah aturan...11
10 Perbandingan rata-rata waktu eksekusi proses training...12
11 Evaluasi kinerja FID3...14
12 Antarmuka grafis aplikasi untuk proses training...14
DAFTAR LAMPIRAN
Halaman 1 Contoh data hasil proses pembersihan data...172 Contoh data hasil fuzzifikasi pada proses transformasi data ...18
3 Contoh data untuk proses training...19
4 Jumlah aturan yang dihasilkan oleh masing-masing training set...20
5 Waktu eksekusi algoritma FID3 untuk masing-masing training set dalam satuan detik...21
PENDAHULUAN Latar Belakang
Organisasi Kesehatan Dunia (WHO) memperkirakan, bahwa 177 juta penduduk dunia mengidap penyakit diabetes melitus atau biasa disingkat diabetes. Jumlah ini akan terus meningkat hingga melebihi 300 juta pada tahun 2025. Dr Paul Zimmet, direktur dari International Diabetes Institute (IDI) di Victoria, Australia, meramalkan bahwa diabetes akan menjadi epidemi yang paling dahsyat dalam sejarah manusia. Hasil survey Organisasi Kesehatan Dunia (WHO) juga menyatakan bahwa jumlah penderita kencing manis (diabetes mellitus) di Indonesia sekitar 17 juta orang (8,6% dari jumlah penduduk) atau menduduki urutan terbesar ke-4 setelah India, Cina dan Amerika Serikat.
Perkembangan yang cepat dalam teknologi pengumpulan dan penyimpanan data telah memudahkan suatu organisasi untuk mengumpulkan sejumlah data berukuran besar. Kondisi ini terjadi pada sebuah rumah sakit yang mempunyai beribu-ribu record data pasien dan jenis penyakitnya, misalnya kumpulan data diabetes yang terkait dengan hasil pemeriksaan laboratorium dari pasien rumah sakit. Data berukuran besar tersebut seringkali dibiarkan menggunung tanpa digunakan secara maksimal. Hal ini disebabkan keterbatasan pengguna komputer untuk mengolah data tersebut menjadi sebuah informasi yang berguna. Padahal jika dianalisis lebih dalam akan menghasilkan informasi atau pengetahuan yang penting dan berharga sebagai penunjang pengambilan keputusan.
Data mining merupakan proses ekstraksi informasi atau pola penting dalam basis data berukuran besar (Han & Kamber 2001). Pada penelitian ini akan diterapkan salah satu teknik dalam data mining, yaitu klasifikasi terhadap data diabetes. Klasifikasi merupakan salah satu metode dalam data mining untuk mengetahui label kelas dari suatu record dalam data. Metode yang digunakan dalam penelitian ini yaitu metode klasifikasi dengan fuzzy decision tree. Penggunaan teknik fuzzy memungkinkan dilakukan penentuan suatu objek yang dimiliki oleh lebih dari satu kelas. Dengan menerapkan teknik data mining pada data diabetes diharapkan dapat ditemukan aturan klasifikasi yang dapat digunakan untuk mengetahui potensi seseorang terserang penyakit diabetes.
Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Menerapkan salah satu teknik data mining yaitu klasifikasi menggunakan metode fuzzy decision tree.
2. Menemukan aturan klasifikasi pada data diabetes yang menjelaskan dan membedakan kelas-kelas atau konsep sehingga dapat digunakan untuk mengetahui potensi penyakit diabetes berdasarkan nilai dari atribut lain yang diketahui.
3. Membangun aplikasi sederhana untuk membuat model atau aturan-aturan klasifikasi.
Ruang Lingkup Penelitian
Ruang lingkup penelitian dibatasi pada: 1. Membangun sebuah model untuk
mengetahui potensi pasien terserang diabetes menggunakan data pemeriksaan lab pasien dari sebuah rumah sakit yang meliputi pemeriksaan GLUN (Glukosa Darah Puasa), GPOST (Glukosa Darah 2 Jam Pasca Puasa), Tg (Trigliserida), HDL (Kolesterol HDL), serta diagnosa pasien berdasarkan nilai GLUN, GPOST, HDL, dan TG.
2. Teknik yang digunakan adalah salah satu teknik dalam data mining yaitu teknik klasifikasi dengan menggunakan metode decision tree. Untuk menangani ketidakpastian dan ketidaktepatan, pendekatan fuzzy digunakan.
3. Penelitian dilakukan dengan mengimplementasikan salah satu teknik fuzzy decision tree yaitu Fuzzy ID3 (Iterative Dichotomiser 3) Decision Tree pada data hasil pemeriksaan lab pasien.
Manfaat Penelitian
Model yang dihasilkan pada penelitian ini diharapkan dapat digunakan oleh pihak yang berkepentingan untuk mengetahui potensi seseorang atau pasien terserang penyakit diabetes, sehingga terjadinya penyakit ini pada seseorang dapat diketahui sedini mungkin dan dapat dilakukan tindakan antisipasi.
TINJAUAN PUSTAKA
Knowledge Data Discovery (KDD)
merupakan sebuah proses yang terdiri dari serangkaian proses iteratif yang terurut dan data mining merupakan salah satu langkah dalam KDD (Han & Kamber 2001). Pada Gambar 1 dapat dilihat tahapan proses KDD secara berurut. Tahapan proses KDD menurut Han & Kamber (2001), yaitu :
1. Pembersihan data
Pembersihan terhadap data dilakukan untuk menghilangkan data yang tidak konsisten atau data yang mengandung noise.
2. Integrasi data
Proses integrasi data dilakukan untuk menggabungkan data dari berbagai sumber.
3. Seleksi data
Proses seleksi data mengambil data yang relevan digunakan untuk proses analisis. 4. Transformasi data
Proses mentransformasikan atau menggabungkan data ke dalam bentuk yang tepat untuk dimining.
5. Data mining
Data mining merupakan proses yang penting dimana metode-metode cerdas diaplikasikan untuk mengekstrak pola-pola dalam data.
6. Evaluasi pola
Evaluasi pola diperlukan untuk mengidentifikasi beberapa pola-pola yang menarik yang merepresentasikan pengetahuan.
7. Presentasi pengetahuan
Penggunaan visualisasi dan teknik representasi untuk menunjukkan pengetahuan hasil peggalian gunung data kepada pengguna.
Gambar 1 Tahapan proses KDD (Han & Kamber 2001)
Data Mining
Data mining merupakan proses ekstraksi informasi data berukuran besar (Han dan Kamber 2001). Data mining merupakan
keseluruhan proses mengaplikasikan komputer dan bermacam-macam teknik untuk menemukan informasi dari sekumpulan data. Dari sudut pandang analisis data, data mining dapat diklasifikasi menjadi dua kategori, yaitu descriptive data mining dan predictive data mining. Descriptive data mining menjelaskan sekumpulan data dalam cara yang lebih ringkas. Ringkasan tersebut menjelaskan sifat-sifat yang menarik dari data. Predictive data mining menganalisis data dengan tujuan mengkonstruksi satu atau sekumpulan model dan melakukan prediksi perilaku dari kumpulan data yang baru. Aplikasi data mining telah banyak diterapkan pada berbagai bidang, seperti analisis pasar dan manajemen, analisis perusahaan dan manajemen resiko, telekomunikasi, asuransi dan keuangan.
Klasifikasi
Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk mengetahui kelas atau objek yang memiliki label kelas yang tidak diketahui. Klasifikasi termasuk ke dalam kategori predictive data mining. Model yang diturunkan didasarkan pada analisis dari training data. Teknik klasifikasi adalah pendekatan sistematis untuk pembuatan model klasifikasi (classifier) dari sebuah data set input.
Proses klasifikasi dibagi menjadi dua fase, yaitu learning dan testing (Han & Kamber 2001). Pada fase learning, sebagian data yang telah diketahui kelas datanya (training set) digunakan untuk membentuk model. Selanjutnya pada fase testing, model yang sudah terbentuk diuji dengan sebagian data lainnya (test set) untuk mengetahui akurasi dari model tersebut. Jika akurasinya mencukupi maka model tersebut dapat dipakai untuk prediksi kelas data yang belum diketahui.
Himpunan Fuzzy
Konsep logika fuzzy pertama kali diperkenalkan oleh Prof. Lotfi A. Zadeh dari Universitas California pada bulan Juni 1965. Logika fuzzy merupakan generalisasi dari logika klasik yang hanya memiliki dua nilai keanggotaan 0 dan 1. Dalam logika fuzzy nilai kebenaran suatu pernyataan berkisar dari sepenuhnya benar ke sepenuhnya salah. Inti dari himpunan fuzzy yaitu fungsi keanggotaan yang menggambarkan hubungan antara
Data Cleaning
Data Integration
Databases Data
Warehouse
Task-relevant Data
Selection and Transformation
Data mining
domain himpunan fuzzy dengan nilai derajat keanggotaan. Dengan teori himpunan fuzzy suatu objek dapat menjadi anggota dari banyak himpunan dengan derajat keanggotaan yang berbeda dalam masing-masing himpunan. Derajat keanggotaan menunjukkan nilai keanggotaan suatu objek pada suatu himpunan. Nilai keanggotaan ini berkisar antara 0 sampai 1 (Cox 2005).
Linguistic Variable (Peubah Linguistik) Linguistic variable merupakan peubah verbal yang dapat digunakan untuk memodelkan pemikiran manusia yang diekspresikan dalam bentuk himpunan fuzzy. Peubah linguistik dikarakterisasi oleh quintaple (x, T(x), X, G, M) dengan x adalah nama peubah, T(x) adalah kumpulan dari linguistic term, G adalah aturan sintaks, M adalah aturan semantik yang bersesuaian dengan setiap nilai peubah linguistik. Sebagai contoh, jika umur diinterpretasikan sebagai peubah linguistik, maka himpunan dari linguistic term T(umur) menjadi :
T(umur) = {sangat muda, muda, tua}
Setiap term dalam T(umur) dikarakterisasi oleh himpunan fuzzy, X menunjukkan nilai interval x. Aturan semantik menunjukkan fungsi keanggotaan dari setiap nilai pada himpunan linguistic term (Cox 2005).
Linguistic Term
Linguistic term didefinisikan sebagai kumpulan himpunan fuzzy yang didasarkan pada fungsi keanggotaan yang bersesuaian dengan peubah linguistik (Au & Chan 2001).
Jika D kumpulan dari record yang terdiri
dari kumpulan atribut , dengan . Atribut I dapat berupa atribut numerik atau kategorikal. Untuk setiap record d elemen D, menotasikan nilai i
dalam record d untuk atribut . Kumpulan linguistic term dapat didefinisikan pada seluruh domain dari atribut kuantitatif. ,
menotasikan linguistic term yang berasosiasi dengan atribut , sehingga himpunan fuzzy dapat didefinisikan untuk setiap .
}
,...,
{
I
1I
nI
=
nv Iv, =1,...,
[ ]
Iv d v I vr L v s r=1,...,v
I
vr
L
Himpunan fuzzy, , didefinisikan sebagai :
vr
L
v s r=1,...,
⎪
⎪
⎩
⎪⎪
⎨
⎧
=
∫ ∑ kontinu jika ) ( ) ( diskret jika ) ( ) ( v I v i v i vr L v I dom v I v i v i vr L v I dom vrL
µ µuntuk semua iv∈dom(Iv), dengan
}
{
v vnv i i
I
dom( )= 1,..., .
Derajat keanggotaan dari nilai
dengan beberapa linguistic term Lvr
dinotasikan oleh
) ( v
v domI
i ∈
vr
L
µ
.Fuzzy Decision Tree (FDT)
Decision tree merupakan suatu pendekatan yang sangat populer dan praktis dalam machine learning untuk menyelesaikan permasalahan klasifikasi. Metode ini digunakan untuk memperkirakan nilai diskret dari fungsi target, yang mana fungsi pembelajaran direpresentasikan oleh sebuah decision tree (Liang 2005).
Decision tree sama dengan satu himpunan aturan IF…THEN. Setiap path dalam tree dihubungkan dengan sebuah aturan, yang mana premis terdiri dari sekumpulan node-node yang ditemui, dan kesimpulan dari aturan terdiri dari kelas yang terhubung dengan leaf dari path (Marsala 1998).
Dalam pohon keputusan, leaf node diberikan sebuah label kelas. Non-terminal node, yang terdiri dari root dan internal node lainnya, mengandung kondisi-kondisi uji atribut untuk memisahkan record yang memiliki karakteristik yang berbeda. Edge-edge dapat dilabelkan dengan nilai-nilai symbolic. Sebuah atribut numeric-symbolic adalah sebuah atribut yang dapat bernilai numeric ataupun symbolic yang dihubungkan dengan sebuah variabel kuantitatif. Sebagai contoh, ukuran seseorang dapat dituliskan sebagai atribut numeric-symbolic: dengan nilai kuantitatif, dituliskan dengan “1,72 meter”, ataupun sebagai nilai numeric-symbolic seperti “tinggi” yang berkaitan dengan suatu ukuran (size). Nilai-nilai seperti inilah yang menyebabkan perluasan dari decision tree menjadi fuzzy decision tree (Yuan dan Shaw 1995). Penggunaan teknik fuzzy memungkinkan untuk mengetahui suatu objek yang dimiliki oleh lebih dari satu kelas.
dari teori himpunan fuzzy dalam decision tree ialah meningkatkan kemampuan dalam memahami decision tree ketika digunakan atribut-atribut kuantitatif. Bahkan, penggunaan teknik fuzzy dapat meningkatkan ketahanan saat melakukan klasifikasi kasus-kasus baru (Marsala 1998).
Fuzzy ID3 Decision Tree
Algoritma ID3 (Iterative Dichotomiser 3) pertama kali diperkenalkan oleh Quinlan. Algoritma ini menggunakan teori informasi untuk menentukan atribut mana yang paling informatif, namun ID3 sangat tidak stabil dalam melakukan penggolongan berkenaan dengan gangguan kecil pada data pelatihan. Logika fuzzy dapat memberikan suatu peningkatan dalam melakukan penggolongan pada saat pelatihan (Liang 2005).
Algoritma fuzzy ID3 merupakan algoritma yang efisien untuk membuat suatu fuzzy decision tree. Algoritma fuzzy ID3 adalah sebagai berikut (Liang 2005):
1. Create a Root node that has a set of fuzzy data with membership value 1.
2. If a node t with a fuzzy set of data D satisfies the following conditions, then it is a leaf node and assigned by the class name.
• The proportion of class Ck is
greater than or equal to θr,
r Ci D D θ ≥ | | | |
• the number of a data set is less than θn
• there are no attributes for more classifications
3. If a node D does no satisfy the above conditions, then it is not a leaf-node. And an new sub-node is generated as follow:
• For Ai’s (i=1,…,L) calculate
the information gain, and select the test attribute Amax
that maximizes them.
• Devide D into fuzzy subset
D1,…,Dm according to Amax, where
the membership value of the data in Dj is the product of
the membership value in D and the value of Fmax,j of the value
of Amax in D.
• Generate new node ti,…,tm for
fuzzy subsets D1,…,Dm and label
the fuzzy sets Fmax,j to edges
that connect between the nodes tjand t.
• Replace D by Dj (j=1,2,…,m) and
repeat from 2 recursively.
FuzzyEntropy dan Information Gain
Information gain adalah suatu nilai statistik yang digunakan untuk memilih atribut yang akan mengekspansi tree dan menghasilkan node baru pada algoritma ID3. Suatu entropy dipergunakan untuk mendefinisikan nilai information gain. Entropy dirumuskan sebagai berikut:
) ( log * )
( 2 i
N
i i
s S P P
H =
∑
− (1)dengan Pi adalah rasio dari kelas Ci pada
himpunan contoh S = {x1,x2,…,xk}.
S C x P
k
j j i
i
∑
= ∈= 1
(2)
Terdapat 2 kasus kasus khusus yang terjadi pada klasifikasi boolean, yang pertama adalah jika semua anggota dari himpunan S memiliki tipe yang sama, maka nilai entropy adalah 0 (nol). Hal ini berarti tidak terjadi ketidakpastian klasifikasi. 0 ) 0 ( log * 0 ) 1 ( log * 1 )
(S =− 2 − 2 = Hs
Kedua, jika jumlah contoh positif sama dengan jumlah contoh negatif, maka nilai entropy adalah 1 (satu), hal ini menandakan terjadi ketidakpastian klasifikasi maksimum.
1 ) 5 . 0 ( log * 5 . 0 ) 5 . 0 ( log * 5 . 0 )
(S =− 2 − 2 =
Hs
Untuk melakukan perluasan atribut, yang didasarkan pada data dari himpunan contoh, terlebih dahulu harus didefinisikan ukuran standar information gain. Information gain digunakan sebagai ukuran seleksi atribut, yang merupakan hasil pengurangan entropy dari himpunan contoh setelah membagi ukuran himpunan contoh dengan jumlah atributnya. Information gain untuk atribut A didefinisikan sebagai berikut:
∑
∈ − = ) ( ) ( | | | | ) ( ) , ( A Values v v v S H S S S H A SG (3)
dengan bobot Wi =
|
|
|
|
S
S
vadalah rasio dari
data dengan atribut v pada himpunan contoh.
entropy untuk atribut dan information gain karena adanya ekspresi data fuzzy. Berikut adalah persamaan untuk mencari nilai fuzzy entropy dari keseluruhan data:
) ( log * ) ( )
( 2 i
N
i i
s
f S H S P P
H = =
∑
− (4)Untuk menentukan fuzzy entropy dan information gain dari suatu atribut A pada algoritma fuzzy ID3 (FID3) digunakan persamaan sebagai berikut:
S S A S H N j ij C i N j ij f
∑
∑
=∑
−= 1 µ log2 µ
) ,
( (5)
) , ( * | | | | ) ( )
( H S A
S S S
H S
G f v
N A v
v f
f = −
∑
⊆ (6)dengan µij adalah nilai keanggotaan dari pola
ke-j untuk kelas ke-i. Hf(S) menunjukkan
entropy dari himpunan S dari data pelatihan pada node. |Sv| adalah ukuran dari subset Sv
S dari data pelatihan xj dengan atribut v. |S|
menunjukkan ukuran dari himpunan S (Liang 2005).
⊆
Threshold
Jika proses learning dari FDT dihentikan sampai semua data contoh pada masing-masing leaf-node menjadi anggota sebuah kelas, akan dihasilkan akurasi yang rendah. Oleh karena itu untuk meningkatkan akurasinya, proses learning harus dihentikan lebih awal atau melakukan pemangkasan tree secara umum (Liang 2005). Untuk itu diberikan 2 (dua) buah threshold yang harus terpenuhi jika tree akan diekspansi, yaitu: • Fuzziness control threshold (FCT) / θr
Jika proporsi himpunan data dari kelas Ck
lebih besar atau sama dengan nilai threshold θr, maka ekspansi tree
dihentikan. Sebagai contoh: jika diberikan θr adalah 85%, pada sebuah
sub-dataset rasio dari kelas 1 adalah 90% dan kelas 2 adalah 10%, maka ekspansi tree dihentikan.
• Leaf decision threshold (LDT) / θn
Jika banyaknya anggota himpunan data pada suatu node lebih kecil dari threshold θn, maka ekspansi tree dihentikan.
Sebagai contoh: sebuah himpunan data memiliki 600 contoh dengan θn adalah
2%. Jika jumlah data contoh pada sebuah node lebih kecil dari 12 (2% dari 600), maka ekspansi tree dihentikan.
K-fold Cross Validation
K-fold cross validation dilakukan untuk membagi training set dan test set. K-fold cross validation mengulang k-kali untuk membagi sebuah himpunan contoh secara acak menjadi k subset yang saling bebas, setiap ulangan disisakan satu subset untuk pengujian dan subset lainnya untuk pelatihan (Fu 1994). Pada metode tersebut, data awal dibagi menjadi k subset atau “fold” yang saling bebas secara acak, yaitu S1,S2,…,Sk,
dengan ukuran setiap subset kira-kira sama. Pelatihan dan pengujian dilakukan sebanyak k kali. Pada iterasi ke-i, subset Si diperlukan
sebagai data pengujian dan subset lainnya diperlukan sebagai data pelatihan. Pada iterasi pertama S2,...,Sk menjadi data pelatihan dan S1
menjadi data pengujian; pada iterasi kedua S1,S3,...,Sk menjadi data pelatihan dan S2
menjadi data pengujian dan seterusnya.
Sistem Inferensi Fuzzy
Sistem inferensi fuzzy adalah suatu framework yang didasarkan pada konsep himpunan fuzzy, fuzzy if-then rules, dan fuzzy reasoning. FIS dapat menerima input berupa bilangan crisp atau bilangan fuzzy, tapi outputnya hampir semua berupa himpunan fuzzy. Pada sistem inferensi fuzzy yang outputnya berupa nilai crisp dibutuhkan metode defuzzifikasi untuk menghasilkan nilai crisp dari suatu himpunan fuzzy. Salah satu metode inferensi fuzzy yang paling umum digunakan adalah metode inferensi Mamdani (Ormos 2004).
METODE PENELITIAN
Proses dasar sistem mengacu pada proses dalam Knowledge Discovery in Database (KDD). Proses tersebut dapat diuraikan sebagai berikut :
a. Pembersihan data, membuang data dengan nilai yang hilang dan data yang duplikat.
b. Transformasi data, proses transformasi data ke bentuk yang dapat di-mining. Sebelum di-mining, data diabetes diubah ke dalam bentuk data fuzzy.
c. Data dibagi menjadi training set dan test set dengan menggunakan metode k-fold cross validation
Langkah-langkah pada metode tersebut yaitu:
1. Menentukan atribut yang akan digunakan.
2. Menentukan banyaknya fuzzy set untuk masing-masing atribut.
3. Menentukan banyaknya training set yang akan digunakan.
4. Menghitung membership value.
5. Memilih besarnya threshold yang akan digunakan.
6. Membangun fuzzy decision tree dengan algoritma Fuzzy ID3.
e. Presentasi pengetahuan, merupakan tahap akhir dimana pada tahap ini pola yang telah ditemukan dipresentasikan ke pengguna dengan teknik visualisasi agar pengguna dapat memahaminya. Deskripsi aturan klasifikasi akan dipresentasikan dalam bentuk aturan logika untuk selanjutnya dievaluasi hasil pengetahuan yang didapatkan.
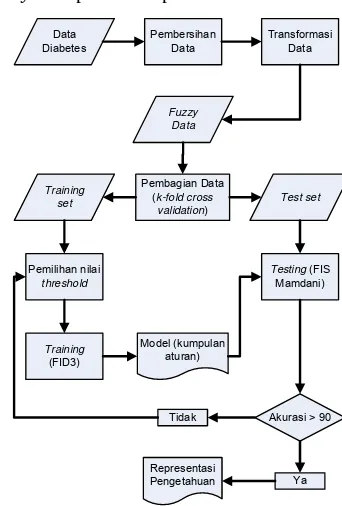
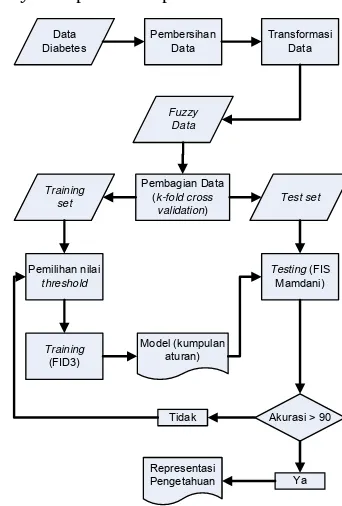
Alur proses untuk membangun sebuah classifier dapat dilihat pada Gambar 2.
Data Diabetes
Pembersihan Data
Transformasi Data
Fuzzy Data
Pembagian Data (k-fold cross
validation)
Training
set Test set
Pemilihan nilai
threshold
Training
(FID3)
Model (kumpulan aturan)
Testing (FIS Mamdani)
Akurasi > 90 Tidak
Ya Representasi
Pengetahuan
Gambar 2 Diagram alur proses klasifikasi
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut :
a. Perangkat keras berupa komputer personal dengan spesifikasi:
• Prosesor AMD Athlon 64 2800+ • Memori DDR 512 MB
• Harddisk 80 GB • Keyboard dan mouse • Monitor
b. Perangkat Lunak
• Sistem operasi Windows XP Profesional
• Matlab 7.0.1 untuk membangun aplikasi
• Microsoft Excel 2003 sebagai media penyimpanan data
HASIL DAN PEMBAHASAN
Sebelum masuk pada proses data mining data diabetes akan melalui tahap praproses. Yang pertama dilakukan adalah menggabungkan 2 (dua) buah file dengan format spreadsheet excel yang masing-masing berisi data catatan medis pasien rawat inap antara lain: KEY_id, TGL_Periksa, MRN (medical record number), tensi, nadi, suhu, tinggi, berat dan diagutama, serta data hasil pemeriksaan laboratorium antara lain: key_transaksi, no.RM (nomor rekam medis/MRN), tgl.proses, ordertest_code, test_name, result, unit, flag, ref_range, status.
Sebelum data digabungkan, terlebih dahulu dilakukan pemilihan atribut yang ada pada data hasil pemeriksaan laboratorium. Atribut yang dipilih untuk membuat aturan atau model dalam melakukan klasifikasi potensi seseorang terserang diabetes pada penelitian ini adalah GLUN, GPOST, HDL, dan TG (Herwanto 2006).
Atribut GLUN, GPOST, HDL, dan TG yang pada awalnya merupakan item dari kolom ordertest_code, masing-masing akan dijadikan sebagai kolom baru, sedangkan item yang lain dari kolom ordertest_code tidak digunakan. Kolom result yang berisi hasil laboratorium dari pemeriksaan GLUN, GPOST, HDL, dan TG akan dijadikan item dari masing-masing atribut tersebut. Setelah pemilihan atribut dilakukan, diperoleh tabel baru yang terdiri dari 5 kolom yaitu MRN, GLUN, GPOST, HDL, dan TG.
Penggabungan data catatan medis rawat inap dan hasil pemeriksaan laboratorium dilakukan berdasarkan kesamaan nilai MRN dari masing-masing record pada kedua tabel tersebut. Hasil akhir dari proses integrasi data berupa tabel baru yang terdiri dari 6 (enam) buah kolom yaitu MRN, GLUN (Glukosa Darah Puasa), GPOST (Glukosa Darah 2 Jam Pasca Puasa), HDL (Kolesterol HDL), TG (Trigliserida) dan diagutama. Tabel hasil penggabungan ini terdiri dari 300 record dan disimpan dalam format spreadsheet excel.
Pembersihan Data
Pembersihan data dilakukan terhadap data yang memiliki nilai kosong dan duplikat. Setelah dilakukan penghapusan record yang mengandung nilai kosong dan atau duplikat diperoleh data bersih sebanyak 290 record. Beberapa contoh data setelah proses pembersihan dapat dilihat pada Lampiran 1.
Transformasi Data
Pada penelitian ini, teknik data mining yang digunakan adalah fuzzy decision tree (FDT), oleh karena itu data yang digunakan harus direpresentasikan ke dalam bentuk fuzzy. Dari 5 (lima) atribut yang digunakan pada penelitian ini 4 di antaranya merupakan atribut yang kontinu, yaitu GLUN, GPOST, HDL, dan TG. Lain halnya dengan atribut diagutama yang merupakan atribut kategorik.
Berdasarkan referensi hasil laboraturium, range normal untuk atribut GLUN, GPOST, HDL, dan TG diperlihatkan pada Tabel 1.
Tabel 1 Nilai referensi hasil laboratorium
Kode
Pemeriksaan Satuan
Nilai Normal
GLUN Mg/DL 70 ~ 100
GPOST Mg/DL 100 ~ 140
HDL Mg/DL 40 ~ 60
TG Mg/DL 50 ~ 150
Atribut yang telah ditransformasi ke dalam bentuk fuzzy antara lain:
• Atribut GLUN
Atribut GLUN dibagi menjadi 4 kelompok atau linguistic term, yaitu rendah (GLUN < 70 mg/DL), sedang (70 mg/DL <= GLUN < 110 mg/DL), tinggi (110 mg/DL <= GLUN < 140 mg/DL), dan sangat tinggi (GLUN >= 140 mg/DL) (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, tinggi, dan sangat tinggi untuk atribut GLUN secara terpisah yaitu:
⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − − < = 75 ; 0 75 65 ; 10 75 65 ; 1 ) ( x x x x x rendah µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= −
− <= < < <= − < = 115 ; 0 115 105 ; 10 115 105 75 ; 1 75 65 ; 10 65 65 ; 0 ) ( x x x x x x x x sedang µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= −
− <= < < <= − < = 145 ; 0 145 135 ; 10 145 135 115 ; 1 115 105 ; 10 105 105 ; 0 ) ( x x x x x x x x tinggi µ ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 145 ; 1 145 135 ; 10 135 135 ; 0 ) ( x x x x x gi sangatTing µ
Himpunan fuzzy untuk setiap linguistic term menggunakan kurva dengan bentuk trapesium seperti pada Gambar 3.
M F GLUN
0 0,2 0,4 0,6 0,8 1
1 18 35 52 69 86 103 120 137
GLUN MF µ_rendah µ_s edang µ_tinggi µ_s angatTinggi
Gambar 3 Himpunan fuzzy atribut GLUN
•
Atribut GPOSTAtribut GPOST dibagi menjadi 4 kelompok atau linguistic term, yaitu rendah (GPOST < 100 mg/DL), sedang (100 mg/DL <= GPOST < 140 mg/DL), tinggi (140 mg/DL <= GPOST < 200 mg/DL), dan sangat tinggi (GPOST >= 200 mg/DL) (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, tinggi, dan sangat tinggi untuk atribut GPOST secara terpisah yaitu:
⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= −
− <= < < <= − < = 145 ; 0 145 135 ; 10 145 135 105 ; 1 105 95 ; 10 95 95 ; 0 ) ( x x x x x x x x sedang µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= −
− <= < < <= − < = 205 ; 0 205 195 ; 10 205 195 145 ; 1 145 135 ; 10 135 135 ; 0 ) ( x x x x x x x x tinggi µ ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 205 ; 1 205 195 ; 10 195 195 ; 0 ) ( x x x x x gi sangatTing µ
Himpunan fuzzy untuk setiap linguistic term menggunakan kurva dengan bentuk trapesium seperti pada Gambar 4.
MF GPOST 0 0,2 0,4 0,6 0,8 1
1 22 43 64 85 106 127 148 169 190 211
GPOST MF µ_rendah µ_sedang µ_tinggi µ_sangatTinggi
Gambar 4 Himpunan fuzzy atribut GPOST
•
Atribut HDLAtribut HDL dibagi menjadi 3 kelompok atau linguistic term, yaitu rendah (HDL < 40 mg/DL), sedang (40 mg/DL <= HDL < 60 mg/DL), dan tinggi (HDL >= 60 mg/DL) (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, tinggi, dan sangat tinggi untuk atribut HDL secara terpisah yaitu: ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − − < = 455 ; 0 45 35 ; 10 45 35 ; 1 ) ( x x x x x rendah µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= −
− <= < < <= − < = 65 ; 0 65 55 ; 10 65 55 45 ; 1 45 35 ; 10 35 35 ; 0 ) ( x x x x x x x x sedang µ ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 65 ; 1 65 55 ; 10 55 55 ; 0 ) ( x x x x x tinggi µ
Himpunan fuzzy untuk setiap linguistic term menggunakan kurva dengan bentuk trapesium seperti pada Gambar 5.
MF HDL 0 0,2 0,4 0,6 0,8 1
1 611 16 21 26 31 36 41 46 51 56 61 66 71 HDL M F µ_rendah µ_sedang µ_tinggi
Gambar 5 Himpunan fuzzy atribut HDL
•
Atribut TGAtribut TG dibagi menjadi 3 kelompok atau linguistic term, yaitu rendah (TG < 50 mg/DL), sedang (50 mg/DL <= TG < 150 mg/DL), dan tinggi (TG >= 150 mg/DL) (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, tinggi, dan sangat tinggi untuk atribut TG secara terpisah yaitu: ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − − < = 55 ; 0 55 45 ; 10 55 45 ; 1 ) ( x x x x x rendah µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= −
− <= < < <= − < = 155 ; 0 155 145 ; 10 155 145 55 ; 1 55 45 ; 10 45 45 ; 0 ) ( x x x x x x x x sedang µ ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 155 ; 1 155 145 ; 10 145 145 ; 0 ) ( x x x x x tinggi µ
Himpunan fuzzy untuk setiap linguistic term menggunakan kurva dengan bentuk trapesium seperti pada Gambar 6.
MF TG 0 0,2 0,4 0,6 0,8 1
1 16 31 46 61 76 91 106 121 136 151 166 TG
MF
µ_rendah µ_sedang µ_tinggi
•
Atribut DiagnosisAtribut Diagnosis selanjutnya akan disebut sebagai CLASS, direpresentasikan oleh dua buah peubah linguistik yaitu ”negatif diabetes” dan ”positif diabetes”. Kedua linguistic termnya tersebut didefinisikan sebagai berikut:
”negatif diabetes” = 0
”positif diabetes” = 1
Data dari atribut GLUN, GPOST, HDL, dan TG kemudian akan ditransformasi ke dalam bentuk fuzzy dengan menghitung derajat keanggotaan fuzzy pada tiap-tiap himpunan dari domain setiap atribut linguistik.
Nilai-nilai dari atribut CLASS yang awalnya berisi hasil diagnosis laboratorium akan ditransformasi menjadi 2 (dua) kategori saja, yaitu negatif diabetes yang di representasikan dengan angka 1, dan positif diabetes yang direpresentasikan dengan angka 2. Nilai atribut CLASS yang akan dikategorikan sebagai positif diabetes adalah diagnosis dengan label E10 (Insulin-dependent diabetes mellitus), E11 (Non-insulin-dependet diabetes mellitus), E12 (Malnutrition-related diabetes mellitus), dan E13 (Unspecified diabetes mellitus), selainnya dikategorikan sebagai negatif diabetes. Contoh hasil dari proses transformasi dapat dilihat pada Lampiran 2.
Untuk kolom MRN akan diubah menjadi kolom No. dan nilainya diubah dari text menjadi angka. Hal ini dilakukan untuk mempermudah pembuatan aplikasi dengan menggunakan Matlab.
Data Mining
Pada tahap ini dilakukan teknik data mining menggunakan algoritma FID3 untuk membangun fuzzy decision tree (FDT). Data yang telah ditransformasi akan dibagi menjadi training set dan test set. Pembagian data ini menggunakan metode 10-fold cross validation. Data akan dibagi menjadi 10 subset (S1,....,S10) yang berbeda dengan jumlah
yang sama besar. Setiap kali sebuah subset digunakan sebagai test set maka 9 buah partisi lainnya akan dijadikan sebagai training set.
• Training
Fase training dilakukan untuk membangun FDT dengan menggunakan algoritma FID3. Proses training harus melalui berbagai tahapan, sebagai contoh
akan dijelaskan pembentukan FDT dengan menggunakan contoh training set yang terdiri dari 15 data atau record. Contoh data untuk proses training dapat dilihat pada pada Lampiran 3.
Pada contoh training set tersebut akan diterapkan algoritma fuzzy ID3 untuk menemukan model atau aturan klasifikasi. Langkah-langkah pembentukan aturan klasifikasi dengan algoritma FID3, yaitu:
1. Membuat root node dari semua data training yang ada dengan memberi nilai derajat keanggotaan untuk semua record sama dengan 1.
2. Menghitung fuzzy entropy dari training set yang ada. Dari hasil perhitungan diperoleh nilai fuzzy entropy sebesar 0.9968. Nilai ini akan digunakan untuk menghitung nilai information gain dari masing-masing atribut.
3. Menghitung information gain dari atribut GLUN, GPOST, HDL, dan TG, masing-masing diperoleh nilai 0.2064, 0.3330, 0.0304, dan 0.0050. Dari hasil tersebut dipilih atribut dengan nilai information gain terbesar yaitu GPOST. Atribut GPOST selanjutnya digunakan untuk mengekspansi tree atau menjadi root-node, tapi pada sub-node selanjutnya atribut GPOST tidak dapat digunakan untuk mengekspansi tree.
4. Data training diekspansi berdasarkan atribut GPOST sehingga diperoleh hasil seperti pada Gambar 7.
Gambar 7 Hasil ekspansi training set berdasarkan atribut GPOST
keanggotaan dari data no.38 pada root node µold = 1, maka nilai derajat
keanggotaannya pada sub-node µnew
adalah:
1 . 0 1 . 0 1⊗ = =
⊗ = l old
new µ µ
µ
5. Menghitung proporsi dari tiap kelas yang ada pada tiap-tiap node. Misalkan, untuk sub-node dengan nilai keanggotaan atribut rendah, proporsi kelasnya adalah:
C1 = 0.1 + 1 + 1 = 2.1
C2 = 1
Proporsi kelas 1 (negatif diabetes)
% 74 . 67 % 100 *
2 1
1 =
+ =
C C
C
Proporsi kelas 2 (positif diabetes)
% 26 . 32 % 100 *
2 1
2 =
+ =
C C
C
6. Pada contoh ini digunakan fuzziness control threshold (θr ) sebesar 80% dan
leaf decision threshold (θn) sebesar
20%*15 = 3. Kedua threshold tersebut akan menentukan apakah sub-node akan terus diekspansi atau tidak. Misalkan sub-node dengan nilai atribut rendah yang memiliki data sebanyak 4, berdasarkan nilai proporsi kelas 1 (67.74%) dan kelas 2 (32.26%) yang lebih kecil dari θr (80%)
dan banyaknya data atau record pada sub-node tersebut lebih besar dari θn, maka
sub-node tersebut akan terus diekspansi. Lain halnya jika θr yang digunakan
adalah 65%, maka sub-node tersebut tidak akan diekspansi.
7. Ekspansi sub-node terus dilakukan sampai tidak ada lagi data yang dapat diekspansi atau tidak ada lagi atribut yang dapat digunakan untuk mengekspansi tree yaitu ketika tree yang terbentuk sudah mencapai kedalaman maksimum atau sub-node tidak memenuhi syarat dari threshold yang diberikan. Jika sub-node sudah tidak dapat diekspansi maka nilai proporsi kelas terbesar merupakan kesimpulan dari sekumpulan aturan yang diperoleh dengan menghubungkan setiap node yang dilewati dari root node hingga leaf node.
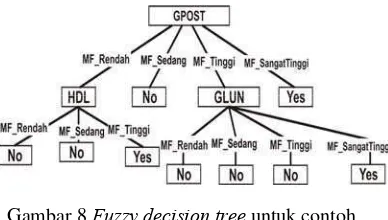
Berdasarkan langkah-langkah algoritma FID3 di atas, diperoleh fuzzy decision tree seperti pada Gambar 8 dan sebuah model yang terdiri dari 9 buah aturan dengan menggunakan contoh training set. Model
atau aturan klasifikasi yang diperoleh dapat dilihat pada Tabel 2.
Gambar 8 Fuzzy decision tree untuk contoh training set
Tabel 2 Aturan klasifikasi contoh training set
No. Aturan
1 IF GPOSTrendah ANDHDL rendah THEN
Negatif Diabetes
2 IF GPOSTrendah ANDHDL sedang THEN
Negatif Diabetes
3 IF GPOSTrendah ANDHDL tinggi THEN
Positif Diabetes
4 IF GPOSTsedang THEN THEN Negatif
Diabetes
5 IF GPOSTtinggi ANDGLUN rendah THEN
Negatif Diabetes
6 IF GPOST tinggi ANDGLUN sedang THEN
Negatif Diabetes
7 IF GPOST tinggi ANDGLUN tinggi THEN
Negatif Diabetes
8 IF GPOST tinggi ANDGLUN sangat tinggi
THEN Positif Diabetes
9 IF GPOSTsangat tinggi THEN Positif
Diabetes
Data hasil transformasi yang telah dibagi menggunakan metode 10-fold cross validation, dikenakan perlakuan yang sama berdasarkan algoritma FID3 untuk melakukan proses training. Proses training dilakukan sebanyak 240 kali. Untuk tiap-tiap training set, proses training dilakukan sebanyak 24 kali, dengan mengubah nilai θr
sebanyak 6 kali yaitu 75%, 80%, 85%, 90%, 95%, dan 98%, dan untuk masing-masing nilai θr yang sama diberikan nilai θn yang
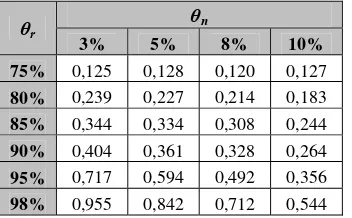
Tabel 3 Rata-rata jumlah aturan
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 7 7 7 6
85% 11 10 10 8
90% 12 11 10 8
95% 20 18 15 11
98% 27 24 20 16
Nilai-nilai θr dan θn yang digunakan
dipilih berdasarkan hasil percobaan, karena dengan nilai-nilai tersebut jumlah model atau aturan yang dihasilkan mengalami perubahan yang cukup signifikan. Dengan nilai θr 70%, aturan yang diperoleh tidak
berbeda dengan nilai θr 75% sehingga nilai
θr hanya dipilih sampai 75%.
Tabel 4 Rata-rata waktu eksekusi dalam satuan detik
θn
θr
3% 5% 8% 10%
75% 0,125 0,128 0,120 0,127
80% 0,239 0,227 0,214 0,183
85% 0,344 0,334 0,308 0,244
90% 0,404 0,361 0,328 0,264
95% 0,717 0,594 0,492 0,356
98% 0,955 0,842 0,712 0,544
Berdasarkan hasil percobaan, semakin tinggi nilai θr semakin banyak pula aturan
yang dihasilkan. Hal ini terjadi karena sebelum suatu node didominasi oleh sebuah kelas dan proporsi untuk kelas tersebut di atas atau sama dengan nilai θr maka tree
akan terus diekspansi. Pada Tabel 3 terlihat bahwa peningkatan yang paling signifikan terjadi pada saat nilai θr dinaikkan dari 90%
menjadi 95% dan dari 95% menjadi 98%. Kondisi semacam ini disebabkan pada saat ekspansi training set yang pertama kali dilakukan banyak sub-node yang proporsi salah satu kelasnya sudah mencapai nilai di atas 90%, sehingga sub-node tersebut tidak perlu diekspansi lagi. Ketika nilai θr
ditingkatkan sampai 95%, baru terjadi ekspansi pada beberapa sub-node yang lain dan hasil proporsi kelas pada node di bawahnya pun ternyata banyak yang lebih rendah dari nilai θr yang mengakibatkan
training set akan terus diekspansi sampai seluruh atribut terpakai.
Jika diamati dengan seksama pada Tabel 3, walaupun nilai θn ditingkatkan, jumlah
aturan yang dihasilkan tidak mengalami penurunan secara signifikan. Berdasarkan pengamatan yang dilakukan, ternyata karakteristik data pada training set yang digunakan tidak terlalu berbeda, pada saat terjadi ekspansi tree data tidak akan terlalu menyebar, karenanya jumlah himpunan data yang ada pada sub-node tidak berbeda jauh dengan jumlah himpunan data yang ada pada root-node. Dengan adanya situasi yang demikian, syarat untuk menghentikan ekspansi tree yaitu jumlah data atau record pada sub-node harus lebih kecil dari nilai θn
sulit untuk tercapai.
Nilai θr yang terlalu rendah dan atau θn
yang terlalu tinggi akan menghasilkan tree dengan ukuran yang kecil sehingga jumlah aturan yang dihasilkan juga sangat sedikit. Hal ini terjadi karena tree yang sedang dibangun mengalami pemangkasan (pruning) pada saat model masih mempelajari struktur dari training set. Sebaliknya, nilai θr yang terlalu tinggi dan
atau θn yang terlalu rendah kadang kala
akan menyebabkan fuzzy decision tree berperilaku seperti decision tree biasa yang tidak memerlukan adanya threshold sehingga menghasilkan tree dengan ukuran sangat besar dan jumlah aturan yang juga sangat banyak, karena tree akan terus diekspansi sampai leaf-node terdalam.
0 5 10 15 20 25 30
75% 80% 85% 90% 95% 98% θr
Ju
m
la
h
A
tu
ran
θn=3% θn=5% θn=8% θn=10%
Gambar 9 Perbandingan rata-rata jumlah aturan
Gambar 9 menunjukkan perbandingan rata-rata jumlah aturan yang dihasilkan pada proses training. Dapat terlihat bahwa semakin tinggi nilai θr akan menyebabkan
jumlah aturan yang dihasilkan juga meningkat. Hal sebaliknya terjadi jika nilai θn semakin tinggi maka aturan yang
0,000 0,200 0,400 0,600 0,800 1,000 1,200
75% 80% 85% 90% 95% 98%
θr
W
a
kt
u
(
d
et
ik
)
θn=3% θn=5% θn=8% θn=10%
Gambar 10 Perbandingan rata-rata waktu eksekusi proses training
Dengan melihat Gambar 9 dan Gambar 10, dapat disimpulkan bahwa, semakin tinggi nilai θr yang digunakan akan
menghasilkan jumlah aturan yang semakin banyak sehingga waktu yang dibutuhkan untuk menghasilkan aturan-aturan tersebut juga meningkat. Hal ini terjadi karena proses yang harus dilakukan untuk membangun tree semakin banyak.
• Testing
Untuk mengukur tingkat akurasi dari model yang dihasilkan pada fase training, proses testing dilakukan sebanyak 240 kali. Proses testing dilakukan dengan cara memasukkan aturan yang diperoleh dari proses training ke dalam sebuah FIS Mamdani untuk menentukan kelas dari masing-masing record pada test set. Untuk satu kali proses training dilakukan satu kali proses testing. Hasil proses testing secara keseluruhan dapat dilihat pada Lampiran 6.
Dengan melihat hasil testing, mengubah nilai θr dan θn tidak menyebabkan adanya
perubahan pada nilai akurasi dari model yang ada, walaupun jumlah aturan yang dihasilkan proses training mengalami peningkatan. Hal ini terjadi karena secara kebetulan semua aturan pada kedua model tersebut memiliki kelas target yang sama yaitu negatif diabetes dan test set yang digunakan juga berasal dari kelas target yang sama sehingga hasil testing dari kedua buah model dengan test set yang sama tidak mengalami perubahan. Namun model dengan aturan yang seragam seperti ini tidak dapat dipakai untuk mengetahui label kelas suatu objek karena berapapun nilai atribut yang diberikan hasilnya akan selalu negatif diabetes. Hasil testing akan berbeda jika aturan-aturan pada model yang dihasilkan memiliki kelas target yang
berbeda. Sebagai contoh lihat Tabel 5 dan Tabel 6.
Tabel 5 Model untuk training set pertama dengan θr (75%) dan θn (3%)
No. Aturan
1 IF GPOSTrendah THEN Negatif Diabetes
2 IF GPOSTsedang THEN Negatif Diabetes
3 IF GPOSTtinggi THEN Negatif Diabetes
4 IF GPOSTsangat tinggi THEN Negatif
Diabetes
Tabel 6 Model untuk training set pertama dengan θr (85%) dan θn (3%)
No. Aturan
1 IF GPOSTrendah THEN Negatif Diabetes
2 IF GPOSTsedang THEN Negatif Diabetes
3 IF GPOSTtinggi THEN Negatif Diabetes
4 IF GPOSTsangat tinggi AND GLUN rendah
THEN Negatif Diabetes
5 IF GPOSTsangat tinggi AND GLUN sedang
AND TG sedang THEN Negatif Diabetes
6 IF GPOSTsangat tinggi AND GLUN sedang
AND TG tinggi THEN Negatif Diabetes
7 IF GPOSTsangat tinggi AND GLUN tinggi
THEN Negatif Diabetes
8 IF GPOSTsangat tinggi AND GLUN sangat
tinggi AND HDL rendah AND TG sedang THEN Negatif Diabetes
9 IF GPOSTsangat tinggi AND GLUN sangat
tinggi AND HDL rendah AND TG tinggi THEN Negatif Diabetes
10 IF GPOSTsangat tinggi AND GLUN sangat
tinggi AND HDL sedang AND TG sedang THEN Negatif Diabetes
11 IF GPOSTsangat tinggi AND GLUN sangat
tinggi AND HDL sedang AND TG tinggi THEN Negatif Diabetes
12 IF GPOSTsangat tinggi AND GLUN sangat
tinggi AND HDL tinggi THEN Negatif Diabetes
Aturan-aturan yang terdapat pada Tabel 5 dan Tabel 6 semuanya memiliki kelas target yang sama yaitu negatif diabetes. Hal ini terjadi karena training set yang digunakan pada saat proses training mayoritas (90%) memiliki label kelas negatif diabetes sehingga aturan-aturan yang dihasilkan juga cenderung memiliki kelas target negatif diabetes.
Pada test set ketujuh dan kedelapan, nilai akurasi mengalami penurunan saat θr
ditingkatkan menjadi 80%. Berdasarkan pengamatan yang dilakukan, keadaan seperti ini dinamakan overfitting karena terlalu tingginya θr untuk training set
tidak sengaja sesuai dengan beberapa titik noise (data yang mengalami kesalahan klasifikasi) pada training set.
Representasi Pengetahuan
Model hasil proses training digunakan untuk mengetahui label kelas pada data yang baru. Model tersebut dipilih berdasarkan 3 (tiga) kriteria berikut yang diurutkan berdasarkan prioritas:
1. Model yang mencakup semua kelas target yang mungkin muncul dalam test set, dalam penelitian ini kelas target yang mungkin muncul yaitu kelas target 1 (negatif diabetes) dan kelas target 2 (positif diabetes).
2. Model dengan akurasi yang tinggi, semakin tinggi akurasinya maka semakin baik model tersebut.
3. Model dengan jumlah aturan yang paling banyak.
Berdasarkan kriteria tersebut maka model yang dipilih adalah hasil training dengan nilai θr dan θn masing-masing 98% dan 3% dari
pasangan training set dan test set kesepuluh dengan jumlah aturan sebanyak 30. Dari 30 aturan tersebut hanya 1 aturan yang mengandung kelas target positif diabetes. Model yang dihasilkan adalah sebagai berikut:
1. IF GPOST rendah AND HDL rendah THEN
Negatif Diabetes
2. IF GPOSTrendah ANDHDL sedang AND TG
rendah THEN Negatif Diabetes
3. IF GPOSTrendah ANDHDL sedang AND TG
sedang AND GLUN rendah THEN Negatif Diabetes
4. IF GPOSTrendah ANDHDL sedang AND TG
sedang AND GLUN sedang THEN Negatif Diabetes
5. IF GPOSTrendah ANDHDL sedang AND TG
sedang AND GLUN tinggi THEN Negatif Diabetes
6. IF GPOSTrendah ANDHDL sedang AND TG
tinggi THEN Negatif Diabetes
7. IF GPOSTrendah ANDHDL tinggi AND GLUN
rendah AND TG sedang THEN Negatif Diabetes
8. IF GPOSTrendah ANDHDL tinggi AND GLUN
rendah AND TG tinggi THEN Negatif Diabetes
9. F GPOSTrendah ANDHDL tinggi AND GLUN
sedang THEN Negatif Diabetes
10. IF GPOSTsedang THEN Negatif Diabetes
11. IF GPOST tinggi AND GLUN rendah THEN
Negatif Diabetes
12. IF GPOSTtinggi AND GLUN sedang THEN
Negatif Diabetes
13. IF GPOSTtinggi AND GLUN tinggi AND HDL
rendah AND TG sedang THEN Negatif Diabetes
14. IF GPOSTtinggi AND GLUN tinggi AND HDL
rendah AND TG tinggi THEN Negatif Diabetes
15. IF GPOSTtinggi AND GLUN tinggi AND HDL
sedang THEN Negatif Diabetes
16. IF GPOSTtinggi AND GLUN tinggi AND HDL
tinggi THEN Negatif Diabetes
17. IF GPOST tinggi AND GLUN sangat tinggi
AND TG sedang THEN Negatif Diabetes
18. IF GPOST tinggi AND GLUN sangat tinggi
AND TG tinggi THEN Positif Diabetes
19. IF GPOST sangat tinggi AND GLUN rendah
THEN Negatif Diabetes
20. IF GPOST sangat tinggi AND GLUN sedang
THEN Negatif Diabetes
21. IF GPOST sangat tinggi AND GLUN tinggi AND
TG sedang THEN Negatif Diabetes
22. IF GPOST sangat tinggi AND GLUN tinggi AND
TG tinggi AND HDL rendah THEN Negatif Diabetes
23. IF GPOST sangat tinggi AND GLUN tinggi AND
TG tinggi AND HDL sedang THEN Negatif Diabetes
24. IF GPOST sangat tinggi AND GLUN tinggi AND
TG tinggi AND HDL tinggi THEN Negatif Diabetes
25. IF GPOST sangat tinggi AND GLUN sangat
tinggi AND TG sedang AND HDL rendah THEN Negatif Diabetes
26. IF GPOST sangat tinggi AND GLUN sangat
tinggi AND TG sedang AND HDL sedang THEN Negatif Diabetes
27. IF GPOST sangat tinggi AND GLUN sangat
tinggi AND TG sedang AND HDL tinggi THEN Negatif Diabetes
28. IF GPOST sangat tinggi AND GLUN sangat
tinggi AND TG tinggi AND HDL rendah THEN Negatif Diabetes
29. IF GPOST sangat tinggi AND GLUN sangat
tinggi AND TG tinggi AND HDL sedang THEN Negatif Diabetes
30. IF GPOST sangat tinggi AND GLUN sangat
tinggi AND TG tinggi AND HDL tinggi THEN Negatif Diabetes
Evaluasi Kinerja FID3
Evaluasi kinerja algoritma FID3 dapat diketahui dengan cara menghitung rata-rata akurasi dari seluruh proses testing pada 10 test set yang berbeda. Evaluasi kinerja dari algoritma FID3 pada nilai θr dan θn yang
berbeda dapat dilihat pada Tabel 7 dan Gambar 11.
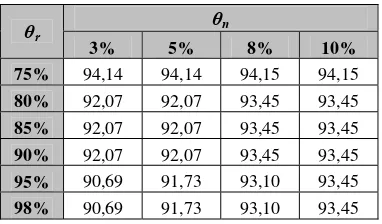
Tabel 7 Evaluasi kinerja FID3
θn
θr
3% 5% 8% 10%
75% 94,14 94,14 94,15 94,15
80% 92,07 92,07 93,45 93,45
85% 92,07 92,07 93,45 93,45
90% 92,07 92,07 93,45 93,45
95% 90,69 91,73 93,10 93,45
88,00 89,00 90,00 91,00 92,00 93,00 94,00 95,00
75% 80% 85% 90% 95% 98% θr
Aku
ras
i
θn=3% θn=5% θn=8% θn=10%
Gambar 11 Evaluasi kinerja FID3
Dari Tabel 7 dan Gambar 11 dapat dilihat bahwa kinerja algoritma FID3 mengalami penurunan jika nilai θr semakin besar dan atau
nilai θn semakin kecil, walaupun penurunan
yang terjadi tidaklah signifikan sehingga masih dapat ditoleransi. Seperti telah dijelaskan sebelumnya kondisi ini disebabkan karena terjadinya fenomena overfitting.
Untuk melakukan proses training dan testing pada saat percobaan telah dibangun sebuah aplikasi sederhana dengan menggunakan Matlab 7.0.1. Pada proses training algoritma yang digunakan adalah FID3, sedangkan pada proses testing digunakan FIS Mamdani. Salah satu antarmuka grafis dari aplikasi tersebut dapat dilihat pada Gambar 12.
Gambar 12 Antarmuka grafis aplikasi untuk proses training
KESIMPULAN DAN SARAN
Kesimpulan
Dari berbagai percobaan yang dilakukan terhadap data Diabetes didapat kesimpulan sebagai berikut :
1. Algoritma FID3 dapat digunakan untuk membuat classifier pada data diabetes.
2. Jumlah aturan yang diperoleh sebanyak 30 buah aturan dengan akurasi sebesar
90,69% pada nilai θr sebesar 98% dan θn
sebesar 3%.
3. Penelitian ini menghasilkan aplikasi sederhana yang dapat digunakan untuk membuat classifier berdasarkan algoritma FID3 dengan menggunakan Matlab 7.0.1.
Saran
Pada penelitian ini masih terdapat beberapa kekurangan yang dapat diperbaiki pada penelitian selanjutnya. Beberapa saran yang dapat dilakukan antara lain:
1. Pada penelitian selanjutnya proses pembentukan decision tree dapat menggunakan algoritma probabilistic fuzzy ID3 sebagai upaya untuk meningkatkan akurasi dari model yang diperoleh.
2. Pada penelitian ini, data yang digunakan kurang representatif karena jumlah data untuk positif diabetes hanya 17 record, sedangkan untuk negatif diabetes sebanyak 273 record. Penelitian selanjutnya diharapkan menggunakan data yang lebih representatif dengan perbandingan jumlah data positif dan negatif diabetes yang sama besar, sehingga aturan klasifikasi yang dihasilkan memiliki akurasi yang lebih baik lagi.
3. Penggunaan kelas target berupa atribut kuantitatif sehingga hasil diagnosis untuk positif dan negatif diabetes didukung oleh nilai derajat keanggotaan yang berkisar dari 0 sampai 1.
DAFTAR PUSTAKA
Cox, E. 2005. Fuzzy Modeling and Algorithms for Data mining and Exploration. USA: Academic Press.
Fu L. 1994. Neural Network In Computer Intelligence. Singapura: McGraw Hill. Han J dan Micheline K. 2001. Data mining
Concepts and Techniques. USA: Academic Press.
Liang, G. 2005. A Comparative Study of Three Decision Tree algorithms: ID3, Fuzzy ID3 and Probabilistic Fuzzy ID3. Informatics & Economics Erasmus University Rotterdam. Rotterdam, the Netherlands.
Marsala, C. 1998. Application of Fuzzy Rule Induction to Data Mining. France: University Pierre et Marie Curie.
Ormos L. 2004. Soft Computing Method On Thom’s Catastrophe Theory For Controlling Of Large-Scale Systems. Hungary. University of Miskolc, Department of Automation.
Tan S, Kumar P, Steinbach M. 2005. Introduction To Data mining. Addison-Wesley.
Lampiran 1 Contoh data hasil proses pembersihan data
No.
GLUN (mg/DL)
GPOST (mg/DL)
HDL (mg/DL)
TG
(mg/DL) CLASS 1 115 159 32 117 1
2 0 0 91 91 1
3 90 145 28 86 1
4 84 90 64 46 1
5 78 149 41 52 1
6 115 138 46 186 1 7 118 181 43 183 1
8 88 83 28 139 1
9 119 116 29 173 1 10 61 63 65 72 1
11 0 0 85 85 1
Lampiran 2 Contoh data hasil fuzzifikasi pada proses transformasi data
No.
GLUN
(mg/ DL)
MF _
Ren dah
MF _
Sed ang
MF_
Tinggi
MF_
Sangat Tinggi
GPOST
(mg/ DL)
MF _
Ren dah
MF _
Sed ang
MF_
Tinggi MF_
Sangat Tinggi
HDL
(mg/ DL)
MF _
Ren dah
MF _
Sed ang
MF_
Tinggi TG
(mg/ DL)
MF _
Ren dah
MF _
Sed ang
MF_
Tinggi
CLASS
1 115 0 0 1 0 159 0 0 1 0 32 1 0 0 117 0 1 0 1
2 0 1 0 0 0 0 1 0 0 0 91 0 0 1 91 0 1 0 1
3 90 0 1 0 0 145 0 0 1 0 28 1 0 0 86 0 1 0 1
4 84 0 1 0 0 90 1 0 0 0 64 0 0,1 0,9 46 0,9 0,1 0 1
5 78 0 1 0 0 149 0 0 1 0 41 0,4 0,6 0 52 0,3 0,7 0 1
6 115 0 0 1 0 138 0 0,7 0,3 0 46 0 1 0 186 0 0 1 1
7 118 0 0 1 0 181 0 0 1 0 43 0,2 0,8 0 183 0 0 1 1
8 88 0 1 0 0 83 1 0 0 0 28 1 0 0 139 0 1 0 1
9 119 0 0 1 0 116 0 1 0 0 29 1 0 0 173 0 0 1 1
10 61 1 0 0 0 63 1 0 0 0 65 0 0 1 72 0 1 0 1
11 0 1 0 0 0 0 1 0 0 0 85 0 0 1 85 0 1 0 1
12 158 0 0 0 1 196 0 0 0,9 0,1 68 0 0 1 85 0 1 0 1
13 134 0 0 1 0 135 0 1 0 0 55 0 1 0 155 0 0 1 1
14 172 0 0 0 1 278 0 0 0 1 54 0 1 0 126 0 1 0 1
Lampiran 3 Contoh data untuk proses training
No.
GLUN
(mg/ DL)
MF _
Ren dah
MF _
Sed ang
MF_
Tinggi
MF_
Sangat Tinggi
GPOST
(mg/ DL)
MF _
Ren dah
MF _
Sed ang
MF_
Tinggi MF_
Sangat Tinggi
HDL
(mg/ DL)
MF _
Ren dah
MF _
Sed ang
MF_
Tinggi TG
(mg/ DL)
MF _
Ren dah
MF _
Sed ang
MF_
Tinggi
CLASS
38 107 0 0,8 0,2 0 104 0,1 0,9 0 0 28 1 0 0 164 0 0 1 1
39 87 0 1 0 0 150 0 0 1 0 30 1 0 0 177 0 0 1 1
40 151 0 0 0 1 212 0 0 0 1 40 0,5 0,5 0 235 0 0 1 1
41 63 1 0 0 0 147 0 0 1 0 26 1 0 0 94 0 1 0 1
42 68 0,7 0,3 0 0 90 1 0 0 0 56 0 0,9 0,1 77 0 1 0 1
43 68 0,7 0,3 0 0 70 1 0 0 0 43 0,2 0,8 0 139 0 1 0 1
44 120 0 0 1 0 151 0 0 1 0 51 0 1 0 126 0 1 0 1
45 71 0,4 0,6 0 0 112 0 1 0 0 68 0 0 1 78 0 1 0 1
46 0 1 0 0 0 0 1 0 0 0 147 0 0 1 147 0 0,8 0,2 2
47 164 0 0 0 1 176 0 0 1 0 51 0 1 0 184 0 0 1 2
48 129 0 0 1 0 246 0 0 0 1 31 1 0 0 535 0 0 1 2
49 187 0 0 0 1 225 0 0 0 1 65 0 0 1 96 0 1 0 2
50 108 0 0,7 0,3 0 259 0 0 0 1 38 0,7 0,3 0 167 0 0 1 2
51 208 0 0 0 1 232 0 0 0 1 40 0,5 0,5 0 58 0 1 0 2
Lampiran 4 Jumlah aturan yang dihasilkan oleh masing-masing training set
Training set pertama
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 4 4 4 4
85% 12 11 11 10
90% 12 11 11 10
95% 21 18 16 12
98% 29 26 23 18
Training set kedua
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 4 4 4 4
85% 4 4 4 4
90% 4 4 4 4
95% 9 9 7 7
98% 9 9 7 7
Training set ketiga
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 4 4 4 4
85% 4 4 4 4
90% 13 11 11 9
95% 23 18 16 12
98% 23 18 16 12
Training set keempat
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 4 4 4 4
85% 12 11 11 10
90% 15 12 11 10
95% 21 16 15 12
98% 29 24 22 19
Training set kelima
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 4 4 4 4
85% 12 12 12 8
90% 15 13 12 8
95% 22 19 17 11
98% 30 27 24 18
Training set keenam
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 4 4 4 4
85% 13 12 10 8
90% 13 12 11 8
95% 23 22 16 11
98% 31 31 23 18
Training set ketujuh
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 10 10 8 8
85% 13 12 10 8
90% 13 12 10 8
95% 21 17 14 10
98% 29 25 22 17
Training set kedelapan LDT
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 11 11 11 9
85% 11 11 11 9
90% 11 11 11 9
95% 21 21 15 12
Lampiran 4 Lanjutan
Training set kesembilan
θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 12 12 12 8
85% 12 12 12 8
90% 12 12 12 8
95% 21 19 16 10
98% 29 27 23 17
Training set kesepuluh θn
θr
3% 5% 8% 10%
75% 4 4 4 4
80% 12 12 10 8