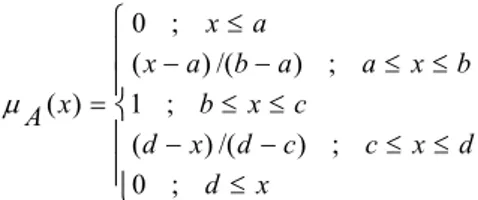WELLYA SEPTIN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2008
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
WELLYA SEPTIN G64104002
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2008
ABSTRAK
WELLYA SEPTIN. Optimasi Fuzzy Decision Tree Menggunakan Algoritme Genetika pada Data Diabetes. Dibimbing oleh IMAS S. SITANGGANG dan IRMAN HERMADI.
Hasil survey Organisasi Kesehatan Dunia (WHO) pada tahun 2004, menyatakan Indonesia menempati urutan keempat terbesar dalam jumlah penderita kencing manis (diabetes melitus) di dunia setelah India, Cina, dan Amerika Serikat. Data diabetes terkait hasil pemeriksaan laboratorium dari pasien di rumah sakit dibiarkan menggunung tanpa digunakan secara maksimal. Oleh karena itu, penelitian dengan mengaplikasikan teknik data mining pada data diabetes perlu dilakukan agar diperoleh informasi mengenai karakteristik pasien yang dinyatakan positif diabetes atau negatif diabetes. Salah satu output dari teknik data mining adalah pohon keputusan (decision tree) yang dapat digunakan untuk memprediksi apakah seseorang menderita diabetes atau tidak. Penelitian ini menggunakan salah satu teknik data mining yaitu teknik klasifikasi dengan menggunakan metode fuzzy decision tree. Algoritme decision tree yang digunakan yaitu fuzzy ID3 (Iterative Dichotomiser 3). Algoritme genetika digunakan sebagai teknik optimasi terhadap fuzzy decision tree (FDT) sehingga diperoleh genetically optimized fuzzy decision tree (G-DT). Bagian FDT yang dioptimasi dengan algoritme genetika adalah fungsi keanggotaan fuzzy.
Hasil penelitian ini berupa model (classifier), fungsi keanggotaan fuzzy yang telah dioptimasi, dan nilai akurasi G-DT yang lebih baik daripada nilai akurasi FDT. Model yang dihasilkan dari proses training G-DT mengandung 27 aturan yang terdiri atas 25 aturan mengandung kelas target negatif diabetes dan dua aturan mengandung kelas target positif diabetes. Model yang dihasilkan dari proses training FDT mengandung 30 aturan yang terdiri atas 29 aturan mengandung kelas target negatif diabetes dan satu aturan mengandung kelas target positif diabetes. Fungsi keanggotaan yang digunakan dalam pembentukan G-DT berbeda dengan FDT. Pada FDT, fungsi keanggotaan fuzzy telah ditentukan dari awal. Sedangkan pada G-DT, fungsi keanggotaan diperoleh selama pembelajaran. Rata-rata nilai akurasi G-DT meningkat sebesar 4.83% dari rata-rata nilai akurasi FDT. Rata-rata akurasi FDT adalah sebesar 90.69%, sedangkan rata-rata akurasi G-DT adalah sebesar 95.52%.
Kata kunci: klasifikasi, decision tree, optimasi fuzzy decision tree, algoritme genetika, genetically optimized fuzzy decision tree
Judul :
Optimasi Fuzzy Decision Tree Menggunakan Algoritme Genetika pada
Data Diabetes
Nama : Wellya Septin
NIM : G64104002
Menyetujui:
Pembimbing I,
Pembimbing II,
Imas S. Sitanggang, S.Si, M.Kom
Irman Hermadi, S.Kom, M.S
NIP 132206235
NIP 132321422
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Drh. Hasim, DEA
NIP 131578806
RIWAYAT HIDUP
Penulis dilahirkan di Bukittinggi pada tanggal 27 September 1986, dari pasangan Ir. Zamri Rasyidin dan Eliza. Penulis merupakan putri kedua dari tiga bersaudara.
Pada tahun 1998, penulis lulus dari SD Negeri 150/IV Kotabaru Kota Jambi, lalu pada tahun yang sama melanjutkan pendidikan di SLTP NEGERI 11 Kota Jambi. Pada tahun 2001, penulis lulus dari SLTP dan melanjutkan sekolah di SMU Negeri 1 Kota Jambi hingga tahun 2004. Pada tahun yang sama penulis berkesempatan untuk melanjutkan studinya di Institut Pertanian Bogor (IPB) melalui jalur USMI (Undangan Seleksi Masuk IPB) sebagai mahasiswa S1 Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama di IPB, penulis aktif dalam kegiatan beberapa kegiatan kemahasiswaan terutama di Himpunan Mahasiswa Ilmu Komputer (HIMALKOM) periode 2005/2006. Pada tahun 2007 penulis mendapatkan beasiswa prestasi belajar dari Pemerintah Daerah (PEMDA) Propinsi Jambi. Pada tahun 2007, penulis melaksanakan kegiatan praktik kerja lapangan di PT Surya Citra Televisi (SCTV) Divisi Broadcast Engineering selama dua bulan. Penulis juga pernah menjadi anggota tim tenaga IT (information technology) PHK TIK Departemen Agronomi dan Hortikultura IPB dalam rangka pengembangan course content praktikum Ekologi Pertanian.
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT atas segala curahan rahmat dan karunia-Nya sehingga tugas akhir ini dapat diselesaikan. Tugas akhir ini berjudul Optimasi Fuzzy Decision Tree Menggunakan Algoritme Genetika pada Data Diabetes. Dalam menyelesaikan tugas akhir ini penulis mendapatkan banyak sekali bantuan, bimbingan dan dorongan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada semua pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain: 1 Kedua orangtua tercinta, papa Ir. Zamri Rasyidin dan mama Eliza atas segala do’a, kasih
sayang, dan dukungannya,
2 Kakak dr. Nella Yesdelita dan adik Rifki Zel tercinta yang selalu memberikan motivasi dalam penyelesaian tugas akhir ini,
3 Ibu Imas S. Sitanggang, S.Si, M.Kom selaku pembimbing pertama atas bimbingan dan arahannya selama pengerjaan tugas akhir ini,
4 Bapak Irman Hermadi S.Kom, MS selaku pembimbing kedua atas bimbingan dan arahannya selama pengerjaan tugas akhir ini,
5 Bapak Hari Agung, S.Kom, M.Si selaku moderator dalam seminar dan penguji dalam sidang, 6 Teny Handhani atas persahabatan, bantuan dan motivasinya,
7 Teman-teman di Pondok Sabrina terutama Popi, Inez, Bibib, Rini dan Yuli atas persahabatan, bantuan dan motivasinya,
8 Tri, Henri, Gananda, Rafi, Hasan, Heni, Yaghi, mba Risha, Syadid, Wawan, Denny, Udin, Yohan atas bantuan dan kebersamaan selama konsultasi bersama,
9 Indri dan Roni atas kesediaannya menjadi pembahas dalam seminar,
10 Kak Firat, mas Irfan, Anizza, Fernissa, Kikis, Marisa, dan Ayu atas bantuan dan motivasinya, 11 Seluruh teman-teman seperjuangan Program Studi Ilmu Komputer angkatan 41 yang tidak
dapat disebutkan namanya satu-persatu.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama pengerjaan penyelesaian tugas akhir ini yang tidak dapat disebutkan satu-persatu. Semoga penelitian ini dapat memberi manfaat.
Bogor, Mei 2008
DAFTAR ISI
Halaman
DAFTAR TABEL... vii
DAFTAR GAMBAR ... vii
DAFTAR LAMPIRAN... vii
PENDAHULUAN Latar Belakang ... 1 Tujuan ... 1 Ruang Lingkup... 1 Manfaat Penelitian ... 2 TINJAUAN PUSTAKA Data Mining ... 2 Klasifikasi ... 2 Logika Fuzzy ... 2 Fungsi Keanggotaaan ... 2
Fuzzy ID3 Decision Tree... 3
Fuzzy Entropy dan Information Gain... 3
Sistem Inferensi Fuzzy ... 4
Fuzzy C-Means (FCM)... 4
K-fold Cross Validation ... 4
Algoritme Genetika... 4
Encoding Kromosom dan Inisialisasi Populasi ... 5
Evaluasi Fitness ... 5
Elitisme ... 5
Seleksi (Selection)... 5
Rekombinasi (Crossover)... 5
Mutasi (Mutation) ... 6
Terminasi Algoritme Genetika... 6
METODE PENELITIAN Data ... 6
Metode ... 6
Pembagian data ... 6
Pembentukan G-DT... 7
Percobaan untuk mencari parameter algoritme genetika yang optimal ... 10
Training G-DT ... 10
Lingkup Pengembangan Sistem ... 11
HASIL DAN PEMBAHASAN Pemilihin Training Set dan Testing Set ... 11
Percobaan untuk Mencari Parameter Algoritme Genetika yang Optimal ... 12
Ukuran populasi sebesar 10... 12
Ukuran populasi sebesar 30 dan 50... 12
Penentuan parameter yang optimal ... 13
Training G-DT ... 14
Representasi Pengetahuan ... 15
Perbandingan G-DT dan FDT ... 16
Proses pembentukan tree... 16
Hasil training ... 17
KESIMPULAN DAN SARAN
Kesimpulan ... 21
Saran... 21
DAFTAR PUSTAKA ... 22
DAFTAR TABEL
Halaman
1 Contoh populasi awal berukuran 10...9
2 Contoh populasi akhir berukuran 10 ...10
3 Hasil eksekusi program G-DT menggunakan 10 training sets dan 10 testing sets...11
4 Persebaran data negatif dan positif diabetes pada setiap training set dan testing set ...11
5 Hasil percobaan dengan variasi tingkat rekombinasi dan tingkat mutasi ...13
6 Hasil percobaan dengan variasi ukuran populasi dan maksimum generasi...13
7 Hasil training untuk training set 2 ...14
8 Hasil training untuk training set 3 ...14
9 Hasil training G-DT untuk setiap training set ...15
10 Hasil training G-DT...17
11 Hasil training FDT...18
DAFTAR GAMBAR
Halaman 1 Fungsi keanggotaan trapezoidal...22 Operator rekombinasi...5
3 Operator mutasi...6
4 Alur penelitian...7
5 Tahapan pembentukan G-DT. ...7
6 Representasi nilai parameter fungsi keanggotaan fuzzy di dalam kromosom...8
7 Contoh kromosom...8
8 Grafik hasil clustering menggunakan FCM. ...8
9 Panjang rentang nilai a, b, c, dan d...8
10 Alur pemilihan parameter yang optimal bagi ukuran populasi sebesar 10...12
11 Himpunan fuzzy atribut GLUN...19
12 Himpunan fuzzy atribut GPOST. ...20
13 Himpunan fuzzy atribut HDL. ...20
14 Himpunan fuzzy atribut TG. ...20
15 Antarmuka grafis aplikasi G-DT...21
DAFTAR LAMPIRAN
Halaman 1 Hasil percobaan untuk 90 kombinasi parameter pada ukuran populasi sebesar 10...242 Hasil percobaan untuk 12 kombinasi parameter pada ukuran populasi sebesar 10...26
3 Hasil percobaan untuk 3 kombinasi parameter menggunakan training set 2 pada ukuran populasi sebesar 10 ...30
4 Hasil percobaan untuk parameter yang optimal pada ukuran populasi sebesar 30 & 50...31
5 Hasil training dari training set 1, 4, 5, 6, 7, 8, 9, dan 10 dengan menggunakan parameter algoritme genetika yang optimal ...31
6 Contoh sebagian data training set 1 dan testing set 1...34
7 Contoh sebagian data training set 1 hasil fuzzikasi untuk membentuk FDT ...35
8 Contoh sebagian data training set 1 hasil fuzzikasi untuk membentuk G-DT ...36
9 Fuzzy decision tree untuk contoh training set 1...37
10 Aturan klasifikasi menggunakan FDT dari contoh training set 1 ...38
11 Genetically optimized fuzzy decision tree untuk contoh training set 1...39
12 Aturan klasifikasi menggunakan G-DT dari contoh training set 1 ...40
13 Fungsi keanggotaan dari training set 1, 2, 3, 4, 5, 7, 8, 9, dan 10...41
PENDAHULUAN
Latar BelakangHasil survey Organisasi Kesehatan Dunia (WHO) pada tahun 2004, menyatakan Indonesia menempati urutan keempat terbesar dalam jumlah penderita kencing manis (diabetes melitus) di dunia setelah India, Cina, dan Amerika Serikat. Pada tahun 2006, jumlah penderita diabetes di Indonesia mencapai 14 juta orang. Dari 14 juta orang, hanya 50% penderita yang sadar mengidap diabetes, dan hanya sekitar 30% diantaranya melakukan pengobatan secara teratur. Sehingga setiap tahun, jumlah penderita diabetes semakin meningkat.
Di lain pihak, data diabetes terkait hasil pemeriksaan laboratorium dari pasien di rumah sakit dibiarkan menggunung tanpa digunakan secara maksimal. Oleh karena itu, penelitian perlu dilakukan untuk menganalisis data diabetes. Salah satunya dengan mengaplikasikan teknik data mining agar diperoleh suatu informasi atau pengetahuan seperti pohon keputusan sebagai penunjang pengambilan keputusan. Dengan demikian jumlah penderita diabetes dapat ditekan. Penelitian ini terkait dengan penelitian yang telah dilakukan oleh Firat Romansyah pada tahun 2007 mengenai data mining dengan judul “Penerapan Teknik Klasifikasi dengan Metode Fuzzy Decision Tree dengan Algoritme ID3 pada Data Diabetes”.
Data mining merupakan proses ekstraksi informasi dari data berukuran besar (Han & Kamber 2006). Klasifikasi merupakan salah satu metode dalam data mining untuk mengetahui label kelas dari suatu record dalam data. Salah satu metode klasifikasi yaitu fuzzy decision tree. Penggunaan teknik fuzzy memungkinkan dilakukan penentuan suatu objek yang dimiliki oleh lebih dari satu kelas. Penelitian sebelumnya telah menghasilkan aturan klasifikasi pada data diabetes dengan menggunakan fuzzy decision tree, sehingga diperoleh informasi untuk memprediksi potensi seseorang terkena diabetes.
Algoritme genetika merupakan algoritme yang dapat menyelesaikan masalah optimisasi. Algoritme genetika dapat menangani beberapa fungsi objektif, bekerja pada sekumpulan calon solusi, dan menggunakan aturan transisi peluang bukan aturan deterministik. Pada penelitian ini, algoritme genetika digunakan untuk mengoptimasi fuzzy decision tree (FDT)
sehingga diperoleh genetically optimized fuzzy decision tree (G-DT) (Pedryez & Sosnowki 2005). Optimasi ini dilakukan untuk meningkatkan nilai akurasi. Dengan demikian, informasi atau pengetahuan untuk memprediksi potensi seseorang terkena diabetes menjadi lebih baik daripada hasil penelitian sebelumnya.
Tujuan
Tujuan penelitian ini adalah:
1 Menerapkan algoritme genetika untuk mengoptimumkan fuzzy decision tree (FDT) sehingga diperoleh genetically optimized fuzzy decision tree (G-DT) pada data diabetes, sehingga diperoleh nilai akurasi yang lebih baik daripada penelitian sebelumnya.
2 Membangun aplikasi sederhana untuk membuat model (aturan klasifikasi) dengan menggunakan fuzzy decision tree yang dioptimasi dengan algoritme genetika.
3 Membandingkan hasil implementasi fuzzy decision tree (FDT) dengan genetically optimized fuzzy decision tree (G-DT). Ruang Lingkup
Ruang lingkup penelitian dibatasi pada: 1 Membangun sebuah model untuk
mengetahui potensi seseorang terkena diabetes dengan menggunakan data hasil pemeriksaan lab dari sebuah rumah sakit yang meliputi pemeriksaan GLUN (Glukosa Darah Puasa), GPOST (Glukosa Darah 2 Jam Pasca Puasa), TG (Trigliserida), HDL (Kolesterol HDL), serta diagnosa pasien berdasarkan nilai GLUN, GPOST, HDL dan TG. Diagnosa pasien ditransformasi menjadi dua kategori, yaitu negatif diabetes dan positif diabetes.
2 Penelitian ini menggunakan salah satu teknik data mining yaitu teknik klasifikasi dengan menggunakan metode fuzzy decision tree. Pendekatan fuzzy digunakan untuk menangani ketidakpastian dan ketidaktepatan. Algoritme fuzzy decision tree yang digunakan yaitu fuzzy ID3 (Iterative Dichotomiser 3). Algoritme genetika digunakan sebagai teknik optimasi terhadap fuzzy decision tree (FDT) sehingga diperoleh genetically optimized fuzzy decision tree (G-DT).
d c b a 1 Manfaat Penelitian
Penelitian ini diharapkan dapat menghasilkan pohon keputusan yang lebih akurat daripada penelitian sebelumnya. Informasi ini dapat digunakan oleh pihak yang berkepentingan untuk mengetahui potensi seseorang terkena diabetes sehingga dapat dilakukan antisipasi sedini mungkin terhadap penyakit diabetes.
TINJAUAN PUSTAKA
Data MiningData mining merupakan proses ekstraksi informasi data berukuran besar (Han & Kamber 2006). Dari sudut pandang analisis data, data mining dapat diklasifikasikan menjadi dua kategori yaitu descriptive data mining dan predictive data mining. Descriptive data mining fokus untuk menemukan pola yang mendeskripsikan data yang dapat diinterprestasikan oleh manusia. Predictive data mining melibatkan beberapa variabel dalam himpunan data untuk memprediksikan nilai variabel lain yang tidak diketahui (Kantardzic 2003).
Klasifikasi
Klasifikasi termasuk ke dalam kategori predictive data mining. Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk mengetahui kelas atau objek yang memiliki label kelas yang tidak diketahui. Model yang diturunkan didasarkan pada analisis dari training data (Han & Kamber 2006).
Proses klasifikasi dibagi menjadi dua fase yaitu learning dan testing. Pada fase learning, sebagian data yang telah diketahui kelas datanya (training set) digunakan untuk membentuk model. Selanjutnya pada fase testing, model yang sudah terbentuk diuji dengan sebagian data lainnya (test set) untuk mengetahui akurasi dari model tersebut. Jika akurasinya mencukupi maka model tersebut dapat dipakai untuk prediksi kelas data yang belum diketahui (Han & Kamber 2006).
Logika Fuzzy
Konsep logika fuzzy pertama kali diperkenalkan oleh Prof. Lotfi A. Zadeh dari Universitas California pada tahun 1965. Logika fuzzy merupakan generalisasi dari
logika klasik (Boolean atau Crisp). Dalam logika fuzzy nilai kebenaran suatu pernyataan berkisar dari sepenuhnya benar ke sepenuhnya salah (Cox 2005).
Inti dari logika fuzzy adalah himpunan fuzzy (fuzzy set) (Cox 2005). Himpunan fuzzy adalah himpunan tanpa batas tegas (crisp boundary) (Kantardzic 2003). Setiap elemen dari himpunan fuzzy memiliki derajat keanggotaan. Derajat keanggotaan menunjukkan nilai keanggotaan suatu objek pada suatu himpunan. Nilai keanggotaan ini berkisar antara 0 sampai 1. Dengan teori himpunan fuzzy suatu objek dapat menjadi anggota dari banyak himpunan dengan derajat keanggotaan yang berbeda dalam masing-masing himpunan (Cox 2005).
Fungsi Keanggotaaan
Inti dari himpunan fuzzy adalah fungsi keanggotaan (membership function). Fungsi keanggotaan menggambarkan hubungan antara domain himpunan fuzzy dengan nilai derajat keanggotaan (Cox 2005).
Jika X adalah kumpulan objek yang ditandai secara umum oleh x, maka himpunan fuzzy A pada X didefinisikan sebagai berikut:
(
)
{
x A x x X}
A= ,μ ( ) | ∈dimana μA(x) adalah fungsi keanggotaan
untuk himpunan fuzzy A. Fungsi keanggotaan memetakan setiap elemen dari X ke nilai derajat keanggotaan (Kantardzic 2003).
Salah satu bentuk fungsi keanggotaan adalah trapezoidal. Fungsi keanggotaan trapezoidal dispesifikasi oleh empat parameter (a, b, c, d) sebagai berikut.
⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ ≤ ≤ ≤ − − ≤ ≤ ≤ ≤ − − ≤ = x d d x c c d x d c x b b x a a b a x a x x A ; 0 ; ) /( ) ( ; 1 ; ) /( ) ( ; 0 ) ( μ
Bentuk fungsi keanggotaan trapezoidal dapat dilihat pada Gambar 1 (Kantardzic 2003).
Fuzzy ID3 Decision Tree
Decision tree merupakan suatu pendekatan yang sangat populer dan praktis dalam machine learning untuk menyelesaikan permasalahan klasifikasi (Liang 2005). Decision tree sama dengan satu himpunan aturan IF...THEN (Marsala 1998). Decision tree terdiri internal node menggambarkan data yang diuji, setiap cabang (branch) menggambarkan nilai keluaran dari data yang diuji, dan leaf node menggambarkan distribusi kelas dari data yang digunakan. Decision tree digunakan untuk mengklasifikasikan suatu sampel data yang tidak dikenal (Han & Kamber 2006).
Fuzzy decision tree merupakan metode perluasan dari decision tree. Fuzzy decision tree menggunakan teori himpunan fuzzy untuk merepresentasikan himpunan data (Liang 2005). Manfaat dari teori fuzzy dalam decision tree adalah meningkatkan kemampuan dalam memahami decision tree ketika digunakan atribut-atribut kuantitatif dan meningkatkan ketahanan saat melakukan klasifikasi kasus-kasus baru (Marsala 1998).
Algoritme ID3 (Iterative Dichotomiser 3) pertama kali diperkenalkan oleh J. Rose Quilan pada tahun 1986. Algoritme fuzzy ID3 merupakan algoritme yang efisien untuk membuat suatu fuzzy decision tree. Algoritme fuzzy ID3 adalah sebagai berikut (Liang 2005):
1 Create a Root node that has a set of fuzzy data with membership value 1
2 If a node t with a fuzzy set of data D satisfies the following conditions, then it is a leaf node and assigned by the class name.
• The proportion of a class Ck
is greater than or equal to Өx, r D Ci D θ ≥ | | | |
• the number of a data set is less than θn
• there are no attributes for more classifications
3 If a node D does no satisfy the above conditions, then it is not a leaf-node. And an new sub-node is generated as follow:
• For Ai’s (i=1,…, L)
calculate the information
gain, and select the test
attribute Amax that
maximizes them.
• Divide D into fuzzy subset
D1 , ..., Dm according to Amax , where the membership
value of the data in Dj is the product of the membership value in D and the value of Fmax,j of the
value of Amax in D.
• Generate new nodes t1 , …,
tm for fuzzy subsets D1 ,
... , Dm and label the fuzzy
sets Fmax,j to edges that
connect between the nodes tj and t
• Replace D by Dj (j=1, 2, …, m) and repeat from 2 recursively.
Dalam pembangunan tree, dilakukan ekspansi tree dan evaluasi dengan nilai threshold. Ada dua nilai threshold yaitu (Liang 2005):
1 Fuzziness control threshold (FCT) / θr Jika proporsi himpunan data dari kelas Ck lebih besar atau sama dengan nilai threshold θr, maka ekspansi tree dihentikan.
2 Leaf decision threshold (LDT) / θn
Jika banyaknya anggota himpunan data pada suatu node lebih kecil dari threshold θn, maka ekspansi tree dihentikan.
Fuzzy Entropy dan Information Gain
Information gain adalah suatu nilai statistik yang digunakan untuk memilih atribut
yang akan mengekspansi tree dan
menghasilkan node baru pada algoritme ID3.
Suatu entropy dipergunakan untuk
mendefinisikan nilai information gain (Liang 2005).
Berikut persamaan untuk mencari nilai fuzzy entropy dari keseluruhan data:
( )
( )
( )
i N i i s f S H S P P H = =∑
− *log2dengan Pi adalah rasio dari kelas Ci pada himpunan contoh S = {x1, x2,…,xk } (Liang 2005). Untuk menentukan fuzzy entropy dan information gain dari suatu atribut A pada algoritma fuzzy ID3 (FID3) digunakan persamaaan berikut: S N j ij C i S N j ij A S f H ( , )=−∑ =1∑ μ log2 ∑ μ
(
Sv A)
f H N A v SV S S f H f G = ( )−∑ ⊆ ∗ ,dengan μij adalah nilai keanggotaan dari pola
ke-j untuk kelas ke-i. Hf(S) menunjukkan entropy dari himpunan S dari data pelatihan pada node. |Sv| adalah ukuran dari subset
S
S
v⊆
dari data pelatihan xj dengan atribut v. |S| menunjukkan ukuran dari himpunan S (Liang 2005).Sistem Inferensi Fuzzy
Sistem inferensi fuzzy adalah suatu framework yang didasarkan pada konsep himpunan fuzzy, fuzzy if-then rules, dan fuzzy reasoning. Salah satu metode inferensi fuzzy yang paling umum digunakan adalah metode sistem inferensi fuzzy Mamdani. Struktur dasar dari sistem inferensi fuzzy terdiri dari tiga komponen yaitu (Jang et al 1997):
1 rule base, terdiri dari aturan-aturan fuzzy (fuzzy rules),
2 database/dictionary, mendefinisikan fungsi keanggotaan yang digunakan pada aturan fuzzy, dan
3 reasoning mechanism, melakukan proses inferensi pada aturan dan fakta yang diberikan untuk memperoleh output atau kesimpulan.
Fuzzy C-Means (FCM)
Fuzzy C-Means atau Fuzzy ISODATA, merupakan algoritme clustering data di mana setiap titik data masuk dalam sebuah cluster dengan ditandai oleh derajat keanggotaan yang bernilai antara 0 dan 1. Oleh karena itu, sebuah titik data dapat menjadi anggota untuk beberapa cluster. FCM ini dimodifikasi oleh Jim Bezdek pada tahun 1973 dari teknik hard C-means (HCM). FCM membagi sebuah koleksi dari n data vektor xi (i = 1, ..., n)
menjadi c kelompok fuzzy, dan menemukan sebuah pusat cluster (cluster center) untuk setiap kelompok di mana meminimalisasi ukuran ketidakmiripan dari fungsi objektif (Jang et al 1997).
K-fold Cross Validation
K-fold cross validation dilakukan untuk membagi training set dan testing set. K-fold cross validation mengulang k-kali untuk membagi sebuah himpunan contoh secara acak menjadi k subset yang saling bebas. Setiap ulangan disisakan satu subset untuk pengujian dan subset lainnya untuk pelatihan (Fu 1994).
Algoritme Genetika
Konsep dasar algoritme genetika (AG) pertama kali dicetuskan pada tahun 1975 oleh John H. Holland dalam bukunya yang berjudul Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelegence (Cox 2005). Algoritme genetika adalah suatu teknik proses komputasi yang pada dasarnya meniru teori evolusi alamiah (Michalewicz 1996).
Menurut Michalewicz (1996), algoritme genetika harus memiliki lima komponen berikut:
1 Representasi genetik untuk solusi-solusi yang potensial pada permasalahan. 2 Cara untuk menciptakan suatu inisialisasi
populasi dari solusi-solusi yang potensial. 3 Fungsi evaluasi yang menilai solusi
dalam kaitannya dengan nilai fitness.
4 Operator-operator genetik yang mengubah komposisi anak (children).
5 Nilai-nilai dari berbagai macam parameter yang digunakan dalam algoritme genetika (ukuran populasi dan peluang-peluang yang akan diterapkan pada operator genetik).
Algoritme genetika adalah sebagai berikut (Lawrence 1991):
1 Initialize a population of chromosomes.
2 Evaluate each chromosomes in the population.
3 Create new chromosomes by mating current chromosomes; apply mutation and recombination as the parent chromosomes mate.
4 Delete members of the
population to make room for the new chromosomes.
5 Evaluate the new chromosomes and insert them into the population.
6 If time is up, stop and return the best chromosomes; if not, go to 3.
Pada algoritma genetika terdapat proses-proses utama yang menjadi prinsip utama dalam evolusi, yaitu rekombinasi (crossover) dan mutasi (mutation). Algoritme ini menggunakan sistem seleksi alamiah (selection) terhadap individu baru yang muncul dari evolusi individu sebelumnya. Individu solusi yang dihasilkan diharapkan
merupakan individu solusi yang terbaik (Michalewicz 1996).
Encoding Kromosom dan Inisialisasi Populasi
Algoritme genetika dimulai dengan membuat representasi dari solusi untuk suatu permasalahan. Hal ini disebut encoding. Encoding schema merupakan cara menerjemahkan masalah ke dalam framework algoritme genetika. Beberapa Encoding schema yaitu binary, negative, floating-point, dan discrete-value numbers. Pada umumnya, algoritme genetika menggunakan binary-coding schema untuk merepresentasikan solusi. Sekumpulan nilai yang diencode menjadi bit string, menyatakan satu kromosom (Kantardzic 2003).
Pada algoritme genetika, yang dievaluasi bukan satu kromosom tetapi sekumpulan kromosom yang disebut populasi (Kantardzic 2003). Jumlah kromosom dalam populasi tergantung pada jumlah variabel dalam pencarian (Cox 2005). Populasi diinisialisasi secara acak dengan pertimbangan ukuran populasi (pop-size) (Kantardzic 2003).
Evaluasi Fitness
Fitness merupakan suatu ukuran yang digunakan untuk membandingkan solusi-solusi dan menentukan solusi-solusi yang lebih baik. Nilai fitness dapat ditentukan dari rumus hasil analisis yang kompleks, model simulasi, dan pengamatan dari percobaan atau permasalahan nyata (Kantardzic 2003).
Elitisme
Elitisme adalah proses mempertahankan kromosom dengan nilai fitness terbaik dengan cara menyalin kromosom dengan fitness terbaik ke generasi selanjutnya. Elitisme digunakan dengan dikombinasikan dengan teknik seleksi untuk menjaga kromosom dengan fitness terbaik tetap bertahan hingga generasi berikutnya (Cox 2005).
Seleksi (Selection)
Seleksi (selection) adalah proses memilih populasi yang relatif baik (nilai fitness baik) untuk dilakukan rekombinasi dan mutasi (Cox 2005). Salah satu metode seleksi yang banyak digunakan yaitu roulette wheel. Roulette wheel menyeleksi populasi baru dengan distribusi probabilitas yang berdasarkan nilai fitness. Algoritme seleksi roulette wheel adalah berikut ini (Michalewicz 1996):
1 Hitung nilai fitness eval(vi) untuk setiap kromosom vi ( i = 1, ..., pop_size).
2 Hitung total fitness untuk populasi:
( )
∑
= =pop size i i v eval F _ 1 )3 Hitung peluang seleksi pi untuk setiap kromosom vi ( i = 1, ..., pop_size).
( )
F v eval p i i =4 Hitung peluang kumulatif qi untuk setiap kromosom vi ( i = 1, ..., pop_size).
∑
= = i j j i p q 15 Proses seleksi dimulai dengan memutar roulette wheel sebanyak ukuran populasi (pop-size) kali. Pada sekali putaran, sebuah kromosom dipilih untuk membentuk populasi yang baru dengan cara berikut:
• Bangkitkan sebuah bilangan acak r pada selang [0, 1].
• Jika r < q1 maka pilih kromosom
pertama (v1); selainnya pilih
kromosom ke-i vi (2 ≤ i ≤ pop_size) sehingga qi-1 < r < qi.
Rekombinasi (Crossover)
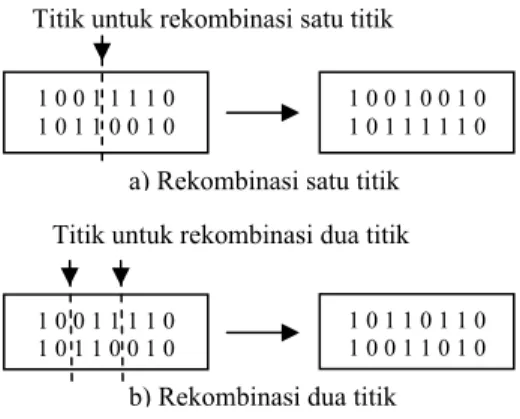
Rekombinasi (crossover) adalah proses pembentukan kromosom baru dengan menggabungkan dua atau lebih kromosom relatif baik (Cox 2005). Ada beberapa teknik untuk melakukan rekombinasi yaitu rekombinasi satu titik (one-point) dan rekombinasi dua titik (two-point). Rekombinasi satu titik memilih titik rekombinasi pada kode genetik secara acak dan kromosom dua parent dipertukarkan pada titik ini. Rekombinasi dua titik memilih dua titik rekombinasi dan bagian kromosom diantara dua titik ini ditukar untuk menghasilkan dua anak (children) dari generasi baru. Rekombinasi satu titik dan rekombinasi dua titik dapat dilihat pada Gambar 2 (Kantardzic 2003).
Gambar 2 Operator rekombinasi. b) Rekombinasi dua titik Titik untuk rekombinasi dua titik Titik untuk rekombinasi satu titik
a) Rekombinasi satu titik 1 0 0 1 1 1 1 0 1 0 1 1 0 0 1 0 1 0 0 1 0 0 1 0 1 0 1 1 1 1 1 0 1 0 0 1 1 1 1 0 1 0 1 1 0 0 1 0 1 0 1 1 0 1 1 0 1 0 0 1 1 0 1 0
Tingkat rekombinasi (crossover rate / pc) menyatakan peluang kromosom akan dipilih untuk rekombinasi. Pada umumnya, nilai tingkat rekombinasi sebesar 0.5 hingga 0.9 merupakan nilai perkiraan tingkat rekombinasi yang baik (Cox 2005).
Rekombinasi dibentuk dengan cara melakukan tiga langkah berikut secara berulang sebanyak jumlah kromosom dalam populasi (Michalewicz 1996).
1 Bangkitkan sebuah bilangan acak r pada selang [0, 1].
2 Jika r < pc , maka kromosom tersebut
dipilih untuk rekombinasi.
3 Untuk setiap pasang kromosom terpilih, bangkitkan bilangan acak pada selang [1, L-1] (L = panjang kromosom). Bilangan ini menunjukkan posisi titik rekombinasi.
Mutasi (Mutation)
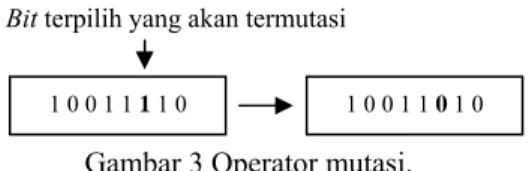
Mutasi (mutation) adalah proses untuk menghasilkan kromosom yang relatif lebih baik dengan mengubah allele (nilai dari solusi/kromosom). Operator mutasi yang sering digunakan adalah mutasi pembalikan yang melakukan pembalikan gen secara acak untuk membentuk individu baru (Cox 2005) (Michalewicz 1996). Mutasi pembalikan dapat dilihat pada Gambar 3 (Kantardzic 2003).
Gambar 3 Operator mutasi.
Tingkat mutasi (mutation rate / pm) menyatakan peluang sebuah gen mengalami perubahan melalui teknik mutasi. Pada umumnya, nilai tingkat mutasi sangat rendah. Nilai tingkat mutasi sebesar 0.01 hingga 1/ukuran populasi merupakan nilai perkiraan yang baik untuk nilai tingkat mutasi (Cox 2005).
Mutasi dibentuk dengan cara melakukan dua langkah berikut secara berulang sebanyak jumlah gen dalam populasi (Michalewicz 1996).
1 Bangkitkan sebuah bilangan acak r pada selang [0, 1].
2 Jika r < pm , maka gen tersebut mengalami
mutasi.
Terminasi Algoritme Genetika
Kriteria algoritme genetika untuk berhenti yaitu:
1 maksimum generasi telah dicapai, 2 waktu eksekusi yang telah cukup lama,
3 satu atau lebih kromosom memiliki nilai fitness yang memenuhi fungsi objektif, 4 fungsi fitness terbaik pada generasi
selanjutnya telah stabil.
METODE PENELITIAN
DataPenelitian ini menggunakan data diabetes yang merupakan hasil pemeriksaan laboratorium pasien dari sebuah rumah sakit. Data hasil pemeriksaan lab pasien yang digunakan dalam penelitian ini meliputi GLUN (Glukosa Darah Puasa), GPOST (Glukosa Darah 2 Jam Pasca Puasa), HDL (Kolesterol HDL), TG (Trigliserida), serta diagnosa pasien berdasarkan nilai GLUN, GPOST, HDL dan TG. Nilai GLUN, GPOST, HDL, TG dinyatakan dalam satuan Mg/DL. Diagnosa pasien ditransformasi menjadi dua kategori, yaitu negatif diabetes yang direpresentasikan dengan angka 1 dan positif diabetes yang direpresentasikan dengan angka 2. Total data yang digunakan dalam penelitian ini berjumlah 290 record.
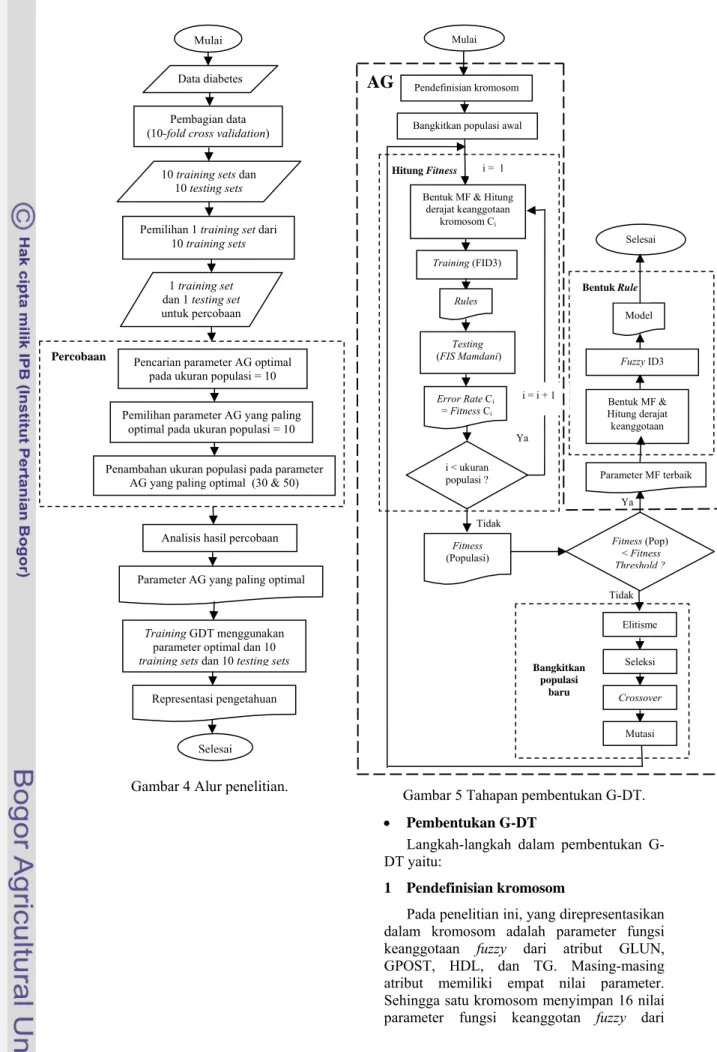
Metode
Metode penelitian yang digunakan dapat dilihat pada Gambar 4. Tahapan pembentukan genetically optimized fuzzy decision tree (G-DT) dapat dilihat pada Gambar 5.
• Pembagian data
Pembagian data menggunakan 10-fold cross validation, sama dengan penelitian sebelumya. Data akan dibagi menjadi training set dan testing set. Data akan dibagi menjadi 10 subset (S1, ..., S10) yang berbeda dengan jumlah yang sama besar. Setiap kali sebuah subset digunakan sebagai testing set maka sembilan buah partisi lainnya akan dijadikan sebagai training set (Romansyah 2007).
Pembagian data dengan metode 10-fold cross validation ini akan menghasilkan sepuluh training sets dan sepuluh testing sets. Jika sepuluh training sets dan sepuluh testing sets digunakan dalam percobaan untuk mencari parameter algoritme genetika yang optimal, maka total percobaan yang harus dilakukan akan banyak sekali. Oleh karena itu, hanya satu dari sepuluh training sets dan testing set yang akan digunakan untuk percobaan. Sedangkan untuk proses training G-DT digunakan sepuluh training sets.
Bit terpilih yang akan termutasi
Gambar 4 Alur penelitian. Gambar 5 Tahapan pembentukan G-DT. • Pembentukan G-DT
Langkah-langkah dalam pembentukan G-DT yaitu:
1 Pendefinisian kromosom
Pada penelitian ini, yang direpresentasikan dalam kromosom adalah parameter fungsi keanggotaan fuzzy dari atribut GLUN, GPOST, HDL, dan TG. Masing-masing atribut memiliki empat nilai parameter. Sehingga satu kromosom menyimpan 16 nilai parameter fungsi keanggotan fuzzy dari Mulai
Pembagian data (10-fold cross validation)
Pemilihan 1 training set dari 10 training sets
Selesai
Parameter AG yang paling optimal
Training GDT menggunakan
parameter optimal dan 10
training sets dan 10 testing sets
Representasi pengetahuan Analisis hasil percobaan 10 training sets dan
10 testing sets
1 training set dan 1 testing set untuk percobaan Data diabetes
Pemilihan parameter AG yang paling optimal pada ukuran populasi = 10
Penambahan ukuran populasi pada parameter AG yang paling optimal (30 & 50) Percobaan Pencarian parameter AG optimal
pada ukuran populasi = 10
AG
Tidak Tidak Seleksi Crossover Mutasi Bangkitkan populasi baru Elitisme Ya Bangkitkan populasi awalFitness (Pop) < Fitness Threshold ? Mulai Pendefinisian kromosom Selesai Fitness (Populasi) Model Bentuk Rule Fuzzy ID3 Bentuk MF & Hitung derajat keanggotaan Training (FID3) Rules Testing (FIS Mamdani) Error Rate Ci = Fitness Ci Hitung Fitness Parameter MF terbaik i < ukuran populasi ? i = i + 1 Bentuk MF & Hitung
derajat keanggotaan kromosom Ci
i = 1
TG HDL
GPOST GLUN
seluruh atribut. Nilai parameter fungsi keanggotaan fuzzy ini direpresentasikan dalam bilangan bulat di dalam kromosom. Representasi nilai parameter fungsi keanggotaan fuzzy untuk atribut GPOST di dalam kromosom dapat dilihat pada Gambar 6, dan contoh kromosom dapat dilihat pada Gambar 7.
Gambar 6 Representasi nilai parameter fungsi keanggotaan fuzzy di dalam kromosom. 88 132 213 299 96 175 296 393
42 66 76 144 98 158 329 467
Gambar 7 Contoh kromosom.
2 Pembangkitan populasi awal
Populasi awal dibangkitkan secara acak dalam rentang nilai tertentu sesuai dengan ukuran populasi. Rentang nilai setiap parameter dalam fungsi keanggotaan fuzzy ditentukan dengan bantuan teknik clustering menggunakan fuzzy C-means (FCM). Data dari setiap atribut (GLUN, GPOST, HDL, TG) akan dikelompokan masing-masing menjadi tiga cluster. Satu cluster dianggap dapat mewakili satu himpunan fuzzy. Grafik hasil clustering dari satu atribut yaitu atribut GPOST dengan menggunakan FCM dapat dilihat pada Gambar 8.
Gambar 8 Grafik hasil clustering menggunakan FCM.
Nilai r adalah anggota cluster 1 yang memiliki derajat keanggotaan paling tinggi. Nilai s adalah anggota cluster 2 yang paling rendah. Nilai t adalah anggota cluster 2 yang paling tinggi. Nilai u adalah anggota cluster 3 yang memiliki derajat keanggotaan paling tinggi.
Grafik fungsi keanggotaan fuzzy dari satu atribut dapat dilihat pada Gambar 6. Empat nilai parameter fungsi keanggotaan fuzzy direpresentasikan oleh nilai a, b, c, dan d. Rentang nilai a, b, c, dan d dapat ditentukan setelah melakukan clustering dengan FCM dan diperoleh nilai r, s, t, dan u. Ilustrasi pencarian rentang nilai a, b, c, dan d yang mungkin dengan melibatkan nilai r, s, t dan u dapat dilihat pada Gambar 9. Panjang rentang nilai a, b, c, dan d adalah 2x. Nilai x merupakan nilai yang paling kecil dari selisih antara nilai minimum dengan r, r dengan s, s dengan t, t dengan u, dan u dengan nilai maksimum, kemudian dikurangi 1 untuk menghindari terjadinya overlap. Besar nilai x diperoleh dengan cara berikut:
x = (minimum ( (r – min), (s – r), (t – s)/4, (u – t), (max–u) ) ) – 1
Gambar 9 Panjang rentang nilai a, b, c, dan d. Sehingga, rentang nilai a, b, c, dan d adalah:
r - x ≤ a ≤ r + x s ≤ b ≤ s + 2x t – 2x ≤ c ≤ t u - x ≤ d ≤ u + x
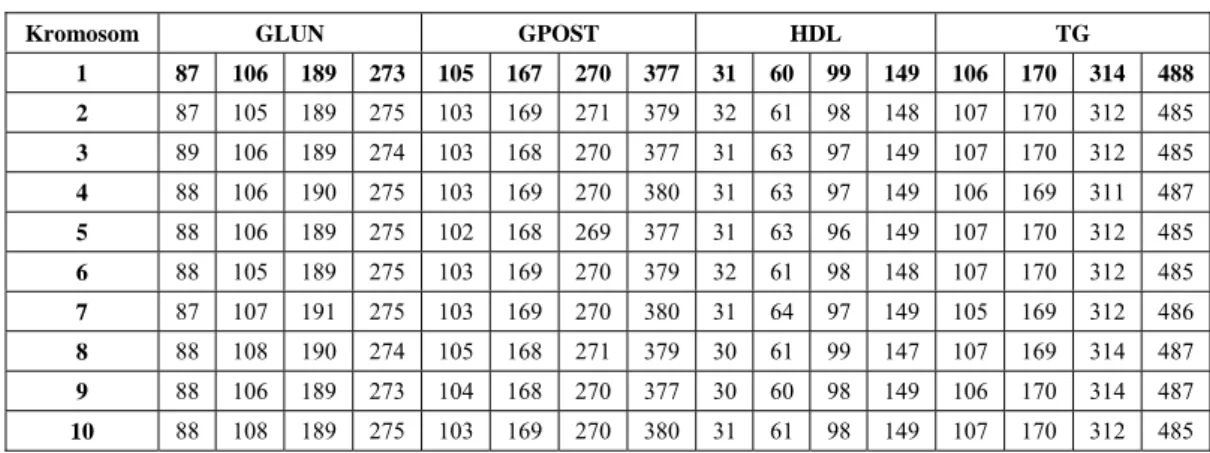
Salah satu contoh populasi awal berukuran 10 dapat dilihat pada Tabel 1.
96 175 296 393 0 100 200 300 400 500 600 700 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 De ra ja t GPOST
Cluster 1 Cluster 2 Cluster 3 r s t u c b min r s t u max x x 2x x 2x x a d GPOST 0 100 200 300 400 500 600 700 0 0.2 0.4 0.6 0.8 1 D e ra ja t ke an ggo taa n
Rendah Sedang Tinggi
Tabel 1 Contoh populasi awal berukuran 10
Kromosom GLUN GPOST HDL TG
1 73 124 194 282 98 165 269 357 43 53 88 144 89 152 311 493 2 82 105 185 291 100 151 258 357 25 61 95 156 97 162 316 493 3 73 122 191 275 94 167 266 355 46 59 81 152 95 173 330 477 4 88 107 190 273 102 167 270 375 29 62 94 139 97 163 313 487 5 84 107 204 289 85 157 262 369 29 68 81 150 90 158 315 483 6 88 116 188 278 104 172 261 358 47 62 78 146 107 170 314 485 7 70 122 189 271 92 152 263 361 42 65 96 142 108 170 330 471 8 89 110 200 280 104 168 273 362 31 70 80 148 109 160 317 478 9 72 115 197 277 96 169 260 360 28 54 98 156 98 164 329 474 10 90 112 195 282 101 158 277 359 42 51 81 147 99 153 320 481
3 Penghitungan nilai fitness
Pada penelitian ini, nilai fitness adalah nilai galat (error). Perhitungan nilai fitness dilakukan untuk setiap kromosom. Langkah-langkah untuk memperoleh nilai galat yaitu: a Bentuk fungsi keanggotaan fuzzy untuk
setiap atribut (GLUN, GPOST, HDL, dan TG) dan hitung derajat keanggotaan setiap data masing-masing atribut. Nilai derajat keanggotaan fuzzy setiap data akan digunakan untuk membentuk tree.
b Bentuk tree dengan menggunakan
algoritme fuzzy ID3, sehingga diperoleh aturan-aturan. Aturan-aturan dan fungsi keanggotaan fuzzy setiap atribut digunakan untuk membentuk FIS Mamdani.
c Melakukan testing dengan menggunakan FIS Mamdani, sehingga diperoleh nilai galat (error).
4 Evaluasi nilai fitness dengan fitness threshold
Nilai fitness terbaik adalah nilai galat yang paling rendah. Evaluasi nilai fitness dilakukan dengan cara membandingkan nilai fitness setiap kromosom dengan nilai fitness threshold. Pada penelitian ini, nilai fitness threshold ditentukan sebesar 0.05 karena diharapkan nilai galat lebih kecil atau sama dengan 0.05.
Jika ada kromosom yang memiliki nilai fitness lebih kecil daripada nilai fitness threshold, maka kromosom tersebut merupakan solusi yang memberikan parameter fungsi keanggotaan fuzzy yang terbaik bagi masing-masing atribut (GLUN, GPOST, HDL, dan TG). Jika solusi belum diperoleh berarti nilai fitness dari semua kromosom yang ada pada populasi masih lebih besar daripada nilai fitness threshold, maka populasi tersebut akan mengalami
elitisme, seleksi, rekombinasi, dan mutasi, sehingga akan terbentuk populasi baru.
5 Pembentukan populasi baru
• Elitisme
Jika ukuran populasi genap, maka dua kromosom yang memiliki nilai fitness terbaik akan dipertahankan untuk berada pada generasi selanjutnya. Jika ukuran populasi ganjil, maka satu kromosom yang memiliki nilai fitness terbaik akan dipertahankan untuk berada pada generasi selanjutnya. Hal ini dikarenakan jumlah kromosom harus genap dalam melakukan rekombinasi.
• Seleksi
Metode seleksi yang digunakan adalah roulette wheel. Seleksi roulette wheel memungkinkan kromosom dengan nilai fitness tinggi memiliki peluang untuk terpilih lebih besar daripada kromosom dengan nilai fitness rendah. Seleksi roulette wheel juga memungkinkan suatu kromosom terpilih lebih dari satu kali.
• Rekombinasi
Rekombinasi yang digunakan adalah rekombinasi satu titik (one-point crossover). Untuk melakukan rekombinasi, jumlah kromosom yang akan mengalami rekombinasi harus genap. Jika jumlah kromosom ganjil, maka salah satu kromosom harus dibuang (dikembalikan ke populasi).
• Mutasi
Mutasi dilakukan dengan cara menambah atau mengurangi satu nilai dari nilai gen yang akan mengalami mutasi secara acak. Penambahan atau pengurangan satu nilai merupakan cara untuk memberikan perubahan kecil pada populasi. Hal ini dikarenakan
representasi kromosom dalam bilangan bulat dan nilai satu merupakan nilai paling kecil yang berarti pada kasus ini.
Setelah dilakukan elitisme, seleksi, rekombinasi, dan mutasi diperoleh populasi baru dan selanjutnya dilakukan perhitungan nilai fitness untuk setiap kromosom pada populasi baru. Untuk memperoleh kromosom yang menjadi solusi, evaluasi nilai fitness
dengan fitness threshold dilakukan kembali. Proses pembentukan populasi baru, perhitungan nilai fitness, dan evaluasi nilai fitness dengan fitness threshold dilakukan secara berulang hingga mencapai kondisi terminasi algoritme genetika yaitu telah mencapai nilai fitness yang diinginkan atau telah mencapai maksimum generasi. Salah satu contoh populasi akhir berukuran 10 dapat dilihat pada Tabel 2.
Tabel 2 Contoh populasi akhir berukuran 10
Salah satu contoh kromosom yang menjadi solusi terbaik adalah kromosom pertama yang nilainya dicetak tebal dari sepuluh kromosom pada populasi akhir yang ada pada Tabel 2.
6 Pembentukan aturan akhir (tree hasil proses G-DT)
Jika parameter fungsi keanggotaan fuzzy yang paling baik telah diperoleh, maka aturan akhir yang merupakan tree dari hasil proses G-DT dapat dibentuk. Langkah-langkah yang dilakukan untuk membentuk aturan akhir (tree hasil proses G-DT) yaitu:
a Bentuk fungsi keanggotaan fuzzy untuk setiap atribut (GLUN, GPOST, HDL, dan TG) dan hitung derajat keanggotaan setiap data masing-masing atribut. Fungsi keanggotaan fuzzy ini merupakan hasil kerja algoritme genetika. Nilai derajat keanggotaan fuzzy setiap data akan digunakan untuk membentuk tree.
b Bentuk tree dengan menggunakan
algoritme fuzzy ID3, sehingga diperoleh aturan-aturan. Aturan-aturan ini merupakan aturan akhir yaitu tree hasil dari proses G-DT.
• Percobaan untuk mencari parameter
algoritme genetika yang optimal
Percobaan untuk mencari parameter algoritme genetika yang optimal dilakukan dengan variasi tingkat rekombinasi, tingkat mutasi, jumlah maksimum generasi, dan ukuran populasi. Variasi keempat nilai parameter itu yaitu:
a tingkat rekombinasi: 50%, 60%, 70%, 80%, 90%, dan 100%,
b tingkat mutasi: 1%, 5%, dan 10%,
c maksimum generasi: 50, 100, 150, 200, dan 250,
d ukuran populasi: 10, 30, dan 50.
Percobaan ini dilakukan dengan menggunakan nilai fuzziness control threshold (FCT) sebesar 98% dan nilai leaf decision threshold (LDT) sebesar 3%. Nilai ini digunakan karena berdasarkan hasil penelitian sebelumnya, nilai FCT dan LDT ini merupakan nilai FCT dan LDT yang menghasilkan tree yang paling baik.
• Training G-DT
Training G-DT dilakukan dengan sepuluh training sets. Setiap training set dilakukan pengulangan training sebanyak sepuluh kali.
Kromosom GLUN GPOST HDL TG
1 87 106 189 273 105 167 270 377 31 60 99 149 106 170 314 488 2 87 105 189 275 103 169 271 379 32 61 98 148 107 170 312 485 3 89 106 189 274 103 168 270 377 31 63 97 149 107 170 312 485 4 88 106 190 275 103 169 270 380 31 63 97 149 106 169 311 487 5 88 106 189 275 102 168 269 377 31 63 96 149 107 170 312 485 6 88 105 189 275 103 169 270 379 32 61 98 148 107 170 312 485 7 87 107 191 275 103 169 270 380 31 64 97 149 105 169 312 486 8 88 108 190 274 105 168 271 379 30 61 99 147 107 169 314 487 9 88 106 189 273 104 168 270 377 30 60 98 149 106 170 314 487 10 88 108 189 275 103 169 270 380 31 61 98 149 107 170 312 485
Lingkup Pengembangan Sistem
Perangkat keras yang digunakan berupa notebook dengan spesifikasi:
• processor: Intel Core 2 Duo 1.66 GHz, • memori: 1,512 GB, dan
• harddisk: 80GB.
Perangkat lunak yang digunakan yaitu: • sistem operasi: Window XP,
• Matlab 7.0.1 sebagai bahasa pemrograman, dan
• Microsoft Excel 2003 sebagai tempat penyimpanan data.
HASIL DAN PEMBAHASAN
Pemilihan Training Set dan Testing SetPembagian data menggunakan 10-fold cross validation menghasilkan sepuluh training sets dan 10 testing sets. Untuk percobaan mencari parameter algoritme genetika yang optimal digunakan hanya satu training set saja. Pemilihan training set ini berdasarkan hasil eksekusi program G-DT dengan menggunakan sepuluh training sets dan sepuluh testing sets serta persebaran data pada masing-masing training set dan testing set. Parameter algoritme genetika yang digunakan dalam pemilihan training set yaitu: fitness threshold = 0.05, ukuran populasi = 10, maksimum generasi = 50, tingkat rekombinasi = 50%, dan tingkat mutasi = 1%. Hasil eksekusi program G-DT menggunakan sepuluh training sets dan sepuluh testing sets dapat dilihat pada Tabel 3.
Tabel 3 Hasil eksekusi program G-DT menggunakan 10 training sets dan 10 testing sets
Dari total data sebanyak 290 record, terdapat data negatif diabetes sebanyak 273
record dan data positif diabetes sebanyak 17 record. Dengan 10-fold cross validation, data sebanyak 290 record dibagi menjadi training set dan testing set. Training set berjumlah 261 record dan testing set berjumlah 29 record. Persebaran data negatif dan positif diabetes pada setiap training set dan testing set dapat dilihat pada Tabel 4.
Tabel 4 Persebaran data negatif dan positif diabetes pada setiap training set dan testing set
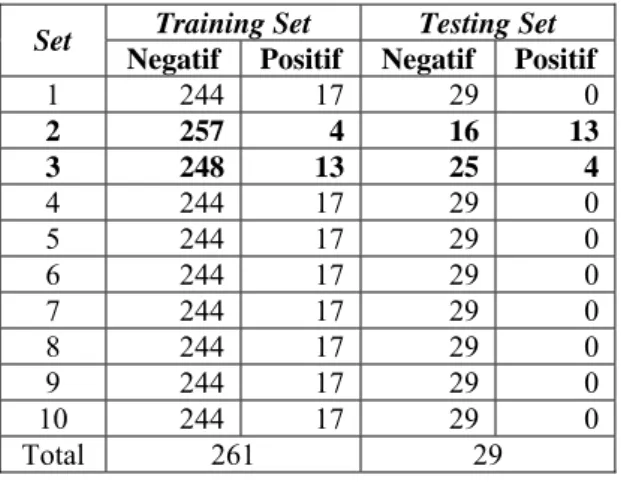
Dari hasil eksekusi program G-DT menggunakan sepuluh training sets dan sepuluh testing sets terlihat bahwa hanya training set 2 dan 3 yang belum memperoleh akurasi 100%. Dengan menggunakan parameter algoritme genetika yang optimal diharapkan akurasi pada training set 2 dan 3 meningkat. Sehingga, training set 2 dan 3 menjadi calon training set yang akan digunakan dalam percobaan mencari parameter algoritme genetika yang optimal.
Untuk menentukan satu training set yang akan digunakan dalam percobaan, persebaran
data pada training set dan testing set 2 dan 3 dilihat. Pada Tabel 4, dapat dilihat bahwa 13 record data positif diabetes dari total 17 record positif diabetes ada pada testing set 2. Hanya 4 record data positif diabetes yang ada pada training set 2. Sedangkan pada training set 3 terdapat 13 record data positif diabetes dan pada testing set 3 terdapat 4 record data positif diabetes. Hal ini menunjukkan bahwa persebaran data pada training set dan testing set 3 lebih baik daripada training set dan testing set 2. Sehingga, percobaan mencari parameter algoritme genetika yang optimal dilakukan dengan menggunakan training set dan testing set 3.
Set Akurasi Jumlah Aturan Waktu Total (detik) Jumlah Iterasi 1 100.00% 20 14,906 1 2 58.62% 17 209,562 50 3 89.66% 25 320,938 50 4 100.00% 20 15,031 1 5 100.00% 21 15,109 1 6 100.00% 21 14,937 1 7 100.00% 22 14,578 1 8 100.00% 19 14,985 1 9 100.00% 22 14,938 1 10 100.00% 21 15,344 1 Rataan 94.83% 20.8
Training Set Testing Set Set
Negatif Positif Negatif Positif
1 244 17 29 0 2 257 4 16 13 3 248 13 25 4 4 244 17 29 0 5 244 17 29 0 6 244 17 29 0 7 244 17 29 0 8 244 17 29 0 9 244 17 29 0 10 244 17 29 0 Total 261 29
Percobaan untuk Mencari Parameter Algoritme Genetika yang Optimal
Setelah memilih training set yang akan digunakan untuk percobaan, percobaan untuk mencari parameter algoritme genetika yang optimal dapat dilakukan. Pertama, percobaan dengan ukuran populasi sebesar 10 dilakukan. Selanjutnya, percobaan dengan ukuran populasi sebesar 30 dan 50 dilakukan. Parameter algoritme genetika yang optimal ditentukan berdasarkan hasil percobaan. • Ukuran populasi sebesar 10
Pada percobaan dengan ukuran populasi sebesar 10, dilakukan dengan variasi tingkat rekombinasi (50%, 60%, 70%, 80%, 90%, dan 100%), tingkat mutasi (1%, 5%, dan 10%), dan maksimum generasi (50, 100, 150, 200, 250). Total percobaan yang dilakukan adalah 90 percobaan. Hasil dari 90 percobaan ini dapat dilihat pada Lampiran 1. Alur pemilihan parameter yang optimal bagi ukuran populasi sebesar 10 dapat dilihat pada Gambar 10.
Gambar 10 Alur pemilihan parameter yang optimal bagi ukuran populasi sebesar 10.
Dari 90 percobaan, diperoleh 58 kombinasi parameter dengan nilai fitness yang terbaik sebesar 0.0690. Dari 58 kombinasi parameter, hanya 12 kombinasi parameter yang memiliki waktu eksekusi kurang dari 360 detik. Dua belas kombinasi parameter tersebut adalah nilai yang dicetak tebal pada Lampiran 1.
Dua belas kombinasi parameter tersebut merupakan parameter algoritme genetika yang baik. Dua belas kombinasi parameter ini dapat digunakan sebagai parameter algoritme genetika untuk training G-DT. Untuk mencari parameter algoritme genetika yang paling optimal diantara 12 kombinasi parameter tersebut, dilakukan percobaan sebanyak 10 kali untuk masing-masing 12 kombinasi parameter. Total percobaan yang dilakukan
adalah 120 percobaan. Hasil percobaan untuk 12 kombinasi parameter dapat dilihat pada Lampiran 2.
Dari 12 kombinasi parameter dan masing-masing dilakukan 10 iterasi, hanya tiga kombinasi parameter yang menghasilkan nilai fitness relatif lebih stabil dengan menghasilkan nilai fitness sebesar 0.0690 sebanyak sembilan buah dan nilai fitness sebesar 0.1034 sebanyak satu buah. Tiga kombinasi parameter tersebut yaitu:
a. tingkat rekombinasi = 80%, tingkat mutasi = 10%, dan maksimum generasi = 50, b. tingkat rekombinasi = 90%, tingkat mutasi
= 10%, dan maksimum generasi = 50, dan c. tingkat rekombinasi = 100%, tingkat
mutasi = 1%, dan maksimum generasi = 50.
Tiga kombinasi parameter di atas merupakan kombinasi parameter yang terbaik bagi training set dan testing set 3. Untuk memperoleh parameter yang lebih optimal lagi, dilakukan percobaan untuk masing-masing tiga kombinasi parameter itu dengan menggunakan training set dan testing set 2. Training set 2 digunakan karena training set 2 merupakan training set yang memiliki akurasi masih di bawah 100% selain training set 3. Percobaan untuk tiga kombinasi parameter ini juga dilakukan masing-masing 10 kali percobaan. Total percobaan yang dilakukan adalah 30 percobaan. Hasil dari 30 kali percobaan ini dapat dilihat pada Lampiran 3.
Dari 30 percobaan, kombinasi parameter yang terdiri dari tingkat rekombinasi sebesar 90%, tingkat mutasi sebesar 10%, dan maksimum generasi sebesar 50 generasi merupakan kombinasi parameter yang terbaik bagi training set dan testing set 2. Parameter ini menghasilkan nilai fitness yang stabil dengan menghasilkan nilai fitness sebesar 0.3793 pada 10 percobaan yang dilakukan. Sehingga, parameter algoritme yang optimal dengan ukuran populasi sebesar 10 yaitu: a tingkat rekombinasi: 90%,
b tingkat mutasi: 10%, dan c maksimum generasi: 50.
• Ukuran populasi sebesar 30 dan 50 Pada percobaan dengan ukuran populasi sebesar 30 dan 50, juga dilakukan dengan variasi tingkat rekombinasi (50%, 60%, 70%, 80%, 90%, dan 100%), tingkat mutasi (1%, 5%, dan 10%), dan maksimum generasi (50, 100, 150, 200, 250). Total percobaan untuk 58 kombinasi parameter
dengan nilai fitness terbaik
12 kombinasi parameter dengan nilai fitness terbaik dan waktu eksekusi < 360 detik
3 kombinasi parameter yang terbaik untuk
training set 3 (pengulangan 10 kali)
1 kombinasi parameter yang terbaik untuk
training set 3 dan 2 Æ parameter AG
masing-masing ukuran populasi adalah 90 percobaan.
Waktu eksekusi dengan ukuran populasi sebesar 30 dan 50 relatif lama (lebih dari 900 detik), sehingga percobaan dengan ukuran populasi sebesar 30 dan 50 ini tidak dilakukan untuk semua kombinasi parameter. Percobaan dilakukan hanya dengan kombinasi parameter yang optimal pada ukuran populasi sebesar 10 yaitu kombinasi parameter yang terdiri dari tingkat rekombinasi sebesar 90% dan tingkat mutasi sebesar 10%. Percobaan dilakukan dengan variasi nilai maksimum generasi (50, 100, 150, 200, dan 250). Total percobaan yang dilakukan adalah 10 percobaan. Hasil percobaan ini dapat dilihat pada Lampiran 4.
Dari hasil percobaan tersebut, besar nilai fitness dengan maksimum generasi sebesar 250 sama dengan nilai fitness dengan maksimum generasi sebesar 50 yaitu sebesar 0.0690. Sehingga, maksimum generasi sebesar 50 merupakan maksimum generasi yang baik bagi ukuran populasi sebesar 30 dan 50. • Penentuan parameter yang optimal
Total percobaan yang dilakukan adalah 250 percobaan. Dari 250 percobaan, dapat disimpulkan hasil percobaan ke dalam dua kelompok yaitu:
a percobaan dengan variasi tingkat rekombinasi dan tingkat mutasi, dan
b percobaan dengan variasi ukuran populasi dan maksimum generasi.
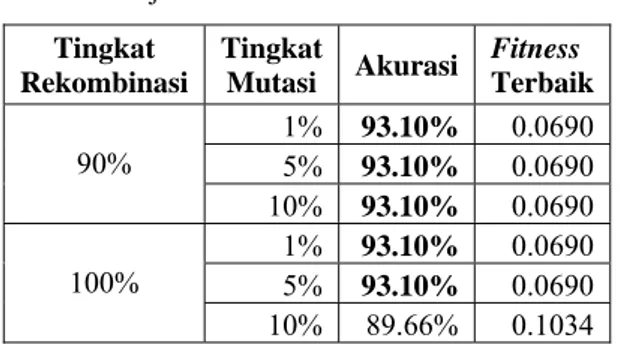
Hasil percobaan dengan variasi tingkat rekombinasi dan tingkat mutasi dapat dilihat pada Tabel 5. Percobaan ini dilakukan pada ukuran populasi sebesar 10 dan maksimum generasi sebesar 50 generasi.
Tabel 5 Hasil percobaan dengan variasi tingkat rekombinasi dan tingkat mutasi
Tabel 5 Lanjutan
Dari Tabel 5, ada 12 kombinasi parameter yang baik yaitu kombinasi parameter yang memiliki nilai fitness sebesar 0.0690. Dari 12 kombinasi parameter ini, telah disimpulkan parameter yang optimal yaitu:
a tingkat rekombinasi: 90%, dan b tingkat mutasi: 10%.
Hasil percobaan dengan variasi ukuran populasi dan maksimum generasi dapat dilihat pada Tabel 6. Percobaan ini dilakukan dengan tingkat rekombinasi sebesar 90% dan tingkat mutasi sebesar 10%.
Tabel 6 Hasil percobaan dengan variasi ukuran populasi dan maksimum generasi
Dari Tabel 6, besar nilai fitness terbaik pada ukuran populasi sebesar 30 dan 50 tidak lebih rendah daripada nilai fitness terbaik pada ukuran populasi sebesar 10. Waktu eksekusi percobaan dengan ukuran populasi sebesar 30 dan 50 lebih lama daripada ukuran populasi sebesar 10. Pada ukuran populasi sebesar 10, 30, dan 50, besar nilai fitness terbaik pada maksimum generasi sebesar 250 tidak lebih
Tingkat Rekombinasi Tingkat Mutasi Akurasi Fitness Terbaik 1% 89.66% 0.1034 5% 93.10% 0.0690 50% 10% 89.66% 0.1034 1% 93.10% 0.0690 5% 93.10% 0.0690 60% 10% 93.10% 0.0690 1% 89.66% 0.1034 5% 93.10% 0.0690 70% 10% 86.21% 0.1379 1% 93.10% 0.0690 5% 89.66% 0.1034 80% 10% 93.10% 0.0690 Tingkat Rekombinasi Tingkat Mutasi Akurasi Fitness Terbaik 1% 93.10% 0.0690 5% 93.10% 0.0690 90% 10% 93.10% 0.0690 1% 93.10% 0.0690 5% 93.10% 0.0690 100% 10% 89.66% 0.1034 Ukuran Popu lasi Maks. Gene Rasi Akurasi Fitness Terbaik Waktu (detik) 50 93.10% 0.0690 331,344 100 93.10% 0.0690 621,937 150 93.10% 0.0690 989,718 200 93.10% 0.0690 1168,190 10 250 93.10% 0.0690 1453,800 50 93.10% 0.0690 1014,110 100 93.10% 0.0690 2406,530 150 93.10% 0.0690 3140,270 200 93.10% 0.0690 4502,950 30 250 93.10% 0.0690 5732,880 50 93.10% 0.0690 1809,130 100 93.10% 0.0690 3866,530 150 93.10% 0.0690 5677,980 200 93.10% 0.0690 7172,590 50 250 93.10% 0.0690 7865,800
rendah daripada nilai fitness terbaik pada maksimum generasi sebesar 50. Waktu eksekusi percobaan dengan maksimum generasi sebesar 250 lebih lama daripada maksimum generasi sebesar 50.
Peningkatan ukuran populasi dan maksimum generasi tidak menghasilkan nilai fitness yang lebih rendah dari 0.0690 dan akurasi lebih tinggi dari 93.10%. Berdasarkan hasil percobaan tersebut ditetapkan bahwa ukuran populasi yang baik adalah 10 dan maksimum generasi yang baik adalah 50 generasi.
Setelah menganalisis hasil percobaan, diperoleh parameter algoritme genetika yang optimal bagi kasus ini. Parameter algoritme genetika yang optimal bagi kasus ini yaitu: a tingkat rekombinasi: 90%,
b tingkat mutasi: 10%, c ukuran populasi: 10, dan d maksimum generasi: 50.
Training G-DT
Setelah parameter algoritme genetika yang optimal diperoleh, proses training G-DT dapat dilakukan. Proses training ini menggunakan sepuluh training sets yang sebelumnya telah dibagi dengan metode 10-fold cross validation. Untuk setiap training set dilakukan 10 kali iterasi. Satu hasil training yang mewakili 10 hasil training dari suatu training set ditentukan dengan kriteria berikut yang diurutkan berdasarkan prioritas:
1 nilai akurasi yang paling tinggi,
2 jumlah aturan yang dihasil yang paling sering muncul (modus), dan
3 waktu eksekusi yang paling cepat.
Hasil training untuk training set 2 dapat dilihat pada Tabel 7. Hasil training set 3 dapat dilihat pada Tabel 8.
Tabel 7 Hasil training untuk training set 2
Tabel 8 Hasil training untuk training set 3
Hasil training dari training set 2 yaitu dari 10 iterasi yang dilakukan diperoleh nilai akurasi yang sama yaitu 62.07%. Jumlah aturan yang paling sering dihasilkan adalah 17 aturan dan 18 aturan. Empat iterasi dari 10 iterasi yang dilakukan menghasilkan aturan yang berjumlah 17 aturan. Empat iterasi menghasilkan aturan yang berjumlah 18 aturan. Tujuh belas dan delapan belas aturan yang dihasilkan ini masing-masing memiliki 1 aturan mengandung kelas target positif diabetes. Dari delapan iterasi ini, yang memiliki waktu eksekusi paling cepat adalah iterasi ke-5 yaitu 200,547 detik. Sehingga, hasil training yang mewakili hasil training dari training set 2 adalah hasil training pada iterasi ke-5.
Hasil training dari training set 3 yaitu dari 10 iterasi yang dilakukan diperoleh nilai akurasi sebesar 93.10% sebanyak 9 iterasi dan nilai akurasi sebesar 89.66% sebanyak 1 iterasi. Jumlah aturan yang paling sering dihasilkan adalah 21 aturan. Tiga iterasi dari 10 iterasi yang dilakukan menghasilkan aturan yang berjumlah 21 aturan. Dua puluh satu aturan yang dihasilkan ini terdiri dari 20 aturan mengandung kelas target negatif diabetes dan 1 aturan mengandung kelas target positif diabetes. Dari tiga iterasi yang menghasilkan 21 aturan ini, yang memiliki waktu eksekusi paling cepat adalah iterasi ke-9 yaitu 264,85ke-9 detik. Sehingga, hasil training yang mewakili hasil training dari training set 3 adalah hasil training pada iterasi ke-9.
Hasil training set 1, training set 4, training set 5, training set 6, training set 7, training set 8, training set 9, dan training set 10 dapat dilihat pada Lampiran 5. Pemilihan satu hasil training untuk mewakili 10 hasil training suatu training set ini juga dilakukan
Set Akurasi Waktu (detik) Jumlah Aturan 1 62.07% 231,344 18 (17 negatif, 1 positif) 2 62.07% 216,141 17 (16 negatif, 1 positif) 3 62.07% 220,281 17 (16 negatif, 1 positif) 4 62.07% 199,360 16 (15 negatif, 1 positif) 5 62.07% 200,547 17 (16 negatif, 1 positif) 6 62.07% 213,359 18 (17 negatif, 1 positif) 7 62.07% 227,078 18 (17 negatif, 1 positif) 8 62.07% 204,969 17 (16 negatif, 1 positif) 9 62.07% 240,250 19 (18 negatif, 1 positif) 10 62.07% 223,735 18 (17 negatif, 1 positif)
Set Akurasi Waktu (detik) Jumlah Aturan 1 93.10% 324,594 28 (26 negatif, 2 positif) 2 93.10% 328,766 26 (25 negatif, 1 positif) 3 93.10% 310,985 21 (20 negatif, 1 positif) 4 93.10% 321,031 25 (23 negatif, 2 positif) 5 89.66% 302,500 20 (19 negatif, 1 positif) 6 93.10% 306,156 22 (20 negatif, 2 positif) 7 93.10% 317,187 25 (24 negatif, 1 positif) 8 93.10% 306,375 21 (20 negatif, 1 positif) 9 93.10% 264,859 21 (20 negatif, 1 positif) 10 93.10% 319,531 24 (23 negatif, 1 positif)
untuk 8 training sets ini. Record yang dicetak tebal pada Lampiran 5 merupakan wakil hasil training dari training set tersebut. Hasil training untuk setiap training set dapat dilihat pada Tabel 9.
Tabel 9 Hasil training G-DT untuk setiap training set
Dari Tabel 9, terlihat bahwa nilai akurasi pada training set 2 dan training set 3 mengalami peningkatan dengan menggunakan parameter algoritme genetika yang optimal. Hasil dari training set menggunakan parameter algoritme genetika yang tidak optimal dapat dilihat pada Tabel 3. Dengan menggunakan parameter yang tidak optimal, untuk training set 2 diperoleh nilai akurasi sebesar 58.62% dan training set 3 diperoleh nilai akurasi sebesar 89.66%. Setelah menggunakan parameter yang optimal, nilai akurasi training set 2 dari 58.62% naik menjadi 62.07%. Pada training set 3, nilai akurasi dari 89.66% naik menjadi 93.10%.
Rata-rata akurasi yang diperoleh dengan menggunakan parameter yang tidak optimal adalah sebesar 94.83%. Rata-rata akurasi yang diperoleh dengan menggunakan parameter yang optimal adalah sebesar 95.52%. Hal ini menunjukkan bahwa terjadi peningkatan rata-rata akurasi dengan menggunakan parameter yang optimal sebesar 0.69%.
Sebagian besar jumlah aturan yang dihasilkan dengan menggunakan parameter
yang optimal mengalami peningkatan dari jumlah aturan yang dihasilkan dengan menggunakan parameter yang tidak optimal. Tujuh dari sepuluh aturan yang dihasilkan mengalami peningkatan dalam hal jumlah. Tiga aturan dihasilkan dengan jumlah yang sama. Hal ini disebabkan perbedaan bilangan acak yang dibangkitkan untuk membentuk populasi awal dan penggunaan parameter yang berbeda. Kedua hal ini menyebabkan solusi yang dihasilkan akan berbeda sehingga tree yang dihasilkan akan berbeda. Parameter yang menghasilkan nilai akurasi tertinggi merupakan parameter yang terbaik.
Rata-rata jumlah aturan yang dihasilkan dengan menggunakan parameter yang tidak optimal adalah 20.8. Rata-rata aturan yang dihasilkan dengan menggunakan parameter yang optimal adalah 22.6. Hal ini menunjukkan bahwa terjadi peningkatan rata-rata jumlah aturan yang dihasilkan dengan menggunakan parameter yang optimal.
Representasi Pengetahuan
Model yang dihasilkan dari proses training digunakan untuk mengetahui label kelas pada data yang baru. Model tersebut dipilih berdasarkan tiga kriteria berikut yang diurutkan berdasarkan prioritas:
1 Model yang mencakup semua kelas target yang mungkin muncul dalam testing set, dalam penelitian ini kelas target yang mungkin muncul yaitu kelas target 1 (negatif diabetes) dan kelas target 2 (positif diabetes).
2 Model dengan akurasi yang paling tinggi, semakin tinggi akurasinya maka semakin baik model tersebut.
3 Model dengan jumlah aturan yang paling banyak.
Berdasarkan kriteria tersebut maka model yang dipilih adalah hasil training dari pasangan training set dan testing set keenam dengan jumlah aturan sebanyak 27 aturan. Dari 27 aturan tersebut hanya 2 aturan yang mengandung kelas target positif diabetes. Model yang dihasilkan adalah sebagai berikut: 1 IF GPOST rendah THEN Negatif
Diabetes
2 IF GPOST sedang AND GLUN rendah AND TG rendah AND HDL rendah THEN Negatif Diabetes
3 IF GPOST sedang AND GLUN rendah AND TG rendah AND HDL sedang THEN Negatif Diabetes
Set Akurasi Jumlah Aturan Waktu Total (detik) 1 100.00% (24 negatif, 2 positif) 26 15,031 2 62.07% (16 negatif, 1 positif) 17 207,204 3 93.10% (20 negatif, 1 positif) 21 271,484 4 100.00% (24 negatif, 1 positif) 25 15,563 5 100.00% (20 negatif, 3 positif) 23 15,188 6 100.00% (25 negatif, 2 positif) 27 15,063 7 100.00% (22 negatif, 0 positif) 22 14,797 8 100.00% (19 negatif, 1 positif) 20 14,625 9 100.00% (22 negatif, 0 positif) 22 15,016 10 100.00% (21 negatif, 2 positif) 23 15,485 Rataan 95.52% 22.6