ABSTRAK
WELLYA SEPTIN. Optimasi Fuzzy Decision Tree Menggunakan Algoritme Genetika pada Data Diabetes. Dibimbing oleh IMAS S. SITANGGANG dan IRMAN HERMADI.
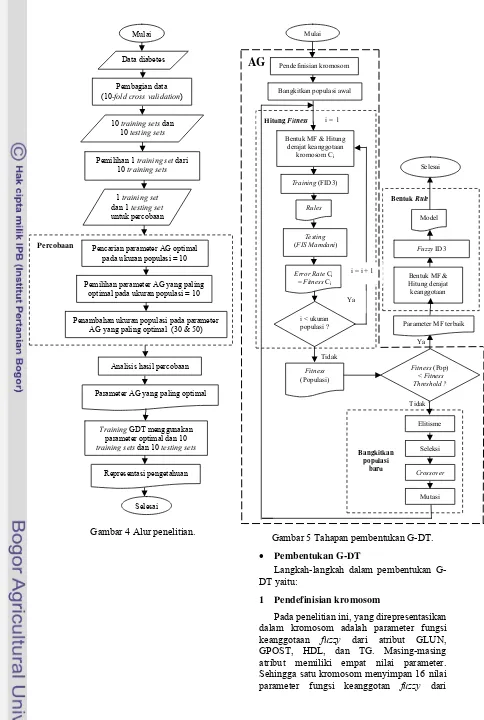
Hasil survey Organisasi Kesehatan Dunia (WHO) pada tahun 2004, menyatakan Indonesia menempati urutan keempat terbesar dalam jumlah penderita kencing manis (diabetes melitus) di dunia setelah India, Cina, dan Amerika Serikat. Data diabetes terkait hasil pemeriksaan laboratorium dari pasien di rumah sakit dibiarkan menggunung tanpa digunakan secara maksimal. Oleh karena itu, penelitian dengan mengaplikasikan teknik data mining pada data diabetes perlu dilakukan agar diperoleh informasi mengenai karakteristik pasien yang dinyatakan positif diabetes atau negatif diabetes. Salah satu output dari teknik data mining adalah pohon keputusan (decision tree) yang dapat digunakan untuk memprediksi apakah seseorang menderita diabetes atau tidak. Penelitian ini menggunakan salah satu teknik data mining yaitu teknik klasifikasi dengan menggunakan metode fuzzy decision tree. Algoritme decision tree yang digunakan yaitu fuzzy ID3 (Iterative Dichotomiser 3). Algoritme genetika digunakan sebagai teknik optimasi terhadap fuzzy decision tree (FDT) sehingga diperoleh genetically optimized fuzzy decision tree (G-DT). Bagian FDT yang dioptimasi dengan algoritme genetika adalah fungsi keanggotaan fuzzy.
Hasil penelitian ini berupa model (classifier), fungsi keanggotaan fuzzy yang telah dioptimasi, dan nilai akurasi G-DT yang lebih baik daripada nilai akurasi FDT. Model yang dihasilkan dari proses training G-DT mengandung 27 aturan yang terdiri atas 25 aturan mengandung kelas target negatif diabetes dan dua aturan mengandung kelas target positif diabetes. Model yang dihasilkan dari proses training FDT mengandung 30 aturan yang terdiri atas 29 aturan mengandung kelas target negatif diabetes dan satu aturan mengandung kelas target positif diabetes. Fungsi keanggotaan yang digunakan dalam pembentukan G-DT berbeda dengan FDT. Pada FDT, fungsi keanggotaan fuzzy telah ditentukan dari awal. Sedangkan pada G-DT, fungsi keanggotaan diperoleh selama pembelajaran. Rata-rata nilai akurasi G-DT meningkat sebesar 4.83% dari rata-rata nilai akurasi FDT. Rata-rata akurasi FDT adalah sebesar 90.69%, sedangkan rata-rata akurasi G-DT adalah sebesar 95.52%.
OPTIMASI FUZZY DECISION TREE MENGGUNAKAN ALGORITME GENETIKA
PADA DATA DIABETES
WELLYA SEPTIN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
22
DAFTAR PUSTAKA
Cox E. 2005. Fuzzy Modeling and Genetic Algorithms for Data Mining and Exploration. USA: Morgan Kaufman Publishers.
Fu L. 1994. Neural Network In Computer Intelligence. Singapura: McGraw Hill. Han J, Kamber M. 2006. Data Mining:
Concepts and Techniques. USA: Morgan Kaufman Publishers.
Jang JSR, Sun CT, Mizutani Eiji. 1997. Neuro-Fuzzy and Soft Computing. London: Prentice-Hall International, Inc.
Kantardzic M. 2003. Data Mining: Concepts, Models, Methods, and Algorithms. Wiley-Interscience.
Lawrence D. 1991. Handbook of Genetic Algorithms. New york: Van Nostrand Reinhold.
Liang G. 2005. A Comparative Study of Three Decision Tree Algorithms: ID3, Fuzzy ID3 and Probabilistic Fuzzy ID3. Rotterdam: Informatic & Ecosnomics Eramus University Rotterdam.
Marsala C. 1998. Application of Fuzzy Rule Induction to Data Mining. France: University Pierre et Marie Curie. Michalewicz Z. 1996. Genetic Algorithms +
Data Structure = Evolution Programs. New York: Springer-Verlag Berlin Heidelberg.
Pedryez W, Sosnowski ZA. 2005. Genetically Optimized Fuzzy Decision Trees. IEEE Transactions on Systems, Man, and Cybernetics vol.35 no.3.
11
Lingkup Pengembangan Sistem
Perangkat keras yang digunakan berupa notebook dengan spesifikasi:
• processor: Intel Core 2 Duo 1.66 GHz,
• memori: 1,512 GB, dan
• harddisk: 80GB.
Perangkat lunak yang digunakan yaitu:
• sistem operasi: Window XP,
• Matlab 7.0.1 sebagai bahasa pemrograman, dan
• Microsoft Excel 2003 sebagai tempat penyimpanan data.
HASIL DAN PEMBAHASAN
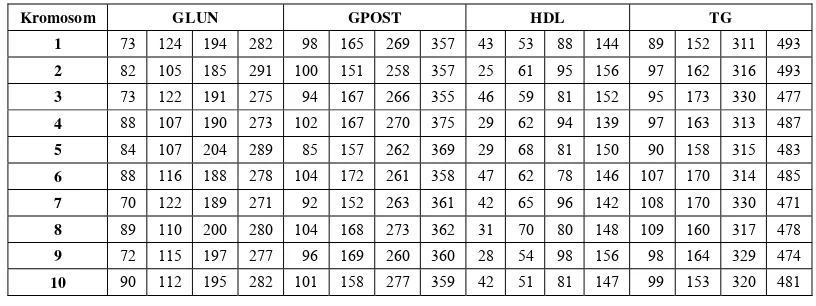
Pemilihan Training Set dan Testing Set Pembagian data menggunakan 10-fold cross validation menghasilkan sepuluh training sets dan 10 testing sets. Untuk percobaan mencari parameter algoritme genetika yang optimal digunakan hanya satu training set saja. Pemilihan training set ini berdasarkan hasil eksekusi program G-DT dengan menggunakan sepuluh training sets dan sepuluh testing sets serta persebaran data pada masing-masing training set dan testing set. Parameter algoritme genetika yang digunakan dalam pemilihan training set yaitu: fitness threshold = 0.05, ukuran populasi = 10, maksimum generasi = 50, tingkat rekombinasi = 50%, dan tingkat mutasi = 1%. Hasil eksekusi program G-DT menggunakan sepuluh training sets dan sepuluh testing sets dapat dilihat pada Tabel 3.
Tabel 3 Hasil eksekusi program G-DT menggunakan 10 training sets dan 10 testing sets
Dari total data sebanyak 290 record, terdapat data negatif diabetes sebanyak 273
record dan data positif diabetes sebanyak 17 record. Dengan 10-fold cross validation, data sebanyak 290 record dibagi menjadi training set dan testing set. Training set berjumlah 261 record dan testing set berjumlah 29 record. Persebaran data negatif dan positif diabetes pada setiap training set dan testing set dapat dilihat pada Tabel 4.
Tabel 4 Persebaran data negatif dan positif diabetes pada setiap training set dan testing set
Dari hasil eksekusi program G-DT menggunakan sepuluh training sets dan sepuluh testing sets terlihat bahwa hanya training set 2 dan 3 yang belum memperoleh akurasi 100%. Dengan menggunakan parameter algoritme genetika yang optimal diharapkan akurasi pada training set 2 dan 3 meningkat. Sehingga, training set 2 dan 3 menjadi calon training set yang akan digunakan dalam percobaan mencari parameter algoritme genetika yang optimal.
Untuk menentukan satu training set yang akan digunakan dalam percobaan, persebaran data pada training set dan testing set 2 dan 3 dilihat. Pada Tabel 4, dapat dilihat bahwa 13 record data positif diabetes dari total 17 record positif diabetes ada pada testing set 2. Hanya 4 record data positif diabetes yang ada pada training set 2. Sedangkan pada training set 3 terdapat 13 record data positif diabetes dan pada testing set 3 terdapat 4 record data positif diabetes. Hal ini menunjukkan bahwa persebaran data pada training set dan testing set 3 lebih baik daripada training set dan testing set 2. Sehingga, percobaan mencari parameter algoritme genetika yang optimal dilakukan dengan menggunakan training set dan testing set 3.
Set Akurasi Jumlah
Aturan
Waktu Total (detik)
Jumlah Iterasi
1 100.00% 20 14,906 1
2 58.62% 17 209,562 50
3 89.66% 25 320,938 50
4 100.00% 20 15,031 1
5 100.00% 21 15,109 1
6 100.00% 21 14,937 1
7 100.00% 22 14,578 1
8 100.00% 19 14,985 1
9 100.00% 22 14,938 1
10 100.00% 21 15,344 1
Rataan 94.83% 20.8
Training Set Testing Set Set
Negatif Positif Negatif Positif
1 244 17 29 0
2 257 4 16 13
3 248 13 25 4
4 244 17 29 0
5 244 17 29 0
6 244 17 29 0
7 244 17 29 0
8 244 17 29 0
9 244 17 29 0
10 244 17 29 0
12
Percobaan untuk Mencari Parameter Algoritme Genetika yang Optimal
Setelah memilih training set yang akan digunakan untuk percobaan, percobaan untuk mencari parameter algoritme genetika yang optimal dapat dilakukan. Pertama, percobaan dengan ukuran populasi sebesar 10 dilakukan. Selanjutnya, percobaan dengan ukuran populasi sebesar 30 dan 50 dilakukan. Parameter algoritme genetika yang optimal ditentukan berdasarkan hasil percobaan.
• Ukuran populasi sebesar 10
Pada percobaan dengan ukuran populasi sebesar 10, dilakukan dengan variasi tingkat rekombinasi (50%, 60%, 70%, 80%, 90%, dan 100%), tingkat mutasi (1%, 5%, dan 10%), dan maksimum generasi (50, 100, 150, 200, 250). Total percobaan yang dilakukan adalah 90 percobaan. Hasil dari 90 percobaan ini dapat dilihat pada Lampiran 1. Alur pemilihan parameter yang optimal bagi ukuran populasi sebesar 10 dapat dilihat pada Gambar 10.
Gambar 10 Alur pemilihan parameter yang optimal bagi ukuran populasi sebesar 10.
Dari 90 percobaan, diperoleh 58 kombinasi parameter dengan nilai fitness yang terbaik sebesar 0.0690. Dari 58 kombinasi parameter, hanya 12 kombinasi parameter yang memiliki waktu eksekusi kurang dari 360 detik. Dua belas kombinasi parameter tersebut adalah nilai yang dicetak tebal pada Lampiran 1.
Dua belas kombinasi parameter tersebut merupakan parameter algoritme genetika yang baik. Dua belas kombinasi parameter ini dapat digunakan sebagai parameter algoritme genetika untuk training G-DT. Untuk mencari parameter algoritme genetika yang paling optimal diantara 12 kombinasi parameter tersebut, dilakukan percobaan sebanyak 10 kali untuk masing-masing 12 kombinasi parameter. Total percobaan yang dilakukan
adalah 120 percobaan. Hasil percobaan untuk 12 kombinasi parameter dapat dilihat pada Lampiran 2.
Dari 12 kombinasi parameter dan masing-masing dilakukan 10 iterasi, hanya tiga kombinasi parameter yang menghasilkan nilai fitness relatif lebih stabil dengan menghasilkan nilai fitness sebesar 0.0690 sebanyak sembilan buah dan nilai fitness sebesar 0.1034 sebanyak satu buah. Tiga kombinasi parameter tersebut yaitu:
a. tingkat rekombinasi = 80%, tingkat mutasi = 10%, dan maksimum generasi = 50, b. tingkat rekombinasi = 90%, tingkat mutasi
= 10%, dan maksimum generasi = 50, dan c. tingkat rekombinasi = 100%, tingkat
mutasi = 1%, dan maksimum generasi = 50.
Tiga kombinasi parameter di atas merupakan kombinasi parameter yang terbaik bagi training set dan testing set 3. Untuk memperoleh parameter yang lebih optimal lagi, dilakukan percobaan untuk masing-masing tiga kombinasi parameter itu dengan menggunakan training set dan testing set 2. Training set 2 digunakan karena training set 2 merupakan training set yang memiliki akurasi masih di bawah 100% selain training set 3. Percobaan untuk tiga kombinasi parameter ini juga dilakukan masing-masing 10 kali percobaan. Total percobaan yang dilakukan adalah 30 percobaan. Hasil dari 30 kali percobaan ini dapat dilihat pada Lampiran 3.
Dari 30 percobaan, kombinasi parameter yang terdiri dari tingkat rekombinasi sebesar 90%, tingkat mutasi sebesar 10%, dan maksimum generasi sebesar 50 generasi merupakan kombinasi parameter yang terbaik bagi training set dan testing set 2. Parameter ini menghasilkan nilai fitness yang stabil dengan menghasilkan nilai fitness sebesar 0.3793 pada 10 percobaan yang dilakukan. Sehingga, parameter algoritme yang optimal dengan ukuran populasi sebesar 10 yaitu: a tingkat rekombinasi: 90%,
b tingkat mutasi: 10%, dan c maksimum generasi: 50.
• Ukuran populasi sebesar 30 dan 50
Pada percobaan dengan ukuran populasi sebesar 30 dan 50, juga dilakukan dengan variasi tingkat rekombinasi (50%, 60%, 70%, 80%, 90%, dan 100%), tingkat mutasi (1%, 5%, dan 10%), dan maksimum generasi (50, 100, 150, 200, 250). Total percobaan untuk 58 kombinasi parameter
dengan nilai fitness terbaik
12 kombinasi parameter dengan nilai fitness terbaik dan waktu eksekusi < 360 detik
3 kombinasi parameter yang terbaik untuk training set 3 (pengulangan 10 kali)
1 kombinasi parameter yang terbaik untuk training set 3 dan 2 Æ parameter AG
13
masing-masing ukuran populasi adalah 90 percobaan.
Waktu eksekusi dengan ukuran populasi sebesar 30 dan 50 relatif lama (lebih dari 900 detik), sehingga percobaan dengan ukuran populasi sebesar 30 dan 50 ini tidak dilakukan untuk semua kombinasi parameter. Percobaan dilakukan hanya dengan kombinasi parameter yang optimal pada ukuran populasi sebesar 10 yaitu kombinasi parameter yang terdiri dari tingkat rekombinasi sebesar 90% dan tingkat mutasi sebesar 10%. Percobaan dilakukan dengan variasi nilai maksimum generasi (50, 100, 150, 200, dan 250). Total percobaan yang dilakukan adalah 10 percobaan. Hasil percobaan ini dapat dilihat pada Lampiran 4.
Dari hasil percobaan tersebut, besar nilai fitness dengan maksimum generasi sebesar 250 sama dengan nilai fitness dengan maksimum generasi sebesar 50 yaitu sebesar 0.0690. Sehingga, maksimum generasi sebesar 50 merupakan maksimum generasi yang baik bagi ukuran populasi sebesar 30 dan 50.
• Penentuan parameter yang optimal
Total percobaan yang dilakukan adalah 250 percobaan. Dari 250 percobaan, dapat disimpulkan hasil percobaan ke dalam dua kelompok yaitu:
a percobaan dengan variasi tingkat rekombinasi dan tingkat mutasi, dan
b percobaan dengan variasi ukuran populasi dan maksimum generasi.
Hasil percobaan dengan variasi tingkat rekombinasi dan tingkat mutasi dapat dilihat pada Tabel 5. Percobaan ini dilakukan pada ukuran populasi sebesar 10 dan maksimum generasi sebesar 50 generasi.
Tabel 5 Hasil percobaan dengan variasi tingkat rekombinasi dan tingkat mutasi
Tabel 5 Lanjutan
Dari Tabel 5, ada 12 kombinasi parameter yang baik yaitu kombinasi parameter yang memiliki nilai fitness sebesar 0.0690. Dari 12 kombinasi parameter ini, telah disimpulkan parameter yang optimal yaitu:
a tingkat rekombinasi: 90%, dan b tingkat mutasi: 10%.
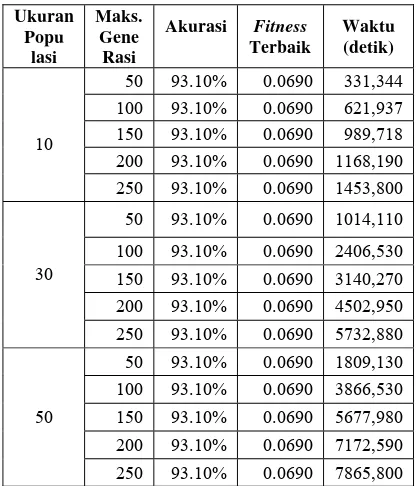
Hasil percobaan dengan variasi ukuran populasi dan maksimum generasi dapat dilihat pada Tabel 6. Percobaan ini dilakukan dengan tingkat rekombinasi sebesar 90% dan tingkat mutasi sebesar 10%.
Tabel 6 Hasil percobaan dengan variasi ukuran populasi dan maksimum generasi
Dari Tabel 6, besar nilai fitness terbaik pada ukuran populasi sebesar 30 dan 50 tidak lebih rendah daripada nilai fitness terbaik pada ukuran populasi sebesar 10. Waktu eksekusi percobaan dengan ukuran populasi sebesar 30 dan 50 lebih lama daripada ukuran populasi sebesar 10. Pada ukuran populasi sebesar 10, 30, dan 50, besar nilai fitness terbaik pada maksimum generasi sebesar 250 tidak lebih
Tingkat Rekombinasi
Tingkat
Mutasi Akurasi
Fitness Terbaik
1% 89.66% 0.1034 5% 93.10% 0.0690 50%
10% 89.66% 0.1034 1% 93.10% 0.0690 5% 93.10% 0.0690 60%
10% 93.10% 0.0690 1% 89.66% 0.1034 5% 93.10% 0.0690 70%
10% 86.21% 0.1379 1% 93.10% 0.0690 5% 89.66% 0.1034 80%
10% 93.10% 0.0690
Tingkat Rekombinasi
Tingkat
Mutasi Akurasi
Fitness Terbaik
1% 93.10% 0.0690 5% 93.10% 0.0690 90%
10% 93.10% 0.0690 1% 93.10% 0.0690 5% 93.10% 0.0690 100%
10% 89.66% 0.1034
Ukuran Popu
lasi
Maks. Gene
Rasi
Akurasi Fitness
Terbaik
Waktu (detik)
50 93.10% 0.0690 331,344 100 93.10% 0.0690 621,937 150 93.10% 0.0690 989,718 200 93.10% 0.0690 1168,190 10
250 93.10% 0.0690 1453,800 50 93.10% 0.0690 1014,110 100 93.10% 0.0690 2406,530 150 93.10% 0.0690 3140,270 200 93.10% 0.0690 4502,950 30
250 93.10% 0.0690 5732,880 50 93.10% 0.0690 1809,130 100 93.10% 0.0690 3866,530 150 93.10% 0.0690 5677,980 200 93.10% 0.0690 7172,590 50
14
rendah daripada nilai fitness terbaik pada maksimum generasi sebesar 50. Waktu eksekusi percobaan dengan maksimum generasi sebesar 250 lebih lama daripada maksimum generasi sebesar 50.
Peningkatan ukuran populasi dan maksimum generasi tidak menghasilkan nilai fitness yang lebih rendah dari 0.0690 dan akurasi lebih tinggi dari 93.10%. Berdasarkan hasil percobaan tersebut ditetapkan bahwa ukuran populasi yang baik adalah 10 dan maksimum generasi yang baik adalah 50 generasi.
Setelah menganalisis hasil percobaan, diperoleh parameter algoritme genetika yang optimal bagi kasus ini. Parameter algoritme genetika yang optimal bagi kasus ini yaitu: a tingkat rekombinasi: 90%,
b tingkat mutasi: 10%, c ukuran populasi: 10, dan d maksimum generasi: 50. Training G-DT
Setelah parameter algoritme genetika yang optimal diperoleh, proses training G-DT dapat dilakukan. Proses training ini menggunakan sepuluh training sets yang sebelumnya telah dibagi dengan metode 10-fold cross validation. Untuk setiap training set dilakukan 10 kali iterasi. Satu hasil training yang mewakili 10 hasil training dari suatu training set ditentukan dengan kriteria berikut yang diurutkan berdasarkan prioritas:
1 nilai akurasi yang paling tinggi,
2 jumlah aturan yang dihasil yang paling sering muncul (modus), dan
3 waktu eksekusi yang paling cepat.
Hasil training untuk training set 2 dapat dilihat pada Tabel 7. Hasil training set 3 dapat dilihat pada Tabel 8.
Tabel 7 Hasil training untuk training set 2
Tabel 8 Hasil training untuk training set 3
Hasil training dari training set 2 yaitu dari 10 iterasi yang dilakukan diperoleh nilai akurasi yang sama yaitu 62.07%. Jumlah aturan yang paling sering dihasilkan adalah 17 aturan dan 18 aturan. Empat iterasi dari 10 iterasi yang dilakukan menghasilkan aturan yang berjumlah 17 aturan. Empat iterasi menghasilkan aturan yang berjumlah 18 aturan. Tujuh belas dan delapan belas aturan yang dihasilkan ini masing-masing memiliki 1 aturan mengandung kelas target positif diabetes. Dari delapan iterasi ini, yang memiliki waktu eksekusi paling cepat adalah iterasi ke-5 yaitu 200,547 detik. Sehingga, hasil training yang mewakili hasil training dari training set 2 adalah hasil training pada iterasi ke-5.
Hasil training dari training set 3 yaitu dari 10 iterasi yang dilakukan diperoleh nilai akurasi sebesar 93.10% sebanyak 9 iterasi dan nilai akurasi sebesar 89.66% sebanyak 1 iterasi. Jumlah aturan yang paling sering dihasilkan adalah 21 aturan. Tiga iterasi dari 10 iterasi yang dilakukan menghasilkan aturan yang berjumlah 21 aturan. Dua puluh satu aturan yang dihasilkan ini terdiri dari 20 aturan mengandung kelas target negatif diabetes dan 1 aturan mengandung kelas target positif diabetes. Dari tiga iterasi yang menghasilkan 21 aturan ini, yang memiliki waktu eksekusi paling cepat adalah iterasi ke-9 yaitu 264,85ke-9detik. Sehingga, hasil training yang mewakili hasil training dari training set 3 adalah hasil training pada iterasi ke-9.
Hasil training set 1, training set 4, training set 5, training set 6, training set 7, training set 8, training set 9, dan training set 10 dapat dilihat pada Lampiran 5. Pemilihan satu hasil training untuk mewakili 10 hasil training suatu training set ini juga dilakukan
Set Akurasi Waktu
(detik)
Jumlah Aturan
1 62.07% 231,344 18 (17 negatif, 1 positif) 2 62.07% 216,141 17 (16 negatif, 1 positif) 3 62.07% 220,281 17 (16 negatif, 1 positif) 4 62.07% 199,360 16 (15 negatif, 1 positif)
5 62.07% 200,547 17 (16 negatif, 1 positif)
6 62.07% 213,359 18 (17 negatif, 1 positif) 7 62.07% 227,078 18 (17 negatif, 1 positif) 8 62.07% 204,969 17 (16 negatif, 1 positif) 9 62.07% 240,250 19 (18 negatif, 1 positif) 10 62.07% 223,735 18 (17 negatif, 1 positif)
Set Akurasi Waktu
(detik)
Jumlah Aturan
1 93.10% 324,594 28 (26 negatif, 2 positif) 2 93.10% 328,766 26 (25 negatif, 1 positif) 3 93.10% 310,985 21 (20 negatif, 1 positif) 4 93.10% 321,031 25 (23 negatif, 2 positif) 5 89.66% 302,500 20 (19 negatif, 1 positif) 6 93.10% 306,156 22 (20 negatif, 2 positif) 7 93.10% 317,187 25 (24 negatif, 1 positif) 8 93.10% 306,375 21 (20 negatif, 1 positif)
9 93.10% 264,859 21 (20 negatif, 1 positif)
15
untuk 8 training sets ini. Record yang dicetak tebal pada Lampiran 5 merupakan wakil hasil training dari training set tersebut. Hasil training untuk setiap training set dapat dilihat pada Tabel 9.
Tabel 9 Hasil training G-DT untuk setiap training set
Dari Tabel 9, terlihat bahwa nilai akurasi pada training set 2 dan training set 3 mengalami peningkatan dengan menggunakan parameter algoritme genetika yang optimal. Hasil dari training set menggunakan parameter algoritme genetika yang tidak optimal dapat dilihat pada Tabel 3. Dengan menggunakan parameter yang tidak optimal, untuk training set 2 diperoleh nilai akurasi sebesar 58.62% dan training set 3 diperoleh nilai akurasi sebesar 89.66%. Setelah menggunakan parameter yang optimal, nilai akurasi training set 2 dari 58.62% naik menjadi 62.07%. Pada training set 3, nilai akurasi dari 89.66% naik menjadi 93.10%.
Rata-rata akurasi yang diperoleh dengan menggunakan parameter yang tidak optimal adalah sebesar 94.83%. Rata-rata akurasi yang diperoleh dengan menggunakan parameter yang optimal adalah sebesar 95.52%. Hal ini menunjukkan bahwa terjadi peningkatan rata-rata akurasi dengan menggunakan parameter yang optimal sebesar 0.69%.
Sebagian besar jumlah aturan yang dihasilkan dengan menggunakan parameter
yang optimal mengalami peningkatan dari jumlah aturan yang dihasilkan dengan menggunakan parameter yang tidak optimal. Tujuh dari sepuluh aturan yang dihasilkan mengalami peningkatan dalam hal jumlah. Tiga aturan dihasilkan dengan jumlah yang sama. Hal ini disebabkan perbedaan bilangan acak yang dibangkitkan untuk membentuk populasi awal dan penggunaan parameter yang berbeda. Kedua hal ini menyebabkan solusi yang dihasilkan akan berbeda sehingga tree yang dihasilkan akan berbeda. Parameter yang menghasilkan nilai akurasi tertinggi merupakan parameter yang terbaik.
Rata-rata jumlah aturan yang dihasilkan dengan menggunakan parameter yang tidak optimal adalah 20.8. Rata-rata aturan yang dihasilkan dengan menggunakan parameter yang optimal adalah 22.6. Hal ini menunjukkan bahwa terjadi peningkatan rata-rata jumlah aturan yang dihasilkan dengan menggunakan parameter yang optimal.
Representasi Pengetahuan
Model yang dihasilkan dari proses training digunakan untuk mengetahui label kelas pada data yang baru. Model tersebut dipilih berdasarkan tiga kriteria berikut yang diurutkan berdasarkan prioritas:
1 Model yang mencakup semua kelas target yang mungkin muncul dalam testing set, dalam penelitian ini kelas target yang mungkin muncul yaitu kelas target 1 (negatif diabetes) dan kelas target 2 (positif diabetes).
2 Model dengan akurasi yang paling tinggi, semakin tinggi akurasinya maka semakin baik model tersebut.
3 Model dengan jumlah aturan yang paling banyak.
Berdasarkan kriteria tersebut maka model yang dipilih adalah hasil training dari pasangan training set dan testing set keenam dengan jumlah aturan sebanyak 27 aturan. Dari 27 aturan tersebut hanya 2 aturan yang mengandung kelas target positif diabetes. Model yang dihasilkan adalah sebagai berikut: 1 IF GPOST rendah THEN Negatif
Diabetes
2 IF GPOST sedang AND GLUN rendah AND TG rendah AND HDL rendah THEN Negatif Diabetes
3 IF GPOST sedang AND GLUN rendah AND TG rendah AND HDL sedang THEN Negatif Diabetes
Set Akurasi Jumlah
Aturan
Waktu Total (detik)
1 100.00% 26
(24 negatif, 2 positif) 15,031
2 62.07% 17
(16 negatif, 1 positif) 207,204
3 93.10% 21
(20 negatif, 1 positif) 271,484
4 100.00% 25
(24 negatif, 1 positif) 15,563
5 100.00% 23
(20 negatif, 3 positif) 15,188
6 100.00% 27
(25 negatif, 2 positif) 15,063
7 100.00% 22
(22 negatif, 0 positif) 14,797
8 100.00% 20
(19 negatif, 1 positif) 14,625
9 100.00% 22
(22 negatif, 0 positif) 15,016
10 100.00% 23
(21 negatif, 2 positif) 15,485
16
4 IF GPOST sedang AND GLUN rendah AND TG rendah AND HDL tinggi THEN Negatif Diabetes
5 IF GPOST sedang AND GLUN rendah AND TG sedang AND HDL rendah THEN Negatif Diabetes
6 IF GPOST sedang AND GLUN rendah AND TG sedang AND HDL sedang THEN Negatif Diabetes
7 IF GPOST sedang AND GLUN rendah AND TG tinggi THEN Negatif Diabetes 8 IF GPOST sedang AND GLUN sedang
AND TG rendah AND HDL rendah THEN Negatif Diabetes
9 IF GPOST sedang AND GLUN sedang AND TG rendah AND HDL sedang THEN Negatif Diabetes
10 IF GPOST sedang AND GLUN sedang AND TG rendah AND HDL tinggi THEN Negatif Diabetes
11 IF GPOST sedang AND GLUN sedang AND TG sedang AND HDL rendah THEN Negatif Diabetes
12 IF GPOST sedang AND GLUN sedang AND TG sedang AND HDL sedang THEN Negatif Diabetes
13 IF GPOST sedang AND GLUN sedang AND TG tinggi AND HDL rendah THEN Negatif Diabetes
14 IF GPOST sedang AND GLUN sedang AND TG tinggi AND HDL sedang THEN Negatif Diabetes
15 IF GPOST sedang AND GLUN tinggi AND TG rendah AND HDL rendah THEN Negatif Diabetes
16 IF GPOST sedang AND GLUN tinggi AND TG rendah AND HDL sedang THEN Negatif Diabetes
17 IF GPOST sedang AND GLUN tinggi AND TG sedang AND HDL rendah THEN Negatif Diabetes
18 IF GPOST sedang AND GLUN tinggi AND TG sedang AND HDL sedang THEN Positif Diabetes
19 IF GPOST sedang AND GLUN tinggi AND TG tinggi THEN Negatif Diabetes 20 IF GPOST tinggi AND TG rendah AND
GLUN sedang THEN Negatif Diabetes 21 IF GPOST tinggi AND TG rendah AND
GLUN tinggi THEN Negatif Diabetes 22 IF GPOST tinggi AND TG sedang AND
HDL rendah AND GLUN rendah THEN Negatif Diabetes
23 IF GPOST tinggi AND TG sedang AND HDL rendah AND GLUN sedang THEN Negatif Diabetes
24 IF GPOST tinggi AND TG sedang AND HDL rendah AND GLUN tinggi THEN Negatif Diabetes
25 IF GPOST tinggi AND TG sedang AND HDL sedang AND GLUN rendah THEN Negatif Diabetes
26 IF GPOST tinggi AND TG sedang AND HDL sedang AND GLUN sedang THEN Negatif Diabetes
27 IF GPOST tinggi AND TG sedang AND HDL sedang AND GLUN tinggi THEN Positif Diabetes
Perbandingan G-DT dan FDT • Proses pembentukan tree
Proses pembentukan G-DT berbeda dengan FDT. Sehingga, tree dan aturan yang dihasilkan G-DT berbeda dengan FDT. Untuk melihat tree dan aturan yang dihasilkan oleh FDT dan G-DT, dilakukan pembentukan FDT dan G-DT menggunakan data training set dan testing set 1. Contoh sebagian data training set dan testing set 1 dapat dilihat pada Lampiran 6. Contoh sebagian data training set 1 hasil fuzzikasi untuk membentuk FDT dapat dilihat pada Lampiran 7. Contoh sebagian data training set 1 hasil fuzzikasi untuk membentuk G-DT dapat dilihat pada Lampiran 8.
Pembentukan FDT menggunakan algoritme FID3. Langkah-langkah dalam pembentukan FDT yaitu:
1 Membuat root node dari semua data training yang ada.
2 Menghitung fuzzy entropy dari training set yang ada. Nilai fuzzy entropy ini akan digunakan untuk menghitung nilai information gain dari masing-masing atribut.
3 Menghitung information gain dari atribut-atribut. Atribut yang memiliki nilai information gain paling tinggi akan dipilih untuk digunakan dalam mengekspansi tree atau menjadi root node, tetapi pada sub-node selanjutnya atribut ini tidak dapat digunakan untuk mengekspansi tree. 4 Ekspansi data training berdasarkan atribut
17
5 Menghitung proporsi dari setiap kelas yang ada pada setiap node.
6 Periksa threshold. Jika proporsi himpunan data dari kelas Ck lebih besar atau sama
dengan nilai fuzziness control threshold (FCT / θr), maka ekspansi tree dihentikan.
Jika banyaknya anggota himpunan data pada suatu node lebih kecil dari leaf decision threshold (LDT / θn), maka
ekspansi tree dihentikan.
7 Ekspansi sub-node terus dilakukan sampai tidak ada lagi data yang dapat diekspansi atau tidak ada lagi atribut yang dapat digunakan untuk mengekspansi tree yaitu ketika tree yang terbentuk sudah mencapai kedalaman maksimum atau sub-node tidak memenuhi syarat dari threshold yang diberikan. Jika sub-node sudah tidak dapat diekspansi maka nilai proporsi kelas terbesar merupakan kesimpulan dari sekumpulan aturan yang diperoleh dengan menghubungkan setiap node yang dilewati dari root node hingga leaf node.
Berdasarkan langkah-langkah algoritme FID3 di atas, diperoleh fuzzy decision tree seperti Lampiran 9 dan sebuah model yang terdiri dari 29 buah aturan dengan menggunakan training set 1. Model atau aturan klasifikasi yang diperoleh dapat dilihat pada Lampiran 10.
Pembentukan G-DT menggunakan algoritme genetika dan algoritme FID3. Langkah-langkah dalam pembentukan G-DT yaitu:
1 Membangkitkan populasi awal berdasarkan data training.
2 Menghitung nilai fitness dengan langkah-langkah berikut:
a Bentuk fungsi keanggotaan fuzzy untuk setiap atribut dan hitung derajat keanggotaan setiap data masing-masing atribut. Nilai derajat keanggotaan fuzzy setiap data akan digunakan untuk membentuk tree. b Bentuk tree dengan menggunakan
algoritme fuzzy ID3, sehingga diperoleh aturan-aturan. Aturan-aturan dan fungsi keanggotaan fuzzy setiap atribut digunakan untuk membentuk FIS Mamdani.
c Melakukan testing dengan menggunakan FIS Mamdani, sehingga diperoleh nilai galat (error). Nilai galat ini merupakan nilai fitness.
3 Mengevaluasi fitness dengan cara memeriksa fitness dengan fitness threshold. Jika fitness lebih kecil daripada fitness threshold, maka parameter fungsi keanggotaan yang terbaik telah diperoleh dan dapat dibentuk tree dengan cara: a Bentuk fungsi keanggotaan fuzzy
untuk setiap atribut dan hitung derajat keanggotaan setiap data masing-masing atribut. Nilai derajat keanggotaan fuzzy setiap data akan digunakan untuk membentuk tree. b Bentuk tree dengan menggunakan
algoritme fuzzy ID3, sehingga diperoleh model.
Jika fitness lebih besar daripada fitness threshold, maka lakukan elitisme, seleksi, rekombinasi, dan mutasi untuk membentuk populasi baru.
4 Melakukan elitisme, seleksi, rekombinasi, dan mutasi sehingga terbentuk populasi baru.
5 Menghitung nilai fitness populasi baru. 6 Evaluasi nilai fitness populasi baru.
7 Iterasi akan terus dilakukan hingga diperoleh solusi yang memenuhi nilai fitness threshold atau telah mencapai maksimum generasi. Jika parameter fungsi keanggotaan yang terbaik telah diperoleh, maka tree dapat dibentuk. Tree yang dihasilkan ini merupakan genetically optimized fuzzy decision tree (G-DT).
Berdasarkan langkah-langkah dalam pembentukan G-DT di atas, diperoleh genetically optimized fuzzy decision tree seperti Lampiran 11 dan sebuah model yang terdiri dari 26 buah aturan dengan menggunakan training set 1. Model atau aturan klasifikasi yang diperoleh dapat dilihat pada Lampiran 12.
• Hasil training
Hasil G-DT dapat dilihat pada Tabel 10. Hasil FDT yang merupakan hasil penelitian sebelumnya dapat dilihat pada Tabel 11. Tabel 10 Hasil training G-DT
Set Akurasi Waktu
(detik)
Waktu Total (detik)
Jumlah Aturan
1 100.00% 8,390 15,031 26 (24 negatif,
2 positif)
2 62.07% 200,547 207,204 17 (16 negatif,
18
Tabel 10 Lanjutan
Tabel 11 Hasil training FDT
Tabel 11 Lanjutan
Dari Tabel 10 dan Tabel 11, terlihat bahwa nilai akurasi G-DT lebih tinggi daripada nilai akurasi FDT. Hal ini menunjukkan bahwa G-DT berhasil meningkatkan nilai akurasi. Nilai akurasi training set 2 dari 55.17% naik menjadi 62.07%. Nilai akurasi training set 3 juga naik dari 82.76% menjadi 93.10%. Nilai akurasi training set 7, trainng set 8, dan training set 10 naik menjadi 100%. FDT hanya menghasilkan 5 nilai akurasi sebesar 100%. Sedangkan G-DT menghasilkan 8 nilai akurasi sebesar 100%.
Rata-rata akurasi yang dihasilkan G-DT juga lebih tinggi daripada rata-rata akurasi yang dihasilkan FDT. Rata-rata nilai akurasi yang dihasilkan FDT adalah sebesar 90.69%. Sedangkan, rata-rata nilai akurasi yang dihasilkan G-DT adalah sebesar 95.52%. Hal ini menunjukkan bahwa G-DT berhasil meningkatkan nilai rata-rata akurasi sebesar
4.83%.
Sebagian besar jumlah aturan yang dihasilkan G-DT untuk setiap training set lebih rendah dari jumlah aturan yang dihasilkan FDT. Sembilan dari sepuluh model yang dihasilkan G-DT memiliki jumlah aturan lebih rendah daripada jumlah aturan yang dihasilkan FDT. Satu model yang dihasilkan G-DT memiliki jumlah aturan yang lebih tinggi daripada jumlah aturan yang dihasilkan FDT. Pada training set 2, jumlah aturan yang dihasilkan FDT adalah sebanyak 9 aturan dan jumlah aturan yang dihasilkan G-DT adalah sebanyak 17 aturan.
Perbedaan jumlah aturan yang dihasilkan ini disebabkan oleh perbedaan proses pembentukan tree pada G-DT dan FDT. Rendahnya jumlah aturan yang dihasilkan G-DT ini disebabkan oleh perbedaan jumlah himpunan fuzzy untuk atribut GLUN dan GPOST yang digunakan dalam pembentukan G-DT dan FDT. Pada FDT, jumlah himpunan fuzzy untuk atribut GLUN dan GPOST adalah sebanyak 4 himpunan fuzzy (rendah, sedang, tinggi, sangat tinggi). Pada G-DT, jumlah himpunan fuzzy untuk atribut GLUN dan GPOST adalah sebanyak 3 himpunan fuzzy
Set Akurasi Waktu
(detik)
Waktu Total (detik)
Jumlah Aturan
3 93.10% 264,859 271,484
21 (20 negatif,
1 positif)
4 100.00% 8,953 15,563
25 (24 negatif,
1 positif)
5 100.00% 8,235 15,188
23 (20 negatif,
3 positif)
6 100.00% 8,453 15,063
27 (25 negatif,
2 positif)
7 100.00% 8,281 14,797
22 (22 negatif,
0 positif)
8 100.00% 7,938 14,625
20 (19 negatif,
1 positif)
9 100.00% 8,250 15,016
22 (22 negatif,
0 positif)
10 100.00% 8,813 15,485
23 (21 negatif,
2 positif)
Rataan 95.52% 22.6
Set Akurasi Waktu
(detik)
Waktu Total (detik)
Jumlah Aturan
1 100.00% 0,750 21,625 29 (29 negatif,
0 positif)
2 55.17% 0,219 21,375
9 (9 negatif,
0 positif)
3 82.76% 0,562 21,500
23 (22 negatif,
1 positif)
4 100.00% 0,735 21,657 29 (29 negatif,
0 positif)
5 100.00% 0,782 21,703 30 (30 negatif,
0 positif)
6 100.00% 0,828 21,906 31 (31 negatif,
0 positif)
7 86.66% 0,766 21,828
29 (27 negatif,
2 positif)
8 89.66% 0,766 21,719
29 (28 negatif,
1 positif)
9 100.00% 0,750 21,797 29 (29 negatif,
0 positif)
Set Akurasi Waktu
(detik)
Waktu Total (detik)
Jumlah Aturan
10 93.10% 0,782 21,750
30 (29 negatif,
1 positif)
19
(rendah, sedang, tinggi). Oleh karena itu, sebagian besar jumlah aturan yang dihasilkan G-DT lebih rendah daripada jumlah aturan yang dihasilkan FDT. Pada umumnya, jika nilai akurasi semakin naik maka jumlah aturan yang dihasilkan semakin turun.
Rata-rata jumlah aturan yang dihasilkan G-DT juga lebih rendah daripada rata-rata jumlah aturan yang dihasilkan FDT. Rata-rata jumlah aturan yang dihasilkan FDT adalah 27 aturan. Sedangkan, rata-rata jumlah aturan yang dihasilkan G-DT adalah 22.6 aturan.
Model yang dihasilkan G-DT juga berbeda dengan model yang dihasilkan FDT. Dengan menggunakan sepuluh training sets, G-DT menghasilkan 8 model yang memiliki aturan yang mengandung kelas target positif diabetes. Sedangkan FDT hanya menghasilkan 4 model yang memiliki aturan yang mengandung kelas target positif diabetes.
Model yang dihasilkan dari proses training FDT mengandung 30 aturan yang terdiri atas 29 aturan mengandung kelas target negatif diabetes dan 1 aturan mengandung kelas target positif diabetes. Model yang dihasilkan dari proses training G-DT mengandung 27 aturan yang terdiri atas 25 aturan mengandung kelas target negatif diabetes dan 2 aturan mengandung kelas target positif diabetes.
Waktu untuk membentuk G-DT lebih lama daripada waktu untuk membentuk FDT. Hal ini disebabkan dalam pembentukan G-DT, FDT dibentuk beberapa kali tergantung besarnya ukuran populasi dan maksimum generasi. Jika besar ukuran populasi dan maksimum generasi semakin besar, maka waktu pembentukan G-DT akan semakin lama. Akan tetapi, jika hasil G-DT diperoleh pada iterasi pertama, waktu total untuk menjalankan program G-DT lebih cepat daripada waktu total untuk menjalankan program FDT. Hal ini terlihat dari waktu eksekusi untuk training set 1, 4, 5, 6, 7, 8, 9, dan 10 pada Tabel 10.
Jumlah himpunan fuzzy dan fungsi keanggotaan yang digunakan dalam pembentukan G-DT berbeda dengan FDT. Pada FDT, fungsi keanggotaan fuzzy telah ditetapkan dari awal. Sedangkan pada G-DT, fungsi keanggotaan diperoleh dari hasil pembelajaran dengan algoritme genetika. Berikut jumlah himpunan fuzzy dan fungsi keanggotaan yang digunakan dalam
pembentukan G-DT dengan menggunakan training set 6.
a Atribut GLUN
Atribut GLUN dibagi menjadi 3 kelompok yaitu rendah, sedang, dan tinggi. Fungsi keanggotaan untuk atribut GLUN yaitu:
( ) ⎪ ⎩ ⎪ ⎨ ⎧ ≥ < ≤ − − < = 126 ; 0 126 70 ; 56 126 70 ; 1 x x x x x rendah μ ( ) ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ ≥ < ≤ −
− ≤ <
< ≤ − < = 282 ; 0 282 202 ; 80 282 202 126 ; 1 126 70 ; 56 70 70 ; 0 x x x x x x x x sedang μ ( ) ⎪ ⎩ ⎪ ⎨ ⎧ ≥ < ≤ − < = 282 ; 1 282 202 ; 80 202 202 ; 0 x x x x x tinggi μ
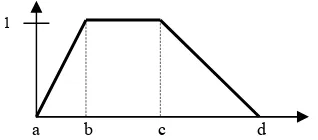
Himpunan fuzzy menggunakan kurva dengan bentuk trapesium seperti Gambar 11.
Gambar 11 Himpunan fuzzy atribut GLUN. b Atribut GPOST
Atribut GPOST dibagi menjadi 3 kelompok yaitu rendah, sedang, dan tinggi. Fungsi keanggotaan untuk atribut GPOST yaitu: ( ) ⎪ ⎩ ⎪ ⎨ ⎧ ≥ < ≤ − − < = 154 ; 0 154 97 ; 57 154 97 ; 1 x x x x x rendah μ ( ) ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ ≥ < ≤ −
− ≤ <
< ≤ − < = 378 ; 0 378 272 ; 106 378 272 154 ; 1 154 97 ; 57 97 97 ; 0 x x x x x x x x sedang μ ( ) ⎪ ⎩ ⎪ ⎨ ⎧ ≥ < ≤ − < = 378 ; 1 378 272 ; 106 272 272 ; 0 x x x x x tinggi μ
0 100 200 300 400 500 600
0 0.2 0.4 0.6 0.8 1 GLUN D eraj at Keangg iot aan
20
Himpunan fuzzy menggunakan kurva dengan bentuk trapesium seperti Gambar 12.
Gambar 12 Himpunan fuzzy atribut GPOST.
c Atribut HDL
Atribut HDL dibagi menjadi 3 kelompok yaitu rendah, sedang, dan tinggi. Fungsi keanggotaan untuk atribut HDL yaitu:
( )
⎪ ⎩ ⎪ ⎨ ⎧ ≥ < ≤ − − < = 61 ; 0 61 35 ; 26 61 35 ; 1 x x x x x rendah μ ( ) ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ ≥ < ≤ −− ≤ < < ≤ − < = 135 ; 0 135 77 ; 58 135 77 61 ; 1 61 35 ; 26 35 35 ; 0 x x x x x x x x sedang μ ( ) ⎪ ⎩ ⎪ ⎨ ⎧ ≥ < ≤ − < = 135 ; 1 135 77 ; 58 77 77 ; 0 x x x x x tinggi μ
Himpunan fuzzy menggunakan kurva dengan bentuk trapesium seperti Gambar 13.
Gambar 13 Himpunan fuzzy atribut HDL.
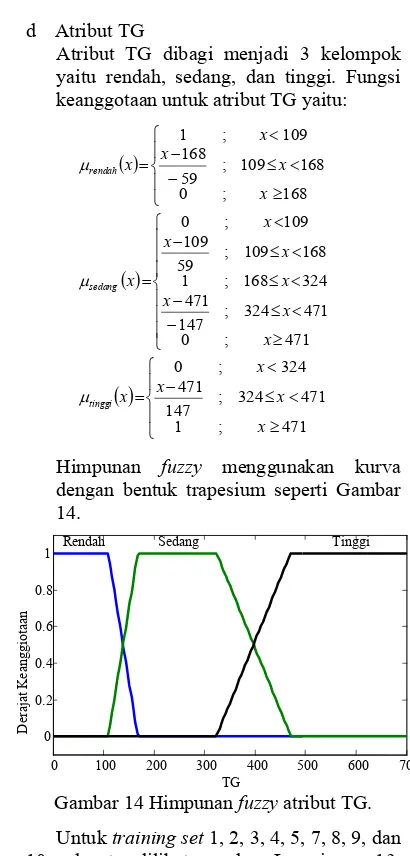
d Atribut TG
Atribut TG dibagi menjadi 3 kelompok yaitu rendah, sedang, dan tinggi. Fungsi keanggotaan untuk atribut TG yaitu:
( ) ⎪ ⎩ ⎪ ⎨ ⎧ ≥ < ≤ − − < = 168 ; 0 168 109 ; 59 168 109 ; 1 x x x x x rendah μ ( ) ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ ≥ < ≤ −
− ≤ <
< ≤ − < = 471 ; 0 471 324 ; 147 471 324 168 ; 1 168 109 ; 59 109 109 ; 0 x x x x x x x x sedang μ ( ) ⎪ ⎩ ⎪ ⎨ ⎧ ≥ < ≤ − < = 471 ; 1 471 324 ; 147 471 324 ; 0 x x x x x tinggi μ
Himpunan fuzzy menggunakan kurva dengan bentuk trapesium seperti Gambar 14.
Gambar 14 Himpunan fuzzy atribut TG. Untuk training set 1, 2, 3, 4, 5, 7, 8, 9, dan 10 dapat dilihat pada Lampiran 13. Sedangkan, jumlah himpunan fuzzy dan fungsi keanggotaan yang digunakan dalam pembentukan FDT yang digunakan pada penelitian sebelumnya dapat dilihat pada Lampiran 14.
Evaluasi Kinerja G-DT
Evaluasi kinerja G-DT dapat diketahui dari akurasi yang dihasilkan pada proses pembentukan G-DT pada training set dan testing set yang berbeda dan rata-rata akurasi keseluruhan training set. Hal ini dapat dilihat pada Tabel 10. Dari tabel 10 terlihat bahwa bahwa rata-rata akurasi G-DT lebih tinggi daripada rata-rata akurasi FDT. Hal ini menunjukkan telah terjadi peningkatan rata-rata akurasi sebesar 4.83% dari rata-rata-rata-rata akurasi FDT.
Dari sepuluh training sets, hanya dua training sets yang tidak memperoleh akurasi
0 100 200 300 400 500 600 700
0 0.2 0.4 0.6 0.8 1 GPOST D eraj at Keangg iot aan
Rendah Sedang Tinggi
0 100 200 300 400 500 600 700
0 0.2 0.4 0.6 0.8 1 TG D eraj at Keangg iot aan
Rendah Sedang Tinggi
0 20 40 60 80 100 120 140 160 180 200
0 0.2 0.4 0.6 0.8 1 D eraj at Keangg iot aan
Rendah Sedang Tinggi
21
100%. Untuk training set dan testing set 2 diperoleh akurasi sebesar 62.07%. Untuk training set dan testing set 3 diperoleh akurasi sebesar 93.10%. Hal ini disebabkan pada testing set 2 dan testing set 3 mengandung data positif diabetes. Sedangkan testing set yang lain tidak mengandung data positif diabetes. Sementara itu, total data positif diabetes berjumlah kecil yaitu hanya 17 record dan total data negatif diabetes berjumlah besar yaitu 273 record. Data ini kurang representatif. Hal ini mengakibatkan jumlah aturan yang dihasilkan yang mengandung kelas target positif diabetes lebih rendah daripada aturan yang mengandung kelas target negatif diabetes. Sehingga, data dengan kelas target positif diabetes sulit untuk dikenali. Oleh karena itu, data testing set 2 dan testing set 3 agak sulit dikenali dan nilai akurasinya relatif lebih rendah.
Untuk melakukan proses pembentukan G-DT telah dibangun sebuah aplikasi sederhana dengan menggunakan Matlab 7.0.1. Salah satu antarmuka grafis dari aplikasi tersebut dapat dilihat pada Gambar 15.
Gambar 15 Antarmuka grafis aplikasi G-DT.
KESIMPULAN DAN SARAN
Kesimpulan
Dari berbagai percobaan yang dilakukan terhadap data diabetes diperoleh kesimpulan sebagai berikut:
1 Algoritme genetika dapat digunakan untuk optimasi fuzzy decision tree (FDT)
sehingga diperoleh genetically optimized fuzzy decison tree (G-DT).
2 Rata-rata nilai akurasi G-DT meningkat sebesar 4.83% dari rata-rata nilai akurasi FDT. Rata-rata akurasi FDT adalah sebesar 90.69%, sedangkan rata-rata akurasi G-DT adalah sebesar 95.52%. 3 Parameter algoritme genetika yang
optimal yaitu:
a fitness threshold: 0.05, b tingkat rekombinasi: 90%, c tingkat mutasi: 10%, d ukuran populasi: 10, dan e maksimum generasi: 50.
4 Dengan menggunakan parameter algoritme genetika yang optimal, nilai akurasi meningkat sebesar 0.69%. Rata-rata akurasi yang diperoleh dengan menggunakan parameter yang tidak optimal adalah 94.83%. Rata-rata akurasi yang diperoleh dengan menggunakan parameter yang optimal adalah 95.52%. 5 Jumlah aturan yang diperoleh oleh G-DT
adalah sebanyak 27 aturan yang terdiri atas 25 aturan mengandung kelas target negatif diabetes dan 2 aturan mengandung kelas target positif diabetes.
6 Jumlah aturan yang diperoleh G-DT lebih rendah daripada jumlah aturan yang diperoleh FDT. Jumlah aturan yang diperoleh FDT adalah 30 aturan. Jumlah aturan yang diperoleh G-DT adalah 27 aturan.
7 Penelitian ini menghasilkan aplikasi sederhana yang dapat digunakan untuk membuat classifier berdasarkan algoritme genetika dan FID3 dengan menggunakan Matlab 7.0.1.
Saran
24
Lampiran 1 Hasil percobaan untuk 90 kombinasi parameter pada ukuran populasi sebesar 10
Tingkat Crossover
Tingkat Mutasi
Maks.
Generasi Akurasi
Waktu (detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
50 89,66% 320,938 50 25 (0) 0,1034 100 89,66% 533,547 100 20 (1) 0,1034 150 93,10% 762,656 150 21 (1) 0,0690 200 89,66% 1197,000 200 24 (1) 0,1034 1%
250 93,10% 1792,580 250 28 (1) 0,0690
50 93,10% 284,406 50 22 (1) 0,0690
100 89,66% 585,859 100 24 (1) 0,1034 150 93,10% 845,891 150 24 (1) 0,0690 200 89,66% 1063,630 200 18 (1) 0,1034
5%
250 93,10% 1271,020 250 20 (1) 0,0690 50 89,66% 301,875 50 24 (3) 0,1034 100 89,66% 522,672 100 22 (1) 0,1034 150 93,10% 981,672 150 27 (1) 0,0690 200 93,10% 1292,670 200 25 (1) 0,0690
50%
10%
250 93,10% 1451,640 250 23 (1) 0,0690
50 93,10% 315,610 50 25 (2) 0,0690
100 93,10% 597,734 100 23 (1) 0,0690 150 89,66% 802,297 150 22 (1) 0,1034 200 89,66% 1028,450 200 20 (1) 0,1034
1%
250 93,10% 1275,480 250 20 (1) 0,0690
50 93,10% 329,094 50 27 (`1) 0,0690
100 89,66% 549,875 100 23 (1) 0,1034 150 89,66% 1104,130 150 29 (2) 0,1034 200 93,10% 1229,920 200 24 (1) 0,0690
5%
250 93,10% 1238,810 250 18 (1) 0,0690
50 93,10% 280,547 50 21 (1) 0,0690
100 93,10% 678,875 100 27 (1) 0,0690 150 93,10% 744,406 150 18 (1) 0,0690 200 93,10% 1002,200 200 22 (1) 0,0690
60%
10%
250 93,10% 1283,950 250 20 (1) 0,0690 50 89,66% 294,219 50 21 (1) 0,1034 100 93,10% 684,062 100 27 (1) 0,0690 150 93,10% 929,750 150 23 (1) 0,0690 200 89,66% 1157,770 200 23 (1) 0,1034 1%
250 89,66% 1426,420 250 23 (1) 0,1034
50 93,10% 308,328 50 22 (1) 0,0690
100 93,10% 552,813 100 19 (1) 0,0690 150 89,66% 935,766 150 24 (1) 0,1034 200 93,10% 1016,780 200 17 (1) 0,0690
5%
250 93,10% 1348,020 250 21 (1) 0,0690 50 86,21% 249,718 50 19 (1) 0,1379 100 93,10% 698,156 100 32 (2) 0,0690 150 93,10% 918,813 150 28 (1) 0,0690 200 93,10% 1219,940 200 25 (1) 0,0690
70%
10%
25
Lanjutan
Tingkat Crossover
Tingkat Mutasi
Maks.
Generasi Akurasi
Waktu (detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
50 93,10% 339,532 50 26 (1) 0,0690
100 89,66% 509,110 100 21 (1) 0,1034 150 89,66% 980,109 150 24 (1) 0,1034 200 93,10% 1322,890 200 26 (1) 0,0690
1%
250 93,10% 1643,280 250 27 (1) 0,0690 50 89,66% 313,047 50 25 (1) 0,1034 100 93,10% 620,031 100 25 (1) 0,0690 150 93,10% 964,328 150 26 (1) 0,0690 200 93,10% 1249,340 200 23 (1) 0,0690 5%
250 89,66% 1374,340 250 21 (1) 0,1034
50 93,10% 285,296 50 22 (1) 0,0690
100 93,10% 513,906 100 21 (1) 0,0690 150 93,10% 1005,910 150 27 (1) 0,0690 200 93,10% 1207,580 200 26 (1) 0,0690
80%
10%
250 89,66% 1236,940 50 19(1) 0,1034
50 93,10% 278,891 50 21 (1) 0,0690
100 89,66% 518,094 100 22 (1) 0,1034 150 89,66% 891,500 150 23 (1) 0,1034 200 89,66% 1088,890 200 22 (1) 0,1034
1%
250 93,10% 1240,310 250 20 (1) 0,0690
50 93,10% 322,313 50 26 (3) 0,0690
100 93,10% 706,078 100 28 (1) 0,0690 150 93,10% 800,484 150 22 (2) 0,0690 200 93,10% 1122,440 200 22 (1) 0,0690
5%
250 89,66% 1466,860 250 24 (1) 0,1034
50 93,10% 331,344 50 28 (2) 0,0690
100 93,10% 621,937 100 25 (1) 0,0690 150 93,10% 989,718 150 23 (1) 0,0690 200 93,10% 1168,190 200 21 (1) 0,0690
90%
10%
250 93,10% 1453,800 250 24 (1) 0,0690
50 93,10% 296,625 50 23 (1) 0,0690
100 89,66% 619,860 100 22 (1) 0,1034 150 93,10% 883,781 150 23 (1) 0,0690 200 93,10% 1354,590 200 26 (1) 0,0690
1%
250 89,66% 1522,090 250 24 (2) 0,1034
50 93,10% 278,891 50 25 (2) 0,0690
100 89,66% 591,531 100 24 (1) 0,1034 150 89,66% 904,672 150 24 (3) 0,1034 200 93,10% 1167,970 200 21 (1) 0,0690
5%
250 89,66% 1476,840 250 23 (1) 0,1034 50 89,66% 321,093 50 25 (1) 0,1034 100 89,66% 674,547 100 27 (1) 0,1034 150 93,10% 827,235 150 21 (1) 0,0690 200 93,10% 1500,420 200 25 (1) 0,0690
100%
10%
26
Lampiran 2 Hasil percobaan untuk 12 kombinasi parameter pada ukuran populasi sebesar 10 Tingkat rekombinasi = 50%
Tingkat mutasi = 5%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 284,406 50 22 (1) 0,0690
2 89,66% 331,953 50 26 (1) 0,1034
3 93,10% 276,828 50 21 (1) 0,0690
4 93,10% 282,782 50 23 (1) 0,0690
5 89,66% 302,062 50 24 (1) 0,1034
6 93,10% 276,922 50 21 (1) 0,0690
7 93,10% 278,406 50 23 (1) 0,0690
8 89,66% 307,843 50 24 (1) 0,1034 9 89,66% 274,890 50 20 (1) 0,1034
10 93,10% 295,157 50 22 (1) 0,0690
Tingkat rekombinasi= 60% Tingkat mutasi = 1%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 315,610 50 25 (2) 0,0690
2 93,10% 315,422 50 26 (1) 0,0690
3 93,10% 307,375 50 24 (1) 0,0690
4 93,10% 271,719 50 20 (1) 0,0690
5 89,66% 315,547 50 25 (1) 0,1034 6 89,66% 306,218 50 24 (2) 0,1034 7 89,66% 265,594 50 20 (1) 0,1034
8 93,10% 308,453 50 23 (1) 0,0690
9 93,10% 332,000 50 25 (1) 0,0690
10 89,66% 285,907 50 23 (1) 0,1034 Tingkat rekombinasi = 60%
Tingkat mutasi = 5%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 329,094 50 27 (`1) 0,0690
2 93,10% 344,547 50 28 (1) 0,0690
3 93,10% 344,297 50 27 (2) 0,0690
4 93,10% 284,531 50 22 (1) 0,0690
5 89,66% 349,375 50 26 (1) 0,1034
6 93,10% 317,188 50 25 (1) 0,0690
7 89,66% 331,188 50 25 (1) 0,1034
8 93,10% 329,078 50 28 (2) 0,0690
9 93,10% 300,906 50 23 (1) 0,0690
27
Lanjutan
Tingkat rekombinasi = 60% Tingkat mutasi = 10%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 280,547 50 21 (1) 0,0690
2 89,66% 319,500 50 26 (1) 0,1034
3 93,10% 285,125 50 22 (1) 0,0690
4 93,10% 330,547 50 25 (1) 0,0690
5 93,10% 293,546 50 21 (1) 0,0690
6 93,10% 260,922 50 21 (1) 0,0690
7 93,10% 315,672 50 23 (1) 0,0690
8 89,66% 282,031 50 21 (1) 0,1034
9 93,10% 271,829 50 22 (1) 0,0690
10 93,10% 257,641 50 21 (1) 0,0690
Tingkat rekombinasi = 70% Tingkat mutasi = 5%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 308,328 50 22 (1) 0,0690
2 93,10% 318,000 50 25 (1) 0,0690
3 93,10% 334,156 50 25 (1) 0,0690
4 93,10% 344,797 50 27 (1) 0,0690
5 93,10% 310,969 50 24 (1) 0,0690
6 93,10% 337,328 50 26 (1) 0,0690
7 93,10% 336,156 50 27 (1) 0,0690
8 89,66% 315,890 50 24 (1) 0,1034
9 93,10% 311,938 50 23 (1) 0,0690
10 89,66% 364,765 50 28 (2) 0,1034
Tingkat rekombinasi = 80% Tingkat mutasi = 1%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 339,532 50 26 (1) 0,0690
2 93,10% 360,234 50 29 (5) 0,0690
3 89,66% 287,625 50 22 (1) 0,1034
4 93,10% 322,375 50 25 (2) 0,0690
5 89,66% 325,172 50 26 (1) 0,1034
6 89,66% 307,922 50 23 (1) 0,1034
7 93,10% 297,297 50 23 (1) 0,0690
8 89,66% 331,016 50 26 (1) 0,1034
9 93,10% 313,687 50 25 (1) 0,0690
28
Lanjutan
Tingkat rekombinasi= 80% Tingkat mutasi = 10%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 285,296 50 22 (1) 0,0690
2 93,10% 326,329 50 25 (1) 0,0690
3 93,10% 337,750 50 27 (2) 0,0690
4 93,10% 277,985 50 21 (1) 0,0690
5 93,10% 298,187 50 22 (1) 0,0690
6 93,10% 323,641 50 25 (1) 0,0690
7 93,10% 329,125 50 22 (1) 0,0690
8 93,10% 348,125 50 27 (1) 0,0690
9 89,66% 340,657 50 26 (1) 0,1034
10 93,10% 291,610 50 21 (1) 0,0690
Tingkat rekombinasi = 90% Tingkat mutasi = 1%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 278,891 50 21 (1) 0,0690
2 93,10% 322,578 50 25 (1) 0,0690
3 93,10% 282,781 50 21 (1) 0,0690
4 93,10% 263,531 50 20 (1) 0,0690
5 89,66% 282,594 50 22 (1) 0,1034
6 93,10% 341,031 50 27 (2) 0,0690
7 89,66% 270,093 50 20 (1) 0,1034
8 89,66% 315,000 50 25 (2) 0,1034
9 93,10% 287,782 50 22 (1) 0,0690
10 93,10% 295,766 50 23 (1) 0,0690
Tingkat rekombinasi = 90% Tingkat mutasi = 5%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 322,313 50 26 (3) 0,0690
2 89,66% 317,047 50 24 (1) 0,1034
3 93,10% 293,438 50 26 (1) 0,0690
4 93,10% 296,734 50 24 (1) 0,0690
5 93,10% 276,937 50 21 (1) 0,0690
6 93,10% 300,235 50 23 (1) 0,0690
7 93,10% 285,062 50 21 (1) 0,0690
8 89,66% 262,234 50 20 (1) 0,1034
9 93,10% 292,860 50 23 (1) 0,0690
29
Lanjutan
Tingkat rekombinasi = 90% Tingkat mutasi = 10%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 331,344 50 28 (2) 0,0690
2 93,10% 335,422 50 26 (1) 0,0690
3 93,10% 317,735 50 21 (1) 0,0690
4 93,10% 327,796 50 25 (2) 0,0690
5 89,66% 309,219 50 20 (1) 0,1034
6 93,10% 312,890 50 22 (2) 0,0690
7 93,10% 328,078 50 25 (1) 0,0690
8 93,10% 313,047 50 21 (1) 0,0690
9 93,10% 271,484 50 21 (1) 0,0690
10 93,10% 326,250 50 24 (1) 0,0690
Tingkat rekombinasi = 100% Tingkat mutasi = 1%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 296,625 50 23 (1) 0,0690
2 93,10% 303,406 50 22 (1) 0,0690
3 93,10% 351,344 50 28 (1) 0,0690
4 93,10% 353,968 50 27 (1) 0,0690
5 93,10% 337,781 50 27 (2) 0,0690
6 93,10% 302,250 50 23 (1) 0,0690
7 93,10% 266,562 50 20 (1) 0,0690
8 93,10% 322,969 50 24 (1) 0,0690
9 93,10% 302,344 50 23 (1) 0,0690
10 89,66% 296,406 50 22 (1) 0,1034
Tingkat rekombinasi = 100% Tingkat mutasi = 5%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 93,10% 278,891 50 25 (2) 0,0690
2 89,66% 318,203 50 23 (1) 0,1034
3 93,10% 331,234 50 25 (1) 0,0690
4 89,66% 276,297 50 21 (1) 0,1034
5 93,10% 297,719 50 23 (1) 0,0690
6 93,10% 266,204 50 20 (1) 0,0690
7 93,10% 330,297 50 25 (1) 0,0690
8 93,10% 298,750 50 23 (1) 0,0690
9 93,10% 342,594 50 27 (2) 0,0690
10 89,66% 260,390 50 19 (1) 0,1034
30
Lampiran 3 Hasil percobaan untuk 3 kombinasi parameter menggunakan training set 2 pada ukuran populasi sebesar 10
Tingkat rekombinasi = 80% Tingkat mutasi = 10%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 62,07% 202,969 50 15 (1) 0,3793
2 62,07% 223,484 50 18 (1) 0,3793
3 62,07% 216,125 50 17 (1) 0,3793
4 62,07% 228,938 50 18 (1) 0,3793
5 62,07% 216,360 50 16 (1) 0,3793
6 62,07% 236,109 50 18 (1) 0,3793
7 55,17% 143,484 50 10 (1) 0,4483
8 62,07% 213,875 50 17 (1) 0,3793
9 62,07% 220,172 50 15 (1) 0,3793
10 62,07% 241,578 50 18 (1) 0,3793
Tingkat rekombinasi = 90% Tingkat mutasi = 10%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 62,07% 238,188 50 18 (1) 0,3793
2 62,07% 223,031 50 17 (1) 0,3793
3 62,07% 226,906 50 17 (1) 0,3793
4 62,07% 206,625 50 16 (1) 0,3793
5 62,07% 207,204 50 17 (1) 0,3793
6 62,07% 220,187 50 18 (1) 0,3793
7 62,07% 233,735 50 18 (1) 0,3793
8 62,07% 211,954 50 17(1) 0,3793
9 62,07% 247,094 50 19 (1) 0,3793
10 62,07% 230,625 50 18 (1) 0,3793
Tingkat rekombinasi = 100% Tingkat mutasi = 1%
No. Akurasi Waktu
(detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
1 62,07% 228,172 50 18 (1) 0,3793
2 62,07% 236,594 50 19 (1) 0,3793
3 55,17% 210,282 50 16 (0) 0,4483
4 55,17% 117,047 50 16 (0) 0,4483
5 58,62% 217,188 50 17 (1) 0,4138
6 62,07% 226,297 50 18 (1) 0,3793
7 62,07% 228,563 50 18 (1) 0,3793
8 62,07% 256,375 50 20 (1) 0,3793
9 62,07% 213,062 50 17 (1) 0,3793
10 62,07% 233,719 50 18 (1) 0,3793
31
Lampiran 4 Hasil percobaan untuk parameter yang optimal pada ukuran populasi sebesar 30 & 50 Ukuran Populasi = 30
Tingkat Crossover
Tingkat Mutasi
Maks.
Generasi Akurasi
Waktu (detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
50 93,10% 1014,110 50 25 (1) 0,0690 100 93,10% 2406,530 100 22 (1) 0,0690 150 93,10% 3140,270 150 25 (1) 0,0690 200 93,10% 4502,950 200 26 (1) 0,0690
90% 10%
250 93,10% 5732,880 250 26 (1) 0,0690
Ukuran Populasi = 50
Tingkat Crossover
Tingkat Mutasi
Maks.
Generasi Akurasi
Waktu (detik)
Jumlah Iterasi
Jumlah Aturan
Fitness Terbaik
50 93,10% 1809,130 50 23 (1) 0,0690 100 93,10% 3866,530 100 25 (1) 0,0690 150 93,10% 5677,980 150 23 (1) 0,0690 200 93,10% 7172,590 200 23 (1) 0,0690
90% 10%
250 93,10% 7865,800 250 21 (1) 0,0690 Ket : angka di dalam kurung pada kolom “jumlah aturan” menunjukkan jumlah aturan yang mengandung kelas target positif diabetes.
Lampiran 5 Hasil training dari training set 1, 4, 5, 6, 7, 8, 9, dan 10 dengan menggunakan parameter algoritme genetika yang optimal
Training 1
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
1 100,00% 8,688 15,281 1 26 24 negatif, 2 positif 2 100,00% 7,922 14,532 1 21 21 negatif, 0 positif 3 100,00% 8,484 15,078 1 24 22 negatif, 2 positif 4 100,00% 8,843 15,531 1 21 21 negatif, 0 positif
5 100,00% 8,390 15,031 1 26 24 negatif, 2 positif
6 100,00% 8,828 15,438 1 26 25 negatif, 1 positif 7 100,00% 8,844 15,406 1 24 22 negatif, 2 positif 8 100,00% 8,172 14,656 1 21 21 negatif, 0 positif 9 100,00% 8,875 15,516 1 26 24 negatif, 2 positif 10 100,00% 8,313 14,875 1 20 18 negatif, 2 positif
Training 4
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
1 100,00% 8,265 14,859 1 22 22 negatif, 0 positif 2 100,00% 8,047 14,641 1 21 20 negatif, 1 positif 3 100,00% 9,218 15,906 1 25 24 negatif, 1 positif 4 100,00% 8,719 15,484 1 25 25 negatif, 0 positif 5 100,00% 8,938 15,641 1 26 25 negatif, 1 positif
6 100,00% 8,953 15,563 1 25 24 negatif, 1 positif
32
Lanjutan
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
8 100,00% 9,062 15,781 1 24 23 negatif, 1 positif 9 100,00% 8,188 14,782 1 23 22 negatif, 1 positif 10 100,00% 8,172 14,703 1 23 23 negatif, 0 positif
Training 5
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
1 100,00% 8,141 14,813 1 21 21 negatif, 0 positif 2 100,00% 9,203 15,797 1 23 21 negatif, 2 positif 3 100,00% 8,968 16,703 1 23 20 negatif, 3 positif 4 100,00% 9,110 15,704 1 24 24 negatif, 0 positif 5 100,00% 8,500 15,156 1 23 23 negatif, 0 positif 6 100,00% 8,344 15,016 1 22 19 negatif, 3 positif 7 100,00% 8,578 15,266 1 22 22 negatif, 0 positif 8 100,00% 8,390 15,062 1 22 20 negatif, 2 positif 9 100,00% 8,422 15,016 1 24 23 negatif, 1 positif
10 100,00% 8,235 15,188 1 23 20 negatif, 3 positif
Training 6
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
1 100,00% 8,547 15,359 1 27 27 negatif, 0 positif 2 100,00% 8,500 15,094 1 23 23 negatif, 0 positif 3 100,00% 8,203 14,906 1 22 20 negatif, 2 positif
4 100,00% 8,453 15,063 1 27 25 negatif, 2 positif
5 100,00% 8,235 14,938 1 24 23 negatif, 1 positif 6 100,00% 9,000 15,594 1 27 24 negatif, 3 positif 7 100,00% 9,016 15,500 1 28 26 negatif, 2 positif 8 100,00% 8,563 15,359 1 20 19 negatif, 1 positif 9 100,00% 9,188 15,922 1 29 27 negatif, 2 positif 10 100,00% 8,578 15,265 1 24 22 negatif, 2 positif
Training 7
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
1 100,00% 8,437 15,281 1 24 24 negatif, 0 positif 2 100,00% 8,140 14,890 1 19 19 negatif, 0 positif
3 100,00% 8,281 14,797 1 22 22 negatif, 0 positif
33
Lanjutan Training 8
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
1 100,00% 8,062 14,875 1 20 19 negatif, 1 positif 2 100,00% 8,781 15,313 1 28 28 negatif, 0 positif 3 100,00% 8,266 14,922 1 23 21 negatif, 2 positif 4 100,00% 8,797 15,250 1 28 28 negatif, 0 positif 5 100,00% 8,312 15,015 1 20 20 negatif, 0 positif 6 100,00% 8,844 15,328 1 23 23 negatif, 0 positif 7 100,00% 8,157 14,688 1 20 20 negatif, 0 positif 8 100,00% 8,172 14,641 1 23 22 negatif, 1 positif
9 100,00% 7,938 14,625 1 20 19 negatif, 1 positif
10 100,00% 8,750 15,594 1 22 21 negatif, 1 positif
Training 9
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
1 100,00% 8,062 14,875 1 20 19 negatif, 1 positif 2 100,00% 8,781 15,313 1 28 28 negatif, 0 positif 3 100,00% 8,266 14,922 1 23 21 negatif, 2 positif
4 100,00% 8,797 15,250 1 28 28 negatif, 0 positif 5 100,00% 8,312 15,015 1 20 20 negatif, 0 positif 6 100,00% 8,844 15,328 1 23 23 negatif, 0 positif 7 100,00% 8,157 14,688 1 20 20 negatif, 0 positif 8 100,00% 8,172 14,641 1 23 22 negatif, 1 positif
9 100,00% 7,938 14,625 1 20 19 negatif, 1 positif
10 100,00% 8,750 15,594 1 22 21 negatif, 1 positif
Training 10
No. Akurasi Waktu
(detik)
Waktu total (detik)
Jumlah Iterasi
Jumlah
Aturan Keterangan
1 100,00% 9,187 15,828 1 22 19 negatif, 3 positif 2 100,00% 9,516 16,063 1 22 21 negatif, 1 positif 3 100,00% 8,828 15,531 1 29 29 negatif, 3 positif 4 100,00% 9,078 15,735 1 25 22 negatif, 3 positif 5 100,00% 9,094 15,750 1 25 23 negatif, 2 positif 6 100,00% 9,094 15,750 1 27 23 negatif, 4 positif
7 100,00% 8,813 15,485 1 23 21 negatif, 2 positif
34
Lampiran 6 Contoh sebagian data training set 1 dan testing set 1 Training set 1
no_rm GLUN GPOST HDL TG CLASS
30 262 434 39 117 1
31 70 80 49 91 1
32 74 130 30 178 1
33 130 210 38 169 1
34 74 225 37 90 1
35 81 118 58 70 1
36 102 107 40 88 1
37 97 105 31 222 1
38 107 104 28 164 1
39 87 150 30 177 1
40 151 212 40 235 1
41 63 147 26 94 1
42 68 90 56 77 1
43 68 70 43 139 1
44 120 151 51 126 1
Testing set 1
no_rm GLUN GPOST HDL TG CLASS
1 115 159 32 117 1
2 0 0 91 91 1
3 90 145 28 86 1
4 84 90 64 46 1
Lampiran 7 Contoh sebagian data training set 1 hasil fuzzikasi untuk membentuk FDT
no_rm GLUN Rendah Sedang Tinggi Sang
at Ting
gi
GPOST Rendah Sedang Tinggi Sang
at Ting
gi
HDL Rendah Sedang Tinggi TG Rendah Sedang Tinggi CLASS
30 262 0 0 0 1 434 0 0 0 1 39 0,6 0,4 0 117 0 1 0 1
31 70 0,5 0,5 0 0 80 1 0 0 0 49 0 1 0 91 0 1 0 1
32 74 0,1 0,9 0 0 130 0 1 0 0 30 1 0 0 178 0 0 1 1
33 130 0 0 1 0 210 0 0 0 1 38 0,7 0,3 0 169 0 0 1 1
34 74 0,1 0,9 0 0 225 0 0 0 1 37 0,8 0,2 0 90 0 1 0 1
35 81 0 1 0 0 118 0 1 0 0 58 0 0,7 0,3 70 0 1 0 1
36 102 0 1 0 0 107 0 1 0 0 40 0,5 0,5 0 88 0 1 0 1
37 97 0 1 0 0 105 0 1 0 0 31 1 0 0 222 0 0 1 1
38 107 0 0,8 0,2 0 104 0,1 0,9 0 0 28 1 0 0 164 0 0 1 1
39 87 0 1 0 0 150 0 0 1 0 30 1 0 0 177 0 0 1 1
40 151 0 0 0 1 212 0 0 0 1 40 0,5 0,5 0 235 0 0 1 1
41 63 1 0 0 0 147 0 0 1 0 26 1 0 0 94 0 1 0 1
42 68 0,7 0,3 0 0 90 1 0 0 0 56 0 0,9 0,1 77 0 1 0 1
43 68 0,7 0,3 0 0 70 1 0 0 0 43 0,2 0,8 0 139 0 1 0 1
Lampiran 8 Contoh sebagian data training set 1 hasil fuzzikasi untuk membentuk G-DT
no_rm GLUN Rendah Sedang Tinggi GPOST Rendah Sedang Tinggi HDL Rendah Sedang Tinggi TG Rendah Sedang Tinggi CLASS
30 262 0 0,32 0,68 434 0 0 1 39 1 0 0 117 0,80 0,20 0 1
31 70 1 0 0 80 1 0 0 49 0,33 0,67 0 91 1 0 0 1
32 74 1 0 0 130 0,48 0,52 0 30 1 0 0 178 0 1 0 1
33 130 0,04 0,96 0 210 0 1 0 38 1 0 0 169 0 1 0 1
34 74 1 0 0 225 0 1 0 37 1 0 0 90 1 0 0 1
35 81 0,96 0,04 0 118 0,62 0,38 0 58 0 1 0 70 1 0 0 1
36 102 0,57 0,43 0 107 0,77 0,23 0 40 1 0 0 88 1 0 0 1
37 97 0,66 0,33 0 105 0,79 0,21 0 31 1 0 0 222 0 1 0 1
38 107 0,47 0,53 0 104 0,8 0,2 0 28 1 0 0 164 0 1 0 1
39 87 0,85 0,15 0 150 0,22 0,78 0 30 1 0 0 177 0 1 0 1
40 151 0 1 0 212 0 1 0 40 1 0 0 235 0 1 0 1
41 63 1 0 0 147 0,26 0,74 0 26 1 0 0 94 1 0 0 1
42 68 1 0 0 90 0,97 0,03 0 56 0 1 0 77 1 0 0 1
43 68 1 0 0 70 1 0 0 43 0,83 0,17 0 139 0,42 0,58 0 1
Lampiran 9 Fuzzy decision tree untuk contoh training set 1
GPOST
HDL
NO TG GLUN
Rendah
Rendah Sedang Tinggi
NO Rendah
TG Sedang
Rendah Sedang Tinggi
NO NO NO
NO Tinggi
TG Rendah
NO Sedang
Tinggi
NO Sedang
NO NO
Sedang
TG
GLUN Tinggi Sangat Tinggi
NO NO GLUN Rendah Sedang Tinggi
NO Sedang
HDL Tinggi
Rendah Sedang Tinggi
NO NO NO
TG Sangat Tinggi
NO Tinggi
NO TG TG
Rendah Sedang Tinggi
HDL Sangat Tinggi
NO S