Metode K-Means Cluster dan Fuzzy C-Means Cluster (Studi Kasus: Indeks Pembangunan Manusia di Kawasan Indonesia Timur tahun 2012)
Teks penuh
Gambar

Dokumen terkait
Dalam ilmu pengolahan citra ada sebuah metode untuk melakukan recognition sebuah citra yang dimana dapat dilakukan dalam jumlah data yang banyak.. Sehingga untuk
Agar proses penggelompokan data lebih cepat, maka penelitian ini menggunakan Fuzzy C-Means yang merupakan salah satu pengelompokan data yang tiap-tiap titik data
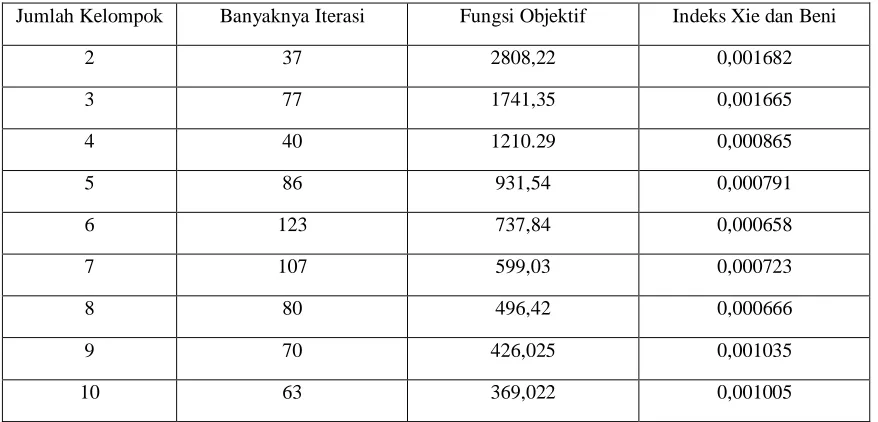
cluster yang sama. Variance between cluster : Tipe varian ini mengacu pada jarak antar cluster... Ada dua ketentuan apabila menentukan cluster ideal menggunakan
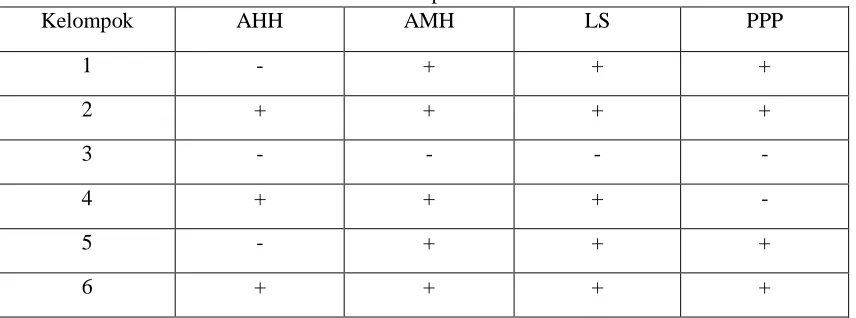
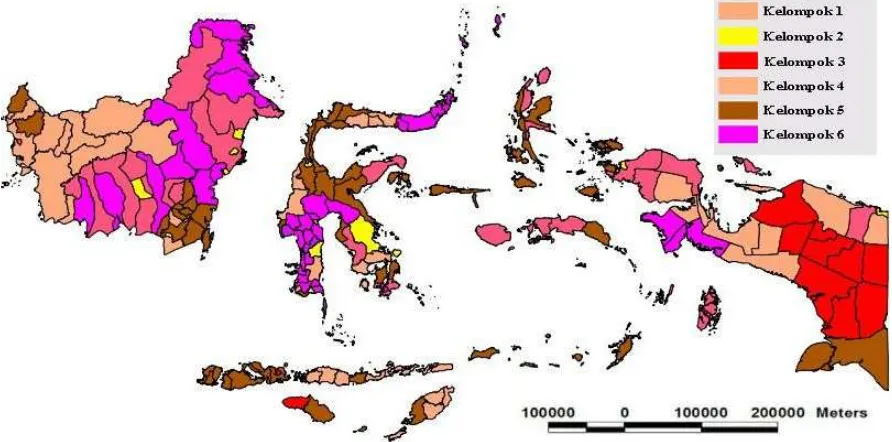
Berdasarkan hasil pengelompokan kabupaten/kota di Provinsi Jawa Tengah menurut indikator IPM diketahui bahwa cluster 4 merupakan cluster yang terbaik karena
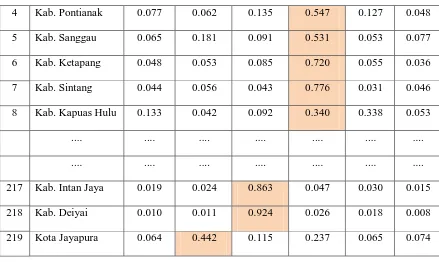
Pada penelitian ini, digunakan dataset IPM tahun 2019 di Indonesia untuk dapat dilakukan proses data mining dengan salah satu metode Unsupervised Learning, yaitu clustering yang
Hasil dari penelitian ini menunjukkan bahwa metode FCM adalah metode yang lebih baik daripada K-Means untuk melakukan clustering pada data user knowledge modeling dikarenakan
Dalam ilmu pengolahan citra ada sebuah metode untuk melakukan recognition sebuah citra yang dimana dapat dilakukan dalam jumlah data yang banyak.. Sehingga untuk
Penelitian ini bertujuan untuk merancang sistem identifikasi kandungan nitrogen berdasarkan warna daun yang diawali dengan proses pembelajaran dengan menggunakan metode clustering
