BAB II
TINJAUAN PUSTAKA
2.1 Konsep Clustering dalam Data Mining
Konsep dasar data mining adalah menemukan informasi tersembunyi dalam sebuah
basis data dan merupakan bagian dari Knowledge Discovery in Databased (KDD)
untuk menemukan informasi dan pola yang berguna dalam data (Durham, 2003). Data
mining mencari informasi baru, berharga dan berguna dalam sekumpulan data dengan
melibatkan komputer dan manusia serta bersifat iteratif baik melalui proses yang
otomatis ataupun manual. Secara umum sifat data mining adalah:
a. Predictive: menghasilkan model berdasarkan sekumpulan data yang dapat
digunakan untuk memperkirakan nilai data yang lain. Metode yang termasuk dalam
prediktif data mining adalah:
- Klasifikasi: pembagian data ke dalam beberapa kelompok yang telah ditentukan
sebelumnya.
- Regresi: memetakan data ke suatu prediction variable.
- Time Series Analisys: pengamatan perubahan nilai atribut dari waktu ke waktu.
b. Descriptive: mengidentifikasi pola atau hubungan dalam data untuk menghasilakn
informasi baru. Metode yang termasuk dalam Descriptive Data Mining adalah:
- Clustering: identifikasi kategori untuk mendeskripsikan data.
- Association Rules: pemetaan data ke dalam subset dengan deskripsi sederhana.
- Sequence Discovery: identifikasi pola sekuensial dalam data.
Clustering membagi data menjadi kelompok-kelompok atau cluster berdasarkan
suatu kemiripan atribut-atribut diantara data tersebut (Durham, 2003). Karakteristik
tiap cluster tidak ditentukan sebelumnya, melainkan tercermin dari kemiripan data
yang terkelompok di dalamnya. Oleh sebab itu hasil clustering seringkali perlu
mengenai karakter domain data tersebut. Selain digunakan sebagai metode yang
independen dalam data mining, clustering juga digunakan dalam pra-pemrosesan data
sebelum data diolah dengan metode data mining yang lain untuk meingkatkan
pamahaman terhadap domain data.
Karakteristik terpenting dari hasil clustering yang baik adalah suatu instance
data dalam suatu cluster lebih “mirip” dengan instance lain di dalam clustering
tersebut daripada dengan instance di luar dari clustering itu. Ukuran kemiripan
(similarity measure) tersebut bisa bermacam-macam dan mempengaruhi perhitungan
dalam menentukan anggota suatu cluster. Jadi tipe data yang akan di-cluster
(kuantitatif atau kualitatis) juga menentukan ukuran apa yang tepat digunakan dalam
suatu algoritma. Selain kemiripan antar data dalam suatu cluster, clustering juga dapat
dilakukan berdasarkan jarak antar data atau cluster yang satu dengan yang lain.
Ukuran jarak (distance atau dissimilarity measure) yang merupakan kebalikan dari
ukuran kemiripan ini juga banyak ragamnya dan penggunaannya juga tergantung pada
tipe data yang akan di-cluster. Kedua ukuran ini bersifat simetris, dimana jika A
dikatakan mirip dengan B maka dapat disimpulkan bahwa B mirip dengan A.
Ada beberapa macam rumus perhitungan jarak antara cluster. Untuk tipe data
numerik, sebuah data det X beranggotakan X1 Є X, i = 1, ..., n, tiap item
direpresentasekan sebagai vektor X1 = {Xi1, Xi2, Xim} dengan m sebagai jumlah
dimensi dari item. Rumus-rumus yang biasa digunakan sebagai ukuran jarak antara Xi
dan Xj untuk data numerik ini antara lain:
a. Euclidean Distance
������ − ���� 2 �
�=1
� 1 2
(1)
Ukuran ini sering digunakan dalam clustering karena sederhana. Ukuran ini
memiliki masalah jika skala nilai atribut yang satu sangat besar dibandingkan nilai
atribut lainnya. Oleh sebab itu, nilai-nilai atribut sering dinormalisasi.
b. City Block Distance atau Manhatta Distance
����� − ���� �
�=1
Jika tiap item digambarkan sebagai sebuah titik dalam grid, ukuran jarak ini
merupakan banyak sisi harus dilewati suatu titik untuk mencapai titik yang lain
seperti halnya dalam sebuah peta jalan.
c. Minkwoski Metric
������ − ����� �
�=1
� 1 �
(3)
Ukuran ini merupakan bentuk umum dari Euclidean Distance dan Manhatta
Distance. Euclidean Distance adalah kasus dimana nilai p = 2 sedangkan Manhatta
Distance merupakan bentuk Minkwoski dengan p = 1. Dengan demikian, lebih
banyak nilai numerik yang dapat ditempatkan pada jarak terjauh di antara 2 vektor.
Seperti pada Euclidean Distance dan juga Manhattan Distance, ukuran ini
memiliki masalah jika salah satu atribut dalam vektor memiliki rentang yang lebih
besar dibanding atribut-atribut lainnya.
d. Cosine – Corelation (ukuran kemiripan dari model Euclidean n-dimensi)
∑��=1����.����
�∑ ���2 ∑ �
��2 �
�=0
(4)
Ukuran ini bagus digunakan pada data dengan tingkat kemiripan tinggi walaupun
sering pula digunakan bersama pendekatan lain untuk membatasi dimensi dari
permasalahan.
Dalam mendefenisikan ukuran jarak antara cluster yang digunkan beberapa
algoritma untuk menentukan cluster mana yang terdekat, perlu dijelaskan
mengenai atribut-atribut yang menjadi referensi dari suatu cluster. Untuk suatu
cluster Km berisi N item {Xm1, Xm2, ..., Xnm}:
- Centroid: suatu besaran yang dihitung dari rata-rata nilai dari setiap item dari
suatu cluster menurut rumus:
�� = ∑
|���|
� �=1
� (5) - Medoid: item yang letaknya paling tengah.
Metode-metode untuk mencari jarak antara cluster:
- Single Link: jarak terkecil antara suatu elemen dalam suatu cluster dengan
- Comple Link: jarak rata-rata antar satu elemen dalam suatu cluster dengan
elemen lain di cluster yang berbeda.
- Average: jarak rata-rata antar satu elemen dalam suatu cluster dengan elemen
lain di cluster yang berbeda.
- Centoid: jarak antara centroid dari tiap cluster dengan centoid cluster lainnya.
- Medoid: jarak antara medoid dari tiap cluster denga medoid cluster lainnya.
2.2 Algoritma Clustering
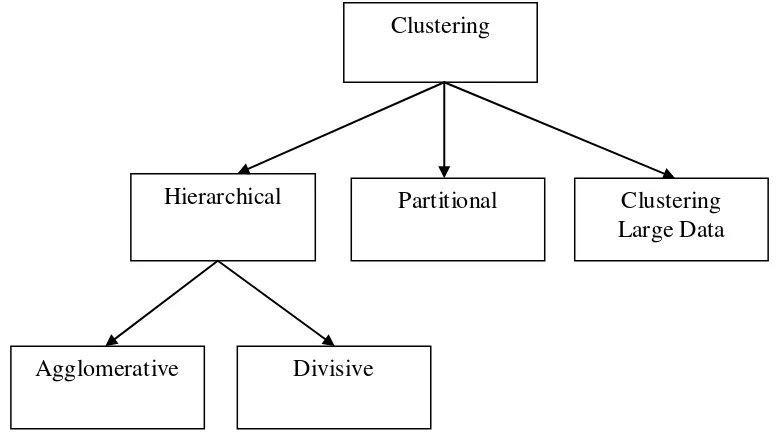
Secara umum pembagian algoritma clustering dapat digambarkan sebagai berikut:
Gambar 2.1 Kategori Algoritma Clustering
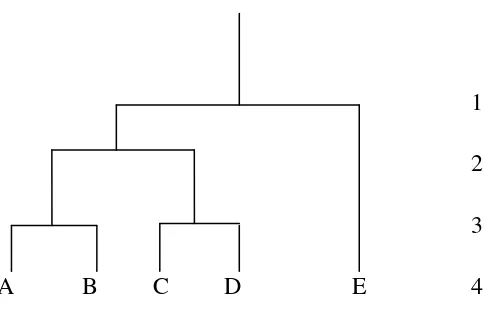
Hierarchical clustering menentukan sendiri jumlah cluster yang dihasilkan.
Hasil dari metode ini adalah suatu struktur data berbentuk pohon yang disebut
dendogram dimana data dikelompokkan secara bertingkat dari yang paling bawah
dimana tiap intance data merupakan satu cluster sendiri, hingga tingkat paling atas
dinamakan keseluruhan data membentuk satu cluster besar berisi cluster-cluster
seperti gambar 2.2
Clustering
Hierarchical Partitional Clustering
Large Data
1
2
3
A B C D E 4
Gambar 2.2 Dendogram
Divisive hierarchical clustering mengelompokkan data dari kelompok yang
terbesar hingga ke kelompok yang terkecil, yaitu masing-masing instance dari
kelompok data tersebut. Sebaliknya, agglomerative hierarchical clustering mulai
mengelompokkan data dari kelompok yang terkecil hingga kelompok yang terbesar.
Beberapa algoritma yang menggunakan metode ini adalah: Robust Clustering Using
Links (ROCK), Chameleon, Cobweb, Shared Nearest Neighbor (SNN).
Partitional clustering yang mengelompokkan data ke dalam k cluster dimana k
adalah banyaknya cluster dari input user. Kategori ini biasanya memerlukan
pengetahuan yang cukup mendalam tentang data dan proses bisnis yang
memanfaatkannya unuk mendapatkan kisaran nilai input yang sesuai. Beberapa
algoritma yang masuk dalam kategori diantara lain : K-Means, Fuzzy C-Means,
Clustering Large Aplications (CLARA), Expectation Maximation (EM), Bond Energy
Algorithm (BEA), algoritma Genetika, Jaringan Saraf Tiruan.
Clustering Large Data, dibutuhkan untuk melakukan clustering pada data yang
volumenya sangat besar sehingga tidak cukup ditampung dalam memori komputer
pada suatu waktu. Biasanya untuk mengatasi masalah besarnya volume data, dicari
teknik-teknik untuk meminimalkan berapa kali algoritma harus membaca seluruh data.
Beberapa algoritma yang masuk dalam kategori ini antara lain: Balance Iteratif
Reducing and clustering using hierarchies (BIRCH), Density Based Spatial
Clustering of Application With Noise (DCSCAN), Clustering Categorical Data Using
2.3 Algoritma C-Means
Pada proses clustering sacara klasik (misalnya pada Clustering K-Means),
pembentukan partisi dilakukan sedemikian rupa sehingga setiap obyek berada tepat
pada satu partisi, karena sebenarnya obyek tersebut terletak di antara 2 atau lebih
partisi yang lain. Pada logika algoritma, metode yang dapat digunkana untuk
melakukan pengelompokan sejumlah data dikenal dengan nama algoritma clustering.
Algoritma Clustering lebih alami jika dibandingkan dengan clustering secara klasik.
Suatu algoritma clustering dikatakan sebagai algoritma clustering jika algoritma
tersebut menggunakan parameter strategis adaptasi secara soct competitive. Sebagian
besar algoritma clustering didasarkan atas optimasi fungsi obyektif atau modifikasi
dari fungsi obyektif tersebut (Kusumadewi. S, Hartati. S. 2006).
Salah satu teknik algoritma clustering adalah Algoritma C-Means. Algoritma
C-Means adalah suatu teknik clustering data yang keberadaan tiap-tiap data dalam suatu
cluster ditentukan oleh nilai/derajat keanggotaan tertentu. Teknik ini pertama kali
diperkenalkan Jim Bezdek pada tahun 1981 (Kusumadewi. S, Hartati. S. 2006).
Berbeda dengan teknik clustering secara klasik (dimana suatu obyek hanya akan
menjadi anggota dari beberapa cluster. Batas-batas cluster dalam Algoritma C-Means
adalah lunak (soft). Kosep dasar Algoritma C-Means, pertama kali adalah menentukan
pusat cluster yang menandai lokasi rata-rata untuk tiap-tiap cluster. Pada kondisi
awal, pusat cluster ini masih belum akurat. Tiap-tiap data memiliki derajat
keanggotaan untuk tiap-tiap cluster. Dengan cara memperbaiki pusat cluster dan nilai
keanggotaan tiap-tiap data secara berulang, maka akan terlihat bahwa pusat cluster
akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimasi
fungsi obyektif. Fungsi obyektif yang digunakan pada Algoritma C-Means adalah
(Kusrini, 2006):
��(�,�;�) =� � (���)�(���)2 �
�=1 �
�=1
(6)
dengan w Є [1, ],
��� = �(��− ��) =�� ���� − ���� �
�=1 �
1 2
x adalah data yang akan di clustering:
nilai Jw terkecil adalah yang terbaik, sehingga:
Jw*(U*, V*; X) = min J (U, V, X) (10)
Algoritma C-Means diberikan sebagai berikut(Kusumadewi, et al, 2006):
1. Menentukan data yang akan di clustering X, berupa matriks berukuran n x m (n =
jumlah sampel data, m = atribut setiap data), Xij = data sampel ke-i (i = 1,2, ... , n),
atribut ke-j (j = 1,2,..., mm).
2. Menentukan:
- Jumlah cluster = c
- Pangkat = w
- Maksimal interaksi = Maxlter
- Error terkecil yang diharapkan =
- Fungsi objektif awal = Po = 0
3. Membangkitkan bilangan random µik i=1,2,3, ..., n: k=1,2,3,.., c: sebagai
elemen-elemen matriks partisi awal U.
Menghitung jumlah setiap kolom:
4. Menghitung pusat cluster ke-k: Vkj, dengan k=1,2,...c: dan j=1,2,...m
��� =∑ �
(���)�.����
� �=1
∑��=1(���)� (14)
5. Menghitung fungsi objektif pada interasi ke-t:
�� =� � ������� −����
6. Menghitung perubahan matriks partisi:
��� =
Digunakan untuk mengukur nilai hasil penyebaran data-data hasil clustering ada dua
macam (Ridho Barakbah, 2009), yaitu:
1. Variance within cluster: Tipe varian ini mengacu pada jarak antar anggota pada
cluster yang sama.
Ada dua ketentuan apabila menentukan cluster ideal menggunakan cara
perbandiangan Variance within Cluster Vw) dan Variance between Cluster (Vb) yaitu
sebagai berikut:
a. Berdasarkan nilai minimum
� = ��
�� (17)
Keterangan:
V = nilai variance
Vw = nilai variance between cluster
VB = nilai variance between cluster
Cluster yang disebut ideal adalah cluster yang memiliki nilai variance yang paling
kecil.
b. Berdasarkan nilai maksimum
� = ��
�� (18)
Keterangan:
V = nilai variance
Vw = nilai variance within cluster
VB = nilai variance between cluster
Cluster yang disebut ideal adalah cluster yang memiliki variance yang paling besar.
Sebelum mencari nilai variance (V), perlu dicari nilai variance within cluster (Vw)
dan nilai variance between cluster (VB) (Ali, Modul ajar cluster analysis).
a. Variance within Cluster (Vw)
�� =
1
� − � � (��−1).��2 �
�=1
Keterangan:
N = jumlah semua data
k = jumlah cluster
ni = jumlah data pada cluster ke-i
Vi2 = variance pada cluster ke-i
Sebelum menghitung variance within perlu menghitung nilai Vi2.
Keterangan:
��2 =
1
��−1� ��� − �̅�� 2 �
�=1
(20)
Vc2 = variance pada cluster c
c = 1...k, dimana k = jumlah cluster
nc = jumlah data pada cluster c
di = data ke-i pada suatu cluster
dl = rata-rata dari data pada suatu cluster
b. Variance between Cluster (VB)
�� =
1
� −1� ��
�
�=1 ��̅�− �̅� 2
(21)
Keterangan:
d = rata-rata dari di
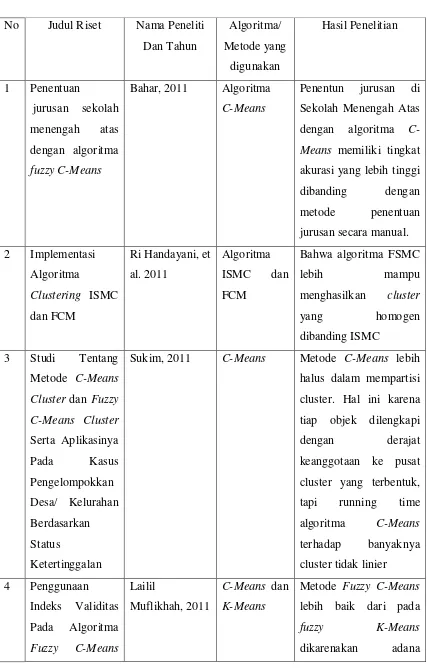
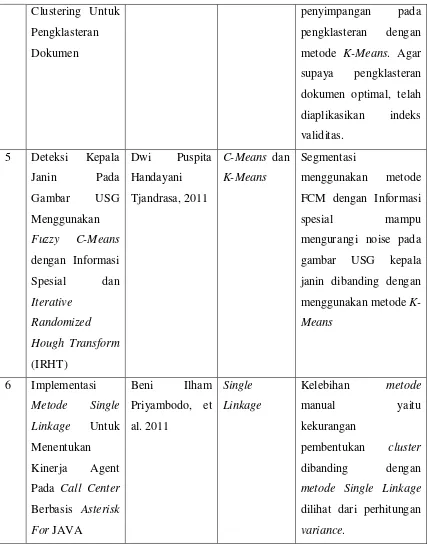
2.5 Riset-riset Terkait
Dalam melakukan penelitian, penulis menggunakan beberapa riset terkait yang
dijadikan yang membuat penelitian berjalan lancar. Adapun riset-riset terkait tersebut
Tabel 2.3 Riset Terkait
No Judul Riset Nama Peneliti
Dan Tahun
Bahar, 2011 Algoritma
C-Means
Penentun jurusan di
Sekolah Menengah Atas
dengan algoritma
C-Means memiliki tingkat
Clustering Untuk
2.6 Perbedaan Dengan Riset Yang Lain
Dalam penelitian ini menggunakan Algoritma C-Means dan Cluster Analysis
(Variance) dengan berbagai data yang akan diolah dan juga menggunakan alat bantu
berupa software Visual Basic sehingga dapat langsung diterapkan untuk penyelesaian
2.7 Kontribusi Riset
Dalam penelitian ini digunakan dua Algoritma C-Means dan Cluster Analysis
(Variance) yang saling mengisi yang diharapkan dari penelitian ini dapat menentukan
berapa sesungguhnya cluster yang ideal yang terbentuk dari range data yang akan di