DAN 2 DAN KLASIFIKASI K NEAREST NEIGBOR
UNTUK MENGIDENTIFIKASI CITRA MINERAL PADA
BATUAN SEDIMEN
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
Muhammad Rizky
10109405
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii Alhamdulillah,
Segala puji dan syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan iman, kekuatan, kecerdasan, kesehatan, semangat yang tinggi, serta semua kekayaan yang dilimpahkan kepada penulis, karena dengan izin dan berkah-Nya lah penelitian ini dapat diselesaikan dengan baik sesuai dengan waktu yang direncanakan.
Skripsi yang berjudul “IMPLEMENTASI METODE EKSTRAKSI STATISTIK ORDE SATU DAN DUA DAN KLASIFIKASI K-NEAREST NEIGHBOR UNTUK MENGIDENTIFIKASI CITRA MINERAL PADA BATUAN SEDIMEN” disusun untuk memperoleh gelar Sarjana Teknik Informatika, Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia.
Pada kesempatan ini penulis hendak menyampaikan terima kasih kepada : 1. Allah SWT atas berkah dan karunia-Nya sehingga penulis dapat
menyelesaikan tugas akhir ini.
2. Kedua orang tua dan adik-adik tercinta, terima kasih yang tak terhingga atas segala dukungan serta doanya sehingga penulis memiliki semangat untuk dapat menyelesaikan tugas akhir ini.
3. Bapak Irfan Maliki, S.T., M.T. selaku dosen pembimbing tugas akhir yang telah memberikan segenap waktu, kekuatan dan inspirasi dalam pembuatan tugas akhir serta banyak memberikan bimbingan dan saran-saran kepada penulis sampai akhirnya penulis dapat menyelesaikan tugas akhir ini. 4. Seluruh dosen teknik informatika yang telah memberikan ilmunya yang
sangat bermanfaat dalam penyusunan tugas akhir ini.
5. Seluruh teman-teman di jurusan IF angkatan 2009 baik yang sudah dan yang belum menyelesaikan kuliahnya.
iv
Penulis telah berupaya dengan semaksimal mungkin dalam penyelesaian tugas akhir ini, namun penulis menyadari masih banyak kelemahan baik dari segi isi maupun tata bahasa, untuk itu penulis mengharapkan kritik dan saran yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Tak lupa penulis mohon maaf apabila dalam penulisan atau penyusunan tugas akhir ini, apabila menyinggung perasaan atau bahkan telah menyakiti pihak tertentu baik yang disengaja maupun tidak disengaja. Kiranya isi tugas akhir ini bermanfaat dalam memperkaya khasanah ilmu pendidikan dan juga dapat dijadikan sebagai salah satu sumber referensi bagi peneliti selanjutnya yang berminat meneliti hal yang sama.
Bandung, Februari 2016
v
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iv
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xi
DAFTAR SIMBOL ... xii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Maksud dan Tujuan ... 4
1.4 Batasan Masalah... 4
1.5 Metode Penelitian... 5
1.5.1 Metode Pengumpulan Data ... 5
1.5.2 Metode Tahapan Analisis ... 6
1.6 Sistematika Penulisan ... 6
BAB 2 TINJAUAN PUSTAKA ... 8
2.1 Pengolahan Citra ... 8
2.2 Operasi Pengolahan Citra ... 8
2.3 Segmentasi Citra ... 11
2.4 Operasi Biner ... 13
2.5 Operasi Morfologi ... 14
vi
2.10 Tekstur... 17
2.11 Analisis Tekstur ... 18
2.12 K Means Clustering ... 19
2.13 Ekstraksi Fitur ... 20
2.14.1 Orde Satu ... 23
2.14.2 Orde Dua ... 24
2.14 Klasifikasi ... 25
2.14.1 Klasifikasi K-Nearest Neighbor ... 28
2.15 Pemrograman Terstruktur ... 31
2.16 Data Flow Diagram (DFD) ... 33
2.17 Matlab (Matrix Laboratory) ... 33
2.18 Sayatan Tipis Batuan Pasir... 34
2.19 Point Counting ... 35
BAB 3 ANALISIS DAN PERANCANGAN ... 37
3.1 Analisis Masalah ... 37
3.2 Analisis Proses ... 37
3.2.1 Input Citra ... 37
3.2.2 Preprocessing ... 38
3.2.2.1 Segmentasi K Means Clustering... 39
3.2.2.2 Deteksi Tepi (sobel) dan pemotongan(Cropping). ... 42
3.2.2.3 Grayscale ... 43
vii
3.2.3.2 Ekstraksi Orde Dua ... 49
3.2.4 Analisis K Nearest Neighbor ... 57
3.3 Perancangan sistem ... 60
3.3.1 Perancangan fungsional ... 60
3.3.1.1 Diagram Konteks ... 60
3.3.1.2 Perancangan Data Flow Diagram (DFD) ... 60
3.3.1.3 Spesifikasi Proses ... 62
3.3.1.4 Perancangan Arsitektur... 65
3.3.1.4.1 Perancangan Struktur Menu ... 65
3.3.1.4.2 Perancangan Interface... 65
3.3.1.4.2 Perancangan Prosedural ... 68
3.3.2 Analisis Kebutuhan Non Fungsional ... 69
3.3.2.1 Analisis kebutuhan perangkat keras ... 69
3.3.2.2 Analisis kebutuhan perangkat lunak ... 70
3.3.2.3 Analisis pengguna ... 70
3.3.2.4 Perancangan Simulasi ... 70
3.3.2.5 Jaringan Semantik ... 73
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 74
4.1 Implementasi ... 74
4.2 Pengujian Performansi ... 78
4.3 Kesimpulan Pengujian ... 86
BAB 5 KESIMPULAN DAN SARAN ... 87
5.1 Kesimpulan ... 87
85
1] Godfrey-Smimth, D. (2005). Beta Dosimetry of Potassium Feldspars in sediment Exstract Using Imaging Microphobe Analysis and Beta Counting. Geochronometria, 7-12.
2] launeau, P. (1994). Mineral Recognition in Digital Images Of Rocks. The Canadian Mineralogist, 919-933.
3] Maharsi, D. N. (2013). Klasifikasi Serat Miring pada Kayu Menggunakan Ekstraksi Ciri Statistik Berdasarkan Pada Pengolahan Citra. bandung.
4] P. Mohaniaiah, P. S. (2013). Image Texture Feature Ekstraction Using GLCM Approach. International Journal of scientific and Research Publication Volume 3, 5] Ting-chuen. (1983). The Aplication of Image Analysis Technique to Mineral Processing. Pattern Recognition Letter 2, 117-123.
6] Williams, L. B. (1988). An automated chemical and modal analysis technique. American Mineralogist, 1-8.
7] King, Hobart. "Sandstone, A clastic sedimentary rock composed of sand-sized grains of mineral, rock or organic material". 25 Desember 2015. http://geology.com/ rocks/sandstone.shtml.
8]Foundation, Wikimedia Inc."Sandstone".25 Desember 2015. https://en.wikipedia.org/ wiki/Sandstone
9] Foundation, Wikimedia Inc."K-means". 26 Desember 2015. https://id.wikipedi a.org/wiki/K-means
10] Cook, John."Three algorithms for converting color to grayscale". 26 Desember 2015.http://www.johndcook.com/blog/2009/08/24/algorithms-convert-color-grayscale/
11] Foundation, Wikimedia Inc."K Nearest Neighbor". 26 Desember 2015. https://id.wikipedia.org/wiki/K-Nearest_Neighbor
13] Handi, Irfan."Batu Pasir adalah".27 Desember 2015.
https://thekoist.wordpress.com /2012/04/26/ komposisi-tekstur-struktur-dan-klasifikasi-batuan-sedimen-batupasir/
14] Purnama, Agus."Operasi Pengolahan Citra Digital".28 Desember 2015. http://elektronika-dasar.web.id/operasi-pengolahan-citra-digital/
[15] Sharif, Mulkan."Implementasi Fuzzy C Means Clustering".29 Desember 2015. http://www.softscients.web.id/2015/07/implementasi-fuzzy-c-means-clustering.html
16] Ahmad, Usman."Image Analysis Using Second Order Statistic of GLCM".29 Desember 2015. https://martendarmawan.wordpress.com/2011/02/25/image-analysis-using-second-order-statistic-of-glcm/
1
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Batu pasir atau arenite adalah jenis batuan sedimen terdiri dari butiran mineral pasir dan bahan organik lain dalam ukuran kecil, batu ini berisi bahan semen seperti silika dan karbonat yang mengikat butiran pasir bersama-sama dan berisi butiran lempung yang menempati ruang antara butiran pasir. Batu pasir adalah jenis yang paling umum dari batuan sedimen yang sering ditambang untuk digunakan sebagai akuifer air tanah dan sebagai reservoir minyak dan gas alam, reservoir adalah tempat terakumulasinya minyak dan gas bumi[8]. Beberapa mineral yang paling umum terdapat pada batu pasir adalah feldspar dan kuarsa[7].
Untuk menentukan jenis dan kandungan mineral pada batu pasir, para geolog masih menggunakan penafsiran dari para ahli untuk menentukan jenis mineral apakah yang terkandung pada citra batuan mineral dan masih menggunakan metode point counting untuk menentukan berapa persen kandungan mineral pada citra sayatan batu hasil foto mikroskop. Metode ini adalah metode statistik yang dilakukan secara manual untuk mengukur persentase kandungan mineral yang ada di dalam batuan sedimen khususnya batu pasir, kekurangan dari metode ini yaitu metode ini memakan waktu yang lama untuk dapat dikerjakan, disamping itu dalam melakukan point counting para geolog masih harus mengidentifikasi mineral tersebut satu per satu sehingga terdapat kemungkinan error akibat bias yang disebabkan inkonsistensi deskriptor, sehingga untuk menerapkan hal ini dibutuhkan inovasi yaitu dengan memanfaatkan pengolahan citra dengan identifikasi ciri tekstur untuk meningkatkan akurasi dalam menentukan jenis kandungan mineral dan efisiensi menghitung persentasi kandungan dari masing-masing mineral pada batu pasir.
menyerupai kemampuan manusia untuk mengklasifikasikan citra karena berbagai hal itu perusahaan Alfa Energy yang bergerak dalam bidang geology memutuskan untuk menggunakan pengolahan citra dalam mengidentifikasi batu-batuan.
Pada pengolahan citra ada beberapa metode yang bisa digunakan untuk mengidentifikasi citra diantaranya metode ekstraksi orde satu dan dua, metode ini adalah metode statistika yang banyak digunakan untuk melakukan ekstraksi pada citra, dan klasifikasi KNN adalah salah satu metode pada image processing yang banyak digunakan untuk mengklasifikasikan citra.
Metode Statistik Orde Satu memiliki beberapa ciri atau parameter yang dapat digunakan untuk menentukan jenis mineral berdasarkan warna keabuan atau grayscale dan Metode Statistik Orde Dua memiliki beberapa ciri atau parameter yang dapat digunakan untuk menentukan jenis mineral berdasarkan tekstur. Pada penelitian sebelumnya yang berjudul “Klasifikasi Serat Miring Pada Kayu Menggunakan
Ekstraksi Ciri Statistik Berdasarkan Pada Pengolahan Citra” penelitian ini menggunakan ekstraksi ciri statistik yaitu orde satu dan dua, penelitian menghasilkan akurasi 92,5791 % saat menggunakan nilai k = 3,5,7 pada model Jarak Euclidean.
Klasifikasi citra menggunakan K-Nearest Neighbor, metode ini digunakan untuk klasifikasi citra uji dengan database ciri hasil ekstraksi fitur, banyaknya digunakan metode K nearest neighbor karena metode ini memiliki ketangguhan terhadap training data yang memiliki banyak noise dan efektif apabila training datanya besar.
Berdasarkan masalah yang telah dijelaskan maka pada penelitian tugas akhir ini akan dilakukan penelitan yang berjudul “Implementasi Metode Ekstraksi Statistik Orde Satu dan Dua dan K-Nearest Neighbor Untuk Mengidentifikasi Citra Mineral Pada
Batuan Sedimen”.
1.2 Rumusan Masalah
Berdasarkan penjelasan yang ada pada latar belakang, terdapat pada beberapa permasalahan yang dapat diuraikan, sebagai berikut :
2. Bagaimana cara mengetahui persentase kadar mineral dari masing-masing mineral dalam citra hasil foto mikroskop.
3. Bagaimana mengimplementasikan Metode Statistika untuk Ekstraksi ciri berdasarkan tekstur, Metode K-Nearest Neighbor untuk klasifikasi jenis mineral batuan pasir.
1.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah mengimplementasikan Algoritma Ekstraksi ciri Statistika Orde Satu dan Dua serta metode K-Nearest Neighbor untuk proses klasifikasi citra batuan mineral.
Tujuan dari penelitian ini adalah
1. Mengetahui jenis kandungan mineral pada citra hasil foto mikroskop.
2. Mengetahui persentase kadar mineral dari masing-masing citra hasil foto mikroskop.
3. Mengetahui kinerja dari algoritma ekstraksi dan klasifikasi yang digunakan.
1.4 Batasan Masalah
Beberapa batasan masalah yang akan dibahas diantaranya : 1. Sistem yang dibangun berbasis desktop,
2. Objek yang diteliti hanya citra sayatan tipis batu pasir hasil foto mikroskop dalam format gambar *.jpg,
3. Kandungan mineral yang dibahas dibatasi hanya 2 jenis mineral pada jenis batuan sedimen yaitu mineral Kuarsa, Feldspar.
4. Untuk proses segmentasi menggunakan algoritma K-Means Clustering, tujuan digunakan K means clustering adalah untuk memisahkan objek-objek yang berbeda pada suatu citra dan hanya mengambil objek yang akan di proses untuk di proses pada tahap ekstraksi citra.
6. Hasil output dari proses klasifikasi adalah data jenis mineral dan jumlah kandungan mineral dalam presentase (%).
1.5 Metode Penelitian
Metode penelitian pada tugas akhir ini menggunakan metode deskriptif, ini adalah metode dalam meneliti status sekelompok manusia, suatu objek, suatu set kondisi, suatu sistem peikiran ataupun suatu kelas peristiwa pada masa sekarang. Tujuan dari penelitian ini adalah untuk membuat deskripsi, gambaran, lukisan secara sistematis, faktual dan akurat mengenai fakta-fakta, sifat-sifat serta hubungan antarfenomena yang diselidiki.
1.5.1 Metode Pengumpulan Data
Metode pengumpulan dan pengembangan perangkat lunak dalam penelitian ini menggunakan beberapa metode diantaranya :
1. Studi Literatur
Studi literatur merupakan teknik pengumpulan data dengan cara mempelajari, meneliti dan menelaah berbagai literatur dari perpustakaan yang bersumber dari buku-buku, literatur, jurnal ilmiah, paper, situs internet dan bacaan yang berkaitan dengan penelitian yang dilakukan. Adapun literatur
yang digunakan terdiri dari buku “Pengolahan Citra Digital” yang ditulis oleh
Usman Ahmad. 2. Wawancara
Wawancara adalah teknik pengumpulan data yang dilakukan dengan cara melakukan tanya jawab, wawancara yang dilakukan dengan pihak Alpha Energy pada tanggal 24 dan 25 agustus 2015 dengan tujuan untuk mendapatkan informasi mengenai sistem yang sedang berlangsung dan permasalahan yang sedang dialami.
1.5.2Metode Tahapan Analisis
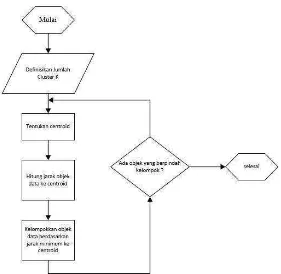
Berdasarkan pengkajian dan evaluasi dari beberapa sumber seperti buku dan jurnal, tahapan analisis yang akan dilakukan pada penelitian ini adalah :
1. Analisis Data masukan, yaitu menganalisis data yang dimasukan, data yang dimasukan berupa citra sayatan batu mineral yang akan di analisis, dengan tahapan preprocessing, dan ekstraksi ciri, hasil akhir tahapan ini adalah ekstraksi ciri.
2. Analisis tahapan pengujian, yaitu melakukan pada tahap pengujian, sehingga didapatkan nilai yang akan digunakan saat menganalisis data keluaran.
3. Analisis Data Keluaran, yaitu melakukan analisis terhadap nilai akhir yang didapatkan pada saat tahap pengujian, dimana data keluaran berupa hasil klasifikasi.
Berikut adalah diagram alur tahapan analisis :
1.6 Sistematika Penulisan
Sistematika penulisan tugas akhir ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah:
BAB 1 Pendahuluan
Menguraikan tentang latar belakang permasalahan yang akan diteliti, mencoba merumuskan inti permasalahan yang diteliti, menentukan maksud dan tujuan dari penelitian, menentukan batasan masalah serta sistematika penulisan.
BAB II Landasan Teori
Membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan pengolahan citra, teori mengenai segmentasi citra, ekstraksi citra dan klasifikasi citra, teori mengenai pemrograman terstruktur dan teori mengenai Matlab.
BAB III Analisis dan Perancangan Sistem
Bab ini Menjelaskan mengenai analisis masalah yang menggambarkan proses identifikasi masalah, analisis proses dan analisis kebutuhan sistem software, hardware dan analisis perhitungan Statistika Orde satu dan dua beserta metode K-Nearest Neighbour pada klasifikasi citra dan anailisis untuk membangun program simulasi.
BAB IV Impelementasi dan Pengujian Sistem
Bab ini membahas tentang pengujian akurasi dan kecepatan Algoritma ekstraksi Orde Satu dan Dua serta klasifikasi K-Nearest Neighbor dengan menggunakan program simulasi yang telah dibuat.
BAB V Kesimpulan dan Saran
7
TINJAUAN PUSTAKA
2.1 Pengolahan Citra
Pengolahan citra digital adalah salah satu cabang dari ilmu informatika yang berkutat untuk melakukan transformasi suatu citra atau gambar menjadi citra lain dengan menggunakan teknik tertentu[14]. Pengolahan citra banyak digunakan dalam berbagai bidang seperti bidang pendidikan, kedokteran, industry dll. Pengolahan citra digital merupakan salah satu disiplin ilmu yang mempelajari hal-hal yang berkaitan dengan perbaikan kualitas gambar(peningkatan kontras, tranformasi, warna, restorasi citra), transformasi gambar(rotasi, translasi, skala, transformasi, geometrik), melakukan pemulihan citra ciri (feature images) yang optimal untuk tujuan analisis, melakukan proses penarikan informasi deskripsi objek atau pengenalan objek yang terkandung pada citra, melakukan kompresi atau reduksi data untuk tujuan penyimpanan data, input pengolahan citra adalah citra, sedangkan outputnya adalah citra hasil pengolahan.
2.2 Operasi Pengolahan Citra
Banyak operasi yang dilakukan dalam pengolahan citra[14], umumnya operasi pengolahan citra dapat diklasifikasikan dalam beberapa jenis sebagai berikut :
1. Perbaikan Kualitas Citra (image enhancement)
Operasi citra jenis ini bertujuan untuk memperbaiki kualitas citra dengan cara memanipulasi parameter-parameter citra, ciri khusus yang terdapat didalam citra lebih ditonjolkan. Contoh-contoh operasi citra perbaikan citra :
1. Perbaikan kontras gelap/terang.
2. Perbaikan tepian objek (edge enhancement). 3. Penajaman (sharpening).
2. Pemugaran Citra (image restoration)
Operasi citra ini bertujuan untuk menghilangkan atau meminimumkan cacat pada citra. Tujuan pemugaran citra hampir sama dengan operasi perbaikan citra, perbedaanya pada pemugaran citra penyebab degradasi gambar diketahui.
Contoh operasi pemugaran citra :
a. Penghilangan kesamaran (debluring). b. Penghilangan derau (noise).
3. Pemampatan citra (image compression)
Jenis operasi ini bertujuan agar citra dipresentasikan dalam bentuk yang lebih kompak sehingga memerlukan memori yang lebih sedikit. Hal penting yang harus diperhatikan dalam pemampatan adalah citra yang telah dimampatkan harus tetap mempunyai kualitas gambar yang bagus.
4. Segmentasi Citra (image segmentation)
Operasi citra jenis ini bertujuan untuk memecah suatu citra kedalam beberapa segmen dengan suatu kriteria tertentu. Jenis operasi ini berkaitan erat dengan pengolahan pola.
5. Pengorakan Citra (image analysis)
Jenis operasi ini bertujuan menghitung besaran kuantitatif dari citra untuk menghasilkan deskripsinya. Teknik pengorakan citra mengekstraksi ciri-ciri tertentu yang membantu dalam identifikasi objek. Proses segmentasi seringkali diperlukan untuk melokalisasi objek yang diinginkan dari sekelilingnya.
Contoh-contoh operasi pengorakan citra : a. Pendeteksian tepi objek (edge detection) b. Ekstraksi batas (boundary)
c. Representasi daerah (region)
6. Rekonstruksi Citra (image reconstruction)
7. Perubahan Model Warna
Warna adalah persepsi yang dirasakan oleh sistem visual manusia terhadap panjang gelombang cahaya yang dipantulkan oleh objek. Setiap warna mempunyai panjang gelombang yang berbeda. Warna merah mempunyai panjang gelombang yang paling tinggi, sedangkan warna ungu mempunyai panjang gelombang rendah. Warna-warna yang diterima oleh mata adalah hasil kombinasi cahaya dengan panjang gelombang berbeda. Penelitian memperlihatkan kombinasi warna memberikan rentang warna yang paling lebar adalah merah(R), hijau(G), Biru(B). a. Citra RGB
Disebut citra true color disimpan dalam citra berukuran (m x n) x 3 yang mendefinisikan warna merah, hijau dan biru untuk setiap pikselnya. Warna pada setiap piksel ditentukan berdasarkan kombinasi dari warna red, green, dan blue (RGB). RGB merupakan citra 24 bit dengan komponen merah, hijau dan biru yang masing-masing umumnya bernilai 8 bit sehingga intensitas kecerahan warna sampai 256 level, sekitar 16 juta warna.
b. Citra keabuan
Citra dengan derajat keabuan berbeda dengan citra RGB, citra ini didefinisikan oleh satu nilai derajat warna. Umumnya bernilai 8 bit sehingga intensitas kecerahan warna sampai 256 level dan kombinasi warnanya 256 varian. Tingkat kecerahan paling rendah yaitu nilai 0 untuk warna hitam dan nilai 255 untuk warna putih. Ada 3 persamaan untuk mengkonversi citra yang memiliki warna RGB ke derajat keabuan[10].
1. Lightness
X = (max(R,G,B)+min(R,G,B))/2 (Persamaan 1)
2. Average
X = (0.21 R + 0.72 G + 0.07 B) / 3 (Persamaan 2) 3. Luminocity
X = 0.21 R + 0.72 G + 0.07 B (Persamaan 3)
Dimana :
2.3 Segmentasi Citra
Segmentasi Citra Digital adalah teknik untuk membagi / memisahkan suatu citra menjadi beberapa daerah(region) atau beberapa objek dimana setiap daerah memiliki kemiripan atribut[4].
Algoritma segmentasi citra didasarkan pada salah satu sifat dari dasar nilai intensitas, yaitu:
a. Discontinuity, pendekatan dengan membagi citra berdasarkan perubahan besar pada nilai intensitasnya, seperti tepi citra.
b. Similiarity, pendekatan dengan membagi citra ke dalam region-region yang serupa sesuai dengan kriteria awal yang diberikan. Contoh pendekatan ini adalah thresholding, region growing, region splitting, merging.
Dengan proses segmentasi masing-masing objek pada citra dapat diambil secara individu sehingga dapat digunakan sebagai input bagi proses lain.
Ada 2 macam segmentation
a. Full segmentation adalah pemisahan suatu objek secara individu dari background dan diberi ID(label) pada tiap-tiap segmen.
b. Partial segmentation adalah pemisahan sejumlah data dari background dimana data yang disimpan hanya data yang dipisahkan saja untuk mempercepat proses selanjutnya.
Segmentasi yang digunakan pada penelitian ini adalah segmentasi berbasis clustering yaitu menggunakan metode K-Means Clustering[15].
Clustering atau analisis cluster adalah pembentukan kelompok data dari himpunan data yang tidak diketahui kelompok-kelompok atau kelas-kelasnya, pengertian lain clustering adalah proses menentukan data-data termasuk ke dalam cluster yang mana. Clustering bukanlah proses klasifikasi karena dalam proses klasifikasi data dikelompokkan ke dalam kelas-kelas yang telah diketahui sebelumnya. Beberapa metode atau model untuk melakukan clustering, seperti :
4. Model subspace
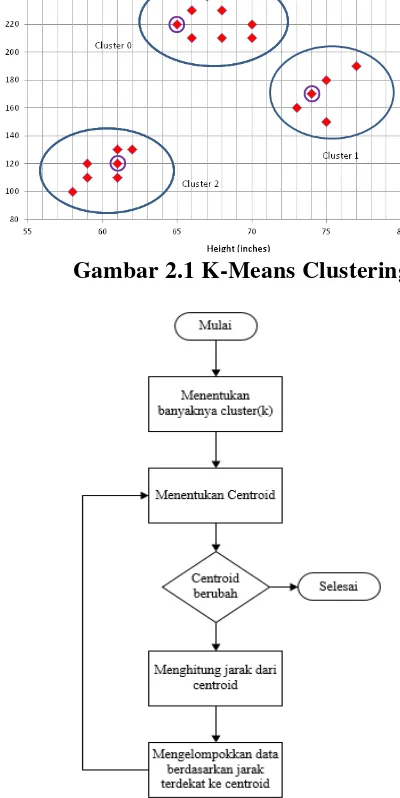
Algoritma K-Means clustering merupakan model centroid. Model centroid adalah model yang menggunakan centroid untuk membuat cluster, centroid adalah nilai titik tengah suatu cluster dan centroid digunakan untuk menghitung jarak suatu objek terhadap centroid[9]. Suatu objek data termasuk dalam suatu cluster jika memiliki jarak terpendek terhadap centroid cluster tersebut.
Gambar 2.1 K-Means Clustering
Gambar 2.2 Diagram Alir K-Means Clustering
mengetahui terlebih dahulu target kelasnya dimana masukan yang diterima adalah data atau objek dan k buah kelompok(cluster) yang di inginkan.
2.4 Operasi Biner
Citra binari adalah citra yang hanya mempunyai dua nilai derajat keabuan yaitu hitam dan putih, dimana piksel objek bernilai 1 dan latar belakang bernilai 0, 0 adalah putih dan 1 adalah hitam, pada citra ini latar belakang berwarna putih sedangkan objek berwarna hitam.
Gambar 2.3 Citra Biner
Untuk fokus pada analisis bentuk morfologi maka intensitas piksel tidak terlau penting dibandingkan bentuk, setelah objek dipisahkan dari latar belakang maka objek dapat dihitung dari citra biner.
Gambar 2.4 kiri : gangguan pada citra biner yang mengandung huruf “i”, kanan :
2.5 Operasi Morfologi
Pemrosesan citra secara morofologi dilakukan pada citra biner, walaupun tidak menutup kemungkinan dilakukan pada citra dengan skala keabuan 0-255. Dengan pendekatan morofologi kita memandang suatu citra sebagai himpunan, bukan sebagai suatu fungsi intensitas terhadap posisi(x,y).
Secara umum pemrosesan citra secara morfologi dilakukan dengan cara passing sebuah structuring element terhadap sebuah citra dengan cara yang hampir sama dengan konvolusi. Structuring element memiliki titik poros yang disebut titik origin/titik asal/titik acuan.
Beberapa operasi morfologi yang dapat kita lakukan adalah 1. Dilasi, erosi
2. Opening, closing
3. Thinning, shrinking, pruning, thickening, skeletonizing, dll.
Salah satu operasi morfologi yang akan digunakan pada penelitian ini adalah operasi dilasi(dilation), dilasi adalah proses penumbuhan / penebalan / penggabungan dari citra biner/titik latar (0) dengan bagian dari objek (1), berdasarkan struktur structuring element yang digunakan. Dilasi berguna ketika diterapkan dalam obyek-obyek yang terputus dikarenakan
1. Hasil pengambilan citra yang terganggu oleh noise,
2. Kerusakan objek fisik yang dijadikan citra digital atau disebabkan resolusi yang kurang bagus. Misalkan teks pada kertas yang sudah rusak sehingga bentuk huruf terputus-putus dan lain sebagainya.
Kegunaan operasi morfologi adalah untuk 1. Menghilangkan noise
2. Mengisolasi objek Algoritma Morfologi Citra
1. Konversi citra ke dalam bentuk skala keabuan (Grayscale) 2. Lakukan binerisasi citra (thresholding)
Operasi dilasi memiliki sifat sama dengan operasi penambahan pada operasi minkowski yaitu menggunakan operasi himpunan gabungan(union). Misalkan A dan B adalah himpunan-himpunan pixel.
Dilasi A ke B dinotasikan dengan A⊕B dan di definisikan sebagai berikut
(Persamaan 4)
Ini berarti bahwa untuk setiap titik x ∈ B, maka dilakukan translasi atau penggeseran dan kemudian
dan kemudian menggabungkan seluruh hasilnya (union). Secara matematis dituliskan
(Persamaan 5)
Dilasi mempunya hukum komutatif, yaitu
(Persamaan 6)
Berikut contoh citra sebelum dan sesudah dilakukan proses dilasi
2.6 Deteksi tepi (Edge Detection)
Deteksi Tepi pada suatu citra adalah suatu proses yang menghasilkan tepi-tepi dari objek-objek citra, tujuannya adalah
1. untuk menandai bagian yang menjadi detail citra
2. untuk memperbaiki detail dari citra yang kabur yang terjadi karena error atau adanya efek dari proses akuisisi citra.
Suatu titik (x,y) dikatakan sebagai tepi(edge) dari suatu citra bila titik tersebut mempunyai perbeaan yang tinggi dengan tetangganya.
Macam metode yang banyak digunakan untuk proses deteksi tepi, antara lain 1. Metode Robert
2. Metode Prewitt 3. Metode Sobel
Pada tahap deteksi tepi digunakan metode sobel karena kemampuannya dalam mengurangi noise sebelum melakukan perhitungan deteksi tepi.
Kernel filter yang digunakan dalam metode sobel adalah
2.7 Labeling
Labeling adalah suatu proses pemberian label yang sama pada sekumpulan piksel pembentuk objek yang saling berdekatan pada suatu citra. Objek yang berbeda memiliki label yang berbeda. Labeling termasuk pada pemrosesan citra pada tahap intermediate level, ia memiliki peran yang penting pada pengolahan citra karea dapat mempermudah proses penganalisaan bentuk dan pengenalan pola pada tahap high level. Labeling memiliki sifat yang dependent dan regional, dependent artinya pemerian label harus memperhitungkan pixel label sebelumnya. Sifat regional adalah pemberian label harus memperhitungkan posisi pixel-pixel secara regional didalam citra.
2.8 Cropping
Cropping citra artinya adalah pengambilan bagian tertentu dari suatu citra digital menjadi matriks baru yang independent. Cropping sangat berguna apabila kita hanya membutuhkan bagian tertentu dari suatu citra digital.
2.9 Grayscale
Merupakan proses untuk mengubah warna menjadi keabu-abuan. Dengan mengubah nilai RGB setiap piksel gambar menjadi satu nilai yang sama sehingga setiap piksel memiliki nilai yang sama untuk ketiga unsur warna serta didapatkan nilai matriks grayscale.
Berikut alur grayscale
Gambar 2.7 Diagram Alir Grayscale
2.10 Tekstur
Tekstur merupakan karakteristik intrinsik dari suatu citra yang terkait dengan tingkat kekasaran (roughness), granularitas (granulation) dan keteraturan (regularity) susunan struktural piksel. Aspek tekstural dari sebuah citra dapat dimanfaatkan sebagai dasar dari segmentasi, klasifikasi maupun interpretasi citra. Tesktur dapat didefinisikan sebagai fungsi dari variasi spasial intensitas piksel (nilai keabuan) dalam citra.
1. Makrostruktur
Tekstur makrostruktur memiliki perulangan pola lokal secara periodik dalam suatu daerah citra, biasanya terdapat pada pola-pola buatan manusia dan cenderung mudah untuk direpresentasikan secara matematis.
2. Mikrostruktur
Pada tektur mikrostruktur, pola-pola lokal dan perulangan tidak terjadi begitu jelas, sehingga tidak mudah untuk memberikan definisi testur yang komprehensif.
Tekstur dapat dicirikan sebagai berikut
a. Pengulangan pola dari variasi lokal sehingga membentuk kesatuan yang utuh
b. Meyediakan informasi susunan spasial dari warna dan intensitas citra c. Dicirikan dengan distribusi spasial dari level intensitas dari nilai piksel
ketetanggaan
d. Tidak bisa didefinisikan per point karena ia merupakan sebuah pola atau kesatuan.
2.11 Analisis Tekstur
Analisis tekstur merupakan dasar dari berbagai macam aplikasi, aplikasi dari analisis tekstur antara lain, penginderaan jarak jauh, pencitraan medis, identifikasi kualitas suatu bahan (kayu, kulit, batu, dan lain-lain). Analisis tekstur bekerja dengan mengamati pola ketetanggaan antar piksel dalam domain spasial. Dua persoalan yang seringkali berkaitan dengan analisis tekstur adalah :
1. Ekstraksi Ciri
Ekstraksi ciri pada citra merupakan langkah awal dalam melakukan klasifikasi dan interpretasi citra. Proses ini berkaitan dengan kuantisasi karakteristik citra ke dalam sekelompok nilai ciri yang sesuai. Dalam praktikum ini kita akan mengamati metode ekstraksi ciri statistik orde pertama dan kedua.
2. Segmentasi Citra
tetapi perlu mempertimbangkan perulangan pola dalam suatu wilayah ketetanggaan lokal.
2.12 K Means Clustering
Salah satu algoritma clustering, bertujuan untuk membagi data menjadi beberapa Kelompok. Algoritma ini menerima data tanpa label kelas. Komputer mengelompokkan sendiri data-data yang menjadi masukan tanpa mengetahui terlebih dahulu target kelasnya. Masukan yang diterima adalah data atau objek dan k buah kelompok(cluster) yang diinginkan dimana centroid adalah titik pusat cluster. Alasan digunakannya K Means Clustering adalah karena data harus dikelompokkan untuk membantu proses klasifikasi.
Algoritma untuk K Means Clustering adalah : 1. Pilih k buah titik centroid secara acak
2. Kelompokkan data sehingga terbetuk K buah cluster dengan titik centroid dari setiap centroid dari setiap cluster merupakan titik centroid yang telah dipilih sebelumnya.
3. Perbaharui nilai titik centroid.
K Means Clustering bisa membantu proses klasifikasi KNN, karena metode ini akan mengelompokkan objek sesuai kriteria masing-masing pada tahap
preprocessing.
2.13 Ekstraksi Fitur
Ekstraksi fitur (fitur extraction) adalah bagian fundamental dari analisis citra. Fitur adalah karakteristik unik dari suatu objek. Karakteristik fitur yang baik sebisa mungkin memenuhi persyaratan berikut
1. Dapat membedakan suatu objek dengan objek lainnya(discrimination). 2. Memperhatikan kompleksitas komputasi daam memperoleh fitur.
3. Tidak terikat (independence) dalam arti bersifat invarian terhadap berbagai transformasi (rotasi, penskalaan, pergeseran dan lain sebagainya)
4. Jumlahnya sedikit, karena fitur yang jumlahnya sedikit dapat menghemat waktu komputasi dan ruang penyimpanan untuk proses selanjutnya (proses pemanfaatan fitur).
Berbagai metode ekstraksi fitur suatu citra 1. Ampitudo
Adalah ciri yang paling sederhana dan mungkin paling berguna bagi suatu objek, ciri ini berhubungan dengan properti fisik suatu objek, seperti luminance, nilai tristimulus, nilai spektral
2. Histogram
Adalah ciri yang didasarkan pada histogram dari suatu citra. Bila x menyatakan tingkat keabuan pada suatu citra maka probabilitas dari x dinyatakan dengan :
� = Banyaknya titik − titik yang memiliki tingkat keabuan xTotal banyaknya titik pada daerah suatu citra
(Persamaan 7)
Beberapa ciri yang dihitung berdasarkan histogram, antara lain a. Rata-rata / mean
Adalah matriks yang dibangun menggunakan histogram tingkat kedua, matriks ini berukuran L x L (L menyatakan tingkat keabuan) dengan elemen P(x1,x2) yang merupakan distribusi probabilitas bersama dari pasangan pixel
dengan tingkat keabuan x1 yang berlokasi pada koordinat (j,k) dengan x2 berlokasi pada koordinat (m,n). koordinat pasangan pixel ini berjarak r dengan sudut Ɵ. Histogram tingkat kedua P(x1,x2) dihitung dengan pendekatan sebagai berikut.
� , =Banyaknya pasangan titik − titik dengan tingkat keabuan x dan xbanyaknya titik pada daerah suatu citra
(Persamaan 12)
Histogram dan Matriks Coocurens dihimpun ke dalam satu analisa yaitu analisa metode statistik, untuk menggambarkan ciri dari setiap citra, metode ini dinamakan analisis tektur karena parameter statistik yang diekstrak dari citra merupakan karakteristik yang merepresentasikan bentuk/pola tekstur dalam citra.
Syarat terbentuknya tekstur :
1. Adanya pola primitif yang terdiri dari satu atau lebih piksel, bentuk nya dapat berupa titik, garis lurus, luasan dan lain-lain yang merupakan elemen dasar dari sebuah bentuk.
2. Pola-pola primitif tadi muncul berulang-ulang dengan interval jarak dan arah tertentu sehingga dapat diprediksi atau ditemukan karakteristik pengulangannya.
Berdasarkan orde statistiknya analisis tektur dapat dikategorikan menjadi 3, yaitu analisis tekstur orde satu, orde dua, dan orde diatas dua. Semakin tinggi orde tingkat kesulitannya juga meningkat.
Pada orde satu kita hanya menganalisa sebaran piksel dengan nilai intensitas tertentu secara global pada citra (menggunakan histogram citra). Analisis orde dua perlu mempertimbangkan korelasi antara 2 piksel dengan nilai intensitas tertentuk yang memiliki hubungan jarak dan arah tertentu.
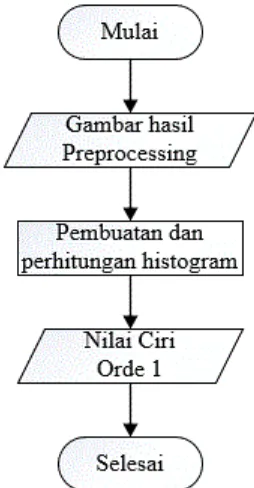
2.14.1 Orde Satu
Ekstraksi ciri orde pertama merupakan metode pengambilan ciri yang didasarkan pada karakteristik histogram citra. Histogram menunjukkan probabilitas kemunculan nilai derajat keabuan piksel pada suatu citra. Dari nilai-nilai pada histogram yang dihasilkan, dapat dihitung beberapa parameter ciri orde pertama, antara lain adalah mean, skewness, variance, kurtosis, dan entropy.
1. Mean (μ)
Menunjukkan ukuran dispersi dari suatu citra Rumus
(Persamaan 13) 2. Variance (σ2)
Menunjukkan variasi elemen pada histogram dari suatu citra Rumus
(Persamaan 14)
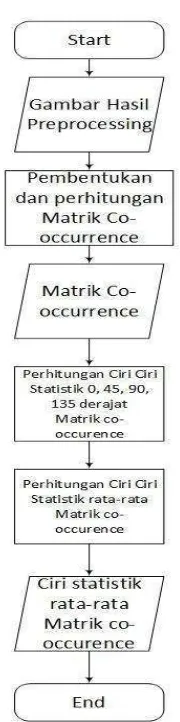
2.14.2 Orde Dua
Statistik orde dua dibutuhkan ketika orde satu tidak dapat mengenali beberapa perbedaan ciri citra. Salah satu teknik untuk memperoleh ciri statistik orde dua adalah dengan menghitung probabilitas hubungan ketetanggaan antara dua piksel pada jarak dan orientasi sudut tertentu. Pendekatan ini bekerja dengan membentuk sebuah matriks kookurensi dari data citra, dilanjutkan dengan menentukan ciri sebagai fungsi dari matriks tersebut[16].
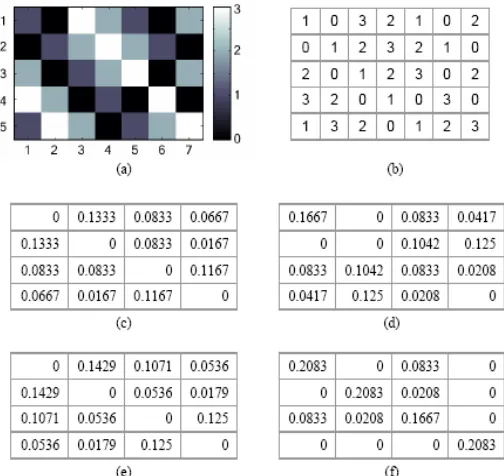
Matriks kookurensi merupakan matriks bujur sangkar dengan jumlah elemen sebanyak kuadrat jumlah level intensitas piksel pada citra. Matriks dihitung dari nilai piksel yang berpasangan dan memiliki intensitas tertentu. Misalkan d adalah jarak antara dua pixel yaitu (x1,y1) dan (x2,y2) dan Ɵ tetha didefinisikan sebagai sudut antara keduanya, maka matriks ini merupakan distribusi spasial dari Pd Ɵ (i,j).
Berikut ilustrasi mengambarkan arah sudut dengan jarak 1 piksel dan 4 jenis sudut yang digunakan
a. 0o = 180o b. 45o = 225o c. 90o = 270o d. 135 o = 315o
Keterangan Gambar (a) Citra Masukan
(b) Nilai intensitas citra masukan
(c) Hasil matriks kookurens 0o setelah normalisasi (d) Hasil matriks kookurensi 45o setelah normalisasi (e) Hasil matriks kookurensi 90o setelah normalisasi (f) Hasil matriks kookurensi 135o setelah normalisasi
Gambar 2.10 Hubungan ketetanggan antar piksel
Setelah memperoleh matriks kookurensi maka dapat dihitung ciri statistik orde dua yang merepresentasikan citra yang diamati. Haralick et al mengusulkan berbagai jenis ciri tekstural yang dapat diekstraksi pada matrik kookurensi. Pada penelitian ini ada 2 ciri statistik orde dua yang akan dihitung seperti contrast dan autocorrelation.
Dimana tahap perhitungannya adalah 1. Contrast
Mengukur frekuensi spasial dari citra dan perbedaan moment matriks. Perbedaan yang dimaksud adalah perbedaan tinggi dan rendahnya piksel. Contrast akan bernilai 0 jika piksel ketetanggaan mempunya nilai yang sama.
(Persamaan 15)
2. Autocorrelation
Tahap mengukur correlation diantara garis diagonal utama.
2.14 Klasifikasi
Klasifikasi secara harfiah adalah penggolongan atau pengelompokan. Menurut kamus besar bahasa indonesia klasifikasi adalah penyusunan bersistem dalam kelompok atau golongan menurut standar yang ditetapkan.
Klasifikasi citra digital merupakan proses pengelompokan piksel ke dalam kelas-kelas tertentu. Tujuan dari proses ini adalah untuk mendapatkan gambar tematik, gambar tematik adalah gambar yang terdiri dari bagian-bagian yang menyatakan suatu objek atau tema tertentu.
Proses klasifikasi ada 2 macam Supervised dan Unsupervised 1. Klasifikasi citra terawasi (supervised)
Klasifikasi ini memasukkan terlebih dahulu setiap piksel citra kedalam suatu kategori objek yang sudah diketahui. Sebelum klasifikasi dilakukan maka harus memasukkan inputan sebagai dasar pengklasifikasian yang akan dilakukan.
Klasifikasi k-nearest neighbor termasuk ke dalam klasifikasi supervised, dimana hasil sampel uji yang baru diklasifikasikan berdasarkan mayoritas dari kategori pada k-NN.
2. Klasifikasi citra tidak terawasi (unsupervised)
Dalam prosesnya klasifikasi ini tidak menggunakan referensi penunjang, proses dilakukan berdasarkan perbedaan tingkat keabuan setiap piksel pada citra. Klasifikasi ini mencari kelompok-kelompok(cluster) piksel-piksel, kemudian menandai setiap piksel ke dalam sebuah kelas berdasarkan parameter-parameter penglompokkan awal yang akan didefinisikan.
Dua klasifikasi ini dapat digabungkan penggunaan nya dalam satu kasus, dimana k means digunakan untuk memisahkan objek-objek yang bermacam-macam dari suatu citra dan ini akan mempercepat proses klasifikasi.
2.14.1 Klasifikasi K-Nearest Neighbor
K-Nearest Neighbor merupakan sebuah metode klasifikasi terhadap sekumpulan data berdasarkan pembelajaran data yang sudah terklasifikasikan sebelumnya. KNN termasuk dalam golongan supervised dimana hasil query instance yang baru diklasifikasikan berdasarkan mayoritas kedekatan jarak dari kategori yang ada dalam KNN. Nantinya kelas yang baru dari suatu data akan dipilih berdasarkan grup kelas yang dekat jarak vektornya.
Alasan digunakan algoritma KNN untuk klasifikasi karena ia memiliki konsistensi yang kuat, menjamin error rate tidak lebih dari dua kali.
query. Klasifikasi menggunakan voting terbanyak diantara klasifikasi dari k obyek. Metode
k-nearest neighbor (KNN) menggunakan klasifikasi ketetanggaan sebagai nilai prediksi dari queryinstance yang baru.
Metode k-nearest neighbor (KNN) sangatlah sederhana, bekerja berdasarkan jarak terpendek dari query instance ke training sample untuk menemukan KNN-nya. Training sample diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menjadi bagian–bagian berdasarkan klasifikasi trainning sample. sebuah titik pada ruang ini ditandai kelas c jika kelas c merupakan klasifikasi yang paling banyak ditemukan pada k buah tetangga terdekat dari titik tersebut. Dekat atau jauhnya tetangga biasanya dihitung berdasrkan Euclidean Distance.
Jarak Euclidian paling sering digunakan menghitung jarak. Jarak euclidean berfungsi menguji ukuran yang bisa dgunakan sebagai interpretasi kedekatan jarak antara dua obyek, yang direpresentasikan sebagai berikut:
� − = √∑ ( − )= (Persamaan 17)
Keterangan:
d = jarak data uji ke data pembelajaran. = data uji ke-j, dengan j = 1, 2, . . . n.
= data pembelejaran ke-j dengan j = 1, 2, . . . n.
Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Nilai K yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation. Kasus khusus dimana klasifikasi diprediksikan berdasarkan trainning data yang paling dekat (dengan kata lain, k=1) disebut metode nearest neighbor.
bagaimana memilih dan memberi bobot terhadap fitur agar performa klasfikasi menjadi lebih baik.
Langkah-langkah untuk menghitung k-nearest neighbor :
1. Menentukan parameter K (jumlah tetangga yang paling dekat).
2. Menghitung kuadrat jarak euclid (query inctance) masing-masing obyek terhadap data sampel yang diberikan.
3. Kemudian mengurutkan objek-objek tersebut kedalam kelompok yang mempunyai jarak euclidean terkecil.
4. Mengumpulkan kategori Y (Klasifikasi nearest neighbor).
5. Dengan menggunakan kategori nearest neighbor yang paling mayoritas maka dapat diprediksikan nilai query instance yang telah dihitung.
Kelebihan dari metode k-nearest neighbor adalah sebagai berikut: 1. Ketangguhan terhadap data yang memiliki banyak noise. 2. Efektif terhadap data yang berukuran besar.
Kekurangan dari metode k-nearest neighbor adalah sebagai berikut: 1. Nilai k harus ditentukan secara manual.
2. Trainning berdasarkan jarak harus menggunakan banyak sampel untuk mendapatkan hasil yang terbaik.
Adapun metode dari KNN pada flowchart berikut :
2.15 Pemrograman Terstruktur
Pemrograman Terstruktur adalah tindakan untuk membuat program yang berisi instruksi-instruksi dalam bahasa komputer yang tersusun secara logis dan sistematis supaya mudah dimengerti, mudah dites dan mudah dimodifikasi. Pemrograman terstruktur adalah bahasa pemrograman yang mendukung pembuatan program sebagai kumpulan prosedur. Prosedur saling memanggil dan dipanggil dari manapun dalam program dan dapat menggunakan parameter yang berbeda-beda untuk setiap pemanggilan. Bahasa pemrograman terstruktur mendukung abstraksi data, pengkodean terstruktur dan kontrol program terstruktur,
sedangkan prosedur sendiri adalah bagian dari program untuk melakukan operasi-operasi yang sudah ditentukan dengan menggunakan parameter tertentu.
Prinsip pemrograman terstruktur
1. Gunakan rancangan pendekatan dari atas ke bawah (top down design), 2. Bagi program ke dalam modul-modul logika sejenis,
3. Gunakan sub-program untuk proses-proses sejenis yang sering digunakan. 4. Gunakan pengkodean terstruktur, seperti if.. then, do..while, dan lain-lain. 5. Gunakan nama-nama bermakna (mnemonic names)
6. jika suatu proses telah sampai pada suatu titik/langkah tertentu, maka proses selanjutnya tidak boleh mengeksekusi langkah sebelumnya.
7. Buatkan dokumentasi yang akurat dan berarti Manfaat pemrograman terstruktur
1. Dapat menangani program yang besar dan komplek 2. Dapat menghindari konflik internal team
3. Membagi kerja team berdasarkan modul-modul program yang sudah dirancang 4. Kemajuan pengerjaan sistem dapat dimonitor dan dikaji
Tujuan pemrograman terstruktur
1. Meningkatkan kehandalan suatu program 2. Program mudah dibaca dan ditelusuri 3. Menyederhanakan kerumitan program
4. Biaya perawatan dan dokumentasi yang dibutuhkan rendah Langkah membuat program yang baik dan terstruktur adalah 1. Mendefiniskan Masalah
2.16 Data Flow Diagram (DFD)
Data Flow Diagram (DFD) adalah alat pembuatan model yang memungkinkan seorang profesioanal sistem menggambarkan sistem sebagai suatu jaringan proses fungsional yang dihubungkan satu sama lain dengan alur data. DFD sering digunakan, khususnya bila fungsi-fungsi sistem merupakan bagian yang lebih penting dan kompleks dari pada data yang dimanipulasi oleh sistem.
DFD bisa dikatakan sebagai alat pembuatan model yang memberikan penekanan hanya pada fungsi sistem. Komponen Data Flow Diagram, menurut yourdan dan deMarco
Komponen Terminator/Entitas Luar
Terminator mewakili entitas eksternal yang berkomunikasi dengan sistem yang sedang dikembangkan. Terminator dikenal dengan nama entitas luar (eksternal entity), terdapat dua jenis terminator :
1. Terminator sumber(source) merupakan terminator yang menjadi sumber. 2. Terminator tujuan (sink) merupakan terminator yang menjadi tujuan
data/informasi sistem. Terminator dapat berupa orang, sekelompok orang, organisasi, departemen di dalam organisasi atau perusahaan yang sama tetapi diluar kendali sistem yang sedang membuatnya. Terminator dapat berupa departemen, divisi atau sistem di luar sistem yang berkomunikasi dengan sistem yang sedang dikembangkan.
2.17 Matlab (Matrix Laboratory)
Matlab adalah salah software aplikasi untuk menyelesaikan berbagai masalah teknis. Matlab mengintegrasikan komputasi, visualisas dan pemrograman daam
suatu model yang sangat mudah untuk dipakai, dimana masalah-masalah dan penyelesaiaannya diekspresikan dalam notasi matematika yang familiar. Penggunaan matlab meliputi bidang-bidang :
1. Pembentukan dan pengembangan Algoritma 2. Matematika dan komputasi
3. Pemodelan, simulasi sistem hingga pembuatan prototype 4. Akusisi data, analisis data, plotting data dan visualisasi
5. Pembuatan software aplikasi termasuk antar muka (Graphical User Interfaces) 6. Matlab memungkinkan manipulasi matriks, pemflotan fungsi dan data.
Matlab merupakan suatu sistem interaktif yang memiliki elemen data dalam suatu array sehingga memungkinkan untuk memecahkan banyak masalah teknis yag terkait dengan komputasi, khususnya yang berhubungan dengan matriks dan formulasi vektor.
Fitur matlab sudah banyak dikembangkan yang lebih dikenal dengan nama toolbox. Toolbox merupakan kumpulan dari fungsi-fungsi Matlab (M-Files) yang telah dikembangkan ke suatu lingkungan kerja matlab untuk memecahkan masalah. Area-area yang sudah dipecahkan dengan toolbox saat ini meliputi pengolahan sinyal, sistem kontrol, neural network, fuzzy logic, wavelets, dan lain-lain.
2.18 Sayatan Tipis Batuan Pasir
2.19 Point Counting
Adalah metode statistik untuk menghitung persentasi suatu mineral pada citra hasil fotomikroskop[17]. Sistem pengidentifikasian yang sedang berjalan menggunakan software Jmicrovision, dimana software ini digunakan untuk menghasilkan titik warna yang berbeda pada objek yang akan diteliti.
Dimana hasil dari software ini adalah gambar dengan hasil titik dengan warna yang berbeda.
Pemberian titik pada citra dilakukan melalui inputan pada program khusus dengan jumlah 300-500 titik, untuk warna dari masing-masing titik ditentukan sebelum nya oleh para geolog, pada citra ini diberikan 4 warna
a. Warna biru muda untuk kuarsa b. Warna merah untuk feldspar
c. Warna biru untuk rongga, rongga tidak berisi mineral
d. Warna hijau untuk mineral lithic, mineral ini adalah mineral gabungan yang jumlah nya hanya 2-3 % dari total jumlah mineral dan mineral ini tidak dihitung.
Gambar 2.15 Tampilan Software JMicro
Pada tugas akhir ini yang dihitung hanya jumlah persentasi dari mineral kuarsa dan feldspar dan jenis mineral yang terkandung.
Cara menghitung manual nya[17] Rumus Total Area = P/Pt
Keterangan
P = jumlah point dari masing-masing warna Pt= total dari semua titik
P/Pt = area fraksi
Pada gambar diatas ada 100 warna merah dari total jumlah titik 500 Jadi perhitungannya
P=100 Pt=500
Total area = P/Pt = 100/500 * 100% = 0.2%
83
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari hasil pengujian dan anlisis maka dapat disimpulkan hal-hal sebagai berikut:
1. Pada penelitian ini tingkat akurasi citra mineral tertinggi diperoleh pada kelas Kuarsa dengan rata-rata nilai akurasi 90%
2. Untuk citra mineral Feldspar rata-rata hasil akurasi 10% hal tersebut dikarenakan jenis citra yang homogen sehingga terjadi kemiripan nilai ekstraksi ciri dari citra antara kelas kuarsa dan feldspar.
5.2 Saran
Dalam pembuatan Tugas Akhir ini, masih terdapat banyak kekurangan yang dapat diperbaiki untuk pengembangan berikutnya. Beberapa saran yang dapat diberikan adalah:
F-1
DAFTAR RIWAYAT HIDUP
DATA PRIBADI
NIM : 10109405
Nama Lengkap : Muhammad Rizky
Jenis Kelamin : Laki-laki
Tempat & Tgl Lahir : Bukittinggi, 9 Oktober 1990
Alamat : Pakan Tangah Jorong Padang Lua II Nagari Padang Lua No 66 C, Kabupaten Agam, Sumatra Barat.
No. Telepon / HP : (+62) 82116320505
E-mail : [email protected]
PENDIDIKAN FORMAL
2009 – 2016 : Universitas Komputer Indonesia 2006 – 2009 : SMA N 3 Bukittingi
MENGIDENTIFIKASI CITRA MINERAL PADA BATUAN SEDIMEN
Muhammad Rizky1 1
Teknik Informatika – Univesitas Komputer Indonesia
Jl. Dipatiukur 112 - 114 Bandung
E-mail : [email protected]
ABSTRAK
Salah satu cara untuk mengenali citra adalah dengan membedakan tekstur citra tersebut. Citra dikatakan memiliki tekstur apabila pola citra terjadi secara berulang-ulang memenuhi semua bidang citra. Citra yang berbeda memiliki ciri-ciri yang berbeda. Ciri-ciri inilah yang menjadi dasar dalam klasifikasi citra berdasarkan tekstur. Terdapat beberapa metode untuk memperoleh ciri-ciri tekstur
dalam suatu citra, beberapa metode untuk
memperoleh ciri-ciri citra tekstur adalah statistik orde satu dan dua. Ciri-ciri tekstur yang didapat dari metode tersebut diantaranya adalah mean, variance, skewness, kurtosis, energy, entropy, dissimiliarity,
contrast, autocorrelation, correlation dan
homogenity. Dari hasil ciri-ciri tersebut kemudian digunakan untuk klasifikasi dengan menggunakan
metode Klasifikasi K-Nearest Neighbor yang
menentukan hasil klasifikasi berdasarkan nilai probabilitas terbesar. Objek yang diuji adalah citra sayatan tipis batuan mineral hasil fotomikroskop berupa file *.jpg.
Dari penelitian yang telah dilakukan, dapat
ditarik kesimpulan sebagai berikut : metode
K-Nearest Neighbor dapat melakukan klasifikasi citra berdasarkan tekstur yang diekstraksi dengan metode ekstraksi orde satu dan dua. Dikarenakan data hasil ekstraksi ciri adalah berupa data continue, atau biasa disebut data nominal, sehingga saat proses klasifikasi data hasil ekstraksi ciri tersebut dapat
langsung digunakan sebagai inputan dalam
klasifikasi K-Nearest Neighbor.
berdasarkan hasil pengujian, kesimpulan
yang didapatkan adalah K-Nearest Neighbor dapat
mengklasifikasi citra dengan baik, dikarenakan data hasil ekstraksi ciri tekstur citra batuan mineral dengan metode statistika orde satu dan dua memiliki interval jarak yang berjauhan antar kelasnya. Sehingga klasifikasi naïve bayes dapat berjalan dengan baik saat melakukan klasifikasi.
Kata kunci : tekstur citra, ekstraksi ciri, orde satu dan dua, klasifikasi, K-Nearest Neighbor
1. PENDAHULUAN
Batu pasir atau arenite adalah jenis batuan
sedimen terdiri dari butiran mineral pasir dan bahan organik lain dalam ukuran kecil, batu ini berisi bahan semen seperti silika dan karbonat yang mengikat butiran pasir bersama-sama dan berisi butiran lempung yang menempati ruang antara butiran pasir. Batu pasir adalah jenis yang paling umum dari batuan sedimen yang sering ditambang untuk digunakan sebagai akuifer air tanah dan sebagai reservoir minyak dan gas alam, reservoir adalah tempat terakumulasinya minyak dan gas bumi[8]. Beberapa mineral yang paling umum terdapat pada batu pasir adalah feldspar dan kuarsa[7].
Untuk menentukan jenis dan kandungan mineral pada batu pasir, para geolog masih menggunakan penafsiran dari para ahli untuk menentukan jenis mineral apakah yang terkandung pada citra batuan mineral dan masih menggunakan
metode point counting untuk menentukan berapa
persen kandungan mineral pada citra sayatan batu hasil foto mikroskop. Metode ini adalah metode statistik yang dilakukan secara manual untuk mengukur persentase kandungan mineral yang ada di dalam batuan sedimen khususnya batu pasir, kekurangan dari metode ini yaitu metode ini memakan waktu yang lama untuk dapat dikerjakan,
disamping itu dalam melakukan point counting para
geolog masih harus mengidentifikasi mineral
tersebut satu per satu sehingga terdapat
kemungkinan error akibat bias yang disebabkan inkonsistensi deskriptor, sehingga untuk menerapkan
hal ini dibutuhkan inovasi yaitu dengan
memanfaatkan pengolahan citra dengan identifikasi ciri tekstur untuk meningkatkan akurasi dalam menentukan jenis kandungan mineral dan efisiensi menghitung persentasi kandungan dari masing-masing mineral pada batu pasir.
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033
Metode Statistik Orde Satu memiliki beberapa ciri atau parameter yang dapat digunakan untuk menentukan jenis mineral berdasarkan warna keabuan atau grayscale dan Metode Statistik Orde Dua memiliki beberapa ciri atau parameter yang dapat digunakan untuk menentukan jenis mineral berdasarkan tekstur. Pada penelitian sebelumnya
yang berjudul “Klasifikasi Serat Miring Pada Kayu
Menggunakan Ekstraksi Ciri Statistik Berdasarkan Pada Pengolahan Citra” penelitian ini menggunakan ekstraksi ciri statistik yaitu orde satu dan dua, penelitian menghasilkan akurasi 92,5791 % saat menggunakan nilai k = 3,5,7 pada model Jarak Euclidean.
Klasifikasi citra menggunakan K-Nearest
Neighbor, metode ini digunakan untuk klasifikasi citra uji dengan database ciri hasil ekstraksi fitur,
banyaknya digunakan metode K nearest neighbor
karena metode ini memiliki ketangguhan terhadap training data yang memiliki banyak noise dan efektif
apabila training datanya besar.
Berdasarkan masalah yang telah dijelaskan maka pada penelitian tugas akhir ini akan dilakukan penelitan dengan menggunakan Metode Ekstraksi Statistik Orde Satu dan Dua dan K-Nearest Neighbor Untuk Mengidentifikasi Citra Mineral Pada Batuan Sedimen.
1.1 Rumusan Masalah
Berdasarkan pendahuluan yang telah
dijelaskan, maka penelitian ini merumuskan masalah yang akan dibahas yaitu :
a. Bagaimana cara mengetahui kandungan jenis
mineral pada batu pasir berdasarkan tekstur dengan menggunakan pengolahan citra.
b. Bagaimana cara mengetahui persentase kadar
mineral dari masing-masing mineral dalam citra hasil foto mikroskop.
c. Bagaimana mengimplementasikan Metode
Statistika untuk Ekstraksi ciri berdasarkan tekstur, Metode K-Nearest Neighbor untuk klasifikasi jenis mineral batuan pasir.
1.2 Maksud dan Tujuan
Maksud dari penelitian ini adalah
mengimplementasikan algoritma statistika orde satu dan dua dengan metode KNN.
Tujuan dari penelitian ini adalah :
a. Mengetahui jenis kandungan mineral pada citra
hasil fotomikroskop
b. Mengetahui persentase kadar mineral dari
masing-masing citra hasil foto mikroskop.
2. ISI PENELITIAN
2.1 Pengolahan Citra
Pemanfaatan citra digital banyak digunakan dalam berbagai bidang seperti bidang pendidikan,
kedokteran, industry dll. Pengolahan citra digital
merupakan salah satu disiplin ilmu yang
mempelajari hal-hal yang berkaitan dengan
perbaikan kualitas gambar(peningkatan kontras, tranformasi, warna, restorasi citra), transformasi
gambar(rotasi, translasi, skala, transformasi,
geometrik), melakukan pemulihan citra ciri (feature
images) yang optimal untuk tujuan analisis, melakukan proses penarikan informasi atau deskripsi objek atau pengenalan objek yang terkandung pada citra, melakukan kompresi atau reduksi data untuk tujuan penyimpanan data, transmisi datam dan waktu proses data,input dai pengolahan citra adalah citra, sedangkan outputnya adalah citra hasil pengolahan.
2.2 Tekstur
Tekstur adalah konsep intuitif yang
mendeksripsikan tentang sifat kehalusan, kekasaran
dan keteraturan dalam suatu daerah
/wilayah(region). Dalam pengolahan citra digital,
tekstur didefiniskan sebagai distribusi spasial dari derajat keabuan di dalam sekumpulan piksel yang bertetangga[7].
Secara umum tekstur mengacu pada pengulangan elemen-elemen tekstur dasar yang disebut primitif
atau tekstel(textur element-texel) syarat-syarat
terbentuknya suatu tekstur antara lain :
1. Adanya pola-pola primitif yang terdiri dari
suatu piksel atau lebih. bentuk-bentuk pola primitif ini dapat berupa titik, garis lurus, garis lengkung, luasan, dan lain-lain yang merupakan elemen dasar dari sebuah tekstur.
2. Pola-pola primitif tersebut muncul
berulang-ulang dengan interval dan arah tertentu sehingga dapat diprediksi atau ditemukan karakteristik pengulangannya.
3. Suatu citra memberikan interpretasi tekstur
yang berbeda jika dilihat dengan jarak dan sudut yang berbeda. Manusia memandang tekstur berdasarkan deskripsi yang bersifat acak, seperti halus, kasar, teratur,tidak teratur dan sebagainya. Hal ini merupakan deskripsi yang tidak tepat dan non kuantitatif, sehingga diperlukan adanya suatu deskripsi yang kuantititif (matematis) untuk memudahkan analisis[7].
Suatu citra memberikan interpretasi tekstur yang berbeda apabila dilihat dengan jarak dan sudut yang berbeda. Manusia memandang tekstur berdasarkan deskripsi yang bersifat acak, seperti halus, kasar, teratur, tidak teratur, dan sebagainya. Hal ini merupakan deskripsi yang tidak tepat dan non-kuantitatif, sehingga diperlukan adanya suatu deskripsi yang kuantitatif (matematis) untuk memudahkan analisis (Ahmad U. , 2005).
identifikasi kualitas suatu bahan (kayu, kulit, tekstil, dan lain-lain), dan juga berbagai macam aplikasi lainnya. Pada analisis citra, pengukuran tekstur dikategorikan menjadi lima kategori utama yaitu : statistis, struktur, geometri, model dasar, dan
pengolahan sinyal. Pendekatan statistis
mempertimbangkan bahwa intensitas dibangkitkan oleh medan acak dua dimensi, metode ini berdasar pada frekuensi ruang. Contoh metode statistis adalah
fungsi autokorelasi, Co-ocurence Matrix,
transformasi fourier, frekuensi tepi, run length dan
lainnya. Teknik struktural berkaitan dengan
penyusunan bagian-bagian terkecil suatu citra. Contoh metode struktural adalah model fraktal. Metode geometri berdasar atas perangkat geometri yang ada pada elemen tekstur. Contoh metode model dasar adalah medan acak. Sedangkan metode pengolahan sinyal adalah metode berdasarkan analisis frekuensi seperti tranformasi gabor dan transformasi wavelet[6].
2.3.1 Metode Cooccurence Matrix
Metode Cooccurence Matrix adalah suatu matriks yang elemen-elemennya merupakan jumlah pasangan piksel yang memiliki tingkat kecerahan tertentu, di mana pasangan piksel itu terpisah dengan
jarak d, dan dengan suatu sudut inklinasi θ. Dengan
kata lain, matriks kookurensi adalah probabilitas
munculnya graylevel i dan j dari dua piksel yang
terpisah pada jarak d dan sudut θ. (Ahmad U. , 2005)
Suatu piksel yang bertetangga yang memiliki
jarak d diantara keduanya, dapat terletak di delapan
arah yang berlainan, hal ini ditunjukkan pada Gambar(2).
Gambar 2 Hubungan ketetanggaan antar piksel
Dalam metode Matrik Co-occurrence
Haralick dkk mengusulkan berbagai jenis ciri statistik tekstur yang dapat diekstraksi Beberapa di antaranya Antara lain adalah : Kontras(contrast),
Homogenitas(homogeneity), Entropi (Entropy),
Energi (Energy) dan Dissimilariti (Dissimilarity). Persamaan untuk fitur tersebut adalah sebagai berikut :
jauh dari diagonal utama, nilai kekontrasan besar. Secara visual, nilai kekontrasan adalah ukuran variasi antar derajat keabuan suatu daerah citra. Hasil perhitungan kontras berkaitan dengan jumlah keberagaman intensitas keabuan dalam citra.
i dan j adalah sifat keabuan dari resolusi 2 piksel yang berdekatan
p (i,j) adalah Probabilitas kolom(i,j)
Homogenitas (Homogenity)
homogenitas yang menunjukkan
kehomogenan citra berderajat keabuan sejenis. Citra homogen akan memiliki harga homogenitas yang besar.
i dan j adalah sifat keabuan dari resolusi 2 piksel yang berdekatan
p (i,j) adalah Probabilitas kolom(i,j).
Entropi (Entropy)
Entropi dapat menunjukkan ketidakteraturan ukuran bentuk, jika nilai Entropinya besar untuk citra dengan transisi derajat keabuan merata dan bernilai kecil jika struktur citra tidak teratur (bervariasi).
Energi menyatakan ukuran konsentrasi
pasangan dengan intensitas keabuan tertentu pada matriks, dimana (i, j) menyatakan nilai pada baris i dan kolom j pada matriks kookurensi.
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033
p (i,j) adalah Cooccurence Matrix Simetris
Ternormalisasi
Dissimilarity
Dissimilarity menyatakan ukuran ketidaksamaan derajat keabuan citra sehingga dapat memberikan petunjuk adanya struktur dalam citra.
p (i,j) adalah frekuensi relatif matriks dari resolusi 2 piksel yang berdekatan.
2.4 Klasifikasi
Klasifikasi merupakan suatu pekerjaan yang melakukan penilaian terhadap suatu obyek data untuk masuk dalam suatu kelas tertentu dari sejumlah kelas yang tersedia. (Prasetyo, 2012). Ada dua pekerjaan utama:
1. Pembangunan model sebagai prototype untuk
disimpan sebagai memori
2. Menggunakan model tersebut untuk
melakukan pengenalan/klasifikasi/prediksi
pada suatu obyek data lain masuk pada kelas mana
2.4.1 Klasifikasi K-Nearest Neighbor
K-Nearest Neighbor merupakan sebuah metode klasifikasi terhadap sekumpulan data
berdasarkan pembelajaran data yang sudah
terklasifikasikan sebelumnya. KNN termasuk dalam
golongan supervised , dimana hasil query instance
yang baru diklasifikasikan berdasarkan mayoritas kedekatan jarak dari kategori yang ada dalam KNN. Nantinya kelas yang baru dari suatu data akan dipilih berdasarkan grup kelas yang dekat jarak vektornya.[8]
Metode k-nearest neighbor (KNN) sangatlah sederhana, bekerja berdasarkan jarak terpendek dari query instance ke training sample untuk menemukan
KNN-nya. Training sample diproyeksikan ke ruang
berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi
menjadi bagian–bagian berdasarkan klasifikasi
trainning sample. sebuah titik pada ruang ini ditandai kelas c jika kelas c merupakan klasifikasi yang paling banyak ditemukan pada k buah tetangga terdekat dari titik tersebut. Dekat atau jauhnya
tetangga biasanya dihitung berdasrkan Euclidean
Distance.
Jarak Euclidian paling sering digunakan
menghitung jarak. Jarak euclidean berfungsi
menguji ukuran yang bisa dgunakan sebagai interpretasi kedekatan jarak antara dua obyek. Yang direpresentasikan sebagai berikut:
Keterangan:
d = jarak data uji ke data pembelajaran.
= data uji ke-j, dengan j = 1, 2, . . . n. = data pembelejaran ke-j dengan j = 1, 2, . . . n.
Ketepatan metode KNN sangan dipengaruhi oleh ada atau tidaknya fitur-fitur yang tidak relevan atau jika bobot fitur tersebut tidak setara dengan relevansinya terhadap klasifikasi. Riset terhadap metode ini sebagian besar membahas bagaimana memilih dan memberi bobot terhadap fitur agar performa klasfikasi menjadi lebih baik.
Langkah-langkah untuk menghitung
k-nearest neighbor :
1. Menentukan parameter K (jumlah tetangga
yang paling dekat).
2. Menghitung kuadrat jarak euclid (query
inctance) masing-masing obyek terhadap data sampel yang diberikan.
3. Kemudian mengurutkan objek-objek
tersebut kedalam kelompok yang
mempunyai jarak euclidean terkecil.
4. Mengumpulkan kategori Y (Klasifikasi
nearest neighbor).
5. Dengan menggunakan kategori nearest
neighbor yang paling mayoritas maka dapat
diprediksikan nilai query instance yang
telah dihitung.
3.5 Metode pengujian keakurasian
Dalam machine learning weka, pengujian keakurasian dapat dilakukan dengan 2 tipe pengujian, yaitu
1.Training set test
2.Supplied set test Training set test
Metode pengujian menggunakan data yang telah di training, dengan kata lain, data training dan data uji adalah data yang sama
1. Supplied set test
Metode pengujian menggunakan data yang berbeda, dengan kata lain, data training berbeda dengan data yang akan diujikan
2. K-fold cross validation
Cross Validation merupakan salah satu teknik
untuk menilai/memvalidasi keakuratan sebuah
model yang dibangun berdasarkan dataset tertentu.
Pembuatan model biasanya bertujuan untuk
melakukan prediksi maupun klasifikasi terhadap suatu data baru yang boleh jadi belum pernah muncul di dalam dataset. Data yang digunakan dalam proses pembangunan model disebut data latih/training, sedangkan data yang akan digunakan untuk memvalidasi model disebut sebagai data test.