PEMODELAN DAN OPTIMASI SUPPORT VECTOR MACHINE (SVM) UNTUK DETEKSI MATA MANUSIA DENGAN 2DPCA
SEBAGAI EKSTRAKSI CIRI
ANDIKA SUNDAWIJAYA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Pemodelan dan Optimasi Support Vector Machine (SVM) untuk Deteksi Mata Manusia dengan 2DPCA sebagai Ekstraksi Ciri adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
ANDIKA SUNDAWIJAYA. Pemodelan dan Optimasi Support Vector Machine (SVM) untuk Deteksi Mata Manusia dengan 2DPCA sebagai Ekstraksi Ciri. Dibimbing oleh AGUS BUONO dan BIB PARUHUM SILALAHI.
Eye tracking telah menjadi salah satu proses yang paling penting dalam hal
interaksi manusia komputer. Eye tracking ini juga telah terbukti berguna dalam
aplikasi yang beragam. Aplikasi spesifik yang termasuk dalam sistem ini antara lain sistem dalam membaca tulisan, membaca musik, pengenalan aktivitas
manusia, persepsi iklan, bermain olahraga, Human Computer Interaction (HCI)
terutama bagi orang-orang cacat, penelitian medis dan area lainnya.
Deteksi mata merupakan hal yang paling penting untuk dilakukan sebagai
landasan awal dalam aplikasi eye tracking. Dengan mendapatkan posisi mata,
tracking mata akan lebih mudah untuk dilakukan pada tahapan selanjutnya (Bhoi dan Mihir 2010). Pada umumnya deteksi mata dilakukan dalam dua langkah yaitu menentukan lokasi wajah untuk mengekstrak daerah mata kemudian deteksi mata dari daerah mata.
Penelitian ini bertujuan melakukan pemodelan dan optimasi parameter kernel SVM dengan GA untuk deteksi mata manusia dengan 2DPCA sebagai ekstraksi ciri. Metodologi penelitian ini terdiri atas beberapa tahapan yaitu
pengambilan data, data preprocessing, ekstraksi fitur, pemodelan deteksi mata
manusia dengan SVM dan GA, pembuatan sistem untuk training dan testing
deteksi mata, analisis, dan penulisan laporan penelitian.
Percobaan dilakukan dengan melakukan ekstraksi fitur menggunakan 2DPCA. Hasil yang diperoleh kemudian divalidasi dengan menggunakan jarak Euclidean. Percobaan ini memperoleh hasil akurasi 68,97 % pada dimensi (d) = 2. Percobaan berikutnya dilakukan dengan menggunakan algoritma SVM sebagai algoritma untuk klasifikasi. Kernel yang digunakan pada SVM adalah linear, RBF dan polynomial. Hasil yang diperoleh dari ketiga kernel tersebut didapatkan hasil
akurasi maksimal pada kernel RBF dengan parameter log2 C = 3 dan log2 Gamma
= -1.
Penelitian ini dibuat menggunakan software Matlab R2008b version 7.7.0.471. Model deteksi mata menggunakan SVM dengan ekstraksi ciri 2DPCA menghasilkan akurasi tertinggi pada kernel RBF dengan nilai Log2 Gamma = -1
dan C > 0 dengan nilai 99,97% pada data training dan 88,16% pada data testing.
SUMMARY
ANDIKA SUNDAWIJAYA Modeling and Optimization of Support Vector Machine (SVM) for Detection of Human Eye and 2DPCA as Feature Extraction. Supervised by AGUS BUONO dan BIB PARUHUM SILALAHI.
Eye tracking has become one of the most important processes in the human computer interaction. Eye tracking has also been shown to be useful in various applications. Specific applications included in this system are the system in handwriting reading, music reading, human activity recognition, perceptions of advertising , sport playing, Human Computer Interaction (HCI), especially for people with disabilities, medical research and other areas.
Eye detection is the most important thing to do as an initial basis in the application of eye tracking. By getting the position of the eye, eye tracking will be easier to do at a later stage (Bhoi and Mihir 2010) . In general, eye detection is done in two steps. It is determine the location of the face to extract the eye area then eye detection from the eye area.
The purpose of this research is perform the modeling and optimization of kernel parameters of SVM with GA for human eye detection with 2DPCA as feature extraction. The research methodology consists of several stage. These are data collection, data preprocessing, feature extraction, modeling the human eye detection with SVM and GA, manufacture training and testing system for eye detection, analysis, and research report writing.
Experiment conducted with feature extraction using the 2DPCA. The results obtained then validated using the Euclidean distance. The experiment results gained 68.97% accuracy on the dimension (d) = 2. The next experiment was performed using the SVM algorithm for the classification algorithm. Kernel used in SVM is linear, RBF, and polynomial. The results of the three kernel maximum accuracy is obtained with the RBF kernel parameters C = 3 and log2 Gamma = -1. This research is made using Matlab R2008b version 7.7.0.471. Eye detection model feature extraction using SVM with 2DPCA produce the highest accuracy on the RBF kernel with value Log2 Gamma = -1 and C > 0 with a value of 99.97 % on the training data and 88.16 % on the testing data.
© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
PEMODELAN DAN OPTIMASI SUPPORT VECTOR MACHINE (SVM) UNTUK DETEKSI MATA MANUSIA DENGAN 2DPCA
SEBAGAI EKSTRAKSI CIRI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2014
Judul Tesis : Pemodelan dan Optimasi Support Vector Machine (SVM) untuk Deteksi Mata Manusia dengan 2DPCA sebagai Ekstraksi Ciri Nama : Andika Sundawijaya
NIM : G651110321
Disetujui oleh Komisi Pembimbing
Dr Ir Agus Buono, MSi MKom Ketua
Dr Ir Bib Paruhum Silalahi, MKom Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Yani Nurhadryani, SSi MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2013 ini ialah image prcessing, dengan judul Pemodelan dan Optimasi Support Vector Machine (SVM) untuk Deteksi Mata Manusia dengan 2DPCA sebagai Ekstraksi Ciri.
Terima kasih penulis ucapkan kepada Bapak Dr Ir Agus Buono, MSi, MKom dan Bapak Dr Ir Bib Paruhum Silalahi, MKom selaku pembimbing yang telah banyak memberi saran. Serta kepada Dr Eng. Wisnu Ananta Kusuma, ST MT yang telah menjadi dosen penguji yang telah memberi banyak masukan kepada penulis. Selain itu, penghargaan penulis sampaikan kepada semua dosen dan staf Departemen Ilmu Komputer IPB, dosen dan staf Program Diploma IPB yang telah membantu selama proses penelitian. Ungkapan terima kasih yang tulus disampaikan kepada ayah, ibu, istri Faldiena Marcelita, ananda Fairel Ahza Adhyastha, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Januari 2014
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN vii
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 3
Manfaat Penelitian 3
Ruang Lingkup Penelitian 3
2 METODE 4
Pengambilan data 4
Preprocessing 5
Ekstraksi Fitur 5
Support Vector Machine (SVM) 5
Genetic Algorithm (GA) 6
Analisis Akurasi Sistem 8
3 HASIL DAN PEMBAHASAN 9
Ekstraksi Fitur dengan 2DPCA 9
Klasifikasi dengan SVM 9
Optimasi menggunakan GA 15
4 SIMPULAN DAN SARAN 17
DAFTAR PUSTAKA 18
LAMPIRAN 20
DAFTAR TABEL
1 Tabel Kontingensi 8
2 Hasil Akurasi dengan Nilai degree yang berbeda 11 3 Hasil Testing Optimasi GA Parameter SVM pada Kernel RBF 16
DAFTAR GAMBAR
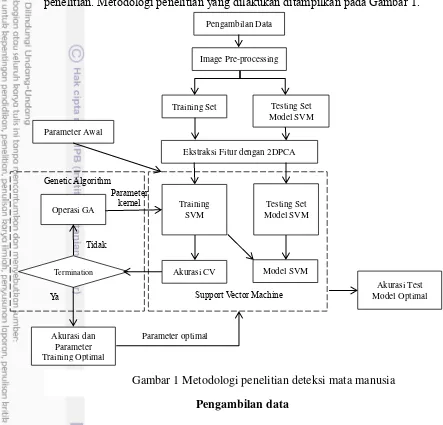
1 Metodologi penelitian deteksi mata manusia 4
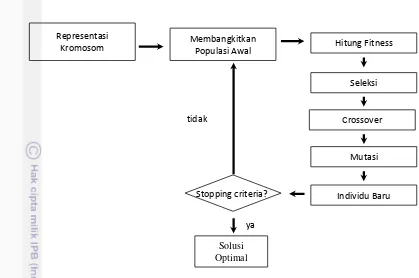
2 Langkah Operasi GA 7
3 Representasi 1 buah Kromosom 7
4 Proses Crosssover pada GA 8
5 Grafik Perbandingan Akurasi dengan Jumlah Fitur pada 2DPCA 9
6 Grafik Perbandingan Akurasi SVM Linear 10
7 Hasil Akurasi Perbandingan C dan Gamma Kernel Polynomial 11 8 Hasil Akurasi Perbandingan C dan Gamma Kernel RBF 12 9 Grafik Perbandingan Nilai Parameter C dengan Akurasi 13 10 Grafik Perbandingan Parameter ɣ dengan Akurasi 13
11 Grafik Perbandingan Akurasi SVM 14
12 Grafik Perbandingan Akurasi SVM Terbaik dan Euclidean 15 13 Grafik Perbandingan Iterasi dengan Fitness pada GA 16
DAFTAR LAMPIRAN
1 Tabel Perbandingan Akurasi dengan Jumlah Fitur pada 2DPCA 21
2 Hasil Akurasi Perbandingan Jumlah Dimensi dan Parameter C pada
SVM Linear 23
3 Hasil Akurasi Perbandingan Parameter Gamma dan C pada SVM
dengan Kernel RBF dengan d = 5 24
4 Hasil Akurasi Perbandingan parameter Gamma pada SVM Polynomial
dengan d = 5 26
5 Hasil Perbandingan Akurasi SVM linear, kernel RBF dan Polynomial
pada data Testing dan Training 28
6 Hasil Perbandingan Akurasi SVM dengan 2DPCA menggunakan jarak
Euclidean 29
1
PENDAHULUAN
Latar Belakang
Eye tracking telah menjadi salah satu proses yang paling penting dalam hal
interaksi manusia komputer. Eye tracking ini juga telah terbukti berguna dalam
aplikasi yang beragam. Aplikasi spesifik yang termasuk dalam sistem ini antara lain sistem dalam membaca tulisan, membaca musik, pengenalan aktivitas
manusia, persepsi iklan, bermain olahraga, Human Computer Interaction (HCI)
terutama bagi orang-orang cacat, penelitian medis dan area lainnya (Orman et al.
2011).
Salah satu aplikasi yang menjanjikan dalam penelitian eye tracking yaitu
penerapan di bidang desain otomotif. Beberapa penelitian telah mengintegrasikan kamera dengan mobil untuk melacak dan mengikuti pergerakan mata. Hal tersebut dilakukan untuk menyediakan kendaraan yang akan mengevaluasi perilaku
pengemudi secara real-time. Salah satu lembaga yang menangani keselamatan lalu
lintas di Amerika Serikat, The National Highway Traffic Safety Administration
(NHTSA) memperkirakan bahwa mengantuk merupakan faktor penyebab utama
dalam 100.000 kecelakaan per tahun seperti yang telah dilaporkan kepolisian kepada lembaga tersebut. Studi lain yang dilakukan NHTSA menunjukkan bahwa 80% dari tabrakan karena terjadi gangguan hanya dalam waktu tiga detik. Dengan melengkapi mobil dengan kemampuan untuk memonitor tingkat kantuk, fokus, dan kelakuan pengemudi maka keselamatan mengemudi dapat ditingkatkan. Aplikasi yang digunakan dapat memberikan peringatan jika sopir mengalihkan
pandangan matanya dari jalan (Orman et al. 2011).
Deteksi mata merupakan hal yang paling penting untuk dilakukan sebagai
landasan awal dalam aplikasi eye tracking. Dengan mendapatkan posisi mata,
tracking mata akan lebih mudah untuk dilakukan pada tahapan selanjutnya (Bhoi dan Mihir 2010). Pada umumnya deteksi mata dilakukan dalam dua langkah yaitu menentukan lokasi wajah untuk mengekstrak daerah mata kemudian deteksi mata dari daerah mata (Wang dan Yang 2006). Sejumlah penelitian telah diterbitkan
dalam beberapa waktu terakhir mengenai hal deteksi mata ini. Beberapa
pendekatan yang berbeda dilakukan untuk deteksi mata/tracking, metode tersebut membutuhkan dukungan perangkat keras tambahan untuk menyelesaikan masalahnya sedangkan untuk metode yang lain cukup menggunakan webcam sederhana. Berbagai metode ini, antara lain Electrooculography (EOG), Infra-Red Oculography, Scleral search coils, dan Image based methods (Orman et al. 2011). Image based methods merupakan metode yang dilakukan pada penelitian ini. Terdapat beberapa metode yang diusulkan untuk deteksi mata pada image. Penelitian yang dilakukan oleh Bhoi dan Mihir (2010) menggunakan metode template matching untuk melakukan deteksi mata. Template mata yang digunakan akan dikorelasikan dengan berbagai daerah pada gambar wajah dengan menggunakan teknik cross correlation. Daerah wajah yang memberikan korelasi maksimum dengan template yang digunakan akan mengakibatkan hubungan yang kuat dengan daerah mata.
Penelitian lain dilakukan oleh Asteriadis et al. (2006) yang menerapkan
2
informasi geometris umum mata dan daerah sekitarnya. Prosesnya sebuah
detektor wajah pertama kali digunakan untuk mendeteksi area dari wajah. Metode
ini memberikan hasil yang sangat baik pada gambar dengan dimensi cukup kecil. Rajpathak et al. (2009) memanfaatkan morfologi dan warna image dalam mendeteksi mata manusia. Dalam penelitiannya diusulkan teknik baru untuk deteksi mata dengan menggunakan warna dan pengolahan gambar morfologi. Teknik yang digunakan adalah mengamati bahwa daerah mata pada gambar ditandai dengan pencahayaan rendah, kepadatan warna tepi yang tinggi dan kontras tinggi dibandingkan dengan bagian lain dari wajah. Metode yang diusulkan didasarkan pada asumsi bahwa gambar wajah dalam posisi frontal dari depan. Langkah yang dilakukan pertama kali, yaitu wilayah kulit dideteksi menggunakan algoritma color based training dan teknik six-sigma yang dioperasikan pada skala RGB, HSV, dan NTSC. Analisis lebih lanjut melibatkan proses morfologi yang menggunakan daerah perbatasan deteksi dan deteksi refleksi sumber cahaya oleh mata, umumnya dikenal sebagai titik mata. Teknik ini memberikan jumlah calon mata yang terbatas dari wilayah yang ada.
Selain penelitian tersebut terdapat beberapa penelitian yang menggunakan metode Support Vector Machine (SVM) dalam melakukan deteksi mata. Salah satu yang dilakukan oleh Qiong Wang dan Jingyu Yang (2006) menyajikan sebuah pendekatan deteksi mata yang efisien untuk still image, citra gray-level yang tidak dibatasi latar belakang. Struktur daerah mata digunakan sebagai isyarat kuat untuk menemukan mata pasangan calon di seluruh gambar. Pasangan mata yang tersimpan dalam vector verifikator oleh support vector machine eye verifier. Selanjutnya, filter variansi mata digunakan untuk mendeteksi dua mata di wilayah mata yang telah diekstrak pada langkah menentukan lokasi pasangan mata. Metode yang diusulkan tahan terhadap latar belakang kompleks, rotasi, kacamata, dan sebagian wajah.
Hasil yang diperoleh pada beberapa penelitian yang telah dijelaskan sebelumnya cukup baik dengan kondisi yang berbeda di setiap penelitiannya. Optimasi dilakukan agar dapat memperoleh peningkatan akurasi dan efisiensi dalam memperoleh hasil. Salah satu algoritma optimasi yang banyak digunakan adalah Genetic Algorithm (GA). GA adalah algoritma meta-heuristik yang meniru proses optimasi jangka panjang mengenai evolusi biologis untuk memecahkan masalah optimasi matematika. Algoritma ini berdasarkan teori Darwin dengan prinsip 'survival of the fittest'. GA telah digunakan dalam hubungannya dengan SVM dalam beberapa cara, misalnya untuk seleksi fitur, mengoptimalkan parameter SVM (dengan asumsi kernel tetap), dan konstruksi kernel (Lessmann et al. 2006).
Ekstraksi fitur dilakukan untuk memilih fitur yang menandai ciri khusus dari area yang akan dideteksi, dalam hal ini adalah mata manusia. Selain pemilihan parameter algoritma yang tepat, pemilihan fitur merupakan salah satu faktor yang akan mempengaruhi akurasi dalam melakukan klasifikasi (Huang dan Wang 2006). Fitur yang telah diseleksi tersebut akan menjadi input algoritma SVM untuk diproses dalam melakukan deteksi. Hal ini telah disampaikan oleh Hoang dan Bui (2011) dalam tulisannya yang menerapkan algoritma 2DPCA untuk melakukan ekstraksi fitur yang akan menjadi input algoritma SVM dalam pengenalan wajah manusia. Percobaan berdasarkan metode yang diusulkan dan
3
menunjukkan bahwa metode yang diusulkan dapat meningkatkan hasil akurasi
klasifikasi. Penelitian ini bertujuan untuk melakukan deteksi mata pada wajah
manusia dengan menggunakan Support Vector Machine dan melakukan optimasi pada parameter kernel SVM dengan GA serta 2DPCA sebagai ekstraksi ciri.
Tujuan Penelitian
Penelitian ini bertujuan melakukan pemodelan dan optimasi parameter kernel SVM dengan GA untuk deteksi mata manusia dengan 2DPCA sebagai ekstraksi ciri.
Manfaat Penelitian
Manfaat yang diperoleh dari hasil penelitian ini adalah sebagai landasan awal dalam melakukan eye tracking. Proses deteksi posisi mata yang tepat akan membuat proses eye tracking akan lebih mudah dan lebih akurat.
Ruang Lingkup Penelitian Ruang lingkup penelitian ini adalah :
1. Menggunakan dataset Image wajah manusia AT&T dataset. 2. Peran GA melakukan optimasi parameter dalam SVM.
4
2
METODE
Metodologi penelitian ini terdiri atas beberapa tahapan yaitu pengambilan
data, data preprocessing, ekstraksi fitur, pemodelan deteksi mata manusia dengan
SVM dan GA, pembuatan sistem deteksi mata, analisis, dan penulisan laporan
penelitian. Metodologi penelitian yang dilakukan ditampilkan pada Gambar 1.
Pengambilan data
Data yang digunakan adalah dataset wajah manusia dari AT&T
Laboratories Cambridge. Dataset yang digunakan merupakan kumpulan gambar wajah yang diambil antara bulan April 1992 dan April 1994.
Terdapat sepuluh gambar wajah yang berbeda dari masing-masing 40 orang
yang berbeda. Gambar tersebut diambil pada waktu yang berbeda, pencahayaan yang berbeda, ekspresi wajah (terbuka/tertutup mata, tersenyum/tidak tersenyum), dan rincian wajah (dengan kacamata/tidak). Semua gambar diambil dengan latar belakang gelap homogen dengan orang dalam posisi tegak frontal (dengan
toleransi untuk beberapa gerakan). Format file yang digunakan dalam format
PGM dengan ukuran masing-masing gambar adalah 92x112 pixel. Selanjutnya,
data ini dibagi menjadi data training dan data testing.
Genetic Algorithm
5
Preprocessing
Pada tahapan ini, dilakukan sejumlah pengolahan image wajah manusia.
Seluruh image wajah manusia dibagi menjadi dua kategori yaitu wajah bagian
mata dan wajah bukan bagian mata. Dalam tahapan ini juga dilakukan pembagian
data yaitu data training dan data testing sebagai input pada proses selanjutnya.
Setiap bagian yang diambil dari image ini mempunyai ukuran nxn pixel dengan n
= 30.
Image yang digunakan pada percobaan ini sejumlah 3840 image bukan mata
dan 1280 image mata. Data ini dibagi dua bagian menjadi 3200 image bukan mata
dan 1024 image mata pada data training, 640 image bukan mata dan 256 image
mata pada data testing. Data training ini akan di-training menggunakan 5 Fold
Cross Validation.
Ekstraksi Fitur
Tahapan ini dilakukan untuk mendapatkan fitur dari potongan/segmentasi
wajah berupa mata dan bukan mata dari masing-masing data. Algoritma yang
akan digunakan untuk mendapatkan fitur adalah 2 Dimensional Principal
Component Analysis (2DPCA). Output dari proses ini berupa matriks ciri dari
setiap bagian image yang diolah. Penjelasan mengenai 2DPCA sebagai berikut
(Yang dan Zhang 2004) :
1. Setiap image/bagian image hasil pra-processing merupakan A1, A2, A3, ... Am
dengan ukuran 30x30 pixel.
2. Hitung matriks kovarian M. Dengan ̅ merupakan rata-rata image.
∑ ̅ ̅
3. Matriks kovarian memiliki n nilai eigen dan n vektor Eigen yang berkorespondensi. Sebanyak n nilai Eigen ini disimpan secara descending (menurun). Eigen vektor (d) yang telah ditentukan sesuai dengan jumlah d nilai yang terbesar dari nilai Eigen sehingga menghasilkan matriks n × d. 4. Fitur (Y) dari sebuah gambar A akan diperoleh dari persamaan berikut.
dengan X merupakan matriks n x d.
Support Vector Machine (SVM)
SVM dirancang untuk permasalahan klasifikasi biner dengan asumsi data
terpisah secara linear (Wu dan Wang 2009). Terdapat data training �, � dengan
� = 1, ... , m, � ∈ ��, � ∈ {+ , }, �� merupakan sampel data input, � adalah
vektor fitur dan � adalah label kelas dari �. Hyperlane �, � merupakan fungsi
diskriminasi linear yang menyelesaikan permasalahan optimasi: �
�, � �, � dengan � �, � + � ≥ , � , … ,
6
Pada kasus data yang dipisahkan non-linear, variabel slack diperkenalkan
ke dalam masalah optimasi menjadi : �
�, �, � �, � + � ∑� �� dengan � �, � + � ≥ ��, � , … , ,
�� ≥ 0
Fungsi decision dari SVM adalah sebagai berikut :
�� ∑ ��� �, + �
��:��
Pada kasus nyata tidak semua data dapat terpisah secara linear, data dapat dipetakan ke dalam dimensi yang lebih besar dengan menggunakan fungsi kernel.
�� ∑ ���� �, + �
��:��
Fungsi kernel yang dipakai dalam penelitian ini :
Linear : � , ′ , ′
Polynomial : � , ′ � , ′ + �, � > 0
Radial basis function (RBF) : � , ′ �−�‖�−�′‖2, � > 0
Genetic Algorithm (GA)
GA merupakan metodologi pencarian solusi optimal berdasarkan analogi seleksi alam Darwin dan genetika dalam sistem biologi. GA bekerja dengan himpunan solusi kandidat yang disebut populasi. Berdasarkan prinsip Darwin, 'survival of the fittest' yang berarti GA memperoleh solusi optimal setelah serangkaian iteratif perhitungan. GA menghasilkan populasi yang berulang dengan alternatif solusi yang diwakili oleh kromosom, sampai hasil yang diperoleh dapat diterima. Terkait dengan karakteristik eksploitasi dan eksplorasi pencarian, GA dapat menangani ruang pencarian yang besar secara efisien, dan memiliki lebih sedikit kesempatan untuk mendapatkan solusi lokal optimal daripada algoritma lainnya (Huang dan Wang 2006). Ide dasar dari GA yang diterapkan pada SVM ini untuk mengkonfigurasi SVM berdasarkan observasi
setting parameter yang diformulasikan sebagai masalah optimasi (Di Martino et.
7
Gambar 2 Langkah Operasi GA
a. Representasi Kromosom
Parameter SVM yang akan dioptimasi adalah nilai Sigma dan C pada kernel RBF. Kedua nilai ini direpresentasikan dalam bentuk biner. Jumlah bit yang digunakan pada penelitian ini sebanyak 10 bit yang tetap pada setiap percobaan. Kromosom X direpresentasikan sebagai X = {p1, p2} dengan p1 merupakan C dan p2 merupakan Gamma pada kernel RBF dapat dilihat pada Gambar 3.
Gambar 3 Representasi 1 buah Kromosom
b. Fungsi fitness
Fungsi fitness yang digunakan adalah analisis akurasi sistem yang dihasilkan oleh algoritma SVM dalam mengklasifikasikan data mata dan bukan mata.
c. Seleksi
Proses seleksi pada sistem ini mengambil metode Roulette Wheel. Dengan
metode ini setiap kromosom mempunyai peluang untuk terpilih kembali pada generasi selanjutnya.
d. Crossover
Setiap pasang kromosom mempunyai peluang untuk terpilih pada proses
Crossover. Kromosom yang terpilih akan dipotong lalu disambungkan dengan
kromosom yang lain. Gambar 4 merupakan ilustrasi proses crossover.
Crossover Representasi
Kromosom
Membangkitkan
Populasi Awal Hitung Fitness
Seleksi
Mutasi
Individu Baru Stopping criteria?
tidak
Solusi Optimal
ya
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 1 1 1 1 0 0 0 0 0 1 1 1 1 1 0 0 0 1 1
8
Gambar 4 Proses Crosssover pada GA
e. Mutasi
Operasi mutasi mengikuti operasi Crossover dan menentukan apakah kromosom harus bermutasi pada generasi berikutnya. Pada proses ini mengubah nilai biner pada posisi random yang telah dibangkitkan.
Analisis Akurasi Sistem
Terdapat beberapa indikator yang digunakan untuk mengevaluasi akurasi model yang dihasilkan oleh algoritma SVM. Penelitian ini yang digunakan tingkat
akurasi, sensitivity, specificity, nilai prediksi positif, dan nilai prediksi negatif
(Hassan et al. 2010). Indikator akurasi dari SVM digunakan sebagai fungsi fitness
sebagai evaluasi pada GA.
Tabel 1 Tabel Kontingensi
2x2 Tabel Kontingensi Mata (+) TargetBukan Mata (-)
Testing Bukan Mata (Mata (+) True Positive (TP) False Negative (FN)
-) False Positive (FP) True Negative (TN)
Tabel 1 merupakan informasi mengenai data aktual dan data yang telah diuji yang telah dilakukan klasifikasi untuk dua kelas. Dengan akurasi yang dirumuskan sebagai berikut :
) (TN FP FN TP
TP TN Akurasi
0 1 1 1 1 0 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 0 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 Kromosom Awal
3
HASIL DAN PEMBAHASAN
Penelitian ini dibuat menggunakan software Matlab R2008b version 7.7.0.471.
Ekstraksi Fitur dengan 2DPCA
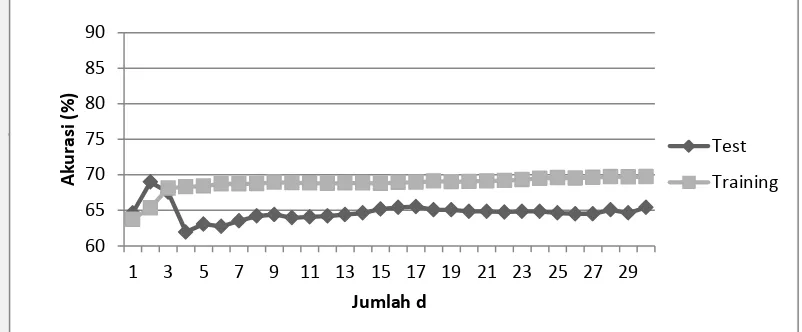
Ekstraksi fitur yang dilakukan 2DPCA menggunakan variasi jumlah d
(jumlah fitur/dimensi) dari 1-30. Gambar 5 merupakan Grafik hasil perbandingan
akurasi dan jumlah d yang dilakukan dengan menghitung kedekatan jarak antara
image training dengan image testing dengan euclidean distance. Hasil selengkapnya mengenai perbandingan akurasi dengan jumlah fitur pada 2DPCA dapat dilihat pada Lampiran 1.
Gambar 5 Grafik Perbandingan Akurasi dengan Jumlah Fitur pada 2DPCA
Pada Gambar 5 dapat terlihat hasil akurasi maksimum didapatkan pada
jumlah d = 2 dengan mendapatkan akurasi sebesar 68,97 %. Hal ini menandakan
bahwa 2 vektor ciri sudah cukup merepresentasikan sebuah image mata atau
bukan mata yang dikenali oleh 2DPCA dengan menggunakan jarak euclid.
Selanjutnya nilai d yang akan dipilih adalah d = 2 – 6 sebagai input pada proses klasifikasi dengan SVM.
Klasifikasi dengan SVM SVM Linear
Proses training ini dilakukan dengan menggunakan algoritma SVM Linear
dengan variasi log2 C antara -5 sampai 9 yang diaplikasikan dengan Cross
Validation = 5 pada data training.
60 65 70 75 80 85 90
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29
A
ku
rasi
(
%
)
Jumlah d
Test
10
Gambar 6 Grafik Perbandingan Akurasi SVM Linear
Pada Gambar 6 dapat dilihat bahwa dengan jumlah d = 5 akan menghasilkan akurasi lebih baik daripada jumlah d yang lain. Kekonsistenan parameter C akan
terlihat dari mulai Log2 C = -2. Hal ini berarti jika parameter C semakin besar,
maka pengaruh ke dalam proses klasifikasi tidak akan terlalu berpengaruh. Dalam percobaan ini, terlihat bahwa SVM membutuhkan jumlah fitur yang lebih besar untuk dapat melakukan proses klasifikasi dengan baik. Akurasi maksimal pada
data training didapatkan pada log2 C = -2 dengan d = 5 yaitu 83,02 % pada CV =
5. Hasil parameter ini diterapkan pada seluruh data training dan data testing untuk
memvalidasi model yang telah didapatkan. Hasil akurasi SVM linear secara lengkap dapat dilihat pada Lampiran 2.
SVM dengan Kernel Polynomial
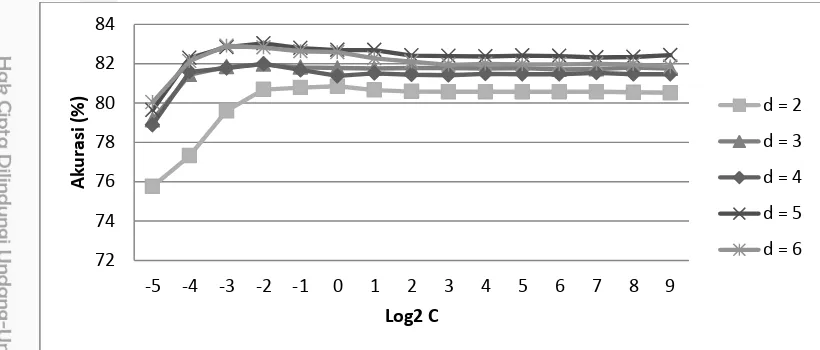
Percobaan ini dilakukan dengan menggunakan kernel Polynomial dengan 3 variasi C dan G sama dengan yang digunakan pada kernel RBF. Namun pada kernel Polynomial ini ditambahkan 1 buah parameter yaitu degree (d). Nilai d yang digunakan adalah 1 – 6. Hasil akurasi SVM dengan kernel Polynomial secara lengkap dapat dilihat pada Lampiran 4.
72 74 76 78 80 82 84
-5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8 9
A
ku
rasi
(
%
)
Log2 C
d = 2
d = 3
d = 4
d = 5
11
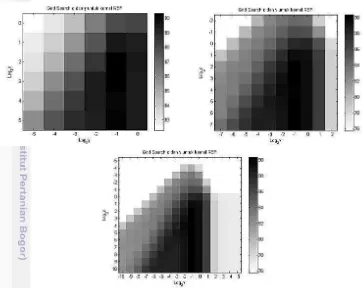
Gambar 7 Hasil Akurasi Perbandingan C dan Gamma Kernel Polynomial
Pada Gambar 7 terlihat bahwa ketiga skenario percobaan ini mendapatkan
hasil akurasi maksimal pada log2 C = 4 dan log2 Gamma = -3 pada d = 3 sebesar
88,80% pada CV = 5 dengan default degree = 3. Dalam percobaan ini, pengaruh
parameter Gamma cukup jelas terlihat pada rentang -5 dan 0, namun hasil yang
didapatkan terpengaruh oleh parameter C dengan pola tertentu. Nilai parameter yang didapatkan dari hasil Grid Search diterapkan kembali untuk menemukan parameter degree yang terbaik. Tabel 2 merupakan hasil akurasi dengan nilai d = 1,2,3,4,5,dan 6.
Tabel 2 Hasil Akurasi dengan Nilai degree yang berbeda
degree 1 2 3 4 5 6
Akurasi 81,74 87,07 88,80 88,39 87,78 87,02
Hasil pada Tabel 2 mendapatkan bahwa dengan meningkatnya parameter d pada kernel polynomial maka hasil akurasi akan terus meningkat. Tetapi degree d
yang terlalu besar menyebabkan algoritma juga akan sulit menemukan hyperplane
yang konsisten, hal ini bisa diperhatikan saat nilai d > 3. Hasil parameter ini
diterapkan pada seluruh data training dan data testing untuk memvalidasi model
12
SVM dengan Kernel RBF
Skenario percobaan ini dilakukan dengan 3 rentang nilai menggunakan
kernel RBF dengan variasi nilai log2 C 0 sampai dengan 5, -2 sampai dengan 7,
dan -5 sampai dengan 10. Nilai log2 G -5 sampai dengan 0, -7 sampai dengan 2,
dan -10 sampai dengan 5. Hal ini dilakukan untuk mencari kemungkinan nilai
akurasi maksimum dalam rentang yang lebih besar. Hasil akurasi SVM dengan kernel RBF secara lengkap dapat dilihat pada Lampiran 3.
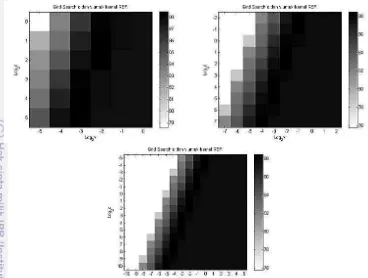
Gambar 8 Hasil Akurasi Perbandingan C dan Gamma Kernel RBF
Pada Gambar 8 terlihat bahwa ketiga skenario percobaan ini mendapatkan
hasil dengan merujuk pada sebuah nilai yaitu log2 C = 3 dan log2 Gamma = -1
pada nilai d = 3, dengan akurasi didapatkan sebesar 90,48% pada CV = 5. Pengaruh parameter Gamma terhadap proses klasifikasi cukup terlihat dengan
kekonsistenan parameter ini pada sebuah nilai yaitu log2 Gamma = -1. Parameter
Gamma ini dipengaruhi oleh parameter C yang mempunyai variasi nilai mulai dari log2 C > 0. Hasil parameter ini diterapkan pada seluruh data training dan data
13
Pengaruh Parameter C terhadap Hasil Akurasi
Gambar 9 Grafik Perbandingan Nilai Parameter C dengan Akurasi
Dari Gambar 9, dapat diperhatikan bahwa kekonsistenan jarang ditemukan
saat nilai log2 C kecil, tetapi kekonsistenan nilai banyak ditemukan pada saat nilai
log2 C semakin besar. Hal ini berlaku pada setiap kernel yang digunakan pada
percobaan yang dilakukan. Pada kernel Polynomial dan RBF nilai parameter ɣ yang digunakan bernilai konstan (tetap).
Parameter C mempengaruhi pencarian bidang pemisah terbaik dari 2 buah kelas yang akan dibedakan. Semakin besar nilai C maka diperlukan nilai penalti
error yang lebih besar (C) dan waktu pelatihan yang lebih lama (jumlah iterasi yang lebih banyak untuk proses optimasi bidang pemisah terbaik). Berdasarkan hasil yang diperoleh, memperlihatkan bahwa data mata dan bukan mata yang akan dipisahkan oleh bidang pemisah memiliki variasi data yang cukup sedikit sehingga menyulitkan algoritma SVM mencari bidang pemisah diantara keduanya.
Pengaruh Parameter ɣ terhadap Hasil Akurasi
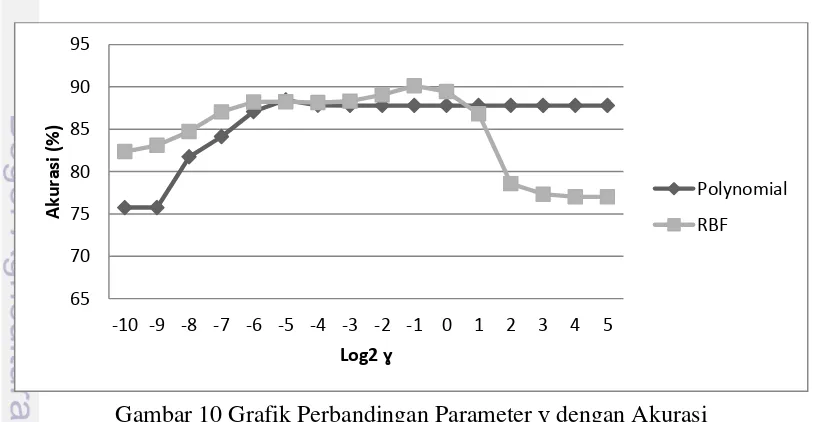
Gambar 10 Grafik Perbandingan Parameter ɣ dengan Akurasi
14
Dari Gambar 10, dapat diperhatikan juga bahwa kekonsistenan jarang
ditemukan saat nilai log2 γ kecil, tetapi kekonsistenan nilai banyak ditemukan
pada saat nilai log2 γ semakin besar. Namun pada saat nilai tertentu besaran
akurasi cenderung turun dan konsisten. Pada kernel Polynomial dan RBF nilai parameter C yang digunakan bernilai konstan (tetap).
Hal ini disebabkan oleh fungsi dari parameter γ itu sendiri dimana γ menentukan level kedekatan antar 2 titik menjadi lebih terpisah saat γ semakin besar sehingga memudahkan untuk menemukan pemisah hyperplane yang konsisten dengan data. Tetapi jika level kedekatan antar 2 titik terlalu tinggi bisa menyebabkan algoritma sulit untuk mencari kekonsistenan hyperplane karena data terkelompok dalam jumlah kecil yang berdekatan. Hal ini bisa dilihat ketika pemakaian nilai log2 γ > -1 pada kernel RBF dan log2 γ > -5 pada kernel polynomial.
Perbandingan Hasil Klasifikasi SVM
Hasil parameter yang telah didapatkan pada percobaan SVM diterapkan
pada seluruh data training dan data testing untuk memvalidasi model yang telah
didapatkan. Percobaan ini dilakukan untuk mendapatkan hasil akurasi terbaik
yang diterapkan pada keseluruhan data training dan testing dengan jumlah d yang
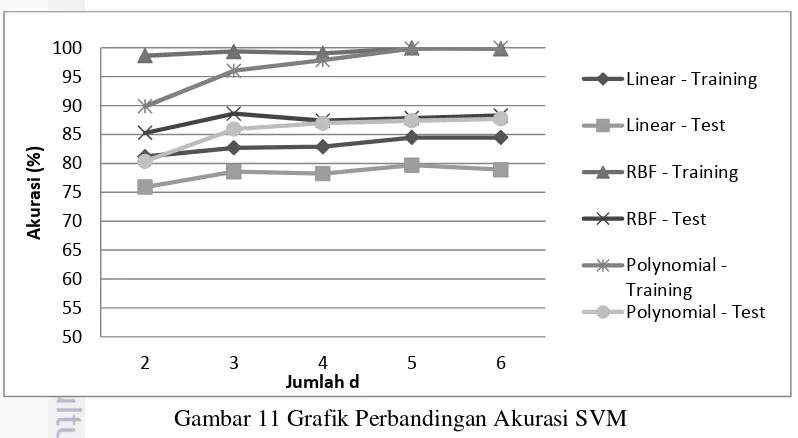
berbeda. Hasil perbandingan akurasi dengan SVM berbeda terlihat pada Gambar 11.
Pada Gambar 11, terlihat bahwa nilai akurasi yang diterapkan pada data
training jauh lebih besar daripada yang diterapkan pada data testing. Terjadi
overfitting pada saat diterapkan pada data training, lalu pada saat diaplikasikan
pada data testing akan terjadi degradasi akurasi yang cukup signifikan. Hal ini
dapat disebabkan oleh variasi imagetraining dan testing bagian mata atau bukan
mata yang mempunyai beberapa posisi yang berbeda karena kemiringan dari wajah ataupun bentuk mata. Hasil perbandingan akurasi SVM secara lengkap dapat dilihat pada Lampiran 5.
Gambar 11 Grafik Perbandingan Akurasi SVM
15
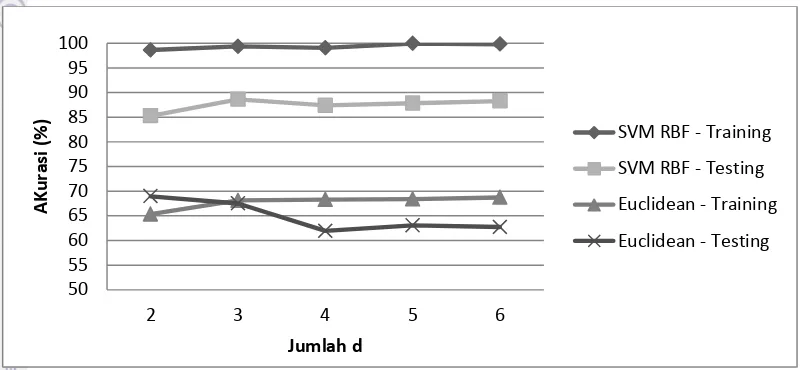
Perbandingan Klasifikasi SVM RBF dengan Euclidean
Hasil klasifikasi SVM yang terbaik, yaitu dengan menggunakan RBF dibandingkan dengan hasil yang didapatkan pada validasi 2DPCA dengan
menggunakan jarak euclidean. Hasil yang didapatkan dapat dilihat pada Gambar
12. Pada Gambar 12 dapat disimpulkan bahwa menggunakan klasifikasi dengan SVM hasil yang didapatkan jauh lebih baik daripada hanya menggunakan
euclidean. Hasil perbandingan akurasi SVM dengan Euclidean secara lengkap dapat dilihat pada Lampiran 6.
Gambar 12 Grafik Perbandingan Akurasi SVM Terbaik dan Euclidean
Optimasi menggunakan GA
Setelah melakukan percobaan pada tahapan sebelumnya, dilakukan proses
optimasi dengan menggunakan GA pada kernel RBF. Berikut ini merupakan inisialisasi awal parameter GA beserta hasil yang didapatkan.
Jumlah bit setiap variabel = 10 Ukuran populasi = 20
Batas bawah variabel C = 2-5 P Pindah Silang = 0.8
Batas atas variabel C = 210 P Mutasi = 0.1
Batas bawah variabel G = 2-10
Batas atas variabel G = 25
50 55 60 65 70 75 80 85 90 95 100
2 3 4 5 6
A
K
u
rasi
(%
)
Jumlah d
SVM RBF - Training
SVM RBF - Testing
Euclidean - Training
16
Gambar 13 Grafik Perbandingan Iterasi dengan Fitness pada GA
Pada Gambar 13 terlihat bahwa GA telah melakukan optimasi dengan baik. Hal ini dapat dilihat dari hasil optimal yang diperoleh dengan menggunakan GA
hampir sama dengan skenario grid search pada percobaan sebelumnya yaitu
90,12% pada CV = 5 dengan parameter Gamma = 0,5009 dan C = 482,01. Hasil optimasi akurasi menggunakan GA secara lengkap dapat dilihat oada Lampiran 7.
Tabel 3 Hasil Testing Optimasi GA Parameter SVM pada Kernel RBF
Pada percobaan ini GA tidak terlalu berperan signifikan terhadap hasil akurasi yang didapatkan. Hal ini disebakan oleh pengaturan parameter yang digunakan oleh GA yang kurang baik, terutama dalam menentukan jumlah digit pada setiap parameter yang digunakan. Hal ini mempengaruhi hasil optimasi yang dilakukan oleh GA dan membuat GA belum mampu bekerja secara optimal. Namun parameter yang didapatkan GA sesuai dengan kesimpulan sementara yang menyatakan bahwa untuk mendapatkan akurasi terbaik dari SVM dengan kernel
RBF, nilai parameter log2 G = -1 dan log2 C > 0. Hasil parameter ini diterapkan
pada seluruh data training dan data testing untuk memvalidasi model yang telah
didapatkan. Hasil yang diperoleh pada terdapat pada Tabel 3.
Hasil yang didapatkan pada data testing, memperlihatkan bahwa akurasi
dengan penerapan parameter training jauh lebih rendah daripada akurasi yang
didapatkan daripada proses pada data training. Pada percobaan ini, proses GA
telah berhasil melakukan optimasi parameter SVM dengan kernel RBF pada sistem deteksi mata.
Data TP TN FN FP Akurasi
Training 1023 3200 1 0 99,97
17
4
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menghasilkan model deteksi mata mengunakan SVM dengan ekstraksi ciri 2DPCA yang dioptimasi menggunakan GA. Klasifikasi dengan algoritma SVM menggunakan SVM linear, kernel polynomial, dan kernel RBF. Hasil yang diperoleh pada percobaan mengunakan SVM, didapatkan hasil maksimal pada kernel RBF dengan nilai 99,36% pada data training dan 88,62% pada data testing dengan nilai parameter log2 C = 3 dan log2 γ = -1.
Pada kasus data yang digunakan pada penelitian ini, kekonsistenan nilai akurasi terjadi saat nilai C semakin besar. Semakin besar nilai C maka diperlukan
nilai penalti error yang lebih besar (C) dan waktu pelatihan yang lebih lama. Hal
ini berarti variasi data bagian mata dan bukan mata tidak terlalu jauh yang mengakibatkan nilai C menjadi besar. Pada parameter γ, kekonsistenan jarang
ditemukan saat nilai log2 γ kecil, tetapi kekonsistenan nilai banyak ditemukan
pada saat nilai log2 γ semakin besar. Namun pada saat nilai tertentu besaran
akurasi cenderung turun dan konsisten. Hal ini disebabkan oleh fungsi dari parameter γ itu sendiri dimana γ menentukan level kedekatan antar 2 titik menjadi lebih terpisah saat γ semakin besar sehingga memudahkan untuk menemukan pemisah hyperplane yang konsisten dengan data. Tetapi jika level kedekatan antar 2 titik terlalu tinggi bisa menyebabkan algoritma sulit untuk mencari kekonsistenan hyperplane karena data cenderung mengelompok dalam kelompok kecil yang berdekatan.
Hasil yang didapatkan oleh algoritma SVM dengan kernel RBF dioptimasi dengan GA. Hasil akurasi tertinggi yang diperoleh pada nilai Log2 Gamma = -1 dan C > 0 dengan nilai 99,97% pada data training dan 88,16% pada data testing. Pada percobaan optimasi yang dilakukan pada penelitian ini, peran GA tidak terlalu berpengaruh terhadap hasil klasifikasi yang telah didapatkan sebelumnya. Hal ini disebabkan pada pengaturan parameter pada GA yang tidak dieksplorasi terlebih dahulu untuk mendapatkan parameter yang tepat, hal ini sekaligus menjadi kelemahan dalam penelitian ini.
Saran
18
DAFTAR PUSTAKA
Asteriadis S, Nikolaidis N, Hajdu A, Pitas I. 2006. An Eye Detection Algorithm Using Pixel to Edge Information. International Symposium on
Communications, Control and Signal Processing (ISCCSP) [Internet].
[diunduh 2012 Okt 12]. Tersedia pada : http://www.eurasip.org/Proceedings /Ext/ISCCSP2006/defevent/papers/cr1124 .pdf
Bhoi N, Mihir MN. 2010. Template Matching based Eye Detection in Facial Image. International Journal of Computer Applications (0975 – 8887). Volume 12 – No.5 [Internet]. [diunduh 2012 Nop 30]; Volume 12 – No.5.
Tersedia pada : http://www. ijcaonline.org/volume15/number4/pxc3872582 .pdf
Di Martino S, Ferrucci F, Gravino C, dan Sarro F. 2011. A Genetic Algorithm to Configure Support Vector Machines for Predicting Fault-Prone Components. D. Caivano et al. (Eds.): PROFES 2011, LNCS 6759, pp. 247–261 [Internet] Tersedia pada : http://www0.cs.ucl.ac.uk/staff/F.Sarro/resource/papers/C6. pdf
Hassan RA, Hegazy A dan Badr AA. 2010. Optimize Support Vector Machine Classifier based on Evolutionary Algorithm for Breast Cancer Diagnosis. International Journal of Computer Science and Network Security (IJCSNS). Volume 10 No.12 [Internet]. [diunduh 2012 Des 18] Volume 10 No.12.
Tersedia pada : http://paper.ijcsns.org/ 07_book/201112/ 20111213.pdf
Hoang Le T, Bui L. 2011. Face Recognition Based on SVM and 2DPCA. International Journal of Signal Processing, Image Processing and Pattern Recognition. Volume 4 No. 3 [Internet]. [diunduh 2012 Des 22] Volume 4
No. 3. Tersedia pada : http://arxiv. org/ftp/arxiv/papers/1110/1110.5404.pdf
Huang C, Wang C. 2006. A GA-based feature selection and parameters optimization for support vector machines. Expert Systems with Applications (31) [Internet]. [diunduh 2012 Okt 15]. Tersedia pada :
http://nlg.csie.ntu.edu.tw/~cjwang/ publications/A%20GA-based%20feature
%20selection%20and%20parameters%20optimizationfor%20support%20ve ctor%20machines.pdf
Lessmann S, Stahlbock R, Crone S F. 2006. Genetic Algorithms for Support Vector Machine Model Selection. International Joint Conference on Neural Networks (IJCNN) [Internet]. [diunduh 2012 Okt 15]. Tersedia pada :
http://www.sven-crone.de/papers/Lessmann,%20Stahlbock,%20Crone%20(
2006)%20Genetic%20Algorithms%20for%20Support%20Vector%20Machi
19 Orman Z, Battal A, Kemer E. 2011. A Study on Face, Eye Detection and Gaze Estimation. International Journal of Computer Science & Engineering Survey (IJCSES). Volume 2 No.3 [Internet]. [diunduh 2012 Sep 17];Volume 2 No.3. Tersedia pada : http://airccse.org/journal/ijcses/papers /0811cses03.pdf
Wu K, Wang S. 2009. Choosing the kernel parameters for support vector machines by the inter-cluster distance in the feature space. Pattern Recognition, Vol. 42 , No. 5. pp. 710-717.
Rajpathak T, Kumar R, Schwartz E. 2009. Eye Detection Using Morphological
and Color Image Processing. Florida Conference on Recent Advances in
Robotics (FCRAR) [Internet]. [diunduh 2012 Okt 5]. Tersedia pada : http://www.mil.ufl.edu/publications/fcrar09/Eye_Detection_Tanmay_Rajpat hak_fcrar_09.pdf
Wang Q, Yang J. 2006. Eye Detection in Facial Images with Unconstrained Background. Journal of Pattern Recognition Research 1 [Internet]. [diunduh
2012 Okt 11] Tersedia pada : http://www.jprr.org/index.php/jprr/article/ viewFile/15/7
Yang J, Zhang D. 2004. Two-Dimensional PCA: A New Approach to Appearance-Based Face Representation and Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence. Volume 26 No.
1. [Internet]. [diunduh 2012 Nop 6]. Tersedia pada :
20
21 Lampiran 1 Hasil Perbandingan Akurasi dengan Jumlah Fitur pada 2DPCA
Data Training
d Akurasi TP TN FN FP
1 64,62 174 405 82 235
2 68,97 157 461 99 179
3 67,52 175 430 81 210
4 61,94 195 360 61 280
5 63,06 194 371 62 269
6 62,72 193 369 63 271
7 63,50 188 381 68 259
8 64,17 188 387 68 253
9 64,40 183 394 73 246
10 63,95 181 392 75 248
11 64,06 176 398 80 242
12 64,17 178 397 78 243
13 64,40 178 399 78 241
14 64,62 176 403 80 237
15 65,18 174 410 82 230
16 65,40 174 412 82 228
17 65,51 174 413 82 227
18 65,07 173 410 83 230
19 65,07 175 408 81 232
20 64,84 175 406 81 234
21 64,84 174 407 82 233
22 64,73 175 405 81 235
23 64,84 175 406 81 234
24 64,84 178 403 78 237
25 64,62 176 403 80 237
26 64,51 177 401 79 239
27 64,51 175 403 81 237
28 65,07 176 407 80 233
29 64,62 176 403 80 237
30 65,40 176 410 80 230
Data Testing
d Akurasi TP TN FN FP
1 63,73 737 1955 287 1245
2 65,34 738 2022 286 1178
3 68,11 758 2119 266 1081
4 68,30 764 2121 260 1079
5 68,39 762 2127 262 1073
22
7 68,70 769 2133 255 1067
8 68,75 768 2136 256 1064
9 68,94 768 2144 256 1056
10 68,87 769 2140 255 1060
11 68,84 770 2138 254 1062
12 68,77 769 2136 255 1064
13 68,84 769 2139 255 1061
14 68,84 768 2140 256 1060
15 68,80 768 2138 256 1062
16 68,92 770 2141 254 1059
17 68,94 770 2142 254 1058
18 69,11 771 2148 253 1052
19 69,01 769 2146 255 1054
20 69,06 769 2148 255 1052
21 69,13 773 2147 251 1053
22 69,18 775 2147 249 1053
23 69,32 776 2152 248 1048
24 69,48 776 2159 248 1041
25 69,58 776 2163 248 1037
26 69,53 779 2158 245 1042
27 69,63 778 2163 246 1037
28 69,72 780 2165 244 1035
29 69,70 777 2167 247 1033
23 Lampiran 2 Hasil Akurasi Perbandingan Jumlah Dimensi dan Parameter C pada
SVM Linear
C d = 2 d = 3 d = 4 d = 5 d = 6
-5 75,76 79,14 78,88 79,64 80,04
-4 77,32 81,44 81,58 82,29 82,13
-3 79,59 81,84 81,77 82,84 82,91
-2 80,68 81,96 81,98 83,03 82,81
-1 80,78 81,82 81,68 82,79 82,62
0 80,85 81,77 81,37 82,69 82,58
1 80,66 81,75 81,51 82,69 82,27
2 80,59 81,77 81,44 82,41 82,10
3 80,56 81,77 81,42 82,39 81,94
4 80,56 81,75 81,49 82,36 81,98
5 80,56 81,77 81,46 82,41 81,96
6 80,56 81,70 81,46 82,39 81,96
7 80,56 81,72 81,53 82,32 81,98
8 80,54 81,79 81,46 82,34 81,96
9 80,52 81,75 81,46 82,43 81,84
24
Lampiran 3 Hasil Akurasi Perbandingan Parameter Gamma dan C pada SVM
dengan Kernel RBF dengan d = 5
Rentang Nilai Gamma (0 s/d 5) dan C (-5 s/d 0)
Gamma/C -5 -4 -3 -2 -1 0
0 82,29 83,17 84,33 86,34 87,86 88,14
1 83,00 83,85 85,63 87,62 89,56 89,32
2 83,26 84,68 86,93 88,64 90,34 89,56
3 83,93 85,94 87,74 89,42 90,22 89,44
4 84,75 86,86 88,49 89,44 90,01 89,44
5 85,87 87,64 88,94 89,25 90,13 89,44
Rentang Nilai Gamma (-2 s/d 7) dan C (-7 s/d 2)
Gamma/C -7 -6 -5 -4 -3 -2 -1 0 1 2
-2 75,76 75,76 75,85 79,88 82,69 83,69 84,35 84,00 78,69 75,76 -1 75,76 75,80 79,73 82,58 83,50 84,73 85,91 85,65 82,05 75,76 0 75,80 79,50 82,29 83,17 84,33 86,34 87,86 88,14 85,72 77,82 1 79,33 81,87 83,00 83,85 85,63 87,62 89,56 89,32 86,74 78,57 2 81,77 82,84 83,26 84,68 86,93 88,64 90,34 89,56 86,81 78,57 3 82,43 83,07 83,93 85,94 87,74 89,42 90,22 89,44 86,81 78,57 4 82,69 83,21 84,75 86,86 88,49 89,44 90,01 89,44 86,81 78,57 5 82,79 83,81 85,87 87,64 88,94 89,25 90,13 89,44 86,81 78,57 6 83,00 84,71 86,96 88,38 88,68 89,09 90,13 89,44 86,81 78,57 7 83,76 85,91 87,59 88,64 88,42 89,06 90,13 89,44 86,81 78,57
Rentang Nilai Gamma (-5 s/d 10) dan C (-10 s/d -6)
Gamma/C -10 -9 -8 -7 -6
-5 75,76 75,76 75,76 75,76 75,76
-4 75,76 75,76 75,76 75,76 75,76
-3 75,76 75,76 75,76 75,76 75,76
-2 75,76 75,76 75,76 75,76 75,76
-1 75,76 75,76 75,76 75,76 75,80
0 75,76 75,76 75,76 75,80 79,50
1 75,76 75,76 75,78 79,33 81,87
2 75,76 75,78 79,12 81,77 82,84
3 75,78 78,98 81,84 82,43 83,07
4 78,95 81,72 82,36 82,69 83,21
5 81,68 82,22 82,48 82,79 83,81
6 82,05 82,24 82,55 83,00 84,71
7 82,15 82,34 82,48 83,76 85,91
8 81,89 82,46 83,14 84,73 87,07
9 82,03 82,74 83,74 85,98 87,67
25
Rentang Nilai Gamma (-5 s/d 10) dan C (-5 s/d 0)
Gamma/C -5 -4 -3 -2 -1 0
-5 75,76 75,76 75,76 75,76 75,97 75,76 -4 75,76 75,76 75,88 79,17 80,73 77,84 -3 75,76 75,88 79,85 82,55 83,36 82,08 -2 75,85 79,88 82,69 83,69 84,35 84,00 -1 79,73 82,58 83,50 84,73 85,91 85,65
0 82,29 83,17 84,33 86,34 87,86 88,14
1 83,00 83,85 85,63 87,62 89,56 89,32
2 83,26 84,68 86,93 88,64 90,34 89,56
3 83,93 85,94 87,74 89,42 90,22 89,44
4 84,75 86,86 88,49 89,44 90,01 89,44
5 85,87 87,64 88,94 89,25 90,13 89,44
6 86,96 88,38 88,68 89,09 90,13 89,44
7 87,59 88,64 88,42 89,06 90,13 89,44
8 88,33 88,42 88,33 89,06 90,13 89,44
9 88,42 88,42 88,30 89,06 90,13 89,44
10 88,23 88,14 88,30 89,06 90,13 89,44
Rentang Nilai Gamma (-5 s/d 10) dan C (1 s/d 5)
Gamma/C 1 2 3 4 5
-5 75,76 75,76 75,76 75,76 75,76
-4 75,76 75,76 75,76 75,76 75,76
-3 75,90 75,76 75,76 75,76 75,76
-2 78,69 75,76 75,76 75,76 75,76
-1 82,05 75,76 75,76 75,76 75,76
0 85,72 77,82 77,01 77,01 77,01
1 86,74 78,57 77,34 77,01 77,01
2 86,81 78,57 77,34 77,01 77,01
3 86,81 78,57 77,34 77,01 77,01
4 86,81 78,57 77,34 77,01 77,01
5 86,81 78,57 77,34 77,01 77,01
6 86,81 78,57 77,34 77,01 77,01
7 86,81 78,57 77,34 77,01 77,01
8 86,81 78,57 77,34 77,01 77,01
9 86,81 78,57 77,34 77,01 77,01
26
Lampiran 4 Hasil Akurasi Perbandingan parameter Gamma pada SVM
Polynomial dengan d = 5
Rentang Nilai Gamma (-5 s/d 10) dan C (-10 s/d -5)
Gamma/C -10 -9 -8 -7 -6 -5
-5 75,75758 75,75758 75,75758 75,75758 75,75758 75,75758 -4 75,75758 75,75758 75,75758 75,75758 75,75758 75,75758 -3 75,75758 75,75758 75,75758 75,75758 75,75758 75,75758 -2 75,75758 75,75758 75,75758 75,75758 75,75758 75,75758 -1 75,75758 75,75758 75,75758 75,75758 75,75758 75,78125 0 75,75758 75,75758 75,75758 75,75758 75,75758 78,57481 1 75,75758 75,75758 75,75758 75,75758 75,75758 81,74716 2 75,75758 75,75758 75,75758 75,75758 75,78125 82,74148 3 75,75758 75,75758 75,75758 75,75758 78,57481 83,47538 4 75,75758 75,75758 75,75758 75,75758 81,74716 84,11458 5 75,75758 75,75758 75,75758 75,78125 82,74148 85,15625 6 75,75758 75,75758 75,75758 78,57481 83,47538 86,41098 7 75,75758 75,75758 75,75758 81,74716 84,11458 87,07386 8 75,75758 75,75758 75,78125 82,74148 85,15625 87,80777 9 75,75758 75,75758 78,57481 83,47538 86,41098 88,2339 10 75,75758 75,75758 81,74716 84,11458 87,07386 88,44697
Rentang Nilai Gamma (-5 s/d 10) dan C (-4 s/d -0)
Gamma/C -4 -3 -2 -1 0
-5 75,75758 81,74716 84,11458 87,07386 88,44697 -4 75,78125 82,74148 85,15625 87,80777 88,30492 -3 78,57481 83,47538 86,41098 88,2339 87,90246 -2 81,74716 84,11458 87,07386 88,44697 87,83144 -1 82,74148 85,15625 87,80777 88,30492 87,80777
0 83,48 86,41 88,23 87,90 87,80777
1 84,11 87,07 88,45 87,83 87,80777
2 85,16 87,81 88,30 87,81 87,80777
3 86,41 88,23 87,90 87,81 87,80777
4 87,07 88,80 87,83 87,81 87,80777
5 87,81 88,30 87,81 87,81 87,80777
27
Rentang Nilai Gamma (-5 s/d 10) dan C (1 s/d 5)
Gamma/C 1 2 3 4 5
28
Lampiran 5 Hasil Perbandingan Akurasi SVM linear, kernel RBF dan Polynomial
pada data Testing dan Training
29 Lampiran 6 Hasil Perbandingan Akurasi SVM dengan 2DPCA menggunakan jarak Euclidean
Hasil Training 2DPCA menggunakan jarak Euclidean
d TP TN FN FP Akurasi
2 68,97 157 461 99 179
3 67,52 175 430 81 210
4 61,94 195 360 61 280
5 63,06 194 371 62 269
6 62,72 193 369 63 271
Hasil Testing 2DPCA menggunakan jarak Euclidean
d TP TN FN FP Akurasi
2 65,34 738 2022 286 1178
3 68,11 758 2119 266 1081
4 68,30 764 2121 260 1079
5 68,39 762 2127 262 1073
6 68,73 768 2135 256 1065
Hasil Training SVM dengan Kernel RBF
d TP TN FN FP Akurasi
2 975 3191 49 9 98,63
3 1000 3197 24 3 99,36
4 991 3193 33 7 99,05
5 1022 3200 2 0 99,95
6 1017 3199 7 1 99,81
Hasil Testing SVM dengan Kernel RBF
d TP TN FN FP Akurasi
2 154 610 102 30 85,27
3 186 608 70 32 88,62
4 181 602 75 38 87,38
5 174 613 82 27 87,83
30
Lampiran 7 Hasil Akurasi SVM dengan Optimasi menggunakan GA
Iterasi Akurasi Iterasi Akurasi Iterasi Akurasi Iterasi Akurasi
1 78,01 26 90,06 51 90,13 76 90,13
2 78,01 27 90,06 52 90,13 77 90,13
3 78,01 28 90,06 53 90,13 78 90,13
4 78,01 29 90,13 54 90,13 79 90,13
5 78,08 30 90,13 55 90,13 80 90,13
6 78,08 31 90,13 56 90,13 81 90,13
7 78,08 32 90,13 57 90,13 82 90,13
8 78,08 33 90,13 58 90,13 83 90,13
9 88,85 34 90,13 59 90,13 84 90,13
10 89,44 35 90,13 60 90,13 85 90,13
11 89,44 36 90,13 61 90,13 86 90,13
12 89,44 37 90,13 62 90,13 87 90,13
13 89,44 38 90,13 63 90,13 88 90,13
14 89,44 39 90,13 64 90,13 89 90,13
15 89,44 40 90,13 65 90,13 90 90,13
16 89,44 41 90,13 66 90,13 91 90,13
17 89,91 42 90,13 67 90,13 92 90,13
18 89,91 43 90,13 68 90,13 93 90,13
19 90,06 44 90,13 69 90,13 94 90,13
20 90,06 45 90,13 70 90,13 95 90,13
21 90,06 46 90,13 71 90,13 96 90,13
22 90,06 47 90,13 72 90,13 97 90,13
23 90,06 48 90,13 73 90,13 98 90,13
24 90,06 49 90,13 74 90,13 99 90,13
Journal of Theoretical and Applied Information Technology
MODELING AND OPTIMIZATION OF SUPPORT VECTOR MACHINE (SVM)
FOR DETECTION OF HUMAN EYE
AND 2DPCA AS FEATURE EXTRACTION
1
ANDIKA SUNDAWIJAYA, 2AGUS BUONO, 3BIB PARUHUM SILALAHI
1
Student of Computer Science Department, Bogor Agricultural University
2
Supervising Committee Chairman, Lecturer of Computer Science Department, Bogor Agricultural University
3
Supervising Committee Member, Lecturer of Math Department, Bogor Agricultural University
E-mail: [email protected], [email protected], [email protected]
ABSTRACT Maximum results are obtained, namely the RBF kernel with value of Log2 Gamma = -1 and C > 0 with an accuracy 99.97% on training data and 88.16% on the testing of data.
Keywords: 2DPCA, Eye Dectetion, Genetic Algorithm, Support Vector Machine
1. INTRODUCTION
Eye tracking has become one of the most important processes in human computer interaction. Eye tracking has also been proven to be useful in various applications. Specific applications that included in this system such as the system in handwriting reading, music reading, human activity recognition, advertising perception, sport playing, Human Computer Interaction (HCI) especially for people with disability, medical research, and other areas [1]
Eye detection is the most important thing to do as an initial basis in eye tracking application. By getting the position of the eye, the eye tracking will be easier to do at a later stage [2]. In general, eye detection is done in two steps, which is determine the location of the face to extract the eye area then detect the eye from the eye area [3]. Numerous studies have been published in recent times about the eye detection. Several different approaches are taken to eye detection or tracking. The method
requires additional hardware support to resolve the problem, while the other methods using a fairly simple webcam. These methods such as Electrooculography (EOG),Infra-Red Oculography, Scleral search coils, and Image based methods [1].
One of the research that used Image based support vector machine verifier eye. Furthermore, eye variance filter is used to detect two eyes in the eye area that has been extracted in the step of determines the location of the pair eyes. The proposed method is resistant to complex background, rotation, eyewear, and partial face [3].
32
efficiency in obtaining results. One of the optimization algorithms that widely used is Genetic Algorithm (GA). GA is a meta-heuristic algorithm that adapting the process of long-term optimization in the biological evolution to solve optimization mathematics case. This algorithm is based on Darwin's theory with 'survival of the fittest' principle. GA algorithm has been used in its connection with SVM in some way, for example the feature selection, optimizing the SVM parameters (assuming fixed kernel) , and the kernel construction [4].
Feature extraction is done to choose the features that tag a special characteristics of the area to be detected, in this case is the human eye. Beside the selection of appropriate parameters of algorithm, feature selection is one of the factors that will affect the accuracy in performing classification [5]. Features that have been selected will become an input to SVM algorithm in the detection process. It was submitted by [6] in his article that apply 2DPCA algorithm to perform feature extraction algorithm that will become an input to SVM in human face recognition. Experiment based on the proposed method and has been applied on two set public data, Feret and AT & T. The result obtained show that the proposed method can improve the accuracy of classification results. Purpose of this study is perform modeling and Support Vector Machine (SVM) kernel parameter optimization with Genetic Algorithm for human eye detection. The benefits that obtained from the results of this research is as early base in performing eye tracking. Precise eye position detection process will make the process of eye tracking easier and more accurate.
2. METHODOLOGY
The methodology of this research consists of several stages of process: data collection, preprocessing, feature extraction with 2DPCA, modelling with SVM, and optimize SVM parameter with GA. The methodology of modeling and optimization of SVM for detection of human eye process is shown in Figure 1.
2.1 Data Collection
The data used is the human face dataset from AT&T Laboratories Cambridge. Dataset used is a collection of face images taken between April 1992 and April 1994.
There are 10 different face images from each of 40 different people. The images were taken at different times, different lighting, facial expressions (open/close eyes, smiling/not smiling), and facial detail (with glasses/without glasses). All images were taken with a dark homogeneous background
with the people in position frontal upright (with tolerance for some movement). Files used in PGM format with the size of each image is 92x112 pixel. Furthermore, the data is divided into training data and testing data.
2.2 Preprocessing
At this stage, some human face images are processed. The entire human face image is divided into two categories. They are eye part of the face and non-eye part of the face. In this stage, data is distributed into training data and testing data as an input to the next process. Each part which is taken from this image has a size nxn pixel with n = 30.
Amount of the image which is used in this experiment is 3840 non eye images 1280 eye images. The data is divided into two sections. 3200 non eye image and 1024 eye image is training data. 640 non eye images and 256 eye images is testing data. The training data will be trained using 5 Fold Cross Validation.
2.3 Feature Extraction
This stage is performed to get the feature of face part/segmentation in the form of eye and non eye from each data. Algorithm that is used to obtain feature is 2 Dimensional Principal Component Analysis (2DPCA). The output of this process is a characteristic matrix of every part of the image that is processed. A description of the 2DPCA is as
corresponding Eigen vectors. n number of Eigen values is stored in descending (down). Eigen vector (d) which has been determined in accordance with the largest number of d values resulting from Eigen value matrix n × d. 8. Feature (Y) of an image A will be obtained
from the following equation.
(2)
where X is an n x d matrix.
2.4 Support Vector Machine (SVM)
SVM is designed for binary classification problem with assuming that the data is linearly separate [8]. There is a training data �, � with �
= 1, ... , m, � ∈ ��, � ∈ {+ , }, �� is the
input data sample, � is the feature vector and � is
Journal of Theoretical and Applied Information Technology
discrimination function that resolves optimization problems:
�
�, � �, � with � �, � + � ≥ , � , … ,
(3)
Minimal distance sampling data and hyperlane (margin) is /‖�‖.
In the case of non-linear separated data, slack
variable is introduced into the optimization problem becomes:
�
�, �, � �, � + � ∑� �� with � �, � +
� ≥ ��, � , … , , ��≥ 0 (4)
Decision function of SVM is as follows:
�� ∑��:�� ��� �, + � (5)
In the real case, not all data can be separated linearly, the data can be mapped into a greater dimension by using a kernel function.
�� ∑��:�� ���� �, + � (6)
Kernel function used in this research:
Linear : � , ′ , ′ (7) natural selection and genetics in biological systems. GA works with a set of candidate solutions called population. Based on the principle of Darwin, 'survival of the fittest' which means GA obtains optimal solution after a series of iterative calculations. GA produces recurrent population with alternative solutions represented by chromosomes, until the result is acceptable. Speaking of exploitation and exploration characteristic of searching, GA can handle a large search space efficiently, and have less chance of getting local optimal solution than other algorithms [5]. The basic idea of GA that applied to SVM is to configure SVM based on parameters setting observations which is formulated as an optimization problem [9].
2.6 Model Accuracy
There are several indicators used to evaluate the accuracy of the model that generated by SVM algorithm. In this research, the level of accuracy, sensitivity, specificity, positive predictive value, and negative predictive value are used [10]. Accuracy indicator from SVM is used as the fitness function in the evaluation of the GA.
Table 4 : 2 x 2 Contingency Table
Category Eye (+) Target Non
Eye (-) T
est
Eye
(+) Positive (TP)True Negative (FN)False Non
Eye (-)
False
Positive (FP) Negative (TN)True Table 1 shows the information about the actual data and tested data that has been classify into two class. With an accuracy which is formulated as
3. RESULTS AND DISCUSSIONS The research is using Matlab R2010b version 7.11.0.584 software. Feature extraction is done using 2DPCA with number variation of d (the number of feature/dimension) from 1-30. Figure 1 is a comparison result of accuracy and number of d which is done by calculating the proximity distance between the training image with the testing image by Euclidean Distance.
34
This training process is performed using
Linear SVM algorithm with log2 C variation
between -5 and 9 which is applied with Cross
Validation = 5 in the training data.
Figure 2 shows that the number of d = 5 will produce better accuracy than the other numbers. Consistency of C parameter is shown start from Log2 C = -2. This means that if the C parameter is
set larger, the influence to the classification process will not be too significant. In this research, it is seen that SVM require a greater number of feature to perform the classification process as well. Maximum accuracy on the training data obtained at Log2 C = -2with d = 5 is 83.02% at CV = 5. Results