PEMODELAN
HYBRID TOURISM RECOMMENDATION
MENGGUNAKAN
HIDDEN MARKOV MODEL
DAN
TEXT
MINING
BERBASIS DATA SOSIAL MEDIA
HUSNUL KHOTIMAH
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Pemodelan Hybrid Tourism Recommendation Menggunakan Hidden Markov Model dan Text Mining Berbasis Data Sosial Media adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
HUSNUL KHOTIMAH. Pemodelan Hybrid Tourism Recommendation Menggunakan Hidden Markov Model dan Text Mining Berbasiskan Data Sosial Media. Dibimbing oleh YANI NURHADRYANI dan TAUFIK DJATNA.
Dalam bidang pariwisata, sistem rekomendasi dapat membantu pengguna mempercepat proses pengambilan keputusan untuk memilih destinasi tempat wisata. Salah satu sistem rekomendasi wisata yang sudah dikembangkan yaitu mobile ecotourism. Rekomendasi yang dihasilkan berbasis jarak dan pemetaan data statis. Sistem mobile ecotourism mengalami masalah seperti pada sistem rekomendasi tradisional yaitu atribut penentu hasil rekomendasi yang sebagian besar masih dalam data statis dan memiliki ketergantungan terhadap data rating.
Penelitian ini bertujuan membangun model rekomendasi untuk mengatasi masalah yang terdapat pada sistem rekomendasi mobile ecotourism. Pada penelitian ini mengusulkan dua model rekomendasi hybrid yaitu model rekomendasi berbasis spasial dan berbasis text mining. Dua model ini menggunakan data media sosial. Data media sosial tumbuh secara cukup signifikan dan alami.
Pemodelan rekomendasi berbasis spasial memberikan rekomendasi berdasarkan jarak dan analisis user mobility behavior. Pemodelan ini melibatkan data histori check-in dari location based social network. Data histori check-in dimodelkan berdasarkan Hidden Markov yang merepresentasikan user mobillity behavior yaitu perilaku dari mobilitas pengguna saat berpindah dari satu lokasi ke lokasi lain. Asumsi yang digunakan yaitu kunjungan pengguna ke suatu lokasi dipengaruhi oleh posisi current location dan waktu kunjungan. Pada Hidden Markov Model perpindahan pengguna dari suatu lokasi ke lokasi lain dimodelkan dalam state observasi dan waktu kunjungan ke suatu lokasi dimodelkan sebagai hidden state. Pemodelan ini menghasilkan daftar lokasi yang dekat dengan lokasi pengguna dan sesuai dengan perilaku pengguna. Model ini sudah diimplementasikan ke dalam bentuk web. Hasil evaluasi model dengan mean average precision menunjukkan nilai sebesar 0.78 yang merepresentasikan bahwa hasil rekomendasi cukup relevan.
Pemetaan data statis antara hobi dan lokasi wisata diselesaikan dengan proses ekstraksi teks pada kumpulan data media sosial objek wisata dan pengguna untuk membangun suatu pemetaan yang bersifat dinamis. Text mining dilakukan untuk mengekstraksi teks sehingga didapatkan penciri dari objek wisata tersebut. Penelitian ini berfokus pada ekstraksi teks berbahasa Indonesia. Rekomendasi dibangun berdasarkan vector space model antara term wisata dan kemunculan term tersebut dalam posting pengguna di jejaring sosial. Pada pemodelan ini juga dilakukan agregasi rekomendasi dengan advice seeking sebagai representasi proses rekomendasi di dunia nyata. Model ini baru dibangun dengan menggunakan bahasa pemrograman R. Hasil dari pemodelan ini kurang baik karena term wisata masih didominasi kata-kata yang tidak representatif.
SUMMARY
HUSNUL KHOTIMAH. Modelling of Hybrid Tourism Recommendation Using Hidden Markov Model and Text Mining Based on Social Media Data. Supervised by YANI NURHADRYANI and TAUFIK DJATNA.
In the field of tourism, the recommender systems can support users accelerate the decision making process to select a tourist destination. One of tourism recommender systems which has been developed including mobile ecotourism. The system give recommendation which is based on distance and static data mapping among hobby and location. It suffers the same problem as the traditional recommender system such as static attribute to determine recommendation result and its dependence on the data rating.
This research proposed two models of hybrid recommendation based on social media data to overcome the limitation of the mobile ecotourism. The motivation of using social media data was related to its significant and natural growth. The proposed models used two different approaches including spatial analytic and text mining.
In spatial analytic, recommendation process involved analysis of user mobility behavior. The analysis was developed based on check-in history of user that obtained from location based social network. The modelling process was based on Hidden Markov Model to represent user mobility behavior which means user‟s movement habits from one location to other location. This model was built under assumption that user‟s visit to a location was influenced by user‟s current location and point of time visit. In the Hidden Markov Model, the user‟s movement from one location to another location was assumed as observation state. Moreover visit time to one location was assumed as hidden state. The result of this recommendation is location list that close to user‟s current location in accordance with user mobility behavior. A web based prototype was built to evaluate the model. The evaluation acquired from real world data showed a mean average precision of 0.78.
The static mapping among hobby and location was solved by dynamic mapping with text extraction based on composite social media data of tourism object and user. Text mining was used to extract identifier of tourism object. This research focussed on text mining in Indonesian language. Recommendation process was developed based on vector space model between tourism term and the occurrence of tourism term on user‟s posting in social network. This modelling used advice seeking technique to represent real world recommendation. We built the model with R programming. This model still could not deal with the occurences of unrepresented term, since they did not represent the real tourism object.
© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
PEMODELAN
HYBRID TOURISM RECOMMENDATION
MENGGUNAKAN
HIDDEN MARKOV MODEL
DAN
TEXT
MINING
BERBASIS DATA SOSIAL MEDIA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2014
Tesis : Pemodelan Hybrid Tourism Recommendation Menggunakan Hidden Markov Model dan Text Mining Berbasis Data Sosial Media
Nama : Husnul Khotimah
NIM : G651130586
Disetujui oleh Komisi Pembimbing
Dr Yani Nurhadryani, SSi MT Ketua
Dr Eng Taufik Djatna, STP MSi Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Eng Wisnu Ananta Kusuma, ST MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2014 ini ialah social media, dengan judul Pemodelan Hybrid Tourism Recommendation Menggunakan Hidden Markov Model dan Text Mining Berbasis Data Sosial Media. Penelitian ini merupakan penelitian unggulan strategis perguruan tinggi skema penelitian dasar untuk bagian yang didanai oleh DIKTI pada program Bantuan Operasional Perguruan Tinggi Negeri (BOPTN).
Terima kasih penulis ucapkan kepada Ibu Dr Yani Nurhadryani dan Bapak Dr Eng Taufik Djatna selaku pembimbing, serta Ibu Dr Imas Sukaesih Sitanggang dan Dr Wisnu Ananta Kusuma yang telah banyak memberi saran. Tidak lupa penulis ucapkan terima kasih kepada kepada ayah, ibu, serta seluruh keluarga atas segala dukungan, doa dan kasih sayangnya. Di samping itu, penghargaan penulis sampaikan terima kasih kepada:
1 Rekan-rekan satu bimbingan di laboratorium SEIS yaitu Kak Neni Rosmawarni, Kak Riva Aktivia, Kak Dean Apriana Ramadhan, Kak Miftakhurrohman, dan Kak Frans Rudolf.
2 Rekan-rekan satu bimbingan di laboratorium komputer Teknik Industri Pertanian, yaitu Kak Elfira Febriani, Kak Nina Hairiyah, M. Zaky Hadi, Kak Nova, Kak Elfa, Pak Iwan, Bu Puspa, Kak Luki, Kak Hety dan KakYoga. 3 Rekan rekan-satu indekost yaitu, Annisa Ghina, Ambar Susan, serta warga
Pondok Nuansa Sakinah.
4 Teman satu perjuangan fast-track IPB yaitu, Gita Adhani, Anisaul Muawwanah, dan teman-teman fast-track angkatan 46.
5 Rekan-rekan Forum Komunikasi Alumni Muslim SMANSA (Forkom Alims). 6 Rekan-rekan Magister Komputer IPB 2012, yaitu Kak Dhieka, Kak Yessi,
Kak Ina, Kak Nia, dan lain-lain.
7 Rekan-rekan Magister Komputer IPB 2013. Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN viii
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 3
Ruang Lingkup Penelitian 3
2 TINJAUAN PUSTAKA 3
Sistem Rekomendasi 3
Location Based Social Network (LBSN) 4
Aspek Sosial Pada Sistem Rekomendasi Berbasis Jejaring sosial 5
Ekstraksi Teks Pada Jejaring Sosial 6
Hidden Markov Model 6
3 METODE 8
Rekomendasi Berbasis LBSN 8
Analisis 8
Perancangan 8
Implementasi 10
Evaluasi Model 10
Rekomendasi Berbasis Ekstraksi Teks 11
Ekstraksi Penciri ObjekWisata 12
User Profiling 14
Vector Space Model – Advice Seeking 14
4 HASIL DAN PEMBAHASAN 15
Rekomendasi Berbasis LBSN 15
Analisis 15
Perancangan 16
Implementasi 20
Hasil Eksperimen 20
Evaluasi Model 22
Rekomendasi Berbasis Ekstraksi Teks 22
Pengumpulan Data 22
Ekstraksi Penciri Objek Wisata 23
User Profiling 25
Vector Space Model – Advice Seeking 25
DAFTAR ISI (lanjutan)
Simpulan 26
Saran 27
DAFTAR PUSTAKA 27
DAFTAR ISTILAH 45
DAFTAR TABEL
1 Confusion matrix untuk penilaian relevansi dokumen (Manning et al.
2008) 10
2 Hasil analisis untuk pemilihan LBSN 16
3 Kelompok kategori waktu 17
4 Kelompok kategori venue 17
5 Daftar venue terdekat berdasarkan hasil retrieve dari Foursquare 21
6 Proses perankingan venue 21
7 Daftar sumber data untuk ekstraksi objek wisata 23
8 Frekuensi term pada setiap objek wisata 24
9 Proses agregasi dari hasil cosine similarity dengan nilai λ=0.3 26
DAFTAR GAMBAR
1 Struktur location based social network yang memiliki 3 layer
(Symeonidis et al. 2014). 4
2 Ilustrasi proses pada Hidden Markov Model 7
3 Ilustrasi proses perubahan state pada data histori lokasi 9 4 Ilustrasi model rekomendasi dengan menggabungkan antara advice
seekingdan ekstraksi ciri dari data jejaring sosial 11 5 Tahapan proses text mining pada kumpulan data sosial media untuk
menghasilkan penciri dari objek 13
6 Ilustrasi dari proses pencarian kedekatan antara objek wisata dan
pengguna dalam vector space model 15
7 Struktur location-based social network (Bao et al. 2012) 16 8 Proses generate rekomendasi dan proses perankingan model
rekomendasi berbasis LBSN 19
9 (a) Contoh hasil pengambilan data awal, (b) Hasil praproses data 21 10 Hasil perhitungan HMM berdasarkan input dari Gambar 9 21 11 Representasi wordcloud dari hasil ekstraksi pada objek wisata
Kebun Raya Bogor 24
12 Hasil ekstrasksi term pada posting jejarung sosial pengguna, (a) merupakan wordcloud keseluruhan term dan (b) merupakan hasil term yang matching dengan korpus wisata 25
DAFTAR LAMPIRAN
1 Entity relationship diagram pada database lokal aplikasi 29 2 Diagram BPMN seluruh aktivitas sistem pada pemodelan
rekomendasi berbasis LBSN 30
3 Antarmuka dari sistem rekomendasi dengan pemodelan berdasarkan
LBSN 31
4 Fungsi pada R untuk proses pembacaan data dan proses normalisasi
5 Fungsi pada R untuk proses pembacaan data dan proses normalisasi
sumber data dari Twitter 35
6 Fungsi pada R untuk proses pembacaan data dan proses normalisasi
sumber data dari Facebook 36
7 Fungsi pada R untuk proses stemming bahasa Indonesia dengan menggunakan Algoritma Nazief dan Adriani (Adriani et al. 2007) 37 8 Fungsi pada R untuk proses pembacaan data dan proses normalisasi
sumber data dari Facebook 41
9 Fungsi pada R untuk normalisasi kata singkatan 42 10 Fungsi pada R untuk menormalkan karakter berulang pada data
jejaring sosial 43
1
PENDAHULUAN
Latar Belakang
Salah satu fungsi dari sistem rekomendasi (Recommender Systems-RSs) ialah untuk mempermudah proses pengambilan keputusan. Sistem rekomendasi bekerja berdasarkan data historis preferensi pengguna yang tercatat di dalam sistem. Tiga jenis data yang menjadi dasar pemberian rekomendasi, yaitu users, items, dan transactions (Ricci et al. 2011). Items merupakan sekumpulan objek yang akan direkomendasikan. Users merupakan data profil dari pengguna. Transactions merupakan data hubungan antara users dan items. Salah satu contoh dari data transaksi adalah rating. Data rating menunjukkan penilaian user terhadap item yang juga sering diasumsikan sebagai representasi dari preferensi pengguna.
Sistem rekomendasi di bidang pariwisata dapat mempermudah penentuan tujuan wisata yang sesuai dengan preferensi pengguna. Pemilihan tujuan wisata ditentukan oleh beberapa faktor pertimbangan yang bersifat individulistis contohnya biaya dan jarak. Rosmawarni et al. (2013) mengembangkan sistem rekomendasi ekowisata (mobile ecotourism). Sistem ini memberikan rekomendasi tempat ekowisata berdasarkan hobi, jarak terhadap current location, dan frekuensi kunjungan.
Terdapat beberapa kekurangan pada aplikasi mobile ecotourism di antaranya (1) aspek spasial dalam rekomendasi hanya berdasarkan jarak current location pengguna dengan posisi objek wisata, dan (2) pemodelan rekomendasi berdasarkan pemetaan antara hobi dengan lokasi yang bersifat statis. Rekomendasi yang diberikan oleh sistem cenderung tidak bervariasi karena data pemetaan hobi-lokasi yang statis. Sistem juga bekerja berdasarkan data histori pengguna, sehingga untuk didapatkan model yang baik pengguna dituntut untuk sering menggunakan aplikasi. Hal ini merupakan kekurangan yang sering muncul pada sistem rekomendasi tradisional yang bekerja berdasarkan data rating.
Jejaring sosial merupakan salah satu sosial media yang memiliki fitur media sharing dan komunikasi online. Hasil survei oleh APJII (2012) menunjukkan situs jejaring sosial menempati urutan pertama situs yang sering dikunjungi saat pengguna mengakses internet. Data pada jejaring sosial tumbuh secara alami dan signifikan. Hal ini juga didukung oleh kemudahan akses jejaring sosial melalui smartphone. Jejaring sosial menyimpan beberapa informasi pengguna seperti data demografi, interest, dan posting dari pengguna. Data tersebut menggembarkan karakteristik dari penggunanya. Penggunaan media sosial yang intens akan mempertajam karakteristik tersebut.
Data jejaring sosial berpotensi menjadi input untuk pemodelan objek pada sistem rekomendasi. He (2010) mengembangkan pemodelan sistem rekomendasi dengan berfokus pada pemodelan user dari data jejaring sosial dan terbukti mampu meningkatkan akurasi hasil rekomendasi. Akan tetapi terdapat beberapa tantangan yang muncul untuk menghasilkan model yang baik dari data media sosial yatu data yang tidak terstruktur.
2
pertama yaitu analisis spasial berdasarkan user mobility behavior untuk memperbaiki pemberian rekomendasi berdasarkan jarak. Model kedua yaitu pendekatan text mining pada kumpulan sosial media untuk memperbaiki pemetaan data statis antara hobi dengan lokasi wisata.
Aspek spasial merupakan salah satu aspek yang berpengaruh pada pemilihan tempat wisata. Perbaikan yang diusulkan pada penelitian ini yaitu membangun model rekomendasi berdasarkan analisis pergerakan pengguna. Jejaring sosial yang didukung dengan location based service (location based social network-LBSN) memudahkan proses analisis terhadap lokasi-lokasi yang pernah dikunjungi oleh pengguna dengan menggunakan data check-in history. Analisis dilakukan berdasarkan user mobility behavior dengan Hidden Markov Model (HMM). Dua aspek dalam proses HMM untuk menganalisis pergerakan pengguna adalah tipe lokasi dan waktu kunjungan.
Data teks merupakan data utama yang terdapat pada sosial media. Oleh karena itu, untuk memperbaiki masalah kedua pada mobile ecotourism digunakan ekstraksi data teks dari kumpulan jejaring sosial. Rekomendasi dimodelkan berdasarkan kedekatan antara objek wisata dan pengguna dalam ruang vektor (vector space model). Pemodelan ini juga menggunakan teknik rekomendasi advice seeking yang merupakan salah satu keunggulan penggunaan data pada jejaring sosial.
Perumusan Masalah
Sistem rekomendasi wisata dapat mempercepat proses pengambilan keputusan dalam pemilihan tempat wisata yang sesuai dengan preferensi pengguna. Rosmawarni et al. (2013) mengembangkan sistem rekomendasi ekowisata untuk wilayah bogor, namun terdapat beberapa kekurangan yang dapat mempengaruhi performa dari sistem. Dua masalah utama dari sistem adalah (1) aspek spasial dalam rekomendasi hanya berdasarkan jarak current location pengguna dengan posisi objek wisata, dan (2) pemodelan rekomendasi berdasarkan pemetaan antara hobi dengan lokasi yang bersifat statis.
Penelitian ini mengajukan solusi untuk memperbaiki dua permasalahan tersebut. Untuk memperbaiki masalah pertama, penelitian ini mengajukan model rekomendasi berdasarkan analisis spasial dari data LBSN dengan memperhatikan perilaku mobilitas dari pengguna. Untuk masalah kedua, penelitian ini mengajukan model rekomendasi dengan melakukan ekstraksi ciri pada kumpulan sosial media objek wisata dan pengguna sehingga didapatkan pemetaan yang dinamis. Pertumbuhan data pada sosial media bersifat cepat dan alami sehingga performa sistem tidak akan bergantung lagi pada data rating di dalam sistem.
Tujuan Penelitian
3 1. Membangun model rekomendasi wisata dengan analisis spasial berdasarkan
data pada jejaring sosial berbasis LBSN.
2. Membangun model rekomendasi wisata dengan ekstraksi teks pada kumpulan jejaring sosial.
Manfaat Penelitian
Manfaat dari dilaksanakannya penelitian ini ialah didapatkannya sistem rekomendasi yang dinamis karena tidak tergantung pada data rating yang dapat menurunkan performa dari sistem. Hal tersebut didukung oleh pertumbuhan data jejaring sosial yang cepat dan dinamis.
Ruang Lingkup Penelitian
Beberapa batasan yang ditetapkan pada penelitian ini, di antaranya: 1. Data jejaring sosial yang digunakan berbasis teks dan lokasi.
2. Pada pemodelan rekomendasi spasial dibangun berdasarkan analisis user mobility behavior dengan HMM.
2
TINJAUAN PUSTAKA
Sistem Rekomendasi
Sistem rekomendasi (Recommender Systems- RSs) merupakan sistem yang dapat memberikan alternatif items yang akan digunakan oleh pengguna. Sistem rekomendasi biasanya diberikan kepada individu-individu yang memiliki kesulitan dalam membuat keputusan karena tidak memiliki cukup pengetahuan/pengalaman (Ricci et al. 2011). Sistem rekomendasi memberikan sejumlah items yang diprediksi sesuai dengan preferensi dari pengguna berdasarkan profile dari pengguna ataupun data-data historis preferensi yang tercatat dalam sistem.
4
Sistem rekomendasi tradisional sangat tergantung pada data rating. Beberapa keterbatasan pada sistem rekomendasi tradisional yaitu sparsity, cold-start dan scalability (Symeonidis et al. 2014). Sparsity merupakan masalah yang timbul akibat kejarangan dari data rating, sehingga sistem tidak mampu menginferensi preferensi pengguna secara optimal. Cold-start merupakan masalah yang timbul pada items atau users baru dan belum memiliki data rating pada matriks transaksi. Scalability merupakan masalah yang timbul akibat data transaksi yang cukup besar pada sistem. Pada penelitian ini, model rekomendasi yang dikembangkan berbasis data media sosial sehingga dapat menutupi kekurangan dari sistem rekomendasi tradisional terutama pada masalah sparsity dan cold-start.
Penelitian ini membangun dua model rekomendasi dengan teknik hybrid. Pada pemodelan rekomendasi berbasis analisis spasial, analisis user mobility behavior mencakup teknik knowledge based dan content based. Sebagai penunjuk arah next location, nilai probability HMM digunakan sebagai pengetahuan yang memandu proses generate rekomendasi. Pembangunan knowledge based juga melibatkan content yang menjadi penciri dari lokasi tersebut. Pada pemodelan rekomendasi berbasis teks mencakup kombinasi antara knowledge based dan comunity based. Proses ekstraksi teks merupakan langkah untuk membangun pengetahuan dalam sistem dan proses advice seeking merupakan proses dari comunity based berdasarkan pertemanan dalam jejaring sosial.
Location Based Social Network (LBSN)
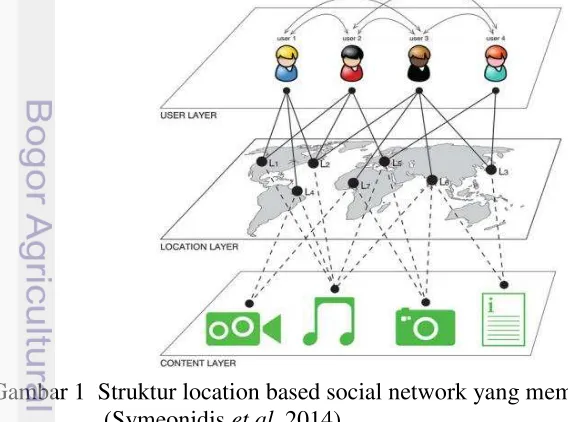
Location based social network (LBSN) merupakan jejaring sosial yang didukung oleh layanan location based service dan data geo-location. LBSN memiliki struktur yang lebih kompleks daripada jejaring sosial biasa, karena terdapat layer lokasi antara layer pengguna dan layer content (Symeonidis et al. 2014) yang dipresentasikan pada Gambar 1. Salah satu keunggulan dari LBSN adalah dapat mendeteksi current location dari pengguna, sehingga pengguna
5 dapat mengekspresikan pengalamannya dan sharing keberadaannya disuatu lokasi. Hal tersebut dikenal dengan istilah check-in. LBSN mencatat daftar lokasi dari check-in history pengguna. Context lokasi yang dapat merepresentasikan preferensi dari pengguna ialah current location dan previous location (Kelm et al. 2013), dua hal tersebut didukung oleh fungsi di dalam LBSN.
Dalam konteks wisata, LBSN dapat membantu pengguna untuk mencari lokasi yang sesuai dengan preferensi pengguna. Fitur yang tersedia pada LBSN juga lebih komplit dan atraktif dalam menunjang pengambilan keputusan. Pada sistem rekomendasi berbasis spasial check-in history dari pengguna dapat diasumsikan sebagai lokasi-lokasi yang sesuai dengan preferensi pengguna. Setiap pengguna memiliki check-in history masing-masing yang mampu mendeskripsikan karakteristik dari pengguna.
Menurut Symeonidis et al. (2014) terdapat 3 jenis layanan rekomendasi yang dapat dibangun dari LBSN yaitu :
1 Generic Recommendation, merupakan pemberian rekomendasi dengan cara sederhana, yaitu dengan menghitung kemunculan lokasi pada daftar check-in dan di rangking berdasarkan kemunculan terbesar.
2 Personalized Recommendation, merupakan pemberian rekomendasi dengan mencari pengguna lain yang memiliki kemiripan histori lokasi. Hal ini memiliki kekurangan pada kompleksitas perhitungan user similarity.
3 Mobility Behaviour Modelling, merupakan pemberian rekomedasi dengan menganalisis pergerakan pengguna berdasarkan perpindahan dari satu lokasi ke lokasi lain.
Penelitian ini berfokus pada mobility behaviour modelling berdasarkan data check-in history. Tujuan dari pendekatan ini adalah memodelkan arah next location yang sesuai dengan pergerakan pengguna dalam ruang spasial. Rekomendasi yang dihasilkan diharapkan sesuai dengan perilaku (kebiasaan) pengguna. Sebagai contoh berdasarkan kebiasaan pengguna, ketika pengguna berada di bandara lokasi selanjutnya yang sering dikunjungi pengguna ialah hotel. Berdasarkan kebiasaan tersebut, ketika bandara terdeteksi sebagai current location dari pengguna, maka hotel akan menjadi lokasi utama yang direkomendasikan dibandingkan tempat lain.
Aspek Sosial Pada Sistem Rekomendasi Berbasis Jejaring sosial
Teknik inferensi pada sistem rekomendasi tradisional tidak mempedulikan hubungan antar pengguna, padahal dalam dunia nyata seseorang akan lebih mempercayai hasil inferensi dari orang yang ia kenal. Bonhard dan sasse (2006) mengkaji aspek sosial pada sistem rekomendasi. Menurutnya aspek tersebut merupakan aspek yang sangat sesuai dengan dunia nyata dan belum tersentuh pada sistem rekomendasi tradisional. Pada penelitian tersebut mengenalkan istilah social recommender dan advice-seeking recommendation yang melibatkan aspek sosial pada pemberian rekomendasi.
6
ini dapat menutupi aspek sosial yang tidak terdapat pada teknik rekomendasi tradisional.
Penelitian ini menerapkan teknik advice seeking recommendation dengan asumsi bahwa pada proses rekomendasi teman dari pengguna memiliki pengaruh pada proses pengambilan keputusan pengguna. Teman dari pengguna dapat dideteksi dari akun media sosial dari pengguna. Bobot rekomendasi didapatkan dengan mengagregasi perhitungan nilai rekomendasi yang didapatkan dari profil pengguna dan profil teman pengguna. Fungsi agregasi yang digunakan ialah weighted-mean aggregation. Dalam formulasi fungsi tersebut terdapat bobot yang merepresentasikan seberapa besar pengguna ingin mendapatkan pengaruh rekomendasi dari teman-temannya. Teknik advice seeking ini dikombinasikan pada pemodelan rekomendasi dengan pendekatan ekstraksi teks pada kumpulan media sosial.
Ekstraksi Teks Pada Jejaring Sosial
Data teks merupakan data utama yang terdapat di jejaring sosial. Sebagian besar data teks disumbang dari data posting oleh pengguna. Kemunculan kata pada posting pengguna dapat menjadi suatu penciri bagi masing-masing pengguna. Pengguna yang menyukai politik akan lebih banyak memiliki posting berkaitan dengan berita politik. Dalam prakteknya seseorang mungkin memiliki lebih dari 1 jejaring sosial. Kumpulan posting pengguna dari berbagai jejaring sosial akan lebih mempertajam penciri dari masing-masing pengguna.
Kebutuhan informasi online pada bidang pariwisata, memberikan peluang bagi organisasi penyelenggara wisata untuk memperluas wilayah promosinya melalui jejaring sosial (Xiang dan Gretzel 2010). Pada penelitian ini juga mengasumsikan kemunculan kata pada konten yang menceritakan objek wisata dapat dijadikan penciri bagi objek wisata tersebut. Proses pencarian ciri bagi suatu objek dari data teks melalui proses ekstraksi dilakukan dengan teknik text mining. Data jejaring sosial yang terus bertambah dapat menjadi solusi bagi data statis sehingga nilai dari atribut pada sistem rekomendasi wisata lebih dinamis.
Zhang et al. (2013) menggabungkan beberapa social media ke dalam satu sistem untuk mengelompokkan teman dan memberikan rekomendasi yang terpersonalisasi berdasarkan penciri suatu teman. Kekurangan dari penelitian ini adalah proses tag ciri pada teman di jejaring sosial masih manual oleh pengguna. Penelitian yang berfokus pada ekstraksi penciri suatu objek melalui data teks dari jejaring sosial ialah analisis sentimen dan opinion mining (Akaichi et al. 2013; Aziz 2013; Martínez-Cámara et al. 2014).
Hidden Markov Model
ke-7 (t+1) dipengaruhi oleh distribusi peluang dari kemunculan hidden state sebelumnya. HMM terdiri atas beberapa elemen di antaranya:
T = panjang dari baris observasi
N = banyaknya hidden state di dalam model M = banyaknya simbol observasi
U = barisan unobservable state O = barisan observable state
Q =
q q1, , ..., 2 qN
, himpunan unobservable state V =
v v1, , ..., 2 vM
, himpunan state observasiA =
aij , aij Pr
qj pada t1 pada qi t
, distribusi peluang dari statetransisi, dengan
1
,
Pr j pada 1 pada i t i t j
t i
count U q U q
q t q t
count U q
B =
b kj
, ( ) = Pr b kj
vk pada t qj pada t
, distribusi peluang dari observable state dengan simbol observasi j yang dipengaruhi oleh kemunculan dari unobservable state dengan simbol k pada waktu ke-t,dengan
,
Pr k pada j pada t j t k
t j
count U q O v
v t q t
count U q
=
j , j Pr
qj pada t1
, distribusi state awal.Dengan menggunakan HMM, baris observasi O1, O2, ..., OT dihasilkan
berdasarkan:
1 Memilih state awal, i1 berdasarkan pada distribusi peluang state awal, ;
2 Tetapkan t =1;
3 Pilih Ot berdasarkan pada b kit
, simbol distribusi peluang pada state it;4 Pilih it+1berdasarkan pada
a ait it1 , it+1 = 1, 2, ..., N, transisi state distribusipeluang untuk state it;
5 Tetapkan t = t+1; kembali pada langkah 3 jika t < T; selainnya hentikan proses. Penelitian ini menggunakan HMM untuk memodelkan user mobility behavior dengan kasus pergerakan pengguna dalam ruang spasial. Terdapat beberapa asumsi yang kemudian dijadikan panduan dalam memodifikasi metode HMM.
8
3
METODE
Penelitian ini mengajukan solusi bagi dua permasalahan yang terdapat pada aplikasi mobile ecotourisme (Rosmawarni et al. 2013). Pendekatan yang digunakan ialah dengan menggunakan data media sosial untuk mengatasi permasalahan yang umumnya terdapat pada sistem rekomendasi tradisional. Model rekomendasi pertama yang dibangun berbasiskan data LBSN dengan mengombinasikan aspek spasial dengan analisis user mobility behavior. User mobility behavior merupakan salah satu layanan rekomendasi dengan melihat pergerakan pengguna dari satu lokasi ke lokasi lain. Model rekomendasi kedua yang dibangun berbasiskan ekstraksi teks yang dikombinasikan dengan teknik rekomendasi advice seeking untuk mencari kedekatan antara pengguna dan objek wisata sehingga proses rekomendasi tidak tergantung pada pemetaan data statis antara hobi dan lokasi wisata.
Rekomendasi Berbasis LBSN
Pemodelan rekomendasi berbasiskan data LBSN berfokus pada mobility behavior modelling berdasarkan daftar lokasi yang pernah disinggahi oleh pengguna (check-in history). User mobility behavior yang dimodelkan dengan HMM berdasarkan urutan kategori lokasi yang dikunjungi dan waktu kunjungan. Output dari model ini digunakan untuk menghitung peluang arah lokasi dari daftar rekomendasi. Peluang tersebut akan menjadi pembobot bagi lokasi terdekat dari current-location pengguna. Pemodelan ini terdiri atas beberapa tahap di antaranya analisis, perancangan, implementasi dan evaluasi model.
Analisis
Tahap pertama ialah melakukan analisis pada jejaring sosial yang termasuk ke dalam kategori LBSN. Analisis bertujuan melihat LBSN yang sesuai untuk mengkonstuksi user mobility behavior dan memiliki atribut yang lebih lengkap. Analisis dilakukan melalui halaman Application Programming Interface (API) explorer yang tersedia di masing-masing jejaring sosial. Hasil analisis akan menjadi dasar pemilihan LBSN yang akan digunakan untuk membangun model rekomendasi.
Perancangan Akuisisi Data
9 Tahap selanjutnya ialah merancang proses akuisi data dan penyimpanan ke dalam database lokal. Jejaring sosial membatasi data dan fungsi yang dapat dijalakan oleh aplikasi. Data yang tersimpan pada jejaring sosial terdiri dari data yang bersifat public dan private. Akses data dibedakan untuk menjaga privasi pengguna. Untuk mendapatkan data ataupun menjalankan fungsi yang bersifat private diperlukan otentifikasi dari pemilik akun. Otentifikasi memiliki makna bahwa pemilik akun telah mengizinkan jejaring sosial untuk melakukan sharing data dengan aplikasi yang dibangun.
Praproses Data
Tahapan ini dimulai dengan mentransformasi data mentah yang terdapat pada database lokal aplikasi. Transformasi data berfungsi untuk menyesuaikan tipe data dari atribut yang akan menjadi input bagi pemodelan rekomendasi dengan HMM. Input data yang digunakan pada pemodelan dengan HMM ialah rangkaian terurut dari data histori check-in pengguna yang terdiri dari kategori lokasi dan kategori waktu saat melakukan kunjungan di suatu lokasi (check-in data). Transformasi dilakukan pada atribut kategori lokasi dan waktu kunjungan. Jika kita melihat titik-titik lokasi (atribut lattitude dan longitude) histori kunjungan pengguna, kemungkinan untuk menemukan pola yang dapat merepresentasikan user mobility behavior akan semakin sulit. Untuk itu, pada penelitian ini, dikategorikan lokasi berdasarkan aktivitas yang dapat merepresentasikan lokasi tersebut.
Perancangan HMM
Tahap ini merancang HMM yang sesuai dengan asumsi yang digunakan. Asumsi yang digunakan pada penelitian ini ialah kunjungan ke suatu lokasi pada waktu ke-t dipengaruhi oleh kunjungan ke lokasi pada waktu sebelumnya (waktu ke t-1) yang juga dipengaruhi oleh pukul berapa dia melakukan kunjungan tersebut. Lokasi yang dikunjungi oleh pengguna berperan sebagai state observasi dan waktu kunjungan sebagai hidden state. Ilustrasi dari asumsi ini dapat dilihat pada Gambar 3.Perancangan melibatkan proses modifikasi dari HMM baku yang diperkenalkan oleh Rabiner dan Juang (1986). Proses modifikasi menukar antara
10
sifat dari hidden state dan state observasi. Pada state observasi terdapat transisi state yang mempengaruhi kemunculan state selanjutnya, namun kemunculan dari state observasi tetap dipengaruhi oleh hidden state. Penelitian ini tidak menggunakan distribusi kemunculan state awal.
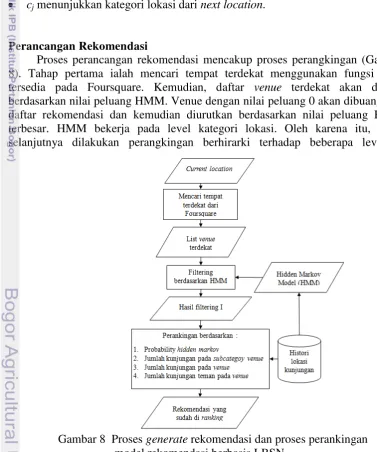
Perancangan Rekomendasi
Proses pemberian rekomendasi terdiri dari beberapa tahap, yaitu pencarian tempat terdekat bedasarkan current location, kemudian di filter berdasarkan nilai dari HMM yaitu venue yang memiliki nilai probability 0 maka akan di hapus. Model HMM bekerja pada level category sehingga granularity titik-titik rekomendasi terlalu umum. Oleh karena itu dilakukan perangkingan rekomendasi berdasarkan data yang terdapat LBSN yang terpilih. sehingga dilakukan juga perankingan berdasarkan level yang lebih rendah dari category yaitu pada level subcategoy dan level venue. Perankingan dibuat berhirarki seperti pada Gambar 8.
Implementasi
Prototipe dibangun dalam sebuah sistem berbasis Web. Bahasa pemrograman yang digunakan adalah PHP dengan lingkungan pengembangan perangkat lunak, yaitu Microsoft Windows 7 Ultimate 32 bit (Microsoft 2009), XAMPP 1.7.3 (Apache 2009) dan database MySQL 5.5 (Oracle 2010).
Evaluasi Model
Proses evaluasi dilakukan dengan menentukan relevansi terhadap 10 rekomendasi teratas yang diberikan oleh sistem. Current location dianggap sebagai query sehingga menghasilkan rekomendasi. Evaluasi model dicobakan dengan posisi current location di 10 kategori lokasi. Dari hasil relevansi tersebut dihitung precision (persamaan 1) dan recall (persamaan 2). Setelah itu dihitung mean average precision (MAP) terhadap 11 titik recall.
Pr ecision :P tp tp fp
(1)
Recall : R tp tp fn
(2)
1 1
1 Q 1 mj
jk
j j k
MAP Q P R
Q m
(3)Tabel 1 Confusion matrix untuk penilaian relevansi dokumen (Manning et al. 2008)
Relevant Non Relevant
Retrieved True Positives (TP) False Positives (FP)
11 Rekomendasi Berbasis Ekstraksi Teks
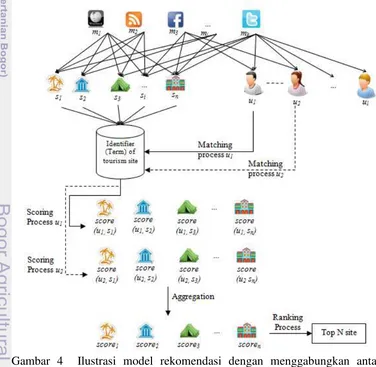
Pemodelan rekomendasi berbasis ekstraksi ciri menggunakan kumpulan data dari berbagai jejaring sosial sebagai input. Proses ekstraksi ciri ini dilakukan dengan pendekatan text mining. Ilustrasi dari metode untuk pemodelan berbasis teks dapat dilihat pada Gambar 4. Beberapa ukuran vektor yang digunakan pada pemodelan ini di antaranya:
Vektor objek wisata: S s s1, ,...,2 sn merupakan vektor yang berisikan
kumpulan objek wisata berukuran n, nilai dari setiap elemen dari vektor ialah nama objek wisata.
Vektor sosial media: M m m1, 2,...,mk merupakan vektor yang berisikan
kumpulan sosial media berukuran k, nilai dari elemen ini ialah nama dari sosial media. Elemen dari vektor tersebut juga merupakan vektor yang berisi fitur dari sosial media yang akan dijadikan input bagi proses ekstraksi ciri. Ukuran setiap vektor mi berbeda-beda tergantung fitur yang terdapat pada sosial media tersebut, sebagai contoh pada sosial media Twitter memiliki fitur 2 fitur yaitu pencarian dengan kata kunci dan posting pengguna sehingga akan memiliki vektor sebagai berikut : mTwitter user s posting search' , .
12
Vektor dokumen objek wisata: D d11,d12,...,d1k,...,dij,...,dn1,dn2,...,dnk merupakan vektor dokumen yang berisikan pemetaan antara setiap elemen dari S terhadap elemen pada M , berukuran nxk. Setiap elemen dari vektor ini berisi dokumen yang menceritakan objek wisata i dari sosial media j. Vektor ini akan menjadi input bagi proses ektraksi ciri objek wisata.
Vektor pengguna: U u u1, ,...,2 ul merupakan vektor yang berisikan kumpulan pengguna pada sistem rekomendasi dan berukuran l. Nilai dari elemen ini ialah nama pengguna.
Vektor dokumen pengguna: P p11,p12,...,p1k,...,pyj,...,pl1,pl2,...,llk merupakan pemetaan antara elemen M dan elemen dari U berukuran lxk. Elemen dari vektor ini didefinisikan sebagai posting dari pengguna y pada sosial media j. Vektor ini akan menjadi input bagi proses user profiling.
User profiling terdiri atas proses ekstraksi ciri dengan metode teks mining dan proses matching antara penciri wisata dan penciri dari konten media sosial pengguna. Proses matching dilakukan melalui vector space model untuk memudahkan proses scoring. Proses scoring merupakan proses perhitungan nilai similarity antara pengguna dan objek wisata.
Penelitian ini berasumsi bahwa konten post media sosial pengguna menunjukkan preferensi dari pengguna tersebut. Hal ini akan berpotensi menimbulkan masalah sparsity, yaitu masalah kejarangan data mapping antara penciri wisata dan penciri dari pengguna. Oleh karena itu, penelitian ini menggabungkan metode advice-seeking pada proses scoring untuk menghindari masalah sparsity yang sering terjadi pada sistem rekomendasi tradisional. Asumsi advice-seeking pada penelitian ini merepresentasi rekomendasi di dunia nyata, yaitu orang yang kita kenal (teman) dapat berkontribusi terhadap pengambilan keputusan seseorang.
Score akhir dari setiap objek wisata merupakan agregasi antara score dari pengguna utama yang akan diberikan rekomendasi dan pengguna yang terdeteksi sebagai teman dari pengguna utama. Hasil agregasi ini kemudian di urutkan berdasarkan nilai terbesar. Pada Gambar 4 pengguna utama yang akan diberikan rekomendasi adalah user1 (u1) dan pengguna di dalam sistem yang juga menjadi
teman pengguna di dalam jejaring sosial ditandai gengan garis putus-putus (- - -) yaitu user2 (u1). Oleh karena itu pada user2 juga dilakukan proses matching &
scoring terhadap setiap objek wisata sebagai bentuk proses advice seeking.
Ekstraksi Penciri ObjekWisata
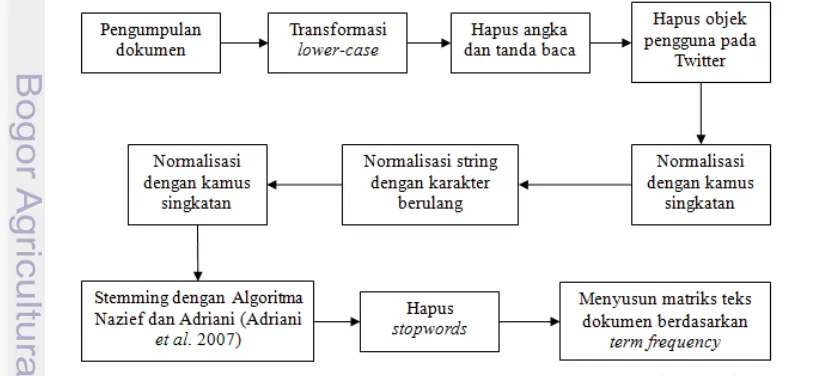
Tahap awal dari proses ini ialah menentukan objek wisata yang akan menjadi obje rekomendasi. Tahap selanjutnya ialah mengumpulkan konten dari objek wisata yang bersumber dari berbagai jejaring sosial seperti akun Twitter dan alamat Facebook dari objek wisata tersebut. Tahap inti dari proses ini ialah mengekstraksi penciri dari objek wisata merupakan term yang terdiri dari satu kata dengan metode text mining.
13 media sosial ialah (1) penggunaan singkatan seperti „spd‟ yang berarti sepeda, (2) penggunaan hashtag yang menekankan poin penting dari posting oleh pengguna seperti #hujan, (3) adanya karakter berulang seperti „bogoooooorrr‟ yang meunjukkan kata „bogor‟. Untuk menanggulangi hal tersebut, penelitian ini menambahkan beberapa proses normalisasi dan transformasi disamping menggunakan proses text mining umum (penghapusan stopwords, penghapusan tanda baca dan angka). Proses ekstraksi ciri pada penelitian ini digambarkan pada Gambar 5. Secara keseluruhan proses normalisasi dan transformasi pada penelitian ini di antaranya :
1) mentransformasi seluruh string ke dalam bentuk lowercase, 2) menghapus tanda baca dan angka,
3) menghapus link, dan objek pengguna dari data Twitter yang dapat terdeteksi dengan ekspresi reguler ((@)[[:graph:]]+) yang memiliki arti kata yang diawali dengan tanda „@‟ dan diikuti oleh graphical characters sebanyak satu atau lebih,
4) menormalisasi kata dengan menggunakan kamus singkatan (Aziz 2013). 5) mentransformasi kata yang tidak terstruktur berdasarkan pengulangan
karakter ke dalam karakter tunggal dengan formulasi transformasi ekspresi reguler:
[a]+ [a] [b]+ [b]
:
[z]+ [z]
[a]+berarti string yang mengantung karakter „a‟ berulang (lebih dari satu karakter) akan ditransformasikan ke dalam karakter „a‟ yang tunggal. 6) menormalisasi kembali kata dengan kamus singkatan untuk mengatasi kata
yang terganti akibat normalisasi pada tahap 5 seperti kata „tinggal‟ yang pada tahap 5 berubah menjadi kata „tingal‟,
7) menormalisasi kata ke dalam kata dasar (stemming) dengan Algoritma Nazief dan Adriani (Adriani et al. 2007),
8) menghapus stopwords yang terdiri dari 126 kata hubung dalam bahasa Indonesia ().
14
Setelah dilakukan normalisasi, kemudian dibangun matriks teks dokumen berdasarkan bobot term frequency (tf). Tahap selanjutnya ialah melakukan term compression untuk menghilangkan term yang kemunculannya jarang. Hal in dilakukan untuk mengantisipasi term yang dihasilkan terlalu besar. Kemudian tahapan selanjutnya ialah proses normalisasi nilai tf dengan normalized sublinear tf scaling (Manning et al. 2008). Nilai tft,s merupakan term frequency dari term t
pada objek wisata s. Transformasi nilai tf ke dalam normalized normalized sublinear tf scaling (wtft,s) dengan persamaan berikut:
,s ,s
,
1 log jika 0 0 selainnya
t t
t s
tf tf
wf
(4)
User Profiling
Tahap awal pada proses ini memiliki proses yang sama seperti proses ekstraksi ciri objek wisata dengan ekstraksi penciri objek wisata. Setelah didapatkan kumpulan term hasil proses ekstraksi dari konten media sosial pengguna, kemudian term tersebut di filter berdasarkan korpus wisata. Proses user profiling bertujuan untuk melihat kemunculan kumpulan term wisata yang terdapat pada kumpulan posting jejaring sosial pengguna.
Vector Space Model–Advice Seeking
Tahap ini merupakan tahap terakhir dari proses rekomendasi. Proses ini berfungsi untuk menghitung nilai kemiripan antara konten media sosial objek wisata dan media sosial dari pengguna. Nilai kemiripan didapatkan dari vector space model dengan konsep cosine similarity pada persamaan 8 (Manning et al. 2008). Skor akhir rekomendasi didapatkan melalui persamaan 9 yang diturunkan dari teknik advice seeking. Persamaan tersebut diturunkan dari persamaan rataan terboboti dengan nilai 0 ≤ λ ≤ 1 yang menunjukkan level kepercayaan dari pengguna terhadap rekomendasi dari temannya. Kemudian hasil rekomendasi diurutkan berdaskan skor yang didapatkan dari persamaan 6.
Pemodelan ini mengombinasikan teknik advice-seeking merupakan salah satu representasi dari kasus rekomendasi di dunia nyata yang dapat mengatasi masalah sparsity. Untuk itu pada pendekatan ini dimodelkan 2 rekomendasi yaitu rekomendasi langsung dan rekomendasi tidak langsung. Rekomendasi langsung dihasilkan dari hasil kalkulasi dari kedekatan antara objek wisata dan pengguna utama yang akan diberikan rekomendasi melalui vector space model berdasarkan nilai cosine similarity (persamaan 5). Rekomendasi tidak langsung dihitung berdasarkan cosine similarity antara teman dari pengguna dan setiap objek wisata yang merupakan implementasi dari proses advice seeking. Nilai cosine similarity terdapat pada rentang [0,1] yang merupakan nilai kemiripan antar dua objek yang diproyeksikan ke dalam ruang vektor (Gambar 6) similarity (s1,u1) = cos θ.
15
, , 1 2 2 , , 1 1 ( ) ( ) ( , ) ( , ) ( ) ( )k i k j
k i k j
n
t u t s
i j k
i j i j n n
i j
t u t s
k k
wf wf
v u v s
score u s sim u s
v u v s
wf wf
(5)
1
, 1 , z i j i j j
score f s finalScore score u s
z
(6)Keterangan :
score (ui, sj) = bobot kemiripan antara penggguna i dan objek wisata j
finalScorej = fungsi agregasi bobot rekomendasi pada objek wisata j
score (fi, sj) = bobot kemiripan antara pengguna i (friend i) yang
merupakan teman dari pengguna u dengan objek wisata j λ = bobot kepercayaan terhadap pengguna lain, 0 ≤ λ ≤ 1
z = jumlah teman dari pengguna u
n = jumlah term hasil ekstraksi ciri dari kumpulan objek wisata
4
HASIL DAN PEMBAHASAN
Rekomendasi Berbasis LBSN Analisis
Tahap analisis dilakukan terhadap 2 LBSN yaitu Fousquare dan Facebook. Facebook memiliki kesamaan struktur dengan Twitter, Path, dan Instagram, sehingga dipilih Facebook karena memiliki fitur yang lebih banyak. Tahap ini melihat banyaknya atribut check-in history yang tersedia. Hasil analisis terdapat pada Tabel 2.
Pada Foursquare didapatkan data check-in berupa waktu check-in dalam tipe data epoch dan venue (lokasi) yang dikunjungi pengguna. Pada Foursquare pengguna membuat data check-in ketika mengunjungi suatu lokasi atau ketika bersama teman dari pengguna yang melakukan check-in pada suatu tempat.
Pada Facebook data check-in didapatkan dari node tagged_place. Hasil retrieve dari node ini memiliki beberapa kekurangan salah satunya dari sisi presisi
16
waktu. Misalkan pengguna mendapat tag foto dari temannya dengan disertai lokasi tempat foto tersebut diambil. Data tersebut dapat menjadi penunjuk bahwa pengguna pernah mengunjungi tempat tersebut. Akan tetapi, waktu dari kunjungan tidak selalu menunjukkan waktu pengguna mengunjungi tempat tersebut, karena waktu yang didapatkan adalah waktu post dari foto tersebut.
Foursquare memiliki atribut yang lebih lengkap dibandingkan dengan Facebook. Setiap lokasi (venue) pada Foursquare terdapat nama, latitude, longitude, kategori lokasi, jumlah orang yang pernah mengunjungi tempat tersebut, jumlah orang yang menyukai tempat tersebut, dan lain-lain. Oleh karena itu, pada pemodelan ini memilih Foursquare sebagai LBSN yang menjadi sumber data bagi model.
Perancangan Akuisisi Data
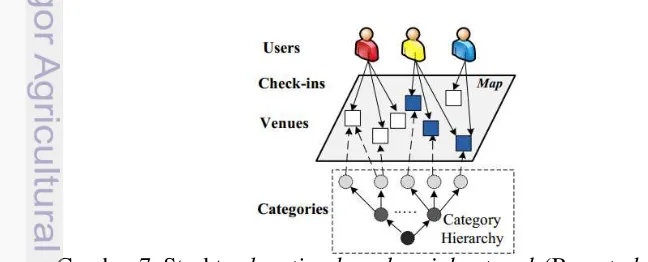
Struktur data dari Foursquare (Gambar 7) terdiri atas 3 kategori yaitu user, venue, dan check-in. Pada data user menggambarkan profil dari pengguna seperti id, first name, last name, gender, hometown location. Data dari check-in berisi histori venue yang dikunjungi pada waktu tertentu. Beberapa atribut dari venue yang digunakan ialah id venue, name venue, subcategory venue, latitude, langitude, city, state, country, total check-in, total users, likes count.
Tabel 2 Hasil analisis untuk pemilihan LBSN
Foursquare Facebook
Alamat API
Explorer
https://developer.foursquare. com/docs/
https://developers.facebook.co m/tools/explorer/
Field padaAPI users/self/checkin tagged_place
Hasil retrieve field
Daftar check-in dari user
yang berisi waktu, posting
(text/gambar), dan venue
Daftar lokasi yang dikunjungi pengguna baik dari post yang di tag oleh orang lain maupun dari post oleh pengguna. Analisis Waktu Memiliki presisi yang lebih
tinggi dari segi waktu.
Tidak selalu menunjukkan waktu pengguna saat mengunjungi lokasi Analisis atribut
lokasi
[image:30.595.93.417.606.737.2]Lengkap Lengkap untuk beberapa lokasi, beberapa lokasi merujuk kepada data Foursquare
17
Penelitian ini melibatkan data check-in history sebagai data input pada proses pemodelan. Data tersebut merupakan data yang bersifat privasi sehingga pengguna akan diminta memasukkan email dan password dari akun Foursquarenya. Kemudian API akan meminta authentification dari pengguna untuk mengizinkan aplikasi mengakses data yang bersifat privasi. Jika pengguna memberikan izin maka API akan memberikan akses token. Akses token berguna untuk mengakses data yang bersifat pribadi. Apabila akses token telah didapat maka aplikasi akan memberikan request data melalui API. Hasil retrieve dri request data akan disimpan ke dalam database lokal dengan struktur entity relationship diagram pada Lampiran 1.
Praproses Data
[image:31.595.203.425.114.194.2]Pemodelan HMM berguna untuk menghitung peluang arah rekomendasi. Pengelompokkan waktu chek-in berdasarkan pada Tabel 3. Foursquare mengelompokkan venue (lokasi) berdasarkan kategori, misalnya untuk perpustakaan akan diberi kategori College & University. Akan tetapi terdapat beberapa lokasi yang tidak memiliki kategori, sehingga pada penelitian ini dirancang kategori baru yaitu „Uncategorized‟. Keseluruhan kategori yang digunakan pada penelitian ini dapat dilihat pada Tabel 4. Asumsi yang digunakan pada penelitian ini kategori dari venue sudah dapat menggambarkan kegiatan yang
Tabel 3 Kelompok kategori waktu
Kategori Waktu Rentang waktu
Pagi 04:00:00 - 09:59:59
Siang 10:00:00 - 14:59:59
Sore 15:00:00 - 19:59:59
Malam 20:00:00 - 23:59:59 Tengah malam 00:00:00 - 03:59:59
Tabel 4 Kelompok kategori venue
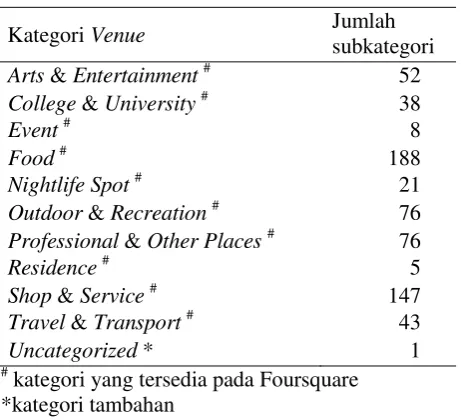
Kategori Venue Jumlah
subkategori
Arts & Entertainment# 52
College & University# 38
Event# 8
Food# 188
Nightlife Spot# 21
Outdoor & Recreation# 76
Professional & Other Places# 76
Residence# 5
Shop & Service# 147
Travel & Transport# 43
Uncategorized * 1
#
[image:31.595.201.432.230.440.2]18
dapat dilakukan di venue tersebut, sehingga tidak diperlukan pengelompokan secara manual. Sebagai contoh tempat dengan kategori Food sangat berelasi dengan aktivitas makan dan beristirahat.
Perancangan HMM
Pemodelan histori lokasi dengan HMM menggunakan 2 jenis data, yaitu kategori lokasi dan waktu check-in. Waktu check-in dibagi menjadi beberapa kelompok waktu. Modifikasi HMM pada penelitian ini terdiri dari 2 matriks yaitu, matriks A dan matriks B. Matriks A merupakan matriks segi berisi peluang transisi kunjungan lokasi berdasarkan kategori, sedangkan matriks B merupakan matriks yang berisi peluang kunjungan ke kategori jika telah diketahui waktu tertentu. Penghilangan matriks (distribusi peluang dari state awal) dengan asumsi bahwa tidak diperhitungkannya peluang awal lokasi yang dikunjungi oleh pengguna. Matriks A berisi nilai aijdengan i,j= merupakan indeks kategori pada lokasi.
Panjangnya baris observasi pada HMM ini terdiri atas 2 lokasi yaitu current location dan next location yang dekat dengan lokasi pengguna. Modifikasi HMM yang dilakukan pada penelitian ini di antaranya:
T = panjang dari baris observasi
N = banyaknya hidden state di dalam model yaitu banyaknya pembagian kategori waktu
M = banyaknya simbol observasi di dalam model yaitu banyaknya kategori lokasi
Q =
d d1, , ..., 2 dN
, himpunan unobservable states, yaitu pembagiankelompok waktu.
V =
c c1, ,..., 2 cM
, himpunan state observasi, yaitu pembagian kategorilokasi
A =
aij , aij Pr
cj pada t1 pada ci t
, distribusi peluang dari state transisi (transisi lokasi)B =
bk
j
, ( ) = Pr b jk
cj pada t dk pada t
, distribusi peluang hubungan antara lokasi dan waktu kunjungan
1
1
1 ,
Pr t i t j
ij t j t i
t i
count l c l c
a l c l c
count l c
(7)
Pr
t
k, t
k
k t j t k
t k
count l c s d
b j l c s d
count s d
(8)
1 1
1
Pr
=Pr Pr Pr
k i l j k ij l
t i t k t j t i t j t l
d c d c b i a b j
l c s d l c l c l c s d
(9)
Keterangan :
lt = lokasi yang dikunjungi baris observasi ke-t
19
, 1, 2, ... ,
i j M , indeks bagi kategori lokasi
1, 2, ... ,
k N , indeks bagi kategori kelompok waktu
1, ... ,
t T , indeks bagi baris observasi
Nilai HMM dihitung berdasarkan urutan waktu check-in dari pengguna. Nilai ini menunjukkan peluang next location yang akan direkomendasikan kepada pengguna. Perhitungan peluang next location terdiri atas dua state observasi dan dua hidden state terurut. Peluang next location disimbolkan dengan Pr d c d c
m i n j
, dengan keterangan: dm menunjukkan waktu kunjungan saat mengunjungi current location,
ci menunjukkan kategori lokasi dari current location,
dn menunjukkan waktu kunjungan saat akan mengunjungi next location,
cj menunjukkan kategori lokasi dari next location.
Perancangan Rekomendasi
[image:33.595.105.483.287.740.2]Proses perancangan rekomendasi mencakup proses perangkingan (Gambar 8). Tahap pertama ialah mencari tempat terdekat menggunakan fungsi yang tersedia pada Foursquare. Kemudian, daftar venue terdekat akan difilter berdasarkan nilai peluang HMM. Venue dengan nilai peluang 0 akan dibuang dari daftar rekomendasi dan kemudian diurutkan berdasarkan nilai peluang HMM terbesar. HMM bekerja pada level kategori lokasi. Oleh karena itu, tahap selanjutnya dilakukan perangkingan berhirarki terhadap beberapa level di
20
antaranya banyaknya kunjungan pada subkategori lokasi, dan banyaknya kunjungan pada lokasi itu sendiri. Asumsi yang digunakan adalah semakin sering pengguna mengunjungi lokasi atau subkategori tersebut maka akan semakin besar peluang bahwa lokasi tersebut sesuai dengan preferensi pengguna.
Implementasi
Hasil dari tahap implementasi adalah prototipe sistem berbasis website. Penelitian ini belum menggunakan real-time API. Oleh karena itu, agar data dalam sistem bersifat dinamis, maka disusun suatu tahapan untuk selalu meng-update data dari pengguna. Data check-in history dari setiap pengguna akan selalu diperbaharui ketika pengguna mengakses aplikasi sehingga model yang dihasilkan dinamis. Alur pemberian rekomendasi digambarkan dalam Bussiness Process Modeling Notation (BPMN) yang terdapat pada Lampiran 2. Tujuan dari pemodelan dengan BPMN adalah mengolah kompleksitas sistem, memudahkan pemantauan komunikasi antar stakeholder, memudahkan tracebility (penelusuran) cara kerja sistem. Pada BPMN tersebut terdapat 3 stakeholder yaitu pengguna, sistem rekomendasi, dan Foursquare API. Proses pada BPMN terdapat komunikasi antar stakeholder sehingga proses dari model rekomendasi dapat berjalan dengan baik. Alur ini terdiri atas proses pertama kali pengguna masuk ke dalam aplikasi sampai ditampilkannya hasil rekomendasi kepada pengguna (Khotimah et al 2014a)
Sistem aplikasi yang dibangun dalam bentuk website memilki beberapa kekurangan. Salah satunya ialah data current location pengguna masih di-input-kan secara manual. Input tersebut berupa titik lattitude dan longitude. Hal ini dikarenakan pada sistem website tidak dapat mendeteksi kedua titik ini secara otomatis, berbeda dengan sistem mobile yang sudah terintegrasi dengan Global Positioning System (GPS).
Kekurangan lainnya ialah proses pencarian current location dan near location yang menggunakan fungsi di dalam Foursquare. Fungsi ini memerlukan nilai titik lattitude dan longitude dengan presisi yang tinggi untuk menghasilkan rekomendasi yang relevan. Presisi yang tinggi dari current location akan menentukan daftar venue terdekat.
Hasil Eksperimen
21
Gambar 9 (a) Contoh hasil pengambilan data awal, (b) Hasil praproses data
Gambar 10 Hasil perhitungan HMM berdasarkan input dari Gambar 9
Tabel 5 Daftar venue terdekat berdasarkan hasil retrieve dari Foursquare
Venue Category Subcategory
A College & Univ College Academic Building
B Food Cafetaria
C Shop & Service Departement Store
D College & Univ College Auditorium
Tabel 6 Proses perankingan venue
Venue Category Probability HMM (1) (2) (3) Ranking
A College & University (C)
Pr(PRPC) = P(R | P) x P (C | R) x P (C | P) = 0.5 x 0.7 x 0.5 = 0.175
15 8 4 1
B Food (F) Pr(PRPF) = P(R | P) x P (F | R) x P (F | P) = 0.5 x 0.15 x 0 = 0
9 5 7 -
C Shop & Service
(S)
Pr(PRPS) = P(R | P) x P (S | R) x P (S | P) = 0.5 x 0.05 x 0 = 0
7 3 2 -
D College & University (C)
Pr(PRPC) = P(R | P) x P (C | R) x P (C | P) = 0.5 x 0.7 x 0.5 = 0.175
5 2 3 2
Keterangan : (1) Jumlah kunjungan user pada subcategoryvenue
(2) Jumlah kunjungan user pada venue
[image:35.595.88.536.53.811.2]22
Perhitungan HMM terbagi menjadi 2 bagian yaitu matriks A dan matriks B. Dari data pada Gambar 9 dihitung matriks A dengan persamaan 7, sedangkan matriks B dihitung dengan persamaan 8. Matriks hasil akhir ditunjukkan pada Gambar 10.
Pemberian rekomendasi berdasarkan current location, kemudian Foursquare akan mencari venue yang terletak yang dekat dengan current location. Berdasarkan kategori di current location, akan dirankingkan venue tersebut berdasarkan HMM. Misalkan current location berada kategori Residence dan daftar venue terdekat terdapat pada Tabel 5. Langkah selanjutnya adalah mencari probability berdasarkan Model HMM (persamaan 9) dan frekuensi check-in dengan 3 kriteria yang tertera pada Tabel 6. Kemudian dengan proses perankingan berhirarki didapatkan daftar venue yang sudah diranking seperti pada Gambar 8.
Evaluasi Model
Evaluasi model dilakukan dengan penilaian secara subjektif dari pengguna dengan pendekatan information retrieval. Evaluasi berdasarkan nilai mean average precision (MAP). Pengaplikasian metode MAP dengan asumsi current location sebagai query dan hasil rekomendasi sebagai hasil retrieval. Evaluasi dilakukan terhadap 10 lokasi teratas dalam daftar rekomendasi. Hasil MAP menunjukkan skor sebesar 0.78 yang menunjukkan nilai relevansi hasil rekomendasi dalam range [0-1].
Rekomendasi Berbasis Ekstraksi Teks Pengumpulan Data
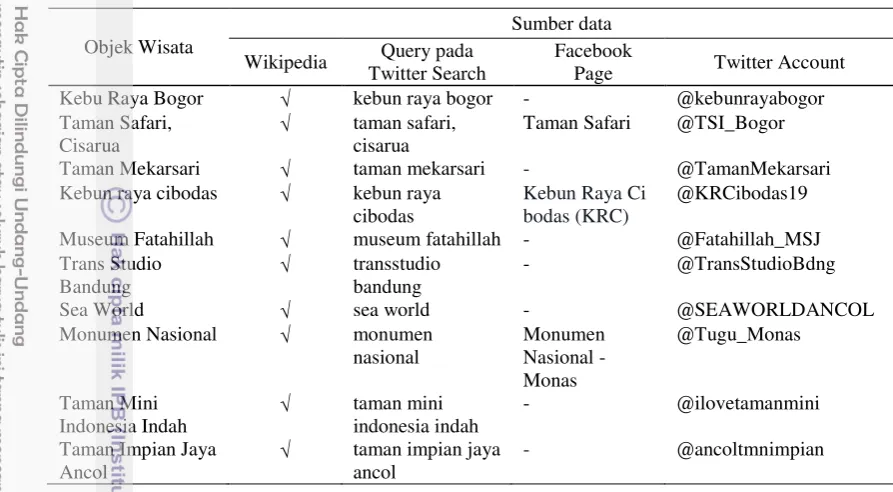
Pada penelitian ini dipilih secara acak 10 objek wisata yang terletak di Provinsi Jawa Barat dan DKI Jakarta. Beberapa sumber data yang digunakan untuk ekstraksi penciri pada objek wisata adalah Wikipedia, Twitter dan Facebook. Hasil identifikasi sumber data terhadap 10 objek wisata terdapat pada Tabel 7.
23
Ekstraksi Penciri Objek Wisata
Proses ekstraksi ciri dilakukan melalui Software R 3.0.1 dengan menggunakan paket tm (fungsi-fungsi text mining). Penelitian ini membedakan menggunakan proses pembacaan data berdasarkan sumbernya. Oleh karena itu dibangun sebuah fungsi untuk membaca setiap sumber data. Untuk sumber Wikipedia input yang diperlukan berupa link url dan proses pengambilan data sekaligus proses normalisasi terletak pada Lampiran 4. Untuk sumber dari Twitter input yang dibutuhkan berupa akun resmi dari pengelola objek wisata dan kata kunci pencarian, proses pengambilan data sekaligus proses normalisasi pada data Twitter menggunakan fungsi pada Lampiran 5. Untuk sumber dari Facebook input yang dibutuhkan berupa ID page resmi dari pengelola objek wisata, proses pengambilan data sekaligus proses normalisasi pada data twitter menggunakan fungsi pada Lampiran 6.
Untuk proses stemming dalam bahasa Indonesia terdapat 2 algoritma yang cukup terkenal yaitu Algoritma Porter (Fadhillah 2003) dan Algoritma Nazief dan Adriani (Adriani et al. 2007). Algoritma Nazief dan Adriani memiliki akurasi yang lebih tinggi daripada Algoritma Porter, walaupun Algoritma Porter memiliki waktu eksekusi yang lebih cepat (Agusta 2009). Hal ini dikarenakan pada Algoritma Nazief dan Adriani bergantung pada kamus kata dasar. Penelitian ini menggunakan kamus kata dasar dari penelitian Hidayatullah (2014). Pada proses normalisasi terdapat proses stemming menggunakan Algoritma Nazief dan Adriani (Adriani et al. 2007). Fungsi R yang digunakan untuk melakukan proses stemming terdapat pada Lampiran 7.
[image:37.595.58.505.108.354.2]Proses normalisasi dilakukan 2 kali proses normalisasi dengan singkatan. Normalisasi yang pertama bertujuan untuk mengubah teks dari jejaring sosial yang berupa singkatan ke dalam bentuk baku, sedangkan proses normalisasi yang kedua dilakukan untuk menormalkan kembali teks yang berubah akibat proses normalisasi dengan ekspresi reguler karakter yang berulang. Fungsi normalisasi
Tabel 7 Daftar sumber data untuk ekstraksi objek wisata
Objek Wisata
Sumber data
Wikipedia Query pada Twitter Search
Page Twitter Account Kebu Raya Bogor kebun raya bogor - @kebunrayabogor Taman Safari,
Cisarua
taman safari, cisarua
Taman Safari @TSI_Bogor
Taman Mekarsari taman mekarsari - @TamanMekarsari Kebun raya cibodas kebun raya
cibodas
Kebun Raya Ci bodas (KRC)
@KRCibodas19
Museum Fatahillah museum fatahillah - @Fatahillah_MSJ Trans Studio
Bandung
transstudio bandung
- @TransStudioBdng
Sea World sea world - @SEAWORLDANCOL
Monumen Nasional monumen nasional Monumen Nasional - Monas @Tugu_Monas Taman Mini Indonesia Indah
taman mini indonesia indah
- @ilovetamanmini
Taman Impian Jaya Ancol
taman impian jaya ancol
24
untuk teks singkatan terdapat pada Lampiran 9, sedangkan proses normalisasi dengan ekspresi reguler untuk karakter yang berulang terdapat pada Lampiran 10. Proses normalisasi singkatan menggunakan database yang memetakan antara kata singkatan dan kata bakunya dari penelitian Aziz (2013). Berdasarkan penelitian Aziz (2013) proses normalisasi menggunakan database memiliki akurasi yang lebih tinggi daripada normalisasi menggunakan fungsi jarak Levenshtein (Freeman et al. 2006).
Setelah dilakukan proses normalisasi lalu data dari berbagai sumber tersebut digabungkan ke dalam satu corpus berdasarkan objek wisata yang sama. Kemudian dilakukan proses penghapusan kata stopword (Lampiran 11) dan dilanjutkan penyusunan term-document matrix dengan setiap objek wisata diasumsikan sebagai dokumen. Hasil dari proses text mining dari 10 tempat wisata didapatkan term sebanyak 5018 term dan sebanyak 81% didominasi oleh term yang kemunculannya jarang. Gambar 11 merupakan representasi term penciri dari Kebun Raya Bogor dalam bentuk wordcloud. Dari gambar tersebut terlihat bahwa dari sekian banyak term yang dihasilkan pada proses text mining, masih banyak term yang tidak representatif atau kata yang representatif tapi kemunculannya tidak signifikan.
[image:38.595.92.466.179.758.2]Gambar 11 Representasi wordcloud dari hasil ekstraksi