SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
DEVI DWIYANTINI
10112359
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
Asslamu’alaikum Warahmatullahi Wabarakatuh.
Alhamdullillahi Rabbil ‘Alamiin, hanya milik Allah SWT segala puja dan puji di langit serta di bumi. Segala kebaikan yang dirasakan oleh seluruh makhluk-Nya adalah berasal dari Allah, Rab semesta alam. Tidak lupa shalawat serta salam tercurah limpahkan kepada Baginda Rasullah SAW.
Skripsi yang telah penulis susun berjudul “TEXT SUMMARIZATION
MENGGUNAKAN METODE KNN DAN MMR PADA ARTIKEL
BERBAHASA INDONESIA”, mencakup analisis, perancangan, implementasi, serta pengujian. Skripsi ini disusun guna memenuhi syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika, Fakultas Teknik dan Ilmu Komputer guna meraih kelulusan dari Universitas Komputer Indonesia.
Penyusunan skripsi ini dapat selesai berkat kesungguhan penulis yang didukung oleh banyak pihak. Oleh karena itu, penulis mengucapkan terima kasih kepada :
1. Allah SWT, atas segala nikmat yang telah diberikan, beserta izin-Nya lah sehingga penulis dapat menyelesaikan skripsi ini.
2. Kedua orang tua yang selalu setia dengan doa dan usaha bagi kami anak-anak mereka.
3. Ibu Ken Kinanti Purnamasari, S.Kom., M.T., selaku dosen pembimbing yang telah banyak meluangkan waktu untuk memberikan bimbingan, nasihat, saran, dan ilmu selama proses penyusunan skripsi ini.
4. Ibu Nelly Indriani W, S.Si., M.T., selaku reviwer yang telah memberikan ilmu serta saran kepada penulis.
iv
7. Teman selalu berempat Amanda, Lia, Dina yang selalu membagi keceriaan kepada penulis.
8. Teman-teman seperjuangan angkatan 2012 terutama kelas IF-9 yang selalu memberi dukungan dan semangat kepada penulis.
9. Semua pihak yang tidak bisa penulis sebutkan satu demi satu.
Penulis menyadari bahwa penulisan skripsi ini masih jauh dari kata sempurna. Sudilah kiranya saran dan kritik yang membangun menjadi pendukung demi terwujudnya karya lebih baik di masa yang akan datang. Akhirnya semoga skripsi ini bermanfaat.
Wassalamu’alaikum wa rahtullah wabarakatuh
Bandung, Agustus 2016
v
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xi
DAFTAR SIMBOL ... xiv
DAFTAR LAMPIRAN ... xviii
BAB I PENDAHULUAN ... 1
1.1.Latar Belakang Masalah ... 1
1.2.Identifikasi Masalah ... 2
1.3.Maksud dan Tujuan ... 2
1.3.1. Maksud ... 2
1.3.2. Tujuan ... 2
1.4.Batasan Masalah... 2
1.5.Metodologi Penelitian ... 3
1.5.1. Metode Pengumpulan Data ... 3
1.5.2. Metode Pembangunan Sistem ... 4
1.6.Sistematika Penulisan... 5
BAB II LANDASAN TEORI ... 7
2.1. Kata ... 7
2.2. Kalimat ... 7
2.3. Berita ... 7
2.4. Artikel ... 8
2.5. Peringkasan Teks Otomatis ... 8
2.5.1. Penelitian Terdahulu ... 9
2.6. Proses Peringkasan Teks Otomatis ... 10
2.6.1. Case Folding ... 10
vi
2.6.7. Metode TF-IDF (Term Frequency-Inversed Document Frequency) ... 14
2.6.8. Cosine Similarity ... 15
2.6.9. Metode KNN (K-Nearest Neighbors) ... 15
2.6.10. Metode MMR (Maximum Marginal Relevance)... 16
2.7. Pengujian Akurasi ... 18
2.8. Bahasa Pemrograman ... 19
2.8.1. PHP ... 19
2.9. Software Pendukung ... 19
2.9.1. XAMPP ... 19
2.9.2. MySQL dan PhpMyAdmin ... 20
2.10. Model Perangkat Lunak ... 21
2.10.1. DFD (Data Flow Diagram) ... 21
2.10.2. Flowchart ... 22
2.10.3. ERD (Entity Relationship Diagram) ... 24
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 27
3.1. Analisis Masalah ... 27
3.2. Analisis Sistem ... 27
3.2.1. Analisis Data Masukan ... 28
3.2.2. Analisis Preprocessing... 29
3.2.2.1. Case Folding ... 29
3.2.2.2. Filtering... 30
3.2.2.3. Tokenizing Kalimat ... 31
3.2.2.4. Tokenizing Kata ... 32
3.2.2.5. Removal Stopword ... 34
3.2.2.6. Stemming ... 36
3.2.2.7. Metode TF-IDF (Term Frequency-Inversed Document Frequency) .. 38
vii
3.4. Hasil Ringkasan ... 56
3.5. Analisis Pengujian ... 57
3.6. Analisis Kebutuhan Non Fungsional ... 60
3.6.1. Analisis Kebutuhan Perangkat Keras ... 60
3.6.2. Analisis Kebutuhan Perangkat Lunak ... 60
3.6.3. Analisis Kebutuhan Pengguna ... 61
3.7. Analisis Kebutuhan Fungsional ... 61
3.7.1. Entity Relationship Diagram (ERD) ... 61
3.7.2. Diagram Konteks ... 62
3.7.3. Data Flow Diagram (DFD) Level 1 ... 62
3.7.4. Data Flow Diagram (DFD) Level 2 ... 63
3.7.5. Deskripsi Proses ... 64
3.7.6. Kamus Data ... 66
3.8. Perancangan Sistem ... 67
3.8.1. Perancangan Basis Data ... 68
3.8.1.1. Struktur Tabel... 68
3.8.2. Perancangan Struktur Menu ... 69
3.8.3. Perancangan Antarmuka ... 70
3.8.3.1. Antarmuka Halaman Berita (T01) ... 70
3.8.3.2. Antarmuka Halaman Preprocessing (T02) ... 71
3.8.3.3. Antarmuka Halaman KNN MMR (T03) ... 72
3.8.4. Jaringan Semantik ... 73
3.8.5. Perancangan Prosedural ... 74
3.8.5.1. Perancangan Algoritma Utama ... 74
3.8.5.2. Perancangan Algoritma Case Folding ... 74
3.8.5.3. Perancangan Algoritma Filtering ... 75
viii
BAB IV IMPLEMENTASI DAN PENGUJIAN ... 81
4.1. Implementasi Sistem ... 81
4.1.1. Implementasi Perangkat Keras ... 81
4.1.2. Implementasi Perangkat Lunak ... 81
4.1.3. Implementasi Basis Data ... 82
4.1.4. Implementasi Antarmuka ... 83
4.2. Pengujian Sistem ... 85
4.2.1. Skenario Pengujian... 85
4.2.1.1. Skenario Pengujian Fungsionalitas ... 85
4.2.1.2. Skenario Pengujian Detail Perancangan ... 86
4.2.1.3. Skenario Pengujian Nilai Performansi ... 89
4.2.2. Hasil Pengujian ... 89
4.2.2.1. Hasil Pengujian Fungsionalitas ... 90
4.2.2.2. Hasil Pengujian Detail Perancangan ... 91
4.2.2.3. Hasil Pengujian Nilai Performansi ... 99
4.2.3. Analisis Hasil Pengujian ... 103
BAB V KESIMPULAN DAN SARAN ... 105
5.1. Kesimpulan ... 105
5.2. Saran ... 105
107
[2] Marlinda. L., & Rianto. H. (2013). Pembelajaran Bahasa Indonesia Berbasis Web Menggunakan Metode Maximum Marginal Relevance. Seminar Nasional Sistem Informasi Indonesia 2-4 Desember 2013, 410-415
[3] Pardede. J., & Sinatria. J. . Implementasi Maximum Marginal Relevance dan Matriks Cosine Similarity pada Aplikasi Peringkasan Dokumen. Itenas Library, 1348-1352
[4] Alguliev. R., & Alguliyev. R. . Effective Summarization Method of Text Documents
[5] Sommerville. I. (2003). Sofware Engineering Edisi 6 Jilid 1 (Rekayasa Perangkat Lunak). Jakarta: Erlangga
[6] Pressman. R. S. (2007). Rekayasa Perangkat Lunak: Pendekatan Praktisi Buku 1. Yogyakarta: Andi
[7] Sasangka. S. S. T. W., & Darheni. N. (2012). Jendela Bahasa Indonesia. Elmatera Publishing
[8] Wijayanti. S. H., Candrayani. A., Hendrawati. I. E. S., & Agustinus. J. W. (2013). Bahasa Indonesia Penulisan dan Penyajian Karya Ilmiah. Rajawali Pers
[9] Sumdiria. H. (2008). Jurnalistik Indonesia Menulis Berita dan Feature Panduan Praktis Jurnalis Profesional. Simbiosa Rekatama Media
[10] Rolnicki. T. E., Tate. C. D., & Taylor. S. A. (2008). Pengantar Dasar Jurnalisme (Scholastic Journalism). Kencana Edisi Kesebelas
[11] Iswanto. (2007). Membangun Aplikasi Berbasis PHP 5 dan Firebird 1.5. Yogyakarta: Andi
[13] Waliprana. W. E., & Khodra. M. L. (2013). Update Summarization Untuk Kumpulan Dokumen Berbahasa Indonesia. Jurnal Cybermatika, Vol. 1 No.2, 6-10
[14] Al-Hashemi. R. (2010). Text Summarization Extraction System (TSES) using Extracted Keyword. International Arab Journal of e-Technology, Vol. 1 No.4
[15] Ridok. A. (2014). Peringkasan Dokumen Bahasa Indonesia Berbasis Non-Negative Matrix Factorization (NMF). Jurnal Teknologi Informasi dan Ilmu Komputer (JTIIK), Vol 1, No. 1, April 2014, 39-44
[16] Handi. (2011). Text Pre-Processing pada Text To Speech Synthesis System untuk Penutur Berbahasa Indonesia. ITS Surabaya
[17] Triawati. C. (2009). Metode Pembobotan Stastical Consept Based untuk Klastering dan Kategorisasi Dokumen Berbahasa Indonesia. Bandung: Institut Teknologi Telkom Bandung
[18] Kusrini., & Luthfi E. T. (2009). Algoritma Data Mining. Yogyakarta: Andi [19] Singal. A. (2001). Modern Information Retrieval
[20] Sutanta. E. (2004). Algoritma Teknik Penyelesaian Permasalahan untuk Komputasi. Yogyakarta: Ghaha Ilmu
[21] Goldstein, J. 2008. Genre Oriented Summarization. Thesis. Pittsburgh : Language Technologies Institute School of Computer science Carnegie
Mellon University.
[22] Ladjamudin. bin A. (2005). Analisis dan Desain Sistem Informasi. Yogyakarta: Graha Ilmu
[23] Jogiyanto. (2005). Analisis & desain. Yogyakarta: Andi
[24] Carbonell. J., & Goldstein. J. (1998). The Use of MMR, Diversity-Based Rerangking for Reordering Documents and Produsing Summaries
[26] Budiyono. W., & Solihin. F. (2014). Aplikasi Peringkas Berita Online Otomatis Menggunakan Metode Ordinary Weighting Pada Situs Pengumpulan Berita. Jurnal Ilmiah NERO, Vol.1, No.2, 53-62
1
1.1. Latar Belakang Masalah
Kebanyakan mesin information retrieval (IR) modern menghasilkan daftar perangkingan dari dokumen, yang diukur dari relevansi dokumen dengan permintaan user (user query). Penaksiran pertama untuk mengukur hasil peringkasan yang relevan adalah dengan mengukur hubungan antar informasi yang ada dalam dokumen dengan query yang diberikan oleh user dan menambah kombinasi linier sebagai sebuah matrik. Kombinasi linier ini disebut “marginal relevance” [24].
Selain digunakan untuk information retrieval, marginal relevance bisa juga digunakan untuk peringkasan dokumen. Berdasarkan penelitian sebelumnya, metode maximum marginal relevance (MMR) sangat berguna untuk memberikan informasi pada dokumen yang bersifat multi redundansi dan dapat meningkatkan kecepatan pengukuran yang tepat dari kesamaan kalimat. Penelitian ini menghasilkan akurasi yang masih rendah (46%). Hal tersebut disebabkan karena query yang tidak terbatas, sehingga user bisa memasukkan kata apa saja pada query
[3]. Pada penelitian lainnya, dengan data yang diambil dari surat kabar online berbahasa Indonesia (30 berita). Diperoleh hasil pengujian rata-rata recall 60%, precision 77%, dan f-measure 66% [25].
untuk mengklasifikasikan kalimat pada penelitian ini adalah metode K-Nearest Neighbors (KNN). Pada penelitian sebelumnya, peringkasan dokumen dengan
metode K-Nearest Neighbors, diperoleh hasil dengan nilai recall 63%, precision 100%, dan f-measure 77% [4].
Berdasarkan uraian di atas, pada penelitian ini akan dilakukan Text Summarization menggunakan metode K-Nearest Neighbors dan Maximum
Marginal Relevance, untuk meringkas sebuah artikel berbahasa Indonesia.
1.2. Identifikasi Masalah
Berdasarkan uraian latar belakang masalah yang telah dijelaskan sebelumnya, maka identifikasi masalah adalah sebagai berikut.
1. Masih rendahnya akurasi peringkasan menggunakan MMR 2. Masih panjangnya ringkasan yang dihasilkan
1.3. Maksud dan Tujuan
1.3.1. Maksud
Penelitian ini bermaksud membuat sistem peringkas teks otomatis. 1.3.2. Tujuan
Tujuan yang ingin dicapai dari penelitian ini adalah untuk membandingkan nilai performansi (recall, precision dan f-measure) dan akurasi peringkasan menggunakan KNN dan MMR dengan peringkasan yang hanya menggunakan MMR.
1.4. Batasan Masalah
Batasan masalah merupakan pembatasan ruang lingkup pekerjaan yang akan dilakukan terhadap permasalahan yang ada. Batasan dalam penelitian adalah sebagai berikut:
1. Dokumen yang akan diringkas adalah dokumen berbahasa Indonesia 2. Dokumen yang digunakan bersumber dari beberapa media internet
4. Dokumen yang digunakan mempunyai judul yang sesuai dengan isi dokumen
1.5. Metodologi Penelitian
Penelitian ini menggunakan Metode Deskriptif [27] yang bertujuan mendapatkan gambaran yang jelas mengenai hal-hal yang diperlukan. Dalam penelitian text summarization ini, data yang diteliti dalam keadaan sebagaimana adanya. Sehingga hasil text summarization tergantung dari data itu sendiri.
Gambar 1. 1 Metodologi Penelitian
1.5.1. Metode Pengumpulan Data
1.5.2. Metode Pembangunan Sistem
Metode pembangunan perangkat lunak yang digunakan adalah prototype [5]. Karena pada pembangunan sistem text summarization didasarkan pada ide pengembangan awal, diuji keberhasilannya, dan menyempurnakannya dengan kembali ke pembangunan. Tahapan-tahapan dari metode prototype dapat dilihat pada Gambar 1.2.
Gambar 1. 2 Metode Prototype [5]
1. Kembangkan spesifikasi abstrak
Merupakan tahap awal untuk menganalisis masalah yang ada, yaitu memahami masalah yang timbul dan mencari solusi untuk memecahkan masalah dalam menghasilkan sebuah text summarization dari artikel berbahasa Indonesia.
2. Buat sistem prototype
mencoba mengimplementasikan metode MMR pada text summarization ke dalam logika-logika program.
3. Gunakan sistem prototype
Program akan diuji, dimana uji coba dilakukan untuk mengetahui kekurangan pada program. Jika masih ada kekurangan, maka prototype direvisi dengan tahapan-tahapan yang sebelumnya telah dilakukan. Proses ini akan terus berulang sampai prototype yang dihasilkan mendekati harapan yang diinginkan.
4. Serahkan sistem
Jika hasil sistem prototype telah mencapai atau mendekati harapan yang diinginkan. Maka sistem text summarization menggunakan KNN dan MMR bisa digunakan dengan baik.
1.6. Sistematika Penulisan
Sistematika penulisan laporan akhir penelitian text summarization disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut.
BAB 1 PENDAHULUAN
Bab ini berisi penjelasan mengenai latar belakang masalah, identifikasi masalah, maksud dan tujuan, batasan masalah, metodologi penelitian, dan sistematika penulisan yang dimaksudkan agar dapat memberikan gambaran tentang urutan pemahaman dalam menyajikan laporan penelitian text summarization.
BAB 2 LANDASAN TEORI
BAB 3 ANALISIS DAN PERANCANGAN
Bab ini menguraikan penjelasan analisis dan perancangan sistem, perhitungan pada metode Term Frequency – Inversed Document Frequency (TF-IDF), cosine similarity, K-Nearest Neighbors (KNN), Maximum Marginal Relevance
(MMR) untuk diaplikasikan pada Text Summarization.
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Bab ini berisi tentang implementasi dari analisis dan perancangan yang telah dilakukan pada bab sebelumnya. Implementasi yang dilakukan terdiri dari implementasi perangkat keras, implementasi perangkat lunak, implementasi basis data dan implementasi antarmuka. Selain itu dilakukan pengujian Text Summarization menggunakan metode K-Nearest Neighbors (KNN) dan Maximum Marginal Relevance (MMR) pada Artikel Berbahasa Indonesia, dengan skenario pengujian dan hasil pengujian.
BAB 5 KESIMPULAN DAN SARAN
Bab ini menjelaskan tentang kesimpulan yang diperoleh dari penelitian Text Summarization menggunakan metode K-Nearest Neighbors (KNN) dan Maximum Marginal Relevance (MMR pada artikel berbahasa Indonesia, serta
7
2.1. Kata
Kata merupakan satuan bahasa yang dapat berdiri sendiri atau merupakan satuan bebas yang paling kecil yang dapat berdiri sendiri. Selain itu, kata merupakan unsur bahasa yang diucapkan atau dituliskan dan merupakan perwujudan kesatuan perasaan dan pikiran yang dapat digunakan dalam berbahasa [7].
2.2. Kalimat
Kalimat adalah satuan bahasa terkecil, dalam wujud lisan atau tulis, yang mengungkapkan pikiran yang utuh. Dalam wujud lisan, tuturan (atau kalimat dalam bentuk tulis) diucapkan dengan nada naik-turun, keras-lembut, disela jeda, dan diakhiri intonasi akhir. Dalam wujud tulis, kalimat diawali dengan huruf kapital dan diakhiri dengan tanda baca titik, tanda tanya, atau tanda seru, kadang kala di tengah-tenganya terdapat tanda baca lain, seperti titik dua, titik koma, dan tanda pisah. Tanda titik, tanda tanya, dan tanda seru dalam bahasa tulis sepadan dengan intonasi akhir dalam bahasa lisan, sedangkan tanda baca lain dalam bahasa tulis sepadan dengan jeda dalam bahasa lisan [8].
2.3. Berita
Berita adalah laporan tercepat mengenai fakta atau ide terbaru yang benar, menarik dan atau penting bagi sebagian besar khalayak, melalui media berkala seperti surat kabar, radio, televisi, atau media online internet [9].
pengadilan, pasar fiansial, dan sebagainya. Soft news (berita ringan) baiasanya kurang penting karena isinya menghibur, walaupun kadang juga memberi informasi penting. Berita ini sering kali bukan berarti terbaru. Di dalamnya memuat berita human intesert atau jenis rubik feature. Berita jenis ini lebih menarik bagi emosi
ketimbang akal pikiran [10].
2.4. Artikel
Artikel adalah tulisan lepas berisi opini seseorang yang mengupas tuntas suatu masalah tertentu yang sifatnya actual dan atau kontroversial dengan tujuan untuk memberitahu (informatif), memengaruhi dan meyakinkan (persuatif argumentatif), atau menghibur khalayak pembaca (rekreatif). Disebut lepas, karena siapa pun pembaca boleh menulis artikel dengan topik bebas sesuai dengan minat dan keahliannya masing-masing. Selain itu juga artikel yang ditulis tersebut tidak terkait dengan berita atau laporan tertentu. Ditulisnya pun boleh kapan saja, di mana saja, dan oleh siapa saja [9].
2.5. Peringkas Teks Otomatis
Peringkas teks otomatis (automatic text summarization) adalah pembuatan bentuk yang lebih singkat dari suatu teks dengan memanfaatkan aplikasi yang dijalankan dan dioperasikan pada komputer. Peringkas teks otomatis mampu menghasilkan ringkasan yang memiliki konten paling penting pada dokumen[13]. Tujuan dari peringkas teks yaitu mengambil intisari informasi dari dokumen sumber dan menjadikannya lebih singkat tanpa menghilangkan topik utama sehingga dapat membantu pengguna lebih cepat memahami makna yang terkandung didalamnya[14].
dihasilkan oleh manusia bersifat tidak ekstraktif, akan tetapi kebanyakan penelitian mengenai peringkasan ini adalah ekstraktif yang memberikan hasil yang lebih baik apabila dibandingkan dengan peringkasan abstraktif [15].
2.5.1. Penelitian Terdahulu
Beberapa penelitian terdahulu yang berkaitan dengan penelitian text summarization, seperti :
Linda Marlinda dan Harsih Rianto dari AMIK Bina Sarana Informatika tahun 2013 dalam penelitiannya yang berjudul “Pembelajaran Bahasa Indonesia Berbasis Web Menggunakan Metode Maximum Marginal Relevance”, menyatakan bahwa siswa dapat lebih memahami penalaran pelajaran Bahasa Indonesia dengan mudah terutama pada soal essay. Dengan 5 pertanyaan essay diberikan kepada 10 orang responden [2].
Muchammad Mustaqhfiri, Zainal Abidin, dan Ririen Kusumawati dari Universitas Islam Negeri Maulana Malik Ibrahim Malang dalam penelitiannya yang berjudul “Peringkasan Teks Otomatis Berita Berbahasa Indonesia Menggunakan Metode Maximum Marginal Relevance” menyatakan bahwa metode maxixmum marginal relevance dapat mengurangi redundansi dengan data uji voba dari surat
kabar berbahasa Indonesia online sebanyak 30 berita. Menghasilkan ringkasan sistem dengan rata-rata recall 60%, precision 77%, dan f-measure 66% dibandingkan dengan ringkasan manual [25].
Jasman Pardede dan Jordy Sinantria dari Itenas Bandung dalam penelitiannya yang berjudul “Implementasi Maximum Marginal Relevance dan Matriks Cosine Similarity pada Aplikasi Peringkas Dokumen” menyatakan bahwa aplikasi automatic summarization mampu menemukan kata yang relevansi dengan query yang diinginkan oleh pengguna, dengan hasil akurasi 46%. Hal tersebut
disebabkan karena query yang tidak dibatasi, sehingga user bisa memasukkan apa saja pada query[3].
menyatakan bahwa metode KNN bisa digunakan untuk meringkas dokumen, dengan hasil recall 63%, precision 100%, f-measure 77%[4].
2.6. Proses Peringkasan Teks Otomatis
2.6.1. Case Folding
Case folding adalah mengubah semua huruf dalam dokumen menjadi huruf kecil. Hanya huruf “a” sampai dengan “z” yang diterima [16].
2.6.2. Filtering
Data teks dalam dokumen yang sebelumnya sudah diubah ke dalam huruf kecil semua. Selanjutnya dilakukan proses filtering teks. Filtering adalah tahapan pemrosesan teks dimana semua teks selain karakter “a” sampai “z” dan titik “.” akan dihilangkan dan hanya menerima spasi [13].
2.6.3. Tokenizing Kalimat
Pemisahan kalimat merupakan proses pemisahan teks pada dokumen menjadi kumpulan kalimat. Teknik yang digunakan dalam pemisahan kalimat adalah memisahkan kalimat dengan tanda titik (.) sebagai delimeter [13].
2.6.4. Tokenizing Kata
Tokenizing adalah pemotongan string input berdasarkan tiap kata yang menyusunnya. Pemecahan kalimat menjadi kata-kata tunggal dilakukan dengan menscan kalimat dengan pemisah (delimeter) spasi [16].
2.6.5. Removal Stopword
Stopword adalah kumpulan kata-kata yang sering muncul dalam dokumen.
Stopword pada umumnya adalah sebuah kata penghubung yang tidak begitu
menggunakan kamus stopword yang sudah ditentukan sebelumnya. Contoh stopword pada bahasa Indonesia adalah di, ke, dari, pada, dan lain-lain [13].
2.6.6. Stemming
Stemming merupakan proses pencarian akar (root) kata dari tiap kata, yaitu
dengan mengembalikan suatu kata berimbuhan ke bentuk dasarnya (stem). Untuk pemrosesan pada bahasa Indonesia, proses stemming dilakukan dengan menghilangkan imbuhan yang mengawali dan mengakhiri kata sehingga diperoleh bentuk dasar dari kata tersebut [13]. Tahap ini kebanyakan dipakai untuk teks berbahasa Inggris dan lebih sulit diterapkan pada teks berbahasa Indonesia. Hal ini dikarenakan bahasa Indonesia tidak memilki rumus bentuk baku yang permanen [16].
Algoritma stemmer yang diperkenalkan Nazief dan Adriani (1996) didefinisikan sebagai berikut:
1. Di awal proses stemming dan setiap langkah yang selanjutnya dilakukan, lakukan pengecekan hasil proses stemming kata yang diinputkan pada langkah tersebut ke kamus kata dasar. Jika kata ditemukan, berarti kata tersebut sudah berbentuk kata dasar dan proses stemming dihentikan. Jika tidak ditemukan, maka langkah selanjutnya dilakukan.
2. Hilangkan Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”). Jika berupa particles (“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “- nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a.
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “ -k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
4. Hilangkan derivation prefixes. a. Langkah 4 berhenti jika:
i. Terjadi kombinasi awalan dan akhiran yang terlarang.
ii. Awalan yang dideteksi saat ini sama dengan awalan yang dihilangkan sebelumnya.
iii. Tiga awalan telah dihilangkan.
b. Identifikasikan tipe awalan dan hilangkan. Awalan terdiri dari dua tipe: i. Standar (“di-”, “ke-”, “se-”) yang dapat langsung dihilangkan dari
kata.
ii. Kompleks (“me-”, “be-”, “pe”, “te-”) adalah tipe-tipe awalan yang dapat bermorfologi sesuai kata dasar yang mengikutinya. Oleh karena itu, gunakan aturan pada Tabel 2.1 untuk mendapatkan hasil pemenggalan yang tepat.
c. Cari kata yang telah dihilangkan awalannya ini di dalam kamus kata dasar. Apabila tidak ditemukan, maka langkah 4 diulangi kembali. Apabila ditemukan, maka keseluruhan proses dihentikan.
5. Apabila setelah langkah 4 kata dasar masih belum ditemukan, maka proses recoding dilakukan dengan mengacu pada aturan pada Tabel 2.1. Recoding
dilakukan dengan menambahkan karakter recoding di awal kata yang dipenggal. Pada Tabel 2.1, karakter recoding adalah huruf kecil setelah tanda hubung („-‟) dan terkadang berada sebelum tanda kurung. Sebagai contoh, kata “menangkap” (aturan 15), setelah dipenggal menjadi “nangkap”. Karena tidak valid, maka recoding dilakukan dan menghasilkan kata “tangkap”.
6. Jika semua langkah gagal, maka input kata yang diuji pada algoritma ini dianggap sebagai kata dasar.
Tabel 2. 1 Aturan Pemenggalan Stemmer Nazief dan Andriani
Aturan Format Kata Pemenggalan
1 berV... ber-V... | be-rV...
3 berCAerV... ber-CaerV... dimana C!=‟r‟
31 pelV... pe-lV... kecuali “pelajar” yang menghasilkan “ajar”
32 peCerV... per-erV... dimana C!={r|w|y|l|m|n}
Keterangan simbol huruf :
C: huruf konsonan V: huruf vokal
A: huruf vokal atau konsonan
P: partikel atau fragmen dari suatu kata, misalnya “er”
2.6.7. Metode TF-IDF (Term Frequency – Inversed Document Frequency)
TF-IDF (Term Frequency – Inversed Document Frequency) digunakan rumus untuk menghitung bobot (w) masing-masing dokumen terhadap kata kunci. TF-IDF banyak digunakan sebagai faktor bobot (w) dalam pencarian informasi dan text mining. Pembobotan diperoleh dari jumlah kemunculan term dalam sebuah
dokumen term frequency (tf) dan jumlah kemunculan term dalam koleksi dokumen inverse document frequency (idf). Variasi dari skema pembobotan TF-IDF sering
digunakan oleh mesin pencari sebagai alat eksekusi. Bobot suatu istilah semakin besar jika istilah tersebut sering muncul dalam suatu dokumen dan semakin kecil jika istilah tersebut muncul dalam banyak dokumen [19].
Dalam tf frekuensi term pilihan paling sederhana adalah dengan menggunakan frequensi baku dalam dokumen, yaitu berapa kali term (t) terjadi dalam dokumen (d) [3]. Nilai idf sebuah term (kata) dapat dihitung menggunakan dalam persamaan (2.1).
� � = log ( ) … .
D adalah jumlah dokumen yang berisi term (t) dan idf adalah jumalh kemunculan (frekuensi) term terhadap D. Adapun algoritma yang digunakan untuk menghitung bobot (w) masing-masing dokumen terhadap kata kunci (query) menggunakan persamaan (2.2).
�.� = �.� ∗ � �� … . Dimana :
D : dokumen ke-d
tf : term frekuensi/ frekuensi kata
w : bobot dokumen ke-d terhadap term ke-t
2.6.8. Cosine Similarity
Cosine similarity digunakan untuk menghitung pendekatan relevansi query
terhadap dokumen. Semakin besar nilai kesamaan vektor query dengan vektor dokumen maka query tersebut dipandang semakin relevan dengan dokumen. Cosinus dari 00 adalah 1, dan kurang dari 1 untuk setiap sudut lainnya. Dengan demikian dua vektor dengan orientasi yang sama memiliki kesamaan cosinus dari 1, dua vektor pada 900 memiliki kesamaan 0. Cosine similarity terutama digunakan dalam ruang positif, dimana hasilnya dibatasi (0,1). Cosine similarity kemudian memberi tolak ukur seberapa mirip dua dokumen [3].
Cosinus dari dua vektor dapat diturunkan dengan menggunakan dot product Euclidean yaitu 1.b = ||a|| ||b|| cos Θ dimana vektor atribut, A dan B kesamaan dan besarnya ditukan dengan persamaan (2.3).
, = ∑��= ��.� ��.�
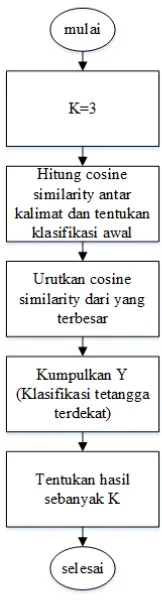
2.6.9. Metode KNN (K-Nearest Neighbor)
K-Nearest Neighbor (KNN) merupakan sebuah metode untuk melakukan klasifikasi terhadap obyek baru berdasarkan (K) tetangga terdekatnya. KNN termasuk algoritma supervised learning, dimana hasil dari query instance yang baru, diklasifikasikan berdasarkan mayoritas dari kategori pada KNN. Kelas yang paling banyak muncul yang akan menjadi kelas hasil klasifikasi.
Gambar 2. 1 Flowchart K-Nearest Neighbors [18]
2.6.10. Metode MMR (Maximum Marginal Relevance)
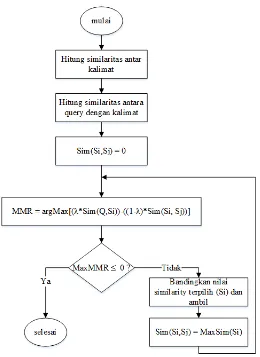
Maximum Marginal Relevance (MMR) adalah sebuah algoritma yang digunakan untuk metode ringkasan ekstrasi yang dapat meringkas satu dokumen atau lebih. Metode ini pertama kali dikemukakan oleh Carbonell dan Goldstein pada tahun 1998. Metode MMR digunakan untuk memilih kalimat dengan mempertimbangkan aspek kerelevanan kalimat dengan query [20]. Cara kerja algoritma MMR meringkas kalimat dengan menghitung kasamaan (similarity) antar bagian kalimat seperti yang dinyatakan pada persamaan (2.4).
= [λ ∗ � ��,� − − λ ∗ � ��,� ] … .
Dimana :
λ : Koefisiensi nilai penekanan kalimat relevan
� 2 : matrik similarity kalimat �, terhadap setiap kalimat Di : kalimat dalam dokumen
D : Kalimat yang telah diekstrak
Q : Query
Sim adalah kosinus kesamaan antara dua vektor fitur. � adalah kofisien untuk mengatur relevansi kalimat dan mengurangi redundansi. Nilai parameter � adalah 1 atau 0 atau diantaranya (0<�<1). Pada saat parameter �=1 maka nilai MMR yang diperoleh cenderung relevan terhadap dokumen asli. Ketika �=0 maka nilai MMR yang diperoleh akan cenderung releven terhadap kalimat yang diekstrak sebelumnya yang akan dibandingkan. Oleh sebab itu, sebuah kombinasi linear dari kedua kriteria dioptimalkan ketika nilai � terdapat pada interval 0<�<1. Untuk peringkasan dengan dokumen yang kecil, seperti artikel berita akan menghasilkan hasil ringkasan yang baik, jika nilai parameter �=0,7 atau �=0,8 [21].
2.7. Pengujian Akurasi
Pengujian yang dilakukan dalam penelitian ini menggunakan pengujian akurasi. Standar pengukuran yang biasa digunakan dalam penelitian text summarization yaitu recall, precision, dan f-measure [25].
Recall adalah tingkat keberhasilan ringkasan. Perhitungan recall dapat dilihat pada persamaan sebagai berikut:
= + … .
dimana
recall : tingkat keberhasilan
tp : jumlah kalimat yang berhasil di ekstrak sistem sesuai dengan kalimat yang diekstrak manusia
fn : jumlah kalimat yang diekstrak manusia tetapi tidak terdapat dalam kalimat yang diekstrak sistem
Precision adalah tingkat ketepatan hasil ringkasan. Perhitungan precision
dapat dilihat pada persamaan berikut:
� � = + … .
dimana,
precision : tingkat ketepatan
tp : jumlah kalimat yang berhasil di ekstrak sistem sesuai dengan kalimat yang diekstrak manusia
fp : jumlah kalimat yang diekstrak sistem tetapi tidak terdapat dalam kalimat yang diekstrak manusia
� − = + � �� � … .
2.8. Bahasa Pemrograman
2.8.1. PHP
PHP adalah kependekan dari PHP Hypertext Preprocessor, bahasa interpreter yang mirip dengan bahasa C dan Perl yang memiliki kesederhanaan dalam perintah, PHP dapat digunakan bersama dengan HTML sehingga memudahkan dalam pembangunan aplikasi web dengan cepat. PHP dapat digunakan untuk meng-update basis data dan menciptakan basis data. Interpreter adalah sebuah program yang digunakan untuk membaca file yang berisi kode program yang akan dijalankan kemuadian interpreter tersebut akan meminta CPU untuk menlakukan perintah yang diterimanya.
Seperti halnya program open source lainnya, PHP dibuat di bawah lisensi GNU, General Public License, yang dapat di download gratis melalui situs http://www.php.net. Awalnya, PHP diciptakan oleh Andi Gutmans untuk menghitung jumlah pengunjung yang mengakses homepage yang dbuatnya. PHP banyak mendukung basis data, seperti MYSQL, PostgresSQL, Interbase, ODBC, mSQL, Oracle, dan Sybase [11].
2.9. Software Pendukung
2.9.1. XAMPP
yang dapat menampilkan halaman web yang dinamis. Untuk mendapatkanya XAMPP anda dapat mendownload langsung dari web resminya.
2.9.2. MySQL dan PhpMyAdmin
MySQL termasuk dalam kategori database management system, yaitu suatu database yang terstruktur dalam pengolahan dan penampilan datanya. MySQL merupakan database yang bersifat client server, di mana data diletakkan di server yang bisa diakses melalui komputer client. Pengaksesan dapat dilakukan apabila komputer telah terhubung dengan server. Berbeda dengan database desktop, di mana segala pemrosesan data harus dilakukan pada komputer yang bersangkutan.
Bila diinstal pada sistem operasi Microsoft Windows, maka MySQL berlisensi shareware, tetapi tidak mempuyai expired date (batas waktu). Sedangkan bila diinstal pada system operasi lainnya, maka berlisensi free sesuai dengan General Public Licence (GPL).
MySQL merupakan database yang dikembangkan dari bahasa SQL (Structured Query Language). SQL merupakan bahasa terstruktur yang digunakan untuk interaksi antara script program dengan databse server dalam hal pengolahan data. Dengan SQL, maka dapat dibuat tabel yang akan diisidata, memanipulasi data seperti menambah, menghapus dan meng-update data, serta membuat suatu perhitungan berdasarkan data yang ditemukan. [12]
Setiap RDBMS (Relation database management System) seperti Orcale, SQL Server, MySQL dan lain-lain, pasti memiliki tool yang dapat digunakan untuk mempermudah pengoperasian database. Oracle memiliki TOAD. SQL Server memiliki Enterprise Manager dan SQL Query Analyzer. Sedangkan MySQL memiliki tool atau aplikasi yang disebut PhpMyAdmin.
PhpMyAdmin merupakan aplikasi berbasiskan web yang dikembangakan menggunakan bahasa PHP. Melalui PhpMyAdmin, user dapat melakukan perintah query tanpa harus mengetikkan seperti pada MS DOS. Perintah tersebut misalnya
2.10. Model Perangkat Lunak
2.10.1. DFD (Data Flow Diagram)
Diagram aliran data merupakan model dari sistem untuk menggambarkan pembagian sistem ke modul yang lebih kecil [22]. Diagram aliran data dipakai untuk menunjukkan bagaimana data mengalir melalui serangkaian langkah pemrosesan. Data ditransformasikan pada setiap langkah sebelum ke tahap berikutnya. Langkah-langkah pemrosesan atau transformasi ini merupakan fungsi program ketika diagram aliran data digunakan untuk mendokumentasikan desain perangkat lunak. Namun demikian, pada model analisis, pemrosesan dapat dilakukan oleh orang atau komputer [5].
Salah satu keuntungan menggunakan diagram aliran data adalah memudahkan pemakai atau user yang kurang menguasai bidang komputer untuk mengerti sistem yang akan dikerjakan [22].
Beberapa komponen yang digunakan di DFD adalah: Simbol bisa dilihat pada daftar simbol Tabel 1. Simbol DFD.
a. Entitas Luar (Boundary)
Entitas luar merupakan kesatuan (entity) di lingkungan luar sistem yang dapat berupa orang, organisasi atau sistem lainnya yang berada di lingkungan luarnya yang akan memberikan input atau menerima output dari sistem [23].
Suatu proses adalah kegiatan atau kerja yang dilakukan oleh orang, mesin atau komputer dari hasil suatu arus data yang masuk kek dalam proses untuk menghasilkan arus data yang akan keluar dari proses [23].
d. Penyimpanan Data (Data Store)
Simpanan data DFD dapat di simbolkan dengan sepasang garis horizontal [23].
Diagram aliran data merupakan model dari sistem untuk menggambarkan pembagian sistem ke modul yang lebih kecil. Untuk memudahkan analisa dimulai dengan [22]:
a. Diagram Konteks (Context Diagram)
Diagram konteks adalah diagram yang terdiri dari suatu proses dan menggambarkan ruang lingkup suatu sistem. Diagram konteks merupakan level tertinggi dari DFD yang menggambarkan seluruh input ke sistem atau output dari sistem [22].
b. Diagram Rinci (Level Diagram)
Diagram rinci adalah diagram yang menguraikan proses apa yang ada dalam diagram zero atau diagram level atasnya [22].
2.10.2. Flowchart
Flowchart dapat diartikan sebagai suatu alat atau sarana yang menunjukkan
langkah-langkah yang harus dilaksanakan dalam penyelesaian suatu permasalahan untuk komputasi dengan cara mengekspresikannya ke dalam serangkaian simbol-simbol grafis khusus [20].
Tujuan utama dari penggunaan flowchart adalah untuk menggambarkan suatu tahapan penyelesaian masalah secara sederhana, terurai, rapi, dan jelas dengan menggunakan simbol-simbol yang standar. Tahap penyelesaian masalah yang disajikan harus jelas, sederhana, efektif, dan tepat. Dalam penulisan flowchart dikenal dua model, yaitu sistem flowchart dan program flowchart [1].
a. Sistem flowchart
Sistem flowchart ini tidak digunakan untuk menggambarkan urutan langkah untuk memecahkan masalah, tetapi hanya untuk menggambarkan prosedur dalam sistem yang dibentuk.
Dalam menggambarkan flowchart biasanya digunakan simbol-simbol yang standar, tetapi pemrogram juga dapat membuat simbol-simbol-simbol-simbol sendiri apabila simbol-simbol yang telah tersedia dirasa masih kurang. Dalam kasus ini pemrogram harus melengkapi gambar flowchart tersebut dengan kamus simbol untuk menjelaskan arti dari masing-masing simbol yang digunakan agara pemrogram lain dapat mengetahui maksud dari simbol-simbol tersebut [1].
Simbol bisa dilihat pada daftar simbol Tabel 2. Simbol sistem flowchart. b. Program flowchart
Program flowchart merupakan diagram alir yang menggambarkan urutan logika dari suatu prosedur pemecahan masalah. Untuk menggambarkan program flowchart telah tersedia simbol-simbol standar, namun demikian seperti halnya pada sistem flowchart, pemrogram dapat menambah khasanah simbol-simbol tersebut asalkan pemrogram melengkapinya dengan penggambaran program flowchart dengan kamus simbol [1].
Simbol bisa dilihat pada daftar simbol Tabel 3. Simbol program flowchart.
Manfaat menggunakan flowchart dalam mengembangkan prosedur pemecahan masalah komputasi.
1. Akan terbiasa berpikir secara sistematis dan terstruktur dalam setiap kesempatan
2. Akan lebih mudah mengecek dan menemukan bagian-bagian prosedur yang tidak valid dan bertele-tele.
Secara umum, proses penyelesaian suatu permasalahan terdiri dari lima langkah utama, yaitu:
1. Dimulainya suatu proses 2. Membaca data masukkan
3. Proses penyelesaian permasalahan 4. Mencetak hasil pengolahan/informasi 5. Diakhirinya semua proses pengolahan [20]
2.10.3. ERD
ERD (Entity Relationship Diagram) adalah suatu model jaringan yang menggunakan susunan data yang disimpan dalam sistem secara abstrak [22]. Komponen-komponen yang digunakan dalam diagram ini adalah:
Simbol bisa dilihat pada daftar simbol Tabel 4. Simbol ERD. a. Entitas
Digambarkan dengan sebuah bentuk persegi panjang. Entity adalah suatu apa saja yang ada di dalam sistem, nyata maupun abstrak dimana data tersimpan atau dimana terdapat data. Entitas diberi nama dengan kata benda dan dapat dikelompokkan dalam empat jenis nama, yaitu orang, benda, lokasi, kejadian (terdapat unsur waktu didalamnya).
b. Relasi atau Hubungan
Digambarkan dengan bentuk kotak berbentuk diamond dengan garis yang menghubungkan ke entity yang terkait. Hubungan atau relasi menunjukkan abstraksi dari sekumpulan hubungan yang mengakibatkan antara entity yang berbeda.
c. Atribut
d. Cardinality
Kardinalitas menunjukkan jumlah maksimum tupel yang dapat berelasi dengan entitas pada entitas yang lain [22]. Terdapat tiga macam kardinalitas relasi, yaitu:
a) One to One
Tingkat hubungan satu ke satu, dinyatakan dengan satu kejadian pada entitas pertama, hanya mempunyai satu hubungan dengan satu kejadian pada entitas yang kedua dan sebaliknya. Yang berarti setiap tupel pada entitas A berhubungan paling banyak satu tupel pada entitas B, dan begitu juga sebaliknya setiap tupel pada entitas B berhubungan dengan paling banyak satu tupel pada entitas A.
b) One to Many atau Many to One
Tingkat hungan satu ke banyak adalah sama dengan banyak ke satu. Tergantung dari arah mana hubungan tersebut dilihat. Untuk satu kejadian pada entitas yang pertama dapat mempunyai banyak hubungan dengan kejadian pada entitas yang kedua. Sebaliknya satu kejadian pada entitas yang kedua hanya dapat mempunyai satu hubungan dengan satu kejadian pada entitas yang pertama.
c) Many to Many
27
Berdasarkan uraian pada latar belakang masalah pada penelitian ini terdapat permasalahan dalam akurasi peringkasan. Pada aplikasi automatic summary mampu menemukan kata yang relevan sesuai dengan kata kunci (query) yang diinginkan oleh pengguna. Namun dengan kata kunci (query) yang dimasukkan secara manual, sehingga user bisa memasukkan kata apa pun, karena kata yang dimasukkan tidak dibatasi [3]. Data uji coba diambil dari surat kabar berbahasa Indonesia online sejumlah 30 berita. Hasil pengujian dibandingkan dengan ringksan manual yang menghasilkan rata-rata recall 60%, precision 77%, dan f-measure 66% [28]. Dan hasil dari summary atau ringkasan mengandung informasi dari teks asli dan panjangnya tidak lebih dari setengah teks asli [26]. Sehingga pada penelitian text summarization ini, menggunakan dua metode, yaitu metode K-Nearest Neighbors (KNN) untuk mengambil setengah teks asli dan metode
Maximum Marginal Relevance (MMR) untuk memilih kalimat yang nantinya akan
terbentuk sebuah ringkasan dari artikel berbahasa Indonesia.
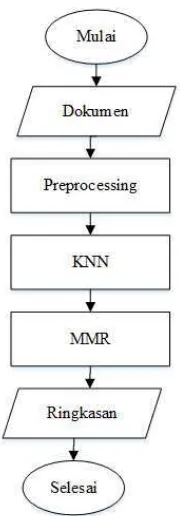
3.2. Analisis Sistem
Sistem text summarization yang akan dibangun dengan gambaran sistem yang tertera pada Gambar 3.1. Tahap sistem peringkasan teks dimulai dari penerimaan input teks dokumen hingga melakukan preprocessing. Hasil dari preprocessing akan klasifikasi terhadap kalimat yang lainnya menggunakan
K-Nearest Neighbors (KNN) untuk menentukan kalimat yang relevan dengan kalimat
Gambar 3. 1 Gambaran Sistem
3.2.1. Analisis Data Masukan
Data masukan yang diperlukan untuk menjalankan sistem ini sebelumnya dimasukkan terlebih dahulu ke dalam database. Sehingga user memilih berita mana yang akan di ringkas. Salah satu contoh data masukkan untuk penelitian text summarization dapat dilihat pada Tabel 3.1 dengan judul “Presiden Kunjungi
Terminal 3 Ultimate Bandara Soekarno-Hatta”.
Tabel 3. 1 Data Masukan
Presiden Kunjungi Terminal 3 Ultimate Bandara Soekarno-Hatta
Jakarta - Presiden Jokowi mengunjungi Terminal 3 Ultimate Bandara Soekarno-Hatta. Presiden
meninjau langsung pembangunan terminal yang sudah hampir selesai itu. Presiden tiba di
Terminal 3 Ultimate Bandara Soekarno-Hatta, Cengkareng, Rabu (11/5/2016) pukul 17:40 WIB.
Saat tiba, Jokowi disambut Menteri BUMN Rini Soemarno dan Dirut Angkasa Pura II Budi
Karya. Presiden langsung masuk ke kompleks terminal yang berukuran luas itu. Nampak para
pekerja masih sibuk bekerja saat Jokowi datang. Jokowi lalu berkeliling ke terminal yang
digadang akan bisa menampung ribuan penumpang itu. Dirut AP II lalu memberikan beberapa
3.2.2. Analisis Preprocessing
Tahap processing merupakan tahapan untuk mempersiapkan data masukan yang akan diolah pada tahap selanjutnya. Preprocessing pada penelitian ini terdiri dari beberapa tahapan, yaitu :,filtering, case folding, tokenizing kalimat, tokenizing kata, removal stopword, stemming, TF-IDF, dan cosine similarity. Proses preprocessing dapat dilihat pada Gambar 3.2.
Gambar 3. 2 Proses Preprocessing
3.2.2.1. Case Folding
Case Folding digunakan untuk mengubah semua huruf teks menjadi
karakter dengan huruf kecil dan pembuangan tanda baca dan angka. Contoh kata “Jakarta” diproses dengan case folding sehingga menghasilkan kata “jakarta”. Proses case folding dapat dilihat pada Gambar 3.3. Dan hasilnya dapat dilihat pada Tabel 3.2.
Gambar 3. 3 Proses Case Folding
Tabel 3. 2 Case Folding
Sebelum Sesudah
Jakarta - Presiden Jokowi mengunjungi
Terminal 3 Ultimate Bandara Soekarno-Hatta.
Presiden meninjau langsung pembangunan
terminal yang sudah hampir selesai itu.
Presiden tiba di Terminal 3 Ultimate Bandara
Soekarno-Hatta, Cengkareng, Rabu
jakarta - presiden jokowi mengunjungi
terminal 3 ultimate bandara soekarno-hatta.
presiden meninjau langsung pembangunan
terminal yang sudah hampir selesai itu.
presiden tiba di terminal 3 ultimate bandara
(11/5/2016) pukul 17:40 WIB. Saat tiba,
Jokowi disambut Menteri BUMN Rini
Soemarno dan Dirut Angkasa Pura II Budi
Karya. Presiden langsung masuk ke kompleks
terminal yang berukuran luas itu. Nampak para
pekerja masih sibuk bekerja saat Jokowi
datang. Jokowi lalu berkeliling ke terminal
yang digadang akan bisa menampung ribuan
penumpang itu. Dirut APII lalu memberikan
beberapa penjelasan kepada Jokowi mengenai
terminal 3 Ultimate yang hampir selesai.
pukul 17:40 wib. saat tiba, jokowi disambut
menteri bumn rini soemarno dan dirut
angkasa pura iibudi karya. presiden langsung
masuk ke kompleks terminal yang berukuran
luas itu. nampak para pekerja masih sibuk
bekerja saat jokowi datang. jokowi lalu
berkeliling ke terminal yang digadang akan
bisa menampung ribuan penumpang itu. dirut
ap ii lalu memberikan beberapa penjelasan
kepada jokowi mengenai terminal 3 ultimate
yang hampir selesai.
3.2.2.2. Filtering
Filtering digunakan untuk pembuangan tanda baca dan angka pada teks,
sehingga pada teks hanya terdapat huruf A..Z, a..z, spasi (“ ”) dan tanda baca titik (“.”). Proses filtering ini diterapkan pada penelitian text summarization bertujuan untuk memudahkan dalam tokenizing kalimat dan pada pembobotan kata (TF-IDF). Contoh pada kalimat “jakarta - presiden jokowi mengunjungi terminal 3 ultimate bandara soekarno-hatta.” setelah diproses filtering menjadi “jakarta presiden jokowi mengunjungi terminal ultimate bandara soekarno hatta.”. Proses filtering dapat dilihat pada Gambar 3.4. Dan hasilnya dapat dilihat pada Tabel 3.3.
Gambar 3. 4 Proses Filtering
Tabel 3. 3 Filtering
Sebelum Sesudah
jakarta - presiden jokowi mengunjungi
terminal 3 ultimate bandara soekarno-hatta.
presiden meninjau langsung pembangunan
terminal yang sudah hampir selesai itu.
presiden tiba di terminal 3 ultimate bandara
jakarta presiden jokowi mengunjungi terminal
ultimate bandara soekarno hatta. presiden
meninjau langsung pembangunan terminal
yang sudah hampir selesai itu. presiden tiba di
soekarno-hatta, cengkareng, rabu (11/5/2016)
pukul 17:40 wib. saat tiba, jokowi disambut
menteri bumn rini soemarno dan dirut angkasa
pura ii budi karya. presiden langsung masuk ke
kompleks terminal yang berukuran luas itu.
nampak para pekerja masih sibuk bekerja saat
jokowi datang. jokowi lalu berkeliling ke
terminal yang digadang akan bisa menampung
ribuan penumpang itu. dirut ap ii lalu
memberikan beberapa penjelasan kepada
jokowi mengenai terminal 3 ultimate yang
hampir selesai.
cengkareng rabu pukul wib. saat tiba jokowi
disambut menteri bumn rini soemarno dan dirut
angkasa pura ii budi karya. presiden langsung
masuk ke kompleks terminal yang berukuran
luas itu. nampak para pekerja masih sibuk
bekerja saat jokowi datang. jokowi lalu
berkeliling ke terminal yang digadang akan
bisa menampung ribuan penumpang itu. dirut
ap ii lalu memberikan beberapa penjelasan
kepada jokowi mengenai terminal ultimate
yang hampir selesai.
3.2.2.3. Tokenizing Kalimat
Tokenizing kalimat digunakan untuk memisahkan teks ke dalam bentuk satuan kalimat. Sehingga setiap kalimat akan dijadikan sebagai ukuran untuk penghitungan pada metode TF-IDF. Tokenizing kalimat pada sistem ini menggunakan delimeter titik (“.”). Proses tokenizing kalimat dapat dilihat pada Gambar 3.5. Dan hasilnya dapat dilihat pada Tabel 3.4.
Gambar 3. 5 Proses Tokenizing Kalimat
Tabel 3. 4 Tokenizing Kalimat
Sebelum Sesudah
Berita No Kalimat
jakarta presiden jokowi mengunjungi terminal
ultimate bandara soekarno hatta. presiden
meninjau langsung pembangunan terminal
yang sudah hampir selesai itu. presiden tiba di
terminal ultimate bandara soekarno hatta
cengkareng rabu pukul wib. saat tiba jokowi
1 jakarta presiden jokowi mengunjungi terminal
ultimate bandara soekarno hatta
2 presiden meninjau langsung pembangunan
terminal yang sudah hampir selesai itu
3 presiden tiba di terminal ultimate bandara
disambut menteri bumn rini soemarno dan dirut
angkasa pura ii budi karya. presiden langsung
masuk ke kompleks terminal yang berukuran
luas itu. nampak para pekerja masih sibuk
bekerja saat jokowi datang. jokowi lalu
berkeliling ke terminal yang digadang akan
bisa menampung ribuan penumpang itu. dirut
ap ii lalu memberikan beberapa penjelasan
kepada jokowi mengenai terminal ultimate
yang hampir selesai.
4 saat tiba jokowi disambut menteri bumn rini
soemarno dan dirut angkasa pura ii budi karya
5 presiden langsung masuk ke kompleks terminal
yang berukuran luas itu
6 nampak para pekerja masih sibuk bekerja saat
jokowi datang
7 jokowi lalu berkeliling ke terminal yang digadang
akan bisa menampung ribuan penumpang itu
8 dirut ap ii lalu memberikan beberapa penjelasan
kepada jokowi mengenai terminal ultimate yang
hampir selesai
3.2.2.4. Tokenizing kata
Tokenizing kata digunakan untuk memisahkan dari setiap kalimat menjadi
satuan kata. Pemisahan kalimat menggunakan delimeter spasi (“ ”). Tokenizing kata dilakukan untuk menghitung kata yang sama dalam satu proses pada TF-IDF. Proses tokenizing dapat dilihat pada Gambar 3.6. Dan hasilnya dapat dilihat pada Tabel 3.5.
Gambar 3. 6 Proses Tokeizing Kata
Tabel 3. 5 Tokenizing Kata
No Sebelum Sesudah
1 jakarta presiden jokowi mengunjungi
terminal ultimate bandara soekarno hatta
jakarta ultimate
presiden bandara
jokowi soekarno
mengunjungi hatta
terminal
2 presiden meninjau langsung pembangunan
terminal yang sudah hampir selesai itu
presiden yang
meninjau sudah
langsung hampir
pembangunan selesai
3 presiden tiba di terminal ultimate bandara
soekarno hatta cengkareng rabu pukul wib
presiden soekarno
4 saat tiba jokowi disambut menteri bumn rini
soemarno dan dirut angkasa pura ii budi
terminal yang berukuran luas itu
presiden terminal
langsung yang
masuk berukuran
ke luas
kompleks itu
6 nampak para pekerja masih sibuk bekerja saat
jokowi datang
digadang akan bisa menampung ribuan
penumpang itu
jokowi akan
lalu bisa
berkeliling menampung
ke ribuan
terminal penumpang
yang itu
digadang
8 dirut ap ii lalu memberikan beberapa
penjelasan kepada jokowi mengenai terminal
beberapa hampir
penjelasan selesai
kepada
3.2.2.5. Removal Stopword
Removal Stopword merupakan proses penghapusan kata umum yang tidak
memiliki makna atau kata yang kurang berarti dan sering muncul. Daftar stopword dapat dilihat pada lampiran Daftar Stopword. Pada sistem ini removal stopword digunakan agar kata umum yang tidak memiliki makna dan sering muncul tidak dihitung pada metode TF-IDF. Proses removal stopword dapat dilihat pada Gambar 3.7. Dan hasilnya dapat dilihat pada Tabel 3.6.
Gambar 3. 7 Proses Removal Stopword
Tabel 3. 6 Removal Stopword
No Sebelum Sesudah
1 jakarta ultimate jakarta ultimate
presiden bandara presiden bandara
jokowi soekarno jokowi soekarno
mengunjungi hatta mengunjungi hatta
terminal terminal
2 presiden yang presiden hampir
meninjau sudah meninjau selesai
langsung hampir langsung
pembangunan selesai pembangunan
terminal itu terminal
3 presiden soekarno presiden soekarno
tiba hatta tiba hatta
3.2.2.6. Stemming
Stemming merupakan proses pembuangan imbuhan pada kata menjadi kata
dasar. Sehingga setiap kata memiliki resepresentasi yang sama. Stemming dilakukan hanya untuk penghitungan pada TF-IDF.
Stemming pada sistem ini diterapkan dengan tujuan setiap kata memiliki representasi yang sama. Dan kata tersebut hanya dilakukan untuk perhitungan TF-IDF. Stemming yang digunakan pada penelitian ini, menggunakan stemming Nazief dan Adriani. Proses stemming dapat dilihat pada Gambar 3.8. Dan hasil stemming dapat dilihat pada Tabel 3.7.
Gambar 3. 8 Proses Stemming
Tabel 3. 7 Stemming
No Sebelum Sesudah
1 jakarta ultimate jakarta ultimate
presiden bandara presiden bandara
jokowi soekarno jokowi soekarno
mengunjungi hatta kunjung hatta
terminal terminal
2 presiden terminal presiden terminal
meninjau hampir tinjau hampir
langsung selesai langsung selesai
pembangunan bangun
3 presiden soekarno presiden soekarno
tiba hatta tiba hatta
di cengkareng di cengkareng
terminal rabu terminal rabu
bandara wib bandara wib
Kemudian kata-kata dikembalikan kembali menjadi sebuah kalimat yang telah dipreprocessing. Kalimat-kalimat ini akan dianggap dokumen pada penghitungan TF-IDF. Kalimat hasil preprocessing dapat dilihat pada Tabel 3.8.
Tabel 3. 8 Hasil Stemming
No Kalimat
S1 jakarta presiden jokowi kunjung terminal ultimate bandara soekarno
S2 presiden tinjau langsung bangun terminal hampir selesai
S4 tiba jokowi sambut menteri bumn rini soemarno dan dirut angkasa pura ii budi karya
S5 presiden langsung masuk ke kompleks terminal ukur luas
S6 para pekerja sibuk bekerja jokowi datang
S7 jokowi keliling ke terminal gadang tampung ribu tumpang
S8 dirut ap ii beri beberapa jelas jokowi terminal ultimate hampir selesai
3.2.2.7. Metode TF-IDF (Term Frequency - Inverse Document Frequency)
Proses selanjutnya yaitu penghitungan bobot kata menggunakan metode TF-IDF. Yaitu dengan menghitung kemunculan satu kata pada setiap kalimat.
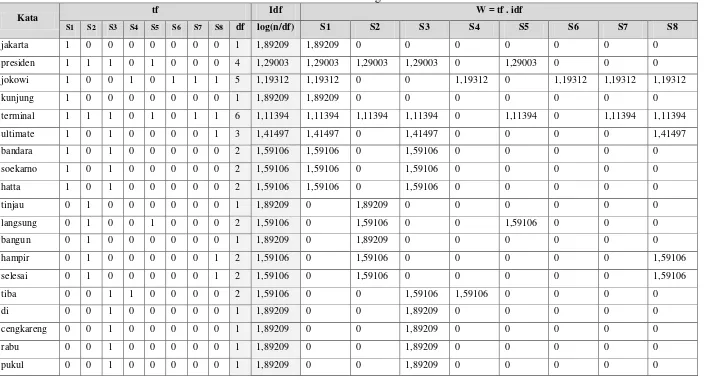
Sebagai contoh, kata “jakarta”.
1. Untuk mengisi kolom tf, hitung kemunculan kata “jakarta” pada setiap kalimat. Kata “jakarta” hanya muncul pada kalimat 1 saja, sehingga pada tf-S1 bernilai 1 dan tf-S lainnya diberi nilai 0.
2. Selanjutnya kolom df, jumlahkan kemunculan kata “jakarta” dalam satu berita (dari tf-S1 sampai tf-S8). Karena kata “jakarta” hanya muncul 1 kali pada kalimat 1, maka df bernilai 1.
3. Mengisi kolom idf, yaitu dengan rumus (2.1) dengan memasukkan nilai n (jumlah kata) dan df (proses no.2). Nilai n=78, dan df=1, sehingga idf kata “jakarta” = log(78/1) = 1,89209
4. Mengisi kolom w, yaitu dengan rumus (2.2) dengan memasukkan nilai tf (proses no.1) dan idf (proses no.3). Sehingga mengisi w-S1 = tf-S1.idf = 1x1,89209=1,89209 dan w-Sselanjutnya
Kata
S1 S2 S3 S4 S5 S6 S7 S8 df log(n/df) S1 S2 S3 S4 S5 S6 S7 S8
jakarta 1 0 0 0 0 0 0 0 1 1,89209 1,89209 0 0 0 0 0 0 0
presiden 1 1 1 0 1 0 0 0 4 1,29003 1,29003 1,29003 1,29003 0 1,29003 0 0 0
jokowi 1 0 0 1 0 1 1 1 5 1,19312 1,19312 0 0 1,19312 0 1,19312 1,19312 1,19312
kunjung 1 0 0 0 0 0 0 0 1 1,89209 1,89209 0 0 0 0 0 0 0
terminal 1 1 1 0 1 0 1 1 6 1,11394 1,11394 1,11394 1,11394 0 1,11394 0 1,11394 1,11394
ultimate 1 0 1 0 0 0 0 1 3 1,41497 1,41497 0 1,41497 0 0 0 0 1,41497
bandara 1 0 1 0 0 0 0 0 2 1,59106 1,59106 0 1,59106 0 0 0 0 0
soekarno 1 0 1 0 0 0 0 0 2 1,59106 1,59106 0 1,59106 0 0 0 0 0
hatta 1 0 1 0 0 0 0 0 2 1,59106 1,59106 0 1,59106 0 0 0 0 0
tinjau 0 1 0 0 0 0 0 0 1 1,89209 0 1,89209 0 0 0 0 0 0
langsung 0 1 0 0 1 0 0 0 2 1,59106 0 1,59106 0 0 1,59106 0 0 0
bangun 0 1 0 0 0 0 0 0 1 1,89209 0 1,89209 0 0 0 0 0 0
hampir 0 1 0 0 0 0 0 1 2 1,59106 0 1,59106 0 0 0 0 0 1,59106
selesai 0 1 0 0 0 0 0 1 2 1,59106 0 1,59106 0 0 0 0 0 1,59106
tiba 0 0 1 1 0 0 0 0 2 1,59106 0 0 1,59106 1,59106 0 0 0 0
di 0 0 1 0 0 0 0 0 1 1,89209 0 0 1,89209 0 0 0 0 0
cengkareng 0 0 1 0 0 0 0 0 1 1,89209 0 0 1,89209 0 0 0 0 0
rabu 0 0 1 0 0 0 0 0 1 1,89209 0 0 1,89209 0 0 0 0 0
sambut 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
menteri 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
bumn 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
rini 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
soemarno 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
dan 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
dirut 0 0 0 1 0 0 0 1 2 1,59106 0 0 0 1,59106 0 0 0 1,59106
angkasa 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
pura 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
ii 0 0 0 1 0 0 0 1 2 1,59106 0 0 0 1,59106 0 0 0 1,59106
budi 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
karya 0 0 0 1 0 0 0 0 1 1,89209 0 0 0 1,89209 0 0 0 0
masuk 0 0 0 0 1 0 0 0 1 1,89209 0 0 0 0 1,89209 0 0 0
ke 0 0 0 0 1 0 1 0 2 1,59106 0 0 0 0 1,59106 0 1,59106 0
kompleks 0 0 0 0 1 0 0 0 1 1,89209 0 0 0 0 1,89209 0 0 0
ukur 0 0 0 0 1 0 0 0 1 1,89209 0 0 0 0 1,89209 0 0 0
luas 0 0 0 0 1 0 0 0 1 1,89209 0 0 0 0 1,89209 0 0 0
para 0 0 0 0 0 1 0 0 1 1,89209 0 0 0 0 0 1,89209 0 0
kerja 0 0 0 0 0 2 0 0 2 1,59106 0 0 0 0 0 1,59106 0 0
sibuk 0 0 0 0 0 1 0 0 1 1,89209 0 0 0 0 0 1,89209 0 0
gadang 0 0 0 0 0 0 1 0 1 1,89209 0 0 0 0 0 0 1,89209 0
tampung 0 0 0 0 0 0 1 0 1 1,89209 0 0 0 0 0 0 1,89209 0
ribu 0 0 0 0 0 0 1 0 1 1,89209 0 0 0 0 0 0 1,89209 0
tumpang 0 0 0 0 0 0 1 0 1 1,89209 0 0 0 0 0 0 1,89209 0
ap 0 0 0 0 0 0 0 1 1 1,89209 0 0 0 0 0 0 0 1,89209
beri 0 0 0 0 0 0 0 1 1 1,89209 0 0 0 0 0 0 0 1,89209
beberapa 0 0 0 0 0 0 0 1 1 1,89209 0 0 0 0 0 0 0 1,89209
Apabila bobot kata telah diperoleh, kemudian hitung vektornya terlebih dahulu, untuk bisa menghitung similaritas antar kalimat dan query, dan similaritas kalimat dan teks.
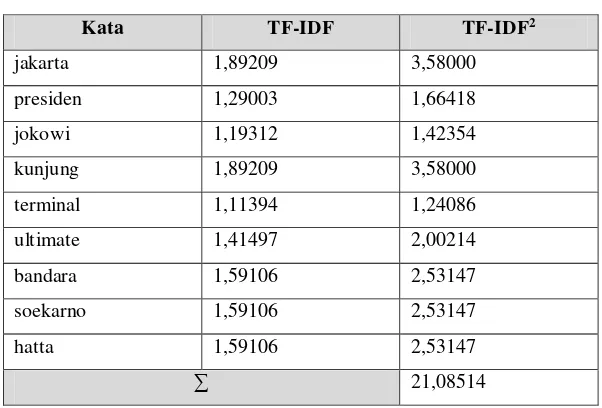
Proses penghitungan ∑ TF-IDF2 terhadap kalimat lain, yaitu dengan mengambil nilai w atau TF-IDF yang telah dihitung sebelumnya, kemudian di pangkat dua. ∑ TF-IDF2 dapat dilihat pada Tabel 3.10.
Tabel 3. 10 Perhitungan ∑ TF-IDF2 S1
Kata TF-IDF TF-IDF2
jakarta 1,89209 3,58000
presiden 1,29003 1,66418
jokowi 1,19312 1,42354
kunjung 1,89209 3,58000
terminal 1,11394 1,24086
ultimate 1,41497 2,00214
bandara 1,59106 2,53147
soekarno 1,59106 2,53147
hatta 1,59106 2,53147
∑ 21,08514
Perhitungan kalimat selanjutnya dapat dilihat pada lampiran Tabel Perhitungan ∑ TF-IDF2. Setelah mendapatkan nilai TF-IDF2 pada setiap kalimat,
kemudian hitung vektor setiap kalimat tersebut dengan mengakarkan jumlah TF-IDF2 setiap kalimat. Berikut adalah perhitungan vektor dari setiap kalimat, dapat dilihat pada Tabel 3.11.
Tabel 3. 11 Perhitungan Vektor
Kalimat ∑ TF-IDF2 Vektor = √∑ TF-IDF2
S1 21,08514 4,59186
S2 17,65946 4,20232
S3 32,93309 5,73874
S6 14,69502 3,83341
S7 23,09589 4,80582
S8 29,11244 5,39559
Setelah mendapatkan vektor, kemudian tiap kalimat dikalikan dengan kalimat yang lain untuk selanjutnya digunakan pada similarity.
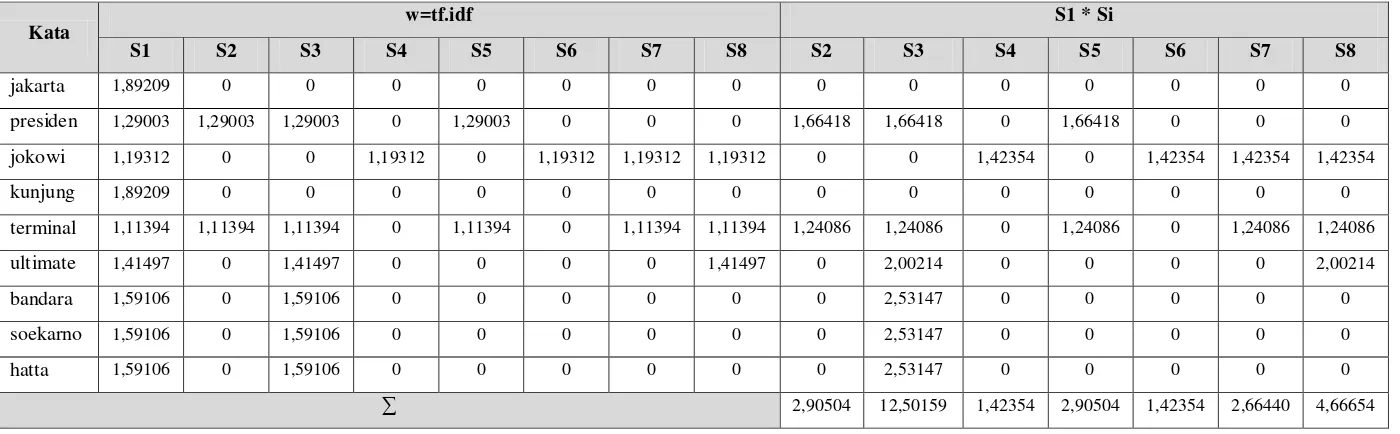
Contoh perkalian kalimat 1 dengan kalimat lain dengan kata “jakarta”, ambil w atau TF-IDF dari kata “jakarta” pada w-S1 dan w-S lainnya, selanjutnya kalikan w-S1 dengan w-S2, w-S1 dengan w-3, dan seterusnya.
Kata w=tf.idf S1 * Si
S1 S2 S3 S4 S5 S6 S7 S8 S2 S3 S4 S5 S6 S7 S8
jakarta 1,89209 0 0 0 0 0 0 0 0 0 0 0 0 0 0
presiden 1,29003 1,29003 1,29003 0 1,29003 0 0 0 1,66418 1,66418 0 1,66418 0 0 0
jokowi 1,19312 0 0 1,19312 0 1,19312 1,19312 1,19312 0 0 1,42354 0 1,42354 1,42354 1,42354
kunjung 1,89209 0 0 0 0 0 0 0 0 0 0 0 0 0 0
terminal 1,11394 1,11394 1,11394 0 1,11394 0 1,11394 1,11394 1,24086 1,24086 0 1,24086 0 1,24086 1,24086
ultimate 1,41497 0 1,41497 0 0 0 0 1,41497 0 2,00214 0 0 0 0 2,00214
bandara 1,59106 0 1,59106 0 0 0 0 0 0 2,53147 0 0 0 0 0
soekarno 1,59106 0 1,59106 0 0 0 0 0 0 2,53147 0 0 0 0 0
hatta 1,59106 0 1,59106 0 0 0 0 0 0 2,53147 0 0 0 0 0
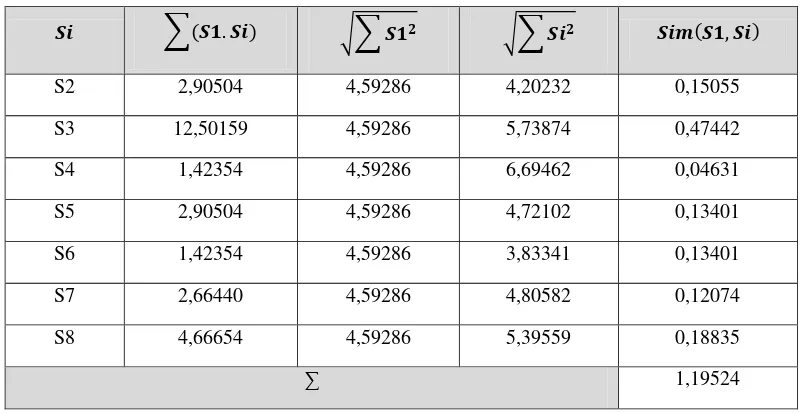
Setelah memperoleh hasil perkalian kalimat 1 dengan kalimat lainnya, selanjutnya menghitung cosine similarity dengan menggunakan rumus
, = ∑ .
√∑ 2√∑ 2
Tabel 3. 13 Perhitungan Cosine Similarity Kalimat 1 (S1)
∑ . √∑ √∑ � ,
S2 2,90504 4,59286 4,20232 0,15055
S3 12,50159 4,59286 5,73874 0,47442
S4 1,42354 4,59286 6,69462 0,04631
S5 2,90504 4,59286 4,72102 0,13401
S6 1,42354 4,59286 3,83341 0,13401
S7 2,66440 4,59286 4,80582 0,12074
S8 4,66654 4,59286 5,39559 0,18835
∑ 1,19524
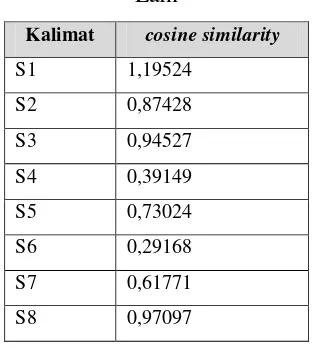
Perhitungan perkalian kalimat selanjutnya dapat dilihat pada lampiran Tabel perkalian antar kalimat. Dan perhitungan cosine similarity selanjutnya dapat dilihat pada lampiran Tabel cosine similarity. Hasil perhitungan cosine similarity antarkalimat dapat dilihat pada Tabel 3.14
Tabel 3. 14 Hasil Cosine Similarity Antar Kalimat
S1 S2 S3 S4 S5 S6 S7 S8
S1 1 0,15055 0,47442 0,04631 0,13401 0,08087 0,12074 0,18835
S2 0,15055 1 0,12046 0 0,27403 0 0,06144 0,27802
S3 0,47442 0,12046 1 0,06589 0,10723 0,06471 0,04499 0,10473
S4 0,04631 0,08998 0 1 0 0 0,04425 0,17957
S5 0,13401 0,14643 0,20066 0 1 0 0,16627 0,04871
S6 0,08087 0 0 0,05547 0 1 0,07727 0,06882
S7 0,12074 0,31214 0,04499 0,04425 0,16627 0,07727 1 0,10275
Hasil total cosine similarity kalimat satu terhadap kalimat yang lain dapat dilihat pada Tabel 3.15.
Tabel 3. 15 Hasil Total Cosine Similarity Kalimat Satu Terhadap Kalimat yang Lain
Kalimat cosine similarity
S1 1,19524
S2 0,87428
S3 0,94527
S4 0,39149
S5 0,73024
S6 0,29168
S7 0,61771
S8 0,97097
3.2.3. Metode KNN (K-Nearest Neighbors)
Gambar 3. 9 Proses KNN
Langkah pertama adalah menentukan parameter K (jumlah tetangga paling dekat). Pada penelitian text summarization ini nilai K = 3 dapat dilihat pada Lampiran F Menentukan Nilai K Pada KNN. Karena dokumen yang dipakai adalah dokumen kecil (artikel berita). Sehingga apabila diambil nilai K-nya terlalu besar maka lingkup tetangganya besar.
Tabel 3. 16 Relevansi Kalimat
Kalimat cosine similarity Klasifikasi
S1 1,19524 Relevan
S2 0,87428 Relevan
S3 0,94527 Relevan
S4 0,39149 Tidak Relevan
S5 0,73024 Tidak Relevan
S6 0,29168 Tidak Relevan
S7 0,61771 Tidak Relevan
S8 0,97097 Relevan
Rata-rata 0,75211
Kemudian urutkan objek yang mempunyai jarak terkecil dengan mengurutkan secara descending atau dari yang terbesar ke yang terkecil. Hasil urutan dapat dilihat pada Tabel 3.17.
Tabel 3. 17 Cosine Similarity Telah Terurut
Ranking Kalimat cosine similarity Klasifikasi
1 S1 1,19524 Relevan
2 S8 0,97097 Relevan
3 S3 0,94527 Relevan
4 S2 0,87428 Relevan
5 S5 0,73024 Tidak Relevan
6 S7 0,61771 Tidak Relevan
7 S4 0,39149 Tidak Relevan
8 S6 0,29168 Tidak Relevan
Selanjutnya kumpulkan Y (klasifikasi tetangga terdekat) dan tentukan hasil berdasarkan K.
Tabel 3. 18 Hasil KNN
Kalimat Tetangga Klasifikasi Tetangga Hasil
![Gambar 2. 1 Flowchart K-Nearest Neighbors [18]](https://thumb-ap.123doks.com/thumbv2/123dok/626444.75714/30.595.243.323.109.434/gambar-flowchart-k-nearest-neighbors.webp)