ANALISIS SELEKSI ATRIBUT PADA ALGORITMA
NAÏVE BAYES DALAM MEMPREDIKSI
PENYAKIT JANTUNG
TESIS
IVAN JAYA
117038072
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
ANALISIS SELEKSI ATRIBUT PADA ALGORITMA
NAÏVE BAYES DALAM MEMPREDIKSI
PENYAKIT JANTUNG
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
IVAN JAYA 117038072
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul :
Analisis Seleksi Atribut Pada Algoritma
Naive
Bayes
Dalam Memprediksi Penyakit Jantung
Nama : IVAN JAYA
Nomor Induk Mahasiswa : 117038072
Program Studi : MAGISTER (S2) TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Prof. Dr. Drs. Iryanto, M.Si Prof. Dr. Herman Mawengkang
Diketahui/disetujui oleh Magister Teknik Informatika Ketua,
PERNYATAAN
ANALISIS SELEKSI ATRIBUT PADA ALGORITMA
NAÏVE BAYES DALAM MEMPREDIKSI
PENYAKIT JANTUNG
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 28 Januari 2014
Ivan Jaya
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai civitas akademik Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini :
Nama : Ivan Jaya
Nim : 117038072
Program Studi : Teknik Informatika
Demi pengembangan ilmu pengetahuan, menyetujui memberikan kepada Universitas Sumatera Utara Hak Bebas Royaliti Non-Ekslusif (Non-Exclusive Royality Free
Right) atas tesis saya yang berjudul:
ANALISIS SELEKSI ATRIBUT PADA ALGORITMA
NAIVE BAYES DALAM MEMPREDIKSI
PENYAKIT JANTUNG
Beserta perangkat yang ada (jika diperlukan). Dengan hak bebas Royaliti
Non-Exclusive ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 28 Januari 2014
Telah di uji pada
Tanggal: 28 Januari 2014
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Herman Mawengkang Anggota : 1. Prof. Dr. Drs. Iryanto, M.Si
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Ivan Jaya, S.Si
Tempat dan Tanggal Lahir : Jakarta, 07 Juli 1984
Alamat Rumah : Bukit Johor Mas Blok C 37 Medan Telepon Rumah/Faks/Hp : 081361593553
E-mail : [email protected]
Instansi Tempat Bekerja : Telkomsel
Alamat Kantor : Jl. M.T. Haryono A-1 Gedung Uni Plaza West Tower Lt.8 Medan
DATA PENDIDIKAN
KATA PENGANTAR
Alhamdulillah puji syukur kehadirat Allah SWT, yang telah memberikan rahmat dan karunia-Nya kepada penulis, sehingga penulis dapat menyelesaikan tesis ini dengan judul: Analisis Seleksi Atribut Pada Algoritma Naïve Bayes dalam Memprediksi Penyakit Jantung.
Tesis ini disusun untuk melengkapi dan memenuhi persyaratan mencapai derajat kesarjanaan Strata-2 pada Program Studi Teknik Informatika, Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara. Penulis menyadari sepenuhnya, bahwa tesis ini selesai karena adanya dukungan dan bantuan dari berbagai pihak. Untuk itu pada kesempatan ini, penulis menyampaikan penghargaan dan ucapan terimakasih yang sedalam-dalamnya kepada:
1. Bapak, Prof. Dr. Herman Mawengkang sebagai Dosen Pembimbing Utama dan Bapak Prof. Dr. Drs. Iryanto, M.Si sebagai Dosen pembimbing kedua, dengan segala perhatian dan kesabaran telah memberikan bimbingan baik selama mengikuti pendidikan maupun dalam penyelesaian tesis ini.
2. Bapak Prof. Dr. Muhammad Zarlis, Bapak Dr. Zakarias Situmorang dan Dr. Benny Benyamin Nasution, sebagai dosen pembanding atas segala kritik dan sarannya.
3. Seluruh Dosen Pengajar Pascasarjana Program Studi Teknik Informatika yang telah memberikan bekal ilmu pengetahuan selama penulis mengikuti pendidikan. 4. Ayahanda, Ibunda, istri dan anak serta keluarga tercinta, atas doa restu dan
motivasinya yang telah diberikan selama ini.
5. Segenap civitas akademika Program Studi Pascasarjana Teknik Informatika Sumatera Utara yang selalu memberikan informasi dan pelayanan kepada penulis dengan tulus dan tak kenal lelah.
Tentulah tiada yang sempurna di dunia ini begitu pula dalam penulisan tesis ini, untuk itu penulis mengharapkan kritik dan saran dari pembaca demi kesempurnaan tesis ini selanjutnya.
Akhir kata penulis berharap semoga tesis ini dapat bermanfaat bagi semua pihak, khususnya dalam bidang pendidikan.
Medan, 28 Januari 2014
ABSTRAK
ATTRIBUTE SELECTION ANALYSIS AT NAIVE BAYES ALGORITHM IN HEART DISEASE PREDICTION
ABSTRACT
Data mining can be used to predict a disease from patient’s medical records. Some of the attribute from the data may have a value that is not relevant to the task of data mining and if included it can interfere and causing confusion for mining algorithm. It’s necessary to do attribute selection which is a process for identifying and eliminating attribute with values that are irrelevant or redundant. This research result the information or data about the difference of accuracy from prediction that used
Naive Bayes algorithm with or without attributes selection. Attribute selection using information gain implemented on Naive Bayes algorithm for classification task in heart disease prediction. Information gain head for sorting attributes based on rank, which is the higher information gain value from an attributes then the more significant the attributes for classification task.
DAFTAR ISI
DAFTAR ISI XII
DAFTAR TABEL XIV
DAFTAR GAMBAR XV
BAB 1 1
PENDAHULUAN 1
1.1. Latar Belakang 1
1.2. Rumusan Masalah 2
1.3. Tujuan Penelitian 2
1.4. Batasan Masalah 3
1.5. Manfaat Penelitian 3
BAB 2 4
LANDASAN TEORI 4
2.1. Data Mining 4
2.1.1. Tugas Utama Data Mining 4
2.1.2. Proses Data Mining 5
2.2. Klasifikasi (Classification) 6
2.2.1. Information Gain 8
2.2.2. Naive Bayes 10
2.3. Diskritisasi 12
2.4. Ukuran Kinerja 15
BAB 3 16
METODOLOGI PENELITIAN 16
3.1. Rancangan Penelitian 16
3.2. Teknik Pengumpulan Data 18
3.3. Alat dan Bahan Penelitian 18
3.3.1. Alat Penelitian 18
3.3.1. Bahan Penelitian 19
BAB 4 24
HASIL DAN PEMBAHASAN 24
4.1. Hasil Pengujian 24
4.1.1. Hasil Pengujian Tahap Pertama 24
4.1.2. Hasil Pengujian Tahap Kedua 26
4.1.3. Percobaan Tahap Ketiga 28
4.1.4. Percobaan Tahap Keempat 29
4.1.5. Percobaan Tahap Kelima 30
4.2. Pembahasan 31
BAB 5 33
KESIMPULAN DAN SARAN 33
5.1. Kesimpulan 33
5.2. Saran 34
DAFTAR PUSTAKA 35
DAFTAR TABEL
TABEL 2.1 Data Set Untuk Resiko Penyakit Jantung (Slocum, 2012) 9
TABEL 2.2 Pembagian Hasil “Yes”Dan “No” (Slocum, 2012) 9
TABEL 2.3 Data Cuaca Dan Keputusan Main Atau Tidak (Santosa, 2007) 11
TABEL 2.4 Confusion Matrix (Xhemali, Et Al. 2009) 15
TABEL 3.1 Diskritisasi Atribut Age 20
TABEL 3.2 Diskritisasi Atribut Trestbps 21
TABEL 3.3 Diskritisasi Atribut Chol 21
TABEL 3.4 Diskritisasi Atribut Thalach 22
TABEL 3.5 Diskritisasi Atribut Oldpeak 22
TABEL 4.1 Hasil Training Data Pada Tahap Pertama 25
TABEL 4.2 Hasil Pengujian Data Testing Pada Tahap Pertama 26
TABEL 4.3 Peringkat Atribut Berdasarkan Nilai Informasi Gain 27
TABEL 4.4 Hasil Pengujian Data Testing Tahap Kedua 27
TABEL 4.5 Hasil Pengujian Data Testing Tahap Ketiga 28
TABEL 4.6 Hasil Pengujian Data Testing Percobaan Tahap Keempat 29
TABEL 4.6 Hasil Pengujian Data Testing Percobaan Tahap Kelima 30
DAFTAR GAMBAR
Gambar 2.1 Langkah Proses Klasifikasi (Han And Kamber, 2006) 7
Gambar 2.2 Implementasi Naive Bayes Pada Data Pasien 12
Gambar 2.3 Data Kontinu Dengan Pasangan Nilai Kategorikal 13
Gambar 2.4 Pemisahan Dengan Informasi Gain 13
Gambar 2.5 Pemisahan Dengan Informasi Gain Terbaik 14
Gambar 3.1 Flowchart Proses Naive Bayes Dengan Dan Tanpa Seleksi Atribut 17
ABSTRAK
ATTRIBUTE SELECTION ANALYSIS AT NAIVE BAYES ALGORITHM IN HEART DISEASE PREDICTION
ABSTRACT
Data mining can be used to predict a disease from patient’s medical records. Some of the attribute from the data may have a value that is not relevant to the task of data mining and if included it can interfere and causing confusion for mining algorithm. It’s necessary to do attribute selection which is a process for identifying and eliminating attribute with values that are irrelevant or redundant. This research result the information or data about the difference of accuracy from prediction that used
Naive Bayes algorithm with or without attributes selection. Attribute selection using information gain implemented on Naive Bayes algorithm for classification task in heart disease prediction. Information gain head for sorting attributes based on rank, which is the higher information gain value from an attributes then the more significant the attributes for classification task.
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Data mining merupakan disiplin ilmu yang mempelajari metode untuk mengekstrak pengetahuan atau menemukan pola dari suatu data (Han and Kamber, 2006). Penerapan data mining sudah dilakukan pada beberapa bidang diantaranya bisnis, ilmu pengetahuan dan kesehatan.
Pada bidang kesehatan, data mining dapat dimanfaatkan untuk memprediksi suatu penyakit dari data rekam medis pasien. Dengan metode klasifikasi pada data mining, data seperti umur, jenis kelamin, tekanan darah dan atribut lainnya, dapat digunakan untuk memprediksi kemungkinan pasien terkena suatu penyakit.
Beberapa penelitian sudah dilakukan terkait penerapan data mining untuk memprediksi suatu penyakit. Salah satunya yaitu pengembangkan suatu sistem pendukung keputusan untuk memprediksi penyakit jantung dengan menggunakan algoritma Naive Bayes (Subbalakshmi, et al. 2011). Pada penelitian yang dilakukan Subbalaksmi, data yang digunakan adalah data penyakit jantung Cleveland Clinic
Foundation yang berasal dari University of California Irvine (UCI) repository dimana seluruh atribut pada data digunakan untuk memprediksi penyakit jantung.
Naive Bayes juga bekerja dengan baik pada banyak permasalahan kompleks, salah satunya diagnosis penyakit dengan berbantuan komputer (Dumitru, 2009).
Beberapa atribut pada data mungkin memiliki nilai yang tidak relevan untuk tugas
mining dan jika mengikutsertakan atribut yang tidak relevan dapat merugikan dan mengacaukan tugas algoritma data mining (Azhagusundari and Thanamani, 2013). Untuk itu perlu dilakukan seleksi atribut yang merupakan proses untuk mengidentifikasi dan menghilangkan atribut dengan nilai yang tidak relevan atau berlebihan (Abraham, et al. 2009).
Seleksi atribut dapat dilakukan dengan metode penyaringan dimana atribut diurutkan sesuai dengan peringkat (ranking) berdasarkan evaluasi dengan kriteria tertentu seperti akurasi dan konsistensi data (Danubianu, et al. 2012). Salah satu algoritma yang digunakan dalam seleksi atribut dengan metode penyaringan adalah informasi Gain. Informasi Gain menggunakan entropy untuk menentukan atribut terbaik. Entropy merupakan ukuran ketidakpastian. Semakin besar nilai informasi gain
dari suatu atribut, maka semakin signifikan atribut tersebut untuk tugas prediksi (Ladha and Deepa, 2011).
Berdasarkan uraian di atas, perlu dilakukan analisis seleksi atribut pada algoritma
Naive Bayes untuk melihat pengaruhnya terhadap akurasi dari hasil prediksi. Di dalam penelitian ini dapat dilihat algoritma mana yang lebih sesuai, Naive Bayes tanpa menggunakan seleksi atribut atau Naive Bayes dengan menggunakan seleksi atribut.
1.2. Rumusan Masalah
Pada penelitian ini ditemukan perubahan nilai akurasi dari hasil prediksi penyakit jantung jika seleksi atribut diterapkan pada algoritma Naive Bayes.
1.3. Tujuan Penelitian
Tujuan dari penelitian ini adalah diperolehnya informasi atau data tentang perbedaan akurasi dari hasil prediksi algoritma Naive Bayes tanpa menggunakan seleksi atribut dan dengan menggunakan seleksi atribut yang dipilih berdasarkan nilai informasi
1.4. Batasan Masalah
Batasan masalah pada penelitian ini adalah sebagai berikut: 1. Waktu pelaksanaan penelitian adalah selama enam bulan.
2. Data yang digunakan dalam penelitian ini adalah data rekam medis penyakit jantung Cleveland Clinic Foundation yang diperoleh dari UCI repository ( http://www.cs.umb.edu/~rickb/files/UCI/heart-c.arff ).
1.5. Manfaat Penelitian
Manfaat dari penelitian ini adalah:
1. Dapat digunakan seseorang dalam pembuatan sistem aplikasi pengambilan keputusan dari sekumpulan data.
BAB 2
LANDASAN TEORI
2.1. Data Mining
Data mining merupakan disiplin ilmu yang mempelajari metode untuk mengekstrak pengetahuan atau menemukan pola dari suatu data (Han and Kamber, 2006). Data mining sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santosa, 2007).
2.1.1. Tugas Utama Data Mining
Secara umum data mining memiliki empat tugas utama (Sahu, et al. 2011): 1. Klasifikasi (Classification)
Klasifikasi bertujuan untuk mengklasifikasikan item data menjadi satu dari beberapa kelas standar. Sebagai contoh, suatu program email dapat mengklasifikasikan email yang sah dengan email spam. Beberapa algoritma klasifikasi antara lain pohon keputusan, nearest neighbor, naïve bayes, neural
networks dan support vector machines. 2. Regresi (Regression)
3. Pengelompokan (Clustering)
Clustering merupakan metode pengelompokan sejumlah data ke dalam klaster (group) sehingga dalam setiap klaster berisi data yang semirip mungkin.
4. Pembelajaran Aturan Asosiasi (Association Rule Learning)
Pembelajaran aturan asosiasi mencari hubungan antara variabel. Sebagai contoh suatu toko mengumpulkan data kebiasaan pelanggan dalam berbelanja. Dengan menggunakan pembelajaran aturan asosiasi, toko tersebut dapat menentuan produk yang sering dibeli bersamaan dan menggunakan informasi ini untuk tujuan pemasaran.
2.1.2. Proses Data Mining
Proses dari data mining mempunyai prosedur umum dengan langkah-langkah sebagai berikut (Kantardzic, 2003):
1. Merumuskan permasalahan dan hipotesis
Pada langkah ini dispesifikasikan sekumpulan variabel yang tidak diketahui hubungannya dan jika memungkinkan dispesifikasikan bentuk umum dari keterkaitan variabel sebagai hipotesis awal.
2. Mengoleksi data
Langkah ini menitikberatkan pada cara bagaimana data dihasilkan dan dikoleksi. Secara umum ada dua kemungkinan yang berbeda. Yang pertama adalah ketika proses pembangkitan data dibawah kendali dari ahli. Pendekatan ini disebut juga dengan percobaan yang dirancang (designed experiment). Kemungkinan yang kedua adalah ketika ahli tidak memiliki pengaruh pada proses pembangkitan data, dikenal sebagai pendekatan observasional.
3. Pra pengolahan data
Pra pengolahan data melibatkan dua tugas utama yaitu: a. Deteksi dan pembuangan data asing (outlier)
mengembangkan metode pemodelan yang kuat yang tidak merespon data asing.
b. Pemberian skala, pengkodean dan seleksi fitur
Pra pengolahan data menyangkut beberapa langkah seperti memberikan skala variabel dan beberapa jenis pengkodean. Sebagai contoh, satu fitur dengan range [0, 1] dan yang lain dengan range [-100, 100] tidak akan memiliki bobot yang sama pada teknik yang diaplikasikan dan akan berpengaruh pada hasil akhir data mining. Oleh karena itu, disarankan untuk pemberian skala dan membawa fitur-fitur tersebut ke bobot yang sama untuk analisis lebih lanjut.
4. Mengestimasi model
Pemilihan dan implementasi dari tehnik data mining yang sesuai merupakan tugas utama dari fase ini. Proses ini tidak mudah, biasanya dalam pelatihan, implementasi berdasarkan pada beberapa model dan pemilihan model yang terbaik merupakan tugas tambahan.
5. Menginterpretasikan model dan menarik kesimpulan
Pada banyak kasus, model data mining akan membantu dalam pengambilan keputusan. Metode data mining modern diharapkan akan menghasilkan hasil akurasi yang tinggi dengan menggunakan model dimensi-tinggi.
Pengetahuan yang baik pada keseluruhan proses sangat penting untuk kesuksesan aplikasi. Tidak perduli seberapa kuat metode data mining yang digunakan, hasil dari model tidak akan valid jika pra pengolahan dan pengkoleksian data tidak benar atau jika rumusan masalah tidak berarti.
2.2. Klasifikasi (Classification)
a. Pembelajaran (learning) : pelatihan data dianalisis oleh algoritma klasifikasi. b. Klasifikasi: data yang diujikan digunakan untuk mengkalkulasi akurasi dari
aturan klasifikasi. Jika akurasi dianggap dapat diterima, aturan dapat diterapkan pada klasifikasi data tuple yang baru.
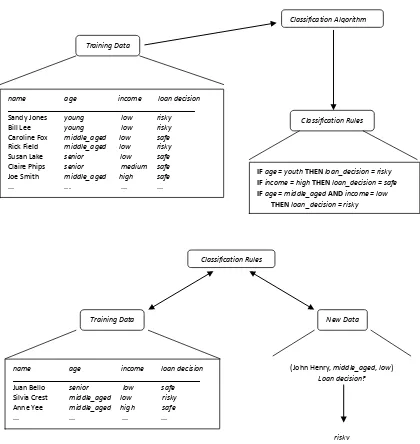
Gambar 2.1 Langkah Proses Klasifikasi (Han and Kamber, 2006) name age income loan decision
_______________________________________________ Sandy Jones young low risky Bill Lee young low risky Caroline Fox middle_aged low safe Rick Field middle_aged low risky Susan Lake senior low safe Claire Phips senior medium safe Joe Smith middle_aged high safe ... ... ... ...
Training Data
Classification Algorithm
Classification Rules
IF age = youth THEN loan_decision = risky IF income = high THENloan_decision = safe IF age = middle_agedAND income = low THEN loan_decision = risky
Classification Rules
Training Data New Data
(John Henry, middle_aged, low) Loan decision?
risky name age income loan decision
2.2.1. Information Gain
Information gain menggunakan entropy untuk menentukan atribut terbaik. Entropy merupakan ukuran ketidakpastian dimana semakin tinggi entropy, maka semakin tinggi ketidakpastian. Rumus dari entropy (Slocum, 2012):
�(�) = − � ��(�) log2��(�)
�
�=1
Dimana:
• E(S) adalah informasi entropy dari atribut S
• n adalah jumlah dari nilai-nilai yang berbeda pada atribut S
• fs(j) adalah frekuensi dari nilai j pada S
• log2adalah logaritma biner
Information gain dari output data atau variabel dependent y yang dikelompokkan berdasarkan atribut A, dinotasikan dengan gain(y,A). Information gain, gain(y,A), dari atribut A relatif terhadap output data y adalah (Santosa, 2007):
����(�,�) =�������(�)− � ��
� �∈�����(�)
������� (��)
dimana nilai(A) adalah semua nilai yang mungkin dari atribut A, dan yc adalah subset dari y dimana A mempunyai nilai c. Term yang pertama pada rumus information gain
di atas adalah entropy total y dan term kedua adalah entropy sesudah dilakukan pemisahan data berdasarkan atribut A.
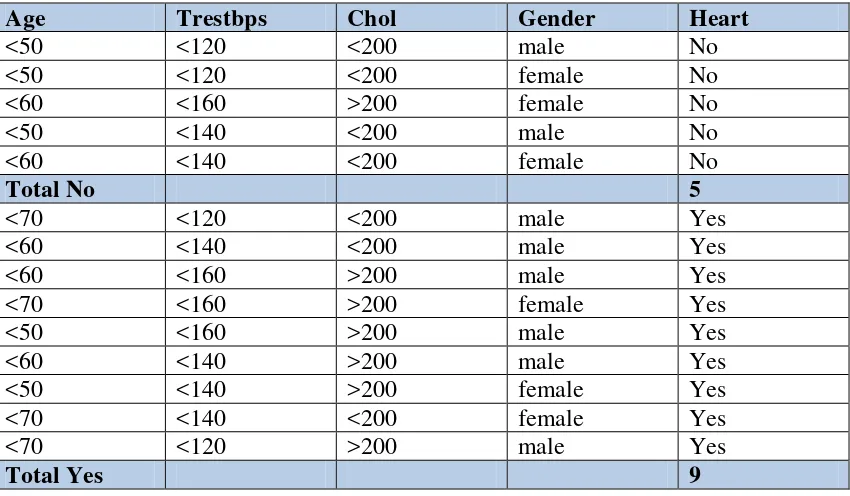
Tabel 2.1 Data Set Untuk Resiko Penyakit Jantung (Slocum, 2012) untuk menghitung entropy yang ditunjukkan pada tabel di bawah:
Tabel 2.2 Pembagian Hasil “Yes”dan “No” (Slocum, 2012)
Pada contoh di atas, total entropy adalah:
E = ((-5/14)log2(5/14)) + ((-9/14)log2(9/14)) = 0.94
Selanjutnya dilakukan perhitungan information gain di masing-masing kolom. Dimulai dari kolom Gender, tinjau nilai Male dan Female dan dihitung entropy “Yes” dan “No” dimana diperoleh Gender/Female (6/14) dan Gender/Male (8/14) dan dikurangi dari total entropy yang sudah dihitung sebelumnya.
Entropy female = Entropy[3, 3] = −3
6log2 3 6−
3 6log2
3 6= 1
Entropy male = Entropy[6, 2] = −6
8log2 6 8−
2 8log2
2
8= 0,811
Gain = TotalEntropy – (6/14 x (EntropyFemale)) – (8/14 x (EntropyMale)) = 0.048
2.2.2. Naive Bayes
Naive Bayes merupakan algoritma klasifikasi yang sederhana dimana setiap atribut bersifat independent dan memungkinkan berkontribusi terhadap keputusan akhir (Xhemali, et al. 2009).
Dasar dari teorema Naïve Bayes yang dipakai dalam pemrograman adalah rumus bayes yaitu sebagai berikut (Han and Kamber, 2006) :
�(�|�) =�(�|�)�(�)
�(�)
dimana P(H|X) merupakan probabilitas H di dalam X atau dengan bahasa lain P(H|X) adalah persentase banyaknya H di dalam X, P(X|H) merupakan probabilitas X di dalam H, P(H) merupakan probabilitas prior dari H dan P(X) merupakan probabilitas prior dari X.
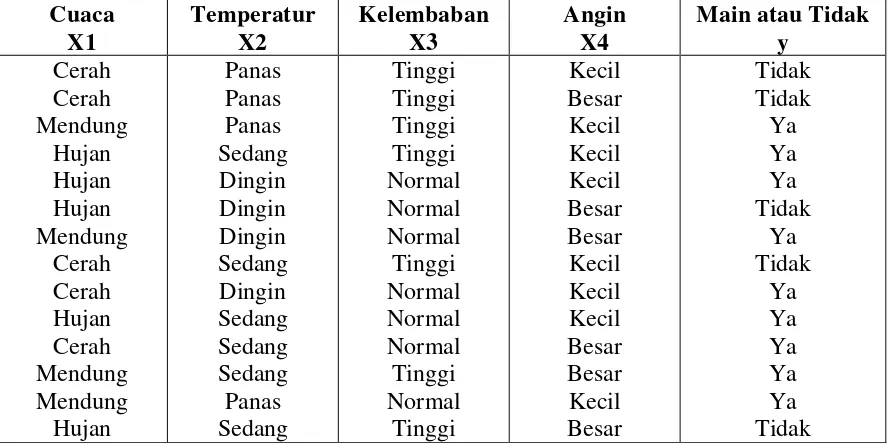
Tabel 2.3 Data Cuaca dan Keputusan Main atau Tidak (Santosa, 2007)
Main atau Tidak y
(Cuaca = Cerah, Temperatur = Dingin, Kelembaban = Tinggi, Angin = Besar) P(main) = 9
P(main) P(Cerah/main) P(Dingin/main) P(Tinggi/main) P(Besar/main) = 9� ∗14 2� ∗9 3� ∗9 3� ∗9 3�9= 0.0053
P(tidak) P(Cerah/tidak) P(Dingin/tidak) P(Tinggi/tidak) P(Besar/tidak) = 5� ∗14 3� ∗5 1� ∗5 4� ∗5 3�5 = 0.0206
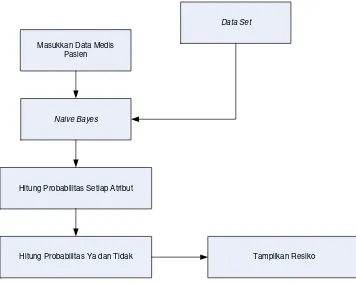
Implementasi dari Naive Bayes pada data pasien dengan menghitung korelasi antara target dan variabel lainnya, dapat digambarkan sebagai berikut (Subbalakshmi, et al. 2011):
Masukkan Data Medis Pasien
Naive Bayes
Hitung Probabilitas Setiap Atribut
Hitung Probabilitas Ya dan Tidak Tampilkan Resiko Data Set
Gambar 2.2 Implementasi Naive Bayes pada data pasien (Subbalakshmi, et al. 2011)
2.3.Diskritisasi
Beberapa data memiliki format yang kompleks dimana terdapat penggabungan tipe data numerik dan diskrit. Data diskrit lebih dekat ke tingkat pengetahuan representasi manusia dan terkadang lebih efisien. (Yul, 2010).
Diskritisasi merupakan peralihan dari data kontinu menjadi data diskrit (kategori) (Gorunescu, 2011). Diskritisasi juga dapat digunakan untuk mengubah atribut dengan nilai numerik menjadi nilai nominal / kategorikal (Sullivan, 2014). Terdapat dua bentuk diskritisasi yaitu diskritisasi yang tidak diawasi (unsupervised) dan diskritisasi yang diawasi (supervised). Diskritisasi yang tidak diawasi diperuntukkan untuk tugas
data miningclustering sedangkan diskritisasi yang diawasi diperuntukkan untuk tugas
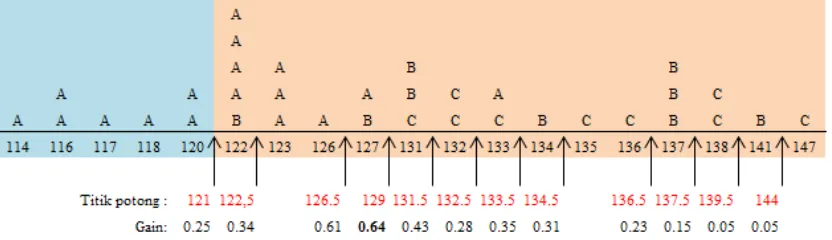
Berikut contoh diskritisasi dengan menggunakan informasi Gain:
A
A
A A B B
A A A A A B C A B C
A A A A A B A A B C C C B C C B C B C
114 116 117 118 120 122 123 126 127 131 132 133 134 135 136 137 138 141 147
Gambar 2.3 Data Kontinu dengan Pasangan Nilai Kategorikal
Dari gambar di atas terlihat data kontinu dari nilai 114 sampai dengan 147 yang memiliki pasangan nilai kategorikal yaitu A, B dan C.
Informasi dari data set:
P[Y=A]=17/35, P[Y=B]=9/35, P[Y=C]=9/35
Info(Data set) = 17/35 x log2(17/35) + 9/35 x log2 (9/35) + 9/35 x log2 (9/35) = 1.51
Gambar 2.4 Pemisahan dengan Informasi Gain
Informasi dari data set setelah pemisahan pada 121: P[Y=A | kiri]=7/7, P[Y=B |kiri]=0/7, P[Y=C |kiri]=0/7
Info(Data set |pemisahan) = 7/35 x Info (data set kiri) + 28/35 x Info (data set kanan) = 7/35 x 0 + 28/35 x 1.58=1.26
Info (data set kanan) =10/28 x log2 (10/28) + 2 x 9/28 x log2 (9/28) =1.58 Informasi Gain setelah pemisahan pada 121 = 1.51 – 1.26 = 0.25
Gambar 2.5 Pemisahan dengan Informasi Gain Terbaik
Dari gambar di atas dapat dilihat bahwa informasi Gain maksimum terdapat pada titik potong 129.
Gain untuk pemotongan baru 126,5 sampai [114, 129]: [114, 126.5], [126.5, 129] adalah:
Info(Y | [114, 129]) = -16/18 x log2(16/18) – 2/18 x log2(2/18) = 0.503 Info(Y | [114, 126.5]) = -15/18 x log2(15/18) – 1/16 x log2(1/16) = 0.337 Info(Y | [126.5, 129]) = -1/2 x log2(1/2) – 1/2 x log2(1/2) = 1
= Info (Y | [114, 129]) – 16/18 x Info (Y | [114, 126.5]) – 2/18 x Info (Y | [126.5, 129])
= 0,503 – 16/18 x 0,337 – 2/18 x 1 = 0.092
2.4.Ukuran Kinerja
Percobaan dari penelitian dievaluasi dengan pengukuran akurasi, presisi, recall dan f-measure. Pengukuran dilakukan dengan menggunakan tabel klasifikasi yang bersifat prediktif, disebut juga dengan Confusion Matrix (Xhemali, et al. 2009).
Tabel 2.4 Confusion Matrix (Xhemali, et al. 2009) Prediksi
Sakit Tidak
Aktual (sebenarnya)
Sakit TP FN
Tidak FP TN
dimana:
TP (True Positive) Jumlah prediksi yang benar dari data yang sakit.
FP (False Positive) Jumlah prediksi yang salah dari data yang tidak sakit.
FN (False Negative) Jumlah prediksi yang salah dari data yang sakit.
TN (True Negative) Jumlah prediksi yang benar dari data yang tidak sakit.
Dari Confusion Matrix dapat diukur akurasi, presisi dan recall untuk menganalisa kinerja dari algoritma dalam melakukan klasifikasi untuk mendeteksi penyakit.
Akurasi merupakan persentase dari prediksi yang benar. Presisi adalah ukuran dari akurasi dari suatu kelas tertentu yang telah diprediksi. Recall merupakan persentase dari data dengan nilai positif yang nilai prediksinya juga positif. Adapun perhitungannya adalah sebagai berikut:
Akurasi = (TP+TN) / (TP+FP+TN+FN) Presisi = TN / (FP+TN)
BAB 3
METODOLOGI PENELITIAN
Seleksi atribut merupakan proses untuk mengidentifikasi dan menghilangkan atribut dengan nilai yang tidak relevan atau berlebihan. Pada penelitian ini dilakukan seleksi atribut dengan menggunakan information gain yang diimplementasikan pada algoritma Naive Bayes untuk tugas klasifikasi dalam memprediksi penyakit jantung.
Information gain bertujuan melakukan pengurutan atribut berdasarkan peringkat (rank) dimana semakin besar nilai information gain dari suatu atribut maka semakin signifikan atribut tersebut untuk tugas prediksi.
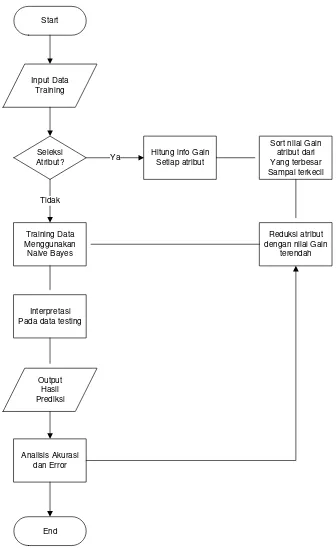
3.1. Rancangan Penelitian
Start
Input Data Training
Seleksi Atribut?
Training Data Menggunakan Naive Bayes
Interpretasi Pada data testing
Tidak
Output Hasil Prediksi
Hitung info Gain Setiap atribut
Sort nilai Gain atribut dari Yang terbesar Sampai terkecil
Reduksi atribut dengan nilai Gain
terendah Ya
End Analisis Akurasi
dan Error
3.2. Teknik Pengumpulan Data
Teknik pengumpulan data yang digunakan peneliti dalam pengumpulan data adalah sebagai berikut:
1. Mengumpulkan literatur, jurnal, paper, dan bacaan-bacaan lainnya yang berhubungan dengan algoritma klasifikasi data mining.
2. Mengumpulkan data penelitian yang diperoleh secara online dari UCI repository.
3. Melakukan observasi terhadap data penelitian yang diperoleh dengan mengajukan pertanyaan-pertanyaan (wawancara) kepada nara sumber yang mengetahui dengan detail setiap atribut pada data penelitian yang digunakan. Pada penelitian ini, peneliti melakukan wawancara dengan dokter spesialis penyakit jantung di rumah sakit Adam Malik Medan yang bernama dr. Cut Aryfa Andra, Sp.JP.
3.3. Alat dan Bahan Penelitian
3.3.1. Alat Penelitian
Pada penelitian ini digunakan alat penelitian berupa perangkat keras dan perangkat lunak sebagai berikut:
a. Perangkat keras
Satu unit komputer dengan spesifikasi sebagai berikut: - Processor Intel Pentium Core i3 1.40 GHz
- RAM DDR2 4 GB. - HDD 200 GB. b. Perangkat lunak
- Sistem operasi Windows 7 Ultimate. - PHP versi 5.4.4
3.3.1. Bahan Penelitian
Bahan penelitian yang digunakan pada penelitian ini adalah data rekam medis penyakit jantung Cleveland yang diperoleh secara online dari website UCI repository. Data ini terdiri dari 14 atribut dimana atribut yang terakhir merupakan kelas. Berikut keterangan dari setiap atribut-nya:
1. age 2. sex
3. cp : jenis nyeri pada dada: - typical_angina
- atypical_angina
- non-anginal pain
- asymptomatic
4. trestbps : tekanan darah saat beristirahat (dalam mm Hg) 5. chol (serum kolesterol dalam mg/dl)
6. fbs (fasting blood sugar > 120 mg/dl)
7. restecg : hasil elektrokardiografi saat istirahat - value 0 : normal
- value 1 : gelombang ST-T yang tidak normal (inversi gelombang T dan/atau elevasi ST atau depresi > 0.05 mV)
- value 2 : menunjukkan kemungkinan atau kepastian hipertrofi ventrikel kiri dengan kriteria Estes.
8. thalach : detak jantung maksimum
9. exang : latihan menyebabkan nyeri dada (1 = Yes, 0 = No)
10.oldpeak : ST depresi diinduksi oleh latihan yang relatif sampai istirahat 11.slope : lekukan dari puncak segmen ST pada saat latihan
Nilai 1 : upsloping Nilai 2 : flat
Nilai 3 : downsloping
12.ca : jumlah pembuluh besar (0-3) diwarnai oleh flourosopy 13.thal : 3 = normal, 6 = fixed defect, 7 = reversable defect
14.num : diagnosa penyakit jantung (status penyakit dari angiografi) Nilai 0 : < 50% diameter penyempitan
Dari wawancara dengan dr. Cut Aryfa Andra, Sp.JP, atribut di atas merupakan atribut yang digunakan untuk penyakit jantung khususnya penyakit jantung koroner. Atribut di atas dapat dibagi menjadi 2 bagian yang disesuaikan dengan gejala penyakit jantung yaitu kronis dan akut. Gejala penyakit jantung kronis memerlukan hampir semua atribut untuk diagnosa gangguan pada jantung dimana atribut nomor 3, 4, 7 sampai 14 merupakan atribut terikat dan atribut nomor 1, 2, 5 dan 6 merupakan atribut bebas (penunjang). Sementara untuk gejala akut, atribut nomor 3 sampai 7 dan 14 merupakan atribut terikat serta atribut nomor 1, 2 dan 13 merupakan atribut penunjang. Atribut nomor 8 sampai 13 berkaitan dengan latihan (treadmill) tidak diikutsertakan. Pada penelitian ini atribut pada data penelitian digunakan hanya untuk memprediksi penyakit jantung dengan gejala koronis.
Beberapa atribut di atas memiliki nilai kontinu. Pada penelitian ini dilakukan diskritisasi terhadap nilai kontinu menjadi nilai diskrit. Data diskrit biasanya memberikan hasil prediksi yang lebih baik dibandingkan data kontinu (Yul, 2010). Adapun atribut-atribut yang didiskretisasi adalah sebagai berikut:
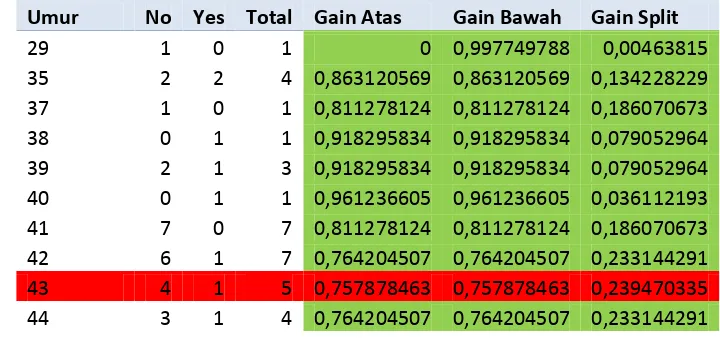
1. Age
Pada atribut age, nilai informasi gain yang tertinggi terdapat pada umur 43 tahun sehingga pada titik tersebut dijadikan pemisah.
Tabel 3.1 Diskritisasi Atribut Age
Umur No Yes Total Gain Atas Gain Bawah Gain Split
29 1 0 1 0 0,997749788 0,00463815
35 2 2 4 0,863120569 0,863120569 0,134228229
37 1 0 1 0,811278124 0,811278124 0,186070673
38 0 1 1 0,918295834 0,918295834 0,079052964
39 2 1 3 0,918295834 0,918295834 0,079052964
40 0 1 1 0,961236605 0,961236605 0,036112193
41 7 0 7 0,811278124 0,811278124 0,186070673
42 6 1 7 0,764204507 0,764204507 0,233144291
43 4 1 5 0,757878463 0,757878463 0,239470335
44 3 1 4 0,764204507 0,764204507 0,233144291
2. Trestbps
Tabel 3.2 Diskritisasi Atribut Trestbps
Trestbps No Yes Total Gain Atas Gain Bawah Gain Split
94 2 0 2 0 0,998121458 0,009309375
100 2 2 4 0,918295834 0,998042334 0,001723025
101 1 0 1 0,863120569 0,998397774 0,003733551
102 2 0 2 0,764204507 0,999010271 0,009011516
105 2 0 2 0,684038436 0,999484234 0,015389331
106 1 0 1 0,650022422 0,999666365 0,018872975
108 3 2 5 0,787126586 0,999801825 0,015806969
110 6 5 11 0,905928216 0,999900157 0,010737602
112 5 2 7 0,898058793 0,99997285 0,015391059
114 0 1 1 0,918295834 1 0,012204101
115 3 0 3 0,89049164 0,999743186 0,019124856
118 5 2 7 0,886540893 0,998875725 0,024571065
120 15 9 24 0,913460145 0,993650712 0,032048286
122 3 1 4 0,909022156 0,990785248 0,037121473
123 0 1 1 0,918295834 0,991927046 0,033312362
124 2 3 5 0,934068055 0,992527016 0,028441564
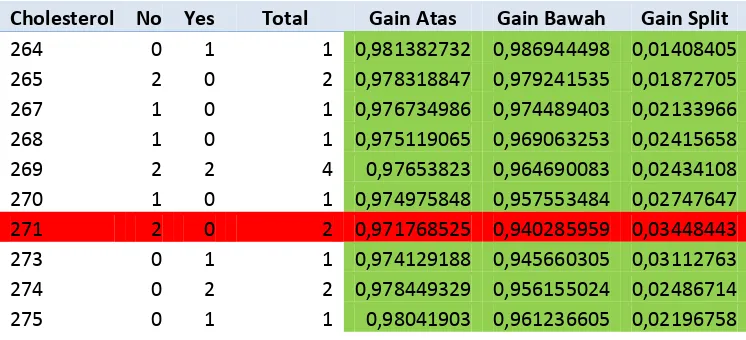
3. Chol
Pada atribut chol, nilai informasi gain yang tertinggi terdapat pada nilai 271 sehingga pada titik tersebut dijadikan pemisah.
Tabel 3.3 Diskritisasi Atribut Chol
Cholesterol No Yes Total Gain Atas Gain Bawah Gain Split
264 0 1 1 0,981382732 0,986944498 0,01408405
265 2 0 2 0,978318847 0,979241535 0,01872705
267 1 0 1 0,976734986 0,974489403 0,02133966
268 1 0 1 0,975119065 0,969063253 0,02415658
269 2 2 4 0,97653823 0,964690083 0,02434108
270 1 0 1 0,974975848 0,957553484 0,02747647
271 2 0 2 0,971768525 0,940285959 0,03448443
273 0 1 1 0,974129188 0,945660305 0,03112763
274 0 2 2 0,978449329 0,956155024 0,02486714
275 0 1 1 0,98041903 0,961236605 0,02196758
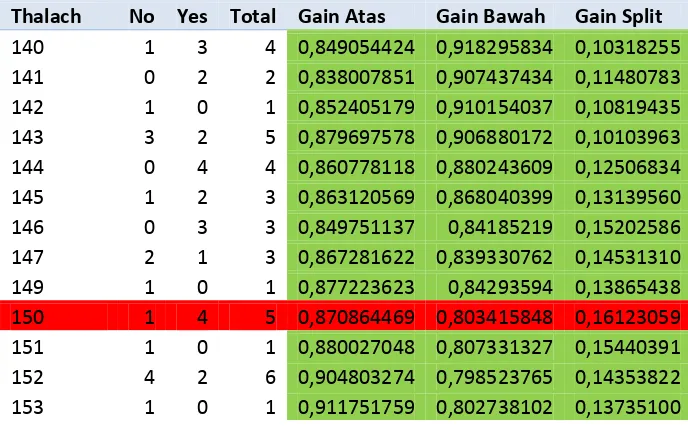
4. Thalach
Tabel 3.4 Diskritisasi Atribut Thalach
Thalach No Yes Total Gain Atas Gain Bawah Gain Split
140 1 3 4 0,849054424 0,918295834 0,10318255
141 0 2 2 0,838007851 0,907437434 0,11480783
142 1 0 1 0,852405179 0,910154037 0,10819435
143 3 2 5 0,879697578 0,906880172 0,10103963
144 0 4 4 0,860778118 0,880243609 0,12506834
145 1 2 3 0,863120569 0,868040399 0,13139560
146 0 3 3 0,849751137 0,84185219 0,15202586
147 2 1 3 0,867281622 0,839330762 0,14531310
149 1 0 1 0,877223623 0,84293594 0,13865438
150 1 4 5 0,870864469 0,803415848 0,16123059
151 1 0 1 0,880027048 0,807331327 0,15440391
152 4 2 6 0,904803274 0,798523765 0,14353822
153 1 0 1 0,911751759 0,802738102 0,13735100
5. Oldpeak
Pada atribut oldpeak, nilai informasi gain yang tertinggi terdapat pada nilai 150 sehingga pada titik tersebut dijadikan pemisah.
Tabel 3.5 Diskritisasi Atribut Oldpeak
Oldpeak No Yes Total Gain Atas Gain Bawah Gain Split
0 59 19 78 1,297267049 0,96036227 0,09573354
1 2 7 9 0,879881309 0,968803551 0,06761714
2 2 6 8 0,921764712 0,975313058 0,04772813
3 0 3 3 0,940285959 0,981453895 0,03627095
4 0 3 3 0,955341377 0,98700443 0,02649572
0.1 4 2 6 0,95356886 0,980310798 0,03148945
0.2 6 2 8 0,946928968 0,961862414 0,04415985
0.3 2 1 3 0,946280454 0,954434003 0,04777398
0.4 1 1 2 0,948078244 0,95204028 0,04770975
3.4. Metode Pengujian
Metode pengujian yang digunakan dalam penelitian ini adalah metode holdout dimana data penelitian dibagi menjadi dua bagian, 2/3 dari jumlah data dijadikan sebagai data
1. Pada tahap pertama data training diproses dengan menggunakan algoritma
Naive Bayes yang melibatkan keseluruhan atribut. Dari data training yang dilatih terbentuk aturan klasifikasi. Kemudian data testing diujikan sehingga diperoleh hasil prediksi dengan nilai akurasi, error dan kecepatan proses.
2. Pada tahap kedua data training terlebih dahulu diproses dengan menggunakan algoritma informasi Gain. Setiap atribut dihitung informasi
Gain-nya dan diurutkan dari nilai yang tertinggi sampai terendah. Atribut terendah direduksi (dibuang), dan sisanya dipilih untuk kemudian di
training dengan menggunakan algoritma Naive Bayes. Kemudian data
testing diujikan sehingga diperoleh hasil prediksi dengan nilai akurasi, error dan kecepatan proses.
3. Hasil prediksi dan kecepatan proses dari tahap kedua dianalisis untuk melihat apakah ada perubahan nilai akurasi, error dan kecepatan proses dari tahap yang pertama.
BAB 4
HASIL DAN PEMBAHASAN
Pada bab ini dijelaskan hasil pengujian yang dilakukan dalam melakukan pelatihan dan tugas klasifikasi dalam memprediksi penyakit jantung dengan menggunakan algoritma Naive Bayes dan informasi Gain sebagai parameter untuk seleksi atribut. Pelatihan data dan tugas klasifikasi diuji dengan menggunakan aplikasi yang penulis bangun dengan menggunakan bahasa pemrograman PHP dan MySQL. Berdasarkan pada hasil pengujian pelatihan dan tugas klasifikasi dari data rekam medis nantinya dapat ditarik kesimpulan, apakah algoritma Naive Bayes dengan seleksi atribut dapat meningkatkan nilai akurasi prediksi penyakit jantung dan kecepatan proses dibandingkan dengan pelatihan dan tugas klasifikasi dengan algoritma Naive Bayes secara umum.
4.1.Hasil Pengujian
Hasil pengujian diukur dari seberapa besar nilai akurasi serta kecepatan dari proses
training dan testing data. Pengukuran akurasi dilakukan dengan menggunakan tabel klasifikasi yang disebut dengan confusion matrix dan kecepatan proses diukur dari lama waktu yang dibutuhkan dalam proses training dan testing data. Jumlah data
training terdiri dari 195 baris data (2/3 dari jumlah baris data penelitian) dan jumlah data testing terdiri dari 101 baris data (1/3 dari jumlah baris data penelitian).
4.1.1. Hasil Pengujian Tahap Pertama
Tabel 4.1 Hasil Training Data Pada Tahap Pertama
Atribut Nilai Hasil Training Data
Yes No
Age >43 0.920455 0.841121
<=43 0.0795455 0.158879
Sex Male 0.840909 0.616822
Female 0.159091 0.383178
Cp
typ_angina 0.0227273 0.121495 atyp_angina 0.0568182 0.121495 non_anginal 0.170455 0.420561
Asympt 0.75 0.224299
Trestbps >122 0.738636 0.64486
<=122 0.261364 0.35514
Chol >271 0.397727 0.224299
<=271 0.602273 0.775701
Fbs T 0.147727 0.186916
F 0.852273 0.813084
Restecg
Normal 0.340909 0.523364
left_vent_hyper 0.659091 0.476636
st_t_wave_abnorma 0 0
Thalach >150 0.340909 0.747664
<=150 0.659091 0.252336
Exang Yes 0.545455 0.158879
No 0.454545 0.841121
Oldpeak Zero 0.170455 0.364486
>0 0.829545 0.635514
Slope
Flat 0.670455 0.28972
Down 0.102273 0.0747664
Up 0.227273 0.635514
Norm 0.204545 0.775701
fixed_defect 0.0681818 0.0373832 reversable_defect 0.727273 0.186916
Berdasarkan hasil dari training data dilakukan pengujian terhadap data testing dan diperoleh hasil prediksi yang ditampilkan dalam tabel confusion matrix berikut:
Tabel 4.2 Hasil Pengujian Data Testing Pada Tahap Pertama
Prediksi
Sakit Tidak Sakit
Aktual (Yang Sebenarnya) Sakit 38 10
Tidak Sakit 7 46
Dari tabel di atas diperoleh nilai prediksi yang benar untuk yang sakit ada 38 orang dan untuk yang tidak sakit ada 46 orang. Sementara prediksi yang salah terdiri dari 10 orang diprediksi tidak sakit (sebenarnya sakit) dan 7 orang diprediksi sakit (sebenarnya tidak sakit). Nilai akurasi dan error dapat diperoleh sebagai berikut:
Akurasi tahap pertama = ��+��
�+� =
38+46
101 = 0,83168 = 83,17% Error tahap pertama = ��+��
�+� =
10+7
101 = 0,16831 = 16,83%
Waktu proses pengujian dari data testing yang melibatkan seluruh atribut dari tabel 4.1 adalah: 0.57582 detik.
4.1.2. Hasil Pengujian Tahap Kedua
Pengujian pada tahap kedua menggunakan beberapa atribut data rekam medis penyakit jantung yang dipilih berdasarkan nilai informasi Gain untuk pelatihan data dan tugas klasifikasi dalam memprediksi penyakit jantung. Atribut diurutkan berdasarkan nilai informasi Gain yang paling tinggi ke yang paling rendah.
Pada tahap ini atribut dengan nilai terkecil (fbs) tidak diikutkan dalam proses
Tabel 4.3 Peringkat Atribut Berdasarkan Nilai Informasi Gain
Atribut Nilai Info Gain
thal 0.252023
cp 0.213794
ca 0.178469
slope 0.128463
thalach 0.123182
exang 0.123127
sex 0.0460524
oldpeak 0.0346693
chol 0.0254546
restecg 0.0243425
age 0.0107875
trestbps 0.00736819
fbs 0.00196676
Pada percobaan ini untuk hasil data training sama dengan tabel 4.1 namun tanpa atribut fbs. Untuk waktu proses training data yang melibatkan 12 atribut adalah: 0,35456 detik.
Berdasarkan hasil dari training data tanpa menggunakan atribut fbs dilakukan pengujian terhadap data testing dan diperoleh hasil prediksi yang ditampilkan dalam tabel confusion matrix berikut:
Tabel 4.4 Hasil Pengujian Data Testing Tahap Kedua
Prediksi
Sakit Tidak Sakit
Aktual (Yang Sebenarnya) Sakit 38 10
Tidak Sakit 6 47
Akurasi tahap kedua = ��+��
�+� =
38+47
101 = 0,84158 = 84,16% Error tahap kedua = ��+��
�+� =
10+6
101 = 0,15841 = 15,84%
Waktu proses pengujian dari data testing yang melibatkan 12 atribut dari tabel 4.1 adalah: 0.65077 detik.
4.1.3. Percobaan Tahap Ketiga
Pada tahap ketiga ini dua atribut dengan nilai informasi gain terendah tidak diikutsertakan yaitu fbs dan trestbps. Untuk hasil data training sama dengan tabel 4.1, namun tanpa atribut fbs dan trestbps. Untuk waktu proses training data yang melibatkan 11 atribut adalah: 0,24825 detik.
Berdasarkan hasil dari training data tanpa menggunakan atribut fbs dan trestbps dilakukan pengujian terhadap data testing dan diperoleh hasil prediksi yang ditampilkan dalam tabel confusion matrix berikut:
Tabel 4.5 Hasil Pengujian Data Testing Tahap Ketiga
Prediksi
Sakit Tidak Sakit
Aktual (Yang Sebenarnya) Sakit 37 11
Tidak Sakit 6 47
Dari tabel di atas diperoleh nilai prediksi yang benar untuk yang sakit ada 37 orang dan untuk yang tidak sakit ada 47 orang. Sementara prediksi yang salah terdiri dari 11 orang diprediksi tidak sakit (sebenarnya sakit) dan 6 orang diprediksi sakit (sebenarnya tidak sakit). Nilai akurasi dan error dapat diperoleh sebagai berikut:
Akurasi tahap ketiga = ��+��
�+� =
37+47
101 = 0,83168 = 83,17% Error tahap ketiga = ��+��
�+� =
11+6
Waktu proses pengujian dari data testing yang melibatkan 12 atribut dari tabel 4.1 adalah: 0.55844 detik.
4.1.4. Percobaan Tahap Keempat
Pada percobaan di tahap keempat ini tiga atribut dengan nilai informasi gain terendah tidak diikutsertakan yaitu fbs, trestbps dan age. Untuk hasil data training sama dengan tabel 4.1 namun tanpa atribut fbs, trestbps dan age. Untuk waktu proses training data yang melibatkan 10 atribut adalah: 0,25818 detik.
Berdasarkan hasil dari training data tanpa menggunakan atribut fbs, trestbps dan
age dilakukan pengujian terhadap data testing dan diperoleh hasil prediksi yang ditampilkan dalam tabel confusion matrix berikut:
Tabel 4.6 Hasil Pengujian Data Testing Percobaan Tahap Keempat
Prediksi
Sakit Tidak Sakit
Aktual (Yang Sebenarnya) Sakit 36 12
Tidak Sakit 7 46
Dari tabel di atas diperoleh nilai prediksi yang benar untuk yang sakit ada 36 orang dan untuk yang tidak sakit ada 46 orang. Sementara prediksi yang salah terdiri dari 12 orang diprediksi tidak sakit (sebenarnya sakit) dan 7 orang diprediksi sakit (sebenarnya tidak sakit). Nilai akurasi dan error dapat diperoleh sebagai berikut:
Akurasi tahap keempat = ��+��
�+� =
36+46
101 = 0,81188 = 81,19%
Error tahap keempat = ��+��
�+� =
12+7
101 = 0,18811 = 18,81%
4.1.5. Percobaan Tahap Kelima
Pada percobaan di tahap kelima ini dilakukan percobaan dengan tidak mengikutsertakan satu atribut yang memiliki nilai informasi gain tertinggi yaitu thal. Untuk hasil data training sama dengan tabel 4.1 namun tanpa atribut thal. Untuk waktu proses training data yang melibatkan 12 atribut adalah: 0,29258 detik.
Berdasarkan hasil dari training data tanpa menggunakan atribut thal dilakukan pengujian terhadap data testing dan diperoleh hasil prediksi yang ditampilkan dalam tabel confusion matrix berikut:
Tabel 4.6 Hasil Pengujian Data Testing Percobaan Tahap Kelima
Prediksi
Sakit Tidak Sakit
Aktual (Yang Sebenarnya) Sakit 36 12
Tidak Sakit 7 46
Dari tabel di atas diperoleh nilai prediksi yang benar untuk yang sakit ada 36 orang dan untuk yang tidak sakit ada 46 orang. Sementara prediksi yang salah terdiri dari 12 orang diprediksi tidak sakit (sebenarnya sakit) dan 7 orang diprediksi sakit (sebenarnya tidak sakit). Nilai akurasi dan error dapat diperoleh sebagai berikut:
Akurasi tahap kelima = ��+��
�+� =
36+46
101 = 0,81188 = 81,19% Error tahap kelima = ��+��
�+� =
12+7
101 = 0,18811 = 18,81%
4.2.Pembahasan
Dari hasil pengujian di atas dapat dilihat perbandingan nilai akurasi, error dan waktu proses pada tahap pertama sampai tahap kelima yang ditampilkan pada tabel berikut:
Tabel 4.7 Hasil Pengujian Percobaan Tahap Pertama Sampai Kelima
Pengujian Atribut yang Jumlah Akurasi Error Waktu Waktu
Direduksi Atribut Testing (detik) Training (detik)
Tahap I - 13 83,17% 16,83% 0,57582 0,38135
Tahap II Fbs 12 84,16% 15,84% 0,65077 0,35456
Tahap III Fbs dan trestbps 11 83,17% 16,83% 0,55844 0,24825
Tahap IV
Fbs, trestbps dan
age 10 81,19% 18,81% 0,52098 0,25818
Tahap V Age 12 81,19% 18,81% 0,70086 0,29258
Gambar 4.1 Perbandingan Akurasi, Error dan Waktu Proses Pengujian
Dari grafik di atas dapat dilihat bahwa hasil pengujian pada tahap kedua dimana atribut fbs tidak diikutsertakan memiliki nilai akurasi yang lebih baik yaitu 84,16%
83,17% 84,16% 83,17% 81,19% 81,19%
16,83% 15,84% 16,83% 18,81% 18,81%
0,57582
0,65077
0,55844
0,52098
0,70086
0,00% 10,00% 20,00% 30,00% 40,00% 50,00% 60,00% 70,00% 80,00% 90,00%
Tahap I Tahap II Tahap III Tahap IV Tahap V
Perbandingan Akurasi, Error dan Waktu
Proses Pengujian
dibandingkan hasil pengujian di tahap pertama yang mengikutsertakan keseluruhan atribut yaitu 83,17%.
Hasil pengujian pada tahap ketiga dimana atribut fbs dan trestbps tidak diikutsertakan memiliki nilai akurasi yang sama dengan hasil pengujian pada tahap pertama yaitu 83,17%.
Hasil pengujian pada tahap keempat dimana atribut fbs, trestbps dan age tidak diikutsertakan memiliki nilai akurasi yang lebih buruk yaitu 81,19% dibandingkan hasil pengujian di tahap pertama yaitu 83,17%.
Hasil pengujian pada tahap kelima dimana atribut thal tidak diikutsertakan memiliki nilai akurasi yang lebih buruk yaitu 81,19% dibandingkan hasil pengujian di tahap pertama yaitu 83,17%.
Dari keseluruhan tahap pengujian, hasil pengujian di tahap kedua merupakan hasil yang terbaik dimana nilai akurasi yang dihasilkan merupakan nilai yang paling tinggi yaitu 84,16%. Untuk waktu proses pengujian tercepat terdapat pada pengujian di tahap keempat yaitu 0,52098 detik.
BAB 5
KESIMPULAN DAN SARAN
5.1.Kesimpulan
Dari hasil penelitian didapatkan kesimpulan sebagai berikut:
1. Seleksi atribut dapat meningkatkan nilai akurasi dan mengurangi nilai error dari tugas klasifikasi. Hal ini dapat dilihat pada pengujian tahap kedua dimana atribut dengan nilai Gain terendah (fbs) tidak diikutsertakan, menghasilkan nilai akurasi 84,16% dan nilai error 15,84%. Sementara jika menggunakan semua atribut (pengujian tahap pertama) akurasi yang diperoleh 83,17% dan
error 16,83%.
2. Dengan menerapkan seleksi atribut, waktu proses untuk pelatihan dan pengujian data sedikit lebih cepat daripada menggunakan atribut secara keseluruhan. Hal ini dapat dilihat pada percobaan tahap pertama dimana waktu proses yang dibutuhkan untuk pengujian adalah 0,57582 detik sementara pengujian dengan waktu proses tercepat terdapat pada pengujian tahap keempat dimana atribut fbs, trestbps dan age tidak diikutsertakan yaitu sebesar 0,52098 detik.
3. Pemilihan atribut mempunyai pengaruh terhadap hasil pengujian. Hal ini dapat dilihat pada percobaan kelima dimana satu atribut dengan nilai informasi gain
4. Tugas klasifikasi dengan seleksi atribut kurang cocok untuk diimplementasikan pada atribut yang memiliki keterikatan untuk diagnosa penyakit jantung. Hal ini dapat dilihat pada pengujian tahap ketiga dan keempat dimana atribut trestbps tidak diikutsertakan sedangkan untuk tugas diagnosa penyakit jantung di lapangan, atribut trestbps diperlukan.
5.2.Saran
Dengan keterbatasan kemampuan dan waktu yang tersedia untuk penelitian ini, maka penulis hanya membahas seleksi atribut dengan informasi Gain yang diterapkan pada algoritma Naive Bayes untuk memprediksi penyakit jantung. Maka untuk mencapai hasil yang maksimal, penulis menyarankan beberapa hal, yaitu:
1. Melakukan seleksi atribut dengan menggunakan metode di luar yang penulis lakukan seperti GainRatio, ChiSquare atau Greedy.
2. Diskritisasi dengan menggunakan metode di luar yang penulis lakukan seperti
ChiSquare, CAIR atau CAIM.
3. Pelatihan dan pengujian data selain menggunakan algoritma Naive Bayes. 4. Pengujian menggunakan data yang memiliki sifat independent (tidak terikat)
DAFTAR PUSTAKA
Abraham, R., Simha, J.B. & Iyengar, S. 2009. Effective Discretization and Hybrid Feature Selection Using Naïve Bayesian Classifier For Medical Data Mining. International
Journal of Computational Intelligence Research 4(10). (Online) http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.185.1680 (20 November 2013)
Azhagusundari, B and Thanami, A.S. 2013. Feature Selection Based on Information Gain.
International Journal and Innovative Technology and Exploring Engineering (IJITEE)
2(2). (Online) http://www.ijitee.org/attachments/File/v2i2/B0352012213.pdf (20 November 2013)
Danubianu, M., Pentiuc, S.G. & Danubianu, D.M. 2012. Data Dimensionality Reduction for Data Mining: A Combined Filter-Wrapper Framework. International Journal of
Computers, Communications & Control7(5). (Online)
http://www.journal.univagora.ro/download/pdf/634.pdf (9 Desember 2012)
Dumitru, D. Prediction of Recurrent Events in Breast Cancer Using the Naive Bayesian Classification. 2009. Annals of University of Craiova, Mathematics and Computer
Science Series36(2). (Online)
http://inf.ucv.ro/~ami/index.php/ami/article/viewFile/290/281.. (29 Januari 2014)
Gorunescu, F. 2011. Data Mining Concepts, Models and Tehniques. Intelligent Systems Reference Library, Volume 12. Springer-Verlag Berlin Heidelberg.
Han, J and Kamber, M. 2006. Data Mining: Concepts and Techniques, Second Edition. Morgan Kauffman Publishers.
Kantardzic, M., 2003. Data Mining: Concepts, Models, Methods, And Algorithms. The Institute of Electrical and Electronics Engineers, Inc.
Ladha, L and Deepa, T. 2011. Feature Selection Methods and Algorithms. International Journal
on Computer Science and Engineering (IJCSE) 3(5). (Online)
http://www.enggjournals.com/ijcse/doc/IJCSE11-03-05-051.pdf (9 Desember 2013)
Sahu, H., Shrma, S. & Gondhalakar, S. 2011. A Brief Overview on Data Mining Survey.
International Journal of Computer Technology and Electronics Engineering 1(3).
Slocum, M. 2012. Decision Making Using ID3 Algorithm. InSight: Rivier Academic Journal
8(2), Fall 2012. (Online) http://www.rivier.edu/journal/ROAJ-Fall-2012/J674-Slocum-ID3-Algorithm.pdf (18 Mei 2013).
Subbalakshmi, G., Ramesh K. & Rao, M.C. 2011. Decision Support in Heart Disease Prediction System Using Naive Bayes. Indian Journal of Computer Science and Engineering2(2): 170-176. (Online) http://www.ijcse.com/docs/IJCSE11-02-02-56.pdf (10 Juni 2013) Sullivan, D.G. 2014. Data Mining. Boston University Lecture. (Online)
http://cs-people.bu.edu/dgs/courses/cs105/lectures/ (29 Januari 2014)
Xhemali, D., Hinde, C.J. & Stone, R.G. 2009. Naive Bayes vs. Decision Trees vs. Neural Networks in the Classification of Training Web Pages. International Journal of
Computer Science Issues4(1): 16-23. (Online) http://ijcsi.org/papers/4-1-16-23.pdf (16 Mei 2013)
LAMPIRAN
DAFTAR PUBLIKASI ILMIAH PENULIS (TESIS)
NO JUDUL ARTIKEL PENULIS PUBLIKASI (SEMINAR / JURNAL, DLL)
WAKTU PUBLIKASI
A. Identitas Responden
Nama Responden: dr. Cut Aryfa Andra, Sp.JP.
1. Usia 31 tahun
2. Pendidikan S2
3. Status Kepegawaian Dokter tetap di rumah sakit Adam Malik Medan 4. Masa Kerja 5 tahun
B. Wawancara Mendalam
1. Apa saja ciri-ciri penyakit jantung? 2. Ada berapa jenis penyakit jantung?
3. Apa saja faktor-faktor penyebab penyakit jantung?
4. Apakah Bapak/Ibu mengetahui data rekam medis dengan atribut-atribut berikut ini: a. Umur
b. Jenis Kelamin
c. Cp (typ_angina, asympt, non_anginal, atyp_angina) d. Trestbps
e. Chol f. Fbs (T, F)
g. Restecg (left_vent_hyper, normal, st_t_wave_abnormality) h. Thalach
i. Exang j. Oldpeak
k. Slope (up, flat, down) l. Ca
m. Thal (fixed_defect, normal, reversable_defect) n. Num (<50, >50_1, >50_2, >50_3, >50_4)
5. Menurut Bapak/Ibu dari ke 14 atribut di no.4, atribut mana saja yang wajib ada untuk mendiagnosa seseorang menderita penyakit jantung?
6. Di rumah sakit sendiri, biasanya untuk pengecekan penyakit jantung, data rekam medis pasien dengan atribut apa saja yang dibutuhkan?
7. Menurut Bapak/Ibu, jika seseorang didiagnosa menderita penyakit jantung, apa yang pertama dilakukan untuk pengobatan?
8. Menurut Bapak/Ibu, apa saja yang harus dihindari penderita penyakit jantung? 9. Menurut Bapak/Ibu, untuk seseorang yang sehat, apa saja yang seharusnya dilakukan
PERTANYAAN HASIL WAWANCARA
1. Apa saja ciri-ciri penyakit jantung? “Untuk gejala kronis: Gampang capek
Untuk gejala akut : Nyeri di dada”
2. Ada berapa jenis penyakit jantung? “Yang Saya ketahui:
- Penyumbatan (Coroner Artery Disease / CAD) - Bawaan Lahir
- Kelainan katup - Infeksi” 3. Apa saja faktor-faktor penyebab
penyakit jantung?
“Faktor-faktor penyebabnya antara lain:
- Kegemukan - Merokok
- Hipertensi / darah tinggi - Gula Darah
- Cholesterol” 4. Apakah Bapak/Ibu mengetahui data
rekam medis dengan atribut-atribut berikut ini:
a. Umur
b. Jenis Kelamin
c. Cp (typ_angina, asympt, non_anginal, atyp_angina) d. Trestbps
e. Chol f. Fbs (T, F)
g. Restecg (left_vent_hyper, normal,
m. Thal (fixed_defect, normal, reversable_defect)
n. Num (<50, >50_1, >50_2, >50_3, >50_4)
“Saya mengetahui atribut-atribut tersebut tetapi Saya ragu (tidak mengetahui) atribut ca, mungkin dilakukan di laboratorium”
5. Menurut Bapak/Ibu dari ke 14 atribut di no.4, atribut mana saja yang wajib ada untuk mendiagnosa seseorang menderita penyakit jantung?
“Untuk gejala kronis: Umur,Jenis kelamin,CP,Trestbps, Restecg Thalach,Exang,Oldpeak, Slope, Thal
Untuk gejala akut (UGD): Umur, Jenis Kelamin, Trestbps,
Chol, Fbs, Restecg, Slope, CP” 6. Di rumah sakit sendiri, biasanya untuk
pengecekan penyakit jantung, data rekam medis pasien dengan atribut apa saja yang dibutuhkan?
“Tergantung dari gejala yang dialami pasien, untuk gejala akut sama dengan yang dijelaskan di nomor 6 tetapi untuk gejala kronis variabel seperti thalach, exang,
oldpeak dan slope jarang dilakukan”.
7. Menurut Bapak/Ibu, jika seseorang didiagnosa menderita penyakit jantung, apa yang pertama dilakukan untuk pengobatan?
“Jika gejala akut akan dilakukan rawat inap dan jika gejala kronis dapat dilakukan pengobatan rawat jalan”
8. Menurut Bapak/Ibu, apa saja yang harus dihindari penderita penyakit jantung?
“Hal yang harus dihindari adalah aktivitas yang berlebihan, faktor penyebab seperti hal-hal yang bisa membuat gula darah dan
kolesterol naik dan peningkatan lemak”
9. Menurut Bapak/Ibu, untuk seseorang yang sehat, apa saja yang seharusnya dilakukan sebagai pencegahan dari serangan penyakit jantung?
10/14/13 www.cs.umb.edu/~rickb/files/UCI/heart-c.arff www.cs.umb.edu/~rickb/files/UCI/heart-c.arff 1/12
% Publication Request: %
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> >>>>>>>
% This file describes the contents of the heart-disease directory.
%
% This directory contains 4 databases concerning heart disease diagnosis.
% All attributes are numeric-valued. The data was collected from the
% four following locations: %
% 1. Cleveland Clinic Foundation (cleveland.data) % 2. Hungarian Institute of Cardiology, Budapest (hungarian.data)
% 3. V.A. Medical Center, Long Beach, CA (long-beach-va.data) % 4. University Hospital, Zurich, Switzerland
(switzerland.data) %
% Each database has the same instance format. While the databases have 76
% raw attributes, only 14 of them are actually used. Thus I've taken the
% liberty of making 2 copies of each database: one with all the attributes
% and 1 with the 14 attributes actually used in past experiments.
%
% The authors of the databases have requested: %
% ...that any publications resulting from the use of the data include the
% names of the principal investigator responsible for the data collection
% at each institution. They would be: %
% 1. Hungarian Institute of Cardiology. Budapest: Andras Janosi, M.D.
% 2. University Hospital, Zurich, Switzerland: William Steinbrunn, M.D.
% 3. University Hospital, Basel, Switzerland: Matthias Pfisterer, M.D.
% 4. V.A. Medical Center, Long Beach and Cleveland Clinic Foundation:
% Robert Detrano, M.D., Ph.D. %
% Thanks in advance for abiding by this request. %
% 2. Source Information: % (a) Creators:
% -- 1. Hungarian Institute of Cardiology. Budapest: Andras Janosi, M.D.
% -- 2. University Hospital, Zurich, Switzerland: William Steinbrunn, M.D.
% -- 3. University Hospital, Basel, Switzerland: Matthias Pfisterer, M.D.
% -- 4. V.A. Medical Center, Long Beach and Cleveland Clinic Foundation:
% Robert Detrano, M.D., Ph.D.
% (b) Donor: David W. Aha ([email protected]) (714) 856-8779 % (c) Date: July, 1988
%
% 3. Past Usage:
% 1. Detrano,~R., Janosi,~A., Steinbrunn,~W., Pfisterer,~M., Schmid,~J.,
% Sandhu,~S., Guppy,~K., Lee,~S., \& Froelicher,~V. (1989). {\it
% International application of a new probability algorithm for the
% diagnosis of coronary artery disease.} {\it American Journal of
% Cardiology}, {\it 64},304--310.
% -- International Probability Analysis % -- Address: Robert Detrano, M.D. % Cardiology 111-C
% V.A. Medical Center % 5901 E. 7th Street % Long Beach, CA 90028
10/14/13 www.cs.umb.edu/~rickb/files/UCI/heart-c.arff www.cs.umb.edu/~rickb/files/UCI/heart-c.arff 2/12
% -- Results in percent accuracy: (for 0.5 probability threshold)
% Data Name: CDF CADENZA % -- Hungarian 77 74 % Long beach 79 77 % Swiss 81 81
% -- Approximately a 77% correct classification accuracy with a % logistic-regression-derived discriminant function
% 2. David W. Aha & Dennis Kibler % --
% %
% -- Instance-based prediction of heart-disease presence with the
% Cleveland database
% -- NTgrowth: 77.0% accuracy % -- C4: 74.8% accuracy
% 3. John Gennari
% -- Gennari, J.~H., Langley, P, \& Fisher, D. (1989). Models of
% incremental concept formation. {\it Artificial Intelligence, 40},
% 11--61. % -- Results:
% -- The CLASSIT conceptual clustering system achieved a 78.9% accuracy
%
% 4. Relevant Information:
% This database contains 76 attributes, but all published experiments
% refer to using a subset of 14 of them. In particular, the Cleveland
% database is the only one that has been used by ML researchers to
% this date. The "goal" field refers to the presence of heart disease
% in the patient. It is integer valued from 0 (no presence) to 4.
% Experiments with the Cleveland database have concentrated on simply
% attempting to distinguish presence (values 1,2,3,4) from absence (value
% 0). %
% The names and social security numbers of the patients were recently
% removed from the database, replaced with dummy values. %
% One file has been "processed", that one containing the Cleveland
% database. All four unprocessed files also exist in this directory.
%
% 5. Number of Instances: % Database: # of instances: % Cleveland: 303
% Hungarian: 294 % Switzerland: 123 % Long Beach VA: 200 %
% 6. Number of Attributes: 76 (including the predicted attribute)
%
% 7. Attribute Information: % -- Only 14 used
% -- 14. #58 (num) (the predicted attribute) %
% 2 ccf: social security number (I replaced this with a dummy value of 0)
% 3 age: age in years
% 4 sex: sex (1 = male; 0 = female)
% 5 painloc: chest pain location (1 = substernal; 0 = otherwise)
% 6 painexer (1 = provoked by exertion; 0 = otherwise) % 7 relrest (1 = relieved after rest; 0 = otherwise) % 8 pncaden (sum of 5, 6, and 7)
% 9 cp: chest pain type % -- Value 1: typical angina % -- Value 2: atypical angina % -- Value 3: non-anginal pain % -- Value 4: asymptomatic
% 10 trestbps: resting blood pressure (in mm Hg on admission to the
% hospital) % 11 htn
% 12 chol: serum cholestoral in mg/dl
% 13 smoke: I believe this is 1 = yes; 0 = no (is or is not a smoker)
% 14 cigs (cigarettes per day)
% 15 years (number of years as a smoker)
% 16 fbs: (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
% 17 dm (1 = history of diabetes; 0 = no such history)
% 18 famhist: family history of coronary artery disease (1 = yes; 0 = no)
% 19 restecg: resting electrocardiographic results % -- Value 0: normal
% -- Value 1: having ST-T wave abnormality (T wave inversions and/or ST
% elevation or depression of > 0.05 mV)
% -- Value 2: showing probable or definite left ventricular hypertrophy
% by Estes' criteria
% 20 ekgmo (month of exercise ECG reading) % 21 ekgday(day of exercise ECG reading) % 22 ekgyr (year of exercise ECG reading)
% 23 dig (digitalis used furing exercise ECG: 1 = yes; 0 = no) % 24 prop (Beta blocker used during exercise ECG: 1 = yes; 0 = no)
% 25 nitr (nitrates used during exercise ECG: 1 = yes; 0 = no) % 26 pro (calcium channel blocker used during exercise ECG: 1 = yes; 0 = no)
% 27 diuretic (diuretic used used during exercise ECG: 1 = yes; 0 = no)
% 28 proto: exercise protocol % 1 = Bruce
% 7 = bike 150 kpa min/min (Not sure if "kpa min/min" is what was
% written!)