SEARCH ENGINE
DOKUMEN RDF TANAMAN OBAT
MENGGUNAKAN SESAME DAN LUCENE
LUTHFI NOVIANDI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Search Engine Dokumen RDF Tanaman Obat menggunakan Sesame dan Lucene adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2014
Luthfi Noviandi
ABSTRAK
LUTHFI NOVIANDI. Search Engine Dokumen RDF Tanaman Obat menggunakan Sesame dan Lucene. Dibimbing oleh JULIO ADISANTOSO.
Bertambahnya keanekaragaman tanaman obat menyebabkan dokumentasi hasil penelitian tanaman obat semakin bertambah, sehingga mengakibatkan kesulitan dalam hal pencarian dokumen. Diperlukan suatu sistem pencarian yang dapat menemukembalikan dokumen yang dicari dengan menggunakan kueri. Pada penelitian ini akan dilakukan pengembangan sistem pencarian pada dokumen RDF menggunakan Sesame dan Lucene. Pembobotan menggunakan Tf-idf sebagai nilai relevansi terhadap dokumen yang ditemukembalikan. Penggunaan sistem Lucene sebagai mesin pencari menghasilkan rata-rata precision pada kueri tanpa term boosting sebesar 0.736. Sedangkan untuk kueri yang diberikan term boosting 5 menghasilkan rata-rata precision yang paling baiksebesar 0.882.
Kata kunci : search engine, lucene, sesame, RDF, Tf-idf, tanaman obat
ABSTRACT
LUTHFI NOVIANDI. Search Engine RDF Document of Medicinal Plants Using Sesame and Lucene. Supervised by JULIO ADISANTOSO.
Increasing the diversity of medicinal plants causing documentation of the results of research medicinal plants was increasing that led to the difficulty in terms of search of a document. Required a searching system that can be retrieves documents using query. In this study, we will develop searching system for RDF documents using Sesame and Lucene. TF-idf used as relevant value about documents retrivied. Query without boosting term generate average precision 0.736 while query with boosting term 5 generate average precision 0.882.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
SEARCH ENGINE
DOKUMEN RDF TANAMAN OBAT
MENGGUNAKAN LUCENE DAN SESAME
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji :
Judul Skripsi : Search Engine Dokumen RDF Tanaman Obat menggunakan Sesame dan Lucene
Nama : Luthfi Noviandi NIM : G64124020
Disetujui oleh
Ir. Julio Adisantoso, M.Kom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah subhanahu wa ta ‘ala atas segala karunia-Nya sehingga karya ilmiah ini dapat diselesaikan.Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Oktober 2014 ini adalah
Search Engine Dokumen RDF Tanaman Obat menggunakan Sesame dan Lucene. Shalawat dan salam disampaikan kepada Nabi Muhammad SAW beserta keluarga, sahabat, dan pengikutnya yang tetap berada di jalan-Nya hingga akhir zaman.
Terima kasih penulis ucapkan kepada Bapak Ir. Julio Adisantoso M.Kom selaku pembimbing. Ungkapan terima kasih juga disampaikan kepada kedua orangtua, Dini, Naila, Muti serta seluruh keluarga dan teman, atas segala doa dan kasih sayangnya. Begitu pula rasa terima kasih penulis ucapkan pada rekan-rekan Ilkomerz Ekstensi 7 yang menjadi bagian hidup penulis selama menempuh pendidikan di Ekstensi Ilmu Komputer IPB.
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Membangun Dokumen RDF 2
Penyimpanan Dokumen RDF pada Sesame 3
Pencarian Menggunakan Lucene 3
Evaluasi 4
HASIL DAN PEMBAHASAN 5
Membangun Dokumen RDF 5
Penyimpanan Dokumen RDF pada Sesame 7
Pencarian Menggunakan Lucene 7
Evaluasi 11
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 14
DAFTAR PUSTAKA 14
LAMPIRAN 15
DAFTAR TABEL
1 Deskripsi dokumen XML tanaman obat 6
2 Deskripsi dokumen RDF tanaman obat 6
3 Hasil temukembali terhadap dokumen RDF tanaman obat dengan kueri
tanpa term boosting 10
4 Hasil temukembali terhadap dokumen RDF tanaman obat pada kueri bukan frase menggunakan term boosting untuk n = 2, 3, 4, 5, 6, 7, 8, 9,
10, 20 11
5 Nilai interpolasi maksimum recall dan precision pada kueri bukan frase
dengan beberapa term boosting 12
6 Nilai rataan interpolasi maksimum recall dan precision pada kueri bukan
frase dengan beberapa term boosting 12
DAFTAR GAMBAR
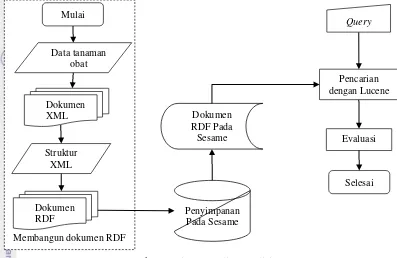
1 Diagram alir penelitian 3
2 Struktur penggunaan class pada Lucene 7
3 Struktur class 'Search_Engine' 8
4 String freetext yang di-index pada Lucene 8
5 Pseudocodefungsi ‘tf’ dan ‘idfFreq’ 9
6 Grafik recall dan precision dengan interpolasi maksimum pada kueri
tanpa term boosting 11
7 Grafik perbandingan recall dan precision dengan interpolasi maksimum antara kueri dengan term boosting dan kueri tanpa term boosting 13
DAFTAR LAMPIRAN
1 Lampiran 1 Contoh Format RDF Tanaman Pandan Wangi 15 2 Lampiran 2 Pseudocode fungsi 'indexing()' yang terdapat pada class
'Search_Engine' 16
3 Lampiran 3 Kueri SPARQL yang digunakan untuk parsing data RDF
Tanaman Obat 16
4 Lampiran 4 Pseudocode fungsi 'doSearch()' yang terdapat pada class
PENDAHULUAN
Latar Belakang
Tanaman obat adalah tanaman yang mengandung bahan yang dapat digunakan sebagai pengobatan dan kandungan kimianya dapat digunakan sebagai bahan obat sintetik (Pribadi 2009). Dengan bertambahnya keanekaragaman tanaman obat, maka dokumentasi hasil penelitian tanaman obat semakin bertambah. Oleh karena itu, dibutuhkan mesin pencari yang dapat mencari definisi dan manfaat dari tanaman obat. Herawan (2011) melakukan penelitian untuk temu kembali informasi dengan ekstraksi ciri dokumen menggunakan chi-square dengan klasifikasi naïve bayes pada dokumen eXtensible Markup Language (XML) tanaman obat.
Dalam pengembangan temu kembali informasi format dokumen yang digunakan bermacam-macam di antaranya freetext atau XML. XML merupakan sintaks dan model data yang direpresentasikan dengan bentuk tree dan bergantung pada konsep tag seperti Hypertext Markup Language (HTML). XML saat ini digunakan untuk membuat infrastruktur web semantik. Salah satu tujuan penting dari web semantik adalah untuk membuat makna informasi yang jelas, sehingga memungkinkan akses yang lebih efektif untuk pengetahuan yang terkandung dalam
lingkungan informasi yang beraneka ragam (Lei et al. 2006). Selain XML, dokumen yang dapat digunakan untuk web semantik yaitu Resource
Description Framework (RDF) yang merupakan spesifikasi yang dibuat oleh World Wide Web Consortion (W3C) sebagai metode umum untuk memodelkan infomasi dengan menggunakan sekumpulan format sintaks.
Minack (2008) melakukan penelitian untuk membuat full-textsearch dengan dokumen RDF. RDF diolah menggunakan bahasa kueri SPARQL, tetapi tidak cukup mampu untuk menangani jumlah data yang besar. SPARQL hanya mampu melakukan penyeleksian berdasarkan regular expression. Sehingga dibutuhkan aplikasi yang dapat melakukan indexing, stemming, dan ranking pada search engine.
Banyak aplikasi mesin pencari yang sudah dikembangkan antara lain Sphinx
dan Lucene. Salah satu aplikasi yang dapat melakukan pencarian terhadap dokumen RDF adalah Lucene. Lucene merupakan aplikasi mesin pencari yang menerapkan konsep full-text search. Lucene memiliki kinerja yang sangat baik walaupun digunakan pada sumber daya yang rendah (Minack 2008). Lucene dapat melakukan
stemming dan lemmatization, pencarian menggunakan frase, wildcard, fuzzy,
2
Perumusan Masalah
Penelitian ini dilakukan untuk menjawab permasalahan:
1. Bagaimana metode untuk mengkonversi format XML menjadi RDF? 2. Apakah Lucene mampu mengindeks dokumen dengan format RDF?
3. Bagaimana kinerja search engine yang dikembangkan dengan menggunakan Lucene pada dokumen RDF?
Tujuan Penelitian
Tujuan penelitian ini yaitu mengimplementasikan sistem Lucene untuk membangun search engine pada dokumen RDF dan mengimplementasikan metode untuk konversi dokumen XML menjadi dokumen RDF.
Manfaat Penelitian
Penelitian ini diharapkan dapat membantu seseorang dalam mencari informasi yang relevan mengenai tanaman obat di Indonesia.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini antara lain:
1. Proses indexing dilakukan terhadap semua atribut field yang terdapat pada dokumen RDF dengan bobot yang tidak dibedakan.
2. Struktur dokumen RDF sama untuk setiap dokumen. 3. Dokumen RDF tidak sampai membentuk ontology.
METODE
Tahapan penelitian terdiri atas membangun dokumen RDF tanaman obat, penyimpanan dokumen ke dalam aplikasi Sesame, proses indexing dan pencarian menggunakan Lucene, serta evaluasi (Gambar 1).
Membangun Dokumen RDF
RDF adalah model metadata dari bahasa yang direkomendasikan oleh W3C untuk membangun infrastruktur web semantik (Gutierrez et al. 2007). Pada RDF, sebuah deskripsi dari sumber direpresentasikan sebagai sejumlah triple, tiga bagian dari setiap triple disebut subyek, predikat, dan obyek. Subyek dari triple adalah
Uniform Resource Identifier (URI) yang mendefinisikan sumber. Obyek dapat berupa nilai literal sederhana, seperti string, numerik, tanggal, atau URI dari sumberdaya lainnya yang berkaitan dengan subyek. Predikat mengindikasikan hubungan antara subyek dan obyek. RDF juga menyediakan sebuah sintaks berbasis XML yang disebut juga RDF/XML.
3 Dokumen XML yang digunakan dalam penelitian ini adalah dokumen tanaman obat yang telah digunakan sebelumnya pada penilitian Herawan (2011). Korpus tersebut terdiri atas 93 dokumen. Data tanaman obat kemudian dikonversi menjadi dokumen RDF/XML dan disimpan ke dalam aplikasi Sesame.
Gambar 1 Diagram alir penelitian
Penyimpanan Dokumen RDF pada Sesame
Pada penelitian ini digunakan Sesame untuk pengolahan data dokumen RDF. Sesame merupakan aplikasi yang dikembangkan oleh Aduna yang menyediakan fungsi untuk parsing, menyimpan, dan kueri pada data RDF. Sesame menyediakan dua bahasa kueri yaitu SeRQL dan SPARQL. SeRQL dan SPARQL merupakan bahasa kueri yang dikembangkan oleh Aduna yang digunakan untuk memanipulasi data dan parsing data RDF. Dokumen RDF tanaman obat disimpan pada aplikasi Sesame untuk di parsing menggunakan kueri SPARQL.
Pencarian Menggunakan Lucene
Indexing dilakukan menggunakan perangkat lunak Lucene yang mencakup tokenisasi, stemming dan lemmatization, pembuangan stopwords, pembobotan, dan penyimpanan hasil indexing ke dokumen Lucene.
Tokenisasi merupakan proses pemotongan teks untuk mendapatkan token dari suatu berkas (Manning et al. 2008). Tokenisasi melakukan pemisahan terhadap isi dokumen menjadi unit yang lebih kecil yang biasa disebut juga kata. Stemming
dan lemmatization merupakan proses pengolahan linguistik tambahan yang dapat ditangani dengan tokenisasi. Tokenisasi dilakukan untuk semua korpus tanaman obat yang telah tersedia. Pada tokensasi juga dilakukan pembuangan stopwords.
Stopwords merupakan kata umum yang sering muncul dalam suatu dokumen dengan jumlah besar tetapi tidak memiliki makna. Stopwords dibuang karena
4
dianggap akan mengurangi akurasi dari informasi yang di temu-kembalikan (Manning et al. 2008). Contoh dari stopwords antara lain “yang”, “dan”, “atau”, “di”, dan lain-lain. Kata yang sudah melalui proses tokenisasi dan pemotongan
stopwords akan diberikan pembobotan.
Pembobotan merupakan proses untuk memberikan nilai bobot pada suatu token untuk merepresentasikan ciri suatu dokumen. Hasil pembobotan akan membentuk suatu sistem peringkat yang akan mengurutkan tokendengan tingkat kemiripan tertinggi ke tingkat kemiripan terendah.
Pada perangkat lunak Lucene digunakan pembobotan term frequency (TF) dan Inverse Document Frequency (IDF). Term frequency melakukan pembobotan untuk menghitung jumlah kemunculan token pada suatu dokumen dan sebagai ukuran untuk tingkat relevansi dokumen (Minack et al. 2008). Inverse document frequency (IDF) akan menghitung jumlah dokumen yang memiliki suatu token tertentu untuk dibandingkan dengan jumlah semua dokumen. Untuk menghitung bobot TF-IDF dari token t pada dokumen d digunakan persamaan (Manning et al.
2008)
. � �, = �, ∗ log �� (1)
dengan N adalah jumlah dokumen tanaman obat, dftadalah jumlah dokumen yang mengandung tokent.
Proses pencarian dapat dilakukan jika dokumen sudah terindeks pada dokumen Lucene. Pencarian dilakukan menggunakan kueri yang berhubungan dengan tanaman obat, kemudian dihitung nilai kemiripannya. Nilai kemiripan akan berpengaruh terhadap hasil temu kembali oleh sistem. Similarity antara kueri dan dokumen diukur menggunakan cosine similarity dengan persamaan (Manning et al. 2008)
dengan boost() merupakan nilai booster yang diberikan terhadap term pada kueri dengan nilai default 1. Nilai booster akan dikalikan terhadap term t yang diberikan
boost.
Evaluasi
5 Pada penelitian ini dilakukan evaluasi temu kembali informasi menggunakan
recall dan precision. Precision didefinisikan sebagai rasio dokumen yang ditemu-kembalikan adalah relevan dengan persamaan (Manning et al. 2008)
� � � = # #� �� � � � �
dimana relevant items retrieved merupakan jumlah dokumen yang relevan yang ditemukembalikan dan retrieved items merupakan jumlah semua dokumen dari hasil pencarian. Recall didefinisikan sebagai rasio dokumen relevan yang ditemukembalikan dengan persamaan (Manning et al. 2008)
= # #� �� � � �
dimana relevant items merupakan jumlah dokumen relevan yang terdapat pada korpus. Nilai rata-rata interpolated precision dapat mencerminkan urutan dari dokumen-dokumen yang relevan pada perangkingan. Standar yang digunakan adalah 11 titik recall standar yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9 dan 1.0 dengan menggunakan interpolasi maksimum yang didefinisikan sebagai (Manning et al. 2008)
��� ( ) = max
�≤
dengan ��� ( ) adalah precision hasil interpolasi pada titik recall ke j, dan
max
�≤ adalah precision maksimum pada selang nilai recall ke-j hingga ke kanan.
HASIL DAN PEMBAHASAN
Membangun Dokumen RDF
Penelitian ini menggunakan dokumen tanaman obat yang didapat dari penelitian Herawan (2011). Jumlah dokumen yang digunakan berjumlah 93 dokumen dengan format XML. Dokumen dikelompokkan menjadi tag-tag seperti pada Tabel 1.
Dokumen XML kemudian dikonversi menjadi format dokumen RDF/XML dengan deskripsi seperti pada Tabel 2. Proses konversi dilakukan secara manual sesuai dengan tag yang digunakan pada dokumen XML. Pada bagian tag
6
Tabel 1 Deskripsi dokumen XML tanaman obat
Nama Tag Deskripsi
<dok>...</dok> Menandakan awal dan akhir dokumen <id>...</id> Id dokumen
<nama>...</nama> Nama tanaman obat <namal>...</namal> Nama latin tanaman obat
<deskripsi>...</deskripsi> Deskripsi tanaman obat yang terdiri dari manfaat, habitus, bagian yang digunakan dan kandungan zat kimia
<fam>...</fam> Famili tanaman obat
<penyakit>...</penyakit> Penyakit yang dapat disembuhkan oleh tanaman obat.
Tabel 2 Deskripsi dokumen RDF tanaman obat
Nama Tag Deskripsi
<rdf:RDF> ... </rdf:RDF> Namespace untuk dokumen RDF
<rdf:Description>..</rdf:Description> Menandakan awal dan akhir dokumen
<rdf:about>..</rdf:about> Id okumen atau merupakan subyek pada RDF.
<tanaman:id>..</tanaman:id> Id dari tanaman obat <tanaman:famili>..</tanaman:famili> Famili tanaman obat <tanaman:nama>..</tanaman:nama> Nama tanaman obat <tanaman:latin>..</tanaman:latin> Menjelaskan nama latin
tanaman obat
<tanaman:bagian>..</tanaman:bagian> Bagian yang digunakan pada tanaman obat
<tanaman:manfaat>..</tanaman:manfaat> Manfaat dari tanaman obat <tanaman:kandungan>..</tanaman:kandungan> Kandungan dari tanaman obat <tanaman:deskripsi>..</tanaman:deskripsi> Menjelaskan deskripsi dari
tanaman obat <tanaman:penyakit>..</tanaman:penyakit> Penyakit yang dapat
disembuhkan oleh tanaman obat
Dokumen RDF didefinisikan menggunakan subyek, predikat, dan obyek. Berikut merupakan contoh definisi pada dokumen obat Pandan Wangi (Lampiran 1):
tanaman_1 memiliki nama Pandan Wangi. tanaman_1 memiliki famili Pancdanaceae.
tanaman_1 memiliki nama latin Pandanaus amaryllifolius Roxb. bagian yang digunakan pada tanaman_1 adalah daun.
7 tanaman_1 memiliki kandungan alkaloida, saponin, flavonoida, tannin, polifenol
dan zat warna.
Penyimpanan Dokumen RDF pada Sesame
Dokumen RDF tanaman obat diberi namespace dengan nama “tanaman”.
Pada field <tanaman:manfaat> dan <tanaman:kandungan> dibuat dalam bentuk rdf:Bag karena pada beberapa dokumen tanaman obat memiliki manfaat dan kandungan yang banyak. Rdf:Bag merupakan tipe data dari RDF yang mendefinisikan bentuk unordered-list.
Dokumen RDF yang telah tersedia disimpan ke dalam aplikasi Sesame dengan nama repositori tanaman-obat. Kueri dibutuhkan untuk parsing data pada dokumen RDF tanaman obat dengan menggunakan bahasa kueri SPARQL.
Pencarian Menggunakan Lucene
Indexing dan pencarian dilakukan dengan menggunakan Lucene, yang merupakan sebuah mesin pencariyang digunakan dalam membangun aplikasi pada penelitian ini, untuk proses indexing, searching, dan ranking. Pada penelitian ini digunakan beberapa class yang terdapat pada library Lucene dan dilakukan penambahan class yang digunakan sebagai penghubung antara pengguna dan Lucene. Struktur penggunaan class dapat dilihat pada Gambar 2.
Gambar 2 Struktur penggunaan class pada Lucene
Class ‘Search_Engine’ merupakan class tambahan yang digunakan untuk menghubungkan Sesame dan Lucene agar dapat melakukan parsing data dan
indexing dokumen RDF. Struktur class ‘Search_Engine’ dapat dilihat pada Gambar
3.
Pada Gambar 3 dapat dilihat bahwa proses indexing dilakukan pada fungsi ‘indexing()’ yang terdapat pada class ‘Search_Engine’ yang terdiri daru proses
parsing data dari Sesame dan proses indexing menggunakan Lucene. Pseudocode pada fungsi ‘indexing()’ dapat dilihat pada Lampiran 2.
Dokumen RDF yang akan di-index disimpan dalam sebuah aplikasi penyimpanan dokumen RDF yaitu Sesame. Indexing dilakukan oleh fungsi “indexing()” yang terdapat pada class “Search_engine”. Fungsi “indexing” akan melakukan parsing data dokumen RDF pada media penyimpanan Sesame dengan kueri seperti pada Lampiran 3. Hasil parsing data yang di-index melalui Lucene merupakan string freetext seperti yang dapat dilihat pada Gambar 4.
8
Gambar 3 Struktur class 'Search_Engine'
Hasil parsing data selanjutnya akan di-index melalui Lucene dengan nama
field ‘id’, ’nama’, ’famili’, ’latin’, ‘bagian’, ‘penyakit’, ‘deskripsi’, ‘manfaat’ dan
‘kandungan’. Hasil indexing akan disimpan pada folder tmp/rdf-indeks yang terdapat pada direktori c:/xampp/htdocs/Lucene/.
Pada penelitian ini digunakan pembobotan Tf-idf seperti pada Persamaan 1.
Pseudocode pembobotan Tf-idf pada Lucene dapat dilihat pada Gambar 5. Hasil akhir pembobotan Tf-idf pada Lucene merupakan hasil kuadrat dari pembobotan.
Gambar 4 String freetext yang di-index pada Lucene class Search_engine {
public function __construct(){}
public function index(){ view untuk user
}
public function indexing(){ parsing data RDF dari Sesame
indexing hasil parsing dengan menggunakan Lucene }
public function getManfaat($id){ parsing data pada field manfaat }
public function getKandungan($id){ parsing data pada field kandungan }
public function sanitize($input){
membersihkan string hasil parsing dari tag html }
public function doSearch(){
pencarian dengan memproses input berupa string kueri }
9
Gambar 5 Pseudocodefungsi ‘tf’ dan ‘idfFreq’
Fungsi ‘idfFreq()’ pada Gambar 5 memiliki parameter ‘document_freq’ yang merupakan jumlah dokumen yang mengandung term t dan parameter ‘total_document’ yang merupakan jumlah dokumen yang terdapat pada korpus. Pada fungsi ‘tf’ terdapat parameter ‘frequency’ yang merupakan frekuensi token t
yang terdapat pada dokumen d.
Pencarian dilakukan pada fungsi ‘doSearch()’ dengan memasukkan kueri pada sistem search engine. Pseudocode fungsi ‘doSearch()’ dapat dilihat pada
Lampiran 4.
Jumlah kueri yang digunakan pada penelitian ini adalah 29 kueri. Kueri pada sistem ini dapat berupa kata tunggal, frase, atau gabungan dari field yang dipilih dengan kata tunggal atau frase. Kueri akan diproses oleh sistem Lucene yang akan me-retrieve dokumen yang relevan beserta scoring-nya. Pada Lucene, jika hasil
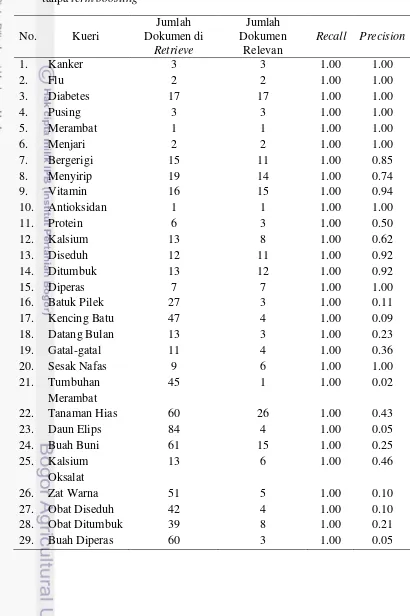
scoring lebih besar dari 1.0 maka nilai scoring akan dibagi dengan nilai skor tertinggi. Pada Tabel 3 ditunjukkan hasil temukembali terhadap dokumen RDF tanaman obat.
Kueri ditentukan dengan cara memilih kata tunggal atau frase yang mewakili isi setiap tanaman obat. Kata-kata tersebut berkaitan dengan penyakit yang dapat disembuhkan, kandungan kimia, karakter fisik, dan cara penggunaan tanaman obat. Pada Lucene disediakan fitur term boosting yang dapat meningkatkan tingkat akurasi hasil temukembali informasi. Pada penelitian ini kueri ‘Tumbuhan Merambat’, ‘Tanaman Hias’, ‘Daun Elips’, ‘Buah Buni’, ‘Zat Warna’, ‘Obat Diseduh’, ‘Obat Ditumbuk’ dan ‘Buah Diperas’ diberikan nilai term boosting 2, 3, 4, 5, 6, 7, 8, 9, 10, dan 20 seperti pada Tabel 4. Kueri yang dipilih untuk kueri term boosting yaitu kueri yang memiliki 2 suku kata tetapi bukan merupakan frase.
Pada Tabel 4 dapat dilihat bahwa kueri menggunakan term boosting dan kueri tanpa term boosting menghasilkan nilai recall dan precision yang sama. Akan tetapi, pada setiap kueri yang diberikan menghasilkan urutan dokumen berbeda yang artinya setiap kueri menghasilkan grafik recall-precision yang berbeda.
Pencarian pada Lucene juga dapat dilakukan berdasarkan field tertentu, misalnya untuk mencari manfaat pada tanaman obat ‘Iler’, maka kueri yang dimasukkan adalah manfaat:Iler. Jika pencarian berdasarkan field mengandung 2 kata atau lebih maka harus disertai dengan tanda kutip agar pencarian dilakukan sesuai dengan kueri frase yang dimasukkan, misalnya manfaat:“Pandan Wangi”.
public function idfFreq(document_freq, total_document) {
return log(total_document/(float)(document_freq+1)) + 1.0; }
public function tf(frequency) {
10
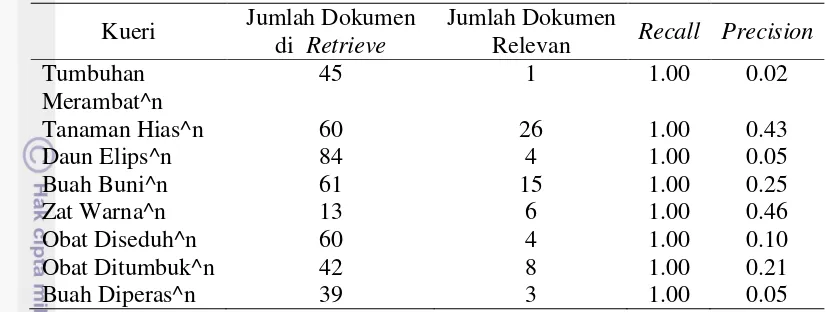
11 Tabel 4 Hasil temukembali terhadap dokumen RDF tanaman obat pada kueri
bukan frase menggunakan term boosting untuk n = 2, 3, 4, 5, 6, 7, 8, 9, 10, 20
Kueri Jumlah Dokumen di Retrieve
Jumlah Dokumen
Relevan Recall Precision Tumbuhan
Evaluasi kinerja search engine dilakukan menggunakan nilai interpolasi maksimum recall dan precision. Pengujian dilakukan terhadap 29 kueri berupa kata tunggal atau frase dan dokumen yang relevan. Setiap kueri akan dihitung nilai
precision pada setiap nilai recall standar yatu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0. Setelah didapatkan nilai precision pada sebelas nilai recall untuk setiap kueri, kemudian dicari nilai interpolasi maksimum recall dan precision. Nilai interpolasi maksimum recall dan precision dapat dilihat pada Gambar 6.
Gambar 6 Grafik recall dan precision dengan interpolasi maksimum pada kueri tanpa term boosting
Dari percobaan yang dilakukan terhadap 29 kueri didapatkan nilai precision
sebesar 0.862. Dapat disimpulkan bahwa kinerja sistem temu kembali informasi memiliki tingkat keakuratan yang baik untuk semua kueri yang diberikan.
Dokumen yang tidak relevan tetapi tetap ditemukembalikan terjadi pada kueri ‘Batuk Pilek’, ‘Kencing Batu’, ‘Datang Bulan’, ‘Gatal-gatal’, ‘Buah Diperas’,
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
Pr
12
Oksalat, ‘Zat Warna’, ‘Obat Diseduh’, dan ‘Obat Ditumbuk. Hal ini disebabkan karena kueri tersebut memiliki banyak arti dalam setiap dokumen tanaman obat, sehingga tidak mampu mewakili informasi yang diinginkan pengguna. Misalnya pada kueri ‘Tumbuhan Merambat’ informasi yang diinginkan pengguna adalah mengenai tanaman obat yang tumbuh merambat, tetapi sistem akan menemukembalikan dokumen yang mengandung kata ‘Tumbuhan’ dan ‘Merambat’. Hal tersebut yang mempengaruhi nilai precision yang didapat pada penelitian ini.
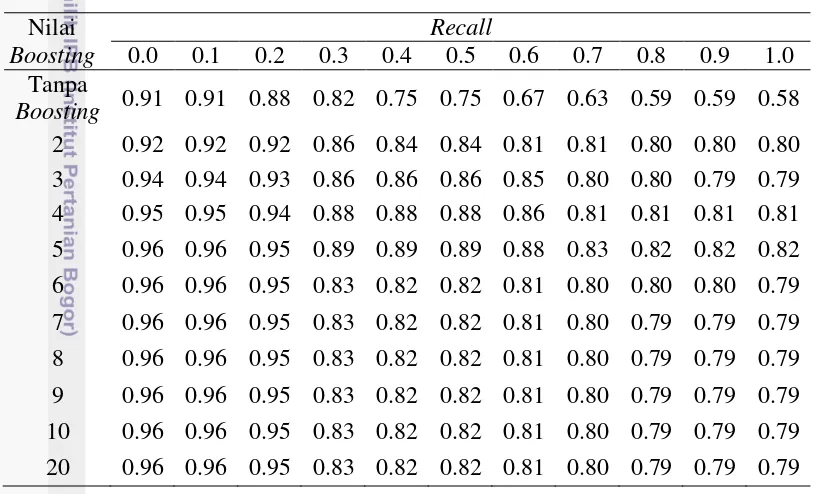
Nilai interpolasi maksimum recall dan precision pada kueri dengan term boosting dapat dilihat pada Tabel 5 dan Nilai rataan interpolasi maksimum recall
dan precision pada kueri dengan term boosting dapat dilihat pada Tabel 6. Tabel 5 Nilai interpolasi maksimum recall dan precision pada kueri bukan frase
dengan beberapa term boosting
Nilai Tabel 6 Nilai rataan interpolasi maksimum recall dan precision pada kueri bukan
frase dengan beberapa term boosting
Nilai Boosting Rataan Interpolasi
Tanpa Boosting 0.736
13 Pada Tabel 5 dapat dilihat bahwa nilai interpolasi maksimum recall dan
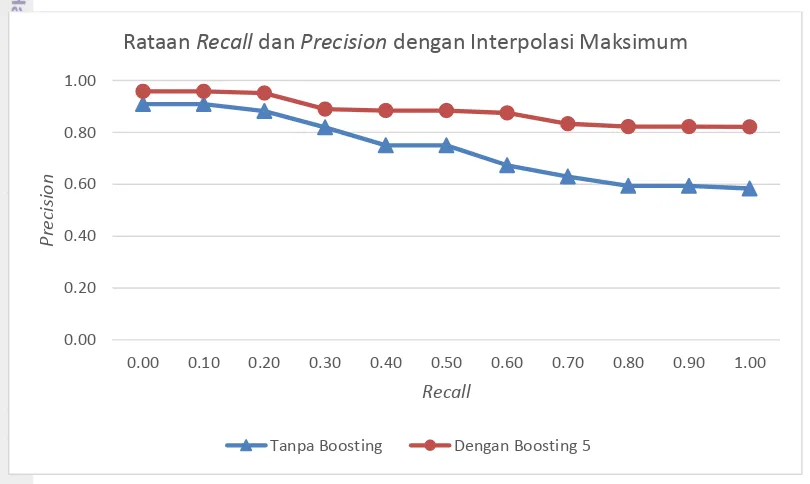
precision pada kueri dengan term boosting lebih tinggi dibandingkan dengan kueri tanpa term boosting, sehingga dapat disimpulkan term boosting mempengaruhi relevansi dokumen yang ditemukembalikan. Akan tetapi pada Tabel 6 ditunjukkan bahwa pada nilaiboosting 7, 8, 9 ,10, dan 20 memiliki rataan interpolasi yang sama, sehingga dapat disimpulkan bahwa nilai boosting lebih dari 7 akan menghasilkan relevansi dokumen yang sama. Nilai boosting 5 menghasilkan relevansi dokumen paling baik yaitu 0.882. Perbandingan rataan interpolasi recall dan precision pada kueri tanpa term boosting dan kueri dengan term boosting 5 dapat dilihat pada Gambar 7.
Gambar 7 Grafik perbandingan recall dan precision dengan interpolasi maksimum antara kueri dengan term boosting dan kueri tanpa term boosting
SIMPULAN DAN SARAN
Simpulan
Pada penelitian ini dapat disimpulkan bahwa:
1. Mesin pencari Lucene dapat digunakan pada dokumen RDF dengan mengaplikasikan Sesame framework (SPARQL dan Repositori) untuk parsing
data RDF.
2. Hasil pencarian yang dilakukan menggunakan 29 kueri menghasilkan nilai rataan precision yang baik yaitu 0.862.
3. Penambahan nilai term boosting meningkatkan nilai rataan precision.
4. Term boosting dengan nilai 5 menghasilkan rataan interpolasi maksimum recall
dan precision yang paling baik yaitu 0.882.
5. Dokumen XML dapat dikonversi menjadi dokumen RDF dengan syarat diketahui struktur dan makna setiap konteks.
0.00
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
Pr
Rataan Recall dan Precision dengan Interpolasi Maksimum
14
Saran
Terdapat beberapa saran untuk penelitian selanjutnya yaitu:
1. Jumlah dokumen tanaman obat yang digunakan sebagai korpus diperbanyak lagi, agar pengukuran relevansi lebih menunjukkan kondisi populasi yang sebenarnya. 2. Menggunakan ontology untuk dokumen RDF agar makna dari informasi pada
dokumen RDF dapat lebih spesifik.
3. Memberikan bobot yang berbeda dengan memperhatikan struktur dokumen RDF dengan memodifikasi fungsi ‘tf()’ dan ‘idfFreq()’ pada Lucene.
DAFTAR PUSTAKA
Broekstra K, Kampman A. 2001. Sesame: A generic Architecture for Storing and Querying RDF and RDF Schema [internet]. [diunduh 2014 November 10]. Tersedia pada: http://iwayan.info/Research/Semantic_Web/Tool/sesame.pdf Gutierrez C, Hurtado C A, Vaisman A. Introducing Time into RDF [internet].
[diunduh 2014 Oktober 15]; 19(2). Tersedia pada: http://www.spatial. cs.umn.edu/Courses/Fall11/8715/papers/time-rdf.pdf
Herawan Y, 2011. Ekstraksi Ciri Dokumen Tumbuhan Obat Menggunakan Chi-Kuadrat dengan Klasifikasi Naive Bayes [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Lei Y, Uren V, Motta E. 2006. SemSearch: A Search Engine for the Semantic Web
[internet]. [diunduh 2014 Oktober 15]. Tersedia pada: http://dee.srv1.eu/refs/ files/1/62.pdf
Manning C D, Raghavan P, Schütze H. 2008. Introduction to Information Retrieval. Cambridge: Cambridge University Press.
Minack E, Sauermann L, Grimnes Gunnar, Fluit C, Broekstra J. 2008. The Sesame LuceneSail: RDF Queries with Full-text Search [internet]. [diunduh 2014 Oktober 15]. Tersedia pada: http://www.dfki.uni-kl.de/~sauermann/papers/ Minack+2008.pdf
Pribadi E R. 2009. Pasokan dan Permintaan Tanaman Obat Indonesia Serta Arah Penelitian dan Pengembangannya [internet]. [diunduh 2014 Oktober 12]; 8(1). Tersedia pada: http://perkebunan.litbang.deptan.go.id/upload.files/File/ publikasi/perspektif/Perps-Vol8_No1_09/N-5%20rini_edited.pdf
[W3C] World Wide Web Consortium. 2004. Resource Description Framework
15
LAMPIRAN
Lampiran 1 Contoh Format RDF Tanaman Pandan Wangi
<rdf:Description rdf:about="tanaman_1"> <tanaman:id>1</tanaman:id>
<tanaman:famili>Pancdanaceae</tanaman:famili> <tanaman:nama>Pandan Wangi</tanaman:nama>
<tanaman:latin>Pandanaus amaryllifolius Roxb</tanaman:latin> <tanaman:bagian>Daun</tanaman:bagian>
<tanaman:manfaat> <rdf:Bag>
<rdf:li>rambut rontok</rdf:li>
<rdf:li>menghitamkan rambut</rdf:li> <rdf:li>menghilangkan ketombe</rdf:li> <rdf:li>lemah saraf (neurastenia)</rdf:li> <rdf:li>tidak nafsu makan</rdf:li>
<rdf:li>rematik</rdf:li> <rdf:li>pegal linu</rdf:li>
<rdf:li>sakit disertai gelisah</rdf:li> </rdf:Bag>
</tanaman:manfaat> <tanaman:kandungan> <rdf:Bag>
<rdf:li>alkaloida</rdf:li> <rdf:li>saponin</rdf:li> <rdf:li>flavonoida</rdf:li> <rdf:li>tannin</rdf:li> <rdf:li>polifenol</rdf:li> <rdf:li>zat warna</rdf:li> </rdf:Bag>
</tanaman:kandungan>
<tanaman:deskripsi>Tumbuh di tempat yang agak lembap, tumbuh subur dari daerah pantai - daerah dengan ketinggian 500m dpl. Perdu tahunan, tinggi 1m-2m. Batang bulat dengan bekas duduk daun, bercabang, menjalar, akar tunjang keluar di sekitar pangkal batang dan cabang. Daun tunggal, duduk, dengan pangkal memeluk batang, tersusun berbaris tiga dalam garis spiral. Helai daun berbentuk pita, tipis, licin, ujung runcing, tepi rata, bertulang sejajar, panjang 40cm-80cm, lebar 3cm-5cm, berduri pada ibu tulang daun permukaan bawah bagian ujung-ujungnya, warna hijau. Bunga majemuk, bentuk bongkol, warnanya putih. Buahnya buah batu, menggantung, bentuk bola, diameter 4cm-7.5cm, dinding buah berambut, warnanya
jingga</tanaman:deskripsi>
16
Lampiran 2 Pseudocode fungsi 'indexing()' yang terdapat pada class
'Search_Engine'
Lampiran 3 Kueri SPARQL yang digunakan untuk parsing data RDF Tanaman Obat
function indexing() {
rmdir(index_directory) Start_sesame
$store = new phpSesame
$sparql = kueri untuk parsing data $resultFormat = phpSesame::SPARQL_XML $lang = “sparql”
$infer = true
$result = $store->query($sparql,$resultFormat,$lang,$infer)
$index = new Zend_Search_Lucene(index_directory)
if($result->hasRows()){
foreach($manfaat->getRows() as $row2) {
foreach($kandungan->getRows() as $row3) {
$isi_kandungan .= $row3['isi_kandungan'].', '; }
$index->addDocument($doc); $total_index++;
} }
17
Lampiran 4 Pseudocode fungsi 'doSearch()' yang terdapat pada class 'Search_Engine'
PREFIX tanaman:<http://localhost/tanaman-obat/rdf#> SELECT *
WHERE {
?tanaman tanaman:nama ?nama . ?tanaman tanaman:habitus ?habitus . ?tanaman tanaman:penyakit ?penyakit . ?tanaman tanaman:famili ?famili . ?tanaman tanaman:bagian ?bagian . ?tanaman tanaman:latin ?latin .
?tanaman tanaman:deskripsi ?deskripsi . }
function doSearch() {
if($this->input->post('submit')) {
$keyword = $this->input->post('query'); $query = $keyword;
$index = new
Zend_Search_Lucene('c:\xampp\htdocs\Lucene\tmp\rdf_indeks');
$hits = $index->find($keyword);
$data['query'] = $query;
$data['count'] = $index->count(); $data['hits_count'] = count($hits); $data['hits'] = $hits;
$page['_contents'] = 'search.view.php'; $data['_title'] = 'Search Engine';
$this->template->load("template/page",$page,$data); }
18
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 24 November 1991 dari pasangan Aminuddin dan Yati Mulyati. Penulis merupakan anak kedua dari tiga bersaudara. Pada tahun 2009 penulis lulus dari Sekolah Menengah Atas (SMA) Plus Bina Bangsa Sejahtera Bogor dan pada tahun yang sama penulis diterima di Institut Pertanian Bogor (IPB) melalui jalur Undangan Seleksi Masuk IPB (USMI) Program Diploma Teknik Komputer.