DETEKSI KEMIRIPAN DOKUMEN TEKS MENGGUNAKAN
ALGORITMA
MANBER
SKRIPSI
IQBAL MAULANA DJAFAR
091402012
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
DETEKSI KEMIRIPAN DOKUMEN TEKS MENGGUNAKAN
ALGORITMA MANBER
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
Sarjana Teknologi Informasi
IQBAL MAULANA DJAFAR
091402012
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
ii
PERSETUJUAN
Judul : DETEKSI KEMIRIPAN DOKUMEN TEKS
MENGGUNAKAN ALGORITMA MANBER
Kategori : SKRIPSI
Nama : IQBAL MAULANA DJAFAR
Nomor Induk Mahasiswa : 091402012
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Sarah Purnamawati, ST., M.Sc Dr. Erna Budhiarti Nababan, M.IT
NIP 19830226 2010122 003 NIP
Diketahui/disetujui oleh
Program Studi S1 Teknologi Informasi
Ketua,
M. Anggia Muchtar, ST., MM.IT
PERNYATAAN
DETEKSI KEMIRIPAN DOKUMEN MENGGUNAKAN
ALGORITMA MANBER
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya Saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing- masing telah disebutkan sumbernya.
Medan,
Iqbal Maulana Djafar
iv
PENGHARGAAN
Alhamdulillah segala puji dan syukur saya sampaikan kehadirat Allah SWT beserta
Nabi Besar Muhammad SAW yang telah memberikan rahmat, hidayah-Nya sehingga
Saya dapat menyelesaikan skripsi ini untuk memperoleh gelar Sarjana Program Studi
S-1 Teknologi Informasi Universitas Sumatera Utara.
Ucapan terima kasih penulis sampaikan kepada:
1. Bapak M. Anggia Muchtar, ST., MM.IT dan M. Fadly Syahputra, B.Sc.,
M.Sc.IT selaku Ketua dan Sekretaris Jurusan Teknologi Informasi Universitas
Sumatera Utara, serta seluruh dosen serta pegawai di Program Studi S-1
Teknologi Informasi.
2. Ibu Dr. Erna Budhiarti Nababan, M.IT selaku pembimbing pertama dan Ibu
Sarah Purnamawati, ST., M.Sc selaku pembimbing kedua Saya yang telah
banyak meluangkan waktunya dan memberikan saran yang bermanfaat dalam
menyelesaikan skripsi ini.
3. Bapak M. Anggia Muchtar, ST., MM.IT dan Bapak Dedy Arisandi, ST.,
M.Kom yang telah bersedia menjadi dosen penguji dan telah memberikan
saran-saran yang baik bagi penulis dalam meyelesaikan skripsi ini.
4. Ayahanda Drs. Djafar Djuned dan Bunda Husna Yaini Djuned yang telah
memberikan dukungan dan motivasi dalam menyelesaikan skripsi ini.
5. Teman-teman seperjuangan stanbuk 2009 yang banyak memberikan semangat
maupun bantuan dalam menyelesaikan skripsi ini.
Dan yang terakhir, penulis mengucapkan terima kasih kepada semua pihak
yang sudah membantu dalam penyelesaian tugas akhir ini meskipun tidak dapat
disebutkan satu per satu. Terima kasih atas saran, motivasi, dan bantuan yang telah
ABSTRAK
Dokumen teks sering dijadikan sebagai objek penjiplakan atau tindak plagiat karena
perkembangan teknologi yang semakin pesat tentu akan memudahkan tindakan
tersebut untuk dilakukan. Oleh karena itu, dirancang sistem berbasis web untuk
mendeteksi kemiripan dokumen teks menggunakan algoritma Manber. Sistem juga
dibangun dengan mengimplementasikan teknik Stemming P orter dan Synonym
Recognition untuk mengatasi teknik penjiplakan seperti Technical Disguise dan
Disguised P lagiarism. Perbedaan hasil yang didapatkan dengan menggunakan teknik
tersebut mencapai 15% dibandingkan tanpa penggunaannya.
Kata Kunci: Plagiat, Kemiripan, Stemming P orter, Synonym Recognition, Algoritma
vi
SIMILARITY DETECTION OF DOCUMENT TEXT USING
MANBER ALGORITHM
ABSTRACT
Document text is an object that often used in plagiarism case because the rapid of
technology development makes this action more easily to do. In this research, a web
based system is designed to detect similarity of document text using Manber
Algorithm. Stemming Porter and Synonym Recognition are also implemented to
overcome some of plagiarism technique like Technical Disguised and Disguised
Plagiarism. The difference result is about 15% compared without using those
techniques.
Keyword: Plagiarism, Similarity, Stemming Porter, Synonym Recognition, Manber
DAFTAR ISI
Hal.
PERSETUJUAN ii
PERNYATAAN iii
PENGHARGAAN iv
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR TABEL x
DAFTAR GAMBAR xi
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 4
1.5 Manfaat Penelitian 4
1.6 Metodologi Penelitian 4
1.7 Sistematika Penulisan 5
BAB 2 TINJAUAN PUSTAKA 7
2.1 Keaslian Dokumen Teks 7
2.2 Penjiplakan 7
2.3 Kemiripan Dokumen Teks 8
2.4 Text Mining 9
2.5 Algoritma Manber 9
2.5.1 P enghapusan Noise Dan Whitespace 10
2.5.2 Metode N-Gram 11
2.5.3 Rolling Hash 12
viii
2.5.5 P ersamaan Jaccard Coefficient 13
2.6 Stemming 14
2.7 Synonym Recognition 15
2.8 Penelitian Terdahulu 15
BAB 3 ANALISIS DAN PERANCANGAN 18
3.1 Data Yang Digunakan 18
3.2 Flowchart Sistem 18
3.3 Activity Diagram 22
3.4 Stemming 23
3.5 Synonym Recognition 28
3.6 Algoritma Manber 29
3.7 Deteksi Kemiripan Teks Secara Manual 31
3.8 Perancangan Database Dan Interface Sistem 33
3.8.1 Database Sistem 33
3.8.2 Interface Sistem 34
BAB 4 IMPLEMENTASI DAN PENGUJIAN 37
4.1 Implementasi 37
4.1.1 Spesifikasi Hardware Dan Software Yang Digunakan 37
4.1.2 Database Tabel Kata Dasar 38
4.1.3 Database Tabel Kata Sinonim 38
4.1.4 Tampilan Awal 39
4.1.5 Tampilan Hasil 40
4.1.6 Stemming 41
4.1.7 Synonym Recognition 42
4.1.8 Algoritma Manber 43
4.2 Pengujian Sistem 44
4.2.1 P engujian Tampilan Sistem 44
4.2.2 P engujian P roses Stemming 46
4.2.3 P engujian Synonym Recognition 48
4.2.4 P engujian Deteksi Kemiripan Teks 49
4.2.6 P engujian Dengan Metode Lainnya 52
BAB 5 KESIMPULAN DAN SARAN 53
5.1 Kesimpulan 53
5.2 Saran 54
DAFTAR PUSTAKA 55
x
DAFTAR TABEL
Hal.
Tabel 2.1 Penelitian Terdahulu 17
Tabel 3.1 Bubuhan Kata Stemming Porter 23
Tabel 3.2 Penambahan Bubuhan Kata 24
Tabel 3.3 Rules Peleburan Huruf 25
Tabel 3.4 Rancangan Tabel Kata Dasar 33
Tabel 3.5 Rancangan Tabel Kata Sinonim 34
Tabel 4.1 Rancangan Pengujian Tampilan Sistem 44
Tabel 4.2 Hasil Pengujian Tampilan Sistem 45
Tabel 4.3 Rancangan Pengujian Rules 46
Tabel 4.4 Hasil Pengujian Rules 47
Tabel 4.5 Rancangan Pengujian SynonymRecognition 48
Tabel 4.6 Hasil Pengujian Synonym Recognition 48
Tabel 4.7 Rancangan Pengujian Kemiripan Teks 49
Tabel 4.8 Hasil Pengujian Kemiripan Teks 51
Tabel 4.9 Rancangan Pengujian Nilai N 51
Tabel 4.10 Hasil Pengujian Nilai N 51
Tabel 4.11 Rancangan Pengujian Dengan Metode Lainnya 52
DAFTAR GAMBAR
Hal.
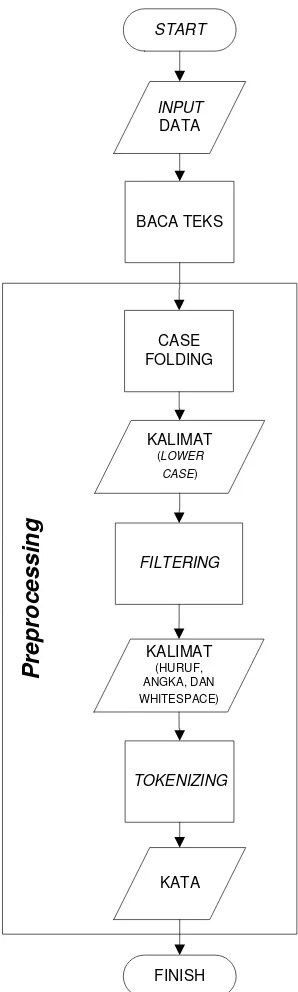
Gambar 3.1 F lowchartP reprocessing 19
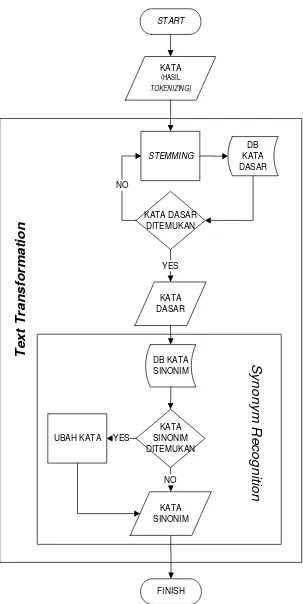
Gambar 3.2 F lowchart Text Transformation 20
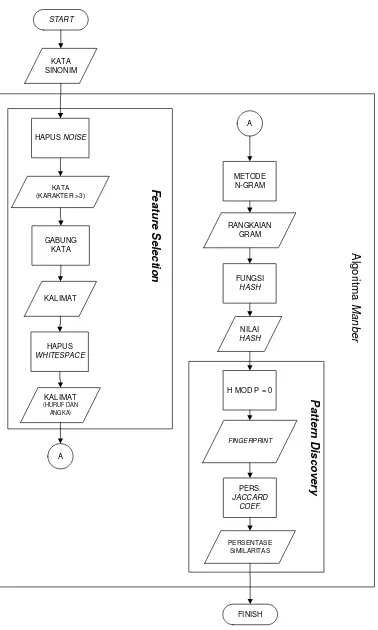
Gambar 3.3 F lowchart F eature Selection & P atter Discovery 21
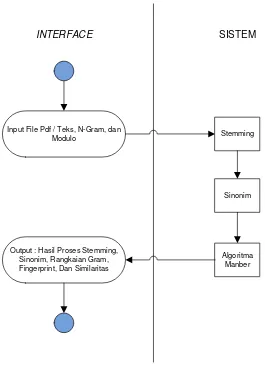
Gambar 3.4 Diagram Activity 22
Gambar 3.5 Proses Stemming 26
Gambar 3.6 Proses Synonym Recognition 28
Gambar 3.7 Proses Algoritma Manber 30
Gambar 3.8 Rancangan Tampilan Awal Sistem 35
Gambar 3.9 Rancangan Tampilan Hasil Sistem 36
Gambar 4.1 Database Tabel Kata Dasar 38
Gambar 4.2 Database Tabel Kata Sinonim 38
Gambar 4.3 Tampilan Awal Sistem 39
Gambar 4.4 Tampilan Hasil Sistem 40
Gambar 4.5 Hasil Implementasi Stemming 42
Gambar 4.6 Hasil Implementasi Synonym Recognition 43
Gambar 4.7 Hasil Proses Algoritma Manber 43
Gambar 4.8 Hasil Akhir Algoritma Manber 44
Gambar 4.9 Pengujian Stemming Dan Rules 47
Gambar 4.10 Pengujian Synonym Recognition 48
Gambar 4.11 Hanya Menggunakan Algoritma Manber 49
v
ABSTRAK
Dokumen teks sering dijadikan sebagai objek penjiplakan atau tindak plagiat karena
perkembangan teknologi yang semakin pesat tentu akan memudahkan tindakan
tersebut untuk dilakukan. Oleh karena itu, dirancang sistem berbasis web untuk
mendeteksi kemiripan dokumen teks menggunakan algoritma Manber. Sistem juga
dibangun dengan mengimplementasikan teknik Stemming P orter dan Synonym
Recognition untuk mengatasi teknik penjiplakan seperti Technical Disguise dan
Disguised P lagiarism. Perbedaan hasil yang didapatkan dengan menggunakan teknik
tersebut mencapai 15% dibandingkan tanpa penggunaannya.
Kata Kunci: Plagiat, Kemiripan, Stemming P orter, Synonym Recognition, Algoritma
SIMILARITY DETECTION OF DOCUMENT TEXT USING
MANBER ALGORITHM
ABSTRACT
Document text is an object that often used in plagiarism case because the rapid of
technology development makes this action more easily to do. In this research, a web
based system is designed to detect similarity of document text using Manber
Algorithm. Stemming Porter and Synonym Recognition are also implemented to
overcome some of plagiarism technique like Technical Disguised and Disguised
Plagiarism. The difference result is about 15% compared without using those
techniques.
Keyword: Plagiarism, Similarity, Stemming Porter, Synonym Recognition, Manber
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Teknologi komputer sudah berkembang pesat dan menjadi sebuah kebutuhan bagi
setiap orang. Tentu perkembangan ini memiliki banyak dampak dalam kehidupan.
Salah satu dampak positifnya adalah untuk membantu dan memudahkan kerja
manusia. Sebagai contoh yaitu dalam melakukan suatu pendeteksian.
Banyak manfaat yang dapat diambil dengan adanya proses pendeteksian,
seperti pendeteksian kemiripan dokumen teks. Deteksi kemiripan dokumen teks
merupakan sebuah upaya yang dilakukan untuk menghindari tindakan plagiarisme
sehingga keaslian dari dokumen teks akan tetap terjaga.
Plagiarisme atau penjiplakan dapat diartikan sebagai sebuah tindakan imitasi
atau pemalsuan baik dari segi bahasa maupun ide dari orang lain dengan
merepresentasikan hal tersebut sebagai hasil karyanya sendiri (Hariharan, 2012).
Plagiarisme dalam bahasa latin diartikan sebagai pencurian, sehingga seseorang yang
melakukan tindak penjiplakan dapat diartikan pula sebagai seorang pencuri.
Ada banyak teknik penjiplakan pada dokumen teks, beberapa diantaranya
adalah copy paste, penulisan kembali sebuah naskah dengan mengubah struktur
penulisannya, pengutipan ide orang lain tanpa mengubah tulisan, dan penjiplakan
dengan cara mengubah bahasa dokumen ke bahasa lainnya tentunya tanpa menuliskan
sumber ide berasal. Oleh sebab itu, penjiplakan menjadi masalah utama dalam ruang
lingkup pendidikan. Hal ini didasarkan pada penelitian yang telah dilakukan oleh
tindak plagiat, baik plagiat dengan cara mencontek tugas biasa maupun tugas akhir.
Tentunya ini akan merugikan kedua belah pihak, baik pelaku dan korban penjiplakan
khususnya.
Penjiplakan pada tingkat pendidikan biasanya terjadi akibat deadline dari suatu
pekerjaan ataupun dari sifat malas yang dimiliki. Adapun tindak penjiplakan yang
sering dilakukan oleh pelajar adalah jenis copy paste, artinya dokumen teks dijiplak
tanpa mengubah isi teks maupun jenis peringkasan dengan cara menutupi bagian yang
disalin. Di dalam dunia pendidikan, suatu karya ilmiah dikatakan sebagai hasil plagiat
atau penjiplakan apabila kutipan yang dilakukan dijiplak secara utuh dan tidak disertai
penyebutan referensi secara benar (Purwitasari, et al. 2009).
Pendeteksian plagiat dapat dilakukan baik secara manual dengan mengecek
langsung dokumen teks ataupun secara semi-otomatis dengan bantuan sistem
komputer. Meskipun pendeteksian secara manual merupakan cara yang paling akurat
dalam mendeteksi plagiat, namun cara ini sangat tidak efektif dan efisien, baik dari
segi waktu, tenaga, maupun biaya. Pencegahan merupakan upaya terbaik untuk
menghalangi munculnya plagiarisme, yaitu dengan menekankan moral masyarakat
dan sistem pendidikan akan bahaya plagiarisme. Cara ini akan memberikan efek
jangka panjang, sehingga diharapkan tindak penjiplakan dapat berkurang ataupun
dituntaskan hingga selesai (Salmuasih, 2013). Pendeteksian plagiarisme pada
dokumen teks dapat dilakukan dengan cara membandingkan kemiripan antara isi
dokumen teks yang akan diuji dengan dokumen teks pembandingnya, dimana
dokumen teks pembanding yang digunakan sudah dinyatakan valid sehingga terhindar
dari tindak penjiplakan.
Pendeteksian kemiripan dokumen teks berbahasa Indonesia secara
semi-otomatis cukuplah sulit untuk dilakukan karena bahasa Indonesia tidak memiliki
rumus bentuk baku yang permanen (Triawati, 2009) ditambah dengan penggunaan
imbuhan, kata ganti orang, dan sinonim kata yang sangat banyak dan memiliki ragam
bentuk serta makna. Tentu hal ini akan semakin memudahkan terjadinya tindak plagiat
dan kesulitan dalam pendeteksiannya.
Salah satu penelitian terdahulu mengenai pendeteksian kemiripan dokumen
teks, yaitu Ramadhani, et al. (2013) yang selain menggunakan algoritma Winnowing,
juga membandingkan algoritma tersebut dengan algoritma Manber. Kesimpulan yang
3
perbedaan hasil similaritas sebesar 4-7% dengan responden yang mencari kesamaan
dokumen secara manual. Meskipun dari segi keakuratan Winnowing lebih unggul,
namun waktu proses algoritma tersebut lebih lama dari algoritma Manber.
Oleh karena itu, dibutuhkan sebuah sistem untuk mendeteksi kemiripan
dokumen teks dengan tingkat keakuratan dan waktu proses yang baik. Adapun
algoritma yang diimplementasikan ke dalam sistem adalah algoritma Manber.
Algoritma ini memiliki waktu proses yang sangat cepat dan ketepatan yang cukup
baik. Algoritma Manber merupakan salah satu dari tiga metode fingerprint selain
Winnowing dan Rabin-Karp. Secara umum, algoritma Winnowing dan Manber
memiliki prinsip kerja yang hampir sama dengan perbedaan, yaitu pada proses
pemilihan fingerprint dokumennya. Proses stemming dan Synonym Recognition juga
akan diimplementasikan ke dalam sistem untuk meningkatkan keakuratan dalam
pendeteksian kemiripan dokumen teks serta mengatasi beberapa teknik penjiplakan.
1.2 Rumusan Masalah
Penjiplakan merupakan perbuatan yang secara sengaja ataupun tidak sengaja
dilakukan dengan cara mengutip sebagian atau seluruh karya orang lain, tanpa
menyatakan sumber secara tepat dan memadai. Salah satu objek yang sering dijadikan
sebagai media penjiplakan adalah dokumen teks. Untuk melihat keaslian dokumen
teks dapat diuji dengan cara membandingkan kemiripan isi dokumen teks. Oleh
karena itu, diperlukan pendekatan untuk mendeteksi kemiripan suatu dokumen teks
dengan dokumen teks lain sehingga tindakan penjiplakan dapat dideteksi dan
dihindari.
1.3 Batasan Masalah
Agar penelitian dapat sesuai dengan permasalahan yang akan diselesaikan, maka
diperlukan beberapa batasan, yaitu sebagai berikut:
1. Hanya menguji dokumen teks, tidak menguji dokumen berupa gambar ataupun
suara.
3. Pengujian dilakukan pada file dengan format pdf.
4. Hanya memperhatikan tulisan, tidak termasuk makna kalimat.
5. Tidak memperhatikan kesalahan dalam penulisan kata (typo).
6. Tidak memperhatikan adanya penulisan sumber rujukan.
7. Pendeteksian pada plagiarisme jenis Technical Disguise, Disguised, dan Copy
& P aste P lagiarism.
1.4 Tujuan
Tujuan dari penelitian ini adalah mendeteksi kemiripan satu dokumen teks uji dengan
satu dokumen teks pembanding menggunakan algoritma Manber disertai penggunaan
teknik stemming dan Synonym Recognition.
1.5 Manfaat
Adapun manfaat dari penelitian ini adalah:
1. Mengefektifkan serta mengefisiensikan waktu, tenaga, dan biaya dalam
mendeteksi kemiripan dokumen teks.
2. Menambah pengetahuan atau wawasan mengenai penjiplakan dan cara untuk
mendeteksi tindakan tersebut.
3. Sebagai bahan untuk pengembangan penelitian selanjutnya.
1.6 Metodologi Penelitian
Adapun metodologi pada penelitian ini adalah:
1. Studi Literatur
Dilakukan pengumpulan referensi melalui berbagai macam buku, jurnal,
5
2. Pengumpulan Data
Dilakukan pengumpulan data dan informasi yang akan diperlukan dalam
penelitian.
3. Analisis dan Perancangan
Dilakukan analisis terhadap studi literatur untuk mengetahui penyelesaian
permasalahan deteksi kemiripan dokumen dan melakukan perancangan sistem.
4. Implementasi
Perancangan sistem yang telah dibuat akan diimplementasikan ke dalam
aplikasi yang dibuat dengan menggunakan bahasa pemrograman PHP dan
database MySQL.
5. Pengujian
Uji coba produk dan evaluasi. Melakukan uji coba program yang telah dibuat.
Kemudian melakukan evaluasi terhadap kekurangan program.
6. Penyusunan Laporan
Dokumentasi dari hasil analisis dan implementasi dari sistem yang dibangun.
1.7 Sistematika Penulisan
Skripsi ini disusun dengan sistematika penulisan, sebagai berikut:
Bab 1: Pendahuluan
Pada bab ini dibahas mengenai latar belakang penulisan, rumusan masalah, batasan
masalah, tujuan, manfaat, metodologi penelitian, dan sistematika penulisan skripsi.
Bab 2: Landasan Teori
Pada bab ini dibahas mengenai teori-teori yang digunakan dalam pengerjaan skripsi.
Teori-teori yang terdapat pada bab ini mencakup algoritma secara umum dan teknik
Bab 3: Analisis Dan Perancangan Sistem
Pada bab ini dibahas mengenai analisis algoritma dan teknik pendukungnya dalam
mendeteksi persentase kemiripan dokumen serta perancangan sistem berdasarkan hasil
analisis yang dilakukan.
Bab 4: Pengimplementasian Dan Pengujian Sistem
Pada bab ini dibahas mengenai implementasi dari sistem dan melakukan pengujian
terhadap kinerja dari sistem yang dibentuk.
Bab 5: Kesimpulan Dan Saran
Pada bab ini berisi tentang kesimpulan yang didapat dari pembuatan skripsi dan
BAB 2
TINJAUAN PUSTAKA
Pada bab ini, akan dibahas landasan teori mengenai pendeteksian kemiripan dokumen
teks yang mengkhususkan pada pengertian dari keaslian dokumen, plagiarisme,
kemiripan dokumen, dan penjelasan mengenai algoritma yang digunakan yaitu
algoritma Manber serta teknik pendukung berupa stemming dan Synonym
Recognition. Pada akhir bab ini akan dipaparkan penelitian-penelitian terdahulu
mengenai pendeteksian kemiripan dokumen teks.
2.1 Keaslian Dokumen Teks
Keaslian sebuah dokumen teks merupakan naskah yang berasal dari ide pengarang
tanpa adanya penambahan ide dari pengarang lainnya. Jika pun ada, nama pengarang
harus dicantumkan di dalam referensi serta tidak menuliskan secara utuh kutipan ide
tersebut melainkan menuliskannya ke dalam bahasa sendiri. Hal ini dilakukan untuk
menghindari tindak plagiarisme.
2.2 Penjiplakan
Penjiplakan atau plagiarisme adalah teknik peniruan atau penyalinan ide orang lain
tanpa menuliskan referensi darimana ide tersebut berasal, artinya secara tidak
langsung penulis sudah menglaim bahwa ide tersebut berasal dari idenya sendiri.
Tidak adanya keinginan ataupun kemudahannya dalam menyalin hasil karya atau ide
Berdasarkan hasil penelitian yang dilakukan oleh Gipp & Meuschke (2011),
dijelaskan bahwa teknik plagiat memiliki ragam bentuk, diantaranya:
1. Copy & P aste P lagiarism, yaitu menyalin seluruh kata tanpa adanya
perubahan konten dari naskah aslinya.
2. Disguised P lagiarism, yaitu menutupi beberapa bagian yang telah disalin dari
naskah aslinya dengan menggunakan konten bermakna sama.
3. Technical Disguise, yaitu menyembunyikan serta melakukan peringkasan pada
beberapa konten dari naskah yang telah disalin.
4. Undue P araphrasing, yaitu mengubah susunan serta bahasa yang digunakan
(dari bahasa yang satu ke bahasa lainnya) dengan menggunakan gaya
penulisannya sendiri tanpa menuliskan sumber aslinya.
5. Translated P lagiarism, yaitu mengubah dari bahasa satu ke bahasa lainnya
tanpa menuliskan sumber aslinya.
6. Idea P lagiarism, yaitu menggunakan ide orang lain tanpa menuliskan sumber
darimana ide berasal.
2.3 Kemiripan Dokumen Teks
Pendeteksian plagiarisme pada dokumen teks dilakukan dengan cara membandingkan
isi dari dokumen yang akan diuji dengan dokumen yang dijadikan sebagai
pembandingnya. Adapun syarat dokumen pembanding adalah sudah dinyatakan
keasliannya sehingga pengujian kemiripan dokumen menjadi valid.
Dalam menentukan hasil akhir pendeteksian kemiripan dokumen teks,
biasanya digunakan persentase similaritas sehingga pembacaan hasil akhir menjadi
lebih mudah. Adapun teknik pendeteksian kemiripan dokumen teks menurut Stein &
Eissen (2006) adalah:
1. Perbandingan Teks Lengkap, yaitu membandingkan seluruh kata yang terdapat
di dalam dokumen teks.
2. Kesamaan Kata Kunci, yaitu membandingkan seluruh kata yang merupakan
perwakilan isi dokumen.
3. F ingerprint, yaitu membandingkan rangkaian pembentuk teks dengan panjang
9
2.4 Text Mining
Text Mining diartikan sebagai penambangan data berupa teks yang bersumber dari
dokumen untuk mencari kata-kata yang merupakan perwakilan isi atau pembentuk
dokumen teks sehingga penganalisisan dapat dilakukan.
Berikut ini merupakan tahapan umum pada proses Text Mining, yaitu
(Nugroho, 2011):
1. Text P reprocessing, yaitu pemrosesan awal yang ditujukan untuk membentuk
teks menjadi data siap olah pada proses selanjutnya.
a. Case F olding, yaitu pengubahan seluruh karakter yang merupakan huruf
kapital menjadi huruf kecil.
b. F iltering, yaitu pengambilan kata-kata yang penting sesuai dengan kondisi
yang diinginkan.
c. Tokenizing, yaitu tahap pemecahan kalimat yang di-input berdasarkan kata
yang menyusunnya, biasanya dipisah oleh karakter whitespace.
2. Text Transformation, yaitu pembentukan teks yang mengacu pada proses
untuk mendapatkan representasi dokumen yang sesuai.
a. Stemming, yaitu pencarian kata dasar dari setiap kata hasil tokenizing.
b. Synonym Recognition, yaitu pengubahan kata yang memiliki makna yang
sama dengan penulisan berbeda.
3. F eature Selection, yaitu pengurangan dimensi teks sehingga nantinya akan
dihasilkan kata-kata yang merupakan dasar dari isi teks.
4. P attern Discovery, yaitu penemuan pola atau pengetahuan dari keseluruhan
teks.
2.5 Algoritma Manber
Algoritma Manber merupakan salah satu dari tiga algoritma yang menggunakan
fingerprint dalam proses penyelesaian permasalahannya, selain algoritma Winnowing
dan Rabin-Karp. Penggunaan fingerprint ini ditujukan agar dapat mengidentifikasi
penjiplakan termasuk bagian-bagian kecil yang mirip dalam dokumen pada dokumen
Setiap algoritma memiliki penyelesaian permasalahan yang berbeda, namun
algoritma Manber dan Winnowing memiliki langkah penyelesaian yang hampir sama.
Adapun perbedaan algoritma Manber dari algoritma Winnowing adalah sebagai
berikut (Kurniawati & Wicaksana, 2008):
1. Jumlah langkah yang lebih sedikit sehingga waktu pemrosesan dokumen
menjadi lebih cepat.
2. Tidak memberikan informasi dimana posisi fingerprint berada.
3. Pemilihan fingerprint yang berbeda. Pada Algoritma Manber, fingerprint
dipilih dari setiap nilai hash yang memenuhi persyaratan H mod P = 0, di mana H adalah nilai hash dan P adalah nilai pembagi yang digunakan, sementara pada Algoritma Winnowing dipilih nilai hash minimum dalam setiap window.
Adapun secara singkat, konsep dasar algoritma Manber dimulai dari tahap awal
baik penghapusan noise dan whitespace hingga hasil akhirnya berupa persentase
adalah :
1. Penghapusan noise dan whitespace.
2. Pembentukan rangkaian gram dengan panjang N karakter.
3. Penghitungan nilai hash dari setiap gram menggunakan fungsi hash.
4. Pemilihan beberapa nilai hash menjadi fingerprint dokumen.
5. Menentukan persentase kemiripan antar dokumen menggunakan persamaan
Jaccard Coefficient.
2.5.1 P enghapusan Noise & Whitespace
Banyak algoritma atau metode yang dapat digunakan untuk mendeteksi kemiripan
dokumen teks. Ada beberapa persyaratan yang harus dipenuhi oleh algoritma
pendeteksi kemiripan dokumen teks (Pratama, 2012), yaitu:
1. Whitespace Insensitivity, artinya dalam melakukan pendeteksian terhadap
dokumen teks, algoritma tidak boleh dipengaruhi oleh spasi, jenis huruf
(kapital atau normal), tanda baca dan sebagainya. Oleh sebab itu, dilakukan
penghapusan terhadap karakter yang tidak relevan tersebut sehingga nantinya
11
2. Noise Surpression, artinya dalam melakukan pendeteksian, algoritma harus
dapat menghindari adanya kata yang tidak penting, misal: “di”, “ke”, dan
sebagainya. Panjang kata yang ditengarai harus cukup untuk membuktikan
bahwa kata-kata tersebut telah dijiplak dan bukan merupakan kata yang umum
digunakan.
3. P osition Independence, artinya pendeteksian tidak boleh bergantung pada
posisi kata sehingga apabila posisi kata berbeda maka pendeteksian tetap dapat
dilakukan.
2.5.2 Metode N-Gram
Algoritma yang menggunakan fingerprint seperti algoritma Manber memiliki satu
metode utama yaitu metode N-Gram. Metode N-Gram merupakan metode yang
berfungsi untuk memecah kata ataupun kalimat menjadi sebuah rangkaian dengan
panjang N karakter. Sebagai contoh :
“KEMEJA”
Dengan menggunakan nilai N = 2, maka akan dihasilkan :
“KE”, “EM”, “ME”, “EJ”, “JA”
Metode N-Gram memunyai peran yang cukup penting karena merupakan
langkah awal dalam proses pembentukan fingerprint. Dengan kata lain, metode
N-Gram memiliki pengaruh terbesar pertama pada hasil akhir yang dikeluarkan.
Pengaruh dari nilai N pada metode N-Gram yaitu semakin kecil nilai N yang
digunakan akan semakin besar pula persentase yang dihasilkan nantinya. Namun,
tidak selalu dengan menggunakan nilai N = 1, hasil yang didapatkan lebih baik.
Alasannya adalah jika kalimat terdiri dari huruf yang sama dengan kalimat
bandingnya, maka akan menghasilkan persentase kemiripan sebesar 100%. Sebagai
contoh :
“RAMAH” : “R”,”A”,”M”,”H” “MARAH” : “M”,”A”,”R”,”H”
Didapatkan 4 huruf yang sama, sehingga menghasilkan persentase sebesar 100%.
Oleh karena itu, penggunaan N-Gram harus disesuaikan dengan kondisi dari teks yang
2.5.3 Hash
Hash merupakan teknik untuk mengubah sebuah string menjadi nilai unik dengan
panjang tertentu yang nantinya akan berfungsi sebagai penanda string tersebut
(Pratama, et al. 2012)
Hash terdiri dari dua elemen, yaitu fungsi hash dan nilai hash. Hubungan
kedua elemen tersebut adalah rangkaian gram yang dihasilkan dari proses N-Gram
kemudian diolah menggunakan fungsi hash sehingga terbentuklah rangkaian nilai
hash yang nantinya akan dipilih menjadi fingerprint dokumen (Purwitasari, et al.
2009).
Fungsi hash yang digunakan pada algoritma Manber adalah fungsi hash yang
mengubah setiap karakter pada rangkaian string ke dalam bentuk kode ASCII dan
memrosesnya ke dalam persamaan (2.1) berikut :
k
ini dapat dikatakan pula sebagai rangkaian pembentuk atau dasar dari dokumen
tersebut. F ingerprint berasal dari rangkaian nilai hash yang sudah memenuhi
persyaratan.
F ingerprint merupakan tujuan pertama dari algoritma yang menggunakan
fingerprint sebagai langkah penyelesaiannya. Masing-masing algoritma memiliki cara
yang berbeda dalam memilih fingerprint. Pada algoritma Manber, pemilihan
fingerprint dilakukan dengan cara mengecek apakah nilai hash memenuhi persamaan
13
Ada tiga faktor yang mempengaruhi pemilihan fingerprint, yaitu :
1. Nilai N pada metode N-Gram, perubahan panjang karakter yang terbentuk
akan mengubah fingerprint yang dipilih.
2. Basis pada fungsi hash, tentunya perubahan basis akan mengubah nilai hash
yang dihasilkan serta fingerprint yang dipilih.
3. Nilai pembagi pada persamaan (2.2). Perubahan pada nilai pembagi akan
mengubah nilai hash yang akan dipilih menjadi fingerprint. Penggunaan nilai
pembagi ini harus disesuaikan dengan kondisi dokumen teks.
2.5.5 P ersamaan Jaccard Coefficient
Persamaan Jaccard Coefficient merupakan persamaan yang digunakan untuk
mengukur nilai similaritas atau kemiripan. Banyak hal yang dapat diukur nilai
similaritasnya, seperti similaritas dokumen teks. Oleh karena itu, persamaan ini
diimplementasikan ke dalam algoritma Manber sebagai pengukur persentase
similaritas dokumen teks. Persamaan Jaccard Coefficient dapat ditulis sesuai dengan
persamaan (2.3) berikut:
2.6 Stemming
Stemming adalah teknik pencarian kata dasar dari setiap kata hasil tokenizing. Di
dalam bahasa Indonesia, stemming digunakan untuk menghilangkan bubuhan yang
melekat pada kata dasar baik imbuhan (awalan, akhiran, sisipan), partikel, dan kata
ganti orang. Sebagai contoh :
“mempermainkannya” = “mem” + ”per” + “main” + “kan” + “nya” Kata “mempermainkannya” merupakan hasil gabungan dari :
1. Satu kata dasar (root word) : “main”
2. Dua imbuhan awal (prefiks) : “mem” dan “per”
3. Satu imbuhan akhir (sufiks) : “kan”
4. Satu kata ganti orang (possessive pronoun) : “nya”
Stemming lebih susah diimplementasikan ke dalam teks berbahasa Indonesia
karena bahasa Indonesia tidak memiliki rumus bentuk baku yang permanen (Triawati,
2009). Banyak penelitian mengenai teknik stemming, salah satunya adalah Stemming
P orter yang akan digunakan pada penelitian ini. Secara singkat langkah penyelesaian
pada Stemming P orter adalah sebagai berikut:
1. Menghapus partikel,
2. Menghapus kata ganti (possessive pronoun),
3. Menghapus awalan pertama. Jika tidak ditemukan, maka lanjut ke langkah 4a,
dan jika ada, maka lanjut ke langkah 4b,
4. a. Menghapus awalan kedua, dan dilanjutkan pada langkah 5a,
b. Menghapus akhiran, jika tidak ditemukan, maka kata diasumsikan sebagai
kata dasar. Jika ditemukan lanjut ke langkah 5b,
5. a. Menghapus akhiran dan kata akhir diasumsikan sebagai kata dasar.
b. Menghapus awalan kedua dan kata akhir diasumsikan sebagai kata dasar.
Pendeteksian kemiripan dokumen sangat bergantung pada proses stemming,
artinya jika proses stemming tidak berjalan dengan baik, maka hasil yang didapatkan
juga tidak akan sesuai. Oleh karena itu, stemming menjadi salah satu kunci untuk
15
2.7 Synonym Recognition
Synonym Recognition atau pengenalan kata bersinonim adalah teknik yang digunakan
untuk mengenali kata dengan penulisan berbeda namun memiliki makna yang sama.
Teknik penjiplakan dokumen teks tidak lepas dari penggunaan kata bersinonim
sehingga dokumen teks hasil penjiplakan berbeda secara penulisan dari dokumen teks
aslinya meskipun makna yang dihasilkan tetaplah sama. Jenis penjiplakan tersebut
dapat digolongkan ke dalam Disguised P lagiarism dan Technical Disguise. Jenis
penjiplakan ini sangat sulit dideteksi oleh sistem yang tidak mengimplementasikan
teknik Synonym Recognition.
Di dalam bahasa Indonesia, hampir setiap kata memiliki sinonim, tentu hal ini
semakin menyulitkan pendeteksian. Apabila sistem penyimpan kata hanya memiliki
sedikit kata bersinonim, maka semakin kecil pula keakuratan pendeteksian. Hal ini
juga dipersulit dengan adanya penulisan kata bersinonim yang sama meskipun
maknanya berbeda, serta sinonim kata yang menggunakan imbuhan.
Synonym Recognition merupakan kunci kedua terpenting setelah stemming.
Hal ini diakibatkan karena banyaknya kata sinonim yang berasal dari kata dasar,
meskipun beberapa sinonim kata memang memiliki imbuhan. Apabila proses
stemming tidak berjalan dengan baik, maka pengenalan kata bersinonim juga menjadi
tidak sesuai, dan berdampak pada berkurangnya keakuratan pendeteksian.
2.8 Penelitian Terdahulu
Pendeteksian kemiripan dokumen teks sudah banyak dilakukan oleh peneliti-peneliti
sebelumnya, baik dengan menggunakan algoritma pendeteksi kemiripan teks yang
berbeda, teknik pendukung yang berbeda maupun pengimplementasian dalam bentuk
yang berbeda, dan lain sebagainya.
Heriyanto (2011) menggunakan algoritma exact match dalam melakukan
penelitiannya. Algoritma exact match tidak memerdulikan proses stemming sehingga
apabila ada kata yang memiliki awalan dan akhiran, maka tidak dianggap sama. Kata
dasar ditambah dengan awalan dan akhiran akan berarti kata yang berbeda-beda. Hal
Ramadhani, et al (2013) menggunakan algoritma Winnowing, dimana
algoritma ini memiliki langkah yang hampir sama dengan algoritma Manber. Sesuai
dengan kesimpulan yang dituliskan bahwa keakuratan pendeteksian cukup baik, yaitu
memberikan selisih perbedaan sebesar 4-7% dengan responden yang mencari
kesamaan dokumen secara manual, namun kecepatan proses algoritma masih kalah
dari algoritma Manber, meskipun dari segi keakuratan Winnowing lebih unggul.
Salmuasih (2013) yang menggunakan algoritma Rabin-Karp dan konsep
similarity menyimpulkan bahwa penggunaan teknik stemming sangat berpengaruh
pada persentase hasil yang didapatkan, serta perlu ditambahkan teknik pengenalan
sinonim. Modulo yang digunakan dalam penelitiannya tidak berpengaruh pada hasil
persentase, namun berpengaruh pada waktu proses.
Goenawan, et al (2005) menyimpulkan bahwa algoritma Edit Distance lebih
tepat digunakan untuk mencari kecocokan antara dua string. Dimana dalam proses
perbandingannya , string kedua dimanipulasi sehingga pada akhirnya serupa dengan
string pertama. Dalam proses pengubahan string tersebut, dibuat sebuah tabel dua
dimensi dengan baris sesuai dengan panjang string terpanjang dan jumlah kolom
sebanyak panjang string terpendek. Keunggulan algoritma Edit Distance yaitu dapat
melihat perbedaan di antara dua string dengan cepat dan akurat.
Dani, et al (2006) lebih meneliti pada kompleksitas waktu algoritma
Levenshtein Distance dan pendeteksian pada kemiripan kode program. Disimpulkan
bahwa kemiripan antar kode program yang diimplementasi dengan bahasa
pemrograman yang berbeda, sebelumnya dapat dilakukan proses deteksi bahasa dan
konversi ke dalam satu bahasa standar yang dipilih. Dalam kata lain, diperlukan
pengubahan bahasa pemrograman satu ke bahasa lain tanpa mengubah inti dari
program tersebut atau dapat disebut sebagai sinonim bahasa pemrograman.
Oleh karena itu, diperlukan sebuah pengembangan sistem menggunakan
algoritma dengan kompleksitas waktu yang baik serta menambahkan teknik stemming
dan Synonym Recognition. Penelitian sebelumnya dapat dipaparkan secara ringkas
17
Tabel 2.1 Penelitian Terdahulu
No. Nama (Tahun) Metode Kelebihan Kelemahan
1. Heriyanto (2011) Exact Match Waktu proses
algoritma yang relatif
singkat
Edit Distance Dapat melihat
perbedaan di antara
dua string dengan
cepat dan akurat
Maksimal string yang
dapat digunakan
kemiripan skala besar
maupun pada data
yang banyak
mengalami
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini akan dibahas mengenai beberapa hal, diantaranya data yang digunakan,
flowchart dan activity diagram sistem serta analisis perancangan sistem baik dalam
mengimplementasikan algoritma Manber serta teknik stemming dan Synonym
Recognition maupun tampilan sistem.
3.1 Data Yang Digunakan
Ada beberapa data yang diperlukan dalam melakukan pendeteksian pada dokumen
teks sesuai dengan algoritma dan teknik yang digunakan pada penelitian ini, yaitu :
1. Data uji dan pembanding, berupa data dengan format pdf atau teks biasa yang
di-input secara manual.
2. Data mengenai kata dasar yang berasal dari Kamus Besar Bahasa Indonesia
(KBBI) dan disimpan ke dalam satu tabel MySql. Tabel terdiri atas id kata
dasar dan kata dasar.
3. Data mengenai sinonim kata yang bersumber dari Kamus Tesaurus Indonesia
dan disimpan ke dalam satu tabel Mysql. Terdiri atas id kata sinonim, sinonim,
dan kata.
3.2 F lowchart Sistem
F lowchart sistem menggambarkan tahapan dari penyelesaian masalah yang dilakukan
19
gambaran dan membantu pengguna untuk lebih memahami rancangan sistem yang
akan dibuat.
F lowchart sistem yang dirancang akan menjelaskan bagaimana proses
pendeteksian kemiripan dokumen teks dilakukan. Pendeteksian dimulai dari
peng-input-an teks kemudian tahap P reprocessing (Gambar 3.1), Text Transformation
(Gambar 3.2), F eature Selection, dan tahap terakhir yaitu pattern discovery yang
terangkum dalam satu algoritma, yaitu algoritma Manber (Gambar 3.3) berikut:
START
DB
21
3.3 Activity Diagram
Activity Diagram sistem menggambarkan urutan aktivitas dari sistem yang dirancang.
Aktivitas sistem digambarkan secara umum artinya tetap terstruktur namun tidak
secara mendetail seperti pembuatan F lowchart. Activity Diagram diharapkan dapat
membantu pemahaman proses rancangan sistem, baik interface maupun aktivitas yang
dilakukan oleh sistem dengan lebih ringkas.
Activity Diagram yang dibuat akan menampilkan bagaimana aktivitas pada
interface dan proses kerja sistem yang dirancang, seperti pada Gambar 3.4:
INTERFACE SISTEM
Stemming
Sinonim
Algoritma Manber Input File Pdf / Teks, N-Gram, dan
Modulo
Output : Hasil Proses Stemming, Sinonim, Rangkaian Gram, Fingerprint, Dan Similaritas
Gambar 3.4 Diagram Activity
Berdasarkan Gambar 3.4, maka proses dimulai dengan user meng-input kedua file pdf
ataupun teks yang akan dibandingkan beserta nilai N yang digunakan sebagai panjang
23
yang sudah diterima sistem, diproses menggunakan teknik stemming, kemudian
dilanjutkan dengan proses Synonym Recognition, dan diakhiri dengan menggunakan
algoritma Manber. Output yang diterima oleh user adalah :
1. Hasil stemming,
2. Hasil Synonym Recognition,
3. Hasil Noise Reduction,
Proses stemming yang digunakan adalah Stemming P orter. Berdasarkan penelitiannya
mengenai perbandingan Stemming P orter dengan Stemming Nazief & Adriani, Agusta
(2009) menyimpulkan bahwa Stemming P orter memiliki waktu proses yang sangat
cepat namun tingkat keakuratannya lebih kecil daripada Stemming Nazief & Adriani
yang menggunakan kamus kata dasar. Meskipun keakuratan kata dasar yang
dihasilkan dengan menggunakan Stemming Nazief & Adriani sangat baik, namun hal
ini berbanding terbalik dengan waktu prosesnya yang sangat lama. Oleh karena itu,
maka digunakanlah Stemming P orter dengan menambahkan kamus kata dasar,
sehingga nantinya akan menghasilkan proses stemming yang cepat dan akurat.
Pada Tabel 3.1, dipaparkan mengenai bubuhan yang akan dideteksi pada
proses Stemming P orter (Agusta, 2009), yaitu :
Tabel 3.1 Bubuhan Kata Stemming Porter
4. Awalan 2 ber-, bel-, be-, per-, pel-, pe-
5. Akhiran -kan, -an, -i
Ada satu imbuhan lainnya, yaitu sisipan. Kata sisipan sangat jarang digunakan dan
memiliki arti yang cenderung sama sehingga sisipan akan digabung ke dalam proses
Synonym Recognition.
Ada beberapa kasus dimana keakuratan kata dasar yang terbentuk tidak sesuai
dengan kata yang berasal dari kamus jika menggunakan bubuhan kata pada Tabel 3.1,
salah satu contohnya adalah :
“sepengetahuanku”
Kata “sepengetahuanku” merupakan hasil gabungan dari :
1. Satu kata dasar : “tahu”
2. Satu imbuhan akhir : “an”
3. Satu kata ganti orang : “ku”
Berdasarkan contoh di atas, terdapat beberapa imbuhan yang tidak tercantum pada
Tabel 3.1 sehingga tidak menghasilkan kata dasar yang sesuai dan masih banyak
kasus lainnya. Oleh karena itu, dibentuk satu bubuhan kata yang lebih sesuai pada
Tabel 3.2 berikut :
Tabel 3.2 Penambahan Bubuhan Kata
No. Jenis Bubuhan
1. Partikel -kah, -lah, -tah, -pun
2. Kata Ganti Orang -ku, -mu, -nya
3. Awalan 1 menge-, meng-, meny-, men-, mem-, me-, peng-,
peny-, pen-, pem-, di-, ber-, ke-, se-
4. Awalan 2 penge-, ber-, bel-, be-, per-, pel-, pe-, ter-, se-
5. Akhiran -kan, -an, -i
Ada beberapa awalan yang diberikan dua posisi yaitu sebagai awalan 1 dan awalan 2
25
Di dalam imbuhan bahasa Indonesia, terdapat beberapa peleburan huruf pada
kata dasar. Peleburan tersebut hanya berasal dari prefiks atau awalan, contoh :
+ kata dasar tidak dimulai dengan
huruf vokal
Menghasil kata dasar yang dimulai
dengan huruf k-
+ kata dasar tidak dimulai dengan
huruf vokal
Menghasil kata dasar yang dimulai
Awalan “bel-” dan “pel-” merupakan imbuhan yang hanya berasal dari peleburan
Secara singkat, proses Stemming dapat dilihat pada gambar 3.5:
KATA
27
Berikut ini merupakan penjelasan dari Gambar 3.5, yaitu :
1. Setiap kata hasil tokenizing dicek ke dalam database kata dasar. Pengecekan
pertama dilakukan untuk mengetahui apakah kata merupakan kata dasar.
a. Jika ya, maka kata merupakan kata dasar.
b. Jika tidak, maka dilakukan pengecekan ke-2.
2. Pengecekan ke-2 dilakukan untuk mengetahui apakah kata memiliki partikel.
a. Jika ya, maka dilakukan penghapusan partikel kemudian melakukan
pengecekan ke dalam database, apakah kata merupakan kata dasar atau
tidak. Jika ya, maka kata merupakan kata dasar. Jika tidak, maka dilakukan
proses ke-3.
b. Jika tidak, maka dilakukan pengecekan ke-3.
3. Pengecekan ke-3 dilakukan untuk mengetahui apakah kata memiliki kata ganti
orang.
a. Jika ya, maka dilakukan penghapusan kata ganti orang kemudian
melakukan pengecekan ke dalam database, apakah kata merupakan kata
dasar atau tidak. Jika ya, maka kata merupakan kata dasar. Jika tidak, maka
dilakukan proses ke-4.
b. Jika tidak, maka dilakukan pengecekan ke-4.
4. Pengecekan ke-4 dilakukan untuk mengetahui apakah kata memiliki awalan 1.
a. Jika ya, maka dilakukan penghapusan awalan 1 kemudian melakukan
pengecekan ke dalam database, apakah kata merupakan kata dasar atau
tidak. Jika ya, maka kata merupakan kata dasar. Jika tidak, maka dilakukan
proses ke-5.
b. Jika tidak, maka dilakukan pengecekan ke-5.
5. Pengecekan ke-5 dilakukan untuk mengetahui apakah kata memiliki awalan 2.
a. Jika ya, maka dilakukan penghapusan awalan 2 kemudian melakukan
pengecekan kembali ke dalam database, apakah kata merupakan kata dasar
atau tidak. Jika ya, maka kata merupakan kata dasar. Jika tidak, maka
dilakukan proses ke-6.
b. Jika tidak, maka dilakukan pengecekan ke-6.
6. Pengecekan ke-6 merupakan proses terakhir. Selain untuk mengetahui apakah
a. Jika ya, maka dilakukan penghapusan akhiran dan diasumsikan bahwa kata
merupakan kata dasar.
b. Jika tidak, maka kata diasumsikan sebagai kata dasar.
3.5 Synonim Recognition
Synonim Recognition merupakan proses yang dilakukan setelah proses stemming. Hal
ini dilakukan karena banyaknya kata sinonim yang berasal dari kata dasar meskipun
beberapa sinonim kata menggunakan imbuhan. Untuk mengatasi permasalahan
tersebut maka sinonim kata yang terdapat di dalam database merupakan kata dasar
meskipun makna yang dari kata menjadi berubah.
Proses pengenalan sinonim ini dilakukan hanya sekali untuk setiap array kata
yang ada sehingga apabila array kata merupakan kata bersinonim maupun tidak, maka
array kata akan tetap dicetak sama seperti array kata sebelum proses Synonym
Recognition. Hal ini dapat diakibatkan oleh tiga faktor, yaitu :
1. Kata adalah kata utama / sinonim kata, maksudnya kata merupakan bentuk
ubahan yang terjadi pada kata yang memiliki sinonim.
2. Kata memang tidak memiliki sinonim.
3. Sinonim tidak terdapat di dalam database.
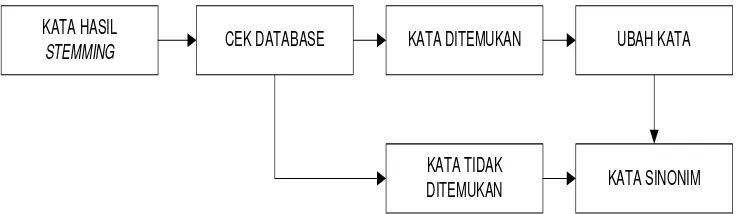
Secara ringkas, proses Synonym Recognition dapat dilihat pada gambar 3.6:
KATA HASIL
STEMMING CEK DATABASE KATA DITEMUKAN
KATA TIDAK DITEMUKAN
UBAH KATA
KATA SINONIM
Gambar 3.6 Proses Synonym Recognition
Berdasarkan Gambar 3.6, dapat dijelaskan bahwa array kata hasil proses stemming
29
1. Jika kata ditemukan, maka kata diubah sesuai dengan sinonim katanya dan
menghasilkan kata sinonim. Jika kata sudah merupakan sinonimnya, maka
kata tidak mengalami perubahan dan tetap menghasilkan kata sinonim.
2. Jika kata tidak ditemukan, maka kata tidak mengalami perubahan dan tetap
menghasilkan kata sinonim.
3.6 Algoritma Manber
Algoritma Manber merupakan proses terakhir setelah proses stemming dan Synonym
Recognition. Untuk mendapatkan hasil yang maksimal, maka proses stemming dan
Synonym Recognition harus dilakukan semaksimal mungkin, karena kedua proses ini
memiliki pengaruh yang cukup besar pada hasil akhir.
Penghapusan noise pada algoritma Manber yang digunakan dalam penelitian
ini sangat bergantung pada proses Synonym Recognition karena noise yang digunakan
merupakan kata dengan panjang karakter kurang dari empat (panjang string < 4). Oleh
karena itu, perubahan kata sinonim yang dilakukan merupakan string dengan panjang
karakter yang lebih kecil. Sebagai contoh, kata “yang” merupakan sinonim dari kata
“nan” sehingga kata tersebut diubah menjadi kata dengan panjang string yang lebih kecil dan dihapus. Proses ini ditujukan selain sebagai syarat algoritma pendeteksi
kemiripan teks, juga untuk mengurangi penggunaan waktu proses yang tidak
diperlukan, meskipun persentase yang dikeluarkan menjadi lebih kecil namun tidak
berbeda jauh dengan hasil tanpa menggunakan noise reduction.
Berdasarkan penjelasan sebelumnya mengenai faktor-faktor yang
mempengaruhi pemilihan fingerprint, maka diberikan beberapa batasan agar tidak
banyak menghasilkan asumsi persentase kemiripan dokumen teks, yaitu :
1. Basis pada fungsi hash yang digunakan adalah 2.
2. Nilai N pada N-Gram disesuaikan dengan banyaknya huruf yang menyusun
teks tersebut, yaitu angka 1 hingga 8.
3. Nilai pembagi yang digunakan untuk pemilihan fingerprint adalah 1 sehingga
seluruh nilai hash akan dijadikan sebagai fingerprint.
Selain itu, penggunaan batasan juga ditujukan untuk memudahkan penggunaan sistem
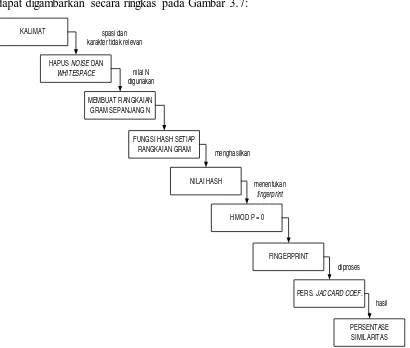
Berikut ini merupakan langkah penyelesaian oleh algoritma Manber yang
dapat digambarkan secara ringkas pada Gambar 3.7:
KALIMAT
Gambar 3.7 Proses Algoritma Manber
Berdasarkan Gambar 3.7, proses algoritma Manber dimulai dengan menghapus noise
dan whitespace, kemudian dilakukan pembuatan rangkaian gram sesuai dengan nilai
N yang dimasukkan pengguna. Setiap rangkaian gram yang terbentuk, diproses
menggunakan fungsi hash. Proses dari fungsi hash akan menghasilkan nilai hash
dimana nilai-nilai hash yang terbentuk akan dipilih untuk dijadikan fingerprint
dokumen. Pemilihan fingerprint harus sesuai dengan persyaratan algoritma Manber,
yaitu hasil modulo nilai hash bernilai 0. Langkah terakhir algoritma Manber adalah
dengan memroses fingerprint tersebut dengan menggunakan persamaan Jaccard
Coefficient. Pertama, fingerprint yang terbentuk dari kedua data (uji dan banding)
diiriskan sehingga terbentuklah satu rangkaian fingerprint yang sama. Kemudian
membuat gabungan dari seluruh fingerprint. Jumlah irisan dibagi dengan jumlah
gabungan fingerprint, hasil bagi ini dikali dengan 100% untuk mendapatkan hasil
31
3.7 Deteksi Kemiripan Teks Secara Manual
Berikut ini merupakan contoh penghitungan manual dari pendeteksian kemiripan teks
pada penjiplakan jenis Disguised P lagiarism, yaitu:
Teks Uji : Tubuh saya memerlukan takaran nutrisi yang mencukupi
supaya tidak segera sakit.
Teks Banding : Agar tubuhnya tidak cepat mengidap penyakit, maka
dibutuhkan tambahan vitamin dengan dosis yang pas.
Gram : 2
1. Case F olding dan hapus karakter tidak relevan yaitu seluruh karakter, kecuali
huruf, angka, dan whitespace.
Teks Uji : tubuh saya perlu takar nutrisi yang cukup supaya tidak segera
sakit
Teks Banding : agar tubuh tidak cepat idap sakit maka butuh tambah vitamin
dengan dosis yang pas
2. Proses Stemming dengan pengecekan pada kamus kata dasar.
Teks Uji : tubuh saya perlu takar nutrisi yang cukup supaya tidak segera
sakit
Teks Banding : agar tubuh tidak cepat idap sakit maka butuh tambah vitamin
dengan dosis yang pas
3. Proses Synonym Recognition dengan pengecekan pada kamus kata sinonim.
Teks Uji : badan aku perlu dosis gizi nan cukup agar tidak cepat sakit
Teks Banding : agar badan tidak cepat idap sakit dan perlu tambah gizi dan
dosis nan cukup
4. Noise Reduction dengan menghapus kata yang memiliki jumlah karakter < 4.
Teks Uji : badan perlu dosis gizi cukup agar tidak cepat sakit
Teks Banding : agar badan tidak cepat idap sakit perlu tambah gizi dosis
5. Hapus whitespace seperti spasi antar kata.
Teks Uji : badanperludosisgizicukupagartidakcepatsakit
Teks Banding : agarbadantidakcepatidapsakitperlutambahgizidosiscukup
6. Rangkaian N-Gram dengan nilai N = 2.
Teks Uji : ba ad da an np pe er rl lu ud do os si is sg gi iz zi ic cu uk ku
up pa ag ga ar rt ti id da ak kc ce ep pa at ts sa ak ki it
Teks Banding : ag ga ar rb ba ad da an nt ti id da ak kc ce ep pa at ti id da ap
ps sa ak ki it tp pe er rl lu ut ta am mb ba ah hg gi iz zi id do
os si is sc cu uk ku up
7. Menentukan nilai hash dengan memasukkan rangkaian gram ke dalam fungsi
hash.
Teks Uji : 293 294 297 304 332 325 316 336 333 334 311 337 335 325
333 311 332 349 309 315 341 331 346 321 297 303 308 344
337 310 297 301 313 299 314 321 310 347 327 301 319 326
Teks Banding : 297 303 308 326 293 294 297 304 336 337 310 297 301 313
299 314 321 310 337 310 297 306 339 327 301 319 326 344
325 316 336 333 350 329 303 316 293 298 311 311 332 349
310 311 337 335 325 329 315 341 331 346
8. Memilih fingerprint dari nilai hash yang memenuhi persyaratan, yaitu
menggunakan (2.2) dengan nilai pembagi P = 1.
Teks Uji : 293 294 297 304 332 325 316 336 333 334 311 337
335 349 307 303 308 344 310 301 313 299 314 321
347 327 319 326
Teks Banding : 297 303 308 326 293 294 304 336 337 310 301 313
299 314 321 306 339 327 319 344 325 316 333 350
329 298 311 332 349 335
9. Menghitung similaritas, yaitu dengan menggunakan (2.3) sehingga didapatkan
33
Jumlah Irisan (Uji, Banding) : 25
Jumlah Gabungan (Uji, Banding) : 33
Berdasarkan penghitungan yang dilakukan, maka dapat dianalisis bahwa :
1. Penghitungan manual berlangsung dalam waktu yang cukup lama.
2. Kemungkinan terjadi kesalahan dalam proses.
3. Membutuhkan alat bantu lain seperti alat hitung dan kamus.
3.8 Perancangan Database Dan Interface Sistem
Sistem pendeteksi dokumen teks yang dirancang terdiri atas dua komponen utama,
yaitu database dan interface sistem.
3.8.1 Database Sistem
Database sistem merupakan tempat penyimpanan data dalam skala kecil maupun
besar. Sub database adalah tabel yang berisi mengenai data spesifik yang dibutuhkan
oleh sistem. Penelitian ini hanya menggunakan dua tabel yang difungsikan untuk
pengecekan kata dasar dan kata bersinonim, yaitu :
Tabel 3.4 Rancangan Tabel Kata Dasar
No. Nama Tipe Ekstra Aksi
1. id_ktdasar int(10) auto increment primary key
2. katadasar varchar(20)
2. Tabel kata sinonim
Tabel ini digunakan pada proses Synonym Recognition. Rancangan tabel
sinonim kata dapat dilihat pada Tabel 3.5 dengan rincian sebagai berikut :
a. id kata sinonim,
b. Sinonim kata, dan
c. Kata dasar.
Tabel 3.5 Rancangan Tabel Kata Sinonim
No. Nama Tipe Ekstra Aksi
1. id_ktsinonim int(10) auto increment primary key
2. katasinonim varchar(20)
3. sinonim varchar(20)
3.8.2 Interface Sistem
Interface sistem merupakan tampilan sistem yang berfungsi untuk membantu
pengguna dalam menggunakan sistem.
Interface sistem pada penelitian ini dibuat sesederhana mungkin dengan tujuan
untuk mengurangi penggunaan waktu yang tidak relevan pada proses sistem serta
membantu pengguna dalam memahami dan menggunakan sistem. Rancangan
interface sistem ini dapat dibagi menjadi dua, yaitu:
1. Tampilan Awal
Tampilan awal digunakan untuk memasukkan data yang diuji maupun
dibandingkan serta nilai-nilai yang diperlukan dalam pemrosesan deteksi
kemiripan teks. Tampilan awal sistem menggunakan lima komponen dasar,
yaitu: iframe, textarea, textbox, button, dan tabel.
Adapun bentuk ataupun gambaran dari tampilan awal sistem yang akan
35
TEXTAREA UJI TEXTAREA BANDING
TOMBOL CETAK
Gambar 3.8 Rancangan Tampilan Awal Sistem
Berikut ini merupakan rincian dari rancangan tampilan awal pada
Gambar 3.6 yang akan dibuat, yaitu :
teks uji secara manual,
i. Textarea banding sebagai media pencetak teks pdf banding dan sebagai
media input teks banding secara manual,
j. Tombol mulai untuk memulai proses pendeteksian.
2. Tampilan Hasil
Tampilan akhir berfungsi untuk menampilkan hasil dari proses pendeteksian
kemiripan dokumen teks. Adapun hasil proses yang akan ditampilkan pada
tampilan hasil adalah:
a. Hasil stemming,
b. Hasil Synonym Recognition,
c. Hasil Noise Reduction,
d. Rangkaian N-Gram,
e. Nilai hash tiap rangkaian gram,
f. F ingerprint dokumen, dan
g. Persentase similaritas dokumen teks.
Rincian tersebut dirancang di dalam satu tabel dan diakhiri dengan waktu proses
pendeteksian, sesuai dengan rancangan pada Gambar 3.9 berikut :
WAKTU PROSES SISTEM
TABEL HASIL
NO PROSES HASIL PROSES PADA TEKS UJI HASIL PROSES PADA TEKS BANDING
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Pada bab ini, akan dibahas mengenai implementasi dari algoritma Manber, teknik
stemming, dan Synonym Recognition sehingga pengujian terhadap sistem dapat
dilakukan, baik untuk tampilan sistem maupun hasil akhir berupa persentase
kemiripan yang dimiliki oleh dokumen teks uji dengan pembandingnya.
4.1 Implementasi
Sistem diprogram dengan menggunakan bahasa pemrograman PHP, artinya sistem
akan dijalankan pada browser sebagai media pemrosesan dan interface sistem.
Database yang digunakan adalah database MySql dengan menggunakan software
XAMPP.
4.1.1 Spesifikasi Hardware Dan Software Yang Digunakan
Berikut ini merupakan spesifikasi yang digunakan dalam pembuatan sistem dapat,
yaitu :
1. P rocessor AMD A8-5600k APU with Radeon™ HD Grapichs (4 CPUs),
~3.6GHz.
2. Kapasitas hard disk 500 GB.
3. Memori RAM yang digunakan 4 GB.
5. XAMPP 1.8.1.
6. Mozilla Firefox 30.0.
4.1.2 Database Tabel Kata Dasar
Tabel kata dasar terdiri atas dua kolom, yaitu id kata dasar dan kata dasar sesuai
dengan Gambar 4.1 berikut :
Gambar 4.1 Database Tabel Kata Dasar
4.1.3 Database Tabel Kata Sinonim
Tabel kata sinonim terdiri atas tiga kolom, yaitu id kata sinonim, kata sinonim, dan
sinonim kata sesuai dengan Gambar 4.2 berikut :
39
4.1.4 Tampilan Awal
Tampilan awal sistem dibuat sederhana agar mudah dalam menggunakan sistem serta
membuang waktu yang tidak relevan, dengan rincian sebagai berikut :
1. Tombol Browse untuk mencari file pdf yang akan diuji dan dibandingkan.
2. Tombol Submit sebagai proses pembacaan file pdf yang sudah ditemukan.
3. IF RAME yang digunakan untuk membaca file pdf yang ditemukan.
4. Tombol cetak pdf untuk proses pencetakan isi iframe ke dalam textarea-nya
masing- masing.
5. Textarea yang digunakan sebagai media cetak hasil pembacaan file pdf dari
iframe dan sebagai input-an teks secara manual yang tidak berasal dari file pdf.
6. Textbox yang digunakan untuk mendapatkan nilai N dalam pembuatan
rangkaian gram dan nilai pembagi modulo pada pemilihan fingerprint.
7. Tombol deteksi untuk memulai proses pendeteksian dan tombol reset untuk
me-refresh atau mengondisikan sistem seperti semula.
Semua elemen terangkum ke dalam sebuah tabel dengan ketebalan garis = 0.
Tampilan awal sistem dapat dilihat pada Gambar 4.3 berikut :
4.1.5 Tampilan Hasil
Tampilan hasil sistem dimuat dalam satu tabel dengan tujuan untuk memudahkan
pengguna dalam membaca hasil yang dikeluarkan, seperti pada Gambar 4.4 berikut :
Gambar 4.4 Tampilan Hasil Sistem
Pada tampilan hasil turut dicantumkan waktu proses sehingga pengguna dapat
mengukur kecepatan dari gabungan algoritma dan kedua teknik pendukungnya.
Berikut ini merupakan kode program yang di implementasikan untuk menampilkan
waktu proses sistem, yaitu :
1. Pada awal kode program :
$mtime = microtime();
41
$totaltime = round($endtime - $starttime , 3);
4.1.6 Stemming
Proses stemming terbagi atas lima tahap, dimana tahap ini harus dilakukan secara
berturut agar mendapatkan hasil yang sesuai. Masing-masing tahap penghapusan
dibuat menjadi paket-paket untuk memudahkan proses pemanggilan fungsi, sebagai
contoh :
function hapuspartikel($kata){ }
Kode program yang digunakan pada penghapusan setiap bubuhan kata harus
dilakukan sesingkat mungkin, salah satu caranya adalah dengan menggabungkan
bubuhan kata yang memiliki panjang string yang sama, seperti :
mencari bubuhan kata yang dicari.
Di dalam pengimplementasiannya, proses stemming setiap bubuhan kata harus
diselingi dengan stemming bubuhan kata selanjutnya. Berikut ini merupakan contoh
kode program yang diimplementasikan ke dalam sistem, yaitu :
if(substr($kata, -2) == 'ku' || substr($kata, -2) == 'mu'){ $kata1 = substr($kata, 0, -2);
$ak1 = hapusakhiran(hapusawalan2(hapusawalan1($kata1))); if(cari($ak1) != 0){
} else{
$kata; }
}
Jika proses pada variable $ak1 tidak dilakukan, maka proses pencarian kata dasar di
dalam kamus tidak akan ditemukan, sehingga menghasilkan kata itu kembali. Gambar
4.6 berikut merupakan contoh pengimplementasian teknik stemming di dalam sistem :
Gambar 4.5 Hasil Implementasi Stemming
4.1.7 Synonym Recognition
Pengimplementasian Synonym Recognition sangat sederhana karena proses yang
dilakukan hanya mengecek database :
$a = mysql_query("select * from tb_katasinonim where sinonim = '$c'");
$b = mysql_fetch_array($a);
Dan melakukan pengubahan jika kata sinonim ditemukan :
if($b){
$d = $b[katasinonim]; }
Jika tidak ditemukan, maka kata tidak berubah :
else{
$d = $c; }
Kata sinonim yang dijadikan sebagai acuan perubahan merupakan kata dengan
43
dapat berjalan. Gambar 4.6 berikut merupakan contoh implementasi Synonym
Recognition setelah proses stemming :
Gambar 4.6 Hasil Implementasi Synonym Recognition
4.1.8 Algoritma Manber
Gambar 4.7 berikut merupakan hasil dari penyelesaian algoritma Manber yang
dilakukan secara berturut di mulai dari penghapusan noise dan whitespace hingga
pemilihan fingerprint, yaitu :
Gambar 4.7 Hasil Proses Algoritma Manber
Proses terakhir algoritma Manber adalah menentukan similaritas dokumen teks
dengan menggunakan persamaan Jaccard Coefficient dengan yang dapat dilihat pada
Gambar 4.8, berikut :
Teks Uji : Tubuh saya memerlukan takaran nutrisi yang mencukupi
Teks Banding : Agar tubuhnya tidak cepat mengidap penyakit, maka
dibutuhkan tambahan vitamin dengan dosis yang pas.
Gram : 2
Modulo : 2
Gambar 4.8 Hasil Akhir Algoritma Manber
4.2 Pengujian Sistem
Pengujian yang dilakukan pada sistem adalah mendeteksi kemiripan satu dokumen
teks uji dengan satu dokumen teks banding baik hanya menggunakan algoritma
Manber saja, dengan menambahkan teknik stemming atau Synonym Recognition saja
maupun kombinasi kedua teknik. Hal ini dilakukan untuk mengetahui seberapa besar
pengaruhnya terhadap hasil dan waktu pemrosesan, serta beberapa pengujian lainnya,
seperti pengujian rules pada proses stemming dan lainnya.
4.2.1 P engujian Tampilan Sistem
Pengujian yang dilakukan pada tampilan sistem berupa fungsi dari tiap komponen,
algoritma serta teknik yang digunakan. Rancangan pengujian dapat dilihat pada Tabel
4.1 dan dilanjutkan dengan hasil pengujian pada Tabel 4.2 berikut ini :
Tabel 4.1 Rancangan Pengujian Tampilan Sistem
No. Komponen Sistem Yang Diuji Butir Uji
1. Tombol Browse Memunculkan window untuk mencari
file pdf yang akan diuji atau banding
2. Tombol Submit Menampilkan isi file pdf ke
masing-masing iframe, baik uji ataupun banding